
Data Analytics with Apache Spark and Cassandra
41
#bigdatabe @maasg Data Analytics with Apache BigData.be Meetup 8/Sep/2015 Gerard Maas @maasg Data Processing Team Lead and
-
Upload
gerard-maas -
Category
Software
-
view
765 -
download
7
Transcript of Data Analytics with Apache Spark and Cassandra

#bigdatabe @maasg
Data Analytics with Apache
BigData.be Meetup 8/Sep/2015
Gerard Maas @maasgData Processing Team Lead
and

#bigdatabe @maasg

#bigdatabe @maasg
Tweet few keywords about your interests and experience.Use hashtag “#bigdatabe”

@maasg#bigdatabe
Agenda
MotivationSparkling RefreshmentQuick Cassandra OverviewConnecting the Dots . . .ExamplesResources

@maasg#bigdatabe
Scalability

@maasg#bigdatabe
Availability

@maasg#bigdatabe
Resilience

@maasg#bigdatabe

@maasg#bigdatabe
Memory CPU’sNetwork

@maasg#bigdatabe
What is Apache Spark?
Spark is a fast and general engine for large-scale distributed data processing.
Fast Functional
val file = spark.textFile("hdfs://...")
val counts = file.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
Growing Ecosystem

@maasg#bigdatabe
The Big Idea...Express computations in terms of transformations and actions on a distributed data set.
Spark Core Concept: RDD => Resilient Distributed Dataset
Think of an RDD as an immutable, distributed collection of objects
• Resilient => Can be reconstructed in case of failure• Distributed => Transformations are parallelizable operations• Dataset => Data loaded and partitioned across cluster nodes (executors)
RDDs are memory-intensive. Caching behavior is controllable.

@maasg#bigdatabe
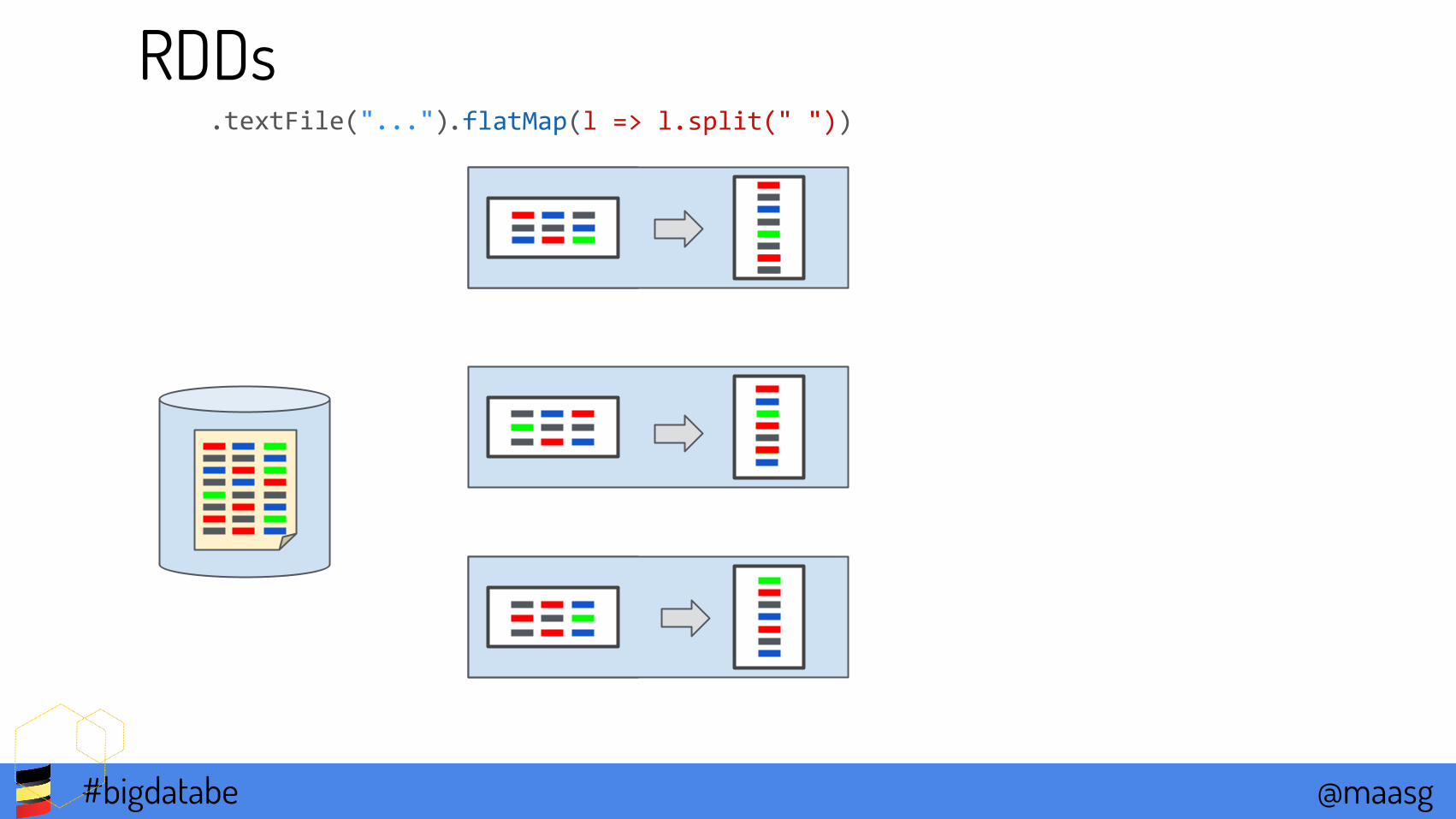
RDDsRDD
PartitionsPartitionsPartitions
@maasg#bigdatabe
RDDs.flatMap(l => l.split(" ")).textFile("...")

