
D A C U C P Performance-Driven Processor Allocation Julita Corbalan, Xavier Martorell, Jesus Labarta...
28
D A C U C P Performance-Driven Processor Allocation Julita Corbalan, Xavier Martorell, Jesus Labarta {juli,xavim,jesus}@ac.upc.es DAC-UPC
-
date post
19-Dec-2015 -
Category
Documents
-
view
217 -
download
1
Transcript of D A C U C P Performance-Driven Processor Allocation Julita Corbalan, Xavier Martorell, Jesus Labarta...

D A C
U
CP
Performance-Driven Processor AllocationPerformance-Driven Processor Allocation
Julita Corbalan, Xavier Martorell, Jesus Labarta
{juli,xavim,jesus}@ac.upc.es
DAC-UPC

CD A C
UP
Performance-Driven Processor Allocation
ObjectiveObjective
Scheduling parallel applications in Shared Memory Multiprogrammed systems
Allocate processors to applications that “can take advantage of them”
Implemented in an SGI Origin2000 with 64 processors

CD A C
UP
Performance-Driven Processor Allocation
OutlineOutline
Introduction & Related Work
NANOS Execution Environment
Performance-Driven Processor Allocation:PDPA
Evaluation
Conclusions & Future Work

CD A C
UP
Performance-Driven Processor Allocation
IntroductionIntroduction
Scheduling problem: allocate processors to applications
Space-Sharing / Time-Sharing
Number of processes = Number of Processors Process Control [Tucker89]
Space-sharing approaches: P fixed at submission time
FCFS, SJF, SCDF [Majumdar88,...] P defined at execution time (Adaptive / Dynamic)
Equal-allocation of the resources: Equipartition [McCan93] Processor allocation proportional to the application
performance

CD A C
UP
Performance-Driven Processor Allocation
Introduction (2)Introduction (2)
Processor allocation proportional to application performance
Drawback: Application performance is not known before its execution
Solution: Calculate it a priori Executing several times with different P and input data Extrapolate the values based on a few samples
These approaches may not be valid: Application performance depends on run-time parameters:
Initial data placement, process migrations, distance between processors and memory, …
It can be impracticable: e.g. infinite input data sets

CD A C
UP
Performance-Driven Processor Allocation
Related WorkRelated Work
Dynamic performance analysis Self-Tuning [Nguyen96], efficiency calculated at run-time
as a function of: idleness, system and communication overhead
Adaptive/Dynamic processor allocation policies Equal_efficiency [Nguyen96], tries to achieve the same
efficiency on all processors Dynamic Allocation, based on the idleness [McCann93] Allocates the knee of the efficiency/execution time curve
[Eager89]

CD A C
UP
Performance-Driven Processor Allocation
Our proposalOur proposal
We propose: Dynamic performance analysis
Real speedup Calculated at run-time
Allocate processors to applications that “can take advantage of them”
Dynamic partitioning Cost conscious re-allocations (memory locality) Really efficient use of processors
Dynamic multiprogramming level Coordination between the medium & long term schedulers

CD A C
UP
Performance-Driven Processor Allocation
OutlineOutline
Introduction & Related work
NANOS Execution Environment
Performance-Driven Processor Allocation:PDPA
Evaluation
Conclusions & Future Work

CD A C
UP
Performance-Driven Processor Allocation
NANOS Execution EnvironmentNANOS Execution Environment
OpenMP ParallelApplications(malleable)
Shared Memory Multiprocessor
Operating System
CPU Manager
Queueing System
….
Start newapplication
Queuedapplications
Proc. request, speedup
Proc. allocated
Newapplication?
Resume,bind, ...
FCFS
SelfAnalyzer
-Request processors-Informs about its performance
-Implements the scheduling policy-Informs the applications about its decisions -Enforces the processor allocation
-Controls the application arrival-Coordinated with the CPU Manager

CD A C
UP
Performance-Driven Processor Allocation
OutlineOutline
Introduction & Related work
NANOS Execution Environment
Performance-Driven Processor Allocation: PDPA Dynamic Performance Analysis: SelfAnalyzer Performance-Driven Processor Allocation policy Dynamic Multiprogramming Level
Evaluation
Conclusions & Future Work

CD A C
UP
Performance-Driven Processor Allocation
Dynamic Performance Analysis: SelfAnalyzerDynamic Performance Analysis: SelfAnalyzer
Based on iterative parallel applications Source code available
SelfAnalyzer calls inserted by the user or the compiler
Source code not available Dynamic Periodicity Detection SelfAnalyzer dynamically loaded
Tool to estimate the application speedup and execution time
Do
!$OMP PARALLEL DO
do
enddo
!$OMP END DO
!$OMP PARALLEL DO
do
enddo
!$OMP END DO
end do

