

A Cassandra Data Model for Serving up Cat Videos (from Cassandra Day Denver 2014)


CDE
• Cloud Database Engineering
• Responsible for providing data stores as
services @ Netflix

CDE Services

Agenda
• Cassandra @ Netflix
• Challenges
• Certification and benchmarking
• CDE Architecture

• 98% of streaming data is stored in Cassandra
• Data ranges from customer details to Viewing history / streaming bookmarks to billing and payment
Cassandra @ Netflix

Cassandra Footprint
• Hundreds of clusters
• Tens of Thousands of nodes
• PBs of data
• Millions of transactions / sec

Challenges
• Monitoring
• Maintenance
• Open source product
• Production readiness


Monitoring
• What do we monitor?– Latencies
• Co-ordinator Read 99th and 95th based on cluster configurations• Co-ordinator Write 99th and 95th based on cluster configurations
– Health• Health check (Powered by Mantis)• Gossip issues• Thrift/ Binary services status • Heap • Dmesg - Hardware and network issues

Monitoring
• Recent maintenances– Jenkins– User initiated maintenances
• Wide row metrics• Log file warning/ errors/exceptions

Common Approach
CRON System
JobRunnerJob
RunnerJobRunnerJob
Runner
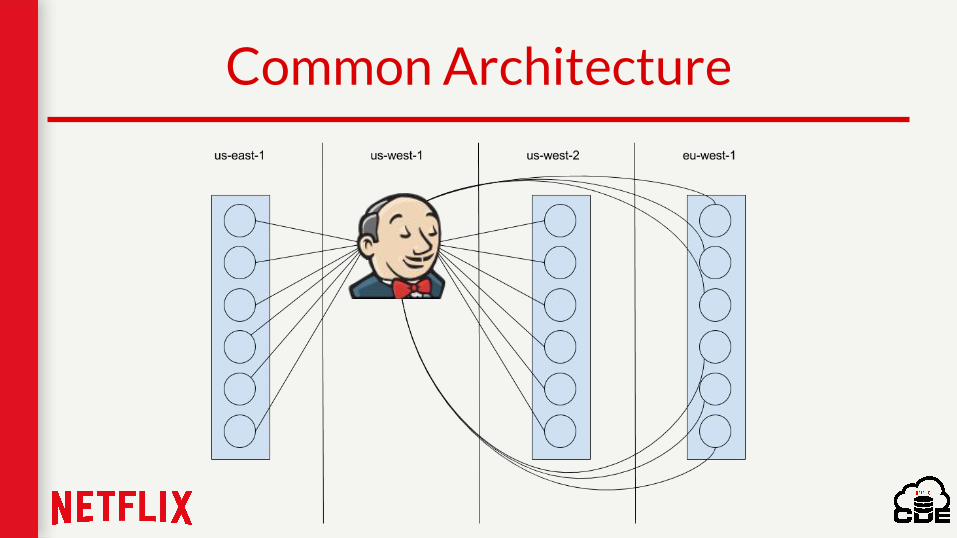
Common Architecture

Problems inherent in polling
● Point-in-time snapshot, no state● Establishing a connection to a cluster when it’s
under heavy load is problematic● Not resilient to network hiccups, especially for
large clusters

A different approach
What if we had a continuous stream of fine-grained snapshots ?

