
Clustering and Load Balancing Optimization for Redundant Content Removal
17
Clustering and Load Balancing Optimization for Redundant Content Removal Shanzhong Zhu (Ask.com) Alexandra Potapova, Maha Alabduljalil (Univ. of California at Santa Barbara) Xin Liu (Amazon.com) Tao Yang (Univ. of California at Santa Barbara)
-
Upload
earlene-marnell -
Category
Documents
-
view
37 -
download
3
description
Clustering and Load Balancing Optimization for Redundant Content Removal. Shanzhong Zhu (Ask.com) Alexandra Potapova, Maha Alabduljalil (Univ. of California at Santa Barbara) Xin Liu (Amazon.com) Tao Yang (Univ. of California at Santa Barbara). Redundant Content Removal in Search Engines. - PowerPoint PPT Presentation
Transcript of Clustering and Load Balancing Optimization for Redundant Content Removal

Clustering and Load Balancing Optimization for Redundant Content Removal
Shanzhong Zhu (Ask.com)
Alexandra Potapova, Maha Alabduljalil (Univ. of California at Santa Barbara)
Xin Liu (Amazon.com)
Tao Yang (Univ. of California at Santa Barbara)

Redundant Content Removal in Search Engines
• Over 1/3 of Web pages crawled are near duplicates
• When to remove near duplicates? Offline removal
Online removal with query-based duplicate removal
Online index matching & result ranking
Duplicate removalUser
query
Final results
Offline data processing
Duplicate filtering
WebPages
Online index

Tradeoff of online vs. offline removal
Online-dominating approach
Offline-dominating approach
Impact to offline High precisionLow recall
Remove fewer duplicates
High precisionHigh recall
Remove most of duplicates
Higher offline burden
Impact to online More burden to online deduplication
Less burden to online deduplication
Impact to overall cost
Higher serving cost Lower serving cost

Challenges &issues in offline duplicate handling
• Achieve high-recall with high precision All-to-all duplicate comparison for complex/deep
pairwise analysis Expensive parallelism management &
unnecessary computation elimination• Maintain duplicate groups instead of duplicate
pairs Reduce storage requirement. Aid winner selection for duplicate removal Continuous group update is expensive.
Approximation. Error handling

Optimization for faster offline duplicate handling
• Incremental duplicate clustering and group management Approximated transitive relationship Lazy update
• Avoid unnecessary computation while balancing computation among machines Multi-dimensional partitioning Faster many-to-all duplicate comparisons
Pagepartition …
Pagepartition
Pagepartition
Pagepartition
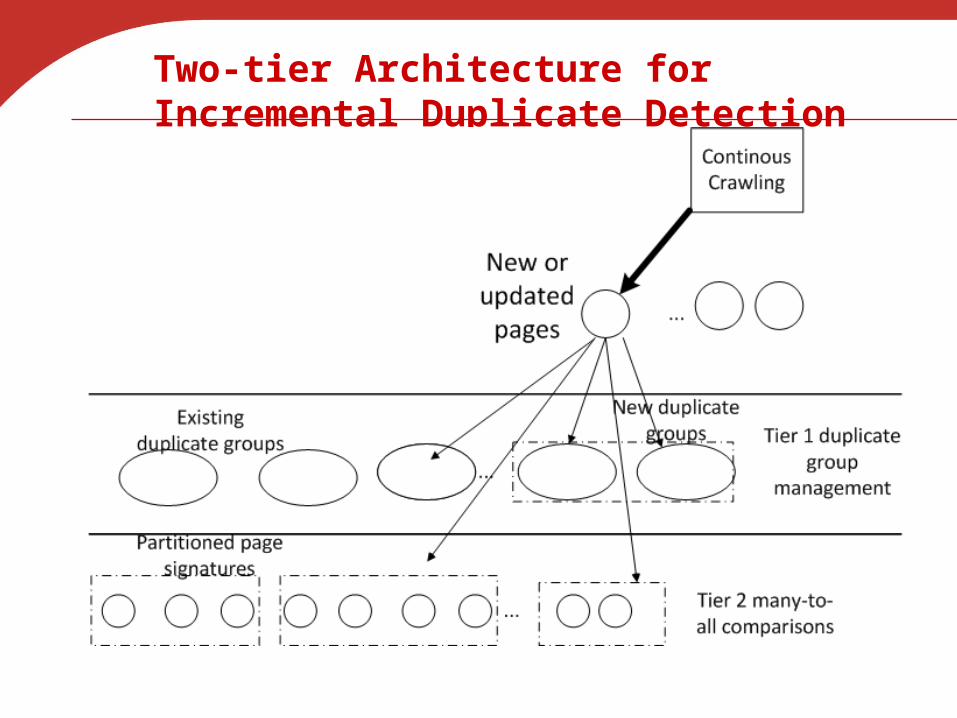
Two-tier Architecture for Incremental Duplicate Detection

