![学位研究 第14号 イギリス高等教育の学位統一への動き —高 …...2008/08/29 · 学位研究 第14号 平成13年3月(論文) [大学評価・学位授与機構研究紀要]](https://static.fdocuments.net/doc/165x107/60d2bef2e90e7e2d0a6b865c/cc-c14-fecec-ae.jpg)
学位研究 第14号 イギリス高等教育の学位統一への動き —高 …...2008/08/29 · 学位研究 第14号 平成13年3月(論文) [大学評価・学位授与機構研究紀要]
Upload
mori-laboCategory
view
655download
1
高位合成でDeepLearningしたい(仮)~素人の犯行~

自己紹介
Twitter● @morittyo
HP● morilab報告書 http://morilab-report.blog.jp/
仕事● RTL設計・検証
○ Verilog , SystemVerilog, VivadoHLS(高位合成)○ 検証メソドロジ(UVM)、ランダム検証、アサーション等

目的(目標)
1. ディープラーニングとやらをC++でゼロから書いてみる
2. Xilinx VivadoHLS WebEditionを使って高位合成する
3. カッコイイ!(予定)

前提
● RTL設計ができる
● VivadoHLSを使っての高位合成経験がある
● ニューラルネットワークに関しては素人

設計環境
● VivadoHLS 2016.2● Windows 10 Home (64bit)● i5-4210U @1.70GHz 2.40GHz● Memory 8GB

まずはDeepLearningのお勉強
初めはネットだけで頑張っていた
…が、断片的な情報ばかりを収集してしまい全体像がわからなくなってしまった
本を買いました。
⇒3割ぐらい理解した気になった。色々間違ってそう。

ニューラルネットワークとは?(ざっくり)

ニューロンモデル
複数から入力を受け付ける
● 出力は1つ
Step1 : 各入力を重みと積和演算する
u = weight * x + bias
Step2 : 活性化関数を通す
y = func(u)
*W2
*W1
*W3
x1
x2
x3
∑ func() y
bias

(単純)パーセプトロン
同一層にあるニューロン同士はネットワー
クが存在しない
入力は前段の層からのみ、出力は後段
の層へのみ伝搬する
同一層
・並列実行って感じがするしRTL(FPGA)向きでは?・高位合成を使えば簡単に違いない!(フラグ)

畳み込みニューラルネット(畳み込み処理)
・ラプラシアンフィルタ+ αといった感じ・これならいけそうな気がする …

畳み込みニューラルネット(MAXプーリング処理)
2x2エリアの中で最大値を採用する
→画像サイズがWidth,Heightどちらも半分になる
データを適度に間引きつつ、入力画像の位置ずれにもそれなりに効果があるものらしい

多層ニューラルネットワーク
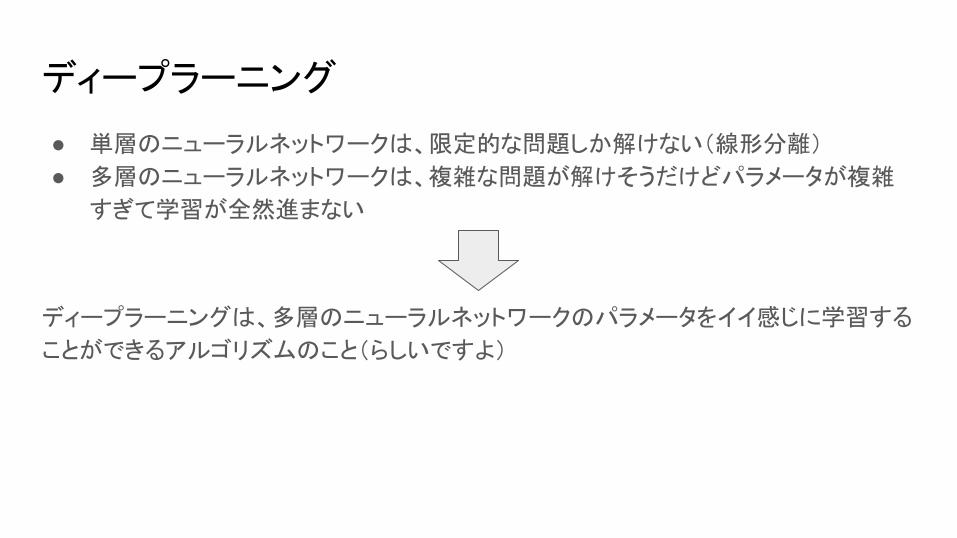
ディープラーニング
● 単層のニューラルネットワークは、限定的な問題しか解けない(線形分離)
● 多層のニューラルネットワークは、複雑な問題が解けそうだけどパラメータが複雑
すぎて学習が全然進まない
ディープラーニングは、多層のニューラルネットワークのパラメータをイイ感じに学習する
ことができるアルゴリズムのこと(らしいですよ)

