
Clustering of graphs and search of assemblages
49
Clustering of graphs and search of assemblages Kirill Rybachuk, DCA
-
Upload
data-centricalliance -
Category
Data & Analytics
-
view
1.226 -
download
1
Transcript of Clustering of graphs and search of assemblages

Clustering of graphs and search of assemblages
Kirill Rybachuk, DCA

What is assemglage?
• Assemblage is an intuitive concept and has no common definition • Global approach: 'such aggregation cannot be for no reason' • Modularity: comparison with random graph (almost Erdös-Renew) • Local approach: 'more connections inside, then outside in the vicinity' • In weak sense: internal degree > external degree • In strong sense: internal degree > external degree for each node • Completely local approach: aggregation of 'similar' nodes • Jaccard measure:
j belong to the same cluster. Another way of looking at it is that an edge that is a
part of many triangles is probably in a dense region i.e. a cluster. We use the Jaccard
measure to quantify the overlap between adjacency lists. Let Adj(i) be the adjacency
list of i, and Adj(j) be the adjacency list of j. For simplicity, we will refer to the
similarity between Adj(i) and Adj(j) as the similarity between i and j itself.
Sim(i, j) =|Adj(i) ∩Adj(j)|
|Adj(i) ∪Adj(j)|(5.1)
Global Sparsification
Based on the above heuristic, a simple recipe for sparsifying a graph is given in
Algorithm 8. For each edge in the input graph, we calculate the similarity of its end
points. We then sort all the edges by their similarities, and return the graph with
the top s% of all the edges in the graph (s is the sparsification parameter that can
be specified by the user). Note that selecting the top s% of all edges is the same as
setting a similarity threshold (that applies to all edges) for inclusion in the sparsified
graph.
Algorithm 8 Global Sparsification AlgorithmInput: Graph G = (V,E), Sparsification ratio s
Gsparse ← ∅for each edge e=(i,j) in E do
e.sim = Sim(i, j) according to Eqn 5.1end for
Sort all edges in E by e.simAdd the top s% edges to Gsparse
return Gsparse
However, the approach given in Algorithm 8 has a critical flaw. It treats all edges
in the graph equally, i.e. it uses a global threshold (since it sorts all the edges in the
graph), which is not appropriate when different clusters have different densities. For
example, consider the graph in Figure 5.2(a). Here, the vertices {1, 2, 3, 4, 5, 6} form
a dense cluster, while the vertices {7, 8, 9, 10} form a less dense cluster. The sparsified
graph using Algorithm 8 and selecting the top 15 (out of 22) edges in the graph is
shown in Figure 5.2(b). As can be seen, all the edges of the first cluster have been
79

Why is this important?1. DMP Segments
2. Recommendations on goods
3. Centricity within
assemblages: actual data flows
4. Comparison to nominal
communities (dormitories, vk
groups)
5. Compression & Visualization

How does one find assemblages?
• Graph partitioning: optimal partitioning into preset number of graphs of k.
how can one find that k well? • Community finding: finding of particular aggregations
k not controlled directly
assemblages don't have to cover
completely
assemblages may overlay

How does one assess success?
• Objective functions• Optimization on graph completely: only approximate heuristics • Comparison of results from various algorithms • Selection of the most optimal k for graph partitioning
• If ground truth is available — use standard metrics for classifying purposes
• Often WTF is the best metric ever — see it with your own eyes

CLIQUES

Cliques
• Just clique: complete sub-graph • Everybody knows everybody • Sometimes maximality required: no one can be added • Brohn-Kerbosch algorithm (1973):
n - number of nodes, d_max - maximum degree
O(n · 3dmax/3)

Disadvantages of cliques
• Too austere assumption • Big cliques are almost absent • Small cliques are present even in Erdös-Renew graph • Disappearance of just one edge destroys the whole clique • No center and outskirts of the assemblage • Symmetry: no sense in centricity

Generalizations
• n-clique: maximum subgraph where distance between any two
nodes is no longer than n. • at n=1 reduces to simple clique • n-clique may be even non-connected inside! • n-club: n-clique with diameter n. Always connected.
• k-core: maximum subgraph where every node has at least k
internal neighbors. • p-clique: each node's internal neighbor share comprises at least p
(0 to 1)

Algorithm for finding k-cores
• Batagelj and Zaversnik algorithm (2003): O(m) where m stands for number of edges • Input: graph G(V,E) • Output: k value for each node

Metrics and objective functions

Modularity
• Assume — degree of node i, • m - number of edges, A - connectivity matrix • Stir all edges retaining distribution of degrees • Probability of i and j connected (roughly!): • Modularity: measure of 'non-randomness' of an assemblage:
ki
kikj
2m
Q =1
2m
!
i,j
"
Aij −kikj
2m
#
I$
ci = cj%

Modularity properties
• m_s: number of edges in assemblage s, d_s: total degree of
nodes in s • maximum value: at S disconnected cliques Q = 1-1/S • Maximum for connected graph: at S equal subgraphs
connected by the same edge • In that case, Q=1-1/S-S/m
Q ≡
!
s
"
ms
m−
#
ds
2m
$2%

Modularity disadvantages
• Resolution limit! • Assemblages with merge into one • If cliques on the picture have dimension of n_s they
merge at • Cluster dimension shifting towards fitting
ms <
√
2m
ns(ns − 1) + 1 < S

WCC• Assume S is an assemblage (its nodes) • V - all nodes • : number of triangles within S where node x is present • number of nodes of S forming at least one triangle with node x • Weighted community clustering for one node:
• Average for the whole assemblage:
WCC(S) =1
|S|
!
x∈S
WCC(x, S)

WCC
• Product of two components • Triangle = 'clique' • To the left: какая доля компашек с участием x находится внутри его «домашнего»
сообщества? • To the right in the numerator: how many people overall are involved in cliques with x? • To the right in the denominator: how many people would have benn involved in cliqes with
x, had S been a clique?

WCC

Algorithms

Newman-Girvan
• Hierarchic divisive algorithm • Sequentially remove edges of greates betweenness • Stop as the criterion is fulfilled (for instance, obtainment of k connected
components) • O(n*m) for calculation of shortest routes • O(n+m) for re-calculation of connected components • The whole algorithm: at least O(n^3) • Not used with graphs exceeding several thousands of nodes

k-medoids
• k-means: normalized space required • Graph determines clearance between nodes only (for instance, 1 - Jaccard), therefore k-
means not suitable • k-medoids: only available points act as centroids • k shall be predetermined (graph partitioning) • the most renowned variant is called PAM

k-medoids: PAM1. Expressedly set k - number of clusters
2. Initialize: select k of random nodes as medoids
3. For each point find the closest medoid thus forming initial clustering
4. minCost = initial configuration losses function
5. For each medoid m:
5.1 For each node v!=m within cluster centered in m:
5.1.1 Shift the medoid to v
5.1.2 Re-distribute all nodes between new medoids
5.1.3 cost=function of losses for the whole graph
5.1.4 if cost<minCost:
5.1.4.1 Remember the medoids
5.1.4.2 minCost=cost
5.1.5 Put the medoid back (to m)
6. Perfor the best substitution of all those found (i.e., change one medoid within one cluster)
7. Repeat items 4-5 until medoids are stable

k-medoids: new heuristics1. While true:
1.1 For each medoid m:
1.1.1 Randomly select s points within cluster centered in m
1.1.2 For each node v of s:
1.1.2.1 Shift the medoid to v
1.1.2.2 Re-distribute all nodes between new medoids
1.1.2.3 cost = function of losses for the whole graph
1.1.2.4 if cost < minCost:
1.1.2.4.1 Remember the medoids
1.1.2.4.2 minCost = cost
1.1.2.5 Put the medoid back (in m)
1.1.3 If the best substitute of s enhances the losses function:
1.1.3.1 Perform the substitution
1.1.3.2 StableSequence=0
1.1.4 Otherwise:
1.1.4.1 StableSequence +=1
1.1.4.2 If StableSequence>threshold:
1.1.4.2.1 Restore the current configuration

k-medoids: clara
• Bagging for graph clustering • Select and cluster random subsample • Remaining nodes are just connected to the nearest medoids in the very end • Run several times to select the best variant • Acceleration only at complexity over O(n) • Complexity of PAN: O(k*n^2*number of iterations) • Complexity of new heuristics: O(k*n*s*number of iterations)

