
Copyright © 2006, Brigham S. Anderson Active Learning as Active Inference Brigham S. Anderson...
108
Copyright © 2006, Brigham S. Anderson Active Learning as Active Inference Brigham S. Anderson www.cs.cmu.edu/~brigham [email protected] School of Computer Science Carnegie Mellon University
-
date post
22-Dec-2015 -
Category
Documents
-
view
228 -
download
2
Transcript of Copyright © 2006, Brigham S. Anderson Active Learning as Active Inference Brigham S. Anderson...

Copyright © 2006, Brigham S. Anderson
Active Learningas
Active Inference
Brigham S. Andersonwww.cs.cmu.edu/~brigham
School of Computer Science
Carnegie Mellon University

2
OUTLINE
• New Active Inference Algorithm
• Active Learning• Background• Application of new algorithm
• Example application to Hidden Markov Models
• Active sequence selection for Hidden Markov Model learning
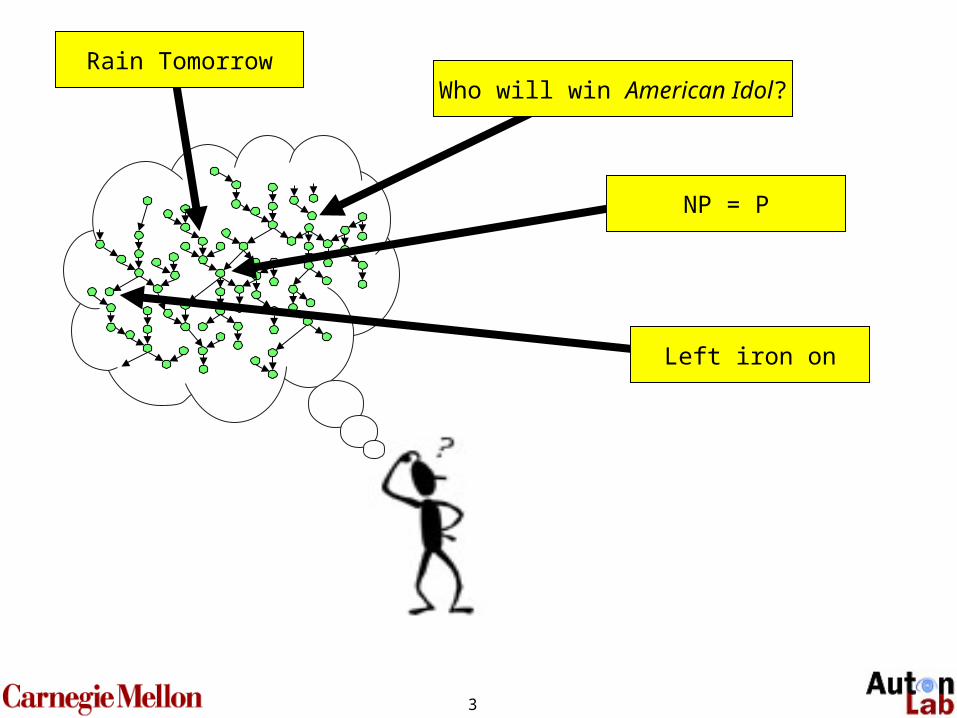
3
Rain TomorrowWho will win American Idol?
NP = P
Left iron on

4
Oracle
I will answer one question.
Choose a node.
?Wow! uh…
Rain tomorrow?NP = P?
Is the iron on?Do I have cancer?NIPS acceptance?
Today’s Lotto numbers?etc…

5
Given: 1. Set of target nodes: X2. Set of query nodes: Y3. Probabilistic model: P(X,Y)4. Uncertainty function: uncertainty(X)
Problem:Choose a node in Y to observe in order to minimize Uncertainty(P(X))
Active Inference
Why is this difficult?
…for every Y, we must evaluate uncertainty({Xi} |Y)
Why is this useful?
Diagnosis,Active Learning,
Optimization,…

6
How do we quantify “uncertainty” of a node?
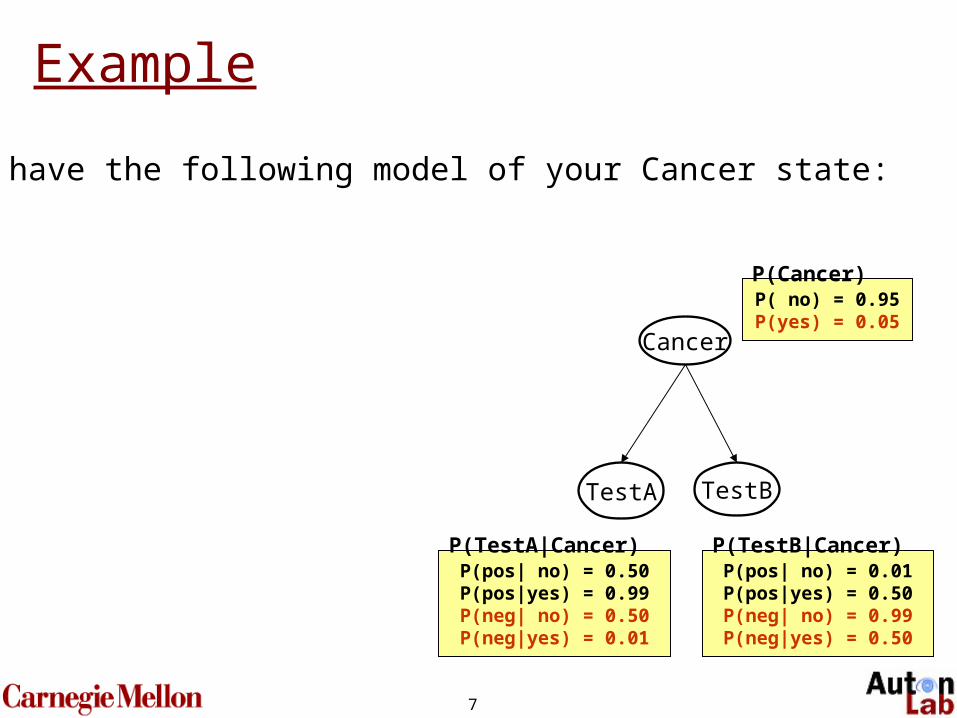
7
Example
Cancer
TestA TestB
P( no) = 0.95P(yes) = 0.05
P(Cancer)
P(pos| no) = 0.01P(pos|yes) = 0.50P(neg| no) = 0.99P(neg|yes) = 0.50
P(TestB|Cancer)P(pos| no) = 0.50P(pos|yes) = 0.99P(neg| no) = 0.50P(neg|yes) = 0.01
P(TestA|Cancer)
You have the following model of your Cancer state:

8
Example• Your uncertainty about P(Cancer) is “bad”
• How can we quantify the badness?
Cancer
TestA TestB
P( no) = 0.95P(yes) = 0.05
P(Cancer)
P(pos| no) = 0.01P(pos|yes) = 0.50P(neg| no) = 0.99P(neg|yes) = 0.50
P(TestB|Cancer)P(pos| no) = 0.50P(pos|yes) = 0.99P(neg| no) = 0.50P(neg|yes) = 0.01
P(TestA|Cancer)
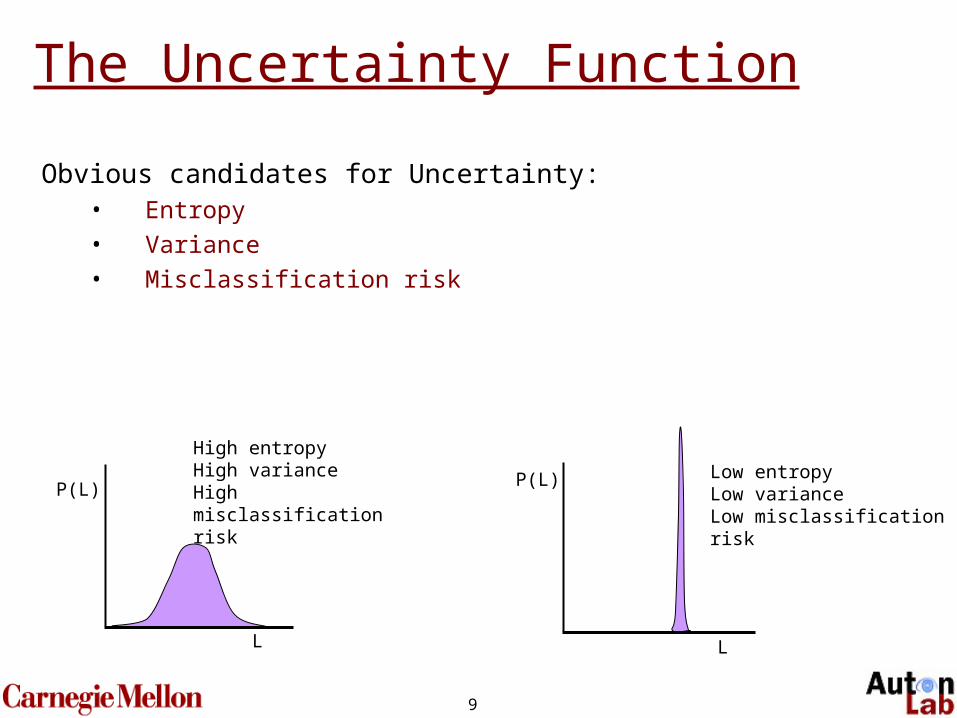
9
Obvious candidates for Uncertainty:• Entropy
• Variance
• Misclassification risk
P(L)
L
P(L)
L
Low entropyLow varianceLow misclassification risk
High entropyHigh varianceHigh misclassification risk
The Uncertainty Function

