
Center for Subsurface Sensing & Imaging Systems Overview of Research Thrust R3 R3 Fundamental...
41
Center for Subsurface Sensing & Imaging Systems verview of Research Thrust R3 R3 Fundamental Research Topics R3A Parallel Processing • Middleware/Parallelization Tools • FPGA Acceleration R3B Solutionware Development • Subsurface Toolboxes • Image and Sensor Data Databases David Kaeli - NU Miriam Leeser - NU Wilson Rivera - UPRM
-
Upload
pauline-jackson -
Category
Documents
-
view
217 -
download
0
Transcript of Center for Subsurface Sensing & Imaging Systems Overview of Research Thrust R3 R3 Fundamental...

Center forSubsurface Sensing & Imaging Systems
Center forSubsurface Sensing & Imaging Systems
Overview of Research Thrust R3
R3 Fundamental Research Topics
R3A Parallel Processing
• Middleware/Parallelization Tools
• FPGA Acceleration
R3B Solutionware Development
• Subsurface Toolboxes
• Image and Sensor Data Databases
R3 Fundamental Research Topics
R3A Parallel Processing
• Middleware/Parallelization Tools
• FPGA Acceleration
R3B Solutionware Development
• Subsurface Toolboxes
• Image and Sensor Data Databases
David Kaeli - NUMiriam Leeser - NU
Wilson Rivera - UPRM
David Kaeli - NUMiriam Leeser - NU
Wilson Rivera - UPRM
R1
R2
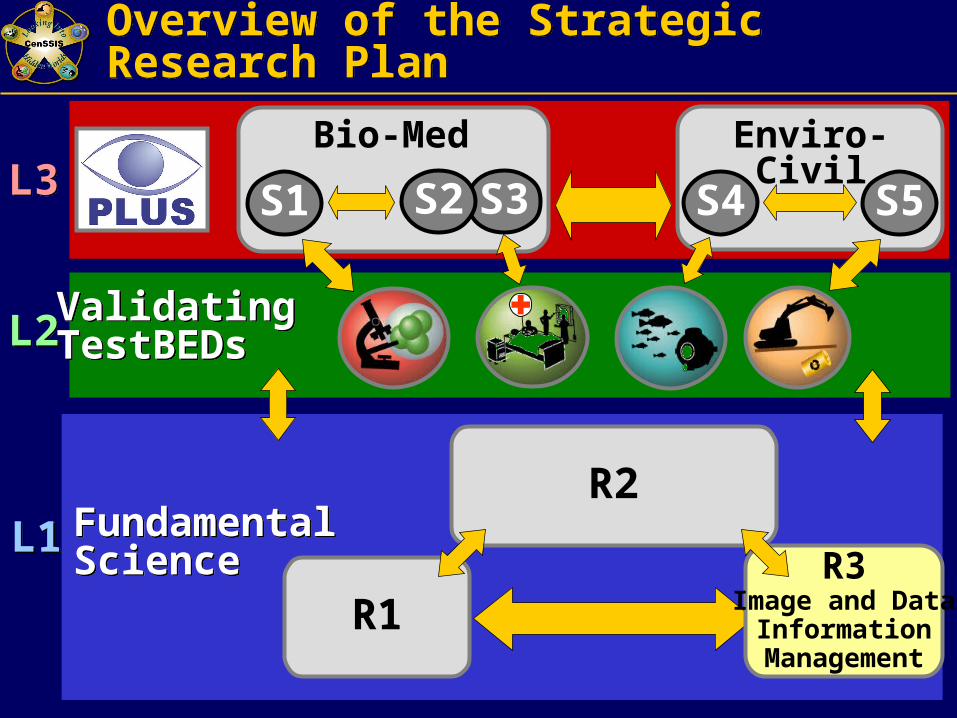
Overview of the Strategic Research PlanOverview of the Strategic Research Plan
FundamentalScienceFundamentalScience
ValidatingTestBEDsValidatingTestBEDs
L1L1
L2L2
L3L3
R3Image and Data
InformationManagement
S1 S4 S5S3S2
Bio-Med Enviro-Civil

CenSSIS Barriers Addressed by R3 ProjectsCenSSIS Barriers Addressed by R3 Projects
Lack of Computationally Efficient, Realistic Models Lack of Computationally Efficient, Realistic Models
Barrier 6 Barrier 6 Lack of Rapid Processing and Management of Large Image DatabasesLack of Rapid Processing and Management of Large Image Databases
Barrier 7 Barrier 7 Lack of Validated, Integrated Processing andComputational ToolsLack of Validated, Integrated Processing andComputational Tools
Barrier 4 Barrier 4
Center forSubsurface Sensing & Imaging Systems
Center forSubsurface Sensing & Imaging Systems
Middleware andParallelization Tools
David Kaeli – NU Wilson Rivera – UPRM
Carmen Carvajal - UPRMMagda El-Shenawee - U Arkansas
Geoff Krapf – NU (undergrad)Waleed Meleis – NU
Craig Shaffer – NU (undergrad)Karen Tompko – U Cincinnati
Yijian Wang - NUJuemin Zhang - NU
David Kaeli – NU Wilson Rivera – UPRM
Carmen Carvajal - UPRMMagda El-Shenawee - U Arkansas
Geoff Krapf – NU (undergrad)Waleed Meleis – NU
Craig Shaffer – NU (undergrad)Karen Tompko – U Cincinnati
Yijian Wang - NUJuemin Zhang - NU

