
David Shotton Image BioInformatics Research Group Department of Zoology University of Oxford, UK...
29
David Shotton Image BioInformatics Research Group Department of Zoology University of Oxford, UK http:/ibrg.zoo.ox.ac.uk *** Research Group Department of Zoology 28 January 2009 The ADMIRAL Project - A Data Management Infrastructure for Research Across the Life sciences http://imageweb.zoo.ox.ac.uk/wiki/index.php/ADMIRAL © David Shotton, 2010 Published under a Creative Commons 3.0 Attribution Licence e-mail: [email protected]
-
date post
21-Dec-2015 -
Category
Documents
-
view
214 -
download
1
Transcript of David Shotton Image BioInformatics Research Group Department of Zoology University of Oxford, UK...

David Shotton
Image BioInformatics Research GroupDepartment of ZoologyUniversity of Oxford, UK
http:/ibrg.zoo.ox.ac.uk
*** Research GroupDepartment of Zoology
28 January 2009
The ADMIRAL Project
- A Data Management Infrastructure for Research Across the Life sciences
http://imageweb.zoo.ox.ac.uk/wiki/index.php/ADMIRAL
© David Shotton, 2010 Published under a Creative Commons 3.0 Attribution Licence
e-mail: [email protected]

The problems of research data management
From a scientist: “I just wrote a paper. It was 2 pages long . . . and had 150 pages of supporting information”
From a PI: “When a group member leaves, it can be extremely difficult to find out what they worked on”
From a PI (somewhat tongue-in-cheek): “Every four years we start to repeat what we’ve done before, because the people who knew have all left”
From a scientist: “For a software solution to succeed, it must:
• Make something possible that currently isn’t, or• Make something easier that’s currently difficult”
One researcher spends more time finding information (6.5 hours per week) than processing it
"Science these days has basically turned into a data management problem"

Characteristics of much biological research data
Bottom-up data flow, lacking central control
Many small research groups with diverse research topics
Distributed research activities and publication structures
Research data heterogeneous and may be poorly structured
Data collection costly in human resources
Data re-acquisition may be impossible, particularly for observational data
Datasets thus often have a high intrinsic value per bit This stands in contrast to high-throughput sequencing or
protein crystal structure determination There data acquisition is capital-intensive, not labour-intensive Raw data has low intrinsic value per bit Re-acquisition becomes cheaper as capital costs fall
While much attention has been given to those who generate large data volumes, the ‘long tail’ of research groups creating moderate amounts of highly valuable data have been ignored. It is these that the ADMIRAL Project seeks to help

The data publication requirements of funding bodies
Most Research Councils have recently introduced policies requiring researchers to set up formal mechanisms to manage created data, including provision for archiving, access and re-use, at the project end
e.g. BBSRC:
“BBSRC expects research data generated as a result of BBSRC support to be made available with as few restrictions as possible in a timely and responsible manner to the scientific community for subsequent research.
“Data should also be retained for a period of ten years after completion of a research project.”
In addition, BBSRC requires new grant applications to contain a data management plan as a pre-requisite for funding
Through ADMIRAL, we hopes to provide assistance in both these areas

Support for ADMIRAL from Chris Holland
“It is challenging to efficiently record, organize and catalogue my data, a situation I share with many of my colleagues, especially those working in the interfacial sciences.
Research groups like mine would benefit greatly from a front-to-back data management system of the sort that you are proposing to develop in the ADMIRAL Project.
That will help us to organise, integrate and eventually publish our data with appropriate linkage to existing public sources, in a technically accessible fashion.”
Our other test users –Seb Shimeld, Alex Kacelnik and Fritz Vollrath – have also given enthusiastic support

