
DAISY Dutch lAnguage Investigation of Summarization technologY Katholieke Universiteit Leuven...
16
DAISY Dutch lAnguage Investigation of Summarization technologY Katholieke Universiteit Leuven Rijksuniversiteit Groningen Q-go
-
Upload
jared-nicholson -
Category
Documents
-
view
219 -
download
4
Transcript of DAISY Dutch lAnguage Investigation of Summarization technologY Katholieke Universiteit Leuven...

DAISYDutch lAnguage Investigationof Summarization technologY
Katholieke Universiteit LeuvenRijksuniversiteit Groningen
Q-go

DAISY on one slide
Segmentation
Rhetoricalclassification
Sentencecompression
Sentencegeneration
Multi-document summarization:Detect differences
Improvement question answering,e.g. e-mail answering
Summarization of web content

Overview
Report of our current progress in:• Corpus building and preprocessing• Segmentation• Sentence generation

Corpus Building and Preprocessing
Target: corpus of questions, short texts and webpages about the same topic
• Freely available: – UWV (questions & answer texts)– SVB (questions)
• Available for internal use: KLM (questions, answer texts, web pages)
• Todo: – web pages SVB– ABN AMRO (committed, not delivered)

Corpus Building and Preprocessing
• POS-tagged and parsed: KLM and UWV• SVB corpus: in progress• Coreference resolution: in progress

Segmentation
Find main content in webpage
Smaller segments Can be obtained from HTML structure <H#>, <P>, <BR>, <UL>, ... Hierarchical Will be refined in relation to rhetorical roles

Segmentation

Segmentation
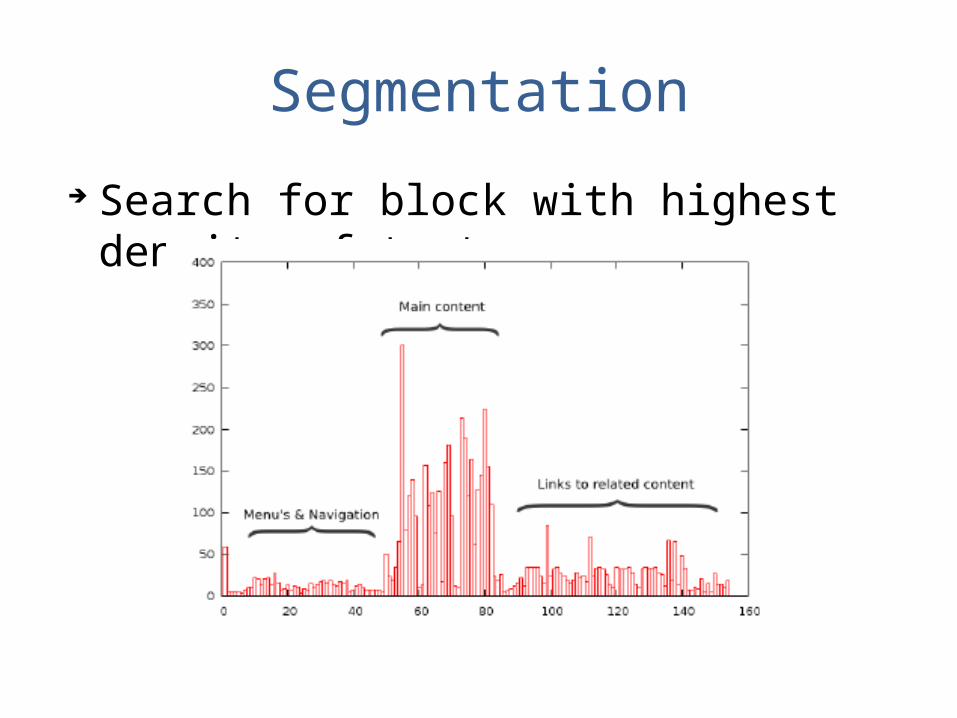
Segmentation
Search for block with highest density of text

Segmentation

Segmentation
Additional heuristics to extend the selection: Find closing tags for all tags that were opened in the
selection Include all text delimited by known tag patterns occurring
just before and after the selection Take the smallest enclosing DIV block

Sentence generation
• Specification of abstract dependency trees– Specify grammatical relations between lexical
items and constituents dominating over lexical items
– Alpino dependency trees without adjacency information
– More variation through underspecification in lexical items, handling of particles

Sentence generation
• Initial implementation generator:– Chart generator (Kay, 1996)– Top-down guidance through expected dependency
relations– Generates substantial part of input created from
the Alpino testsuites– Included in recent Alpino versions
• Further work: optimization (time and space)

Sentence generation
• Selecting the most fluent sentence through fluency ranking:– N-gram language model– Log-linear model– Experiments with Velldall (2007) and parse
disambiguation feature templates.• Need more insight about feature overlap• Experiment with more feature templates

Sentence generation
• Evaluation:– Corpus sentences used as a reference for the most
fluent realization– Fairly strict, since there can be multiple fluent
sentences– Where is the ceiling?– More annotated material!– FLAN: FLuency ANnotator (web application)

Thanks!


















