
Computazione per l’interazione naturale: Regressione...
23
Computazione per l’interazione naturale: Regressione probabilistica Corso di Interazione Naturale Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano [email protected] boccignone.di.unimi.it/IN_2018.html • Assumiamo rumore gaussiano additivo • Allora Regressione lineare //modelli probabilistici: stima di ML precisione
-
Upload
truongnhan -
Category
Documents
-
view
218 -
download
0
Transcript of Computazione per l’interazione naturale: Regressione...
Computazione per l’interazione naturale: Regressione probabilistica
Corso di Interazione Naturale
Prof. Giuseppe Boccignone
Dipartimento di InformaticaUniversità di Milano
[email protected]/IN_2018.html
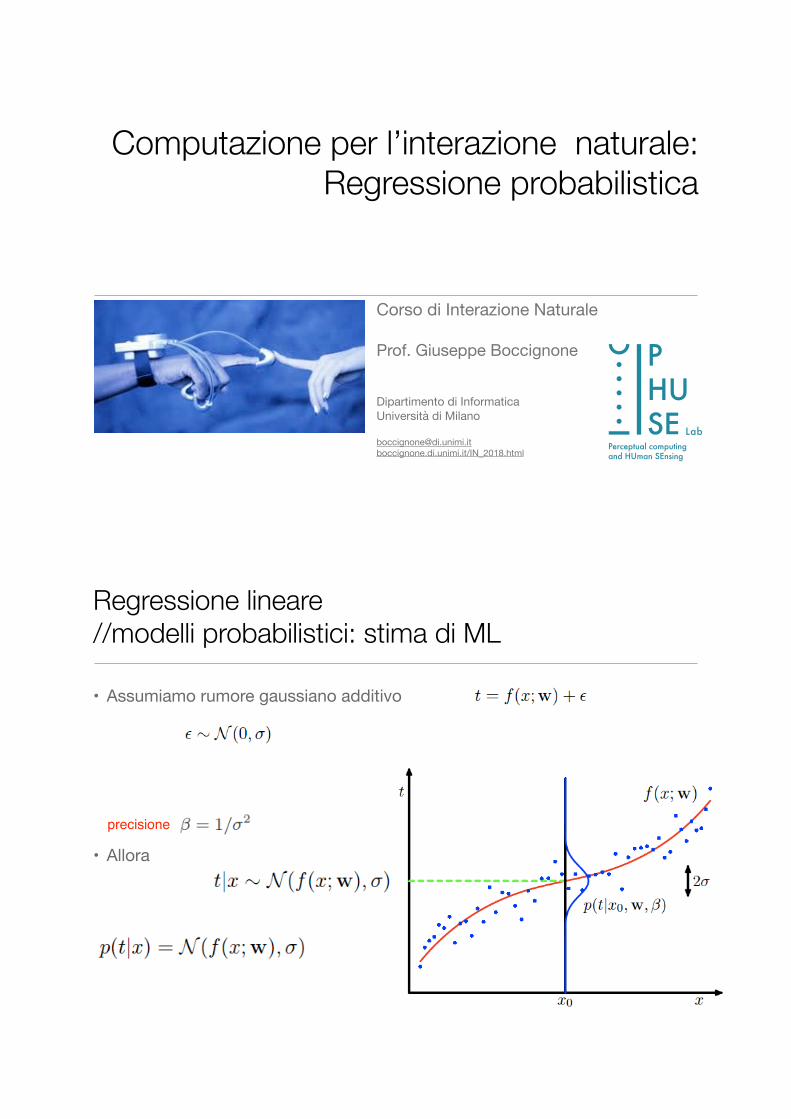
• Assumiamo rumore gaussiano additivo
• Allora
Regressione lineare //modelli probabilistici: stima di ML
precisione
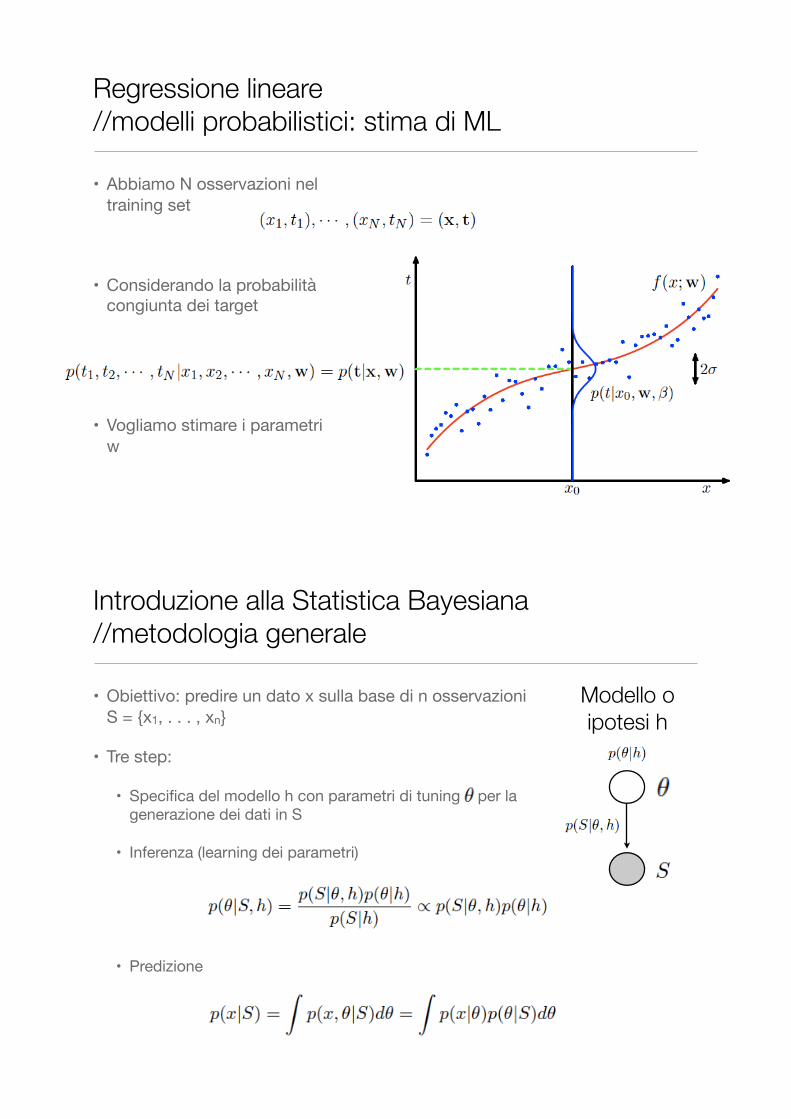
• Abbiamo N osservazioni nel training set
• Considerando la probabilità congiunta dei target
• Vogliamo stimare i parametri w
Regressione lineare //modelli probabilistici: stima di ML
Introduzione alla Statistica Bayesiana //metodologia generale
• Obiettivo: predire un dato x sulla base di n osservazioni S = {x1, . . . , xn}
• Tre step:
• Specifica del modello h con parametri di tuning per la generazione dei dati in S
