
COMP60411 Semi-structured Data and the Web A bit of XPath, Namespaces, and XML schema...
130
1 COMP60411 Semi-structured Data and the Web A bit of XPath, Namespaces, and XML schema week 2 Conny Hedeler & Uli Sattler University of Manchester Thursday, 2 October 14
Transcript of COMP60411 Semi-structured Data and the Web A bit of XPath, Namespaces, and XML schema...

1
COMP60411Semi-structured Data and the Web
A bit of XPath, Namespaces, and XML schema
week 2
Conny Hedeler & Uli SattlerUniversity of Manchester
Thursday, 2 October 14

If you have arrived late...
• welcome: I hope you have a good start and catch up quickly!
• Check out
http://studentnet.cs.manchester.ac.uk/pgt/COMP60411/
for all relevant information
• Speak to me in the break
2Thursday, 2 October 14

….plagiarism again...
• Work through the online course available in the
CS-PGT-Welcome
Community in Blackboard
– ..possibly a second time– if you have questions, ask!– don’t risk your marks – don’t risk your degree
3Thursday, 2 October 14

4
Any questions?
Thursday, 2 October 14

5
XML documents...
There are various standards, tools, APIs, data models for XML:• to describe XML documents &
validate XML document against:– we have seen: DTDs– today: XML schema
• to parse & manipulate XML documents programmatically: – we have seen: SAX (and DOM)– in next week’s coursework: DOM
• transform an XML document into another XML document or into an instance of another formats, e.g., html, excel, relational tables
– ….another form of manipulation
Thursday, 2 October 14

6
Manipulation of XML documents
• XPath for navigating through and querying of XML documents
• XQuery – more expressive than XPath, uses XPath– for querying and data manipulation– Turing complete– designed to access large amounts of data,
to interface with relational systems• XSLT
– similar to XQuery in that it uses XPath, ....– designed for “styling”, together with XSL-FO or CSS
• contrast this with DOM and SAX:– a collection of APIs for programmatic manipulation – includes data model and parser – to build your own applications
Thursday, 2 October 14

7
XPath
• designed to navigate to/select parts in a well-formed XML document• no transformational capabilities (as in XQuery and XSLT) • is a W3C standard:
– XPath 1.0 is a 1999 W3C standard– XPath 2.0 is a 2007 W3C standard that extends/is a superset of XPath 1.0
• richer set of WXS datatypes• support type information from WXS validation
– see http://www.w3.org/TR/xpath20• allows to select/define parts of an XML document: sequence of nodes• uses path expressions
– to navigate in XML documents– to select node-lists in an XML document – similar to expressions in a traditional computer file system
• provides numerous built-in functions– e.g., for string values, numeric values, date and time comparison, node
and QName manipulation, sequence manipulation, Boolean values, etc.
sequence vs set?
XML Schemalater more
rm */*/*.pdf
Thursday, 2 October 14

8
XPath: Datamodel
• remember how an XML document can be seen as a node-labelled tree– with element names as labels
• XPath operates on the abstract, logical structure of an XML document, rather than its surface syntax - but not on DOM tree!
• XPath uses XQuery/XPath Datamodel – there is a translation at http://www.w3.org/TR/xpath20/#datamodel
• see XPath process model…– it is similar to the DOM tree
• easier• handles attributes differently
Thursday, 2 October 14

9
Element
Element Element Attribute
Element
Element Element Attribute
Element
Element Element Attribute
Element
Element Element Attribute
LevelLevelLevel Data unit examplesInformation or
Property required
Information or Property required
cognitivecognitivecognitive
applicationapplicationapplication
tree adorned with...tree adorned with...tree adorned with...
namespacenamespace schemanamespacenamespace schema nothing a schema
treetreetree well-formednesswell-formedness
tokencomplexcomplex <foo:Name t=”8”>Bob
tokensimplesimple <foo:Name t=”8”>Bob
charactercharactercharacter < foo:Name t=”8”>Bob which encoding(e.g., UTF-8)
which encoding(e.g., UTF-8)
bitbitbit 10011010
parsing
serializing
choice: DOM treeInfosetXPath….
Thursday, 2 October 14

Standard Datamodel
eg. DOM or XPath
XPath processing - a simplified view
10
(Schema-aware) Parser
Schema
XML document
Input/Output Generic tools
XPath expression
XPath parser
XPath treeXPath
Execution Engine
Node Sequence
Thursday, 2 October 14

11Thursday, 2 October 14
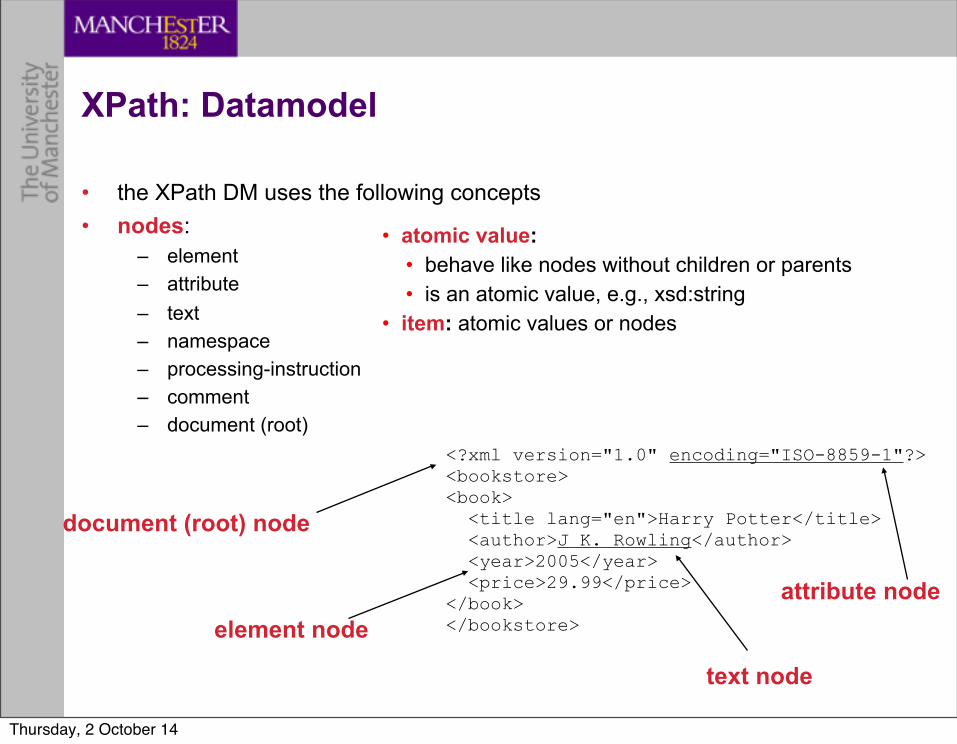
XPath: Datamodel
• the XPath DM uses the following concepts• nodes:
– element– attribute– text– namespace – processing-instruction– comment – document (root)
• atomic value: • behave like nodes without children or parents• is an atomic value, e.g., xsd:string
• item: atomic values or nodes
<?xml version="1.0" encoding="ISO-8859-1"?><bookstore><book> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price></book></bookstore>
attribute nodeelement node
text node
document (root) node
Thursday, 2 October 14

13
<?xml version="1.0" encoding="UTF-8"?><network> <description name="Boston"> This is the configuration of our network in the Boston office. </description> <host name="agatha" type="server" os="linux"> <interface name="eth0" type="Ethernet"> <arec>agatha.example.edu</arec> <cname>mail.example.edu</cname> <addr>192.168.0.4</addr> </interface> <service>SMTP</service> <service>POP3</service> <service>IMAP4</service> </host> <host name="gil" type="server" os="linux">
XPath Data Model
From:http://oreilly.com/perl/excerpts/system-admin-with-perl/ten-minute-xpath-utorial.html
Thursday, 2 October 14

Comparison XPath DM and DOM datamodel
• XPath DM and DOM DM are similar, but different – most importantly regarding names and values of nodes
but also structurally (see ★)
– in XPath, only attributes, elements, processing instructions, and namespace nodes have names, of form (local part, namespace URI)
– whereas DOM uses pseudo-names like #document, #comment, #text– In XPath, the value of an element or root node is the concatenation of
the values of all its text node descendants, not null as it is in DOM:• e.g, XPath value of <a>A<b>B</b></a> is “AB”
★ XPath does not have separate nodes for CDATA sections (they are merged with their surrounding text)
– XPath has no representation of the DTD 14
DocumentnodeType = DOCUMENT_NODEnodeName = #documentnodeValue = (null)
ElementnodeType = ELEMENT_NODEnodeName = mytextnodeValue = (null)firstchild lastchild attributes
<N>here is some text and<![CDATA[some CDATA < >]]></N>
Thursday, 2 October 14