k-medoids for DMP segments
• Plot graph for domains • Data: selection of users, and set of visited domains for each of them • Assume U_x is all users visited domain x • Weight of edge between domains x and y:
• Cutting of noises:
1. Threshold for nodes (domains): at least 15 visits
2. Threshold for edges: affitinty of at least 20
affinity(x, y) =|Ux ∩ Uy||U |
|Ux||Uy|=
p̂(x, y)
p̂(x)p̂(y)
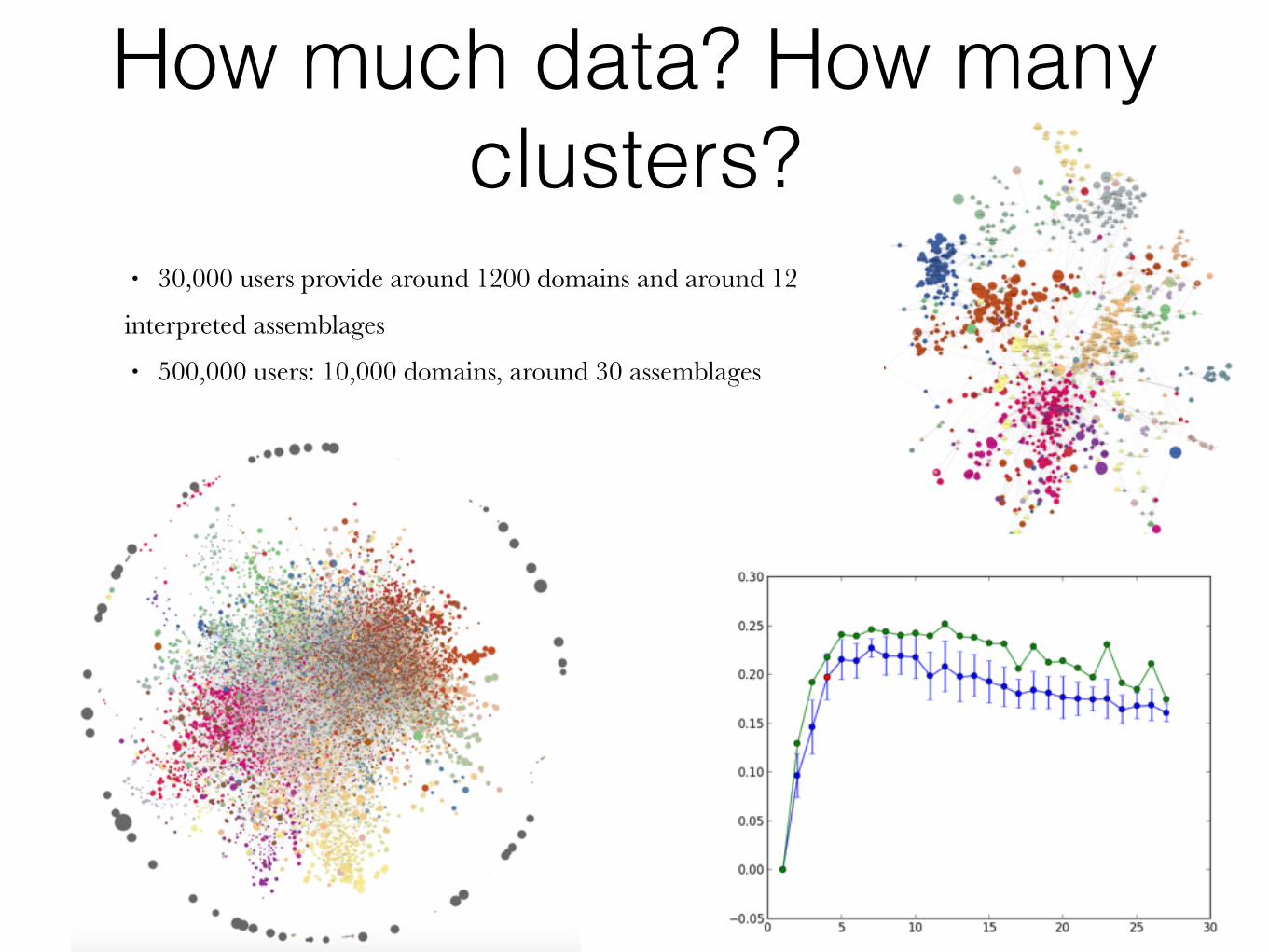
How much data? How many clusters?
• 30,000 users provide around 1200 domains and around 12
interpreted assemblages • 500,000 users: 10,000 domains, around 30 assemblages

Interpreting the picture
• Node size: number of visits • Node color: assemblage • Edge color = assemblage color if internal,
otherwise grey • Edge thickness: affinity • Too complicated for networkX! • Disadvantages of networkX visualization:
1. Non-flexible
2. Non-interactive
3. Unstable
4. Slow
• Use graph-tool if possible!

News sites

Movies and TV series

Research papers, cartoons, and cars

Culinary

Kazakhstan

Books & Laws

Pre-processing: Local sparsification
• Sparsify the graph retaining the assemblage structure • Algorithms are faster, and pictures are prettier • Option 1: sort all neighbors per Jaccasrd measure in descension, and remove the tail • Minus: dense communities remain untouched, and those sparse get destroyed completely • Option 2: sort neighbors for each node and retain edges
• d_i — degree of i, e from 0 to 1. At e=0,5 sparsification is tenfold
• Power law retained, and connectedness almost retained!
min{1,dei}

Local sparsification: demonstration
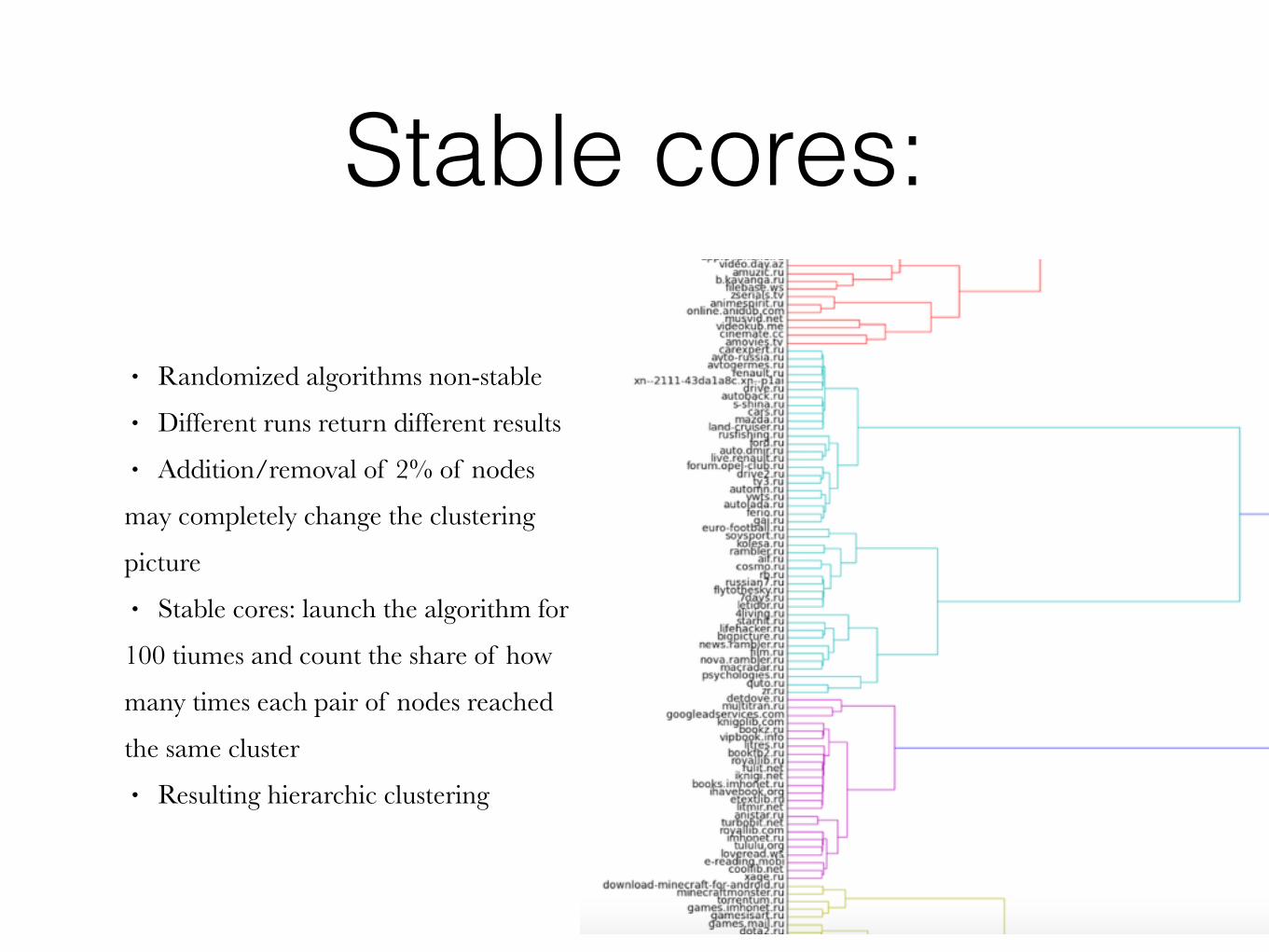
Stable cores:
• Randomized algorithms non-stable • Different runs return different results • Addition/removal of 2% of nodes
may completely change the clustering
picture • Stable cores: launch the algorithm for
100 tiumes and count the share of how
many times each pair of nodes reached
the same cluster • Resulting hierarchic clustering

Louvain
• Blondel et al, 2008 • The most audacious of all modularity-based algorithms • Multi-level assemblages • Very fast • 1. Initializing: all nodes separately (n assemblages with 1 node) • 2. Unify assemblage pairs in iterations providing the greatest modularity increment
• 3. As the incrementation ceases, represent each assemblage as 1 node in a new graph• 4. Repeat clauses 2 to 3 until only 2 assemblages remain

Louvain: illustration
• Cell phone operator from Belgium • 2.6 million customers • 260 assemblages with over 100
customers, 36 with over 10,000 • 6 assemblage levels • French and Dutch segments are
almost independent

