
Click to edit Master title style Batch RL Approximate...
33
2/18/15 1 Click to edit Master title style Click to edit Master subtitle style 2/18/15 1 Approximate Models for Batch RL Emma Brunskill
Transcript of Click to edit Master title style Batch RL Approximate...

2/18/15 1
Click to edit Master title style
Click to edit Master subtitle style
2/18/15 1
Approximate Models for Batch RL
Emma Brunskill
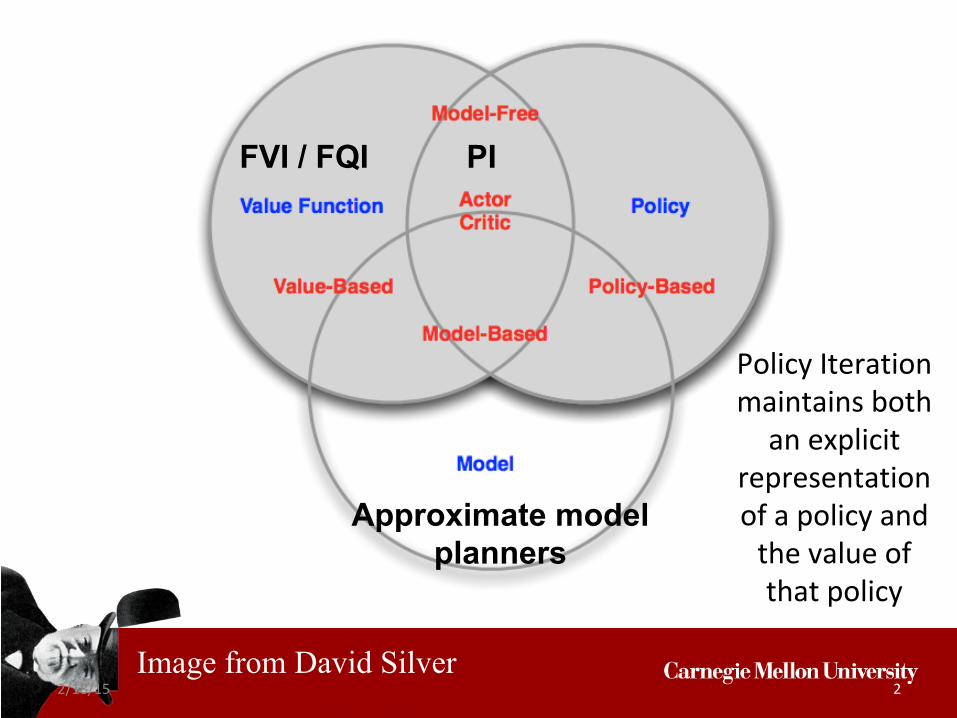
2/18/15 2
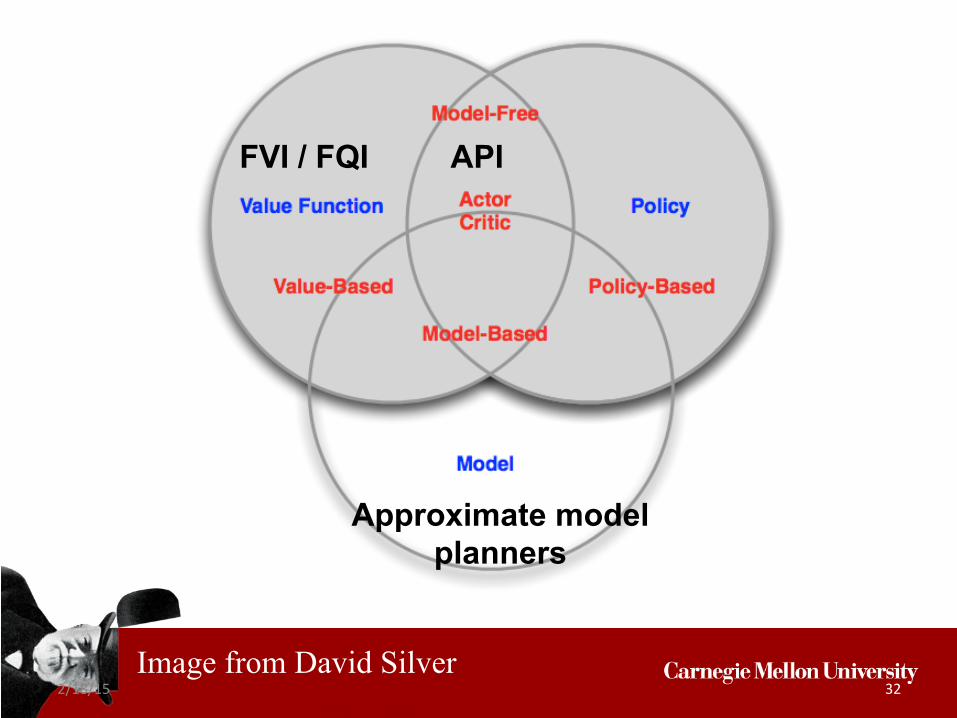
Image from David Silver
FVI / FQI
Policy Iteration maintains both
an explicit representation of a policy and
the value of that policy
PI
Approximate model planners
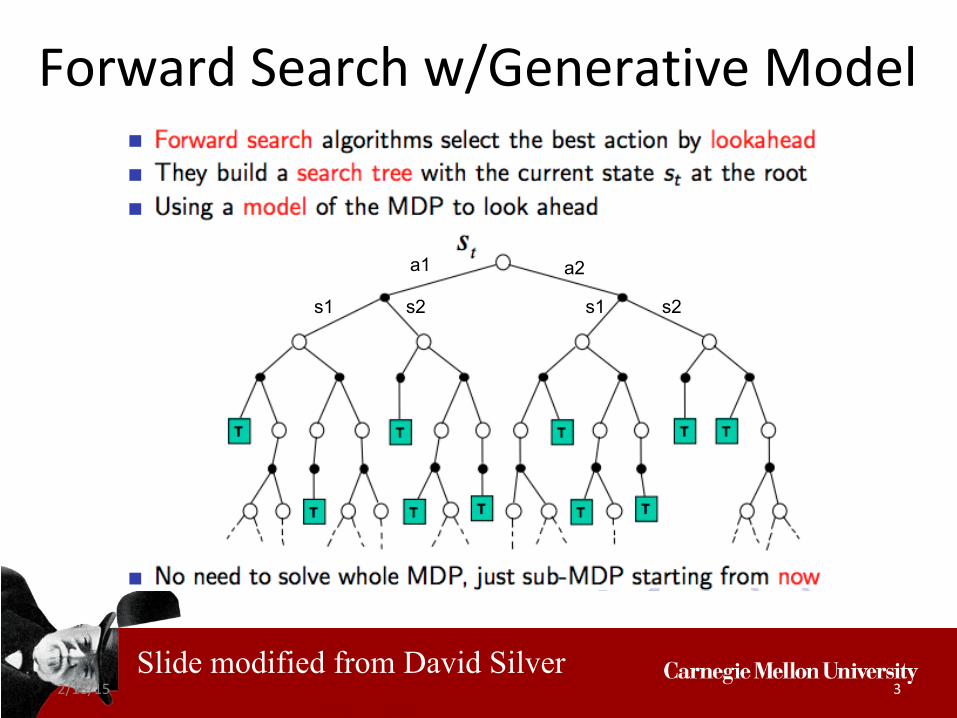
