
Deep$Learning$ - UFPEtbl/Aulas/AM/Deep Learning.pdf · Deep$Learning$ Anderson$Tenório$...
63
Deep Learning Anderson Tenório Bacharel em Engenharia da Computação, POLIUPE Mestre em Ciência da Computação, CInUFPE Doutorando em Ciência da Computação, CInUFPE
Transcript of Deep$Learning$ - UFPEtbl/Aulas/AM/Deep Learning.pdf · Deep$Learning$ Anderson$Tenório$...

Deep Learning
Anderson Tenório Bacharel em Engenharia da Computação, POLI-‐UPE
Mestre em Ciência da Computação, CIn-‐UFPE Doutorando em Ciência da Computação, CIn-‐UFPE

Agenda
• Aprendizagem de Máquinas e Redes Neurais • MoJvação • Introdução • Arquiteturas Deep Learning • Aplicações
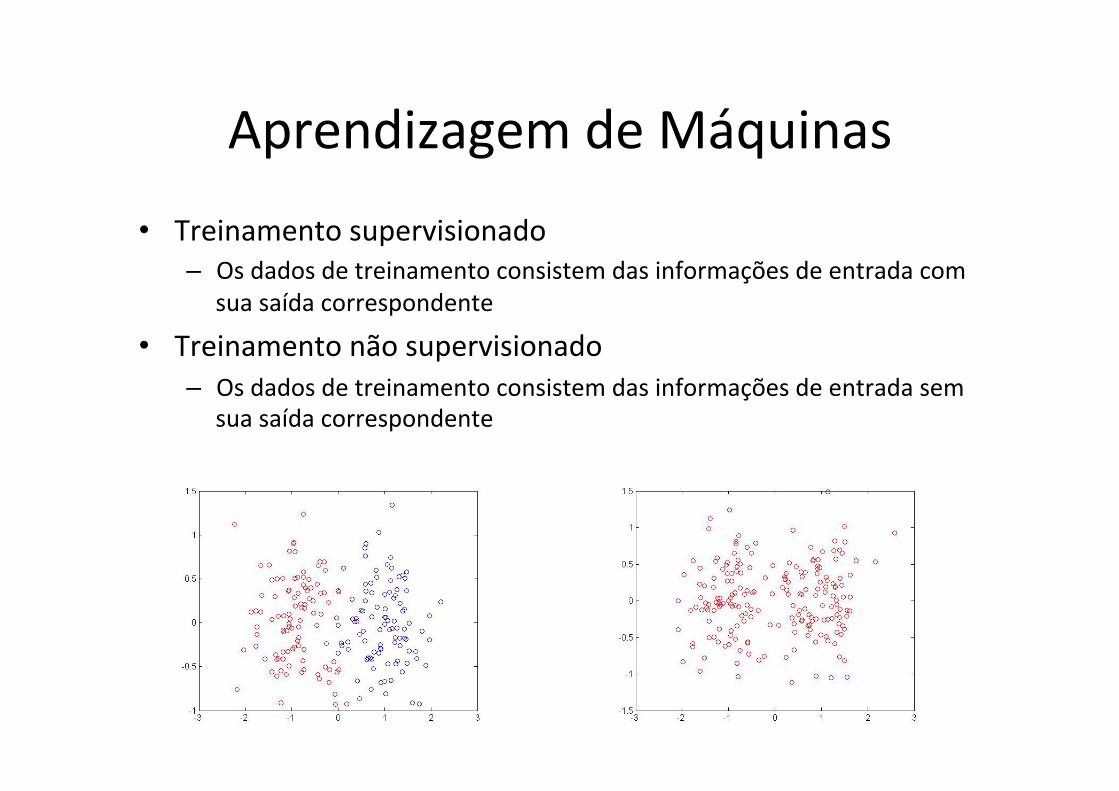
Aprendizagem de Máquinas • Treinamento supervisionado
– Os dados de treinamento consistem das informações de entrada com sua saída correspondente
• Treinamento não supervisionado – Os dados de treinamento consistem das informações de entrada sem
sua saída correspondente

Redes Neurais
• Duas camadas (uma camada escondida e uma camada de saída)

MoJvação
• PermiJr aos computadores modelar nosso mundo bem o suficiente para exibir o que nós chamamos de inteligência tem sido o foco de pesquisas de mais da metade de um século
• Para alcançar esse objeJvo, é claro que a grande quanJdade de informação sobre o nosso mundo deve ser de alguma forma armazenada, explicitamente ou implicitamente, no computador
• Já que não podemos formalizar manualmente a informação, uJlizamos algoritmos de aprendizagem

