
CS-495/595 Hadoop (part 2) Lecture #5 Dr. Chuck Cartledge ...ccartled/Teaching/2015... · When will...
32
1/32 Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References CS-495/595 Hadoop (part 2) Lecture #5 Dr. Chuck Cartledge Dr. Chuck Cartledge Dr. Chuck Cartledge Dr. Chuck Cartledge Dr. Chuck Cartledge Dr. Chuck Cartledge Dr. Chuck Cartledge Dr. Chuck Cartledge Dr. Chuck Cartledge Dr. Chuck Cartledge Dr. Chuck Cartledge Dr. Chuck Cartledge Dr. Chuck Cartledge Dr. Chuck Cartledge Dr. Chuck Cartledge Dr. Chuck Cartledge Dr. Chuck Cartledge Dr. Chuck Cartledge Dr. Chuck Cartledge Dr. Chuck Cartledge Dr. Chuck Cartledge 11 Feb. 2015 11 Feb. 2015 11 Feb. 2015 11 Feb. 2015 11 Feb. 2015 11 Feb. 2015 11 Feb. 2015 11 Feb. 2015 11 Feb. 2015 11 Feb. 2015 11 Feb. 2015 11 Feb. 2015 11 Feb. 2015 11 Feb. 2015 11 Feb. 2015 11 Feb. 2015 11 Feb. 2015 11 Feb. 2015 11 Feb. 2015 11 Feb. 2015 11 Feb. 2015
Transcript of CS-495/595 Hadoop (part 2) Lecture #5 Dr. Chuck Cartledge ...ccartled/Teaching/2015... · When will...

1/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
CS-495/595Hadoop (part 2)
Lecture #5
Dr. Chuck CartledgeDr. Chuck CartledgeDr. Chuck CartledgeDr. Chuck CartledgeDr. Chuck CartledgeDr. Chuck CartledgeDr. Chuck CartledgeDr. Chuck CartledgeDr. Chuck CartledgeDr. Chuck CartledgeDr. Chuck CartledgeDr. Chuck CartledgeDr. Chuck CartledgeDr. Chuck CartledgeDr. Chuck CartledgeDr. Chuck CartledgeDr. Chuck CartledgeDr. Chuck CartledgeDr. Chuck CartledgeDr. Chuck CartledgeDr. Chuck Cartledge
11 Feb. 201511 Feb. 201511 Feb. 201511 Feb. 201511 Feb. 201511 Feb. 201511 Feb. 201511 Feb. 201511 Feb. 201511 Feb. 201511 Feb. 201511 Feb. 201511 Feb. 201511 Feb. 201511 Feb. 201511 Feb. 201511 Feb. 201511 Feb. 201511 Feb. 201511 Feb. 201511 Feb. 2015

2/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
Table of contents I
1 Miscellanea
2 The Book
3 Chapter 3
4 Chapter 4
5 Chapter 6
6 Chapter 8
7 Break
8 Assignment #2
9 Exam
10 Conclusion
11 References

3/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
Corrections and additions since last lecture.
Updated assignment #2(check the assignmentwrite-up)
“Google is serious abouttaking on telecom”[3]
White House working onSafeguarding AmericanConsumers and Families[5, 11]
Samsung Smart TV islistening to you [10, 9]

4/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
Hadoop, The Definitive Guide
Version 3 is specified in thesyllabus [12]
Version 4 came out inNovember 2015
We’ll use Version 3 as muchas possible

5/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
The HDFS
Things that HDFS is good at:
LARGE files (> terabyte)
Streaming access (WORM)
Commodity hardware(failures are common)
Image from [7].
HDFS is a robust, reliable distributed file system.

6/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
The HDFS
Things that HDFS is not good at:
Low-latency data access(HDFS is based on an RPCmodel)
Lots of small files (overheadper file is constant)
Multiple writers, writes onlyat the end of a file
Image from [7].
File access can be slow because of RPC overhead.

7/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
The HDFS
Namenode and datanodes
Namenode containsmeta-data about files
Datanodes contain blocks
File blocks are replicatedacross datanodes
Loss of a datanode can bedetected and a replicatecreated
Loss of a namenode iscatastrophic Image from [4].
All communication is via RPC.

8/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
The HDFS
A better view

9/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
The HDFS
What happens if you lose your namenode?
Namenode is a single point of failure.
Have secondary namenodeavailable
Namenode keeps edit log ofdatanode actions
Namenode monitors health ofdatanodes
New primary namenode has to readedit log, get state of all datanodes
Large cluster can take up to 30 minutesto become fully functional.
Namenode should be run on a highly reliable hardware suite.
10/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
The HDFS
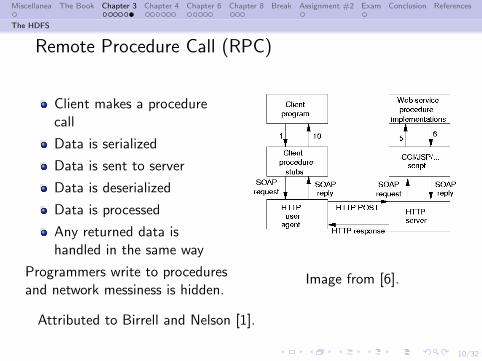
Remote Procedure Call (RPC)
Client makes a procedurecall
Data is serialized
Data is sent to server
Data is deserialized
Data is processed
Any returned data ishandled in the same way
Programmers write to proceduresand network messiness is hidden.
Image from [6].
Attributed to Birrell and Nelson [1].