10
Notation• Given that you have not had any tests yet, what is your
P(Cancer)?
•
05.0
95.0)( CancerCancerP
Cancer
TestA TestB
P( no) = 0.95P(yes) = 0.05
P(Cancer)
P(pos| no) = 0.01P(pos|yes) = 0.50P(neg| no) = 0.99P(neg|yes) = 0.50
P(TestB|Cancer)P(pos| no) = 0.50P(pos|yes) = 0.99P(neg| no) = 0.50P(neg|yes) = 0.01
P(TestA|Cancer)
k
X
p
p
p
XP2
1
)(
Notation
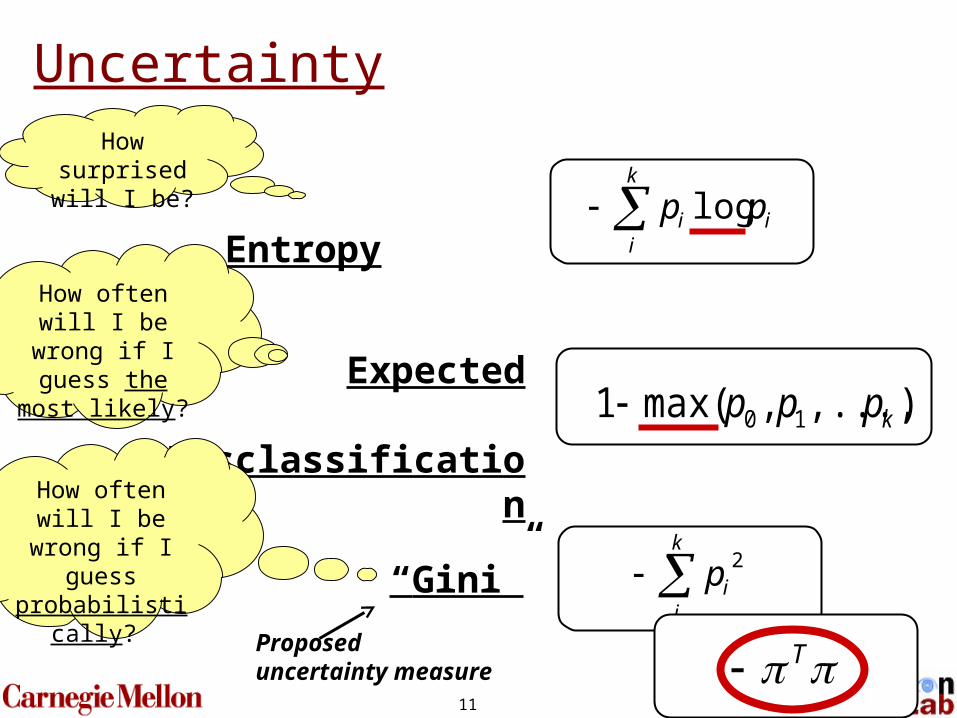
11
k
iii pp log Entropy
How surprised will I be?
Uncertainty
),...,,max(1 10 kppp
How often will I be wrong if I
guess the most likely? Expected
Misclassification
How often will I be wrong if I
guess probabilistically? “Gini”
k
iip2
TProposeduncertainty measure
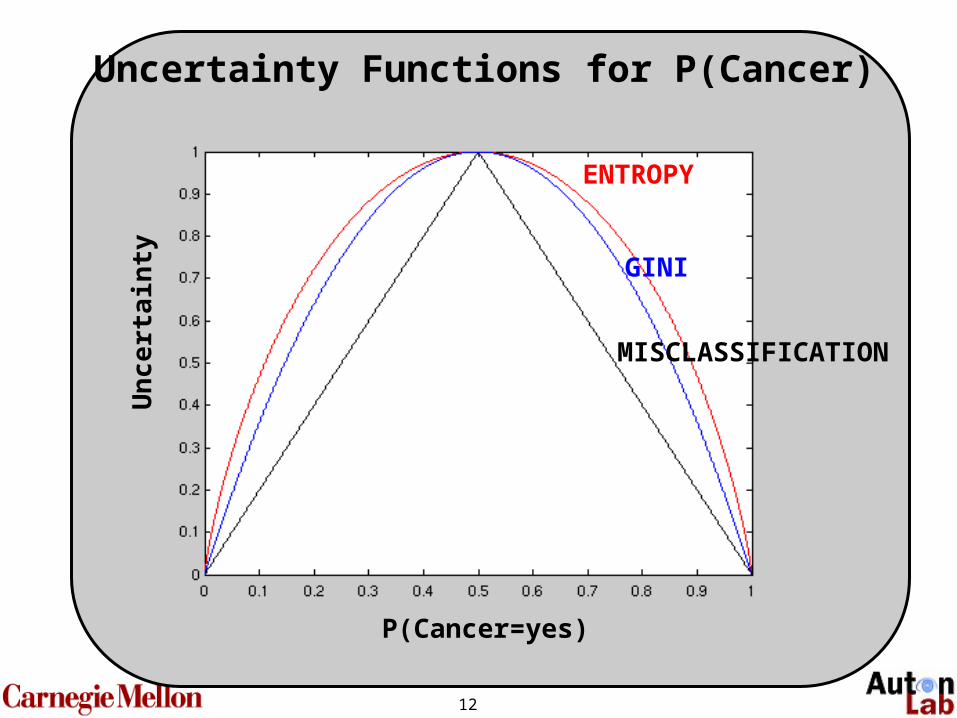
12
GINI
MISCLASSIFICATION
ENTROPY
P(Cancer=yes)
Uncertainty Functions for P(Cancer)
Un
cer
tain
ty
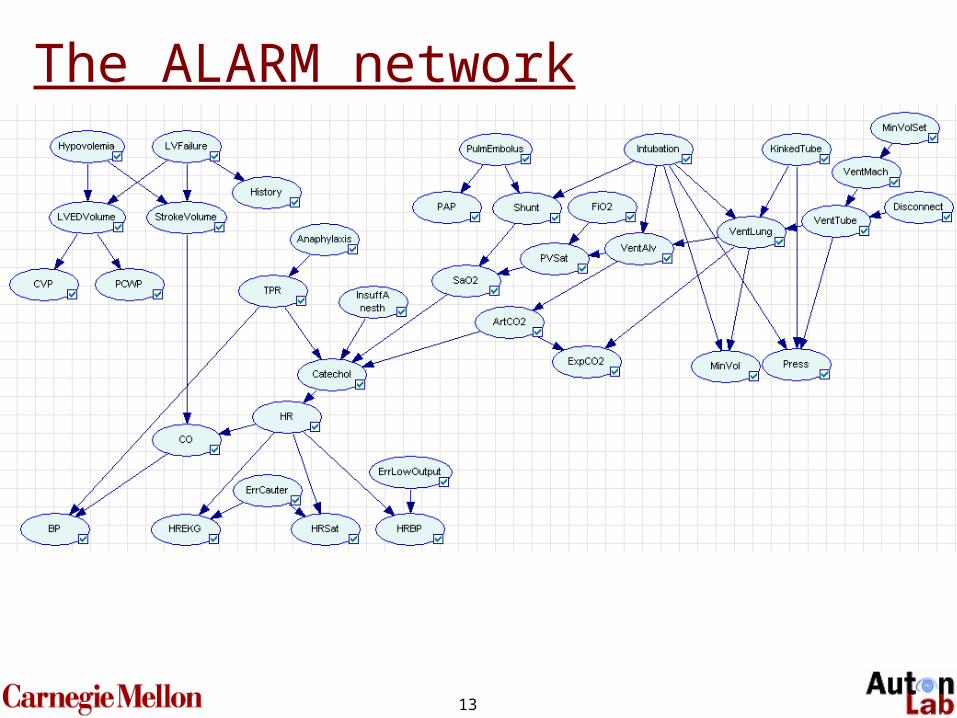
13
The ALARM network
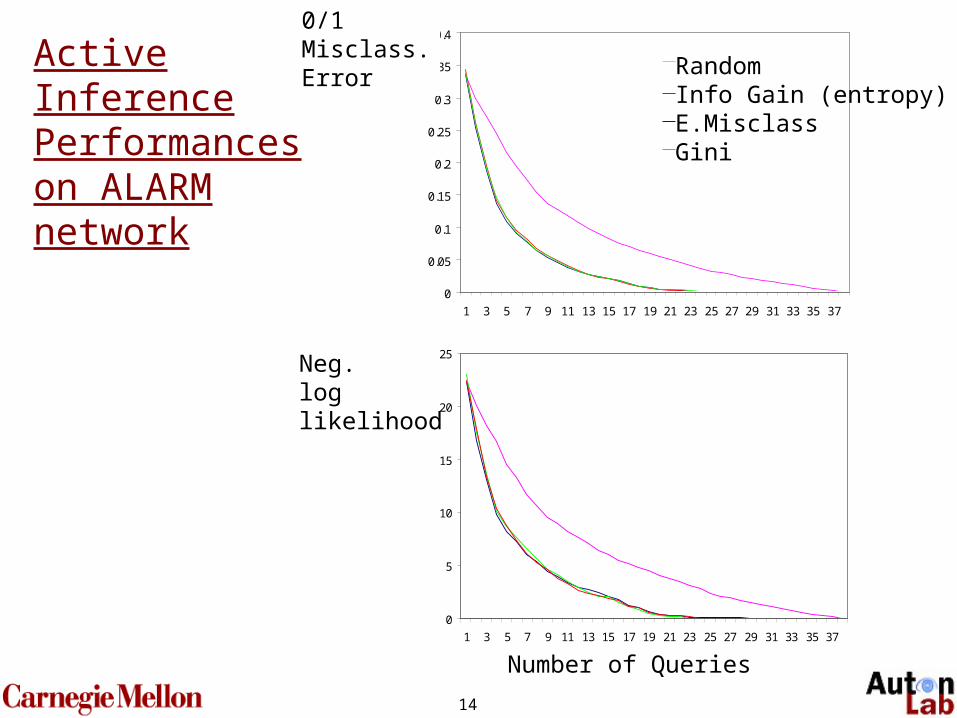
14
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37
RandomInfo Gain (entropy)E.MisclassGini
0
5
10
15
20
25
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37
0/1Misclass.Error
Neg.loglikelihood
Number of Queries
Active Inference Performances on ALARM network
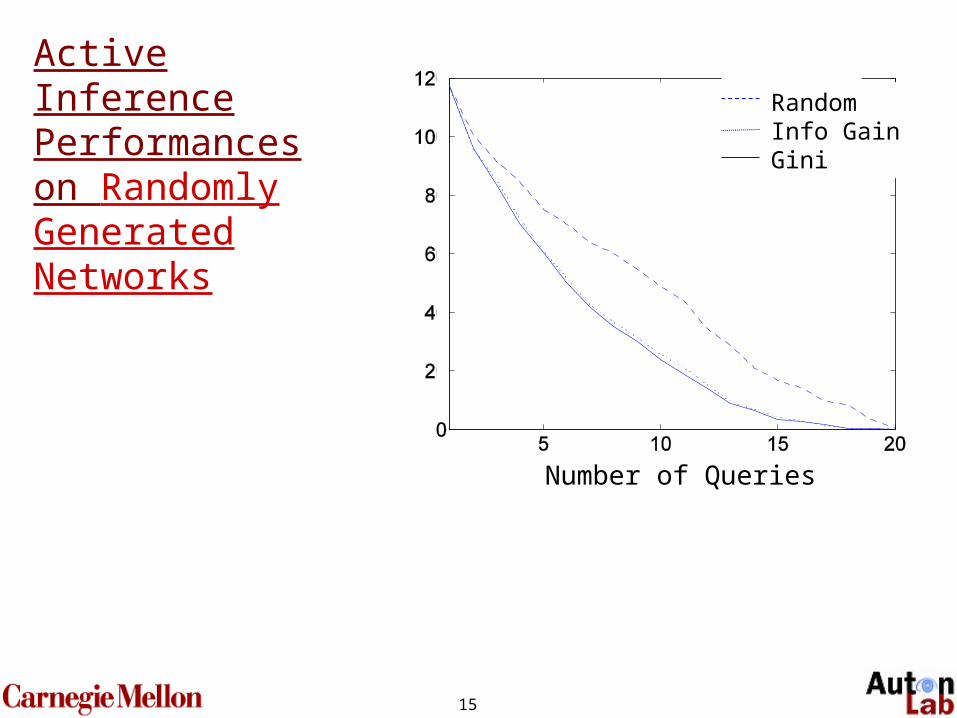
15
Active Inference Performances on Randomly Generated Networks
Number of Queries
RandomInfo GainGini

16
Some Nice Gini Properties
• For multinomials, minimizing Σpi2 minimizes the sum of
eigenvalues of the covariance matrix.
• Can incorporate misclassification costs naturally:
WTT

17
GINI Active Inference Problem
Given: 1. Set of target nodes: X
2. Set of query nodes: Y
3. Probabilistic model: P(X,Y)
4. Uncertainty function: gini(X)
Problem:Find the one node in Y expected to minimize gini(X)
mTm
TT
mXginiXginiXginigini
2211
21 )()()()(XCan do it in O(N) for polytrees(Anderson & Moore, 2005)
18
Polytrees

19
Given: 1. Target node: Cancer2. Observable nodes: {TestA, TestB}3. Probabilistic model: P(Cancer,TestA,TestB)4. Uncertainty function: gini(Cancer)
Problem:Choose the test expected to minimize gini(Cancer) if we
perform it
Example Problem Cancer
TestA TestB

20
• In order to know how a test will affect our P(Cancer), we need to know the conditional probabilities between the test results and Cancer.

21
CPT Matrices
Define.If A and B are discrete random variables, then CA|B is a CPT matrix where the ijth element is P(A=i|B=j)
Theorem.If A and B are discrete random variables, and CA|B is a CPT matrix,
I.e., inferring one variable’s distribution from another is a linear operation given the CPT matrix
BBAA C |

22
)1(
)0(
)1,1()0,1(
)1,0()0,0(
)1(
)0(
)1|1()0|1(
)1|0()0|0(
|
CancerP
CancerP
ACancerPACancerP
ACancerPACancerP
AP
AP
ACancerPACancerP
ACancerPACancerP
C AACancerCancer
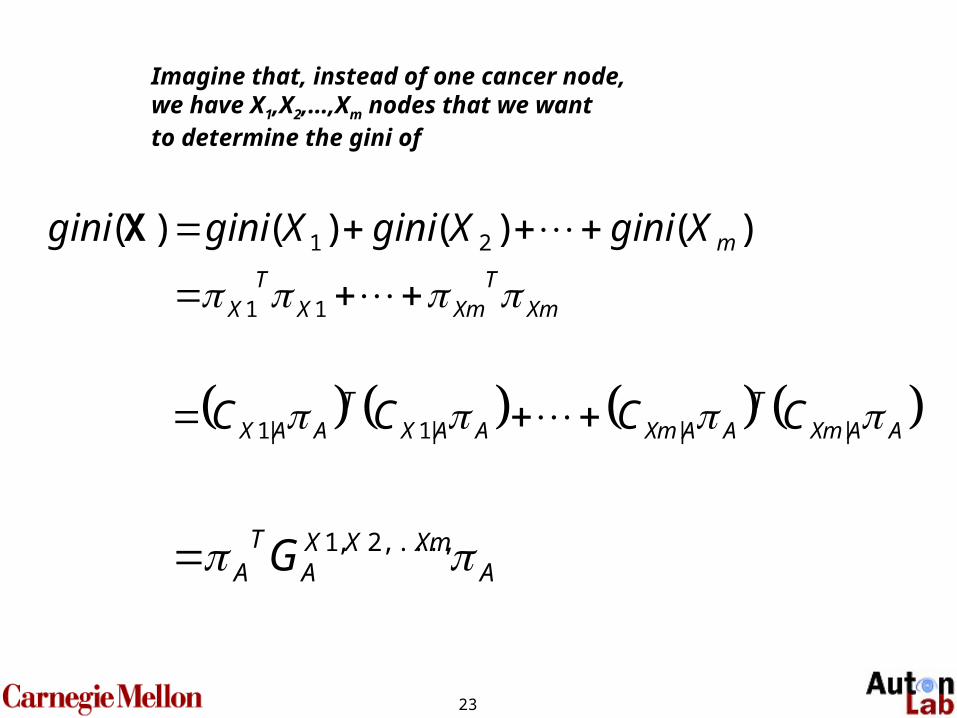
23
AAXmT
AAXmAAXT
AAX CCCC |||1|1
XmT
XmXT
X
mXginiXginiXginigini
11
21 )()()()(X
Imagine that, instead of one cancer node,we have X1,X2,…,Xm nodes that we want to determine the gini of
AXmXX
ATA G ,...,2,1

