Data Science Crash Course Hadoop Summit SJ
52
Robert Hryniewicz Data Evangelist @RobHryniewicz Hands-on Intro to Data Science with Apache Spark Crash Course
-
Upload
daniel-madrigal -
Category
Technology
-
view
230 -
download
1
Transcript of Data Science Crash Course Hadoop Summit SJ

RobertHryniewiczDataEvangelist@RobHryniewicz
Hands-onIntrotoDataSciencewithApacheSpark
Crash�Course

2 ©HortonworksInc.2011–2016.AllRightsReserved
Plan for Today• Data Science & ML• ML Examples• Overview of ML methods• K-means, Decision Trees & Random Forests• Spark MLlib & ML• Lab Overview

3 ©HortonworksInc.2011–2016.AllRightsReserved
DataScienceExamples

4 ©HortonworksInc.2011–2016.AllRightsReserved
5 ©HortonworksInc.2011–2016.AllRightsReserved
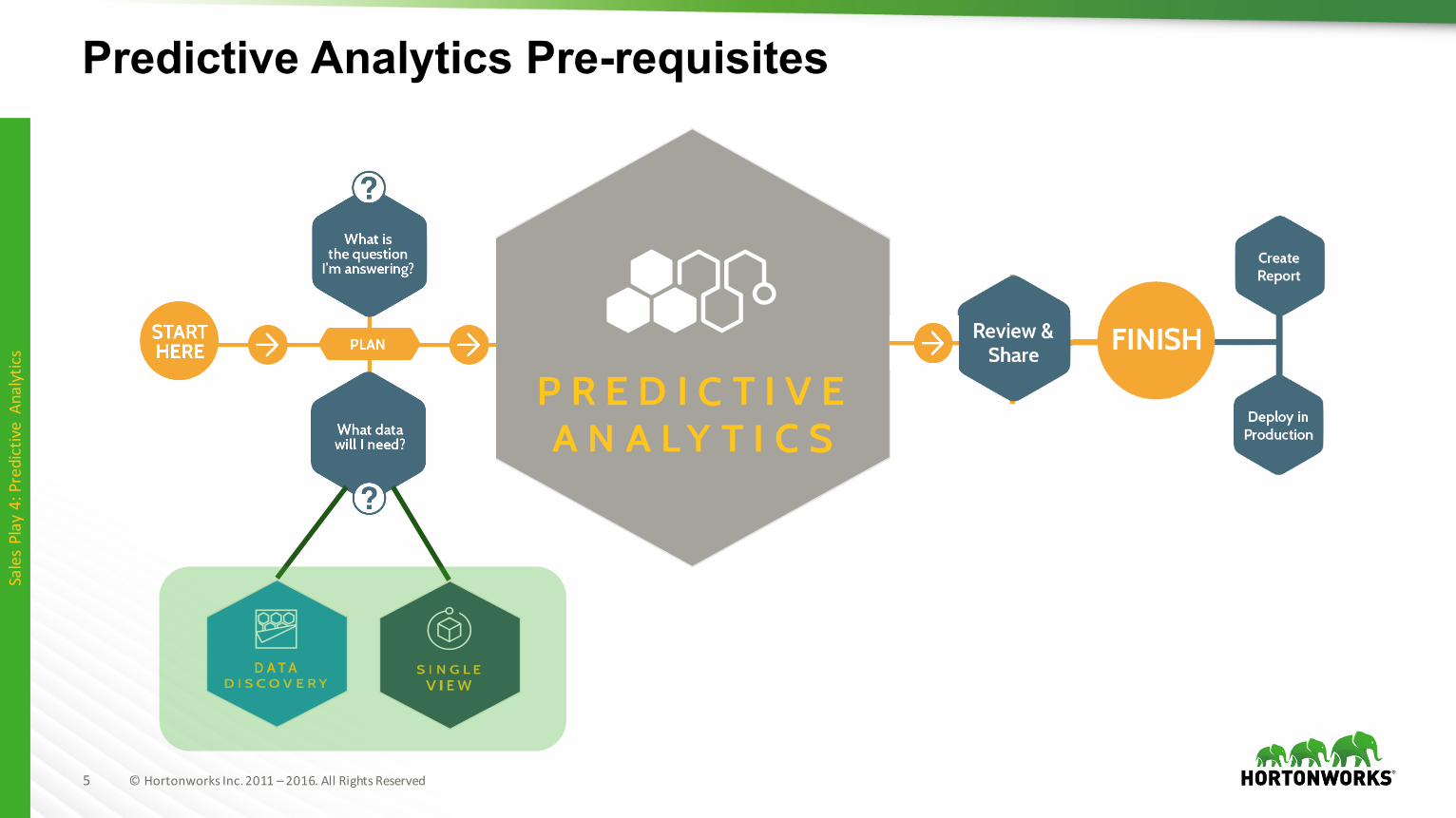
Predictive Analytics Pre-requisitesSalesPlay4:Predictive
Analytics
6 ©HortonworksInc.2011–2016.AllRightsReserved
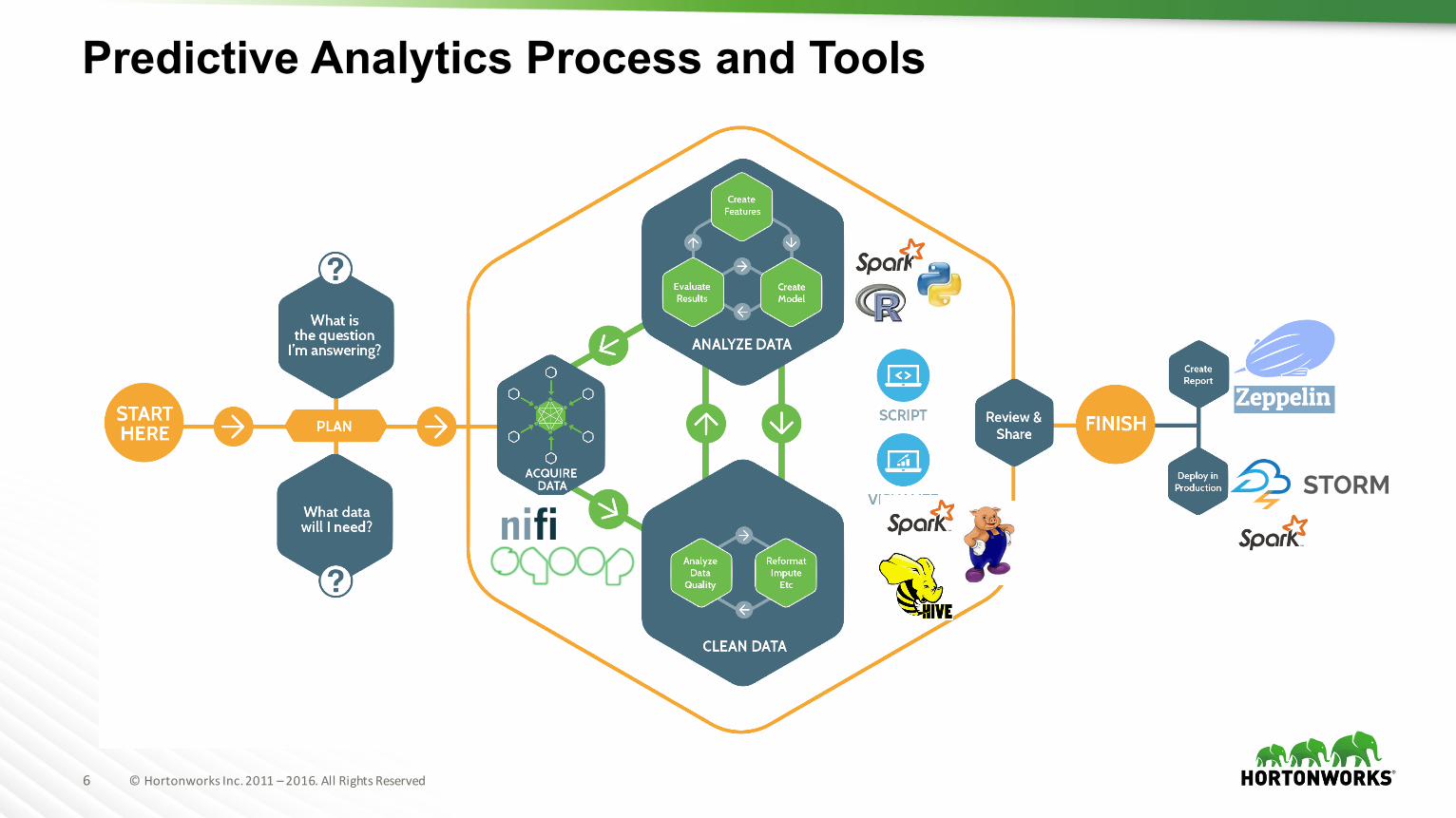
Predictive Analytics Process and Tools

