
Data sharing as part of the research ecosystem
27
Varsha Khodiyar, PhD Data Curation Editor, Scientific Data Nature Publishing Group @varsha_khodiyar @scientificdata Data sharing as part of the research ecosystem Scientific Data’s approach to data publishing Weather, climate and air quality BoF, 3 rd March
-
Upload
varsha-khodiyar -
Category
Science
-
view
187 -
download
2
Transcript of Data sharing as part of the research ecosystem

Varsha Khodiyar, PhD
Data Curation Editor, Scientific Data
Nature Publishing Group
@varsha_khodiyar
@scientificdata
Data sharing as part of the research ecosystem
Scientific Data’s approach to data publishing Weather, climate and air quality BoF, 3rd March

Why the push to share data?
Research conduct
Publication bias – what is submitted
Experimental design
Statistics
Lab supervision and training
Research reporting and sharing
Gels, microscopy images
Statistical reporting
Methods description
Data deposition and availability
2

Generating research data is expensive
Just 18.1% NIH grant applications funded in 2014*
• Hours spent writing grants?
• Hours spent reviewing grants?
Resources are finite/expensive
• Modified animals
• Specialized reagents
Time and effort taken in the laboratory to generate good, valid data
* report.nih.gov/success_rates/Success_ByIC.cfm

• Diversity of analyses and opinion
• New research
• testing of new hypotheses
• new analysis methods
• meta-analyses to create new datasets
• studies on data collection methods
• Education of new researchers
• Increased return on investment in research
Vickers AJ: Whose data set is it anyway? Sharing raw data from randomized trials. Trials 2006, 7:15
Hrynaszkiewicz I, Altman DG: Towards agreement on
best practice for publishing raw clinical trial data. Trials 2009, 10:17
Sharing data promotes

Data needs to be…
Discoverable
Need to know it’s
there
Accessible
Must be able to get to the
data
Usable
Require sufficient
information about how
the data was generated
Persistent
Historical data access
as part of the scientific
record, as well as for
new research
Reliable
Data provenance informs data
reuse decisions
Joint Declaration of Data Citation Principles www.force11.org/group/joint-declaration-data-citation-principles-final
Achieving human and machine accessibility of cited data in scholarly publications Starr et al. PeerJ Computer Science (2015). doi:10.7717/peerj-cs.1
Making data count Kratz & Strasser. Sci. Data (2015). doi:10.1038/sdata.2015.39
The FAIR guiding principles for scientific data management and stewardship Williams et al. Sci. Data (in press)

Researchers already share data
• Most researchers are sharing
data, and using the data of
others
• Direct contact between
researchers (on request) is a
common way of sharing data
• Repositories are second most
common method of sharing
Kratz and Strasser (2015) doi: 10.1371/journal.pone.0117619 9

But… Sharing of data upon request from published articles
• relies heavily on trust
• when stored informally, disappears at a rate of ~17% per year (Vines et al. 2014; doi: 10.1016/j.cub.2013.11.014)
Data shared in a repository
• often not reusable due to insufficient context
• may not be possible to determine reliability (peer review?)
• may not be easily findable, if not referenced in a scholarly article
• no scholarly credit for data producers

Synthesis
Analysis
Conclusions
What did I do to generate the data?
How was the data processed?
Where is the data?
Who did what and when?
Methods and technical analyses supporting the quality of the measurements.
Do not contain tests of new scientific hypotheses
Comparison of data paper to traditional article

Data papers and journals
• Ensure formal storage in repository
• Allow space for authors to include sufficient context for reuse
• Peer reviewers often specifically requested to comment on data archive reusability
• Data paper are formal works, giving scholarly credit to data producers
• Formal data citations enabling data discovery via bibliographic indexes that researchers are used to using

Data journals and multidisciplinary research Cross-domain data sharing vital for solving the most pressing world issues:
• Public health (social science, epidemiology & molecular biology)
• Resource management & sustainability (energy research, policy, ecology & climate science)
Differences between researchers of vocabulary and expressions of reliability, mean clear descriptions of data become even more essential for cross-domain data sharing.
Multidisciplinary data journals (e.g. Data Science Journal, Scientific Data):
• provide a data sharing outlet to researchers in all domains
• help datasets cross domain boundaries, data is more visible and searchable i.e. less siloing
10

Increasing the discoverability of data
• Is data truly discoverable by researchers outside the original authors domain? • Too many papers to read in each person’s own field.
• Could increasing the machine accessibility of data, result in increased data reuse?

Data Descriptors have human and machine readable components
12
Human readable representation of
study i.e. article (HTML &
PDF)
Human readable representation of
study i.e. article (HTML
& PDF)
Machine readable
representation of study
i.e. metadata

• We capture metadata about the data being described in each Data Descriptor
• The manuscript captures human readable metadata needed for data reuse
• The curated metadata records capture machine readable metadata needed for machine based data discovery
Metadata at Scientific Data

Use of community endorsed ontologies and controlled vocabularies
14
Controlled vocabulary = list of standardized phrases of scientific concepts Ontology = controlled vocabulary with defined relationships between terms

Metadata for data discovery
Search by: • Data Repositories • Experiment design • Measurements made • Technologies used • Factor types • Sample Characteristics
• Organism • Environment types • Geographic locations
scientificdata.isa-explorer.org

Scientific Data’s Repository List
Browse our recommended data repositories online.
• We currently list almost 80 repositories, across biological, medical,
physical and social sciences
• When required, we provide guidance to authors on the best place to
store their data
www.nature.com/sdata/data-policies/repositories