Mantis Streaming System
Stream processing system built on Apache Mesos
– Provides a flexible programming model– Models computation as a distributed DAG– Designed for high throughput, low latency
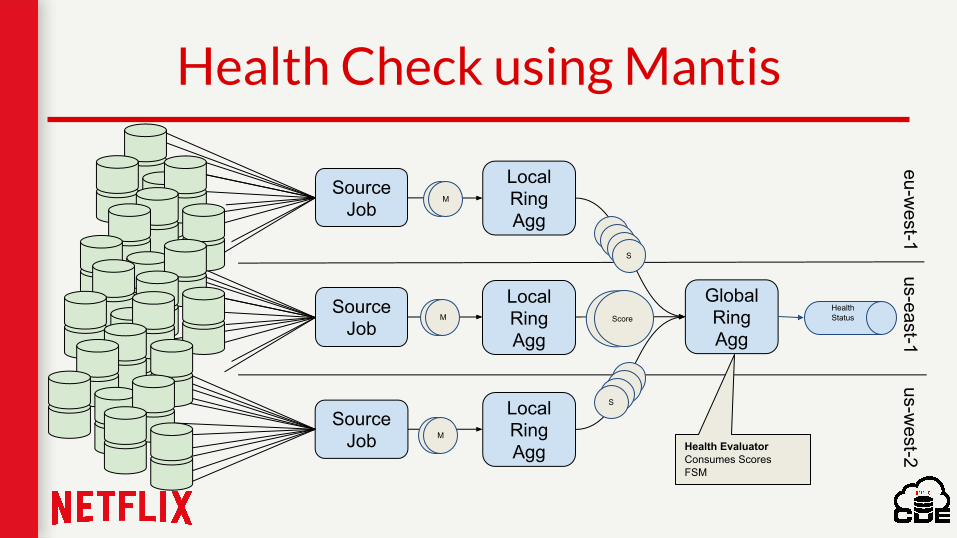
Health Check using Mantis
SourceJob
LocalRingAgg
GlobalRingAgg
SourceJob
SourceJob
eu-west-1
us-east-1us-w
est-2
LocalRingAgg
LocalRingAgg
Score
S
Health EvaluatorConsumes ScoresFSM
Health Status
S
SS
SS
SS
Score
MM
MM
MM

That’s great, but...
Now the health of the fleet is encapsulated in a
single data stream, so how do we make sense of
that ?

Real Time Dash (Macro View)
Macro View of the fleet
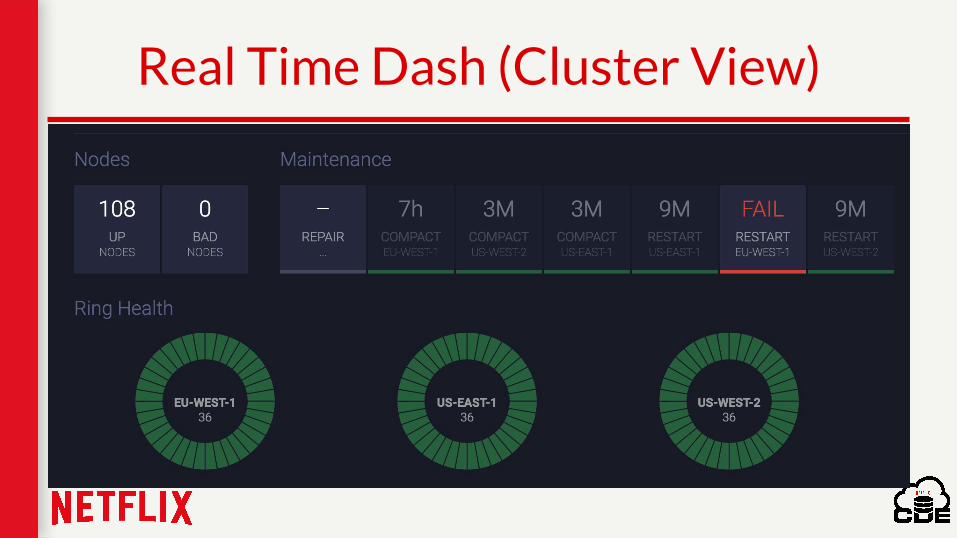
Real Time Dash (Cluster View)
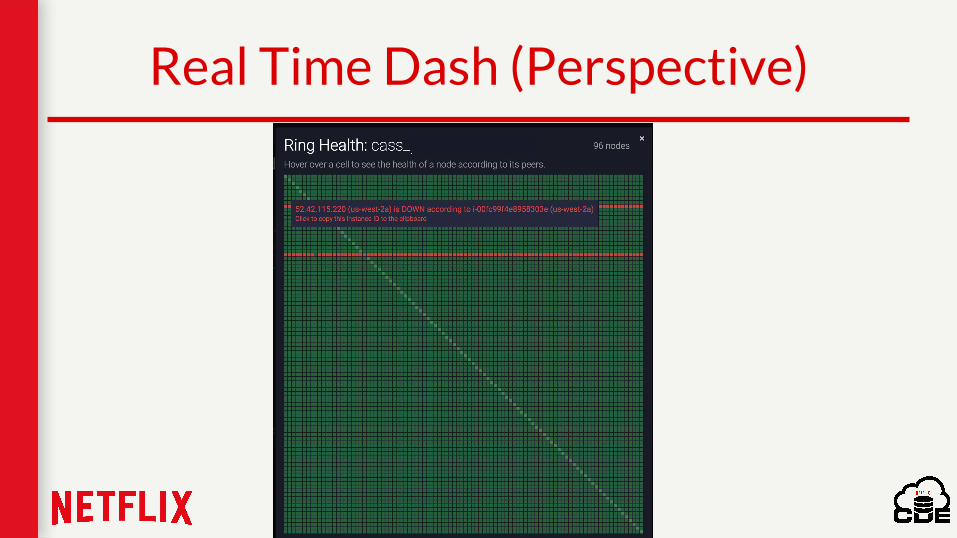
Real Time Dash (Perspective)