2/18/15 3
Forward Search w/Generative Model
Slide modified from David Silver
a2 a1
s1 s2 s1 s2
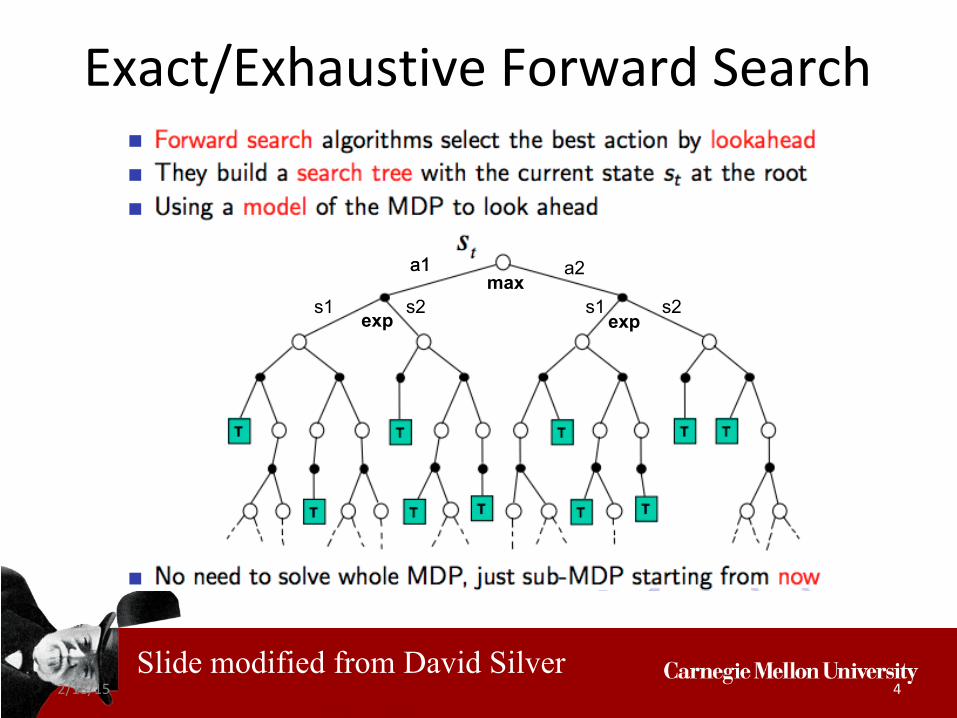
2/18/15 4
Exact/Exhaustive Forward Search
Slide modified from David Silver
a2 a1
s1 s2 s1 s2max
a1
expexp
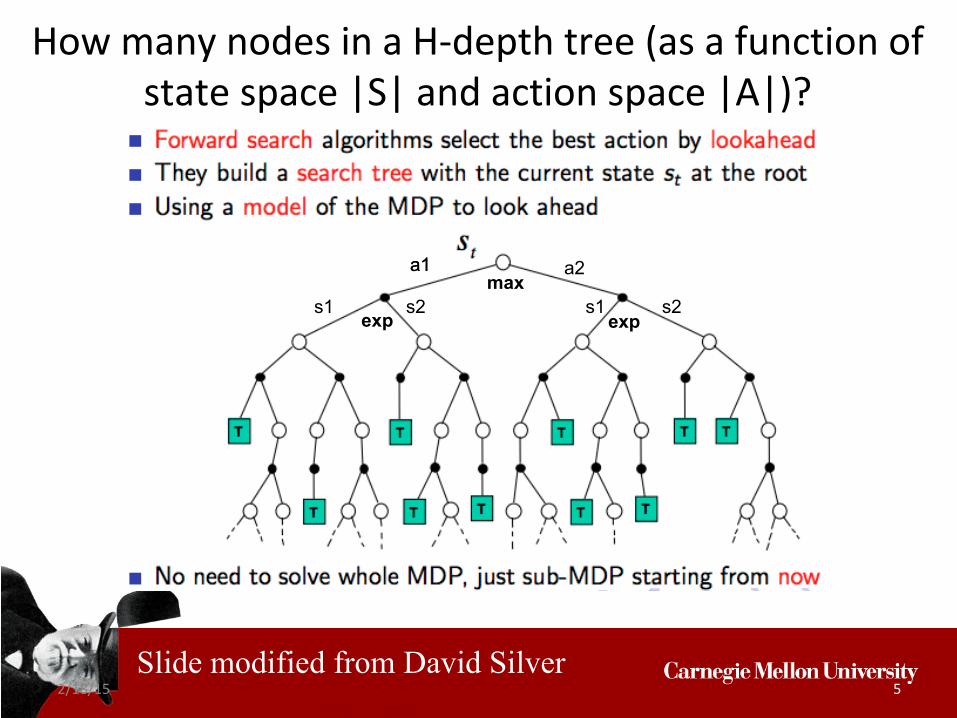
2/18/15 5
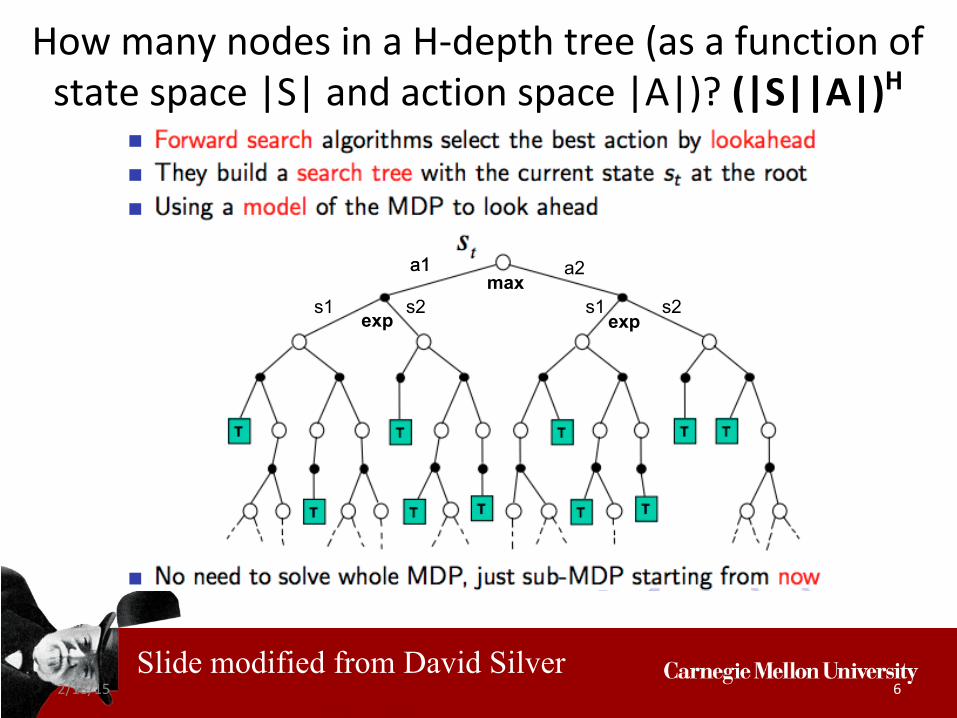
How many nodes in a H-depth tree (as a function of state space |S| and action space |A|)?
Slide modified from David Silver
a2 a1
s1 s2 s1 s2max
a1
expexp
2/18/15 6
How many nodes in a H-depth tree (as a function of state space |S| and action space |A|)? (|S||A|)H
Slide modified from David Silver
a2 a1
s1 s2 s1 s2max
a1
expexp

