
Computer Architecture 2012 – probabilistic L1 filtering 1 Computer Architecture Probabilistic L1...
36
Computer Architecture 2012 – probabilistic L1 filtering 1 Computer Architecture Probabilistic L1 Cache Filtering By Dan Tsafrir 7/5/2012 Presentation based on slides by Yoav Etsion
-
Upload
joella-king -
Category
Documents
-
view
216 -
download
0
Transcript of Computer Architecture 2012 – probabilistic L1 filtering 1 Computer Architecture Probabilistic L1...

Computer Architecture 2012 – probabilistic L1 filtering1
Computer Architecture
Probabilistic L1 Cache Filtering
By Dan Tsafrir 7/5/2012Presentation based on slides by Yoav Etsion

Computer Architecture 2012 – probabilistic L1 filtering2
Lecture is based on… Paper titled
“L1 cache filtering through random selection of memory references”
Authors Yoav Etsion and Dror G. Feitelson (from the Hebrew U.)
Published in PACT 2007: the international conference on parallel
architectures and complication techniques Can be downloaded from
http://www.cs.technion.ac.il/~yetsion/papers/CorePact.pdf

Computer Architecture 2012 – probabilistic L1 filtering3
MOTIVATION

Computer Architecture 2012 – probabilistic L1 filtering4
A Case for more efficient caches CPUs get more and more cache dependent
Growing gap between CPU and memory Growing popularity of multi-core chips
Common solution: larger caches, but… Larger caches consume more power Longer wire delays yield longer latencies

Computer Architecture 2012 – probabilistic L1 filtering5
Efficiency through insertion policies
Need smarter caches
We focus on insertion policies Currently everything goes into the cache Need to predict which blocks will be evicted quickly… … and prevent them from polluting the caches
Reducing pollution may enable use of low-latency, low-power, direct-mapped caches Less pollution yields fewer conflicts
The Problem: “It is difficult to make predictions, especially about the
future”(many affiliations)

Computer Architecture 2012 – probabilistic L1 filtering6
CDF,RESIDENCY LENGTHS,MASS-COUNT DISPARITY
background

Computer Architecture 2012 – probabilistic L1 filtering7
PDF(probability distribution function) In statistics, a PDF is, roughly, a function f describing
The likelihood to get some value in some domain For example, f can specify how many students have a
first name comprised of exactly k Hebrew letters f(1) = 0%
f(2) = 22% ( ,דן, רם, שי, שי, שי, שי, גל, חן, חן, בן(... ,גד, טל, ליf(3) = 24% ( ,גיל, גיל, רון, שיר, שיר, שיר, שיר, נגה(... ,משה, חיה, רחל, חנהf(4) = 25% ( ,יואב, אחמד, אביב, מיכל, מיכל, נועה, נועה( ...,נועה, נועה, נועהf(5) = 13% ( ,אביטל, ירוחם, עירית, יהודה, חנניה, אביבה( ... ,אביתר, אביעדf(6) = 9% ( ,יחזקאל, אביבית, אבינעם, אביגיל, שלומית( ... ,אבשלום, אדמונדf(7) = 6% ( ,אביגדור, אבינועם, מתיתיהו,, עמנואלה( ...אנסטסיהf(8) = 0.6% (אלכסנדרה, ...)f(9) = 0.4% (קונסטנטין, ...)f(10) = 0
Note that sigma[ f(k) ] = 100%

Computer Architecture 2012 – probabilistic L1 filtering8
CDF(cumulative distribution function) In statistics, a CDF is, roughly, a function F describing
The likelihood to get some value in some domain, or less For example, f can specify how many students have a
first name comprised of exactly k Hebrew letters, or less F(1) = 0% = f(0) = 0%
F(2) = 22% = f(0)+f(1)+f(2) = 0%+22%F(3) = 46% = f(0)+f(1)+f(2) = 0%+22%+24%F(4) = 71% = f(0)+f(1)+f(2)+f(3)= 0%+22%+24%+25%F(5) = 84% = F(4)+f(5) = 71% + 13%F(6) = 93% = F(5)+f(6) = 84% + 9%F(7) = 99% = F(6)+f(7) = 93% + 6%F(8) = 99.6% = F(7)+f(8) = 99% + 0.6%F(9) = 100% = F(8)+f(9) = 99.6% + 0.4%F(10) = 100%
Generally, F(x) = , monotonically non-decreasing

