
Cognitive Architecture for Reasoning about Adversaries T-REX: A Domain-Independent System for...
20
Cognitive Architecture for Reasoning about Adversaries T-REX: A Domain-Independent System for Automated Cultural Information Extraction Massimiliano Albanese V.S. Subrahmanian University of Maryland Institute for Advanced Computer Studies College Park, Maryland, USA
-
date post
21-Dec-2015 -
Category
Documents
-
view
212 -
download
0
Transcript of Cognitive Architecture for Reasoning about Adversaries T-REX: A Domain-Independent System for...

Cognitive Architecture for Reasoning about Adversaries
T-REX: A Domain-Independent System for Automated Cultural Information Extraction
Massimiliano AlbaneseV.S. Subrahmanian
University of Maryland Institute for Advanced Computer Studies
College Park, Maryland, USA

2Cognitive Architecture for Reasoning about Adversaries
Introduction
Several applications require the ability to extract fine-grained information from huge text collections
» Intelligence agencies may need detailed information about diverse cultural groups around the world in order to understand and model their behavior
» A real-time “violence-watch” around the world would require the ability to identify several attributes for every “violent event” reported in the online press
Traditional search engines
» Are not able to provide such information without sorting through a long list of documents
» Are not able to integrate information from different sources

3Cognitive Architecture for Reasoning about Adversaries
Key contributions
Domain-independent framework for information extraction
» A schema describing the information the user wants to extract is provided as an input
Key features
» Scalability: the system is designed to massively scale to large volumes of data
• It currently searches through 109 online news sites from 66 countries around the world, processing about 45,000 articles/day (about 10 millions distinct urls explored so far, with 7 millions triples extracted)
» Multilingual support: the system is designed to work with different languages
• English, Spanish and Chinese
» Flexibility: several elements can be easily customized
• List of sources, topics of interest, type of information to extract

4Cognitive Architecture for Reasoning about Adversaries
T-REX architecture
Crawling and parsing

5Cognitive Architecture for Reasoning about Adversaries
Multilingual Annotation Interface
Sentence being annotated
Parse tree edit panel
List of triples that can be extracted from the sentence
Constraint selection panel

6Cognitive Architecture for Reasoning about Adversaries
Annotation Process: Motivation
The same fact can be reported in many slightly different ways
» At least 73 civilians were killed February 1 in simultaneous suicide bombings at a Hilla market
» More than 73 civilians were massacred in February in suicide attacks at a Hilla marketplace
» 74 people were killed on February 1, 2007 in multiple bombings at a Hilla market
Other similar events may be reported through similar sentences, describing the same set of attributes
» About 23 U.S. soldiers were killed in August 2005 in a suicide attack in Baghdad
Sentences describing the same type of fact in slightly different ways can be grouped into a single class
» Learning an “extraction rule” for each class of interest to a given application enables to extract the desired information from any article

7Cognitive Architecture for Reasoning about Adversaries
Annotation Process: Step 1
The annotator is presented with one or more parse trees for the sample sentence
At least 73 civilians were killed February 1 in simultaneous suicide
bombings at a Hilla market

8Cognitive Architecture for Reasoning about Adversaries
Annotation Process: Step 2
The annotator marks as “variable” all the nodes that may have different text in other sentences of the same class

9Cognitive Architecture for Reasoning about Adversaries
Annotation Process: Step 3
If needed, the annotator add constraints to variable nodes

10Cognitive Architecture for Reasoning about Adversaries
Annotation Process: Constraints
IS_ENTITY
» restricts a noun phrase to be a “named entity”
IS_DATE
» restricts a noun phrase to be a temporal expression
X_VERBS
» restricts a verb to be any member of a class X of verbs
• e.g. the constraint MURDER_VERBS requires a verb to be any of the following: kill, assassinate, murder, execute, etc.
X_NOUNS
» restricts a noun to be any member of a class X of nouns
• e.g. the constraint ATTACK_NOUNS requires a noun to be any of the following: assault, attack, clash, etc.

11Cognitive Architecture for Reasoning about Adversaries
Annotation Process: Step 4
The annotator describes the semantics of the annotated sentence in term of triples, mapping attributes to variable nodes

12Cognitive Architecture for Reasoning about Adversaries
Annotations in Multiple Languages
English Chinese simplified (中文 )
Spanish (Español)

13Cognitive Architecture for Reasoning about Adversaries
Rule Extraction Engine
An extraction rule is of type Head Body A rule is learned through the following
steps
» abstraction• each variable node is assigned a numeric
identifier, its text and child nodes are removed
› the model becomes independent of the particular sentence
» body definition • the body of the rule is built by serializing
the parse tree of the annotated sentence in Treebank II Style
» head definition • the head is defined as a conjunction of
RDF statements, one for each triple defined in the last step of the annotation process

14Cognitive Architecture for Reasoning about Adversaries
Rule Matching Engine (1/2)
Extracts RDF triples, by matching sentence from texts being analyzed against the set of extraction rules
Continuously fetches documents relevant to the application of interest
If the parse tree of a sentence satisfies the condition in the body of a rule an
RDF triple is instantiated for each statement in the head of the rule
CompareNodes() determines if the parse tree of a sentence satisfies the
condition in the body of a rule