2/18/15 7
Sparse Sampling: Don’t Enumerate All Next States, Instead Sample Next States s’ ~ P(s’|s,a)
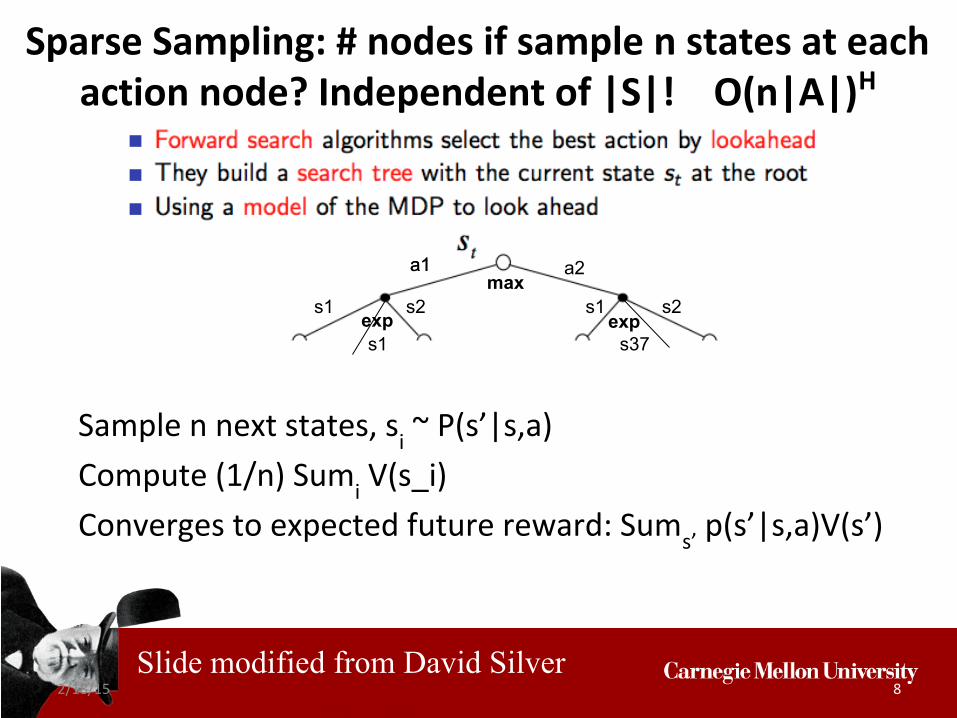
Sample n next states, si ~ P(s’|s,a)
Compute (1/n) Sumi V(s_i)
Converges to expected future reward: Sums’ p(s’|s,a)V(s’)
Slide modified from David Silver
a2 a1
s1 s2 s1 s2max
a1
expexp s1 s37
2/18/15 8
Sparse Sampling: # nodes if sample n states at each action node? Independent of |S|! O(n|A|)H
Sample n next states, si ~ P(s’|s,a)
Compute (1/n) Sumi V(s_i)
Converges to expected future reward: Sums’ p(s’|s,a)V(s’)
Slide modified from David Silver
a2 a1
s1 s2 s1 s2max
a1
expexp s1 s37

