
Conditioned allophony in speech perception: An MEG study Mary Ann Walter & Valentine Hacquard...
24
Conditioned allophony in speech perception: An MEG study Mary Ann Walter & Valentine Hacquard [email protected] [email protected] Dept. of Linguistics & Philosophy, MIT KIT/MIT MEG Lab 2 nd Old World Conference in Phonology CASTL-Tromsø, January 20-22, 2005
-
date post
21-Dec-2015 -
Category
Documents
-
view
215 -
download
0
Transcript of Conditioned allophony in speech perception: An MEG study Mary Ann Walter & Valentine Hacquard...

Conditioned allophony in speech perception: An MEG study
Mary Ann Walter & Valentine Hacquard
[email protected] [email protected]
Dept. of Linguistics & Philosophy, MIT
KIT/MIT MEG Lab
2nd Old World Conference in Phonology
CASTL-Tromsø, January 20-22, 2005

Questions about (conditioned) allophony:
• Structural properties of a language’s phonology significantly affect the perception of speech sounds (particularly well-documented wrt phonemic inventory (Kuhl 1993, Best 1995))
• How perceptible are differences between allophones to speakers?
• How does the perceived similarity of allophones compare to that of phonemes, free variants, and other kinds of contrast?
• What implications follow for models of phonology and similarity computation?

Overview:
• Subphonemic perceptibility
• MEG and the MMF
• Where allophones fit in:
• Russian/Korean
• French/Spanish
• Quebecois French
• Results: Equivocal, but ours suggest that allophones affiliate with structural, phonemic contrasts, rather than within-category free variants