MCL
• Markov Cluster Algorithm (van Dongen, 1997-2000) • Normalize columns of connectedness matrix: • 'Share of money for each friend' or 'Probability of random walk transition' • Repeat 3 steps in iterations:
• Expand:
• Inflate: (number of clusters grows as r grows)
• Prune: zero out the least elements in each column
• Repeat until M converges • Complexity: ~n*d^2 for the first iteration (the following will be faster)
3.1 Preliminaries
Let G = (V, E) be our input graph with V and E denoting the node set and edge
set respectively. Let A be the |V|× |V| adjacency matrix corresponding to the graph,
with A(i, j) denoting the weight of the edge between the vertex vi and the vertex vj .
This weight can represent the strength of the interaction in the original network - e.g.
in an author collaboration network, the edge weight between two authors could be the
frequency of their collaboration. If the graph is unweighted, then the weight on each
edge is fixed to 1. As many interaction networks are undirected, we also assume that
G is undirected, although our method is easy to extend to directed graphs. Therefore
A will be a symmetric matrix.
3.1.1 Stochastic matrices and flows
A column-stochastic matrix is simply a matrix where each column sums to 1. A
column stochastic (square) matrix M with as many columns as vertices in a graph G
can be interpreted as the matrix of the transition probabilities of a random walk (or
a Markov chain) defined on the graph. The ith column of M represents the transition
probabilities out of the vi; therefore M(j, i) represents the probability of a transition
from vertex vi to vj. We use the terms stochastic matrix and column-stochastic matrix
interchangeably.
We also refer to the transition probability from vi to vj as the stochastic flow or
simply the flow from vi to vj. Correspondingly, a column-stochastic transition matrix
of the graph G is also refered to as a flow matrix of G or simply a flow of G. Given
a flow matrix M , the ith column contains the flows out of node vi, or its out-flows ;
correspondingly the ith row contains the in-flows. Note that while all the columns (or
out-flows) sum to 1, the rows (or in-flows) are not required to do so.
The most common way of deriving a column-stochastic transition matrix M for a
graph is to simply normalize the columns of the adjacency matrix to sum to 1
M(i, j) =A(i, j)
!nk=1 A(k, j)
In matrix notation, M := AD−1, where D is the diagonal degree matrix of G with
D(i, i) =!n
j=1 A(j, i). We will refer to this particular transition matrix for the graph
29
as the canonical transition matrix MG. However, it is worth keeping in mind that
one can associate other stochastic matrices with the graph G.
Both MCL and our methods introduced in Section 3.2 can be thought of as sim-
ulating stochastic flows (or simulating random walks) on graphs according to certain
rules. For this reason, we refer to these processes as flow simulations.
3.1.2 Markov Clustering (MCL) Algorithm
We next describe the Markov Clustering (MCL) algorithm for clustering graphs,
proposed by Stijn van Dongen [41], in some detail as it is relevant to understanding
our own method.
The MCL algorithm is an iterative process of applying two operators - expansion
and inflation - on an initial stochastic matrix M , in alternation, until convergence.
Both expansion and inflation are operators that map the space of column-stochastic
matrices onto itself. Additionally, a prune step is performed at the end of each
inflation step in order to save memory. Each of these steps is defined below:
Expand: Input M , output Mexp.
Mexp = Expand(M)def= M ∗M
The ith column of Mexp can be interpreted as the final distribution of a random walk of
length 2 starting from vertex vi, with the transition probabilities of the random walk
given by M . One can take higher powers of M instead of a square (corresponding to
longer random walks), but this gets computationally prohibitive very quickly.
Inflate: Input M and inflation parameter r, output Minf .
Minf (i, j)def=
M(i, j)r
!nk=1 M(k, j)r
Minf corresponds to raising each entry in the matrix M to the power r and then
normalizing the columns to sum to 1. By default r = 2. Because the entries in the
matrix are all guaranteed to be less than or equal to 1, this operator has the effect of
exaggerating the inhomogeneity in each column (as long as r > 1). In other words,
flow is strengthened where it is already strong and weakened where it is weak.
Prune: In each column, we remove those entries which have very small values (where
“small” is defined in relation to the rest of the entries in the column), and the retained
30
as the canonical transition matrix MG. However, it is worth keeping in mind that
one can associate other stochastic matrices with the graph G.
Both MCL and our methods introduced in Section 3.2 can be thought of as sim-
ulating stochastic flows (or simulating random walks) on graphs according to certain
rules. For this reason, we refer to these processes as flow simulations.
3.1.2 Markov Clustering (MCL) Algorithm
We next describe the Markov Clustering (MCL) algorithm for clustering graphs,
proposed by Stijn van Dongen [41], in some detail as it is relevant to understanding
our own method.
The MCL algorithm is an iterative process of applying two operators - expansion
and inflation - on an initial stochastic matrix M , in alternation, until convergence.
Both expansion and inflation are operators that map the space of column-stochastic
matrices onto itself. Additionally, a prune step is performed at the end of each
inflation step in order to save memory. Each of these steps is defined below:
Expand: Input M , output Mexp.
Mexp = Expand(M)def= M ∗M
The ith column of Mexp can be interpreted as the final distribution of a random walk of
length 2 starting from vertex vi, with the transition probabilities of the random walk
given by M . One can take higher powers of M instead of a square (corresponding to
longer random walks), but this gets computationally prohibitive very quickly.
Inflate: Input M and inflation parameter r, output Minf .
Minf (i, j)def=
M(i, j)r
!nk=1 M(k, j)r
Minf corresponds to raising each entry in the matrix M to the power r and then
normalizing the columns to sum to 1. By default r = 2. Because the entries in the
matrix are all guaranteed to be less than or equal to 1, this operator has the effect of
exaggerating the inhomogeneity in each column (as long as r > 1). In other words,
flow is strengthened where it is already strong and weakened where it is weak.
Prune: In each column, we remove those entries which have very small values (where
“small” is defined in relation to the rest of the entries in the column), and the retained
30

MCL: example
Figure 3.1: Toy example graph for illustrating MCL.
Interpretation of M as a clustering: As just mentioned, after some number of
iterations, most of the nodes will find one “attractor” node to which all of their flow
is directed i.e. there will be only one non-zero entry per column in the flow matrix
M. We declare convergence at this stage, and assign nodes which flow into the same
node as belonging to one cluster.
3.1.3 Toy example
We give a simple example of the MCL process in action for the graph in Fig-
ure 3.1.3. The initial stochastic matrix M0 obtained by adding self-loops to the graph
and normalizing each column is given below
M0 =
⎛
⎜
⎜
⎜
⎜
⎜
⎜
⎜
⎜
⎜
⎝
0.33 0.33 0.25 0 0 0
0.33 0.33 0.25 0 0 0
0.33 0.33 0.25 0.25 0 0
0 0 0.25 0.25 0.33 0.33
0 0 0 0.25 0.33 0.33
0 0 0 0.25 0.33 0.33
⎞
⎟
⎟
⎟
⎟
⎟
⎟
⎟
⎟
⎟
⎠
32
The result of applying one iteration of Expansion, Inflation and the Prune steps
is given below:
M1 =
⎛
⎜
⎜
⎜
⎜
⎜
⎜
⎜
⎜
⎜
⎝
0.33 0.33 0.2763 0 0 0
0.33 0.33 0.2763 0 0 0
0.33 0.33 0.4475 0 0 0
0 0 0 0.4475 0.33 0.33
0 0 0 0.2763 0.33 0.33
0 0 0 0.2763 0.33 0.33
⎞
⎟
⎟
⎟
⎟
⎟
⎟
⎟
⎟
⎟
⎠
Note that the flow along the lone inter-cluster edge (M0(4, 3)) has evaporated to 0.
Applying one more iteration results in convergence.
M2 =
⎛
⎜
⎜
⎜
⎜
⎜
⎜
⎜
⎜
⎜
⎝
0 0 0 0 0 0
0 0 0 0 0 0
1 1 1 0 0 0
0 0 0 1 1 1
0 0 0 0 0 0
0 0 0 0 0 0
⎞
⎟
⎟
⎟
⎟
⎟
⎟
⎟
⎟
⎟
⎠
Hence, vertices 1, 2 and 3 flow completely to vertex 3, where as the vertices 4, 5 and
6 flow completely to vertex 4. Hence, we group 1, 2 and 3 together with 3 being the
“attractor” of the cluster, and similarly for 4, 5 and 6.
3.1.4 Limitations of MCL
The MCL algorithm is a simple and intuitive algorithm for clustering graphs that
takes an approach that is different from that of the majority of other approaches to
graph clustering such as spectral clustering [104, 36], divisive/agglomerative clustering
[89], heuristic methods [64] and so on. Further more, it does not require a specification
of the number of clusters to be returned; the coarseness of the clustering can instead
be indirectly affected by varying the inflation parameter r, with lower values of r (upto
1) leading to coarser clusterings of the graph. MCL has received a lot of attention
in the bioinformatics field, with multiple researchers finding it to be very effective at
clustering biological interaction networks ([22, 77]).
However, there are two major limitations to MCL:
33
The result of applying one iteration of Expansion, Inflation and the Prune steps
is given below:
M1 =
⎛
⎜
⎜
⎜
⎜
⎜
⎜
⎜
⎜
⎜
⎝
0.33 0.33 0.2763 0 0 0
0.33 0.33 0.2763 0 0 0
0.33 0.33 0.4475 0 0 0
0 0 0 0.4475 0.33 0.33
0 0 0 0.2763 0.33 0.33
0 0 0 0.2763 0.33 0.33
⎞
⎟
⎟
⎟
⎟
⎟
⎟
⎟
⎟
⎟
⎠
Note that the flow along the lone inter-cluster edge (M0(4, 3)) has evaporated to 0.
Applying one more iteration results in convergence.
M2 =
⎛
⎜
⎜
⎜
⎜
⎜
⎜
⎜
⎜
⎜
⎝
0 0 0 0 0 0
0 0 0 0 0 0
1 1 1 0 0 0
0 0 0 1 1 1
0 0 0 0 0 0
0 0 0 0 0 0
⎞
⎟
⎟
⎟
⎟
⎟
⎟
⎟
⎟
⎟
⎠
Hence, vertices 1, 2 and 3 flow completely to vertex 3, where as the vertices 4, 5 and
6 flow completely to vertex 4. Hence, we group 1, 2 and 3 together with 3 being the
“attractor” of the cluster, and similarly for 4, 5 and 6.
3.1.4 Limitations of MCL
The MCL algorithm is a simple and intuitive algorithm for clustering graphs that
takes an approach that is different from that of the majority of other approaches to
graph clustering such as spectral clustering [104, 36], divisive/agglomerative clustering
[89], heuristic methods [64] and so on. Further more, it does not require a specification
of the number of clusters to be returned; the coarseness of the clustering can instead
be indirectly affected by varying the inflation parameter r, with lower values of r (upto
1) leading to coarser clusterings of the graph. MCL has received a lot of attention
in the bioinformatics field, with multiple researchers finding it to be very effective at
clustering biological interaction networks ([22, 77]).
However, there are two major limitations to MCL:
33
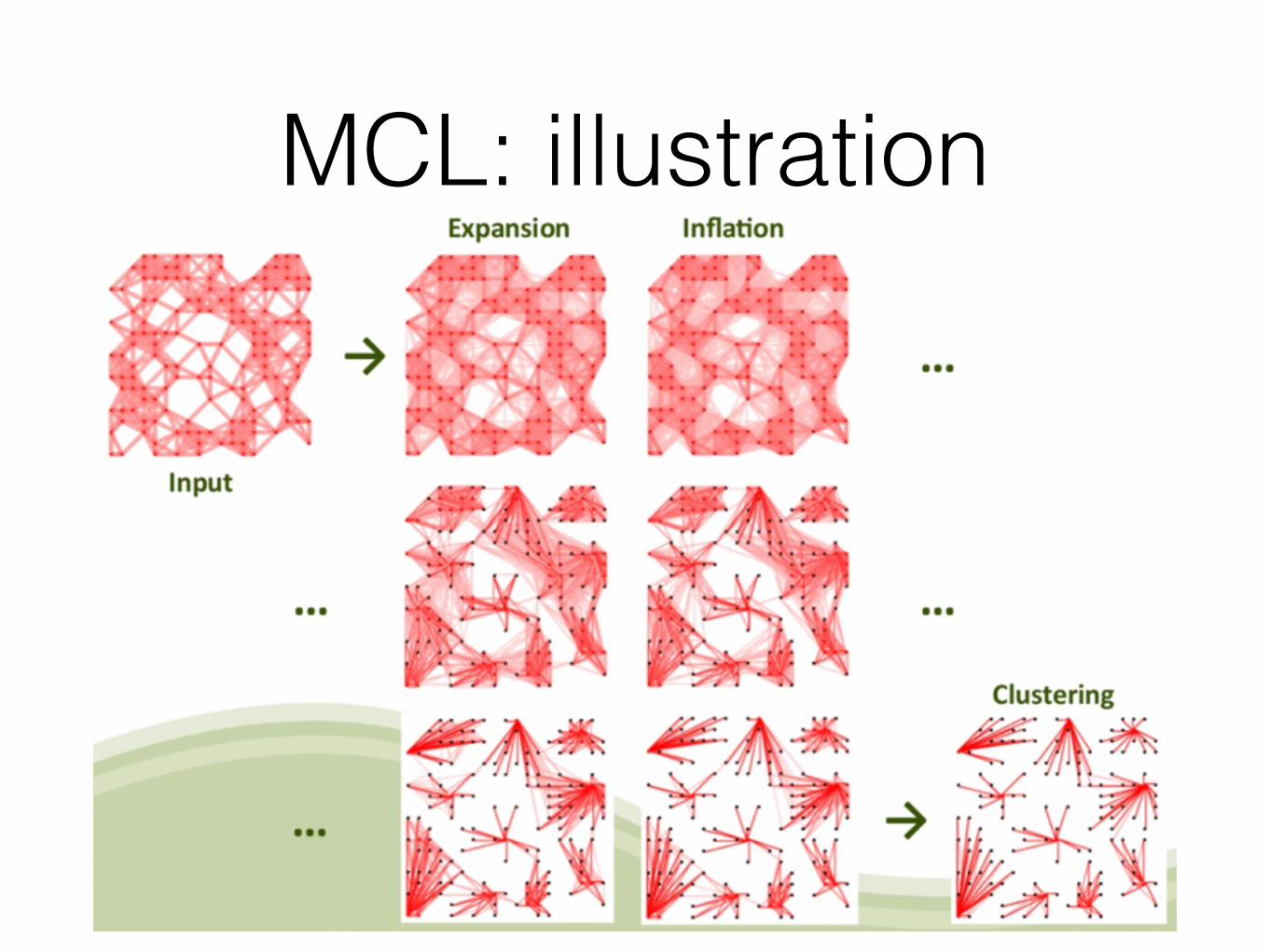
MCL: illustration