7 ©HortonworksInc.2011–2016.AllRightsReserved
MachineLearning
“… science of how computers learn without being explicitly programmed” – Andrew Ng

8 ©HortonworksInc.2011–2016.AllRightsReserved
MachineLearningMethods

9 ©HortonworksInc.2011–2016.AllRightsReserved
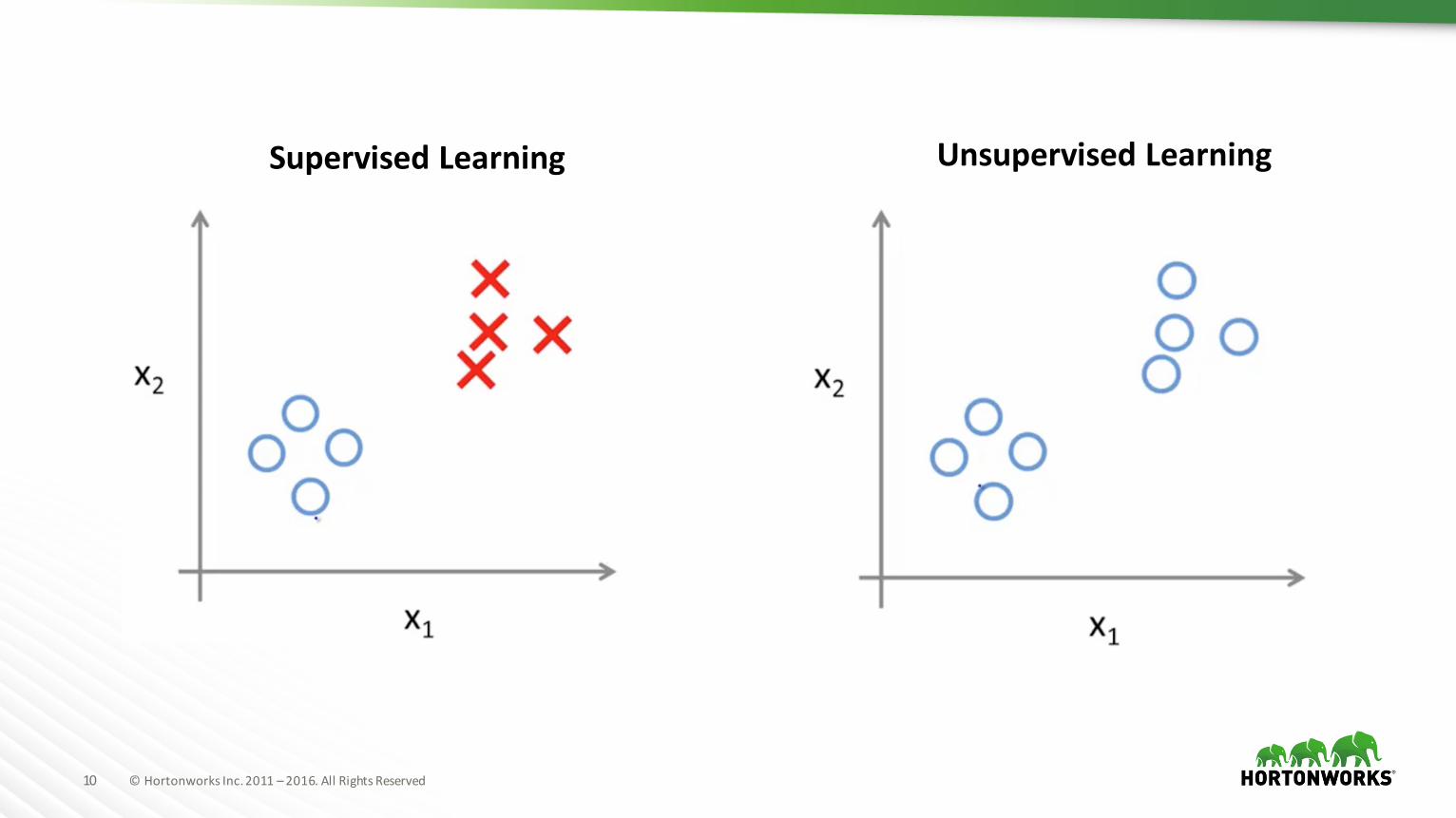
Supervisedvs
UnsupervisedLearning
Exampleslabeled.
Examplesnotlabeled.
10 ©HortonworksInc.2011–2016.AllRightsReserved
UnsupervisedLearningSupervisedLearning

11 ©HortonworksInc.2011–2016.AllRightsReserved
CLASSIFICATIONIdentifyingtowhichcategoryanobjectbelongsto.
Applications:spamdetection,imagerecognition,...
Algorithms:k-nn,decisiontrees,randomforest,...

12 ©HortonworksInc.2011–2016.AllRightsReserved
REGRESSIONPredictingacontinuous-valuedattribute
associatedwithanobject.
Applications:drugresponse,stockprices,…
Algorithms: linearregression,…

13 ©HortonworksInc.2011–2016.AllRightsReserved
CLUSTERINGAutomaticgroupingofsimilarobjectsintosets.
Applications:customersegmentation,topicmodeling,…
Algorithms: k-means,LDA,…

14 ©HortonworksInc.2011–2016.AllRightsReserved
COLLABORATIVEFILTERINGFillinthemissingentriesofauser-itemassociationmatrix.
Applications:Productrecommendation,…
Algorithms: Alternating Least Squares (ALS)

15 ©HortonworksInc.2011–2016.AllRightsReserved
DIMENSIONALITYREDUCTIONReducingthenumberofrandomvariablestoconsider.
Applications:visualization,increasedefficiency,…Algorithms: PCA,t-SNE,…

16 ©HortonworksInc.2011–2016.AllRightsReserved
PREPROCESSINGFeatureextractionandnormalization
Applications:transforminginputdatasuchastextasinputtoMLalgorithms
Algorithms:TF-IDF,word2vec,onehotencoding,…

17 ©HortonworksInc.2011–2016.AllRightsReserved
MODELSELECTIONComparing,validatingandchoosingparametersandmodels.
Applications:improvedaccuracyviaparametertuning
Algorithms:gridsearch,metrics…

18 ©HortonworksInc.2011–2016.AllRightsReserved
SparkMLlib

19 ©HortonworksInc.2011–2016.AllRightsReserved
SparkMachineLearningLibrary
à Clustering– k-meansclustering– latentDirichlet allocation(LDA)
à Dimensionalityreduction– singularityvaluedecomposition(SVD)– principalcomponentanalysis(PCA)
à FeatureExtractors&Transformers– word2vec
à Basicstatistics– summarystatistics– hypothesistesting– randomnumbergeneration
à Classificationandregression– linearmodels(SVMs,log&linearregression)– decisiontrees– ensemblesoftrees(RandomForests&GBTs)
à Collaborativefiltering– alternatingleastsquares(ALS)

20 ©HortonworksInc.2011–2016.AllRightsReserved
K-MeansClustering(UnsupervisedLearning)

