C++ dla każdego
733
"C++ dla każdego"
-
Upload
catherine-landry -
Category
Documents
-
view
162 -
download
2
Transcript of C++ dla każdego

"C++ dla każdego"

Część I (19)
Rozdział 1. Zaczynamy (21)
Rozdział 2. Anatomia programu C++ (37)
Rozdział 3. Zmienne i stałe (49)
Rozdział 4. Wyrażenia i instrukcje (69)
Rozdział 5. Funkcje (95)
Rozdział 6. Programowanie zorientowane obiektowo (129)
Rozdział 7. Sterowanie przebiegiem działania programu (159)
Część II (191)
Rozdział 8. Wskaźniki (193)
Rozdział 9. Referencje (223)
Rozdział 10. Funkcje zaawansowane (253)
Rozdział 11. Analiza i projektowanie zorientowane obiektowo (287)
Rozdział 12. Dziedziczenie (321)
Rozdział 13. Tablice i listy połączone (351)
Rozdział 14. Polimorfizm (391)
Część III (435)
Rozdział 15. Specjalne klasy i funkcje (437)
Rozdział 16. Dziedziczenie zaawansowane (463)
Rozdział 17. Strumienie (511)
Rozdział 18. Przestrzenie nazw (549)
Rozdział 19. Wzorce (565)
Rozdział 20. Wyjątki i obsługa błędów (609)
Rozdział 21. Co dalej (635)
Dodatki (683)
Dodatek A Dwójkowo i szesnastkowo (685)
Dodatek B Słowa kluczowe C++ (695)
Dodatek C Kolejność operatorów (697)

Część 1.
Rozdział 1. Zaczynamy
Wprowadzenie Witamy w „C++ dla każdego.” Ten rozdział pomoże ci efektywnie programować w C++.
Dowiesz się z niego:
• dlaczego C++ jest standardowym językiem tworzenia oprogramowania
• Jakie kroki należy wykonać przy opracowaniu programu w C++
• w jaki sposób wpisać, skompilować i zbudować swój pierwszy, działający program w C++.
Krótka historia języka C++ Od czasu pierwszych komputerów elektronicznych, zbudowanych do wspomagania artyleryjskich obliczeń trajektorii podczas drugiej wojny światowej, języki programowania przebyły długą drogę. Na początku programiści używali najbardziej prymitywnych instrukcjami komputera: języka
1

maszynowego. Te instrukcje były zapisywane jako długie ciągi zer i jedynek. Dlatego wymyślono tzw. asemblery, zamieniające instrukcje maszynowe na czytelne dla człowieka i łatwiejsze do zapamiętania mnemoniki, takie jak ADD czy MOV.
Z czasem pojawiły się języki wyższego poziomu, takie jak BASIC czy COBOL. Te języki umożliwiały stosowanie zapisu przypominającego słowa i zdania, np. LET I = 100. Te instrukcje były tłumaczone przez interpretery i kompilatory na język maszynowy.
Interpreter tłumaczy odczytywany program, bezpośrednio zamieniając jego instrukcje (czyli kod) na działania. Kompilator natomiast tłumaczy kod na pewną formę pośrednią. Ten proces jest nazywany kompilacją; w jej wyniku otrzymujemy plik obiektowy. Następnie kompilator wywołuje program łączący (tzw. linker), który zamienia plik obiektowy na program wykonywalny.
Ponieważ interpretery odczytują kod programu bezpośrednio i wykonują go na bieżąco, są łatwiejsze w użyciu dla programistów. Obecnie większość programów interpretowanych jest nazywanych skryptami, zaś sam interpreter nosi nazwę Script Engine (w wolnym tłumaczeniu: motor skryptu).
Niektóre języki, takie jak Visual Basic, nazywają interpreter biblioteką czasu działania. Java nazywa swój interpreter maszyną wirtualną (VM, Virtual Machine), jednak w pewnych przypadkach taka maszyna wirtualna jest dostarczana przez przeglądarkę WWW (taką jak Internet Explorer lub Netscape).
Kompilatory wymagają wprowadzenia dodatkowego kroku związanego z kompilowaniem kodu źródłowego (czytelnego dla człowieka) na kod obiektowy (czytelny dla maszyny). Ten dodatkowy krok jest dość niewygodny, ale dzięki niemu kompilowane programy działają bardzo szybko, gdyż czasochłonne zadanie przetłumaczenia kodu źródłowego na język maszynowy jest wykonywane tylko raz (podczas kompilacji) i nie jest już konieczne podczas działania programu.
Kolejną zaletą wielu języków kompilowanych (takich jak C++) jest posiadanie tylko programu wykonywalnego (bez konieczności posiadania interpretera). W przypadku języka interpretowanego, do uruchomienia programu konieczne jest posiadanie interpretera.
Przez wiele lat głównym celem programistów było uzyskanie niewielkich fragmentów szybko działającego kodu. Programy musiały być niewielkie, gdyż pamięć była droga; musiały być także szybkie, gdyż droga była również moc obliczeniowa. Gdy komputery stały się mniejsze, tańsze i szybsze, a także gdy spadła cena pamięci, te priorytety uległy zmianie. Obecnie czas pracy programisty jest dużo droższy niż koszty eksploatacji większości komputerów wykorzystywanych w codziennej pracy. Teraz najważniejszy jest dobrze napisany, łatwy w konserwacji kod. Łatwość konserwacji oznacza, że gdy zmienią się wymagania wobec działania programu, program można zmienić i rozbudować, bez ponoszenia większych wydatków.
UWAGA Słowo „program” jest używane w dwóch kontekstach: w odniesieniu do zestawu poszczególnych instrukcji (kodu źródłowego), tworzonego przez programistę oraz w odniesieniu się do całego programu przyjmujacego postać pliku wykonywalnego. Może to powodować znaczne nieporozumienia, w związku z czym będziemy starać się dokonać rozróżnienia pomiędzy kodem źródłowym a plikiem wykonywalnym.
2

