
chp%3A10.1007%2F978-3-642-28145-7_11
10
Toward Techniques for Auto-tuning GPU Algorithms Andrew Davidson and John Owens University of California, Davis Abstract. We introduce a variety of techniques toward autotuning data- parallel algorithms on the GPU. Our techniques tune these algorithms in- dependent of hardware architecture, and attempt to select near-optimum parameters. We work towards a general framework for creating auto- tuned data-parallel algorithms, using these techniques for common al- gorithms with varying characteristics. Our contributions include tuning a set of algorithms with a variety of computational patterns, with the goal in mind of building a general framework from these results. Our tuning strategy focuses first on identifying the computational patterns an algorithm shows, and then reducing our tuning model based on these observed patterns. Keywords: GPU Computing, Auto-Tuning Algorithms, Data-Parallel Programming, CUDA. 1 Introduction Given the complexity of emerging heterogeneous systems where small parameter changes lead to large variations in performance, hand-tuning algorithms have be- come impractical, and auto-tuning algorithms have gained popularity in recent years. When tuned, these algorithms select near-optimum parameters for any machine. We demonstrate a number of techniques which successfully auto-tune parameters for a variety of GPU algorithms. These algorithms are commonly used, were not synthetically created and were chosen to rely on different param- eters and be performance bound in different ways. Both work by Liu et al. [4] and Kerr et al. [2] use adaptive database methods for deriving relationships between input sets and their direct influence on the parameter space. Work by Li et al. [3] focuses on tuning one GEMM algorithm, while work by Ryoo et al. [5] mainly deals with kernel and compiler level opti- mizations for one machine (an 8800GTX). Our work differs from these in that we first try to identify computational patterns between algorithms and then tune their parameters using a number of different techniques. Rather than use a single database method for all of our algorithms, which might be susceptible to non-linear relations, we try to identify relationships be- tween each algorithm, possible input sets on any given machine; we then choose a tuning strategy accordingly. Since we now have these relationships, we can heav- ily prune the parameter search space before attempting to tune the algorithm, K. J´ onasson (Ed.): PARA 2010, Part II, LNCS 7134, pp. 110–119, 2012. c Springer-Verlag Berlin Heidelberg 2012
description
paper
Transcript of chp%3A10.1007%2F978-3-642-28145-7_11

Toward Techniques
for Auto-tuning GPU Algorithms
Andrew Davidson and John Owens
University of California, Davis
Abstract. We introduce a variety of techniques toward autotuning data-parallel algorithms on the GPU. Our techniques tune these algorithms in-dependent of hardware architecture, and attempt to select near-optimumparameters. We work towards a general framework for creating auto-tuned data-parallel algorithms, using these techniques for common al-gorithms with varying characteristics. Our contributions include tuninga set of algorithms with a variety of computational patterns, with thegoal in mind of building a general framework from these results. Ourtuning strategy focuses first on identifying the computational patternsan algorithm shows, and then reducing our tuning model based on theseobserved patterns.
Keywords: GPU Computing, Auto-Tuning Algorithms, Data-ParallelProgramming, CUDA.
1 Introduction
Given the complexity of emerging heterogeneous systems where small parameterchanges lead to large variations in performance, hand-tuning algorithms have be-come impractical, and auto-tuning algorithms have gained popularity in recentyears. When tuned, these algorithms select near-optimum parameters for anymachine. We demonstrate a number of techniques which successfully auto-tuneparameters for a variety of GPU algorithms. These algorithms are commonlyused, were not synthetically created and were chosen to rely on different param-eters and be performance bound in different ways.
Both work by Liu et al. [4] and Kerr et al. [2] use adaptive database methodsfor deriving relationships between input sets and their direct influence on theparameter space. Work by Li et al. [3] focuses on tuning one GEMM algorithm,while work by Ryoo et al. [5] mainly deals with kernel and compiler level opti-mizations for one machine (an 8800GTX). Our work differs from these in that wefirst try to identify computational patterns between algorithms and then tunetheir parameters using a number of different techniques.