CenSSIS Middleware Tools CenSSIS Middleware Tools
Parallelization of MATLAB, C/C++ and Fortran codes using Message Passing Interface (MPI) – a software pathway to exploiting GRID-level resources
Presently utilizing local Beowulf clusters, NCSA resources (Mariner Center at BU) and Internet-2
Profile-guided program instrumentation/optimization Utilizing MPI-2 to address barriers in I/O performance Building on existing Grid Middleware such as Globus
Toolkit, MPICH-G2 and GridPort
Parallelization of MATLAB, C/C++ and Fortran codes using Message Passing Interface (MPI) – a software pathway to exploiting GRID-level resources
Presently utilizing local Beowulf clusters, NCSA resources (Mariner Center at BU) and Internet-2
Profile-guided program instrumentation/optimization Utilizing MPI-2 to address barriers in I/O performance Building on existing Grid Middleware such as Globus
Toolkit, MPICH-G2 and GridPort
MATLAB
C/C++
Fortran
Parallelization
MPI
MPICH-G2
UPC
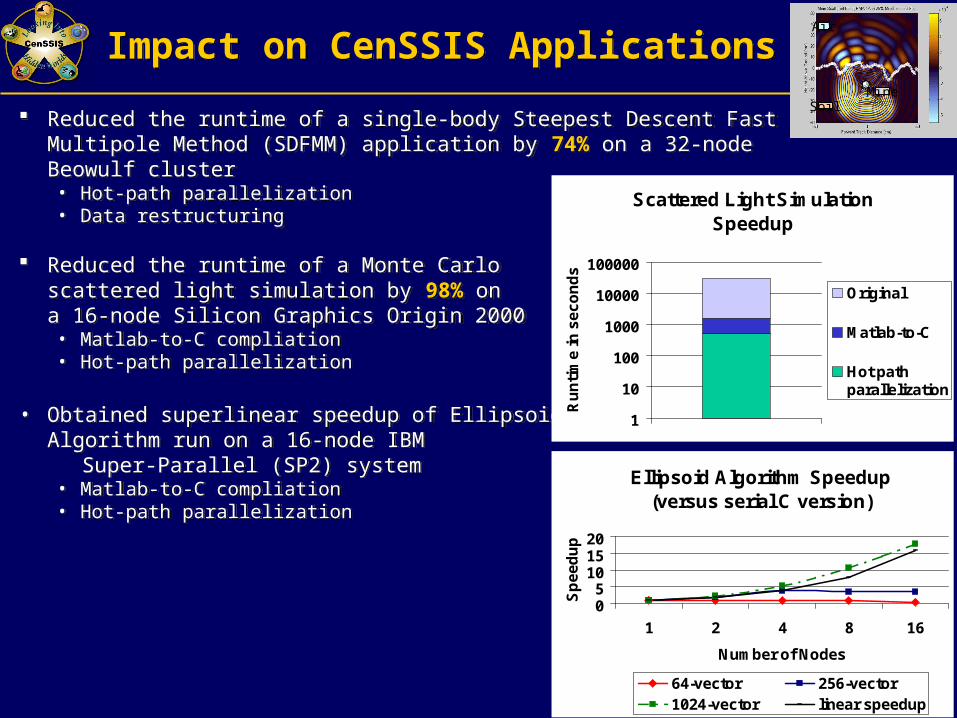
Impact on CenSSIS ApplicationsImpact on CenSSIS Applications
Reduced the runtime of a single-body Steepest Descent Fast Multipole Method (SDFMM) application by 74% on a 32-node Beowulf cluster• Hot-path parallelization• Data restructuring
Reduced the runtime of a Monte Carloscattered light simulation by 98% on a 16-node Silicon Graphics Origin 2000• Matlab-to-C compliation• Hot-path parallelization
• Obtained superlinear speedup of Ellipsoid Algorithm run on a 16-node IBM
Super-Parallel (SP2) system• Matlab-to-C compliation• Hot-path parallelization
Reduced the runtime of a single-body Steepest Descent Fast Multipole Method (SDFMM) application by 74% on a 32-node Beowulf cluster• Hot-path parallelization• Data restructuring
Reduced the runtime of a Monte Carloscattered light simulation by 98% on a 16-node Silicon Graphics Origin 2000• Matlab-to-C compliation• Hot-path parallelization
• Obtained superlinear speedup of Ellipsoid Algorithm run on a 16-node IBM
Super-Parallel (SP2) system• Matlab-to-C compliation• Hot-path parallelization
Soil
Air
Mine
Scattered Light Simulation Speedup
1
10
100
1000
10000
100000
Ru
nti
me
in s
ec
on
ds
Original
Matlab-to-C
Hot pathparallelization
Ellipsoid Algorithm Speedup(versus serial C version)
05
101520
1 2 4 8 16
Number of Nodes
Sp
ee
du
p
64-vector 256-vector1024-vector linear speedup
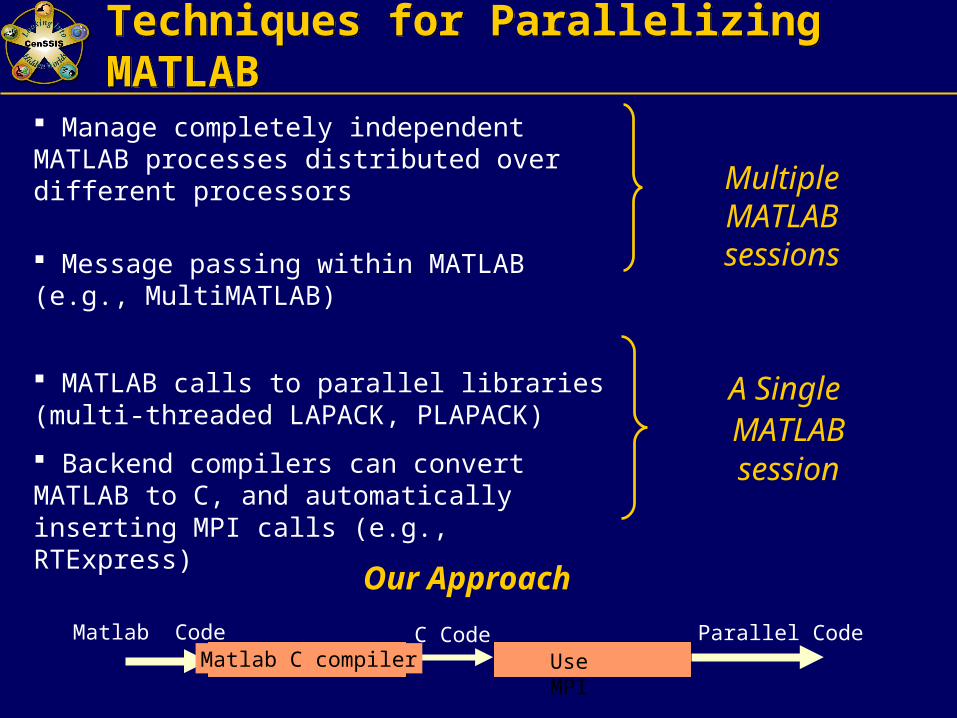
Techniques for Parallelizing MATLABTechniques for Parallelizing MATLAB
Manage completely independent MATLAB processes distributed over different processors
Message passing within MATLAB (e.g., MultiMATLAB)
MATLAB calls to parallel libraries (multi-threaded LAPACK, PLAPACK)
Backend compilers can convert MATLAB to C, and automatically inserting MPI calls (e.g., RTExpress)
Multiple MATLAB sessions
A Single MATLAB session
Matlab Code C Code Parallel CodeMatlab C compiler Use MPI
Our Approach
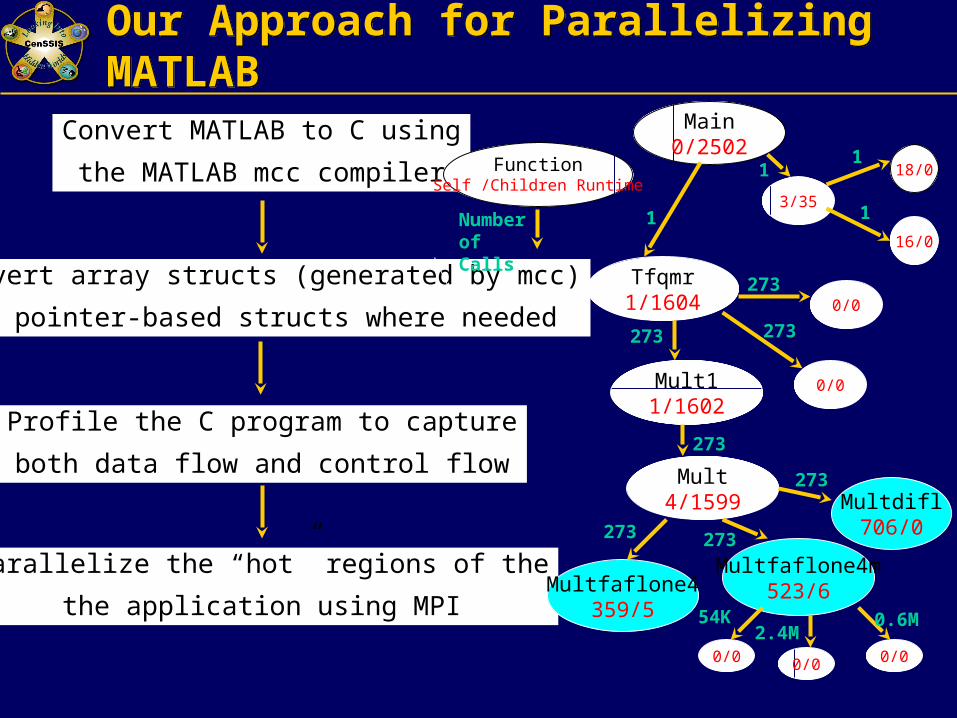
Our Approach for Parallelizing MATLABOur Approach for Parallelizing MATLAB
Convert MATLAB to C using
the MATLAB mcc compiler
Profile the C program to capture
both data flow and control flow
Parallelize the “hot” regions of the
the application using MPI
Convert array structs (generated by mcc)
to pointer-based structs where needed
Main0/2502
Tfqmr1/1604
3/35
Mult11/1602
Mult4/1599
Multfaflone4m523/6Multfaflone4
359/5
Multdifl706/0
0/0
0/0
0/0
18/0
16/0
0/0 0/0
11
1 1
273
273
273
273
273
273
273
54K2.4M
0.6M
FunctionSelf /Children Runtime
Number of Calls