• Inferenza (learning dei parametri)
• Predizione
Modello o ipotesi h

• Rinunciando ad un approccio completamente Bayesiano, si possono ottenere stime puntuali dei parametri (ovvero i parametri diventano “numeri” e non VA)
• Stima Maximum A Posteriori (MAP)
• Stima di massima verosimiglianza (Maximum Likelihood, ML)
Statistica Bayesiana //stime puntuali
Esempio: stima di massima verosimiglianza //caso Gaussiano
• Insieme di campioni x1, . . . , xn da distribuzione Gaussiana di parametri ignoti (identicamente distribuiti)
• Campioni estratti indipendentemente:
• allora
• oppure usando la log-verosimiglianza
L’ipotesi i.i.d

• Un vettore aleatorio
forma quadratica di x
Esempio: stima di massima verosimiglianza //caso Gaussiano
• per il singolo campione
• Se con covarianza nota e media da stimare
• per il singolo campione
• derivando il secondo termine rispetto a (il primo è costante rispetto a teta)
• per tutti i campioni
• ponendo uguale a 0
Esempio: stima di massima verosimiglianza // della Gaussiana
media empirica

• Se con covarianza e media da stimare
• per il singolo campione
• derivando il secondo termine rispetto a e ripetendo il procedimento di prima
Esempio: stima di massima verosimiglianza // Parametri della Gaussiana
media empirica
covarianza empirica
• Training set
• La likelihood è
Regressione lineare //stima di ML dei parametri
