
Computing & Information Sciences Kansas State University Kansas State University Olathe Workshop on...
106
Computing & Information Sciences Kansas State University Kansas State University Olathe Workshop on Big Data – August, 2014 KSU Laboratory for Knowledge Discovery in Databases Kansas State University Olathe Tuesday, 12 August 2014 William H. Hsu http://www.cis.ksu.edu/~bhsu Laboratory for Knowledge Discovery in Databases, Kansas State University http://www.kddresearch.org Acknowledgements K-State Manhattan: Majed Alsadhan, Scott Finkeldei, Kyle Hudson, Surya Teja Kallumadi K-State Olathe: Dr. Prema Arasu, Dana Reinert, Paige Adams, Cathy Danahy, Angela Cummins, Emily Surdez, Quentin New, Amy Burgess Big Data Workshop: Day 1 Part II – Beginner Tutorial on MapReduce
-
Upload
lynn-mcgee -
Category
Documents
-
view
213 -
download
0
Transcript of Computing & Information Sciences Kansas State University Kansas State University Olathe Workshop on...

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Kansas State University Olathe
Tuesday, 12 August 2014
William H. Hsuhttp://www.cis.ksu.edu/~bhsu
Laboratory for Knowledge Discovery in Databases, Kansas State University
http://www.kddresearch.org
Acknowledgements
K-State Manhattan: Majed Alsadhan,
Scott Finkeldei, Kyle Hudson, Surya Teja Kallumadi
K-State Olathe: Dr. Prema Arasu, Dana Reinert,
Paige Adams, Cathy Danahy, Angela Cummins, Emily Surdez,
Quentin New, Amy Burgess
Big Data Workshop: Day 1Part II – Beginner Tutorial on MapReduce

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
What is MapReduce?What is MapReduce?
A programming model (& its associated implementation) For processing large data set Exploits large set of commodity computers Executes process in distributed manner Offers high degree of transparencies In other words:
simple and maybe suitable for your tasks !!!
© 2006, H. Setiawan, National University of Singapore
http://bit.ly/mapreduce-intro-setiawan

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Distributed GrepDistributed Grep
Very
big
data
Split data
Split data
Split data
Split data
grep
grep
grep
grep
matches
matches
matches
matches
catAll
matches

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Distributed Word CountDistributed Word Count
Very
big
data
Split data
Split data
Split data
Split data
count
count
count
count
count
count
count
count
mergemerged
count

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Map ReduceMap Reduce
Map:Accepts input
key/value pairEmits intermediate
key/value pair
Reduce :Accepts intermediate
key/value* pairEmits output key/value
pair
Very
big
data
ResultM
A
P
R
E
D
U
C
E
Partitioning
Function

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Partitioning FunctionPartitioning Function

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Partitioning Function (2)Partitioning Function (2)
Default : hash(key) mod R Guarantee:
Relatively well-balanced partitionsOrdering guarantee within partition
Distributed Sort
Map: emit(key,value)
Reduce (with R=1): emit(key,value)

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
MapReduceMapReduce
Distributed GrepMap:
if match(value,pattern) emit(value,1)
Reduce: emit(key,sum(value*))
Distributed Word CountMap:
for all w in value do emit(w,1)
Reduce: emit(key,sum(value*))

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
MapReduce TransparenciesMapReduce Transparencies
Plus Google Distributed File System : Parallelization Fault-tolerance Locality optimization Load balancing

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Suitable for your task ifSuitable for your task if
Have a cluster Working with large dataset Working with independent data (or assumed) Can be cast into map and reduce

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
MapReduce outside GoogleMapReduce outside Google
Hadoop (Java)
Emulates MapReduce and GFS The architecture of Hadoop MapReduce and DFS is master/slave
Master SlaveMapReduce jobtracker tasktrackerDFS namenode datanode

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Example Word Count (1)Example Word Count (1)
Map
public static class MapClass extends MapReduceBase implements Mapper { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(WritableComparable key, Writable value, OutputCollector output, Reporter reporter) throws IOException { String line = ((Text)value).toString(); StringTokenizer itr = new StringTokenizer(line); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); output.collect(word, one); } }}

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Example Word Count (2)Example Word Count (2)
Reduce
public static class Reduce extends MapReduceBase implements Reducer { public void reduce(WritableComparable key, Iterator values, OutputCollector output, Reporter reporter) throws IOException { int sum = 0; while (values.hasNext()) { sum += ((IntWritable) values.next()).get(); } output.collect(key, new IntWritable(sum)); }}

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Example Word Count (3)Example Word Count (3)
Main
public static void main(String[] args) throws IOException { //checking goes here JobConf conf = new JobConf();
conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(MapClass.class); conf.setCombinerClass(Reduce.class); conf.setReducerClass(Reduce.class); conf.setInputPath(new Path(args[0])); conf.setOutputPath(new Path(args[1])); JobClient.runJob(conf);}

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
One time setupOne time setup
set hadoop-site.xml and slaves Initiate namenode Run Hadoop MapReduce and DFS Upload your data to DFS Run your process… Download your data from DFS

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
SummarySummary
A simple programming model for processing large dataset on large set of computer cluster
Fun to use, focus on problem, and let the library deal with the messy detail

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
ReferencesReferences
Original paper (http://labs.google.com/papers/mapreduce.html) On wikipedia (http://en.wikipedia.org/wiki/MapReduce) Hadoop – MapReduce in Java (http://lucene.apache.org/hadoop/) Starfish - MapReduce in Ruby (http://rufy.com/starfish/)

