
Spark Summit San Francisco 2016 - Matei Zaharia Keynote: Apache Spark 2.0
Upload
godatadrivenCategory
view
371download
1
Deep Learning and Streaming in Apache Spark 2.2
Matei Zaharia@matei_zaharia

Evolution of Big Data SystemsTremendous potential, but very hard to use at first:
• Low-level APIs (MapReduce)
• Separate systems for each workload (SQL, ETL, ML, etc)

How Spark Tackled this Problem1) Composable, high-level APIs• Functional programs in Scala, Python, Java, R• Opens big data to many more users
2) Unified engine• Combines batch, interactive, streaming• Simplifies building end-to-end apps
SQLStreaming ML Graph
…

Expanding Spark to New Areas
Structured Streaming
Deep Learning
1
2

Real-Time Applications TodayIncreasingly important to put big data in production• Real-time reporting, model serving, etc
But very hard to build: • Disparate code for streaming & batch• Complex interactions with
external systems• Hard to operate and debug
Goal: unified API for end-to-end continuous appsBatch
Job
Ad-hocQueries
InputStream
AtomicOutput
Continuous Application
Static Data
Batch Jobs
>_

Structured StreamingNew end-to-end streaming API built on Spark SQL• Simple APIs: DataFrames, Datasets and SQL – same as in batch.
Event-time processing and out-of-order data.• End-to-end exactly once: Transactional both in processing & output.• Complete app lifecycle: Code upgrades, ad-hoc queries and more.
Marked GA in Apache Spark 2.2

Simple APIs: Benchmark
7
KStream<String, ProjectedEvent> filteredEvents = kEvents.filter((key, value) -> {return value.event_type.equals("view");
}).mapValues((value) -> {return new ProjectedEvent(value.ad_id, value.event_time);
});
KTable<String, String> kCampaigns = builder.table("campaigns", "campaign-state");KTable<String, CampaignAd> deserCampaigns = kCampaigns.mapValues((value) -> {Map<String, String> campMap = Json.parser.readValue(value);return new CampaignAd(campMap.get("ad_id"), campMap.get("campaign_id"));
});KStream<String, String> joined =filteredEvents.join(deserCampaigns, (value1, value2) -> {return value2.campaign_id;
}, Serdes.String(), Serdes.serdeFrom(new ProjectedEventSerializer(), new ProjectedEventDeserializer()));
KStream<String, String> keyedByCampaign = joined.selectKey((key, value) -> value);KTable<Windowed<String>, Long> counts = keyedByCampaign.groupByKey().count(TimeWindows.of(10000), "time-windows");
Filter by click type and project
Join with campaigns table
Group and windowed count
streams

KTable<String, String> kCampaigns = builder.table("campaigns", "campaign-state");KTable<String, CampaignAd> deserCampaigns = kCampaigns.mapValues((value) -> {Map<String, String> campMap = Json.parser.readValue(value);return new CampaignAd(campMap.get("ad_id"), campMap.get("campaign_id"));
});KStream<String, String> joined =filteredEvents.join(deserCampaigns, (value1, value2) -> {return value2.campaign_id;
}, Serdes.String(), Serdes.serdeFrom(new ProjectedEventSerializer(), new ProjectedEventDeserializer()));
KStream<String, ProjectedEvent> filteredEvents = kEvents.filter((key, value) -> {return value.event_type.equals("view");
}).mapValues((value) -> {return new ProjectedEvent(value.ad_id, value.event_time);
});
KStream<String, String> keyedByCampaign = joined.selectKey((key, value) -> value);KTable<Windowed<String>, Long> counts =keyedByCampaign.groupByKey().count(TimeWindows.of(10000), "time-windows");
8
DataFrames
Simple APIs: Benchmarkstreams
events.where("event_type = 'view'").join(table("campaigns"), "ad_id").groupBy(
window('event_time, "10 seconds"),'campaign_id)
.count()