Eliminating I/O Barriers in ParallelSubsurface ApplicationsEliminating I/O Barriers in ParallelSubsurface Applications
Many SSI applications tend to be file bound or memory bound (or both)
While we can use MPI to parallelize processing and use MPI collective-I/O to accelerate I/O, we still are limited to accessing a file on a single disk
Our present work looks at parallelizing I/O by partitioning files associated with MPI processes
We attempt to utilize, slower and commodity (IDE) local secondary storage
Many SSI applications tend to be file bound or memory bound (or both)
While we can use MPI to parallelize processing and use MPI collective-I/O to accelerate I/O, we still are limited to accessing a file on a single disk
Our present work looks at parallelizing I/O by partitioning files associated with MPI processes
We attempt to utilize, slower and commodity (IDE) local secondary storage
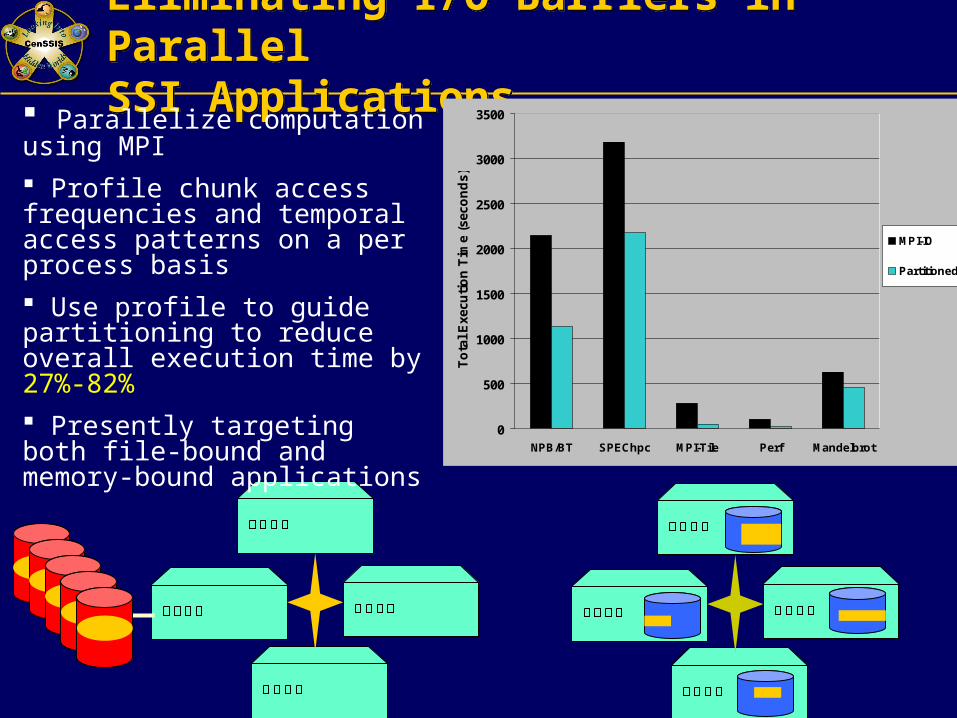
Eliminating I/O Barriers in ParallelSSI ApplicationsEliminating I/O Barriers in ParallelSSI Applications
0
500
1000
1500
2000
2500
3000
3500
NPB/BT SPEChpc MPI-Tile Perf MandelbrotT
ota
l E
xecu
tio
n T
ime
(sec
on
ds)
MPI-IO
Partitioned
Parallelize computation using MPI
Profile chunk access frequencies and temporal access patterns on a per process basis
Use profile to guide partitioning to reduce overall execution time by 27%-82%
Presently targeting both file-bound and memory-bound applications

Some Recent PublicationsSome Recent Publications
“Profile-based Characterization and Tuning Subsurface Sensing Applications”, M. Ashouei, D. Jiang, W. Meleis, D. Kaeli, M. El-Shenawee, E. Mizan, M. and C. Rappaport, Special issue of the SCS Journal, November 2002.
“Parallel Implementation of the Steepest Descent Fast Multipole Method (SDFMM) on a Beowulf Cluster for Subsurface Sensing Application”, D. Jiang, W. Meleis, M. El-Shenawee, E. Mizan, M. Ashouei, and C. Rappaport, IEEE Microwave and Wireless Components Letters, January 2002.
“Electromagnetics Computations Using MPI Parallel Implementation of the Steepest Descent Fast Multipole Method (SDFMM)”, M. El-Shenawee, C. Rappaport, D. Jiang, W. Meleis, and D. Kaeli, Applied Computational Electromagnetics Society Journal, August 2002.
“An efficient parallel algorithm for solving unsteady nonlinear equations”, W. Rivera, J. Zhu, and D. Huddleston, Proc. International Conference on Parallel Processing, IEEE Computer Society, 2002.
“Mapping and characterization of applications in heterogeneous distributed systems,” J. Yeckle and W. Rivera , To appear in Proceed. of the 7th World Multiconference on Systemics, Cybernetics and Informatics (SCI2003).
“Profile-Guided I/O Partitioning”, Y. Wang and D. Kaeli, Submitted to ICS’03.
“Profile-based Characterization and Tuning Subsurface Sensing Applications”, M. Ashouei, D. Jiang, W. Meleis, D. Kaeli, M. El-Shenawee, E. Mizan, M. and C. Rappaport, Special issue of the SCS Journal, November 2002.
“Parallel Implementation of the Steepest Descent Fast Multipole Method (SDFMM) on a Beowulf Cluster for Subsurface Sensing Application”, D. Jiang, W. Meleis, M. El-Shenawee, E. Mizan, M. Ashouei, and C. Rappaport, IEEE Microwave and Wireless Components Letters, January 2002.
“Electromagnetics Computations Using MPI Parallel Implementation of the Steepest Descent Fast Multipole Method (SDFMM)”, M. El-Shenawee, C. Rappaport, D. Jiang, W. Meleis, and D. Kaeli, Applied Computational Electromagnetics Society Journal, August 2002.
“An efficient parallel algorithm for solving unsteady nonlinear equations”, W. Rivera, J. Zhu, and D. Huddleston, Proc. International Conference on Parallel Processing, IEEE Computer Society, 2002.
“Mapping and characterization of applications in heterogeneous distributed systems,” J. Yeckle and W. Rivera , To appear in Proceed. of the 7th World Multiconference on Systemics, Cybernetics and Informatics (SCI2003).
“Profile-Guided I/O Partitioning”, Y. Wang and D. Kaeli, Submitted to ICS’03.