15
XPath: core terms -- relation between nodes
• We know trees already: – each node has at most one parent
• each node but the root node has exactly one parent • the root node has no parent
– each node has zero or more children– ancestor is the transitive closure of parent,
i.e., a node’s parent, its parent, its parent, ...– descendant is the transitive closure of child,
i.e., a node’s children, their children, their children, ...• when evaluating an XPath expression p, we assume that we know
– which document and– which context we are evaluating p over– … we see later how they are chosen/given
• an XPath expression evaluates to a node sequence, – a node is a document/element/attribute node or an atomic value– document order is preserved among items
Thursday, 2 October 14

16
<?xml version="1.0" encoding="UTF-8"?><network> <description name="Boston"> This is the configuration of our network in the Boston office. </description> <host name="agatha" type="server" os="linux"> <interface name="eth0" type="Ethernet"> <arec>agatha.example.edu</arec> <cname>mail.example.edu</cname> <addr>192.168.0.4</addr> </interface> <service>SMTP</service> <service>POP3</service> <service>IMAP4</service> </host> <host name="gil" type="server" os="linux">
XPath - by example
Thursday, 2 October 14

17
<?xml version="1.0" encoding="UTF-8"?><network> <description name="Boston"> This is the configuration of our network in the Boston office. </description> <host name="agatha" type="server" os="linux"> <interface name="eth0" type="Ethernet"> <arec>agatha.example.edu</arec> <cname>mail.example.edu</cname> <addr>192.168.0.4</addr> </interface> <service>SMTP</service> <service>POP3</service> <service>IMAP4</service> </host> <host name="gil" type="server" os="linux">
XPath - abbreviated syntaxby example
context node
XPath expression: */*[2]
Thursday, 2 October 14

18
<?xml version="1.0" encoding="UTF-8"?><network> <description name="Boston"> This is the configuration of our network in the Boston office. </description> <host name="agatha" type="server" os="linux"> <interface name="eth0" type="Ethernet"> <arec>agatha.example.edu</arec> <cname>mail.example.edu</cname> <addr>192.168.0.4</addr> </interface> <service>SMTP</service> <service>POP3</service> <service>IMAP4</service> </host> <host name="gil" type="server" os="linux">
XPath - abbreviated syntaxby example
context node
XPath expression: */*[2]/*[1]/*[3]
Thursday, 2 October 14

19
<?xml version="1.0" encoding="UTF-8"?><network> <description name="Boston"> This is the configuration of our network in the Boston office. </description> <host name="agatha" type="server" os="linux"> <interface name="eth0" type="Ethernet"> <arec>agatha.example.edu</arec> <cname>mail.example.edu</cname> <addr>192.168.0.4</addr> </interface> <service>SMTP</service> <service>POP3</service> <service>IMAP4</service> </host> <host name="gil" type="server" os="linux">
XPath - abbreviated syntaxknow your context node
context node
XPath expression: */*[2]
Thursday, 2 October 14

20
<?xml version="1.0" encoding="UTF-8"?><network> <description name="Boston"> This is the configuration of our network in the Boston office. </description> <host name="agatha" type="server" os="linux"> <interface name="eth0" type="Ethernet"> <arec>agatha.example.edu</arec> <cname>mail.example.edu</cname> <addr>192.168.0.4</addr> </interface> <service>SMTP</service> <service>POP3</service> <service>IMAP4</service> </host> <host name="gil" type="server" os="linux">
XPath - abbreviated syntaxabsolute paths context node
/*
XPath expression: /*/*[1]
Thursday, 2 October 14

21
<?xml version="1.0" encoding="UTF-8"?><network> <description name="Boston"> This is the configuration of our network in the Boston office. </description> <host name="agatha" type="server" os="linux"> <interface name="eth0" type="Ethernet"> <arec>agatha.example.edu</arec> <cname>mail.example.edu</cname> <addr>192.168.0.4</addr> </interface> <service>SMTP</service> <service>POP3</service> <service>IMAP4</service> </host> <host name="gil" type="server" os="linux">
XPath - abbreviated syntaxlocal globally
XPath expression://service
Thursday, 2 October 14

22
<?xml version="1.0" encoding="UTF-8"?><network> <description name="Boston"> This is the configuration of our network in the Boston office. </description> <host name="agatha" type="server" os="linux"> <interface name="eth0" type="Ethernet"> <arec>agatha.example.edu</arec> <cname>mail.example.edu</cname> <addr>192.168.0.4</addr> </interface> <service>SMTP</service> <service>POP3</service> <service>IMAP4</service> </host> <host name="gil" type="server" os="linux">
XPath - abbreviated syntaxlocal globally
XPath expression://*
Thursday, 2 October 14

23
<?xml version="1.0" encoding="UTF-8"?><network> <description name="Boston"> This is the configuration of our network in the Boston office. </description> <host name="agatha" type="server" os="linux"> <interface name="eth0" type="Ethernet"> <arec>agatha.example.edu</arec> <cname>mail.example.edu</cname> <addr>192.168.0.4</addr> </interface> <service>SMTP</service> <service>POP3</service> <service>IMAP4</service> </host> <host name="gil" type="server" os="linux">
XPath - abbreviated syntaxattributes
XPath expression://*[@name=”agatha”]
Thursday, 2 October 14

24
Find more about XPath: read up and
play with examples, e.g., in
Thursday, 2 October 14

Modellingincluding a discussion of M1 and M1a
Thursday, 2 October 14

Case study 1
...as easy as 1 + 1?
Thursday, 2 October 14

Task: Design a simple format (not M1)• Design a format for arithmetic expressions!
– This is our CW1 domain– High level description:
• addition, multiplication, subtraction over the integers– Examples in informal notation
• 4+5*7• “Twelve minus fifty-nine plus one, that sort of thing.”
• Request – Design a reasonable XML format for this domain– Provide a DTD that describes that format
• i.e., we use schema as medium of communication
• We have choices!– First choice is the root element name
• Let’s say, “expression”
Thursday, 2 October 14

Work from an example!
Thursday, 2 October 14

Pick a root element
Thursday, 2 October 14

Work from an example!
Thursday, 2 October 14

Picking good example(s) - how? • Different principles
– Coverage: hit all features– Simplicity: easy to get right or get something– Corner cases: the hard situations– Realism: hit an actual situation
• Trade off principles– E.g., coverage vs. simplicity– More examples may be better than one!
• Your example(s) should– Give you insight into the domain– Highlight benefits or drawbacks– Force (or elicit) design decisions
• Ours– 2+3*(5-4)
Thursday, 2 October 14

Initial design thoughts• Three kinds of design issues/choices:
– Elements vs. attributes vs. text• Also type of textual content
– Structural relationships• E.g., nesting
– Naming
• Choices on one constrain the others– Suppose we decide to represent operators with elements– We cannot then use the names “+”, “*”, and “-”
• They aren’t legal element names
• Design 1 “Elements for everything” – Names: plus, minus, times, open_parens, close_parens, int– Structure?
Thursday, 2 October 14

A flat style
Thursday, 2 October 14

How to evaluate our design/format?• Establish evaluation axes and measures
• Coverage• Does it capture all of my domain?• E.g., is there an arithmetic expression I can’t encode?
• Usability• Can people write/read/otherwise use your format?• Is working with the format error prone?
• Naturalness/Fit/Fidelity• Is your format “natural”?• Does your format make good use of the data model?
• Evolvability• Can we extend the format with minimal disruption?• ………. change …………………………………….. ?
• Again, there may be trade offs– It depends on the context and interests
Thursday, 2 October 14

Fit? Is there structure? No...
Thursday, 2 October 14

Maybe indentation will help?
Thursday, 2 October 14

The system can’t see/show structure!
What is the structure of 2+3*(5-4)?
Thursday, 2 October 14

Exercise: draw parse/structure tree of
2+3*(5-4)
(3+2*3) + (5-(1+2)*(2+2))
...then evaluate these expressions.
→ do we need structure to evaluate expressions?
Thursday, 2 October 14