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
What is Cloud Computing?What is Cloud Computing?
“Cloud” refers to large Internet services like Google, Yahoo, etc that run on 10,000’s of machines
More recently, “cloud computing” refers to services by these companies that let external customers rent computing cycles on their clustersAmazon EC2: virtual machines at 10¢/hour, billed hourlyAmazon S3: storage at 15¢/GB/month
Attractive features:Scale: up to 100’s of nodesFine-grained billing: pay only for what you useEase of use: sign up with credit card, get root access
© 2009, M. Zaharia, University of California – Berkeley
http://bit.ly/compute-clouds-zaharia

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
What is MapReduce?What is MapReduce?
Simple data-parallel programming model designed for scalability and fault-tolerance
Pioneered by GoogleProcesses 20 petabytes of data per day
Popularized by open-source Hadoop projectUsed at Yahoo!, Facebook, Amazon, …
© 2009, M. Zaharia, University of California – Berkeley
http://bit.ly/compute-clouds-zaharia

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
What is MapReduce used for?What is MapReduce used for?
At Google:
Index construction for Google SearchArticle clustering for Google NewsStatistical machine translation
At Yahoo!:
“Web map” powering Yahoo! SearchSpam detection for Yahoo! Mail
At Facebook:
Data miningAd optimizationSpam detection

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Example: Facebook LexiconExample: Facebook Lexicon
www.facebook.com/lexicon

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Example: Facebook LexiconExample: Facebook Lexicon
www.facebook.com/lexicon

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
What is MapReduce used for?What is MapReduce used for?
In research:Astronomical image analysis (Washington)Bioinformatics (Maryland)Analyzing Wikipedia conflicts (PARC)Natural language processing (CMU) Particle physics (Nebraska)Ocean climate simulation (Washington)<Your application here>

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
OutlineOutline
MapReduce architecture
Example applications
Getting started with Hadoop
Higher-level languages over Hadoop: Pig and Hive
Amazon Elastic MapReduce

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
MapReduce Design GoalsMapReduce Design Goals
1. Scalability to large data volumes:1000’s of machines, 10,000’s of disks
2. Cost-efficiency:Commodity machines (cheap, but unreliable)Commodity networkAutomatic fault-tolerance (fewer administrators)Easy to use (fewer programmers)

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Typical Hadoop ClusterTypical Hadoop Cluster
Aggregation switch
Rack switch
40 nodes/rack, 1000-4000 nodes in cluster 1 Gbps bandwidth within rack, 8 Gbps out of rack Node specs (Yahoo terasort):
8 x 2GHz cores, 8 GB RAM, 4 disks (= 4 TB?)
Image from http://wiki.apache.org/hadoop-data/attachments/HadoopPresentations/attachments/YahooHadoopIntro-apachecon-us-2008.pdf

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Typical Hadoop ClusterTypical Hadoop Cluster
Image from http://wiki.apache.org/hadoop-data/attachments/HadoopPresentations/attachments/aw-apachecon-eu-2009.pdf

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
ChallengesChallenges
1. Cheap nodes fail, especially if you have many
Mean time between failures for 1 node = 3 yearsMean time between failures for 1000 nodes = 1 daySolution: Build fault-tolerance into system
2. Commodity network = low bandwidth
Solution: Push computation to the data
3. Programming distributed systems is hard
Solution: Data-parallel programming model: users write “map” & “reduce” functions, system distributes work and handles faults

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Hadoop ComponentsHadoop Components
Distributed file system (HDFS)
Single namespace for entire clusterReplicates data 3x for fault-tolerance
MapReduce framework
Executes user jobs specified as “map” and “reduce” functions
Manages work distribution & fault-tolerance

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Hadoop Distributed File SystemHadoop Distributed File System
Files split into 128MB blocks Blocks replicated across several
datanodes (usually 3) Single namenode stores metadata (file
names, block locations, etc) Optimized for large files, sequential
reads Files are append-only
Namenode
Datanodes
1234
124
213
143
324
File1

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
MapReduce Programming ModelMapReduce Programming Model
Data type: key-value records
Map function:
(Kin, Vin) list(Kinter, Vinter)
Reduce function:
(Kinter, list(Vinter)) list(Kout, Vout)

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Example: Word CountExample: Word Count
def mapper(line):
foreach word in line.split():
output(word, 1)
def reducer(key, values):
output(key, sum(values))

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Word Count ExecutionWord Count Execution
the quick
brown fox
the fox ate
the mouse
how now
brown cow
Map
Map
Map
Reduce
Reduce
brown, 2
fox, 2
how, 1
now, 1
the, 3
ate, 1
cow, 1
mouse, 1
quick, 1
the, 1brown, 1
fox, 1
quick, 1
the, 1fox, 1the, 1
how, 1now, 1
brown, 1
ate, 1mouse, 1
cow, 1
Input Map Shuffle & Sort Reduce Output

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
MapReduce Execution DetailsMapReduce Execution Details
Single master controls job execution on multiple slaves
Mappers preferentially placed on same node or same rack as their input block
Minimizes network usage
Mappers save outputs to local disk before serving them to reducers
Allows recovery if a reducer crashesAllows having more reducers than nodes

