Damn physics: Building a data center for virtualization
39
Damn physics: Building a datacenter for virtualization Kristian Köhntopp Old fart Syseleven
Transcript of Damn physics: Building a data center for virtualization

Damn physics: Building a datacenter for virtualization
Kristian Köhntopp Old fart
Syseleven
Hardware for hipstersKristian Köhntopp Old fart
Syseleven

„Infrastructure as code.“
3

Infrastructure as Code4
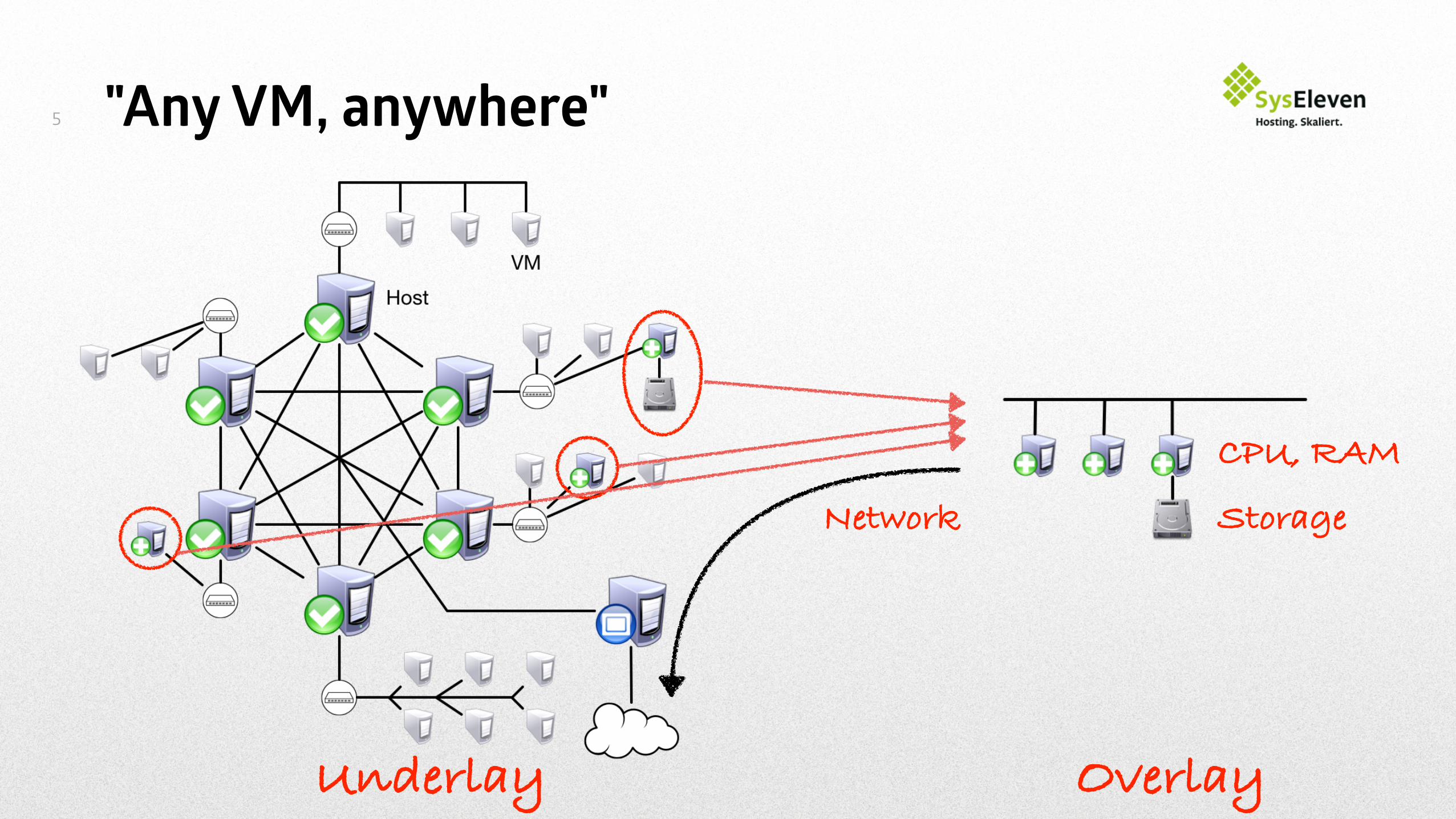
"Any VM, anywhere"5
CPU, RAM
StorageNetwork
OverlayUnderlay