@maasg#bigdatabe
RDDs.flatMap(l => l.split(" ")).textFile("...") .map(w => (w,1))
111111
111111
111111

@maasg#bigdatabe
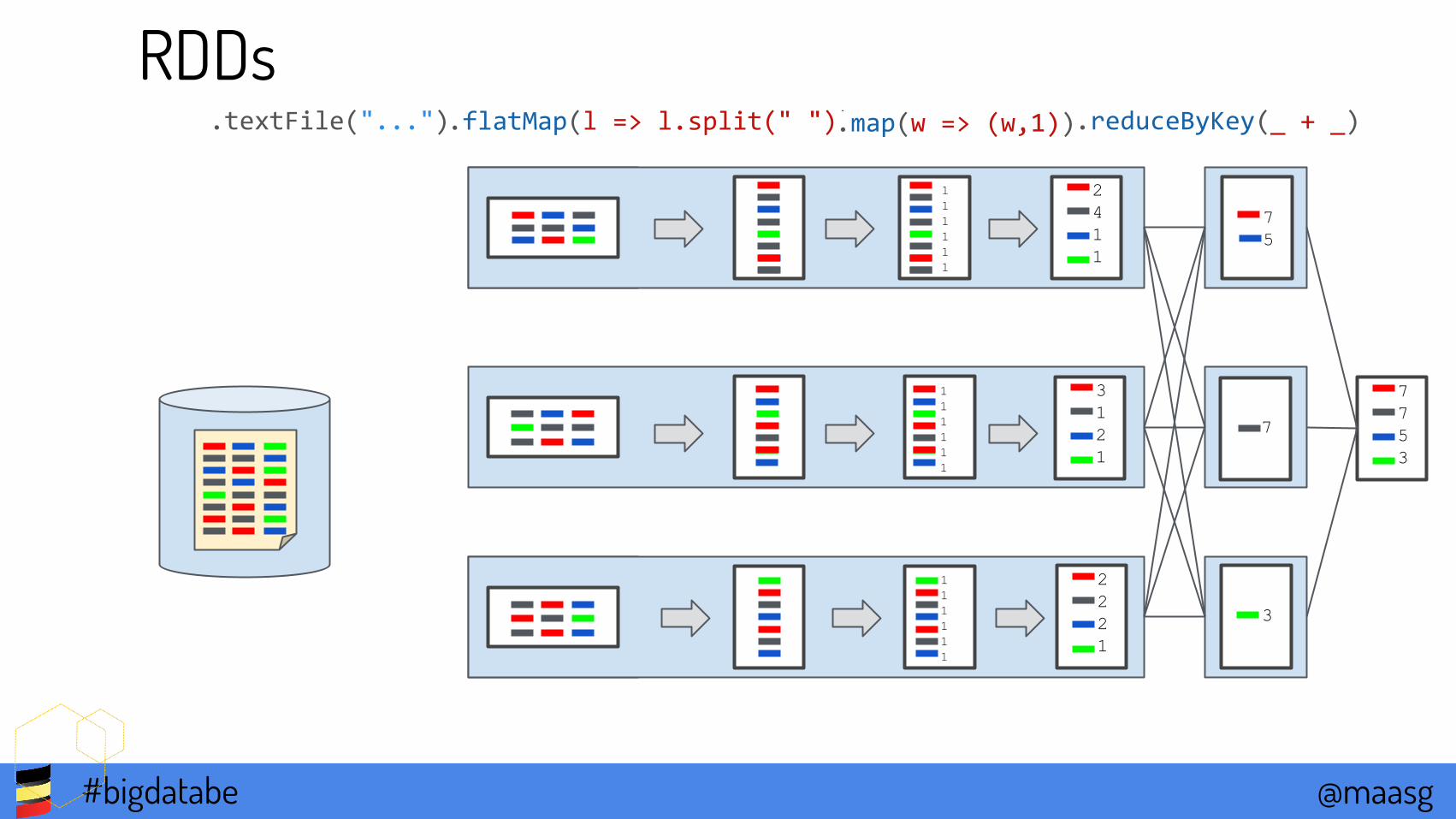
RDDs.flatMap(l => l.split(" ")).textFile("...") .map(w => (w,1))
111111
111111
111111
.reduceByKey(_ + _)
2411
2221
3121

