DataStax GeekNet Webinar - Apache Cassandra: Enterprise NoSQL
Upload
datastax-academyCategory
view
3.274download
3
©2015 DataStax Confidential. Do not distribute without consent.
https://goo.gl/JtC9YR @AlTobey
Extreme Cassandra Optimization: The Sequel
1

init()•This is all specific to Cassandra 2.1 •I will try to call out dangerous and apocryphal settings •Focus is on the low-hanging fruit
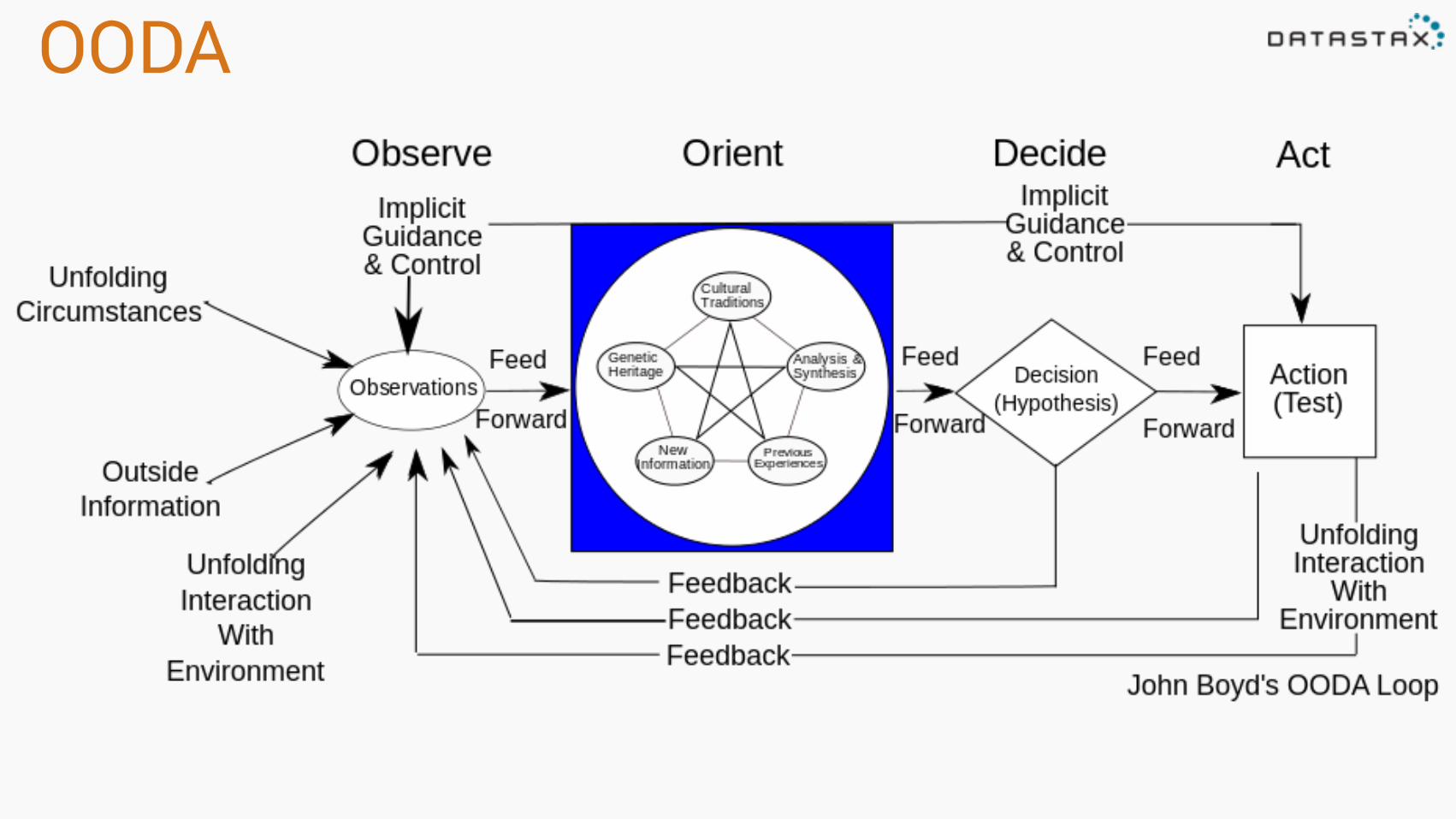