Rather than use a single database method for all of our algorithms, whichmight be susceptible to non-linear relations, we try to identify relationships be-tween each algorithm, possible input sets on any given machine; we then choose atuning strategy accordingly. Since we now have these relationships, we can heav-ily prune the parameter search space before attempting to tune the algorithm,
K. Jonasson (Ed.): PARA 2010, Part II, LNCS 7134, pp. 110–119, 2012.c© Springer-Verlag Berlin Heidelberg 2012

Toward Techniques for Auto-tuning GPU Algorithms 111
resulting in very fast tuning runs. For our set of algorithms, we show a quicktuning run (less than a few minutes for most machines) can generate the neededinformation to automatically choose near-optimum parameters for future runs.We will next discuss the general strategy (or philosophy) we used for developingeach of our auto-tuned algorithms.
2 Algorithms
Algorithms designed in a data-parallel fashion are concerned with maintainingthe highest throughput possible. This means parameters are often dependent notonly on the machine, but also upon the workload being operated on. With thisin mind, when attempting to auto-tune an algorithm we approach the problemusing this philosophy:
– Identify the tunable parameters for the algorithm.– Look for a relationship between the input space, and the parameter space.– If such a relationship exists, we must build a model from the input space to
parameter space, or model the parameter space solely on machine charac-teristics.
Therefore when considering the input parameters for each algorithm we iden-tify two axes of tuning, workload specific and machine specific. The relationshipbetween these two may vary widely between algorithms, but we concentrate onidentifying common patterns between certain algorithms that can be used as astarting point for general tuning. As an example, in our N-Body algorithm wediscovered a heavy dependence between our input parameters and the workload(input space). Yet for our reduction kernel, once the workload reaches a criticalsize, our tuning parameters rely solely on machine specific parameters. There-fore using micro-benchmarks we developed a model that estimates the correctparameters. Sections 2.2 covers this strategy in more depth. Next we will in-troduce our auto-tuning test suite, and the approaches we took to quickly tuneeach algorithm.
2.1 Test Suite
We studied four parallel algorithms extensively in our work. Reduction, a com-mon parallel primitive which operates on a large set of values and reduces thatset to one value. Next, scalar product, which sums up the products betweentwo vectors. An N-Body algorithm which simulates the gravitational interac-tions between a set of objects. Finally, SGEMM, a fast matrix multiply. For thereduction, scalar product and N-Body algorithms we used the kernels found inthe NVIDIA SDK as our base algorithms. These algorithms have already beenhighly optimized, and are considered standards for benchmarking. Since manyof these algorithms have been hand-tuned for certain machines, we may receiveonly a marginal performance boost for certain devices and workloads. In par-ticular, the NVIDIA SDK has changed a number of default parameters to obtain

112 A. Davidson and J. Owens
optimal performance on GT200 series cards. As a result, performance sufferson older cards which highlights the importance of auto-tuning algorithms whichscale with architecture changes. For our SGEMM algorithm we used Chien’shighly tuned and optimized kernel [1] which demonstrates higher performancethan that released by NVIDIA’s SGEMM. In our final auto-tuned algorithm wewish to trim as much of the parameter search space as possible, while maintainingan accurate model to select parameters.
Auto-tuning algorithms that use standard techniques such as model driveninputs, with interpolation between points, may result in sub-optimal parameters(one method does not fit all). This is where the major challenge lies, as greatcare must be taken to ensure your auto-tuning strategy is not susceptible tounpredictable non-linear effects.
2.2 Reduction
We made a few minor improvements to NVIDIA’s SDK reduction kernel code.We chose this algorithm as it is obviously memory bound and each item can beaccessed in any order (coalesced reads would obviously be preferred). Thereforetuning reduction would give insight into many other common parallel algorithms,such as scan and sort, which have similar computational patterns. For the reduc-tion kernel, the parameters that require tuning are the number of threads perblock, and the number of blocks. The optimum set of parameters may fluctuatewith respect to the number of elements we reduce.