L’ipotesi i.i.d
funzione di costo
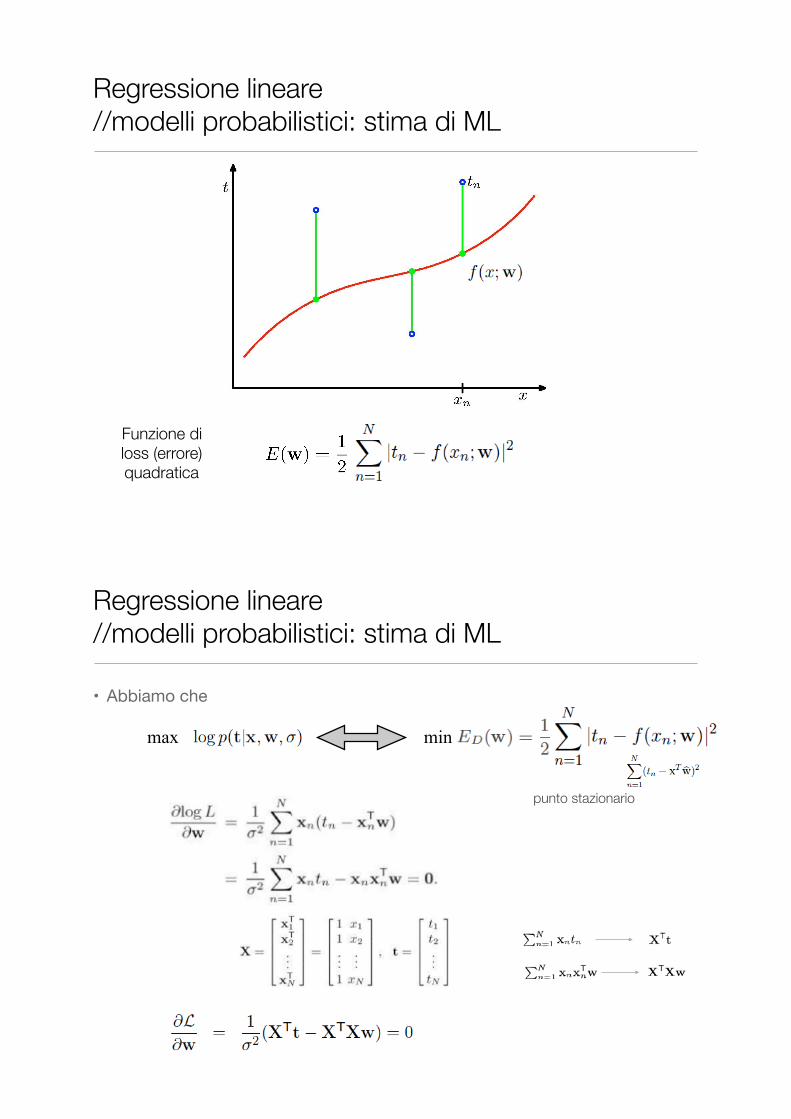
Funzione di loss (errore) quadratica
Regressione lineare //modelli probabilistici: stima di ML
• Abbiamo che
max min
Regressione lineare //modelli probabilistici: stima di ML
punto stazionario
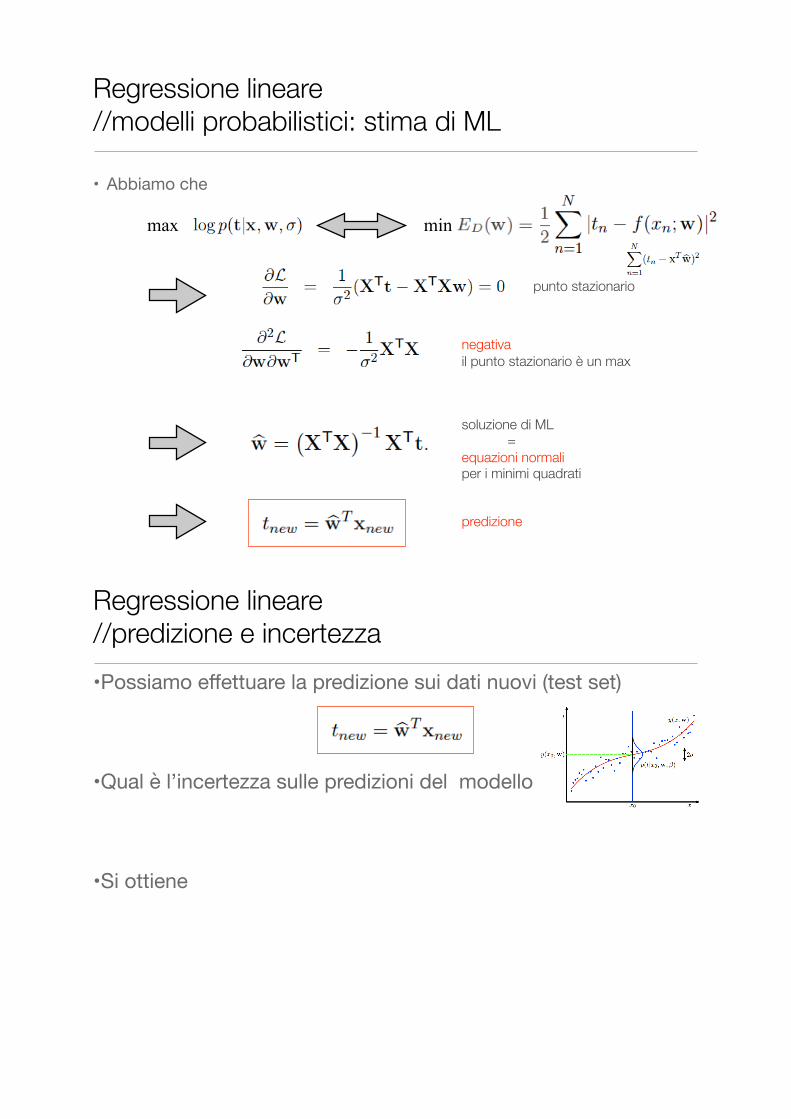
• Abbiamo che
max min
soluzione di ML = equazioni normali per i minimi quadrati
Regressione lineare //modelli probabilistici: stima di ML
negativa il punto stazionario è un max
punto stazionario
predizione
•Possiamo effettuare la predizione sui dati nuovi (test set)
•Qual è l’incertezza sulle predizioni del modello?
•Si ottiene
Regressione lineare //predizione e incertezza

Regressione lineare //predizione e incertezza
l’incertezza è legata alla covarianza dei parametri stimati !!
•Possiamo effettuare la predizione sui dati nuovi (test set)
•Qual è l’incertezza sulle predizioni del nostro modello?•Usiamo la covarianza...
• Analogamente possiamo anche fornire una stima ML della varianza del rumore, assumendo
Regressione lineare //modelli probabilistici: stima di ML
REGRESSIONE PROBABILISTICA
THE AUTHOR
Assumendo w = !w
(1)∂L
∂σ= −
N
σ+
1
σ2
N"
n=1
(tn − xT !w)2 = 0
(2) !σ2 =1
N
N"
n=1
(tn − xT !w)2 =
1
N(t−X!w)T (t−X!w)
1
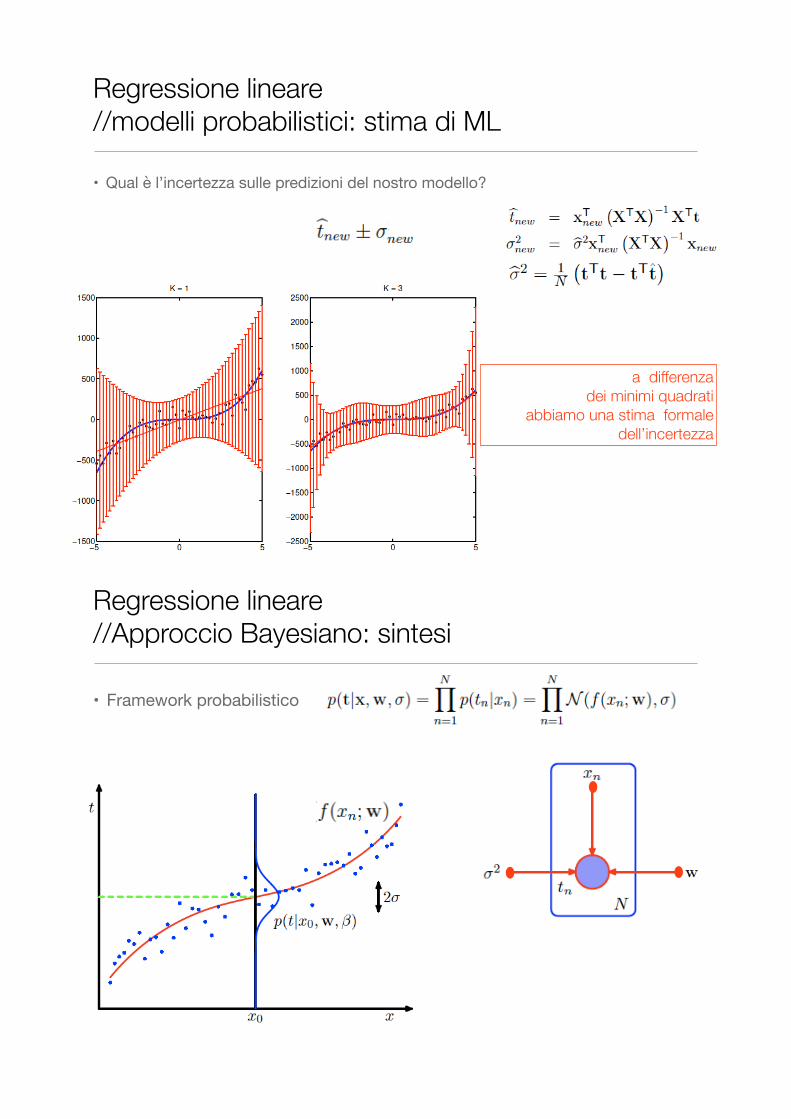
• Qual è l’incertezza sulle predizioni del nostro modello?
