

Calcul intensif Argos - indico.lal.in2p3.fr · 22 Dell Confidential – Shared Under NDA Only HPC...
35
HPC EMEA Team Calcul intensif Argos 15 Mai 2012 1 Marc Mendez-Bermond Architecte solutions de calcul intensif
Transcript of Calcul intensif Argos - indico.lal.in2p3.fr · 22 Dell Confidential – Shared Under NDA Only HPC...

HPC EMEA Team
Calcul intensif Argos 15 Mai 2012
1
Marc Mendez-Bermond Architecte solutions de calcul intensif

HPC EMEA Team
Agenda • Contexte • Technologies • Evolutions • Position Dell • Questions/réponses

HPC EMEA Team HPC EMEA Team
Applications HPC

HPC EMEA Team
Le calcul hautes performances Usage et évolution • Objet
– Simuler les phénomènes pour s’affranchir du coût, de la complexité ou de la période des systèmes étudiés – Assurer un traitement massif de données
• Historique
– Des systèmes main-frame aux grappes de calcul – Loi de Moore, de Amhdal et quelques autres – Révolution multi-coeur – Système hybrides à coprocesseurs
• Simulation/prototypage numérique
– 3ème discipline après la théorie et l’expérimentation – Ne pas oublier le traitement massif de données !
Confidential 4

HPC EMEA Team
Le calcul hautes performances Contraintes • Ere SMP :
– Nombre de processeurs en augmentation constante (max. 2048) – Complexité des systèmes – Technologies propriétaires
• Ere Beowolf :
– Nombre de systèmes grandissant (> 10000) – Utilisabilité et complexité d’administration – Technologies ouvertes
• Ere hybride :
– Toutes les contraintes du Beowolf – Stress du gestionnaire de ressources – Difficulté de programmation
Confidential 5

HPC EMEA Team HPC EMEA Team
Le calcul intensif en 2012 et au-delà • La simulation et le traitement de données massif sont la clé du progrès – Adoption soutenue – Analyses de gigantesques quantités de données – Rapport GES consommés / GES économisés > 10 !
• Systèmes massivement parallèles, accélérateurs – Rupture technologique au bénéfice du rapport perf/conso – Nécessité d’adapter l’application et son environnement – Evolution planifiée de ces technologies
• Evolutions des technologies existantes – Processeurs, stockage, réseaux – Efficacité énergétique en objectif principal
• Le HPC devient un outil – Systèmes clé en main ou accompagnement sur le long terme – Systèmes dynamiques orientés services : Cloud Computing

HPC EMEA Team
Parallèlisme
• Une application HPC décompose le domaine de travail (données) en sous-domaines. • Chaque sous-domaine subit l’exécution d’une boucle de calculs “simples” répétés une multitude de fois pour
obtenir la précision souhaitée et la convergence du résultat vers la solution recherchée. • Chaque boucle est nommée une itération, généralement pour un pas de temps. • Le résultat peut être celui de la dernière itération (analyse de risques) ou de chacune des itérations (météo
sur les heures à venir, déformation d’une coque de voiture).
Confidential 7

HPC EMEA Team
Le parallèlisme et ses avantages
Confidential 8
• Décomposition en sous-domaines selon le phénomène simulé (3D ici) • Motif de communications entre les sous-domaines spécifique • Permet de soulager :
– Stress processeur : multiplier leur nombre plutôt que leur performance – Quantité de mémoire par système : systèmes plus économiques
• Inconvénients : – Travail à fournir pour sortir d’un motif séquentiel – Optimisation pour le passage à l’échelle en fonction des objectifs visés – Infrastructure logicielle et matérielle complexifiée
1 problème de taille N Tséq. = X * Y * Z
N problèmes de taille 1 T// = x * y * z + séq. global

HPC EMEA Team HPC EMEA Team
Solutions HPC Vision du centre de calcul
Exploitation Acquisition
Données d’entrée Résultats bruts Résultats finaux
Post- traitement
Calcul
Cluster
Viz 3D
Nœud dédié
Cluster
Stockage Stockage Stockage
Grille

HPC EMEA Team
Gestion des systèmes parallèles
Confidential 10
Noeuds de calcul
Noeuds de service
Serveurs de stockage Serveur maitre, compilation,
supervision, portail, licences, ...
Réseau d’interconnexion

HPC EMEA Team
Gestion des systèmes parallèles
Confidential 11
Administration Gestionnaire de travaux Développement APIs Surveillance Déploiement

