
Db2 for z/OS Utilities - Let's get it all sorted out · · 2017-09-14Db2 for z/OS Utilities -...
41
Db2 for z/OS Utilities - Let's get it all sorted out Christian Michel
Transcript of Db2 for z/OS Utilities - Let's get it all sorted out · · 2017-09-14Db2 for z/OS Utilities -...

Db2 for z/OS Utilities -Let's get it all sorted out
Christian Michel

Notices and Disclaimers
2
Copyright © 2017 by International Business Machines Corporation (IBM). No part of this document may be reproduced or transmitted in any form without written permission from IBM.
U.S. Government Users Restricted Rights - Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM.
Information in these presentations (including information relating to products that have not yet been announced by IBM) has been reviewed for accuracy as of the date of initial publication and could include unintentional technical or typographical errors. IBM shall have no responsibility to update this information. THIS DOCUMENT IS DISTRIBUTED "AS IS" WITHOUT ANY WARRANTY, EITHER EXPRESS OR IMPLIED. IN NO EVENT SHALL IBM BE LIABLE FOR ANY DAMAGEARISING FROM THE USE OF THIS INFORMATION, INCLUDING BUT NOT LIMITED TO, LOSS OF DATA, BUSINESS INTERRUPTION, LOSS OF PROFIT OR LOSS OF OPPORTUNITY. IBM products and services are warranted according to the terms and conditions of the agreements under which they are provided.
Any statements regarding IBM's future direction, intent or product plans are subject to change or withdrawal without notice.
Performance data contained herein was generally obtained in a controlled, isolated environments. Customer examples are presented as illustrations of how those customers have used IBM products and the results they may have achieved. Actual performance, cost, savings or other results in other operating environments may vary.
References in this document to IBM products, programs, or services does not imply that IBM intends to make such products, programs or services available in all countries in which IBM operates or does business.
Workshops, sessions and associated materials may have been prepared by independent session speakers, and do not necessarily reflect the views of IBM. All materials and discussions are provided for informational purposes only, and are neither intended to, nor shall constitute legal or other guidance or advice to any individual participant or their specific situation.
It l counsel as to the identification and ustomer may need to take to comply
with such laws. IBM does not provide legal advice or represent or warrant that its services or products will ensure that the customer is in compliance with any law.

Notices and
3
Information concerning non-IBM products was obtained from the suppliers of those products, their published announcements or other publicly available sources. IBM has not tested those products in connection with this publication and cannot confirm the accuracy of performance, compatibility or any other claims related to non-IBM products. Questions on the capabilities of non-IBM products should be addressed to the suppliers of those products. IBM does not warrant the quality of any third-party products, or the ability of any such third- SCLAIMS ALL WARRANTIES, EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE.
The provision of the information contained herein is not intended to, and does not, grant any right or license under any IBM patents, copyrights, trademarks or other intellectual property right.
IBM, the IBM logo, ibm.com, Aspera®, Bluemix, Blueworks Live, CICS, Clearcase, Cognos®, DOORS®, EmptorisFASP®, FileNet®, Global Business Services ®, Global Technology Services ®, IBM ExperienceOne SmartCloud®, IBM Social Business®, Information on Demand, ILOG, Maximo®, MQIntegrator®, MQSeries®, Netcool®, OMEGAMON, OpenPower, PureAnalytics PureApplication®, pureCluster PureCoverage®, PureData®, PureExperience®, PureFlex®, pureQuery®, pureScale®, PureSystems®, QRadar®, Rational®, Rhapsody®, Smarter Commerce®, SoDA, SPSS, Sterling Commerce®, StoredIQ, Tealeaf®, Tivoli®, Trusteer®, Unica®, urban{code}®, Watson, WebSphere®, Worklight®, X-Force® and System z® Z/OS, are trademarks of International Business Machines Corporation, registered in many jurisdictions worldwide. Other product and service names might be trademarks of IBM or other companies. A current list of IBM trademarks is available on the Web at "Copyright and trademark information" at: www.ibm.com/legal/copytrade.shtml.