@maasg#bigdatabe
RDDs.flatMap(l => l.split(" ")).textFile("...") .map(w => (w,1))
111111
111111
111111
.reduceByKey(_ + _)
2411
2221
3121
75
7
3
@maasg#bigdatabe
RDDs.flatMap(l => l.split(" ")).textFile("...") .map(w => (w,1))
111111
111111
111111
.reduceByKey(_ + _)
2411
2221
3121
75
7753
7
3

@maasg#bigdatabe
RDD LineageEach RDDs keeps track of its parent.This is the basis for DAG scheduling and fault recoveryval file = spark.textFile("hdfs://...")val wordsRDD = file.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)val scoreRdd = words.map{case (k,v) => (v,k)}
HadoopRDD
MappedRDD
FlatMappedRDD
MappedRDD
MapPartitionsRDD
ShuffleRDD
wordsRDD MapPartitionsRDD
MappedRDDscoreRDDrdd.toDebugString is your friend

@maasg#bigdatabe
What is Apache Cassandra?Cassandra is a distributed, high performance, scalable and fault tolerant column-oriented “noSQL” database.
Bigtable
Data Model- wide rows, sparse arrays- high write throughput
DynamoDB
Infrastructure- P2P gossip- “kv” store- Tunable consistency

@maasg#bigdatabe
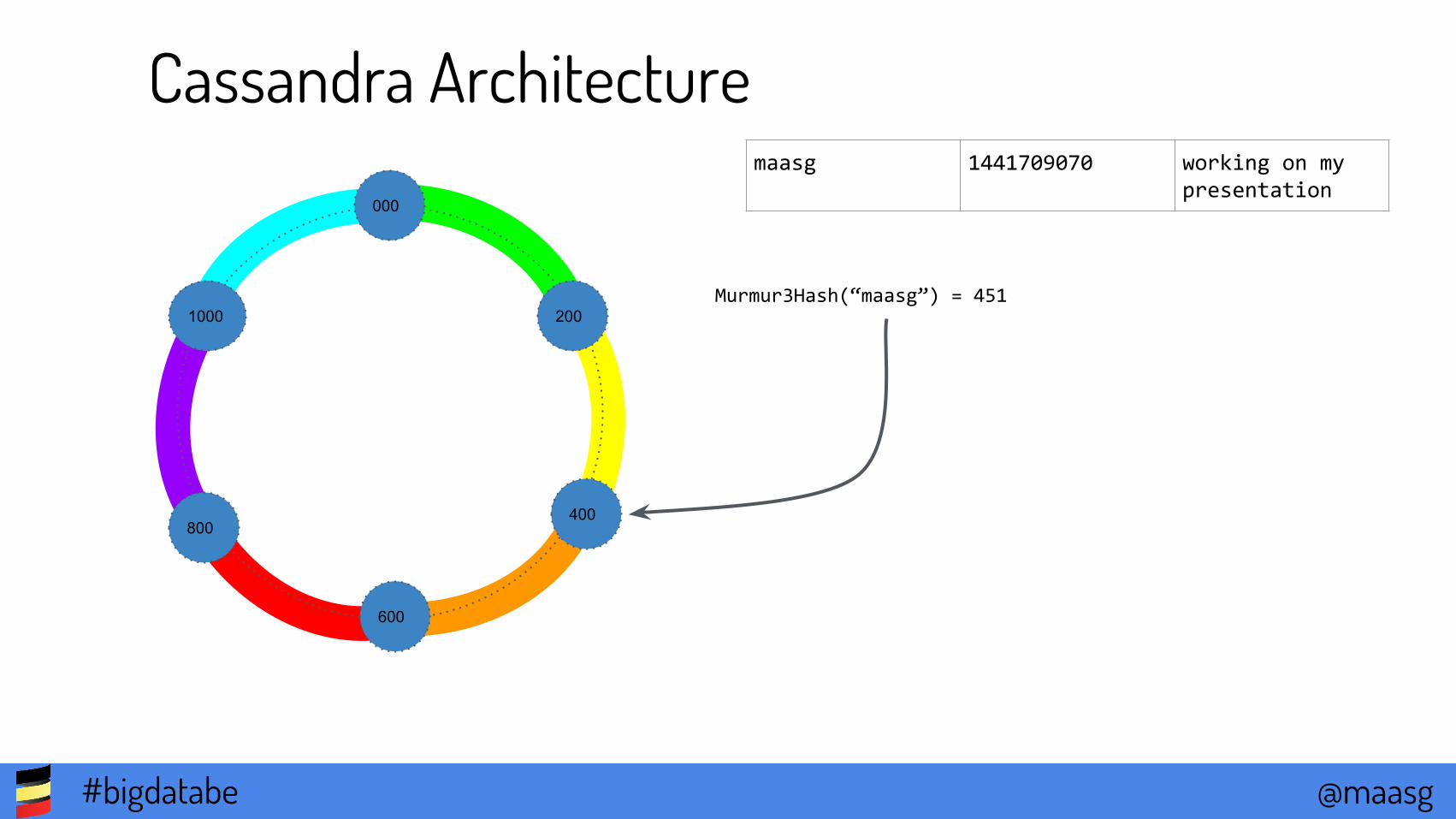
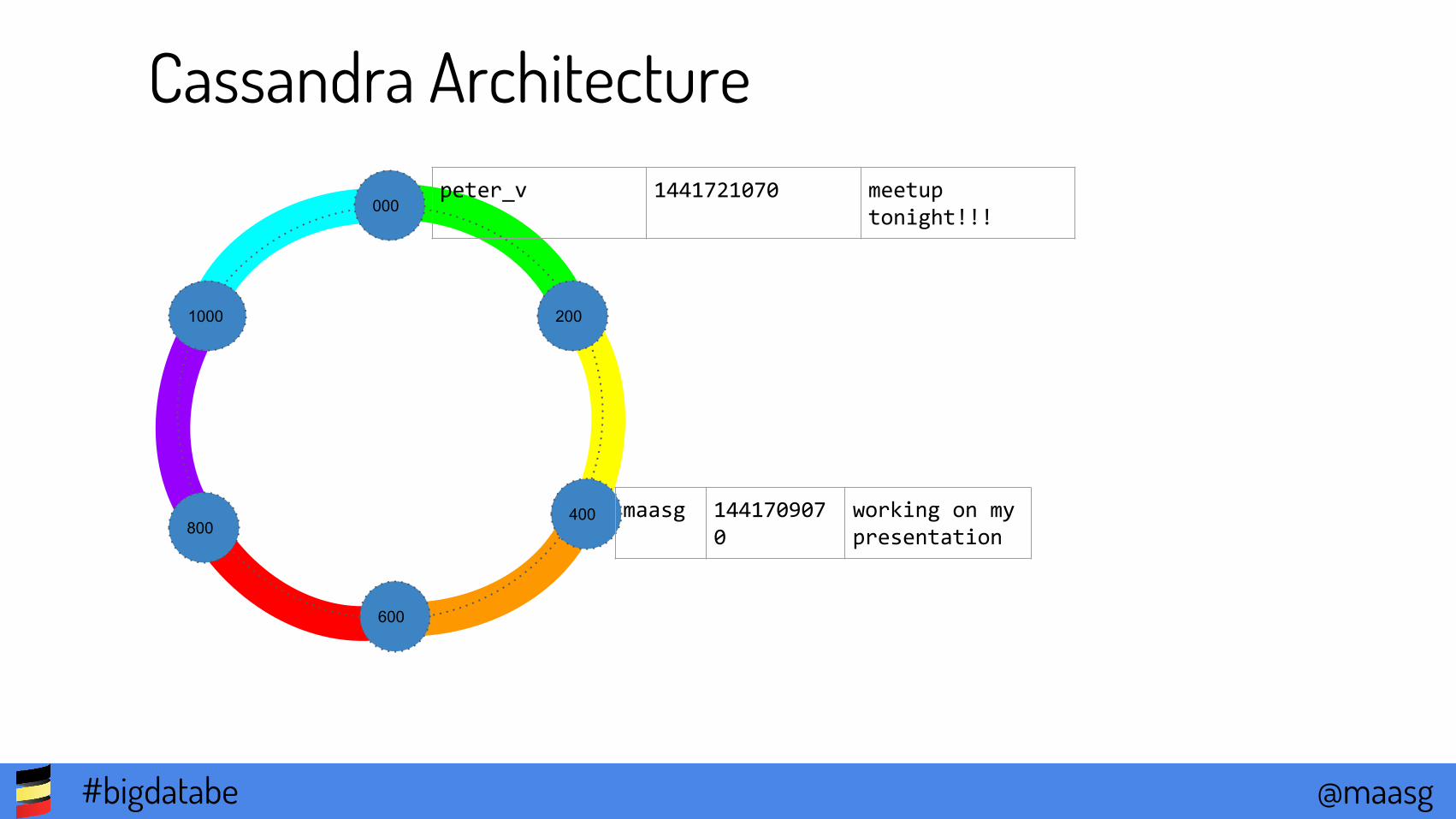
Cassandra ArchitectureNodes use gossip to communicate ring state
Data is distributed over
the cluster
Each node is responsible for a segment of tokens
Data is replicated to n (configurable) nodes