Grid ComputingGrid Computing
Solving Subsurfacing Barriers using Grid Computing Deployment of distributed CenSSIS
applications Development of adaptive middleware
Profile-guided parallelization/optimization
Multi-language support
Profile-guided I/O partitioning
Interaction with distributed image database resources
CenSSIS/HP Industrial Relations Strong links with Latin American Universities interested
in Grid Computing Student and/or faculty interchange program with
CenSSIS schools Leadership in leading IEEE/ACM GRID Computing
Workshops
Solving Subsurfacing Barriers using Grid Computing Deployment of distributed CenSSIS
applications Development of adaptive middleware
Profile-guided parallelization/optimization
Multi-language support
Profile-guided I/O partitioning
Interaction with distributed image database resources
CenSSIS/HP Industrial Relations Strong links with Latin American Universities interested
in Grid Computing Student and/or faculty interchange program with
CenSSIS schools Leadership in leading IEEE/ACM GRID Computing
Workshops
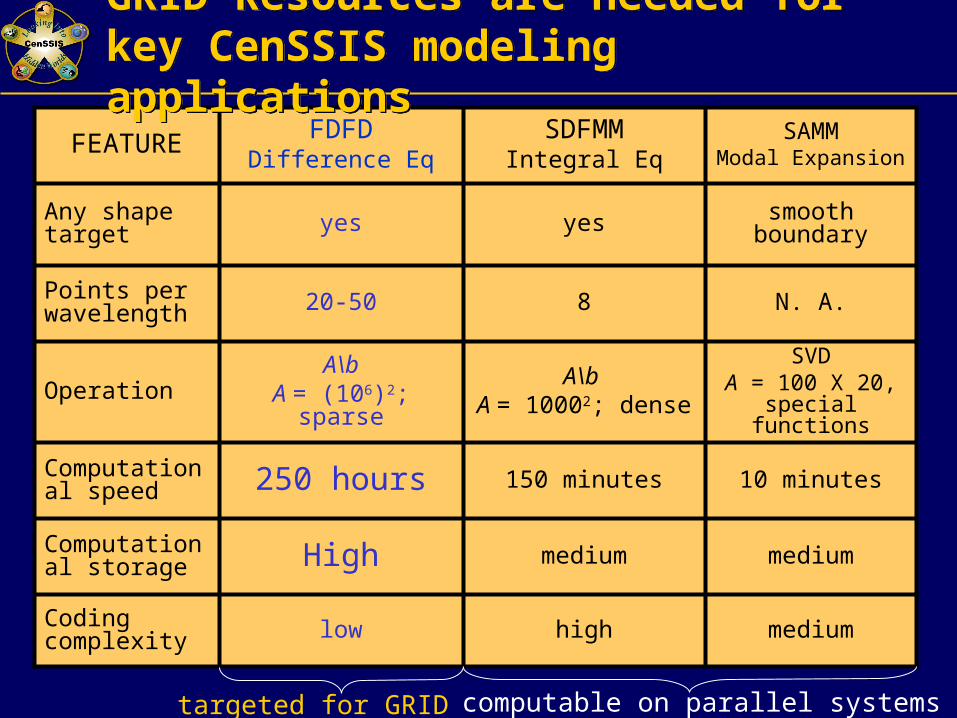
SVDA = 100 X 20,
special functions
A\b A = 10002; dense
A\bA = (106)2; sparse
Operation
low
High
250 hours
20-50
yes
FDFDDifference Eq
high
medium
150 minutes
8
yes
SDFMMIntegral Eq
N. A.Points per wavelength
mediumCoding complexity
medium
10 minutes
smooth boundary
SAMMModal Expansion
Computational storage
Computational speed
Any shape target
FEATURE
GRID Resources are needed for key CenSSIS modeling applicationsGRID Resources are needed for key CenSSIS modeling applications
computable on parallel systemstargeted for GRID systems
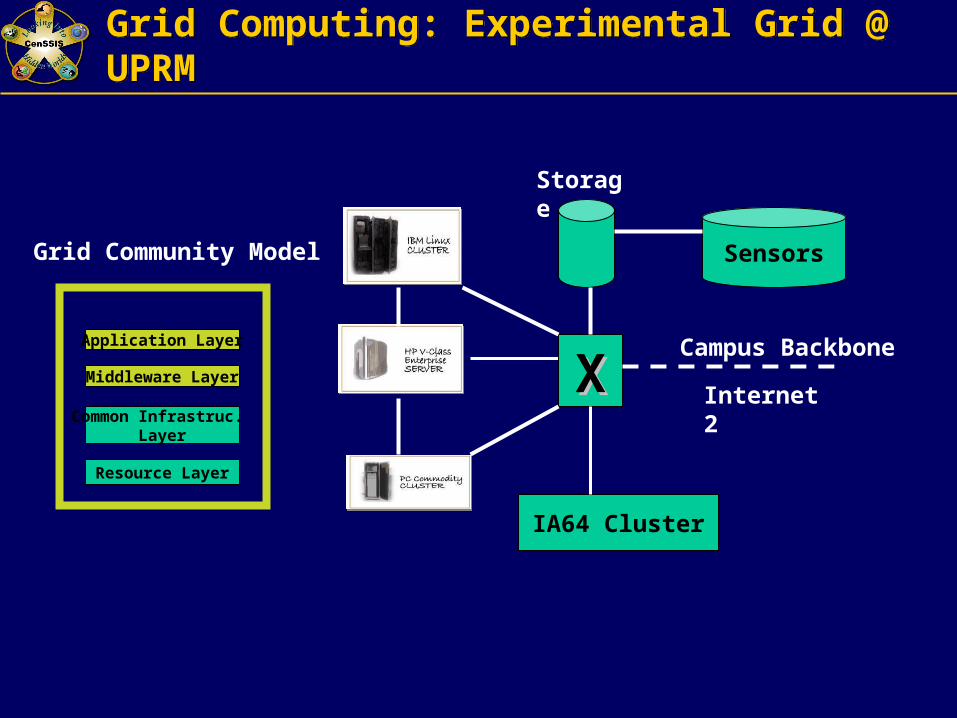
Grid Computing: Experimental Grid @ UPRMGrid Computing: Experimental Grid @ UPRM
ΧΧ
Sensors
Campus Backbone
Internet 2
IA64 Cluster
Storage
Application Layer
Middleware Layer
Common Infrastruc. Layer
Resource Layer
Grid Community Model
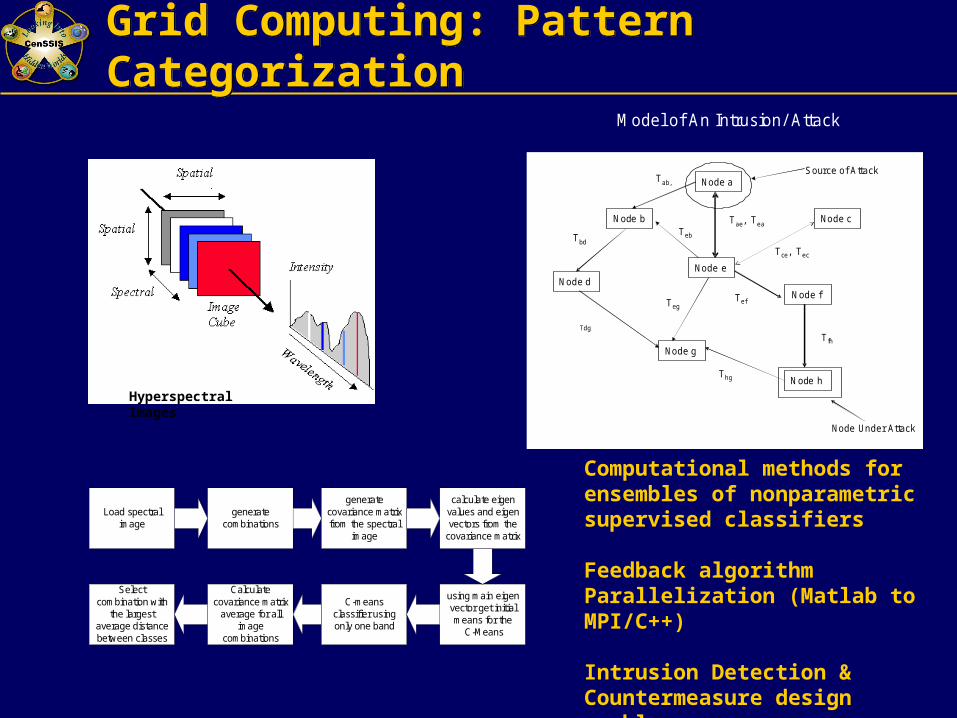
Grid Computing: Pattern CategorizationGrid Computing: Pattern Categorization
generatecombinations
generatecovariance matrixfrom the spectral
image
Load spectralimage
calculate eigenvalues and eigenvectors from the
covariance matrix
using main eigenvector get initialmeans for the
C-Means
C-meansclassifier usingonly one band
Calculatecovariance matrix
average for allimage
combinations
Selectcombination with
the largestaverage distancebetween classes
Model of An Intrusion/ Attack
Node b
Node h
Node g
Node e Node d
Node a
Node f
Node c
Tab,
Tae, Tea
Tce, Tec
TebTbd
Tdg
TegTef
Thg
T fh
Source of A ttack
Node Under Attack
Hyperspectral Images
Computational methods for ensembles of nonparametric supervised classifiers
Feedback algorithm Parallelization (Matlab to MPI/C++)
Intrusion Detection & Countermeasure design problems

Grid Computing: LATAM Task ForceGrid Computing: LATAM Task Force
Create a LATAM Task Force on Grid Computing.
Universidad de Chile, ChileRicardo Baeza, PhD in Computer Science, University of Waterloo
Universidad de los Andes, VenezuelaHerbert Hoeger, PhD in Computer Science, University of Iowa
Universidad de Sau Paulo, BrasilMarcio Lobo, PhD in Computer Science, TUD, Germany
Instituto Tecnologico de Monterrey, MexicoCesar Vargas, PhD in Electrical Engineering, Louisiana State University
Universidad del Valle, ColombiaAngel Garcia, PhD in Telecommunications, UPV-Spain.
Hold a Grid Workshop for these researchers/educators at UPRM, and invite both CenSSIS and HP people to serve as reviewers and panelists (slated for Nov. 2003).
Provide tutorials and short courses on Grid-level computing.
We will utilize CenSSIS problems as the motivating examples that will be parallelized. Implementations will be prototyped at UPRM, NU and BU.
Create a LATAM Task Force on Grid Computing.
Universidad de Chile, ChileRicardo Baeza, PhD in Computer Science, University of Waterloo
Universidad de los Andes, VenezuelaHerbert Hoeger, PhD in Computer Science, University of Iowa
Universidad de Sau Paulo, BrasilMarcio Lobo, PhD in Computer Science, TUD, Germany
Instituto Tecnologico de Monterrey, MexicoCesar Vargas, PhD in Electrical Engineering, Louisiana State University
Universidad del Valle, ColombiaAngel Garcia, PhD in Telecommunications, UPV-Spain.
Hold a Grid Workshop for these researchers/educators at UPRM, and invite both CenSSIS and HP people to serve as reviewers and panelists (slated for Nov. 2003).
Provide tutorials and short courses on Grid-level computing.
We will utilize CenSSIS problems as the motivating examples that will be parallelized. Implementations will be prototyped at UPRM, NU and BU.

