











![TWM GAP V1[1].0](https://static.fdocuments.net/doc/165x107/577d36b11a28ab3a6b93c171/twm-gap-v110.jpg)
Deep learning Libs @twm
70
深層学習ライブラリの 現在 2015-10-24 @WebTokyoMining 1
-
Upload
yuta-kashino -
Category
Technology
-
view
16.098 -
download
0
Transcript of Deep learning Libs @twm

深層学習ライブラリの 現在
2015-10-24 @WebTokyoMining
1

今日の内容• 自己紹介
• 深層学習 学習リソース
• 神経回路網と実装
• 深層学習ライブラリ
• 主要深層学習ライブラリの特徴
• モデル実装の違い2

自己紹介
3

自己紹介• バクフー株式会社 代表取締役 柏野 雄太 (かしの ゆうた)
• 大規模リアルタイムデータのデータプラットフォーム
• PPPP preprocess /process /persistence /providing
4

自己紹介• 大規模リアルタイムのデータプラットフォーム
リアルタイムデータ 前処理 処理 ストア 提供
tweets 整形 自然言語処理・分類 API, 検索, 可視化
気象データ 変換 分類・異常値検知 API, 検索,ストリーミング
位置データ 変換 分類 API, 検索, ストリーミング
経済データ 整形・変換 異常値検知 API, 検索, 可視化6

自己紹介• Zope3の開発
• Python • いくつかの本
• PyCon JP 2015でのトーク
• バックグラウンドは宇宙物理学
• 大規模データ統計解析,科学計算
• 深層学習ウオッチャー: 2012年Hinton講義
https://goo.gl/GG4Bo8
https://www.coursera.org/course/neuralnets7

ご注意
8

本日のターゲット層• PyLearn2やCaffeやChainerなどのexampleを動作させたけれど,その後どうすればわからない人
• 岡谷本を読んだけれど,結構目が泳いでしまった人
• Model Zooの学習済みモデルしか利用したことの無い人
9

このトークで話さないこと• モデルを沢山だしません
• 最新の学術的トピックもだしません
• Dropout, Whitening, Batch Normalisation, Maxoutなど重要ですがややこしくなるものは割愛します
• モデルの評価,グリッドサーチ,計算機実験の話もしません
• シンギュラリティや「人工知能」の話もしません10

深層学習ライブラリ狂騒• 2014年から2015年の前半,毎週のように新しい深層学習ライブラリが話題に
• 新しいライブラリの出現は最近はピークアウトしています
• 今回のトークを申し出た時期は,狂騒的な時期でした
• 状況が変化していますので,話す内容も少し汎用的なものにします.
11

DLのモデリングができる
深層学習の基礎を取得済み
12

深層学習 学習リソース
13

動画講義 (全力でオススメ)
• Deep Learning Summer School 2015
• Hugo Larochelle (Twitter/U of Sherbrooke)
• Nando de Freitas (Oxford)
• CS231n: CNN for Visual Recognition
• CS224d: DL for Natural Language Processing
http://videolectures.net/deeplearning2015_montreal/
http://cs231n.stanford.edu/
http://cs224d.stanford.edu/index.html
https://www.cs.ox.ac.uk/people/nando.defreitas/machinelearning/
https://goo.gl/UWtRWT
14

書籍• 古典: Bengio et.al. 2015 DLBook
• Theano Tutorial
• Neural Networks and Deep Learning
• 岡谷貴之著 深層学習 (機械学習プロ)
• 神嶌敏弘編 深層学習: Deep Learning
http://www.iro.umontreal.ca/~bengioy/dlbook/
http://neuralnetworksanddeeplearning.com/
http://deeplearning.net/tutorial/deeplearning.pdf
15