11/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
Hadoop I/O
Hadoop supports file I/O
HDFS’s primary concerns
Data integrity – ensuringthat data is complete andintact
1 Checks CRCs2 Bit rot3 Creates new replications
when and where necessary
Data compression1 Minimizing data size2 Network activity3 Adds processing time
Hadoop ensure data integrity, minimizes data size, is not fast.

12/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
Hadoop I/O
Not all data compression algorithms are the same
All compression routines have the same basic goal.
File extensions areassumed/expected
Not all algorithms are CLIcompatible
Not all compressed files aresplittable
Splittable is important. If afile can not be split, therecan only be one reader.
Low level routines are available, some work better than others.

13/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
Hadoop I/O
Comparing compression algorithms
All algorithms trade off space and time
Compressing 145,293,291 bytes.Algo. Bytes Comp. Dec.bzip2 11,676,524 33 9
gzip 59,029,162 16 1lzop 91,913,688 1 0
gzip is a good, middle of the road performer.
14/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
Hadoop I/O
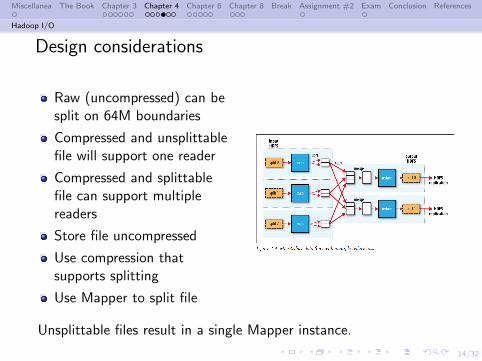
Design considerations
Raw (uncompressed) can besplit on 64M boundaries
Compressed and unsplittablefile will support one reader
Compressed and splittablefile can support multiplereaders
Store file uncompressed
Use compression thatsupports splitting
Use Mapper to split file
Unsplittable files result in a single Mapper instance.

15/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
Hadoop I/O
Serialization
The process of turning structured objects into a byte stream.Used extensively in Hadoopinter-process communications(RPC).
Compact
Fast
Extensible
Interoperable
Hadoop serialization is not Java serialization.

16/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
Hadoop I/O
Summary
The HDFS is:
Optimized for LARGE files
Distributed, robust, andresilient
Supports multiple readers
Limited support for writers
Has native support for rawand compressed files
Most file operations are RPCbased.
The HDFS should be considered a WORM system.

17/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
How MapReduce works
Classic organization
Client – our CLINodes may be on differentmachinesCommunication between machinesis via HFDSHeart beat messages
1 Tasktracker – every 5 seconds2 No heartbeat after 10 minutes –
node is down and won’t use it3 Child process – every few seconds4 Jobtracker – every second5 Progress – every second (just
indicates nothing is “stuck”)
Remember: Hadoop is in Java, Mapperand Reducers may not be
Lots of timers and periodics to monitor activity and detect whensomething is “hung” or dead.

18/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
How MapReduce works
Progress
What is it and how is it reported? Not possible to show absolute progressbecause there may not be anyway to know ahead of time how much workneeds to be done.
Have to report something:
Reading by a Mapper orReducer
Writing by a Mapper orReducer
Setting the status description
Incrementing a counter(expensive operation)
Using the progress() function
If progress is not being made, Hadoop will terminate the processes.

19/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
How MapReduce works
Classic Hadoop vs. YARN Hadoop
Hadoop version 1 vs. Yet Another Resource Negotiator (YARN)Hadoop version 2
Architectural differences:
Job tracker and Task trackerreplaced by Resource Manager,Application Master, and Nodemanager
Mappers and Reducers written thesame way
Interfaces allow things to beswapped out with minimal impact.
Image from [8]. .
Hadoop administrators are intimately concerned with thedifferences between classic and YARN installations.

20/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
How MapReduce works
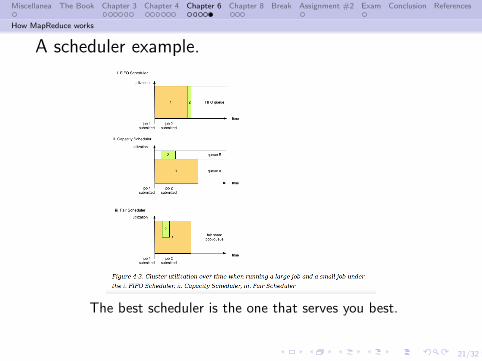
Schedulers
When will MY job be run?
Different types of schedulers:
FIFO – default in Hadoopver. 1 – first come firstserved
Fair – also available – jobsplaced in user pool, one jobper pool is scheduled
Capacity – default inHadoop ver. 2 – similar toFair, but adds priorities andrelationships between pools
Image from [13].
Different schedulers do things differently.
21/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
How MapReduce works
A scheduler example.
The best scheduler is the one that serves you best.