Center forSubsurface Sensing & Imaging Systems
Center forSubsurface Sensing & Imaging Systems
Field Programmable Gate Arrays For
Subsurface Imaging
Miriam Leeser – NUWang Chen - NUSrdjan Coric - NUShawn Miller - NU
Seth Molloy – NU (undergrad) Josh Noseworthy – NU (undergrad)
Haiqian Yu - NU
Miriam Leeser – NUWang Chen - NUSrdjan Coric - NUShawn Miller - NU
Seth Molloy – NU (undergrad) Josh Noseworthy – NU (undergrad)
Haiqian Yu - NU

Field Programmable Gate Arrays for Subsurface ImagingField Programmable Gate Arrays for Subsurface Imaging
Backprojection for Computed Tomography image reconstruction Sponsored by Mercury Computer
Accelerating Finite Difference Time Domain (FDTD) in hardware Collaboration with Carey Rappaport, NU
Retinal Vascular Tracing in real time Collaboration with Badri Roysam and Chuck Stewart, RPI
Diverse problems, similar solutions:
FPGAs are particularly well suited for accelerating image processing algorithms
Backprojection for Computed Tomography image reconstruction Sponsored by Mercury Computer
Accelerating Finite Difference Time Domain (FDTD) in hardware Collaboration with Carey Rappaport, NU
Retinal Vascular Tracing in real time Collaboration with Badri Roysam and Chuck Stewart, RPI
Diverse problems, similar solutions:
FPGAs are particularly well suited for accelerating image processing algorithms

BackprojectionBackprojection
Backprojection algorithm used in medical imaging Traditionally performed by custom hardware
Application specific integrated circuits and/or custom board designs
New systems require greater flexibility Algorithms under development for 3D
reconstruction Application specific integrated circuits viewed as costly both in time and NRE
FPGA implementation offers significant advantages Algorithm flexibility and re-use
Fixed point and quantization effects matter Difference between fixed and floating point must
be small
Backprojection algorithm used in medical imaging Traditionally performed by custom hardware
Application specific integrated circuits and/or custom board designs
New systems require greater flexibility Algorithms under development for 3D
reconstruction Application specific integrated circuits viewed as costly both in time and NRE
FPGA implementation offers significant advantages Algorithm flexibility and re-use
Fixed point and quantization effects matter Difference between fixed and floating point must
be small

Projection Parallelism for PerformanceProjection Parallelism for Performance
Projections
Imagecolumns
Data dependency for backprojection processing
Imagerows
ProjectionsImage
columns
Parallelism implemented in FireBird (Max 16-way parallel)
Imagerows
ProjectionsImage
columns
1024 projections x 1024 samples/projection Each used to reconstruct a 512 x 512 image

Backprojection Speedup Due to Parallelism - Expandable to n-way parallelBackprojection Speedup Due to Parallelism - Expandable to n-way parallel
SU
B
ROUND
ROUND
ROUND
SU
BS
UB
LUT 3.1
LUT 3.2
LUT 2.1
LUT 2.2
LUT 1.1
LUT 1.2
LUT 4.1
LUT 4.2
EVENWRITE
COUNTERODD
WRITECOUNTER
ODDRAMODD
RAM
EVENRAMEVEN
RAM
ODDRAMODD
RAM
EVENRAMEVEN
RAM
ODDRAMODD
RAM
EVENRAMEVEN
RAM
ODDRAMODD
RAM
EVENRAMEVEN
RAM
SU
B
SU
BS
UB
SU
BS
UB M
UL
TM
UL
TM
UL
TM
UL
T
AD
D
PROJECTIONCOUNTER
MU
X
AD
D
LUT 1.3
MU
X
AD
DLUT 2.3
MU
X
AD
D
LUT 3.3
MU
X
AD
D
LUT 4.3
DE
MU
X
ROUND
DE
MU
XD
EM
UX
DE
MU
X
MU
XM
UX
MU
XM
UX
SW
AP
MU
XM
UX
SW
AP
MU
XM
UX
SW
AP
MU
XM
UX
SW
AP
MU
XM
UX
AD
D
AD
DA
DD
AD
D
AD
DA
DD
AD
D LOCALRAM
LOCALRAM
15
16
2525
2525
25
17
5 4
9
9
10
9
9
10
14
1315
16
17
25
25
9
9
8
LEFTMEZZANINE
RAM
RIGHTMEZZANINE
RAM
4 9
4 9
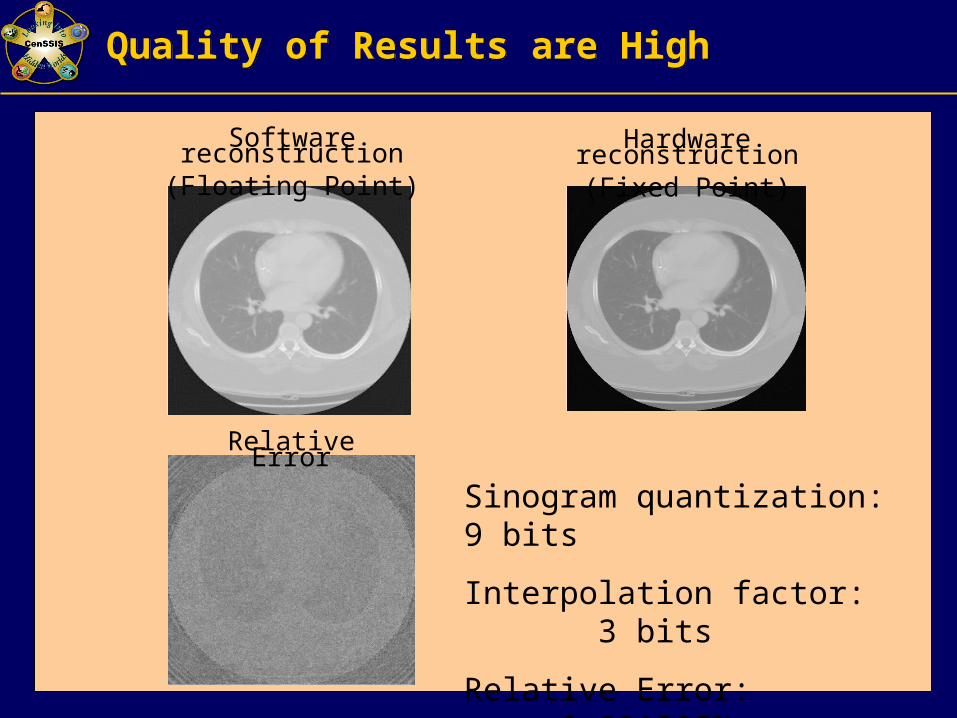
Quality of Results are HighQuality of Results are High
Software reconstruction(Floating Point)
Hardware reconstruction(Fixed Point)
Relative Error
Sinogram quantization: 9 bits
Interpolation factor: 3 bits
Relative Error: 0.001295%
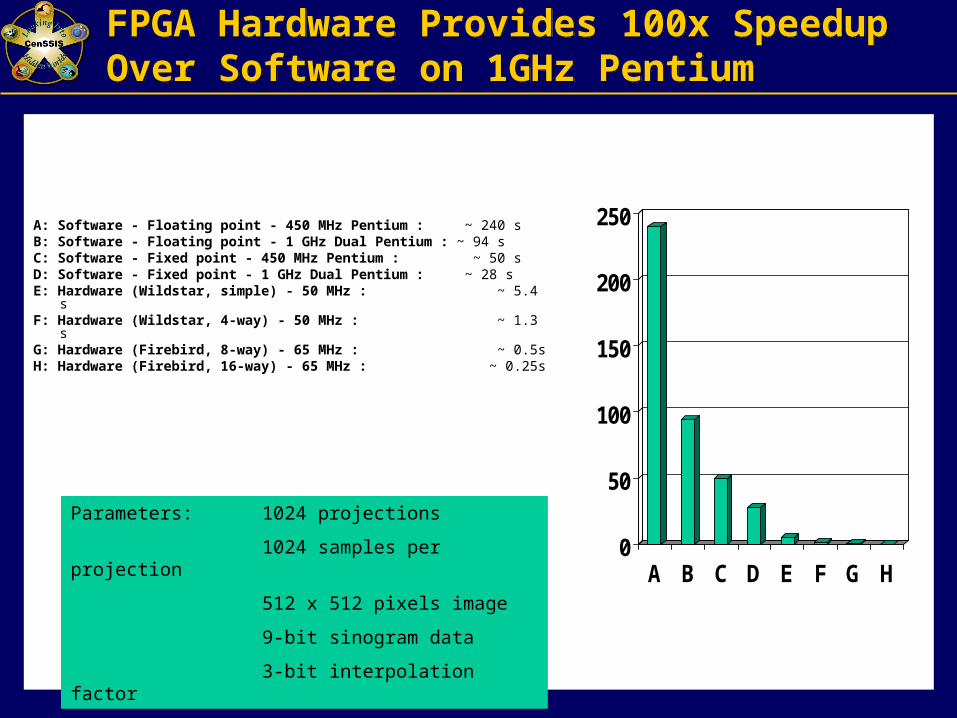
FPGA Hardware Provides 100x Speedup Over Software on 1GHz PentiumFPGA Hardware Provides 100x Speedup Over Software on 1GHz Pentium
A: Software - Floating point - 450 MHz Pentium : ~ 240 sB: Software - Floating point - 1 GHz Dual Pentium : ~ 94 sC: Software - Fixed point - 450 MHz Pentium : ~ 50 sD: Software - Fixed point - 1 GHz Dual Pentium : ~ 28 sE: Hardware (Wildstar, simple) - 50 MHz : ~ 5.4 sF: Hardware (Wildstar, 4-way) - 50 MHz : ~ 1.3 sG: Hardware (Firebird, 8-way) - 65 MHz : ~ 0.5sH: Hardware (Firebird, 16-way) - 65 MHz : ~ 0.25s
0
50
100
150
200
250
A B C D E F G H
Parameters: 1024 projections
1024 samples per projection
512 x 512 pixels image
9-bit sinogram data
3-bit interpolation factor