“I don’t need Ubuntu, I need functionality”
• Infrastructure, Platform, Software as a Service • Machinery (“virtual root server”), • Installation and Upgrade details (“Managed Hosting”), • A remote thing with a network API that “is available”
and “performs”.
6

“There is no cloud. Just other people's computers.”https://twitter.com/xdamman/status/538394792540254208

Ok, so I got a box
• 10k get you • 40-50 cores, • 256G memory, • 2x 10GBit and • 12x 3TB SATA
• +3k for additional 3TB SSD, • +10k to get a box with only fans as moving parts
8

Example: HP DL 380 G8http://hpserver.by/images/detailed/1/hp_dl380p_gen8_inside_in_t7e8-xt.jpg (C) 2014 HP Press Material

Relevant stats?
• 2/42 HU in a rack, 200W idle, a lot more under load, • multiple 1G or 10G links with 1/20000s ping latency • local disks (200 commit/s per disk) • SSD (20000 commit/s per disk) • loads of compute and memory for the app
• see how we do not care at all of CPU and RAM?
10

Other relevant stats
• There is iLO and remote KVM • in Java, does not work in all browsers • in Gfx mode • and a POST takes 300s until boot loader start
11


The compute unit
• Remember how I said we don’t care about CPU/RAM? • I lied. Slices, with no leftovers: • composition of slices = composition of phy hardware. • 1core : 4G memory = 1 compute unit.
• flavors instead of sliders for CPU and memory. • flavors = integer * unit.
13

Life inside a populated box
• Total box: • Disk: 12x 200 IOPS, SSD: 3x 20k IOPS, Net: 20GBit
• divide by number of instances we put in there: • Per compute unit:
• Disk: 48 IOPS, SSD: 1200 IOPS, Net: 400 MBit (50 MB/sec)
14

–Gaylord Aulke
„I’ve got a customer where the most simple database query sometimes take a very long time to complete.“
15