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
An Optimization: The CombinerAn Optimization: The Combiner
def combiner(key, values):
output(key, sum(values))
A combiner is a local aggregation function for repeated keys produced by same map
Works for associative functions like sum, count, max
Decreases size of intermediate data
Example: map-side aggregation for Word Count:

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Word Count with CombinerWord Count with Combiner
Input Map & CombineShuffle & Sort Reduce Output
the quick
brown fox
the fox ate
the mouse
how now
brown cow
Map
Map
Map
Reduce
Reduce
brown, 2
fox, 2
how, 1
now, 1
the, 3
ate, 1
cow, 1
mouse, 1
quick, 1
the, 1brown, 1
fox, 1
quick, 1
the, 2fox, 1
how, 1now, 1
brown, 1
ate, 1mouse, 1
cow, 1

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Fault Tolerance in MapReduceFault Tolerance in MapReduce
1. If a task crashes:Retry on another node
OK for a map because it has no dependenciesOK for reduce because map outputs are on disk
If the same task fails repeatedly, fail the job or ignore that input block (user-controlled)
Note: For these fault tolerance features to work, your map and reduce tasks must be side-effect-free

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Fault Tolerance in MapReduceFault Tolerance in MapReduce
2. If a node crashes:Re-launch its current tasks on other nodesRe-run any maps the node previously ran
Necessary because their output files were lost along with the crashed node

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Fault Tolerance in MapReduceFault Tolerance in MapReduce
3. If a task is going slowly (straggler):Launch second copy of task on another node (“speculative
execution”)Take the output of whichever copy finishes first, and kill the
other
Surprisingly important in large clustersStragglers occur frequently due to failing hardware,
software bugs, misconfiguration, etcSingle straggler may noticeably slow down a job

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
TakeawaysTakeaways
By providing a data-parallel programming model, MapReduce can control job execution in useful ways:Automatic division of job into tasksAutomatic placement of computation near dataAutomatic load balancingRecovery from failures & stragglers
User focuses on application, not on complexities of distributed computing

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
OutlineOutline
MapReduce architecture
Example applications
Getting started with Hadoop
Higher-level languages over Hadoop: Pig and Hive
Amazon Elastic MapReduce

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
1. Search1. Search
Input: (lineNumber, line) records Output: lines matching a given pattern
Map:
if(line matches pattern): output(line)
Reduce: identify functionAlternative: no reducer (map-only job)

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
pigshee
pyak
zebra
aardvarkantbeecow
elephant
2. Sort2. Sort
Input: (key, value) recordsOutput: same records, sorted by key
Map: identity functionReduce: identify function
Trick: Pick partitioningfunction h such thatk1<k2 => h(k1)<h(k2)
Map
Map
Map
Reduce
Reduce
ant, bee
zebra
aardvark,elephant
cow
pig
sheep, yak
[A-M]
[N-Z]

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
3. Inverted Index3. Inverted Index
Input: (filename, text) records Output: list of files containing each word
Map:
foreach word in text.split(): output(word, filename)
Combine: uniquify filenames for each word
Reduce:def reduce(word, filenames): output(word, sort(filenames))

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Inverted Index ExampleInverted Index Example
to be or not to be afraid, (12th.txt)
be, (12th.txt, hamlet.txt)
greatness, (12th.txt)not, (12th.txt,
hamlet.txt)of, (12th.txt)
or, (hamlet.txt)to, (hamlet.txt)
hamlet.txt
be not afraid of greatnes
s
12th.txt
to, hamlet.txtbe, hamlet.txtor, hamlet.txtnot, hamlet.txtbe, 12th.txtnot, 12th.txtafraid, 12th.txtof, 12th.txtgreatness, 12th.txt

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
4. Most Popular Words4. Most Popular Words
Input: (filename, text) records Output: top 100 words occurring in the most files
Two-stage solution:
Job 1: Create inverted index, giving (word, list(file)) records
Job 2: Map each (word, list(file)) to (count, word) Sort these records by count as in sort job
Optimizations:
Map to (word, 1) instead of (word, file) in Job 1 Count files in job 1’s reducer rather than job 2’s mapper Estimate count distribution in advance and drop rare words

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
5. Numerical Integration5. Numerical Integration
Input: (start, end) records for sub-ranges to integrateEasy using custom InputFormat
Output: integral of f(x) dx over entire range
Map: def map(start, end): sum = 0 for(x = start; x < end; x += step): sum += f(x) * step output(“”, sum)
Reduce:def reduce(key, values): output(key, sum(values))

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
OutlineOutline
MapReduce architecture
Example applications
Getting started with Hadoop
Higher-level languages over Hadoop: Pig and Hive
Amazon Elastic MapReduce