Computer Architecture 2012 – probabilistic L1 filtering9
Cache residency A “residency”
Is what we call a block of memory• From the time it was inserted to the cache• Until the time it was evicted
Each memory block can be associated with many residencies during a single execution
“Residency length” Number of memory references (= load/store operation)
served by the residency
“The mass of residency length=k” Percent of memory references (throughout the entire program
execution) that were served by residencies of length k

Computer Architecture 2012 – probabilistic L1 filtering10
Computing residency length on-the-fly
At runtime, residency length is generated like so (assume C++):
class Cache_Line_Residency { private:
int counter; // the residency length public:
Cache_Line_Residency() { // constructor: a new object allocated
// when a cache-line is allocated for a
counter = 0; // newly inserted memory block}~Cache_Line() { // destructor: called when
the block is// evicted from the cache (or when
the// program ends)
cout << counter << endl;}void do_reference() { // invoked whenever the cache line
is// referenced (read from or written
to)counter++;
}};
ctor
dtor
accessmemory

Computer Architecture 2012 – probabilistic L1 filtering11
013304744600…
0
Example Assume:
Size of cache: 4 bytes Size of cache line: 2 bytes (namely, there are two lines) Cache is directly mapped => address x maps into x % 4 A program references memory (order: top to bottom):
ad
dre
sses
(of
mem
ory
refe
rence
s)
(1)x(2)x(2) x (1)(2) x (2)(3)x (2)(1)x (2)(1) x (1)(2)x (1)
(3) x (2)(1)x (2)(2)x (2)
(90)x (2)
resid
ency
#1
#3
#4
#2
#5
print 3
print 3
print 2
print 90print 2program end
(3)x (1)

Computer Architecture 2012 – probabilistic L1 filtering12
013304744600…
0
Example – CDF of residency lengths
ad
dre
sses
(of
mem
ory
refe
rence
s)
(1)x(2)x(2) x (1)(2) x (2)(3)x (2)(1)x (2)(1) x (1)(2)x (1)
(3) x (2)(1)x (2)(2)x (2)
(90)x (2)
resid
ency
#1
#3
#4
#2
#5
print 3
print 3
print 2
print 90print 2program end
(3)x (1)
So printed residency lengths are: 3, 2, 3, 90, 2Thus, CDF of residency length is:• 40% of residencies have length <= 2
= |[2,2]| / |[3,2,3,90,2]|• 80% of residencies have length <= 3
= |[2,2,3,3]| / |[3,2,3,90,2]|• 100% of residencies have length <= 90
= |[2,2,3,3,90]| / |[3,2,3,90,2]|
2 3 90lengths
CD
F 60%
80%
100%
40%
20%

Computer Architecture 2012 – probabilistic L1 filtering13
013304744600…
0
Example – CDF of mass of references
ad
dre
sses
(of
mem
ory
refe
rence
s)
(1)x(2)x(2) x (1)(2) x (2)(3)x (2)(1)x (2)(1) x (1)(2)x (1)
(3) x (2)(1)x (2)(2)x (2)
(90)x (2)
resid
ency
#1
#3
#4
#2
#5
print 3
print 3
print 2
print 90print 2program end
(3)x (1)
So printed residency lengths are: 3, 2, 3, 90, 2Thus, CDF of mass of references (“refs”) is:• 4% of refs are to residencies with length
<= 2= (2+2) / (3+2+3+90+2)
• 10% of refs are to residencies with len <= 3= (2+2+3+3) / (3+2+3+90+2)
• 100% of refs are to residencies w len <= 90= (2+2+3+3+90) / (3+2+3+90+2)
2 3 90lengths
CD
F 60%
80%
100%
40%
20%