• Use of sort in utilities
• Sort work space allocation and estimation
• DFSORT specifics
• Db2 Sort specifics
• Summary
4
Agenda

• Utilities are doing bulk operations on Db2 objects
– Data rows in tables
– Index keys in indexes
• Many utilities are used to tidy up object organization
– Requires sort order to be re-established
• Size of data being sorted can be huge
– Db2 utilities rely on external sort programs
• Use optimized sort algorithms
• Have ability to spill over to disk if memory is not sufficient
• CPU spent in sorting is a significant portion of utility CPU
– Make sure to provide an environment to run in the most efficient way
5
Introduction

• it should run without intervention required by the DBAs or SysProgs
– No tuning required
– Optimal performance out of the box
– Minimal resource requirements
6
Expectation About Sorting

• Sample invocation of sort for REBUILD INDEX
– Non partitioned table space, 1 index
7
Invoking Sort
TS IX
UNLOAD SORT BUILD STATS

• Most utilities can use parallel sorts to reduce elapsed time
• Parallelization over table space partitions or indexes
• Needs separate sort work data sets and sort output data sets for each subtask
– Use dynamic allocation for those data sets
– Can use hard coded data sets, but need to follow naming scheme correctly
• Increases load on system
– More CPU needed in parallel
– More concurrent I/O
– More memory required
• Can actually reduce amount of sort work space needed
8
Improving Elapsed Time with Parallel Sorts

• Utilities determine the degree of parallelism based on– Specification of SORTDEVT to allow dynamic allocation, or naming of hard coded sort work
data set DD cards
– Number of CPUs available (some utilities)
– Available memory below and above the line
– Estimated number of sort work data sets required, depending on size of data
• Recommendations for optimal degree of parallelism– Specify SORTDEVT option
– Use Db2 allocation of sort work data sets (UTSORTAL=YES)
– Provide sufficient memory size in REGION
• If degree of parallelism needs to be limited– Use PARALLEL n option in DB2 11
– Or, use //UTPRIN01.. //UTPRINnn DD cards to limit number of tasks
9
Degree of Parallelism
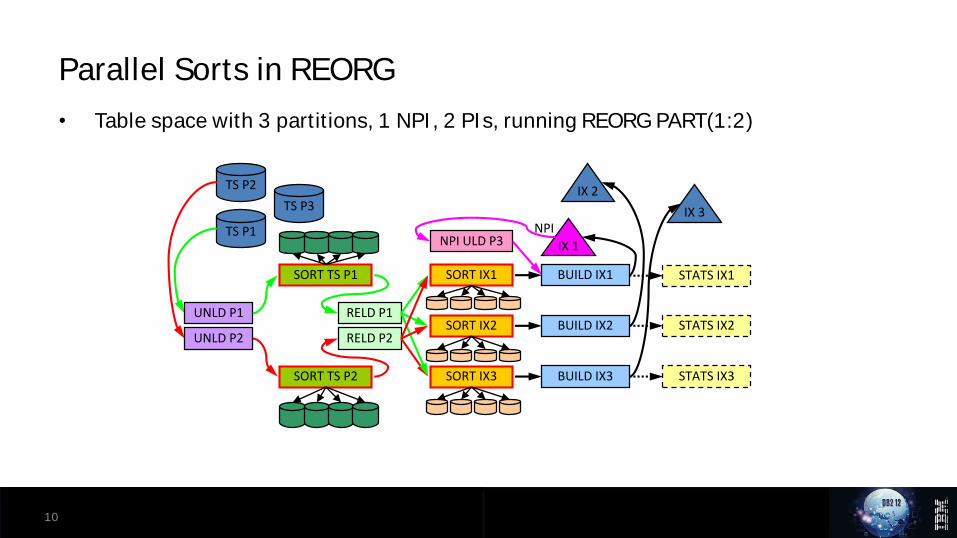
• Table space with 3 partitions, 1 NPI, 2 PIs, running REORG PART(1:2)
10
Parallel Sorts in REORG
TS P1IX 1
RELD P1
SORT IX1 BUILD IX1
SORT IX2 BUILD IX2 STATS IX2RELD P2
SORT IX3 BUILD IX3 STATS IX3
TS P2 IX 2
IX 3TS P3
NPI ULD P3
SORT TS P2
SORT TS P1
UNLD P1
UNLD P2
NPI
STATS IX1

• In most cases the amount of data being sorted can not be processed entirely in memory
• Sort work data sets will be used to store partially sorted data fragments, which will be merged at the end
• Sort work data sets can be allocated:
– By user in JCL - inflexible, not recommended
– Dynamically in Db2 (UTSORTAL=YES), or in sort program
• Most flexible, as it adjusts to current estimates
• Requires SORTDEVT to be specified
• Do not specify SORTNUM (often too large)
• Ideally keep total number of sort work data sets low (below the line memory impact, affects parallelism)
11
Sort Work Space