問題点
とりあえず多層ニューラルネットワークで出力するまでを高位合成してみる
ディープラーニングの学習アルゴリズムが難しくてよくわからない(致命的)

C++実装

Matrixクラス
とりあえず行列演算用クラスを作成
● まずはC++に慣れよう
● クラス記述がちゃんと高位合成できるかどうかも知りたい
数学力に乏しいためかあまり活用できていない気がする…

MNISTクラス
MNISTデータセットを読み出すだけのクラス
● http://yann.lecun.com/exdb/mnist/
以下のイメージファイルとラベルファイルに対応
● TRAINING SET LABEL FILE (train-labels-idx1-ubyte)
● TRAINING SET IMAGE FILE (train-images-idx3-ubyte)
高位合成はされないが、テスト時に使用

MNISTデータセット
MNISTデータセットとは?
● 28x28=784画素からなる8ビット(255諧調)モノクロ画像
● 0~9の手書き文字
● 答え(ラベル)付き
● 機械学習業界では有名なデータ(らしい)
● イケてる機械学習だと正解率99%以上とか
実際の背景色は0x00(黒)

convolution_perceptronクラス
畳み込みニューラルネットのモデル
入力層(L1)、中間層(L2)にて使用
● 畳み込み演算○ 入力画像 (幅= IN_X、高さ=IN_Y)○ フィルタウインドウ(幅= CNV_X、高さ=CNV_Y)○ 額縁補正 →外周データは0扱いとし、演算対象と同じ画像サイズで出力
● プーリング演算○ ウインドウ(2x2固定)
○ 最大値選択
● 活性化関数○ ReLU →0以下を0にクリッピングする関数。演算負荷が少なく、学習結果も良いらしい。

relu_perceptron_fnnクラス
単純パーセプトロンのモデル
中間層(L3)にて全結合層として使用
● 活性化関数○ ReLU

softmax_perceptron_fnnクラス
単純パーセプトロンのモデル
→ relu_perceptron_fnnクラスから派生
出力層(L4)で使用
● 活性化関数○ ソフトマックス
■ 出力は正規化され、合計値が常に同じ
■ 活性化関数にてexp関数を使用

なんとなく実装完了
実装にかかった時間はおよそ3日
● C++のテンプレートと仮想関数に嵌るなど
● 学習部分が無いのでとても残念な感じのコード○ 学習後のパラメータを使って動かすことは出来る …
● GitHubに一応コミットしてあります(クソコード)
○ https://github.com/morilab/deep_learning_hls

高位合成にむけて

インターフェース
インターフェース仕様は性能に大きく影響する
● 入力画像○ 28x28x8bit (MNIST)
● パーセプトロン用パラメータ○ Weight○ Filter○ Bias
● 判定結果○ 0~9の各確率
● 学習用パラメータ○ 教師信号(0~9のいずれか)○ 学習率○ その他?(良く分かっていない)

入力画像
● ディープラーニングによる学習を行う場合は大量の画像データを切り替える
● MNISTデータセットを使いたいのでそちらに合わせる
● リードのみ
→今回はサイズがそれほど大きくないのでブロックRAMでの実装を目指す
サイズ : 28x28x8=6272Bit / 784Byte

パーセプトロン用パラメータ● 各パラメータは主に学習時に更新される(リードライト)
● ユーザーは基本的にあまり操作しない○ 初期値の設定→バイアスは0、その他はランダム
○ 学習値の設定→1回設定するのみ
● かなり容量が必要…実用的に動かすには一部外部メモリを使わないと難しい?○ Bias : [L1Size]+([L1Size]*[L2Size])+[L3Size]+[L4Size(10)]○ Filter : [L1Size]*[WindowSize1]+[L1Size]*[L2Size]*[WindowSize2]○ Weight : ([L2Size]*[L2OutFrame(49)])*[L3Size]+[L3Size]*[L4Size(10)]○ →L1Size=32,L2Size=64,L3Size=1024,WindowSize=5x5で見積もると…
Bias=3,114要素,Filter=52,000要素,Weight=3,221,504要素 合計約3.3M要素
サイズの調整が必要 でかい!!