2/18/15 9
Sparse Sampling: # nodes if sample n states at each action node? Independent of |S|! O(n|A|)H
Upside: Can choose n to achieve bounds on the accuracy of the value function at the root state, independent of state space size
Downside: Still exponential in horizon, n still large for good bounds
Slide modified from David Silver
a2 a1
s1 s2 s1 s2max
a1
expexp s1 s37

2/18/15 10
Limitation of Sparse Sampling
Slide modified from Alan Fern

2/18/15 11
Monte Carlo Tree Search
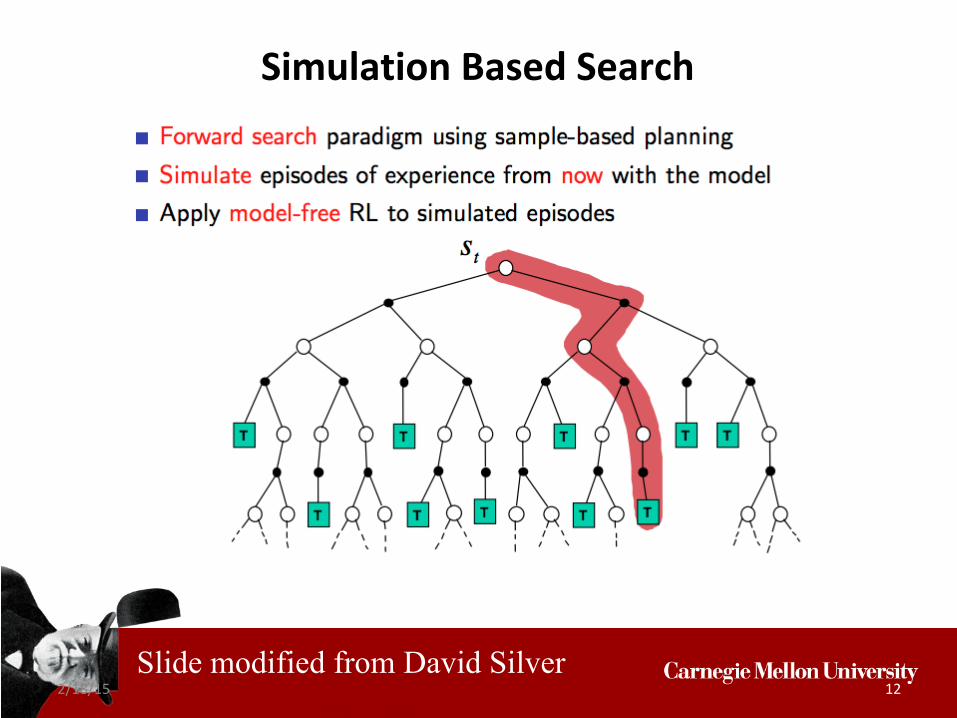
Combine ideas of sparse sampling with an adaptive method for focusing on more promising parts of the ree
Here “more promising” means the actions that are seem likely to yield higher long term reward
Uses the idea of simulation search
2/18/15 12
Simulation Based Search
Slide modified from David Silver

2/18/15 13
Simulation based Search
Slide modified from David Silver

2/18/15 14
Simple Monte Carlo Search
Slide modified from David Silver
rollout policy dafa
greedy improvement with respect to fixed rollout policy