FDTD Equations Discretize Maxwell’s Equations – GPR ModelingFDTD Equations Discretize Maxwell’s Equations – GPR Modeling
• Update each space cell's electric and magnetic field by using previous values of this cell and its neighbors cells around it
• Extremely computationally expensive• Benefits from hardware acceleration
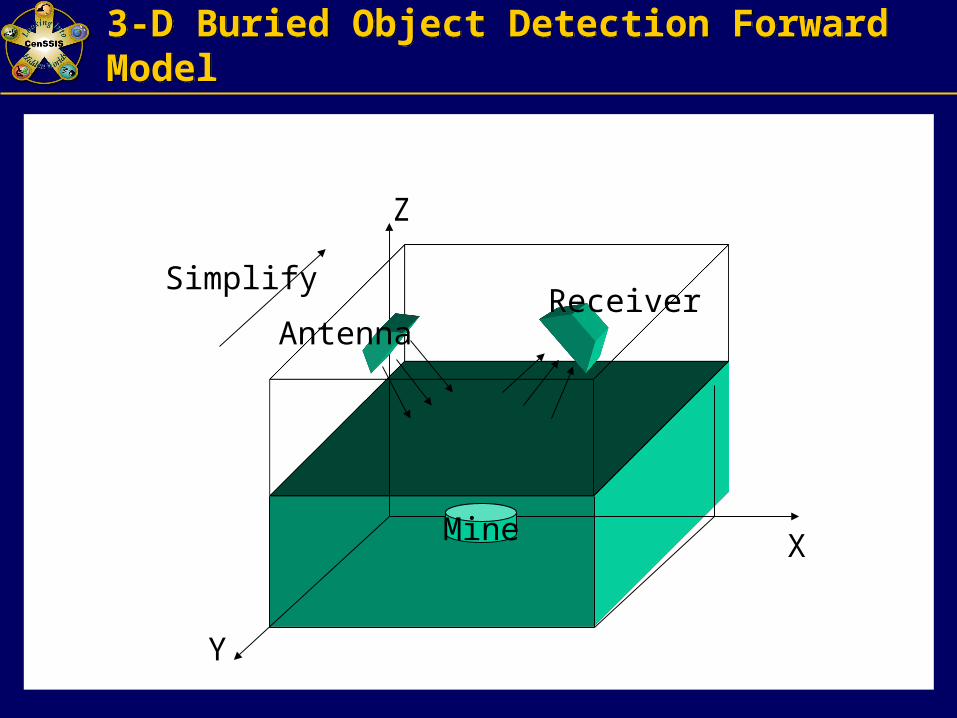
3-D Buried Object Detection Forward Model3-D Buried Object Detection Forward Model
Mine X
Y
Z
AntennaReceiver
Simplify
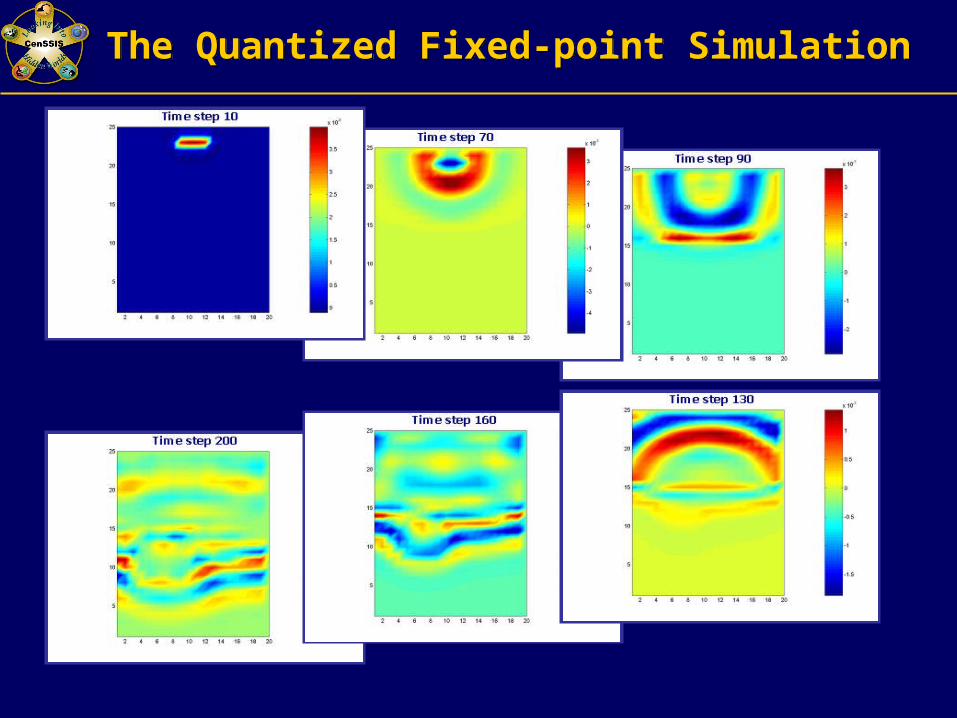
The Quantized Fixed-point SimulationThe Quantized Fixed-point Simulation
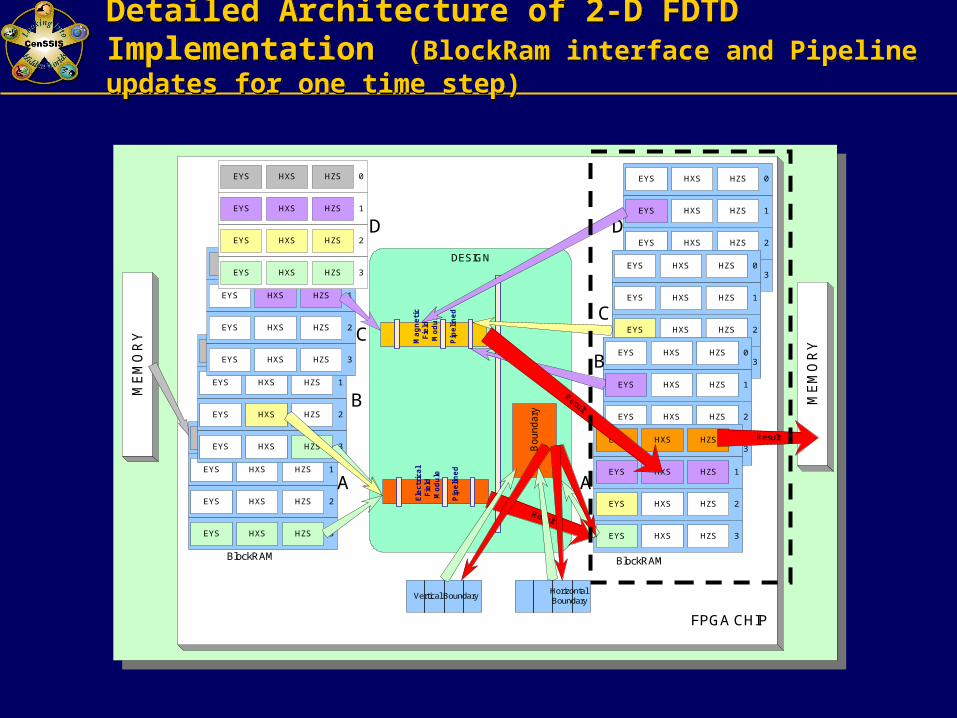
Detailed Architecture of 2-D FDTD Implementation (BlockRam interface and Pipeline updates for one time step)Detailed Architecture of 2-D FDTD Implementation (BlockRam interface and Pipeline updates for one time step)
FPGA CHIP
DESIGN
Ele
ctri
cal
Fie
ldM
odule
Pip
elined
Magneti
cFie
ldM
odule
Pip
elined
ME
MO
RY
ME
MO
RY
BlockRAM
1EYS HZSHXS
2EYS HZSHXS
3EYS HZSHXS
0EYS HZSHXS
1EYS HZSHXS
2EYS HZSHXS
3EYS HZSHXS
0EYS HZSHXS
1EYS HZSHXS
2EYS HZSHXS
3EYS HZSHXS
0EYS HZSHXS
1EYS HZSHXS
2EYS HZSHXS
3EYS HZSHXS
0EYS HZSHXS
1EYS HZSHXS
2EYS HZSHXS
3EYS HZSHXS
0EYS HZSHXS
1EYS HZSHXS
2EYS HZSHXS
3EYS HZSHXS
0EYS HZSHXS
1EYS HZSHXS
2EYS HZSHXS
3EYS HZSHXS
0EYS HZSHXS
1EYS HZSHXS
2EYS HZSHXS
3EYS HZSHXS
0EYS HZSHXS
D D
CC
B
B
A A
Result
BlockRAM
Bo
un
da
ry
Vertical BoundaryHorizontalBoundary
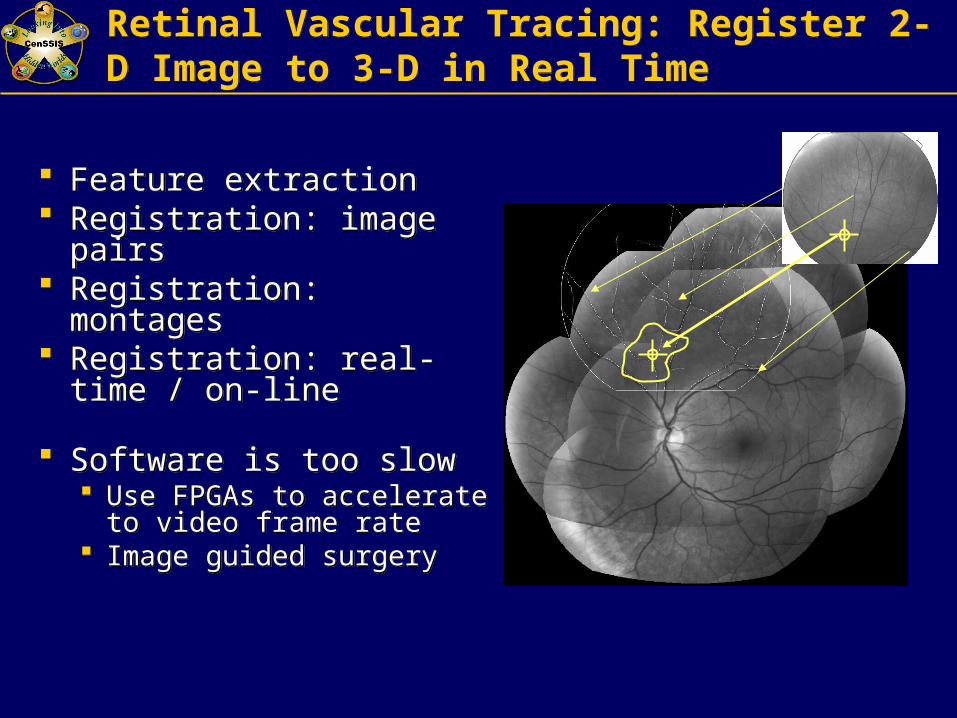
Retinal Vascular Tracing: Register 2-D Image to 3-D in Real TimeRetinal Vascular Tracing: Register 2-D Image to 3-D in Real Time
Feature extraction Registration: image pairs Registration: montages Registration: real-time /
on-line
Software is too slow Use FPGAs to accelerate
to video frame rate Image guided surgery
Feature extraction Registration: image pairs Registration: montages Registration: real-time /
on-line
Software is too slow Use FPGAs to accelerate
to video frame rate Image guided surgery
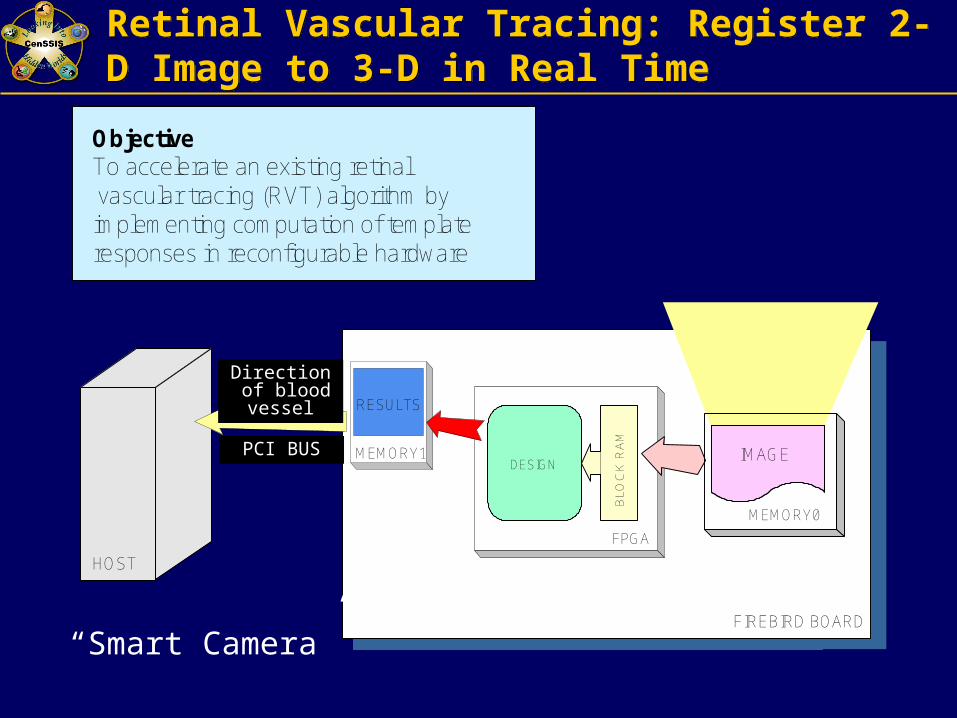
Retinal Vascular Tracing: Register 2-D Image to 3-D in Real TimeRetinal Vascular Tracing: Register 2-D Image to 3-D in Real Time
FIREBIRD BOARD
HOST
Direction ofblood vessel
PCI BUS
ObjectiveTo accelerate an existing retinalvascular tracing (RVT) algorithm byimplementing computation of templateresponses in reconfigurable hardware
FPGA
BL
OC
KR
AM
DESIGN
MEMORY0
IMAGEMEMORY1
RESULTS
“Smart Camera”
Direction of blood vessel
PCI BUS
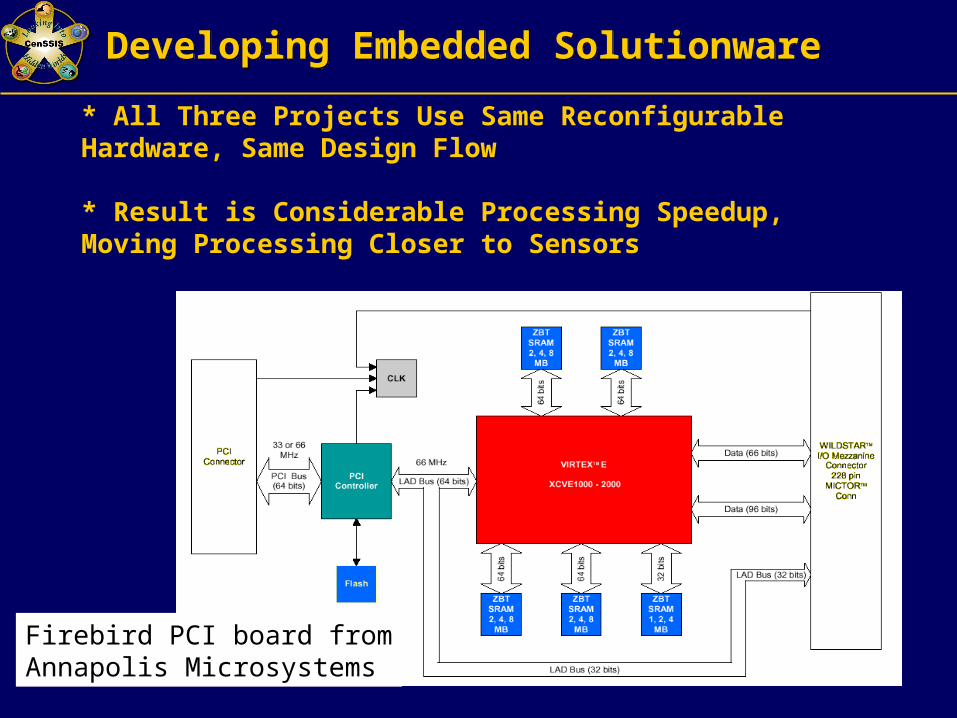
Developing Embedded SolutionwareDeveloping Embedded Solutionware
* All Three Projects Use Same Reconfigurable Hardware, Same Design Flow
* Result is Considerable Processing Speedup, Moving Processing Closer to Sensors
Firebird PCI board fromAnnapolis Microsystems

