
Deep Learning for Vision Part I-Basicsmedialab.sjtu.edu.cn/teaching/CV/Lec/Lec6-DP... ·...
83
Deep Learning for Vision Part I-Basics Associate Prof. Bingbing Ni (倪冰冰) Shanghai Jiao Tong University
Transcript of Deep Learning for Vision Part I-Basicsmedialab.sjtu.edu.cn/teaching/CV/Lec/Lec6-DP... ·...

Deep Learning for Vision
Part I-Basics
Associate Prof. Bingbing Ni (倪冰冰)
Shanghai Jiao Tong University

I guess you are coming to this lecture because of the following:

All about Concepts
It seems to be extremely complicated!
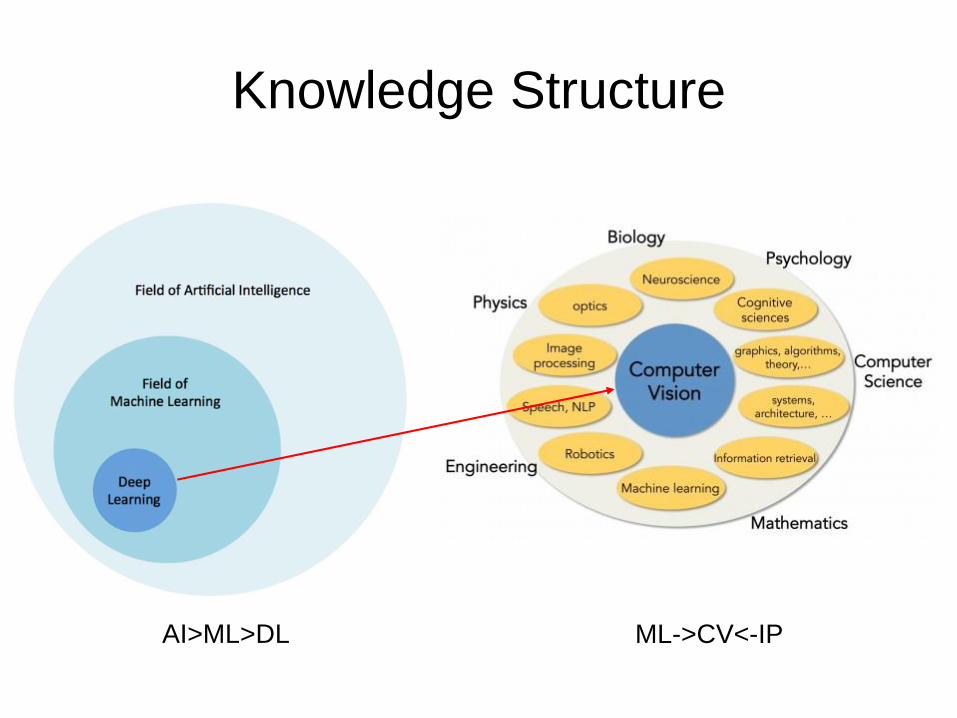
Knowledge Structure
AI>ML>DL ML->CV<-IP

A Little Bit Background of ML/DL
Does Machine Learning algorithms behave like human brain?

The Truth
Unfortunately, the below is the only thing Machine
Learning can do…
Data Label
Learn the mapping function!
Take supervised
learning as example:

CV: From Shallow to Deep

Machine Learning is Simple
In fact, only TWO steps
Design a cost
functionOptimize it

Course Schedule
Lecture 1 Lecture 2 Lecture 3 Lecture 4
Part I Basics:
neurons,
structure,
training
Deep learning
for image
classification
Deep learning
for detection,
segmentation,
tracking
Advances:
RNN,
attention
and more
Part II A tutorial on
state-of-the-art
toolboxes for
deep learning
(by Xiankai Lu)
Two
presentations: 1)
deep learning for
face analysis (by
Peng Zhou)
2) video
segmentation
(by Rui Yang)
A tutorial on
deep learning
for crowd
analysis (by
Minsi Wang)
A tutorial on
GAN (TBD)

