
CS 61C: Great Ideas in Computer Arch(h )hitecture (Machine...
60
CS 61C: Great Ideas in Computer h ( h ) Architecture (Machine Structures) Instruction Level Parallelism: Multiple Instruction Issue Guest Lecturer: Justin Hsia
Transcript of CS 61C: Great Ideas in Computer Arch(h )hitecture (Machine...

CS 61C: Great Ideas in Computer h ( h )Architecture (Machine Structures)Instruction Level Parallelism:
Multiple Instruction IssueGuest Lecturer: Justin Hsia

You Are Here!
• Parallel RequestsAssigned to computer Smart
PhWarehouse
S l
Software Hardware
Assigned to computere.g., Search “Katz”
• Parallel ThreadsAssigned to core
PhoneScale Computer
HarnessParallelism &A hi Hi hAssigned to core
e.g., Lookup, Ads
• Parallel Instructions>1 instruction @ one time
Achieve HighPerformance
Core Core…
( h )
Computer
>1 instruction @ one timee.g., 5 pipelined instructions
• Parallel Data1 d t it @ ti
Memory (Cache)
Input/Output Core
Instruction Unit(s) FunctionalToday’s>1 data item @ one timee.g., Add of 4 pairs of words
• Hardware descriptionsll f
Cache
Instruction Unit(s)Unit(s)
A3+B3A2+B2A1+B1A0+B0
Today sLecture
All gates functioning in parallel at same time
Summer 2011 -- Lecture #23
Logic Gates7/28/2011 2

AgendaAgenda
• Control HazardsControl Hazards• Higher Level ILP• Administrivia• Administrivia• Dynamic Scheduling
T h l B k• Technology Break• Example AMD Barcelona• Big Picture: Types of Parallelism• Summary
Summer 2011 -- Lecture #237/28/2011 3

Review: HazardsSituations that prevent starting the next instruction
in the next clock cycley1. Structural hazards
– A required resource is busy (e.g., needed in multiple t )stages)
2. Data hazard– Data dependency between instructionsData dependency between instructions.– Need to wait for previous instruction to complete its
data read/write3 C l h d3. Control hazard
– Flow of execution depends on previous instruction
Summer 2011 -- Lecture #237/28/2011 4

Review: Load / Branch Delay SlotsReview: Load / Branch Delay Slots• Stall is equivalent to nop
lw $t0, 0($t1) AL
UI$ Reg D$ Reg
bubble
bubble
bubble
bubble
bubblenop
sub $t3,$t0,$t2
AL
UI$ Reg D$ Reg
A
and $t5,$t0,$t4
or $t7 $t0 $t6 I$
ALReg D$
AL
UI$ Reg D$ Reg
or $t7,$t0,$t6 I$ LUReg D$
Summer 2011 -- Lecture #237/28/2011 5

AgendaAgenda
• Control HazardsControl Hazards• Higher Level ILP• Administrivia• Administrivia• Dynamic Scheduling
T h l B k• Technology Break• Example AMD Barcelona• Big Picture: Types of Parallelism• Summary
Summer 2011 -- Lecture #237/28/2011 6

Greater Instruction-Level Parallelism (ILP)
§4.10 ParaGreater Instruction Level Parallelism (ILP)
• Deeper pipeline (5 => 10 => 15 stages)
allelism andDeeper pipeline (5 > 10 > 15 stages)
– Less work per stage shorter clock cycle• Multiple issue is superscalar
d AdvancedMultiple issue is superscalar– Replicate pipeline stages multiple pipelines– Start multiple instructions per clock cycle
d InstructioStart multiple instructions per clock cycle– CPI < 1, so use Instructions Per Cycle (IPC)– E.g., 4 GHz 4-way multiple-issue
on Level Pag , y p• 16 BIPS, peak CPI = 0.25, peak IPC = 4
– But dependencies reduce this in practice
rallelism
Summer 2011 -- Lecture #237/28/2011 7

Multiple IssueMultiple Issue
• Static multiple issueStatic multiple issue– Compiler groups instructions to be issued together– Packages them into “issue slots”– Compiler detects and avoids hazards
• Dynamic multiple issue– CPU examines instruction stream and chooses instructions
to issue each cycleC il h l b d i i t ti– Compiler can help by reordering instructions
– CPU resolves hazards using advanced techniques at runtime
Summer 2011 -- Lecture #237/28/2011 8