24
• So, we want GA{targets} for each node A in the query nodes.
• How to compute all of these GA{targets} matrices efficiently?
• Can do it with dynamic programming because…
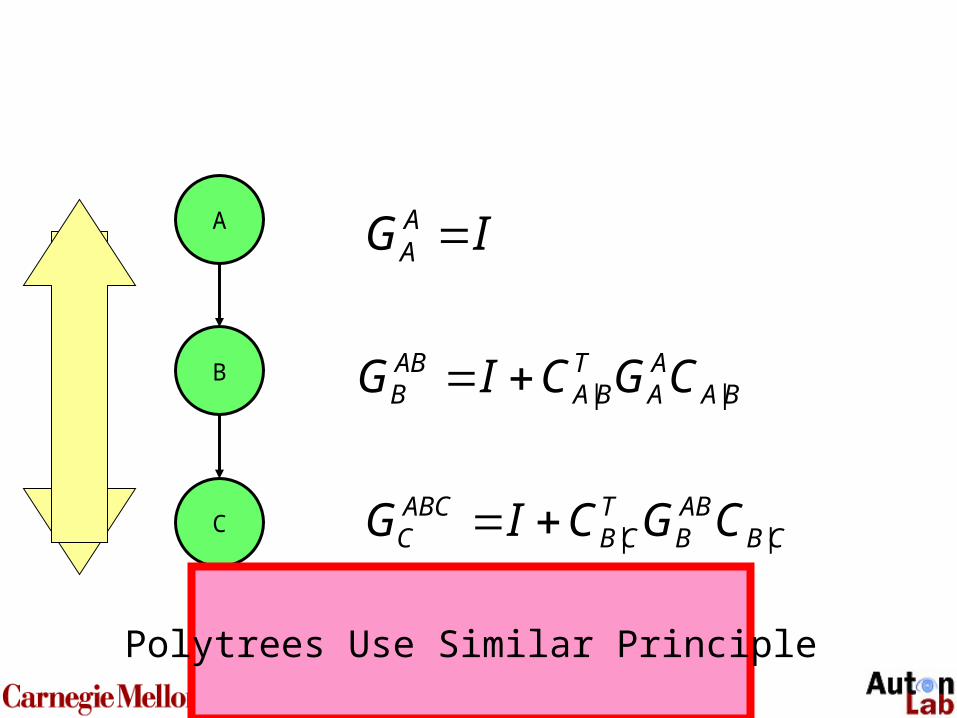
Theorem.For any nodes X, Y, and set of nodes Z, if X and Z are conditionally independent given Y, then
XYYT
XYX CGCG ||ZZ
25
IG AA
BAAA
TBA
ABB CGCIG ||
A
B
CCB
ABB
TCB
ABCC CGCIG ||
Polytrees Use Similar Principle

26
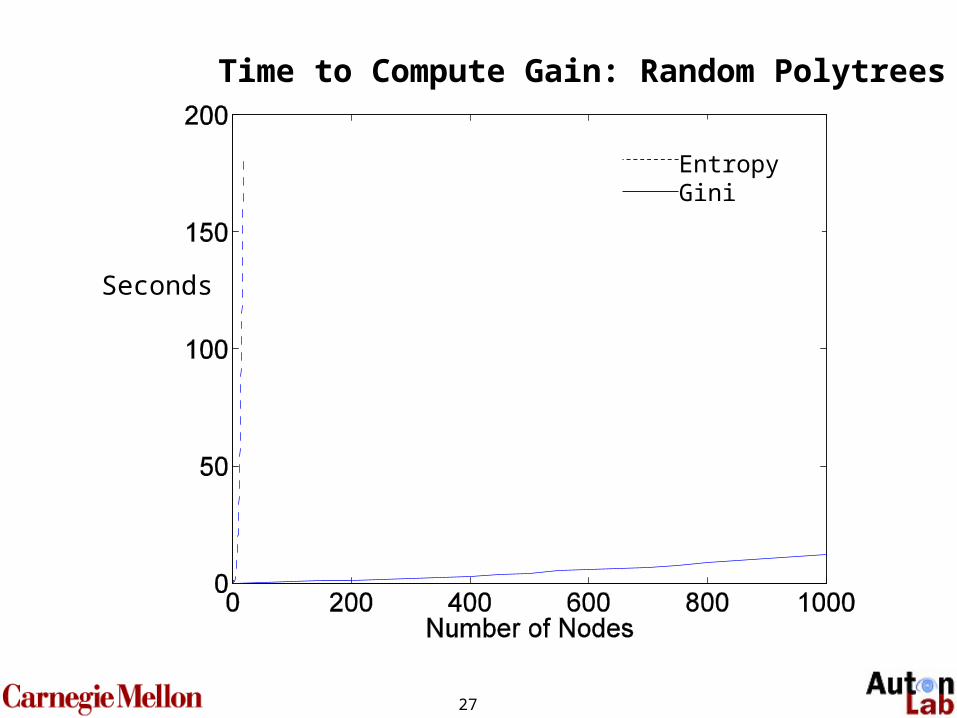
Fast Active Inference
• Information gain is quadratic in the number of nodes to compute (there is no way to do message-passing.)
• Gini is linear in the number of nodes.
27
Seconds
Time to Compute Gain: Random Polytrees
EntropyGini

28
Applications
• Active learning• Diagnosis• Optimization of noisy functions

29
OUTLINE
• New Active Inference Algorithm
• Active Learning• Background• Application of new algorithm
• Example application to Hidden Markov Models
• Active sequence selection for Hidden Markov Model learning
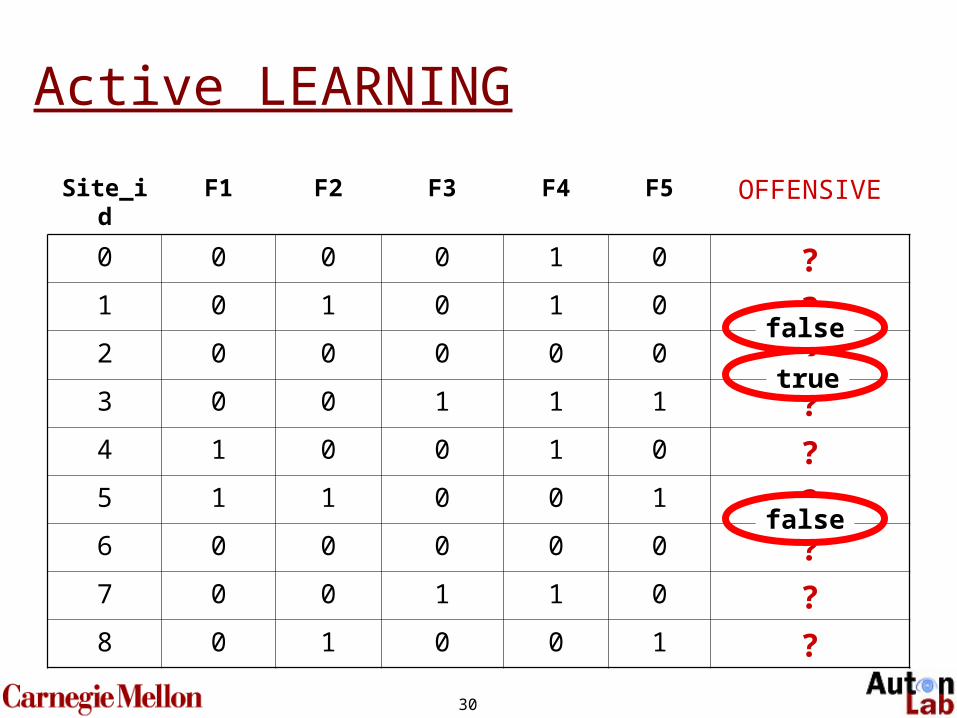
30
Site_id F1 F2 F3 F4 F5 OFFENSIVE
0 0 0 0 1 0 ?1 0 1 0 1 0 ?2 0 0 0 0 0 ?3 0 0 1 1 1 ?4 1 0 0 1 0 ?5 1 1 0 0 1 ?6 0 0 0 0 0 ?7 0 0 1 1 0 ?8 0 1 0 0 1 ?
Active LEARNING
true
false
false

31
Active Learning Flavors
Select Queries Construct Queries
Pool Sequential
Myopic Batch
Specifically, we’re not doingdecision processes, POMDPs,or any kind of policy learning.
We’re asking: what is the onelabel you most want to see?

32
Active Learning
f1
L1
Ө
Li : label of example
Ө: Model parameter(s)
fi : feature(s) of example

33
Active Learning
f1
L1 L2 L3L4
f5
L5
Ө
f3 f4
TRUE FALSEFALSE
Inference f2
At each iteration, we select the one bestnode to observe that will minimize ourexpected uncertainty about the Ө node.
How do we select a node to minimizethe uncertainty of the target node, Θ?

34
Active Learning• Coincidentally, the Cancer network is analogous to our
Active learning problem.
Cancer
TestA TestB
f1
L1 L2 L3L4
f5
L5
Ө
f3 f4f2
Select L to minimize uncertainty of Ө
Select test to minimize uncertainty of Cancer

35
Active Learning• Which page do I show the human expert in order to learn
my is-offensive model Ө?
• Which email do I show the user in order to learn my is-spam model Ө?
Active Inference• Which question do I ask the user in order to infer his
preference nodes?
• What question do I ask the user in order to infer his printer-state node(s)?

36
Active Learning Basics
Uncertainty Sampling uncertainty(L)
Query by Committee disagreement(L)
Information Gain H(Θ) – H(Θ |L)

37
Active Learning Basics
Uncertainty Sampling uncertainty(L)
Query by Committee disagreement(L)
Information Gain H(Θ) – H(Θ |L)
Gini GainGini(Θ) – Gini(Θ |L) New

38
Active Learning Basics
Uncertainty Sampling uncertainty(L)
Query by Committee disagreement(L)
Information Gain H(Θ) – H(Θ |L)
Gini GainGini(Θ) – Gini(Θ |L)

39
Uncertainty Sampling (Lewis and Gale, 1994)
BASIC IDEA: choose uncertain labels.
Talk Assumption: uncertainty is entropy
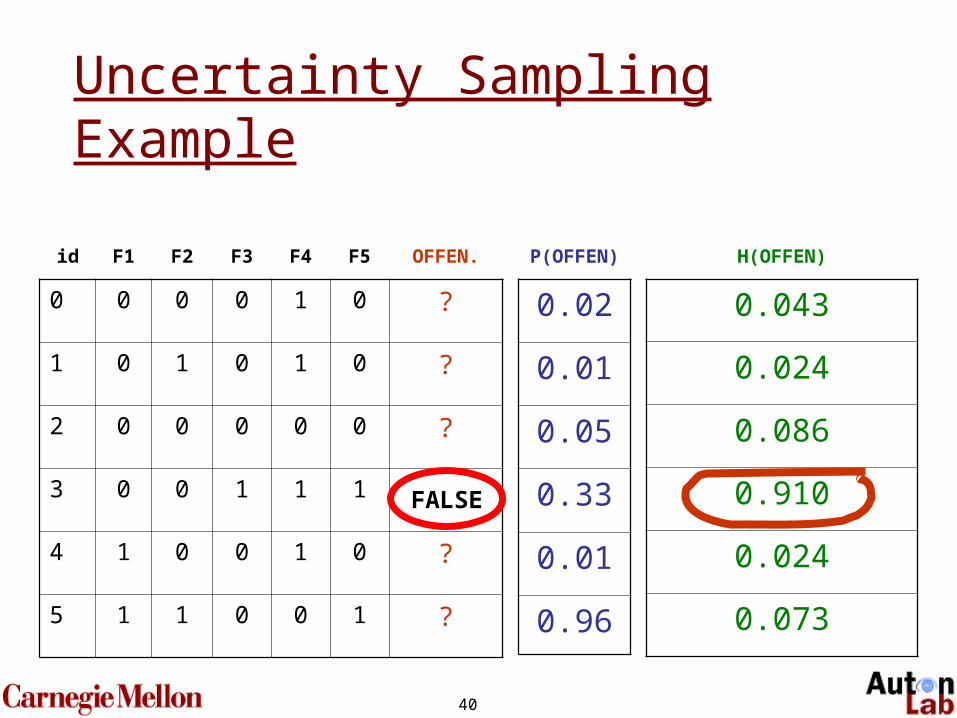
40
id F1 F2 F3 F4 F5 OFFEN.
0 0 0 0 1 0 ?
1 0 1 0 1 0 ?
2 0 0 0 0 0 ?
3 0 0 1 1 1 ?
4 1 0 0 1 0 ?
5 1 1 0 0 1 ?
P(OFFEN)
0.02
0.01
0.05
0.33
0.01
0.96
H(OFFEN)
0.043
0.024
0.086
0.910
0.024
0.073
Uncertainty Sampling Example
FALSE

41
Uncertainty SamplingBASIC IDEA: choose the sample you are most uncertain about
GOOD: easyGOOD: sometimes works
BAD: H(L) measures information gained about the sample, not the model
Attracted to noisy samples

42
Uncertainty Sampling
BAD: H(L) measures information gained about the sample, not the model
Attracted to noisy samples
…but at least H(L) upper bounds the informationgain of L w.r.t. the model (or anything else.)