判定結果
● 0~9の各確率を正規化して出力する
● 判定時はライトのみ、学習時はリードライト
● 数が10個と少ないのでレジスタ実装で問題なさそう

これらを踏まえて…

設計仕様
ニューラルネットワーク構成
1層目 2層目 3層目 4層目
セット数 20 20 500 10
フィルタ 5x5 5x5 - -
活性化関数 ReLU ReLU ReLU SoftMax
入力 28x28x8Bit (白黒)
内部変数型 S2.6 (-2.0~1.984375)
出力 各8Bit

Solution1

とりあえず高位合成してみる
ディレクティブなしの状態
クロック:100MHz(10ns)
ターゲット:xc7z020clg484-1 (ZedBoard)
レイテンシ:約200ms
さすがに200msはシミュレー
ションしたくない…合成は30分弱

デフォルト設定での合成
ディレクティブ(高位合成に対する指示)が何もない場合、
● ループは記述通りに実装されるため、リソースは少ないがレイテンシは大きい
● パイプライン化を行わない
● ループなどの並列実行を行わない
…というふうに、並列化を行わないためレイテンシが(恐らく)最大となる回路を生成
演算処理はProjectSettingにあるクロック周波数を元に適度にFFを挟んだ回路になる
⇒周波数設定を弄るとレイテンシサイクルが減るが、処理の絶対時間は大体同じ

モジュールIFがどうなったか見てみる
項目 I/F セット数 詳細
Input Frame Memory 1 Address[9:0],Data[7:0]
L1 Filter Memory 1 Address[8:0],Data[7:0]
L1 Bias Memory 1 Address[4:0],Data[7:0]
L2 Filter Memory 1 Address[13:0],Data[7:0]
L2 Bias Memory 1 Address[8:0],Data[7:0]
L3 Weight Memory 1 Address[18:0],Data[7:0]
L3 Bias Memory 1 Address[8:0],Data[7:0]
L4 Weight Memory 1 Address[12:0],Data[7:0]
L4 Bias Memory 1 Address[3:0],Data[7:0]
Result Validつき出力
8 Data[7:0]
配列はデフォルトですべて1次元メモリ
(合成結果には接続すべきメモリは含まれない)
● L3_Weightが512kバイト空間をご所望
良し悪しは兎も角、概ね想定通りの結果
1次元メモリなので基本的に異なる要素へのアク
セスができない
(リードだけの場合、2PortRAMの2面読み出しに
なることはある)

レイテンシの内訳を見てみる(全体)
レイテンシ表示は以下のようになっている
[Latency] = [Iteration Latency] × [Trip count]
問題がTrip Count(ループ回数)か、Iteration Latency(1回分の処理にかかるサイクル数)かを考えていく
Loop14が全体レイテンシの約65%を占めてい
る。もう少し細かく見てみることにする。

レイテンシの内訳を見てみる(Loop14)
多重ループになっている
下位レイテンシが上位のいてレーションレイ
テンシになるが、このとき(基本)+2される
⇒多重ループはレイテンシに無駄が出る
ディレクティブを挿入して改善することができる

ループ部分にラベルを追加
ディレクティブの追加にはループにラベルが必要。ログも通し番号でラベルを付けられてしまうため解析が大変
→“<クラス名>_<機能名>_<階層>”という形ですべてのループにラベルを付加した
チューニング、解析いずれにしてもラベルの追加は必須!

ラベル付加後のレイテンシ内訳
ラベルがあると見やすい!
(何故かレイテンシ変わってるけど)
IterationLatencyが大きいところに注目
→下位ループのLatencyを合計した値から大
きく離れている
演算に必要なデータが揃っていないため無駄
に待たされている可能性が高い
→畳み込み演算のFilter/Weightパラメータが
1個づつしか参照できないためでは?