21 ©HortonworksInc.2011–2016.AllRightsReserved
Why K-Means
à Simple&fastalgorithm tofindclusters
à Commontechniqueforanomalydetection
à Drawbacks– Doesn'tworkwellwithnon-circularclustershape– Numberofclusterandinitialseedvalueneedtobespecifiedbeforehand– Strongsensitivitytooutliersandnoise– Lowcapabilitytopassthelocaloptimum.
22 ©HortonworksInc.2011–2016.AllRightsReserved
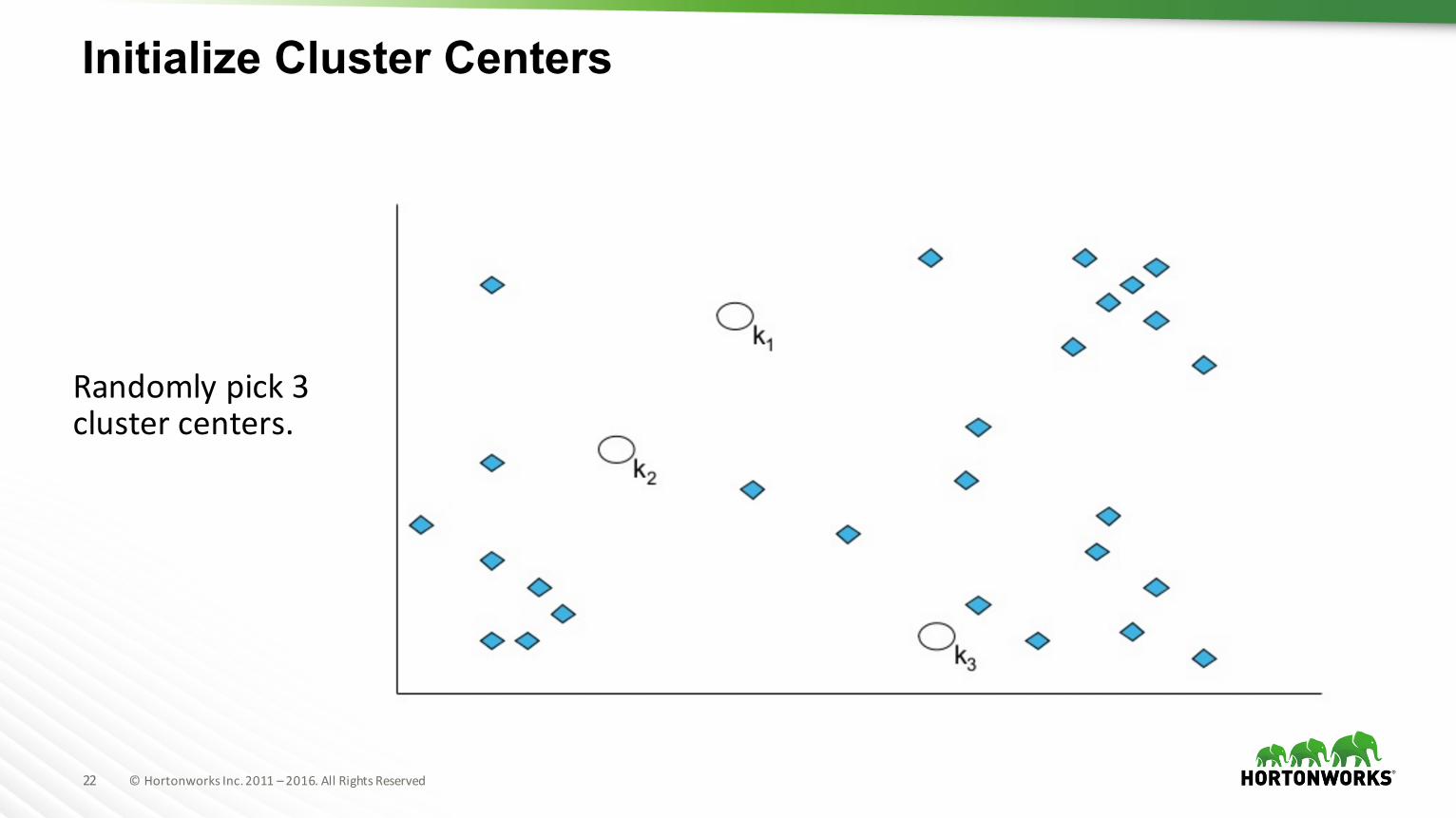
Initialize Cluster Centers
Randomlypick3clustercenters.

23 ©HortonworksInc.2011–2016.AllRightsReserved
Assign Each Point
Assigneachpointtothenearestclustercenter.
24 ©HortonworksInc.2011–2016.AllRightsReserved
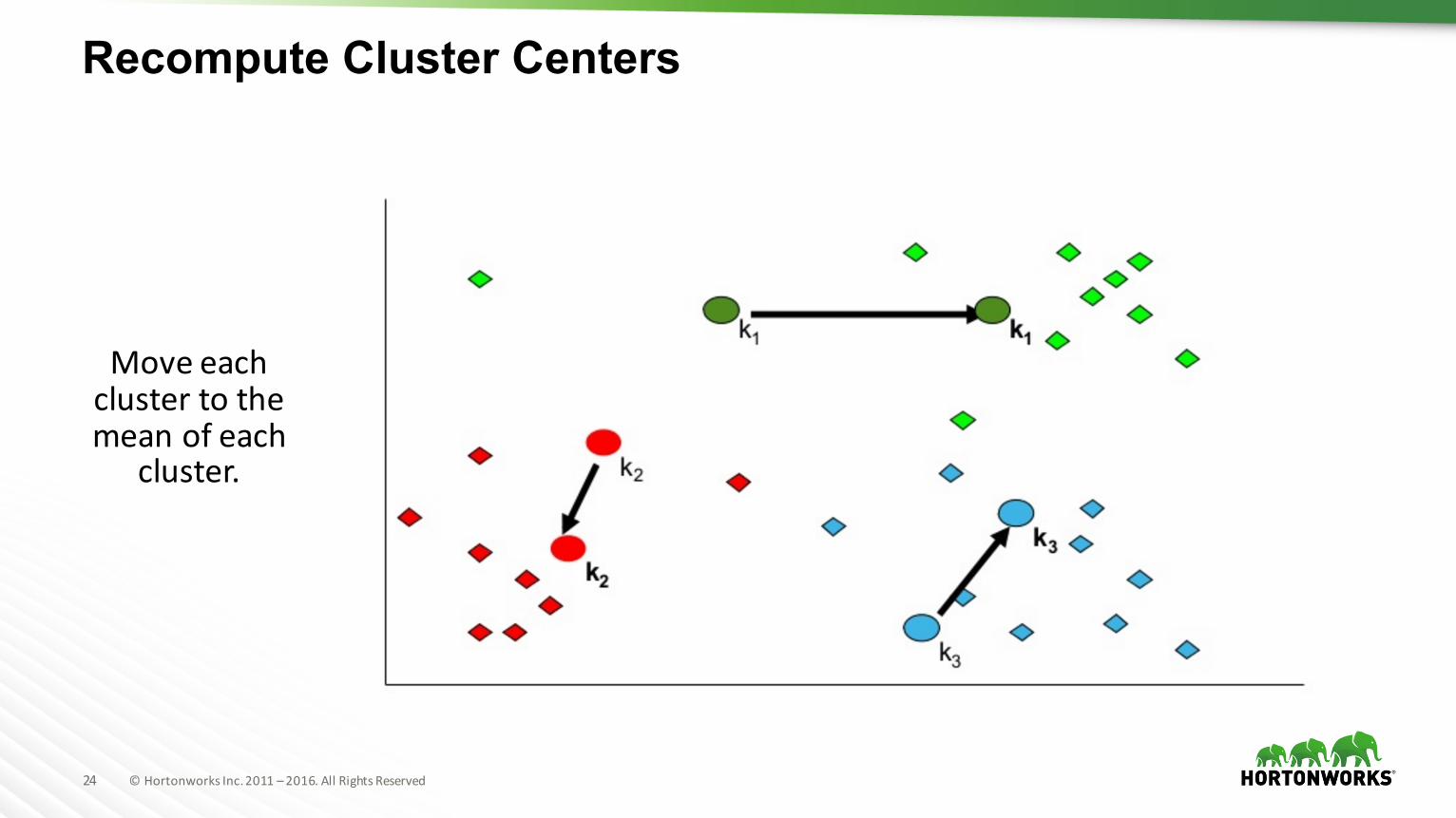
Recompute Cluster Centers
Moveeachclustertothemeanofeach
cluster.

