



Deep Neural Networks that talk (Back)… with style
52
WITH STYLE DEEP NEURAL NETWORKS THAT TALK (BACK)… @graphific Roelof Pieters Vienna 2016
-
Upload
roelof-pieters -
Category
Education
-
view
755 -
download
2
Transcript of Deep Neural Networks that talk (Back)… with style

WITH STYLE
DEEP NEURAL NETWORKS THAT TALK (BACK)…
@graphific
Roelof Pieters
Vienna 2016
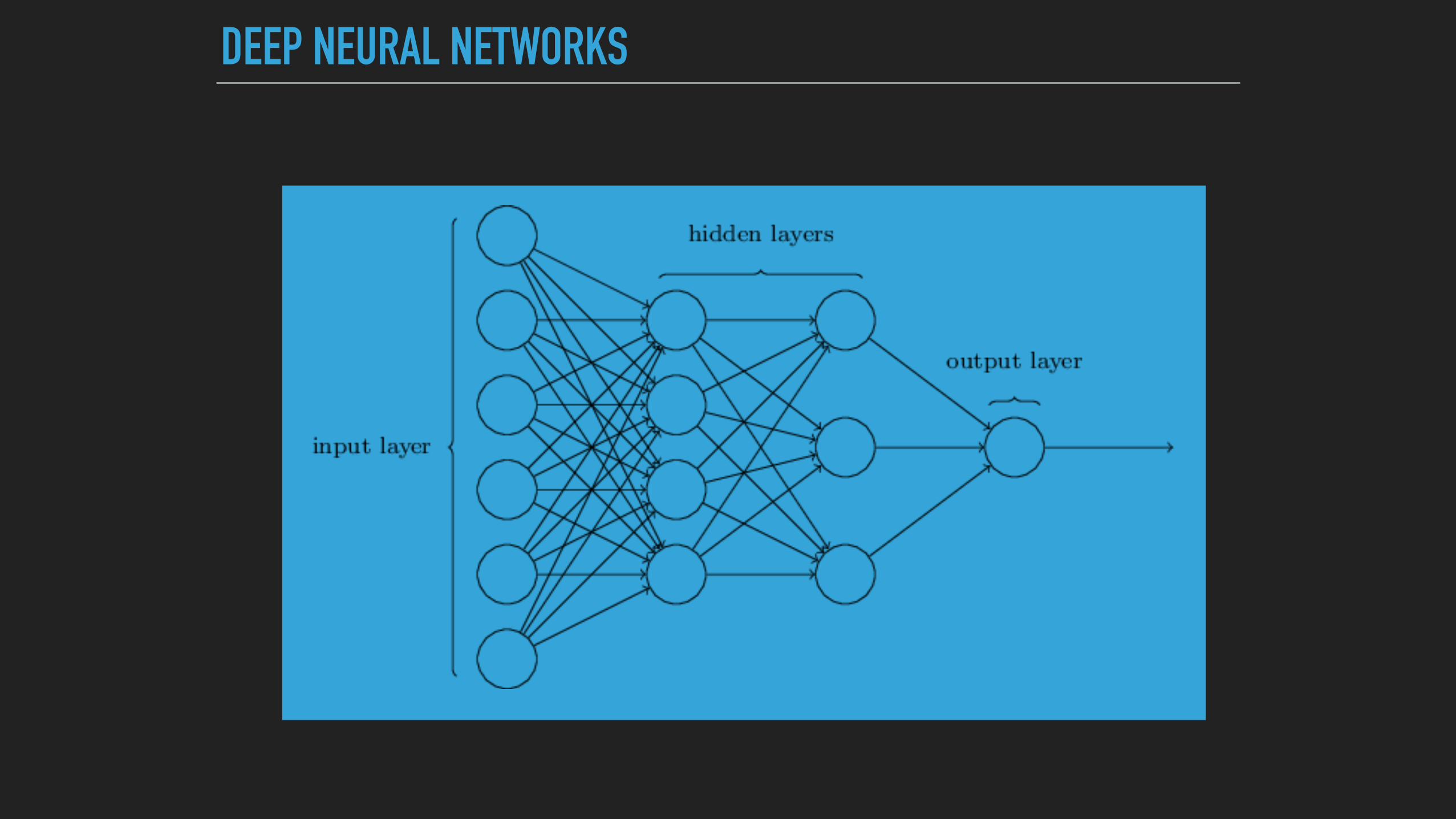
DEEP NEURAL NETWORKS