2/18/15 15
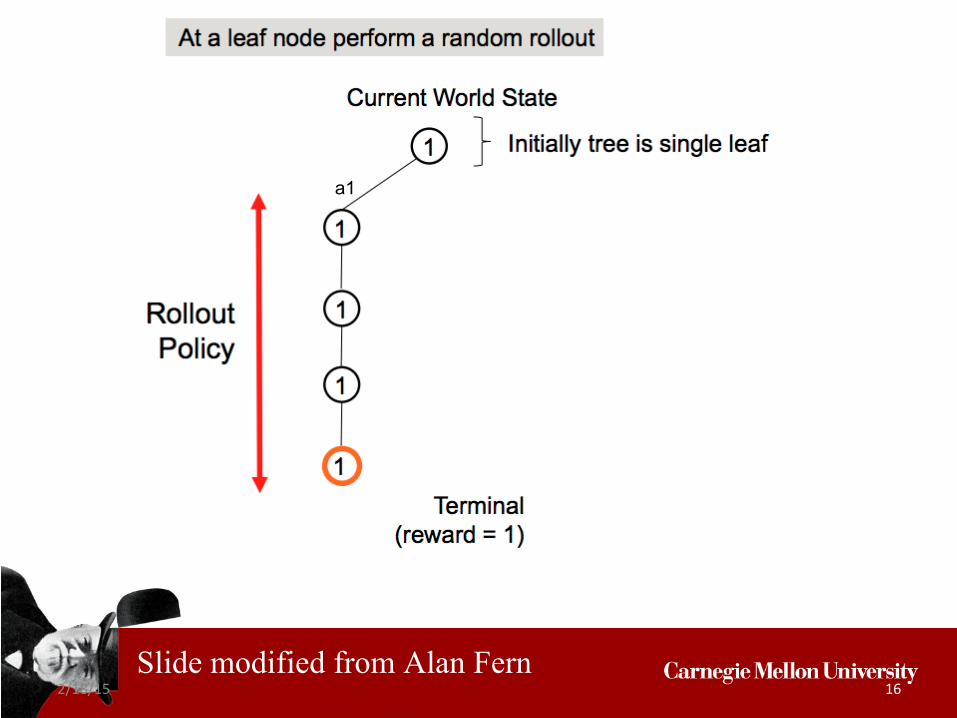
Upper Confidence Tree (UCT)[Kocsis & Szepesvari, 2006]
Slide modified from Alan Fern
• Combine forward search and simulation search• Instance of Monte-Carlo Tree Search
• Repeated Monte Carlo simulation of rollout policy• Rollouts add one or more nodes to search tree
• UCT• Uses optimism under uncertainty idea• Some nice theoretical properties
• Much better realtime performance than sparse sampling
