

Deep Neural Networks for Multimodal Learning
28
Deep Neural Networks for Multimodal Learning Presented by: Marc Bolaños Álvaro Peris Francisco Casacuberta Marc Bolaños Petia Radeva
-
Upload
marc-bolanos-sola -
Category
Science
-
view
188 -
download
1
Transcript of Deep Neural Networks for Multimodal Learning

Deep Neural Networks for Multimodal Learning
Presented by: Marc Bolaños
Álvaro Peris
Francisco Casacuberta
Marc Bolaños
Petia Radeva

Multimodal TasksVideo
DescriptionMultimodal Translation
Multimodal Description
Visual Question Answering
Dense Captioning
Image Description

Multimodal TasksVideo
DescriptionMultimodal Translation
Multimodal Description
Visual Question Answering
Dense Captioning
Image Description

Multimodal TasksVideo
DescriptionMultimodal Translation
Multimodal Description
Visual Question Answering
Dense Captioning
Image Description
Two young guys with shaggy hair look at their hands while hanging out in the yard.Two young, White males are outside near many bushes.Two men in green shirts are standing in a yard.A man in a blue shirt standing in a garden.Two friends enjoy time spent together.
Dos hombres están en el jardín.

Multimodal TasksVideo
DescriptionMultimodal Translation
Multimodal Description
Visual Question Answering
Dense Captioning
Image Description
A man is smiling at a stuffed lion.
Un hombre sonríe a un león de peluche.

Multimodal TasksVideo
DescriptionMultimodal Translation
Multimodal Description
Visual Question Answering
Dense Captioning
Image Description
Q: What kind of store is this?A: bakery
Q: What number is the bus?A: 48

Multimodal TasksVideo
DescriptionMultimodal Translation
Multimodal Description
Visual Question Answering
Dense Captioning
Image Description

Multimodal Tasks - Basic NN Components
Long-Short Term Memory (LSTM)Convolutional Neural Network (CNN)
Attention Mechanism
where
is
the
giraffe
LSTM
LSTM
LSTM
LSTMdónde
está
la
jirafa
LSTM
LSTM
LSTM
LSTM <EOS>
.
.
.
v1
v2
vn
α1(t)
α2(t)
αn(t)
.
.
.
LSTMt-1
n
∑ αi(t) vi
i=1LSTMt

[Task 1] Video Description
Venugopalan S, Xu H, Donahue J, Rohrbach M, Mooney R, Saenko K. Translating videos to natural language using deep recurrent neural networks. arXiv preprint arXiv:1412.4729. 2014 Dec 15.
Two men working on a high building
Two teams are playing soccer
● 1970 open domain clips collected from YouTube.● Annotated using a crowdsourcing platform.● Variable number of captions per video.● 80.000 different video-caption pairs.
Microsoft Video Description (MSVD) Dataset

[Task 1] Video Description - Model
CNN( )
CNN( )
CNN( )
.
.
.
LSTM j=1
LSTM j=J
LSTM j=2
LSTM j=J
LSTM j=2
LSTM j=1
.
.
.
.
.
.
LSTM t=1
LSTM t=2
.
.
.
.
.
.
SOFT ATTENTION
MODEL
LSTM t=T
ENCODER DECODER
.
.
.
Two
elephants
water
.
.
.
.
.
.
Álvaro Peris, Marc Bolaños, Petia Radeva, and Francisco Casacuberta. "Video Description using Bidirectional Recurrent Neural Networks." In Proceedings of the International Conference on Artificial Neural Networks (ICANN) (IN PRESS) (2016)
Sentence generation: argmaxy P(y|y1 ,...,yt-1,x1,...,xJ)