Approximation in Incremental Duplicate Group Management
• Example of incremental group merging/splitting
• Approximation Group is unchanged when updated pages are still similar to
group signatures Group splitting does not re-validate all relations
• Error of transitive relation after content update A<->B, B<-> C A<->C A <->C may not be true if content B is updated.
• Error prevention during duplicate filtering: double check similarity threshold between a winner and a
loser

Multi-dimensional page partitioning
• Objective One page is mapped to one unique partition Dissimilar pages are mapped to different partitions. Reduce unnecessary cross-partition comparisons.
• Partitioning based on document length Outperform signature-based mapping for higher
recall rates.• Multi-dimensional mapping
Improve load imbalance caused by skewed length distribution
Pages Pages Pages…

Multi-dimensional page partitioning
Dictionary
Sub-dictionary
Sub-dictionary
A=(600) A=(280,320)
1D length space
2D length space

When does Page A compare with B?
• Page length vector A= (A1, A2) , B=(B1,B2)
• Page A needs to be compared with B only if
• τ is the similarity threshold• ρ is a fixed interval enlarging factor

Implementation and Evaluations
• Implemented in Ask.com offline platform with C++ for processing billions of documents
• Impact on relevancy Continuously monitor top query results. Error rate of false removal is tiny.
• Impact on cost. Compare two approaches
– A: Online dominating. Offline removes 5% duplicates first. Most of duplicates hosted in online tier-2 machines
– B: Offline dominating.
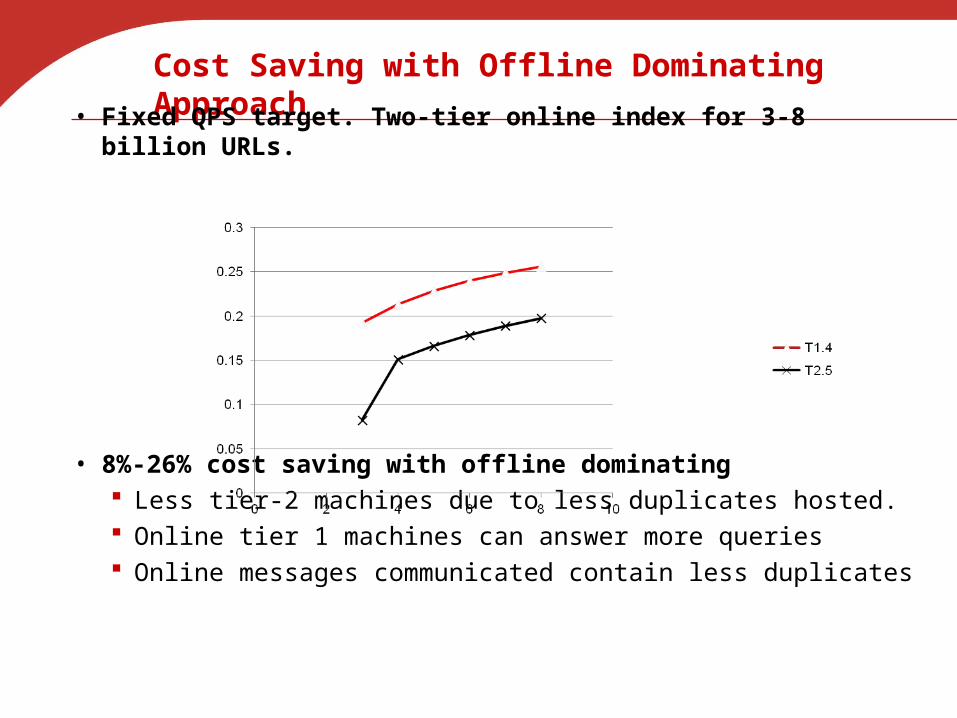
Cost Saving with Offline Dominating Approach
• Fixed QPS target. Two-tier online index for 3-8 billion URLs.
• 8%-26% cost saving with offline dominating Less tier-2 machines due to less duplicates hosted. Online tier 1 machines can answer more queries Online messages communicated contain less duplicates

Reduction of unnecessary inter-machine communiation & comparison
Up to 87% saving when using up to 64 machines

Effectiveness of 3D mapping
• Load balance factor with upto 64 machines
• Speedup of processing throughput

Benefits of incremental computation
• Ratio of non-incremental duplicate detection time over incremental one for a 100 million dataset. Upto 24-fold speedup.
• During a crawling update, 30% of updated pages havesignatures similar to group signatures

Accuracy of distributed clustering and duplicate group management
Relative error in precision compared to a single-machine configuration
Relative error in recall

Conclusion remarks
• Budget-conscious solution with offline dominating redundant removal Up to 26% cost saving.• Approximated incremental scheme for
duplicate clustering with error handling Upto 24-fold speedup Undetected duplicates are handled online.
• 3D mapping still reduces unnecessary comparisons (upto 87%) while balancing load (3+ fold improvement)


