9
streamsSimple APIs: Benchmark
SQL
SELECT COUNT(*)FROM eventsJOIN campaigns USING ad_idWHERE event_type = 'view'GROUP BY
window(event_time, "10 seconds"),campaign_id)
KTable<String, String> kCampaigns = builder.table("campaigns", "campaign-state");KTable<String, CampaignAd> deserCampaigns = kCampaigns.mapValues((value) -> {Map<String, String> campMap = Json.parser.readValue(value);return new CampaignAd(campMap.get("ad_id"), campMap.get("campaign_id"));
});KStream<String, String> joined =filteredEvents.join(deserCampaigns, (value1, value2) -> {return value2.campaign_id;
}, Serdes.String(), Serdes.serdeFrom(new ProjectedEventSerializer(), new ProjectedEventDeserializer()));
KStream<String, ProjectedEvent> filteredEvents = kEvents.filter((key, value) -> {return value.event_type.equals("view");
}).mapValues((value) -> {return new ProjectedEvent(value.ad_id, value.event_time);
});
KStream<String, String> keyedByCampaign = joined.selectKey((key, value) -> value);KTable<Windowed<String>, Long> counts =keyedByCampaign.groupByKey().count(TimeWindows.of(10000), "time-windows");
streams
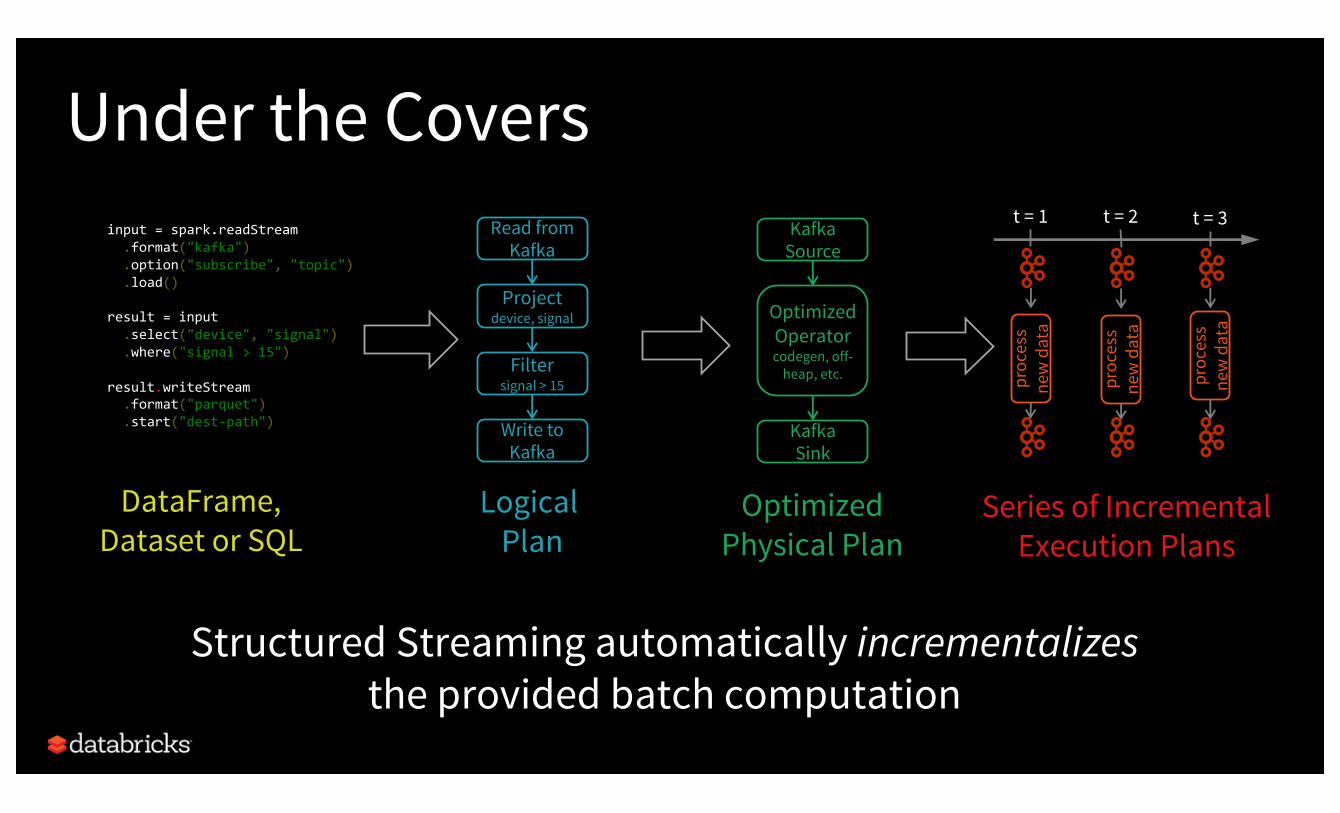
DataFrame,Dataset or SQL
input = spark.readStream.format("kafka").option("subscribe", "topic").load()
result = input.select("device", "signal").where("signal > 15")
result.writeStream.format("parquet").start("dest-path")
Logical Plan
Read from Kafka
Projectdevice, signal
Filtersignal > 15
Write to Kafka
Under the Covers
Structured Streaming automatically incrementalizesthe provided batch computation
Series of IncrementalExecution Plans
Kafka Source
Optimized Operatorcodegen, off-
heap, etc.
KafkaSink
OptimizedPhysical Plan
proc
ess
new
dat
a
t = 1 t = 2 t = 3
proc
ess
new
dat
a
proc
ess
new
dat
a