Superscalar Laundry: Parallel per stageSuperscalar Laundry: Parallel per stage12 2 AM6 PM 7 8 9 10 11 1
Ta
Time
A (light clothing)303030 3030
sk B
C
( g g)(dark clothing)(very dirty clothing)
Ord
CD
E
( y y g)(light clothing)(dark clothing)
M HW h i f ll l k ?
der
E
F
(dark clothing)(very dirty clothing)
• More resources, HW to match mix of parallel tasks?Summer 2011 -- Lecture #237/28/2011 9

Pipeline Depth and Issue WidthPipeline Depth and Issue Width• Intel Processors over Time
Microprocessor Year Clock Rate Pipeline Stages
Issue width
Cores Power
i486 1989 25 MHz 5 1 1 5WPentium 1993 66 MHz 5 2 1 10WPentium Pro 1997 200 MHz 10 3 1 29WP4 Willamette 2001 2000 MHz 22 3 1 75WP4 Prescott 2004 3600 MHz 31 3 1 103WCore 2 Conroe 2006 2930 MHz 14 4 2 75WCore 2 Conroe 2006 2930 MHz 14 4 2 75WCore 2 Yorkfield 2008 2930 MHz 16 4 4 95WCore i7 Gulftown 2010 3460 MHz 16 4 6 130W
Summer 2011 -- Lecture #237/28/2011 10

Pipeline Depth and Issue WidthPipeline Depth and Issue Width10000
1000
Clock
Power
100
Power
Pipeline Stages
10Issue width
11989 1992 1995 1998 2001 2004 2007 2010
Cores
Summer 2011 -- Lecture #23
1989 1992 1995 1998 2001 2004 2007 2010
7/28/2011 11

Static Multiple IssueStatic Multiple Issue
• Compiler groups instructions into issueCompiler groups instructions into issue packets– Group of instructions that can be issued on a– Group of instructions that can be issued on a
single cycle– Determined by pipeline resources requiredDetermined by pipeline resources required
• Think of an issue packet as a very long instruction (VLIW)instruction (VLIW)– Specifies multiple concurrent operations
Summer 2011 -- Lecture #237/28/2011 12

Scheduling Static Multiple IssueScheduling Static Multiple Issue
• Compiler must remove some/all hazardsCompiler must remove some/all hazards– Reorder instructions into issue packets
No dependencies with a packet– No dependencies with a packet– Possibly some dependencies between packets
• Varies between ISAs; compiler must know!• Varies between ISAs; compiler must know!
– Pad with nop if necessary
Summer 2011 -- Lecture #237/28/2011 13

MIPS with Static Dual IssueMIPS with Static Dual Issue• Dual-issue packets
/b h– One ALU/branch instruction– One load/store instruction
64 bit aligned– 64-bit aligned• ALU/branch, then load/store• Pad an unused instruction with nop
Address Instruction type Pipeline Stages
n ALU/branch IF ID EX MEM WB
n + 4 Load/store IF ID EX MEM WB
n + 8 ALU/branch IF ID EX MEM WB
n + 12 Load/store IF ID EX MEM WB
n + 16 ALU/branch IF ID EX MEM WB
Summer 2011 -- Lecture #23
n + 20 Load/store IF ID EX MEM WB
7/28/2011 14

Hazards in the Dual-Issue MIPSHazards in the Dual Issue MIPS
• More instructions executing in parallelMore instructions executing in parallel• EX data hazard
– Forwarding avoided stalls with single-issueForwarding avoided stalls with single issue– Now can’t use ALU result in load/store in same packet
• add $t0, $s0, $s1l d $ 2 0($t0)load $s2, 0($t0)
• Split into two packets, effectively a stall
• Load-use hazardLoad use hazard– Still one cycle use latency, but now two instructions
• More aggressive scheduling required
Summer 2011 -- Lecture #23
gg g q
7/28/2011 15

Scheduling ExampleScheduling Example• Schedule this for dual-issue MIPS
Loop: lw $t0, 0($s1) # $t0=array elementaddu $t0, $t0, $s2 # add scalar in $s2sw $t0, 0($s1) # store resultaddi $s1, $s1,–4 # decrement pointerbne $s1, $zero, Loop # branch $s1!=0
ALU/b h L d/ t lALU/branch Load/store cycleLoop: nop lw $t0, 0($s1) 1
addi $s1, $s1,–4 nop 2
dd $ 0 $ 0 $ 2 3addu $t0, $t0, $s2 nop 3
bne $s1, $zero, Loop sw $t0, 4($s1) 4
IPC 5/4 1 25 (c f peak IPC 2)Summer 2011 -- Lecture #23
IPC = 5/4 = 1.25 (c.f. peak IPC = 2)7/28/2011 16

