
Christian Steinle, University of Heidelberg, Institute of Computer Engineering1 L1 Hough Tracking on...
18
Christian Steinle, University of Heidelberg, Institute of Comp uter Engineering 1 L1 Hough Tracking on a Sony Playstation III Christian Steinle, Andreas Kugel, Reinhard Männer Computer Engineering, University of Heidelberg • Contents – Motivation for the Playstation implementation – Algorithm adaption – Job restrictions – Algorithm implementation – Status
-
Upload
solomon-york -
Category
Documents
-
view
215 -
download
1
Transcript of Christian Steinle, University of Heidelberg, Institute of Computer Engineering1 L1 Hough Tracking on...

Christian Steinle, University of Heidelberg, Institute of Computer Engineering
1
L1 Hough Tracking on a Sony Playstation III
Christian Steinle, Andreas Kugel, Reinhard MännerComputer Engineering, University of Heidelberg
• Contents
– Motivation for the Playstation implementation– Algorithm adaption– Job restrictions– Algorithm implementation– Status

Christian Steinle, University of Heidelberg, Institute of Computer Engineering
2
• Hough Space: 1 dimension for 1 parameter of a track– bending 1/Pz, angle (Px/Pz) and Py/Pz)– Hough Space dimensions: 95 x 31 (cells) x 191 (layers)
– Detector slice with constant angle corresponds to one 2D Hough histogram
– Detector slices are overlapping (multiple scattering)
Z
X
Y
Py/Pz
Px/P z
1 /Pz
Motivation for the Playstation implementation

Christian Steinle, University of Heidelberg, Institute of Computer Engineering
3
Motivation for the Playstation implementation
• L1 Hough Tracking algorithm development in HDL for FPGA HDL descriptions for all critical functional units
• Synthesis result of a single histogram layer implemented with registers shows the requirement of about 30.000 logic cells
50% of FPGA (XC4VLX60: 59,904) registers used for layer
• Conclusion: Develop a multi-chip solution

Christian Steinle, University of Heidelberg, Institute of Computer Engineering
4
Motivation for the Playstation implementation
• Conclusion: Use the CellBE of a Sony Playstation III as cheap and
flexible rapid prototyping system
Multi-chip algorithm Multi-core platform

Christian Steinle, University of Heidelberg, Institute of Computer Engineering
5
Algorithm adaption
• Conclusion: Two parallelism levels:
multiple processors work on input hit data in parallel vector capable ALUs process multiple layers in parallel
Creation of input data packages as so-called jobs

Christian Steinle, University of Heidelberg, Institute of Computer Engineering
6
Job restrictions
1. Balance workload for the processors
• Number of histogram layers: 191• Number of processors for a Sony Playstation III: 6
– Cell BE: 8 but 1 disabled and 1 reserved for OS
yersForJobnumberOfLa32:n1Restrictio

Christian Steinle, University of Heidelberg, Institute of Computer Engineering
7
Job restrictions
2. Optimal use of the processor‘s vector capable ALU
• Each histogram cell contains a 5 bit signature (1bit/detector)
• The vector capable ALU is 128 bit 128 bit / 5 bit / signature = 25 signatures in parallel
• Speed gain by using an implicite type instead of bit manipulation
unsigned char (8 bit) is ALU and memory applicable Each histogram cell contains actually 3 unused bits 128 bit / 8 bit / signature = 16 signatures in parallel
• Random access requires the composing of the processing ALU vector with 16 elements from the memory

Christian Steinle, University of Heidelberg, Institute of Computer Engineering
8
Job restrictions
• Hough transformed Hit contains γmin and γmax
Hit is inserted into γmax - γmin + 1 consecutive layers
• Speed gain by optimizing the histogram memory structure while using the consecutive histogram layer entries for a single hit
Direct memory access on up to 16 consecutive layers in parallel
Each hit in a job is systolically processed just once in parallel A single hit can contribute to more than one job (γmax - γmin >
16, γmax of hit > γmax of actual job) yersForJobnumberOfLa16:n2Restrictio

Christian Steinle, University of Heidelberg, Institute of Computer Engineering
9
Job restrictions
3. Optimal use of the processor‘s local storage
• Local storage contains program code, static data, heap and stack
• Conclusion: Used memory for job = codingTable + histogram + input data Available memory = stackPointer – heapPointer -
securityRegion ForJobusedMemoryemoryavailableM:n3Restrictio