Rozwiązywanie problemów Problemy, które obecnie rozwiązują programiści, są zupełnie inne niż problemy rozwiązywane dwadzieścia lat temu. W latach osiemdziesiątych programy były tworzone w celu zarządzania dużymi ilościami nie poddanych obróbce danych danych. Zarówno osoby piszące kod, jak i osoby korzystające z programów, zajmowały się komputerami profesjonalnie. Obecnie z komputerów korzysta dużo osób, większość z nich ma niewielkie pojęcie o tym, jak działa program i komputer. Komputery są narzędziem używanym przez ludzi do konkretnej pracy, a nie w celu dodatkowego zmagania się z samym komputerem.
Można uważać za ironię, że wraz z pojawieniem się coraz łatwiejszych do opanowania przez ogół użytkowników programów, tworzymy programy, które same w sobie stają się coraz bardziej wymyślne i skomplikowane. Minęły już czasy wpisywania przez użytkownika tajemniczych poleceń po znaku zachęty, które powodowały wyświetlenie strumienia nie przetworzonych danych. Obecne programy korzystają z wymyślnych „przyjaznych interfejsów użytkownika”, posiadających wiele okien, menu, okien dialogowych oraz innych elementów, które wszyscy dobrze znamy.
Wraz z rozwojem sieci WWW, komputery wkroczyły w nową erę penetracji rynku; korzysta z nicj więcej osób niż kiedykolwiek, a ich oczekiwania są bardzo duże. Przez kilka lat, jakie upłynęły od czasu pierwszego wydania tej książki, programy stały się bardziej złożone, w związku z czym powstało zapotrzebowanie na pomocne w ich opanowaniu techniki programistyczne.
Wraz ze zmianą wymagań dotyczących oprogramowania, zmieniły się także same języki i technika pisania programów. Choć historia tych przemian jest fascynująca, w tej książce skupimy się na transformacjach jakie nastąpiły w trakcie przejścia od programowania proceduralnego do programowania obiektowego.
Programowanie proceduralne, strukturalne i obiektowe Do niedawna program był traktowany jako seria procedur, działających na danych. Procedura (funkcja) jest zestawem specyficznych, wykonywanych jedna po drugiej instrukcji. Dane były całkowicie odseparowane od procedur, zaś zadaniem programisty było zapamiętanie, która funkcja wywołuje inne funkcje, oraz jakie dane były w wyniku tego zmieniane. W celu uniknięcia wielu potencjalnych błędów opracowane zostało programowanie strukturalne.
Główną ideą programowania strukturalnego jest: „dziel i rządź.” Program komputerowy może być uważany za zestaw zadań. Każde zadanie, które jest zbyt skomplikowane aby można było je łatwo opisać, jest rozbijane na zestaw mniejszych zadań składowych, aż do momentu gdy, wszystkie zadania są wystarczająco łatwe do zrozumienia.
Na przykład, obliczenie przeciętnej pensji przeciętnego pracownika przedsiębiorstwa jest dość złożonym zadaniem. Można je jednak podzielić na następujące podzadania:
1. Obliczenie, ile zarabiają poszczególne osoby.
2. Policzenie ilości pracowników.
3