HPC EMEA Team
Topologies des grappes de calcul Fat-tree
Confidential 12
L2
L1 L1 L1 L1 L1
L1
• Structure quasi-plane et homogène • Latences moyenne très faible • Faibles contentions
HPC EMEA Team
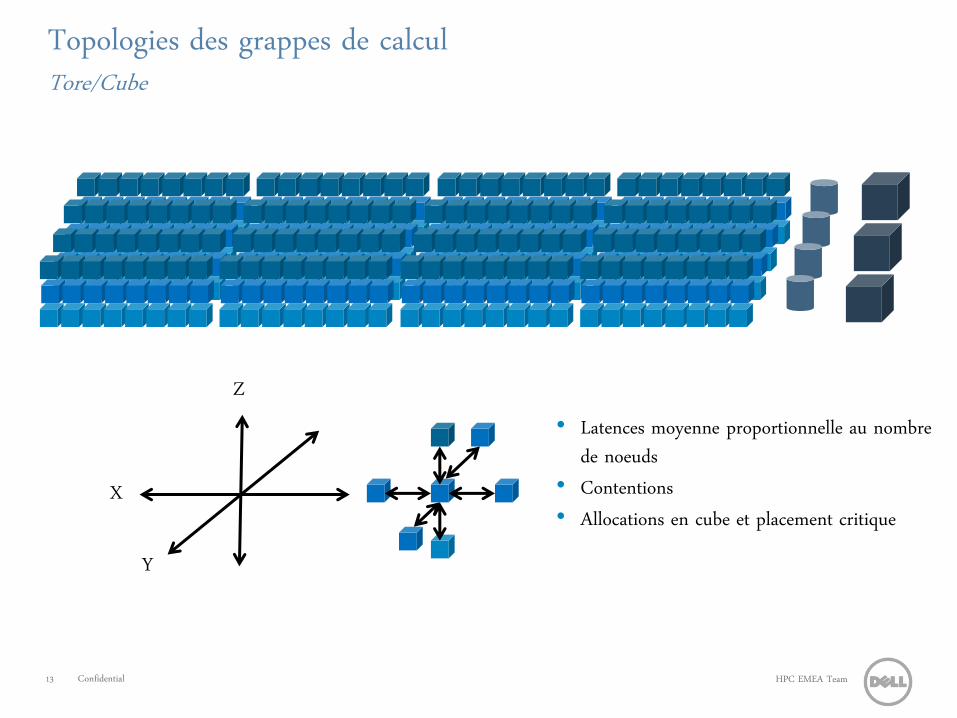
Topologies des grappes de calcul Tore/Cube
Confidential 13
X
Y
Z • Latences moyenne proportionnelle au nombre
de noeuds • Contentions • Allocations en cube et placement critique

HPC EMEA Team
Consommations/dissipations Une course au MegaWatt
Confidential 14
• L’échelle des systèmes devient ingérable > 100000 noeuds ~1000000 coeurs 12 PFlop/s (K Super Computer)
• Systèmes généralistes :
Haute efficacité : 1 GFlop/s/W (K Super Computer) Très haute efficacité : 2 GFlop/s/W (BG/Q) Ultra haute efficacité : 6 GFlop/s/W (architecture de calcul spécifique) Dell/TACC Stampede : ~1.8 GFlop/s/W (SnB + MIC)
• Pour 1 EFlop/s :
Technologies actuelles : 1000 MW Loi de Moore : 200-300 MW Cible réaliste : 50 MW max.

HPC EMEA Team
Topologies des noeuds de calcul Considérations énergétiques
Coeurs L1
L2
L3
RAM/CTRL
DEVICES
Calcul DP : 20 pJ
Short XFER : 2 pJ
Long-range XFER : 150-300 pJ
Off-chip DRAM : ~15 nJ
Egalement : • L’ordonnanceur d’une unité de calcul peut aujourd’hui consommer 2nJ pour une
opération de 25pJ • L’équilibre entre les différents débits, latences et capacités est primordial pour
maintenir l’efficacité de l’ensemble !
LR Off-chip XFER : 240 fJ/mm/bit/transition (256b, 100mm: 3 nJ)

HPC EMEA Team
Topologies des CI Localisation des échanges et transferts
Chip Echelon (17x17mm) • Localité des caches • Interfaces RAM/NW proches des cœurs • Accès courtes distances • Structure symétrique
• Concept minimaliste : maximum de puissance de calcul sur un
minimum de surface pour MoBo totalement spécifique
Chip MIC & Fermi • Applications de la plupart des principes de localité • Besoin d’exprimer/gérer la localité