Through experiments and benchmarking, we were able to show a standardbehavior for the optimum parameter set given a number of elements. Using theresults from these tests, our auto-tuning method first searches for a thread capfor all elements, which is assumed to fully occupy the machine. The thread capis defined as the maximum number of threads optimum to any valid input set(no optimum parameters will have more total threads than the thread cap).
Since our input set is a one-dimensional array in the reduction algorithm, it iseasy to test what this thread cap is, and where it applies. All workloads greaterthan the number of elements where this thread cap applies, is also bound by thethread cap. Next we test for a lower switchpoint where the CPU outperformsthe GPU, and the optimum parameters for that point. Using these two points,and their associated number of elements, we are able to select a number of totalthreads (threads per block and number of blocks) for any input set.
Therefore this algorithm is highly machine dependent, less workload depen-dent, and therefore much easier to tune. Highly workload dependent algorithmsrequire micro-benchmarks in order to correlate the workload space with the pa-rameter space. The next algorithms considered are cases where the workload hasa more dominant effect on the parameter space.
2.3 Scalar Product
This algorithm is also memory bound and available in NVIDIA’s SDK. Howeverthe parameters for tuning the Scalar Product kernel are more complex as the

Toward Techniques for Auto-tuning GPU Algorithms 113
vector size and total number of vectors adds a dimension to the tuning process.Therefore while applying some of the same principles from our reduction methodfor a thread cap and associated work cap (the minimum workload at which ourthread cap is applied), we also select a set of distributed points (vsizei, ni) suchthat vsizei < vsizem and ni < nm, that are under the work cap and test for theoptimum number of threads, these points will operate as a nearest neighbor spline.
Here our machine dependent parameters help prune our tuning space, as wegeneralize parameters for all input sets outside these limits. For all input setsunder the thread cap we pre-tune each point from our distributed and selectparameters for the knot closest to the input set. This works due to the finegrained corelation between the input set and the parameter set. We used anearest neighbor approach rather than an interpolation approach, as our testsshowed the closest knot approach generally performed better and performancewas more stable (less variance).
Since we prune all points greater than (vsizem, nm), where vsizem and nm aredependent on machine parameters. We have therefore reduced the tuning spaceto a smaller subset of the original input space.
2.4 N-Body
We selected the N-Body algorithm as it has block-wise tunable parameters, ismore arithmetically intense, and therefore not global memory bound. The tun-able parameters in this case are two dimensions of block sizes that will be sharedper block. Therefore tuning these parameters involves a tradeoff in register us-age, and the amount of data sharing per block. These parameters are fairlyfine-grained, and when paired with a fine-grained input set we find that thereis a corelation between the input space and parameter space. In other words,the optimum parameter points does not vary widely between input set ai andai + δx. Where δx is a small variation of the input set ai.
This motivates us to use a nearest-neighbor spline technique and concentrateon intensely tuning a few distributed points. This technique allows us to greatlyreduce the tuning search space to only a small subset, while maintaining nearoptimum performance for all inputs.
2.5 SGEMM
As mentioned previously we used Lung Sheng Chien’s optimized code [1] (whichis a further optimization of Vasily Volkov’s code [6]) as the base kernel for ourautotuning method. There are a number of variations to this set of code; weselected the one with best performance, that would not lead to out-of-boundproblems (method8 in Chien’s benchmark suite). Using templates, we createdtwenty-one valid versions of this method that relied on three input parameters.Due to Chien’s reliance on precompiling kernels into cubin binaries before runs,we created twenty-one associated binaries for each version. Experimental resultsshowed that a number of these valid versions were inherently inefficient, andwere removed from the tuning suite.