Then the box dies
• That data is in a box • The box falls over
• Well, shit. • Actually, 50x customers -> support. Even worse.
• And even for Maintenance Reboots -> support shitstorm.
16
http://commons.wikimedia.org/wiki/File:Burning_Logitech_12.jpg CC-BY-SA 3.0 by http://commons.wikimedia.org/wiki/User:Diether
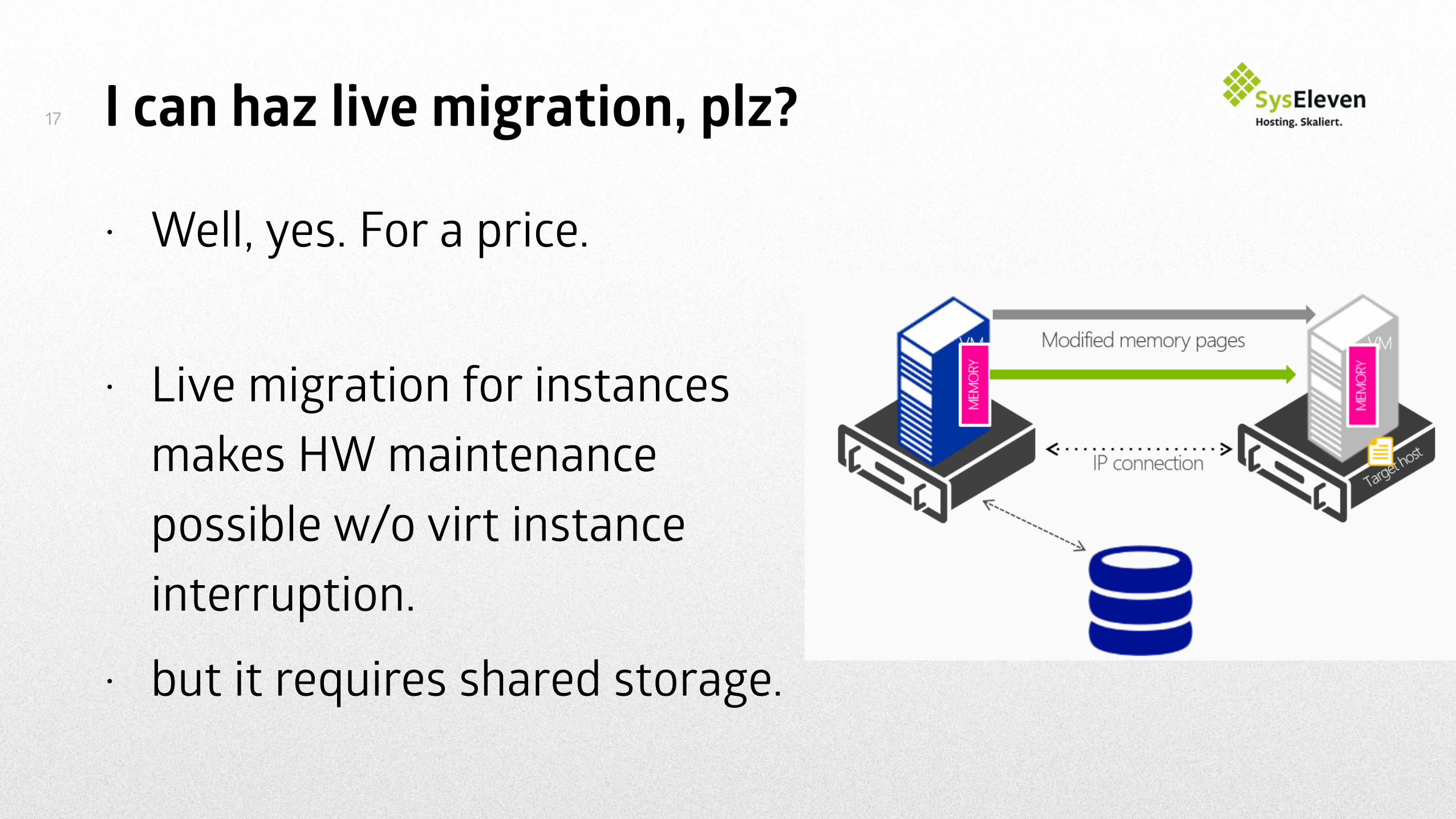
I can haz live migration, plz?
• Well, yes. For a price.
• Live migration for instances makes HW maintenance possible w/o virt instance interruption.
• but it requires shared storage.
17

You keep mentioning that price
• shared storage = one or two network writes • this chains you to 600 MB/
sec • latency is at least 1/20000s, • so you can never have more
than 10k-20k commit/s
18

Can’t we have a storage network?
• Yes, and it can even be Infiniband.
• Do you want to hard or soft partition network capacity? • Do you want a second network infrastructure, topology
or even protocol stack? • What is the additional port budget?
19

Model A: Local instance storage
• frequent maintenance reboots visible to instance • no rescheduling of load from busy instances to others
• probably better local IOPS than with network volume
20

Model B: Shared storage
• maintenance invisible • rescheduling of load by migration to other nodes possible
• but nothing does this (automatically) • IOPS completely network dependent
• provided nothing else bottlenecks first
21