MoJvação
• Muito esforço (e progresso!) tem sido feito em entender e melhorar algoritmos de aprendizagem, mas o desafio em IA permanece
• Temos algoritmos capazes de entender cenas e descrevê-‐las em linguagem natural?
• Temos algoritmos capazes de inferir conceitos semân9cos suficientes a ponto de interagir com humanos?
MoJvação

MoJvação
• Um modo plausível e comum de extrair informação úJl a parJr de imagens naturais envolve transformar gradualmente os pixels “crus” em representações mais abstratas – Presença de bordar, detecção de formas locais, idenJficação de categorias etc
• Assim, uma máquina que expresse “inteligência” requer funções matemáJcas altamente variáveis – Não-‐lineares em termos de entradas cruas, sendo capazes de apresentar muitas variações

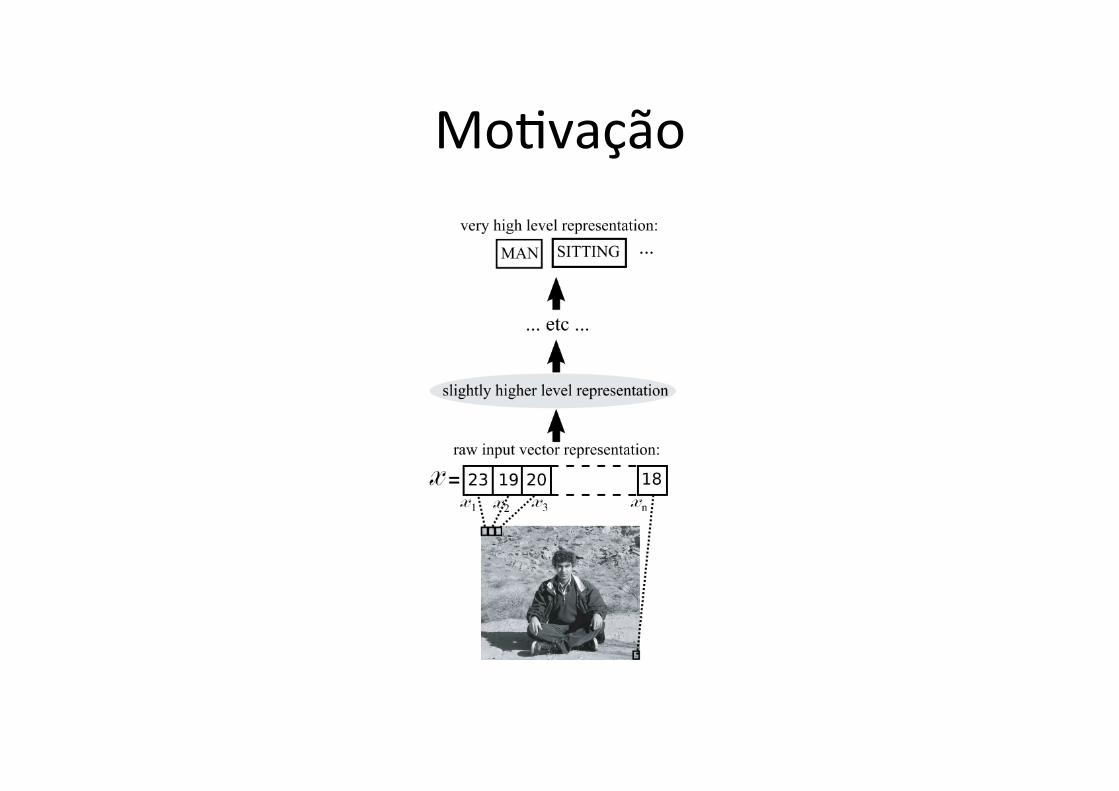
MoJvação • A imagem anterior contém uma abstração de alto nível chamada HOMEM
• Corresponde a um grande conjunto de imagens possíveis – Podendo ser muito diferentes uma das outras em termos de, por exemplo, distância euclidiana
• A abstração HOMEM pode ser encarada como uma categoria ou caracterísJca/feature (discreta ou con^nua)
• Muitos conceitos em nível mais baixo ou intermediário poderiam ser úteis para construir um detector mais sofisJcado

MoJvação
• O foco em arquiteturas profundas é automaJcamente descobrir essas abstrações – ParJndo features com níveis mais baixos até conceitos de nível mais alto
• UJlizar algoritmos de aprendizagem que descubram essas abstrações com o mínimo esforço humano possível – Sem a necessidade de prover um grande conjunto de dados rotulados (textos e imagens da internet, por exemplo)