43
We can do better thanuncertainty sampling

44
Query By Committee (QBC) (Seung, Opper, and Sompolinsky, 1992)
IDEA: choose labels your models disagree on.
ASSUMPTION: no noise
ASSUMPTION: perfectly learnable model
E.g., if half your version space says X is true, and the other half says it is false, you’re guaranteed to reduce your version space by half if you find out X.
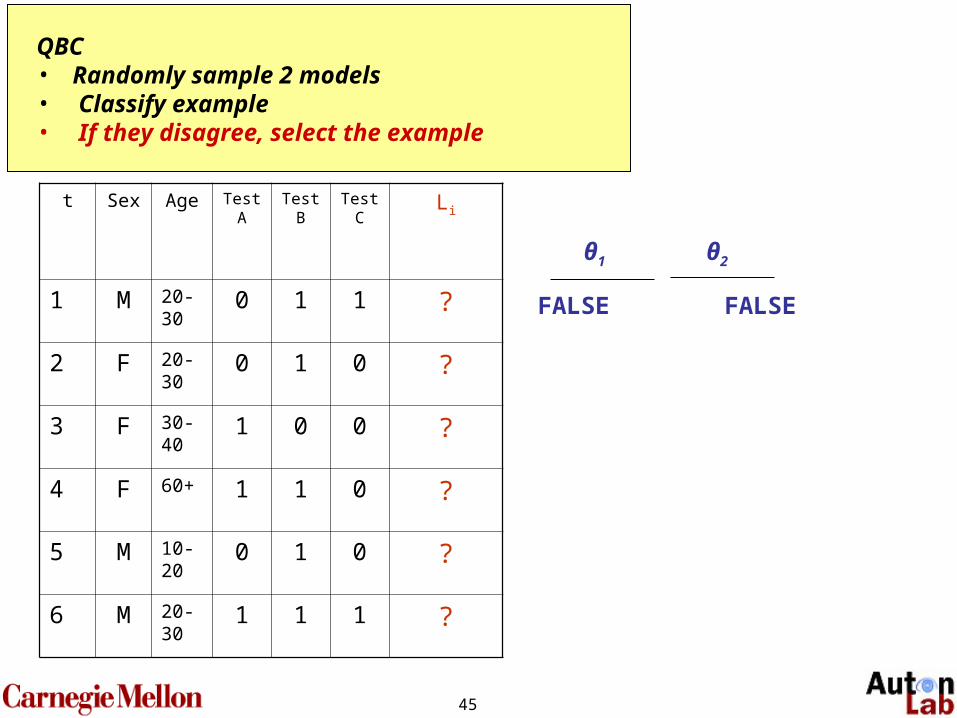
45
t Sex Age Test A
Test B
Test C
Li
1 M 20-30
0 1 1 ?
2 F 20-30
0 1 0 ?
3 F 30-40
1 0 0 ?
4 F 60+ 1 1 0 ?
5 M 10-20
0 1 0 ?
6 M 20-30
1 1 1 ?
QBC • Randomly draw 2 models from model space• Classify the example• If they disagree, select the example
QBC • Randomly draw 2 models from model space• Classify the example• If they disagree, select the example
QBC • Randomly draw 2 models from model space• Classify the example• If they disagree, select the example
QBC • Randomly sample 2 models• Classify example• If they disagree, select the example
FALSE FALSE
θ1 θ2
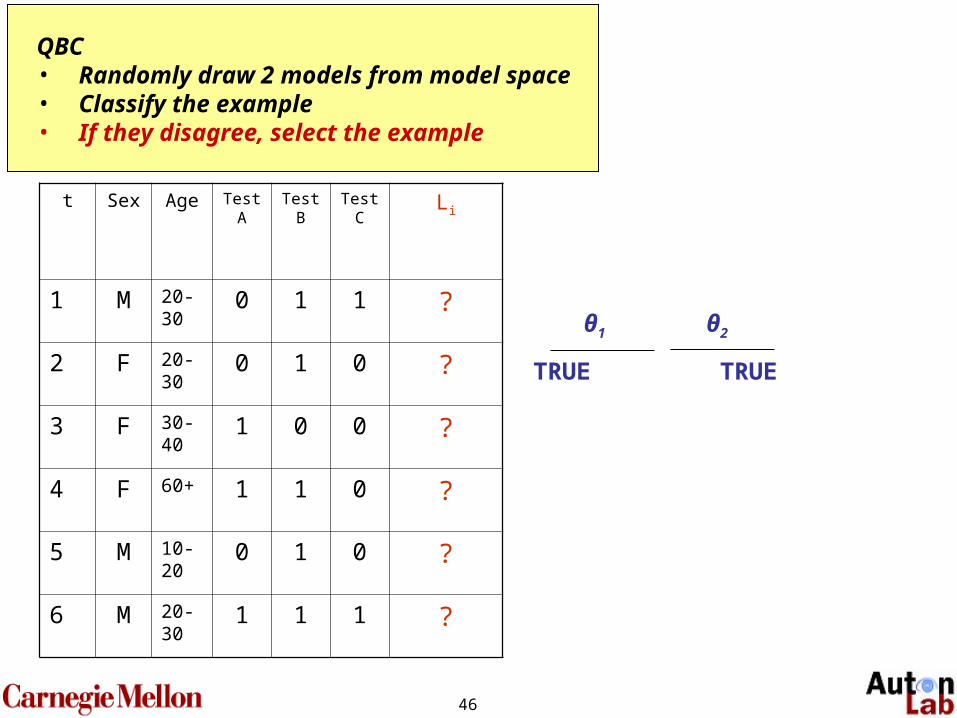
46
t Sex Age Test A
Test B
Test C
Li
1 M 20-30
0 1 1 ?
2 F 20-30
0 1 0 ?
3 F 30-40
1 0 0 ?
4 F 60+ 1 1 0 ?
5 M 10-20
0 1 0 ?
6 M 20-30
1 1 1 ?
QBC • Randomly draw 2 models from model space• Classify the example• If they disagree, select the example
QBC • Randomly draw 2 models from model space• Classify the example• If they disagree, select the example
QBC • Randomly draw 2 models from model space• Classify the example• If they disagree, select the example
QBC • Randomly draw 2 models from model space• Classify the example• If they disagree, select the example
TRUE TRUE
θ1 θ2
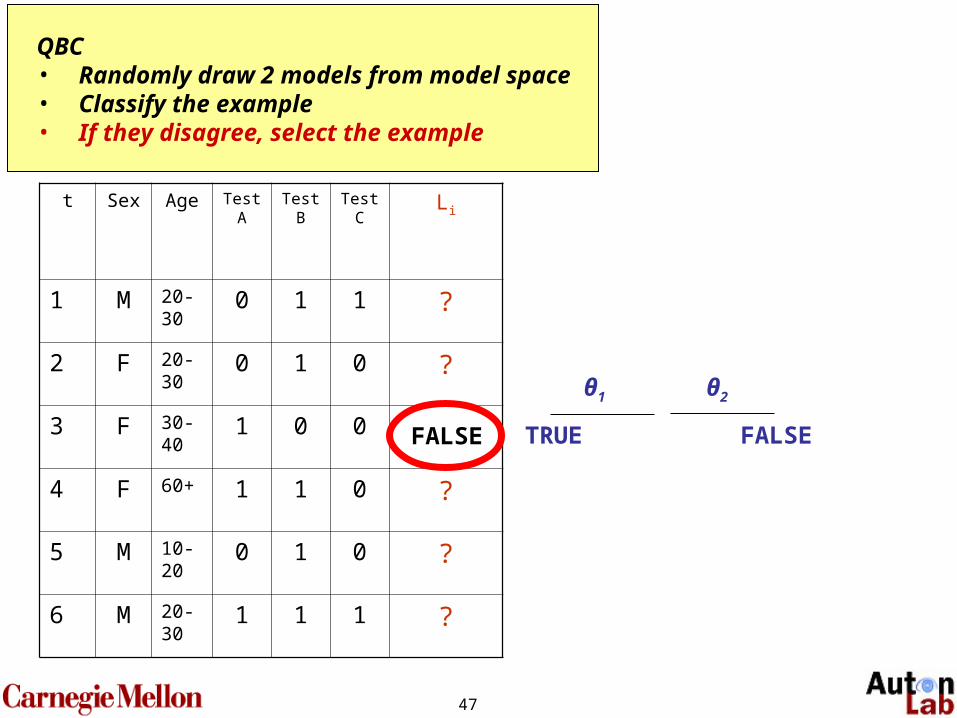
47
t Sex Age Test A
Test B
Test C
Li
1 M 20-30
0 1 1 ?
2 F 20-30
0 1 0 ?
3 F 30-40
1 0 0 ?
4 F 60+ 1 1 0 ?
5 M 10-20
0 1 0 ?
6 M 20-30
1 1 1 ?
QBC • Randomly draw 2 models from model space• Classify the example• If they disagree, select the example
QBC • Randomly draw 2 models from model space• Classify the example• If they disagree, select the example
QBC • Randomly draw 2 models from model space• Classify the example• If they disagree, select the example
QBC • Randomly draw 2 models from model space• Classify the example• If they disagree, select the example
TRUE FALSEFALSE
θ1 θ2

48
Query By Committee (QBC)
IDEA: choose labels your models disagree on.
In the noise-free case, H(L) is entirely due to uncertainty about the model, so it reduces to uncertainty sampling!
If we allow noisy samples and use a model posterior instead of a version space, QBC starts to look exactly like…

49
Active Learning Basics
Uncertainty Sampling uncertainty(L)
Query by Committee disagreement(L)
Information Gain H(Θ) – H(Θ |L)
Gini GainGini(Θ) – Gini(Θ |L)
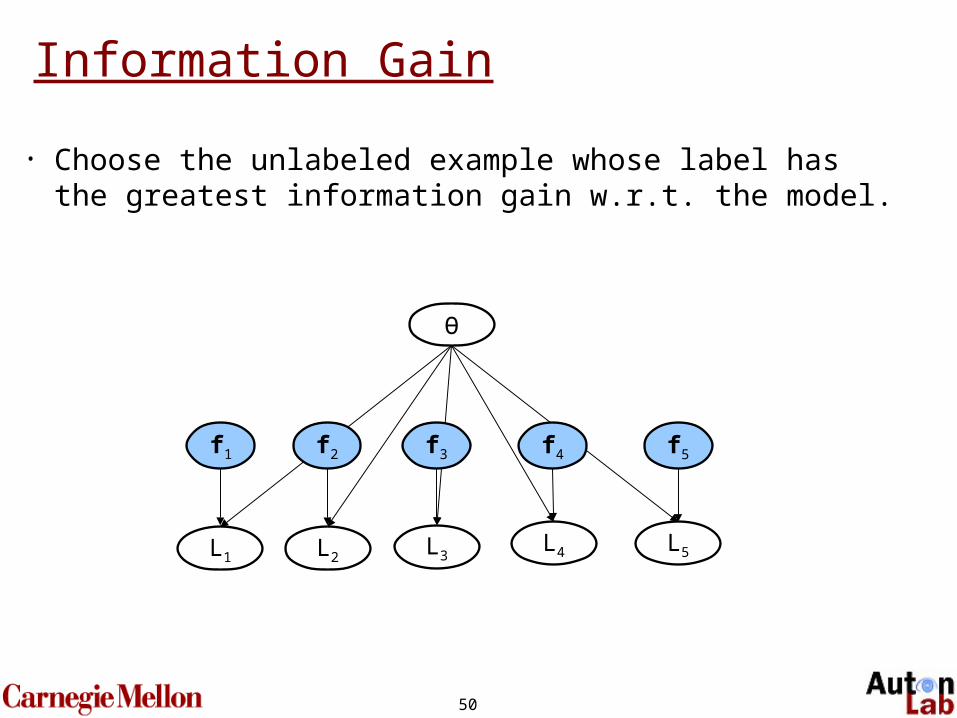
50
Information Gain
• Choose the unlabeled example whose label has the greatest information gain w.r.t. the model.
f1
L1 L2 L3L4
f5
L5
Ө
f3 f4f2