COMMON GENERATIVE ARCHITECTURES▸ AE/VAE
▸ DBN
▸ Latent Vectors/Manifold Walking
▸ RNN / LSTM /GRU
▸ Modded RNNs (ie Biaxial RNN)
▸ CNN + LSTM/GRU
▸ X + Mixture density network (MDN)
▸ Compositional Pattern-Producing Networks (CPPN)
▸ NEAT
▸ CPPN w/ GAN+VAE.
▸ DRAW
▸ GRAN
▸ DCGAN
▸ DeepDream & other CNN visualisations
▸ Splitting/Remixing NNs:
▸ Image Analogy
▸ Style Transfer
▸ Semantic Style Transfer
▸ Texture Synthesis

DEEP NEURAL NETWORKS
▸ Here we mean the recurrent variants…
(karpathy.github.io/2015/05/21/rnn-effectiveness/)

▸ One to one
▸ just like a normal neural network
▸ ie Image Categorization
RECURRENT NEURAL NETWORKS
EEVEE

▸ One to many
▸ example: image captioning
RECURRENT NEURAL NETWORKS
(Vinyals et al., 2015)

▸ Many to one
▸ example: sentiment analysis
RECURRENT NEURAL NETWORKS
+++

▸ Many to many
▸ output at end (machine translation?) or at each timestep (char-rnn !!)
RECURRENT NEURAL NETWORKS

NEURAL NETWORKS CAN…

SAMPLE / CONDUCT / PREDICT

NEURAL NETWORKS CAN SAMPLE (XT > XT+1)
RECURRENT NEURAL NETWORK (RNN/LSTM) SAMPLING
▸ (Naive) Sampling
▸ Scheduled Sampling (ML) Bengio et al 2015
▸ Sequence Level (RL) Ranzati et al 2016
▸ Reward Augmented Maximum Likelihood (ML+RL) Nourouzi et al forthcoming

▸ Approach used for most recent “creative” generations
▸ (Char-RNN, Torch-RNN, etc)
LSTM SAMPLING (GRAVES 2013)

SCHEDULED SAMPLING (BENGIO ET AL 2015)
▸ At training start with ground truth and slowly move towards using model predictions as next steps

SEQUENCE LEVEL TRAINING (RANZATO ET AL 2016)
▸ Use model predictions as next steps, but continuous reward/loss through Reinforcement Learning

REWARD AUGMENTED MAXIMUM LIKELIHOOD (NOUROUZI ET AL FORTHCOMING)
▸ Generate targets sampled around the correct solution
▸ “giving it mostly wrong examples to learn the right ones”

NEURAL NETWORKS CAN…

TRANSLATE
TRANSLATE

TRANSLATE (X == Y)
Are you going to Nuclai?
will there!
Damn right you are homey!
Ofcourse beI