MoJvação
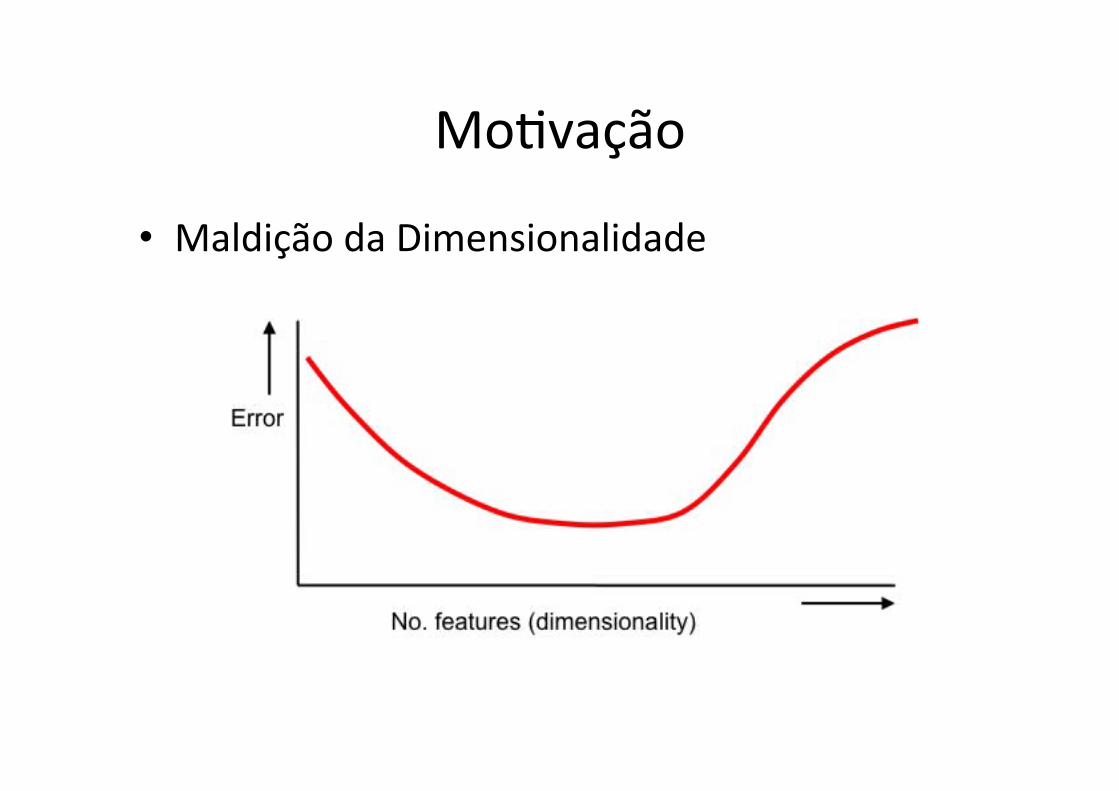
• Redes Neurais ArJficiais feed-‐forward – MALDIÇÃO DA DIMENSIONALIDADE
MoJvação
• Maldição da Dimensionalidade

MoJvação
• Uma das soluções encontradas para a maldição de dimensionalidade é pré-‐processamento de dados – Redução da dimensionalidade (às vezes por humanos)
– Desafiante e altamente dependente da tarefa • Se pensarmos no cérebro humano, não há indícios de que ele resolve esse problema dessa forma

Introdução • Métodos Deep Learning (DL) focam em aprender caracterísJcas de nível mais alto pela composição de caracterísJcas de nível mais baixo – Tendo o cérebro humano como inspiração
• Aprender caracterísJcas automaJcamente em múlJplos níveis de abstração permite ao sistema mapear funções complexas sem depender de caracterísJcas intermediárias inteligíveis aos humanos – Essa habilidade é necessária porque o tamanho dos dados tende a crescer

Introdução
• Algoritmos Deep Learning podem ser considerados como processos de aprendizagem que descobrem múlJplos níveis de abstração
• As representações mais abstratas podem ser mais úteis em extrair informações para classificadores ou preditores – CaracterísJcas intermediárias aprendidas podem ser comparJlhadas entre diferentes tarefas