Center forSubsurface Sensing & Imaging Systems
Center forSubsurface Sensing & Imaging Systems
Solutionware Development• Subsurface Toolboxes
• Image and Sensor Data Databases
Solutionware Development• Subsurface Toolboxes
• Image and Sensor Data DatabasesDavid Kaeli – NU
Chuck Stewart – RPIEmmanuel Arzuaga – UPRM
Jennifer Black – NUKyle Guilbert – NU (undergrad)
Matthew Kowalski – NU (undergrad)Chakib Ouarraoui – NU
Amitha Perera - RPIBecky Norum – NU
Derek Uluski – NU (undergrad)
David Kaeli – NUChuck Stewart – RPI
Emmanuel Arzuaga – UPRMJennifer Black – NU
Kyle Guilbert – NU (undergrad)Matthew Kowalski – NU (undergrad)
Chakib Ouarraoui – NUAmitha Perera - RPIBecky Norum – NU
Derek Uluski – NU (undergrad)
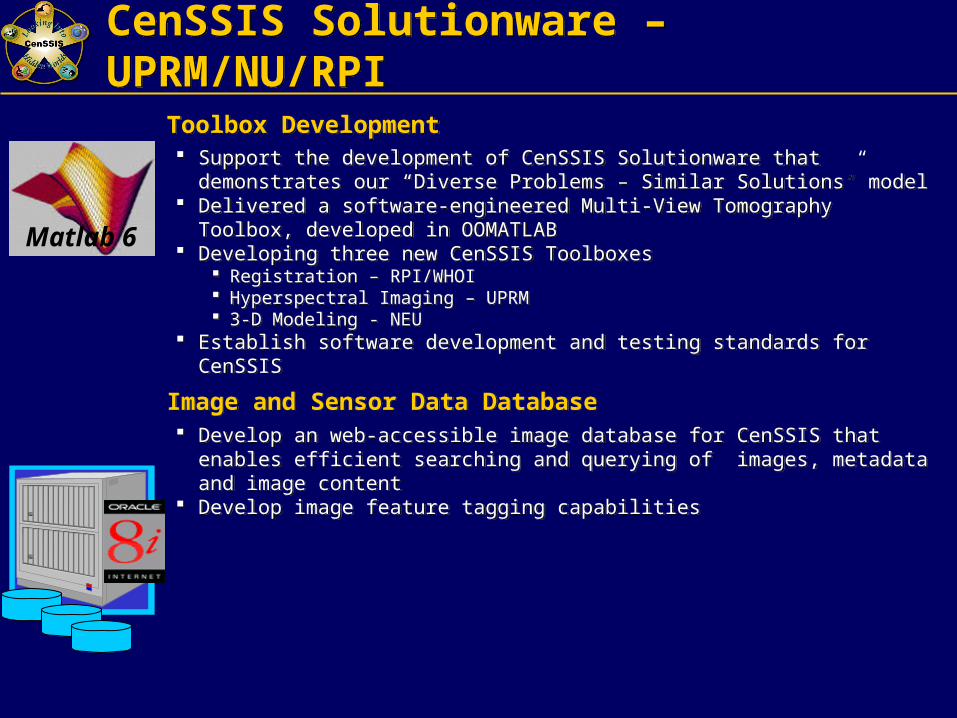
CenSSIS Solutionware – UPRM/NU/RPICenSSIS Solutionware – UPRM/NU/RPI
Toolbox Development Support the development of CenSSIS Solutionware that demonstrates
our “Diverse Problems – Similar Solutions” model Delivered a software-engineered Multi-View Tomography Toolbox,
developed in OOMATLAB Developing three new CenSSIS Toolboxes
Registration – RPI/WHOI Hyperspectral Imaging – UPRM 3-D Modeling - NEU
Establish software development and testing standards for CenSSIS
Image and Sensor Data Database Develop an web-accessible image database for CenSSIS that enables
efficient searching and querying of images, metadata and image content
Develop image feature tagging capabilities
Toolbox Development Support the development of CenSSIS Solutionware that demonstrates
our “Diverse Problems – Similar Solutions” model Delivered a software-engineered Multi-View Tomography Toolbox,
developed in OOMATLAB Developing three new CenSSIS Toolboxes
Registration – RPI/WHOI Hyperspectral Imaging – UPRM 3-D Modeling - NEU
Establish software development and testing standards for CenSSIS
Image and Sensor Data Database Develop an web-accessible image database for CenSSIS that enables
efficient searching and querying of images, metadata and image content
Develop image feature tagging capabilities
Matlab 6

