
Continuos Random Variables and Moment Generating Functions ... · Continuos Random Variables and...
22
Continuos Random Variables and Moment Generating Functions OPRE 7310 Lecture Notes by Metin C ¸ akanyıldırım Compiled at 12:41 on Wednesday 22 nd August, 2018 1 Absolutely Continuous and Singularly Continuous Random Variables As we observed earlier, there are continuous random variables that take every value in an interval. Such variables take uncountable values and we have developed the notion of P( A) for A ∈F of the probability model (Ω, F ,P). Starting from this probability model, we can still write F X ( a)= P( X(ω) ∈ (-∞, a]). So the cumulative distribution functions (cdfs) for the continuous random variables have the same properties as the cdfs of the discrete variables. Continuity of random variable X is equivalent to the continuity of F X , where continuity of function F X is well-established. Absolute continuity of X refers to the absolute continuity of the cdf F X : That is, ∑ n i=1 F X (b i ) - F X ( a i ) can be bounded by ϵ for every given δ that bounds ∑ n i=1 (b i - a i ) for finitely many disjoint n intervals ( a i , b i ). Hence, an absolutely continuous function maps sufficiently tight intervals to arbitrarily tight inter- vals. In the special case, an absolutely continuous function maps intervals of length zero to intervals of length zero (p.413 Billingsley 1995). In other words, you cannot make something out of nothing by passing it through an absolutely continuous function. In the definition of absolute continuity, for every given ϵ satisfying ∑ n i=1 F X (b i ) - F X ( a i ) < ϵ,a δ indepen- dent of the number n of intervals is to be chosen to satisfy ∑ n i=1 (b i - a i ) < δ. When δ is chosen, the number of intervals is not known. The same δ should work regardless of the number of intervals. Moreover, only finite number of intervals are considered in the definition. Example: Cantor function (also called Devil’s staircase) is defined along with the Cantor set. Cantor set is obtained by starting with [0, 1] and removing the open interval in the middle 1/3 of the remaining intervals; see Table 1. This set has uncountable number of points but its length (Lebesgue measure) is zero. Cantor function is a limit of series of functions F n defined over [0, 1] where F n (0)= 0 and F n (1)= 1. Cantor function turns out to be continuous, increasing and constant outside Cantor set. Hence, Cantor function increases only inside Cantor set and increases from 0 to 1. That is, Cantor function maps Cantor set of length zero to the interval of [0, 1] and it is not absolutely continuous. If you think of Cantor function as the cdf F for random variable X, then X becomes a continuous random variable but it is not absolutely continuous. For a different characterization of Cantor function, see Chalice (1991) which provides an operational description: Any increasing real-valued function on [0, 1] that has a) F(0)= 0, b) F( x/3)= F( x)/2, c) F(1 - x)= 1 - F( x) is the Cantor function. ⋄ Itera- Length of Length of removed tion n Available intervals available intervals intervals in this iteration 0 (0, 1) 1 1/3 1 (0, 1/3), (2/3, 1) 2/3 = 1 - 1/3 (1/3)(2/3) 2 (0, 1/9), (2/9, 3/9), (6/9, 7/9), (8/9, 1) (2/3) 2 = 2/3 - (1/3)(2/3) (1/3)(2/3) 2 3 (0, 1/27), (2/27, 3/27), (6/27, 7/27), (8/27, 9/27) (18/27, 19/27), (20/27, 21/27), (24/27, 25/27), (26/27, 1) (2/3) 3 =(2/3) 2 - (1/3)(2/3) 2 (1/3)(2/3) 3 4 ... (2/3) 4 (1/3)(2/3) 4 ... ... ... ... n ... (2/3) n (1/3)(2/3) n Table 1: Size of Cantor’s set as n → ∞ iterations is lim n→∞ (2/3) n = 0. 1
Transcript of Continuos Random Variables and Moment Generating Functions ... · Continuos Random Variables and...

Continuos Random Variables and Moment Generating FunctionsOPRE 7310 Lecture Notes by Metin Cakanyıldırım
Compiled at 12:41 on Wednesday 22nd August, 2018
1 Absolutely Continuous and Singularly Continuous Random Variables
As we observed earlier, there are continuous random variables that take every value in an interval. Suchvariables take uncountable values and we have developed the notion of P(A) for A ∈ F of the probabilitymodel (Ω,F , P). Starting from this probability model, we can still write FX(a) = P(X(ω) ∈ (−∞, a]). Sothe cumulative distribution functions (cdfs) for the continuous random variables have the same propertiesas the cdfs of the discrete variables.
Continuity of random variable X is equivalent to the continuity of FX, where continuity of function FX iswell-established. Absolute continuity of X refers to the absolute continuity of the cdf FX: That is, ∑n
i=1 FX(bi)−FX(ai) can be bounded by ϵ for every given δ that bounds ∑n
i=1(bi − ai) for finitely many disjoint n intervals(ai, bi). Hence, an absolutely continuous function maps sufficiently tight intervals to arbitrarily tight inter-vals. In the special case, an absolutely continuous function maps intervals of length zero to intervals oflength zero (p.413 Billingsley 1995). In other words, you cannot make something out of nothing by passingit through an absolutely continuous function.
In the definition of absolute continuity, for every given ϵ satisfying ∑ni=1 FX(bi)− FX(ai) < ϵ, a δ indepen-
dent of the number n of intervals is to be chosen to satisfy ∑ni=1(bi − ai) < δ. When δ is chosen, the number
of intervals is not known. The same δ should work regardless of the number of intervals. Moreover, onlyfinite number of intervals are considered in the definition.
Example: Cantor function (also called Devil’s staircase) is defined along with the Cantor set. Cantor set isobtained by starting with [0, 1] and removing the open interval in the middle 1/3 of the remaining intervals;see Table 1. This set has uncountable number of points but its length (Lebesgue measure) is zero. Cantorfunction is a limit of series of functions Fn defined over [0, 1] where Fn(0) = 0 and Fn(1) = 1. Cantor functionturns out to be continuous, increasing and constant outside Cantor set. Hence, Cantor function increasesonly inside Cantor set and increases from 0 to 1. That is, Cantor function maps Cantor set of length zeroto the interval of [0, 1] and it is not absolutely continuous. If you think of Cantor function as the cdf F forrandom variable X, then X becomes a continuous random variable but it is not absolutely continuous. For adifferent characterization of Cantor function, see Chalice (1991) which provides an operational description:Any increasing real-valued function on [0, 1] that has a) F(0) = 0, b) F(x/3) = F(x)/2, c) F(1− x) = 1− F(x)is the Cantor function. ⋄
Itera- Length of Length of removedtion n Available intervals available intervals intervals in this iteration0 (0, 1) 1 1/31 (0, 1/3), (2/3, 1) 2/3 = 1 − 1/3 (1/3)(2/3)2 (0, 1/9), (2/9, 3/9), (6/9, 7/9), (8/9, 1) (2/3)2 = 2/3 − (1/3)(2/3) (1/3)(2/3)2
3 (0, 1/27), (2/27, 3/27), (6/27, 7/27), (8/27, 9/27)(18/27, 19/27), (20/27, 21/27), (24/27, 25/27), (26/27, 1) (2/3)3 = (2/3)2 − (1/3)(2/3)2 (1/3)(2/3)3
4 . . . (2/3)4 (1/3)(2/3)4
. . . . . . . . . . . .n . . . (2/3)n (1/3)(2/3)n
Table 1: Size of Cantor’s set as n → ∞ iterations is limn→∞(2/3)n = 0.
1