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Getting Started with HadoopGetting Started with Hadoop
Download from hadoop.apache.org To install locally, unzip and set JAVA_HOME Details: hadoop.apache.org/core/docs/current/quickstart.html
Three ways to write jobs:Java APIHadoop Streaming (for Python, Perl, etc)Pipes API (C++)
Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
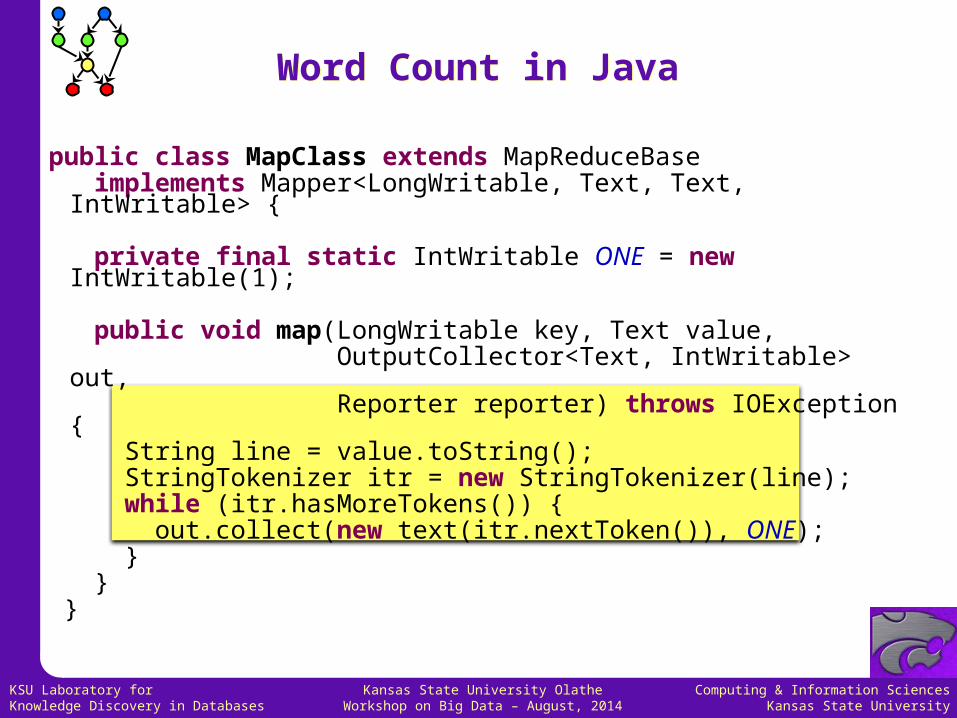
Word Count in JavaWord Count in Java
public class MapClass extends MapReduceBase implements Mapper<LongWritable, Text, Text,
IntWritable> { private final static IntWritable ONE = new
IntWritable(1); public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable>
out, Reporter reporter) throws IOException
{ String line = value.toString(); StringTokenizer itr = new StringTokenizer(line); while (itr.hasMoreTokens()) { out.collect(new text(itr.nextToken()), ONE); } } }

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Word Count in JavaWord Count in Java
public class ReduceClass extends MapReduceBase implements Reducer<Text, IntWritable, Text,
IntWritable> { public void reduce(Text key, Iterator<IntWritable>
values, OutputCollector<Text, IntWritable>
out, Reporter reporter) throws
IOException { int sum = 0; while (values.hasNext()) { sum += values.next().get(); } out.collect(key, new IntWritable(sum)); } }

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Word Count in JavaWord Count in Java
public static void main(String[] args) throws Exception { JobConf conf = new JobConf(WordCount.class); conf.setJobName("wordcount");
conf.setMapperClass(MapClass.class); conf.setCombinerClass(ReduceClass.class); conf.setReducerClass(ReduceClass.class); FileInputFormat.setInputPaths(conf, args[0]); FileOutputFormat.setOutputPath(conf, new Path(args[1]));
conf.setOutputKeyClass(Text.class); // out keys are words (strings)
conf.setOutputValueClass(IntWritable.class); // values are counts
JobClient.runJob(conf); }

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Word Count in Python with Hadoop Streaming
Word Count in Python with Hadoop Streaming
import sysfor line in sys.stdin: for word in line.split(): print(word.lower() + "\t" + 1)
import syscounts = {}for line in sys.stdin: word, count = line.split("\t”) dict[word] = dict.get(word, 0) +
int(count)for word, count in counts: print(word.lower() + "\t" + 1)
Mapper.py:
Reducer.py:

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
OutlineOutline
MapReduce architecture
Example applications
Getting started with Hadoop
Higher-level languages over Hadoop: Pig and Hive
Amazon Elastic MapReduce

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
MotivationMotivation
Many parallel algorithms can be expressed by a series of MapReduce jobs
But MapReduce is fairly low-level: must think about keys, values, partitioning, etc
Can we capture common “job building blocks”?

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
PigPig
Started at Yahoo! Research Runs about 30% of Yahoo!’s jobs Features:
Expresses sequences of MapReduce jobsData model: nested “bags” of itemsProvides relational (SQL) operators (JOIN,
GROUP BY, etc)Easy to plug in Java functionsPig Pen development environment for Eclipse

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
An Example ProblemAn Example Problem
Suppose you have user data in one file, page view data in another, and you need to find the top 5 most visited pages by users aged 18 - 25.
Load Users
Load Pages
Filter by age
Join on name
Group on url
Count clicks
Order by clicks
Take top 5
Example from http://wiki.apache.org/pig-data/attachments/PigTalksPapers/attachments/ApacheConEurope09.ppt