Loop UnrollingLoop Unrolling
• Replicate loop body to expose moreReplicate loop body to expose more parallelism
• Use different registers per replication• Use different registers per replication– Called register renaming
A id l i d i d d i– Avoid loop-carried anti-dependencies• Store followed by a load of the same register• Aka “name dependence”• Aka name dependence
– Reuse of a register name
Summer 2011 -- Lecture #237/28/2011 17

Loop Unrolling ExampleLoop Unrolling ExampleALU/branch Load/store cycle
Loop: addi $s1, $s1,–16 lw $t0, 0($s1) 1
nop lw $t1, 12($s1) 2
addu $t0, $t0, $s2 lw $t2, 8($s1) 3
addu $t1, $t1, $s2 lw $t3, 4($s1) 4
addu $t2, $t2, $s2 sw $t0, 16($s1) 5
addu $t3, $t4, $s2 sw $t1, 12($s1) 6
nop sw $t2, 8($s1) 7
bne $s1, $zero, Loop sw $t3, 4($s1) 8
• IPC = 14/8 = 1.75– Closer to 2, but at cost of registers and code size
Summer 2011 -- Lecture #237/28/2011 18

AgendaAgenda
• Control HazardsControl Hazards• Higher Level ILP• Administrivia• Administrivia• Dynamic Scheduling
T h l B k• Technology Break• Example AMD Barcelona• Big Picture: Types of Parallelism• Summary
Summer 2011 -- Lecture #237/28/2011 19

AdministriviaAdministrivia
• Project 2 Part 2 due SundayProject 2 Part 2 due Sunday.– Slides at end of July 12 lecture contain useful info.
• Lab 12 cancelled!• Lab 12 cancelled!– Replaced with free study session where you can
catch up on labs / work on project 2catch up on labs / work on project 2.– The TAs will still be there.
ll b d l d ( / )• Project 3 will be posted late Sunday (7/31)– Two-stage pipelined CPU in Logisim
Summer 2011 -- Lecture #237/28/2011 20

AgendaAgenda
• Control HazardsControl Hazards• Administrivia• Higher Level ILP• Higher Level ILP• Dynamic Scheduling
T h l B k• Technology Break• Example AMD Barcelona• Big Picture: Types of Parallelism• Summary
Summer 2011 -- Lecture #237/28/2011 21

Dynamic Multiple IssueDynamic Multiple Issue
• “Superscalar” processorsSuperscalar processors• CPU decides whether to issue 0, 1, 2, …
instructions each cycleinstructions each cycle– Avoiding structural and data hazards
• Avoids need for compiler scheduling– Though it may still help– Code semantics ensured by the CPU
Summer 2011 -- Lecture #237/28/2011 22

Dynamic Pipeline SchedulingDynamic Pipeline Scheduling
• Allow the CPU to execute instructions out ofAllow the CPU to execute instructions out of order to avoid stalls– But commit result to registers in order– But commit result to registers in order
• Examplel $ 0 20($ 2)lw $t0, 20($s2)addu $t1, $t0, $t2subu $s4 $s4 $t3subu $s4, $s4, $t3slti $t5, $s4, 20
– Can start subu while addu is waiting for lw
Summer 2011 -- Lecture #23
Can start subu while addu is waiting for lw
7/28/2011 23

Why Do Dynamic Scheduling?Why Do Dynamic Scheduling?
• Why not just let the compiler schedule code?Why not just let the compiler schedule code?• Not all stalls are predicable
h i– e.g., cache misses
• Can’t always schedule around branches– Branch outcome is dynamically determined
• Different implementations of an ISA have different latencies and hazards
Summer 2011 -- Lecture #237/28/2011 24

SpeculationSpeculation
• “Guess” what to do with an instruction– Start operation as soon as possible– Check whether guess was right
f l h• If so, complete the operation• If not, roll-back and do the right thing
• Common to both static and dynamic multiple issuey p• Examples
– Speculate on branch outcome (Branch Prediction)• Roll back if path taken is different
– Speculate on load• Roll back if location is updated
Summer 2011 -- Lecture #23
p
7/28/2011 25

Pipeline Hazard:Matching socks in later loadMatching socks in later load
12 2 AM6 PM 7 8 9 10 11 1
Ta A bubble
Time303030 3030 30 30
sk B
COrd
CD
Eder
E
F
• A depends on D; stall since folder tied up; Summer 2011 -- Lecture #237/28/2011 26

Out-of-Order Laundry: Don’t WaitOut of Order Laundry: Don t Wait12 2 AM6 PM 7 8 9 10 11 1
Ta
Time
A303030 3030 30 30
bubble
sk B
COrd
CD
E
A d d i d
der
E
F• A depends on D; rest continue; need more resources to
allow out-of-orderSummer 2011 -- Lecture #237/28/2011 27