神経回路網と実装
16

神経回路の数理表現
17
h
(k)(x) = g(a(k)(x))
a
(k)(x) = b
(k) +W
(k)h
(k�1)(x)
…
…
…1
1
1b(3)
b(2)
b(1)W (1)
W (2)
W (3)
x1 x2 xd
a
(3)(x) = b
(3) +W
(3)h
(2)(x)
= b
(3) +W
(3)g(b(2) +W
(2)h
(1)(x))
= b
(3) +W
(3)g(b(2) +W
(2)g(b(1) +W
(1)x))
h
(0)(x) = x
h
(1)(x) = g(a(1)(x))
h
(2)(x) = g(a(2)(x))
a
(1)(x) = b
(1) +W
(1)h
(0)(x)
a
(2)(x) = b
(2) +W
(2)h
(1)(x)
a
(3)(x) = b
(3) +W
(3)h
(2)(x)
h
(3)(x) = o(a(3)(x))
= f(x)
a
(1)(x)
a
(2)(x)
a
(3)(x)
h
(2)(x)
h
(1)(x)
f(x) = h
(3)(x)
g
g
o
b(1)W (1)
b(3)
b(2)
W (2)
W (3)
x

マルチレイヤー神経回路• L個の隠れ層の神経回路
• プレ活性
• 隠れ層活性
• 出力層活性
• レイヤーは関数適用に他ならない
18
h
(k)(x) = g(a(k)(x))
a
(k)(x) = b
(k) +W
(k)h
(k�1)(x)
h
(L+1)(x) = o(a(L+1)(x))
= f(x)
a
(1)(x)
a
(2)(x)
a
(3)(x)
h
(2)(x)
h
(1)(x)
f(x) = h
(3)(x)
g
g
o
b(1)W (1)
b(3)
b(2)
W (2)
W (3)
x

機械学習と損失関数• パラメータ・トレーニングセット
• 目的関数最小化
• 損失関数・正則関数a
(1)(x)
a
(2)(x)
a
(3)(x)
h
(2)(x)
h
(1)(x)
f(x) = h
(3)(x)
g
g
o
b(1)W (1)
b(3)
b(2)
W (2)
W (3)
x
l(f(x), y)
✓ = {W (1), b(1), ...,W (L+1), b(L+1)}
(x(t), y(t))
⌦(✓)
l(f(x(t);✓), y(t)) = �logf(x(t)
)y
L(✓) =1
T
X
t
l(f(x(t);✓), y(t)) + �⌦(✓)
argmin✓L(✓)
19

勾配降下と確率的勾配降下• 目的関数Lを最小化:勾配の方向にθを動かす
• 確率的勾配降下:ミニバッチ t だけをみて勾配計算
� = �r✓l(f(x(t);✓), y(t))
✓ ✓ + ↵�
Lの等高線
α: 学習率
20

勾配の計算:誤差逆伝搬• 目的関数を最小にするには勾配の計算が必要
• 勾配の計算=誤差逆伝搬 � = �r✓l(f(x(t);✓), y(t))
✓ ✓ + ↵�
a
(1)(x)
a
(2)(x)
a
(3)(x)
h
(2)(x)
h
(1)(x)
f(x) = h
(3)(x)
g
g
o
b(1)W (1)
b(3)
b(2)W (2)
W (3)
x
l(f(x), y)
a
(1)(x)
a
(2)(x)
a
(3)(x)
h
(2)(x)
h
(1)(x)
f(x) = h
(3)(x)
g
g
o
b(1)W (1)
b(3)
b(2)W (2)
W (3)
x
l(f(x), y)
rW
(2) l(f(x), y) ra
(2)(x)l(f(x), y)h(2)(x)T
ra
(2)(x)l(f(x), y) rh
(2)(x)l(f(x), y)� [..., g0(a(2)(x)), ...]
rh
(2)(x)l(f(x), y) W
(3)Tra
(3)(x)l(f(x), y)
21