51
Information Gain
)|()();( LHHLIG
)|()( LHLH
• Choose the unlabeled example whose label has the greatest information gain w.r.t. the model.
Interesting:Uncertainty sampling Information Gain
when H(L|Θ) is small relative to H(L).
52
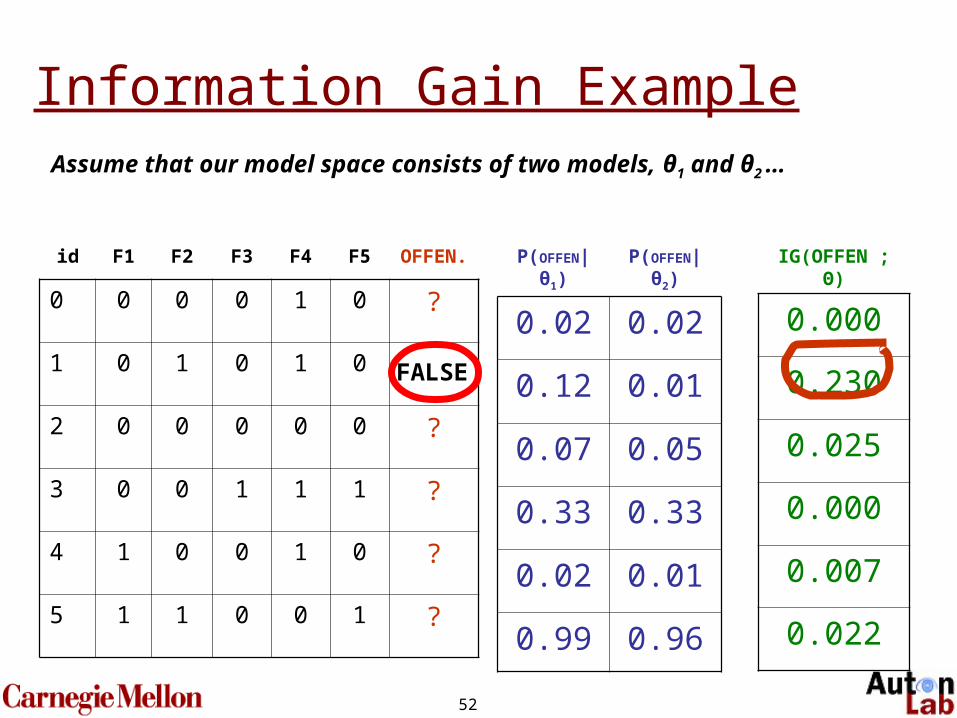
id F1 F2 F3 F4 F5 OFFEN.
0 0 0 0 1 0 ?
1 0 1 0 1 0 ?
2 0 0 0 0 0 ?
3 0 0 1 1 1 ?
4 1 0 0 1 0 ?
5 1 1 0 0 1 ?
P(OFFEN|θ1) P(OFFEN|θ2)
0.02 0.02
0.12 0.01
0.07 0.05
0.33 0.33
0.02 0.01
0.99 0.96
IG(OFFEN ; Θ)
0.000
0.230
0.025
0.000
0.007
0.022
Information Gain Example
FALSE
Assume that our model space consists of two models, θ1 and θ2 …

53
Active Learning Basics
Uncertainty Sampling uncertainty(L)
Query by Committee disagreement(L)
Information Gain H(Θ) – H(Θ |L)
Gini GainGini(Θ) – Gini(Θ |L)
54
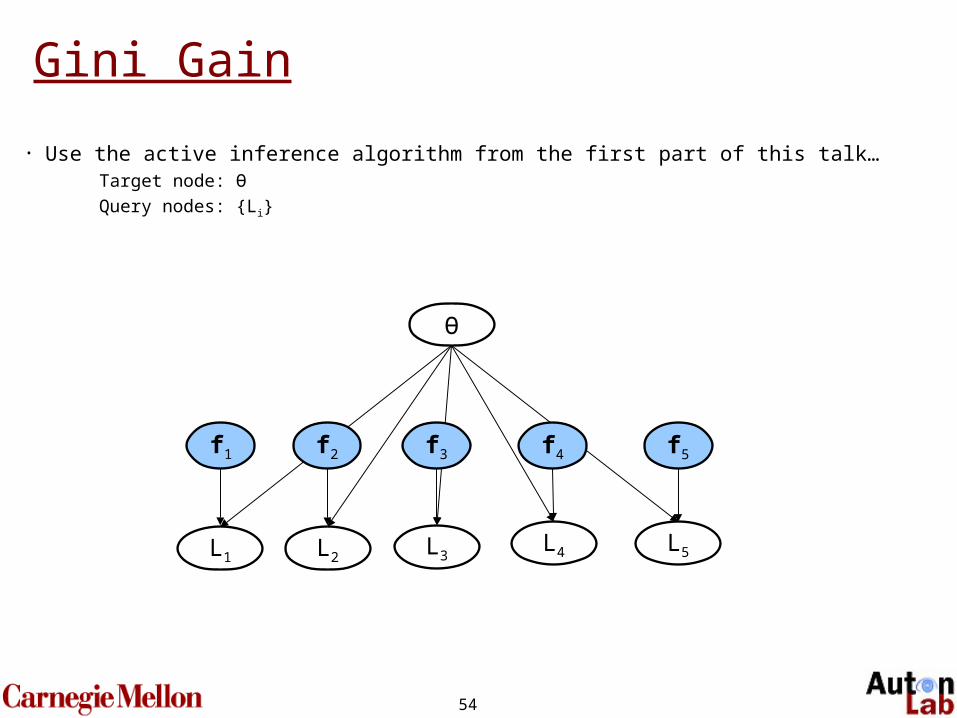
Gini Gain
• Use the active inference algorithm from the first part of this talk… Target node: Ө
Query nodes: {Li}
f1
L1 L2 L3L4
f5
L5
Ө
f3 f4f2

55
Gini Gain
Definition.The Gini gain between two random variables X and Y, denoted as GG(X;Y), is defined as
)(
)|()(Xdomx
YTY xXYginixP
)|()();( XYginiYginiXYGG

56
Active Learning Basics
Uncertainty Sampling uncertainty(L) PRO: Simple
CON: Misled by noise
Query by Committee disagreement(L) PRO: Simple
CON: No good theory for noise
Information Gain H(Θ) – H(Θ |L) PRO: Information theory-based
CON: Does not scale well
Gini GainGini(Θ) – Gini(Θ |L)
PRO: Scales extremely well.
Can use confusion costs.

57
Interesting Question
• Can we “fix” uncertainty sampling by approximating H(L|Ө)?
If we can do this, it will approximate information gain

58
We’re Still Not Happy• All of the active learning methods used this model:
f1
L1 L2 L3L4
f5
L5
Ө
f3 f4f2
…But something seems wrong…

59
We’re Still Not Happy
Ө
f’1
Z1
f’2
Z2 Z3
L1
f2
L2
f’3
f1
L3
f4
L4
f3
Test Set
Training Set
We usually don’t want information about the model…We want information about the test set labels!
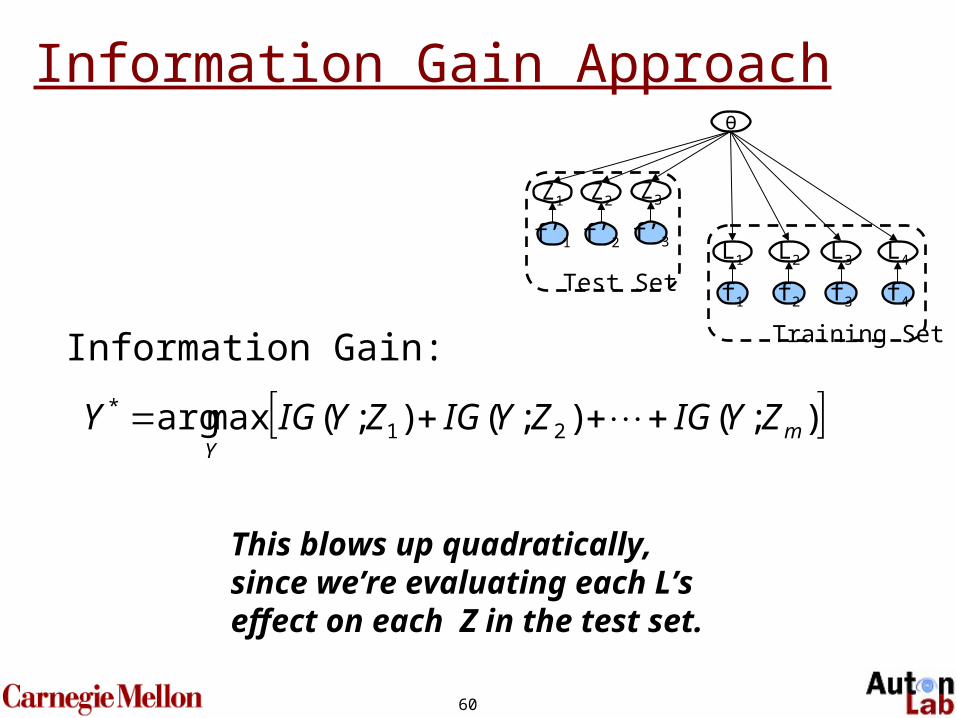
60
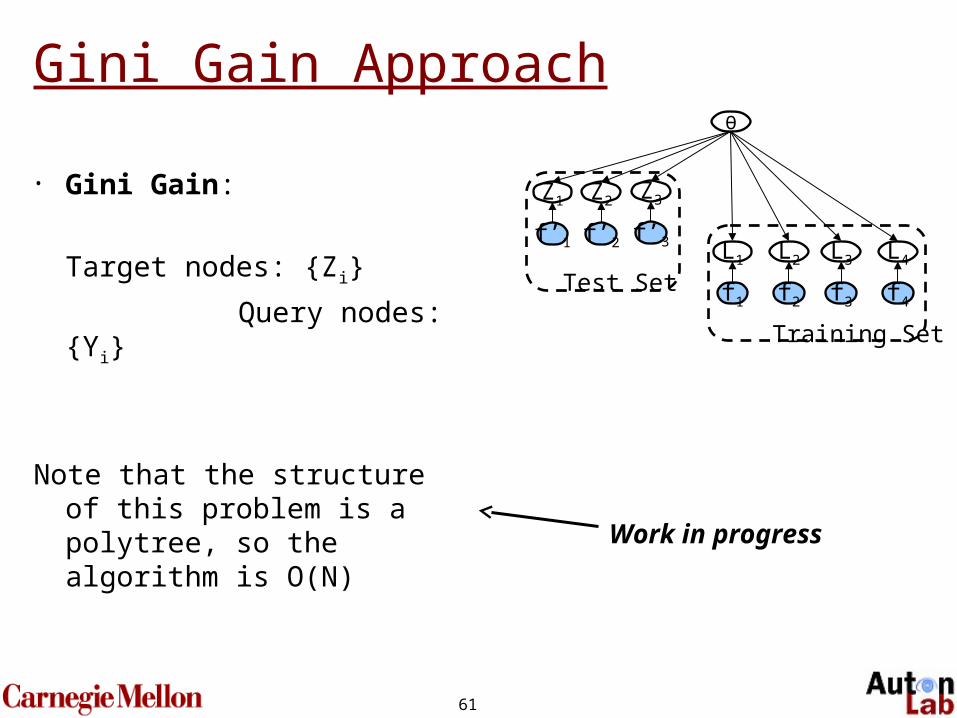
Information Gain Approach
Information Gain:
Ө
f’1
Z1
f’2
Z2 Z3
L1
f2
L2
f’3
f1
L3
f4
L4
f3Test Set
Training Set
);();();(maxarg 21*
mY
ZYIGZYIGZYIGY
This blows up quadratically,since we’re evaluating each L’s effect on each Z in the test set.
61
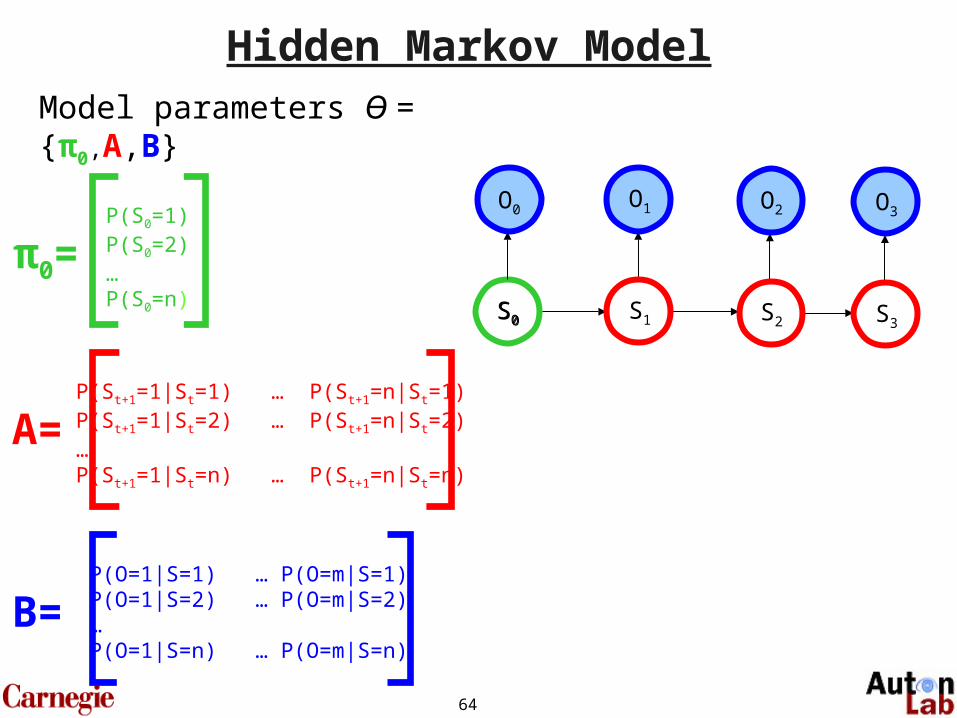
Gini Gain Approach
• Gini Gain:
Target nodes: {Zi}
Query nodes: {Yi}
Note that the structure of this problem is a polytree, so the algorithm is O(N)
Ө
f’1
Z1
f’2
Z2 Z3
L1
f2
L2
f’3
f1
L3
f4
L4
f3Test Set
Training Set
Work in progress