Regressione lineare //modelli probabilistici: stima di ML
a differenza dei minimi quadrati
abbiamo una stima formale dell’incertezza
• Framework probabilistico
Regressione lineare //Approccio Bayesiano: sintesi

• Framework probabilistico
Regressione lineare //Approccio Bayesiano: sintesi
Regola di Bayes
Regola di Bayes per la regressione
Probabilità congiunta
• I pesi w non sono semplici parametri ma variabili aleatorie su cui fare inferenza abbiamo cioè un modello generativo
Regressione lineare //Approccio Bayesiano: sintesi

• I pesi w non sono semplici parametri ma variabili aleatorie su cui fare inferenza abbiamo cioè un modello generativo
Regressione lineare //Approccio Bayesiano: sintesi
Probabilità congiunta (probabilità di tutto)
• I pesi w non sono semplici parametri ma variabili aleatorie su cui fare inferenza abbiamo cioè un modello generativo
• Si introduce una probabilità a priori su w (che regolarizza: favorisce piccoli w)
• Dai dati di training si calcola la probabilità a posteriori
Regressione lineare //Approccio Bayesiano: sintesi
Iperparametri
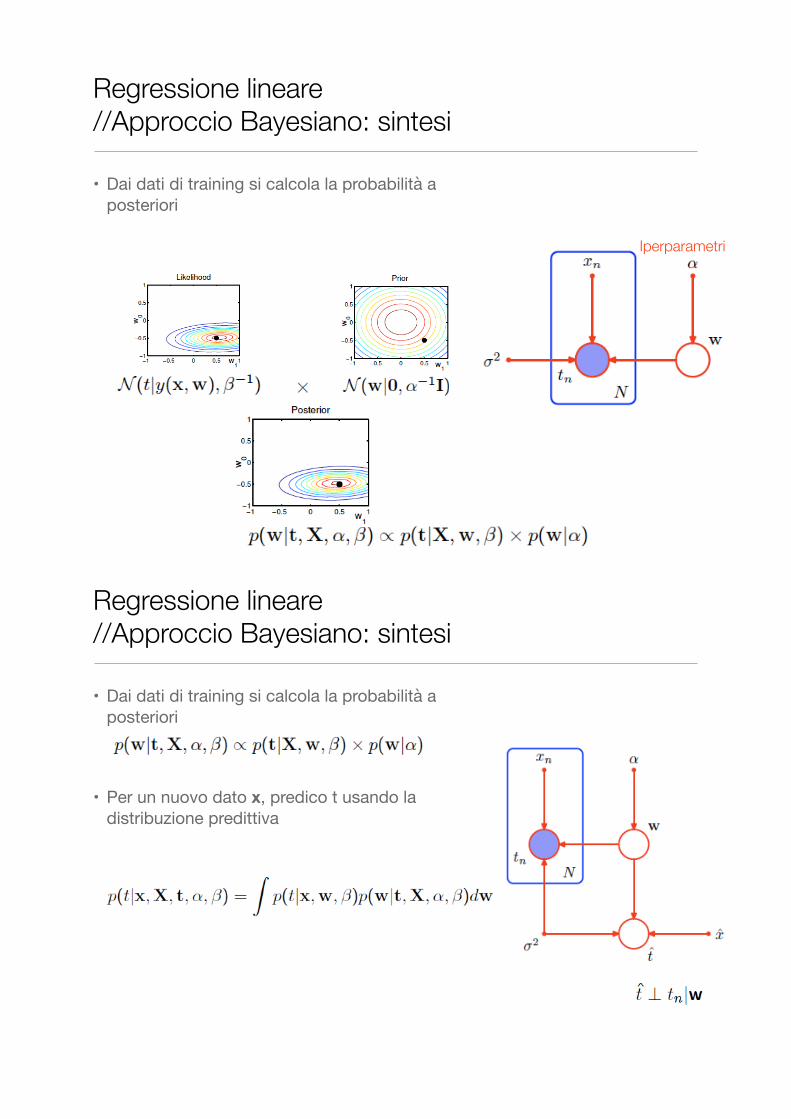
• Dai dati di training si calcola la probabilità a posteriori
Regressione lineare //Approccio Bayesiano: sintesi
Iperparametri
• Dai dati di training si calcola la probabilità a posteriori
• Per un nuovo dato x, predico t usando la distribuzione predittiva
Regressione lineare //Approccio Bayesiano: sintesi
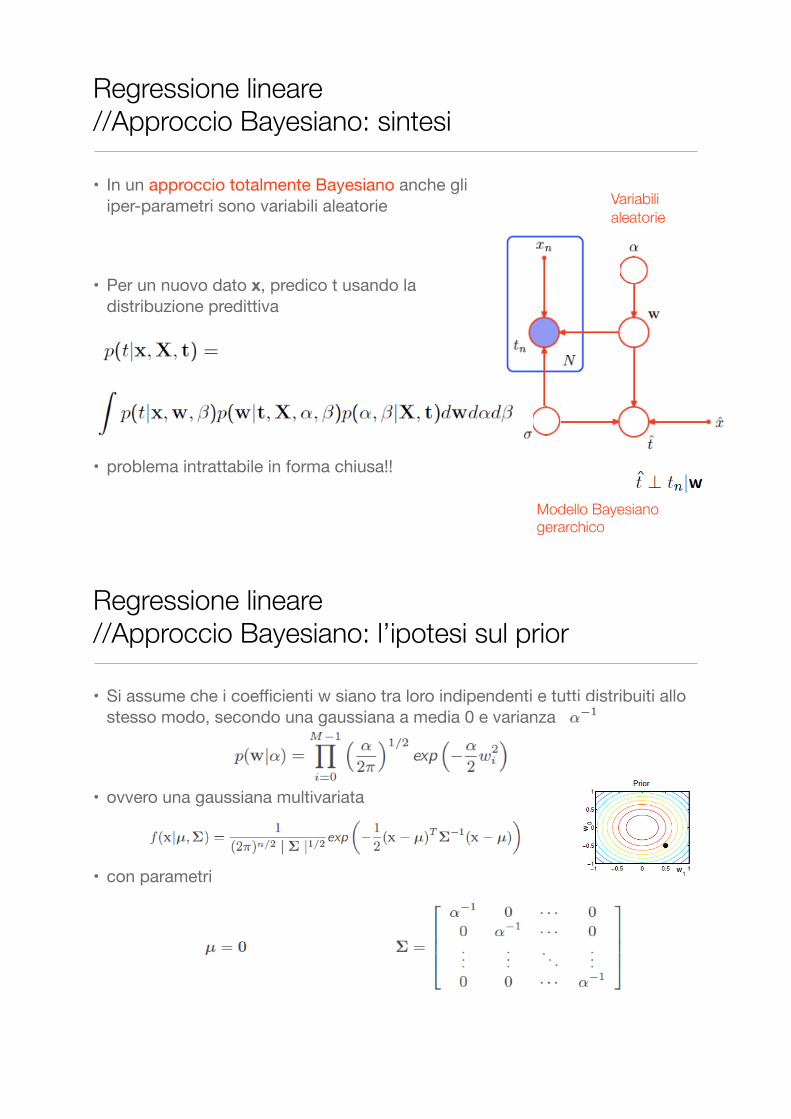
• In un approccio totalmente Bayesiano anche gli iper-parametri sono variabili aleatorie
• Per un nuovo dato x, predico t usando la distribuzione predittiva
• problema intrattabile in forma chiusa!!
Regressione lineare //Approccio Bayesiano: sintesi
Variabili aleatorie
Modello Bayesiano gerarchico
• Si assume che i coefficienti w siano tra loro indipendenti e tutti distribuiti allo stesso modo, secondo una gaussiana a media 0 e varianza
• ovvero una gaussiana multivariata
• con parametri