@maasg#bigdatabe
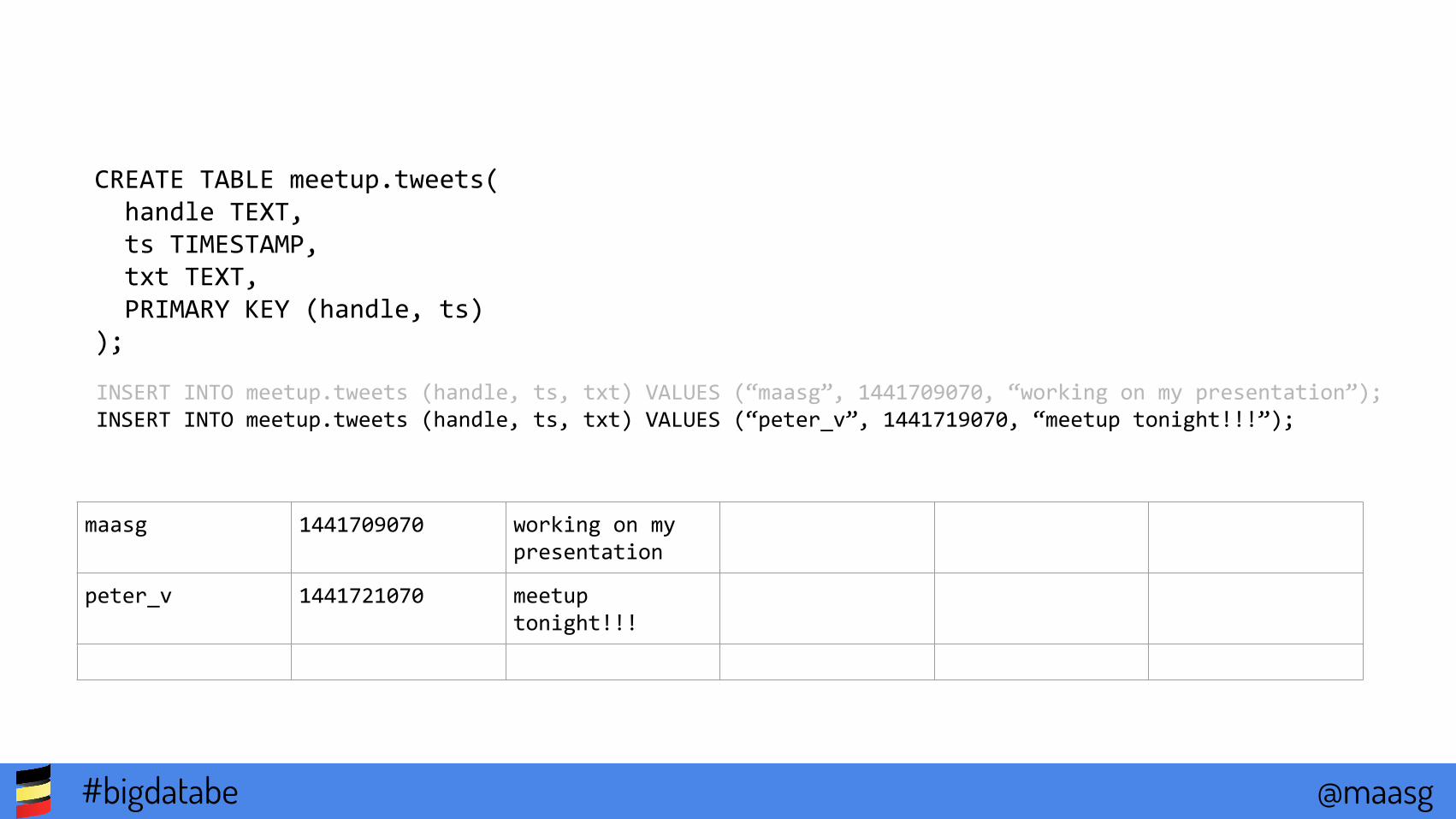
CREATE TABLE meetup.tweets( handle TEXT, ts TIMESTAMP, txt TEXT, PRIMARY KEY (handle, ts));
INSERT INTO meetup.tweets (handle, ts, txt) VALUES (“maasg”, 1441709070, “working on my presentation”);
maasg 1441709070 working on my presentation
@maasg#bigdatabe
CREATE TABLE meetup.tweets( handle TEXT, ts TIMESTAMP, txt TEXT, PRIMARY KEY (handle, ts));
INSERT INTO meetup.tweets (handle, ts, txt) VALUES (“maasg”, 1441709070, “working on my presentation”);INSERT INTO meetup.tweets (handle, ts, txt) VALUES (“peter_v”, 1441719070, “meetup tonight!!!”);
maasg 1441709070 working on my presentation
peter_v 1441721070 meetup tonight!!!

@maasg#bigdatabe
CREATE TABLE meetup.tweets( handle TEXT, ts TIMESTAMP, txt TEXT, PRIMARY KEY (handle, ts));
INSERT INTO meetup.tweets (handle, ts, txt) VALUES (“maasg”, 1441709070, “working on my presentation”);INSERT INTO meetup.tweets (handle, ts, txt) VALUES (“peter_v”, 1441719070, “meetup tonight!!!”);INSERT INTO meetup.tweets (handle, ts, txt) VALUES (“maasg”, 1441719110, “almost ready”);
maasg 1441709070 working on my presentation
1441719110 almost ready
peter_v 1441721070 meetup tonight!!!