Structured Streaming reuses the Spark SQL Optimizer
and Tungsten Engine.
11https://data-artisans.com/blog/extending-the-yahoo-streaming-benchmark
Throughput At ~200ms Latency
700K
15M
65M
010203040506070
Kafka Streams
Flink Structured Streaming
Mill
ions
5xlower cost
Performance: Benchmark

What About Latency?Continuous processing mode for execution without microbatches• <1 ms latency (same as per-record streaming systems)• No changes to user code• Proposal in SPARK-20928
Databricks blog post: tinyurl.com/spark-continuous-processing

Structured Streaming Use Cases
Cloud big data platform serving 500+ orgs
Metrics pipeline: 14B events/h on 10 nodes
Dashboards Analyzeusagetrendsinrealtime
Alerts Notifyengineersofcriticalissues
Ad-hocAnalysis Diagnoseissueswhentheyoccur
ETL Clean and store historical data
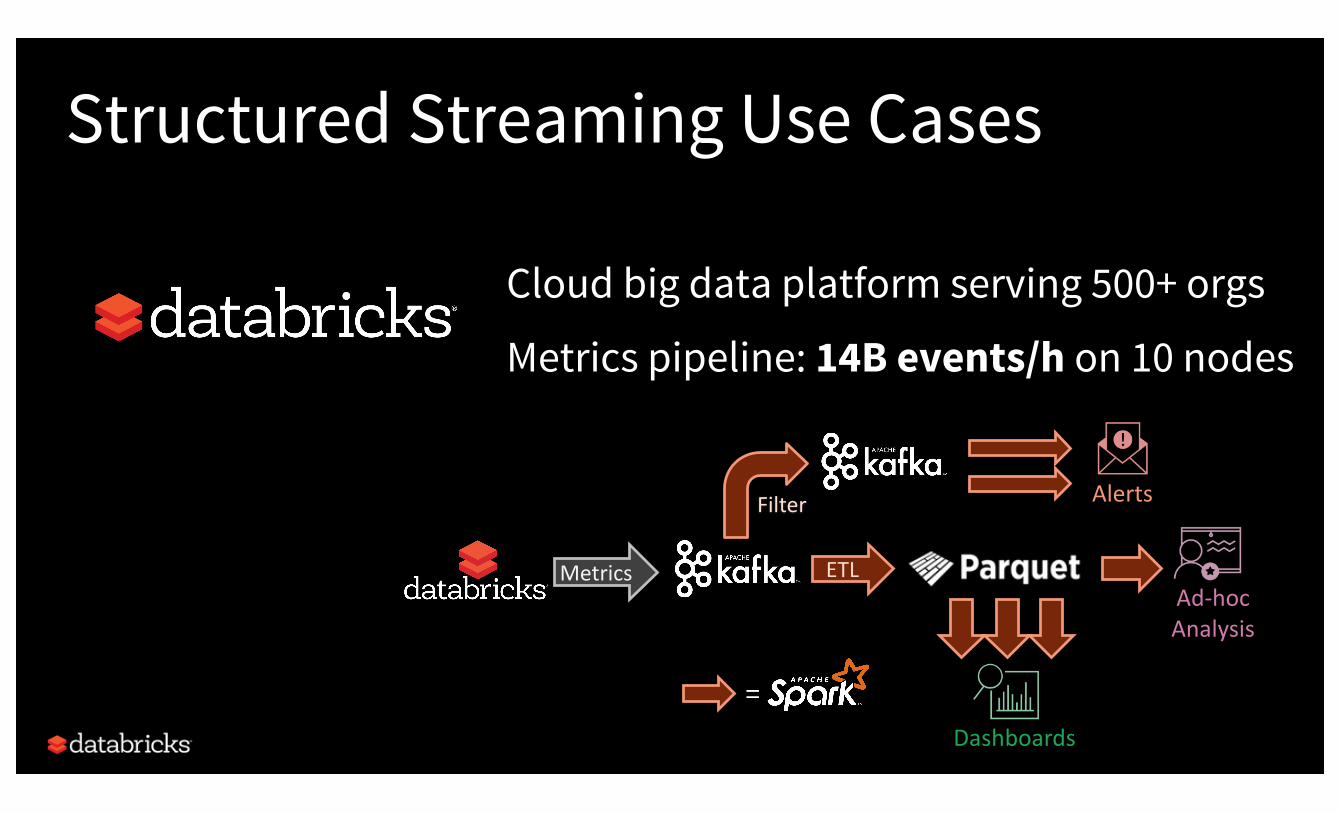
Structured Streaming Use Cases
Cloud big data platform serving 500+ orgs
Metrics pipeline: 14B events/h on 10 nodes
=
Metrics
Filter
ETL
Dashboards
Ad-hocAnalysis
Alerts