CD A C
UP
Performance-Driven Processor Allocation
T(b) T(P)
B Proc. P Proc.
...
Dynamic Performance Analysis: SelfAnalyzer(2)Dynamic Performance Analysis: SelfAnalyzer(2)
Speedup calculated as the relationship between T(1) and T(P)
)()()(
bAFPTbT
Speedup
T(1) T(P)
)()1(pT
TSpeedup...
1 Proc. P Proc.
Serialization!!

CD A C
UP
Performance-Driven Processor Allocation
Performance-Driven Processor AllocationPerformance-Driven Processor Allocation
Space-Sharing
Allocation for acceptable efficiency (S(p)/p) In the range [low_eff , high_eff] [50%-70%]
Run-To-Completion Minimum allocation of one processor
Dynamic partitioning, re-allocations when: Applications inform about their speedups Application arrival/Application end
Remembers the application state Allocation, performance

CD A C
UP
Performance-Driven Processor Allocation
Performance-Driven Processor Allocation(2)Performance-Driven Processor Allocation(2)
NO_REFNO_REF
DECDEC STABLESTABLE INCINC
NewApplP=min(Free Proc., Proc. Requested)
Eff(p)<high_eff&&
Eff(p)>low_eff
Eff(p)<low_effP=P-step
Eff(p)>low_eff
Eff(p)>high_effP=P+min(free,step)
Eff(p)<high_eff ORNot proportional benefit
System Changes System Changes
Policy parameters: step, low_eff and high_eff

CD A C
UP
Performance-Driven Processor Allocation
Dynamic Multiprogramming LevelDynamic Multiprogramming Level
Multiprogramming level (ML) Number of applications running concurrently Static/Dynamic ML
Coordination between the medium & long term schedulers
If (new_appl_fits()?) start_new_appl()new_appl_fits() defined by the scheduling policy
• Free processors during several quanta start_new_appl() implemented by the queuing system

CD A C
UP
Performance-Driven Processor Allocation
OutlineOutline
Introduction & Related work
NANOS Execution Environment
Performance-Driven Processor Allocation:PDPA
Evaluation Processor Allocation Policies Applications & Workloads Execution Time & Processor Allocation
Conclusions & Future Work

CD A C
UP
Performance-Driven Processor Allocation
Processor Allocation PoliciesProcessor Allocation Policies
Equip: equal CPUs to each running application
PDPA + DML : our proposal
Equal_eff: equal efficiency in all the processors
SGI-MP: native IRIX Scheduler MP_BLOCKTIME=200000 OMP_DYNAMIC=TRUE

CD A C
UP
Performance-Driven Processor Allocation
Applications & WorkloadsApplications & Workloads
Architecture & System SGI Origin2000 with 64 processors + IRIX 6.5.8
Applications: Open MP Swim(44.2), Bt(20.85), Hydro2d(6.3), apsi(1)
Workloads Multiprogramming Level set to 4 Request = 32 processors each application
Swim Bt Hydro2d apsi
W1 6 6W2 6 6W3 6 6W4 12

CD A C
UP
Performance-Driven Processor Allocation
Exec.Time & Proc. AllocationExec.Time & Proc. Allocation
W1
0
100
200
300
400
swim bt total
Exe
cutio
n t
ime
(se
)
EQUIP PDPA EQUAL_EFF SGI-MP
W1
05
1015202530
swim bt
Allo
catio
n
EQUIP PDPA EQUAL_EFF SGI-MP
ML=4
DML=5
Limited processor allocation
Appl. exc. time slightly increased
Total execution time reduced

