
Cassandra Day Atlanta 2015: Feeding Solr at Large Scale with Apache Cassandra
24
Feeding Solr at Large Scale with Cassandra @ Cassandra Day Atlanta 2015-03-19
-
Upload
planet-cassandra -
Category
Technology
-
view
246 -
download
4
Transcript of Cassandra Day Atlanta 2015: Feeding Solr at Large Scale with Apache Cassandra

Feeding Solr at Large Scale with Cassandra
@
Cassandra Day Atlanta 2015-03-19

About Me Joseph Streeky Manager, Search Framework Development ● Joined Careerbuilder in 2005 ● BS Computer Science - Georgia Tech ● Natural Language Processing - Columbia University ● Software Engineering for SaaS - University of California, Berkeley

About Me Joshua Smith
Database Administrator III [email protected]
● Joined Careerbuilder in 2011 ● Took over management of Cassandra in 2013 ● BS Computer Science - Georgia Tech

About Careerbuilder is the global leader in human capital solutions, helping companies target and attract their most important assets - their people. ● More than 22 Million unique visitors a month ● More than 300,000 employers post more than 1 million
jobs on Careerbuilder ● Careerbuilder operates in the United States, Europe,
Canada and Asia. Its sites, combined with partnership and acquisitions, give Careerbuilder a presence in more than 55 countries worldwide.

About Search @ • 1 million ac*ve jobs each month • 60 million ac*vely searchable resumes • 500 globally distributed search servers (in the U.S., Europe, & the cloud)
• Thousands of unique, dynamically generated search indexes • 1.5 billion search documents • 2-‐3 million searches an hour

Search Powers…

Feeding Solr at Large Scale with Cassandra

Feeding Platform Requirements ● Volume Requirements
o 1000+ documents / second ● Able to scale linearly ● Highly available ● Easily able to deploy to multiple location
(Private datacenter vs AWS)

Technologies Technologies
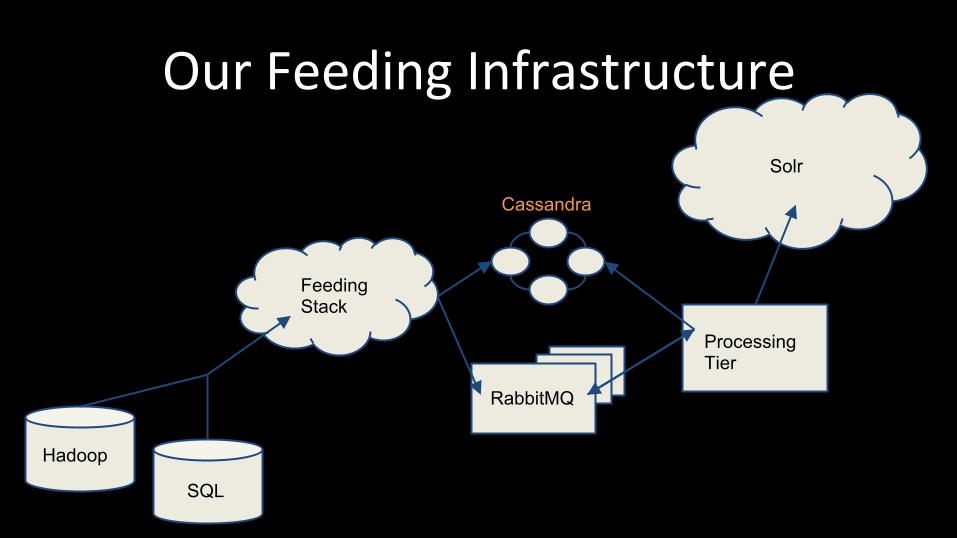
Our Feeding Infrastructure
Feeding Stack
Hadoop
SQL
RabbitMQ
Cassandra
Processing Tier
Solr