Out-of-Order Execution (1/3)Out of Order Execution (1/3)Basically, unroll loops in hardware1. Fetch instructions in program order (≤4/clock)
2. Predict branches as taken/untaken
3. To avoid hazards on registers, rename registersi f i l i ( 80 i )using a set of internal registers (~80 registers)
Summer 2011 -- Lecture #237/28/2011 28

Out-of-Order Execution (2/3)Out of Order Execution (2/3)Basically, unroll loops in hardware4. Collection of renamed instructions might
execute in a window (~60 instructions)
5. Execute instructions with ready operands in 1 of multiple functional units (ALUs, FPUs, Ld/St)
6. Buffer results of executed instructions until predicted branches are resolved in reorder buffer
Summer 2011 -- Lecture #237/28/2011 29

Out-of-Order Execution (3/3)Out of Order Execution (3/3)Basically, unroll loops in hardware7. If predicted branch correctly, commit results in
program order
8 If predicted branch incorrectly discard all8. If predicted branch incorrectly, discard all dependent results and start with correct PC
Summer 2011 -- Lecture #237/28/2011 30

Dynamically Scheduled CPUDynamically Scheduled CPUPreserves dependenciesBranch prediction,
Register renaming
Wait here until all operands
Register renaming
all operands available
Results also sent to any waiting
Execute…
reservation stations
Reorder buffer for register and memory writes Can supply operands
… and Hold
Summer 2011 -- Lecture #23
for issued instructions
7/28/2011 31

Out-Of-Order IntelOut Of Order Intel• All use O-O-O since 2001
Microprocessor Year Clock Rate Pipeline Stages
Issue width
Out-of-order/ Speculation
Cores Power
i486 1989 25MHz 5 1 No 1 5Wi486 1989 25MHz 5 1 No 1 5W
Pentium 1993 66MHz 5 2 No 1 10W
Pentium Pro 1997 200MHz 10 3 Yes 1 29W
P4 Willamette 2001 2000MHz 22 3 Yes 1 75WP4 Willamette 2001 2000MHz 22 3 Yes 1 75W
P4 Prescott 2004 3600MHz 31 3 Yes 1 103W
Core 2006 2930MHz 14 4 Yes 2 75W
Core 2 Yorkfield 2008 2930 MHz 16 4 Yes 4 95WCore 2 Yorkfield 2008 2930 MHz 16 4 Yes 4 95W
Core i7 Gulftown 2010 3460 MHz 16 4 Yes 6 130W
Summer 2011 -- Lecture #237/28/2011 32

AgendaAgenda
• Control HazardsControl Hazards• Administrivia• Higher Level ILP• Higher Level ILP• Dynamic Scheduling
T h l B k• Technology Break• Example AMD Barcelona• Big Picture: Types of Parallelism• Summary
Summer 2011 -- Lecture #237/28/2011 33

AgendaAgenda
• Control HazardsControl Hazards• Administrivia• Higher Level ILP• Higher Level ILP• Dynamic Scheduling
T h l B k• Technology Break• Example AMD Barcelona• Big Picture: Types of Parallelism• Summary
Summer 2011 -- Lecture #237/28/2011 34

AMD Opteron X4 Microarchitecture§4.11 Reaal Stuff: The72 physical
registers
16 architectural registers
x86 instructions
e AMD O
pt
registers
renaming
RISC operations
eronX4 (Baarcelona) P
Queues:- 106 RISC ops - 24 integer ops Pipeline
- 36 FP/SSE ops- 44 ld/st
Summer 2011 -- Lecture #237/28/2011 35

AMD Opteron X4 Pipeline FlowAMD Opteron X4 Pipeline Flow• For integer operations
12 stages (Floating Point is 17 stages) Up to 106 RISC-ops in progress
• Intel Nehalem is 16 stages for integer operations, d il l d b lik l i il bdetails not revealed, but likely similar to above. Intel calls RISC operations “Micro operations” or “μops”
Summer 2011 -- Lecture #237/28/2011 36

Does Multiple Issue Work?Does Multiple Issue Work?
Y b h ’d lik
The BIG Picture
• Yes, but not as much as we’d like• Programs have real dependencies that limit ILP
S d d i h d t li i t• Some dependencies are hard to eliminate– e.g., pointer aliasing
• Some parallelism is hard to exposeSome parallelism is hard to expose– Limited window size during instruction issue
• Memory delays and limited bandwidthy y– Hard to keep pipelines full
• Speculation can help if done well
Summer 2011 -- Lecture #237/28/2011 37