62
OUTLINE
• New Active Inference Algorithm
• Active Learning• Background• Application of new algorithm
• Example application to Hidden Markov Models
• Active sequence selection for Hidden Markov Model learning

63
The SwitchMaster™(powered by Hidden Markov Models!)
INPUT
Binary stream of motion / no-motion
OUTPUT
Probability distribution over • Phone, • Meeting, • Computer, and • Out
E.g., “There is an 86% chancethat the user is in a meeting right now.”
64
S0S0
O1
S1
O2
S2
O3
S3
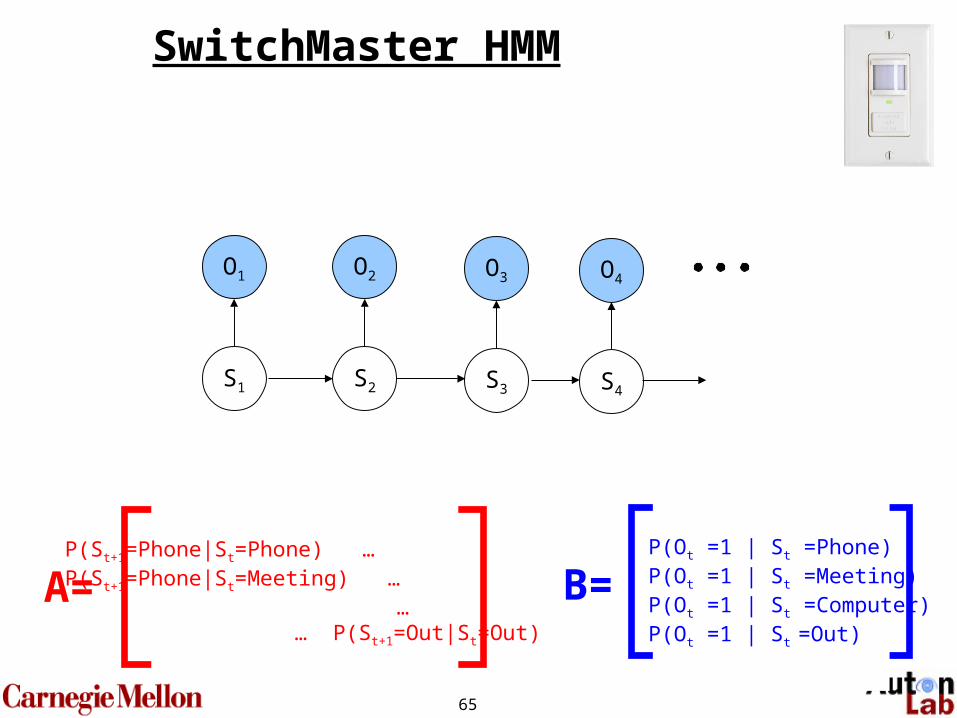
Model parameters Ө = {π0,A,B}
B=P(O=1|S=1) … P(O=m|S=1)P(O=1|S=2) … P(O=m|S=2)…P(O=1|S=n) … P(O=m|S=n)
A=P(St+1=1|St=1) … P(St+1=n|St=1)P(St+1=1|St=2) … P(St+1=n|St=2)…P(St+1=1|St=n) … P(St+1=n|St=n)
Hidden Markov Model
π0=P(S0=1)P(S0=2)…P(S0=n)
O0
65
O1 O2 O3 O4
SwitchMaster HMM
S1 S2 S3 S4
B= P(Ot =1 | St =Phone) P(Ot =1 | St =Meeting) P(Ot =1 | St =Computer) P(Ot =1 | St =Out)
A=P(St+1=Phone|St=Phone) …P(St+1=Phone|St=Meeting) … … … P(St+1=Out|St=Out)
66
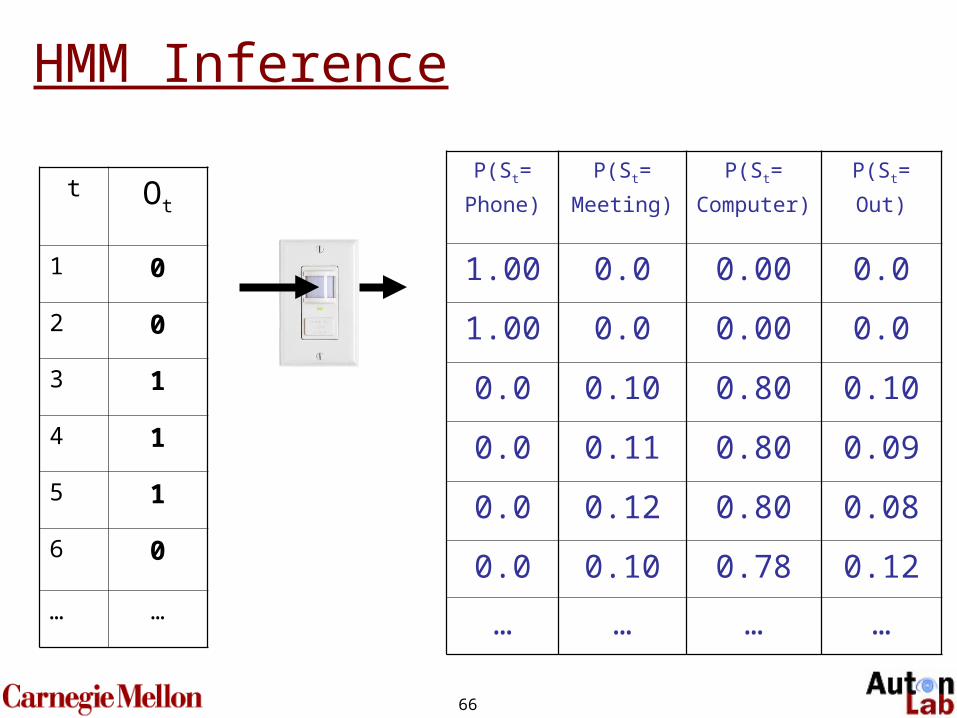
HMM Inference
t Ot
1 0
2 0
3 1
4 1
5 1
6 0
… …
P(St=
Phone)
P(St=
Meeting)
P(St=
Computer)
P(St=
Out)
1.00 0.0 0.00 0.0
1.00 0.0 0.00 0.0
0.0 0.10 0.80 0.10
0.0 0.11 0.80 0.09
0.0 0.12 0.80 0.08
0.0 0.10 0.78 0.12
… … … …