Computer Architecture 2012 – probabilistic L1 filtering14
Superimposing graphs
2 3 90lengths
CD
F 60%
80%
100%
40%
20%
residency
lengths
memory
references the
“mass”
the“counters”
“mass-count disparity” (disparity = לּות �נ�י, נ�ב�ָּד� is the (ֹׁשֹונּות, ֹׁשterm describing the phenomenon shown in the graph, whereby:• most of the mass resides in very few counters, and • most of the counters count very little mass

Computer Architecture 2012 – probabilistic L1 filtering15
RESULTS FROMREAL BENCHMARKS

Computer Architecture 2012 – probabilistic L1 filtering16
Methodology Using all benchmarks from the SPEC-CPU 2000
benchmarks suite In this presentation we show only four But we include all the rest in the averages
The benchmarks were compiled for The Alpha AXP architecture
All benchmarks were fast-forwarded 15 billion instructions (to skip any initialization code) and were then executed for another 2 billion instructions
Unless otherwise stated, all simulated runs utilize a 16KB direct-mapped cache

Computer Architecture 2012 – probabilistic L1 filtering17
C
DF
CDF of residency length
(of 4 SPEC benchmark apps)
Vast majority of residencies are relatively short Which likely means they are transient
Small fraction of residencies are extremely long
Crafty Vortex Facerec Spsl
data
inst
ruct
ions
length of residency

Computer Architecture 2012 – probabilistic L1 filtering18
CDF of mass of residencies(of 4 SPEC benchmark apps)
Fraction of memory references serviced by each length
Most references target residencies longer than, say, 10
C
DF
Crafty Vortex Facerec Spsl
data
inst
ruct
ions
length of residency

Computer Architecture 2012 – probabilistic L1 filtering19
Superimposing graphs reveals mass-count disparity
Mass
C
DF
Crafty Vortex Facerec Spsl
data
inst
ruct
ions
length of residency
Count
Every x value along the curves reveals how many of the residencies account for how much of the mass
For example, in Crafty, 55% if the (shortest) residencies account for only 5% of the mass
Which means the other 45% (longer) residencies account for 95% of the mass

Computer Architecture 2012 – probabilistic L1 filtering20
The joint-ratiomass-disparity metric
Mass
Crafty Vortex
Joint-Ratio Facerec Spsl
C
DF
Crafty Vortex Facerec Spsl
data
inst
ruct
ions
length of residency
The divergence between the distributions (= the mass-count disparity) can be quantified by the “joint ratio”
It’s a generalization of the proverbial 20/80 principle Definition: the joint ratio is the unique point in the graphs
where the sum of the two CDFs is 1 Example: in the case of Vortex, the joint ratio is 13/87 (blue
arrow in middle of plot), meaning 13% of the (longest) residencies hold 87% of the mass of the memory references, while the remaining 87% of the residencies hold only 13% of the mass
Count

Computer Architecture 2012 – probabilistic L1 filtering21
The W1/2 mass-disparity metric
Mass
W1/2
C
DF
Crafty Vortex Facerec Spsl
data
inst
ruct
ions
length of residency
Count
Definition: overall mass (in %) of the shorter half of the residencies
Example: in Vortex and Facerec W1/2 is less than 5% of the references
Average W1/2 across all benchmarks is < 10% (median of W1/2 is < 5%)

Computer Architecture 2012 – probabilistic L1 filtering22
The N1/2 mass-disparity metric
Mass
C
DF
Crafty Vortex Facerec Spsl
data
inst
ruct
ions
length of residency
Count
Definition: % of longer residencies accounting for half of the mass
Example: in Vortex and Facerec N1/2 is less than 1% of the references
Average N1/2 across all benchmarks is < 5% (median of N1/2 is < 1%)
N1/2

Computer Architecture 2012 – probabilistic L1 filtering23
DESIGNING A NEW INSERTION POLICY
Let us utilize our understandings for…