114 A. Davidson and J. Owens
We found that for larger matrices, one parameter set would deliver near opti-mum performance. Therefore, our strategy was to find the optimum parameterset (of the twenty-one available) for a given machine which would allow us totune all input-sets larger than a certain matrix size. It was also noticed that ingeneral, this preferred kernel had higher register usage per thread than other ker-nels. Whether or not this is a rule of thumb one can follow for quickly selectingan appropriate variation, requires more testing on a wider variety of devices.
For smaller matrices, our tests on a GTX260 and an 8600 GTS showed thatthere was more variety and workload dependence on the optimal kernel. There-fore, our complete tuning strategy for this algorithm is as follows:
– Find optimal kernel for large matrices. This relies on machine specific pa-rameters.
– Find matrix size for which we switch strategies.– Test a variety of candidates from a pre-tuning run, and finely tune all small
matrices with these candidates.
Though this algorithm requires us to finely tune for smaller matrices, we gain anadvantage by pruning all matrices greater than the switchpoint. Since smallermatrices are solved much faster, we are able to prune the most vital section oftuning space. Also, since we only select a few valid candidates for the smallermatrices, we further eliminate unnecessary kernel tests.
3 Results
We tested our methods, and ran a number of experiments on a higher end GTX260 and GTX 280, medium-end 8800GT and 5600FX, and a low-end 8600 GTS.We had access to a Tesla C1060 for our reduction tests, however it was unavail-able for test runs for our other algorithms.
In the next subsections, we will compare the performance for each of ourauto-tuned algorithms versus the untuned default algorithms. For all auto-tunedalgorithms, tuning runs are very short (around one to five minutes) due to ourcarefully pruning the tuning space so that we gather only necessary informationfor our tuning process.
3.1 Reduction
Figure 1 compares the performance of our auto-tuning method against that ofthe SDK’s default parameters. The results show a speedup that brings memoryperformance close to bandwidth limit. Our auto-tuned method(blue plot) per-forms as well as a brute force check on all possible parameters (red dotted line),while only taking a minute or less to run a one-time tuning run. As a mem-ory bound function, we found performance depended directly on the numberof memory controllers available to the machine. Though this cannot be queried
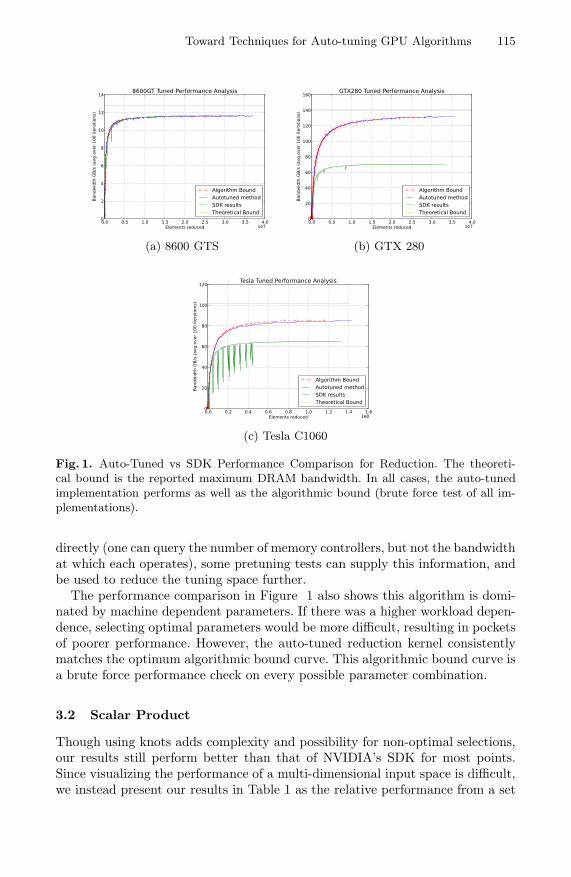
Toward Techniques for Auto-tuning GPU Algorithms 115
(a) 8600 GTS (b) GTX 280
(c) Tesla C1060
Fig. 1. Auto-Tuned vs SDK Performance Comparison for Reduction. The theoreti-cal bound is the reported maximum DRAM bandwidth. In all cases, the auto-tunedimplementation performs as well as the algorithmic bound (brute force test of all im-plementations).
directly (one can query the number of memory controllers, but not the bandwidthat which each operates), some pretuning tests can supply this information, andbe used to reduce the tuning space further.