MCL: problems and solutions
• Problems: • Too many clusters • Learning rate r reduces: less clusters, but works slower • Non-balanced clusters: one giant and a pile of those having 2 to 3 nodes • The thing is in re-learning! • Try to make distribution of flow from neighboring nodes similar • Regularization of (R-MCL): Mexp = M*M0
Mexp = M ∗M0

SCD: step 1
• Approximate maximization of WCC • Count the triangles first • Remove all edges that form no triangles • Rough partitioning (algorithm 1): • 1. Sort the nodes on the basis of local cluster
factor • 2. First assemblage: first node + all neighbors • 3. Second assemblage: first node of those
remaining (not visited yet) + all its neighbors • 4. ... • Complexity: O(n*d^2+n*log(n))

SCD: step 2
• Improve the algorithm 1 results in iterations until
WCC ceases improving (algorithm 2) • * Find bestMovement for each node
(MapReduce)• bestMovement: add / remove / transfer • * Perform bestMovement simultaneously for all
nodes • * Complexity: O(1) per one bestMovement, O(d
+1) for one node, O(m) for the whole graph • * Whole algorithm: O(m*log(n))
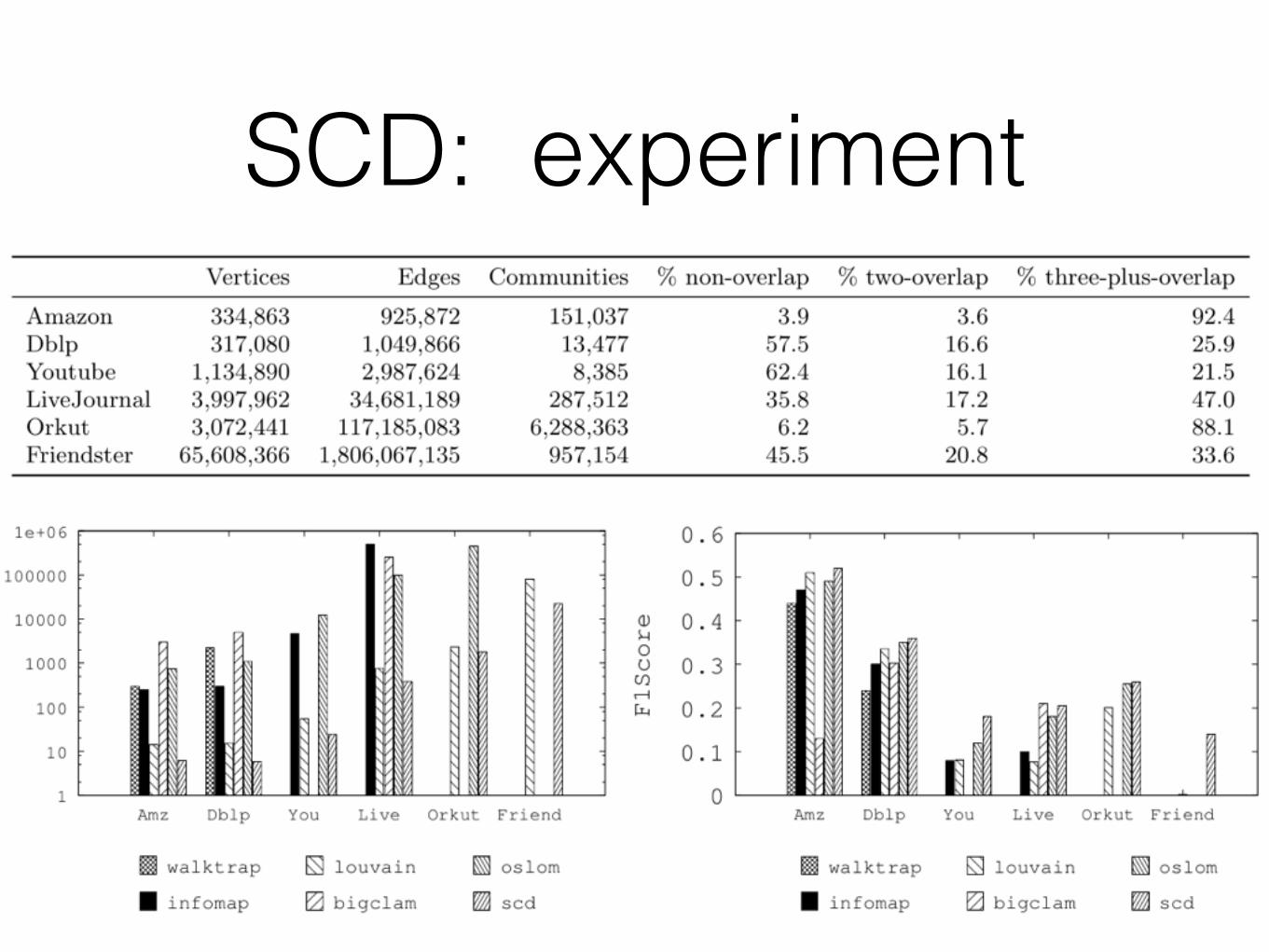
SCD: experiment