15Cognitive Architecture for Reasoning about Adversaries
Rule Matching Engine (2/2)
CompareNodes() recursively explores the parse tree of the sentence being processed and the annotated parse tree of a rule
Checks satisfaction of constraints for variable nodes
Checks constant nodes
Pairwise compares child nodes of non terminal nodes

16Cognitive Architecture for Reasoning about Adversaries
Example of Matching
Var#1 = “About 23” Var#2 = “U.S. soldiers”Var#3 = “were”Var#4 = “killed”Var#5 = “August 23”Var#6 = “a suicide attack”Var#7 = “Baghdad”
(KillingEvent9,victim,U.S. soldiers)(KillingEvent9,numberOfVictims,about 23)(KillingEvent9,date,August 23)(KillingEvent9,location,Baghdad)
The sentence satisfies the body of the rule
e.g. “About 23 U.S. soldiers were killed August 23 in a suicide attack in Baghdad”
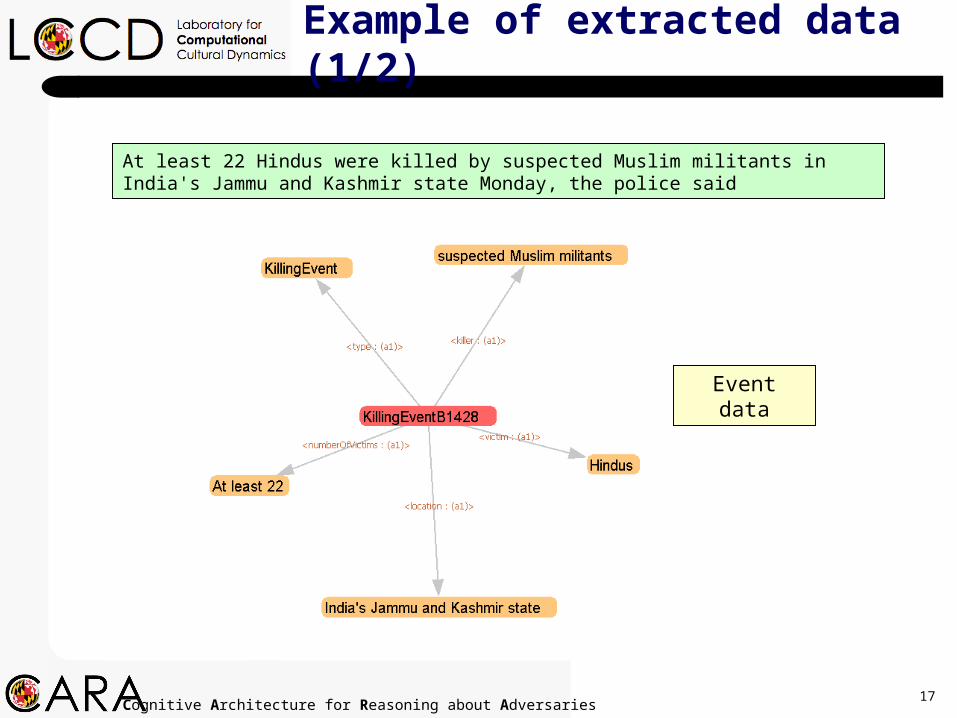
17Cognitive Architecture for Reasoning about Adversaries
Example of extracted data (1/2)
At least 22 Hindus were killed by suspected Muslim militants in India's Jammu and Kashmir state Monday, the police said
Event data

18Cognitive Architecture for Reasoning about Adversaries
Example of extracted data (2/2)
Link depth 2 from Pushtuns

19Cognitive Architecture for Reasoning about Adversaries
T-REX implementation
The implementation of T-REX consists of several components running on different nodes of a distributed system
» Multilingual Annotation Interface: web-based tool, that is part of the web interface of T-REX (implemented as a Java Applet)
» Annotated RDF Database System for storage of annotated RDF triples: the underlying relational DBMS is PostgreSQL 8.2
» Rule Matching Engine: a pipeline of several components
• Crawler: explores news sources for relevant documents
• Parsers for every language: process sentences from relevant documents, producing constituent trees in Treebank II Style
• Extractor: implements the Rule Matching Engine logic
Distribution, Database Partitioning, and Multithreading ensure scalability

20Cognitive Architecture for Reasoning about Adversaries
Conclusions
We have presented a general, multi-lingual and flexible framework for information extraction» Domain specific application are enabled by targeting the
extraction to the instantiation of a schema of interest
» Addition of other languages is a relatively simple task, once a set of linguistic resources are available for those languages
We have implemented a complex prototype that has proved to» effectively extract information for different applications
» scale massively Future efforts will be devote to
» define pruning strategies to make the extraction process faster
» define strategies to manage inconsistencies in the extracted data
» extend the system to other languages (mainly Asian languages)


















