

CHAPTER 2 Populations and Samples Graduate school approach to problem solving.
65
CHAPTER 2 Populations and Samples
-
date post
20-Dec-2015 -
Category
Documents
-
view
227 -
download
2
Transcript of CHAPTER 2 Populations and Samples Graduate school approach to problem solving.

CHAPTER 2
Populations and Samples

OUTLINE 2.1 Selecting Appropriate Samples
Explains why the selection of an appropriate sample has an important bearing on the reliability of inferences about a population
2.2 Why Sample?
Gives a number of reasons sampling is often preferable to census taking 2.3 How Samples are Selected
Explains how samples are selected 2.4 How to Select a Random Sample
Illustrates with a specific example the method of selecting a random sample using a computer statistical package 2.5 Effectiveness of a Random Sample
Demonstrates the credibility of the random sampling process 2.6 Missing and incomplete Data
Explains the problem of missing or incomplete data and offers suggestions on how to minimize this problem

LEARNING OBJECTIVES 1. Distinguish between
a. populations and samples
b. parameters and statistics
c. various methods of sampling
2. Explain why the method of sampling is important
3. State why samples are used
4. Define random sample
5. Explain why it is important to use random sampling
6. Select a random sample using a computer statistical program
7. Suggest methods for dealing with missing data

SELECTING APPROPRIATE SAMPLES
A. Population – a set of persons (or objects) having a common observable characteristic
B. Sample – a subset of a population
C. The WAY a sample is selected is more important than the size of the sample
D. An appropriate sample should be representative of the population
E. A set of observations may be summarized by a descriptive statistic called a parameter

SELECTING APPROPRIATE SAMPLES
F. Random sample
1. Every subject has an equal opportunity for being selected
2. Technique most likely to yield a representative sample
3. Obstacles
a. Response rate – how many will respond
b. Sampling bias – some segment of the population may be over or under represented
c. May be too costly

WHY SAMPLE?
A. Random sampling - Each subject in the population has an equal chance of being selected1. Avoids known and unknown biases on average2. Helps convince others that the trial was conducted properly3. Basis for statistical theory that underlies hypothesis tests and
confidence intervals
B. Convenience samples1. selected at will or in a particular program2. seldom representative of the underlying population3. used when random samples are virtually impossible to select

WHY SAMPLE?
C. Systematic sampling1. used when a sampling frame – a complete, nonoverlapping list
of the persons or objects constituting the population is available2. randomly select a first case then proceed by selecting every
case
D. Stratified sampling – used when we wish the sample to represent the various strata (subgroups) of the population proportionately or to increase the precision of the estimate
E. Cluster sampling1. select a simple random sample (number of city blocks)2. More economical than random selection of persons throughout
the city

HOW TO SELECT A RANDOM SAMPLE
• Random Numbers Table: Appendix E, pg. 335
• Computer statistical package SPSS

EFFECTIVENESS OF A RANDOM SAMPLE
• A. Reliability is usually demonstrated by
– 1. defining fairly small population
– 2. selecting from it all conceivable samples of a particular size
– 3. mean average is computed
– 4. the variation for the population is observed
– 5. a comparison of these sample means (statistics) with the population mean (population) neatly demonstrates the credibility of the sampling
scheme

MISSING AND INCOMPLETE DATA
A. Bias may be introduced because of possible differences between respondents and nonrespondents
B. Limits the ability to accurately draw inferences about the population
C. Subjects may drop out of the study
D. Ways to deal with missing data1. Last observation carry-forward – take the last observed value prior to
dropout and treat them as final data

Understanding and Reducing Errors
• Goals of Data Collection and Analysis– Promoting accuracy and precision– Reducing differential and nondifferential errors– Reducing intraobserver and interobserver variablity
• Accuracy and Usefulness– False-positive and false-negative results– Sensitivity and specificity– Predictive values– Likelihood rations, odds ratios, and cutoff ratios– Receiver operating characteristic (ROC) curves
• Measuring Agreement– Overall percentage agreement– Kappa test ratio