Support for ADMIRAL from Alex Kacelnik
“I believe that the ADMIRAL project is timely and that it could play a significant role both locally (in Oxford) and internationally, as it can foster a change in culture regarding the long term treatment of behavioural and related data.
In particular, it will assist me in fulfilling my intention to make the raw data from my experiments on starlings available publicly in the long run for people to re-do whatever analysis they wish on that material.
Similarly, the results of our problem solving experiments with New Caledonian crows are typically collected in video format, and experience has repeatedly shown that re-analysis of video data can lead to substantial re-interpretation of old data, hence long-term, accessible storage of video data is essential.”
Our other test users – Chris Holland, Seb Shimeld and Fritz Vollrath – have given similar enthusiastic support

Support for ADMIRAL from Seb Shimeld
“We work with a dozen different species, and the resulting complexity of images (species, stages, genes, experiments, visualisation methods) generates a huge storage and management challenge.
We struggle even with the basics of efficient cataloguing and archiving of these data, and most of my colleagues are in a similar position.
I can see huge benefits in effective, integrated image data management that is technically accessible to research groups such as mine. Gaps exist from the basic level of archive, search and retrieval of data to the juicy prospect of rendering data accessible to other scientists.
I think this later point is particularly pertinent, I would estimate less than 1% of image data in my field become publicly available, as images are cherry-picked for publication.”
Our other test users – Chris Holland, Alex Kacelnik and Fritz Vollrath – have given similar enthusiastic support

Support for ADMIRAL from Fritz Vollrath
“I am writing now to say how delighted I am that you wish to include our data in your development of a general data management infrastructure suitable for different types of life science research datasets.
I am particularly interested in the fact that this will be a Web-based data management system, since this means that we will be able to deposit data into it directly from Kenya, secure in the knowledge that the data will be securely managed and backed up, selectively sharable with trusted colleagues, and also securely archived for long-term preservation in the Oxford University Library Service's DataBank.
As you know, we are keen for many of our maps and datasets to be publicly available, as well as being securely archived, and we look forward to exploring with you how this might be accomplished as part of the ADMIRAL Project.”
Our other test users – Chris Holland, Seb Shimeld and Alex Kacelnik – have given similar enthusiastic support

RIN survey of information use in the life sciences
(Report available at http://tinyurl.com/yjawuk4)
“The availability of powerful new information and communications technologies have brought major changes for life science researchers “
“Life scientists grapple with the new functionalities and possibilities of use offered by emerging information policies, tools and services”
“The groups expressed a strong desire for information support, if possible closely integrated with their research teams and laboratories”

Barriers to data sharing
(From that RIN Report, Nov 2009)
Concerns about potential misuse
Ethical constraints
Intellectual property issues
Data ownership
“Above all, as researchers, we see data as a critical part of our ‘intellectual capital’, generated through a considerable investment of time, effort and skill.
“In a competitive environment, our willingness to share is therefore subject to reservations, in particular as to the control we have over the manner and timing of sharing.
“Any sharing or publishing environment must therefore have secure embargo procedures, such that we can state at the outset when in the future we are happy for the data to be published, safe in the knowledge that our wishes will be honoured.”

Characterizing research activities – three phases
Information discovery
Data acquisition
Data management Data analysis
Data sharingData processing
Study concept and design
Hypothesis generation
Data archiving
Results and conclusions
Seminars and conference presentations
Articles and reports
Undertaking experiments

Information management in biological research can be quite complex
Information flow in an epidemiological study of zoonotic diseases

Where is the pain?
Remembering, a year later, what this photograph is supposed to represent
Finding that spreadsheet on my hard drive – what was its name?
Repeating experiments – which protocol did I use?
Getting hold of data created by other group members
Maintaining group knowledge when key personnel leave
Dealing with bureaucracy – COSHH forms
Keeping inventories up to date
Recording workflows
Retrieving relevant facts for paper writing
Finding the right image for the article

Reposito
ry s
ubm
ission e
ffort
Inve
stm
ent in
local
data
managm
ent
Raw research data in assorted formats with inadequate metadata
Raw research data metadata
in assorted formats with good semantic
Research data, well managed in local research repository
Subm
ission too h
ard
- w
ill n
eve
r happen
Manual s
ubm
ission
- h
ero
ic a
nd rare
Bulk ingest in repository format makes submission trivially easy
Institutional repository
Easing the pain of data archiving and publication