25 ©HortonworksInc.2011–2016.AllRightsReserved
K-means Clustering
26 ©HortonworksInc.2011–2016.AllRightsReserved
San Francisco
27 ©HortonworksInc.2011–2016.AllRightsReserved
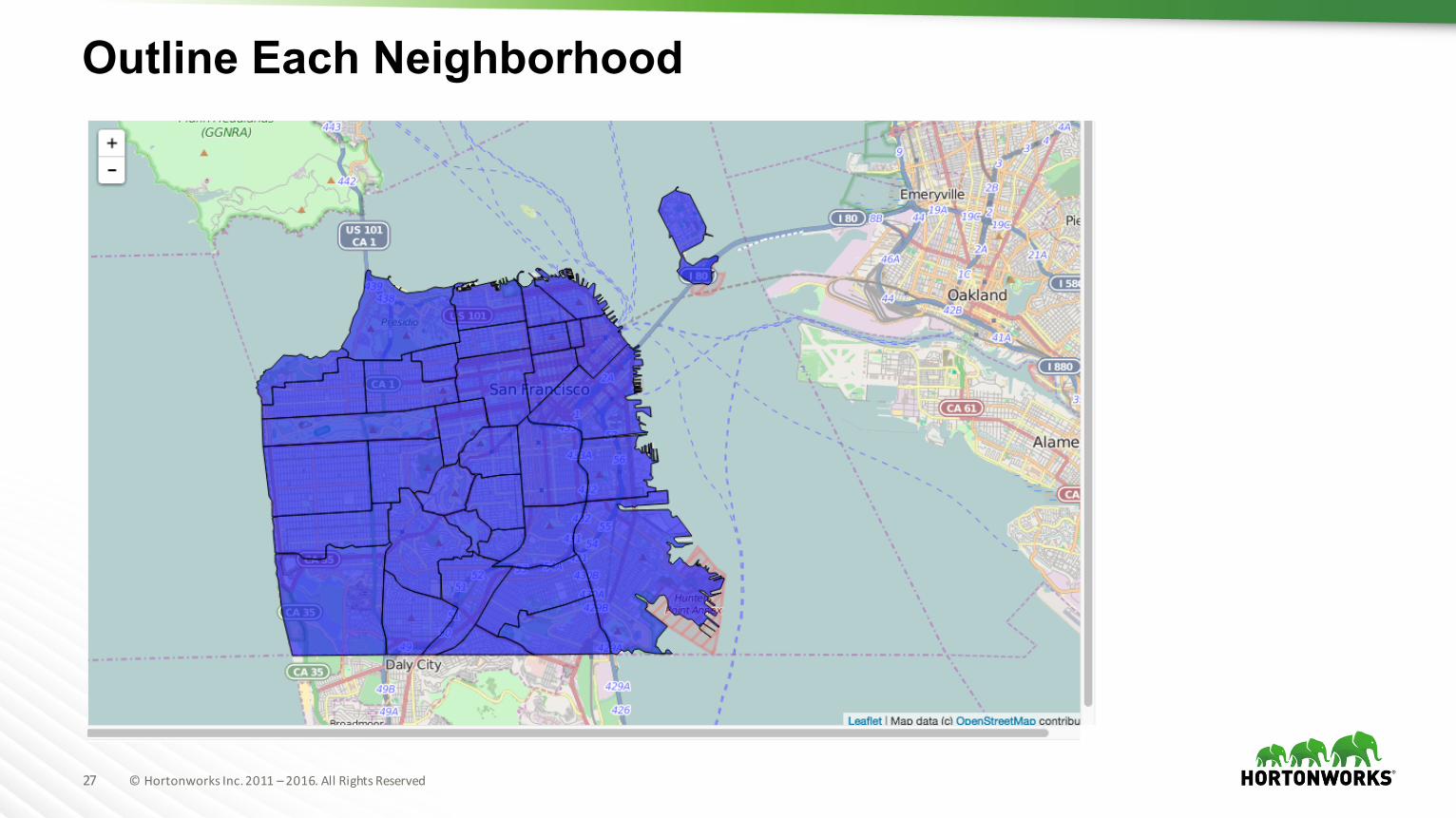
Outline Each Neighborhood
28 ©HortonworksInc.2011–2016.AllRightsReserved
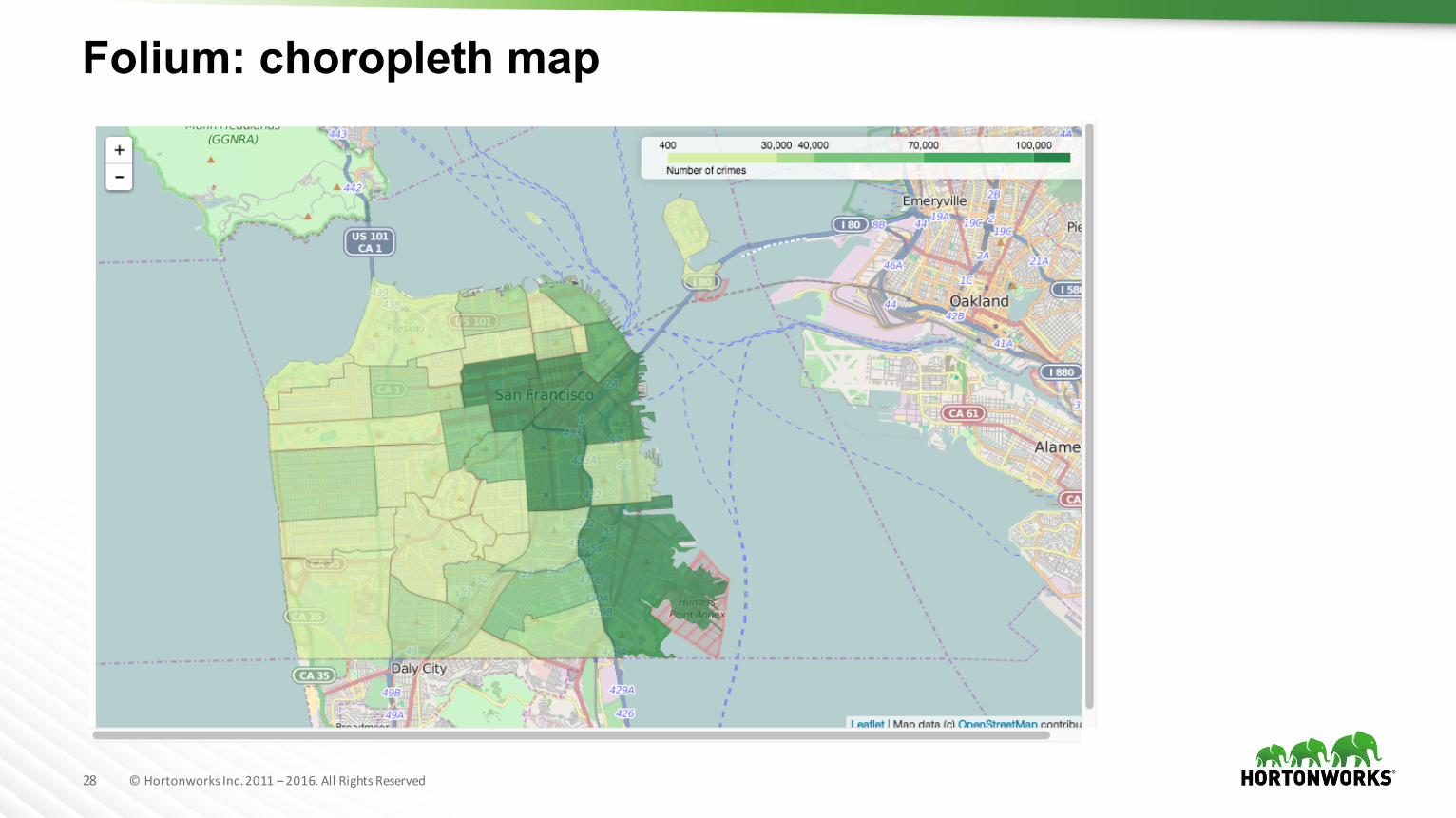
Folium: choropleth map