HPC EMEA Team
Topologie globale (calcul + I/O) Super Calculateur K
Confidential 17

HPC EMEA Team
Résumé topologie/architecture
• Système HPC actuel – hautement hiérarchique – non-transparent – faiblement contrôlable
• La piste vers l’exaflop – fortement contrainte par la consommation électrique et le refroidissement – améliorer la localité des données : cache, mémoire, stockage ... – intégrer de manière optimale la pile d’exécution et l’architecture matérielle – optimiser les technologies matérielles
• Position de Dell – intégrateur de technologies – expertise et collaboration
Confidential 18

HPC EMEA Team
Effets collatéraux • Système HPC actuel
– COTS • Le système exaflopique
– Retour des systèmes spécifiques/propriétaires › Pénibilité : développement vs production
– Divergence : courte à moyenne durée › Consolidation : nécessité de regrouper les moyens › Rentabilité/coût à prouver
• Convergence avec le marché de masse – Impact du mobile/portable
› Puissance applicative › Efficacité énergétique
– Généralisation du parallélisme (OpenCL, ...) › Applications multimédia › Applications temps-réel
Confidential 19

HPC EMEA Team
Approche de Dell
• Modèle ouvert – Technologies standards (aujourd’hui x86) – Investigation constante de nouvelles technologies – Système de haute productivité : « le cluster pour vos travaux quotidiens »
• Approche technologique – Partenariats étroits pour :
› meilleure perception du marché › études communes › relever les défis scientifiques ou industriels
– Différentiateurs technologiques plus marqués à venir ...
Confidential 20

HPC EMEA Team HPC EMEA Team
4 nœuds DP/2U POWEREDGE C6220 Intel Sandy-Bridge EP
4 nœuds DP/2U POWEREDGE C6105
AMD Valencia
Confidential
2 nœuds QP/2U POWEREDGE C6145
AMD Interlagos
3U PCIe EXPANSION CHASSIS POWEREDGE C410X
8/12 nœuds UP/3U POWEREDGE C5220
Intel Ivy-Bridge
Les serveurs de la dimension HyperScale
5-10 nœuds DP/4U POWEREDGE C8000 Intel Sandy-Bridge EP

HPC EMEA Team 22 Dell Confidential – Shared Under NDA Only
PowerEdge C6220 Performance de calcul ultime en format ultra-dense
4 nœuds biprocesseurs Intel E5-2600 = 2U
Idéal pour : Solutions HPC ou Big-Data ultra-denses
Rendement • 100W de moins sur le châssis • Validé pour opération à 40 voire
45°C • Gain de 65% en flops/W • Efficacité PSU > 94%
Flexibilité • Configurations indépendantes par
tiroir • Tiroirs DH pour accélérateurs ou I/O • Distribution disques « dynamique »
Performances • E5-2600 : 8 flop/c DP • 4 canaux RAM 1600 • Sockets <= 135W • PCI Express Gen3 :
• 1 ou 2x 16x • 1 mezzanine 8x
Ouverture : RHEL, SuSE, CentOS, Ubuntu, FreeBSD

HPC EMEA Team
PowerEdge C6220: nouvelles économies d’énergie
Optimisations composants et efficacité énergétique : 100 Watts d’économie au niveau châssis.
Calculs : #1. Alimentations à 94% d’efficacité contre 92% pour le C6100 : 2% * 1400W = 28W, 1200W=24W #2. Distribution des alimentations : 9.2W * 4 = 36.8W #3. Economie ventilation : Plein régime = 64.4W Total = 129W pour 2 PSU 1400W, 125W pour 2 PSU 1200W Economies : 100W (conservatif) Sources : • Inventec, Power Bus-bar Testing Result, June 2011, Ivan Wu • Inventec, The Comparison of 8038 Fan and 6038 Fan by Beryllium in x86, June 14, 2011, Biot Huang and Roger Yeh, Engineers, Thermal Design Dept. Processors: • PowerEdge C6220: Intel Romley EP series E5-2600 series up to 8 cores TDP supported up to 135W • PowerEdge C6100: Intel Westmere Xeon 56xx series up to 6 cores capped at 95W power

HPC EMEA Team
Châssis C8000 ”Zeus” Next-Generation Infrastructure for PowerEdge C