ADMIRAL
Short-term goal To make your lives easier, in terms of data management
Immediate objective To create some simple services that works for you
Long-term goal To create the next-generation infrastructure for research data
High-level problem How best to capture, preserve and publish knowledge relevant
to biological research
We’ve had some ideas . . .
. . . but what we do will be determined by what you want, developed in a process of ‘agile development’ in response to your feedback on early prototypes

ADMIRAL ideas
Phase One - Basic data management and archiving: By early autumn
Storage - a local ‘mapped’ Life Science Data Store for research data of any file format, selectively sharable, with automated daily backup, and additional Web access
Annotation – use of our Shuffl tool to permit both simple annotation of data files, and easy visualization of numerical datasets
Packaging of data files and minimal descriptive metadata for archiving
Submission of selected quality datasets to the new Oxford DataBank for long-term preservation, at a timing decided by the data owner, automatically
Phase Two – Advanced annotation and data publication: By March 2011
Web services to enrich metadata, e.g. automatic provision of full bibliographic details from a PubMed ID, mark-up of recognised entities (genes, proteins, Gene Ontology terms, etc.), and retrieval of latitude and longitude for named places
Formal annotations developed from free text tagging, for example using BioPortal to access the ~150 ontologies in the OBO Foundry.
Publication of selected datasets with descriptive metadata, citable DOIs and CC data licences, on embargo dates set by data owners, with links to relevant research papers

The principle of ‘sheer curation’
In creating the ADMIRAL infrastructure for data management, we will practice ‘sheer curation’ (http://en.wikipedia.org/wiki/Sheer_curation):
working with you rather than against you
exploiting data management tools (e.g. spreadsheets) with which you are already familiar
harvesting metadata automatically where possible
providing services that are of immediate benefit in your day-to-day activities
making curation activities sufficiently lightweight and transparent that they do not impose a significant cognitive overhead

The importance of initial requirements analysis
To create useful data management services, we need to know
what you are currently doing
where your pain points are
what solutions and services you would really like
First, I am asking you and all your research group members to complete an initial ADMIRAL Research Data Survey by the end of this week
It should take no more than half an hour of your time
You should each regard this as an essential priority activity
I would then like each of you to keep an ADMIRAL Lab Data Notebook for the five consecutive working days next week, in which you note the information sources you use and the data sets you create, and then finally link them into an information workflow diagram
This should take no more than 10 minutes a day, and will become part of your normal lab notebook completion activities

An example of a day entry in the Lab Data Notebook
Your name: Josephine Bloggs Today's date: 22 Nov 2009
Creation of new information (Please list each data file or information record you create during the day)
Nature of informationSequence of cloned Cione gene
fragmentGel photoIn situ micrograph of Cione embryoEndNote records for two new papersDescription of new gene in lab
notebook
How will you use it?Determine function from homologyDetermine size of cloned fragmentDetermine expression pattern of
geneReference list in planned research
articleInformation for planned research
article
Time spent creating information (h:mm): 3 h Time spent using new information (h:mm): 30 m
Use of third party information (Please list each data or information source you use during the day)
Information sourceBLASTFlyBaseBerkeley Drosophila Genome ProjectMedline
Nature of informationDiscover homologues of new
sequenceInfo on Drosophila homologueExpression patterns of gene in
Drosophila embryoReferences and abstracts of two
papers on gene
Time spent acquiring information (h:mm): 45 m Time spent using third-party info (h:mm): 1 h