As the last example shows, there are random variables that have continuous FX at every point in theirdomain but fail the absolute continuity property for FX. These random variables are called singularly con-tinuous. Their cdf’s being not absolutely continuos can map intervals of length zero to intervals of positivelength. They really make something out of nothing. Singularly continuous random variables are pathologi-cal and require very special construction, so we ignore them throughout this course.
The discrete random variable X has the probability mass function P(X = a), which is mostly nonzero.For an absolutely continuous random variable, we must set P(X = a) = 0. Otherwise, P(X = a) > 0 impliesthat the set of Lebesgue measure A = [a, a] has P(A) > 0, which contradicts the absolute continuity of X or itscdf FX(a) = P(X ≤ a). FX is absolutely continuous if and only if there exists a nonnegative function fX suchthat
FX(a) =∫ a
−∞fX(u)du.
Example: Cantor function is differentiable almost everywhere in its domain [0, 1] but it is not absolutelycontinuous. So differentiable almost everywhere is a weaker condition than absolute continuity. To obtainabsolute continuity of F starting from differentiability almost everywhere of F, we need two more conditions:i) the derivative f = F′ is integrable and ii) F(b)− F(a) =
∫ ba f (u)du. This is also known as the fundamental
theorem of calculus for Lebesgue integral. Note that Cantor function does not satisfy ii). For more details onCantor distribution, see §2.6 of Gut (2005). ⋄
In our discussion below, we focus on absolutely continuous random variables and presume that abso-lute continuity is equivalent to continuity. Hence, we drop “absolute” and write only continuous randomvariables. This convention implies that for every cdf FX of a continuous random variable X there exists fXsatisfying FX(a) =
∫ a−∞ fX(u)du and dF(u) = f (u)du. Since fX exists, we call it the probability density
function (pdf) of continuous random variable X.By assuming absolute continuity, we guarantee the existence of a density. However, we cannot guarantee
the existence of a unique density as illustrated next.
Example: Consider the absolutely continuous cdf F(x) = 1I0≤x≤1x + 1Ix>1. Let f0(x) = 1I0≤x≤1 and letfa(x) = f0(x) + a1Ix=a for a ∈ [0, 1]. Since an alteration at a single point or alterations at countably manypoints do not affect the integral, we have∫ x
0fa(u)du = x = F(x) for 0 ≤ a, x ≤ 1.
Hence each function in the uncountable family fa : a ∈ [0, 1] is a density for F(x) = 1I0≤x≤1x + 1Ix>1. ⋄
Although the last example provides uncountably many densities for single cdf, all densities differ fromeach other only at a single point. So all the densities are the same almost everywhere, except for countablymany points. If you want a more interesting example with different and continuous densities, you must firstnote that two different continuous functions must differ over an interval I ; otherwise, one of them must bediscontinuous. The question can be reframed as: Is it possible to find functions f1, f2 and interval I such thatf1(u) = f2(u) for u ∈ I and
∫ x−∞ f1(u)du =
∫ x−∞ f2(u)du for every x? Requiring
∫ x−∞ f1(u)du =
∫ x−∞ f2(u)du
for every x is equivalent to requiring∫
A f1(u)du =∫
A f2(u)du for every set A. The functions f1, f2 thatsatisfy
∫A f1(u)du =
∫A f2(u)du for every set A must be the same almost everywhere, that is, they cannot
differ over any interval. Hence, various densities associated with a cdf can differ only over a countable setand they cannot be all continuous.
Contrary to what is commonly thought, the derivation of probability models proceeds from (Ω,F , P) toF(x) := P(X ≤ x) without any reference to a density. A density is often an outcome of this process butnot the input. The connection to a density, if it exists, is through integral. This puts integral at the center
2

of probability theory. For a practitioner though, the process can be reversed by assuming the existence of adensity and starting the formulation with a density. When the density exists, the probability manipulationscan be more intuitive.
Example: Consider a continuous random variable X whose domain is [x, x] so that its density is positiveover [x, x]. For x ≤ a < b ≤ x, does strict inequality between a and b imply strict inequality between F(a)and F(b)? We already know that the strict inequality implies F(a) ≤ F(b) for both discrete and continuousvariables. Now by using the density of the continuous random variable:
F(b) =∫ b
xf (u)du =
∫ a
xf (u)du +
∫ b
af (u)du︸ ︷︷ ︸>0
>∫ a
xf (u)du = F(a). ⋄
When existence of a density is assumed for a continuous random variable X, there is tendency to relatethe probability P(X = x) with the density fX(x) for an arbitrary x; this tendency is perhaps carried over fromP(Y = y) = pY(y) for the discrete random variable Y and its pmf pY. With the existence of a density, X isabsolutely continuous and the probability must map each singleton x to zero: P(X = x) = 0. On the otherhand, fX(x) is not necessarily unique and we do not know which one to relate to P(X = x) = 0. In summary,we should not seek a relationship between the probability P(X = x) and the density fX(x) for continuousrandom variables.
2 Moments and Independence
The expectation of a continuous random variable is defined analogously
E(X) =∫ ∞
−∞u f (u)du.
The properties listed for discrete random variables continue to hold for continuous random variables:i) Linearity of expectation: For constant c, E(cg(X)) = cE(g(X)). For functions g1, g2, . . . , gN , E(g1(X) +
g2(X) + · · ·+ gN(X)) = E(g1(X)) + E(g2(X)) + · · ·+ E(gN(X)).ii) For constant c, E(c) = c and V(c) = 0.iii) Nonlinearity of variance: For constant c, V(cg(X)) = c2V(g(X)).iv) V(X) = E(X2)− (E(X))2.
Example: For a continuous random variable X, let f (u) = cu2 + u for 0 ≤ u ≤ 1; otherwise, f (u) = 0. Whatvalue of c makes f a legitimate density so that it integrates to one? Find E(X).
1 = F(1) =∫ 1
0(cu2 + u)du = (c/3)u3 + (1/2)u2∣∣u=1
u=0 = c/3 + 1/2,
so c = 3/2. For the expected value
E(X) =∫ 1
0u((3/2)u2 + u)du = (3/8)u4 + (1/3)u3
∣∣∣u=1
u=0= 3/8 + 1/3 = 17/24. ⋄
The definition of independence extends to continuous random variables X and Y. If we have
P(X ≤ a, Y ≤ b) = P(X ≤ a)P(Y ≤ b) for all a, b ∈ ℜ,
random variables X and Y are said to be independent.
3

Starting from P(X ≤ a, Y ≤ b) = P(X ≤ a)P(Y ≤ b), we can write P(X ≤ a, Y ≤ b) in terms of the pdfsof X and Y.
P(X ≤ a, Y ≤ b) = P(X ≤ a)P(Y ≤ b) =∫ a
−∞fX(x)dx
∫ b
−∞fY(y)dy =
∫ a
−∞
∫ b
−∞fX(x) fY(y)dxdy.
This equality allows us to interpret fX(x) fY(y) as the pdf of (X, Y). Thus, for independent continuous ran-dom variables (X, Y) the density is the product of densities of X and Y.
Example: For two independent random variables, we check the equality E(X1X2) = E(X1)E(X2):
E(X1X2) =∫ ∞
−∞
∫ ∞
−∞(x1x2) fX1(x1) fX2(x2)dx1dx2 =
∫ ∞
−∞x1 fX1(x1)dx1
∫ ∞
−∞x2 fX2(x2)dx2
= E(X1)E(X2).
The first equality above uses the fact that the fX(x) fY(y) is the pdf of (X, Y). ⋄
For two independent continuous random variables, we can check the equality V(X1 + X2) = V(X1) +V(X2). In summary, we have
v) For two independent random variables X1 and X2, E(X1X2) = E(X1)E(X2).vi) Additivity of variance for two independent random variables X1 and X2, V(X1 + X2) = V(X1) +V(X2).
3 Common Continuous Random Variables
Some commonly used continuous random variables are introduced below.
3.1 Uniform Random Variable
A uniform random variable X takes values between x and x, and the probability of X being in any subintervalof [x, x] of a given length δ is the same:
P(a ≤ X ≤ a + δ) = P(b ≤ X ≤ b + δ) for x ≤ a, b ≤ a + δ, b + δ ≤ x.
Uniform random variable over [x, x] is denoted by U(x, x)
Example: What is the pdf of a uniform random variable over [x, x]? Since P(a ≤ X ≤ a + δ) = P(b ≤ X ≤b + δ), f (u) = c must be constant over x ≤ u ≤ x. We need 1 = F(x):
1 =∫ x
xf (u)du =
∫ x
xcdu = c(x − x).
Hence, f (u) = 1/(x − x) for x ≤ u ≤ x.
Example: Find E(X). Since the probability distributed uniformly over [x, x], the expected value is (x + x)/2.You can confirm this by using integration. ⋄
Example: For two independent uniform random variables X1, X2 ∼ U(0, 1), find P(X1 ≥ X2).
P(X1 ≥ X2) =∫
x1≥x2
(1)(1)dx1dx2 =∫ 1
x1=0
∫ x1
x2=0dx2dx1 =
∫ 1
x1=0x1dx1 = x2
1/2|x1=1x1=0 = 1/2. ⋄
Example: For two independent uniform random variables X1, X2 ∼ U(0, 1), find the pdf of maxX1, X2.
P(maxX1, X2 ≤ a) = P(X1 ≤ a, X2 ≤ a) = P(X1 ≤ a)P(X2 ≤ a) = a2 for 0 ≤ a ≤ 1.
Differentiating a2, we obtain fmaxX1,X2 = 2a for 0 ≤ a ≤ 1. ⋄
4