OODA
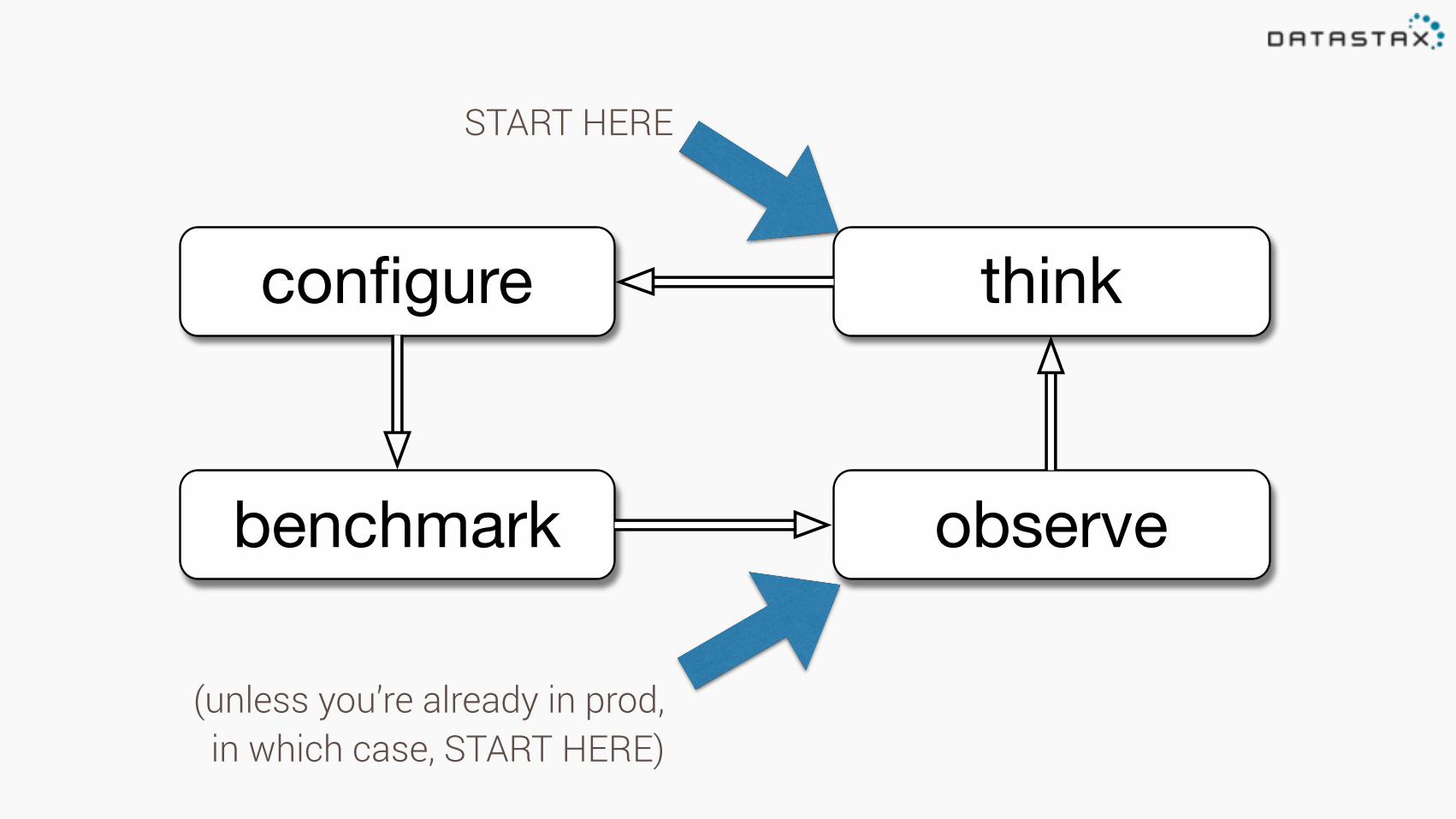
benchmark
configure
observe
think
START HERE
(unless you’re already in prod, in which case, START HERE)

Questions to ask:•Look at the available hardware and make an educated guess •How many sockets/cores? Hyperthreading? NUMA? •How much RAM? •memory bandwidth matters •What kind of storage? •How much per node? •What kind of network interface is it? •Some clouds have PPS limit