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
In MapReduceIn MapReduceimport java.io.IOException; import java.util.ArrayList; import java.util.Iterator; import java.util.List; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.Writable; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.mapred.FileInputFormat; import org.apache.hadoop.mapred.FileOutputFormat; import org.apache.hadoop.mapred.JobConf; import org.apache.hadoop.mapred.KeyValueTextInputFormat; import org.apache.hadoop.mapred.Mapper; import org.apache.hadoop.mapred.MapReduceBase; import org.apache.hadoop.mapred.OutputCollector; import org.apache.hadoop.mapred.RecordReader; import org.apache.hadoop.mapred.Reducer; import org.apache.hadoop.mapred.Reporter; import org.apache.hadoop.mapred.SequenceFileInputFormat; import org.apache.hadoop.mapred.SequenceFileOutputFormat; import org.apache.hadoop.mapred.TextInputFormat; import org.apache.hadoop.mapred.jobcontrol.Job; import org.apache.hadoop.mapred.jobcontrol.JobControl; import org.apache.hadoop.mapred.lib.IdentityMapper; public class MRExample { public static class LoadPages extends MapReduceBase implements Mapper<LongWritable, Text, Text, Text> { public void map(LongWritable k, Text val, OutputCollector<Text, Text> oc, Reporter reporter) throws IOException { // Pull the key out String line = val.toString(); int firstComma = line.indexOf(','); String key = line.substring(0, firstComma); String value = line.substring(firstComma + 1); Text outKey = new Text(key); // Prepend an index to the value so we know which file // it came from. Text outVal = new Text("1" + value); oc.collect(outKey, outVal); } } public static class LoadAndFilterUsers extends MapReduceBase implements Mapper<LongWritable, Text, Text, Text> { public void map(LongWritable k, Text val, OutputCollector<Text, Text> oc, Reporter reporter) throws IOException { // Pull the key out String line = val.toString(); int firstComma = line.indexOf(','); String value = line.substring(firstComma + 1); int age = Integer.parseInt(value); if (age < 18 || age > 25) return; String key = line.substring(0, firstComma); Text outKey = new Text(key); // Prepend an index to the value so w e know which file // it came from. Text outVal = new Text("2" + value); oc.collect(outKey, outVal); } } public static class Join extends MapReduceBase implements Reducer<Text, Text, Text, Text> { public void reduce(Text key, Iterator<Text> iter, OutputCollector<Text, Text> oc, Reporter reporter) throws IOException { // For each value, figure out which file it's from and store it // accordingly. List<String> first = new ArrayList<String>(); List<String> second = new ArrayList<String>(); while (iter.hasNext()) { Text t = iter.next(); String value = t.toString(); if (value.charAt(0) == '1') first.add(value.substring(1)); else second.add(value.substring(1));
reporter.setStatus("OK"); } // Do the cross product and collect the values for (String s1 : first) { for (String s2 : second) { String outval = key + "," + s1 + "," + s2; oc.collect(null, new Text(outval)); reporter.setStatus("OK"); } } } } public static class LoadJoined extends MapReduceBase implements Mapper<Text, Text, Text, LongWritable> { public void map( Text k, Text val, OutputCollector<Text, LongWritable> oc, Reporter reporter) throws IOException { // Find the url String line = val.toString(); int firstComma = line.indexOf(','); int secondComma = line.indexOf(',', first Comma); String key = line.substring(firstComma, secondComma); // drop the rest of the record, I don't need it anymore, // just pass a 1 for the combiner/reducer to sum instead. Text outKey = new Text(key); oc.collect(outKey, new LongWritable(1L)); } } public static class ReduceUrls extends MapReduceBase implements Reducer<Text, LongWritable, WritableComparable, Writable> { public void reduce( Text key, Iterator<LongWritable> iter, OutputCollector<WritableComparable, Writable> oc, Reporter reporter) throws IOException { // Add up all the values we see long sum = 0; while (iter.hasNext()) { sum += iter.next().get(); reporter.setStatus("OK"); } oc.collect(key, new LongWritable(sum)); } } public static class LoadClicks extends MapReduceBase implements Mapper<WritableComparable, Writable, LongWritable, Text> { public void map( WritableComparable key, Writable val, OutputCollector<LongWritable, Text> oc, Reporter reporter) throws IOException { oc.collect((LongWritable)val, (Text)key); } } public static class LimitClicks extends MapReduceBase implements Reducer<LongWritable, Text, LongWritable, Text> { int count = 0; public void reduce( LongWritable key, Iterator<Text> iter, OutputCollector<LongWritable, Text> oc, Reporter reporter) throws IOException { // Only output the first 100 records while (count < 100 && iter.hasNext()) { oc.collect(key, iter.next()); count++; } } } public static void main(String[] args) throws IOException { JobConf lp = new JobConf(MRExample.class); lp.setJobName("Load Pages"); lp.setInputFormat(TextInputFormat.class);
lp.setOutputKeyClass(Text.class); lp.setOutputValueClass(Text.class); lp.setMapperClass(LoadPages.class); FileInputFormat.addInputPath(lp, new Path("/user/gates/pages")); FileOutputFormat.setOutputPath(lp, new Path("/user/gates/tmp/indexed_pages")); lp.setNumReduceTasks(0); Job loadPages = new Job(lp); JobConf lfu = new JobConf(MRExample.class); lfu.setJobName("Load and Filter Users"); lfu.setInputFormat(TextInputFormat.class); lfu.setOutputKeyClass(Text.class); lfu.setOutputValueClass(Text.class); lfu.setMapperClass(LoadAndFilterUsers.class); FileInputFormat.addInputPath(lfu, new Path("/user/gates/users")); FileOutputFormat.setOutputPath(lfu, new Path("/user/gates/tmp/filtered_users")); lfu.setNumReduceTasks(0); Job loadUsers = new Job(lfu); JobConf join = new JobConf(MRExample.class); join.setJobName("Join Users and Pages"); join.setInputFormat(KeyValueTextInputFormat.class); join.setOutputKeyClass(Text.class); join.setOutputValueClass(Text.class); join.setMapperClass(IdentityMapper.class); join.setReducerClass(Join.class); FileInputFormat.addInputPath(join, new Path("/user/gates/tmp/indexed_pages")); FileInputFormat.addInputPath(join, new Path("/user/gates/tmp/filtered_users")); FileOutputFormat.setOutputPath(join, new Path("/user/gates/tmp/joined")); join.setNumReduceTasks(50); Job joinJob = new Job(join); joinJob.addDependingJob(loadPages); joinJob.addDependingJob(loadUsers); JobConf group = new JobConf(MRExample.class); group.setJobName("Group URLs"); group.setInputFormat(KeyValueTextInputFormat.class); group.setOutputKeyClass(Text.class); group.setOutputValueClass(LongWritable.class); group.setOutputFormat(SequenceFileOutputFormat.class); group.setMapperClass(LoadJoined.class); group.setCombinerClass(ReduceUrls.class); group.setReducerClass(ReduceUrls.class); FileInputFormat.addInputPath(group, new Path("/user/gates/tmp/joined")); FileOutputFormat.setOutputPath(group, new Path("/user/gates/tmp/grouped")); group.setNumReduceTasks(50); Job groupJob = new Job(group); groupJob.addDependingJob(joinJob); JobConf top100 = new JobConf(MRExample.class); top100.setJobName("Top 100 sites"); top100.setInputFormat(SequenceFileInputFormat.class); top100.setOutputKeyClass(LongWritable.class); top100.setOutputValueClass(Text.class); top100.setOutputFormat(SequenceFileOutputF ormat.class); top100.setMapperClass(LoadClicks.class); top100.setCombinerClass(LimitClicks.class); top100.setReducerClass(LimitClicks.class); FileInputFormat.addInputPath(top100, new Path("/user/gates/tmp/grouped")); FileOutputFormat.setOutputPath(top100, new Path("/user/gates/top100sitesforusers18to25")); top100.setNumReduceTasks(1); Job limit = new Job(top100); limit.addDependingJob(groupJob); JobControl jc = new JobControl("Find top 100 sites for users 18 to 25"); jc.addJob(loadPages); jc.addJob(loadUsers); jc.addJob(joinJob); jc.addJob(groupJob); jc.addJob(limit); jc.run(); } }
Example from http://wiki.apache.org/pig-data/attachments/PigTalksPapers/attachments/ApacheConEurope09.ppt

