
Clustering Applications in Web Mining and Web Personalization
17
Clustering Applications in Web Mining and Web Personalization Bamshad Mobasher DePaul University
-
Upload
idona-martinez -
Category
Documents
-
view
33 -
download
1
description
Clustering Applications in Web Mining and Web Personalization. Bamshad Mobasher DePaul University. Clustering Application: Web Usage Mining. Discovering Aggregate Usage Profiles - PowerPoint PPT Presentation
Transcript of Clustering Applications in Web Mining and Web Personalization

ClusteringApplications in Web Mining and
Web Personalization
Bamshad MobasherDePaul University
Bamshad MobasherDePaul University

2
Clustering Application: Web Usage Mining
i Discovering Aggregate Usage Profiles4 Goal: to effectively capture “user segments” based on their common usage patterns
from potentially anonymous click-stream data4 Method: Cluster user transactions to obtain user segments automatically, then
represent each cluster by its centroidh Aggregate profiles are obtained from each centroid after sorting by weight and filtering
out low-weight items in each centroid
4 Note that profiles are represented as weighted collections of items (pages, products, etc.)h weights represent the significance of the item within each cluster
4 profiles are overlapping, so they capture common interests among different groups/types of users (e.g., customer segments)

3
Profile Aggregation Based on Clustering Transactions (PACT)
i Discovery of Profiles Based on Transaction Clusters4 cluster user transactions - features are significant items present in the
transaction 4 derive usage profiles (set of item-weight pairs) based on characteristics of each
transaction cluster as captured in the cluster centroid
i Deriving Usage Profiles from Transaction Clusters4 each cluster contains a set of user transactions (vectors)4 for each cluster compute centroid as cluster representative