• For sorts with different record lengths, separate sorts have the smallest sort work space footprint:
Required space: 1,350 MB for all 3 sort tasks
12
Reducing Sort Work Space Overhead
400 MB 800 MB10,000,000
IX entries
IX1: key len 40 bytes IX2: key len 80 bytes IX3: key len 15 bytes
150
MB
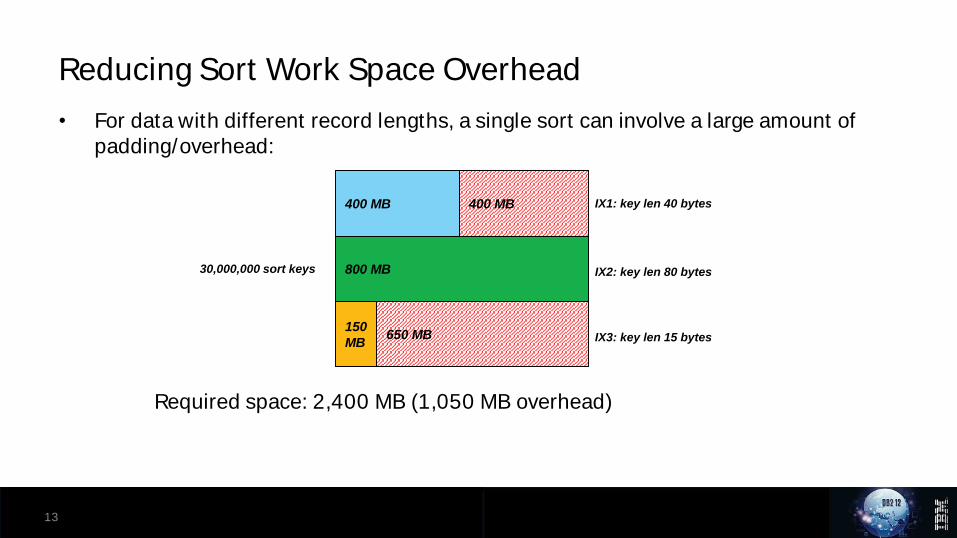
• For data with different record lengths, a single sort can involve a large amount of padding/overhead:
Required space: 2,400 MB (1,050 MB overhead)
13
Reducing Sort Work Space Overhead
150
MB
400 MB
800 MB
650 MB
30,000,000 sort keys
400 MB IX1: key len 40 bytes
IX2: key len 80 bytes
IX3: key len 15 bytes

• Data sets with DSNTYPE=LARGE supported
– Assign DATACLAS through ACS routine
• When sorting large amounts of data, provide large volumes in your sort pool (e.g. 3390 Mod-54)
• Data sets need to be single volume
– Turn off any space constraint relief functions which allocate on multiple volumes
•
Optimizer
• To avoid underestimating SORTNUM values for DFSORT, use Db2 allocation of sort work data sets (UTSORTAL=YES)
14
Allocating Sort Work Data Sets

• Db2 determines sort work data set size for each sort from RTS
• Db2 allocates sort work data sets before invoking sort– Ensure that sufficient disk space is available
– Know exactly how many data sets were allocated
– Determine degree of parallelism according to available storage and allocations
– Data sets allocated as large as possible (max ~ 3390 Mod-54 volume size)
– If smaller volumes used, or not enough space, allocation request size will be reduced, the following DFSMS message does not indicate problems:
IGD17272I VOLUME SELECTION HAS FAILED FOR INSUFFICIENT SPACE FOR
DATA SET SYS13274.T181504.RA000.CHMREOR.R0D91890
JOBNAME (CHMREOR) STEPNAME (DSNUPROC)
PROGNAME (DSNUTILB) DDNAME (DA01WK02)
REQUESTED SPACE QUANTITY = 40788119 KB
STORCLAS (TEMP) MGMTCLAS ( ) DATACLAS ( )
STORGRPS (TEMP MIGPOOL )
• Invoke sort with pre-allocated sort work data sets
• Db2 de-allocates data sets after sort completion
15
Db2 Allocated Sort Work Data Sets

• Single utility sort: SORTWKnn / UTPRINT
• Parallel index sorts: SWmmWKnn / UTPRINmm
• Single data sort: DATAWKnn / UTPRINT
• Parallel data sorts: DAmmWKnn / DTPRINmm
• RUNSTATS / inline RN01WKnn / RNPRIN01
statistics: ST01WKnn / STPRIN01
ST02WKnn / UTPRINT
V11: RNmmWKnn / RNPRINmm
16
Sort related DD Cards