Benefits
● Faster detection of issues● Greater accuracy● Massive reduction in false positives● Separation of concerns (decouples detection
from remediation)


Known problems
• Distributed persistent stores (Not stateless)• Unresponsive nodes • Cloud• Configurations setup and tuning• Hot nodes / token distribution• Resiliency


• Bootstrapping and automated token assignment
• Backup and recovery/restore
• Centralized configuration management
• REST API for most nodetool commands
• C* JMX metrics collection
• Monitor C* health
Building C* in cloud with Priam
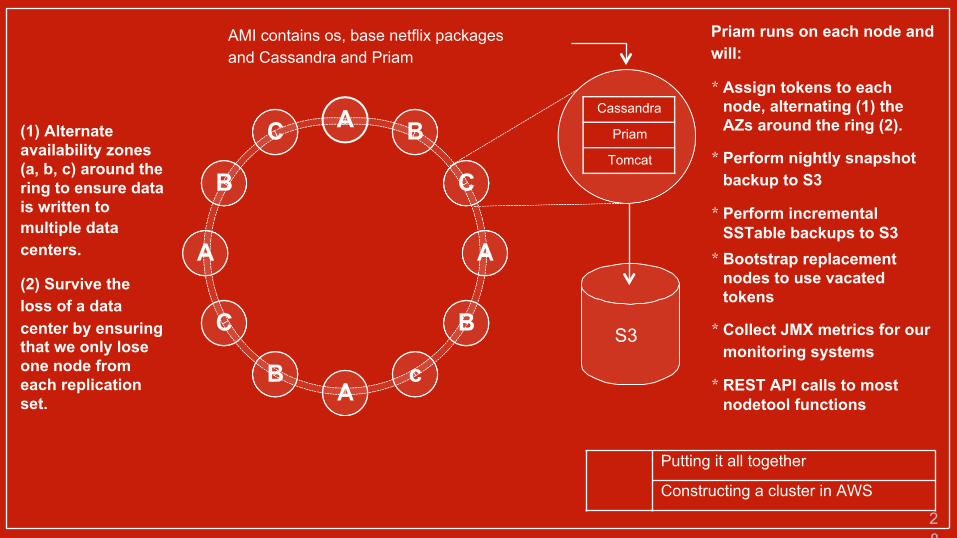
(1) Alternate availability zones (a, b, c) around the ring to ensure data is written tomultiple data centers.
(2) Survive the loss of a datacenter by ensuring that we only lose one node from each replication set.
A B
C
A
B
cA
B
C
A
B
C
Priam runs on each node and will:
* Assign tokens to each node, alternating (1) the AZs around the ring (2).
* Perform nightly snapshot backup to S3
* Perform incremental SSTable backups to S3
* Bootstrap replacement nodes to use vacated tokens
* Collect JMX metrics for our monitoring systems
* REST API calls to most nodetool functions
Cassandra
Priam
Tomcat
Putting it all together
Constructing a cluster in AWS
AMI contains os, base netflix packages and Cassandra and Priam
S3
28
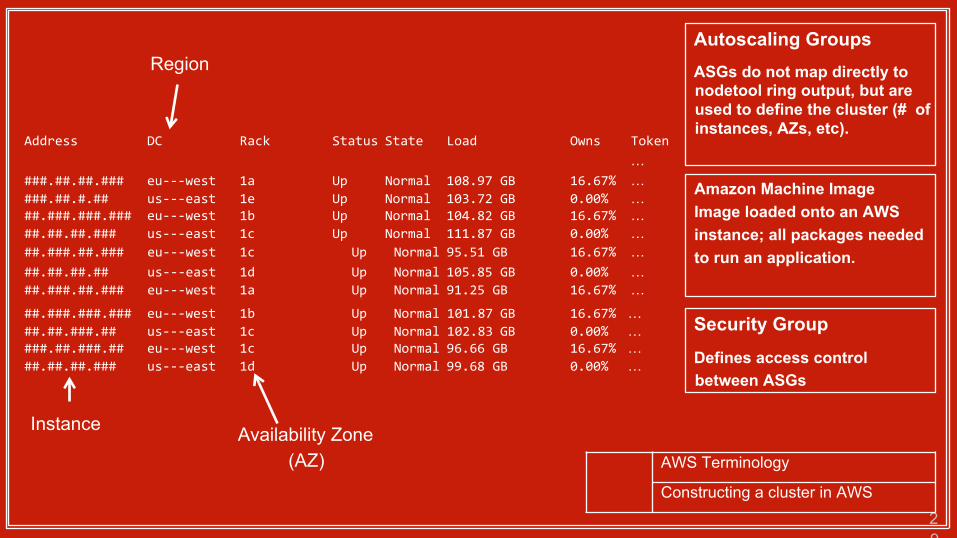
Address DC Rack Status State Load Owns Token
…###.##.##.### eu---west 1a Up Normal 108.97 GB 16.67% …###.##.#.## us---east 1e Up Normal 103.72 GB 0.00% …##.###.###.### eu---west 1b Up Normal 104.82 GB 16.67% …##.##.##.### us---east 1c Up Normal 111.87 GB 0.00% …