Spinner• Based on label propagation
• Implemented in Okapi (Mahout) by Telefonica • Symmetrize initial graph D: weight w(u,v)=1 if the edge was located
in one direction, and 2 if in both directions • * Regulate the balance: set maximum number of edges possible within
the assemblage (c may alter from 1 to 10-15): • * Assemblage workload l: current number of edges in the community
l: • * Relative workload: • * Pre-set number of clusters k similar to k-medoids method; c=1,...k • * What label shall be assigned to node v? The one that is most
common amongst neighbors of v: • * Balanced state amendment:
V is the set of vertices in the graph and E is the set of edges suchthat an edge e 2 E is a pair (u,v) with u,v 2 V . We denote byN(v) = {u : u 2 V,(u,v) 2 E} the neighborhood of a vertex v, andby deg(v) = |N(v)| the degree of v. In a k-way partitioning, wedefine L as a set of labels L= {l1, . . . , lk} that essentially correspondto the k partitions. a is the labeling function a : V ! L such thata(v) = l j if label l j is assigned to vertex v.
The end goal of Spinner is to assign partitions, or labels, to eachvertex such that it maximizes edge locality and partitions are bal-anced.
3.1 K-way Label PropagationWe first describe how to use basic LPA to maximize edge locality
and then extend the algorithm to achieve balanced partitions. Ini-tially, each vertex in the graph is assigned a label li at random, with0 < i k. Subsequently, every vertex iteratively propagates its la-bel to its neighbors. During this iterative process, a vertex acquiresthe label that is more frequent among its neighbors. Every vertex vassigns a different score for a particular label l which is equal to thenumber of neighbors assigned to label l. A vertex shows preferenceto labels with high score. More formally:
score(v, l) = Âu2N(v)
d (a(u), l) (1)
where d is the Kronecker delta. The vertex updates its label to thelabel lv that maximizes its score according to the update function:
lv = argmaxl
score(v, l) (2)
We call such an update a migration as it represents a logical vertexmigration between two partitions.
When multiple labels satisfy the update function, we break tiesrandomly, but prefer to keep the current label if it is among them.This break-tie rule improves convergence speed [6], and in our dis-tributed implementation reduces unnecessary network communica-tion (see Section 4). The algorithm halts when no vertex updatesits label.
Note that the original formulation of LPA assumes undirectedgraphs. However, very often graphs are directed (e.g. the Web).Even the data models of systems like Pregel allow directed graphs,to support algorithms that are aware of graph directness, like PageR-ank. To use LPA as is, we would need to convert a graph to undi-rected. The naive approach would be to create an undirected edgebetween vertices u and v whenever at least one directed edge existsbetween vertex u and v in the directed graph.
This approach, though, is agnostic to the communication patternsof the applications running on top. Consider the example graph inFigure 1 that we want to partition to 3 parts. In the undirected graph(right), there are initially 3 cut edges. At this point, according to theLPA formulation, which is agnostic of the directness of the originalgraph, any migration of a vertex to another partition is as likely, andit would produce one cut edge less.
However, if we consider the directness of the edges in the orig-inal graph, not all migrations are equally beneficial. In fact, eithermoving vertex 2 to partition 1 or vertex 1 to partition 3 would inpractice produce less cut edges in the directed graph. Once thegraph is loaded into the system and messages are sent across thedirected edges, this latter decision results in less communicationover the network.
Figure 1: Conversion of a directed graph (left) to an undirectedgraph (right).
Spinner considers the number of directed edges connecting u,vin the original directed graph D, by introducing a weighting func-tion w(u,v) such that:
w(u,w) =
(1, if (u,v) 2 D� (v,u) 2 D2, if (u,v) 2 D^ (v,u) 2 D
(3)
where � is the logical XOR. We extend now the formulation in (1)to include the weighting function:
score0(v, l) = Âu2N(v)
w(u,v)d (a(u), l) (4)
In practice, the new update function effectively counts the num-ber of messages exchanged locally in the system.
3.2 Balanced Label PropagationUntil now we have not considered partition balance. In Spin-
ner, we take a different path from previous work [24, 25], wherea centralized component is added to LPA to satisfy global balanceconstraints, possibly limiting scalability. Instead, as our aim is toprovide a practical and scalable solution, Spinner relaxes this con-straint, only encouraging a similar number of edges across the dif-ferent partitions. As we will show, this decision allows a fully de-centralized algorithm. While in this work we focus on the presenta-tion and evaluation of the more system-related aspects of Spinner,we plan to investigate theoretical justifications and guarantees be-hind our approach in future work.
Here, we consider the case of a homogeneous system, whereeach machine has equal resources. This setup is often preferredin synchronous graph processing systems like Pregel, to minimizethe time spent by faster machines waiting at the synchronizationbarrier for stragglers.
We define the capacity C of a partition as the maximum numberof edges it can have so that partitions are balanced:
C = c · |E|k
(5)
Parameter c > 1 ensures additional capacity to each partition isavailable for migrations. We define the load of a partition as theactual number of edges in that partition:
B(l) = Âv2G
deg(v)d (a(v), l) (6)
A larger value of c increases the number of migrations to eachpartition allowed at each iteration, possibly speeding up conver-gence, but it may increase unbalance, as more edges are allowed tobe assigned to each partition over the ideal value |E|
k .
3
V is the set of vertices in the graph and E is the set of edges suchthat an edge e 2 E is a pair (u,v) with u,v 2 V . We denote byN(v) = {u : u 2 V,(u,v) 2 E} the neighborhood of a vertex v, andby deg(v) = |N(v)| the degree of v. In a k-way partitioning, wedefine L as a set of labels L= {l1, . . . , lk} that essentially correspondto the k partitions. a is the labeling function a : V ! L such thata(v) = l j if label l j is assigned to vertex v.
The end goal of Spinner is to assign partitions, or labels, to eachvertex such that it maximizes edge locality and partitions are bal-anced.
3.1 K-way Label PropagationWe first describe how to use basic LPA to maximize edge locality
and then extend the algorithm to achieve balanced partitions. Ini-tially, each vertex in the graph is assigned a label li at random, with0 < i k. Subsequently, every vertex iteratively propagates its la-bel to its neighbors. During this iterative process, a vertex acquiresthe label that is more frequent among its neighbors. Every vertex vassigns a different score for a particular label l which is equal to thenumber of neighbors assigned to label l. A vertex shows preferenceto labels with high score. More formally:
score(v, l) = Âu2N(v)
d (a(u), l) (1)
where d is the Kronecker delta. The vertex updates its label to thelabel lv that maximizes its score according to the update function:
lv = argmaxl
score(v, l) (2)
We call such an update a migration as it represents a logical vertexmigration between two partitions.
When multiple labels satisfy the update function, we break tiesrandomly, but prefer to keep the current label if it is among them.This break-tie rule improves convergence speed [6], and in our dis-tributed implementation reduces unnecessary network communica-tion (see Section 4). The algorithm halts when no vertex updatesits label.
Note that the original formulation of LPA assumes undirectedgraphs. However, very often graphs are directed (e.g. the Web).Even the data models of systems like Pregel allow directed graphs,to support algorithms that are aware of graph directness, like PageR-ank. To use LPA as is, we would need to convert a graph to undi-rected. The naive approach would be to create an undirected edgebetween vertices u and v whenever at least one directed edge existsbetween vertex u and v in the directed graph.
This approach, though, is agnostic to the communication patternsof the applications running on top. Consider the example graph inFigure 1 that we want to partition to 3 parts. In the undirected graph(right), there are initially 3 cut edges. At this point, according to theLPA formulation, which is agnostic of the directness of the originalgraph, any migration of a vertex to another partition is as likely, andit would produce one cut edge less.
However, if we consider the directness of the edges in the orig-inal graph, not all migrations are equally beneficial. In fact, eithermoving vertex 2 to partition 1 or vertex 1 to partition 3 would inpractice produce less cut edges in the directed graph. Once thegraph is loaded into the system and messages are sent across thedirected edges, this latter decision results in less communicationover the network.
Figure 1: Conversion of a directed graph (left) to an undirectedgraph (right).
Spinner considers the number of directed edges connecting u,vin the original directed graph D, by introducing a weighting func-tion w(u,v) such that:
w(u,w) =
(1, if (u,v) 2 D� (v,u) 2 D2, if (u,v) 2 D^ (v,u) 2 D
(3)
where � is the logical XOR. We extend now the formulation in (1)to include the weighting function:
score0(v, l) = Âu2N(v)
w(u,v)d (a(u), l) (4)
In practice, the new update function effectively counts the num-ber of messages exchanged locally in the system.
3.2 Balanced Label PropagationUntil now we have not considered partition balance. In Spin-
ner, we take a different path from previous work [24, 25], wherea centralized component is added to LPA to satisfy global balanceconstraints, possibly limiting scalability. Instead, as our aim is toprovide a practical and scalable solution, Spinner relaxes this con-straint, only encouraging a similar number of edges across the dif-ferent partitions. As we will show, this decision allows a fully de-centralized algorithm. While in this work we focus on the presenta-tion and evaluation of the more system-related aspects of Spinner,we plan to investigate theoretical justifications and guarantees be-hind our approach in future work.