Solution2
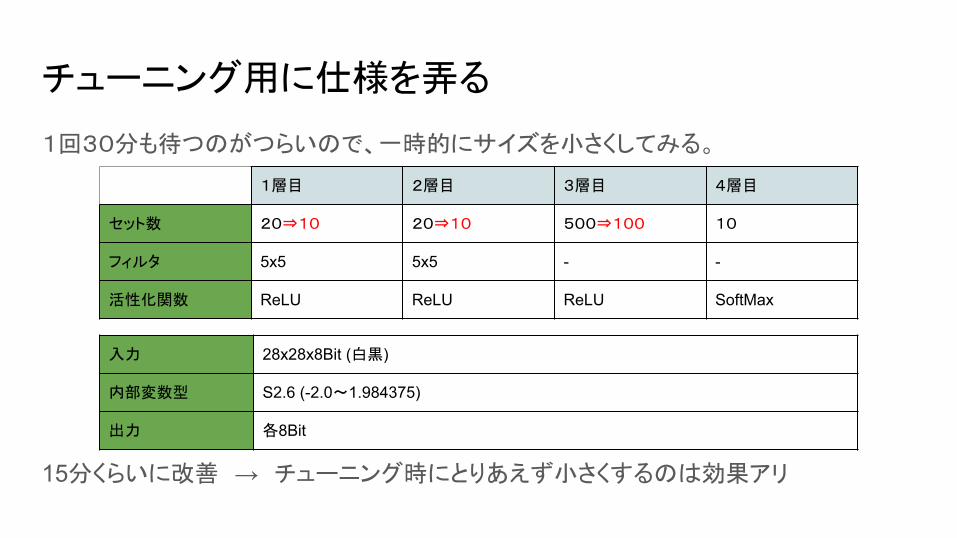
チューニング用に仕様を弄る
1回30分も待つのがつらいので、一時的にサイズを小さくしてみる。
1層目 2層目 3層目 4層目
セット数 20⇒10 20⇒10 500⇒100 10
フィルタ 5x5 5x5 - -
活性化関数 ReLU ReLU ReLU SoftMax
入力 28x28x8Bit (白黒)
内部変数型 S2.6 (-2.0~1.984375)
出力 各8Bit
15分くらいに改善 → チューニング時にとりあえず小さくするのは効果アリ

とりあえずPIPELINEいれてみる
トップ関数にPIPELINEを入れてみる
設定はII(開始間隔)=1にしてみる
→ 目標値なので達成されるかどうかはわからないが、とりあえず入れてみる
VivadoHLSでは良くあること…終わるかどうかも分からないので止める
24時間経っても高位合成終わらず

Solution2

トップ関数を分離する
全体を一気に高位合成するのは作業効率が悪く現実的ではない
→4層をそれぞれ関数に分離し、個別に高位合成することにする
各層のチューニングが終わったら、その設定をもってトップで高位合成をする。
トップの合成が終わらない場合は、最悪各合成結果をRTLレベルで手で接続する

Layer4だけを高位合成する

とりあえず高位合成してみる
Layer4が比較的簡単そうだったので、まずはここから。
セット数は目標仕様の設定(L3=500,L4=10)これをベースにチューニングをしていく
合成は3分弱

入出力をバラす
入出力はデフォルトなのでデータ幅=8Bitのメモリになっている
出力は10個バラにする
→HLS_ARRAY_PARTITION complete
その他は32Bit幅のメモリに変更する
→HLS_ARRAY_RESHAPE cyclic factor=4
原因不明の死…blockにすると通る…とりあえずblockで続けることに。。。
Layer4()
weight bias
[31:0] [31:0][7:0]
[7:0]in
[31:0]
Array reshapingさん、突如StackDumpをキメる

ループ部分を見直す
Cコードを忠実に実行してくれているので、無駄が多い
値の0初期化に6,520
入力取り込みに1,000
パラメータ取り込みに10,030
これは省略しよう