Allophone perceptibility:
• Speakers produce consistent and finely controlled distinctions between allophones
• Suggests they must be able to perceptually distinguish them, at least proprioceptively
• Anecdotally this often seems not to be the case
• When measured experimentally, subjects typically distinguish allophones at above chance levels, but much less easily and well than phoneme pairs (for aspiration in English, see Pegg & Werker 1997, Whalen et al. 1997, Utman et al. 2000, Jones 2001)
• For the segment pair we will discuss (e and ε), evidence is contradictory:
• Pallier et al (1997) find that the pair is indistinguishable for Spanish speakers for whom they are conditioned allophones, even when bilingual in a language in which they are phonemic (Catalan)
• Escudero and Boersma (2002) find that discrimination does improve for such speakers, however
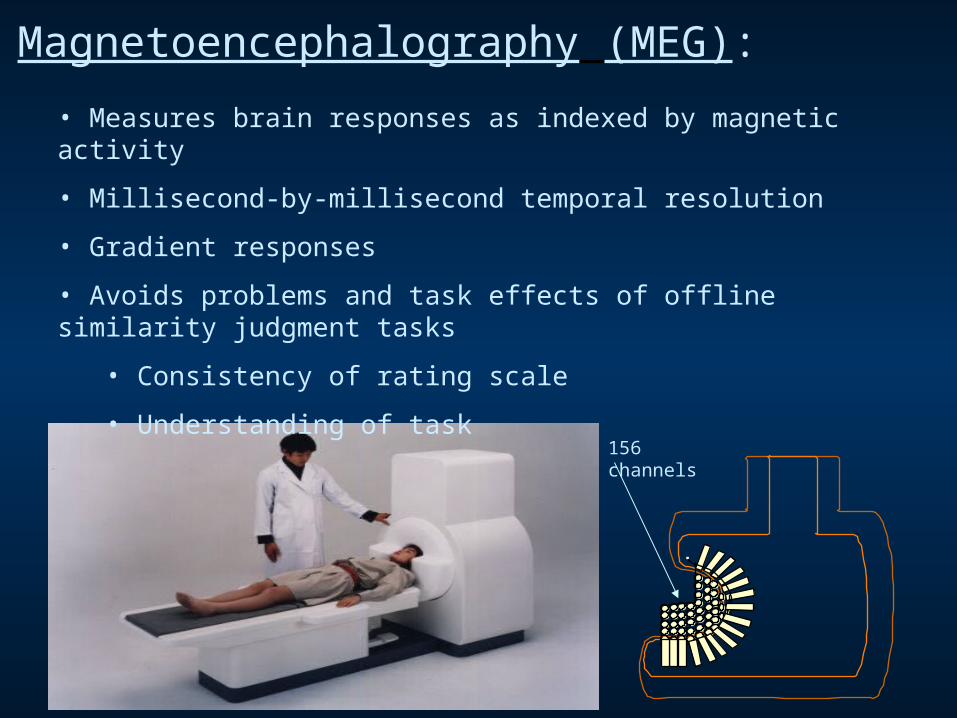
Magnetoencephalography (MEG):
• Measures brain responses as indexed by magnetic activity
• Millisecond-by-millisecond temporal resolution
• Gradient responses
• Avoids problems and task effects of offline similarity judgment tasks
• Consistency of rating scale
• Understanding of task
156 channels
Origin of signal in auditory cortex
The mismatch field response (MMF):
• An non-attentive auditory response that indexes perceived (cf tone experiments) (dis)similarity
• One of a number of language-sensitive neural responses
• Peaks between 180-250 ms post stimulus onset
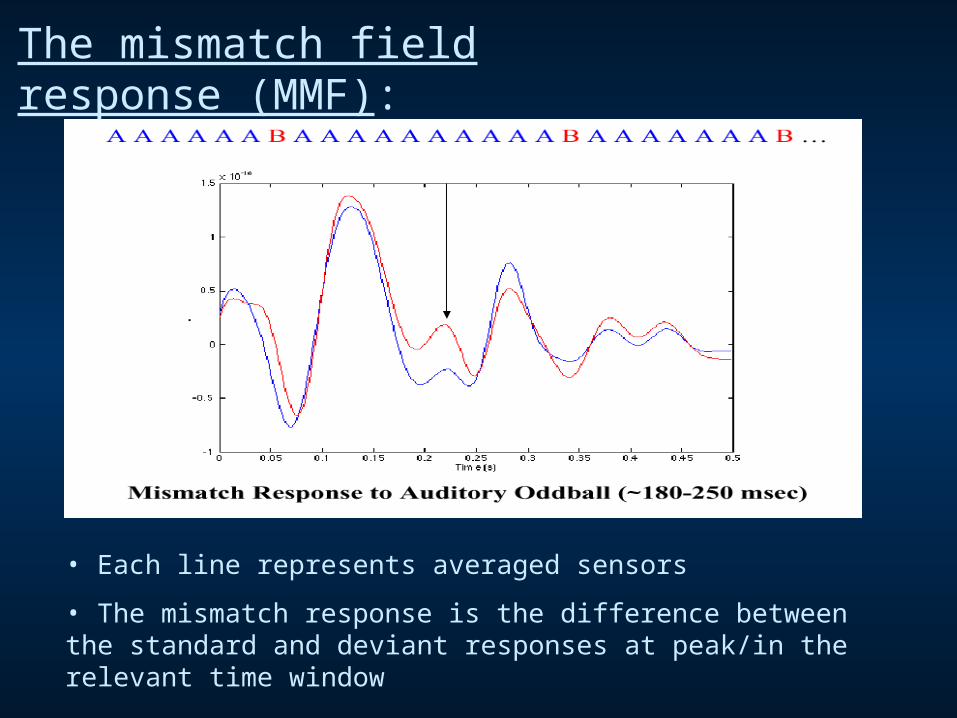
The mismatch field response (MMF):
• Each line represents averaged sensors
• The mismatch response is the difference between the standard and deviant responses at peak/in the relevant time window