Here, we consider the case of a homogeneous system, whereeach machine has equal resources. This setup is often preferredin synchronous graph processing systems like Pregel, to minimizethe time spent by faster machines waiting at the synchronizationbarrier for stragglers.
We define the capacity C of a partition as the maximum numberof edges it can have so that partitions are balanced:
C = c · |E|k
(5)
Parameter c > 1 ensures additional capacity to each partition isavailable for migrations. We define the load of a partition as theactual number of edges in that partition:
B(l) = Âv2G
deg(v)d (a(v), l) (6)
A larger value of c increases the number of migrations to eachpartition allowed at each iteration, possibly speeding up conver-gence, but it may increase unbalance, as more edges are allowed tobe assigned to each partition over the ideal value |E|
k .
3
We introduce a penalty function to discourage assigning verticesto nearly full partitions. Given a partition indicated by label l, thepenalty function p(l) is defined as follows:
p(l) = B(l)C
(7)
To integrate the penalty function we normalize (4) first, and re-formulate the score function as follows:
score00(v, l) = Âu2N(v)
w(u,v)d (a(u), l)Âu2N(v) w(u,v)
�p(l) (8)
3.3 Convergence and HaltingConvergence and halting of LPA are not well understood. LPA is
formally equivalent to minimizing the Hamiltonian for a ferromag-netic Potts model [6]. The global optimum solution for any graphwould assign the same label to each vertex. However, as verticesmake decisions based on local information, LPA converges to localoptima. This characteristic is at the basis of the ability of LPA todetect communities [6]. Unfortunately, even in asynchronous sys-tems, LPA does not prevent cycles where the partitioning fluctuatesbetween the same states, preventing the algorithm to converge. Insuch cases, the halting condition described in Section 3.1 will notwork. A number of strategies have been proposed to guarantee thehalting of LPA in synchronous systems. These strategies are eitherbased on different heuristics applied to tie breaking and halting cri-teria, or on the order with which vertices are evaluated [27]. How-ever, due to the contribution of the penalty function introduced inSection 3.2, these cannot be applied to to our approach.
We use a different strategy instead. At a given iteration, we de-fine the score of the partitioning for graph G as the sum of thecurrent scores of each vertex:
score(G) = Âv2G
score00(v,a(lv)) (9)
In practice, this is the aggregate score that the vertices try to op-timize by making local decisions. We consider a partitioning tobe in a stable state, when the score of the graph is not improvedmore than a given e for more than w consecutive iterations. Thealgorithm halts when a stable state is reached. While through ewe can control the trade-off between the cost of executing the al-gorithm for more iterations and the improvement obtained by thescore function, with w it is possible to require a more strict defini-tion of stability, as absence of improvement is accepted for a largernumber of iterations.
Note that this condition, commonly used by iterative hill-climbingoptimization algorithms, does not guarantee halting at the optimalsolution. However, as we present in Section 3.4, according to ourapproach the partitioning algorithm is expected to be restarted pe-riodically to adapt to changes to the graph or the compute environ-ment. Within this continuous perspective, the impact of occasion-ally halting in a suboptimal state is minimal.
3.4 Incremental Label PropagationGraphs are dynamic. Edges and vertices are added and removed
over time. As the graph changes, the computed partitioning be-comes outdated, possibly degrading the global score. We want toupdate the partitioning to the new topology without repartitioningfrom scratch. As the graph changes affect local areas of the graph,we want to update the latest stable partitioning only in the portionsthat are affected by the graph changes.
Due to its local and iterative nature, LPA lends itself to incre-mental computation. Intuitively, the effect of the graph changes
is to “push” the current stable state away from the local optimumit converged to, towards a state with lower global score. As a re-sult, we restart the algorithm with the effect of letting the algorithmlook for a new local optimum. The vertices evaluate their new localscore, possibly deciding to migrate to another partition. The algo-rithm continues as described previously. As far as new vertices isconcerned, we assign them to the least loaded partition.
The number of iterations required to converge to a new stablestate depends on the number of graph changes and the last state.Clearly, not every graph change will have the same effect. Some-times, no iteration may be necessary at all. In fact, certain changesmay not affect any vertex to the point that the score of a differentlabel is higher than the current one. As no migration is caused, thestate remains stable. On the other hand, other changes may causemore migrations due to the disruption of certain weak local equilib-riums. In this sense, the algorithm behaves as a gradient descendingoptimization algorithm.
3.5 Elastic Label PropagationBecause the partitions are tied to machines, capacity C should be
bound to a maximum capacity Cmax that depends on the resourcesavailable to the machines. As the graph grows, the capacity C ofthe partitions will eventually reach the maximum capacity Cmax.In this case, a number of machines can be added, and the graphcan be spread across these new machines as well. Moreover, thenumber of machines can be increased to increase parallelization.On the other hand, as the graph shrinks or the number of availablemachines decreases, a number of partitions can be removed. In thiscase, a number of vertices should migrate from these partitions tothe remaining ones.
In both cases, we want the algorithm to adapt to the new numberof partitions without repartitioning the graph from scratch. More-over, we want the algorithm to make decisions based on a decentral-ized and lightweight heuristics. We let each vertex decide indepen-dently whether it should migrate. To do so, we use a probabilisticapproach. When n new partitions are added to the system, eachvertex will migrate with a probability p such that:
p =n
k+n(10)
In the trivial case where n partitions are removed, all the verticesassigned to those partitions migrate. In both cases, the verticeschoose uniformly at random the partition to migrate to. After thevertices have migrated, we restart the algorithm to adapt the parti-tioning to the new assignments. As in the case of incremental LPA,the number of iterations required to converge to a new stable statedepends on a number of factors, such as the graph size, the numberof partitions added or removed, etc.
This simple strategy clearly disrupts the current partitioning de-grading the global score. However, it has a number of interestingcharacteristics. First, it matches our requirements of a decentral-ized and lightweight heuristic. The heuristic does not need a globalview of the partitioning or a complex computation to decide whichvertices to migrate. Second, by choosing randomly, the partitionsremain fairly balanced. Third, it injects a factor of randomizationinto the optimization problem that may allow the solution to jumpout of a local optimum.
Given a large n, the cost of adapting the partitioning to the newnumber of partitions may be quite large, due to the random migra-tions. However, in a real system, the frequency with which par-titions are added or removed is low, compared for example to thenumber of times a partitioning is updated due to graph changes.Although vertices are shuffled around, the locality of the vertices
4
We introduce a penalty function to discourage assigning verticesto nearly full partitions. Given a partition indicated by label l, thepenalty function p(l) is defined as follows:
p(l) = B(l)C
(7)
To integrate the penalty function we normalize (4) first, and re-formulate the score function as follows:
score00(v, l) = Âu2N(v)
w(u,v)d (a(u), l)Âu2N(v) w(u,v)
�p(l) (8)
3.3 Convergence and HaltingConvergence and halting of LPA are not well understood. LPA is
formally equivalent to minimizing the Hamiltonian for a ferromag-netic Potts model [6]. The global optimum solution for any graphwould assign the same label to each vertex. However, as verticesmake decisions based on local information, LPA converges to localoptima. This characteristic is at the basis of the ability of LPA todetect communities [6]. Unfortunately, even in asynchronous sys-tems, LPA does not prevent cycles where the partitioning fluctuatesbetween the same states, preventing the algorithm to converge. Insuch cases, the halting condition described in Section 3.1 will notwork. A number of strategies have been proposed to guarantee thehalting of LPA in synchronous systems. These strategies are eitherbased on different heuristics applied to tie breaking and halting cri-teria, or on the order with which vertices are evaluated [27]. How-ever, due to the contribution of the penalty function introduced inSection 3.2, these cannot be applied to to our approach.
We use a different strategy instead. At a given iteration, we de-fine the score of the partitioning for graph G as the sum of thecurrent scores of each vertex:
score(G) = Âv2G
score00(v,a(lv)) (9)
In practice, this is the aggregate score that the vertices try to op-timize by making local decisions. We consider a partitioning tobe in a stable state, when the score of the graph is not improvedmore than a given e for more than w consecutive iterations. Thealgorithm halts when a stable state is reached. While through ewe can control the trade-off between the cost of executing the al-gorithm for more iterations and the improvement obtained by thescore function, with w it is possible to require a more strict defini-tion of stability, as absence of improvement is accepted for a largernumber of iterations.