AgendaAgenda
• Higher Level ILPHigher Level ILP• Administrivia
i S h d li• Dynamic Scheduling• Example AMD Barcelona• Technology Break• Big Picture: Types of ParallelismBig Picture: Types of Parallelism• Summary
Summer 2011 -- Lecture #237/28/2011 38

New-School Machine Structures(It’s a bit more complicated!) Lab 14(It s a bit more complicated!)
• Parallel RequestsAssigned to computer Smart
PhWarehouse
S l
Software HardwareLab 14
Assigned to computere.g., Search “Katz”
• Parallel ThreadsAssigned to core
PhoneScale Computer
HarnessParallelism &A hi Hi hAssigned to core
e.g., Lookup, Ads
• Parallel Instructions>1 instruction @ one time
Achieve HighPerformance
Core Core…
( h )
ComputerProject 1
>1 instruction @ one timee.g., 5 pipelined instructions
• Parallel Data1 d t it @ ti
Memory (Cache)
Input/Output Core
Instruction Unit(s) Functional
Project 2
>1 data item @ one timee.g., Add of 4 pairs of words
• Hardware descriptionsll f
Main Memory
Instruction Unit(s)Unit(s)
A3+B3A2+B2A1+B1A0+B0
All gates functioning in parallel at same time
Summer 2011 -- Lecture #23
Logic Gates
y
Project 37/28/2011 39

Big Picture on ParallelismBig Picture on Parallelism
Two types of parallelism in applicationsTwo types of parallelism in applications1. Data-Level Parallelism (DLP): arises because
there are many data items that can bethere are many data items that can be operated on at the same time
2 T k L l P ll li i b k f2. Task-Level Parallelism: arises because tasks of work are created that can operate largely in
ll lparallel
Summer 2011 -- Lecture #237/28/2011 40

Big Picture on ParallelismBig Picture on ParallelismHardware can exploit app DLP and Task LP in four ways:1. Instruction-Level Parallelism: Hardware exploits
application DLP using ideas like pipelining and speculative executionspeculative execution
2. SIMD architectures: exploit app DLP by applying a single instruction to a collection of data in parallel
3 Th d L l P ll li l it ith DLP3. Thread-Level Parallelism: exploits either app DLP or TLP in a tightly-coupled hardware model that allows for interaction among parallel threads
4. Request-Level Parallelism: exploits parallelism among largely decoupled tasks and is specified by the programmer of the operating systemp g p g y
Summer 2011 -- Lecture #237/28/2011 41

I LP SIMD Th d LP R LP l fPeer Instruction
Instr LP, SIMD, Thread LP, Request LP are examples of
• Parallelism above the Instruction Set Architecture
• Parallelism explicitly at the level of the ISA
• Parallelism below the level of the ISA
Inst. LP SIMD Thr. LP Req. LPRed = = = ∧
∨ = = ∧
Green = = ∧ ∧
∨ = ∧ ∧
Purple = ∧ ∧ ∧Purple ∧ ∧ ∧
Blue ∧ ∧ ∧ ∧Summer 2011 -- Lecture #237/28/2011 42

I LP SIMD Th d LP R LP l fPeer Answer
Instr LP, SIMD, Thread LP, Request LP are examples of
• Parallelism above the Instruction Set Architecture
• Parallelism explicitly at the level of the ISA
• Parallelism below the level of the ISA
Inst. LP SIMD Thr. LP Req. LPRed = = = ∧
∨ = = ∧
Green = = ∧ ∧
∨ = ∧ ∧
Purple = ∧ ∧ ∧Purple ∧ ∧ ∧
Blue ∧ ∧ ∧ ∧Summer 2011 -- Lecture #237/28/2011 43

St t if th f ll i t h i i t d i il ithPeer Question
State if the following techniques are associated primarily with a software- or hardware-based approach to exploiting ILP (in some cases, the answer may be both): Superscalar, Out-of-Order execution Speculation Register RenamingOrder execution, Speculation, Register Renaming
Super-scalar
Out of Order
Specu-lation
Register Renamingscalar Order lation Renaming
Red HW HW HW HWSW SW SW SWSW SW SW SW
Green Both Both Both BothHW HW Both Both
Purple HW HW HW BothBlue HW HW HW SW
Summer 2011 -- Lecture #237/28/2011 44

St t if th f ll i t h i i t d i il ithPeer Answer
State if the following techniques are associated primarily with a software- or hardware-based approach to exploiting ILP (in some cases, the answer may be both): Superscalar, Out-of-Order execution Speculation Register RenamingOrder execution, Speculation, Register Renaming
Super-scalar
Out of Order
Specu-lation
Register Renamingscalar Order lation Renaming
Red HW HW HW HWO SW SW SW SWOrange SW SW SW SWGreen Both Both Both Both
HW HW Both BothPink HW HW HW BothBlue HW HW HW SW
Summer 2011 -- Lecture #237/28/2011 45