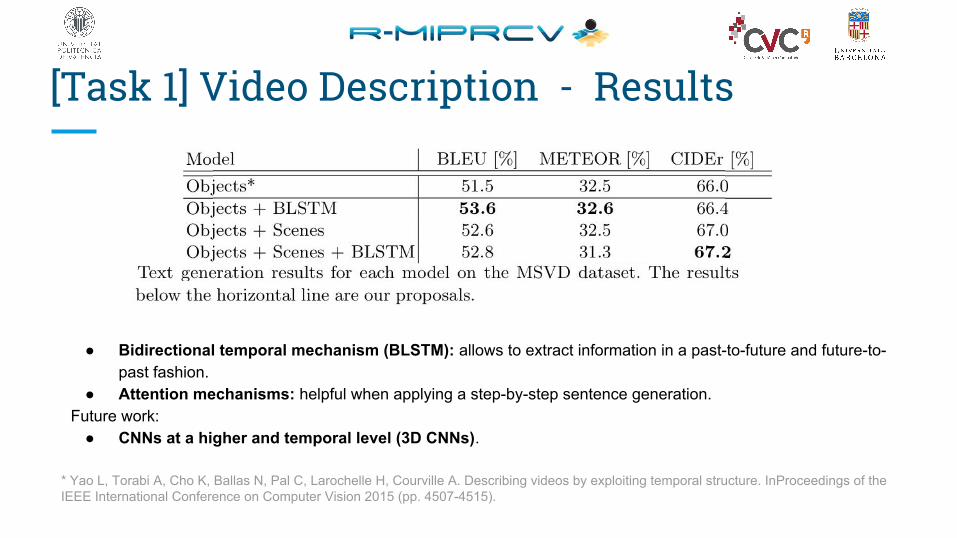
[Task 1] Video Description - Results
* Yao L, Torabi A, Cho K, Ballas N, Pal C, Larochelle H, Courville A. Describing videos by exploiting temporal structure. InProceedings of the IEEE International Conference on Computer Vision 2015 (pp. 4507-4515).
● Bidirectional temporal mechanism (BLSTM): allows to extract information in a past-to-future and future-to-past fashion.
● Attention mechanisms: helpful when applying a step-by-step sentence generation.Future work:
● CNNs at a higher and temporal level (3D CNNs).

[Task 2] Visual Question AnsweringVQA Dataset Open-Ended question answering task
Antol S, Agrawal A, Lu J, Mitchell M, Batra D, Lawrence Zitnick C, Parikh D. Vqa: Visual question answering. InProceedings of the IEEE International Conference on Computer Vision 2015 (pp. 2425-2433).
● 200.000 images● 3 questions per image● 10 (SHORT) answers per question annotated by
different users

[Task 2] VIBIKNet for VQA
SO
FTM
AX
text embedding(GLOVE initialization)
LSTMforward
LSTMforward
LSTMforward
visual embedding
LSTMbackward
LSTMbackward
LSTMbackward
KCNN(L2 norm)
element-wise summation
vector concatenation
BidirectionalLSTM
[ , ]
[ , ]
where
is
the
giraffe
LSTMforward
LSTMbackward
behind fence
Marc Bolaños, Álvaro Peris, Francisco Casacuberta and Petia Radeva. "VIBIKNet: Visual Bidirectional Kernelized Network for Visual Question Answering" Challenge on Visual Question Answering CVPR (no proceedings) (2016)
Answer generation: argmaxa P(a|q1 ,...,qn,x)

[Task 2] VIBIKNet for VQA - Results

[Task 2] VIBIKNet for VQA - Results
Model Accuracy [%] on dev 2014 Accuracy [%] on test 2015
Yes/No Number Other Overall Yes/No Number Other Overall
LSTM 79.00 38.16 33.68 52.88 - - - -
BLSTM 79.13 38.26 33.52 52.96 78.30 38.88 38.97 54.86
BLSTMtrain+dev
- - - - 78.88 36.33 40.27 56.1
● Classification models work better than generative models on datasets with simple answers.● Models for compacting and jointly describing the information (KCNN) present in the
images seem promising.● The use of pre-trained but adaptable representations is crucial for small and medium-sized
datasets.