Computer Architecture 2012 – probabilistic L1 filtering24
Probabilistic insertion? The mass-disparity we’ve identified means
A small number of long residencies account for most memory references; but still most residencies are short
So when randomly selecting a residency It would likely be a short residency
Which means we have a way to approximate the future: Given a block about to be inserted into cache,
probabilistically speaking, we know with high degree of certainty that it’d be disadvantageous to actually insert it…
So we won’t! Instead, we’ll flip a coin…• Heads = insert block to cache (small probability)• Tails = insert block to a small filter (high probability)
Rationale Long residencies will enjoy many coin-flips, so chances are
they’ll eventually get into the cache Conversely, short residencies have little chance to get in

Computer Architecture 2012 – probabilistic L1 filtering25
Design Direct-mapped L1 + small
fully-associative filter w/ CAM
Insertion policy for lines not in L1: for each mem ref, flip biased coin to decide if line goes into filter or into L1
SRAM is cache memory Not to be confused with
DRAM Holds blocks that, by the
coin flip, shouldn’t be inserted to L1
Usage First, search data in L1 If not found, search in filter If not found, go to L2, and
then use above insertion policy
L1 with random filter

Computer Architecture 2012 – probabilistic L1 filtering26
Result Long residencies end up in
L1 Short residencies tend to
end up in filter
Benefit of randomness Filtering is purely
statistical, eliminating the need to save any state or reuse information!
Explored filter sizes 1KB, 2KB, and 4KB Consisting of 16, 32, and
64 lines, respectively Results presented in slides:
were achieved using a 2K filter
L1 with random filter

Computer Architecture 2012 – probabilistic L1 filtering27
Exploring coin bias
Find the probability minimizing the miss-rate High probability swamps cache Low probability swamps filter
Constant selection probabilities seem sufficient Data miss-rate reduced by ~25% for P = 5/100 Inst. miss-rate reduced by >60% for P = 1/1000
Data Instruction
Reductionin miss rate

Computer Architecture 2012 – probabilistic L1 filtering28
Exploring coin bias
Random sampling with probability P turned out equivalent toperiodic sampling at a rate of ~1/P Do not need real randomness
Majority of memory refs serviced by L1 cache, whereas majority of blocks remain in the filter; specifically: L1 services 80% - 90% of refs With only ~35% of the blocksData Instruction
Reductionin miss rate

Computer Architecture 2012 – probabilistic L1 filtering29
Problem – CAM is wasteful & slow Fully-associative filter uses CAM (content addressable
memory) Input = address; output (on a hit) = “pointer” into SRAM
saying where’s the associated data CAM lookup done in parallel
Parallel lookup drawbacks Wastes energy Is slower (relative to direct-
mapped)
Possible solution Introducing the “WLB”…

Computer Architecture 2012 – probabilistic L1 filtering30
WLB is a small direct-mapped lookup table caching the most recent CAM lookups (Recall: given an address, CAM returns a pointer into SRAM;
it’s a search like any search and therefore can be cached) Fast, low-power lookups
Filter usage when addingto it the WLB First, search data in L1 In parallel search its address in WLB If data not in L1 but WLB hits
• Access the SRAM without CAM If data not in L1 and WLB misses
• Only then use the slower / wasteful CAM
If not found, go to L2 as usual
Wordline look-aside Buffer (WLB)

Computer Architecture 2012 – probabilistic L1 filtering31
Effectiveness of WLB?Data Instruction
WLB is quite effective with only 8 entries (for both I and D) Eliminates 77% of CAM data lookups Eliminates 98% of CAM instructions lookups
Since WLB is so small and simple (direct map) It’s fast and consumes extremely low power Therefore, it can be looked up in parallel with main L1 cache
size of WLB [number of entries]