Regressione lineare //Approccio Bayesiano: l’ipotesi sul prior

• Sappiamo che (the Matrix cookbook)
Regressione lineare //Approccio Bayesiano: l’ipotesi sul prior
• Nel nostro caso, con un po’ di conti... (e non scrivendo le variabili x per semplificare la notazione)
• con
Regressione lineare //Approccio Bayesiano: l’ipotesi sul prior

• In questo setting
• Si noti che
• 1. Per
• ritroviamo la regressione di ML
• 2. Calcolando la log posteriori
• ritroviamo la ML regolarizzata
Regressione lineare //Approccio Bayesiano: l’ipotesi sul prior
Regressione lineare //Approccio Bayesiano: learning sequenziale
osservo
osservo
rette campionate dalla distribuzione
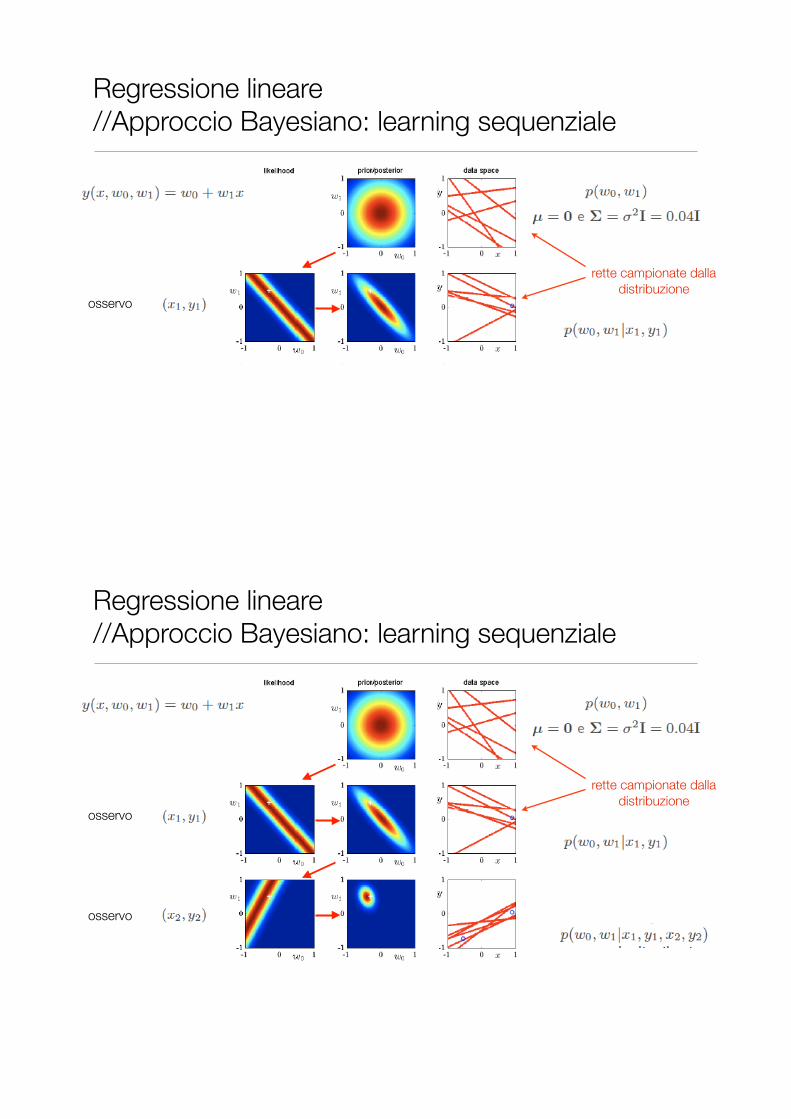
Regressione lineare //Approccio Bayesiano: learning sequenziale
osservo
osservo
rette campionate dalla distribuzione
Regressione lineare //Approccio Bayesiano: learning sequenziale
osservo
osservo
rette campionate dalla distribuzione
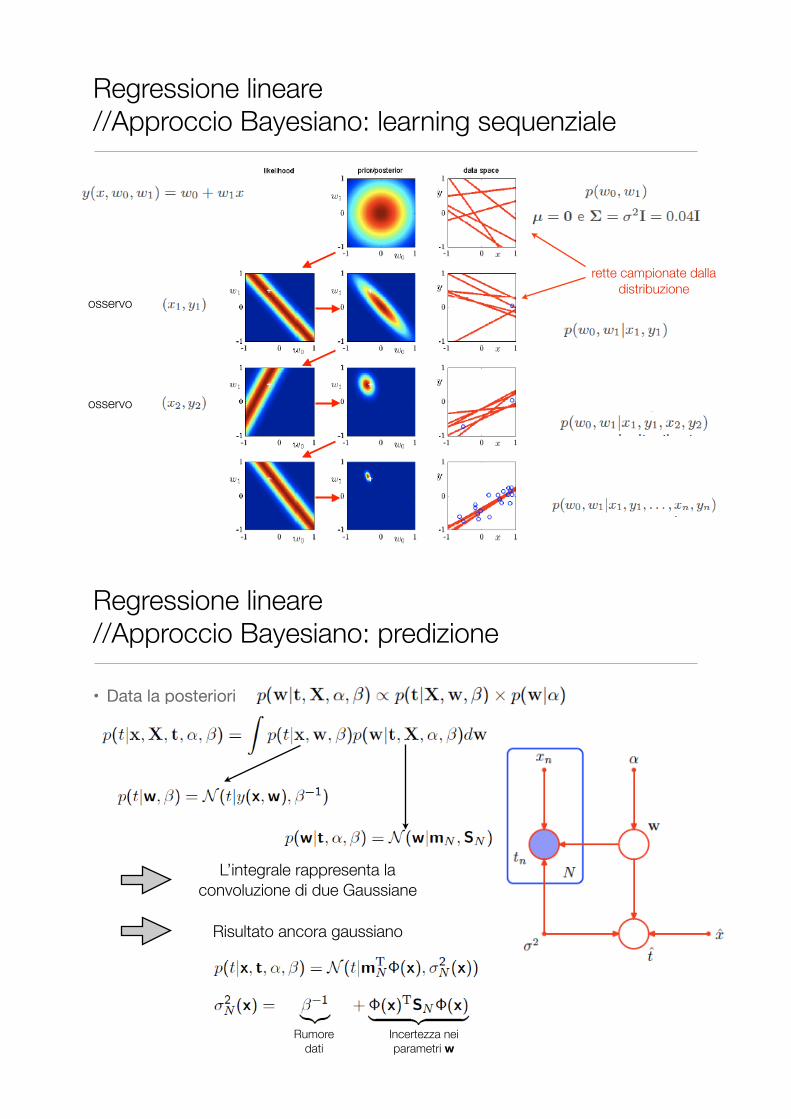
Regressione lineare //Approccio Bayesiano: learning sequenziale
osservo
osservo
rette campionate dalla distribuzione
• Data la posteriori
Regressione lineare //Approccio Bayesiano: predizione
L’integrale rappresenta la convoluzione di due Gaussiane
Risultato ancora gaussiano
Rumore dati
Incertezza nei parametri w

Regressione lineare //Approccio Bayesiano: predizione
Rumore dati
Incertezza nei parametri w
• Al crescere del numero di elementi nel training set:
• il secondo termine della varianza diminuisce, e quindi la distribuzione tende a concentrarsi intorno al valore previsto
• solo il primo termine rimane significativo, mostrando che la sola incertezza rimanente è quella relativa ai dati osservati
Regressione lineare //Approccio Bayesiano: esempio
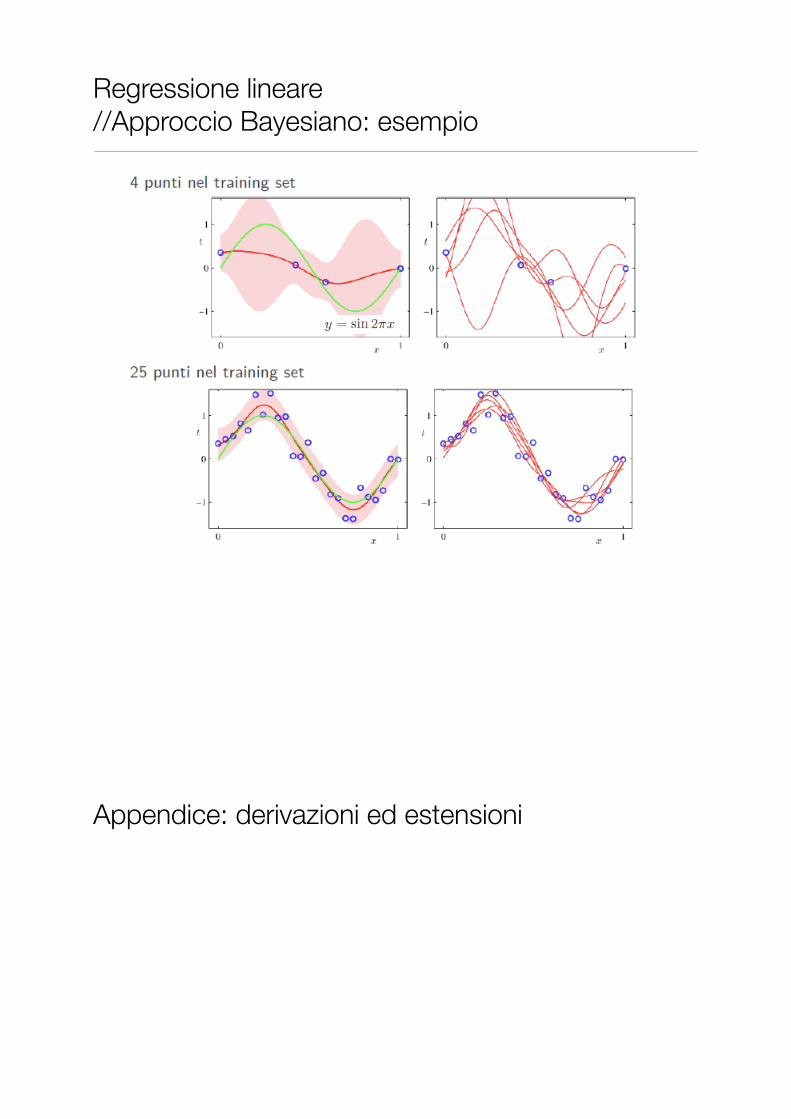
Regressione lineare //Approccio Bayesiano: esempio
Appendice: derivazioni ed estensioni

• Qual è l’incertezza sui parametri stimati?
• E’ legata alla covarianza dei parametri stimati...