HPC EMEA Team
C8220x Lames double largeur - 2S Romley EP
Architecture 2S Intel Xeon E5-2600 Series CPUs Intel C600 Chipset
Memory 16 DIMM Slots DDR3 ECC RDIMM Max 256GB 1600MHz
PCI Expansion 2x PCI-E x16 Slots (Stacked or In-line for GPU Support)
Mezzanine Slot PCI-E x8 Mezz Drive Controller Intel C600 (Patsburg)
Drive Bays Up to 8 x 2.5” or 4x 3.5” Internal 2x 2.5” External (Full-Width sled only)
HDD’s SAS/SSD/SATA/NLSAS NIC Dual Intel 825xx 10 GbE NIC
Management IPMI 2.0 DCMI 1.0 AST2300 (iKVM) Dedicated Management

HPC EMEA Team
C8220 Lame simple largeur - 2S Romley EP
Architecture 2S Intel Xeon E5-2600 Series CPUs Intel C600 Chipset
Memory 16 DIMM Slots DDR3 ECC RDIMM Max 256GB 1600MHz
PCI Expansion 1x PCI-E x16 Slot (Single-Width) Mezzanine Slot PCI-E x8 Mezz
Drive Controller Intel C600 (Patsburg)
Drive Bays 2 x 2.5” Internal
HDD’s SAS/SSD/SATA/NLSAS NIC Dual Intel 825xx 10 GbE NIC
Management IPMI 2.0 DCMI 1.0 AST2300 (iKVM) Dedicated Management

HPC EMEA Team 27 Dell Confidential
C8000xd Lame stockage double largeur
Form Factor 4U Chassis Up to 4 Full Width Sleds w/ Internal PSU’s Up to 5 Full Width Sleds w/ External PSU’s
Connectivity External, front accessible 5 x4 Mini-SAS Single Channel per HDD
SAS Expander LSI SAS Expander 5 x4 Mini-SAS connections
Drive Bays Up to 12 x 3.5” Hot Swap HDD HDD’s 3.5” SATA/NL SAS/SAS
2.5”Drives available via 3.5”carrier

HPC EMEA Team
Configurations calcul Optimisation de l’infrastructure
Confidential
Fond de panier
C8220
X
PSU
PSU
Fond de panier C8
220
C8220
C8220
C8220
C8220
C8220
C8220
C8220
PSU
PSU
C8220
X
C8220
X
C8220
X
Fond de panier
C8220
X
Fond de panier
C8220
C8220
C8220
C8220
C8220
C8220
C8220
C8220
C8220
X
C8220
X
C8220
X
C8220
X
C8220
C8220
PSU PSU
8x
lames
C8220
10
x lam
es C8
220
4x
lames
C8220
X (8
GPU)
5x
lam
es C8
220X
(10 G
PU)

HPC EMEA Team
Configurations stockage Haute densité
Confidential Dell Confidential – NDA Required
Fond de panier
C8220
X
PSU
PSU
Fond de panier C8
220
PSU
Fond de panier
C8220
X
Fond de panier
C8220
C8220
PSU PSU
C8220
XD
C8220
XD
C8220
XD
C8220
XD
C8220
XD
C8220
XD
C8220
XD
C8220
XD
C8220
XD
C8220
XD
C8220
XD
C8220
XD
C8220
XD
C8220
XD
C8220
XD
1 serv
erur R
omley
EP
48 H
DD –
144T
o 2 s
erveur
s Rom
ley EP
2x
24 H
DD –
2x 72
To
1 serv
eur Ro
mley
EP
36 H
DD –
108 T
o 1 s
erveur
Roml
ey EP
48
HDD
– 14
4 To

HPC EMEA Team Dell Confidential
Châssis et Infrastructure PDU
Dell Confidential – NDA Required
Form Factor • 4U Chassis • 4 Double-Width/8 Single-Width (Internal PSU’s) • 5 Double-Width/10 Single-Width (External PDU)
Management • Independent BMC Management • Shared Rack-Level Management
Power Supply • Internal PSU’s – Up to 4x 1400W (2 SW sleds) • External PDU’s – Up to 5 chassis powered per PDU
(5+1x 1400W) Cooling • Front-to-back airflow
• Front cabling • Rear hot aisle • Designed for Dell Fresh Air

