
Cassandra Essentials Day Cambridge
31
1
-
Upload
marc-fielding -
Category
Data & Analytics
-
view
34 -
download
0
Transcript of Cassandra Essentials Day Cambridge

1

2

We specialize in addressing 5 major KPIS Velocity - achieve goals faster Security Availability Performance Cost And help in strategies to optimize those KPIs
3

• Explosion in data volumes –More types of data tracked –Higher detail levels –Retention over time
•Need to manage with existing staff •Globally-distributed data •Rise of public clouds for real business use •Limited budgets and resources
4
5

• Peer-to-peer architecture • No single master or directory node • Data divided into partitions with primary keys • Allocated to a node using a hash function • Clients can connect to any node
6

• Additional nodes bring extra storage and processing capacity • Vertical scaling too • No built-in size limits • Data distributed by hash function - no central directory required
7

8

• Log-structured data format appends all changes • Particularly fast for writes • No read-before-write • High concurrency through load distribution • Smart routing to nearest replica
9

Log-structured data is a new concept for people coming from relational databases For speed, we never look at the current data That means that inserts and updates are the same In this example, Billy has his first name updated to William The last line is a deletion, or “tombstone” as referred to in Cassandra, and tracks that a deletion has taken place
10

• Data is replicated across multiple nodes • Administrator can control how many • All nodes can serve data • Peer-to-peer “gossip” of state information • Automatic retry and routing around failed nodes
11

• Supports multiple geographic regions • Simultaneously active in all • Automatic replication • Can run across both your own datacenter and the cloud • Can be used for workload isolation too
12

Easiest way to show is as an example Assuming replication factor of 3: all data is on all nodes Insert on A Data will be replicated everywhere Buy do you wait until all nodes respond? What if node C is down? OK, write one What if C comes back up? You read old data Fix: force read on a majority of nodes (quorum) for strong consistency model But you trade off overhead doing reads twice, and waiting for two writes
13