22/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
MapReduce Features
Counters
Hadoop has its own counters, and supports global user definedcounters.
Applications can access andincrement counters
Counters are global, acrossall Mappers and Reducers,so incrementing them canbe expensive
Details, counters are definedby Java enum
Hadoop supplies counters, you can create counters, you can usecounters.

23/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
MapReduce Features
Sorting
Sorting is based on the “Key”Keys can be:
Simple – RawComparator()will work
Compound – comparator()and partitioner() need towork on the correct part ofthe “key” Image from [2].
Sorting can be very complex, depending on your application.

24/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
MapReduce Features
Joins
These are exactly the same as traditional SQL database joins.
Depending on your application, joinscan happen:
Mapper – inputs have to bestrictly partitioned
Reducer – inputs have to be“tagged” to be processedcorrectly
Image from [2].
“MapReduce can perform joins between large datasets, but writing the code todo joins from scratch is fairly involved. Rather than writing MapReduceprograms, you might consider using a higher-level framework such as Pig, Hive,or Cascading, in which join operations are a core part of the implementation.”[12]

25/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
Break time.
Take about 10 minutes.

26/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
An inverted word list.
Looking at where words are used.
A simply stated problem: whereare certain words used?
Undergrad students – whichlines have the word “loue”
Grad student – which linesof have the word “loue”,which have the word“course”, and which haveboth
Interested in the line numbersand the line itself.An example: 1408: And wonnethy loue, doing thee iniuries:

27/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
Mechanics of the exam
Closed book
No “cheat” sheets
Anything from the lectures(and supporting material) isfair game
Anything that was discussedin class is fair game
Anything that should havebeen experienced, orencountered in theassignments is fair game
Each question will have twoparts
1 An undergrad part2 A graduate part
Undergrads can attempt graduate part without penality.

28/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
What have we covered?
Spent time on the HDFS,identifying its strengths andweaknessesDiscussed importance of HDFSname and data nodesWent over RPCs and its strengthsand weaknessesTalked about Hadoop file I/O andcompressionTalked about Hadoop ver. 1 andver. 2Talked about assignment #2Talked about the examChapter 11 will NOT be on theexam
Next lecture: Hadoop book, Chapter 11 and exam

29/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
References I
[1] Andrew D Birrell and Bruce Jay Nelson, Implementing remoteprocedure calls, ACM Transactions on Computer Systems(TOCS) 2 (1984), no. 1, 39–59.
[2] Iv’an de Prado Alonso, Mapreduce & hadoop api revised,http://www.datasalt.com/2012/02/mapreduce-hadoop-
problems/, 2012.
[3] Brian Fung, Google is serious about taking on telecom,http://www.washingtonpost.com/blogs/the-switch/
wp/2015/02/06/google-is-serious-about-taking-on-
telecom-heres-why-itll-win/.
[4] Pramod Kumar Gampa, Hdfs architecture,http://pramodgampa.blogspot.com/2013/08/hdfs-in-
detail.html, 2013.

30/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
References II
[5] Paul Hastings and Mathew Gibson, In visit to ftc, presidentoutlines broad privacy agenda, offers scant details,http://www.lexology.com/library/detail.aspx?g=
73df90aa-bcfa-4b49-9523-73c372f74695.
[6] Jan Newmarch, Web services, http://jan.newmarch.name/internetdevices/webservices/tutorial.html.
[7] Sreenivas Pasam, Apache hadoop, https://pasamtimes.wordpress.com/category/cloud-computing/, 2011.
[8] Tavish Srivastava, Hadoop beyond traditional mapreducesimplified, http://www.analyticsvidhya.com/blog/2014/11/hadoop-mapreduce/, 2014.

31/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
References III
[9] BBC staff, Not in front of the telly: Warning over ’listening’tv, http://www.bbc.com/news/technology-31296188,2015.
[10] Samsung staff, Samsung global privacy policy - smarttvsupplement,https://www.samsung.com/uk/info/privacy-SmartTV.
html?CID=AFL-hq-mul-0813-11000170, 2015.
[11] White House staff, Big data: Seizing opportunities, preservingvalues interim progress report, Tech. report, White House,2015.
[12] Tom White, Hadoop: The definitive guide, 3rd edition,O’Reilly Media, Inc., 2012.

32/32
Miscellanea The Book Chapter 3 Chapter 4 Chapter 6 Chapter 8 Break Assignment #2 Exam Conclusion References
References IV
[13] , Hadoop: The definitive guide, 4th edition, O’ReillyMedia, Inc., 2015.



![Big Data: Data Wrangling Boot Camp Big Data VsBig Data: Data Wrangling Boot Camp Big Data Vs Chuck Cartledge, PhDChuck Cartledge, PhDChuck Cartledge, ... small (9%) [19]. Most Big](https://static.fdocuments.net/doc/165x107/5ecc091b087ff73ee102b195/big-data-data-wrangling-boot-camp-big-data-vs-big-data-data-wrangling-boot-camp.jpg)