Christian Steinle, University of Heidelberg, Institute of Computer Engineering
10
Algorithm implementation
• Configuration part on the PPU

Christian Steinle, University of Heidelberg, Institute of Computer Engineering
11
Algorithm implementation
• Configuration part on the SPU

Christian Steinle, University of Heidelberg, Institute of Computer Engineering
12
Algorithm implementation
• Different versions of the job creation are possible
– CODEVERSION 1:• Create all jobs with a loop over all hits before the SPU processing
– CODEVERSION 2:• Create all jobs with a loop over all jobs before the SPU processing
– CODEVERSION 3:• Create the jobs parallely pipelined with the SPU processing
– CODEVERSION 4:• Create the jobs for dedicated SPUs when they are ready

Christian Steinle, University of Heidelberg, Institute of Computer Engineering
13
Algorithm implementation
• Processing part one on the PPU

Christian Steinle, University of Heidelberg, Institute of Computer Engineering
14
Algorithm implementation
• Processing part two on the PPU

Christian Steinle, University of Heidelberg, Institute of Computer Engineering
15
Algorithm implementation
• Processing part three on the PPU

Christian Steinle, University of Heidelberg, Institute of Computer Engineering
16
Algorithm implementation
• Different versions of the histogram memory usage
– MEMORYVERSION 1:• Use vector type for memory and computation
– MEMORYVERSION 2:• Use smallest type for a single histogram cell in the memory and
build vector type for computation
– MEMORYVERSION 3:• Use smallest type for histogram cells in parallel layers and build
vector type for computation
Christian Steinle, University of Heidelberg, Institute of Computer Engineering
17
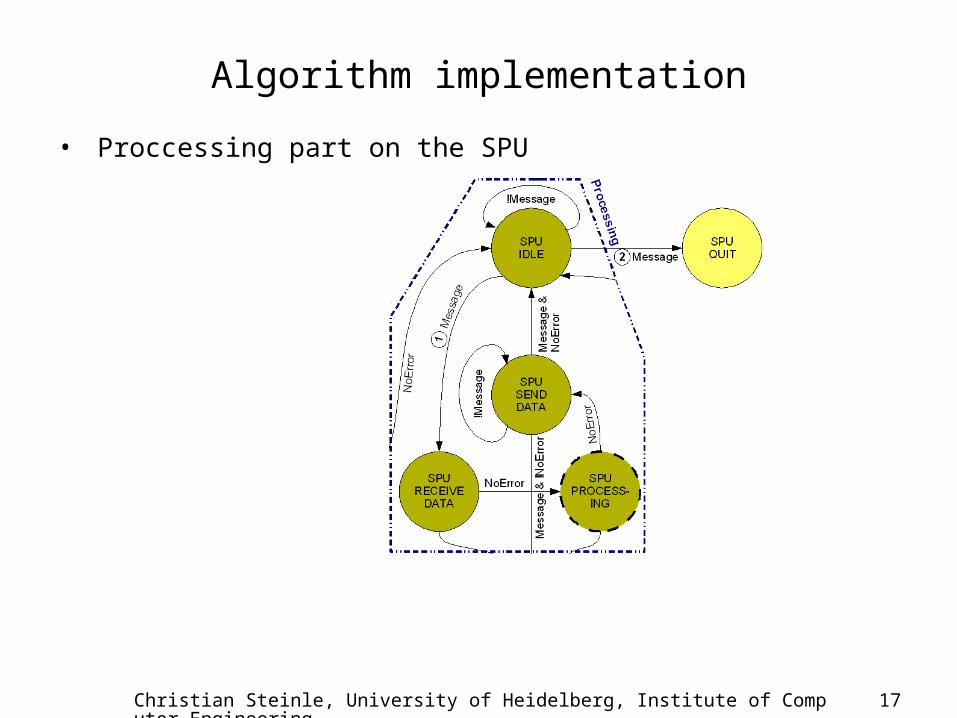
Algorithm implementation
• Proccessing part on the SPU

Christian Steinle, University of Heidelberg, Institute of Computer Engineering
18
Status
• Algorithm adaption is implemented
• Hough processing has to be implemented:– Actual step in scalar version: peakfinding2D– Missing steps in scalar version: peakfinding3D– Actual step in vector version: diagonalization– Missing steps in vector version: peakfinding2D, peakfinding3D
• Measure the timing
• Compare the timing with– the timing of the C++ framework implementation– the estimated timing of the FGPA implementation

