Promoting Precision and Accuracy
• Accuracy: The ability of a measurement to be correct on the average.
• Precision: the ability of a measurement to give the same result or a very similar result with repetition of the test. (reproducibility, reliability)
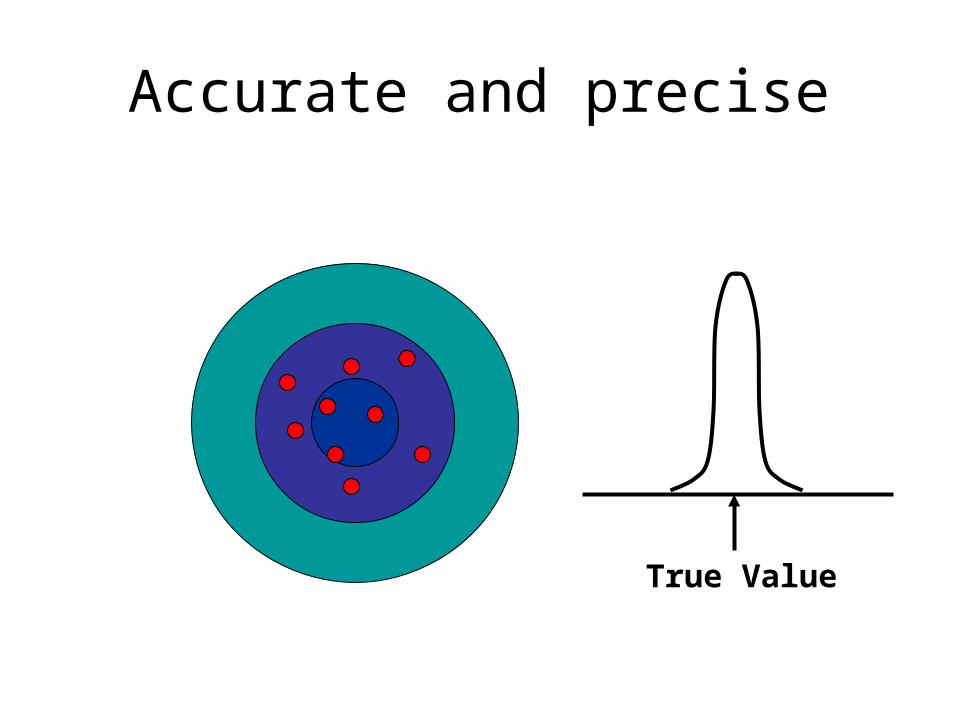
Accurate and precise
True Value

Precise only
True Value

Accurate only
True Value

Neither Accurate nor Precise
True Value

Differential and nondifferential error
• Bias is a differential error– A nonrandom, systematic, or consistent
error in which the values tend to be inaccurate in a particular direction.
• Nondifferential are random errors

Bias• Three most problematic forms of bias in
medicine:– 1. Selection (Sampling) Bias:
The following are biases that distort results because of the selection process
• Admission rate (Berkson’s) bias– Distortions in risk ratios occur as a result of different
hospital admission rate among cases with the risk factor, cases without the risk factor, and controls with the risk factor –causing greatly different risk-factor probabilities to interfere with the outcome of interest.
• Nonresponse bias– i.e. noncompliance of people who have scheduled
interviews in their home.
• Lead time bias– A time differential between diagnosis and treatment
among sample subjects may result in erroneous attribution of higher survival rates to superior treatment rather than early detection.

Bias• Three most problematic forms of bias in
medicine:– 1. Selection (Sampling) Bias1. Selection (Sampling) Bias
• Admission rate (Berkson’s) biasAdmission rate (Berkson’s) bias• Nonresponse biasNonresponse bias• Lead time biasLead time bias
– 2. Information (misclassification) Bias2. Information (misclassification) Bias• Recall biasRecall bias
– Differentials in memory capabilities of sample subjectsDifferentials in memory capabilities of sample subjects
• Interview biasInterview bias– ““blinding of interviewers to diseased and control blinding of interviewers to diseased and control
subjects is often difficult.subjects is often difficult.
• Unacceptability biasUnacceptability bias– Patients reply with “desirable” answersPatients reply with “desirable” answers

Bias• Three most problematic forms of bias in
medicine:– 1. Selection (Sampling) Bias
• Admission rate (Berkson’s) bias• Nonresponse bias• Lead time bias
– 2. Information (misclassification) Bias• Recall bias• Interview bias• Unacceptability bias
– 3. Confounding3. Confounding• A confounding variable has a relationship with both A confounding variable has a relationship with both
the dependent and independent variables that masks the dependent and independent variables that masks or potentiates the effect of the variable on the study.or potentiates the effect of the variable on the study.