Data citation for humans

<ref-list content-type="data-citations"> <ref id="d1"> <element-citation> <source>Oak Ridge National Laboratory Distributed Active Archive Center</source> <ext-link ext-link-type="dummy" specific-use="url" xlink:href="http://dx.doi.org/10.3334/ORNLDAAC/1292">http://dx.doi.org/10.3334/ORNLDAAC/1292</ext-link> <year>2015</year> <collab> <contrib-group> <contrib> <name> <surname>Law</surname> <given-names>B. E.</given-names> </name> </contrib> <contrib> <name> <surname>Berner</surname> <given-names>L. T.</given-names> </name> </contrib> </contrib-group> </collab> </element-citation> </ref> </ref-list>
Data citation for machines
• JATS 1.0 XML • Data citations list marked up as data
citations • “dummy” value designed to, in the
future, support a tool to generate links to datasets in approved repositories from dataset IDs

What types of data can be published?
19
Decades old
dataset
Standalone dataset
Data that has been used in an analysis
article
Large consortium
dataset
Data from a single
experiment
Data that the researcher finds
valuable and that others might find
useful too
Data associated with a high impact
analysis article

When can a Data Descriptor be published?
20
After data analysis has
been published
Before analysis has been published
Authors not intending to analyse data
Data Descriptors can be submitted and published
at any point in the research workflow, i.e.
whenever it makes most sense for your data
After data analysis has
been published
Before the analysis has
been published
Publication alongside analysis
article

Some of our climate sciences Data Descriptors
21
See more at www.nature.com/scientificdata

Data as part of the research workflow?
Papers usually written after analyses, key details can be forgotten
• Ideally metadata would be captured during data generation process
• Takes time and effort to capture adequate metadata of sufficient quality for data reuse
Machine readable metadata
• Metadata format needs to be decided prospectively
• Researchers require professional expertise and guidance to use ontologies (essential for machine readability and discovery)
How to ensure data generators are able to capture metadata easily and in sufficient detail for reuse?
22

Data reuse by (some of) the same researchers
23

Data reuse by other researchers in the same field
24
“The Data Descriptor made it easier to use the data, for me it was critical that everything was there…all the technical details like voxel size.”
Professor Daniele Marinazzo

Data reuse by the non-research community
25
http://www.nytimes.com/interactive/2014/12/30/science/history-of-ebola-in-24-outbreaks.html
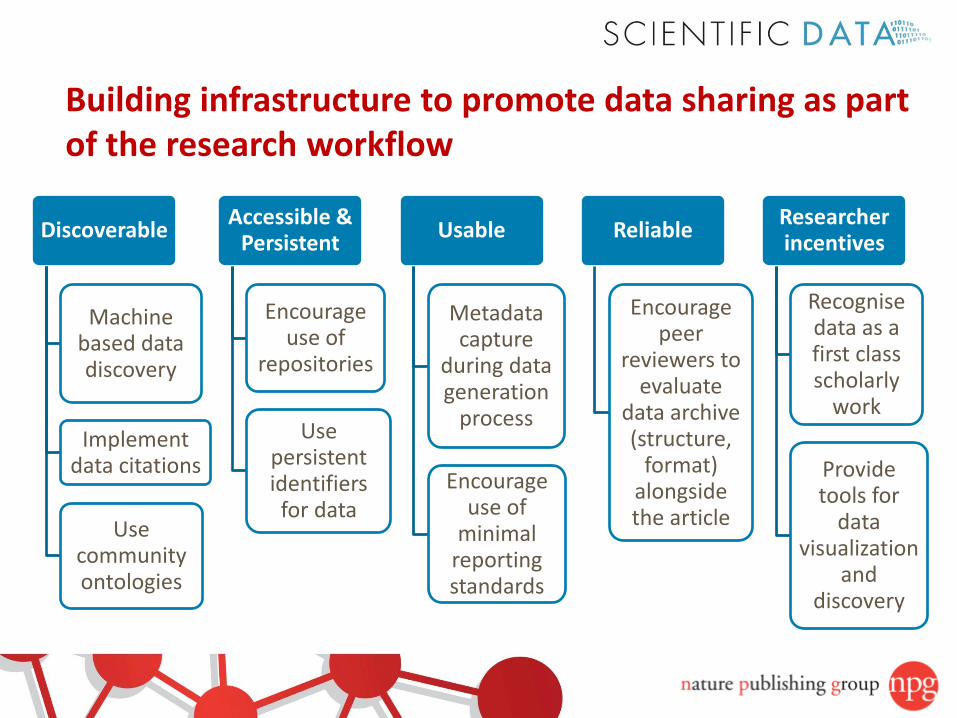
Discoverable
Machine based data discovery
Implement data citations
Use community ontologies
Accessible & Persistent
Encourage use of
repositories
Use persistent identifiers
for data
Usable
Metadata capture
during data generation
process
Encourage use of
minimal reporting standards
Reliable
Encourage peer
reviewers to evaluate
data archive (structure,
format) alongside the article
Researcher incentives
Recognise data as a first class scholarly
work
Provide tools for
data visualization
and discovery
Building infrastructure to promote data sharing as part of the research workflow

Visit nature.com/sdata Email [email protected] Tweet @ScientificData
Honorary Academic Editor Susanna-Assunta Sansone Managing Editor Andrew L. Hufton Data Curation Editor Varsha K. Khodiyar Advisory Panel and Editorial Board including senior researchers, funders, librarians and curators
Supported by


