@maasg#bigdatabe
maasg 1441709070 working on my presentation
1441719110 almost ready
peter_v 1441721070 meetup tonight!!!
...
Partition Key
Clustering Key
@maasg#bigdatabe
Cassandra Architecture
1000
000
200
400
600
800
maasg 1441709070 working on my presentation
Murmur3Hash(“maasg”) = 451

@maasg#bigdatabe
Cassandra Architecture
1000
000
200
400
600
800maasg 1441709070 working on my
presentation

@maasg#bigdatabe
Cassandra Architecture
1000
000
200
400
600
800maasg 1441709070 working on my
presentation
peter_v 1441721070 meetup tonight!!!
Murmur3Hash(“peter_v”) = 42
@maasg#bigdatabe
Cassandra Architecture
1000
000
200
400
600
800maasg 144170907
0working on my presentation
peter_v 1441721070 meetup tonight!!!

@maasg#bigdatabe
Cassandra Architecture
1000
000
200
400
600
800maasg 1441709070 working on my
presentation
peter_v 1441721070 meetup tonight!!!
1441719110 almost ready

@maasg#bigdatabe
+
Spark Cassandra Connectorhttps://github.com/datastax/spark-cassandra-connector

@maasg#bigdatabe
“This library lets you expose Cassandra tables as Spark RDDs, write Spark RDDs to Cassandra tables, and execute arbitrary CQL queries in your Spark applications.”
@maasg#bigdatabe
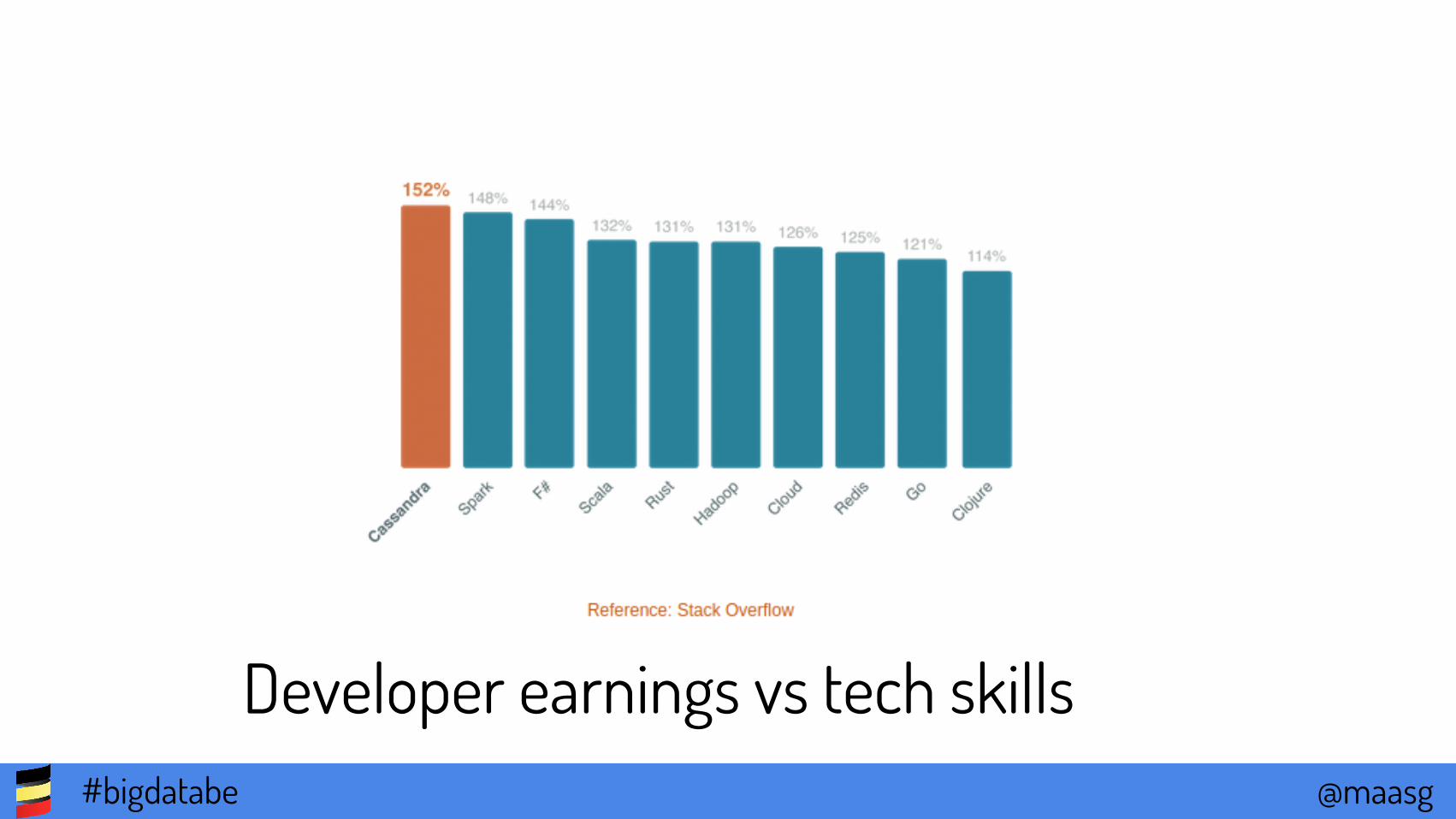
Developer earnings vs tech skills
@maasg#bigdatabe
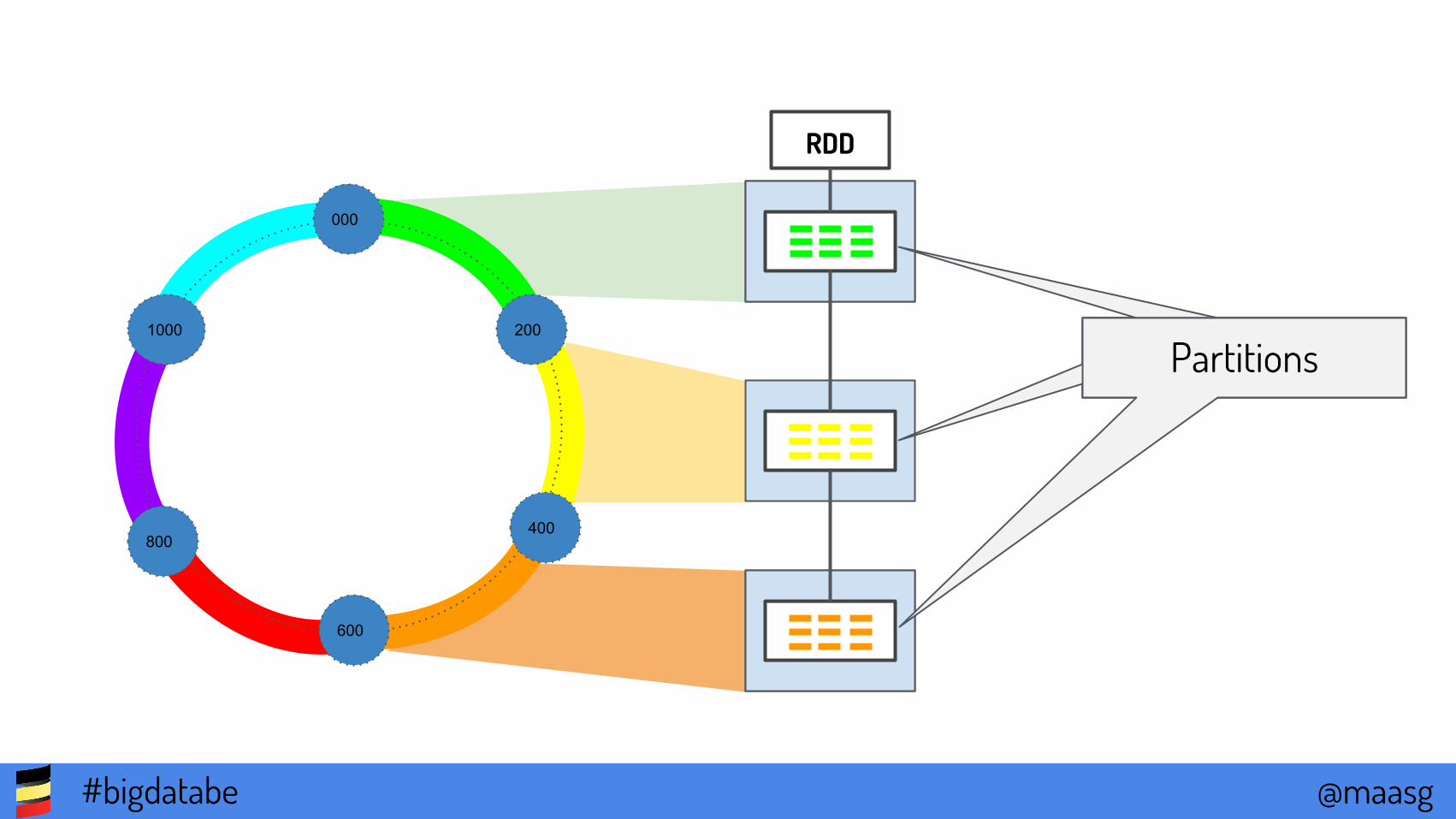
RDD
PartitionsPartitionsPartitions1000
000
200
400
600
800

@maasg#bigdatabe
RDD
PartitionsPartitionsPartitions1000
000
200
400
600
800
cassandraTable, joinWithCassandraTable
repartitionByCassandraReplica