References
Stanford: Andrew Ng CS228 Machine Learning
Stanford: Fei-Fei Li CS231n Convolutional Neural Networks for
Visual Recognition

Term Paper
• Write a research report on one of the recommended directions
• 10% of CA
• Evaluation metric: Methodology 30%
Organization 30%
Comprehension 20%
Insight 20%
• Deadline: Friday of week 10, please submit softcopy to Minsi Wang (Email:[email protected])

Today’s Agenda
• Review of shallow learning for CV
• Neuron basics
• Network structure
• Training the network
• Tips on training

Introduction: Classification

Problem Definition

Image Comparison

Challenge
How to compare between images?

Solution: Visual Feature
Visual feature design: to achieve certain level of “invariance”

Visual Features

Visual Features

Visual Features

From Feature to Classifier

Classifier
Feature f(x)
“x”
Label:
“cat”

Linear Classifier

Linear Classifier
yi = f(x,W) = wiTx + bDecision boundaries:

Loss Function

Loss Function

Optimization: Gradient Decent

Many Classifiers
kNN classifier
SVM classifier
Boosting classifier Random forest classifier

Training and Testing
Select feature,
classifier
prototype

From Shallow to Deep

From Shallow to Deep

Introduction
Biological neural network example

Introduction
Biological neural network example
马克.夏卡尔超现实主义画家

Introduction
Human brain
树突
轴突突触
Connection and message passing!

Neuron
Model of a neuron

Neuron
Model of a neuron

Neuron
Model of a neuron

Neuron
Types of activation functions

Neuron
Types of activation functions

Neuron
Derivative of a Sigmoid function

Neuron
An example

Neuron
An example

Network Architecture
What is network architecture?

Network Architecture
Single layer feed forward network

Network Architecture
Multi-layer feed forward network

Network Architecture
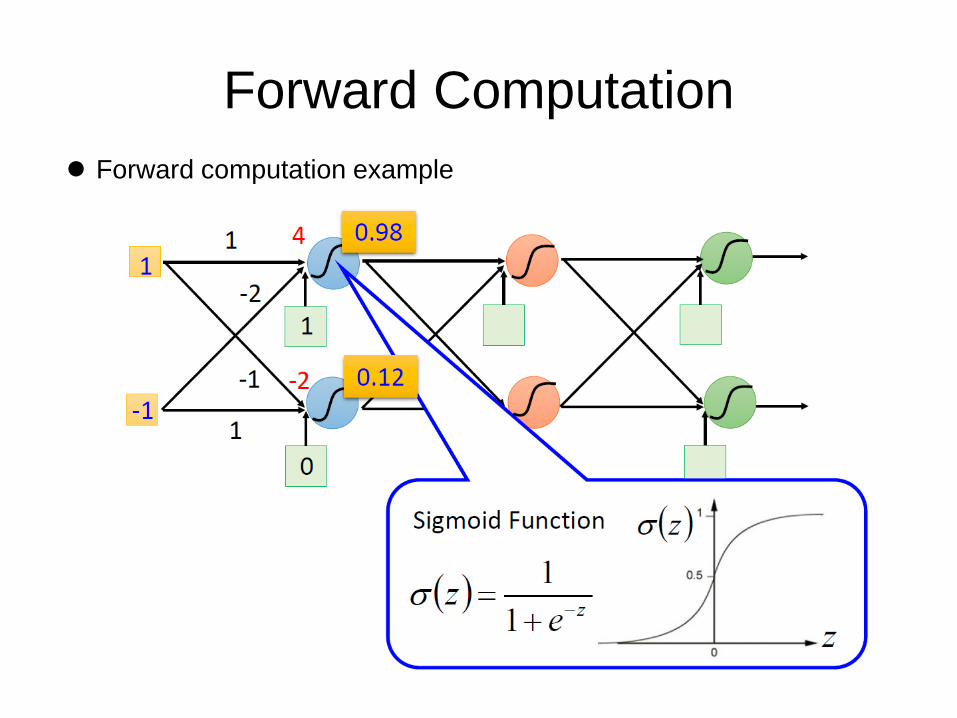
Forward Computation
Forward computation example