NEURAL NETWORKS CAN…
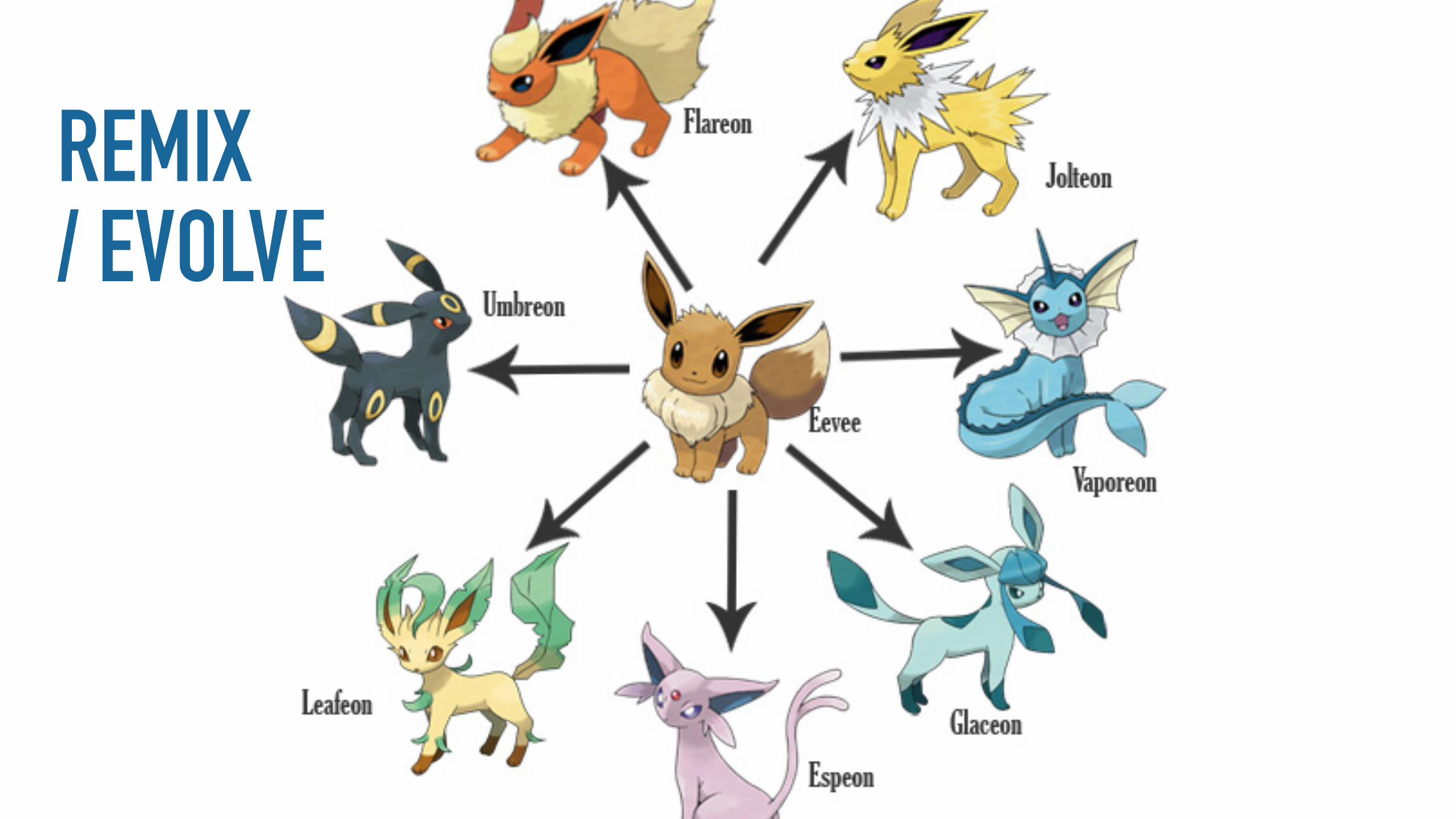
REMIX/ EVOLVE

NEURAL NETWORKS CAN (RE)MIX / TRANSFER (X > Y) / (Z = X+Y)

NEURAL NETWORKS CAN…

HALLUCINATE

NEURAL NETWORKS CAN HALLUCINATE {*X*}

NEURAL NETWORKS CAN
HALLUCINATE {*X*}
https://www.youtube.com/watch?v=oyxSerkkP4o
https://vimeo.com/134457823 https://www.youtube.com/watch?v=tbTJH8aPl60
https://www.youtube.com/watch?v=NYVg-V8-7q0