• Poichè ML è stimatore unbiased:
Regressione lineare //modelli probabilistici: stima di ML
rumore a media 0
• Qual è l’incertezza sulle stime del nostro modello?
• E’ legata alla covarianza dei parametri stimati...
• Si ottiene
Regressione lineare //modelli probabilistici: stima di ML
piccola curvatura =
elevata varianza =
parametri poco significativi
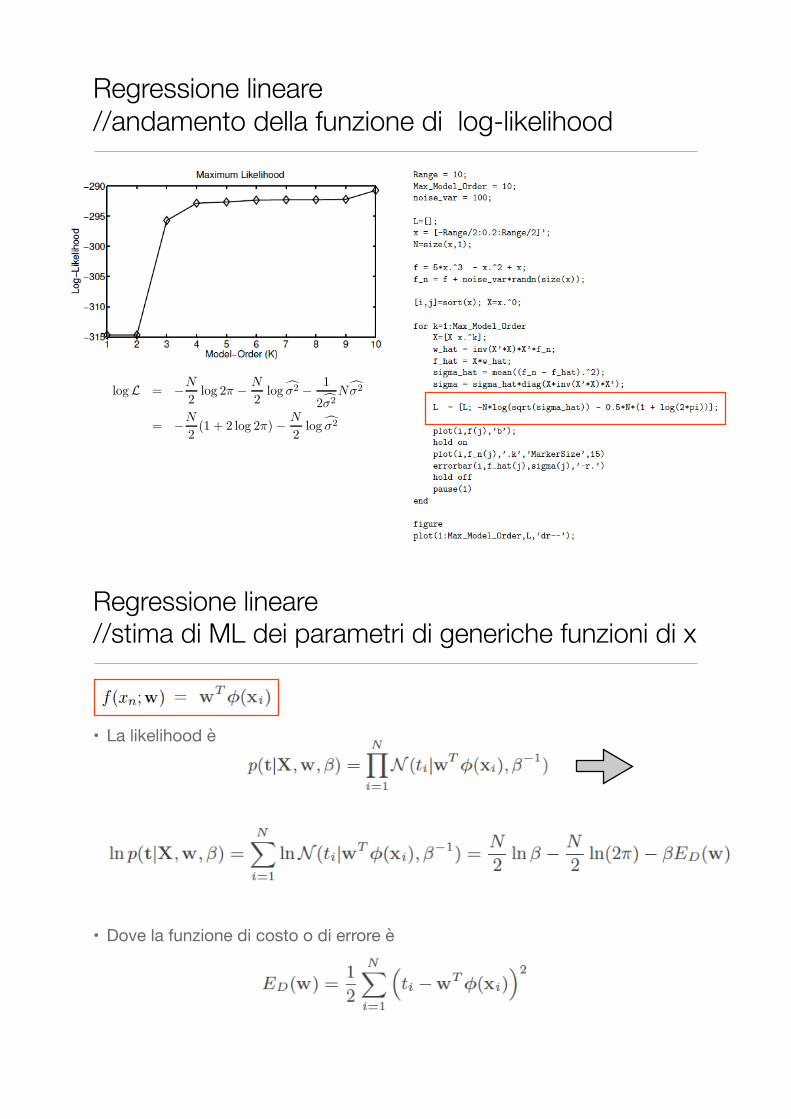
Regressione lineare //andamento della funzione di log-likelihood
REGRESSIONE PROBABILISTICA
THE AUTHOR
Assumendo w = !w
(1)∂L
∂σ= −
N
σ+
1
σ2
N"
n=1
(tn − xT !w)2 = 0
(2) !σ2 =1
N
N"
n=1
(tn − xT !w)2 =
1
N(t−X!w)T (t−X!w)
Relazione tra w e !w
Ep(t|X,w,σ) [!w] =
#!wp(t|X,w,σ)dt(3)
= (XTX)−1
XT
#tp(t|X,w,σ)dt
= (XTX)−1
XTEp(t|X,w,σ) [t]
= (XTX)−1
XTXw
= w
Predizione:
(4) tnew = !wTxnew
σ2new = var{tnew} = Ep(t|X,w,σ)
$t2new
%− (Ep(t|X,w,σ) [tnew])
2(5)
= σ2xTnew(X
TX)−1
xnew
= xTnewcov{!w}xnew
likelihood:
logL = −N
2log 2π −
N
2log&σ2 −
1
2&σ2N&σ2(6)
= −N
2(1 + 2 log 2π)−
N
2log&σ2
1
• La likelihood è
• Dove la funzione di costo o di errore è
Regressione lineare //stima di ML dei parametri di generiche funzioni di x

max min
equazioni normali per i minimi quadrati
Regressione lineare //stima di ML dei parametri di generiche funzioni di x
• Abbiamo generalizzato il risultato già ottenuto per la retta
equazioni normali per i minimi quadrati
design matrix
Regressione lineare //modelli probabilistici: stima di ML

• Possiamo computare il Minimo di ED(w) anche in modo non analitico: metodo di discesa del gradiente (procedura iterativa)
• Inizializzazione
• while ( ~ condizioneTerminazione)
Regressione lineare //modelli probabilistici: stima di ML
i = i+1;
604 B Optimization
a) b)
5 Iterations
Steepest Descent