Forward Computation
Forward computation example

Forward Computation
Implementation of forward computation
MN
X: M-by-1 vector; W1: N-by-M matrix; b1: N-by-1 vector; h1: N-by-1 vector
W1* X = h1

Backward Computation
“Backforward” means to compute derivative for each network
parameter

Backward Computation

Backward Computation
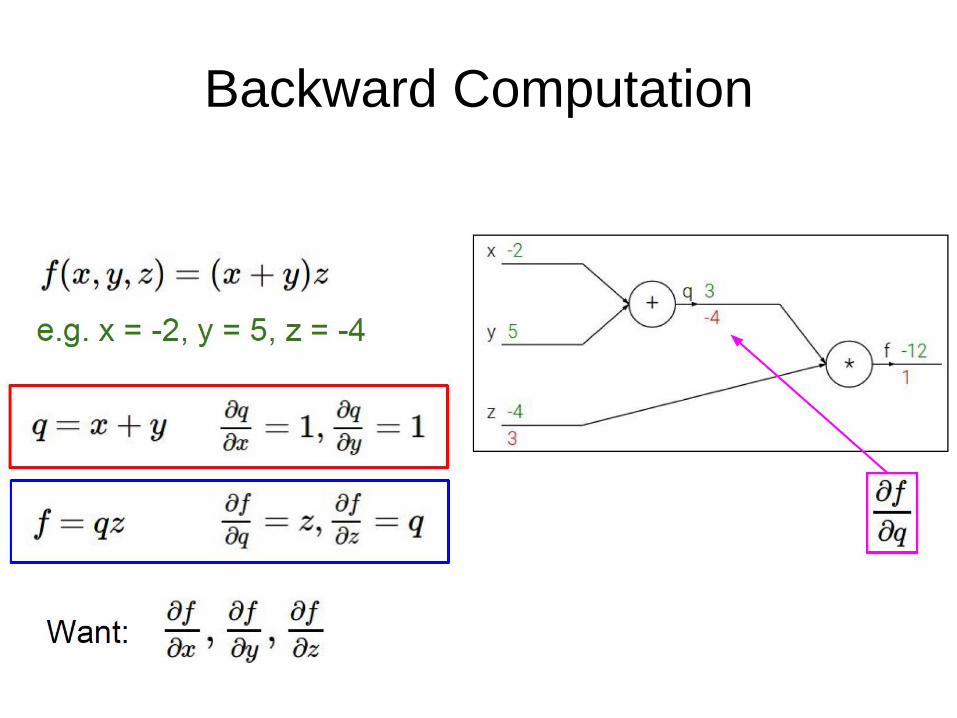
Backward Computation

Backward Computation

Backward Computation

Back Propagation
Information flow backward to update network parameters

Back Propagation
Implementation of forward-backward computation for a neuron

Back Propagation
Back-Prop (formal derivation)
- Two types of derivatives
Gradient of node output
Gradient of weight
𝑘-th layer(𝑘 − 1)-th layer (𝑘 + 1)-th layer
𝑗
𝑖

To get derivatives for all nodes and
weights
- Forward pass to compute
function signals for each neuron
- Backward pass to recursively
compute the gradients for each
neuron from output layer to the
first hidden layer.
Then apply gradient descent updating
to reduce the cost function
Back Propagation

Network Training
Prepare the training data { 𝒙1, 𝑦1 , 𝒙2, 𝑦2 , … , (𝒙𝑁, 𝑦𝑁)}- Raw data + label