“And in Conclusion, …”And in Conclusion, …
• Big Ideas of Instruction Level ParallelismBig Ideas of Instruction Level Parallelism• Pipelining, Hazards, and Stalls• Forwarding Speculation to overcome Hazards• Forwarding, Speculation to overcome Hazards• Multiple issue to increase performance
IPC instead of CPI– IPC instead of CPI• Dynamic Execution: Superscalar in-order issue,
branch prediction register renaming out ofbranch prediction, register renaming, out-of-order execution, in-order commit – “unroll loops in HW” hide cache missesunroll loops in HW , hide cache misses
Summer 2011 -- Lecture #237/28/2011 46

But waitBut wait… h ’ ???there’s more???
If we have timeIf we have time…

Review: C Memory Management
• C has three pools of data memory (+ code memory) stack
~ FFFF FFFFhex
( code memory)– Static storage: global variable storage,
basically permanent, entire program run– The Stack: local variable storage,
t t ddparameters, return address– The Heap (dynamic storage): malloc() grabs space from here, free() returns it
h• Common (Dynamic) Memory Problems– Using uninitialized values– Accessing memory beyond your allocated static data
heap
region– Improper use of free/realloc by messing
with the pointer handle returned by malloc– Memory leaks: mismatched malloc/free
code~ 0– Memory leaks: mismatched malloc/free
pairs
7/28/2011 48Summer 2011 -- Lecture #23
0hexOS prevents accesses
between stack and heap (via virtual memory)

Simplest ModelSimplest Model
• Only one program running on the computerOnly one program running on the computer– Addresses in the program are exactly the physical
memory addressesmemory addresses
• Extensions to the simple model:What if less physical memory than full address– What if less physical memory than full address space?What if we want to run multiple programs at the– What if we want to run multiple programs at the same time?
7/28/2011 Summer 2011 -- Lecture #23 49

Problem #1: Physical Memory Less h h ll ddThan the Full Address Space
• One architecture, ,many implementations, with possibly different
stack~ FFFF FFFFhex
with possibly different amounts of memory
• Memory used to very heapMemory used to very expensive and physically bulky static data
heap
• Where does the stack grow from then?
code~ 0hex
“Logical” Real
7/28/2011 Summer 2011 -- Lecture #23 50
“Virtual”
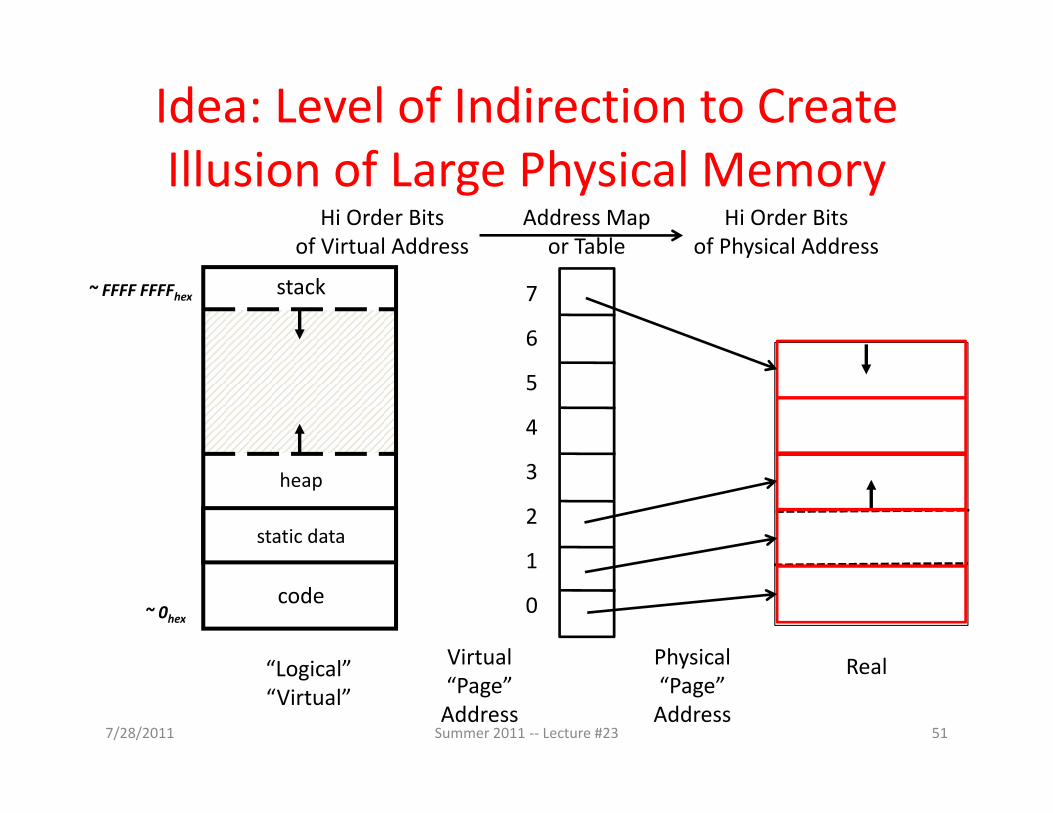
Idea: Level of Indirection to Create ll f h lIllusion of Large Physical Memory
Address Mapor Table
Hi Order Bitsof Virtual Address
Hi Order Bitsof Physical Address
stack~ FFFF FFFFhex 7
6
or Tableof Virtual Address of Physical Address
5
4
static data
heap 3
2
1code
~ 0hex
“L i l” RealVirtual Physical
1
0
7/28/2011 Summer 2011 -- Lecture #23 51
“Logical”“Virtual”
RealVirtual“Page”
Address
Physical“Page”
Address