4 a set of item-weight pairs: for transaction cluster C, select each pageview pi such that (in the cluster centroid) is greater than a pre-specified thresholdc
iu
4
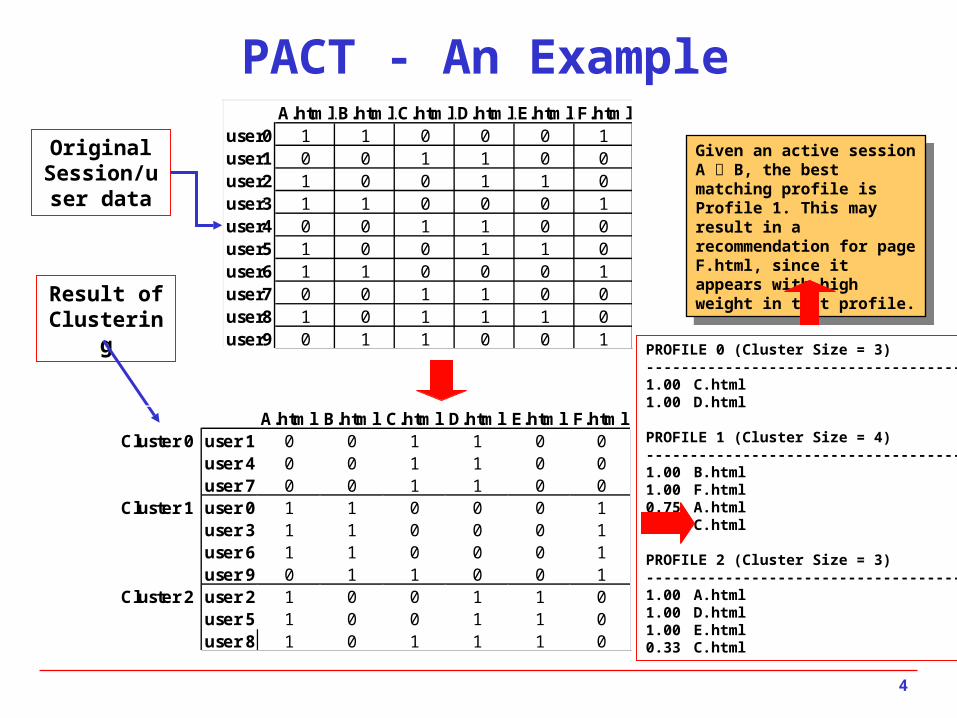
PACT - An ExampleA.html B.html C.html D.html E.html F.html
user0 1 1 0 0 0 1user1 0 0 1 1 0 0user2 1 0 0 1 1 0user3 1 1 0 0 0 1user4 0 0 1 1 0 0user5 1 0 0 1 1 0user6 1 1 0 0 0 1user7 0 0 1 1 0 0user8 1 0 1 1 1 0user9 0 1 1 0 0 1
A.html B.html C.html D.html E.html F.htmlCluster 0 user 1 0 0 1 1 0 0
user 4 0 0 1 1 0 0user 7 0 0 1 1 0 0
Cluster 1 user 0 1 1 0 0 0 1user 3 1 1 0 0 0 1user 6 1 1 0 0 0 1user 9 0 1 1 0 0 1
Cluster 2 user 2 1 0 0 1 1 0user 5 1 0 0 1 1 0user 8 1 0 1 1 1 0
PROFILE 0 (Cluster Size = 3)--------------------------------------1.00 C.html1.00 D.html
PROFILE 1 (Cluster Size = 4)--------------------------------------1.00 B.html1.00 F.html0.75 A.html0.25 C.html
PROFILE 2 (Cluster Size = 3)--------------------------------------1.00 A.html1.00 D.html1.00 E.html0.33 C.html
Original Session/user
data
Result ofClustering
Given an active session A B, the best matching profile is Profile 1. This may result in a recommendation for page F.html, since it appears with high weight in that profile.
Given an active session A B, the best matching profile is Profile 1. This may result in a recommendation for page F.html, since it appears with high weight in that profile.

5
Web Usage Mining: clustering example
i Transaction Clusters: 4 Clustering similar user transactions and using centroid of each cluster as an
aggregate usage profile (representative for a user segment)
Support URL Pageview Description
1.00 /courses/syllabus.asp?course=450-96-303&q=3&y=2002&id=290
SE 450 Object-Oriented Development class syllabus
0.97 /people/facultyinfo.asp?id=290 Web page of a lecturer who thought the above course
0.88 /programs/ Current Degree Descriptions 2002