67
Good Morning Sir!
Here’s the video footage of yesterday.
Could you just go through it and label each frame?
Good Morning Sir!
Can you tell me what you are doing in this frame of video?
Active Learning!
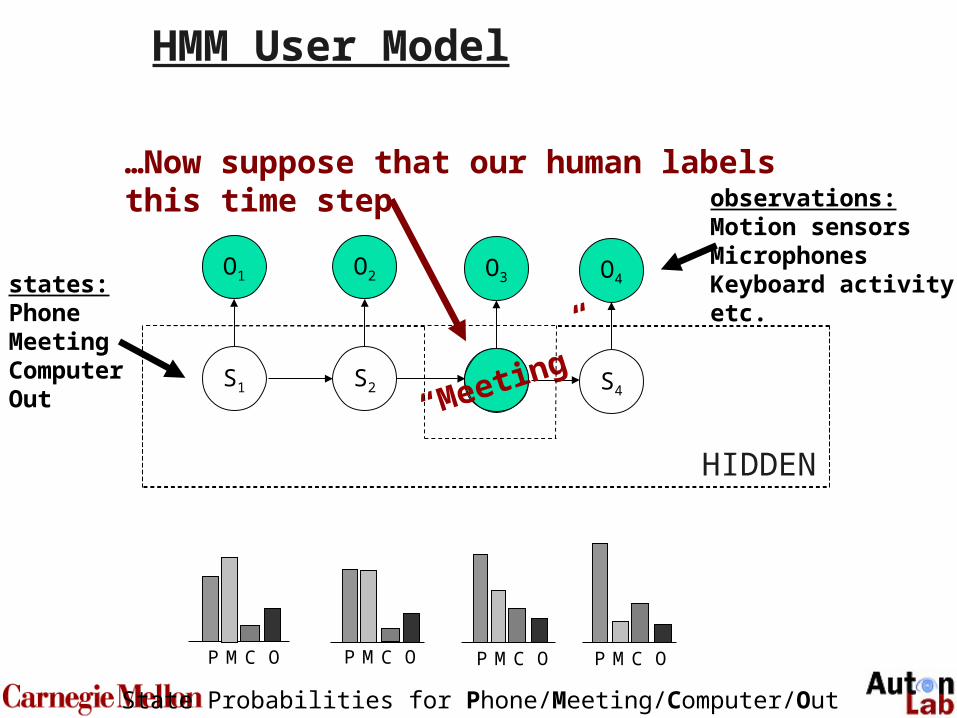
68
O1
S1
O2
S2
O3
S3
O4
S4
observations:Motion sensorsMicrophonesKeyboard activityetc.
states:PhoneMeetingComputerOut
HIDDEN
“Meeting”
P M C O P M C O P M C O P M C O
State Probabilities for Phone/Meeting/Computer/Out
…Now suppose that our human labelsthis time step
HMM User Model
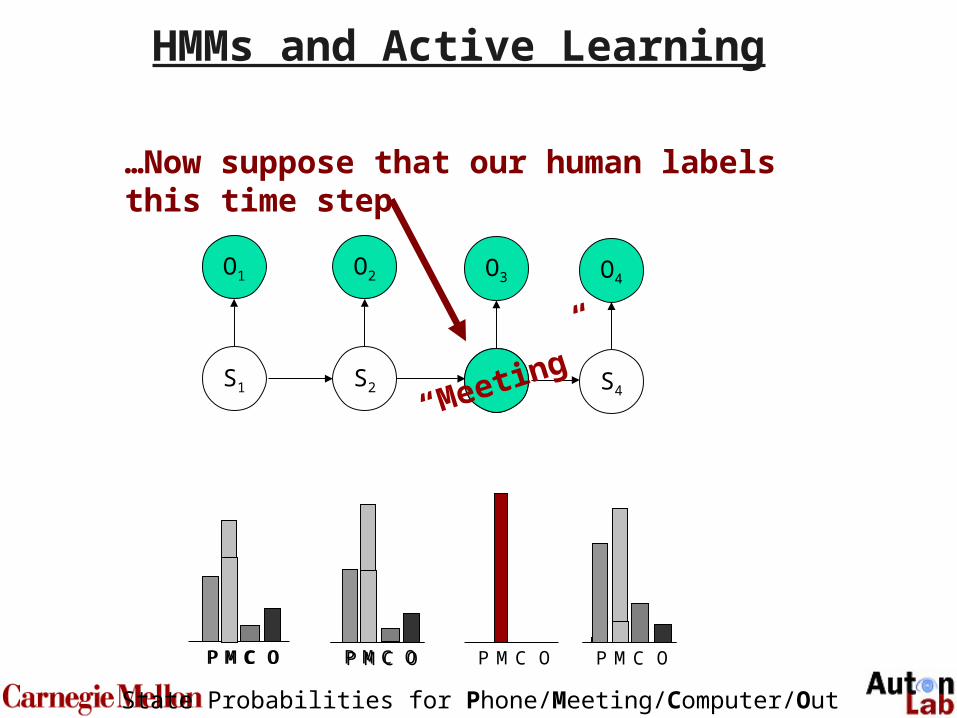
69
O1
S1
O2
S2
O3
S3
O4
S4“Meeting”
State Probabilities for Phone/Meeting/Computer/Out
P M C OP M C O P M C O P M C OP M C O P M C O
HMMs and Active Learning
…Now suppose that our human labelsthis time step
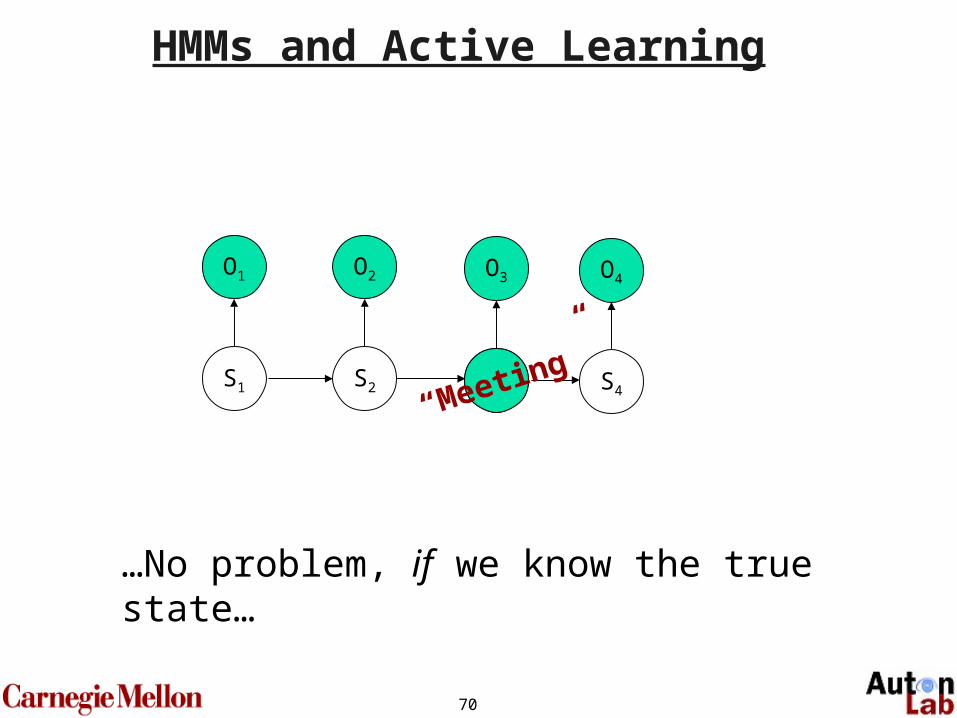
70
O1
S1
O2
S2
O3
S3
O4
S4“Meeting”
…No problem, if we know the true state…
HMMs and Active Learning
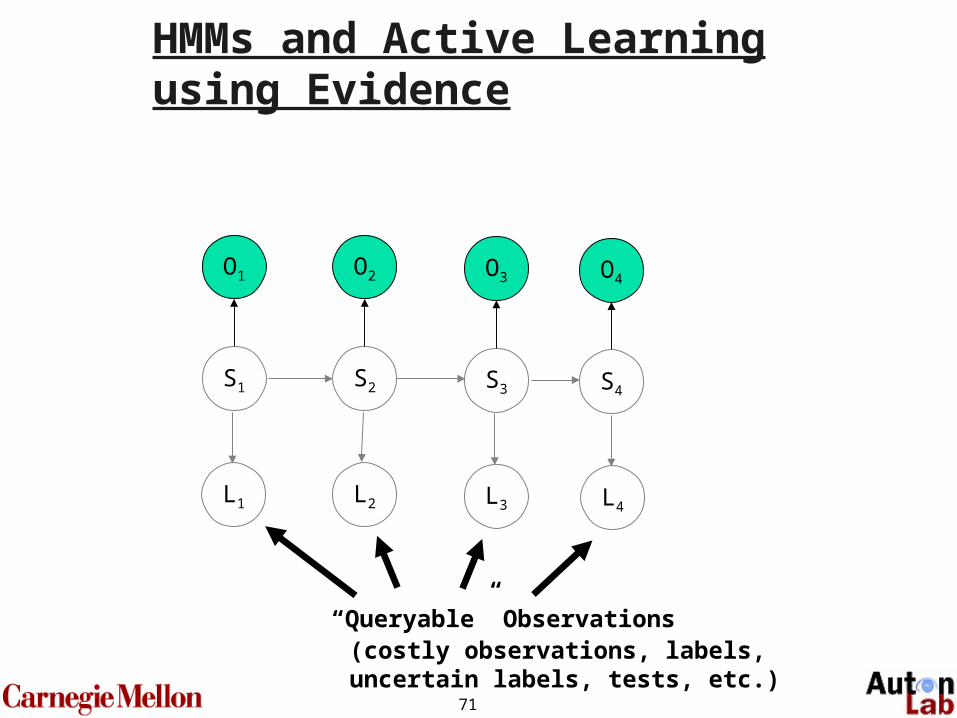
71
O1
S1
O2
S2
O3
S3
O4
S4
L1 L2 L3 L4
“Queryable” Observations
HMMs and Active Learning using Evidence
(costly observations, labels, uncertain labels, tests, etc.)
72
O1
S1
O2
S2
O3
S3
O4
S4
L1 L2 L3 L4
P M C O P M C O P M C O P M C O
State Probabilities for Phone/Meeting/Computer/Out
P M C O P M C O P M C O P M C O
State Probabilities for Phone/Meeting/Computer/Out
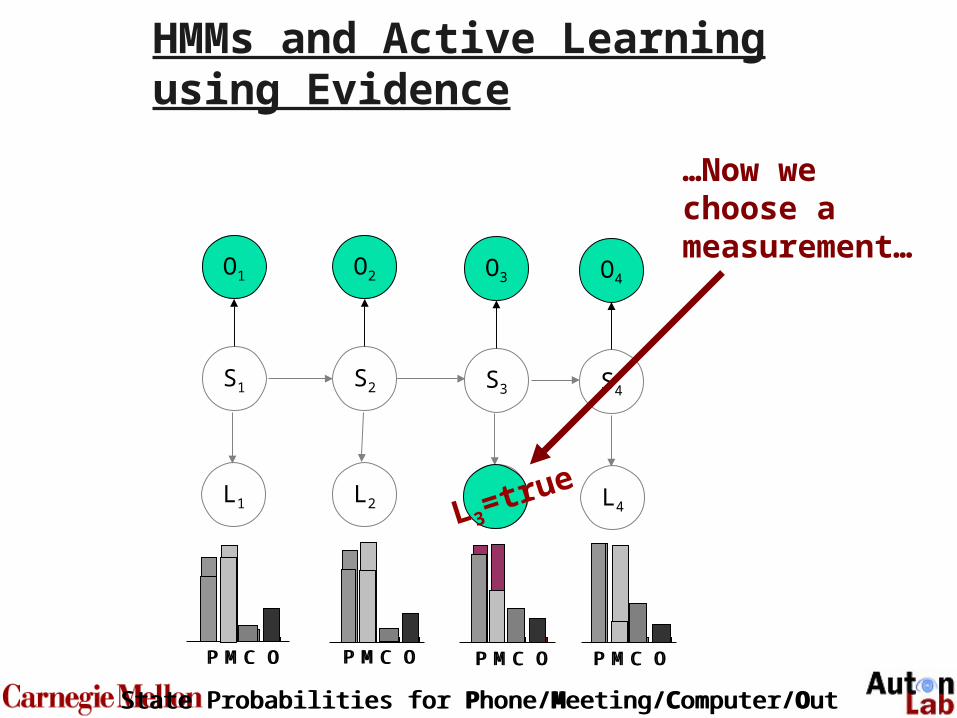
HMMs and Active Learning using Evidence
L3=true
…Now we choose a measurement…
73
O1
S1
O2
S2
O3
S3
O4
S4
L1 L2 L3 L4L3=true
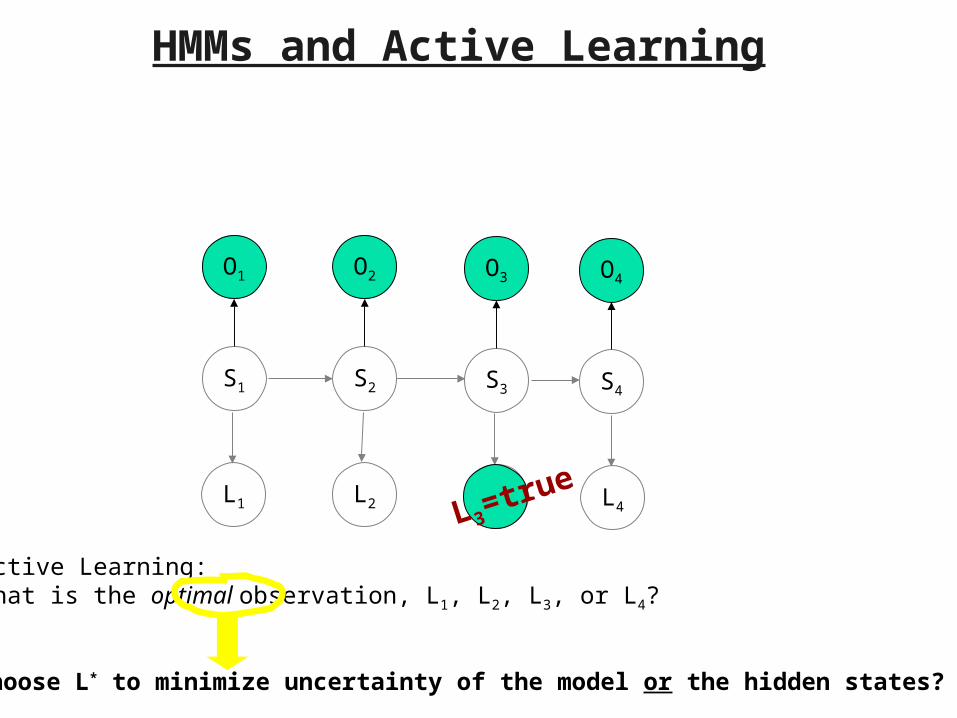
HMMs and Active Learning
Active Learning:What is the optimal observation, L1, L2, L3, or L4?
Choose L* to minimize uncertainty of the model or the hidden states?

74
O1
S1
O2
S2
L1 L2
O3
S3
L3
HMMs and Active Learning
O4
S4
L4
O5
S5
L5
O6
S6
L6
O7
S7
L7
?
L2=true
L2=false
L2=true
??hmm…

75
hmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmm…

76
HMMs and Active Learning
The SwitchMaster™ is trying to minimize the uncertainty of some target node(s)
…What are its target nodes?
77
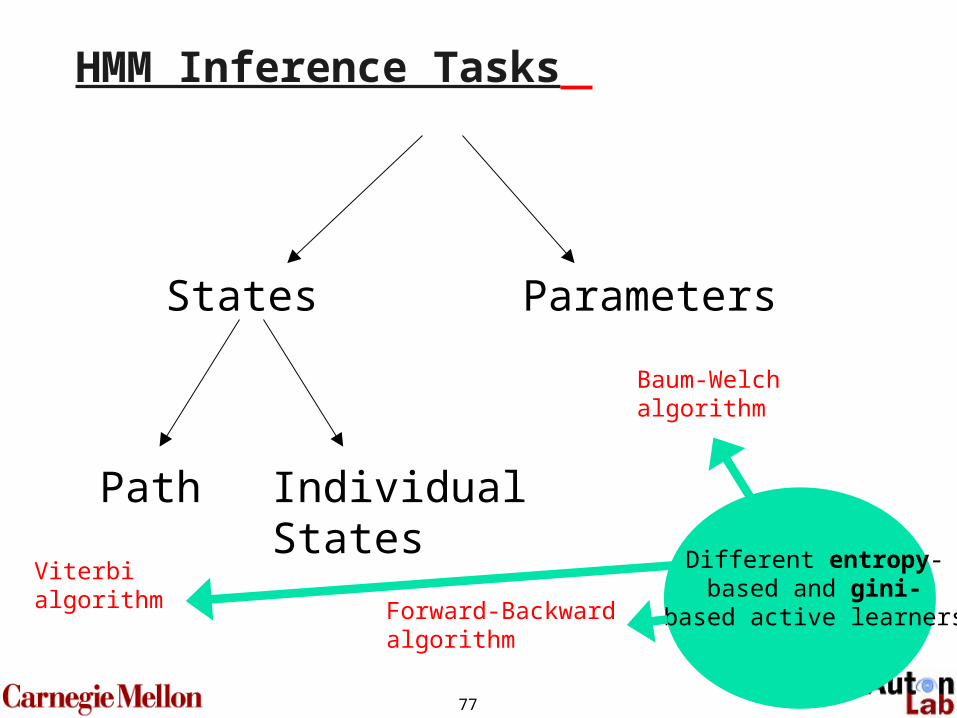
HMM Inference Tasks
States
Path IndividualStates
Viterbialgorithm Forward-Backward
algorithm
Baum-Welchalgorithm
Different entropy-based and gini-
based active learners
Parameters

78
Path States Model
Entropy
Gini
)(H
jointT
joint T
tS
TS tt
T
ttSH )(
T
),...,,( 21 TSSSH
Efficient myopic algorithms for each of these objective functions
in Anderson and Moore, 2005