2/18/15 16
a1
Slide modified from Alan Fern
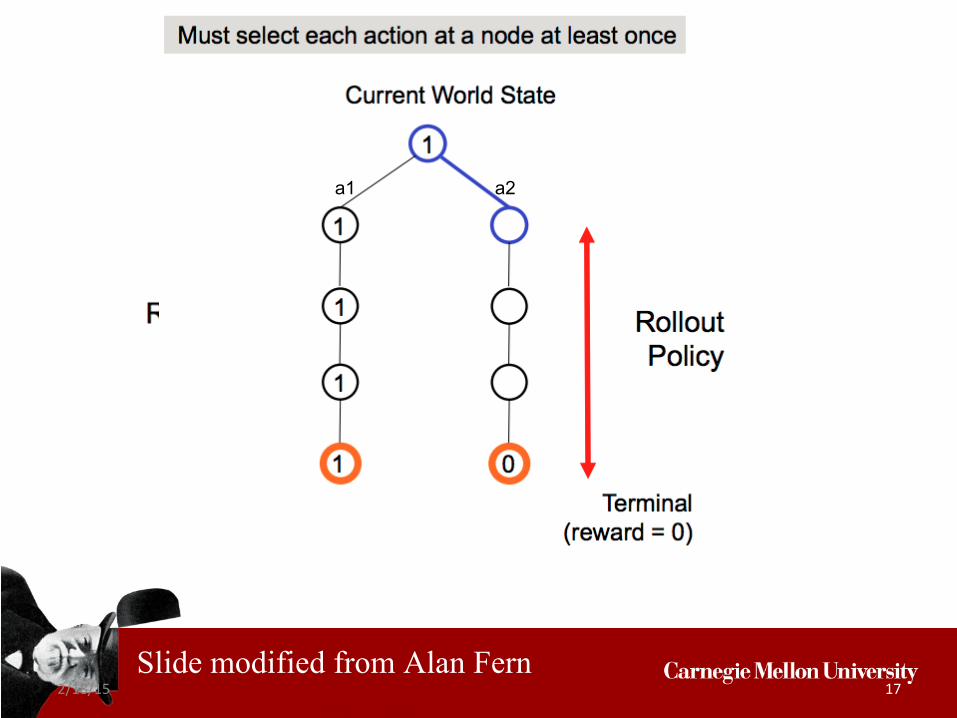
2/18/15 17
a1 a2
Slide modified from Alan Fern
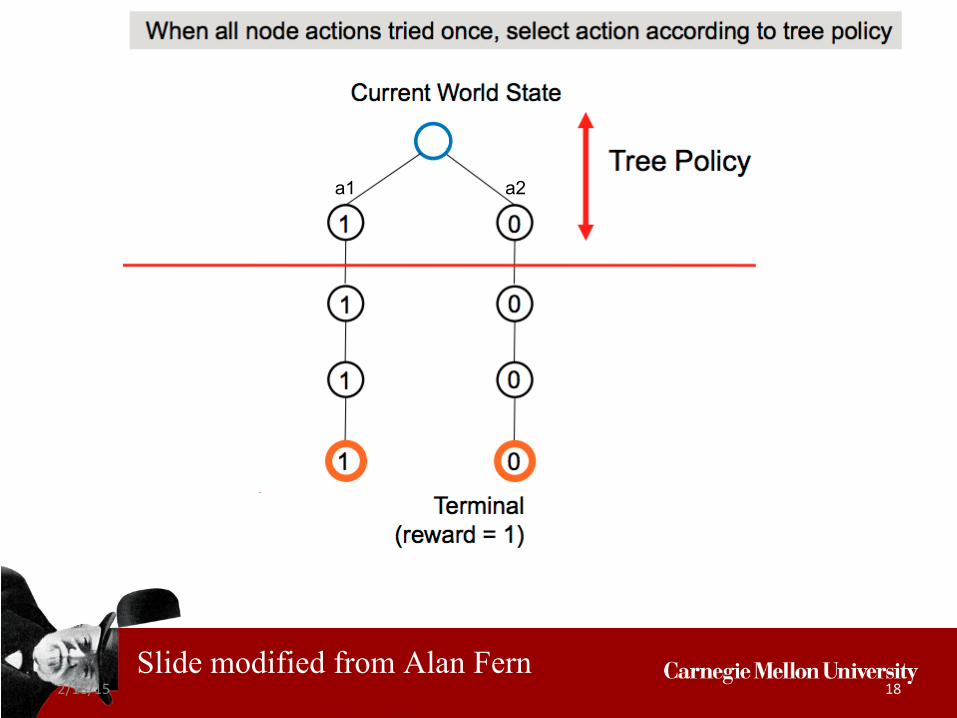
2/18/15 18
a1 a2
Slide modified from Alan Fern
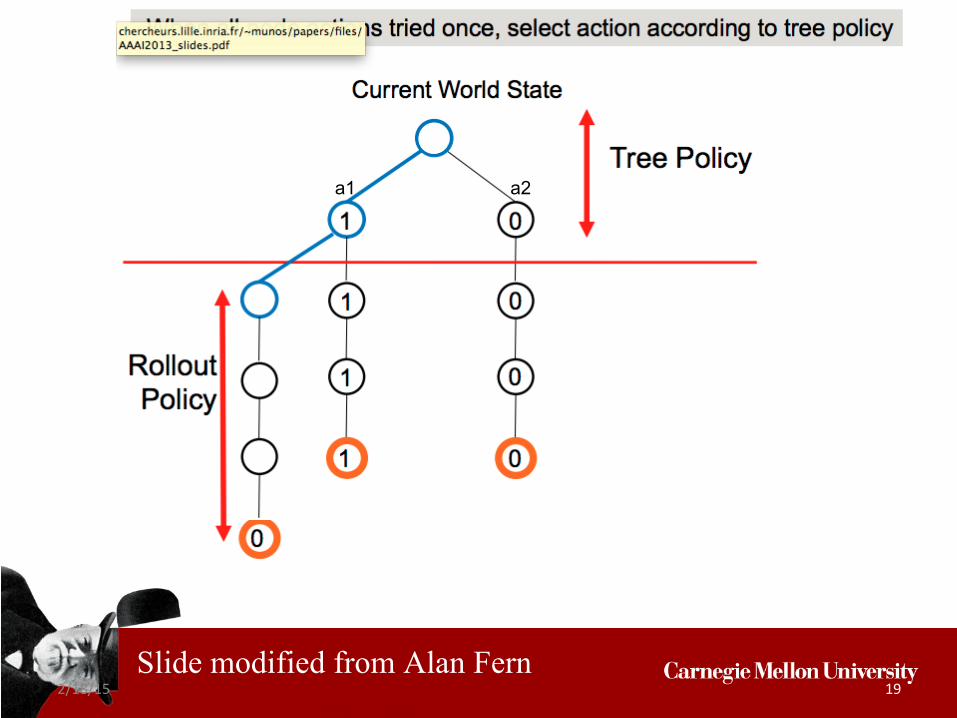
2/18/15 19
a1 a2
Slide modified from Alan Fern
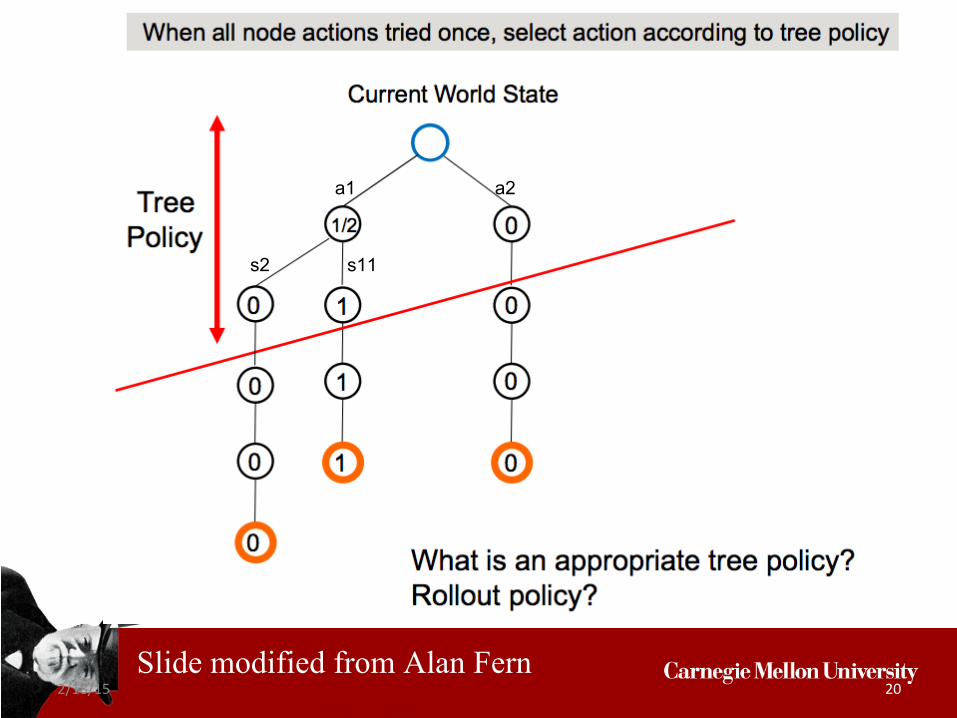
2/18/15 20
a1 a2
s2 s11
Slide modified from Alan Fern