勾配の計算:誤差逆伝搬• Hugo Larochelleの講義にGo https://goo.gl/UWtRWT
a
(1)(x)
a
(2)(x)
a
(3)(x)
h
(2)(x)
h
(1)(x)
f(x) = h
(3)(x)
g
g
o
b(1)W (1)
b(3)
b(2)W (2)
W (3)
x
l(f(x), y)
a
(1)(x)
a
(2)(x)
a
(3)(x)
h
(2)(x)
h
(1)(x)
f(x) = h
(3)(x)
g
g
o
b(1)W (1)
b(3)
b(2)W (2)
W (3)
x
l(f(x), y)
rW
(2) l(f(x), y) ra
(2)(x)l(f(x), y)h(2)(x)T
ra
(2)(x)l(f(x), y) rh
(2)(x)l(f(x), y)� [..., g0(a(2)(x)), ...]
rh
(2)(x)l(f(x), y) W
(3)Tra
(3)(x)l(f(x), y)
22

勾配の計算:誤差逆伝搬• 主要DLライブラリは勾配を自動に計算 • 実はあまり気にしないでいい
a
(1)(x)
a
(2)(x)
a
(3)(x)
h
(2)(x)
h
(1)(x)
f(x) = h
(3)(x)
g
g
o
b(1)W (1)
b(3)
b(2)W (2)
W (3)
x
l(f(x), y)
a
(1)(x)
a
(2)(x)
a
(3)(x)
h
(2)(x)
h
(1)(x)
f(x) = h
(3)(x)
g
g
o
b(1)W (1)
b(3)
b(2)W (2)
W (3)
x
l(f(x), y)
rW
(2) l(f(x), y) ra
(2)(x)l(f(x), y)h(2)(x)T
ra
(2)(x)l(f(x), y) rh
(2)(x)l(f(x), y)� [..., g0(a(2)(x)), ...]
rh
(2)(x)l(f(x), y) W
(3)Tra
(3)(x)l(f(x), y)
23

ライブラリ利用で必要なのは• データを入れる場所:テンソル • レイヤーの表現 • 活性化関数・出力関数 • 損失関数 • 最適化法 • 勾配計算(誤差伝搬)
• GPUへの対応
a
(1)(x)
a
(2)(x)
a
(3)(x)
h
(2)(x)
h
(1)(x)
f(x) = h
(3)(x)
g
g
o
b(1)W (1)
b(3)
b(2)
W (2)
W (3)
x
l(f(x), y)
24

深層学習ライブラリ
25

DLライブラリ@GitHub
• GitHubにあるWatcherが二人以上 2015-10-20
• “deep learning” : 393
• “theano”: 239
• “caffe”: 281
• 多すぎて全部フォローなどできません.
26

DLライブラリ@GitHub
• “deep learning”をライブラリ別にみると…
27

DLライブラリ@GitHub
• “deep learning”を言語別にみると…
28

DLライブラリ@GitHub
• “theano”をライブラリ別にみると…
29

深層学習汎用ライブラリ
• 汎用ライブラリ(General Purpose) =色々なモデルを構築できる OverFeatのようにCNN特化でなく
• オープンソースである.
• 開発が継続中である.
30

DLライブラリ世代論• 第一世代: GPU対応
• Theano, Torch
• 第二世代: プレトレーニングモデル利用 DIY時代
• Caffe, PyLearn2
• 第三世代: より使いやすく,より速くmulti-GPU
• Keras, Lasagne, Chainer, Neon
31

主要ライブラリ7つ
• Theano
• Torch7
• Caffe
• Keras
• Lasagne
• Chainer
• Neon
32

主要深層学習 ライブラリの特徴
33

Theano• James Bergstra+ (montreal/Bengio) • Python/Cython • GPU:独自(CUDA/cuDNN)
• DLライブラリの草分け
• 強力な自動微分機能,NumPyとシームレス
• 独自のPython → C変換で高速
• 数々のDLライブラリのビルディングブロックに
• 益々開発が活発になっている
https://github.com/Theano/Theano
34
Licence multiGPU Binding ActivityBSD △ ◎