0.85 /programs/courses.asp?depcode=96&deptmne=se&courseid=450
SE 450 course description in SE program
0.82 /programs/2002/gradds2002.asp M.S. in Distributed Systems program description
Sample cluster centroid from dept. Web site (cluster size =330)

6
Clustering Application: Discovery of Content Profiles
i Content Profiles4 Goal: automatically group together documents which partially deal with
similar concepts4 Method:
h identify concepts by clustering features (keywords) based on their common occurrences among documents (can also be done using association discovery or correlation analysis)
h cluster centroids represent docs in which features in the cluster appear frequently
4 Content profiles are derived from centroids after filtering out low-weight docs in each centroid
4 Note that each content profile is represented as a collections of item-weight pairs (similar to usage profiles)h however, the weight of an item in a profile represents the degree to which features in
the corresponding cluster appear in that item.
7
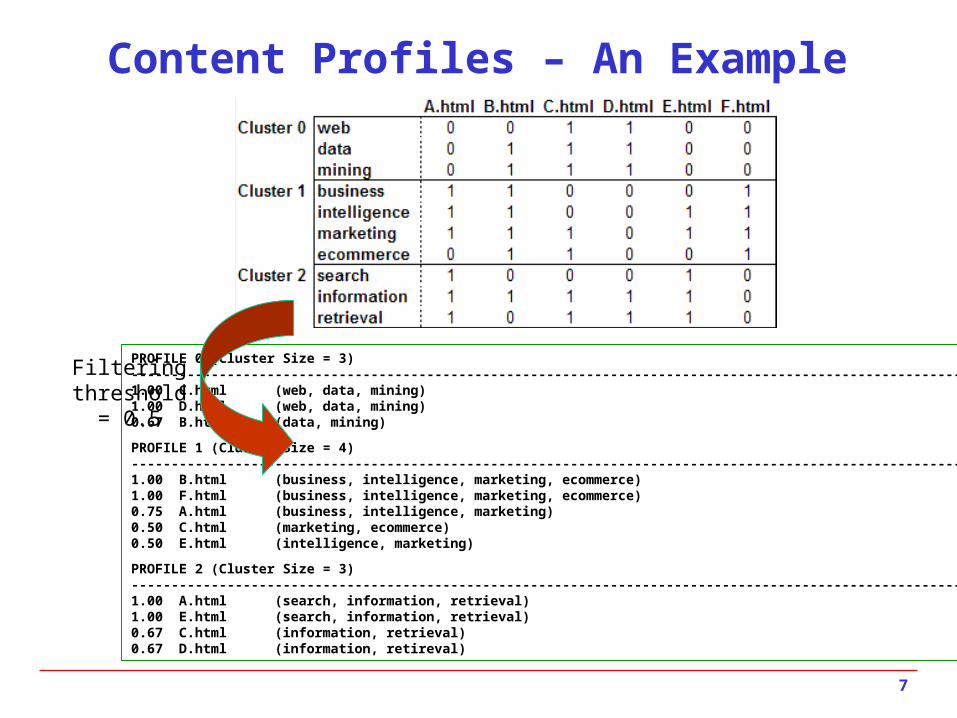
Content Profiles – An Example
PROFILE 0 (Cluster Size = 3)--------------------------------------------------------------------------------------------------------------1.00 C.html (web, data, mining)1.00 D.html (web, data, mining)0.67 B.html (data, mining)
PROFILE 1 (Cluster Size = 4)-------------------------------------------------------------------------------------------------------------1.00 B.html (business, intelligence, marketing, ecommerce)1.00 F.html (business, intelligence, marketing, ecommerce)0.75 A.html (business, intelligence, marketing)0.50 C.html (marketing, ecommerce)0.50 E.html (intelligence, marketing)
PROFILE 2 (Cluster Size = 3)-------------------------------------------------------------------------------------------------------------1.00 A.html (search, information, retrieval)1.00 E.html (search, information, retrieval)0.67 C.html (information, retrieval)0.67 D.html (information, retireval)