• Good estimates are essential for successful sorting• Utilities consult several sources for estimates
– Real-Time Statistics (RTS), most accurate– RUNSTATS statistics, mostly accurate if sufficiently current– Page set size / table definition, usually very inaccurate– SYSREC data set size and record length
• Utilities first estimate number of rows in table space or partition, then number of index keys derived from rows
• Compressed rows often need to be expanded during REORG– To build new compression dictionary– When materializing table alterations– For DISCARD processing– Can significantly increase sort work space requirement - keep this in mind when planning sort pool
size
• MAXROWS, PCTFREE, old or missing RUNSTATS can make it very difficult to estimate uncompressed average row length correctly
17
Estimating Sort Work Space

• The following catalog tables and columns are used for sort estimates in various utilities:– SYSTABLEPART: AVGROWLEN,PAGESAVE
– SYSTABLESPACE: AVGROWLEN, NACTIVEF
– SYSTABLES: AVGROWLEN, NPAGES
– SYSTABSTATS: NPAGES
– SYSTABLESPACESTATS: TOTALROWS, DATASIZE, NPAGES
– SYSINDEXSPACESTATS: TOTALENTRIES
• We combine values from these tables to compensate missing values, usual order is RTS first, then RUNSTATS values.
•SORTKEYS are often useful (automatically generated during UNLOAD)– Especially if SYSREC is compressed or uses variable record length
18
Estimation using Statistics
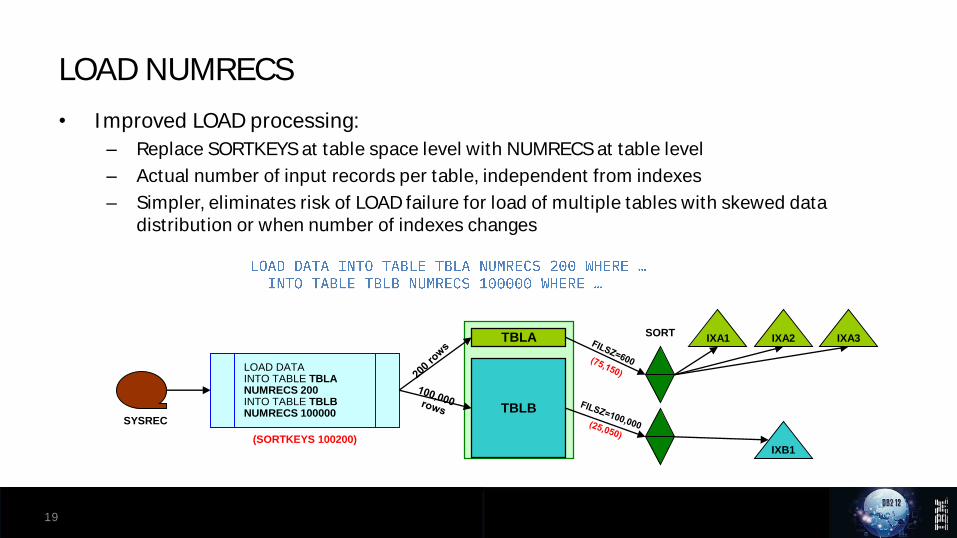
• Improved LOAD processing:
– Replace SORTKEYS at table space level with NUMRECS at table level
– Actual number of input records per table, independent from indexes
– Simpler, eliminates risk of LOAD failure for load of multiple tables with skewed data distribution or when number of indexes changes
19
LOAD NUMRECS
LOAD DATAINTO TABLE TBLA NUMRECS 200INTO TABLE TBLB NUMRECS 100000
SYSREC
TBLA
TBLB
SORTIXA1 IXA2 IXA3
IXB1(SORTKEYS 100200)

• In order to predict the minimum required disk space to run a REORG, you need to collect some information on the table (space) and index key characteristics:
– Number of rows in the table (assuming a single table table space)
– Uncompressed average row length of data rows
– Key length of all indexes
• Remember to pad out all variable length key columns to maximum length
• Add 2 bytes for each variable length column
• Add another byte for each nullable column
– Identify clustering index (unless running with SORTDATA NO)
20
Predicting Sort Work Space Use