Introdução
• A profundidade de uma arquitetura diz respeito ao número de níveis de composição de operações não lineares na função aprendida – Numa rede neural, corresponde ao número de camadas
• Funções que podem ser representadas por uma arquitetura de profundidade k podem requerer um número exponencial de elementos computacionais para que sejam representadas por uma arquitetura de profundidade k – 1 – Algumas funções do mundo real não podem ser representadas por arquiteturas rasas

Introdução
• Por décadas, diversos pesquisadores tentaram, sem sucesso, treinar redes neurais de múlJplas camadas profundas – Sendo as redes inicializadas com pesos aleatórios, elas geralmente ficavam presas em mínimos locais
– À medida que a profundidade aumentava, tornava-‐se ainda mais digcil uma boa generalização

Introdução
• Em 2006, Hinton et al descobriram que os resultados de uma rede neural profunda poderiam ser sensivelmente melhorados quando pré-‐treinadas com um algoritmo de aprendizagem não-‐supervisionado, uma camada após outra e parJndo da primeira camada
• Esse trabalho inicializou a área hoje conhecida como Deep Learning

Introdução • Treinar redes com muitas camadas (vs. redes “rasas” com uma ou
duas camadas) • MúlJplas camadas constroem um espaço de caracterísJcas
melhorado – Primeira camada aprende as caracterísJcas de primeira ordem (por
exemplo, bordas) – Segunda camada aprende caracterísJcas de maior ordem (por
exemplo, combinação de bordas e outras caracterísJcas) – As camadas são treinadas de modo não-‐supervisionado de modo a
descobrir caracterísJcas gerais do espaço de entrada – As caracterísJcas finais alimentam uma camada supervisionada
• A rede inteira é então ajustada de modo supervisionado – Deep Learning é indicado em tarefas cujo espaço de entrada seja
localmente estruturado – espacial ou temporal • Imagens, linguagem etc

Introdução

Por que Deep Learning? • Plausibilidade biológica – córtex visual • Problemas que podem ser representados com um número polinomial de nós com k camadas podem requerer número exponencial de nodos com k-‐1 camadas
• Funções muito variáveis podem ser eficientemente representadas com arquiteturas profundas – Menos pesos/parâmetros para atualizar do que uma rede rasa menos eficiente
• SubcaracterísJcas criadas em arquiteturas profundas podem ser comparJlhadas entre múlJplas tarefas – Transferência de aprendizado

Trabalhos Prévios
• Fukushima (1980) – Neo-‐Cognitron • LeCun (1998) – ConvoluJonal Neural Networks – Similar a Neo-‐Cognitron
• MLP mulJcamadas com backpropagaJon – Tentado mas sem muito sucesso
• Muito lento • Difusão do gradiente
– Alguns trabalhos mostraram melhoramentos significaJvos por “pacientemente” treinarem MLP profundas com BP em máquinas rápidas (GPU)

ConvoluJnal Neural Networks • Cada camada combina (merge, suaviza) trechos (patches) das camadas
anteriores – Tipicamente tenta comprimir dados grandes (imagens) em um conjunto
menor de caracterísJcas robustas – Convoluções básicas podem ainda criar muitas caracterísJcas
• Pooling – Esse passo comprime e suaviza os dados – Normalmente toma a média ou o valor máximo entre trechos disjuntos
• Frequentemente filtros de convolução e pooling são feitos manualmente • Após essa convolução manual/não treinada/parcialmente treinada o novo
conjunto de caracterísJcas é usado para treinar um modelo supervisionado
• Requer regularidades na vizinhança no espaço de entrada (por exemplo, imagens)

ConvoluJonal Neural Networks

Treinando Redes Profundas
• Construir um espaço de caracterísJcas – É o que é feito com camadas escondidas em uma MLP, mas em uma arquitetura rasa
– Treinamento não supervisionado entre camadas podem decompor o problema em sub-‐problemas (com níveis mais altos de abstração) a serem decompostos mais uma vez pelas camadas subsequentes

Treinando Redes Profundas
• Dificuldades do treinamento supervisionado em redes profundas – As camadas no MLP não aprendem bem • Difusão do gradiente • Treinamento muito lento • Camadas mais baixas tendem a fazer um mapeamento aleatório
– Frequentemente há mais dados não rotulados do que dados rotulados
– Mínimo local