Filtering threshold = 0.5

8
User Segments Based on Contenti Essentially combines usage and content profiling techniques
discussed earlier
i Basic Idea:4 for each user/session, extract important features of the selected
documents/items4 based on the global dictionary create a user-feature matrix4 each row is a feature vector representing significant terms associated with
documents/items selected by the user in a given session4 weight can be determined as before (e.g., using tf.idf measure)4 next, cluster users/sessions using features as dimensions
i Profile generation:4 from the user clusters we can now generate overlapping collections of features
based on cluster centroids4 the weights associated with features in each profile represents the significance
of that feature for the corresponding group of users.
9
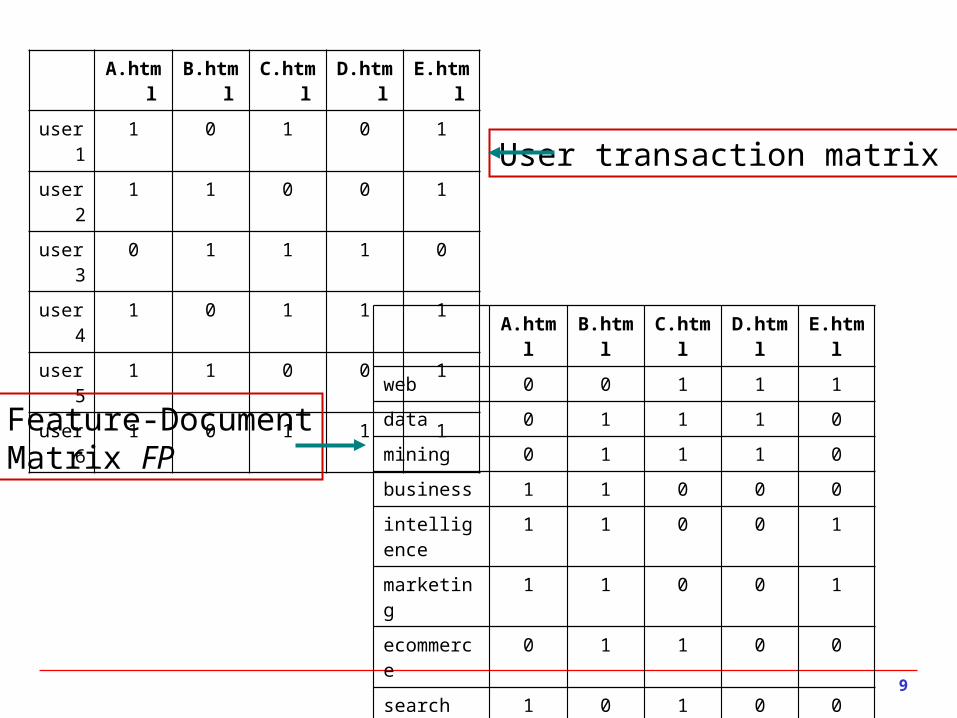
A.html B.html C.html D.html E.html
user1 1 0 1 0 1
user2 1 1 0 0 1
user3 0 1 1 1 0
user4 1 0 1 1 1
user5 1 1 0 0 1
user6 1 0 1 1 1
A.html B.html C.html D.html E.html
web 0 0 1 1 1
data 0 1 1 1 0
mining 0 1 1 1 0
business 1 1 0 0 0
intelligence 1 1 0 0 1
marketing 1 1 0 0 1
ecommerce 0 1 1 0 0
search 1 0 1 0 0
information 1 0 1 1 1
retrieval 1 0 1 1 1
User transaction matrix UT
Feature-DocumentMatrix FP
10
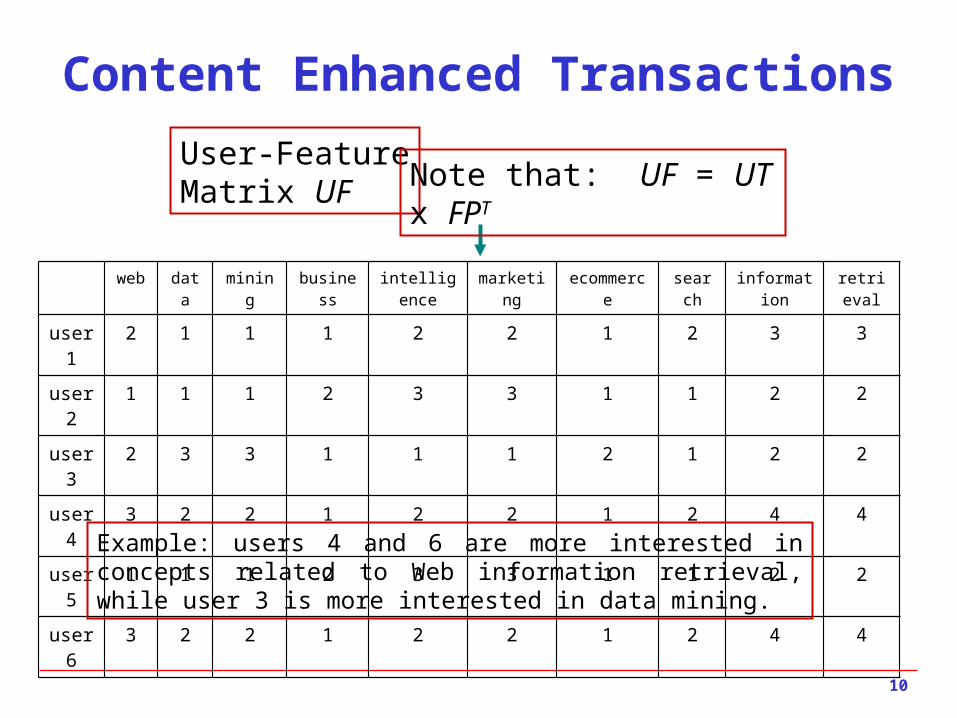
Content Enhanced Transactions
web data mining business intelligence marketing ecommerce search information retrieval
user1 2 1 1 1 2 2 1 2 3 3
user2 1 1 1 2 3 3 1 1 2 2
user3 2 3 3 1 1 1 2 1 2 2
user4 3 2 2 1 2 2 1 2 4 4
user5 1 1 1 2 3 3 1 1 2 2
user6 3 2 2 1 2 2 1 2 4 4
User-FeatureMatrix UF Note that: UF = UT x FPT
Example: users 4 and 6 are more interested in concepts related to Web information retrieval, while user 3 is more interested in data mining.