• Why should we care what “the system formatter” does?– It’s a warning sign
• We cannot enforce relevant syntax constraints– E.g., “Parenthesis must balance”
• For every ( there is a )– We cannot express that to an arbitrary depth!
• Wait! maybe we can?
Cool CS fact: Regular expressions can’t express nesting!
The system can’t see/show structure!
Thursday, 2 October 14

really doesn’t work:
Try to write (5 - (3-2))
Thursday, 2 October 14

Other aspects of “Fit”• Queries! E.g., over (10 + 5) * (6 - 4)
– “Get all parenthesized expressions”• I.e., (10 + 5) and (6 - 4)
– “Get the content of the first parenthesized expression”• I.e., 10 + 5
– “Get the first element of the first parenthesized expression”• I.e., 10
– We need to parse! We need a stack!
• DTD constraints– We talked about
• SAX processing• DOM processing
– DOM tree looks like the SAX messages – No nesting! Shallow tree!
Which of these queries can we answer in XPath?
Thursday, 2 October 14

SAX Processing
<?xml version="1.0" encoding="UTF-8"?><expression> <int>2</int> <plus/> <int>3</int> <times/> <open_parens/> <int>5</int> <minus/> <int>4</int> <close_parens/></expression>
startDocumentstartElement [null] [expression] [expression]comment [ A simple expression which touches all features. 2+3*(5-4) ] [21] [68]startElement [null] [int] [int]
characters [2] [102] [1]endElement [null] [int] [int]startElement [null] [plus] [plus]endElement [null] [plus] [plus]startElement [null] [int] [int]
characters [3] [131] [1]endElement [null] [int] [int]startElement [null] [times] [times]endElement [null] [times] [times]startElement [null] [open_parens] [open_parens]endElement [null] [open_parens] [open_parens]startElement [null] [int] [int]
characters [5] [180] [1]endElement [null] [int] [int]startElement [null] [minus] [minus]endElement [null] [minus] [minus]startElement [null] [int] [int]
characters [4] [210] [1]endElement [null] [int] [int]startElement [null] [close_parens] [close_parens]endElement [null] [close_parens] [close_parens]endElement [null] [expression] [expression]endDocument
You will have to do your own matching/checking of parenthesis!
Thursday, 2 October 14

Done with this: New design• Design 1
– Elements for everything– Names: plus, minus, times, open_parens, close_parens, int– Structure = Flat
• Design 2– Elements for everything– Names: plus, minus, times, parens, int– Structure = Nested parenthesis/make subexpressions clear!
• Is this better?
Thursday, 2 October 14
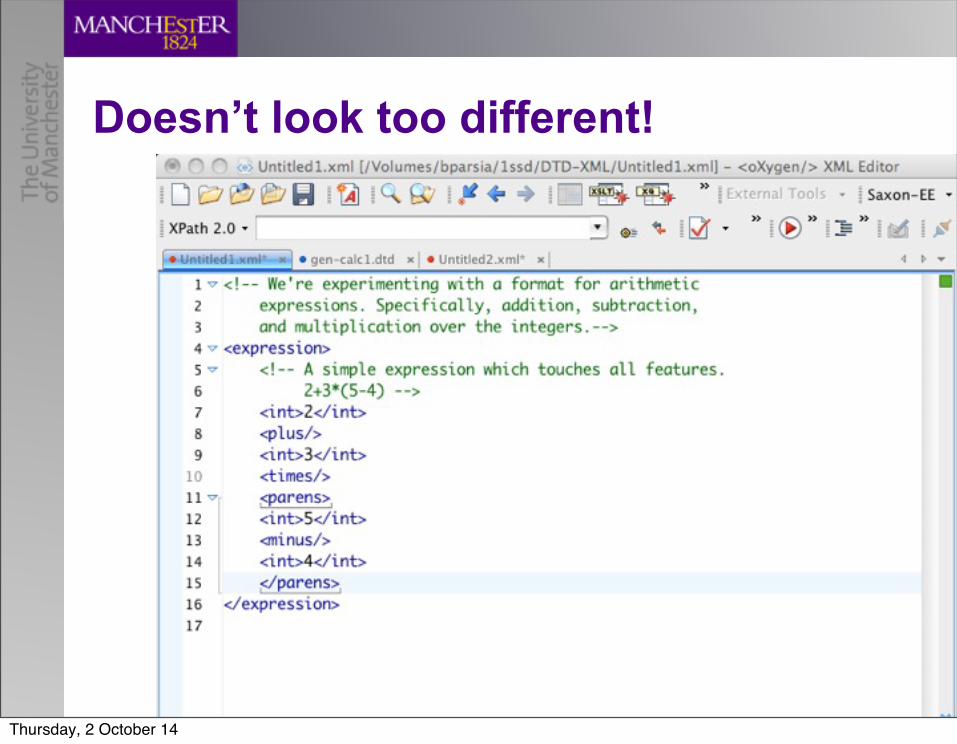
Doesn’t look too different!
Thursday, 2 October 14

But the system understands structure!
Thursday, 2 October 14

Evaluating Design 2• Design 2
– Elements for everything– Names: plus, minus, times, parens, int– Structure = Nested parens
• DTD constraints✓ we can enforce correct
nesting of parenthesis– many parentheses:
2+(3*(5-4))
• SAX/DOM?– Some tree
structure, but still some flat analysis
• Queries?
<!ELEMENT expression (parens | (int, (minus|times|plus), int) | (parens, (minus|times|plus), int) | (int, (minus|times|plus), parens) | (parens, (minus|times|plus), parens))><!ELEMENT parens (parens | (int, (minus|times|plus), int) | (parens, (minus|times|plus), int) | (int, (minus|times|plus), parens) | (parens, (minus|times|plus), parens))><!ELEMENT plus EMPTY><!ELEMENT minus EMPTY><!ELEMENT times EMPTY><!ELEMENT int (#PCDATA)>]>
<expression> <int>2</int> <plus/> <parens> <int>3</int> <times/> <parens> <int>5</int> <minus/> <int>4</int> </parens> </parens></expression>
Thursday, 2 October 14

Design 2: queries are easier!• (10 + 5) * (6 - 4)
“Get all parenthesized expressions” = //parens
Thursday, 2 October 14

• (10 + 5) * (6 - 4) “Get the content of the first parenthesized expression” = //parens[1]/*
Design 2: queries are easier!
Thursday, 2 October 14

• (10 + 5) * (6 - 4) “Get the first element of the first parenthesized expression” = //parens[1]/*[1]
Design 2: queries are easier!
Thursday, 2 October 14

• Flat vs. nested parens– Both Design 1 and 2 encode parenthesization!– But Design 2 does it in a more “XML natural” way:
• All XML sensitive tools and languages “do more” with Design 2• Key features of our information are salient to those tools!
• Is this the best use of the model?
Design 2: uses data model well!
Thursday, 2 October 14

Take it further! • Design 1
– Elements for everything– Names: plus, minus, times, open_parens, close_parens, int– Structure = Flat
• Design 2– Elements for everything– Names: plus, minus, times, parens, int– Structure = Nested parens
• Design 3– Elements for everything– Names: plus, minus, times, int– Structure = Nested operators, not parens!
Thursday, 2 October 14
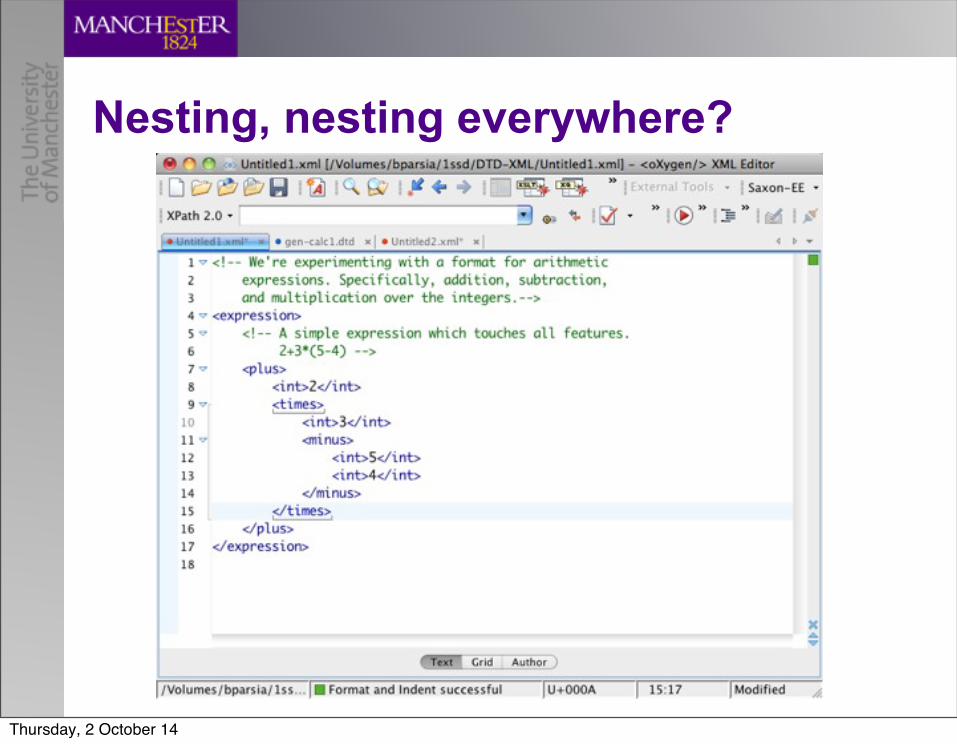
Nesting, nesting everywhere?
Thursday, 2 October 14