Ok, so my data leaves the box
• it is now in a different, larger box: • up to 16 of the above 2HU
machines in a rack • 1 or 2 top-of-rack switches, 16x
10Gbit in, 40GBit out • 1:4 oversubscription
22
https://www.flickr.com/photos/clonedmilkmen/3604999084, Cloned Milkmen (CC-BY-SA)
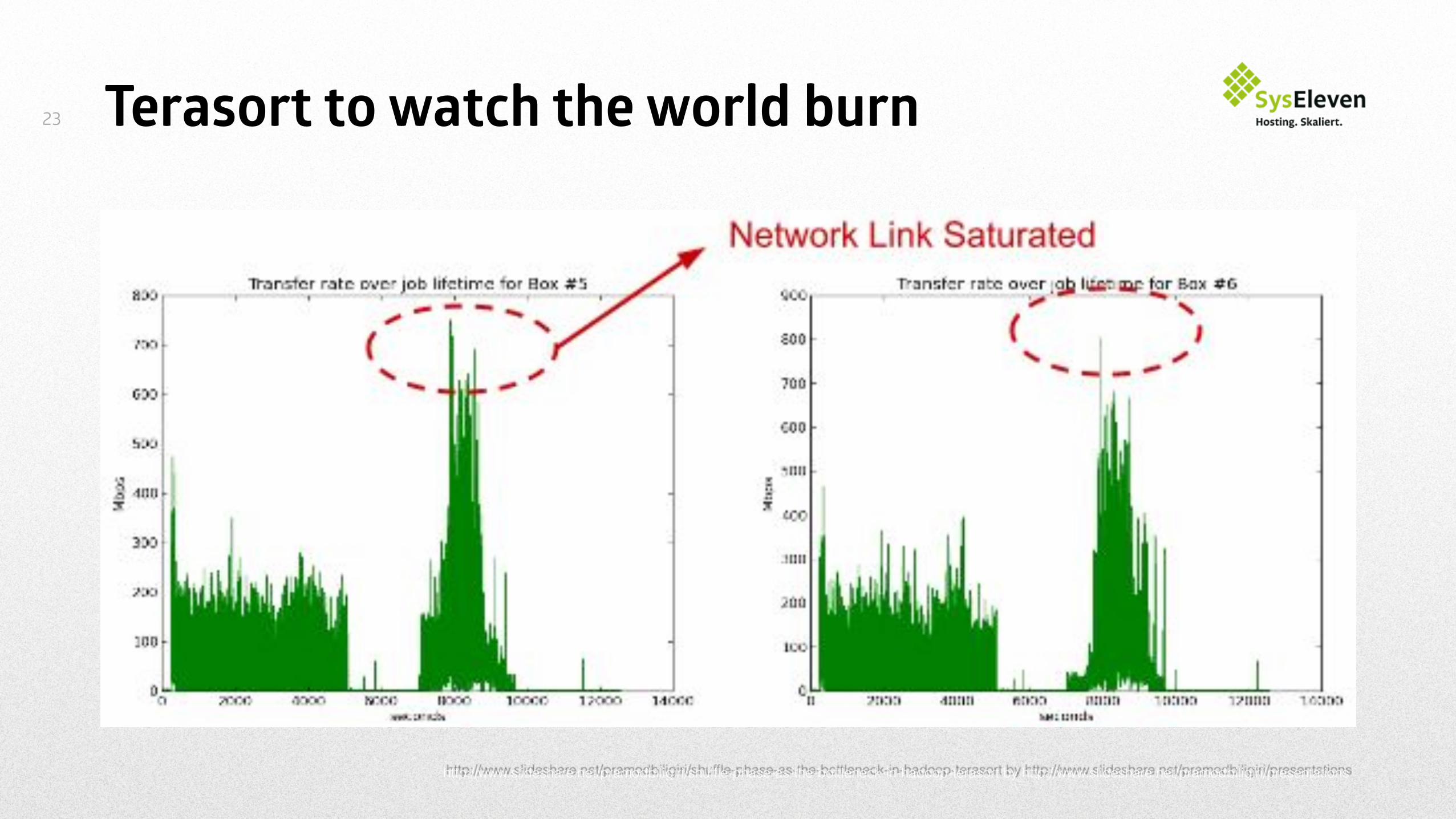
Terasort to watch the world burn23