Torch7• Ronan Collobert (FB AI), Koray Kavukcuoglu (G
DeepMind), Clement Farabet (Twitter)
• GPU: cutorch (CUDA/cuDNN/OpenMP)
• Model: Lua
• Matlab風のコーディングをLuaでする
• Lua.JITでCになるので高速
• 拡張性が高い →ライブラリが充実
• 全然現役
http://ronan.collobert.com/pub/matos/2011_torch7_nipsw.pdf
https://github.com/torch/torch7
35
Licence multiGPU Binding ActivityBSD ○ C/C++ ◎

Caffe• Yangqing Jia (Google)
• GPU: 独自(CUDA/cuDNN)
• Model:Protocol Buffer
• モデルプログラムをさせない: ”DIY DL for Vision"
• Model Zoo, Reference models
• 最近元気がない…
https://github.com/BVLC/caffe/
36
Licence multiGPU Binding ActivityBSD - python/matlab △

Keras• François Chollet (Google)
• GPU: Theano
• Model: Python
• クリーンでクリアなモデリング
• Theanoを隠蔽.Theanoの内部データはとれない:ある層の勾配
• 人気が急上昇中
https://github.com/fchollet/keras
37
Licence multiGPU Binding ActivityMIT △ O

Lasagne• Sander Dieleman (G DeepMind)
• GPU: Theano
• Model: Python
• Theano + layer + activ./loss func + optimizer
• 最後には必ずTheanoを触る必要がある
• Theano好きには○,ただ最近元気がない
https://github.com/torch/torch7
38
Licence multiGPU Binding ActivityMIT △ △

Chainer• 得居誠也 (PFI/PFN)
• GPU: cupy (CUDA, cuDNN) 以前はPyCUDA
• Model: Python
• 動的グラフなど設計思想が違う革命児
• ギリギリまでPythonオブジェクトなのでデバグが異常に楽
• PFI/PFNの主力兵器になる可能性
https://github.com/pfnet/chainer
http://www.ustream.tv/recorded/64082997http://goo.gl/z2IjsY
39
Licence multiGPU Binding ActivityMIT ○ ◎

Neon• Arjun Bansal+ (Nervana Systems) G/Fでない…
• GPU: PyCUDAベースの独自
• Model: Python
• 関数・レイヤーなど良く整備され準備されたAPI群を装備
• シングルマシンにおいて汎用DLライブラリ最速
https://github.com/nervanasystems/neon
40
Licence multiGPU Binding ActivityApache ○ ○
https://github.com/soumith/convnet-benchmarks

Reference Manual / Code
• ライブラリを使うには
• Exampleの後は,Reference Manual熟読しましょう.設計思想がわかります.
• そしてソースコードを読みましょう.
41