2/18/15 21
Slide modified from Alan Fern
(Upper Confidence Bound)
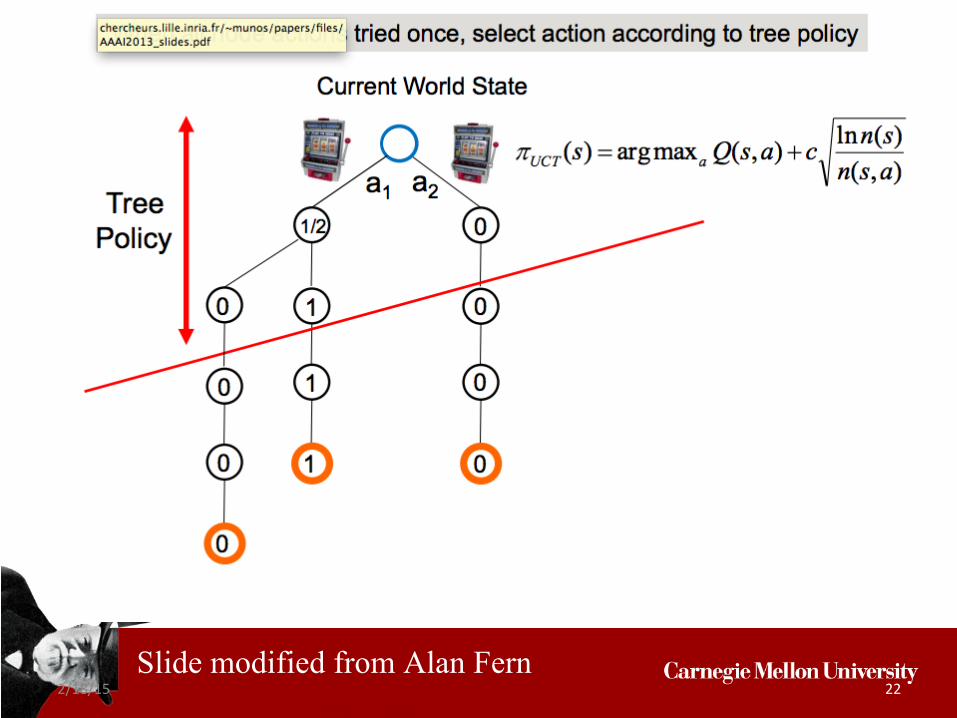
2/18/15 22
Slide modified from Alan Fern
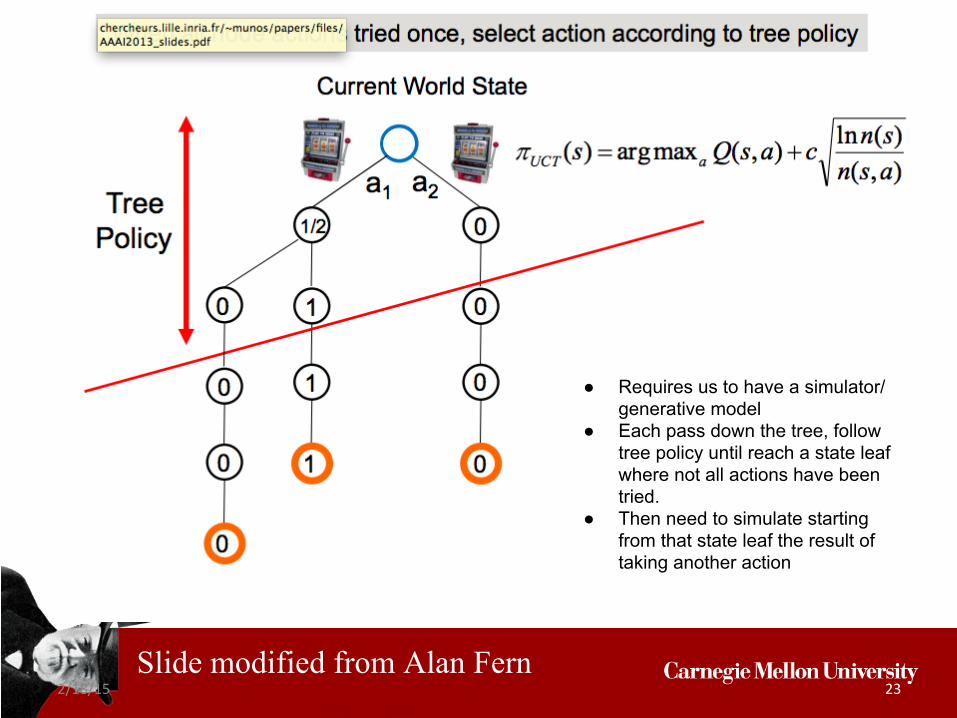
2/18/15 23
Slide modified from Alan Fern
● Requires us to have a simulator/ generative model
● Each pass down the tree, follow tree policy until reach a state leaf where not all actions have been tried.
● Then need to simulate starting from that state leaf the result of taking another action