11
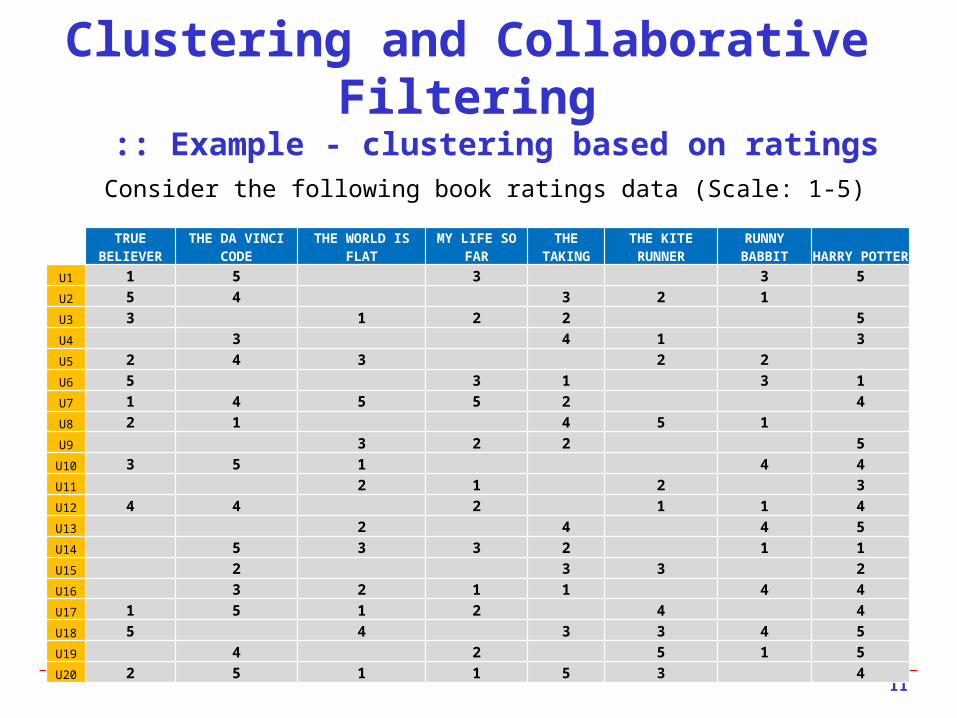
Clustering and Collaborative Filtering :: Example - clustering based on ratings
TRUE
BELIEVERTHE DA VINCI
CODETHE WORLD IS
FLATMY LIFE SO
FARTHE
TAKINGTHE KITE RUNNER
RUNNY BABBIT
HARRY POTTER
U1 1 5 3 3 5U2 5 4 3 2 1 U3 3 1 2 2 5U4 3 4 1 3U5 2 4 3 2 2 U6 5 3 1 3 1U7 1 4 5 5 2 4U8 2 1 4 5 1 U9 3 2 2 5
U10 3 5 1 4 4U11 2 1 2 3U12 4 4 2 1 1 4U13 2 4 4 5U14 5 3 3 2 1 1U15 2 3 3 2U16 3 2 1 1 4 4U17 1 5 1 2 4 4U18 5 4 3 3 4 5U19 4 2 5 1 5U20 2 5 1 1 5 3 4
Consider the following book ratings data (Scale: 1-5)
12
Clustering and Collaborative Filtering :: Example - clustering based on ratings
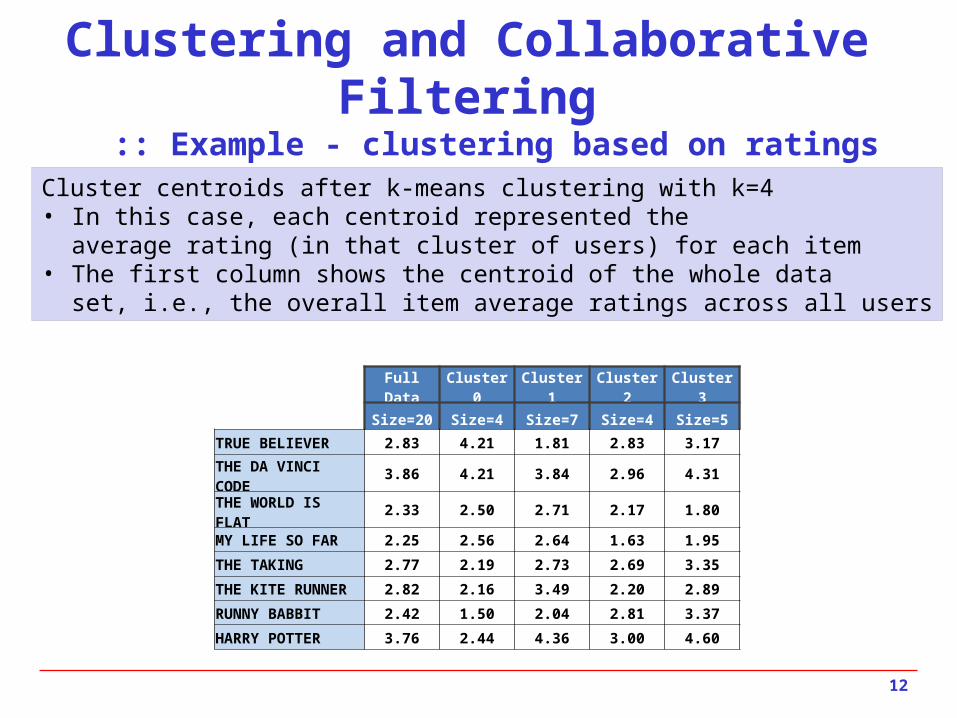
Cluster centroids after k-means clustering with k=4• In this case, each centroid represented the
average rating (in that cluster of users) for each item• The first column shows the centroid of the whole data