Types of Variation
• Discrete variables– Nominal variables– Dichotomous (Binary) variables
• Ordinal (Ranked) variables
• Continuous (Dimensional) variables
• Ratio variables
• Risks and Proportions as variables

Types of Variation
• Nominal variablesNominal variables

Nominal
AA
OOBB
ABAB
Social Security Number
123 45 6789312 65 8432555 44 7777

Types of Variation
• Nominal variablesNominal variables
• Dichotomous (Binary) variablesDichotomous (Binary) variables

Dichotomous (Binary) Dichotomous (Binary) variablesvariables
WNL
Not WNL
Accept
Reject
Normal
Abnormal

Types of Variation
• Nominal variables
• Dichotomous (Binary) variables
• Ordinal (Ranked) variablesOrdinal (Ranked) variables

Ordinal (Ranked) variablesOrdinal (Ranked) variables
Strongly agree, agree, neutral, disagree, strongly disagree

Types of Variation
• Nominal variables
• Dichotomous (Binary) variables
• Discrete variables
• Ordinal (Ranked) variables
• Continuous (Dimensional) Continuous (Dimensional) variablesvariables

Continuous (Dimensional) Continuous (Dimensional) variablesvariables
Height Blood Pressure Weight
Temperature32° F

Types of Variation
• Nominal variables
• Dichotomous (Binary) variables
• Discrete variables
• Ordinal (Ranked) variables
• Continuous (Dimensional) variables
• Ratio variablesRatio variables

Ratio variablesRatio variables
• A continuous scale that has a true zero point

Types of Variation
• Nominal variables• Dichotomous (Binary) variables• Discrete variables• Ordinal (Ranked) variables• Continuous (Dimensional) variables• Ratio variables
• Risks and Proportions as variablesRisks and Proportions as variables

Risks and Proportions as Risks and Proportions as variablesvariables
• Variables created by the ratio of discrete counts in the numerator to counts in the denominator.

CHAPTER 3
Organizing and Displaying Data

OUTLINE
3.1 CLASSIFYING AND ORGANIZING DATA
Explains and illustrates numerical scales and distinguishes among qualitative data, discrete quantitative data, and continuous qualitative data
3.2 FIGURES, TABLES, AND GRAPHS
Gives brief overview of each
3.3 CREATING TABLES
Gives instructions on how to organize data in the form of a frequency table
3.4 GRAPHING DATA
Discussing and illustrating various methods of graphing with an emphasis on those that apply specifically to frequency distributions

LEARNING OBJECTIVES 1. Distinguish between
a. qualitative and quantitative variables
b. discrete and continuous variables
c. symmetrical, bimodal, and skewed distributions
d. positively and negatively skewed distributions
2. Construct and interpret a frequency table that includes class intervals, class frequency, valid percent, and cumulative percent
3. Indicate the appropriate types of graphs for displaying quantitative and qualitative data
4. Distinguish which forms of data presentation are appropriate for different situations

CLASSIFYING AND ORGANIZING DATA
• A. General Data Organization/Presentation Methods
– 1. Tables
– 2. Graphs
– 3. Numerical Techniques
• B. Common Scales used to Measure Data
– 1. Qualitative Data –variables that yield nominal level data• a. Nominal – primarily used for grouping or categorizing data• b. Ordinal – ordered series of relationships
– 2. Quantitative Data – numerically measured variables• a. Interval – the number zero is an artificial 0, i.e. temperature• b. Ratio - the number zero is true or absolute, total absence of the characteristic being measured, i.e. $ in your
wallet

CLASSIFYING AND ORGANIZING DATA
• C. Discrete Quantitative Variables
– 1. discontinuous variables
– 2. must always be integers – whole numbers
• D. Continuous Quantitative Variables
– 1. may take fractional values
– 2. Examples
• a. age• b. height• c. weight