Structured Streaming Use Cases
Monitor quality of live video in production across dozens of online properties
Analyze data from 1000s of WiFi hotspots to find anomalous behavior
More info: see talks at Spark Summit 2017

Expanding Spark to New Areas
Structured Streaming
Deep Learning
1
2
Deep Learning has Huge Potential
Unprecedented ability to work with unstructured data such as images and text

But Deep Learning is Hard to Use
Current APIs (TensorFlow, Keras, BigDL, etc) are low-level• Build a computation graph from scratch• Scale-out typically requires manual parallelization
Hard to expose models in larger applications
Very similar to early big data APIs (MapReduce)

Our GoalEnable an order of magnitude more users to build applications using deep learning
Provide scale & production use out of the box

Deep Learning PipelinesA new high-level API for deep learning that integrates with Apache Spark’s ML Pipelines• Common use cases in just a few lines of code• Automatically scale out on Spark• Expose models in batch/streaming apps & Spark SQL
Builds on existing DL engines (TensorFlow, Keras, BigDL)

Image Loading
from sparkdl import readImagesimage_df = readImages(sample_img_dir)

Applying Popular ModelsPopular pre-trained models included as MLlib Transformers
predictor = DeepImagePredictor(inputCol="image", outputCol="predicted_labels", modelName="InceptionV3")
predictions_df = predictor.transform(image_df)