set, i.e., the overall item average ratings across all users
Full Data Cluster 0 Cluster 1 Cluster 2 Cluster 3
Size=20 Size=4 Size=7 Size=4 Size=5TRUE BELIEVER 2.83 4.21 1.81 2.83 3.17
THE DA VINCI CODE 3.86 4.21 3.84 2.96 4.31
THE WORLD IS FLAT 2.33 2.50 2.71 2.17 1.80
MY LIFE SO FAR 2.25 2.56 2.64 1.63 1.95
THE TAKING 2.77 2.19 2.73 2.69 3.35
THE KITE RUNNER 2.82 2.16 3.49 2.20 2.89
RUNNY BABBIT 2.42 1.50 2.04 2.81 3.37
HARRY POTTER 3.76 2.44 4.36 3.00 4.60
13
Clustering and Collaborative Filtering :: Example - clustering based on ratings
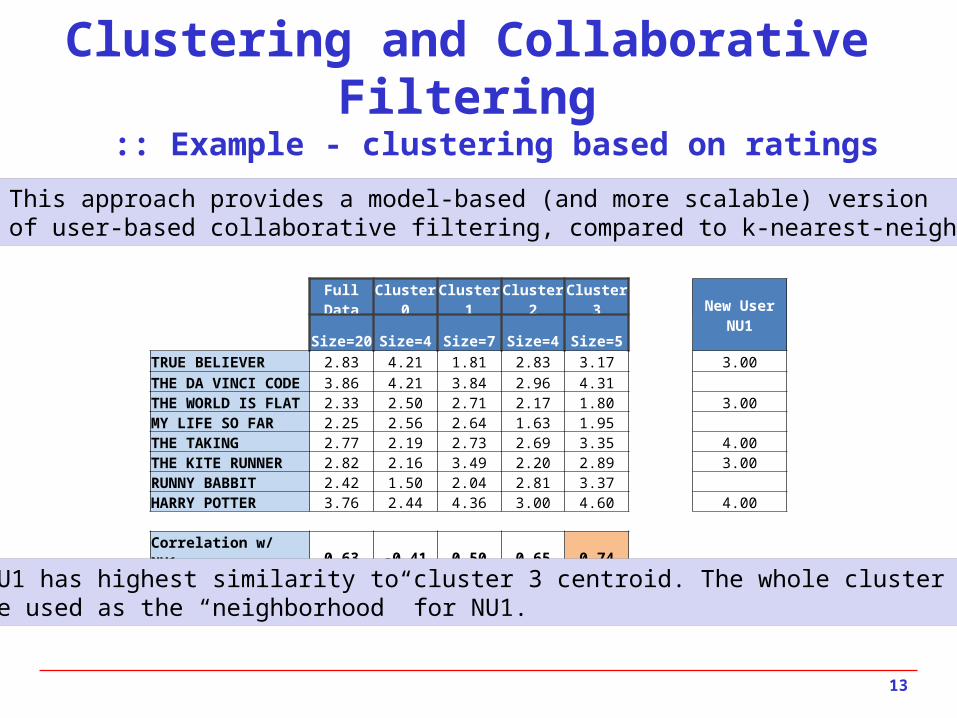
This approach provides a model-based (and more scalable) versionof user-based collaborative filtering, compared to k-nearest-neighbor
Full Data Cluster 0 Cluster 1 Cluster 2 Cluster 3 New User NU1 Size=20 Size=4 Size=7 Size=4 Size=5 TRUE BELIEVER 2.83 4.21 1.81 2.83 3.17 3.00THE DA VINCI CODE 3.86 4.21 3.84 2.96 4.31 