Greedy Layer-‐Wise Training 1. Treinar primeira camada uJlizando dados sem rótulos – Já que não há targets nesse nível, rótulos não importam
2. Fixar os parâmetros da primeira camada e começar a treinar a segunda usando a saída da primeira camada como entrada não supervisionada da segunda camada
3. RepeJr 1 e 2 de acordo com o número de camadas desejada (construindo um mapeamento robusto)
4. Usar a saída da camada final como entrada para uma camada/modelo supervisionada e treinar de modo supervisionado (deixando pesos anteriores fixos)
5. Liberar todos os pesos e realizar ajuste fino da rede como um todo uJlizando uma abordagem supervisionada

Greedy Layer-‐Wise Training • Evita muitos dos problemas associados ao treinamento de uma rede profunda de modo totalmente supervisionado – Cada camada toma foco total no processo de aprendizagem
– Pode tomar vantagem de dados não rotulados – Quando a rede completa é treinada de modo supervisionado, os pesos já estão minimamente ajustados (evita mínimos locais)
• As duas abordagens mais comuns desse processo – Stacked Auto-‐Encoders – Deep Belief Nets

Auto-‐Aprendizagem vs Aprendizado Não Supervisionado
• Quando se usa aprendizagem não supervisionada como pré-‐processador para aprendizagem supervisionada, Jpicamente os exemplos são da mesma distribuição
• Na auto-‐aprendizagem, a fase supervisionada não requer dados da mesma distribuição – Maior disponibilidade – Mas se os dados são muito diferentes...
• Similaridades: ambos podem transferir conhecimento

Auto-‐Encoders • Um Jpo de modelo não supervisionado que tenta descobrir caracterísJcas
genéricas dos dados – Aprende a idenJficar funções através do aprendizado de sub-‐caracterísJcas;
compressão; pode usar novas caracterísJcas como um novo conjunto de treinamento

Stacked Auto-‐Encoders • Bengio (2007) • Empilhar muitos auto-‐encoders esparsos e treiná-‐los de forma gulosa • Desprezar a camada decoder (saída)
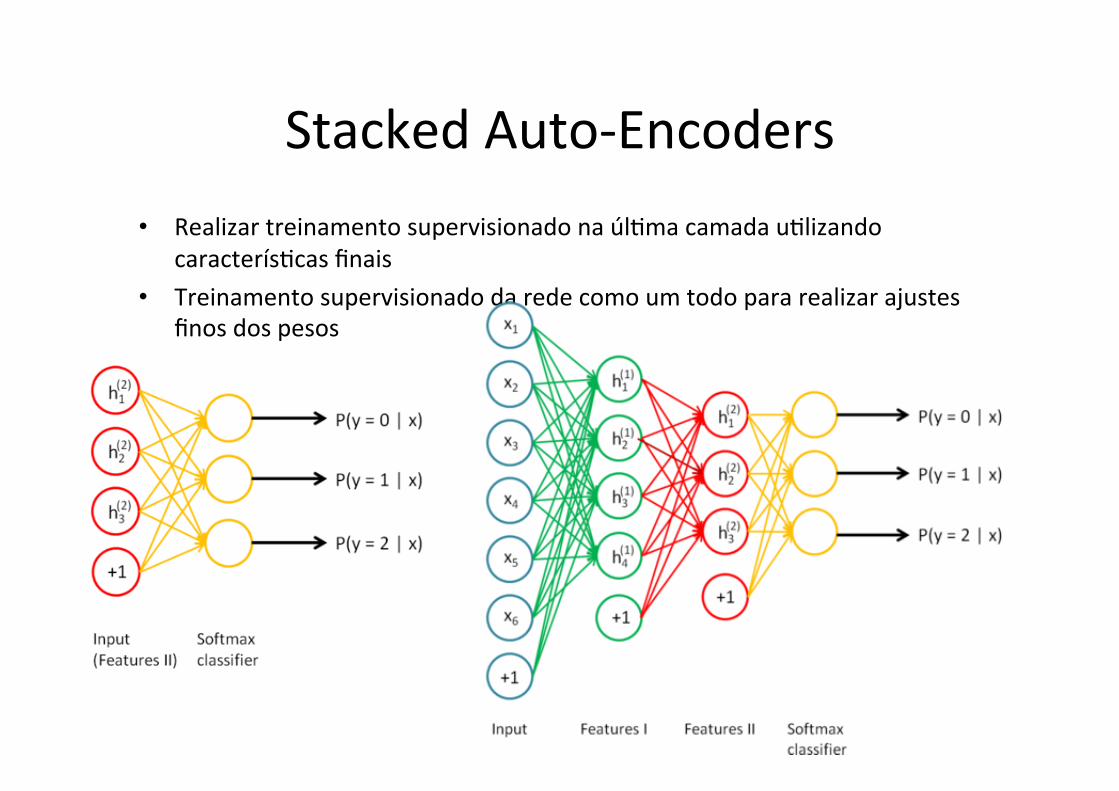
Stacked Auto-‐Encoders • Realizar treinamento supervisionado na úlJma camada uJlizando
caracterísJcas finais • Treinamento supervisionado da rede como um todo para realizar ajustes
finos dos pesos