Fast Model Training via Transfer Learning
Example: identify James Bond cars

Transfer Learning

Transfer Learning
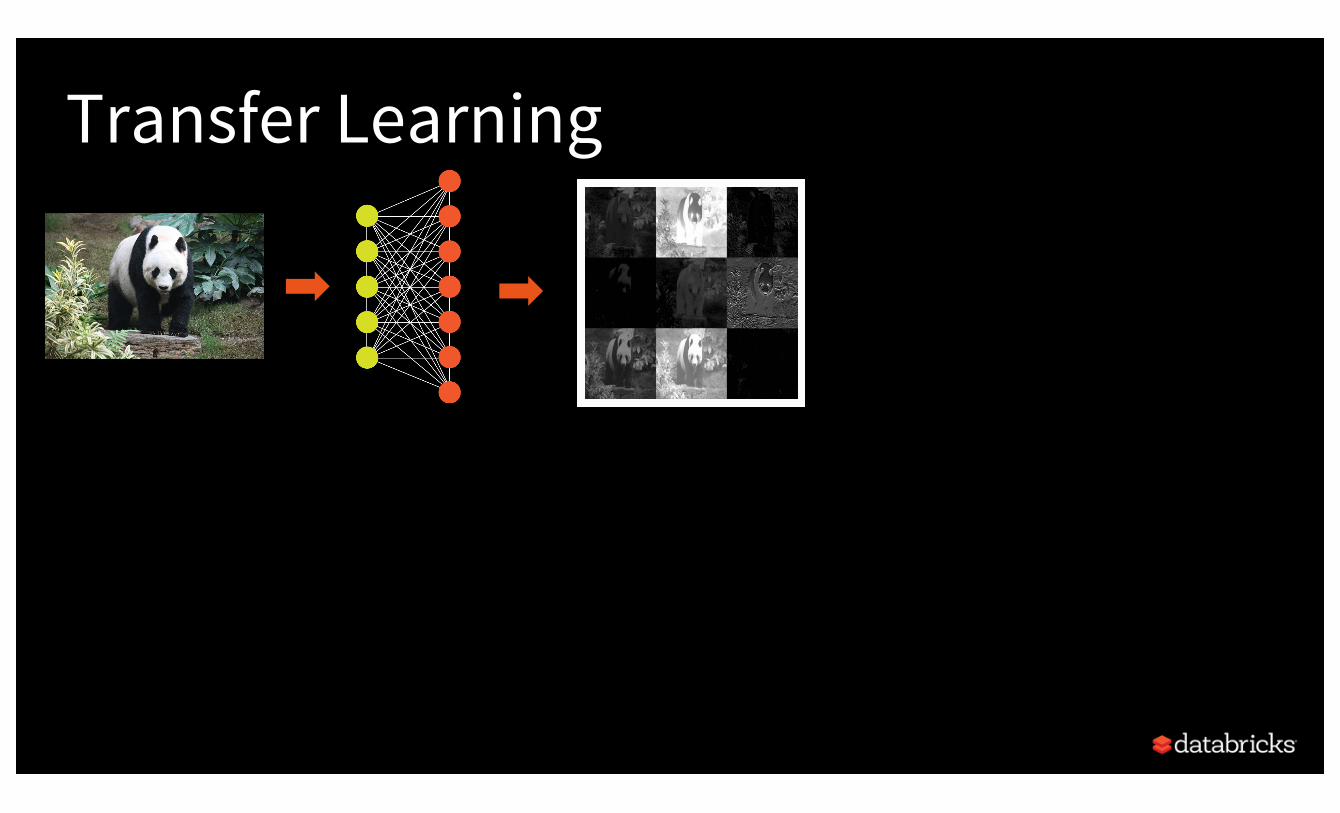
Transfer Learning