Evaluating Design 3• Design 3
– Elements for everything– Names: plus, minus, times, int– Structure = Nested operators
(no parens!)
• DTD constraints– Lots!
• SAX/DOM processing– Natural tree structure
• Usability– Fewer elements (and concepts!)
• Queries?– All our old ones are irrelevant!– Our new ones are more “content oriented”
• “Get all additions of subtractions”
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE expression [<!ELEMENT expression (plus | times | minus | int )><!ELEMENT plus ((plus | times | minus | int ), (plus | times | minus | int ))><!ELEMENT times ((plus | times | minus | int ), (plus | times | minus | int ))><!ELEMENT minus ((plus | times | minus | int ), (plus | times | minus | int ))><!ELEMENT int (#PCDATA)>]><expression> <plus> <int>2</int> <times> <int>3</int> <minus> <int>5</int> <int>4</int> </minus> </times> </plus></expression>
Thursday, 2 October 14

Last twiddle to get to calc1
• Design 3.1– Elements for everything– Elements for everything except integer values– Names: plus, minus, times, int, value– Structure = Nested operators (no parens!)
• Another subtle change– allow more than 2 parameter for plus and times
not <int>3</int>but <int value="3"/>...why?
<plus> <int value="3"/> <int value="5"/> <int value="7"/> </plus>
Thursday, 2 October 14

Look familiar?
Thursday, 2 October 14

We have our language design!• Design 3.1
– Elements for everything• Elements for everything except int values
– Names: plus, minus, times, int, value– Structure = Nested operators (no parens!)
• plus and times that >= 2 parameters
• We’re done, right?– We need to capture it– Say in a DTD– Our DTD needs evaluation too!
Thursday, 2 October 14

Two versions
<!ENTITY % expr "(plus | times | minus | int )"><!ELEMENT expression %expr;><!ELEMENT plus (%expr;, (%expr;)+)><!ELEMENT times (%expr;, (%expr;)+)><!ELEMENT minus (%expr;, %expr;)><!ELEMENT int EMPTY><!ATTLIST int value NMTOKEN #REQUIRED>
<!ELEMENT expression (plus | times | minus | int )><!ELEMENT plus ((plus | times | minus | int ), (plus | times | minus | int )+)><!ELEMENT times ((plus | times | minus | int ), (plus | times | minus | int )+)><!ELEMENT minus ((plus | times | minus | int ), (plus | times | minus | int ))><!ELEMENT int EMPTY><!ATTLIST int value NMTOKEN #REQUIRED>
They say exactly the same thing! The latter says it better (slightly)
or
?
Thursday, 2 October 14

What does calc1.dtd give us?• For CW1 SaxCalc
– It documents the format– It could be used for authoring
• Autocompletion, error correction• Can (partially) generate examples
– It could be used to check input• e.g. using a validating parser
• But it doesn’t capture all our constraints• Integers only as values!
<plus> <int value="3"/> <int value="five"/> <int value="7"/> </plus>
Thursday, 2 October 14

Remember validity?• XML 1.0 Definition
– <http://www.w3.org/TR/REC-xml/#sec-prolog-dtd– [Definition: An XML document is valid if
it has an associated DTD and if the document complies with the constraints expressed in it.]
– Two conditions (beyond being well-formed):• A declaration
– document type declaration to establish association • satisfaction of the constraints in the definition
– document type definition (the DTD)
• ...also known as “internally valid”– (Though that’s a bit of misnomer; the spec calls this “Valid”)– The document says what it is
Thursday, 2 October 14

Is this a good notion?• SaxCalc Error handling
– What would a user want us to do?
<expression> <plus> <times> <int value="7"/> <minus> <int value="4"/> <int value="24"/> </minus> </times> <int value="7"/> </plus></expression>
<html> <expression> <plus> <times> <int value="7"></int> <minus> <int value="4"></int> <int value="24"></int> </minus> </times> <int value="7"></int> </plus> </expression></html>
<html> <expression> <plus> Multiplication is cool! <times> <int value="7"></int> <minus> <int value="4"></int> <int value="24"></int> </minus> </times> <int value="7"></int> </plus> </expression></html>
Thursday, 2 October 14

External validation• One XML doc can be valid w.r.t. many DTDs
– Some tighter, some looser
• Different schemas can offer different things– External validation breaks self-describingness
another DTDa DTD
all XML docs
Thursday, 2 October 14

External validation (2)• Internal validation can go wrong in a lot of ways
– Missing declaration (to tell where/which DTD)• User forgot
– Missing definition (in DTD) • Internal subsets are verbose and hard to update• Web based schema have problems
– Can’t depend on them: app breaks if the server dies– Hard on the server
• External validation with DTDs– Poorly handled by SAX
• Even redirecting may be hard– Other schema languages do better
• javax.xml.validation.Validator;
Thursday, 2 October 14

Error handling - a taster• Do we need anything?
– In SaxCalc, you could get errors “for free”– parseInt() failures– Keep track of arguments– Why not “hard code”?
• May need to track characters()• But throwing unhandled exceptions is cool, right?
– You’ll get a stack trace!
• Separate input checking and evaluation– Allow the format to evolve more or less separately
• Within certain constraints
• What about non-well-formed documents?
Thursday, 2 October 14

DTDs as a (schema) language• Usability
✓ Syntax isn’t too bad✓ Regular expression syntax is terse, yet readable(ish)
• Some things get awkward
• Expressivity (what can we say?)- Can’t constrain text to be integers
• Maintainability, readability, evolvability- Parameter entities are pretty weak- Textual macros!
• Computability– How hard/costly is it to validate?– ...later more
Can we do better?
Thursday, 2 October 14

Case study 2
Thursday, 2 October 14

M1: An XML Syntax for Documents
For this exercise, you have to design a suitable XML format, generate an example document in this format, and write a DTD that describes it.
The format should be suitable to store, share, and work with documents, i.e., structured pieces of text with titles, authors, a table of content, sections, a bibliography, etc. More precisely, your format should be able to capture documents of the following kind:
• a document has one or more authors; for each author, we consider their name and possibly their institution
• ...
Thursday, 2 October 14

Decisions you had to make for M1• Naming elements• Nesting structure
– but not much– most was constrained by M1
• How much detail?– for names of authors?
• How to deal with ToC and Bibliography?– to prevent errors, – e.g., ToC entries without sections
• Element or Attribute for “content”? – Title– Name– Text Snippets– ...all of this is text?
Thursday, 2 October 14

What can DTD say about attributes?• In DTD, we can restrict attribute values to
– CDATA (any text, most general)– NMTOKEN (a single name) and NMTOKENS (a list of names)– ENTITY and ENTITIES
• predefined: < & > " …• user defined external unparsed:
– ID, IDREF and IDREFS (uniqueness constraints apply across doc)– enumerated values (standard) – NOTATION (basically unused)
• For our documents: – NMTOKEN/NMTOKENS for title? No!
• “XML is tricky!” wouldn’t be a legal title!– NMTOKEN/NMTOKENS for name? Possible. – ID and IDREF for ToC and Bibliography
<!ENTITY my_pic SYSTEM "pics/pretty.jpg" NDATA jpeg><!ELEMENT pic EMPTY><!ATTLIST pic file ENTITY #REQUIRED><image file="my_pic"/>
Thursday, 2 October 14

What can DTD say about elements?• Nesting structure:
✓ sections in sections or chapters✓ title in document✓ entries in ToC and Bibliography
• Text content: parsed character data!
• So, for our text content:– snippet’s text, section/chapter/... titles cannot be NMTOKENS attribute
• e.g., “!” isn’t allowed➡ either CDATA attributes or text elements
– Names can be • attributes with NMTOKENS range (think of “Elizabeth Garrett Anderson”) • or text elements
– ...a matter of taste
<!ELEMENT snippet (#PCDATA)>
Thursday, 2 October 14