Matrixクラスのコード改善
コンストラクタにある0初期化部分をコメントアウト
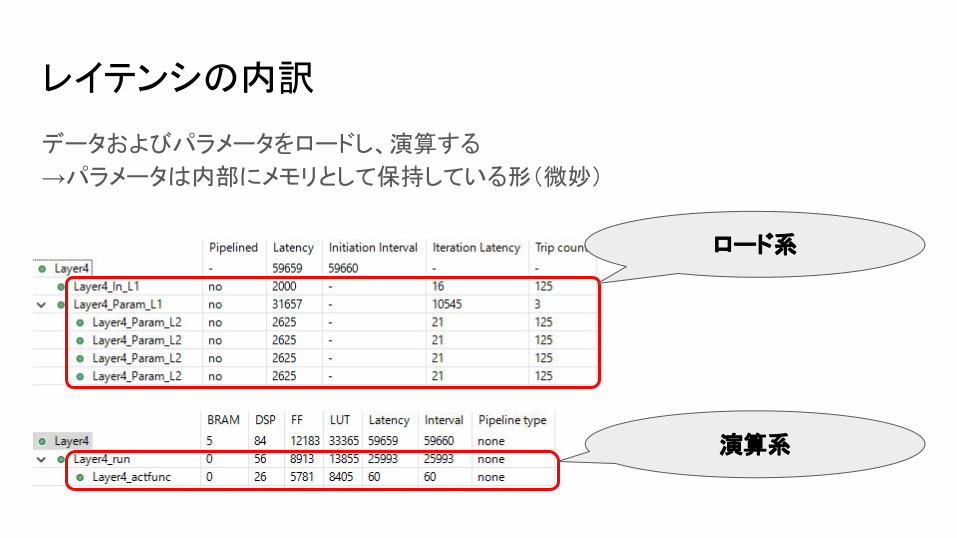
レイテンシの内訳
データおよびパラメータをロードし、演算する
→パラメータは内部にメモリとして保持している形(微妙)
演算系
ロード系

演算系(Layer4_run)の詳細
レイテンシ的にはRun2,Run3(SoftMax処理)よりも、
Run1(畳み込み演算)を改善しないとダメ

ディレクティブを入れやすいようにコードを書き直す
演算子のオーバーロードを使って行列演
算を書いたはいいが、このままでは細か
くディレクティブが書けない模様。。。
ベタ書きに直した

演算部チューニング結果
500回ループするRun1_L2をパイプライン指示
→間隔2、レイテンシ4に
Run1_L1をUNROLLで2パラ指示
→Run1_L2の繰り返し回数を半分(5回)に

ロード系のチューニング
In_L1とParam_L2は同じループ、かつ独立した処理
→ループのマージができる
In_Param_L2は500回繰り返すところなのでパイプライン化を指示
Param_L1をUNROLLで4パラ指示

ロード部チューニング結果

Layer4チューニング結果
● レイテンシは半分以下になったが、DSPとLUTのリソースは改善の必要あり
● 入出力、パラメータを内部で保持する形になっているのでLayer1~3では別の
チューニングを行う必要がある

今回のまとめ

成功したこと
● なんとなく高位合成できた○ C++でクラスやテンプレートを使ったコードでも大丈夫だった
○ ディレクティブなしでとりあえず合成できた
● テンプレート使用しても合成できた
○ 一時的に規模を小さくすることで合成時間を短縮できるので、素早いチューニングができる
● 細かいチューニング○ ソースコードは弄らず、ディレクティブのみなら複数の Solutionをプロジェクトで持てる
○ 関数単位でチューニングしていくのが良さそう
○ 良い合成結果を出すためにはソースコードの修正が必要

失敗したこと
● 現実的な合成結果には到達せず○ ディレクティブなしの結果は基本クソ( FPGAの演算に求めるのは並列実行)
○ 畳み込み演算(Layer1,2)は現実的な合成結果にするにはソースコードの根本改善が必要
○ ディレクティブ設定しても落ちたり帰ってこなかったりで大変
● 今回のクラス構造は失敗○ 派生クラスから基底クラスへ細やかなディレクティブ指示ができない(気がする)
● ベタでフラットに関数を並べたようなコードが結局チューニングしやすい○ C/C++で書くけど変に抽象化や汎用化するとチューニングできない
● ポインタをもっと活用しないとダメ○ Layer4のパラメータは内部ブロックで持てる量だったが、 Layer2は絶対無理
○ Layer間のデータ受け渡しが無駄に発生するコードになってしまった
● ディープラーニングできなかった○ もっと勉強します…

というわけで…● 性能のいいもの(動くもの)を高位合成で作るのは大変
● 高位合成は得手不得手がかなりある
● 高位合成するコードはハード屋がゼロから作ろう
● VivadoHLSはまだバグる

Appendix

DirrectiveFileは頻繁に狂う
DirectiveWindowから設定変更はラクチン
でもそれ、本当に変更されてますか??
毎回directives.tclを確認しよう!
ファイルと表示が合わなくなったらDirectiveWindowタブを閉
じてWindow>ShowView>Directivesで再度開くべし
DirectiveWindowは嘘つきです
(重要)


