The performance comparison in Figure 1 also shows this algorithm is domi-nated by machine dependent parameters. If there was a higher workload depen-dence, selecting optimal parameters would be more difficult, resulting in pocketsof poorer performance. However, the auto-tuned reduction kernel consistentlymatches the optimum algorithmic bound curve. This algorithmic bound curve isa brute force performance check on every possible parameter combination.
3.2 Scalar Product
Though using knots adds complexity and possibility for non-optimal selections,our results still perform better than that of NVIDIA’s SDK for most points.Since visualizing the performance of a multi-dimensional input space is difficult,we instead present our results in Table 1 as the relative performance from a set
116 A. Davidson and J. Owens
of random inputs. Our results in Table 1 show good speedups for almost allcases on the GTX 280 and 260 (achieving nearly 30 percent performance booston the 280). While the performance gains on the 8800GT and 5600FX were notas drastic, we still were able to boost performance slightly.
Table 1. Performance speedups comparison of auto-tuned kernel vs default for a setof 1000 random selected points
Architecture (GPU) Speedup
GTX 280 1.2817
GTX 260 1.1511
8800 GT 1.0201
5600 FX 1.0198
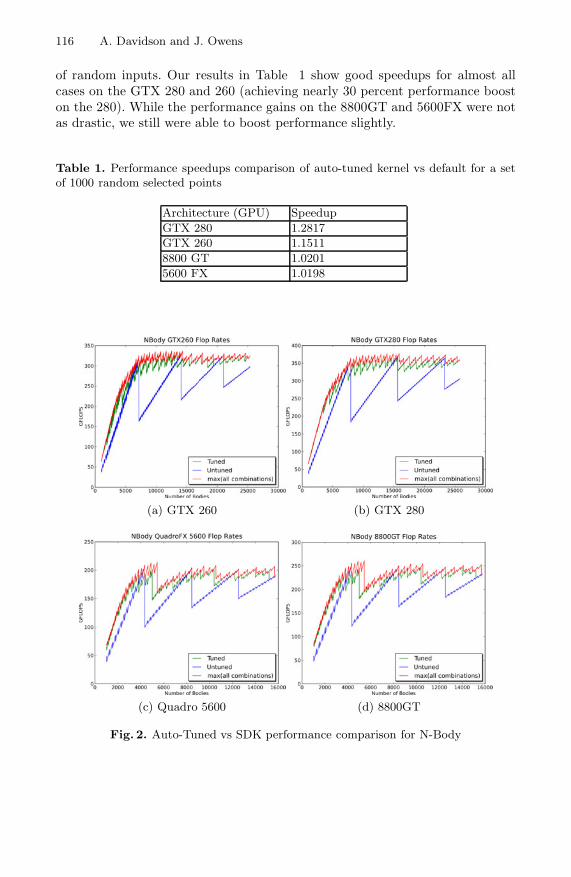
(a) GTX 260 (b) GTX 280
(c) Quadro 5600 (d) 8800GT
Fig. 2. Auto-Tuned vs SDK performance comparison for N-Body
Toward Techniques for Auto-tuning GPU Algorithms 117
3.3 N-Body
Figure 2 shows the performance comparison of our spline auto-tuned strategyversus the default parameters. The spikes in performance from the untunedimplementation illustrate the workload dependence to the parameter space. Asthe workload changes, the untuned parameters fall in and out of sync with theoptimum implementation.
Our spline strategy helps to minimize these spikes in performance, and main-tain near-optimumperformance by updating parameters as the workload changes.In some cases the speedups from these can be up to 2x that of the untuned per-formance. One can also vary the amount of tuning in order to get nearer andnearer to the optimum performance. The example in Figure 2 has twenty tunedpoints which are used as a reference.