The mismatch field response (MMF):Voicing (Sharma & Dorman 1999)
VOT (ms)
0 10 20 30 40 50 60 70
d t
d t
t1 t2
• Significant MMF for both pairs ( within-category differences perceptible)
• Significantly greater MMF for the cross-category pair, despite equal acoustic distance
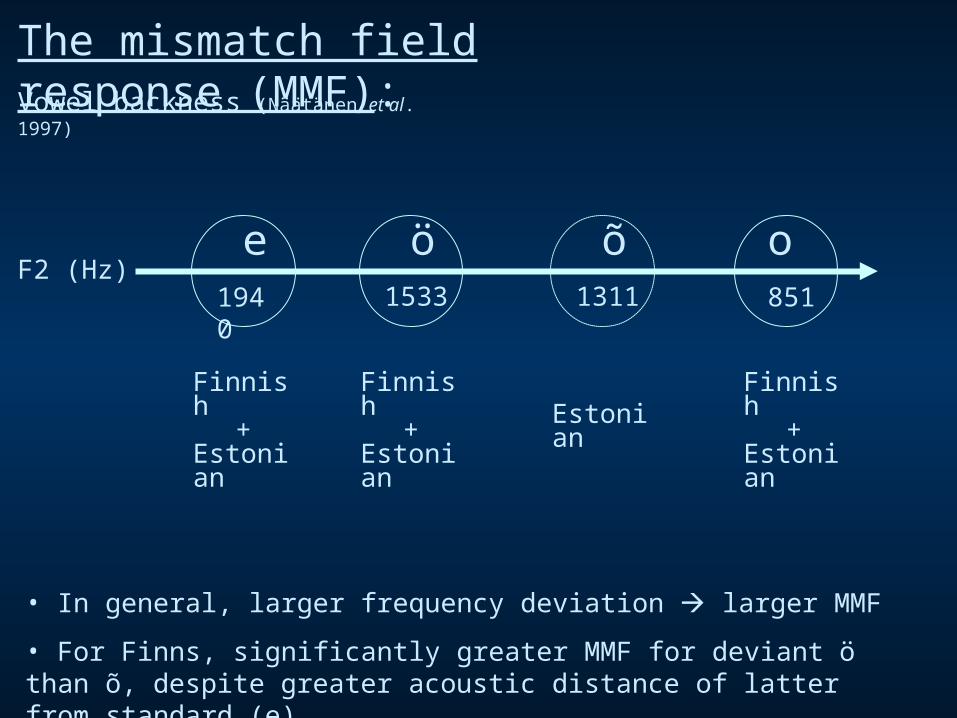
The mismatch field response (MMF):Vowel backness (Näätänen et al. 1997)
F2 (Hz)
• In general, larger frequency deviation larger MMF
• For Finns, significantly greater MMF for deviant ö than õ, despite greater acoustic distance of latter from standard (e)
e1940
o851
õ1311
ö1533
Finnish+
Estonian
Finnish+
Estonian Estonian
Finnish+
Estonian

• Studies have examined contrasts of:
• phonemic pairs versus within-category free variants (Sharma & Dorman)
• phonemic pairs versus non-prototypical segments (Näätänen et al.)
Phonemic contrasts have a special status in speech processing
• Are they the only ones?
• Allophonic contrasts are also encoded in a language’s phonology
• Allophones show a bimodal distribution on the surface, like phonemes
Contrast types and the MMF:

Predictions:
Phonemes a-e a-e a-e
Allophones e-ε e-ε e-ε
Free variants ε1- ε2 ε1 - ε2 ε1 - ε2
MMF Amplitude

Allophonic mismatches:Russian/Korean Voicing (Kazanina & Phillips 2004)
Russian:
d/t phonemically distinct
• Phonemes elicit a significant MMF response; allophones not at all
Korean:
d/t distributed allophonically (intervocalic voicing)
?

Predictions:
Phonemes a-e a-e a-e
Allophones e-ε e-ε e-ε
Free variants ε1- ε2 ε1 - ε2 ε1 - ε2
Kazanina & Phillips 2004
MMF Amplitude

vs.
• French: phonemic contrast
• Spanish (Buenos Aires): allophonic contrast
e / __ C ]σ
• Spanish (Puerto Rican): free variation
Allophonic mismatches:French/Spanish vowel tenseness – a three-way comparison
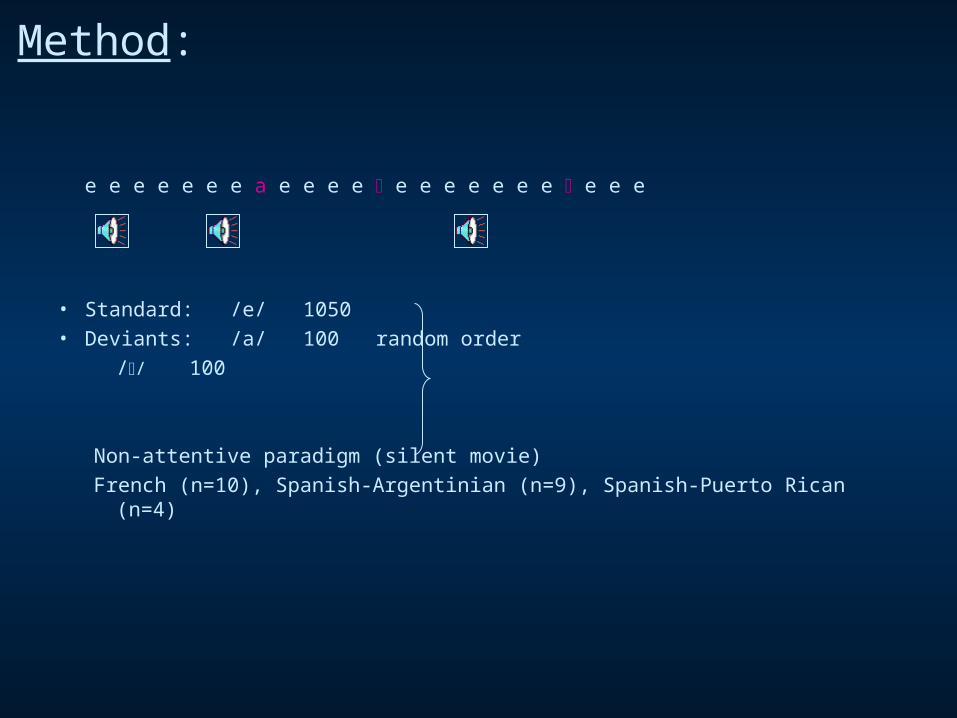
e e e e e e e a e e e e e e e e e e e e e e
• Standard: /e/ 1050
• Deviants: /a/ 100 random order
// 100
Non-attentive paradigm (silent movie)
French (n=10), Spanish-Argentinian (n=9), Spanish-Puerto Rican (n=4)
Method:

Results:
0
1E-14
2E-14
3E-14
4E-14
5E-14
6E-14
F A PR
T
E
e
a
• Middle bars represent baseline response to standard /e/, flanking bars are responses to deviants // (left) and /a/ (right)
• Mismatch response is significant for both deviants for all language groups (p<.02) (contrast with Kazanina and Phillips’ findings)
E-e Mismatch Wave Peaks
0
5
10
15
20
25
30
35
fT x
10^5
French
Argentinian
Puerto Rican
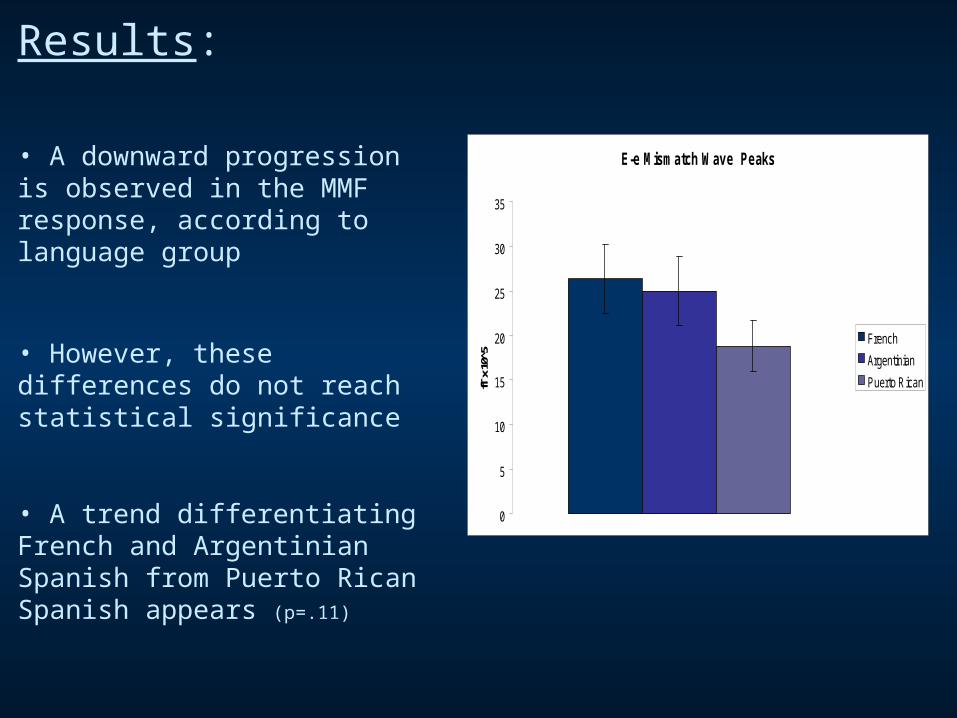
Results:
• A downward progression is observed in the MMF response, according to language group
• However, these differences do not reach statistical significance
• A trend differentiating French and Argentinian Spanish from Puerto Rican Spanish appears (p=.11)