Chapters, sections and ToC entries?• We can use ID/IDREF
– to ensure that all ToC entries relate to some chapter (or section)
• Can we say more in DTD? 1. eg that every chapter has a ToC entry? 2. eg that order of chapters in document is the same as in ToC? 3. eg that title of section in ToC is the same as in content?
• Observations about our format? – It contains some redundancy:
4. is redundancy good or bad?5. could we avoid it? 6. if yes, which?
Thursday, 2 October 14

Case study 3
or, my brain hurts
Thursday, 2 October 14

M1a: An XML Syntax for DTDs
• DTD is a language for describing XML– But DTD as a language is not homoiconic
• That is, they are not represented in the same language they represent
• The meta level and the object level are distinct• Thus, e.g., can’t use XPath to count element declarations
– Can’t use DTDs to define subsets or extensions
• Is homoiconicity desirable?
As we have seen in the lecture, DTDs do not have an XML based syntax, which makes their manipulation by XML tools difficult. In this assignment, you will design a way of expressing the constraints of a DTD using XML. This will allow you to translate any DTD into its corresponding XML-based version. Your task is to design and write a DTD for such an XML-based version, then translate a sample DTD file into your XML-based syntax.
Thursday, 2 October 14

An argument
• The finding: published DTDs are broken• Explanation: Ad hoc syntax inhibits tools• Solution: Use XML for the syntax
“This issue will be addressed by proposals that use XML as the syntax to describe DTDs themselves”
…the first striking and unexpected observation is that most published DTDs are not correct, with missing elements, wrong syntax or incompatible attribute declarations. This might prove that such DTDs are being used for documentation purposes only and are not meant to be used for validation at all. The reason might be that because of the ad-hoc syntax of DTDs [..], there are no standard tools to validate them.
http://www.springerlink.com/content/jrabc1a5hvpdmhc9/Everything You Ever Wanted to Know About DTDs, But Were Afraid to Ask
Thursday, 2 October 14

A modelling challenge!
• First, get clear on the domain– What are we trying to represent?
• Element declarations• attribute declarations • comments
– What is the structure of the information?– e.g., of an example element declaration <!ELEMENT foo EMPTY>
• Covering? Simple? Corner case? Realistic?
• What’s a reasonable, simple first design?– I trust we don’t need to consider flat designs.– How about a bit of CDATA, i.e., move declarations as thus:
• <dtdx> <![CDATA[<!ELEMENT foo EMPTY>]]></dtdx>
another schema
a schema
all XML docsM1a said so!
Thursday, 2 October 14

That was not a good design• Design 1
– Move the DTD into an element
• Design 2– Lots of elements, some attributes– comment, element, choice, seq, plus, etc.– Some nesting: mirror the syntax tree of
• element declaration– regular expression in the content model
• attribute declaration
Doesn’t really change the DTD syntax: • Validation is not helpful• No nice querying• Still need a traditional DTD (DTD/trad)
syntax parser
Thursday, 2 October 14

A sub-optimal example• In the sketch below, how would we express the constraint
“every element name that is referred to in a content description is declared”
<element name="plus"> <seq> <choice> <plus/> <times/> <minus/> <int/> </choice> <choice> <plus/> <times/> <minus/> <int/> </choice> </seq></element>
<element name="expression"> <choice> <plus/> <times/> <minus/> <int/> </choice> </element>
<!ELEMENT expression (plus | times | minus | int )>
<!ELEMENT plus ((plus | times | minus | int ), (plus | times | minus | int )+)>
Thursday, 2 October 14

Why do attributes help here?• We know: DTDs can constrain attributes
– better than it can constrain elements in two ways:• (weak) type constraints• uniqueness via ID/IDREF
– Both are helpful for representing DTD syntax!
Thursday, 2 October 14

It’s verbose - here is our calc1.xml<!DOCTYPE dtdx SYSTEM "dtdx1.dtd"><dtdx> <comment>I omit most comments for brevity in this example.</comment> <element name="expression"> <choice> <ref to="plus"/> <ref to="times"/> <ref to="minus"/> <ref to="int"/> </choice> </element> <element name="plus"> <seq> <choice> <ref to="plus"/> <ref to="times"/> <ref to="minus"/> <ref to="int"/> </choice> <plus> <choice> <ref to="plus"/> <ref to="times"/> <ref to="minus"/> <ref to="int"/> </choice> </plus> </seq> </element>
<element name="times"> <seq> <choice> <ref to="plus"/> <ref to="times"/> <ref to="minus"/> <ref to="int"/> </choice> <plus> <choice> <ref to="plus"/> <ref to="times"/> <ref to="minus"/> <ref to="int"/> </choice> </plus> </seq> </element> <element name="minus"> <seq> <choice> <ref to="plus"/> <ref to="times"/> <ref to="minus"/> <ref to="int"/> </choice> <choice> <ref to="plus"/> <ref to="times"/> <ref to="minus"/> <ref to="int"/> </choice> </seq> </element> <element name="int"><empty/></element> <attlist on="int"> <attdef name="value"> <tokenized type="NMTOKEN"/> <required/> </attdef> </attlist></dtdx>
Therefor all the attributes?
Thursday, 2 October 14

Examples• Key constraints
– Every element can have at most one declaration• <!ATTLIST element name ID #REQUIRED>
– Every ref must have a corresponding def• <!ATTLIST ref to IDREF #REQUIRED>
– Every attlist ref must have a corresponding def• <!ATTLIST attlist on IDREF #REQUIRED>
• Type constraints– ID and IDREFs must be NMTOKENS
• Convenient!– Tokenized attribute values have a constraint set
• <!ATTLIST tokenized type (ID | IDREF | IDREFS | ENTITY | ENTITIES | NMTOKEN | NMTOKENS) #REQUIRED>
• (This could be done with an element.)
<element name="expression"> <choice> <ref to="plus"/> <ref to="times"/> <ref to="minus"/> <ref to="int"/> </choice> </element>
Thursday, 2 October 14

Our Design• Design 1
– Move the DTD into an element
• Design 2.1– Lots of elements, attributes for type and key constraints– comment, element, choice, seq, plus, etc.– Some nesting
• Mirror the syntax tree!– Use ID and IDREF as appropriate
Thursday, 2 October 14

Tail wagging dog• One design decision is odd:
– Attributes for name, ref, etc.– Not driven by general design considerations
• Driven by limitations of our schema language!
• Another disadvantage of DTDs!✓ “Ad hoc” syntax– Expressivity limitations (enough to distort modelling)
• Key constraints only on attribute content• Type constraints only on attribute content• Limited types (no integers!)
– Poor structured development support• Parameter entities!
Thursday, 2 October 14

Evaluating Design 2.1
• Authoring– a bit verbose, but good editor support
• DTD constraints– not bad at all!
• SAX/DOM processing– pretty good
• Queries?
Design 2.1– Lots of elements, attributes for type
& key constraints– comment, element, choice, seq, plus, etc.– Some nesting
• Mirror the syntax tree!– Use ID and IDREF as appropriate
Thursday, 2 October 14

Queries: Assume you want to retrieve from DTDx schema: • “Get all comments”
– //comment
• “Get all elements with a top level choice– //element/choice/..
• “Get all elements with a choice anywhere”– /*/element//choice/ancestor::element
• “Get all attribute declarations on <int>”– /*/attlist[@on="int"]
• “How many comments?”– count(//comment)
➡ Queryability excellent!
Thursday, 2 October 14

XML Namespaces
or, making things “simpler”
by making them much more complex
Thursday, 2 October 14

An observation• Both calc1-bjp and dtdx-bjp have a “plus” element
<plus> <int value="4"/> <int value="5"/> </plus>
<plus> <choice> ... </choice> </plus>
• We have an element name conflict!• How do we distinguish plus[arithmetic] and plus[reg-exp]?
• Semantically?• In a combined document?
Thursday, 2 October 14

Uniquing the names (1)• We can add some characters
• No name clash now• But the “meaningful” part of name (plus) is hard to see• “calcplus” isn’t a real word!
<calcplus> <int value="4"/> <int value="5"/> </calcplus>
<dtdxplus> <choice> ... </choice> </dtdxplus>
Thursday, 2 October 14

Uniquing the names (2)• We can use a separator or other convention
<calc:plus> <int value="4"/> <int value="5"/> </calc:plus>
<dtdx:plus> <choice> ... </choice> </dtdx:plus>
• No name clash now• The “meaningful” part of the name is clear• The disambiguator is clear
• But we can get clashes!• Need a registry to coordinate?
Thursday, 2 October 14