3.4 SGEMM
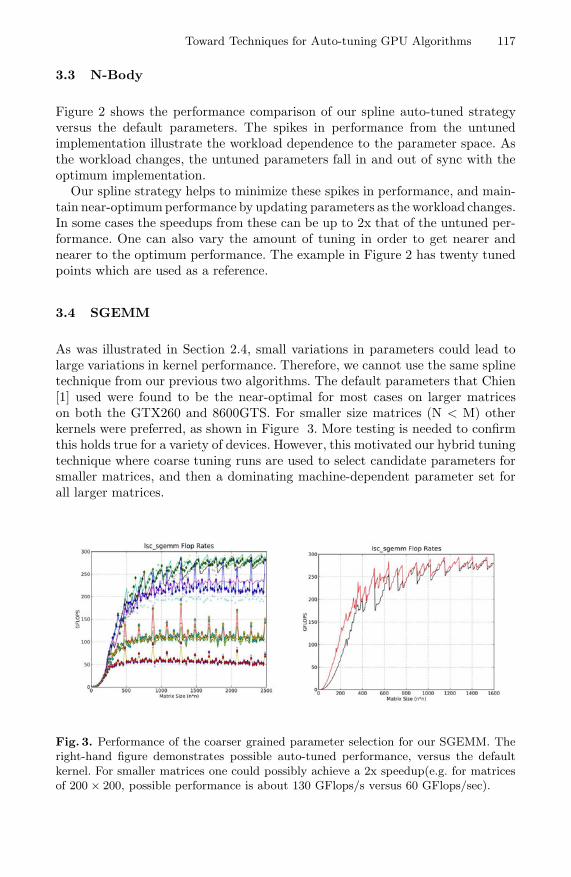
As was illustrated in Section 2.4, small variations in parameters could lead tolarge variations in kernel performance. Therefore, we cannot use the same splinetechnique from our previous two algorithms. The default parameters that Chien[1] used were found to be the near-optimal for most cases on larger matriceson both the GTX260 and 8600GTS. For smaller size matrices (N < M) otherkernels were preferred, as shown in Figure 3. More testing is needed to confirmthis holds true for a variety of devices. However, this motivated our hybrid tuningtechnique where coarse tuning runs are used to select candidate parameters forsmaller matrices, and then a dominating machine-dependent parameter set forall larger matrices.
Fig. 3. Performance of the coarser grained parameter selection for our SGEMM. Theright-hand figure demonstrates possible auto-tuned performance, versus the defaultkernel. For smaller matrices one could possibly achieve a 2x speedup(e.g. for matricesof 200 × 200, possible performance is about 130 GFlops/s versus 60 GFlops/sec).

118 A. Davidson and J. Owens
3.5 General Auto-tuning Summary and Practices
This section serves as both a summary of our previous techniques, and to whichtypes of algorithms each are applicable. Table 2 shows our tested algorithms, andhow strongly their optimum parameters are machine and workload dependent.Once these are identified, one can begin developing an auto-tuning scheme forparameter selection.
Generally speaking, we find that for strongly workload dependent algorithmswith a fine-grained input set and fine-grained parameter set, nearest neighborspline strategies have returned good results. This was evident in both our N-Bodyand Scalar Product tuned algorithms. For our reduction kernel, we saw a strongdependence between our thread parameters and the device parameters (memorycontrollers). Therefore our strategy relies on this simple relationship. Finally,our SGEMM kernel displayed various levels of dependency, and we thereforedeveloped a hybrid strategy for different workload ranges.
Table 2. Table summarizing each auto-tuned algorithm’s dependencies on device spe-cific parameters and workload specific parameters(input space)
Algorithm Name Device Dependency Workload Dependency
Reduction Strong Weak
Scalar Product Medium Strong
N-Body Weak Strong
SGEMM Strong Medium
4 Conclusion
We believe that hand-tuning algorithms for each machine will become an im-practical method as systems become more diverse in capability, and algorithmbounds become more complex. Therefore, developing methods that either fullyautomate or assist the tuning process, could prove powerful tools for developersto boost utilization.