• Get the uncompressed average row length from output of previous REORG which(re-)compressed the data:
DSNU244I -DB2A 099 08:01:42.22 DSNURWT - COMPRESSION REPORT FOR TABLE SPACE
DBDB2SRA.TSDB2SRA, PARTITION 1
25426 KB WITHOUT COMPRESSION
6016 KB WITH COMPRESSION
76 PERCENT OF THE BYTES SAVED FROM COMPRESSED DATA ROWS
99 PERCENT OF THE LOADED ROWS WERE COMPRESSED
383 BYTES FOR AVERAGE UNCOMPRESSED ROW LENGTH
93 BYTES FOR AVERAGE COMPRESSED ROW LENGTH
• Alternatively use compressed average row length either from RTS or RUNSTATS and derive uncompressed length using SYSIBM.SYSTABLEPART.PAGESAVE (rounding up):
• RTS: Compr_Avg_Row_Len = SYSIBM.SYSTABLESPACESTATS.DATASIZE / SYSIBM.SYSTABLESPACESTATS.TOTALROWS
• RUNSTATS: Compr_Avg_Row_Len = SYSIBM.SYSTABLEPART.AVGROWLEN
=> Uncompr_Avg_Row_Len Compr_Avg_Row_Len * 100 / (100 PageSave)
21
Predicting Sort Work Space Use Decompressing

• Use this simplified formula to get a rough estimate:Data_Sort_Work_Space = 1.2 * Number_of_Rows *
(Uncompr_Avg_Row_Len + 4 + Cluster_IX_Key_Len + Online_REORG_Overhead)
Online_REORG_Overhead (SHRLEVEL CHANGE): 11 (up to DB2 10) or 18 (DB2 11)
Index_Sort_Work_Space = 1.2 * Number_of_Rows *
(Sum_of_all_IX_Key_Lens + 10 * Number_of_IXs + Mapping_IX_Len)
Sum_of_all_IX_Key_Lens / Number_of_IXs: exclude clustering IX
Mapping_IX_Len (SHRLEVEL CHANGE): 29 (6 byte LRSN) or 33 (10 byte LRSN)
• We assume a buffer of at least 20% (factor 1.2) for sort work data set sizing
• When indexes can not be sorted in the optimal degree of parallelism, then the sort work space requirement will most likely be larger, data sorts are not affected by this.
22
Predicting Sort Work Space Use Calculation

• In case of sort failure, check DFSORT messages first:ICE046A 0 SORT CAPACITY EXCEEDED - RECORD COUNT 14097566
ICE253I 0 RECORDS SORTED - PROCESSED: 14097566, EXPECTED: 1000
FILSZ estimate too low
ICE201I H RECORD TYPE IS V - DATA STARTS IN POSITION 5
ICE046A 0 SORT CAPACITY EXCEEDED - RECORD COUNT 1409756
ICE253I 0 RECORDS SORTED - PROCESSED: 1409756, EXPECTED: 1385967
ICE098I 0 AVERAGE RECORD LENGTH - PROCESSED: 8069, EXPECTED: 2134
Average row length incorrect
(FILSZ within acceptable range, less than 10% error)
23
Detecting Estimation Errors
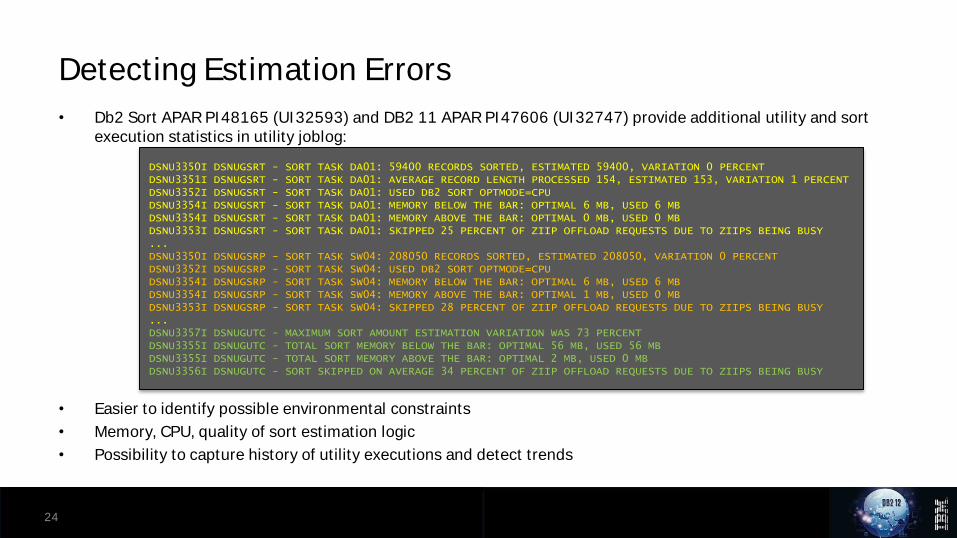
• Db2 Sort APAR PI48165 (UI32593) and DB2 11 APAR PI47606 (UI32747) provide additional utility and sort execution statistics in utility joblog:
• Easier to identify possible environmental constraints
• Memory, CPU, quality of sort estimation logic
• Possibility to capture history of utility executions and detect trends
24
Detecting Estimation Errors
DSNU3350I DSNUGSRT - SORT TASK DA01: 59400 RECORDS SORTED, ESTIMATED 59400, VARIATION 0 PERCENTDSNU3351I DSNUGSRT - SORT TASK DA01: AVERAGE RECORD LENGTH PROCESSED 154, ESTIMATED 153, VARIATION 1 PERCENTDSNU3352I DSNUGSRT - SORT TASK DA01: USED DB2 SORT OPTMODE=CPUDSNU3354I DSNUGSRT - SORT TASK DA01: MEMORY BELOW THE BAR: OPTIMAL 6 MB, USED 6 MBDSNU3354I DSNUGSRT - SORT TASK DA01: MEMORY ABOVE THE BAR: OPTIMAL 0 MB, USED 0 MBDSNU3353I DSNUGSRT - SORT TASK DA01: SKIPPED 25 PERCENT OF ZIIP OFFLOAD REQUESTS DUE TO ZIIPS BEING BUSY...DSNU3350I DSNUGSRP - SORT TASK SW04: 208050 RECORDS SORTED, ESTIMATED 208050, VARIATION 0 PERCENTDSNU3352I DSNUGSRP - SORT TASK SW04: USED DB2 SORT OPTMODE=CPUDSNU3354I DSNUGSRP - SORT TASK SW04: MEMORY BELOW THE BAR: OPTIMAL 6 MB, USED 6 MBDSNU3354I DSNUGSRP - SORT TASK SW04: MEMORY ABOVE THE BAR: OPTIMAL 1 MB, USED 0 MBDSNU3353I DSNUGSRP - SORT TASK SW04: SKIPPED 28 PERCENT OF ZIIP OFFLOAD REQUESTS DUE TO ZIIPS BEING BUSY...DSNU3357I DSNUGUTC - MAXIMUM SORT AMOUNT ESTIMATION VARIATION WAS 73 PERCENTDSNU3355I DSNUGUTC - TOTAL SORT MEMORY BELOW THE BAR: OPTIMAL 56 MB, USED 56 MBDSNU3355I DSNUGUTC - TOTAL SORT MEMORY ABOVE THE BAR: OPTIMAL 2 MB, USED 0 MBDSNU3356I DSNUGUTC - SORT SKIPPED ON AVERAGE 34 PERCENT OF ZIIP OFFLOAD REQUESTS DUE TO ZIIPS BEING BUSY