CLASSIFYING AND ORGANIZING DATA
• E. Spreadsheet Data Hints
– 1. Verify the accuracy of manually input data
– 2. For nominal or ordinal data – change the computer default decimal setting to zero decimal places
– 3. Subject ID numbers
• a. usually use the first column• b. set the decimal number to zero

FIGURES, TABLES, AND GRAPHS
As defined by Publication Manual of the
American Psychological Association (APA),
Fifth Edition

FIGURES, TABLES, AND GRAPHS
• A. FIGURES – 1. any type of illustration other than a table– 2. examples
• a. charts• b. graphs• c. photographs• d. drawing
• • B. GRAPH - one particular type of figure
• C. TABLE – typically used to display quantitative data
• D. Primary Purpose of Graphs & Tables
To visually display information in a manner that makes it easy for readers to comprehend

FREQUENCY TABLES
• A. Frequency – refers to the number of cases with a particular value
• B. Percent– 1. Valid Percent – percentage out of 100, using only those subjects with data– 2. Cumulative Percent – percentage of all previous cases plus the current interval
• C. Class Intervals – usually equal in length thereby aiding the comparisons between two intervals
• D. Interval Width – the number of units between the upper and lower limits or, class limits
• E. Range – difference between the highest and lowest numbers
• F. Class Boundaries – true limits, points that demarcate the true upper limit of one class and true lower limit of the next

GRAPHING DATA
• A. Must be self-explanatory
– 1. descriptive title
– 2. Labeled axes
– 3. Indication of units observation

GRAPHING DATA
• B. Histograms
– 1. pictorial representation of the frequency table
– 2. Components
• a. Abscissa– i. Horizontal axis which depicts the class boundaries (no
limits)
• b. Perpendicular Ordinate – i. vertical axis which depicts the frequency (or relative frequency) of
observations– ii. Should begin at zero
• c. Height of the vertical scale should be three-fourths the length of the vertical scale

GRAPHING DATA
• C. Frequency Polygons
– 1. Construction
• a. uses the same axes as the histogram• b. constructed by marking a point (at same height as the histogram’s bar) at the midpoint
of the class interval• c. These points are then connected
– 2. Superior to histograms for comparing two frequency distributions
– 3. Shapes
• a. Symmetrical Distribution – Bell-Shaped• b. Bimodal Distribution – two peaks• c. Rectangular Distribution – each class interval is equally represented

GRAPHING DATA
• D. Cumulative Frequency Polygons
– 1. Also called Ogive
– 2. Horizontal scale – same as histograph
– 3. Vertical scale indicates cumulative or relative cumulative frequency
– 4. Construction• a. place a point at the upper class boundary of each class interval• b. Each point represents the cumulative relative frequency for that class• c. Points should then be connected
– 5. Percentiles – may be obtained from the ogive

GRAPHING DATA
• E. Stem-and-Leaf Displays
– 1. Innovative technique of summarizing data that utilizes characteristics of the frequency distribution of the histogram
– 2. Stems – represent the class intervals
– 3. Leaves – strings of values within each class interval

GRAPHING DATA
• F. Bar Charts
– 1. Particularly useful for displaying nominal or ordinal data
– 2. Relative frequencies are shown by heights
– 3. Scale on the vertical axis should begin at zero
• G. Pie Charts
– 1. A common device for displaying data arranged in categories
– 2. Useful for conveying data that consists of a small number of categories

GRAPHING DATA
• H. Box-and-Whisker Plots
– 1. Uses median and quartile statistics to graphically examine data
– 2. Median – the score that divides a ranked series into two equal halves
– 3. Mean – the average of the two middle scores if there are an equal number of scores
– 4. Quartiles
• a. locate the median in the ordered list of observations
– - 1st quartile is the median of the observations below this median
– - 3rd quartile is the median of the observations above the original median

GRAPHING DATA
• I. Computerized Graphing
– 1. Easily generated by a variety of statistical programs
– 2. Standard programs can be found at:
• a. www.minitab.com
• b. www.JMP.com
• c. www.spss.com
– 3. Microsoft Excel
– 4. Freeware sites:
• a. www.statsci.org/free.html
• b. www.statistics.com

CONCLUSION
The principles of tabulating and graphing data are essential if we are to understand and evaluate the flood of data with which we are bombarded. By proper use of these principles, statisticians can present data accurately and lucidly. It is also important to know which method of presentation to choose for each specific type of data. Tables are usually comprehensive, but they do not convey the information as quickly or as impressively as do graphs. Remember that graphs and tables must tell their own story and stand on their own.