29 ©HortonworksInc.2011–2016.AllRightsReserved
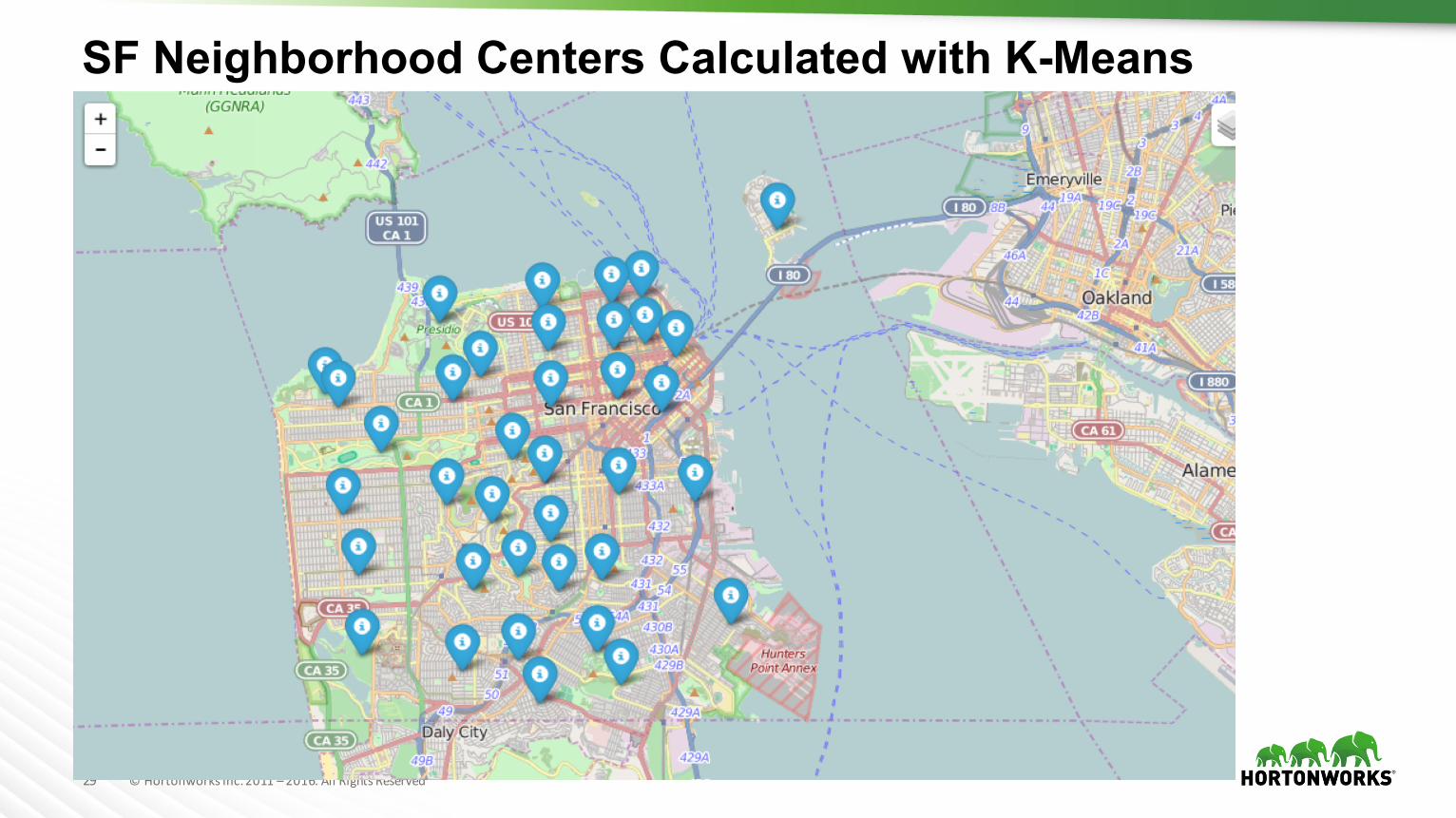
SF Neighborhood Centers Calculated with K-Means
30 ©HortonworksInc.2011–2016.AllRightsReserved
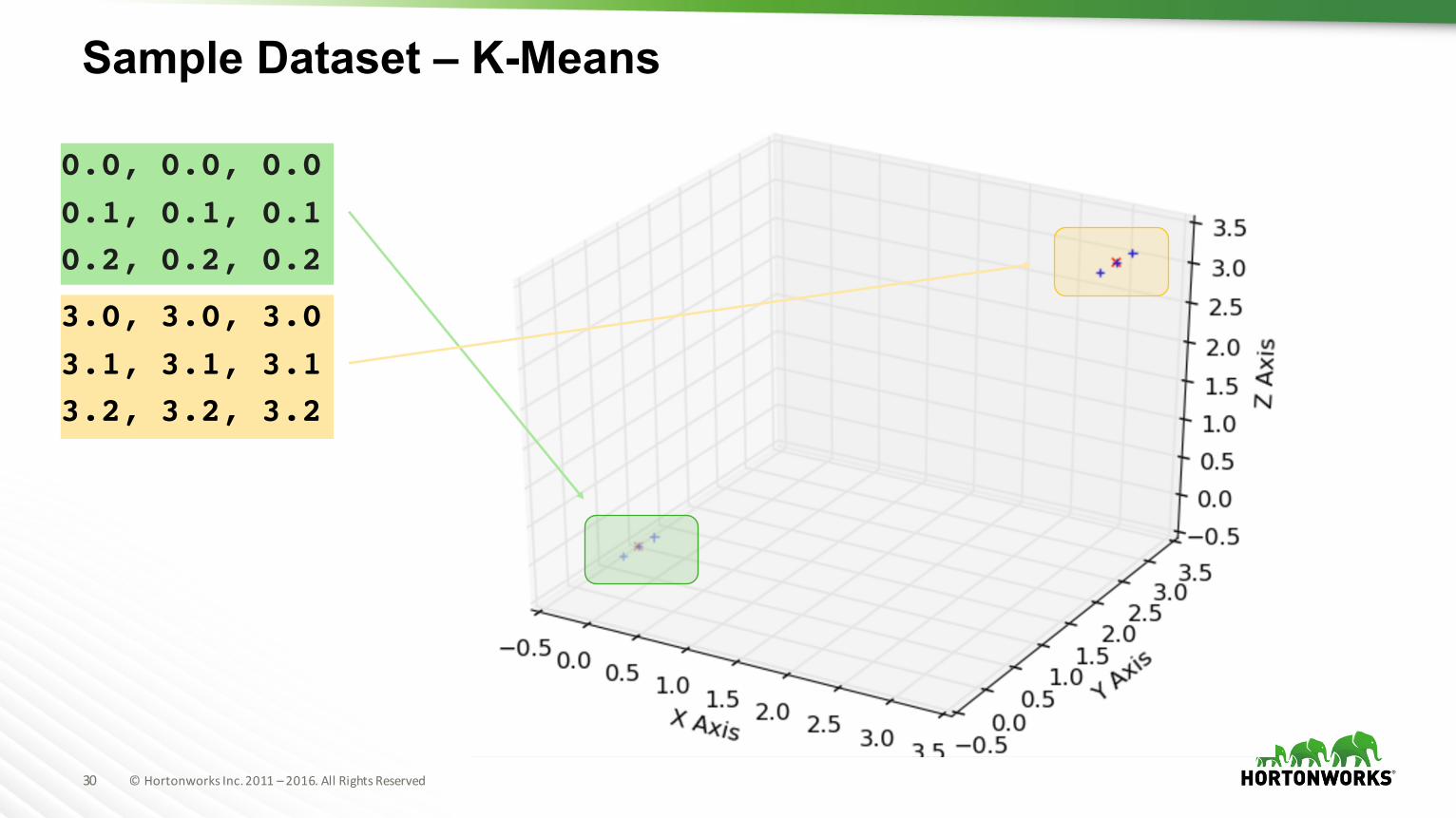
Sample Dataset – K-Means
0.0, 0.0, 0.00.1, 0.1, 0.10.2, 0.2, 0.2
3.0, 3.0, 3.03.1, 3.1, 3.13.2, 3.2, 3.2