3.2 Exponential Random Variable
An exponential random variable X takes values between 0 and ∞, and the probability of X being in anyinterval [a, a + δ] exponentially decreases as a increases towards b:
P(a ≤ X ≤ a + δ) = exp(−λ(a − b))P(b ≤ X ≤ b + δ) for 0 ≤ a ≤ b and δ ≥ 0,
where the decay parameter λ is the parameter of the distribution. First letting δ → ∞ and then setting a = 0,we obtain the cdf
P(a ≤ X) = exp(−λ(a− b))P(b ≤ X) =⇒ P(b ≤ X) = exp(−λb) =⇒ FX(b) = P(X ≤ b) = 1− exp(−λb).
FX is differentiable and its derivative yields the density
fX(x) = λ exp(−λx) for 0 ≤ x.
We use Expo(λ) to refer to exponential random variable.
Example: Find E(Xk). For k = 1 and k = 2 we have
E(X) =∫ ∞
0xλe−λxdx = −xe−λx
∣∣∣∞
0+
∫ ∞
0e−λxdx = 0 − 1
λe−λx
∣∣∣∞
0=
1λ
.
E(X2) =∫ ∞
0x2λe−λxdx = −x2e−λx
∣∣∣∞
0+
∫ ∞
02xe−λxdx = 0 +
2λ
∫ ∞
0xλe−λxdx =
2λ
1λ=
2λ2 .
Let us suppose that E(Xk) = k!/λk as an induction hypothesis and find E(Xk+1) = (k + 1)!/λk+1:
E(Xk+1) =∫ ∞
0xk+1λe−λxdx = −xk+1e−λx
∣∣∣∞
0+
∫ ∞
0(k + 1)xke−λxdx =
k + 1λ
∫ ∞
0xkλe−λxdx =
k + 1λ
E(Xk)
=(k + 1)!
λk+1 .
This confirms the induction hypothesis and we conclude E(Xk) = k!/λk. ⋄
From the cdf, we can obtain the complementary cdf F(x) = exp(−λx). So we have F(a + b)/F(a) = F(b)which gives us the memoryless property:
P(X > a + b|X > a) =P(X > a + b)
P(X > a)=
F(a + b)F(a)
= F(b) = P(X > b).
Translated into lifetime of a machine, the memoryless property implies the following: If a machine is func-tioning at time a (has not failed over [0, a]), the probability that it will be functioning at time a + b (will notfail over [0, a + b]) is exactly the same as the probability that it functioned for the first b time units after its in-stallation. This implies that if the machine has not failed, it is as good as new. “As good as new” assumptionis used in reliability theory along with other assumptions such as “new better than used”.
3.3 Pareto Random Variable
In the exponential random variable, the complementary cdf is P(Expo(λ) > x) = exp(−λx) so the tail ofthe distribution decays exponentially. Can the decay be slower than exponential? We know exp(λx) ≥ xα
as x → ∞ for any α, so exp(−λx) ≤ x−α. This inspires us to build a distribution based on the power of xto have slower decay in the tail or a fatter (bigger) tail with respect to exponential distribution. We define
5

the associated variable X between x and ∞ and the probability of X being in the interval [a, ∞] is inverselyproportional to its powers:
P(X ≥ a) ∝ a−α for a ≥ x and α ≥ 0.
Since 1 = P(X ≥ x), we have no choice but set
P(X ≥ a) =( x
a
)αfor a ≥ x.
This leads to FX(x) = 1 − (x/x)α and fX(x) = αxα/xα+1. We can use Par(α, x) to denote a Pareto randomvariable.
Example: Find E(X). For α > 1,
E(X) =∫ ∞
xx
αxα
xα+1 dx = α∫ ∞
x
xα
xαdx =
−α
α − 1xα
xα−1
∣∣∣∣∞
x=
αxα − 1
.
For α = 1,
E(X) =∫ ∞
xx
xx2 dx =
∫ ∞
x
xx
dx = x log x|∞x → ∞.
This also implies that E(X) diverges for any α ≤ 1. Pareto random variable presents an example where eventhe first moment does not exist. Note that when the first moment does not exist, the higher moments do noteither. ⋄
We can build some intuition about diverging moments of Pareto random variable by comparing it toexponential random variable. To make the comparison sound, we consider α > 1 and set first momentsequal to each other: 1/λ = αx/(α − 1). For further specification, suppose x = 1 so that α = 1/(1 − λ) forλ < 1. In short, we compare Expo(λ) with Par(1/(1− λ), 1). In our comparison, we want to find an intervalwhere the tail of Par(1/(1 − λ), 1) is larger than the tail of Expo(λ):
P(Par(1/(1 − λ), 1) ≥ x) = x−1/(1−λ) ≥ e−λx = P(Expo(λ) ≥ x).
For fixed λ and sufficiently large x, ln(x)/x ≤ λ(1 − λ). This inequality implies (1/(1 − λ)) ln(x) ≤ λxand in turn x−1/(1−λ) ≥ e−λx. When λ = 0.2, the inequality ln(x)/x ≤ λ(1 − λ) holds for x ≥ 19, e.g.,ln(19)/19 = 0.1549 ≤ 0.16 = 0.2(1 − 0.2). When λ = 0.4, it holds for x ≥ 10, e.g., ln(10)/10 = 0.2302 ≤0.24 = 0.4(1 − 0.4). For every λ, we can find an interval of the form [x, ∞) such that Pareto random variableplaces more probability into this interval than Exponential random variable. In summary, Pareto randomvariable has a heavier tail than Exponential random variable.
Distributions whose tails are heavier than Exponential are called heavy tail distributions. Pareto is anexample of heavy tail distributions. Heavy tail distributions leave significant probability to their tails wherethe random variable takes large values. Multiplication of these large values by large tail probabilities canyield to infinite mean and variance. This may be disappointing but does not indicate any inconsistencywithin the probability theory. If anything, you should be careful when applying results requiring finitemoments to arbitrary random variables.
A practitioner would wonder if heavy tail random variables show up in real life? The answer is definitely.For example, wealth distribution in a population tends to have a heavy tail: there are plenty of individualswith very large amount of wealth. The drop in the number of individuals possessing a particular level ofwealth is decreasing in that wealth but not exponentially; it is decreasing according to a power law. Phoneconversation duration tends to have heavy tails: there are plenty of phone conversations with a very longduration. Number of tweets sent by an individual can have heavy tails: there are plenty of individuals
6