Problem #2: Multiple Programs h h h ’ ddSharing the Machine’s Address Space
• How can we runHow can we run multiple programs without
stack~ FFFF FFFFhex stack~ FFFF FFFFhex
accidentally stepping on same
dd ? heap heapaddresses?• How can we
protect programsstatic data
heap
static data
heap
protect programs from clobbering each other?
code~ 0hex
Application 1
code~ 0hex
Application 2each other?
7/28/2011 Summer 2011 -- Lecture #23 52

Idea: Level of Indirection to Create ll f ddIllusion of Separate Address Spaces
stack~ FFFF FFFFhex
heap
7
6
7
6
code
static data
heap
~ 0hex
5
4
5
4
3
2
1
stack~ FFFF FFFFhex
3
2
1
Real
1
0
static data
heap
1
0
O bl i li i OR
7/28/2011 Summer 2011 -- Lecture #23 53
Realcode
~ 0hex
One table per running application ORswap table contents when switching

Extension to the Simple ModelExtension to the Simple Model
• Multiple programs sharing the same address spaceu t p e p og a s s a g t e sa e add ess space– E.g., Operating system uses low end of address range
shared with application– Multiple programs in shared (virtual) address space
• Static management: fixed partitioning/allocation of space• Dynamic management: programs come and go take differentDynamic management: programs come and go, take different
amount of time to execute, use different amounts of memory
• How can we protect programs from clobbering each h ?other?
• How can we allocate memory to applications on demand?demand?
7/28/2011 Summer 2011 -- Lecture #23 54

Static Division of Shared ddAddress Space
• E.g., how to manage thestack~ FFFF FFFFhex E.g., how to manage the carving up of the address space among OS and
heap
Application
(4 GB- 64 MB)
applications?• Where does the OS end code
static data
heap
~ 1000 0000hex
64 MB)
and the application begin?• Dynamic management,
h ld b
stack~ 0FFF FFFFhex
with protection, would be better!
static data
heapOperatingSystem
228
bytes(64 MB)
7/28/2011 Summer 2011 -- Lecture #23 55
code~ 0hex