Encoder Esparso • Auto-‐encoders farão frequentemente uma redução dimensionalidade
– Do Jpo PCA ou não linear • Isso leva a uma representação “densa”
– Todas as caracterísJcas Jpicamente tem valores não zero para qualquer entrada
• Entretanto, essa representação distribuída tem algumas desvantagens – Mais digcil para as camadas capturar as caracterísJcas (matemaJcamente
provado que uma boa generalização é necessário que o número total de bits para codificar o conjunto de treinamento deve ser pequeno)
– Memória maior e velocidade menor – Não é biologicamente plausível
• Uma representação esparsa uJliza mais caracterísJcas onde em um dado tempo um número significante de caracterísJcas terá valor 0

Como implementar Auto-‐Encoder esparso?
• UJlizar mais nodos escondidos no encoder • UJlizar técnicas de regularização que encorajem esparsidade – Penalizar soluções com muitos nós não zero – Decaimento de pesos

Denoising Auto-‐Encoders
• EstocasJcamente corrompe instâncias de treinamento, mas também treina o auto-‐encoder para codificar as instâncias não corrompidas
• Tenta desfazer o processo de corrupção • Melhores resultados empíricos

Deep Belief Networks (DBN)
• Geoffrey Hinton (2006) • UJliza treinamento guloso, onde cada camada é uma RBM (Restricted Boltzmann Machine)

Restricted Boltzmann Machine
• Duas caracterísJcas definem uma RBM – Estados das unidades: obJdas através de uma distribuição de probabilidades
– Pesos da rede: obJdos através de treinamento
• O objeJvo da RBM é esJmar a distribuição dos dados de entrada. O objeJvo é determinado pelos pesos, dadas as entradas
• Energia da RBM iji
i jjj
jji
ii vwhhbvahvE ,),( ∑∑∑∑ −−−=

Treinamento RBM
• Estado inicial Jpicamente atribuído por um exemplo de treinamento x (binários ou reais)
• Sampling is an iteraJve back and forth process – P(hi = 1|x) = sigmoid(Wix + ci) // ci é o bias dos nodos escondidos
– P(xi = 1|h) = sigmoid(W'ih + bi) // bi é o bias dos nodos visíveis
• ConstraJve Divergence (CD-‐k): quanto contraste existe entre o exemplo original e o gerado depois de k passos
• Tipicamente se usa CD-‐1 (bons resultados empíricos) – Suficiente para guiar o gradiente na direção correta

€
Δwij = ε(h1, j ⋅ x1,i −Q(hk+1, j =1 | xk+1)xk+1,i

Treinamento RBM

Treinamento DBN • Mesma abordagem gulosa • Primeiro treinar RBM mais baixo usando CD
• Congelar pesos e treinar camadas subsequentes
• Conectar saídas a um modelo supervisionado
• Finalmente, descongelar todos os pesos e treinar todo o modelo com um algoritmo supervisionado (backpropagaJon ou wake-‐sleep)

Deep Belief Networks
• Esta abordagem não supervisionada aprende caracterísJcas gerais que podem auxiliar no processo de fazer os padrões encontrados no conjunto de treinamento mais prováveis
• Os padrões são potencialmente úteis para outros objeJvos com o conjunto de treinamento (classificação, compressão, etc.)
• Pode uJlizar conexões laterais (não mais máquinas de Boltzmann restritas) – Amostragem se torna mais digcil

Stacked Auto-‐Encoders vs DBN • DBNs Jpicamente mais eficientes do que o Stacked Auto-‐Encoder original
• Entretanto, ao uJlizar versão esparsa ou “denoising”, Stacked Auto-‐Encoder se torna compeJJvo
• Stacked Auto-‐Encoder não é originalmente um modelo generaJvo (por exemplo, não são capazes de gerar amostras que podem ter seu desempenho avaliado qualitaJvamente) – Trabalhos recentes com denoising auto-‐encoders apresentaram essa capacidade