Uniquing the names (3)• Use URls for disambiguation
<http://bjp.org/calc/:plus> <int value="4"/> <int value="5"/> </http://bjp.org/calc/:plus>
<http://bjp.org/dtdx/:plus> <choice> ... </choice> </http://bjp.org/dtdx/:plus>
• No name clash now• The “meaningful” part of the name clear• The disambiguator is clear
• Clashes are hard to get• Existing URI allocation mechanism
• But not well formed!
Thursday, 2 October 14

Uniquing the names (4)• Combine the (2) and (3)!
<calc:plus xmlns:calc="http://bjp.org/calc/"> <int value="4"/> <int value="5"/> </calc:plus>
<dtdx:plus xmlns:dtdx="http://bjp.org/dtdx/"> <choice> ... </choice>
</dtdx:plus>
• No name clash now• The “meaningful” part of the name clear• The disambiguator is clear
• Clashes are hard to get• Existing URI allocation mechanism
• But well formed!• But the model doesn’t know
Thursday, 2 October 14

Layered!
Thursday, 2 October 14

Anatomy & Terminology of Namespaces
• Namespace declarations, e.g., xmlns:calc="http://bjp.org/calc/"– looks like/can be treated as a normal attribute
• Qualified names (“QNames”), e.g., calc:plus consist of – Prefix, e.g., calc– Local name, e.g., plus
• Expanded name, e.g., {http://bjp.org/calc/}plus– they don’t occur in doc– but we can talk about them!
• Namespace name, e.g., http://bjp.org/calc/
<calc:plus xmlns:calc="http://bjp.org/calc/"> <int value="4"/> <int value="5"/> </calc:plus>
Thursday, 2 October 14

We don’t need a prefix
• We can have “default” namespaces– Terser/Less cluttered– Retro-fit legacy documents– Safer for non-namespace aware processors
• But trickiness!– What’s the expanded name of “int” in each document?
– Default namespaces and attributes interact weirdly...
<plus xmlns="http://bjp.org/calc/"> <int value="4"/> <int value="5"/> </plus>
<calc:plus xmlns:calc="http://bjp.org/calc/"> <int value="4"/> <int value="5"/> </calc:plus>
{http://bjp.org/calc/}int {}int
Thursday, 2 October 14

Multiple namespaces• We can have multiple declarations• Each declaration has a scope• The scope of a declaration is:
– the element where the declaration appears together with– the descendants of that element...
• ...except those descendants which have a conflicting declaration– (and their descendants, etc.)
• I.e., a declaration with the same prefix
• Scopes nest and shadow– Deeper nested declarations redefine/overwrite outer declarations
<plus xmlns="http://bjp.org/calc/" xmlns:n="http://bjp.org/numbers/ > <n:int value="4"/> <n:int value="5"/> </plus>
<plus xmlns="http://bjp.org/calc/"> <int xmlns="http://bjp.org/numbers/ value="4"/> <int value="5"/> </plus>
Thursday, 2 October 14

Some clicker tests...<a:expression xmlns="foo1" xmlns:a="foo2" xmlns:b="bah"> <b:plus xmlns:a="foobah"> <int value="3"/> <a:int value="3"/> </b:plus></a:expression>
Thursday, 2 October 14

Much more about NS in our future
• Issues: Namespaces are increasingly controversial• Modelling principles• Schema language support
– Speaking of which...
Thursday, 2 October 14

DTDs and Namespaces
• Another expressivity limitation– DTDs were designed before namespaces
• and were never updated– DTDs only “understand” XML without namespaces
• Namespaces are syntactically layered– So we can do something with them– But not with full generality
• General schema principle– If two documents are “the same” according to the data model,
(equivalent) then: • if one is valid wrt a schema so should the other
– Not true for namespace equivalent documents and DTDs
Thursday, 2 October 14

An example• A simple document with a namespace
– <foo xmlns="http://ex.org/"> <bar/></foo>
• We can write a DTD for it– <!DOCTYPE foo [
<!ELEMENT foo (bar)> <!ATTLIST foo xmlns CDATA #FIXED "http://ex.org/"> <!ELEMENT bar EMPTY>]><foo xmlns="http://ex.org/"> <bar/></foo>
– This document is valid!
Thursday, 2 October 14

An example (cont)• 3 simple documents with a namespace
• We can compare with another document– (a)-(c) are, from a namespace point of view, the same – they simply uses different prefixes! – But (b) & (c) are not valid wrt our DTD (whereas (a) is):
(b) <ex1:foo xmlns:ex1="http://ex.org/"> <ex1:bar/> </ex1:foo>
(a) <foo xmlns="http://ex.org/"> <bar/> </foo>
(c) <ex2:foo xmlns:ex2="http://ex.org/"> <ex2:bar/> </ex2:foo>
<!ELEMENT foo (bar)> <!ATTLIST foo xmlns CDATA #FIXED "http://ex.org/"> <!ELEMENT bar EMPTY>
Thursday, 2 October 14

Problems with DTDs• “Ad hoc”, non-XML based syntax• Expressivity limitations (enough to distort modelling)
– Key/uniqueness constraints only on attribute content– Type constraints only on attribute content
• and only limited types: no integers, date, string,...– No namespace support– ...
• Poor structured development support– Parameter entities!
• Poor support from tools and APIs– External validation tricky in SAX
• Some security issues
Thursday, 2 October 14

Security aside• Risk for Consumers:
– Entity expansion attacks ( http://bit.ly/ds6wYt )– Billion laughs: Exponential Entity Expansion
– Disappearing DTDs• Network failure or removal
• Risk for Publishers:– Accidental DoS (http://hsivnen.iki.fi/no-dtd/)
“the RSS 0.91 DTD is retrieved over 4 million times per day. That’s nuts. Burdening a single third party like that for something as useless as a DTD makes no sense”.
Thursday, 2 October 14

Should you use DTDs?• Probably not, but
• The syntax is reasonable for authoring and reading➡ prototyping
• There are a fair number of DTDs out there• A common denominator• Namespace lack hurts a lot
• As we’ll see• They are a good starting point
Thursday, 2 October 14

XML Schema -
another schema language for XML
102Thursday, 2 October 14

103
Schema languages for XML
e.g., DTDprovide means to define the legal structure of an XML document
cartoon-uli.dtdcartoon.dtd
all XML docs
Thursday, 2 October 14

104
Schema languages for XML
provide means to define the legal structure of an XML document
cartoon.dtd, a DTD for cartoon descriptions
<?xml version="1.0" encoding="UTF-8"?><!ELEMENT cartoon (prolog, panels)> <!ATTLIST cartoon copyright CDATA #REQUIRED> <!ATTLIST cartoon year CDATA #REQUIRED> <!ELEMENT prolog (series, author, characters)> <!ELEMENT series (#PCDATA)> <!ELEMENT author (#PCDATA)> <!ELEMENT characters (character)*> ...
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE cartoon SYSTEM "cartoon.dtd"><cartoon copyright="United Feature Syndicate" year="2000"> <prolog> <series>Dilbert</series> <author>Scott Adams</author> <characters> <character>The Pointy-Haired Boss</character> <character>Dilbert</character> </characters> ...
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE cartoon SYSTEM "cartoon.dtd"><cartoon copyright="Bill Watterson" year="1994"> <prolog> <series>Calvin and Hobbs</series> <author>Bill Watterson</author> <characters> <character>Calvin</character> <character>Hobbs</character> <character>Snowman</character> </characters> ...
...
...
Thursday, 2 October 14

105
Schema languages for XML
A variety of schema languages have been developed for XML; they vary w.r.t. • their expressive power:
– “do I have a means to express foo?”– “how hard is it to describe foo?”– e.g., try to say, in a DTD that
“element must contain, in any order, an element1, an element2, ..., and an element27”
• ease of use/understanding: – “how easy it is to write a schema?”– “how easy is it to understand a schema written by somebody else?”
• the complexity of validating a document w.r.t. a schema: – “how much space/time does it take to verify whether a document is
valid w.r.t. a schema (in the size of document and schema)?”– e.g., checking this for DTDs requires only space linear in depth of the
document
Thursday, 2 October 14

106
Schema languages for XML
...can I express the same constraints “better” in a different schema language?
cartoon.xsdcartoon.dtd
all XML docs
Thursday, 2 October 14