• Make sure Real-Time Statistics exist and are not misleading, e.g. after DSN1COPY
– Check SYSTABLESPACESTATS.TOTALROWS and DATASIZE, and SYSINDEXSPACESTATS.TOTALENTRIES
– If incorrect after DSN1COPY, either set these values to NULL or to estimated numbers, they exact 0 (zero) however is not a good value for non-empty table space
–
• Update all to corresponding values, or disable others by setting to NULL
• Check last run time of RUNSTATS and consider re-run:
– Average row length changed significantly
– Compression ratio changed significantly
• If MAXROWS set to a small number (> 1)
– Is it really needed, or can it be removed?
25
Correcting Estimation Errors

26
Real-Time Statistics Queries
SELECT DBNAME,NAME,PARTITION,TOTALROWS,DATASIZE,SPACE,NACTIVE,NPAGES,UPDATESTATSTIME,LOADRLASTTIME,REORGLASTTIME,STATSLASTTIME,REORGINSERTS,REORGDELETES,REORGUPDATES,REORGMASSDELETE,STATSINSERTS,STATSDELETES,STATSUPDATES,STATSMASSDELETE,DBID,PSID,INSTANCE
FROM SYSIBM.SYSTABLESPACESTATS WHERE DBNAME='dbname' AND NAME='name'ORDER BY PARTITION,INSTANCE;
SELECT DBNAME,INDEXSPACE,CREATOR,NAME,PARTITION,TOTALENTRIES,NLEAF,NACTIVE,NPAGES,SPACE,UPDATESTATSTIME,LOADRLASTTIME,REBUILDLASTTIME,REORGLASTTIME,STATSLASTTIME,DBID,ISOBID,PSID,INSTANCE
FROM SYSIBM.SYSINDEXSPACESTATS WHERE DBNAME='dbname' AND PSID IN(SELECT PSID FROM SYSIBM.SYSTABLESPACE WHERE DBNAME='dbname' AND NAME='name')
ORDER BY NAME,PARTITION,INSTANCE;