Table Shell
Title
Box Head
Stub
Cell
Note
Source
What are the data?Who?Where are the data?When?
Captions or column headings
Row captions
“The intersection of a column and a row”
Explanation
References

Charts
• Bar: One or more variables • Grouped Bar: From tables w/two or three variables• Stacked Bar: A total category w/frequencies within• Pie: Percentages• Histograms: Continuous data• Frequency polygons: Continuous data• Line Graphs: Time trends/survival curves• Scatter diagrams: two continuous variables

Bar Chart

Grouped Bar

Stacked Bar

PIE
1
2
3
4
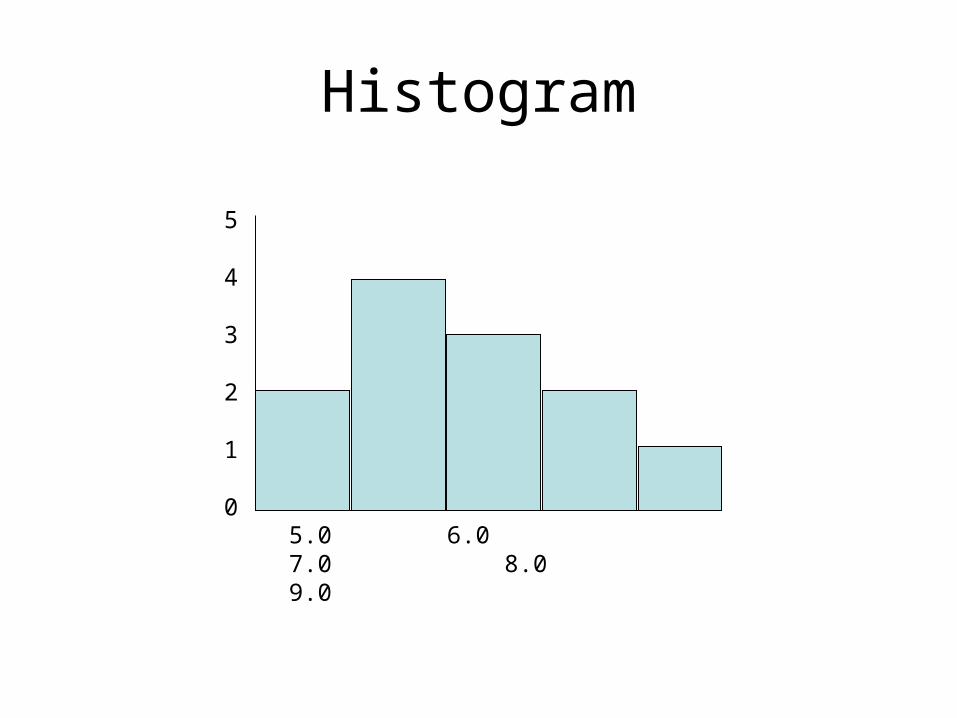
Histogram
5
4
3
2
1
05.0 6.0 7.0 8.0 9.0

Frequency Polygon
5
4
3
2
1
05.0 6.0 7.0 8.0 9.0

Asymmetric Distributions
-4 -3 -2 -1 0 1 2 3 4
Positively Skewed RightNegatively Skewed Left

Distributions (Kurtosis)
-4 -3 -2 -1 0 1 2 3 4
Flat curve =Higher level of deviation from the mean
High curve =Smaller deviation from the mean

Distributions (Bimodal Curve)
-4 -3 -2 -1 0 1 2 3 4

Line Graphs
1997 1998 1999 2000 2001 2002
1100010000 9000 8000 7000 6000

Scatter Diagrams
X
Y
Height
Weight
72717069686766656463626160
100 110 120 130 140 150 160 170 180 190 200 210


