107
Schema languages for XML
...can I express the even better constraints “better” in a different schema language?
cartoon.xsdcartoon.dtd
all XML docs
Thursday, 2 October 14

108
XML Schema
• XML Schema is also referred to as – XML Schema Definition – XSD
• is a W3C standard, see http://www.w3.org/XML/Schema• can be seen as “successor” of DTDs:
– a DTD is not a well-formed XML document– an XML Schema is a well-formed XML document– XML Schema is mostly more expressive than DTDs
• we’ll talk about this at length– in contrast to DTDs, XML Schema supports
• namespaces, so we can combine several documents: for schema validation, universal names are used (rather than qualified names)
• datatypes, including simple datatypes for parsed character data and for attribute values, e.g., for date (when was 11/10/2006?)
• more uniqueness/key constraints – XML provides more support for describing the (element and mixed)
content of elements
Thursday, 2 October 14

109
XML Schema: a first example
<?xml version="1.0"?>
<!DOCTYPE note SYSTEM "note.dtd">
<note> <to>Tove</to> <from>Jani</from> <sentOn>2007-01-29</sentOn> <body> Have a nice weekend! </body></note>
<?xml version="1.0" encoding="UTF-8"?><!ELEMENT note (to, from, sentOn,heading, body)><!ELEMENT to (#PCDATA)><!ELEMENT from (#PCDATA)><!ELEMENT sentOn (#PCDATA)><!ELEMENT body (#PCDATA)>
note.dtd:
Example with DTD:
Thursday, 2 October 14

XML Schema: a first example
<?xml version="1.0"?>
<note xmlns= "http://www.w3schools.com" xmlns:xs= "http://www.w3.org/2001/XMLSchema" xmlns:xsi= "http://www.w3.org/2001/XMLSchema-instance"> <to>Tove</to> <from>Jani</from> <sentOn>2007-01-29</sentOn> <body> Have a nice weekend! </body></note>
<?xml version="1.0"?><xs:schema xmlns:xs= "http://www.w3.org/2001/XMLSchema" targetNamespace= "http://www.w3schools.com" xmlns="http://www.w3schools.com" elementFormDefault="qualified"> <xs:element name="note"> <xs:complexType> <xs:sequence> <xs:element name="to" type="xs:string"/> <xs:element name="from" type="xs:string"/> <xs:element name="sentOn" type="xs:date"/> <xs:element name="body" type="xs:string"/> </xs:sequence> </xs:complexType></xs:element></xs:schema>
note.xsd:
Thursday, 2 October 14

111
• to validate an XML document against an XML schema, – we use a validating XML parser that supports XML Schema– e.g., DOM level 2, SAX2
• in XML Schema, – each element and type can only be declared once – almost all elements can contain an element
<xs:annotation>...</xs:annotation> as 1st child: useful, e.g., for
• XML Schema provides support for modularity & re-use through– xs:import, xs:include, xs:redefine
<xs:simpleType name="northwestStates"> <xs:annotation><xs:documentation>States in the Pacific Northwest of US </xs:documentation></xs:annotation> <xs:restriction base="xs:string"></xs:restriction> </xs:simpleType>
your application
Schema-ware parser
Schema
XML documentSerializer
Standard API eg. DOM or Sax
Thursday, 2 October 14

112
XML Schema & Namespaces
• most XML Schemas start like this, in note.xsd
<?xml version="1.0" encoding="UTF-8"?><xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" targetNamespace="http://www.w3schools.com" xmlns="http://www.w3schools.com" elementFormDefault="qualified" >…..</xs:schema>
• and a document using such a schema looks like this:
<?xml version="1.0"?><note xmlns="http://www.w3schools.com" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
XML Schemanamespacee.g. for datatypes
Target namespaceof elements defined in thisschema
“This document uses a schema”
Local (default) namespace
Thursday, 2 October 14

XML Schema & Namespaces
• in contrast to DTDs, XML Schema supports namespaces• a XML Schema either has
– no namespace or– 2 namespaces:
• targetNamespace for those elements defined in schema and • XMLSchema namespace http://www.w3.org/2001/XMLSchema
113
<?xml version="1.0"?><xs:schema xmlns:xs= "http://www.w3.org/2001/XMLSchema" targetNamespace= "http://www.w3schools.com" xmlns="http://www.w3schools.com" elementFormDefault="qualified"> <xs:element name="note"> <xs:complexType> <xs:sequence> <xs:element name="to" type="xs:string"/> ...
note.xsd:
<?xml version="1.0"?>
<p:note xmlns:p="http://www.w3schools.com" xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <p:to>Tove</p:to>
<?xml version="1.0"?>
<note xmlns="http://www.w3schools.com" xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <to>Tove</to>
Thursday, 2 October 14

114
XML Schema core concepts: data types
• in the previous examples, we used 2 Built-in datatypes:
– xs:string– xs:date
• many more:– built-in/atomic/
primitive e.g., xs:dateTime
– composite/user-defined e.g., xs:lists, xs:union
– through restrictions/user-defined e.g., ints < 10
Thursday, 2 October 14

115
XML Schema core concepts: datatypes
• each XML datatype comes with a – value space, e.g., for xs:boolean, this is {true, false}.– lexical space, e.g., for xs:boolean, this is {true, false, 1, 0}, and – lexical-to-value mapping that has to be neither injective nor surjective
(for boolean, it’s surjective, but not injective)– constraining facets that can be used in restrictions of that datatype,
e.g., maxInclusive, maxExclusive, minInclusive, minExclusive for most
Thursday, 2 October 14

116
XML Schema: types
We can define types in XSD, in two ways: • xs:simpleType for simple types, to be used for
– attribute values and– elements without element child nodes and without attributes
• xs:complexType for complex types, to be used for – elements with
• element content or• mixed element content or • text content and attributes
Thursday, 2 October 14

117
XML Schema: element type definition
• can be anonymous, e.g., in the definition of age or person below:
• can be named, e.g.,
<xs:element name="Age"> <xs:simpleType> <xs:restriction base="xs:integer"> <xs:minInclusive value="3"/> <xs:maxInclusive value="7"/> </xs:restriction> </xs:simpleType> </xs:element>
<xs:element name="person"> <xs:complexType> <xs:sequence> <xs:element name="Name" type="Nametype"/> <xs:element name="DoB" type="xs:date"/> </xs:sequence> <xs:attribute name="friend" type="xs:boolean"/> </xs:complexType> </xs:element>
<xs:element name="Age" type="AgeType"/> <xs:simpleType name="AgeType"> <xs:restriction base="xs:integer"> <xs:minInclusive value="3"/> <xs:maxInclusive value="7"/> </xs:restriction> </xs:simpleType>
<xs:element name="person" type="PersonType"/> <xs:complexType name ="PersonType"> <xs:sequence> <xs:element name="Name" type="Nametype"/> <xs:element name="DoB" type="xs:date"/> </xs:sequence> <xs:attribute name="friend" type="xs:boolean"/> </xs:complexType>
Thursday, 2 October 14

118
XML Schema: atomic simple types
• are based on the numerous built-in datatypes • that can be restricted using xs:restriction facets, e.g.,
enumeration <xs:simpleType name=”bikeType”> <xs:restriction base="xs:string"> <xs:enumeration value=”MTB"/> <xs:enumeration value=”road"/> </xs:restriction></xs:simpleType>
length <xs:simpleType name=“eightChar”><xs:restriction base="xs:string"> <xs:length value="8"/> </xs:restriction></xs:simpleType>
maxLengthminLength
<xs:simpleType name=“medStr”> <xs:restriction base="xs:string"> <xs:minLength value="5"/> <xs:maxLength value="8"/></xs:restriction></xs:simpleType>
maxExclusive/maxInclusiveminExclusive/minInclusive
<xs:simpleType name=“age”> <xs:restriction base="xs:integer”> <xs:minInclusive value="0"/> <xs:maxInclusive value="120"/> </xs:restriction></xs:simpleType>
patterns (using regular expressions close to Perl’s)
<xs:simpleType name=“simpleStr”><xs:restriction base="xs:string"> <xs:pattern value="([a-z][A-Z])+"/></xs:restriction></xs:simpleType>
Thursday, 2 October 14