[Task 3] Image Description
img1 CNN
LSTM A
LSTM
LSTM
.
.
.
rally
road
.
.
.
● Image Description formulated as a translation problem:
Sentence generation: argmaxy P(y|y1 ,...,yt-1,x)
Basic initial tests on Flickr8k obtaining a result of BLEU = 20.2%

Embed.
[Task 4] Multimodal Translation
● Translation problem aided by image information:
Embed
Embed
.
.
.
LSTM t=1
LSTM t=2
.
.
.
SOFT ATTENTION
MODEL
LSTM t=T
ENCODER DECODER
Dos
elefantes
agua
.
.
.
Sentence translation: argmaxy P(y|y1 ,...,yt-1, x, z1,...,zJ)
Two
elephants
water
z1
.
.
.
z2
zJ
KCNN[ , ]
[ , ]
[ , ]
Basic initial tests on Flickr30k ACLTask1 Challenge obtaining a result of METEOR = 41.2%
BLSTM...

Future Directions
We are working on adding several state-of-the-art architectures and ideas:
● Highway Networks
● Compact Bilinear Pooling
● Class Activation Maps
Srivastava RK, Greff K, Schmidhuber J. Highway networks. arXiv preprint arXiv:1505.00387. 2015 May 3.
Gao Y, Beijbom O, Zhang N, Darrell T. Compact bilinear pooling. arXiv preprint arXiv:1511.06062. 2015 Nov 19.
Zhou B, Khosla A, Lapedriza A, Oliva A, Torralba A. Learning Deep Features for Discriminative Localization. arXiv preprint arXiv:1512.04150. 2015 Dec 14.

Collaboration supported by the R-MIPRCV:
● Stay of Marc Bolaños (CVC-UB) at UPV, 2015.● Stay of Álvaro Peris (UPV) at UB, 2016.● To be extended with the incorporation of UGR (stay of a PhD student October, 2016).
Publications and challenges:
● ICANN’2016● CVPR’2016
Resume
www.github.com/MarcBS/VIBIKNet
Download VIBIKNet


Multimodal Tasks - Basic NN Components
Convolutional Neural Network (CNN)

Multimodal Tasks - Basic NN Components
where
is
the
giraffe
LSTM
LSTM
LSTM
LSTMdónde
está
la
jirafa
LSTM
LSTM
LSTM
LSTM <EOS>
Long-Short Term Memory (LSTM)

Multimodal Tasks - Basic NN Components
Attention Mechanism
.
.
.
v1
v2
vn
α1(t)
α2(t)
αn(t)
.
.
.
LSTMt-1
LSTMt

[Task 2] VIBIKNet for VQA - Kernelized CNN
Object Detector PCA
Gaussian Mixture Model(Fisher Vectors)
PCA
GoogLeNet
PCA
PCA
PCA
GoogLeNet
GoogLeNet
GoogLeNet
CNNfeaturevector
KCNNfeaturevector
Liu Z. Kernelized Deep Convolutional Neural Network for Describing Complex Images. arXiv preprint arXiv:1509.04581. 2015 Sep 15.

Embed.
[Task 4] Multimodal Translation
● Translation problem aided by image information:
Embed
Embed
.
.
.
LSTM j=1
LSTM j=J
LSTM j=2
LSTM j=J
LSTM j=2
LSTM j=1
.
.
.
.
.
.
LSTM t=1
LSTM t=2
.
.
.
.
.
.
SOFT ATTENTION
MODEL
LSTM t=T
ENCODER DECODER
Dos
elefantes
agua
.
.
.
.
.
.
Sentence translation: argmaxy P(y|y1 ,...,yt-1, x, z1,...,zJ)
Two
elephants
water
z1
.
.
.
z2
zJ
KCNN[ , ]
[ , ]
[ , ]
Basic initial tests on Flickr30k ACLTask1 Challenge obtaining a result of BLEU = 20.2

Deep Neural Networks for Multimodal Learning
Presented by: Marc Bolaños
where
is
the
giraffe
behind
CNN
BLSTM
the
fence
LSTM
[Task 1] Video Description - Results
* Yao L, Torabi A, Cho K, Ballas N, Pal C, Larochelle H, Courville A. Describing videos by exploiting temporal structure. InProceedings of the IEEE International Conference on Computer Vision 2015 (pp. 4507-4515).
● Bidirectional temporal mechanism (BLSTM): allows to extract information in a past-to-future and future-to-past fashion.
● Attention mechanisms: helpful when applying a step-by-step sentence generation.Future work:
● CNNs at a higher and temporal level (3D CNNs).

