sending a large number of tweets. A large number of ideas can be communicated by using only a smallportion of words in a language. A large number of failures (80%)are caused by only a few (20%) root causes,which is known as Pareto rule in quality management. Number of failures caused by a root cause can haveheavy tails: there are plenty of root causes leading to a large number of failures.
At the end of the 19th century, V. Pareto fit a distribution to the empirical wealth data in several countries.On page 501 of Pareto (1897), he says:
. . . every endeavor must be made to discover if the distribution of wealth presents any uniformityat all. Fortunately the figures representing the distribution of wealth group themselves accordingto a very simple law, which I have been enabled to deduce from unquestioned statistical data.. . . N = A/(x + b)α. In which N represents the number of individuals having an income greaterthan x.
In his formula b, α are constants to be estimated. Judging from the data, he suggests low values for b and1 ≤ α ≤ 2. Regardless of the parameter values, he puts forward the pareto random variable X to model thewealth of individuals in a population.
3.4 Erlang and Gamma Random Variables
An Erlang random variable is obtained by summing up independent exponential random variables. Forexample, let X1 ∼ Expo(λ), X2 ∼ Expo(λ) and X1 ⊥ X2, and define X := X1 + X2, then X has an Erlangdistribution with parameters (2, λ).
Example: For X1 ∼ Expo(λ), X2 ∼ Expo(λ), X1 ⊥ X2 and X := X1 + X2, find the pdf of X. We start withthe cdf of X1 + X2,
P(X ≤ x) = P(X1 + X2 ≤ x) =∫ x
0P(X2 ≤ x − u)λe−λudu =
∫ x
0(1 − e−λ(x−u))λe−λudu
=∫ x
0λe−λudu −
∫ x
0λe−λxdu = −e−λx + 1 − λxe−λx.
Then
fX(x) =d
dxP(X ≤ x) = λe−λx − λe−λx + λ2xe−λx = λe−λx(λx). ⋄
If we add up α many independent Exponential random variables for integer α, the sum turns out to be anErlang random variable with parameters (α, λ). The pdf of Erlang can be extended to real valued α by usingΓ function:
fX(x) =λe−λx(λx)α−1
Γ(α)for x ≥ 0 and α > 0.
You can specialize this formula to α = 2 to see that it is consistent with the result of the last exercise. We useGamma(α, λ) to denote a Gamma random variable.
Example: UTD’s SOM has routers at every floor of the building to provide wireless Internet service. Since theservice must be provided without an interruption as much as practically possible, a failed router is replacedimmediately. We are told that the first floor had 7 failed routers and running the 8th now. On the other hand,the second floor had 4 routers and running the 5th now. Suppose that all these routers are identical withExpo(λ) lifetime with parameter λ measured in year−1. P(Gamma(8, λ) ≥ 10) represents the unconditionalprobability that the routers on the first floor will last for 10 years. If we are told that the SOM building is inoperation for 8 years, then this probability can be revised as P(Gamma(8, λ) ≥ 10|Gamma(8, λ) ≥ 8). Similar
7
probabilities for the second floor are P(Gamma(5, λ) ≥ 10) and P(Gamma(5, λ) ≥ 10|Gamma(5, λ) ≥ 8). ⋄
Example: For integer α, find E(Gamma(α, λ)) and V(Gamma(α, λ)). We can start with the first two momentsof Exponential random variable: E(Expo(λ)) = 1/λ and E(Expo(λ)2) = 2/λ2, which imply V(Expo(λ)) =1/λ2. Since α is integer, we can think of Gamma as sum of α independent exponential random variables sothat we can apply the formulas for the expected value and variance of sum of independent random variables.E(Gamma(α, λ)) = α/λ and V(Gamma(α, λ)) = α/λ2. ⋄
Lastly, Gamma(ν/2, 1/2) gets a special name and it is called a χ2 random variable with ν degrees offreedom, whose density is
fχ2(x) =xν/2−1e−x/2
2ν/2Γ(ν/2)for x ≥ 0.
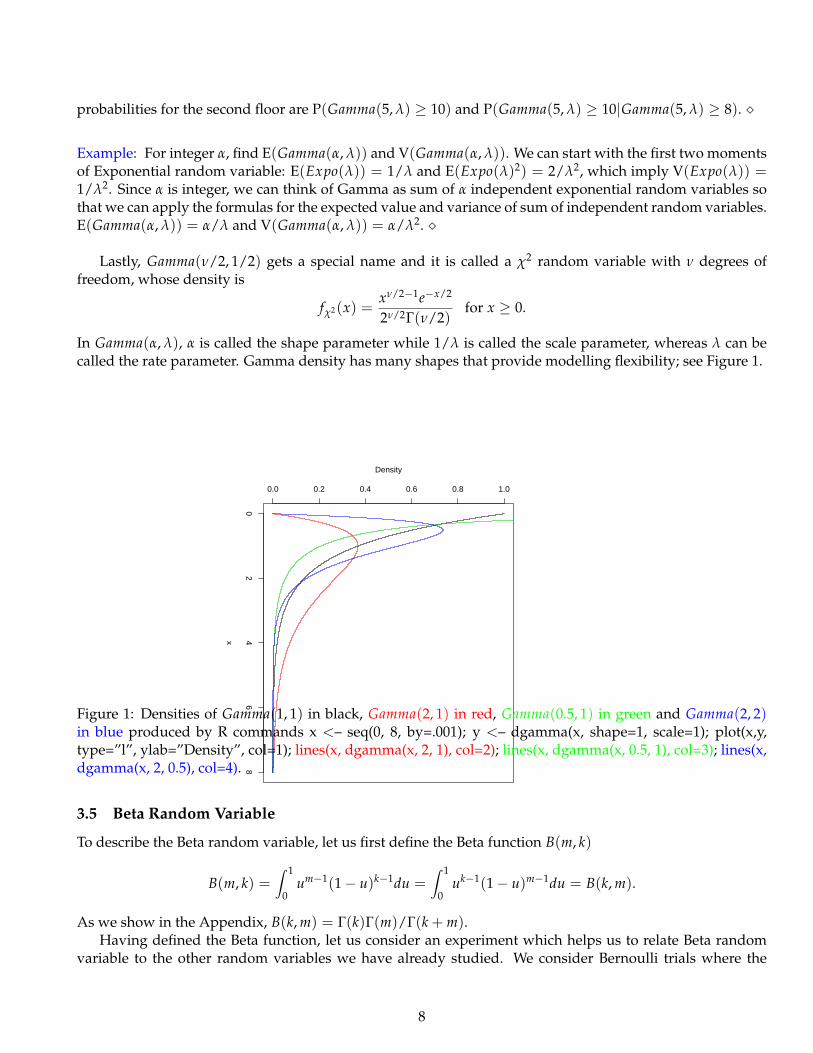
In Gamma(α, λ), α is called the shape parameter while 1/λ is called the scale parameter, whereas λ can becalled the rate parameter. Gamma density has many shapes that provide modelling flexibility; see Figure 1.
02
46
8
0.0 0.2 0.4 0.6 0.8 1.0
x
Density
Figure 1: Densities of Gamma(1, 1) in black, Gamma(2, 1) in red, Gamma(0.5, 1) in green and Gamma(2, 2)in blue produced by R commands x <– seq(0, 8, by=.001); y <– dgamma(x, shape=1, scale=1); plot(x,y,type=”l”, ylab=”Density”, col=1); lines(x, dgamma(x, 2, 1), col=2); lines(x, dgamma(x, 0.5, 1), col=3); lines(x,dgamma(x, 2, 0.5), col=4).
3.5 Beta Random Variable
To describe the Beta random variable, let us first define the Beta function B(m, k)
B(m, k) =∫ 1
0um−1(1 − u)k−1du =
∫ 1
0uk−1(1 − u)m−1du = B(k, m).
As we show in the Appendix, B(k, m) = Γ(k)Γ(m)/Γ(k + m).Having defined the Beta function, let us consider an experiment which helps us to relate Beta random
variable to the other random variables we have already studied. We consider Bernoulli trials where the
8

success probability is constant but unknown. That is, let P be a random variable denoting the success prob-ability and suppose that the success probabilities in each of the Bernoulli trials is P. After n trials, supposethat we observe m success. Given these m successes we can update the distribution of P, we are seekingP(P = p|Bin(n, P) = m):
P(P = p|Bin(n, P) = m) =P(P = p, Bin(n, P) = m)
P(Bin(n, P) = m)=
P(P = p, Bin(n, P) = m)
∑0<u<1 P(P = u, Bin(n, P) = m).
We approximate P(P = p, Bin(n, P) = m) by fP(p)P(Bin(n, P) = m) which leads to ∑u P(P = u, Bin(n, P) =m) ≈
∫ 10 fP(u)P(Bin(n, u) = m)du where fP is the pdf of the success probability P. These lead to
fP|Bin(n,p)=m(p) =fP(p)P(Bin(n, P) = m)∫ 1
0 fP(u)P(Bin(n, u) = m)du=
fP(p)Cnm pm(1 − p)n−m∫ 1
0 fP(u)Cnmum(1 − u)n−mdu
.
To simplify further, suppose that fP is the uniform density, then
fP|Bin(n,p)=m(p) =pm(1 − p)n−m∫ 1
0 um(1 − u)n−mdu=
pm(1 − p)n−m
B(m + 1, n − m + 1)
The density on the right-hand side is pdf of a new random variable, which is the success probability con-ditioned on m successes in n trials when the success probability before the trials is thought to be uniformlydistributed. This random variable is called a Beta random variable.
In general, a Beta random variable X can be denoted as Beta(α, λ) and its density is
fX(x) =xα−1(1 − x)λ−1
B(α, λ)for α, λ > 0 and 0 ≤ x ≤ 1.
Beta random variable can be used to represent percentages and proportions.
Example: Find E(X).
E(X) =∫ 1
0x
xα−1(1 − x)λ−1
B(α, λ)dx =
1B(α, λ)
∫ 1
0xα(1 − x)λ−1dx =
B(α + 1, λ)
B(α, λ)=
Γ(α + 1)Γ(λ)Γ(α + λ)
Γ(α + λ + 1)Γ(α)Γ(λ)
=α
α + λ. ⋄
Example: Monthly maintenance cost for a house, when measured in thousands, has a pdf fX(x) = 3(1− x)2.How much money should be budgeted each month for maintenance so that the actual cost exceeds thebudget only with 5% chance. The cost has Beta(1, 3) random variable and we want to find budget B suchthat P(Beta(1, 3) ≥ B) = 0.05 or P(Beta(1, 3) ≤ B) = 0.95.
0.95 =∫ B
03(1 − x)2dx = −(1 − x)3|B0 = 1 − (1 − B)3 =⇒ B = 1 − 0.051/3 = 0.63
or $630 needs to be reserved. ⋄
3.6 Normal Random Variable
Normal random variable plays a central role in probability and statistics. Its density has light tails so manyobservations are expected to be distributed around its mean. The density is a symmetric and has a rangeover the entire real line, so the normal random variable can take negative values. The density for normallydistributed X is
fX(x) =1√2πσ
e−(x−µ)2
2σ2 for σ > 0 and µ, x ∈ ℜ.
9