モデル実装の違い
42
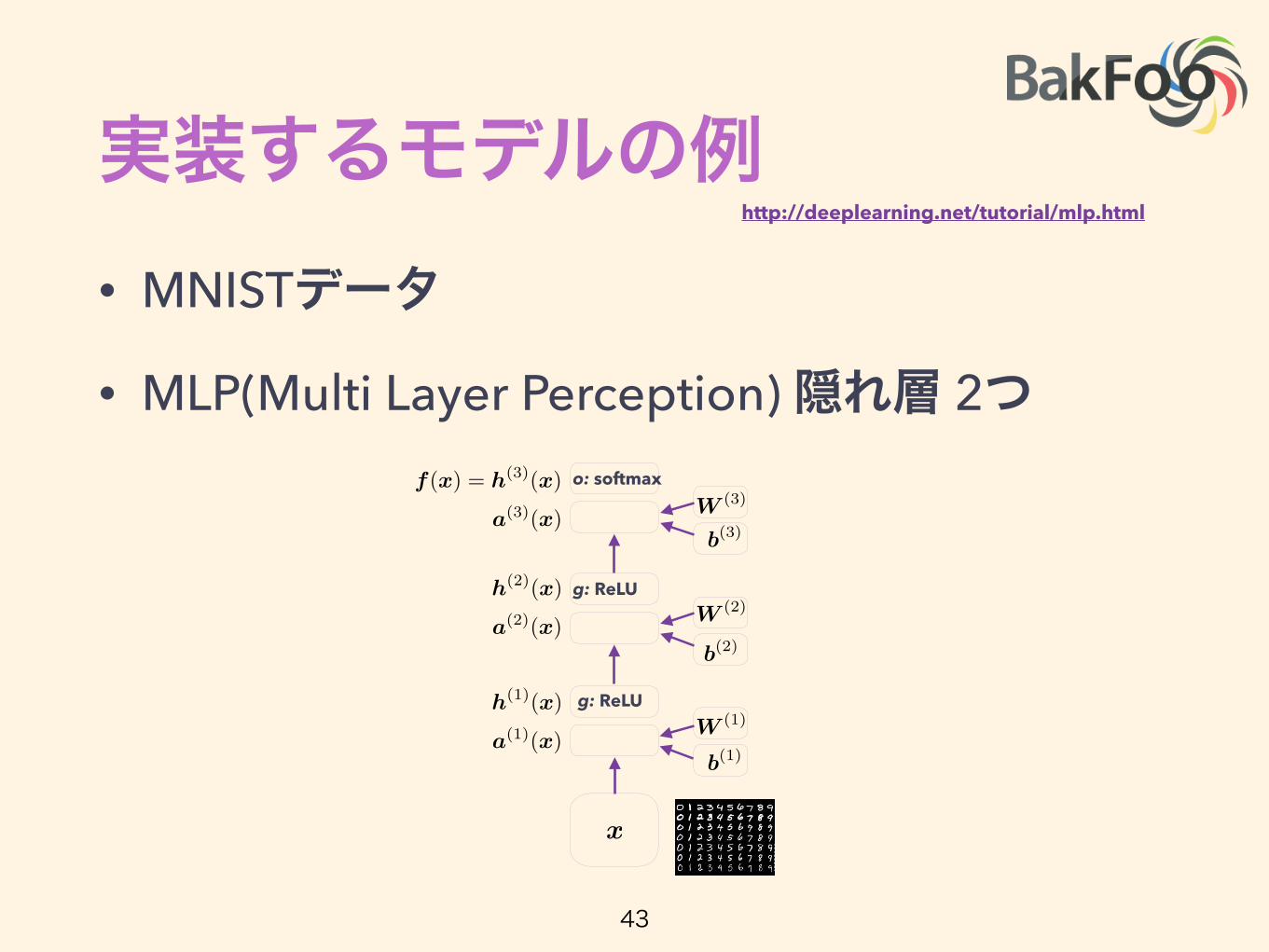
実装するモデルの例• MNISTデータ
• MLP(Multi Layer Perception) 隠れ層 2つ
43
http://deeplearning.net/tutorial/mlp.html
a
(1)(x)
a
(2)(x)
a
(3)(x)
h
(2)(x)
h
(1)(x)
f(x) = h
(3)(x)
b(1)W (1)
b(3)
b(2)
W (2)
W (3)
x
o: softmax
g: ReLU
g: ReLU

Theano https://github.com/Theano/Theano
45
活性化関数,損失関数,レイヤー定義
b(1)W (1)
b(3)
b(2)W (2)
W (3)
x
o: softmax
g: ReLU
g: ReLU

Theano https://github.com/Theano/Theano
46
ネットワーク・グラフ構築+学習
b(1)W (1)
b(3)
b(2)W (2)
W (3)
x
o: softmax
g: ReLU
g: ReLU

Theano https://github.com/Theano/Theano
47
まとめ
テンソル theano.tensor
レイヤー -
モデル構築 高階関数で連鎖させる
活性化関数 theano.tensor.nnet
損失関数 theano.tensor.nnet
最適化 -
勾配計算 theano.gradient
GPUマップ shared, function
その他