An example of an information workflow

The importance of feedback for iterative development
As we develop ADMIRAL tools and services to meet your needs
we will let you test these out in your everyday work, and
will ask you to give us feedback to guide our iterative development
Within 6 months, we hope you will be using the Life Science Data Store on a daily basis, and archiving valuable datasets in the Oxford DataBank
By the project end, we hope to provide you with better metadata creation services, and hope that you will be publishing key datasets to the Web
The development work and user interactions will be undertaken by
my senior computing officer, Graham Klyne, who is project manager
assisted by Dr Diana Galletly, who started work on 18 January
We hope that buzz about ADMIRAL services will spread virally, so that others within the Department will wish to use them

Sustainability
It is important that the ADMIRAL services we develop during this short JISC project are sustained after the end of the current grant
The Oxford University Library Service is committed to long-term archival care of datasets submitted by ADMIRAL to the Oxford DataBank
We will work with the Zoology IT support staff, Simon Ellis and his colleagues, to ensure the long-term maintenance of the local services
Given sufficient demand from research groups, financial support for the local services will be forthcoming, albeit at a cost
As part of the ADMIRAL Project, we will create a downloadable Zoology data management template that group leaders can use in grant applications
This template will have estimates of the true costs of data management, archiving and support services, that you can use in your grant applications

This isn’t just a waste of time !
We recently created FlyTED (the Drosophila Testis Gene Expression Database), for Helen White-Cooper’s gene expression research images
http://www.fly-ted.org
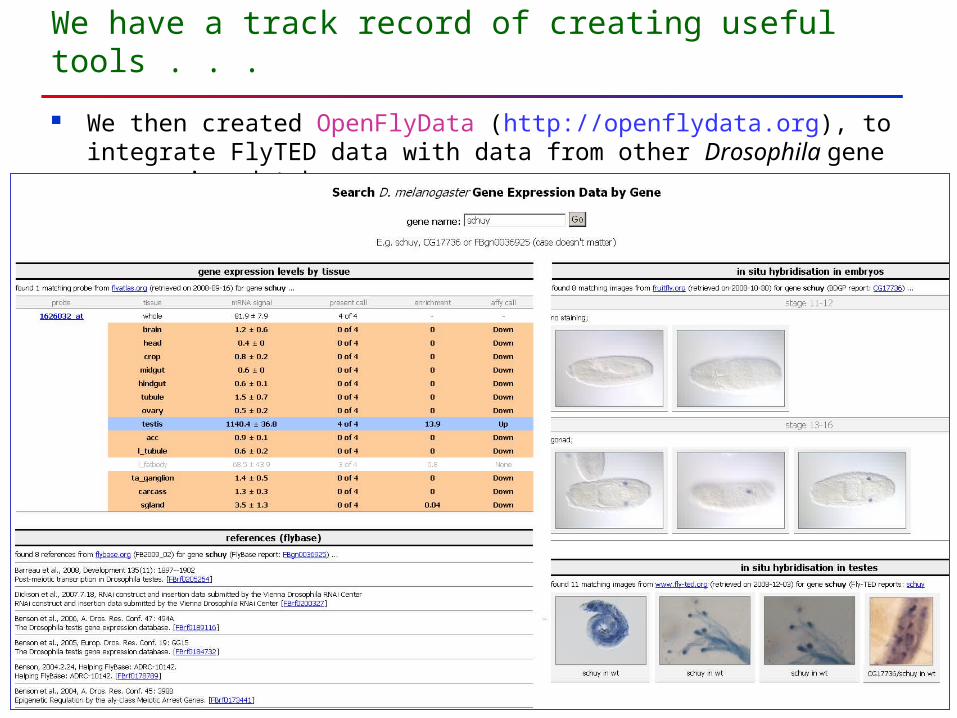
We have a track record of creating useful tools . . .
We then created OpenFlyData (http://openflydata.org), to integrate FlyTED data with data from other Drosophila gene expression databases

Helen White-Cooper’s response . . .
Quotes from her letter of 21 April 2009
“Our collaborations have been very helpful to me for my research. The added value of our data being available in a well-designed searchable database is immense.
“In addition, your group’s integration of my data with that on other sites has been incredibly helpful.
“If we had had your software tools to support the organization and annotation of our data in the first place, the process would have been much more streamlined, as much effort was needed to check and correct errors in our original data.”