Transfer Learning
Transfer Learning
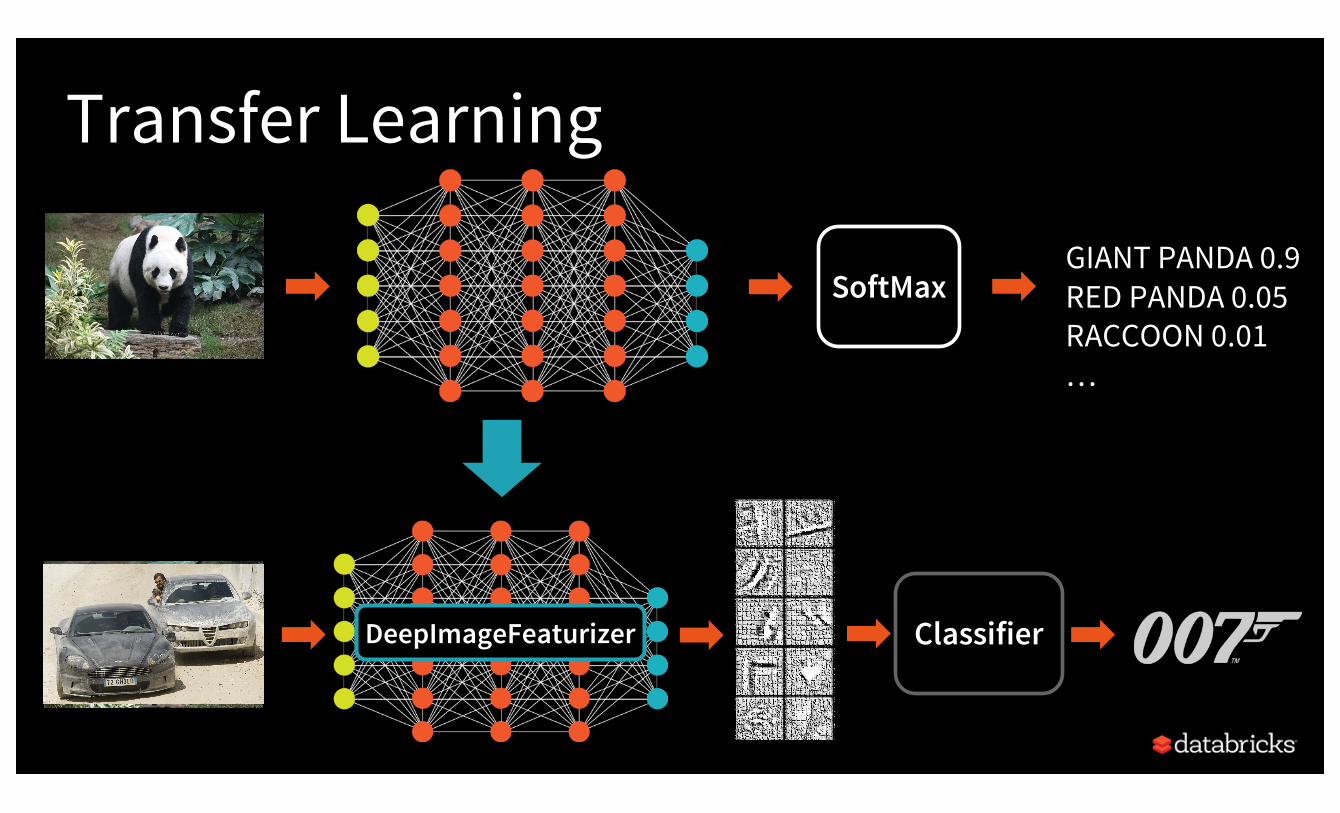
SoftMaxGIANT PANDA 0.9RED PANDA 0.05RACCOON 0.01…
Classifier
Transfer Learning