Network Training
Identify a loss function
- e.g., square error or cross-entropy

Network Training
Identify a loss function
- e.g., square error or cross-entropy

Network Training
Sum up the loss for all training data Total Loss

Network Training
To optimize 𝐿 𝜃 , w.r.t. 𝜃 = {𝑤11, 𝑤12, . . , 𝑤𝑚1, …𝑤𝑚𝑛, 𝑏1, 𝑏2, … 𝑏𝑚}- Solution: gradient descent
- Non-convex, highly non-linear, many local minima

Network Training
Not easy to get rid of the local minima problem

Network Training Must-Knows
1. Data Preprocessing
Zero mean and unit variance normalization

Network Training Must-Knows
1. Data Preprocessing
PCA and whitening is also sometimes applied for normalization

Network Training Must-Knows
2. Select proper loss function

Network Training Must-Knows
2. Select proper loss function

Network Training Must-Knows
3. Weight initialization
Very important as many local minima
Idea 1: all zero initialization
- Each neuron same output, same gradient
Idea 2: small random number
- May leads to non-homogeneous distribution of activations
across layers of a network
- May apply variance calibration for each neuron
Before calibration After calibration
0.01
1.0
Activations

Network Training Must-Knows
Deeper network, more parameters, better fitting? Better performance?

Network Training Must-Knows
Deeper network, more parameters, better fitting? Better performance?

Network Training Must-Knows
3. Vanishing gradient issue
Activation: Sigmoid
𝜕𝜎 𝑥 /𝜕𝑥 ≈ 0, when𝑥 = 10, or 𝑥 = −10, called
saturation!
Saturation kills the gradients!𝜕𝐿
𝜕𝑥1=
𝜕𝜎(𝑥2)
𝜕𝑥1….
𝜕𝜎(𝑥𝑚−1)
𝜕𝜎 𝑥𝑚−2.
𝜕𝑥𝑚
𝜕𝜎 𝑥𝑚−1.𝜕𝜎(𝑥𝑚)
𝜕𝑥𝑚.
𝜕𝐿
𝜕𝜎 𝑥𝑚

Network Training Must-Knows
3. Vanishing gradient issue
Activation: Sigmoid
- What happens if the inputs 𝑥 are all positive?
- Then the gradients 𝜕𝐿/𝜕𝒘are always all positive or negative!
- Sigmoid outputs are not zero centered!
- Influence the subsequent layer nodes

Network Training Must-Knows
3. Vanishing gradient issue
Rectified Linear Unit (ReLU)
- Not saturated in + region (mitigate
vanishing gradients!)
- Fast to compute, in practice fast
convergence
- Not zero centered
- Still saturated in - region

Network Training Must-Knows

Network Training Must-Knows
3. Vanishing gradient issue
Leaky ReLU
- Not saturated both regions! (+,-)
- Computationally efficient
- Convergence fast
- Double parameter number

Network Training Must-Knows
4. Learning rate
Learning rate is critical for obtaining a good convergence
General idea: reduce the learning
rate by some factor for every few
epochs
- At the beginning, far from the
destination, so use larger rate
- After several epochs, close to
the destination, so reduce the
rate
Put a learning rate jump figure!

Network Training Must-Knows
4. Learning rate
Idea: adaptively adjust the learning rate w.r.t. the gradient
- Learning rate is smaller and smaller
- Smaller derivative, larger learning rate

Network Training Must-Knows
5. Dropout
In Training: Randomly set some neurons to zero in the forward pass
- Each time before updating the parameters, choose with random
𝑝% neurons to dropout
- Use the new network for training
- Actually change the network structure

Network Training Must-Knows
5. Dropout
In Testing: No hard dropout
- If the dropout rate at the training time is 𝑝%, all weights time (1 −𝑝)% for testing

Network Training Must-Knows
5. Dropout
The philosophy of dropout
- When team up, everyone will expect the partner do the work,
nothing will be done finally
- However, if you know your partner will dropout, you will do better
- In testing, as there is no dropout, the results will be best

Network Training Must-Knows
“average”
5. Dropout
Dropout is kind of ensemble! – recall that ensemble always yields
better results


