• Still not able to fix wrong estimate?– In some extreme cases decompression factor can not be estimated correctly
• Very high compression factor but compressed pages only partially filled
•
• If Db2 is not allocating sort work data sets– UTSORTAL=NO, or UTSORTAL=YES, IGNSORTN=NO, and SORTNUM xx option specified
– override FILSZ/AVGRLEN in DFSPARM//DFSPARM DD SYSIN *
OPTION FILSZ=Unnnnn,AVGRLEN=mmm
/*
• Use hard coded sort work data sets as workaround
•
• nn
• Contact IBM to determine root cause and workaround/fix
27
Correcting Estimation Errors

• Many installation options for DFSORT available, however most shops should be fine with defaults for almost all options
– Use PARMLIB members ICEPRMxx and /S ICEOPT to dynamically activate new installation option settings instead of old ICEAM2 method
– Db2 will query some installation options, but will not be able to see overrides specified in //DFSPARM
• Only area to consider for tuning is memory management
28
Utilities and DFSORT

• Main storage (program memory)– Used for actual sorting of data chunks
– Most important to be sized correctly
– Controlled by REGION size or IEFUSI exit, and DSA option in DFSORT
– Typical range up to a few hundred MB per invocation
• Memory Objects (storage above the bar)– Used as work space instead of DASD
– Holds presorted chunks of data
– Controlled by MEMLIMIT option (JCL), or MOSIZE option in DFSORT
– Can be up to several GB in size
• Hiper Spaces (auxiliary storage)– Used as work space instead of DASD
– Controlled by HIPRSIZE option in DFSORT
– Can use MANY GBs of memory
29

• Some customers experience paging when running utilities with parallel sort tasks and large amounts of data
– Caused by huge memory consumption for sort work space
– Mostly by Hiper Space, sometimes by use of Memory Objects
– Can easily be controlled by setting DFSORT option EXPOLD=0 (instead of MAX) to prevent
– z/OS 2.1 provided changed installation options for less demanding allocation of memory (TUNE=STOR, EXPOLD=50%) with more intermediate checking of available resources, this should be sufficient in most cases already
• Do NOT reduce REGION or DSA when paging occurs
– Amount of saved memory is usually small compared to memory used for sort work space
– Impact on performance can be dramatic when main memory is limited
30
DFSORT & Paging

• Some examples for auxiliary memory use messages:ICE199I 0 MEMORY OBJECT USED AS MAIN STORAGE = 0M BYTES
ICE299I 0 MEMORY OBJECT USED AS WORK STORAGE = 129M BYTES
ICE180I 0 HIPERSPACE STORAGE USED = 0K BYTES
ICE188I 0 DATA SPACE STORAGE USED = 0K BYTES
A gentle use of 129 MB memory objects (above the bar)
ICE199I 0 MEMORY OBJECT USED AS MAIN STORAGE = 0M BYTES
ICE299I 0 MEMORY OBJECT USED AS WORK STORAGE = 0M BYTES
ICE180I 0 HIPERSPACE STORAGE USED = 23972100K BYTES
ICE188I 0 DATA SPACE STORAGE USED = 0K BYTES
A heavy use of ~23 GB Hiperspace for just this sort, this could be a contributor to cause paging!
• Use EXPOLD, EXPMAX, MOSIZE, HIPRMAX to control use of auxiliary memory in DFSORT.
31
DFSORT Memory Message Sample

• Used as work storage while actually sorting data
• If insufficient memory available, many small chunks have to be sorted and merged later
– Drives up CPU consumption
– Increases sort work space requirement
– May cause sort failure
• Controlled by MAINSIZE, TMAXLIM, DSA, and REGION
32
DFSORT Main Memory Consumption
DFSORT
Options: MAINSIZE=MAX,DSA=64M,TMAXLIM=6M
Initial allocation: 6 MB (TMAXLIM)
Maximum allocation: 64 MB (DSA)
64 MB
6 MB

• DSA (Dynamic Storage Adjustment) specifies maximum amount of memory that can be used by a DFSORT instance
• Smaller sorts typically do not exploit that limit
• As a rule of thumb you can use this table to estimate DFSORT memory consumption:
•
• Default DSA was 64 MB up to z/OS 1.13, 128 MB since z/OS 2.1– Sorting more than 100 GB of data can already exceed current DSA setting
– Alarming message (short of failure), action required:ICE247I 0 INTERMEDIATE MERGE ENTERED PERFORMANCE MAY BE DEGRADED
33
DFSORT Typical Memory Sizes
Size of data sorted Main memory needed in DFSORT
1 GB ~ 10 MB
100 GB ~ 50-80 MB
1 TB ~ 250-350 MB