The cumulative distribution function at an arbitrary x cannot be found analytically so we refer to publishedtables or software for probability computation. Nevertheless, we can analytically integrate over the entirerange. We use Normal(µ, σ2) to denote a normal random variable with mean µ and standard deviation σ.
Example: Establish that the normal density integrates to 1 over ℜ. We first establish by using z = (x − µ)/σthat ∫ ∞
−∞
1√2πσ
e−(x−µ)2
2σ2 dx =∫ ∞
−∞
1√2π
e−z2/2dz
Equivalent to checking that the last integral is 1 is to check that the multiplication of integrals below is 1:∫ ∞
−∞
1√2π
e−z21/2dz1
∫ ∞
−∞
1√2π
e−z22/2dz2 =
12π
∫ ∞
−∞
∫ ∞
−∞e−(z2
1+z22)/2dz1dz2.
Now consider the transformation r2 = z21 + z2
2 and θ = arccos(z1/r). Hence, z1 = r cos θ and z2 = r sin θ.The Jacobian for this transformation is
J(r, θ) =
cos θ −r sin θ
sin θ r cos θ
,
whose determinant is just r. Thus,
12π
∫ ∞
−∞
∫ ∞
−∞e−(z2
1+z22)/2dz1dz2 =
12π
∫ 2π
0
∫ ∞
0re−r2/2drdθ =
12π
∫ 2π
0dθ︸ ︷︷ ︸
=2π
∫ ∞
0re−r2/2dr︸ ︷︷ ︸=1
= 1. ⋄
Example: Find E(X). Using z = (x − µ)/σ
E(X) =∫ ∞
−∞x
1√2πσ
e−(x−µ)2
2σ2 dx =∫ ∞
−∞(µ + zσ)
1√2π
e−z2/2dz = µ∫ ∞
−∞
1√2π
e−z2/2dz︸ ︷︷ ︸=1
+σ√2π
∫ ∞
−∞ze−z2/2dz︸ ︷︷ ︸=0
= µ.
The last integral is zero because ue−u2/2 = −(−u)e−(−u)2/2 and so∫ 0−∞ ze−z2/2dz =
∫ 0∞(−u)e−(−u)2/2(−du) =∫ 0
∞ ue−u2/2du = −∫ ∞
0 ue−u2/2du. ⋄
Example: What is the distribution of aX + b if X ∼ Normal(µ, σ2). We can consider P(aX + b ≤ u) = P(X ≤(u − b)/a) and differentiate this with respect to u:
ddu
P(X ≤ (u − b)/a) =d
du
∫ (u−b)/a
−∞
1√2πσ
e−(x−µ)2
2σ2 dx =1a
1√2πσ
e−((u−b)/a−µ)2
2σ2 =1√
2πaσe−
(u−b−aµ)2
2a2σ2 .
aX + b has Normal(aµ + b, a2σ2) distribution. ⋄
From the last example, we can see that any random variable can be standardized by deducting its meanand dividing by its standard deviation, the standard normal random variable is Normal(0, 1).
Example: We know E(Normal(µ, σ2)) = µ obtained from integrating over (−∞, ∞), find the partial integra-tion over (−∞, a).
E(Normal(µ, σ2)1INormal(µ,σ2)≤a) =∫ a
−∞x
1√2πσ
e−(x−µ)2
2σ2 dx =∫ (a−µ)/σ
−∞(µ + zσ)
1√2π
e−z2/2dz
= µFNormal(0,1)
(a − µ
σ
)+ σ
∫ (a−µ)2/(2σ2)
∞
1√2π
e−udu
= µFNormal(0,1)
(a − µ
σ
)− σ fNormal(0,1)
(a − µ
σ
)10

Above we use u = z2/2 substitution. This formula can be used as a starting point to compute expectedvalues of some other functions involving X and a. ⋄
3.7 Lognormal Random Variable
X is a lognormally distributed random variable if ln X is Normal(µ, σ2). That is, X can be expressed as
X = eY for Y ∼ Normal(µ, σ2).
So the range for X is [0, ∞). Having a nonnegative range can make the lognormal distribution more usefulthan the normal distribution to model quantities such as income, city sizes, marriage age and number ofletters in spoken words, which are all nonnegative.
Example: Find the pdf of X.
P(X ≤ x) = P(Y ≤ ln x) =∫ ln x
−∞
1√2πσ
e−(y−µ)2
2σ2 dy.
Taking the derivative with respect to x
fX(x) =d
dxP(X ≤ x) =
1x
1√2πσ
e−(ln x−µ)2
2σ2 . ⋄
Example: Find E(Xk)
E(Xk) = E((eY)k) = E(ekY) =∫ ∞
−∞eky 1√
2πσe−
(y−µ)2
2σ2 dy = ekµ∫ ∞
−∞eku 1√
2πσe−
u2
2σ2 du
= ekµek2σ2/2∫ ∞
−∞
1√2πσ
e−(u−kσ2)2
2σ2 du = ekµek2σ2/2. ⋄
3.8 Mixtures of Random Variables
Given two random varaible X and Y, their mixture Z can be obtained as
Z =
X with probability pY with probability 1 − p
.
Then we have
FZ(z) = P(Z ≤ z) = pP(X ≤ z) + (1 − p)P(Y ≤ z) = pFX(z) + (1 − p)FY(z).
We can easily obtain the pdf of Z if both X and Y are continuous random variables.When one of the mixing distributions is discrete and another one is continuous, we do not have a pdf.
Example: Consider the mixture of a mass at [Z = 0] and an exponential distribution
FZ(z) =
q if z = 0q + (1 − q)(1 − exp(−λz)) if z > 0
.
This cdf is not continuous at 0, so Z is not a continuous random variable. Z takes values in ℜ, its range isuncountable, so Z is not a discrete random variable either. ⋄
11

Random variables derived from others through max or min operators can have masses at the end of theirranges. Product returns due to unmet expectations to a retailer can be treated as negative demand, then thedemand D takes values in ℜ. If you want only the new customer demand for products, you should considermax0, D which has a mass at 0. When a person buys a product, you know that his willingness to pay Wis more than the price p. Willingness-to-pay of customers who already bought the product is maxp, W.When you have a capacity of c and accept only demand that is less than the capacity, the accepted demandbecomes minc, D. The last two derived random variables have masses at p and c.
4 Moment Generating Functions
A variable X can be summarized by its mean E(X), second moment E(X2) and variance V(X). But manyrandom variable have the same mean and variance (so the same second moment). To distinguish randomvariables we can use their moment generating functions: mX(t) := E(exp(tX)). For discrete and continuousnonnegative random variables, the moment generating functions are obtained in analogous ways:
mX(t) =∞
∑x=−∞
exp(tx)pX(x) and mX(t) =∫ ∞
−∞exp(tx) fX(x)dx.
Although the moment generating function is defined for every t, we need it to be finite in a neighborhood oft = 0. This technical condition holds for most of the random variables.
By using Taylor expansion of exp(t) at t = 0,
exp(tx) = 1 + tx +(tx)2
2!+
(tx)3
3!+ · · ·+ (tx)i
i!+ . . . .
Inserting this into mX(t) for a discrete random variable,
mX(t) =∞
∑x=−∞
(1 + tx +
(tx)2
2!+ · · ·+ (tx)i
i!+ . . .
)pX(x)
= 1∞
∑x=−∞
pX(x) + t∞
∑x=−∞
xpX(x) +t2
2!
∞
∑x=−∞
x2 pX(x) + · · ·+ ti
i!
∞
∑x=−∞
xi pX(x) + . . .
= 1 + tE(X) +t2
2!E(X2) + · · ·+ ti
i!E(Xi) + . . .
=∞
∑i=0
ti
i!E(Xi).
Form the last equality, we obtain mX(t = 0) = 1. To pick up only the E(X) term on the right-hand side, weconsider the derivative of mX(t) with respect to t. Provided that derivative can be pushed into the summationin the last equation above, we can obtain
dk
dtk mX(t) =∞
∑i=0
E(Xi)1i!
dk
dtk ti = E(Xk) +∞
∑i=k+1
E(Xi)i(i − 1) . . . (i − k + 1)
i!ti−k = E(Xk) +
∞
∑i=k+1
E(Xi)ti−k
(i − k)!.
For example,
d1
dt1 mX(t) = E(X1) +∞
∑i=2
E(Xi)ti−1
(i − 1)!and
d2
dt2 mX(t) = E(X2) +∞
∑i=3
E(Xi)ti−2
(i − 2)!.
Then
E(Xk) =dk
dtk mX(t)∣∣∣∣t=0
.
12