119
XML Schema: composite simple types
• we can use built-in datatypes not only in restrictions, • but also in compositions to construct:
– xs:list– xs:union
<xs:simpleType name='myList'> <xs:list itemType='xs:integer'/> </xs:simpleType> <xs:simpleType name='ShortList'> <xs:restriction base='myList'> <xs:maxLength value='8'/>! </xs:restriction> </xs:simpleType>
<xs:simpleType name="colourList"> <xs:list> <xs:simpleType> <xs:restriction base="xs:string"> <xs:enumeration value="red"/> <xs:enumeration value="green"/> <xs:enumeration value="blue"/> </xs:restriction> </xs:simpleType> </xs:list> </xs:simpleType>
<xs:simpleType name="colourListOrDate"> <xs:union memberTypes="colourList xs:date"/></xs:simpleType>
Thursday, 2 October 14

120
XML Schema: simple types• can be used in
– element declarations, for elements without element child nodes(instead of PCDATA in DTDs)
– attribute declarations(instead of CDATA in DTDs)
• as in DTDs, we can specify fixed or default values
<xs:complexType name="PersonType"> <xs:sequence> <xs:element name="Name" type="xs:string"/> <xs:element name="DoB" type="xs:date"/> </xs:sequence> <xs:attribute name="friend" type="xs:boolean" default="true"/> <xs:attribute name="phone" type="xs:string"/> </xs:complexType>
Thursday, 2 October 14

121
XML Schema: simple content
• for elements – where we cannot use xs:simpleType because of attribute declarations– but that have simple (e.g., text) content only, ➥ we can use xs:simpleContent, e.g.
<xs:element name="size"> <xs:complexType> <xs:simpleContent> <xs:extension base="xs:integer"> <xs:attribute name="country" type="xs:string"/> </xs:extension> </xs:simpleContent> </xs:complexType> </xs:element>
• xs:simpleType for – attribute values and– elements without element child
nodes and without attributes
Remember how easy DTDs are?
Thursday, 2 October 14

122
XML Schema: complex types
<xs:complexType name="nametype"> <xs:sequence> <xs:element name="fname" type="xs:string"/> <xs:element name="lname" type="xs:string"/> </xs:sequence> </xs:complexType>
• element order enforcement constructs: – sequence: order preserving– all: like sequence, but not
order preserving– choice: choose exactly one
• these constructs can be combined with minOccurs and maxOccurs,– by default both are “1”, – but they can be set to any non-negative integer or “unbounded”, e.g.
<xs:complexType name="nametype"> <xs:sequence> <xs:element name="fname" type="xs:string"/> <xs:element name="mname" type="xs:string" minOccurs="0" maxOccurs="7"/> <xs:element name="lname" type="xs:string"/> </xs:sequence> </xs:complexType>
• xs:complexType for – elements with
• element content or• mixed element content or • text content and attributes
1 fname0-7 mname1 lname
Thursday, 2 October 14

123
XML Schema: mixed content
• to allow for mixed content, set attribute mixed=“true”, e.g.,
– like in DTDs, we • cannot constrain where the text occurs between elements,• can only say that content can be mixed
<xs:complexType name="PersonType" mixed="true"> <xs:sequence> <xs:element name="Name" type="xs:string"/> <xs:element name="DoB" type="xs:date"/> </xs:sequence> <xs:attribute name="friend" type="xs:boolean" default="true"/> <xs:attribute name="phone" type="xs:string"/> </xs:complexType>
Thursday, 2 October 14

124
XML Schema: restriction and extension
• we have already used xs:extension and xs:restriction both for– simple types and– complex types
• they are XML Schema’s mechanisms for inheritance• extension: specifying a new type X by adding declarations to Y’s
– this “appends” X’s definition to Y’s, e.g.,
<xs:simpleType name="AgeType"> <xs:restriction base="xs:integer"> <xs:minInclusive value="3"/> <xs:maxInclusive value="7"/> </xs:restriction> </xs:simpleType> <xs:complexType name="NewAgeType"> <xs:simpleContent> <xs:extension base="AgeType"> <xs:attribute name="range" type="xs:string"/> </xs:extension> </xs:simpleContent> </xs:complexType>
<xs:complexType name="PersonType"> <xs:sequence> <xs:element name="Name" type="xs:string"/> <xs:element name="DoB" type="xs:date"/> </xs:sequence> <xs:attribute name="friend" type="xs:boolean" default="true"/> <xs:attribute name="phone" type="xs:string"/> </xs:complexType>
<xs:complexType name="LongPersonType"> <xs:complexContent> <xs:extension base="PersonType"> <xs:sequence> <xs:element name="address" type="xs:string"/> </xs:sequence> </xs:extension> </xs:complexContent></xs:complexType>
Thursday, 2 October 14

125
XML Schema: restriction and extension
• restriction: easy for simple types we have seen it several times
• “cumbersome” for complex types: specifying a new type X by restricting a complex type Y requires the reproduction of Y’s definition, e.g.,
<xs:complexType name="PersonType"> <xs:sequence> <xs:element name="Name" type="xs:string"/> <xs:element name="DoB" type="xs:date"/> </xs:sequence> <xs:attribute name="friend" type="xs:boolean"/> <xs:attribute name="phone" type="xs:string"/> </xs:complexType>
<xs:complexType name="StrictPersonType"> <xs:complexContent> <xs:restriction base="PersonType"> <xs:sequence> <xs:element name="Name"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:pattern value="[A-Z]([a-z]+)”"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="DoB" type="xs:date"/> </xs:sequence> <xs:attribute name="friend" type="xs:boolean"/> <xs:attribute name="phone" type="xs:string"/> </xs:restriction> </xs:complexContent></xs:complexType>
<xs:simpleType name="AgeType"> <xs:restriction base="xs:integer"> <xs:minInclusive value="3"/> <xs:maxInclusive value="7"/> </xs:restriction> </xs:simpleType>
Thursday, 2 October 14

126
XML Schema: restriction and extension
• usage: in a document, an element of a type X derived by restriction or extension from Y can be used in place of an element of type Y…
– provided you say so, i.e., make element’s type X explicit, e.g., in
• this means that a validating XML parser has to manage a schema’s type hierarchy – to ensure that LongPersonType was really derived from the type expected for
person– but it doesn’t have to “guess” an element’s type from its properties
• also: compare they “pain & gain” of using types to “pain & gain” of using substitution groups!
<person phone="2"> <Name>Peter</Name> <DoB>1966-05-04</DoB> </person> <person xsi:type="LongPersonType" phone="5432" friend="0"> <Name>Paul</Name> <DoB>1967-05-04</DoB> <address>Manchester</address> </person>
Thursday, 2 October 14

127
XML Schema: substitution groups
• closely related to the mechanism of restriction/extension are • substitution groups,
i.e., a mechanism to allow to replace one element with a group of others
<xs:element name="Name" type="xs:string"/><xs:element name="Nome" substitutionGroup="Name"/>
<xs:complexType name="custinfo"> <xs:sequence> <xs:element ref="Name"/> </xs:sequence></xs:complexType>
<xs:element name="Customer" type="custinfo"/><xs:element name="Cliente" substitutionGroup="Customer"/>
<Customer> <Nome> Uli </Nome></Customer>
<Cliente> <Name> Uli </Name></Cliente>
<Cliente> <Nome> Uli </Nome></Cliente>
<Customer> <Name> Uli </Name></Customer>
all these validate against
Thursday, 2 October 14

128
XML Schema: summary of complex types
• we have simple and complex types:– simple types for attribute values and text in elements– complex types for elements with child elements or attributes
• we have simple and complex content of elements: – simple content:
• elements with only text between tags and possibly attributes – complex content:
• element content (elements only)• mixed content (elements and text)• empty content (at most attributes)
• a complex content type can be specified in 3 ways: using – element order enforcement constructs (all, sequence, choice) – a single child simpleContent:
derive a complex type from a simple or complex type with simple content– a single child complexContent:
derive a complex type from another complex type using restriction or extension
Use tools to:• design/find examples• modify & learn
Thursday, 2 October 14

Comparing XML Schema & DTDs
• You know one better than the other…one is simpler than the other…• in DTDs, no equivalent to ALL in XML Schema• in DTDs, no cool & useful datatypes, lists, unions,…• in DTDs, no restrictions & extension, no types
– in a document, an element of a type derived by restriction from Y can be used in place of an element of type Y
– this can make writing complex schemas easier!– but this means that a validating XML parser has to manage a schema’s type
hierarchy • we will see later that both DTDs and XML have additional constraints on
content models– so that matching a node’s childnode sequence against the corresponding
content model is easier– ...will be discussed next week
• is there a set of XML documents (e.g., your cartoon descriptions) – for which we can formulate a DTD– but not an XML schema?– or the other way round? ...more next week 129
Thursday, 2 October 14

Let’s have a look at this week’s coursework
130Thursday, 2 October 14


