DeepImageFeaturizer
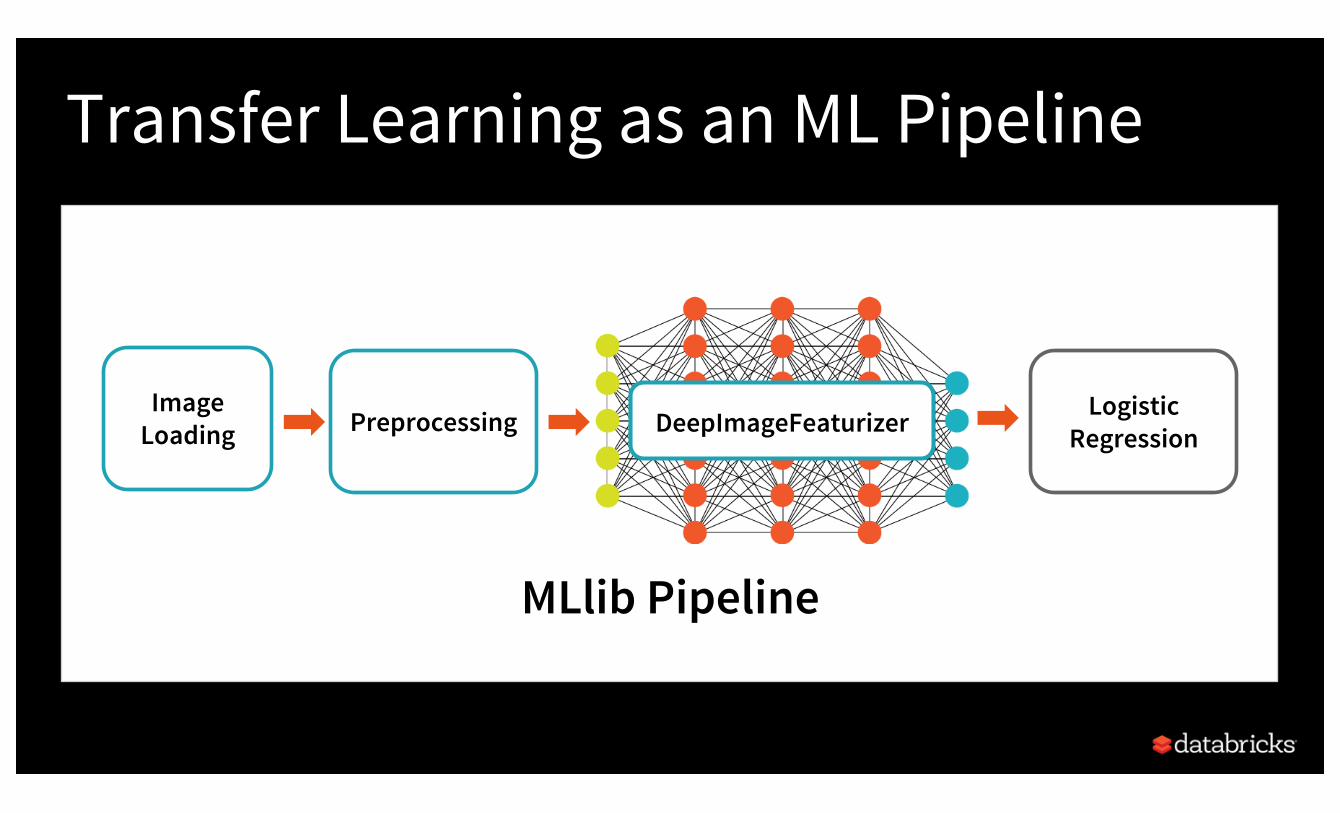
Transfer Learning as an ML Pipeline
MLlib Pipeline
ImageLoading Preprocessing Logistic
RegressionDeepImageFeaturizer