@maasg#bigdatabe
Examples
@maasg#bigdatabe
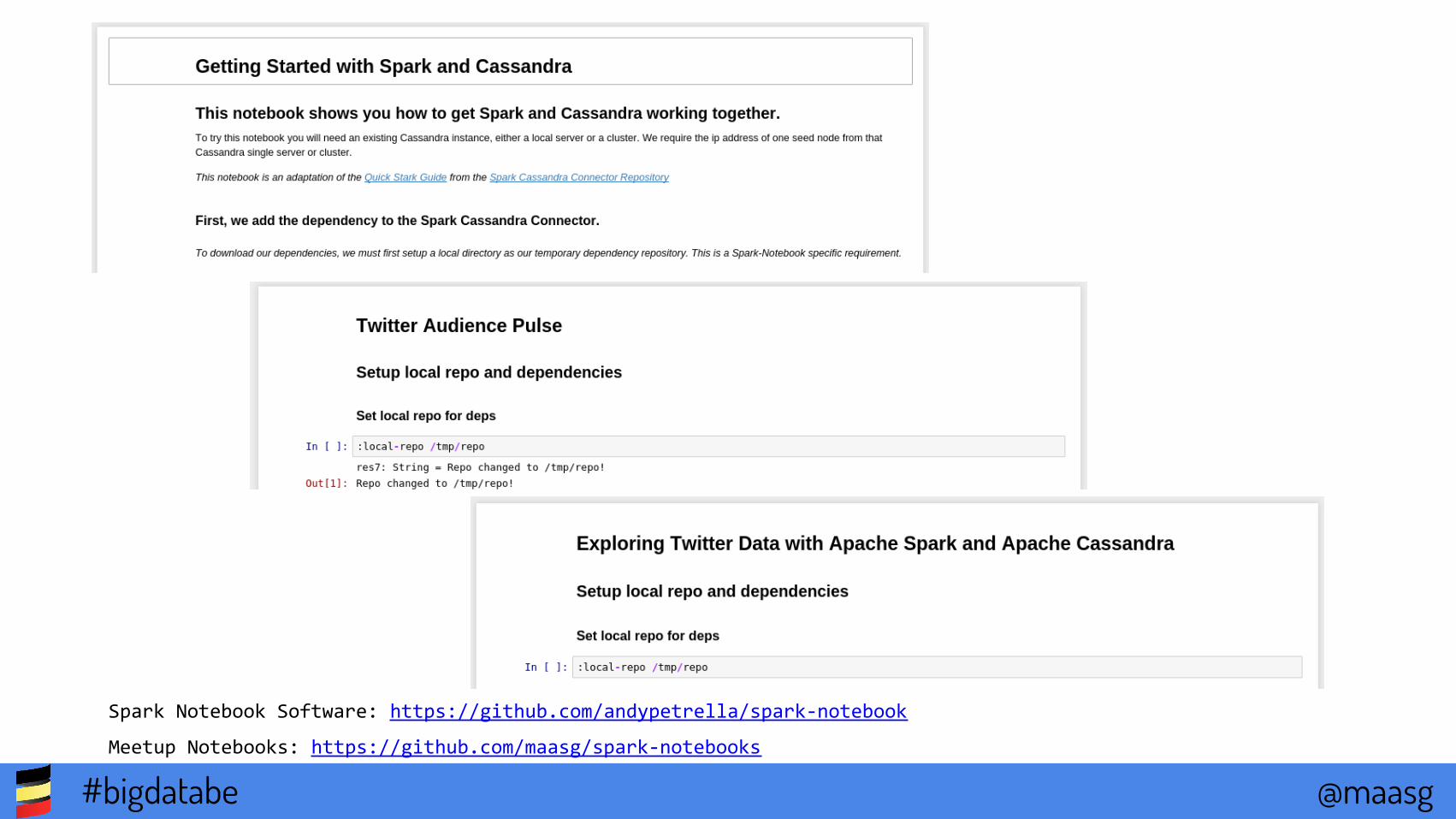
Spark Notebook Software: https://github.com/andypetrella/spark-notebook
Meetup Notebooks: https://github.com/maasg/spark-notebooks

@maasg#bigdatabe
Resources
Project website: http://spark.apache.org/Spark presentations: http://spark-summit.org/2015Starting Questions: http://stackoverflow.com/questions/tagged/apache-sparkMore Advanced Questions: [email protected] Code: https://github.com/apache/sparkGetting involved: http://spark.apache.org/community.html

@maasg#bigdatabe
Resources
Project website: http://cassandra.apache.org/ Community Site: www.planetcassandra.org Questions: http://stackoverflow.com/questions/tagged/cassandra Training: https://academy.datastax.com/ Spark Cassandra Connector: https://github.com/datastax/spark-cassandra-connector Excellent deep-dive in data locality implementation:http://www.slideshare.net/SparkSummit/cassandra-and-spark-optimizing-russell-spitzer-1

@maasg#bigdatabe
Resources
Spark-Notebook: https://github.com/andypetrella/spark-notebook
Meetup code: https://github.com/maasg/spark-notebooks
Slides (soon): http://www.virdata.com/category/tech/

@maasg#bigdatabe
Acknowledgments

@maasg#bigdatabe
Want to work with this exciting tech? We are hiring!


