0x00b0
0x00b0
Hypervisor IOMMUvCPU0
vCPU1
vCPU2
vCPU3
application
kernel
vCPU0
vCPU1
vCPU2
vCPU3
application
0x00b0
0x00b0
kernel
hypervisors

containers (Docker)
0x00b0
0x00b0
kernel
0x00b0
0x00b0
bridge
veth
application
iptables
application
host networking
Docker networking

benchmark
configure
observe
think
YOU ARE HERE

JVM•Use Hotspot Java 8 >= u45 • Java 7 is EOL and slower •OpenJDK is fine •Zulu is a handy way to get the latest •http://www.azulsystems.com/products/zulu
•Speaking of Azul … •Some Datastax customers are having success with C4 •But I can’t talk about any of them

cassandra-env.sh: G1GC#JVM_OPTS="$JVM_OPTS -Xmn${HEAP_NEWSIZE}" # REJOICE!
JVM_OPTS="$JVM_OPTS -XX:+UseG1GC"JVM_OPTS="$JVM_OPTS -XX:InitiatingHeapOccupancyPercent=20"JVM_OPTS="$JVM_OPTS -XX:G1RSetUpdatingPauseTimePercent=5"#JVM_OPTS="$JVM_OPTS -XX:ParallelGCThreads=24"#JVM_OPTS="$JVM_OPTS -XX:ConcGCThreads=24"#JVM_OPTS="$JVM_OPTS -XX:MaxGCPauseMillis=500"JVM_OPTS="$JVM_OPTS -XX:+ParallelRefProcEnabled"
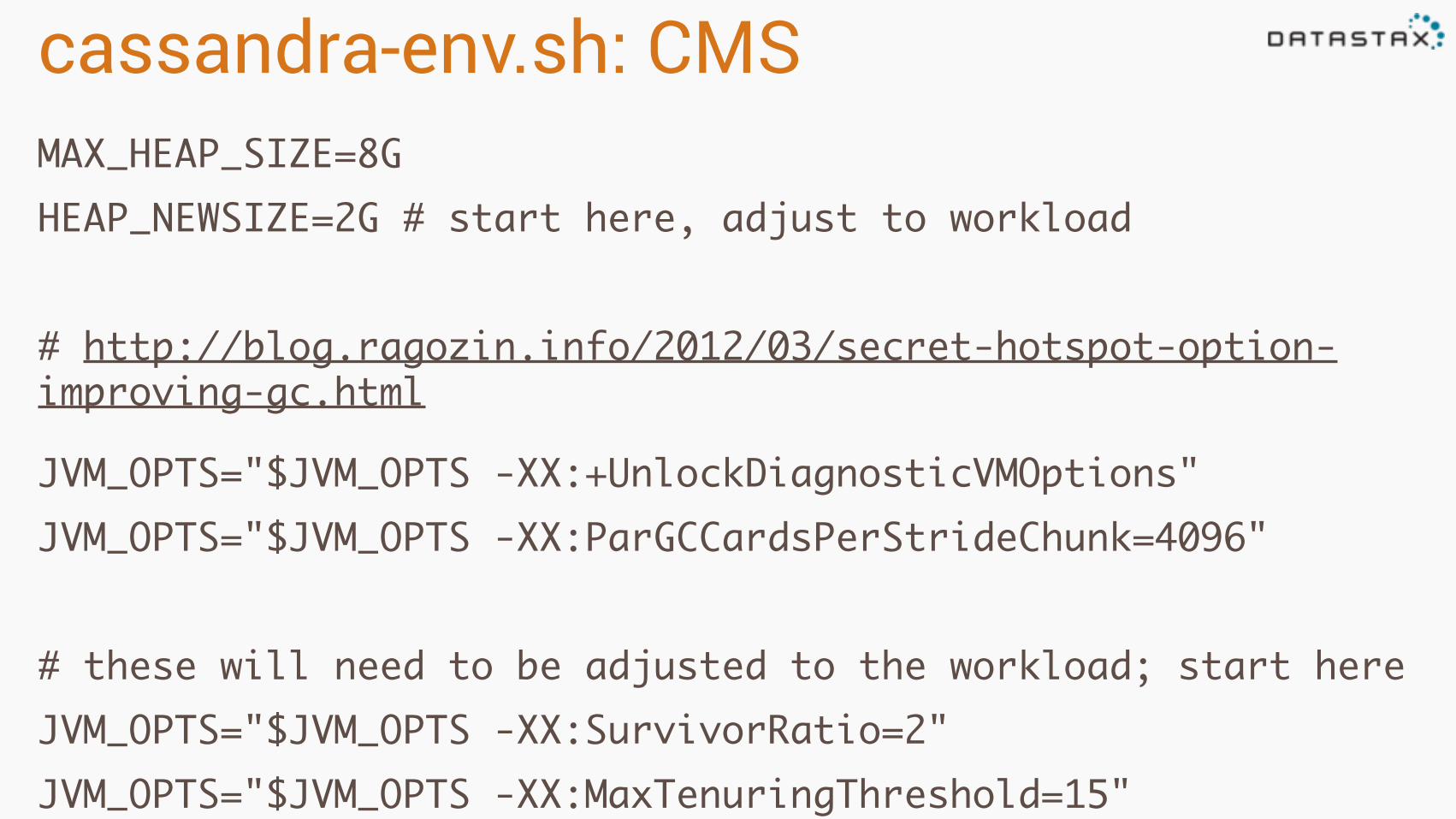
cassandra-env.sh: CMSMAX_HEAP_SIZE=8GHEAP_NEWSIZE=2G # start here, adjust to workload
# http://blog.ragozin.info/2012/03/secret-hotspot-option-improving-gc.html
JVM_OPTS="$JVM_OPTS -XX:+UnlockDiagnosticVMOptions"JVM_OPTS="$JVM_OPTS -XX:ParGCCardsPerStrideChunk=4096"
# these will need to be adjusted to the workload; start hereJVM_OPTS="$JVM_OPTS -XX:SurvivorRatio=2"JVM_OPTS="$JVM_OPTS -XX:MaxTenuringThreshold=15"