Figure B.3 Optimization on a two dimensional function (color representsheight of function). We wish to find the parameters that minimize thefunction (green cross). Given an initial starting point ✓0 (blue cross), wechoose a direction and then perform a local search to find the optimal pointin that direction. a) One way to chose the direction is steepest descent:at each iteration, we head in the direction where the function changes thefastest. b) When we initialize from a di↵erent position, the steepest descentmethod takes many iterations to converge due to oscillatory behavior. c)Close-up of oscillatory region (see main text). d) Setting the direction usingNewton’s method results in faster convergence. e) Newton’s method does notundergo oscillatory behavior when we initialize from the second position.
where the derivative @f/@✓ is the gradient vector, which points uphill, and � isthe distance moved downhill in the opposite direction �@f/@✓. The line searchprocedure (section B.3) selects the value of �.
Steepest descent sounds like a good idea but can be very ine�cient in certainsituations (figure B.3b). For example, in a descending valley, it can oscillate ine↵ec-tually from one side to the other rather than proceeding straight down the center:the method approaches the bottom of the valley from one side, but overshootsbecause the valley itself is descending, so the minimum along the search directionis not exactly in the valley center (figure B.3c). When we re-measure the gradientand perform a second line search, we overshoot in the other direction. This is notan unusual situation: it is guaranteed that the gradient at the new point will beperpendicular to the previous one, so the only way to avoid this oscillation is tohit the valley at exactly right angles.
Copyright c�2011,2012 by Simon Prince; published by Cambridge University Press 2012.For personal use only, not for distribution.
• Possiamo computare il Minimo di ED(w) anche in modo non analitico: e.g. metodo di discesa del gradiente
• Inizializzazione
• while ( ~ condizioneTerminazione)
Regressione lineare //modelli probabilistici: stima di ML
i = i+1;
604 B Optimization
a) b)
5 Iterations