Note that this condition, commonly used by iterative hill-climbingoptimization algorithms, does not guarantee halting at the optimalsolution. However, as we present in Section 3.4, according to ourapproach the partitioning algorithm is expected to be restarted pe-riodically to adapt to changes to the graph or the compute environ-ment. Within this continuous perspective, the impact of occasion-ally halting in a suboptimal state is minimal.
3.4 Incremental Label PropagationGraphs are dynamic. Edges and vertices are added and removed
over time. As the graph changes, the computed partitioning be-comes outdated, possibly degrading the global score. We want toupdate the partitioning to the new topology without repartitioningfrom scratch. As the graph changes affect local areas of the graph,we want to update the latest stable partitioning only in the portionsthat are affected by the graph changes.
Due to its local and iterative nature, LPA lends itself to incre-mental computation. Intuitively, the effect of the graph changes
is to “push” the current stable state away from the local optimumit converged to, towards a state with lower global score. As a re-sult, we restart the algorithm with the effect of letting the algorithmlook for a new local optimum. The vertices evaluate their new localscore, possibly deciding to migrate to another partition. The algo-rithm continues as described previously. As far as new vertices isconcerned, we assign them to the least loaded partition.
The number of iterations required to converge to a new stablestate depends on the number of graph changes and the last state.Clearly, not every graph change will have the same effect. Some-times, no iteration may be necessary at all. In fact, certain changesmay not affect any vertex to the point that the score of a differentlabel is higher than the current one. As no migration is caused, thestate remains stable. On the other hand, other changes may causemore migrations due to the disruption of certain weak local equilib-riums. In this sense, the algorithm behaves as a gradient descendingoptimization algorithm.
3.5 Elastic Label PropagationBecause the partitions are tied to machines, capacity C should be
bound to a maximum capacity Cmax that depends on the resourcesavailable to the machines. As the graph grows, the capacity C ofthe partitions will eventually reach the maximum capacity Cmax.In this case, a number of machines can be added, and the graphcan be spread across these new machines as well. Moreover, thenumber of machines can be increased to increase parallelization.On the other hand, as the graph shrinks or the number of availablemachines decreases, a number of partitions can be removed. In thiscase, a number of vertices should migrate from these partitions tothe remaining ones.
In both cases, we want the algorithm to adapt to the new numberof partitions without repartitioning the graph from scratch. More-over, we want the algorithm to make decisions based on a decentral-ized and lightweight heuristics. We let each vertex decide indepen-dently whether it should migrate. To do so, we use a probabilisticapproach. When n new partitions are added to the system, eachvertex will migrate with a probability p such that:
p =n
k+n(10)
In the trivial case where n partitions are removed, all the verticesassigned to those partitions migrate. In both cases, the verticeschoose uniformly at random the partition to migrate to. After thevertices have migrated, we restart the algorithm to adapt the parti-tioning to the new assignments. As in the case of incremental LPA,the number of iterations required to converge to a new stable statedepends on a number of factors, such as the graph size, the numberof partitions added or removed, etc.
This simple strategy clearly disrupts the current partitioning de-grading the global score. However, it has a number of interestingcharacteristics. First, it matches our requirements of a decentral-ized and lightweight heuristic. The heuristic does not need a globalview of the partitioning or a complex computation to decide whichvertices to migrate. Second, by choosing randomly, the partitionsremain fairly balanced. Third, it injects a factor of randomizationinto the optimization problem that may allow the solution to jumpout of a local optimum.
Given a large n, the cost of adapting the partitioning to the newnumber of partitions may be quite large, due to the random migra-tions. However, in a real system, the frequency with which par-titions are added or removed is low, compared for example to thenumber of times a partitioning is updated due to graph changes.Although vertices are shuffled around, the locality of the vertices
4
V is the set of vertices in the graph and E is the set of edges suchthat an edge e 2 E is a pair (u,v) with u,v 2 V . We denote byN(v) = {u : u 2 V,(u,v) 2 E} the neighborhood of a vertex v, andby deg(v) = |N(v)| the degree of v. In a k-way partitioning, wedefine L as a set of labels L= {l1, . . . , lk} that essentially correspondto the k partitions. a is the labeling function a : V ! L such thata(v) = l j if label l j is assigned to vertex v.
The end goal of Spinner is to assign partitions, or labels, to eachvertex such that it maximizes edge locality and partitions are bal-anced.
3.1 K-way Label PropagationWe first describe how to use basic LPA to maximize edge locality
and then extend the algorithm to achieve balanced partitions. Ini-tially, each vertex in the graph is assigned a label li at random, with0 < i k. Subsequently, every vertex iteratively propagates its la-bel to its neighbors. During this iterative process, a vertex acquiresthe label that is more frequent among its neighbors. Every vertex vassigns a different score for a particular label l which is equal to thenumber of neighbors assigned to label l. A vertex shows preferenceto labels with high score. More formally:
score(v, l) = Âu2N(v)
d (a(u), l) (1)
where d is the Kronecker delta. The vertex updates its label to thelabel lv that maximizes its score according to the update function:
lv = argmaxl
score(v, l) (2)
We call such an update a migration as it represents a logical vertexmigration between two partitions.
When multiple labels satisfy the update function, we break tiesrandomly, but prefer to keep the current label if it is among them.This break-tie rule improves convergence speed [6], and in our dis-tributed implementation reduces unnecessary network communica-tion (see Section 4). The algorithm halts when no vertex updatesits label.
Note that the original formulation of LPA assumes undirectedgraphs. However, very often graphs are directed (e.g. the Web).Even the data models of systems like Pregel allow directed graphs,to support algorithms that are aware of graph directness, like PageR-ank. To use LPA as is, we would need to convert a graph to undi-rected. The naive approach would be to create an undirected edgebetween vertices u and v whenever at least one directed edge existsbetween vertex u and v in the directed graph.
This approach, though, is agnostic to the communication patternsof the applications running on top. Consider the example graph inFigure 1 that we want to partition to 3 parts. In the undirected graph(right), there are initially 3 cut edges. At this point, according to theLPA formulation, which is agnostic of the directness of the originalgraph, any migration of a vertex to another partition is as likely, andit would produce one cut edge less.
However, if we consider the directness of the edges in the orig-inal graph, not all migrations are equally beneficial. In fact, eithermoving vertex 2 to partition 1 or vertex 1 to partition 3 would inpractice produce less cut edges in the directed graph. Once thegraph is loaded into the system and messages are sent across thedirected edges, this latter decision results in less communicationover the network.
Figure 1: Conversion of a directed graph (left) to an undirectedgraph (right).
Spinner considers the number of directed edges connecting u,vin the original directed graph D, by introducing a weighting func-tion w(u,v) such that:
w(u,w) =
(1, if (u,v) 2 D� (v,u) 2 D2, if (u,v) 2 D^ (v,u) 2 D
(3)
where � is the logical XOR. We extend now the formulation in (1)to include the weighting function:
score0(v, l) = Âu2N(v)
w(u,v)d (a(u), l) (4)
In practice, the new update function effectively counts the num-ber of messages exchanged locally in the system.
3.2 Balanced Label PropagationUntil now we have not considered partition balance. In Spin-
ner, we take a different path from previous work [24, 25], wherea centralized component is added to LPA to satisfy global balanceconstraints, possibly limiting scalability. Instead, as our aim is toprovide a practical and scalable solution, Spinner relaxes this con-straint, only encouraging a similar number of edges across the dif-ferent partitions. As we will show, this decision allows a fully de-centralized algorithm. While in this work we focus on the presenta-tion and evaluation of the more system-related aspects of Spinner,we plan to investigate theoretical justifications and guarantees be-hind our approach in future work.
Here, we consider the case of a homogeneous system, whereeach machine has equal resources. This setup is often preferredin synchronous graph processing systems like Pregel, to minimizethe time spent by faster machines waiting at the synchronizationbarrier for stragglers.
We define the capacity C of a partition as the maximum numberof edges it can have so that partitions are balanced:
C = c · |E|k
(5)
Parameter c > 1 ensures additional capacity to each partition isavailable for migrations. We define the load of a partition as theactual number of edges in that partition:
B(l) = Âv2G
deg(v)d (a(v), l) (6)
A larger value of c increases the number of migrations to eachpartition allowed at each iteration, possibly speeding up conver-gence, but it may increase unbalance, as more edges are allowed tobe assigned to each partition over the ideal value |E|
k .
3