cassandra-env.sh: More JVM flagsJVM_OPTS="$JVM_OPTS -XX:-UseBiasedLocking"JVM_OPTS="$JVM_OPTS -XX:+UseTLAB -XX:+ResizeTLAB"JVM_OPTS="$JVM_OPTS -XX:+AlwaysPreTouch" # esp. Docker!JVM_OPTS="$JVM_OPTS -XX:+DisableExplicitGC"JVM_OPTS="$JVM_OPTS -XX:+PerfDisableSharedMem"

cassandra.yaml: IO threads
concurrent_reads: 128concurrent_writes: 128

cassandra.yaml: memtables
memtable_heap_space_in_mb: 2048
memtable_cleanup_threshold: 0.10
memtable_flush_writers: 4
#memtable_allocation_type: offheap_objects # MAYBE
Set these together!

cassandra.yaml: commitlog# Cassandra >= 2.1.9commitlog_segment_recycling: false
# on SSDs and some HDD RAIDtrickle_fsync: truetrickle_fsync_interval_in_kb: 1024
# and/or set vm.dirty_background_bytes lowecho 8388608 > /proc/sys/vm/dirty_background_bytes

cassandra.yaml: miscellaneousnum_tokens: 32 # or 1, if you prefer
# default in OSS is “all”internode_compression: dc
# Cassandra >= 2.1.5otc_coalescing_strategy: TIMEHORIZON
# https://issues.apache.org/jira/browse/CASSANDRA-8611streaming_socket_timeout_in_ms: 600000