What if node C is down? A will hang. OK, write one What if C comes back up? You read old data Fix: force read on a majority of nodes (quorum) for strong consistency model But you trade off overhead doing reads twice, and waiting for two writes
14
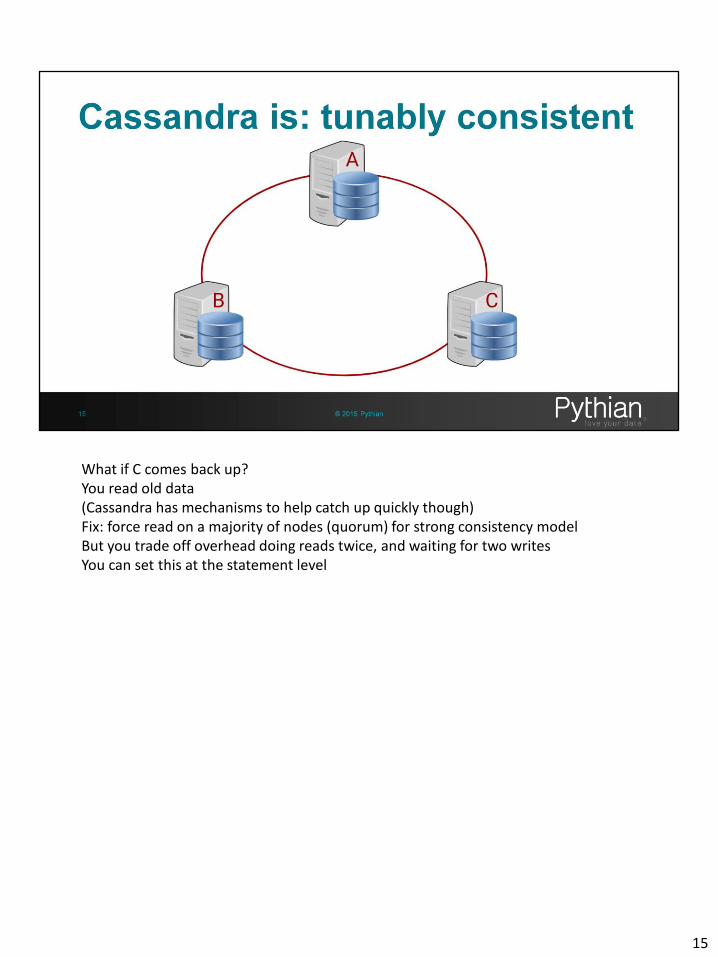
What if C comes back up? You read old data (Cassandra has mechanisms to help catch up quickly though) Fix: force read on a majority of nodes (quorum) for strong consistency model But you trade off overhead doing reads twice, and waiting for two writes You can set this at the statement level
15
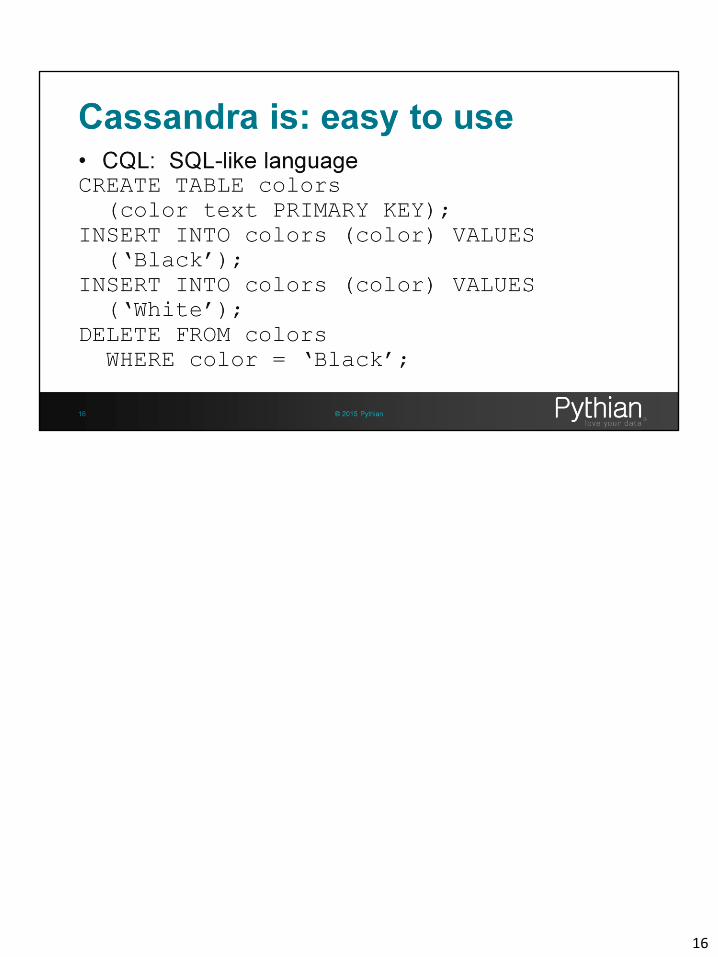
16

17

This afternoon you’ll hear a lot about data modeling in Cassandra A common theme: don’t treat it like an Excel spreadsheet Cassandra doesn’t do joins between tables Instead, data nesting can store similar data together
18

• Selects ideally on primary key • Duplicate data for frequently-used queries • But ad-hoc queries could have hundreds of combinations • Not efficient to duplicate at this level • Need to run aggregate functions: SUM(), GROUP BY, etc
19