Steepest Descent
Figure B.3 Optimization on a two dimensional function (color representsheight of function). We wish to find the parameters that minimize thefunction (green cross). Given an initial starting point ✓0 (blue cross), wechoose a direction and then perform a local search to find the optimal pointin that direction. a) One way to chose the direction is steepest descent:at each iteration, we head in the direction where the function changes thefastest. b) When we initialize from a di↵erent position, the steepest descentmethod takes many iterations to converge due to oscillatory behavior. c)Close-up of oscillatory region (see main text). d) Setting the direction usingNewton’s method results in faster convergence. e) Newton’s method does notundergo oscillatory behavior when we initialize from the second position.
where the derivative @f/@✓ is the gradient vector, which points uphill, and � isthe distance moved downhill in the opposite direction �@f/@✓. The line searchprocedure (section B.3) selects the value of �.
Steepest descent sounds like a good idea but can be very ine�cient in certainsituations (figure B.3b). For example, in a descending valley, it can oscillate ine↵ec-tually from one side to the other rather than proceeding straight down the center:the method approaches the bottom of the valley from one side, but overshootsbecause the valley itself is descending, so the minimum along the search directionis not exactly in the valley center (figure B.3c). When we re-measure the gradientand perform a second line search, we overshoot in the other direction. This is notan unusual situation: it is guaranteed that the gradient at the new point will beperpendicular to the previous one, so the only way to avoid this oscillation is tohit the valley at exactly right angles.
Copyright c�2011,2012 by Simon Prince; published by Cambridge University Press 2012.For personal use only, not for distribution.


