The last equation makes it clear why mX(t) is called a moment generating function.If two moment generating functions are equal, what can we say about the corresponding random vari-
ables? Moment generating functions are related to power series in the appendix to motivate that mX(t) =mY(t) implies X ∼ Y. So moment generating functions uniquely identify random variables.
Example: If X and Y are two independent random variables with mX and mY, what is the moment generatingfunction mX+Y of the sum of these variables? We proceed directly as
mX+Y(t) = E(exp(t(X + Y))) = E(exp(tX))E(exp(tY)) = mX(t)mY(t),
where independence of exp(tX) and exp(tY) is used in the middle equality. ⋄
Example: Find the moment generating function for the Bernoulli random variable. Use this function toobtain the moment generating function of the Binomial random variable. For a Bernoulli random variableXi with success probability p,
mXi(t) = E(exp(tXi)) = exp(t0)(1 − p) + exp(t1)p = (1 − p) + p exp(t).
Binomial random variable B(n, p) is a sum of n Bernoulli random variables so
m∑ni=1 Xi
(t) = Πni=1mXi(t) = ((1 − p) + p exp(t))n. ⋄
Example: For an exponential random variable X find the moment generating function mX(t) and the mo-ments E(Xk).
mX(t) = E(etX) =∫ ∞
0etxλe−λxdx = λ
∫ ∞
0e−(λ−t)xdx = λ
(− 1
λ − te−(λ−t)x
∣∣∣∣∞
0
)=
λ
λ − t= λ(λ − t)−1.
Then
E(Xk) =dk
dtk mX(t)∣∣∣∣t=0
= λdk
dtk (λ − t)−1∣∣∣∣t=0
= λ(k!)(λ − t)−k−1∣∣∣t=0
=k!λk . ⋄
Example: Find the moment generating function for Gamma(n, λ) for integer n ≥ 1.
mGamma(n,λ)(t) = Πni=1mExpo(λ)(t) =
(λ
λ − t
)n
. ⋄
Example: Find the moment generating function for X = Normal(µ, σ2) and use this moment generatingfunction to obtain the distribution of two independent Normal random variables X1 + X2, where X1 =Normal(µ1, σ2
1 ) and X2 = Normal(µ2, σ22 ). We have
mX(t) =∫ ∞
−∞ext 1√
2πσe−0.5(x−µ)2/σ2
dx = eµt∫ ∞
−∞
1√2π
eσtze−0.5z2dz = eµt+0.5σ2t2
∫ ∞
−∞
1√2π
e−0.5(z−σt)2dz︸ ︷︷ ︸
=1
= eµt+0.5σ2t2,
where the second equality follows from x = µ + σz and the third equality follows from −0.5z2 + σtz =−0.5(z − σt)2 + 0.5σ2t2.
mX1+X2(t) = mX1(t)mX2(t) = eµ1t+0.5σ21 t2
eµ2t+0.5σ22 t2
= e(µ1+µ2)t+0.5(σ21+σ2
2 )t2,
13

so X1 + X2 ∼ Normal(µ1 + µ2, σ21 + σ2
2 ). ⋄
Example: For a random variable X, the moment generating function is argued to be
mX(t) = 1 +∞
∑i=1
ti
(i − 1)!.
Find E(X), E(X2), E(Xk) for k ≥ 3 and determine if mX(t) can be a valid moment generating function.
E(X) =ddt
mX(t)∣∣∣∣t=0
= 1 +2t1!
+3!t2
2!+
4t3
3!+ . . .
∣∣∣∣t=0
= 1.
E(X2) =d2
dt2 mX(t)∣∣∣∣t=0
= 2 +3(2)t
2!+
4(3)t2
3!+ . . .
∣∣∣∣t=0
= 2.
E(X3) =d3
dt3 mX(t)∣∣∣∣t=0
= 3 +4(3)(2)t
3!+ . . .
∣∣∣∣t=0
= 3.
E(X4) =d4
dt4 mX(t)∣∣∣∣t=0
= 4 + . . . |t=0 = 4.
E(Xk) =dk
dtk mX(t)∣∣∣∣t=0
=k!
(k − 1)!+
k . . . (k − 2)tk!
+3t2
2+ . . .
∣∣∣∣t=0
= k.
Let Y = X3 a new random variable. We have V(Y) = E(Y2) − E(Y)2 = E(X6) − E(X3)2 = d6mX(t)/dt6
− (d3mX(t)/dt3)2∣∣t=0 = 6 − 32 = −3. This points to a contradiction and mX(t) cannot be moment generat-
ing function for any random variable. A moment generating function needs to yield a “positive” value whenit is differentiated, differenced and evaluated in certain ways. ⋄
As the last example shows, an arbitrary function cannot be a moment generating function. The lastexample hints at some sort of a “positivity” property for a moment generating function. This can be astarting point to answer the question: Is there a set of conditions to check on mX(t) to decide if it correspondsto random variable X or its pmf pX / pdf fX? This question has a complicated answer that goes well beyondthe scope of this note. It is answered fully for a similar transformation (characteristic function rather thanmoment generating function). A characteristic function must be positive definite; see appendix for details.
5 Application: From Lognormal Distribution to Geometric Brownian Motion
If St denotes the price of a security (a stock, a bond, or their combinations) at time t ≥ 0 for given S0 = s0known now, we can consider
St
S0=
St
St−1
St−1
St−2. . .
S2
S1
S1
S0.
Suppose that each ratio Si/Si−1 is independent of the history Si−1, Si−2, . . . , S1, S0 and is given by a Lognor-mal distribution with parameters µ and σ.
Since Si+1/Si and Si/Si−1 are independent and lognormally distributed with parameters µ and σ2, wehave ln Si+1 − ln Si ∼ Normal(µ, σ2) and ln Si − ln Si−1 ∼ Normal(µ, σ2). Their sum is ln Si+1 − ln Si−1 =ln Si+1 − ln Si + ln Si − ln Si−1 ∼ Normal(2µ, 2σ2). Hence, Si+1/Si−1 has lognormal distribution with pa-rameters 2µ and 2σ2. This line of logic yields that St/S0 has lognormal distribution with parameters tµ andtσ2.
14

Another way to represent security price at time t is to write
St = s0Xt,
where Xt is a lognormal random variable with parameters tµ and tσ2. Then we can immediately obtain themean and variance of the security price
E(St) = s0E(Xt) = s0etµ+tσ2/2.
V(St) = s2oV(Xt) = s2
o(e2tµ+2tσ2 − e2tµ+tσ2
) = s2oe2tµ+tσ2
(etσ2 − 1)
St as constructed above is a Geometric Brownian Motion process. Note we have not constructed theprocess at noninteger times, so strictly speaking we have constructed a discrete-time process that coincideswith the Geometric Brownian Motion at integer times.
15