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Users = load ‘users’ as (name, age);Filtered = filter Users by age >= 18 and age <= 25; Pages = load ‘pages’ as (user, url);Joined = join Filtered by name, Pages by user;Grouped = group Joined by url;Summed = foreach Grouped generate group, count(Joined) as clicks;Sorted = order Summed by clicks desc;Top5 = limit Sorted 5;
store Top5 into ‘top5sites’;
Example from http://wiki.apache.org/pig-data/attachments/PigTalksPapers/attachments/ApacheConEurope09.ppt
In Pig LatinIn Pig Latin

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Ease of TranslationEase of Translation
Notice how naturally the components of the job translate into Pig Latin.
Load Users
Load Pages
Filter by age
Join on name
Group on url
Count clicks
Order by clicks
Take top 5
Users = load …Filtered = filter …
Pages = load …Joined = join …Grouped = group …Summed = … count()…Sorted = order …Top5 = limit …
Example from http://wiki.apache.org/pig-data/attachments/PigTalksPapers/attachments/ApacheConEurope09.ppt

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Ease of TranslationEase of Translation
Notice how naturally the components of the job translate into Pig Latin.
Load Users
Load Pages
Filter by age
Join on name
Group on url
Count clicks
Order by clicks
Take top 5
Users = load …Filtered = filter …
Pages = load …Joined = join …Grouped = group …Summed = … count()…Sorted = order …Top5 = limit …
Job 1
Job 2
Job 3
Example from http://wiki.apache.org/pig-data/attachments/PigTalksPapers/attachments/ApacheConEurope09.ppt

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
HiveHive
Developed at Facebook Used for majority of Facebook jobs “Relational database” built on Hadoop
Maintains list of table schemasSQL-like query language (HQL)Can call Hadoop Streaming scripts from HQLSupports table partitioning, clustering, complex
data types, some optimizations

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Sample Hive QueriesSample Hive Queries
SELECT p.url, COUNT(1) as clicks FROM users u JOIN page_views p ON (u.name =
p.user)WHERE u.age >= 18 AND u.age <= 25GROUP BY p.urlORDER BY clicksLIMIT 5;
• Find top 5 pages visited by users aged 18-25:
• Filter page views through Python script:
SELECT TRANSFORM(p.user, p.date)USING 'map_script.py'AS dt, uid CLUSTER BY dtFROM page_views p;

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
OutlineOutline
MapReduce architecture
Example applications
Getting started with Hadoop
Higher-level languages over Hadoop: Pig and Hive
Amazon Elastic MapReduce

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Amazon Elastic MapReduceAmazon Elastic MapReduce
Provides a web-based interface and command-line tools for running Hadoop jobs on Amazon EC2
Data stored in Amazon S3 Monitors job and shuts down machines after use Small extra charge on top of EC2 pricing
If you want more control over how you Hadoop runs, you can launch a Hadoop cluster on EC2 manually using the scripts in src/contrib/ec2