Computer Architecture 2012 – probabilistic L1 filtering32
PERFORMANCEEVALUATION

Computer Architecture 2012 – probabilistic L1 filtering33
Methodology 4 wide, out-of-order micro-architecture (SimpleScalar)
(You’ll understand this when we learn out-of-order execution) Simulated L1
16K, 32K, 64K, with several set-associative configuration; latency:• Direct-mapped: 1 cycle• Set-associative: 2 cycles
Simulated filter 2K, fully-associative, with 8-entry WLB; latency: 5 cycles
• 1 cycle = for WLB (in parallel to accessing the cache)• 3 cycles = for CAM lookup• 1 cycle = for SRAM access
Simulated L2 512K; latency: 16 cycles
Simulated main-memory Latency: 350 cycles

Computer Architecture 2012 – probabilistic L1 filtering34
Results – runtime
Comparing random sampling filter cache to other common cache designs
Outperforms a 4-way cache double its size! Interesting: DM’s low-latency compensates for conflict misses
16K DM + filter 32K DM + filtera
vera
ge
rela
tiv
e
imp
rov
eme
nt
[%]
Computer Architecture 2012 – probabilistic L1 filtering36
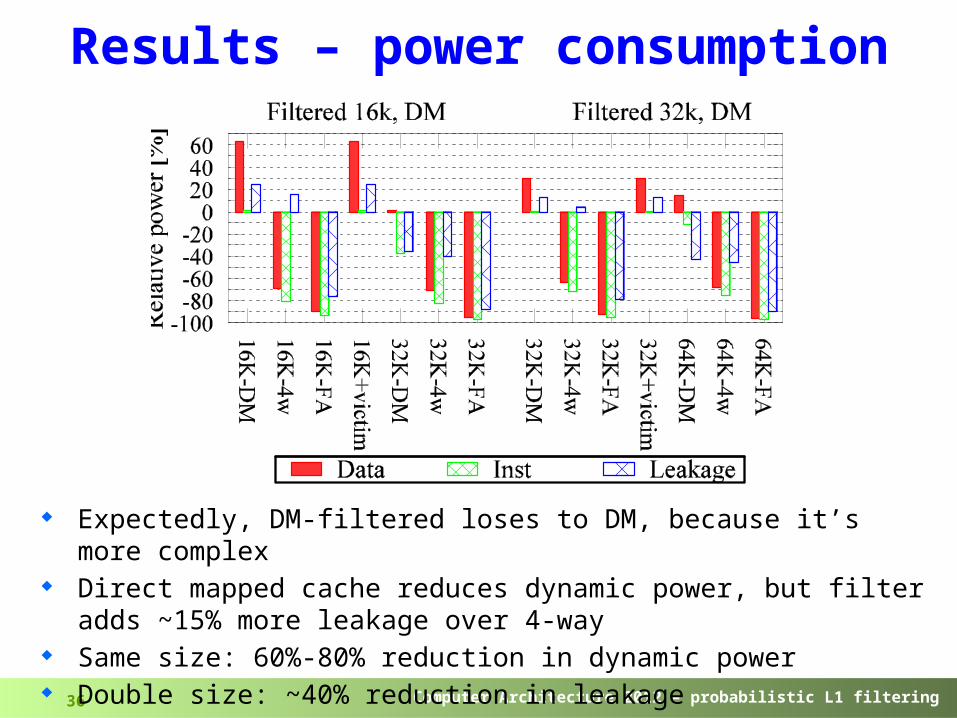
Results – power consumption
Expectedly, DM-filtered loses to DM, because it’s more complex
Direct mapped cache reduces dynamic power, but filter adds ~15% more leakage over 4-way
Same size: 60%-80% reduction in dynamic power Double size: ~40% reduction in leakage

Computer Architecture 2012 – probabilistic L1 filtering37
Conclusions
The Mass-Count disparity phenomenon can be leveraged for caching policies
Random Sampling effectively identifies frequently used blocks Adding just 2K filter is better than doubling the cache size,
both in terms of IPC and power
The WLB is effective at eliminating costly CAM lookups Offering fast, low-power access while maintaining fully-
associativity benefits


