6 Exercises
1. Find E(Beta(a, b)2).
2. Let us consider the following transform nX(t) = ln E(exp(tX)). Clearly, nX(0) = 0. Determine whatmoments (d/dx)nX(x)|x=0 and (d2/dx2)nX(x)
∣∣x=0 correspond to. That is, express these in terms of
E(Xk) for integer k.
3. For the transform nX(t) = log E(exp(tX)), what is nXi(t) = log E(exp(tXi)) for Bernoulli distributedXi? Can you use nXi(t) to easily compute the nX(t) for the Binomial random variable X = ∑n
i=1 Xi,how?
4. For two independent random variables X and Y, let X ∼ U(0, 1) and Y ∼ U(0, 1) and find the pdf ofX + Y.
5. Let Y ∼ Expo(λ) and set X := ⌊Y⌋+1. ⌊y⌋ is the floor function for a possibly fractional number y,it returns the largest integer smaller than or equal to y. What is the distribution of X; is it one of thecommon distributions?
6. Which random variable has the moment generating function m(t) = exp(t(µ+ a))(1− exp(−2at))/(2at)for parameters µ, a?
7. When X is demand and a is inventory, E(1IX≥a(X − a)) is the expected inventory shortage. For X =Normal(µ, σ2) and Z = Normal(0, 1), establish that
Inventory Shortage: E(1IX≥a(X − a)) = σ fZ
(a − µ
σ
)− (a − µ)
(1 − FZ
(a − µ
σ
)).
8. When X is demand and a is inventory, E(1IX≤a(a − X)) is the expected leftover inventory. For X =Normal(µ, σ2) and Z = Normal(0, 1), establish that
Leftover Inventory: E(1IX≤a(a − X)) = (a − µ)FZ
(a − µ
σ
)+ σ fZ
(a − µ
σ
).
9. When X is demand and a is inventory, express E(1IX≤a(a − X)) − E(1IX≥a(X − a)) in English. ForX = Normal(µ, σ2), find this quantity in terms of a, µ, σ, cdf and pdf of Z = Normal(0, 1).
10. For X = Normal(µ, σ2) find a formula to compute E(minX, a) in terms of only a, µ, σ, cdf and pdf ofZ = Normal(0, 1).
11. We set October as month 0, and use S1 and S2 to denote stock prices for months of November and De-cember. We assume that S2/S1 and S1/S0 have independent Lognormal distributions. In other words,log(S2/S1) and log(S1/S0) both have normal distributions with mean 0.09 and standard deviation 0.06.Find the probability that the stock price increases either in October or November. Find the probabilitythat the stock price increases at the end of two months with respect to the initial price in October.
12. A bond’s price is normalized to s0 = 1 last year. The price changes every quarter by a multiple Mt sothe price St at the end of quarter t is given by St = MtSt−1 for S0 = s0. The logarithm of the multiple Mthas normal distribution whose variance remains constant at σ2 over the quarters but its mean increasesproportionally E(ln Mt) = µt. What is the distribution of S4 at the end of the year? Suppose thatµ = 0.03 and σ = 0.1, what is the probability that bond’s price at least doubles in a year?
16

13. A nonnegative random variable X has finite kth moment if E(Xk) < ∞. For a given positive integer k,we can compute the kth moment with an alternative formula by using the tail probability as
E(Xk) = m∫ ∞
0xnP(X > x)dx
for appropriate numbers m, n ≤ k. Find out what m, n are in terms of k. Specialize your formula tok = 1 and k = 2 and provide these special versions.
14. A lake hosts N = 3 frogs, which start taking sunbathes together everyday. Frogs are very particularabout the dryness of their skin so they jump into water after a while and finish their sunbathing. Eachfrog takes a sunbathe for Expo(λ) amount of time independent of other frogs. Let Xn be the durationof the time at least n frogs are sunbathing together. Find the cdfs of X1 and X3. Does X1 or X3 have oneof the common distributions?
15. Let X1, X2, . . . , Xn be random variables and their sum be Sn = X1 +X2 + · · ·+Xn. Futhermore, supposethat Sn is a Gamma random variable with parameters (n, λ).a) Is it always true that each Xi is an exponential random variable with parameter λ? If yes, prove thisstatement. Otherwise, provide a counterexample.
b) Supose that Xi’s are identically distrubted. Is it always true that each Xi is an exponential randomvariable with parameter λ? If yes, prove this statement. Otherwise, provide a counterexample.
c) Supose that Xi’s are independent and identically distrubted. Is it always true that each Xi is anexponential random variable with parameter λ? If yes, prove this statement. Otherwise, provide acounterexample.
d) Supose that Xi’s are independent. Is it always true that each Xi is an exponential random variablewith parameter λ? If yes, prove this statement. Otherwise, provide a counterexample.
16. Suppose that Xi is the wealth of individuals in country i, whose population is ni, for i = 1, 2. Let X1, X2be iid Pareto random variables such that P(Xi ≥ a) = 1/a for a ≥ 1. P(Xi ≥ a) can also be interpretedas the percentage of the population with wealth a or more. We make some groups of individuals bypicking n1 individual from country 1 and n2 individuals country 2 such that n1/n2 = n1/n2: Therepresentation of each country in these groups is proportional to its sizes. Let X be the average wealthof individuals in any one of these groups: X = (n1X1 + n2X2)/(n1 + n2). Groups have identicallydistributed average wealths and we are interested in the distribution of this wealth.a) The tail probability of X can be expressed as
P(X ≥ a) =1a+
(aρ
)−1 ( a1 − ρ
)−1 ln
(aρ− 1
)+ ln
(a
1 − ρ− 1
)for an appropriate parameter ρ. Derive this tail probability expression and find what exactly ρ is. Hint:
For a − mx ≥ 0,∫(1/(a − mx))(1/x2)dx = (m/a2)
(ln
(x/(a − mx)
))− 1/(ax).
b) Evaluate the tail probability formula obtained above at extreme values of range of X to see if you get0 and 1.
17. Suppose that Xi is the wealth of individuals in country i, whose population is ni, for i = 1, 2. Let X1, X2be iid Pareto random variables such that P(Xi ≥ a) = 1/a for a ≥ 1. P(Xi ≥ a) can also be interpretedas the percentage of the population with wealth a or more. We make some groups of individuals bypicking n1 individual from country 1 and n2 individuals country 2 such that n1/n2 = n1/n2: Therepresentation of each country in these groups is proportional to its sizes. Let X be the average wealth
17

of individuals in any one of these groups: X = (n1X1 + n2X2)/(n1 + n2). The tail probability of X canbe expressed as
P(X ≥ a) =1a+
(aρ
)−1 ( a1 − ρ
)−1 ln
(aρ− 1
)+ ln
(a
1 − ρ− 1
).
a) Evaluate the tail probability as one of the countries becomes very large, i.e., ni → ∞.
b) Evaluate the tail probability when the countries have the same size.
c) When countries have the same size, what is the largest difference between P(X ≥ a) and P(X1 ≥ a),i.e., what is the maximum value of |P(X ≥ a)− P(X1 ≥ a)|?
18. Suppose that Xi is the wealth of individuals in country i, whose population is ni, for i = 1, 2. Let X1 bePareto random variable such that P(Xi ≥ a) = 1/a for a ≥ 1. People in country 2 are twice as rich asthe people in country 1 and their wealth also has a pareto distribution.
a) Find the tail probability of X2, i.e., P(X2 ≥ a).
b) Suppose X1 and X2 are independent. If we randomly pick an individual from either country 1or 2, what is the probability that he has wealth a or more. Does the wealth of a randomly chosenindividual have a pareto distribution? Does the tail of this wealth distribution resemble the tail of aPareto distribution for some range of values? Identify that range, if there is one.
18

7 Appendix: Change of Variables in Double Integrals and Beta Function
Suppose that we want to write∫∫
S f (x, y)dxdy as∫∫
T F(u, v)dudv. This is changing variables from (x, y)to (u, v). The initial region S is in the xy plane while its transform T is in uv plane. We assume that thetransformation between S and T is one-to-one. Then there will be functions U, V : S → T, explicitly writtenas
u = U(x, y) and v = V(x, y) for (x, y) ∈ S, (u, v) ∈ T,
as well as functions X, Y : T → S
x = X(u, v) and y = Y(u, v) for (x, y) ∈ S, (u, v) ∈ T.
Note that X and Y are functions of (u, v), so we can think of partial derivatives of the form ∂X/∂u, ∂X/∂v,∂Y/∂u, ∂Y/∂v. If the partials do not exist at certain (x, y) and differ in some subsets of S, you can considerthe transformation over each subset separately from the other subsets. With the partials, Jacobian J matrixcan be made up
J(u, v) =
∂X∂u
∂X∂v
∂Y∂u
∂Y∂v
.
What we need is the determinant det(J(u, v)) of the Jacobian. Note that there is no precedence between Xand Y, so the Jacobian for the desired transformation might be constructed as
J′(u, v) =
∂Y∂u
∂Y∂v
∂X∂u
∂X∂v
.
We have det(J(u, v)) = −det(J′(u, v)), so which determinant should we use? The answer is that shufflingrows or columns of the Jacobian does not matter because what we actually use is the absolute value of thedeterminant of the Jacobian. Then we have the change-of-variable formula∫∫
Sf (x, y)dxdy =
∫∫T
f (X(u, v), Y(u, v))|J(u, v)|dudv.
Example: Use change of variable rule above to establish the connection between Beta function and Gammafunction:
B(k, m) =∫ 1
0uk−1(1 − u)m−1du =
Γ(k)Γ(m)
Γ(k + m).
We start with Γ(k)Γ(m) and proceed as follows
Γ(k)Γ(m) =∫ ∞
0e−xxk−1dx
∫ ∞
0e−yyk−1dy =
∫ ∞
0
∫ ∞
0e−(x+y)xk−1yk−1dxdy.
Let u = x/(x + y) and v = x + y so that x = X(u, v) = uv and Y(u, v) = v(1 − u). Then the Jacobian matrixis
J(u, v) =
v u
−v 1 − u
,
whose determinant is v(1 − u) + vu = v. Hence,
Γ(k)Γ(m) =∫ ∞
0
∫ 1
0e−v(uv)k−1((1 − u)v)m−1vdudv =
∫ ∞
0e−vvm+k−1dv
∫ 1
0uk−1(1 − u)m−1du,
which can be written as Γ(k)Γ(m) = Γ(k + m)∫ 1
0 uk−1(1 − u)m−1du to establish the desired equality. ⋄
19