CD A C
UP
Performance-Driven Processor Allocation
Exec.Time & Proc. AllocationExec.Time & Proc. Allocation
W2
0
200
400
600
800
1000
bt apsi total
Exe
cutio
n t
ime
(se
c)
EQUIP PDPA EQUAL_EFF SGI-MP
W2
0
10
20
30
bt apsi
Allo
catio
n
EQUIP PDPA EQUAL_EFF SGI-MP
Performance affected by the multiprogrammed execution
Total exec. Time improved
DML=10
Processors are efficiently used
Allocation proportional to the performance
CD A C
UP
Performance-Driven Processor Allocation
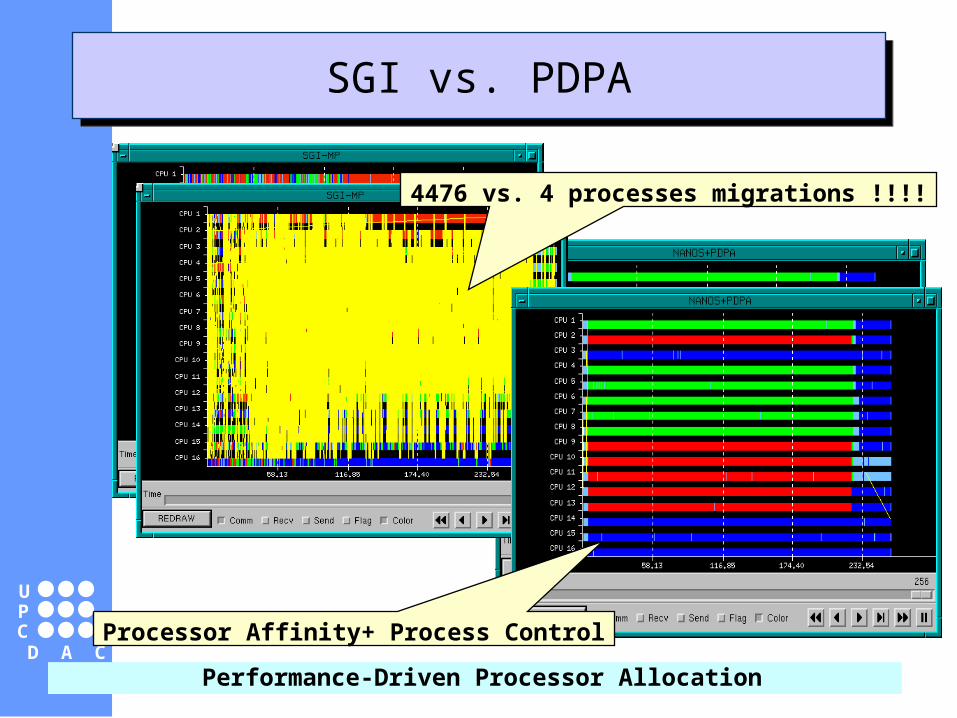
SGI vs. PDPASGI vs. PDPA
Processor Affinity+ Process Control
4476 vs. 4 processes migrations !!!!

CD A C
UP
Performance-Driven Processor Allocation
PDPA behavior (zoom)PDPA behavior (zoom)
Tuning algorithm

CD A C
UP
Performance-Driven Processor Allocation
OutlineOutline
Introduction & Related Work
NANOS Execution Environment
Performance-Driven Processor Allocation:PDPA
Evaluation
Conclusions & Future Work

CD A C
UP
Performance-Driven Processor Allocation
ConclusionsConclusions
It is important to provide an accurate performance information
SelfAnalyzer: dynamic, accurate, easy to use
PDPA allocates processors to applications that “can take advantage of them”
The Dynamic Multiprogramming Level improves the system performance
Coordinating the medium & long term schedulers

CD A C
UP
Performance-Driven Processor Allocation
Future WorkFuture Work
Dynamic performance analysis Non-iterative applications
PDPA Space Sharing+Time Sharing Evaluation in a open environment Step, low_eff and high_eff need further research Number of reallocations limited
Coordination medium & long term schedulers New policies

CD A C
UP
Performance-Driven Processor Allocation
More contact info...More contact info...
http://www.ac.upc.es/NANOS
http://www.ac.upc.es/homes/juli [email protected]

CD A C
UP
Performance-Driven Processor Allocation
Related WorkRelated Work
Dynamic performance analysis Self-Tuning [Nguyen96], efficiency calculated at run-time
as a function of: idleness, system and communication overhead
Dynamic processor allocation policies Equal_efficiency [Nguyen96], tries to achieve the same
efficiency on all processors Dynamic Allocation, based on the idleness [McCann93] Allocates the knee of the efficiency/execution time curve
[Eager89]
It does not calculate the real speedup
It does not ensure an efficient use of processors
Excessive number of reallocations
Uses a priori information

CD A C
UP
Performance-Driven Processor Allocation
Performance-Driven Processor Allocation(3) Performance-Driven Processor Allocation(3)
Advantages PDPA works with run-time information Ensures that processors are always efficiently
used
Drawbacks The tuning algorithm can introduce overhead
inside the application Dynamic step
Some processors can remain unallocated Dynamic Multiprogramming Level


