31 ©HortonworksInc.2011–2016.AllRightsReserved
DecisionTrees&RandomForests(SupervisedLearning)

32 ©HortonworksInc.2011–2016.AllRightsReserved
WhyDecisionTrees?
à Simpletounderstandandinterpret. (Andexplaintoexecutives.)
à Requireslittledatapreparation. (Othertechniquesoftenrequiredatanormalisation, dummyvariablesneedtobecreatedandblankvaluestoberemoved.)
à Performswellwithlargedatasets.
33 ©HortonworksInc.2011–2016.AllRightsReserved
VisualIntrotoDecisionTrees
à http://www.r2d3.us/visual-intro-to-machine-learning-part-1
34 ©HortonworksInc.2011–2016.AllRightsReserved
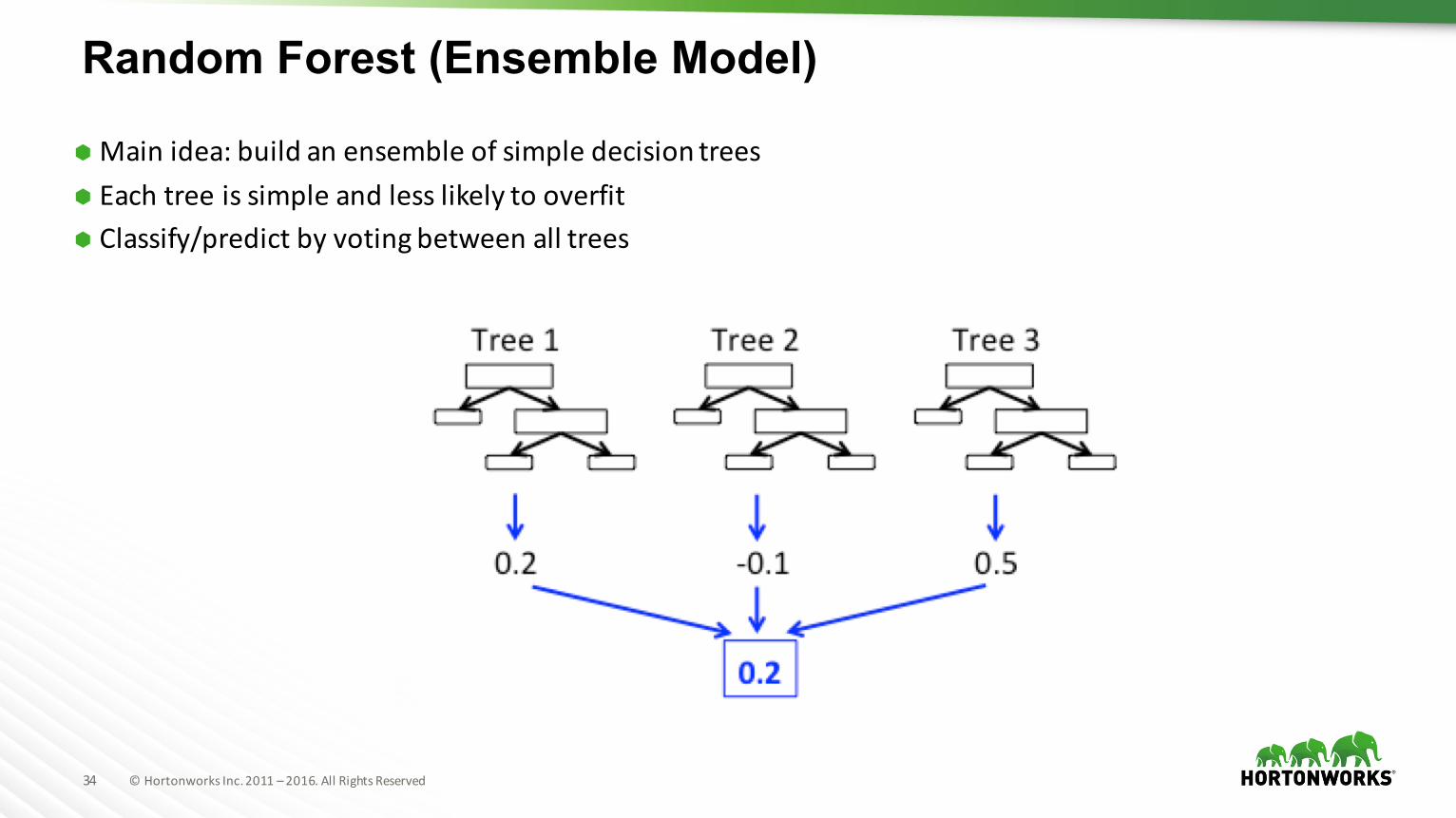
Random Forest (Ensemble Model)
ÃMainidea:buildanensembleofsimpledecisiontreesà Eachtreeissimpleandlesslikelytooverfità Classify/predictbyvotingbetweenalltrees

35 ©HortonworksInc.2011–2016.AllRightsReserved
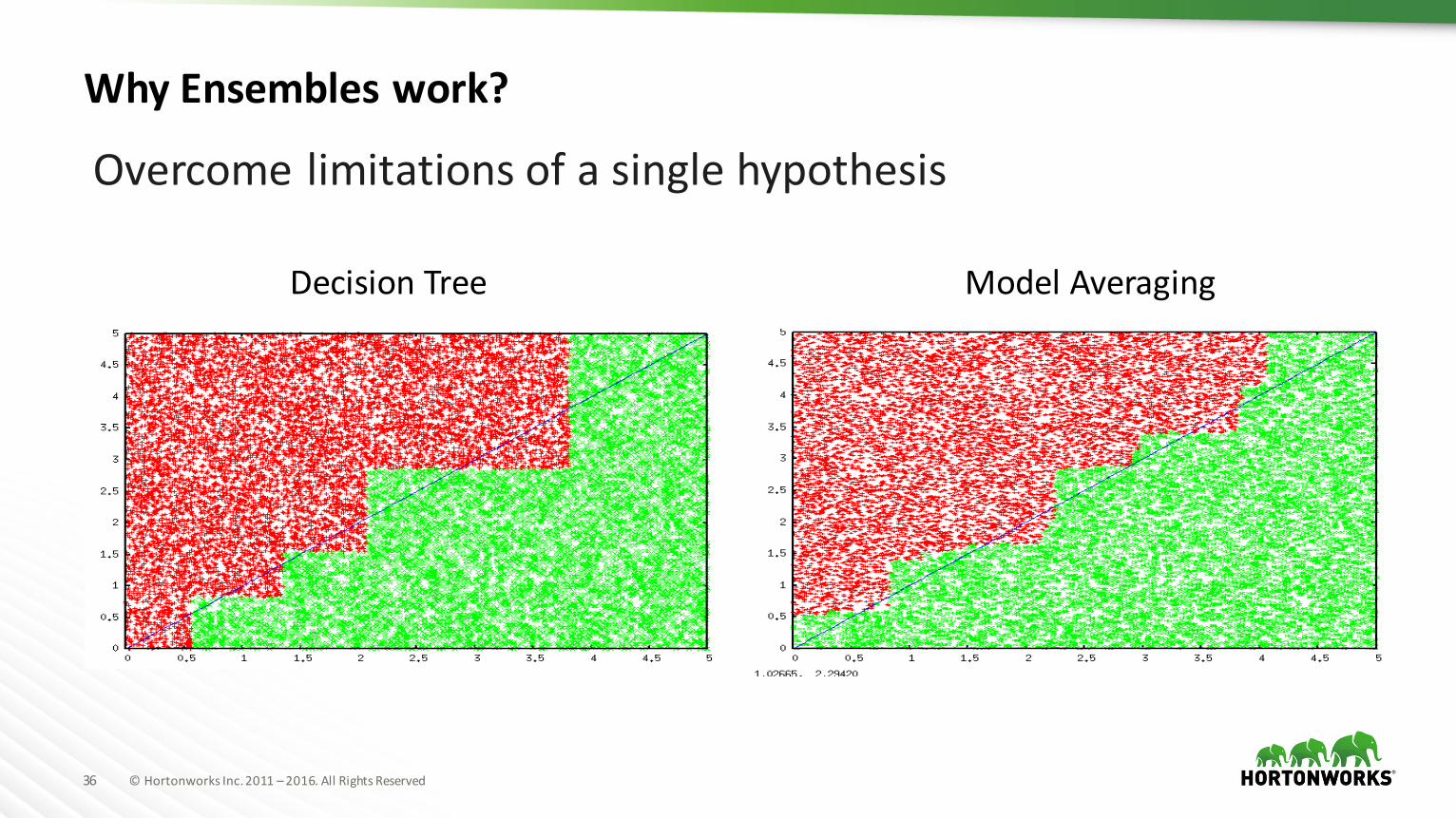
DecisionTreevsRandomForest
36 ©HortonworksInc.2011–2016.AllRightsReserved
Overcomelimitationsofasinglehypothesis
DecisionTree ModelAveraging
WhyEnsembleswork?