Spinner: Scalability• Calculation within Pregel — perfect for label propagation
• Easy to add and remove clusters (1 cluster per 1 worker) • Easy re-calculation in case of addition / removal of nodes • Scalability of Spinner upon clustering of a random graph (Watts-Strogatz) • Saving of resources upon addition of new edges or new assemblages (workers)
(a) Partitioning of the Twitter graph. (b) Partitioning of the Yahoo! graph.Figure 4: Partitioning of (a) the Twitter graph across 256 partitions and (b) the Yahoo! web graph across 115 partitions. The figureshows the evolution of metrics f , r , and score(G) across iterations.
(a) Runtime vs. graph size (b) Runtime vs. cluster size (c) Runtime vs. k
Figure 5: Scalability of Spinner. (a) Runtime as a function of the number of vertices, (b) runtime as a function of the number ofworkers, (c) runtime as a function of the number of partitions.
supersteps. This approach allows us to factor out the runtime of al-gorithm as a function the number of vertices and edges.
Figure 5.2 presents the results of the experiments, executed ona AWS Hadoop cluster consisting of 116 m2.4xlarge machines. Inthe first experiment, presented in Figure 5(a), we focus on the scal-ability of the algorithm as a function of the number of vertices andedges in the graph. For this, we fix the number of outgoing edgesper vertex to 40. We connect the vertices following a ring latticetopology, and re-wire 30% of the edges randomly as by the func-tion of the beta (0.3) parameter of the Watts-Strogatz model. Weexecute each experiment with 115 workers, for an exponentiallyincreasing number of vertices, precisely from 2 to 1024 millionvertices (or one billion vertices) and we divide each graph in 64partitions. The results, presented in a loglog plot, show a lineartrend with respect to the size of the graph. Note that for the firstdata points the size of the graph is too small for such a large clus-ter, and we are actually measuring the overhead of Giraph.
In the second experiment, presented in Figure 5(b), we focuson the scalability of the algorithm as a function of the number ofworkers. Here, we fix the number of vertices to 1 billion, still con-structed as described above, but we vary the number of workerslinearly from 15 to 115 with steps of 15 workers (except for the laststep where we add 10 workers). The drop from 111 to 15 secondswith 7.6 times more workers represents a speedup of 7.6.
In the third experiment, presented in Figure 5(b), we focus onthe scalability of the algorithm as a function of the number of parti-tions. Again, we use 115 workers and we fix the number of verticesto 1 billion and construct the graph as described above. This time,we increase the number of partitions exponentially from 2 to 512.Also here, the loglog plot shows a near-linear trend, as the com-plexity of the heuristic executed by each vertex is proportional tothe number of partitions k, and so is cost of maintaining partition
(a) Cost savings (b) Partitioning stabilityFigure 6: Adapting to dynamic graph changes. We vary thepercentage of new edges in the graph and compare our adap-tive re-partitioning approach and re-partitioning from scratchwith respect to (a) the savings in processing time and messagesexchanged, and (b) the fraction of vertices that have to moveupon re-partitioning.
loads and counters through the sharded aggregators provided byGiraph.
5.3 Partitioning dynamic graphsDue to the dynamic nature of graphs, the quality of an initial
partitioning degrades over time. Re-partitioning from scratch canbe an expensive task if performed frequently and with potentiallylimited resources. In this section, we show that our algorithm min-imizes the cost of adapting the partitioning to the changes, makingthe maintenance of a well-partitioned graph an affordable task interms of time and compute resources required.
Specifically, we measure the savings in processing time and num-ber of messages exchanged (i.e. load imposed on the network) rel-ative to the approach of re-partitioning the graph from scratch. Wetrack how these metrics vary as a function of the degree of change
8
(a) Partitioning of the Twitter graph. (b) Partitioning of the Yahoo! graph.Figure 4: Partitioning of (a) the Twitter graph across 256 partitions and (b) the Yahoo! web graph across 115 partitions. The figureshows the evolution of metrics f , r , and score(G) across iterations.
(a) Runtime vs. graph size (b) Runtime vs. cluster size (c) Runtime vs. k
Figure 5: Scalability of Spinner. (a) Runtime as a function of the number of vertices, (b) runtime as a function of the number ofworkers, (c) runtime as a function of the number of partitions.
supersteps. This approach allows us to factor out the runtime of al-gorithm as a function the number of vertices and edges.
Figure 5.2 presents the results of the experiments, executed ona AWS Hadoop cluster consisting of 116 m2.4xlarge machines. Inthe first experiment, presented in Figure 5(a), we focus on the scal-ability of the algorithm as a function of the number of vertices andedges in the graph. For this, we fix the number of outgoing edgesper vertex to 40. We connect the vertices following a ring latticetopology, and re-wire 30% of the edges randomly as by the func-tion of the beta (0.3) parameter of the Watts-Strogatz model. Weexecute each experiment with 115 workers, for an exponentiallyincreasing number of vertices, precisely from 2 to 1024 millionvertices (or one billion vertices) and we divide each graph in 64partitions. The results, presented in a loglog plot, show a lineartrend with respect to the size of the graph. Note that for the firstdata points the size of the graph is too small for such a large clus-ter, and we are actually measuring the overhead of Giraph.
In the second experiment, presented in Figure 5(b), we focuson the scalability of the algorithm as a function of the number ofworkers. Here, we fix the number of vertices to 1 billion, still con-structed as described above, but we vary the number of workerslinearly from 15 to 115 with steps of 15 workers (except for the laststep where we add 10 workers). The drop from 111 to 15 secondswith 7.6 times more workers represents a speedup of 7.6.
In the third experiment, presented in Figure 5(b), we focus onthe scalability of the algorithm as a function of the number of parti-tions. Again, we use 115 workers and we fix the number of verticesto 1 billion and construct the graph as described above. This time,we increase the number of partitions exponentially from 2 to 512.Also here, the loglog plot shows a near-linear trend, as the com-plexity of the heuristic executed by each vertex is proportional tothe number of partitions k, and so is cost of maintaining partition
(a) Cost savings (b) Partitioning stabilityFigure 6: Adapting to dynamic graph changes. We vary thepercentage of new edges in the graph and compare our adap-tive re-partitioning approach and re-partitioning from scratchwith respect to (a) the savings in processing time and messagesexchanged, and (b) the fraction of vertices that have to moveupon re-partitioning.
loads and counters through the sharded aggregators provided byGiraph.
5.3 Partitioning dynamic graphsDue to the dynamic nature of graphs, the quality of an initial
partitioning degrades over time. Re-partitioning from scratch canbe an expensive task if performed frequently and with potentiallylimited resources. In this section, we show that our algorithm min-imizes the cost of adapting the partitioning to the changes, makingthe maintenance of a well-partitioned graph an affordable task interms of time and compute resources required.
Specifically, we measure the savings in processing time and num-ber of messages exchanged (i.e. load imposed on the network) rel-ative to the approach of re-partitioning the graph from scratch. Wetrack how these metrics vary as a function of the degree of change
8
(a) Cost savings (b) Partitioning stabilityFigure 7: Adapting to resource changes. We vary the num-ber of new partitions and compare our adaptive approach andre-partitioning from scratch with respect to (a) the savings inprocessing time and messages exchanged, and (b) the fractionof vertices that have to move upon re-partitioning.
in the graph. Intuitively, larger graph changes require more time toadapt to an optimal partitioning.
For this experiment, we take a snapshot of the Tuenti [3] socialgraph that consists of approximately 10 million vertices and 530million edges, and perform an initial partitioning. Subsequently,we add a varying number of edges that correspond to actual newfriendships and measure the above metrics. We perform this ex-periment on an AWS Hadoop cluster consisting of 10 m2.2xlargeinstances.
Figure 6(a) shows that for changes up to 0.5%, our approachsaves up to 86% of the processing time and, by reducing vertex mi-grations, up to 92% of the network traffic. Even for large graphchanges, the algorithm still saves up to 80% of the processing time.Note that in every case our approach converges to a balanced parti-tioning, with a maximum normalized load of approximately 1.047,with 67%-69% local edges, similar to a re-partitioning from scratch.
5.4 Partitioning stabilityAdapting the partitioning helps maintain good locality as the
graph changes, but may also require the graph management sys-tem (e.g. a graph DB) to move vertices and their associated state(e.g. user profiles in a social network) across partitions, poten-tially impacting performance. Aside from efficiency, the value ofan adaptive algorithm lies also in maintaining stable partitions, thatis, requiring only few vertices to move to new partitions upon graphchanges. Here, we show that our approach achieves this goal.
We quantify the stability of the algorithm with a metric we callpartitioning difference. The partitioning difference between twopartitions is the percentage of vertices that belong to different par-titions across two partitionings. This number represents the frac-tion of vertices that have to move to new partitions. Note that thismetric is not the same as the total number of migrations that occurduring the execution of the algorithm which only regards cost ofthe execution of the algorithm per se.
In Figure 6(b), we measure the resulting partitioning differencewhen adapting and when re-partitioning from scratch as a functionof the percentage of new edges. As expected, the percentage of ver-tices that have to move increases as we make more changes to thegraph. However, our adaptive approach requires only 8%-11% ofthe vertices to move compared to a 95%-98% when re-partitioning,minimizing the impact.
5.5 Adapting to resource changesHere, we show that Spinner can efficiently adapt the partitioning
when resource changes force a change in the number of partitions.Initially, we partition the Tuenti graph snapshot described in Sec-tion 5.3 into 32 partitions. Subsequently we add a varying number
of partitions and either re-partition the graph from scratch or adaptthe partitioning with Spinner.
Figure 7(a) shows the savings in processing time and number ofmessages exchanged as a function of the number of new partitions.As expected, a larger number of new partitions requires more workto converge to a good partitioning. When increasing the capacityof the system by only 1 partition, Spinner adapts the partitions 74%faster relative to a re-partitioning.
Similarly to graph changes, a change in the capacity of the com-pute system may result in shuffling the graph. In Figure 7(b), wesee that a change in the number of partitions can impact partitioningstability more than a large change in the input graph (Figure 6(b)).Still, when adding only 1 partition Spinner forces less than 17% ofthe vertices to shuffle compared to a 96% when re-partitioning fromscratch. The high percentage when re-partitioning from scratch isexpected due to the randomized nature of our algorithm. Note,though, that even a deterministic algorithm, like modulo hash par-titioning, may suffer from the same problem when the number ofpartitions changes.
5.6 Impact on application performanceIn this section, we focus on the impact on runtime performance
of using the partitioning computed by Spinner in Giraph, while run-ning real analytical applications. First, we focus on assessing theimpact of partitioning balance on worker load balance. To this end,we evaluate the impact of the unbalanced obtained by a randompartitioning of the Twitter graph across 256 partitions, as describedin Sec. 5.1, and presented in Figure 4.
We use our computed partitioning in Giraph as follows. Theoutput of the partitioning algorithm is a list of pairs (vi, l j) thatassigns each vertex to a partition. We make use of this output toload vertices assigned to the same partition in the same worker. Bydefault, when a graph is loaded for a computation, Giraph assignsvertices to workers according to hash partitioning, e.g. vertex vi isassigned to one of the k workers according to h(vi) mod k. To usethe results of our partitioning in Giraph, and make sure that verticeswith the same label are assigned to the same worker, we plugged thefollowing partitioning strategy into Giraph. Given that each vertexhas an id vi assigned, which uniquely identifies it, and that the idis used to assign the vertex to a worker through hash partitioning,we define a new vertex id type. This new vertex id type is definedas the computed pair (vi, l j), where l j is the partition the vertexwas partitioned to. When Giraph computes the hash partitioningfunction for a vertex vi (for example when the vertex is initiallyloaded into memory, or when a message is sent to that vertex andthe destination worker needs to be identified), the function utilizesthe l j field of the pair, ensuring that vertices labelled with the samelabel are partitioned consistently. For conditions where the actual idof the vertex is required, such as in the getId() call of the API, vi isreturned instead. This way, our partitioning strategy is transparentto the user and no change in user code is required. It also does notrequire an external directory table where the mapping is stored.
Intuitively, an unbalanced partitioning would generate unevenload across the workers. In a synchronous engine like Giraph, theresult would be that the most loaded worker would force the otherworkers idling at the synchronization barrier. To validate this hy-pothesis, we run 20 iterations of PageRank on the Twitter graphacross 256 workers by using (i) standard hash partitioning (ran-dom), and (ii) the partitioning computed by Spinner. For each run,we measure the time to compute a superstep by all the workers(Mean), the fastest (Min) and the slowest (Max) (standard devia-tion is computed across the 20 iterations). Table 4 shows the resultsof this experiment. The results show that with hash partitioning the
9

Tools
• Network X: cliques, k-cores, blockmodels • graph-tool: very fast blockmodels, visualization • okapi (mahout): k-cores, Spinner • GraphX (spark): nothing as yet • Gephi: MCL, Girvan-Newman, Chinese Whispers • micans.org: MCL by the creator • mapequation.org: Infomap • sites.google.com/site/findcommunities: Louvain from the creators (C++) • pycluster (coming soon): k-medoids

Further reading• Mining of Massive Datasets (ch.10 «Mining social networks
graphs», pp 343-402) • Data Clustering Algorithms and Applications (ch 17 «Network
clustering», pp 415-443) • SNA Course at Coursera: www.coursera.org/course/sna • Great review on community finding: snap.stanford.edu/class/
cs224w-readings/ fortunato10community.pdf • Articles with analysed methods and relevant cases (to be sent)

THANK YOU








![Density-Based Clustering Validationzimek/publications/SDM2014/DBCV.pdf · into clustering validation. Pal and Biswas [25] build graphs (Minimum Spanning Trees) for each clustering](https://static.fdocuments.net/doc/165x107/5f02a0677e708231d4053441/density-based-clustering-zimekpublicationssdm2014dbcvpdf-into-clustering-validation.jpg)