http://www.slideshare.net/pramodbiligiri/shuffle-phase-as-the-bottleneck-in-hadoop-terasort by http://www.slideshare.net/pramodbiligiri/presentations
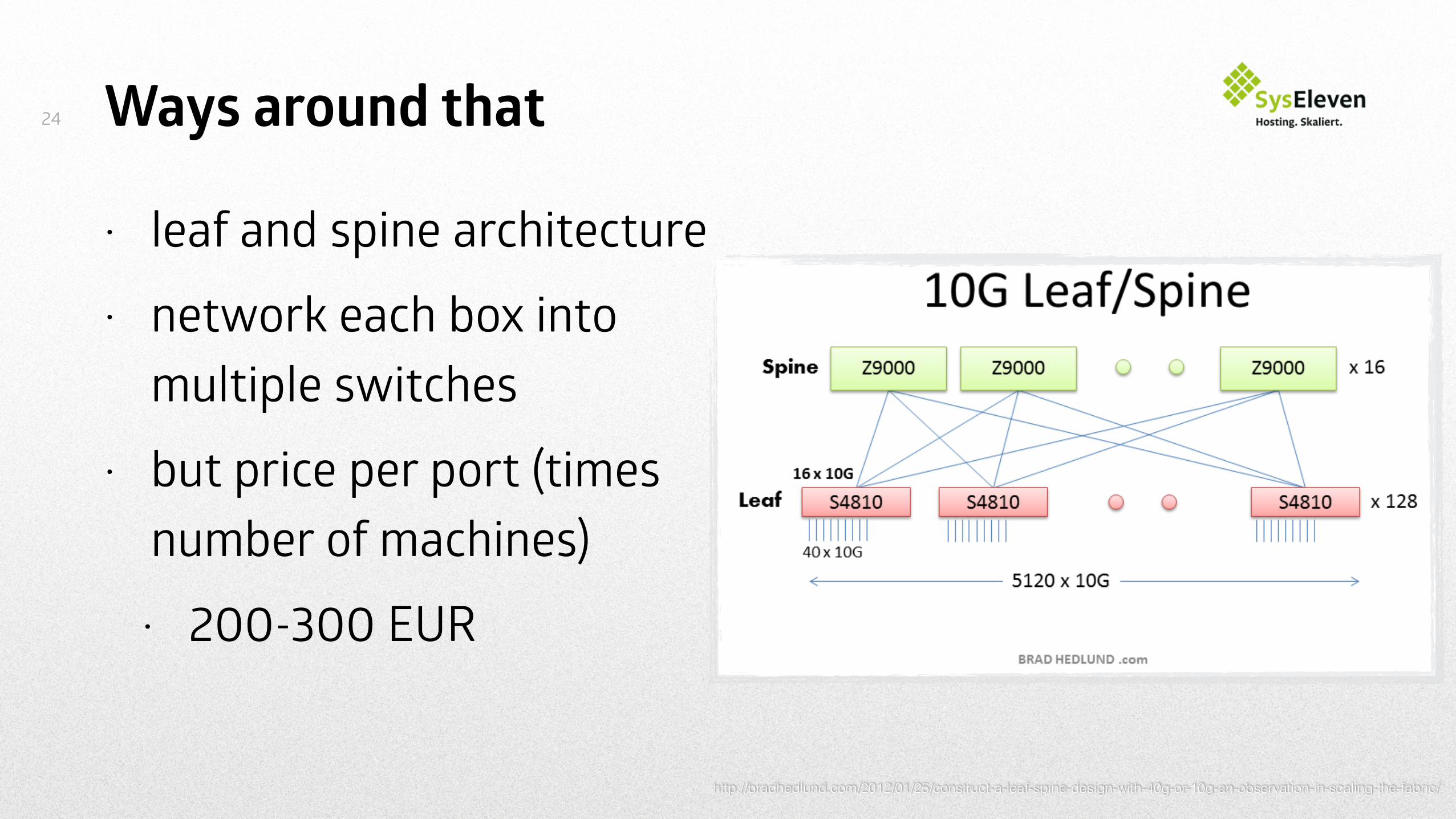
Ways around that
• leaf and spine architecture • network each box into
multiple switches • but price per port (times
number of machines) • 200-300 EUR
24
http://bradhedlund.com/2012/01/25/construct-a-leaf-spine-design-with-40g-or-10g-an-observation-in-scaling-the-fabric/