Torch7 https://github.com/torch/torch7
50
まとめ
テンソル torch.Tensor
レイヤー nnの”SimpleLayers”
モデル構築 nnの"Containers"にaddしていく
活性化関数 nnの"Transfer functions"
損失関数 nnの"Criterions"
最適化 optim
勾配計算 nnの"Criterions"のbackwardメソッド
GPUマップ cutorch他
その他

Caffe https://github.com/BVLC/caffe/
51
ネットワーク・グラフ構築

Caffe https://github.com/BVLC/caffe/
52
学習

Caffe https://github.com/BVLC/caffe/
53
まとめ
テンソル Blobs (ndarrayと互換性がある)
レイヤー Layers
モデル構築 protcol bufferにレイヤーを一層一層グラフ構成
活性化関数 Activation/Neuron Layers これもレイヤー
損失関数 Loss
最適化 Solver
勾配計算 Solverが自動で逆誤差伝搬
GPUマップ CUDAドライバのフラグをみて勝手に
その他

Keras https://github.com/fchollet/keras
55
ネットワーク・グラフ構築+学習
b(1)W (1)
b(3)
b(2)W (2)
W (3)
x
o: softmax
g: ReLU
g: ReLU

Keras https://github.com/fchollet/keras
56
まとめ
テンソル numpy.ndarray, theano.tensor
レイヤー keras.layers
モデル構築 keras.modelsオブジェクトにaddしていく
活性化関数 keras.layers.core
損失関数 keras.layers.core
最適化 keras.optimizers
勾配計算 Theano(Kerasからは見えない)
GPUマップ Theano
その他

Lasagne https://github.com/torch/torch7
57
ネットワーク・グラフ構築
b(1)W (1)
b(3)
b(2)W (2)
W (3)
x
o: softmax
g: ReLU
g: ReLU

Lasagne https://github.com/torch/torch7
59
まとめ
テンソル theano.tensor
レイヤー lasagne.layers
モデル構築 lasagne.layersオブジェクトを高階関数で連鎖させる
活性化関数 lasagne.layers
損失関数 lasagne.objectives
最適化 lasagne.updates
勾配計算 Theano(Lasagneからは見えない)
GPUマップ Theano
その他

Chainer https://github.com/pfnet/chainer
61
ネットワーク・グラフ構築
b(1)W (1)
b(3)
b(2)W (2)
W (3)
x
o: softmax
g: ReLU
g: ReLU

Chainer https://github.com/pfnet/chainer
63
まとめ
テンソル chainer.Variable (勾配情報なども.ndarrayの拡張的な)
レイヤー chainer.Function
モデル構築 高階関数の連鎖でgraphをつくる.
活性化関数 chainer.functions
損失関数 chainer.functions
最適化 chainer.Optimizer
勾配計算 chainer.Function.backward()
GPUマップ Function.to_gpu(), chainer.cuda.to_gpu
その他
勾配情報を保持したいときはcainer.FunctionSetにまとめて格納

Neon https://github.com/nervanasystems/neon
67
まとめ
テンソル numpy.ndarray
レイヤー neon.layers
モデル構築 neon.layersを選びリストに追加.neon.models.Modelに
活性化関数 neon.transforms.activation
損失関数 neon.transforms.cost
最適化 neon.optimizers
勾配計算 neon.backends.autodiff
GPUマップ
その他

パフォーマンス• AlexNet (One Weird Trick paper) - Input 128x3x224x224
https://github.com/soumith/convnet-benchmarks
68

まとめ• 深層学習ライブラリは第三世代.どれも甲乙つけがたい.第一世代も現役.
• ライブラリを利用する前に,深層学習の基礎を学びましょう
• ライブラリを利用するにはリファレンスを熟読してソースコードを読みましょう
69


