Transfer Learning Code
featurizer = DeepImageFeaturizer(modelName="InceptionV3”)lr = LogisticRegression()p = Pipeline(stages=[featurizer, lr])
model = p.fit(train_images_df)
Automatically distributed across cluster!

Transfer Learning Results

Distributed Model Tuning
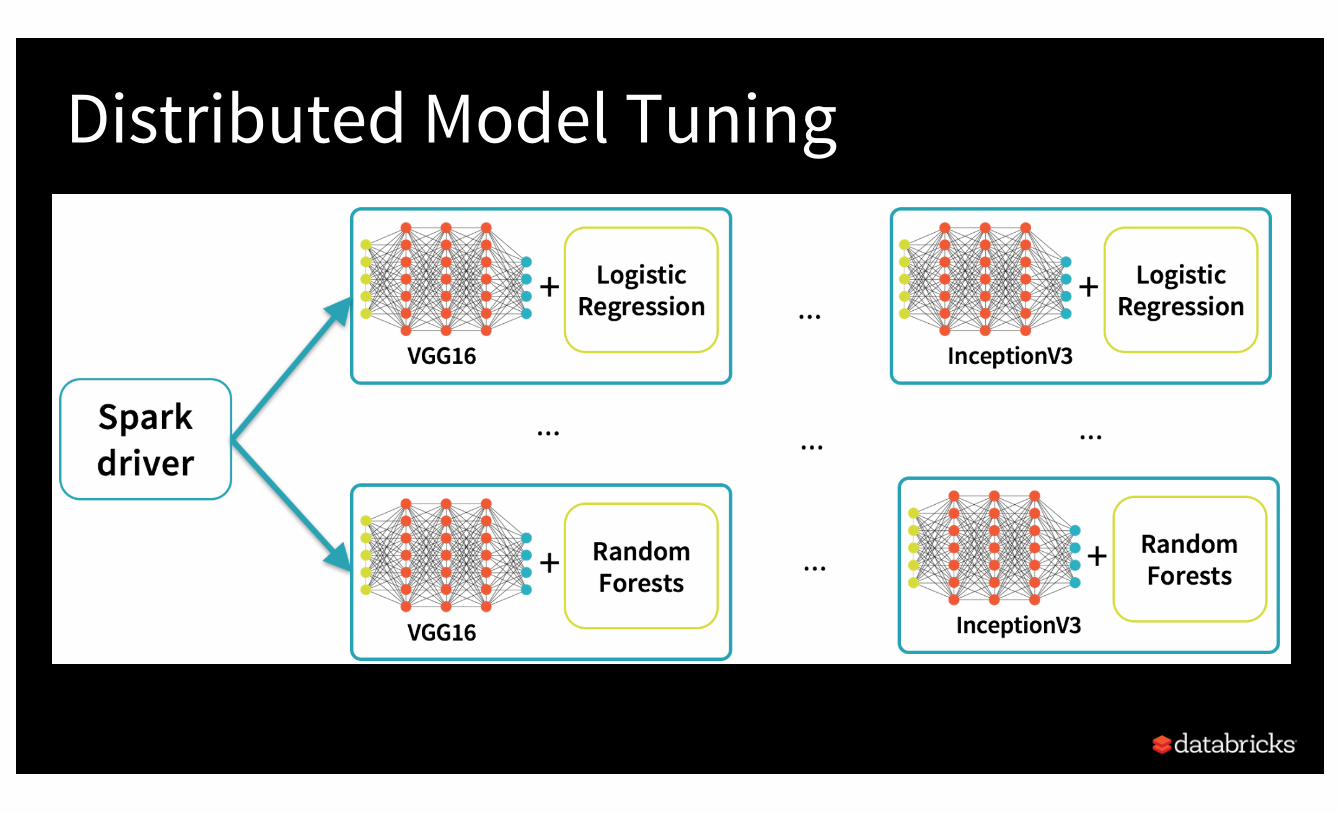
Distributed Model Tuning

Distributed Model Tuning CodemyEstimator = KerasImageFileEstimator(
inputCol='input', outputCol='output', modelFile='/model.h5')
params1 = {'batch_size':10, epochs:10}
params2 = {'batch_size':5, epochs:20}
myParamMaps = ParamGridBuilder() \
.addGrid(myEstimator.kerasParams, [params1, params2]).build()
cv = CrossValidator(myEstimator, myEvaluator, myParamMaps)
cvModel = cv.fit()

Sharing and Applying Models
Take a trained model / Pipeline, register a SQL UDF usable by anyone in the organization
In Spark SQL:
registerKerasUDF("my_object_recognition_function", keras_model_file="/mymodels/007model.h5")
select image, my_object_recognition_function(image) as objects from traffic_imgs
Cannowapplyinstreaming,batchorinteractivequeries!

Other Upcoming Features
Distributed training of one model via TensorFlowOnSpark(https://github.com/yahoo/TensorFlowOnSpark)
More built-in data types: text, time series, etc

Scalable Deep Learning made Simple
High-level API for Deep Learning, integrated with MLlib
Scales common tasks with transformers and estimators
Expose deep learning models in MLlib and Spark SQL
Early release of Deep Learning Pipelines:github.com/databricks/spark-deep-learning

ConclusionAs new use cases mature for big data, systems will naturally move from specialized/complex to unified
We’re applying the lessons from early Spark to streaming & DL • High-level, composable APIs• Flexible execution (SQL optimizer, continuous processing)• Support for end-to-end apps

https://spark-summit.org/eu-2017/15% discount code: MateiAMS

Free preview release:dbricks.co/2sK35XT


