79
T
tt
YSYIGY );(maxarg*
L1
S1
L2
S2
L3
S3
L4
S4
O(T2MN2)
Active State Learningwith Information Gain

80
Path States Model
Entropy
Gini
)(H
jointT
joint T
tS
TS tt
T
ttSH )(
T
),...,,( 21 TSSSH

81
L1
S1
L2
S2
L3
S3
L4
S4
O(T2MN2)O(TMN2)2
);(maxarg* T
tt
YSYGGY
Active State Learningwith Gini

82
States:
Emacs-LatexEmacs-CodeShellEmailOther
1 keystroke = 1 timestep
20,000 timesteps
Observations:
Key duration (msec)Key transition time (msec)Key category (alpha,space,enter,punc,edit)
Experiment: User Model
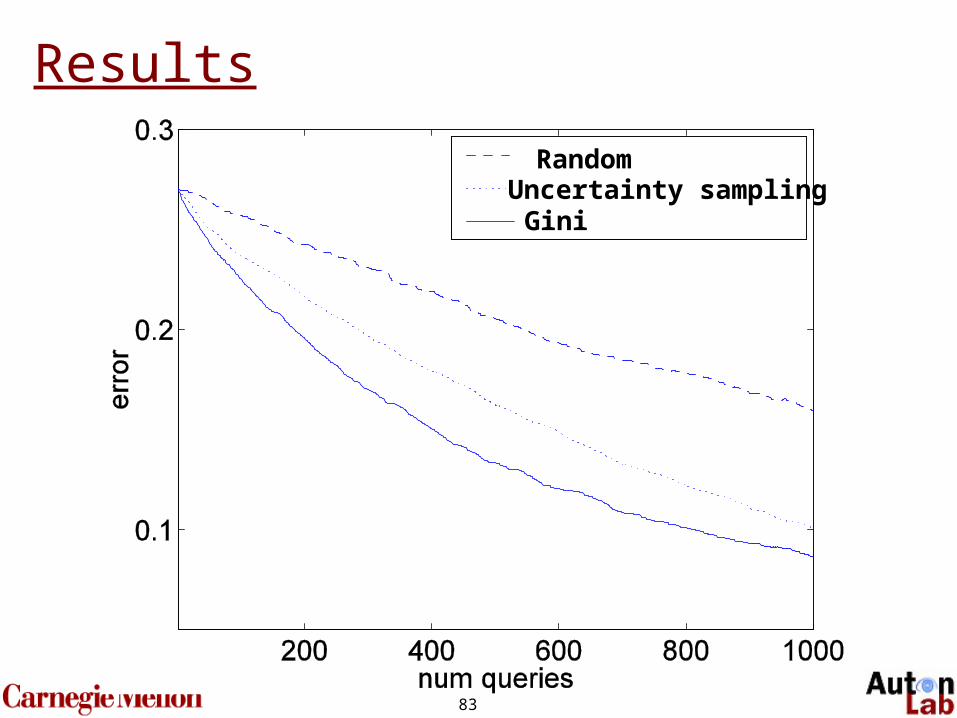
83
GiniUncertainty samplingRandom
Results

84
OUTLINE
• New Active Inference Algorithm
• Active Learning• Background• Application of new algorithm
• Example application to Hidden Markov Models
• Active sequence selection for Hidden Markov Model learning (Anderson, Siddiqqi, and Moore, 2006)

85
Actively Selecting Excerpts
Good Morning Sir!
Could you please label the following scene from yesterday…
86
0 0 0 1 0 1 1 1 0 0 1 0 1 1 0 0 0 0 1 1 1 1 1 1 1
There are O(T2) of them!
OK, which subsequence would be most informative
about my model?

87
0 0 0 1 0 1 1 1 0 0 1 0 1 1 0 0 0 0 1 1 1 1 1 1 1
?
P P P M M M C
hmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmm…
Note: the expertannotates each of the states

88
0 0 0 1 0 1 1 1 0 0 1 0 1 1 0 0 0 0 1 1 1 1 1 1 1
P P P M M M C
Possible applications of “excerpt selection”• Selecting utterances from audio
• Selecting excerpts from text
• Selecting sequences from DNA
89
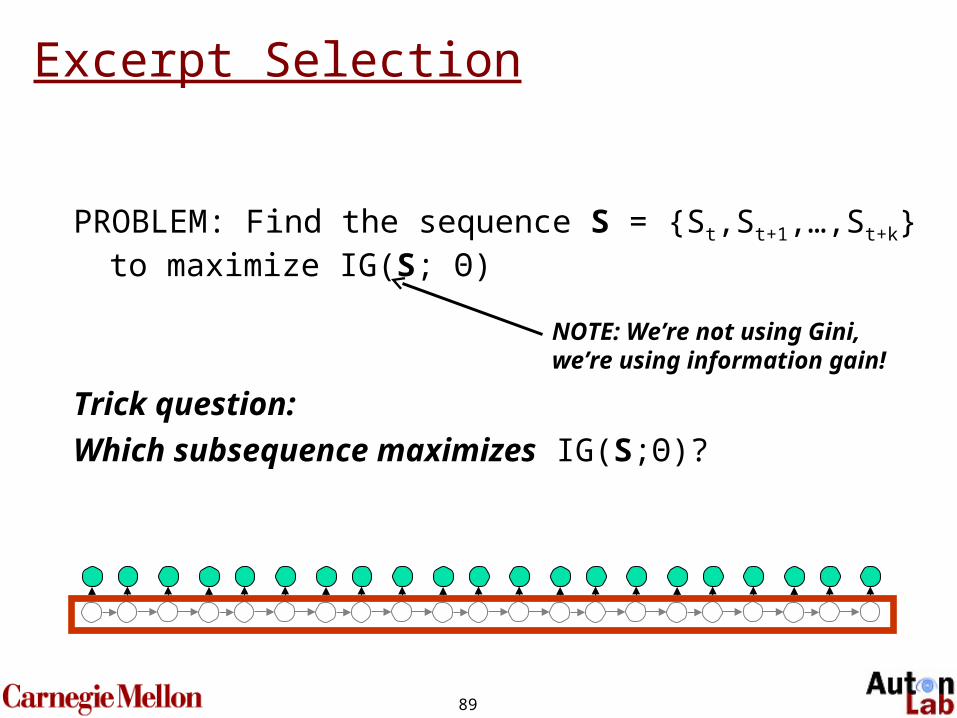
Excerpt Selection
PROBLEM: Find the sequence S = {St,St+1,…,St+k} to maximize IG(S; Θ)
Trick question:
Which subsequence maximizes IG(S;Θ)?
NOTE: We’re not using Gini,we’re using information gain!

90
Sequence Selection
SSS );();( IGscore
We have to include the cost incurred when we force an expert to sit down and label 1000 examples…
So there is a constantcost, α, associated with providing each label
This is computed fromthe entropy of thesequence, H(S). Howdo we compute H(S)?

91
What is the Entropy of a Sequence?
• H(S1:4) = H(S1,S2,S3,S4) = ?
The Chain Rule of Entropy
H(S1,S2,S3,S4) = H(S1) + H(S2 |S1) + H(S3 |S1,S2) + H(S4 |S1,S2,S3)
…but we have some structural information:
S1 S2 S3 S4
H(S1,S2,S3,S4) = H(S1) + H(S2 |S1) + H(S3 |S2) + H(S4 |S3)

92
Entropy of a Sequence
kt
tiiitkttt SSHSHSSSH )|()(),...,,( 11
We still get the H(St) and H(St+1|St)values from P(St | O1:T), andP(St+1 | St, O1:T)

93
Score of a Sequence
S
SSSS
Lt
tiiit
Lt
tiiit SSHSHSSHSH
HH
),|()|()|()(
)|()();score(
11

94
How can I find thebest excerpt of
length k?
0 0 0 0 1 0 1 1 1 0 0 1 0 1 1 0 0 0 0 1 1 1 1 1

95
Find Best Sequence ofLength k
1. Score each length-k subsequence according to
score(S;Ө) = H(S) – H(S|Ө)
2. Select the best one
0 0 0 0 1 0 1 1 1 0 0 1 0 1 1 0 0 0 0 1 1 1 1 1
k=5 *** Some simple cachinggives O(T)

96
Yeah, but what if I don’t know k?
I want to find thebest excerpt of
any length
0 0 0 0 1 0 1 1 1 0 0 1 0 1 1 0 0 0 0 1 1 1 1 1

97
Find Best Sequence ofAny Length
1. Score all possible intervals
2. Pick the best one
0 0 0 0 1 0 1 1 1 0 0 1 0 1 1 0 0 0 0 1 1 1 1 1
Hmm…
That’s O(T2).
We could cleverly cache some of the computation as we go…
But we’re still going to be O(T2)
98
-2
-1
0
1
2
3
4
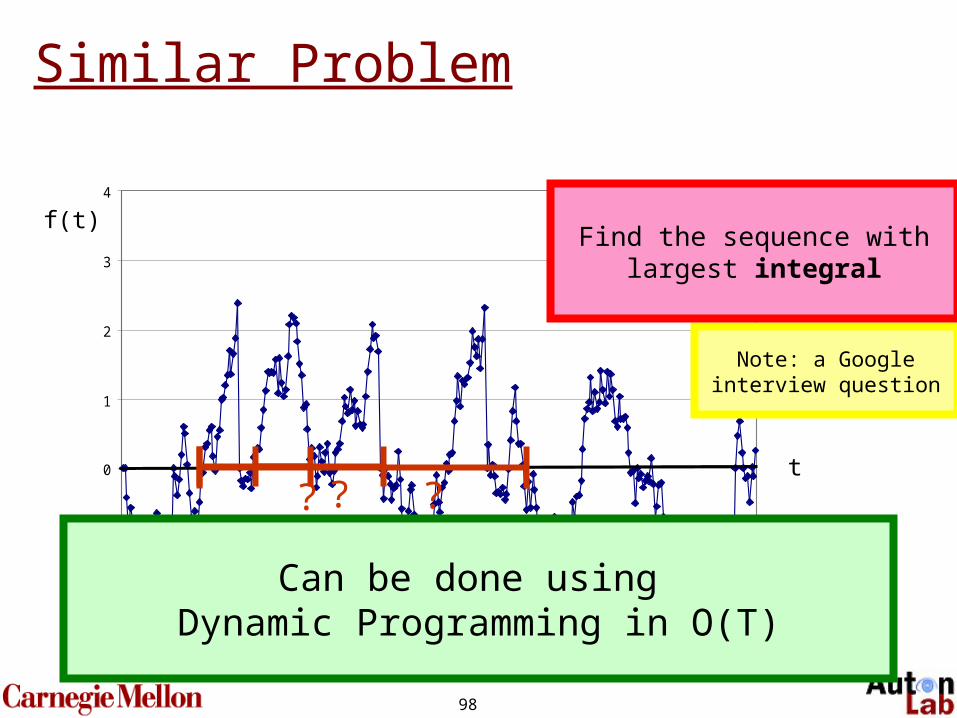
Similar Problem
t
f(t)
?? ?
Note: a Googleinterview question
Find the sequence withlargest integral
Can be done using Dynamic Programming in O(T)

99
state(t) = the best interval so far, and the best interval ending at t
state(t+1) = if f(t) + score of best-ending-at-t < 0 then start a new best-ending-at-t else “keep going”
DP Intuition

100
Find Best Sequence ofAny Length
0 0 0 0 1 0 1 1 1 0 0 1 0 1 1 0 0 0 0 1 1 1 1 1
***
Use DP to find the subsequence that maximizes
score(S;Ө) = H(S) – H(S|Ө) – α|S|

101
Not Just HMMs
This active learning algorithm can be applied to any sequential process with the Markov property
E.g., Kalman filters
102
SUMMARY
• Linear time active inference using Gini
• Applications to Hidden Markov Models• Applications to general Active Learning
• Active sequence selection
Ө
f’1
Z1
f’2
Z2 Z3
L1
f2
L2
f’3
f1
L3
f4
L4
f3

103
Future Work
• On-line active learning• Batch active learning• Optimization of noisy functions

104

105
Selective Sampling Bias?

106
Related Work
• Label selection for tracking in text HMMs (Scheffer, et al. 2001)
• Nonmyopic label selection for tracking with chain models (Krause & Guestrin, 2005)
• Label selection for model learning in general graphical models (Tong & Koller, 2001)

107
AAXmT
AAXmAAXT
AAX CCCC |||1|1
mTm
TT
mXginiXginiXginigini
2211
21 )()()()(X
AAXmTAXm
TAAAX
TAX
TA CCCC |||1|1
Imagine that, instead of one cancer nodewe’re interested in, we have X1,X2,…,Xm thatwe want to determine the gini of
AAXmTAXmAX
TAX
TA CCCC |||1|1
AXmXX
ATA G ,...,2,1

108
[a*,b*] : best interval so far
atemp : start of best interval ending at t
sum(a*,b*)
sum(atemp,t )
Rules: if ( sum(atemp,t-1) + y(t) < 0 ) then atemp= t
if ( sum(atemp,t) > sum(a*,b*) ) then [a*,b*] = [atemp,t]
state(t) =


