Current/Future Toolbox DevelopmentCurrent/Future Toolbox Development
Development of multi-language toolboxes – C, Fortran, C++, Java, MATLAB and OO-MATLAB
Delivered the MVT Toolbox – open source Presently working on three additional toolbox efforts Developing a parallelized version of the MVT Toolbox Adopted Software Engineering Institute Capability Maturing
Model (CMM) Level 3 standards Software library and bug tracking being developed (CVS and
Bugzilla) Software Engineers on staff at NU, UPRM and RPI
Development of multi-language toolboxes – C, Fortran, C++, Java, MATLAB and OO-MATLAB
Delivered the MVT Toolbox – open source Presently working on three additional toolbox efforts Developing a parallelized version of the MVT Toolbox Adopted Software Engineering Institute Capability Maturing
Model (CMM) Level 3 standards Software library and bug tracking being developed (CVS and
Bugzilla) Software Engineers on staff at NU, UPRM and RPI
Matlab 6
MVT MSD LPM Modeling
Detectors
Sources
Object


















![BeneHeart R3/BeneHeart R3A Électrocardiographe Manuel de l ... › DocumentiGIMA › Manuali › FR › M33301FR.pdf · Les crochets [ ] sont utilisés pour entourer les textes apparaissant](https://static.fdocuments.net/doc/165x107/5f0cf9687e708231d4380d97/beneheart-r3beneheart-r3a-lectrocardiographe-manuel-de-l-a-documentigima.jpg)