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Elastic MapReduce WorkflowElastic MapReduce Workflow

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Elastic MapReduce WorkflowElastic MapReduce Workflow

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Elastic MapReduce WorkflowElastic MapReduce Workflow

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Elastic MapReduce WorkflowElastic MapReduce Workflow

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
ConclusionsConclusions MapReduce programming model hides the complexity of work
distribution and fault tolerance
Principal design philosophies:
Make it scalable, so you can throw hardware at problems
Make it cheap, lowering hardware, programming and admin costs
MapReduce is not suitable for all problems, but when it works, it may save you quite a bit of time
Cloud computing makes it straightforward to start using Hadoop (or other parallel software) at scale

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
MapReduce: RecapMapReduce: Recap
Programmers must specify:map (k, v) → <k’, v’>*reduce (k’, v’) → <k’, v’>*All values with the same key are reduced together
Optionally, also:partition (k’, number of partitions) → partition for k’Often a simple hash of the key, e.g., hash(k’) mod nDivides up key space for parallel reduce operationscombine (k’, v’) → <k’, v’>*Mini-reducers that run in memory after the map
phaseUsed as an optimization to reduce network traffic
The execution framework handles everything else…
Adapted from slides © 2012, J. Lin & R. Jin
http://bit.ly/jin-cloud-2012

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
“Everything Else”“Everything Else”
The execution framework handles everything else…Scheduling: assigns workers to map and reduce tasks “Data distribution”: moves processes to dataSynchronization: gathers, sorts, and shuffles
intermediate dataErrors and faults: detects worker failures and restarts
Limited control over data and execution flowAll algorithms must expressed in m, r, c, p
You don’t know:Where mappers and reducers runWhen a mapper or reducer begins or finishesWhich input a particular mapper is processingWhich intermediate key a particular reducer is
processing

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
combinecombine combine combine
ba 1 2 c 9 a c5 2 b c7 8
partition partition partition partition
mapmap map map
k1 k2 k3 k4 k5 k6v1 v2 v3 v4 v5 v6
ba 1 2 c c3 6 a c5 2 b c7 8
Shuffle and Sort: aggregate values by keys
reduce
reduce
reduce
a 1 5 b 2 7 c 2 9 8
r1 s1 r2 s2 r3 s3

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Tools for SynchronizationTools for Synchronization
• Cleverly-constructed data structures
– Bring partial results together• Sort order of intermediate keys
– Control order in which reducers process keys
• Partitioner
– Control which reducer processes which keys
• Preserving state in mappers and reducers
– Capture dependencies across multiple keys and values

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Preserving StatePreserving State
Mapper object
configure
map
close
stateone object per task
Reducer object
configure
reduce
close
state
one call per input key-value pair
one call per intermediate key
API initialization hook
API cleanup hook

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Scalable Hadoop Algorithms: ThemesScalable Hadoop Algorithms: Themes
Avoid object creation
Inherently costly operationGarbage collection
Avoid buffering
Limited heap sizeWorks for small datasets, but won’t scale!

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Importance of Local AggregationImportance of Local Aggregation
Ideal scaling characteristics:
Twice the data, twice the running timeTwice the resources, half the running time
Why can’t we achieve this?
Synchronization requires communicationCommunication kills performance
Thus… avoid communication!
Reduce intermediate data via local aggregation
Combiners can help

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Shuffle and SortShuffle and Sort
Mapper
Reducer
other mappers
other reducers
circular buffer
(in memory)
spills (on disk)
merged spills (on disk)
intermediate files (on disk)
Combiner
Combiner

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Word Count: BaselineWord Count: Baseline
What’s the impact of combiners?

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Word Count: Version 1Word Count: Version 1
Are combiners still needed?

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Word Count: Version 2Word Count: Version 2
Are combiners still needed?
Key: preserve state across
input key-value pairs!

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Design Pattern for Local AggregationDesign Pattern for Local Aggregation
“In-mapper combining”Fold the functionality of the combiner into the
mapper by preserving state across multiple map calls
AdvantagesSpeedWhy is this faster than actual combiners?
DisadvantagesExplicit memory management requiredPotential for order-dependent bugs

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Combiner DesignCombiner Design
Combiners and reducers share same method signatureSometimes, reducers can serve as combinersOften, not…
Remember: combiner are optional optimizationsShould not affect algorithm correctnessMay be run 0, 1, or multiple times
Example: find average of all integers associated with the same key

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Computing the Mean: Version 1Computing the Mean: Version 1
Why can’t we use reducer as combiner?

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Computing the Mean: Version 2Computing the Mean: Version 2
Why doesn’t this work?

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Computing the Mean: Version 3Computing the Mean: Version 3
Fixed?

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Computing the Mean: Version 4Computing the Mean: Version 4
Are combiners still needed?

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Algorithm Design: Running ExampleAlgorithm Design: Running Example
Term co-occurrence matrix for a text collectionM = N x N matrix (N = vocabulary size)Mij: number of times i and j co-occur in some
context (for concreteness, let’s say context = sentence)
Why?Distributional profiles as a way of measuring
semantic distanceSemantic distance useful for many language
processing tasks

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
MapReduce: Large Counting ProblemsMapReduce: Large Counting Problems
• Term co-occurrence matrix for a text collection= specific instance of a large counting problem
– A large event space (number of terms)– A large number of observations (the
collection itself)– Goal: keep track of interesting statistics
about the events• Basic approach
– Mappers generate partial counts– Reducers aggregate partial counts
How do we aggregate partial counts efficiently?