• DSA of 64 MB used to be adequate for many years
• Now it has become a limiting factor for the amount of data that can be sorted effectively
• Many shops are reluctant to increase DSA fearing side effects
• APAR PI07216 ignores DSA installation option of DFSORT within Db2
– Db2 will calculate memory available to each sort subtask depending on number of subtasks and available REGION size
– Db2 will pass new DSA value to DFSORT
• Can be larger than DSA installation option
• Total of all DSA values passed to subtasks will never exceed REGION
• DB2 11 further enhanced DSA calculation per task by assigning memory depending on size of data being sorted
34
Overcoming DSA Limits

• Even with all DSA changes applied, DFSORT could still be running with constrained memory.
• A first sign of constrained memory would be the full exploitation of the given DSA per instance, e.g.:
ICE093I 0 MAIN STORAGE = (MAX,83886080,83886080)
ICE131I 80
– DSA was set to 80 MB which equals 83,886,080 Bytes!
– DFSORT used all allowed memory in this task.
– This can still be ok, but at some point this will have an effect on required sort work space and performance.
• Last warning before failure:ICE247I 0 INTERMEDIATE MERGE ENTERED PERFORMANCE MAY BE DEGRADED
35
Is DFSORT still short on Memory?

• When DFSORT allocates sort work data sets, guidance on number of data sets is needed
– Specify through SORTNUM parameter
– Or DYNALLOC option in DFSORT
• DFSORT will always allocate as many sort work data sets as specified
– Can waste valuable resources for small sorts
• No additional sort work space can be allocated later on if running out of space
– Because of bad estimates
– Because of limited memory (DSA, intermediate merge)
36
DFSORT and Sort Work Data Sets

• Provides high speed utility sort processing for Db2 for z/OS
• More effective sort algorithms to save CPU and elapsed time
– Specifically tailored to the way how utilities operate
• Much higher zIIP offload capability for further CPU savings
• More robust against incorrect estimates
– Can allocate additional sort work data sets later on
• Specific adaptations to utilities processing not found in any other sort product:
– Special sort algorithm only found in Db2 Sort
– API to optimally distribute available memory resources among parallel sorts (even across address spaces)
– Tight integration with Db2 code for further CPU improvements
• Easy installation and customization
37
Db2 Sort for z/OS

• Use of Db2 Sort 2.1 with Db2 utilities, as compared with running Db2 utilities alone, may see: *
– Reduction of Sort CPU usage
• Up to 84.8% reduction on machines with zIIP engines
• Up to 49.1% reduction on machines without zIIP engines
– Reduction of Utility CPU usage
• Up to 60.6% reduction on machines with zIIP engines
• Up to 39.7% reduction on machines without zIIP engines
– Reduction of Utility Elapsed Time
• Up to 44.6% reduction on machines with zIIP engines
• Up to 46% reduction on machines without zIIP engines
38
Db2 Sort 2.1 Performance Benefits
* The information contained on this slide is distributed AS IS. Performance data and results presented were determined in various controlled laboratory environments, using specific, limited test configurations, and are for reference purposes only. Tests were run against the most current versions of Db2 Sort and Db2 Utilities Suite generally available as of October 24th, 2014. Results reported for machines with zIIP engines reflect a situation where all Db2 Sort program zIIP eligible instructions are successfully dispatched to execute on available zIIP processor(s). The results that may be obtained in other operating and production environments may vary significantly. Users of the product should verify the applicable results they might achieve for their specific environment.

• it should run without intervention required by the DBAs or SysProgs
Can be achieved if no artificial constraints added
– No tuning required
Stick with DFSORT/Db2 Sort default options, maybe change EXPOLD
– Optimal performance out of the box
Sort products already tune themselves
– Minimal resource requirements
Need to face reality about grown data volumes requiring a certain amount of resources
39
Expectation About Sorting

• Understanding on how sorting works in utilities
• Basic requirements for successful sorting
• Which knobs to turn for tuning if any
• Further performance improvements and robustness with Db2 Sort for z/OS
40
Summary

Christian Michel
Db2 for z/OS Utilities DevelopmentIBM Germany Research & Development
E-mail: [email protected]
41
Questions?

![AO3. Sorted.[1]](https://static.fdocuments.net/doc/165x107/577d2c5c1a28ab4e1eabfd81/ao3-sorted1.jpg)
