###.##.##.### us---east 1e Up Normal 102.71 GB 0.00% …##.###.###.### eu---west 1b Up Normal 101.87 GB 16.67% …##.##.###.## us---east 1c Up Normal 102.83 GB 0.00% …###.##.###.## eu---west 1c Up Normal 96.66 GB 16.67% …##.##.##.### us---east 1d Up Normal 99.68 GB 0.00% …
Instance
Region
Availability Zone (AZ)
Autoscaling GroupsASGs do not map directly to nodetool ring output, but are used to define the cluster (# of instances, AZs, etc).
Amazon Machine Image Image loaded onto an AWS instance; all packages needed to run an application.
29
##.###.##.### eu---west 1c Up Normal 95.51 GB 16.67% …##.##.##.## us---east 1d Up Normal 105.85 GB 0.00% …##.###.##.### eu---west 1a Up Normal 91.25 GB 16.67% …
AWS Terminology
Constructing a cluster in AWS
Security Group
Defines access control between ASGs

Resiliency
• Instance
• AZ
• Multiple AZ
• Region

Resiliency - Instance
• RF=AZ=3
• Cassandra bootstrapping works really well
• Replace nodes immediately
• Repair on regular interval

Resiliency - One AZ
• RF=AZ=3• Alternating AZs ensures that each AZ has a full replica of
data• Provision cluster to run at 2/3 capacity• Ride out a zone outage; do not move to another zone• Bootstrap one node at a time• Repair after recovery

Resiliency - Multiple AZ
• Outage; can no longer satisfy quorum
• Restore from backup and repair

Resiliency - Region
• Connectivity loss between regions – operate as island
clusters until service restored
• Repair data between regions