Arquiteturas Deep Learning

Aplicações
• Reconhecimento de fala e processamento de sinais – A Microso� lançou em 2012 uma nova versão do MAVIS (Microso/ Audio Video Indexing Service), sistema de voz baseado em Deep Learning • O sistema reduziu a taxa de erro de palavras nos quatro maiores benchmarks em torno de 30%
• Nessas aplicações, geralmente são uJlizadas ConvoluJonal Neural Networks
• Deep Learning possui resultado estado-‐da-‐arte em transcrição polifônica, melhorando as taxas de erro de 5% a 30% na maioria das bases de dados benchmark

Aplicações
• Reconhecimento de objetos – Os primeiros modelos Deep Learning focaram no problema de classificação de imagens digitais MNIST, derrotando a supremacia das Support Vector Machines, com taxa de erro de 1,4%
– O estado-‐da-‐arte nessa tarefa (taxa de erro de 0,27%) também é um modelo Deep Learning
– Deep Learning possui resultado estado-‐da-‐arte na base de dados de reconhecimento de imagens naturais ImageNet, diminuindo a taxa de erro de 26,1% para 15,3%

Aplicações
• MNIST

Deep Learning -‐ Aplicações
• ImageNet

Aplicações
• Processamento de linguagem natural – Combinando a ideia de representação distribuída para dados simbólicos e uma arquitetura convolucional, Colobert et al. desenvolveram o sistema SENNA
– Esse sistema comparJlha representações entre tarefas como modelagem de linguagem, rotulação de regras de semânJca e parsing sintáJco, obtendo resultados que superam ou se aproximam do estado-‐da-‐arte

Aplicações
• Transferência de aprendizagem e aprendizagem mul9tarefa – Transferência em aprendizagem é a habilidade do algoritmo de aprendizagem de extrapolar pontos em comum em diferentes tarefas e transferir conhecimento entre elas
– Conferências como ICML e NIPS possuem desafios nessa área, com arquiteturas DL vencedoras
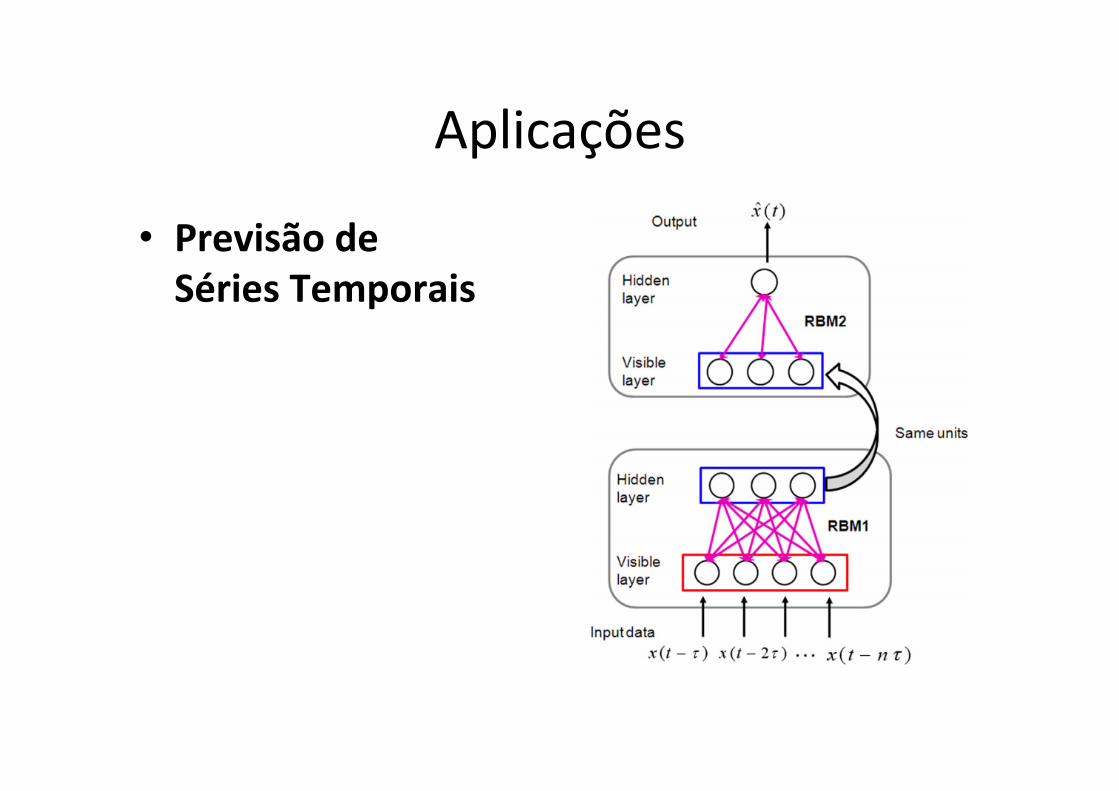
Aplicações
• Previsão de Séries Temporais