First Idea: Base + Bounds Registersf d dfor Location Independence
Location-independent programsProgramming and storage management ease:
d f bprog1 m
ory
Max addr
need for a base register
Protection ical
Mem
Independent programs should not affect each other inadvertently: need for a prog2
Phys
i
bound register
Historically base + bounds registers were
p g
0 addr
7/28/2011 Summer 2011 -- Lecture #23 56
Historically, base + bounds registers were a very early idea in computer architecture
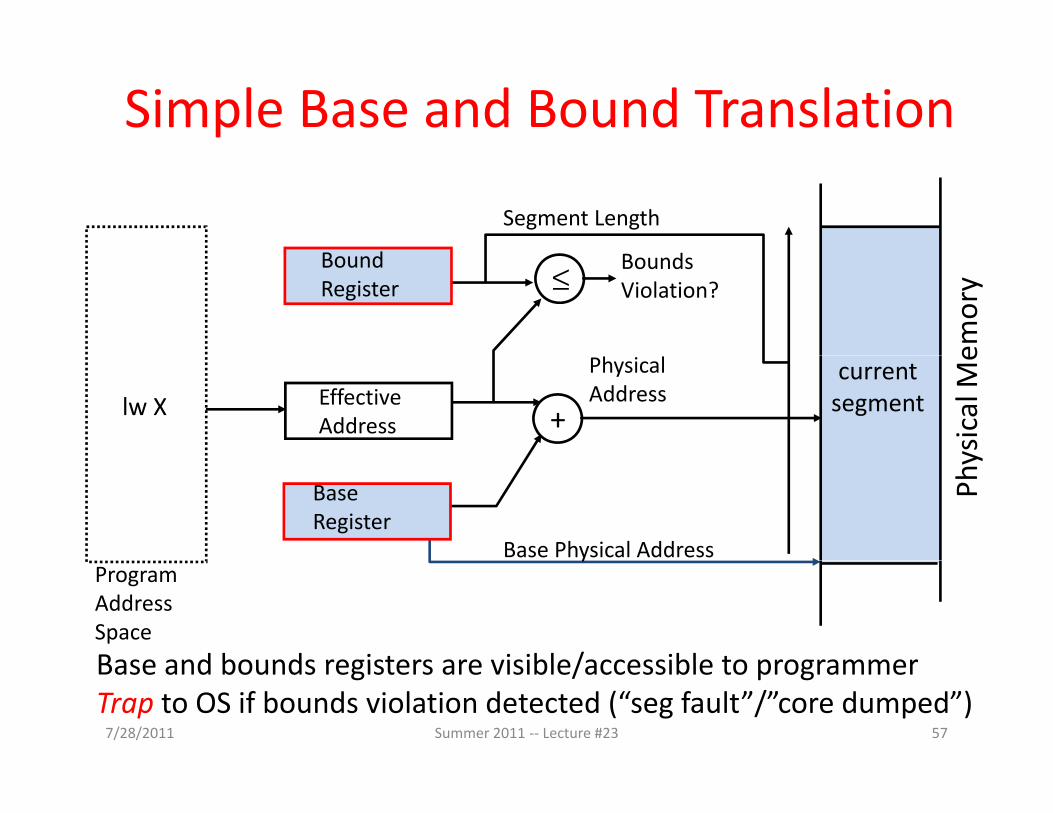
Simple Base and Bound Translation
B d d
Segment Length
BoundRegister ≤
BoundsViolation?
emor
y
lw X
ysic
al M
e
currentsegment+
PhysicalAddressEffective
Address
Phy
BaseRegister
Base Physical AddressProgramAddressSpaceBase and bounds registers are visible/accessible to programmer
y
57
Base and bounds registers are visible/accessible to programmerTrap to OS if bounds violation detected (“seg fault”/”core dumped”)
7/28/2011 Summer 2011 -- Lecture #23

Programs Sharing Memory
OSSpace
OSSpace
pgms 4 & 5 arrive
pgms 2 & 5leave OS
S
free
Space
16K24K
pgm 1pgm 2
Space
16K24K
pgm 1pgm 2
Space
16K24K
pgm 1
24K
32Kpgm 3
16K
32Kpgm 3
pgm 48K
16K
32K
pgm 48K
pgm 3
24K 24Kpgm 5
32K
24K
pg
Why do we want to run multiple programs? Run others while waiting for I/O
Wh t t f i h th ’ d t ?
58
What prevents programs from accessing each other’s data?
7/28/2011 Summer 2011 -- Lecture #23Student Roulette?

Restriction on Base + Bounds RegsRestriction on Base + Bounds Regs
Want only the Operating System to be able to a t o y t e Ope at g Syste to be ab e tochange Base and Bound Registers
Processors need different execution modes1. User mode: can use Base and Bound Registers,
but cannot change them2. Supervisor mode: can use and change Base and
Bound Registers– Also need Mode Bit (0=User, 1=Supervisor) to
determine processor mode– Also need way for program in User Mode to invokeAlso need way for program in User Mode to invoke
operating system in Supervisor Mode, and vice versa7/28/2011 Summer 2011 -- Lecture #23 59

Programs Sharing Memory
OS OSpgms 4 & 5 arrive
pgms 2 & 5leave OS
free
Space
16K24K
pgm 1pgm 2
Space
16K24K
pgm 1pgm 2
OSSpace
16K24K
pgm 124K
24K
32K
pgm 2
pgm 3
24K16K
32K
pgm 2
pgm 3
pgm 48K
24K16K
32K
pgm 48K
pgm 332K
24K
pgm 3 32K
24K
pgm 3
pgm 5
32K
24K
pgm 3
As programs come and go, the storage is “fragmented”. Therefore, at some stage programs have to be moved
60
g p garound to compact the storage. Easy way to do this?
7/28/2011 Summer 2011 -- Lecture #23Student Roulette?


