Future work is needed in developing firmer relationships between algorithmswith similar computational patterns, and developing auto-tuning schemes be-tween these algorithms. Testing on newer architectures, such as the recentlyreleased Fermi architecture is also needed. The Fermi 400x series cards containa number of new features that would change tuning strategies for a number ofalgorithms. On top of faster global memory bandwidth, more shared memorywithin blocks, and compute power, these additions include faster atomic opera-tions than previous cards, and more computational power for double precisionoperations.
Our work has shown a number of autotuning practices and methods whichboost performance for a number of common algorithms. We believe this is animportant stepping stone in developing a generalized tuning methodology fordata parallel programs.

Toward Techniques for Auto-tuning GPU Algorithms 119
References
1. Chien, L.S.: Hand-Tuned SGEMM On GT200 GPU. Technical Report, Tsing HuaUniversity (2010), http://oz.nthu.edu.tw/~d947207/NVIDIA/SGEMM/HandTunedSgemm 2010 v1.1.pdf
2. Kerr, A., Diamos, G., Yalamanchili, S.: Modeling GPU-CPU Workloads and Sys-tems. In: GPGPU 2010: Proceedings of the 3rd Workshop on General-Purpose Com-putation on Graphics Processing Units, pp. 31–42. ACM, New York (2010)
3. Li, Y., Dongarra, J., Tomov, S.: A Note on Auto-Tuning GEMM for GPUs. In:Allen, G., Nabrzyski, J., Seidel, E., van Albada, G.D., Dongarra, J., Sloot, P.M.A.(eds.) ICCS 2009. LNCS, vol. 5544, pp. 884–892. Springer, Heidelberg (2009)
4. Liu, Y., Zhang, E., Shen, X.: A Cross-Input Adaptive Framework for GPU ProgramOptimizations. In: IPDPS 2009: Proceedings of the 2009 IEEE International Sym-posium on Parallel and Distributed Processing, pp. 1–10. IEEE Computer SocietyPress, Washington, DC (2009)
5. Ryoo, S., Rodrigues, C.I., Stone, S.S., Baghsorkhi, S.S., Ueng, S.Z., Stratton, J.A.,Hwu, W.W.: Program Optimization Space Pruning for a Multithreaded GPU. In:CGO 2008: Proceedings of the Sixth Annual IEEE/ACM International Symposiumon Code Generation and Optimization, pp. 195–204 (April 2008)
6. Volkov, V., Demmel, J.W.: Benchmarking gpus to tune dense linear algebra. In:SC 2008: Proceedings of the 2008 ACM/IEEE Conference on Supercomputing,pp. 1–11. IEEE Press, Piscataway (2008)






![[Doi 10.1007%2F978!94!010-1592-9_9] Merlan, Philip -- From Platonism to Neoplatonism Conclusion](https://static.fdocuments.net/doc/165x107/577cbfd11a28aba7118e347f/doi-1010072f97894010-1592-99-merlan-philip-from-platonism-to-neoplatonism.jpg)
![[Doi 10.1007%2F978!94!010-1592-9_8] Merlan, Philip -- From Platonism to Neoplatonism METAPHYSICA GENERALIS in ARISTOTLE](https://static.fdocuments.net/doc/165x107/55cf8f65550346703b9be565/doi-1010072f97894010-1592-98-merlan-philip-from-platonism-to-neoplatonism.jpg)





![[28145] Funktionswörter im Polnischen Leiter: Prof. Dr. Peter Kosta](https://static.fdocuments.net/doc/165x107/56815414550346895dc211a6/28145-funktionswoerter-im-polnischen-leiter-prof-dr-peter-kosta.jpg)