Mídia

Mídia
Scientists See Promise in Deep-Learning Programs John Markoff November 23, 2012

Mídia

Mídia

Mídia

Demos (h�p://deeplearning.net/demos/)
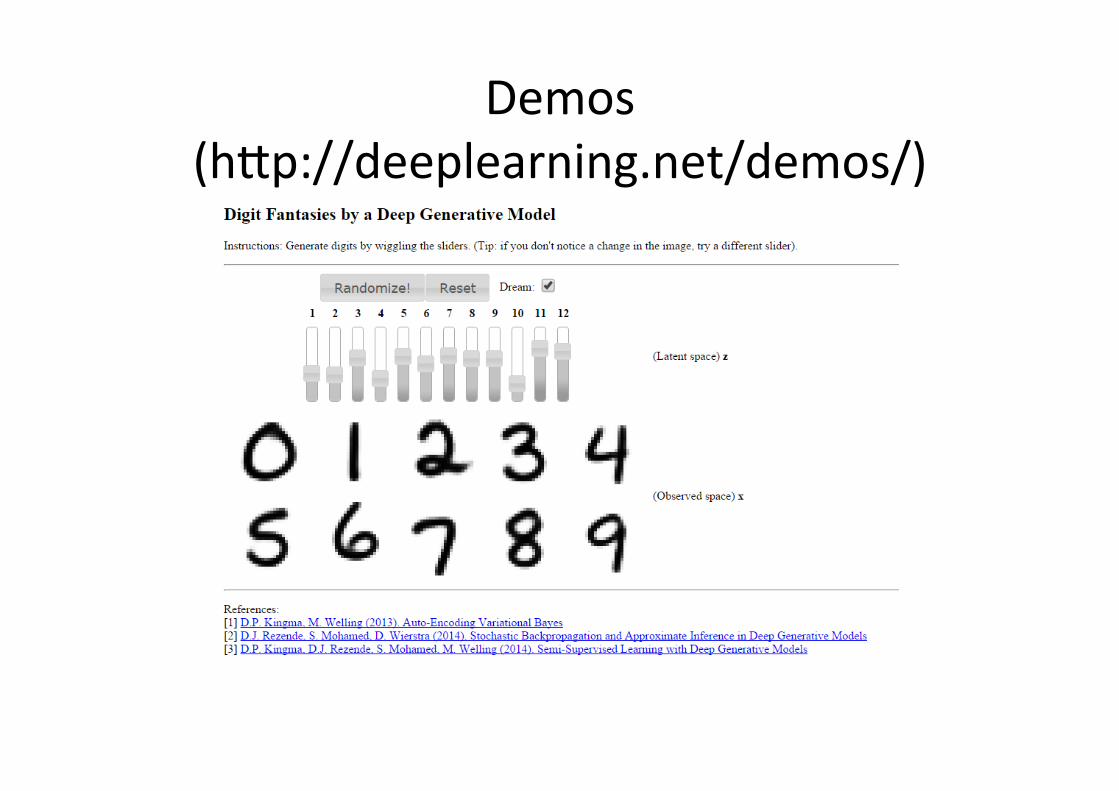
Demos (h�p://deeplearning.net/demos/)

Demos (h�p://deeplearning.net/demos/)

Demos (h�p://deeplearning.net/demos/)

So�ware

Futuro • Codificação esparsa, onde a alta dimensionalidade dos
dados é reduzida através do uso da teoria dos sinais comprimidos, permiJndo representações acuradas desses sinais em vetores com tamanho menor. Sparse Auto-‐Encoders já uJlizam esse conceito
• Aprendizagem semi-‐supervisionada, onde a dimensionalidade é reduzida medindo-‐se as similaridades entre amostras de treinamento, projetando essas similaridades em espaços com menor dimensão
• Escala • UJlização de abordagens evolucionárias em alguns
procedimentos dos modelos Deep Learning

Por onde começar?
• Deep Learning in Neural Networks -‐ An Overview, Jurgen Schmidhuber
• Deep Learning of RepresentaJons -‐ Looking Forward, Yoshua Bengio
• Learning Deep Architectures for AI, Yoshua Bengio
• RepresentaJon Learning -‐ A Review and New PerspecJves, Yoshua Bengio et al


