37 ©HortonworksInc.2011–2016.AllRightsReserved
DiabetesDataset– DecisionTrees/RandomForest
Labeledsetwith8Features
-1 1:-0.294118 2:0.487437 3:0.180328 4:-0.292929 5:-1 6:0.00149028 7:-0.53117 8:-0.0333333+1 1:-0.882353 2:-0.145729 3:0.0819672 4:-0.414141 5:-1 6:-0.207153 7:-0.766866 8:-0.666667 -1 1:-0.0588235 2:0.839196 3:0.0491803 4:-1 5:-1 6:-0.305514 7:-0.492741 8:-0.633333 +1 1:-0.882353 2:-0.105528 3:0.0819672 4:-0.535354 5:-0.777778 6:-0.162444 7:-0.923997 8:-1 -1 1:-1 2:0.376884 3:-0.344262 4:-0.292929 5:-0.602837 6:0.28465 7:0.887276 8:-0.6 +1 1:-0.411765 2:0.165829 3:0.213115 4:-1 5:-1 6:-0.23696 7:-0.894962 8:-0.7 -1 1:-0.647059 2:-0.21608 3:-0.180328 4:-0.353535 5:-0.791962 6:-0.0760059 7:-0.854825 8:-0.833333
...

38 ©HortonworksInc.2011–2016.AllRightsReserved
MachineLearninginSpark

39 ©HortonworksInc.2011–2016.AllRightsReserved
SparkEcosystem
SparkCore
SparkSQL SparkStreaming MLlib GraphX
40 ©HortonworksInc.2011–2016.AllRightsReserved
MachineLearningwithSpark(MLlib &ML)
à Original“lower”API
à BuiltontopofRDDs
à MaintenancemodestartingwithSpark2.0
MLlib
à Newer“higher-level”APIforconstructingworkflows
à BuiltontopofDataFrames
ML
Both algorithms implemented to take advantage of data
parallelism

41 ©HortonworksInc.2011–2016.AllRightsReserved
Predict
Model
Supervised Learning: End-to-End Flow
Feature Extraction Train the Model
ModelData items
Labels
Data item Feature Extraction Label
Training(batch)
Predicting(real time or batch)
Feature Matrix
Feature Vector
Training set

42 ©HortonworksInc.2011–2016.AllRightsReserved
Spark ML: Spark API for building ML pipelines
Featuretransform
1
Featuretransform
2
Combinefeatures
RandomForest
InputDataFrame(TRAIN)
InputDataFrame(TEST)
OutputDataframe
(PREDICTIONS)
Pipeline
PipelineModel
43 ©HortonworksInc.2011–2016.AllRightsReserved
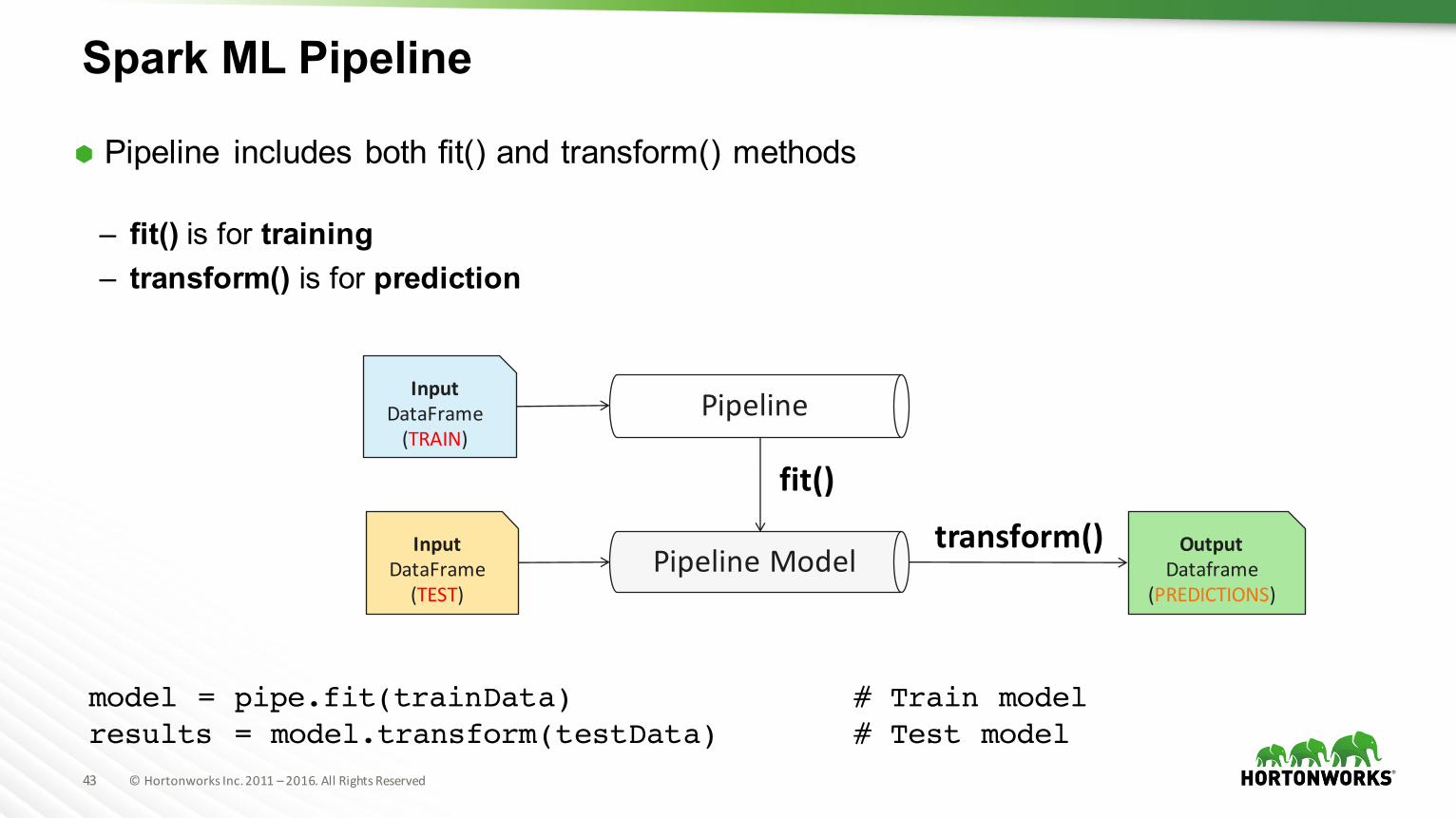
Spark ML Pipeline
à Pipeline includes both fit() and transform() methods
– fit() is for training– transform() is for prediction
InputDataFrame(TRAIN)
InputDataFrame(TEST)
OutputDataframe
(PREDICTIONS)
Pipeline
PipelineModel
fit()transform()
model = pipe.fit(trainData) # Train modelresults = model.transform(testData) # Test model

44 ©HortonworksInc.2011–2016.AllRightsReserved
Spark ML – Simple Random Forest Example
indexer = StringIndexer(inputCol=”district", outputCol=”dis-inx")
parser = Tokenizer(inputCol=”text-field", outputCol="words")
hashingTF = HashingTF(numFeatures=50, inputCol="words", outputCol="hash-inx")
vecAssembler = VectorAssembler(
inputCols =[“dis-inx”, “hash-inx”],
outputCol="features")
rf = RandomForestClassifier(numTrees=100, labelCol="label", seed=42)
pipe = Pipeline(stages=[indexer, parser, hashingTF, vecAssembler, rf])
model = pipe.fit(trainData) # Train model
results = model.transform(testData) # Test model