2/18/15 24
Guarantees on UCT
Slide modified from Remi Munos

2/18/15 25
Slide modified from slides from Alan Fern & David Silver
Computer GoPrevious game tree approaches faired poorly

2/18/15 26
Rules of Go
Slide modified from David Silver

2/18/15 27
Position Evaluation in Go
Slide modified from David Silver
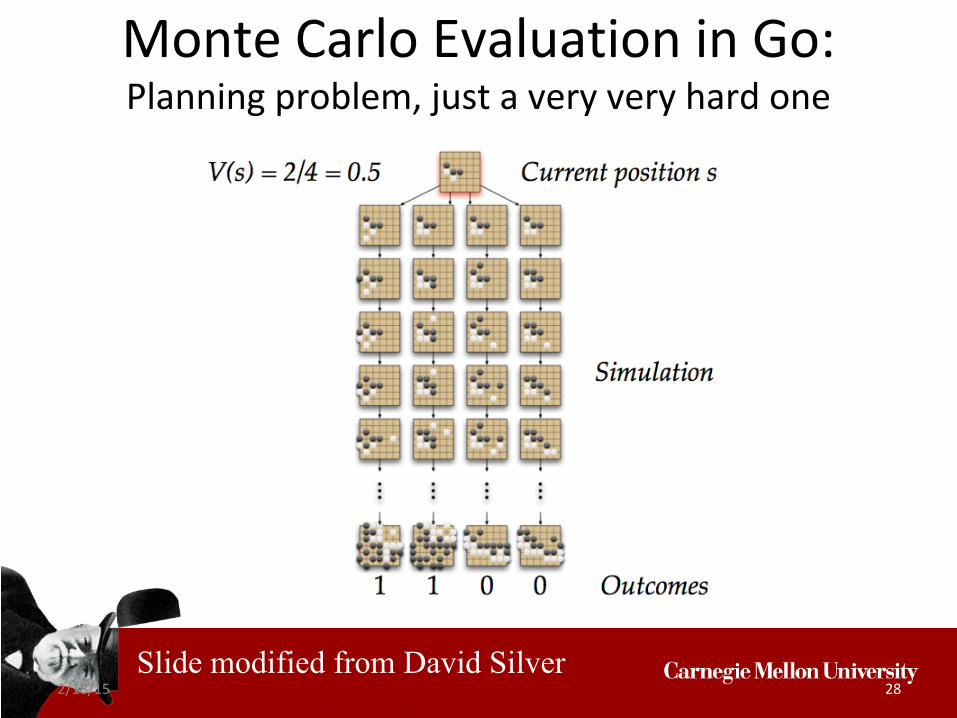
2/18/15 28
Monte Carlo Evaluation in Go:Planning problem, just a very very hard one
Slide modified from David Silver
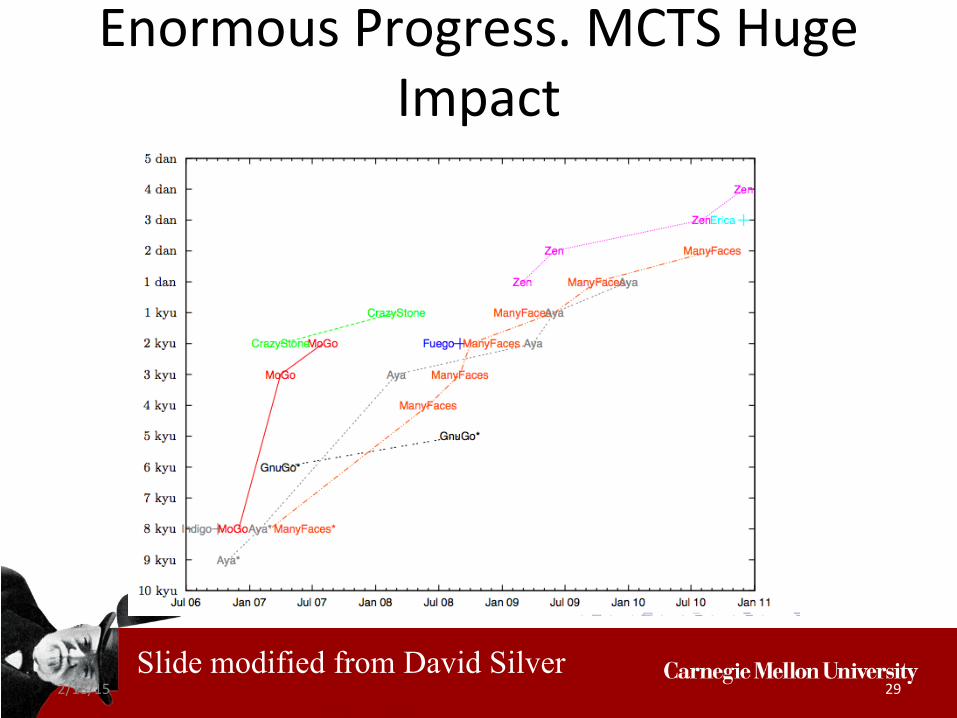
2/18/15 29
Enormous Progress. MCTS Huge Impact
Slide modified from David Silver

2/18/15 30
Going Back to Batch RL...
• Use supervised learning method to compute model
• Use learned model with MCTS planning• Note: error in model will impact error in
estimated values!
• Computes an action for current state, take action, then redo planning for next state

2/18/15 31
Autonomous Driving using Texplore (Hester and Stone 2013)
2/18/15 32
Image from David Silver
FVI / FQI API
Approximate model planners

2/18/15 33


