cassandra: schema• The data model is the single most important factor for performance!
• Check your compression block size (per table)
• Use size-tiered compaction (STCS) • leveled compaction (LCS) for read-heavy workloads on fast storage
• the current default of 160MB sstable_size_in_mb is fine
• DTCS for time series (http://www.datastax.com/dev/blog/dtcs-notes-from-the-field)
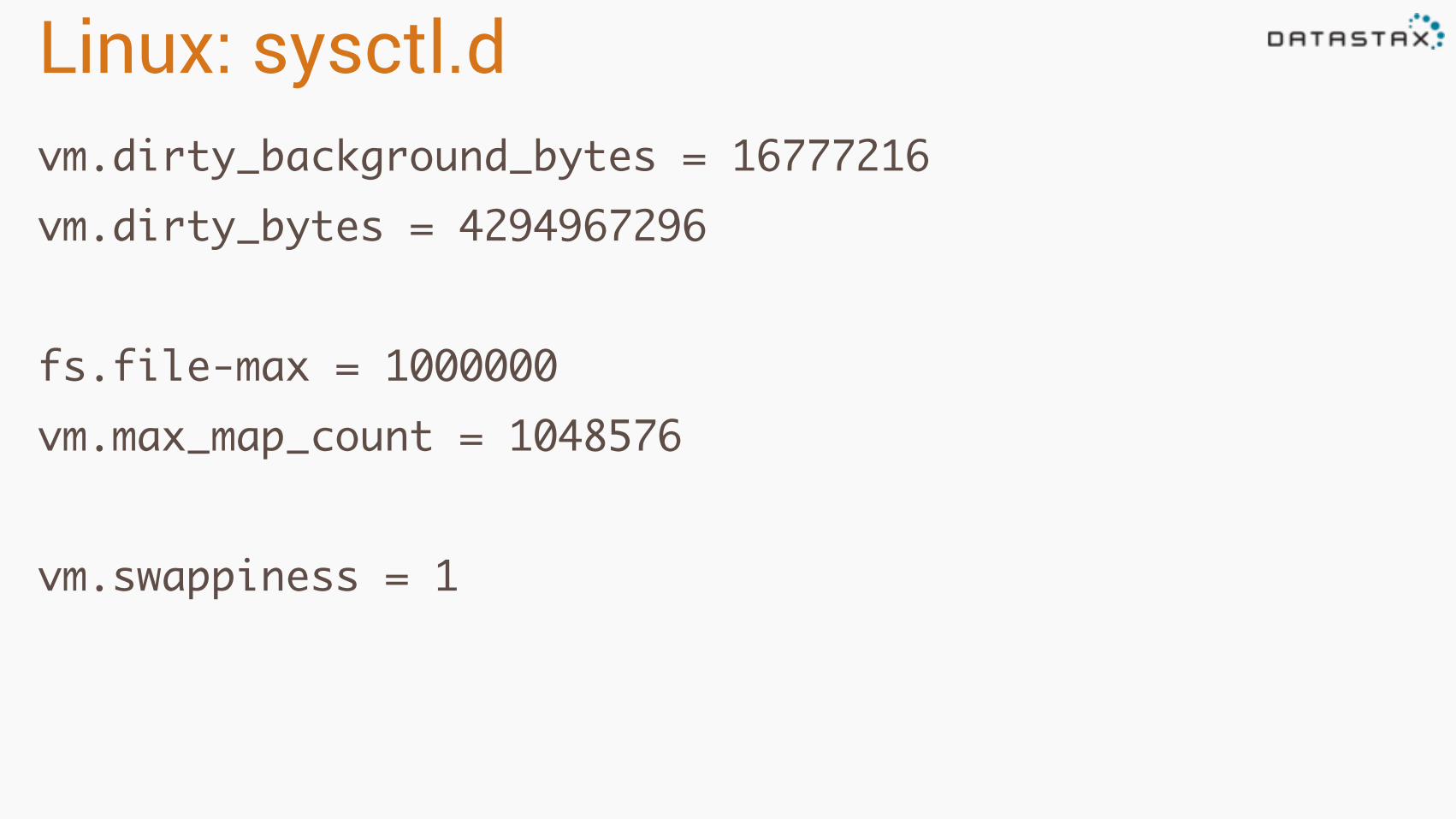
Linux: sysctl.dvm.dirty_background_bytes = 16777216vm.dirty_bytes = 4294967296
fs.file-max = 1000000vm.max_map_count = 1048576
vm.swappiness = 1

Linux: storagecd /sys/blockfor drive in sd* xvd* vd* nvme*do echo deadline > $drive/queue/scheduler
echo 8 > $drive/queue/read_ahead_kb
# only on fast SSDs echo 0 > $drive/queue/nomergesdone

Linux: RAID & filesystems•use xfs •ext4 if you must •ZFS if you love yourself and want to be happy •btrfs if you like to live dangerously •RAID*: Pass stripe size & width to mkfs whenever possible •RAID0 is by far the most common choice •RAID10 is fine if you can afford the disks •RAID5/6 in some circumstances, but there’s a tradeoff •JBOD is great but has tradeoffs

Linux kernel boot parametersisolcpus=0
idle=mwaitintel_idle.max_cstate=0 processor.max_cstate=0
idle=halt (C1 only)
idle=poll (for extreme cases, wastes power)
Disable in BIOS