45 ©HortonworksInc.2011–2016.AllRightsReserved
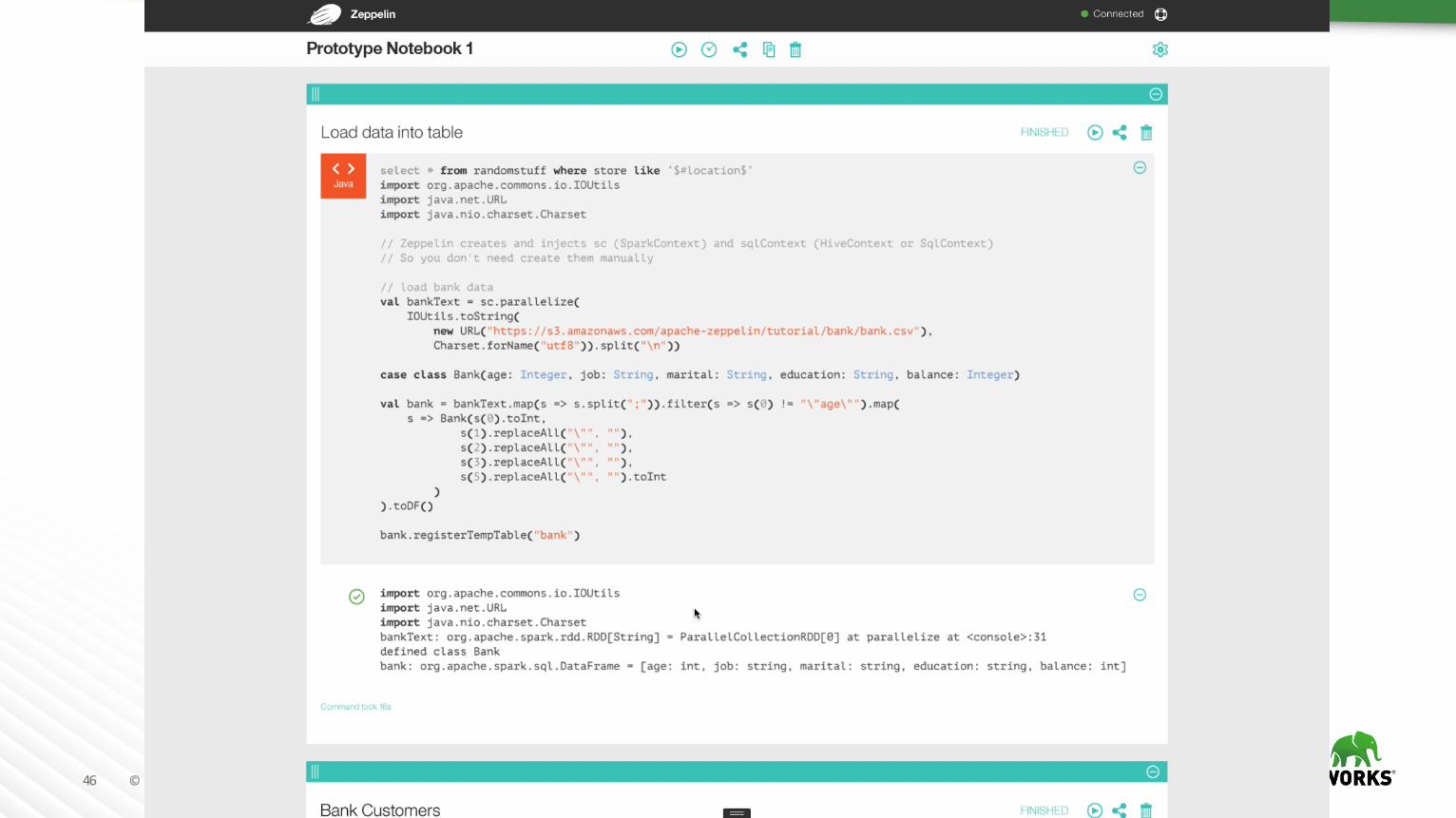
ApacheZeppelin– AModernWeb-basedDataScienceStudio
à Dataexplorationanddiscovery
à Visualization
à DeeplyintegratedwithSparkandHadoop
à Pluggableinterpreters
à Multiplelanguagesinonenotebook:R,Python,Scala
46 ©HortonworksInc.2011–2016.AllRightsReserved

47 ©HortonworksInc.2011–2016.AllRightsReserved
Exporting ML Models - PMML
à PredictiveModelMarkupLanguage(PMML)à Supportedmodels
–K-Means– LinearRegression–RidgeRegression– Lasso– SVM–Binary

48 ©HortonworksInc.2011–2016.AllRightsReserved
Additional Resources
• MachineLearning• NaturalLanguageProcessing(NLP)
• ScalableMachineLearning• IntroductiontoStatistics

49 ©HortonworksInc.2011–2016.AllRightsReserved
Lab Overviewtinyurl.com/hwx-intro-to-ml-with-spark
50 ©HortonworksInc.2011–2016.AllRightsReserved
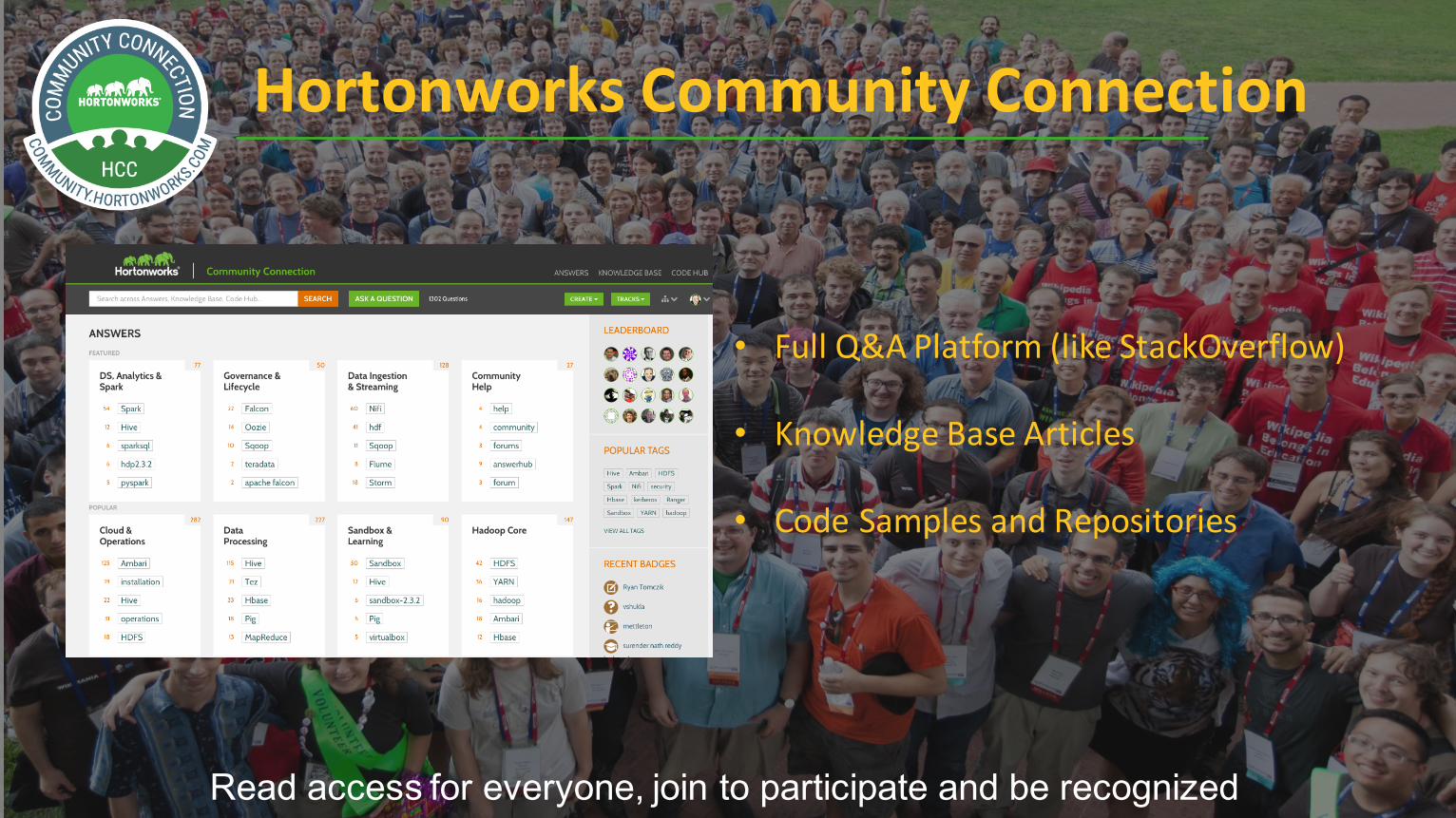
HortonworksCommunityConnection
Read access for everyone, join to participate and be recognized
• FullQ&APlatform(likeStackOverflow)
• KnowledgeBaseArticles
• CodeSamplesandRepositories

51 ©HortonworksInc.2011–2016.AllRightsReserved
CommunityEngagement
community.hortonworks.com©HortonworksInc.2011–2015.AllRightsReserved
7,500+RegisteredUsers
15,000+Answers
20,000+TechnicalAssets
One Website!

RobertHryniewicz@RobHryniewicz
Thanks!