Predictions:
Phonemes a-e a-e a-e
Allophones e-ε e-ε e-ε
Free variants ε1- ε2 ε1 - ε2 ε1 - ε2
Kazanina & Phillips 2004
MMF Amplitude
?
0
10
20
30
40
50
60
French Argentinian Puerto Rican
e-ae-E
*
*
T x
10^
-13
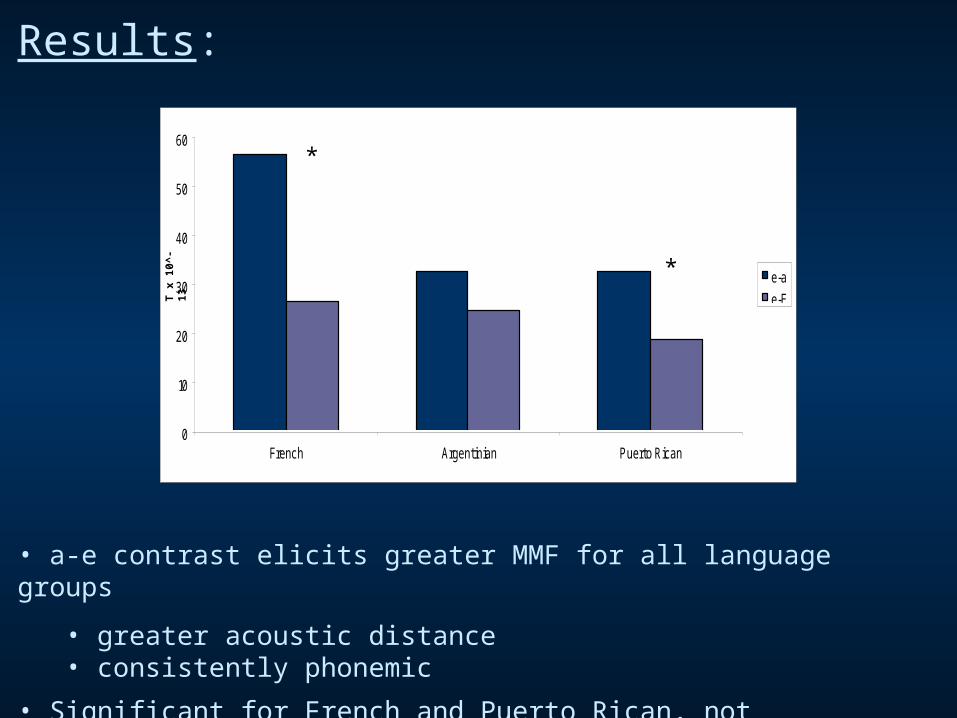
Results:
• a-e contrast elicits greater MMF for all language groups
• greater acoustic distance • consistently phonemic
• Significant for French and Puerto Rican, not Argentinian (p<.001, p=.043 vs p=.095)

Results:
• For Argentinian speakers the a-e and e-ε contrasts are both phonologically relevant, and therefore qualitatively of the same type
MMF amplitude not significantly different
• For Puerto Rican speakers one is phonologically relevant (a-e) and one is not (free variants e-ε) – the contrasts are of qualitatively different types
MMF amplitudes are significantly different
• For French the responses also differ, though both contrasts are phonemic
• French MMF responses greater across the board (inventory size effect) (Hacquard & Walter 2003)
• Differences also spread wider and reach significance sooner

Results:
• Why the inconsistencies between these two studies?
• K&P manipulate VOT in stimuli
not a primary cue for voicing in Korean
• K&P include multiple tokens in each category
biases subjects toward focusing on categorically phonemic distinctions
• Use of consonants versus vowels
different timing of acoustic information results in different processing

Experiment 2 (in progress):
Quebecois French – a within-language three-way comparison
High vowels alternate between long/tense and short/lax (Dumas 1976, Dechaine 1991, Martin 2002)
word-final word-initial word-medialopen syllable long long/short short/devoiced/deletedclosed syllable short short short/devoiced
i u
I U
ε
free variants
phonemic phonemic
allophonic allophonic
allophonic
Stay tuned!

Conclusions:
• Allophones are distinguishable in early speech processing
• Allophones appear to pattern with other structural, phonological contrasts, in contrast to within-category free variants
• In conjunction with behavioral research on the relative (im)perceptibility of allophone pairs, these results necessitate a model of phonology in which similarity may be computed over at least three domains: phonemic, allophonic, and acoustic

Thank you – now let’s look at the sun!


