20

21
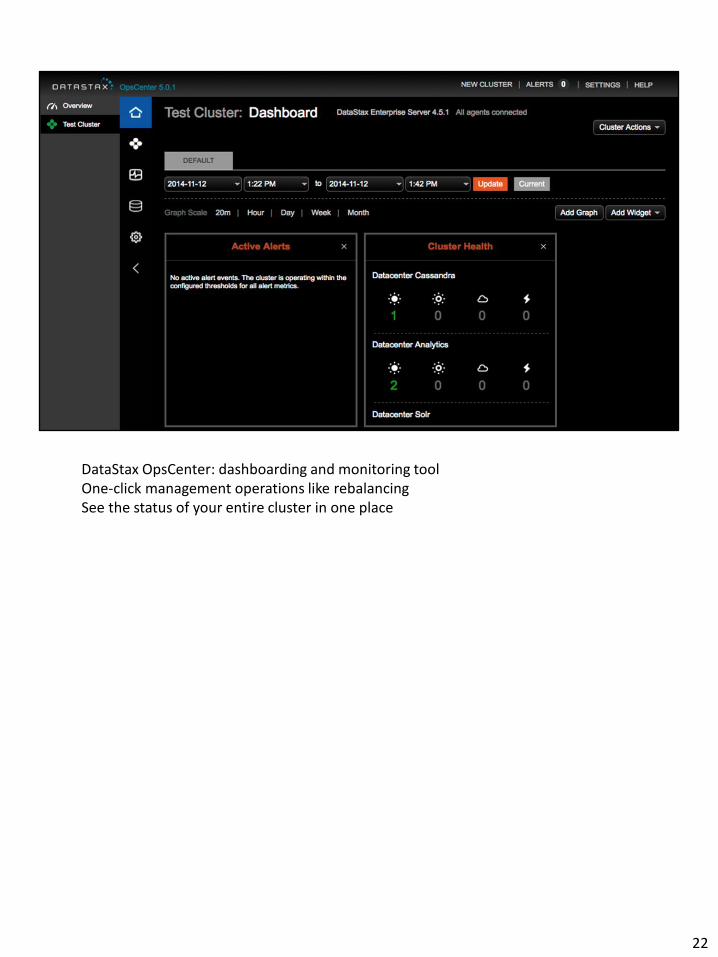
DataStax OpsCenter: dashboarding and monitoring tool One-click management operations like rebalancing See the status of your entire cluster in one place
22

DataStax DevCenter: integrated development for environment Visual view of database structure Interactive query execution
23

24

25

26

If you’re not quite so skilled on Cassandra, Azure, or both, Pythian can help (pass onto Jeff?)
34
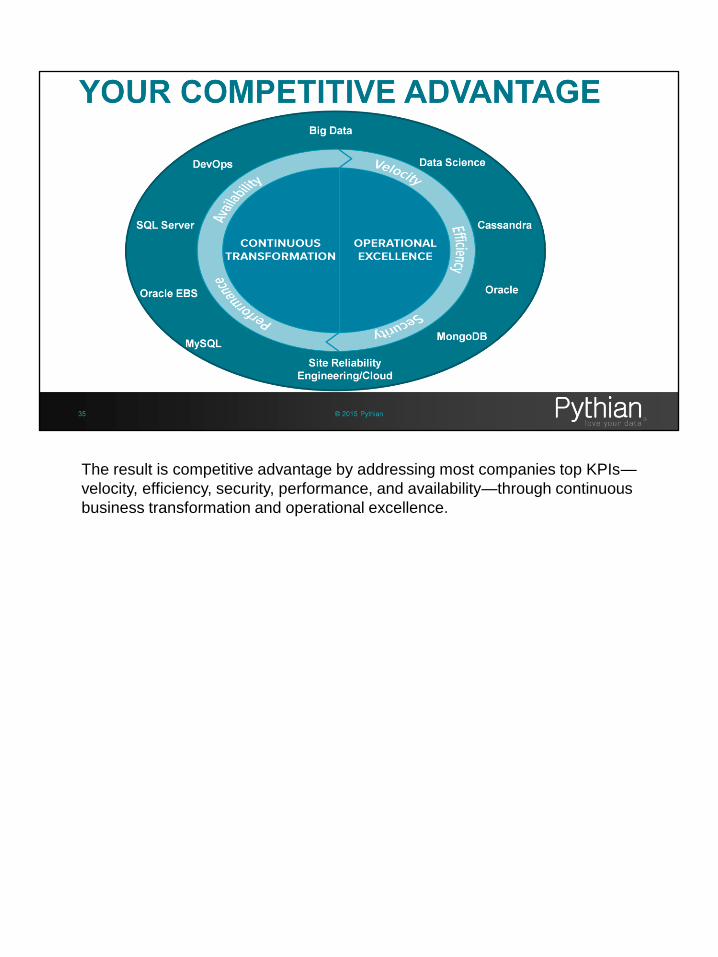
The result is competitive advantage by addressing most companies top KPIs—
velocity, efficiency, security, performance, and availability—through continuous
business transformation and operational excellence.


37

38


