Assume I have infinite money…
• Still a single flow goes through a single switch • hashing (src ip, src port, dst ip, dst port), limits
effectivity • depending on hashing, limit is 2k, 20k or 200k nodes
per cluster • 200k requires google grade fairy dust
25

Ok, so my data leaves the rack, too
• It is now in a larger box: • rows of racks in a data
center • problems here are usually
hard-hardware problems (cooling and other very material infrastructure)
26
web.de Amalienbadstrasse, Karlsruhe, (C) 2004 Kristian Köhntopp

Cooling? How’s that a concern?
• 6 blade centers or 16 2HU servers ~ 20kW per rack
• Cool by air flow: • “specific heat
capacity” (warm 1kg by 1K) • air flow separation by aisle
27
web.de Amalienbadstrasse, Karlsruhe, (C) 2004 Kristian Köhntopp

Cooling? How’s that a concern?
• Cool with water in the rack door: rack is airtight
• install fire extinguisher inside the rack
• Density actually goes down
28

Cooling? How’s that a concern?
• Water cooling: much higher specific heat capacity. • Leaks?
• Lowest disk must be higher than highest drop of water in the rack.
• nightmarish placement constraint
29

„Interesting tech, dude. Why would I care?“
30

Currencies in densely packed virtualized systems
• Primary currencies: disk latency, disk IOPS • Expensive code looks like this:
• for ($a in $k => $v) { START TRANSACTION WRITE INSERT INTO … COMMIT
• or variations thereof.
31

Currencies in densely packed virtualized systems
• Network latencies, as they pile up • What does that mean for your microservices?
• Coscheduling: Failure resiliency, scaleout vs. latencies
32

– Actual developer (name withheld)
„ So to solve the problem we wrote a global sequence number server.“
33

Currencies in densely packed virtualized systems
• Network latencies, as they pile up • What does that mean for your microservices?
• benefit: horizontal scaleout enabled (if stateless) • cost: pile up latencies, pile up network load, magnify
network jitter • good if you have async IO. • so, good if you aren't on PHP
34

I really need these 200k commit/s
• Really? Sucks to be you. • Locally? Or over the network, even
• what happens when the instance vanishes? • Remote commit/s in Amazon -> €rror
35

I really need these 200k commit/s
• Here is your Fusion-IO, 200k commit/s on flash • Box goes boom, how do you feel? • Ah, but if you ship writes remotely ACID: 20k/s max
• If you do 2PC, Raft or Paxos, a lot less. • Yeah, distributed transactions suck, even if the network
is fine.
36

Call me maybe
• So what happens when the network isn’t fine? • actually, when it isn't, add multi-second timeouts in
which you have 0 commit/s • and that is assuming that it is down only for a short
moment, cluster leader re-elections take time.
• Read up: http://aphyr.com/tags/jepsen
37

YOLO!
• Example Elasticsearch • Example Aerospike BCache instructions for Aerospike.
38

„If you eat fom the trashcan, the cuisine becomes weird.“
39