Summary: What ADMIRAL will offer
A secure local Life Science Data Store, regularly backed up, to which you can save data files as easily as saving to your hard drive
The ability to share access to your datasets with colleagues, both here and elsewhere, under password control
A Web-based data annotation and visualization tool, Shuffl
A search facility to permit you to find your data files easily
Behind-the-scenes data management
archiving of those datasets you choose to the Oxford DataBank
implementing your embargo dates for data publication
for those datasets you choose to publish, assignment of Science Commons Open Access licenses, and DOIs, making them citable
Having citable datasets will enhance your CV
Datasets, as well as papers, count in evaluating your research record
The availability of ADMIRAL services will help you complete the required data management plan for your next grant application

The conventional research data lifecycle
Scholarly publications:conference papers and
journal articles
Raw data in research note-books and live PC files
Research resultsand conclusions
Data selection and interpretation
Publicationactivities
Research datasets abandoned on local hard drives or CD-ROMs
Hypothesis formulation and project design
Experimentation and data creation
Research plan
Institutionalrepositories
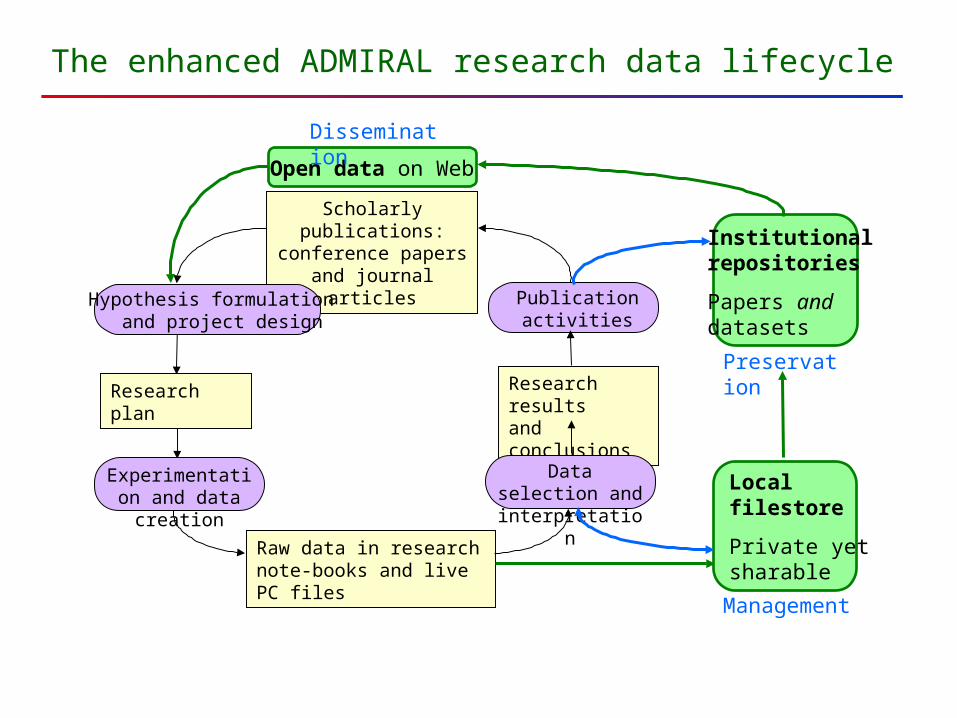
The enhanced ADMIRAL research data lifecycle
Scholarly publications:conference papers and
journal articles
Raw data in research note-books and live PC files
Research resultsand conclusions
Hypothesis formulation and project design
Experimentation and data creation
Data selection and interpretation
Publicationactivities
Research plan
Institutionalrepositories
Papers and datasets
Local filestore
Private yetsharable
Open data on Web
Management
Dissemination
Preservation

end
“Good data management is as vital to our research activities as e-mail and
toilets"


