Feeding Steps ● Content Creation - Translate to Solr Indexing Format (we use XML) ● Shard - Determine Routing Rules related to this document ● Batch - Group together documents that have the same routing rules for
batch feeding ● Send - Send the batch to Solr ● Verify - Verify that Solr received the batch ● Reprocess - For any set of documents that failed during any step of
the process we place the document(s) here for reprocessing

Our Search Infrastructure
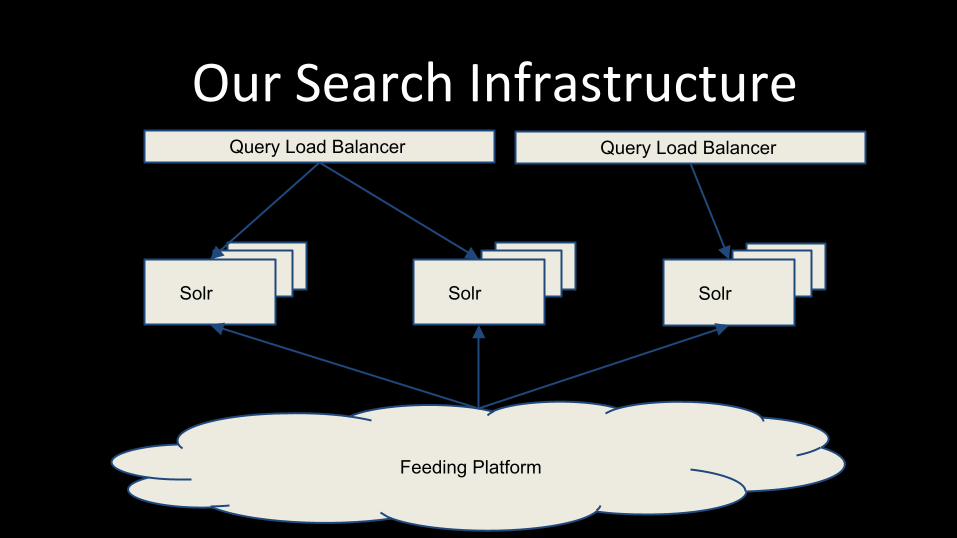
Solr Solr Solr
Feeding Platform
Our Search Infrastructure Query Load Balancer Query Load Balancer

Feeding Solr at Large Scale with Cassandra

Storage in Cassandra
● Two column families per pool o Initial data o Translated for Solr
● Both have a DocumentID as the key ● The initial data column family is the key and some
number of columns based on user data ● The Translated column family is just a DocumentID and
a single content field

Read and Wri6ng ● Quorum Read ● Quorum Write ● Needed for our specific use case, if we fail to read the
newest data we have to automated way to recover

Cassandra Ring Specs ● 3 Node ring test ● 21 Nodes Production
o 56 TB o Datastax Cassandra o Version 2.0.5 o Vnodes o RF = 3 o 4K write/s - 3K read/s

Cassandra Node Specs ● Dell R620 ● 2 x E5-2630 V2 ● 2.60 GHZ CPU ● 128 GB RAM ● 3 x 1.6TB SAS SSD in RAID 5

Pre 1.2 Performance Stuff ● Compaction Fun ● Cold Read problem ● Garbage collection

Compaction Fun ● Cassandra version 1.0.8 ● Single threaded compaction ● Eating up heap space until OOM
error ● JNA not installed ● Reduced memtable and cache size ● increased the heap size to 12 GB

Cold Read Problem ● Refeeding involves all documents ● Each row will be read multiple times ● Cold reads means lots of seeks ● Spinning disks HATE seeks

SSD ● Nightly repair times decreased from 23
hours to less than 3 hours ● Write latency decreased from 15 ms to 2.4
ms ● cassandra.yaml
o concurrent_reads: 96 o concurrent_writes: 192

AWS vs Private ● Combination of AMI and chef to configure ● R3.XLarge with EBS optimized
o 4 vCPU, 30 GB RAM, Provisioned IOPS ● RF = 3 ● 2 Availability zones for high availability and
local quorum ● Comparable performance to local datacenter ● Currently deploying version 2.0.12



