THE WORLD IS FLAT 2.33 2.50 2.71 2.17 1.80 3.00MY LIFE SO FAR 2.25 2.56 2.64 1.63 1.95 THE TAKING 2.77 2.19 2.73 2.69 3.35 4.00THE KITE RUNNER 2.82 2.16 3.49 2.20 2.89 3.00RUNNY BABBIT 2.42 1.50 2.04 2.81 3.37 HARRY POTTER 3.76 2.44 4.36 3.00 4.60 4.00 Correlation w/ NU1 0.63 -0.41 0.50 0.65 0.74
NU1 has highest similarity to cluster 3 centroid. The whole cluster couldbe used as the “neighborhood” for NU1.
14
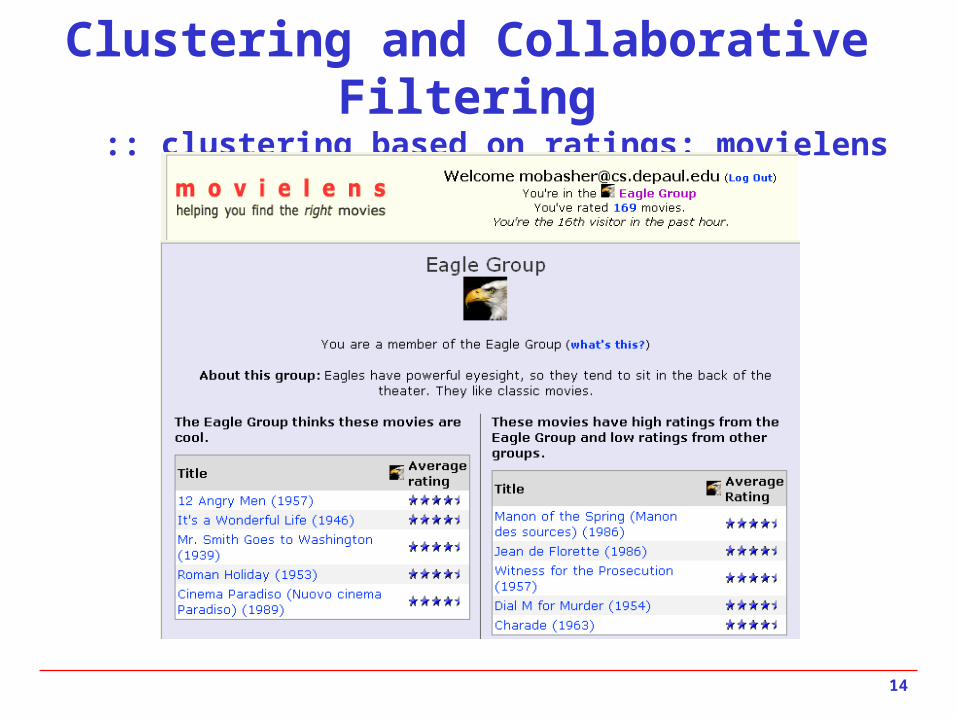
Clustering and Collaborative Filtering :: clustering based on ratings: movielens

15
Clustering on the Social Web :: tag clustering example

16
Hierarchical Clustering:: example – clustered search results
Can drill down within clusters to view sub-topics or to view the relevant subset of results

ClusteringApplications in Web Mining and
Web Personalization
Bamshad MobasherDePaul University
Bamshad MobasherDePaul University


