HPC EMEA Team
Modular Category Attributes Target Customers Dell Source
Micro-modular • Inexpensive • Easy to deploy in existing raised-floor
environments
• Virtually any enterprise customer with existing data center GICS
Containerized • Convenient, efficient packaging of
power/cooling for 5 to 20 racks • Rapid deployment, • ISO 20, 40 and 53 ft sizes
• Universities; Federal • Range of businesses • Customers looking for fast, often temporary
capacity or DR
GICS
Modular Raised-floor
• Cost-effective, rapid deployment • Flexible, multi-use space • Raised-floor look & feel
• Wide range of Public or Enterprise customers • Want white space and traditional look & feel GICS
MDC (DCS Modular Data Center)
• Custom engagements • Right-sized power & cooling module design • Hyper-efficient (PUE <1.1) • Large scale (>1MW) projects
• Large search, Web 2.0 Co’s • Customers w/ large-scale deployment plans w/
unique needs • Clear IT vision; little need for open white space
DCS (Data Center Solutions)
Pre-fab raised floor • Large-scale deployments • Traditional raised-floor • Standardized design, speeds deployment and
lowers cost
• Large enterprise • Customer that need flexible white-space GICS
Modular Data Center Solutions Portfolio
• All products provide the benefits of modularization (cost, speed, efficiency)
31

HPC EMEA Team
Texas Advanced Computing Center's Stampede to enable data-intensive computing, and scientific visualization for nation's scientists
Organization The expert staff and world-class computing systems of the Texas Advanced Computing Center support cutting-edge research in nearly every field of science, powering the discoveries of tomorrow Challenge Advanced computing enables complex computational science and engineering research, and is critical in areas such as weather forecasting, climate modeling, energy exploration and production, drug discovery, new materials design and manufacturing, and more efficient and safer automobiles and airplanes. Solution Several thousand Zeus (PowerEdge C8000-series) with graphics processing units (GPUs) for remote visualization. Altogether, Stampede will have a peak performance of 10 petaflops, 272 terabytes (272,000 gigabytes) of total memory, and 14 petabytes (14 million gigabytes) of disk storage Benefits •Support more than a thousand projects in computational and data-driven science and engineering •Help train the next generation of researchers in advanced computational science and technology
"Stampede will usher forth a new era of computational simulation in which observational and experimental data are assimilated into large-scale models to create better predictions, accompanied by quantified uncertainties." Omar Ghattas, professor of Geological Sciences and Mechanical Engineering, and director of the Center for Computational Geosciences in the Institute for Computational Engineering and Sciences at The University of Texas at Austin
Read the press release Watch the video See the case study

HPC EMEA Team
Microsoft Bing Maps a path to one of the world’s most efficient data centers
Company Microsoft Bing Maps takes diverse satellite and aerial pictures and stitches them together to produce street-side views, bird’s-eye views, site pictures, and road maps. Challenge Bing Maps needed an extremely cost-effective, highly efficient computing solution to power a high-performance compute- and storage-intensive application running a customized parallel processing system built on SQL. This solution needed to be up to the challenges that come with processing and storing mountains of data on an hourly basis. Solution Dell Data Center Solutions created custom Modular Data Centers that hold 440 AMD processor-based Nucleon servers with 178 petabytes of storage running on high-speed Mellanox InfiniBand, transferring close to 250TB in 24 hours. Power usage effectiveness (PUE) has been measured at 1.03 under heavy load. Benefits •1/5 the cost of power for 5x the amount of compute density •8x reduction in data center operational costs when compared to traditional models. •From paved site to up and running in about 60 days
“Dell had a solution that was designed for high efficiency, density, and low cost. Their container allowed us to have a flexible IT unit, which gave us room to customize or modify to meet our needs. It was a clean and simple solution, and it was obvious that we were not going to be paying for items within the solution that we didn’t need.” Brad Clark, group program manager, Bing Imagery Technologies
See the press release Read the case study

HPC EMEA Team HPC EMEA Team
Centres de compétences
Programme XSEDE : simulation climat, météo, énergies, pharmaceutique, matériaux, aéronautique, automobiles ...
Texas Advanced Computing Center 10 Pflop/s – 15 Po
Centre de calcul IN2P3 Villeurbanne, Rhône > 1000 serveurs > 3000 disques Partenariat technologique
Programme LHC (Atlas, CMS, LhCB, Alice), astrophysique et astroparticules, sciences de la vie.














![[ towards a ] Full Combination - indico.lal.in2p3.fr · Learning from the past ... analysis don’t matter here ... CMS γγ (dijet) CMS 4l . Combining mass measurements • When](https://static.fdocuments.net/doc/165x107/5b8981e87f8b9abf5c8df83f/-towards-a-full-combination-learning-from-the-past-analysis-dont.jpg)



