
Clinical Applications of Speech Technology Phil Green Speech and Hearing Research Group Dept of...
25
Clinical Applications of Speech Technology Phil Green Speech and Hearing Research Group Dept of Computer Science University of Sheffield [email protected]
-
Upload
crystal-harper -
Category
Documents
-
view
213 -
download
0
Transcript of Clinical Applications of Speech Technology Phil Green Speech and Hearing Research Group Dept of...

Clinical Applications of Speech Technology
Phil GreenSpeech and Hearing Research GroupDept of Computer ScienceUniversity of [email protected]

CAST December 2007
Talk Overview• SPandH - Speech and Hearing @ Sheffield• The CAST group• Building Automatic Speech Recognisers –
conventional methodology• ASR for clients with speech disorders• Kinematic Maps• Voice-driven Environmental Control• VIVOCA• Customising Voices• Future Directions

CAST December 2007
SPandH
Phonetics &Linguistics
Hearing & Acoustics
Electrical Engineering &Signal Processing
Speech & Language Therapy
Auditory Scene Analysis
Missing Data Theory
Glimpsing
CAST

Prof Mark HawleySchool of Health and Related ResearchAssistive Technology
Prof Pam EnderbyInstitute of General Practice and Primary CareUniversity of SheffieldSpeech Therapy
Prof Phil GreenProf Roger K MooreSpeech and Hearing Research GroupDepartment of Computer ScienceUniversity of SheffieldSpeech Technology
Dr Stuart CunninghamDepartment of Human Communication SciencesUniversity of SheffieldSpeech Perception, Speech Technology
Contact: [email protected]

CAST December 2007
Conventional Automatic Speech Recogniser Construction
Standard technique uses generative statistical models:
Each speech unit is modeled by an HMM with a number of states.Each state is characterised by a mixture Gaussian distribution over the components of the acoustic vector x.
Parameters of the distributions estimated in training (EM – Baum-Welch)
All this is the acoustic model. There will also be a language model.
Decoding finds model & state sequence most likely to generate X .
Training based on large pre-recorded speaker-independent speech corpus

CAST December 2007
Dysarthria
• Loss of control of speech articulators
• Stroke victims, cerebral palsy, MS..• Effects 170 per 100,000 population• Severe cases unintelligible to
strangers:
• Often accompanied by physical disability
channel
lamp
radio

CAST December 2007
STARDUST: ASR for Dysarthric Speakers
• NHS NEAT Funding• Environmental control• Small vocabulary, isolated words• Speaker-dependent• Sparse training data• Variable training data
CAST December 2007
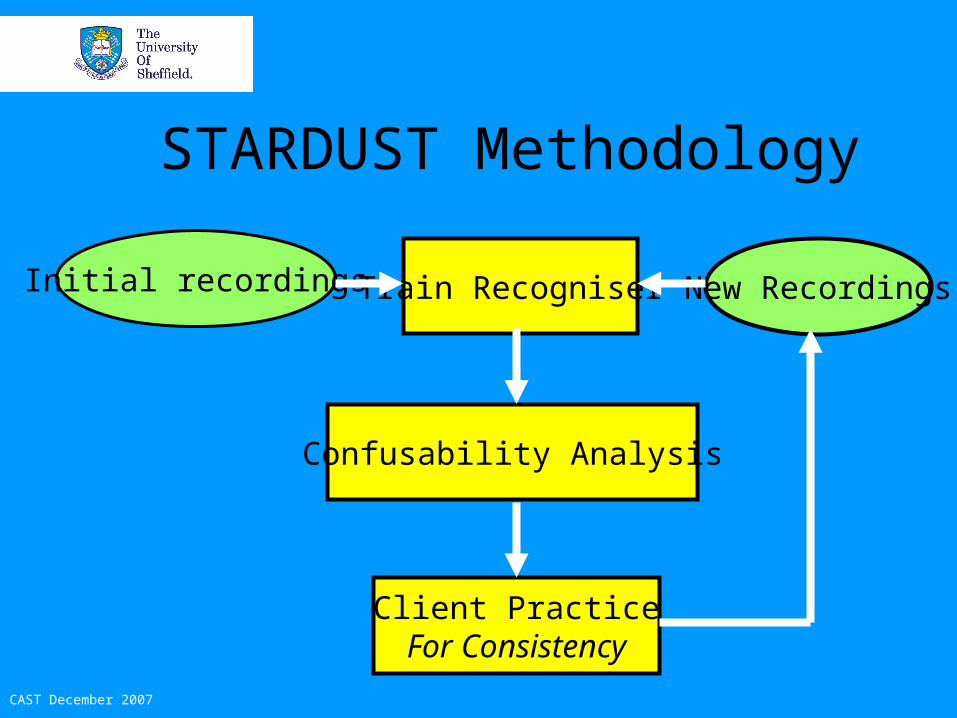
STARDUST Methodology
Initial recordings Train Recogniser
Confusability Analysis
Client PracticeFor Consistency
New Recordings