▸ Possible to learn and generate:
▸ Audio
▸ Images
▸ Text
▸ … anything basically…
▸Revolution ?
RECURRENT NEURAL NETWORKS

IF I CAN’T DANCE IT’S NOT MY REVOLUTION.
Emma Goldman

http://www.creativeai.net/posts/qPpnatfMqwMKXPEw7/chor-rnn-generative-choreography-using-deep-learning

http://www.creativeai.net/posts/qPpnatfMqwMKXPEw7/chor-rnn-generative-choreography-using-deep-learning

RECURRENT NEURAL NETWORKS
Robin Sloan, Writing with the machine

EARLY LSTM MUSIC COMPOSITION (2002)
Douglas Eck and Jurgen Schmidhuber (2002) Learning The Long-Term Structure of the Blues?

AUDIO GENERATION: MIDI
Douglas Eck and Jurgen Schmidhuber (2002) Learning The Long-Term Structure of the Blues?
▸ https://soundcloud.com/graphific/pyotr-lstm-tchaikovsky
A Recurrent Latent Variable Model for Sequential Data, 2016,
J. Chung, K. Kastner, L. Dinh, K. Goel, A. Courville, Y. Bengio
+ “modded VRNN:

AUDIO GENERATION: MIDI
Douglas Eck and Jurgen Schmidhuber (2002) Learning The Long-Term Structure of the Blues?
▸ https://soundcloud.com/graphific/neural-remix-net
A Recurrent Latent Variable Model for Sequential Data, 2016,
J. Chung, K. Kastner, L. Dinh, K. Goel, A. Courville, Y. Bengio
+ “modded VRNN:

https://soundcloud.com/graphific/neural-remix-net
Gated Recurrent Unit (GRU)stanford cs224d projectAran Nayebi, Matt Vitelli (2015) GRUV: Algorithmic Music Generation using Recurrent Neural Networks
AUDIO GENERATION: RAW (MP3)

BOTS?
PLAY SAFE…


PLAYING WITH NEURAL NETS #1PLAYING WITH NEURAL NETS #1

PLAYING WITH NEURAL NETS #2PLAYING WITH NEURAL NETS #2

PLAYING WITH NEURAL NETS #3PLAYING WITH NEURAL NETS #3

PLAYING WITH NEURAL NETS #4PLAYING WITH NEURAL NETS #4

Wanna be Doing Deep Learning?

python has a wide range of deep learning-related libraries available
Deep Learning with Python
Low level
High level
deeplearning.net/software/theano
caffe.berkeleyvision.org
tensorflow.org/
lasagne.readthedocs.org/en/latest
and of course:
keras.io

https://medium.com/@ArtificialExperience/creativeai-9d4b2346faf3

Questions?love letters? existential dilemma’s? academic questions? gifts?
find me at:www.csc.kth.se/~roelof/
@graphific
Consulting / Projects / Contracts / $$$ / more love letters?http://www.graph-technologies.com/

WHAT ABOUT CONVNETS?▸ Awesome for interpreting features
▸ Recurrence can be “kind” of achieved with
▸ long splicing filters
▸ pooling layers
▸ smart architectures

Yoon Kim (2014) Convolutional Neural Networks for Sentence Classification
Xiang Zhang, Junbo Zhao, Yann LeCun (2015) Character-level Convolutional Networks for Text Classification
NLP

AUDIOKeunwoo Choi, Jeonghee Kim, George Fazekas, and Mark Sandler (2016) Auralisation of Deep Convolutional Neural Networks: Listening to Learned Features

AUDIO
Keunwoo Choi, George Fazekas, Mark Sandler (2016) Explaining Deep Convolutional Neural Networks on Music Classification
audio at: https://keunwoochoi.wordpress.com/2016/03/23/what-cnns-see-when-cnns-see-spectrograms/

AUDIO


