8 Appendix: Induction over Natural Numbers
In these notes, we take natural numbers as N = 0, 1, 2, . . . by choosing to include 0 in N . However,0, 1, 2, . . . is not a workable definition for natural numbers and needs formalization. This formalization isnot trival and achived in late 19th century by Peano. It requires 5 axioms to define the set of natural numbers.
P1: 0 ∈ N .P2: There is a successor function δ : N → N . For each x ∈ N , there is a successor δ(x) of x and δ(x) ∈ N .P3: For every x ∈ N , we have δ(x) = 0.P4: If δ(x) = δ(y) for x, y ∈ N , then x = y.P5: If S ⊂ N is such that i) 0 ∈ S and ii) x ∈ N ∩ S =⇒ δ(x) ∈ S, then S = N .
By P1 and P3, 0 can be thought as the initial element of natural numbers in the sense that 0 is not asuccessor of any other natural numbers. P2 introduces the successor function and P4 requires that if thesuccessors of two numbers are equal, then these numbers are equal. P5.i is the base step for initializing Sand P5.ii is the induction step for enlargening S.
These axioms are adapted from p.23 of Gunderson (2011) – “Handbook of Mathematical Induction”. Inthe next few pages of his book, Gunderson uses axioms P1− P5 to prove some properties of natural numberssuch as:• A natural number cannot be a successor of its own: If x ∈ N , then δ(x) = x.• Each natural number except 0 has a unique predecessor: If x ∈ N \ 0, then there exists y such thatx = δ(y).• There exists a unique function f : N ×N → N such that f (x, 1) = δ(x) and f (x, δ(y)) = δ( f (x, y)) forx, y ∈ N .This function f turns out to be summation: f (x, y) = x + y. Hence, δ(x) = f (x, 1) = x + 1 is the successor ofx. Hence, natural numbers start with 0, includes its successor 1=0+1, includes 2=1+1, and so on.
We can now present the idea of induction as a theorem and prove it.Induction Theorem: If S(n) is a statement involving n and if i) S(0) holds and ii) For every k ∈ N ,S(k) =⇒ S(k + 1), then S(n) holds for every n ∈ N .One cannot help but realize the similarity between the theorem statement and axiom P5. So the proof isbased on P5. Let A = n ∈ N : S(n) is true . Then by condition i) in the theorem statement, 0 ∈ A. By ii) inthe theorem statement and S(k = 0) true, we obtain that S(k + 1 = 1) is true. Then 1 ∈ A. In general, k ∈ Aimplies k + 1 ∈ A. Hence A = N by P5. That is, S(n) holds for every n ∈ N .
Does the induction extend to infinity? To answer this, we ask a more fundamental question: Is infinity anatural number? We need to be more specific about what infinity “∞” is. Infinity is a symbol that denotessomething intuitively larger than all the numbers and can be operated under summation: ∞ + a = ∞ fora ∈ N . In particular, ∞ + 1 = ∞. We can use this last equality to check whether ∞ ∈ N .
Actually, ∞ /∈ N . To use proof by contradicction suppose that ∞ ∈ N . Then it has a successor δ(∞).Infinity cannot have itself as its successor, so ∞ = δ(∞) = ∞ + 1. Contradicting to this is the property ofinfinity ∞ = ∞ + 1 presented above. This contradiction establishes ∞ /∈ N . In sum, the induction theorempresented above does not apply to infinity ∞.
There can be other versions of the induction theorem (by initializing with S(m) for m > 0 or by assum-ing S(m) for all m ≤ k in the kth induction step). I have even found a description of induction over realnumbers by considering intervals and proceeding from a tighter interval towards a broader one (see The In-structor’s Guide to Real Induction by P.L.Clark at http://arxiv.org/abs/1208.0973) but I am not in a positionto validate/illustrate this approach.
20

9 Appendix: From Power Series to Transforms and Back
Moment generating function can be thought as a power series
m(t) =∞
∑n=0
p(n) exp(nt) =∞
∑n=0
anxn =: f (x),
where the series coefficient an = p(n) of the pmf of the random variable and x = exp(t).For a power series that has a positive radius of convergence (convergence for some interval of ℜ), it is
known that the power series is infinitely differentiable around x = 0 and
an =f (n)(0)
n!.
If another series g(x) = ∑n bnxn has non-zero radius of convergence and f (x) = g(x) for an interval around0, we obtain
an =f (n)(0)
n!=
f (n)(0)n!
= bn.
That is, all of the coefficients of the power series must be equal for the series to be equal.This result establishes a one-to-one correspondence between power series and their coefficients. It also
establishes a one-to-one correspondence between moment generating function of a random variable and itspmf but proving that a given moment generating function can belong to a single random variable is involved.One of the transforms is the moment generating function. Another one is generating function (sometimesalso called z-transform) E(zX) for a constant z. Laplace transform is E(exp(−tX)). The characteristic functionis E(exp(itX)) for the complex number i =
√−1. Note that all these transforms involve power series – over
real or complex numbers.A question stated in the main body is recovering the random variable from its transformation. We discuss
this for the continuous random varaible X, whose characteristic function is defined as
φX(t) =∫ ∞
−∞exp(itx) fX(x)dx.
By using Euler’s formula exp(ix) = cos(x) + i sin(x) and | exp(ix)| = cos2(x) + sin2(x) = 1, we obtain| exp(itx)| = 1. Hence, |φX(t)| ≤
∫ ∞−∞ fX(x)dx = 1 and the characteristic function always exists. In addition
to this advantage, the characteristic function can be defined for general functions (not necessarily densities)and then it is called Fourier-Steiltjes Transformation, which has its own literature.
Example: Find the characteristic function for an exponential random variable with rate 1.
φX(t) =∫ ∞
−∞exp(itx) fX(x)dx =
∫ ∞
0exp(itx) exp(−x)dx =
∫ ∞
0exp(−(1 − it)x)dx
= − 11 − it
exp(−(1 − it)x)∣∣∣∣∞
0=
11 − it
. ⋄
A characteristic function can be inverted to obtain the corresponding density. The inversion formula
fX(x) =1
2π
∫ ∞
−∞exp(−itx)φX(t)dt
is puzzlingly similar to the transformation formula. Every characteristic function may not correspond to aprobability density. The following theorem has necessary and sufficient conditions and settles this issue.
Theorem 1. Bochner’s Theorem A function φ(t) is the charecteristic function of a random variable if and only if ithas φ(0) = 1, it is continuous and positive definite.
21

A function φ : ℜ → ℜ is positive definite if for all real numbers x1, x2, . . . , xn and all complex numbersz1, z2, . . . , zn, it satisfies
n
∑j=1
n
∑k=1
φ(xj − xk)zjzk ≥ 0,
where zk is the conjugate of zk. For more details, see chapter 7 of Borovkov (2013).
References
A.A. Borovkov. 2013. Probability Theory. Translation of the fifth edition in Russian “Teoriya Veroyatnostei”published by Springer.
P. Billingsley. 1995. Probability and Measure. 3rd edition published by Wiley & Sons.D.R. Chalice. 1991. A Characterization of the Cantor Function. The American Mathematical Monthly, Vol.98,
No.3: 255-258.A. Gut. 2005. Probability: A Graduate Course. 1st edition published by Springer.V. Pareto. 1897. The new theories of economics. Journal of Political Economy, Vol.5, No.4: 485-502.
22


