CAST December 2007
STARDUST training results
Client
Sentence Intelligibility
(%)
Word Intelligibility
(%)
Vocabulary Size
Pre-training
(%)
Post-training
(%)
CC 6 10 11 95.79 100.00
PH 34 22 10 96.22 100.00
GR 0 0 10 82.00 86.00
JT 10 22 13 96.92 99.74
KD - - 13 80.00 90.77
MR - - 11 77.27 95.45
FL - - 11 92.73 96.36
ECS trial: halved the average time to execute a command

CAST December 2007
STARDUST Consistency Training

CAST December 2007
STARDUST Clinical Trial

CAST December 2007
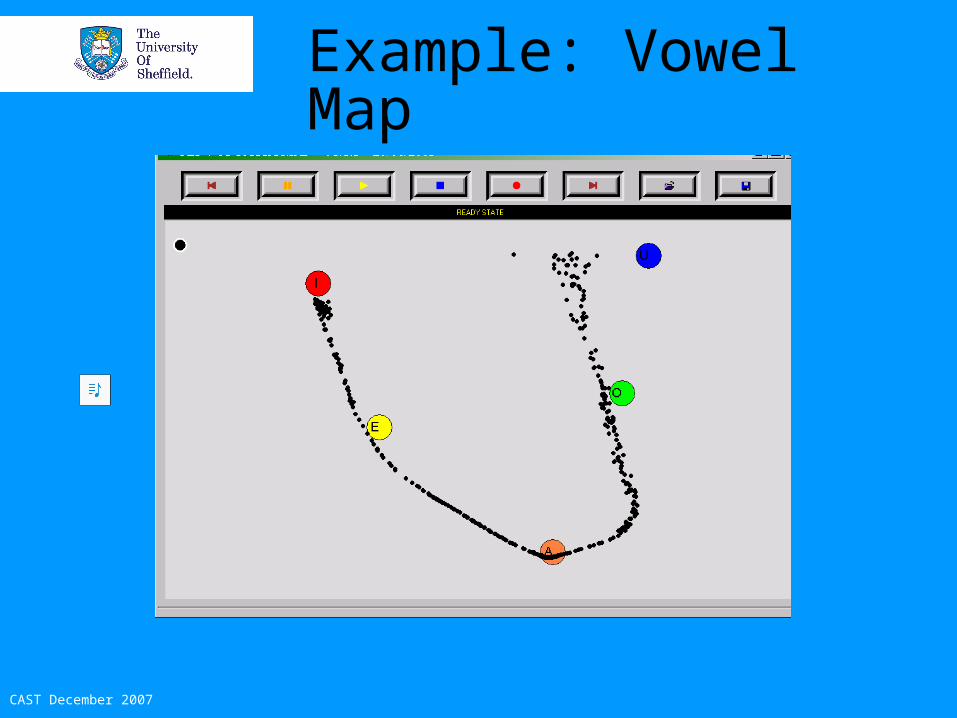
OPTACIA: Kinematic Maps
• Pronunciation Training Aid• EC Funding• Speech acoustics mapped to x,y position in
map window in real time• Mapping by trained Neural Net• Customise for exercises and clients
ANN Mapping
SignalProcessing
sh
s
i
Speech
CAST December 2007
Example: Vowel Map