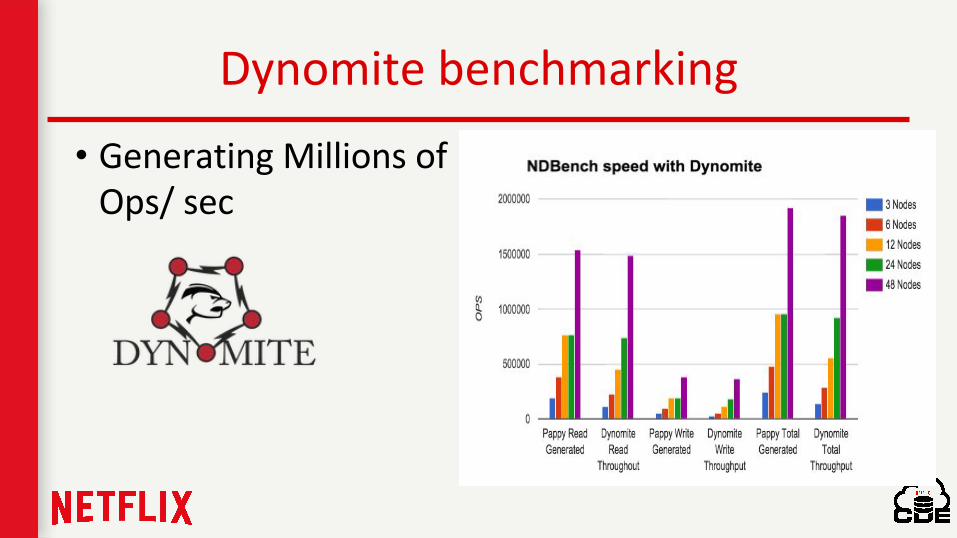
NdBench - Netflix Data Benchmark


••••••


•
-
-
-

•

Stitching it together
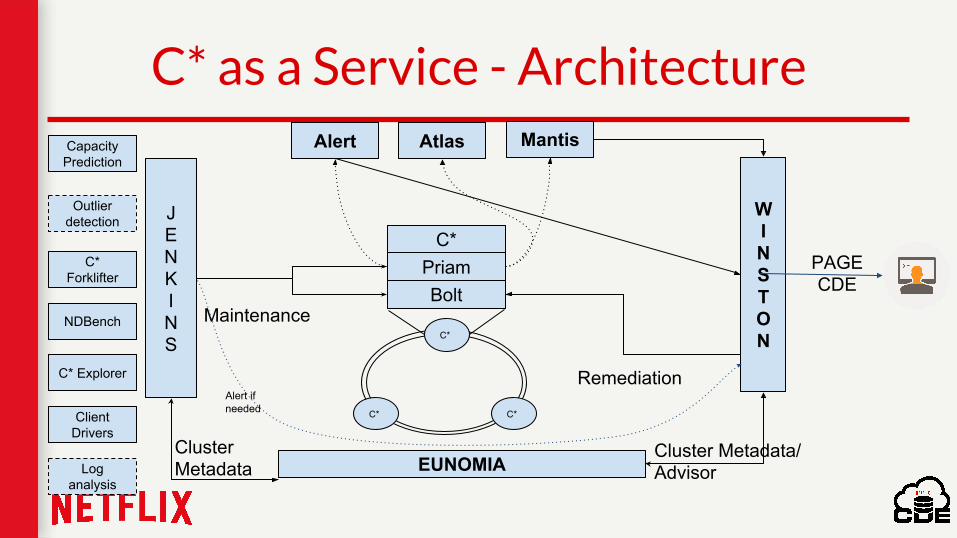
C* as a Service - Architecture
JENKINS
WINSTON
EUNOMIA
Alert Atlas Mantis
C*
C*
C*PriamBolt
Cluster Metadata
Cluster Metadata/ Advisor
Maintenance
Remediation
C*
PAGE CDE
Alert if needed
Capacity Prediction
Outlier detection
C* Forklifter
NDBench
C* Explorer
Client Drivers
Log analysis



