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
First Try: “Pairs”First Try: “Pairs”
Each mapper takes a sentence:
Generate all co-occurring term pairsFor all pairs, emit (a, b) → count
Reducers sum up counts associated with these pairs Use combiners!

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Pairs: Pseudo-CodePairs: Pseudo-Code

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
“Pairs” Analysis“Pairs” Analysis
Advantages
Easy to implement, easy to understand Disadvantages
Lots of pairs to sort and shuffle around (upper bound?)
Not many opportunities for combiners to work

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Another Try: “Stripes”Another Try: “Stripes”
Idea: group together pairs into an associative array
Each mapper takes a sentence:
Generate all co-occurring term pairsFor each term, emit a → { b: countb, c:
countc, d: countd … } Reducers perform element-wise sum of associative arrays
(a, b) → 1
(a, c) → 2
(a, d) → 5
(a, e) → 3
(a, f) → 2
a → { b: 1, c: 2, d: 5, e: 3, f: 2 }
a → { b: 1, d: 5, e: 3 }
a → { b: 1, c: 2, d: 2, f: 2 }
a → { b: 2, c: 2, d: 7, e: 3, f: 2 }+
Key: cleverly-constructed data structure
brings together partial results

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Stripes: Pseudo-CodeStripes: Pseudo-Code

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
“Stripes” Analysis“Stripes” Analysis
Advantages
Far less sorting and shuffling of key-value pairs
Can make better use of combiners Disadvantages
More difficult to implementUnderlying object more heavyweightFundamental limitation in terms of size of
event space

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Cluster size: 38 cores
Data Source: Associated Press Worldstream (APW) of the English Gigaword Corpus (v3), which contains 2.27 million documents (1.8 GB compressed, 5.7 GB uncompressed)

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Relative FrequenciesRelative Frequencies
How do we estimate relative frequencies from counts?
Why do we want to do this? How do we do this with MapReduce?
'
)',(count
),(count
)(count
),(count)|(
B
BA
BA
A
BAABf

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
f(B|A): “Stripes” f(B|A): “Stripes”
Easy!
One pass to compute (a, *)Another pass to directly compute f(B|A)
a → {b1:3, b2 :12, b3 :7, b4 :1, … }

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
f(B|A): “Pairs” f(B|A): “Pairs”
For this to work:
Must emit extra (a, *) for every bn in mapper
Must make sure all a’s get sent to same reducer (use partitioner)
Must make sure (a, *) comes first (define sort order)
Must hold state in reducer across different key-value pairs
(a, b1) → 3
(a, b2) → 12
(a, b3) → 7
(a, b4) → 1
…
(a, *) → 32
(a, b1) → 3 / 32
(a, b2) → 12 / 32
(a, b3) → 7 / 32
(a, b4) → 1 / 32
…
Reducer holds this value in memory

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
“Order Inversion”“Order Inversion”
• Common design pattern
– Computing relative frequencies requires marginal counts
– But marginal cannot be computed until you see all counts
– Buffering is a bad idea!– Trick: getting the marginal counts to arrive at the
reducer before the joint counts• Optimizations
– Apply in-memory combining pattern to accumulate marginal counts
– Should we apply combiners?

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Synchronization: Pairs vs. StripesSynchronization: Pairs vs. Stripes
Approach 1: turn synchronization into an ordering problemSort keys into correct order of computationPartition key space so that each reducer gets the
appropriate set of partial resultsHold state in reducer across multiple key-value pairs to
perform computation Illustrated by the “pairs” approach
Approach 2: construct data structures that bring partial results togetherEach reducer receives all the data it needs to complete
the computation Illustrated by the “stripes” approach

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Secondary SortingSecondary Sorting
MapReduce sorts input to reducers by key
Values may be arbitrarily ordered What if want to sort value also?
E.g., k → (v1, r), (v3, r), (v4, r), (v8, r)…

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Secondary Sorting: SolutionsSecondary Sorting: Solutions
Solution 1:Buffer values in memory, then sortWhy is this a bad idea?
Solution 2:“Value-to-key conversion” design pattern: form
composite intermediate key, (k, v1)Let execution framework do the sortingPreserve state across multiple key-value pairs
to handle processingAnything else we need to do?

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Recap: Tools for SynchronizationRecap: Tools for Synchronization
• Cleverly-constructed data structures
– Bring data together• Sort order of intermediate keys
– Control order in which reducers process keys
• Partitioner
– Control which reducer processes which keys
• Preserving state in mappers and reducers
– Capture dependencies across multiple keys and values

Computing & Information SciencesKansas State University
Kansas State University OlatheWorkshop on Big Data – August, 2014
KSU Laboratory forKnowledge Discovery in Databases
Issues and TradeoffsIssues and Tradeoffs
• Number of key-value pairs
– Object creation overhead– Time for sorting and shuffling pairs across the
network• Size of each key-value pair
– De/serialization overhead• Local aggregation
– Opportunities to perform local aggregation varies– Combiners make a big difference– Combiners vs. in-mapper combining– RAM vs. disk vs. network


