CAST December 2007
SPECS: Speech-Driven Environmental Control Systems• NHS HTD Funding
• Industrial exploitation
• STARDUST on ‘balloon board’
CAST December 2007
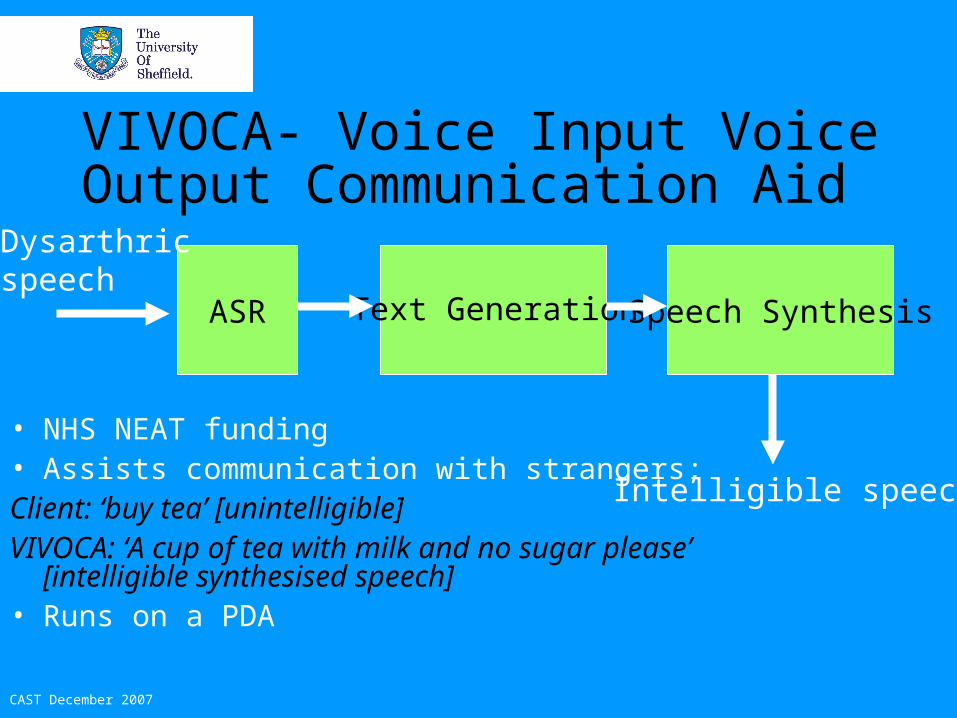
VIVOCA- Voice Input Voice Output Communication Aid
• NHS NEAT funding• Assists communication with strangers;Client: ‘buy tea’ [unintelligible]VIVOCA: ‘A cup of tea with milk and no sugar
please’ [intelligible synthesised speech]• Runs on a PDA
Text GenerationASR
Dysarthricspeech
Speech Synthesis
Intelligible speech

CAST December 2007
Voices for VIVOCA
• It is possible to build voices from training data
• A local voice is preferable
• Yorkshire voices:• Ian MacMillan • Christa Ackroyd

CAST December 2007
Concatenative synthesis
Input data
Text inputSynthesised speech
Speech recordings
Unitsegmentation
Unit database
Unitselection
Concatenation+ smoothing
i a
sh
Festvox: http://festvox.org/
+… + + …

CAST December 2007
Concatenative synthesis
High qualityNatural soundingSounds like original speakerNeed a lot of data (~600 sentences)Can be inconsistentDifficult to manipulate prosody

CAST December 2007
HMM synthesis
y e s
yes

CAST December 2007
HMM synthesis: adaptation
Input data
Text input
Average speaker model
Synthesisedspeech
Speech recordings
Training
Synthesis
e
t
HTS http://hts.sp.nitech.ac.jp/
Adapted speaker model
Adaptation
e
t
Speechrecordings
100
200

CAST December 2007
HMM synthesis
ConsistentIntelligibleEasier to manipulate prosodyNeeds relatively little input for
adaptation data (>5 sentences)Less natural than concatenative

CAST December 2007
Personalisation for individuals with progressive speech disorders • Voice banking
• Before deterioration
• Capturing the essence of a voice• During deterioration

CAST December 2007
HMM synthesis: adaptation for dysarthric speech
Input data
Text input
Average speaker model
Synthesisedspeech
Speech recordings
Training
Synthesis
e
t
HTS http://hts.sp.nitech.ac.jp/
Adapted speaker model
Adaptation
e
t
Speechrecordings
Duration, phonation and energy information

CAST December 2007
Future directions
• Personal Adaptive Listeners (PALS)
• ‘Home Service’
• Companions

CAST December 2007
The PALS ConceptA PAL is a portable (PDA, wearable..) device which you
ownYour PAL is like your valet• It knows a lot about you..
• The way you speak, the words you like to use• Your interests, contacts, networks
• You talk with it • The knowledge makes conversational dialogues viable
• It does things for you• Bookings, appointments, reminders• Communication• Access to services..
• It learns to do a better job• By explicit training (this is how I refer to things, these are the
names I use..) USER-AS-TEACHER• By Automatic Adaptation: acoustic models, language models,
dialogue models


