Disable Frequency Scaling# make sure the CPUs run at max frequencyfor sysfs_cpu in /sys/devices/system/cpu/cpu[0-9]*do echo performance > $sysfs_cpu/cpufreq/scaling_governordone

Docker
benchmark
configure
observe
think
YOU ARE HERE

BENCHMARKETING

cassandra-stresscassandra-stress \ write \ n=100M \ cl=LOCAL_QUORUM \ -col "size=fixed(128)" "n=fixed(10)" \ -schema "replication(factor=3)" \ -rate threads=512 limit=35000/s \ -errors ignore \ -mode native cql3 \ -node 127.0.0.1

ops/smean median p95 p99 p99.9 max

cassandra-stress: user schemacassandra-stress \ user \ n=100M \ cl=LOCAL_QUORUM \ profile=bank_stress.yaml \ 'ops(simple=1)' \ no-warmup \ -rate threads=512 limit=35000/s \ -errors ignore \ -node 127.0.0.1

benchmark
configure
observe
think
YOU ARE HERE

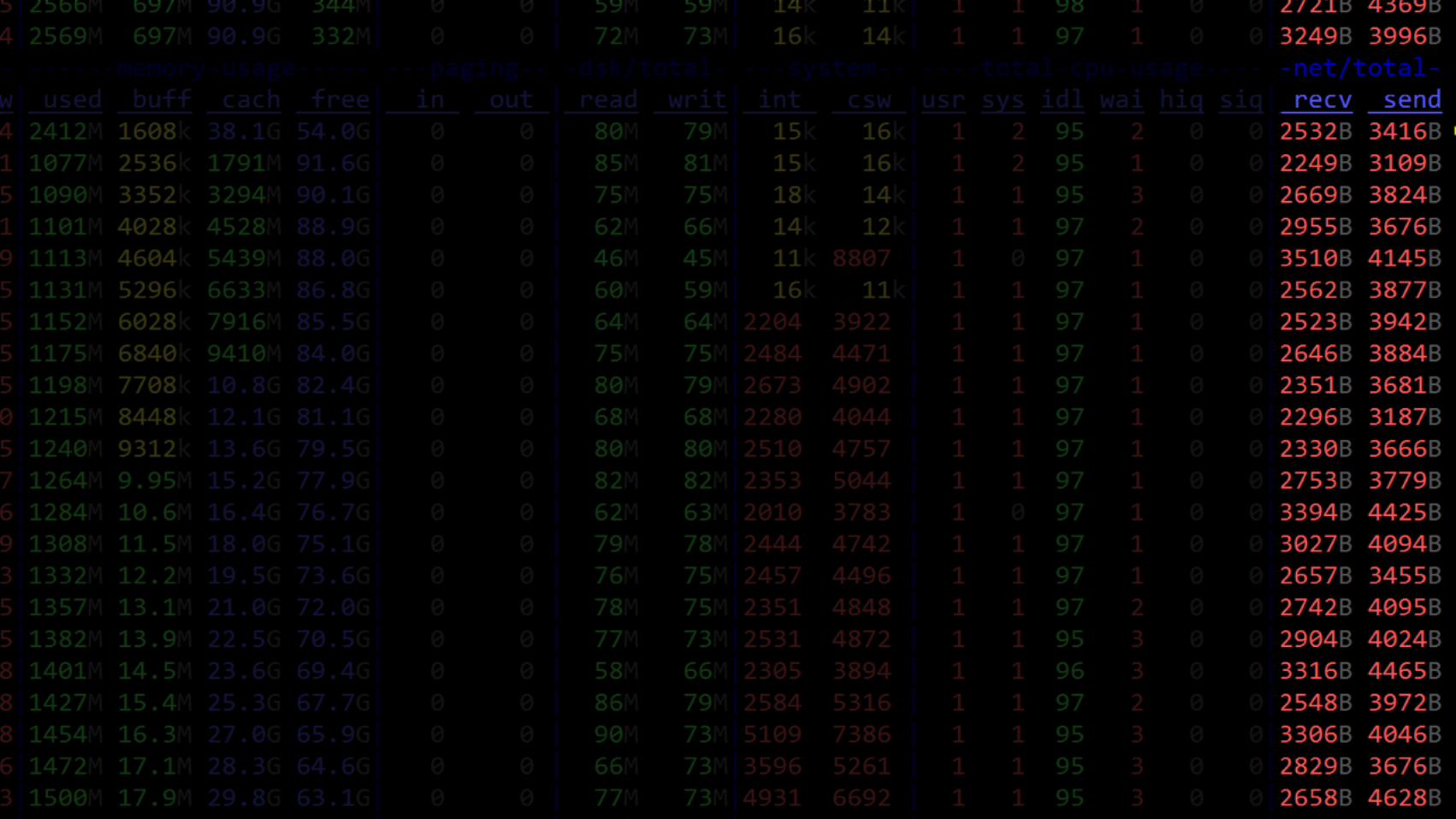
drop cache
increase RA
job done


drop cache
332MiB free
91.6GiB free







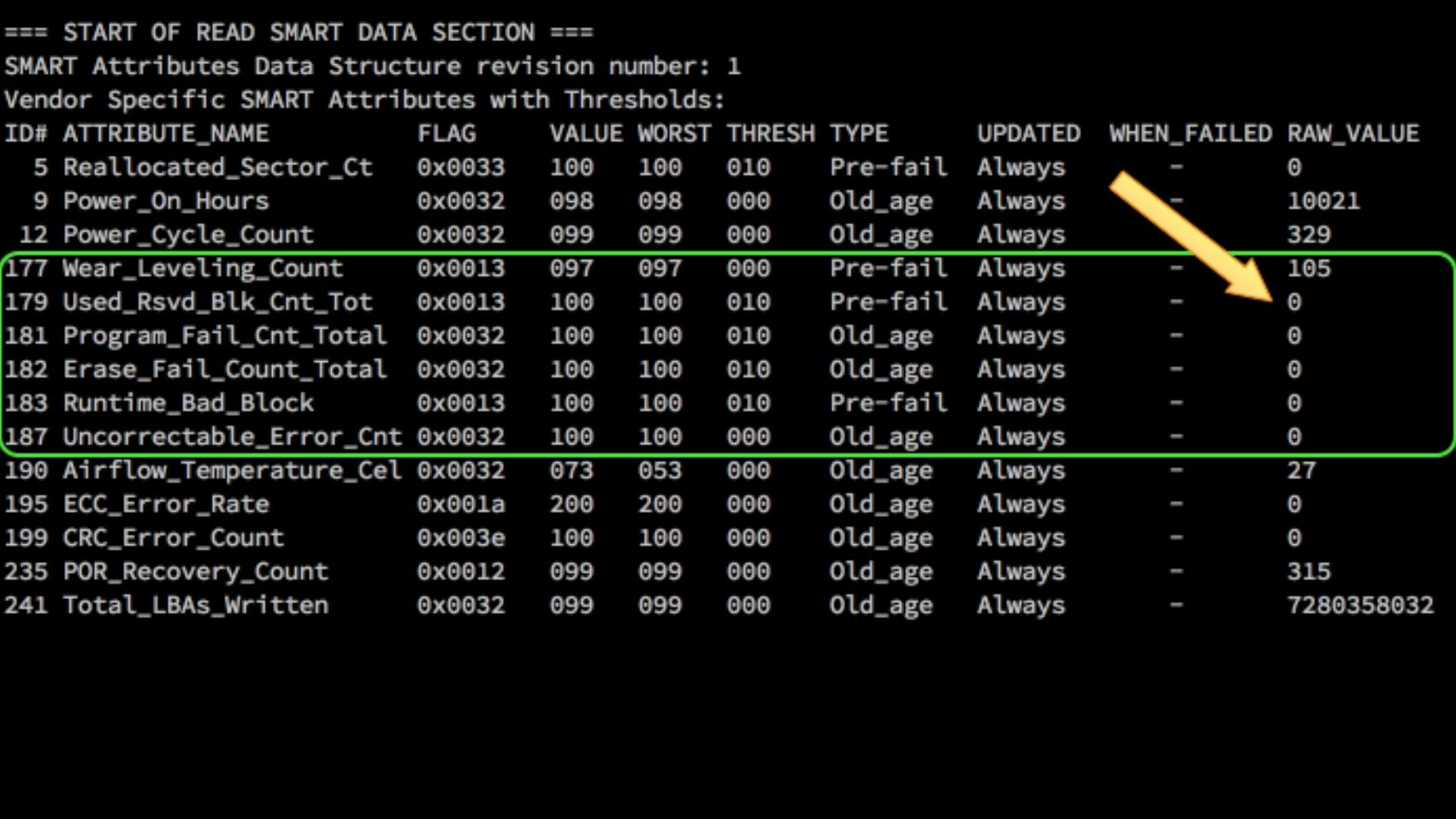
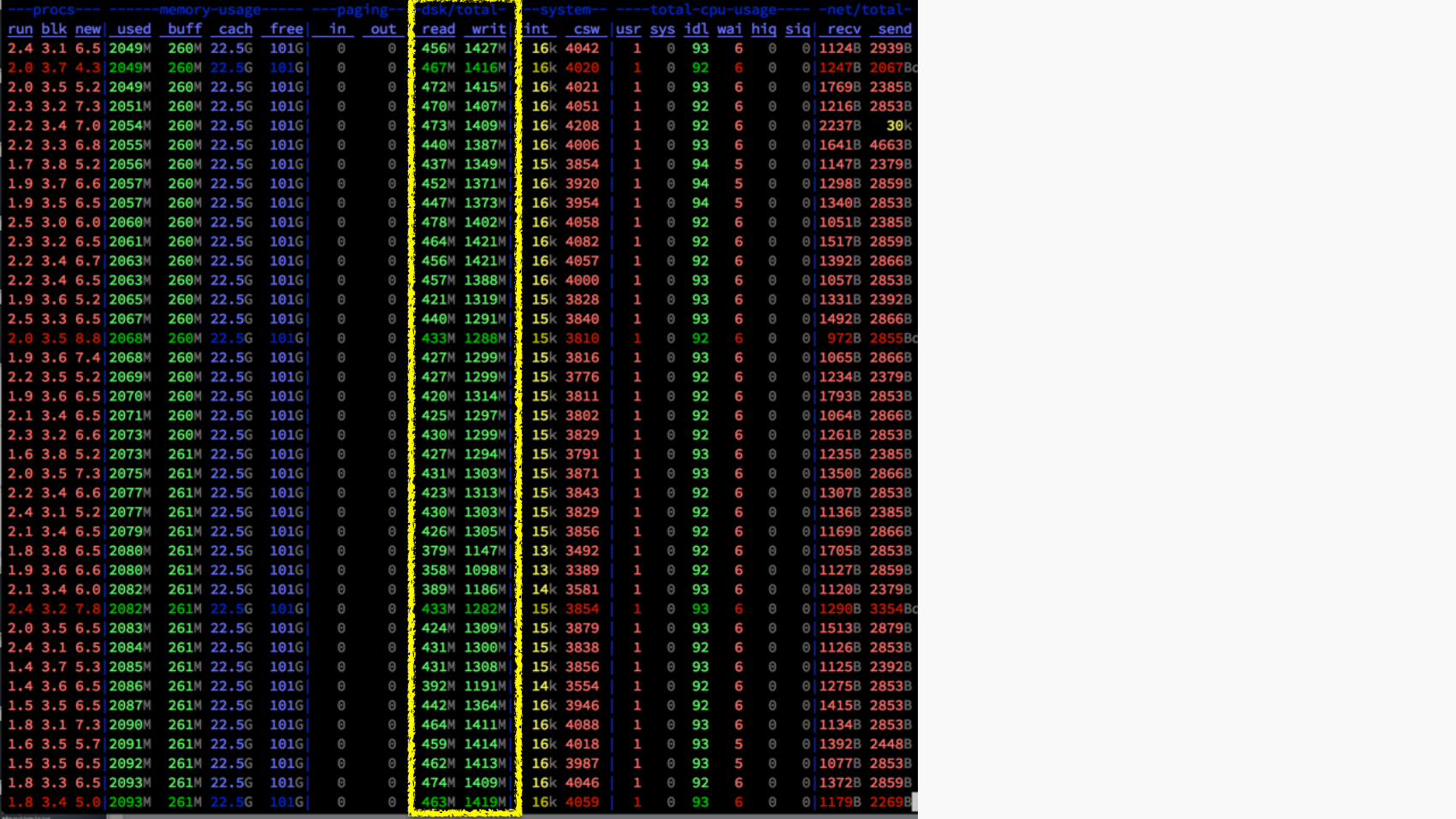

lspci -vv