3. Zsumowanie wszystkich pensji.
4. Podzielenie tej sumy przez ilość pracowników.
Sumowanie pensji można podzielić na następujące kroki:
1. Odczytanie danych dotyczących każdego pracownika.
2. Odwołanie się do danych dotyczących pensji.
3. Dodanie pensji do naliczanej sumy.
4. Przejście do danych dotyczących następnego pracownika.
Z kolei, uzyskanie danych na temat pracownika można rozbić na:
1. Otwarcie pliku pracowników.
2. Przejście do właściwych danych.
3. Odczyt danych z dysku.
Programowanie strukturalne stanowi niezwykle efektywny sposób rozwiązywania złożonych problemów. Jednak pod koniec lat osiemdziesiątych ograniczenia takiej metody programowania objawiły się aż nazbyt jasno.
Po pierwsze, w trakcie tworzenia oprogramowania naturalnym dążeniem jest traktowanie danych (na przykład danych pracownika) oraz tego, co można z nimi zrobić (sortować, modyfikować, itd.), jako pojedynczej całości. Niestety, w programowaniu strukturalnym struktury danych są oddzielone od manipulujących nimi funkcji, a w programie strukturalnym nie istnieje naturalny sposób ich połączenia. Programowanie strukturalne jest często nazywane programowaniem proceduralnym, gdyż skupia się na procedurach (a nie na „obiektach”).
Po drugie, programiści zmuszeni są wciąż wymyślać nowe rozwiązania starych problemów. Czasem nazywa się to „wymyślaniem koła”; stanowi to przeciwieństwo „ponownego wykorzystania.” Idea ponownego wykorzystania oznacza tworzenie komponentów, posiadających znane wcześniej właściwości, które mogą być w miarę potrzeb dołączane do programu. Pomysł został zapożyczony z rozwiązań sprzętowych — gdy inżynier potrzebuje nowego tranzystora, zwykle nie musi go wymyślać — przegląda duże pudło z tranzystorami i wybiera ten, który spełnia dane wymagania, ewentualnie tylko nieco go modyfikując. Inżynier oprogramowania nie miał podobnej możliwości.
Na to zapotrzebowanie próbuje odpowiedzieć programowanie zorientowane obiektowo, dostarcza ono technik zarządzania złożonymi elementami, umożliwia ponowne wykorzystanie komponentów i łączy w logiczną całość dane oraz manipulujące nimi funkcje.
Zadaniem programowania zorientowanego obiektowo jest modelowanie „obiektów” (tzn. rzeczy), a nie „danych.” Modelowanymi obiektami mogą być zarówno elementy na ekranie, takie jak
4

przyciski czy pola list, jak i obiekty świata rzeczywistego, np. motocykle, samoloty, koty czy woda.
Obiekty posiadają charakterystyki (szybki, obszerny, czarny, mokry) oraz możliwości (przyspieszanie, latanie, mruczenie, bulgotanie). Zadaniem programowania zorientowanego obiektowo jest reprezentacja tych obiektów w języku programowania.
C++ i programowanie zorientowane obiektowo Język C++ wspiera programowanie zorientowane obiektowo, obejmuje swym działaniem trzy podstawy takiego stylu programowania: kapsułkowanie, dziedziczenie oraz polimorfizm.
Kapsułkowanie Gdy inżynier chce dodać do tworzonego urządzenia rezystor, zwykle nie buduje go samodzielnie od początku — podchodzi do pojemnika z rezystorami, sprawdza kolorowe paski, oznaczające właściwości, i wybiera potrzebny element. Z punktu widzenia inżyniera rezystor jest „czarną skrzynką” — nieważny jest sposób w jaki działa (o ile tylko zachowuje się zgodnie ze swoją specyfikacją). Inżynier nie musi zastanawiać się nad wnętrzem rezystora, aby użyć go w swoim projekcie.
Właściwość samozawierania się jest nazywana kapsułkowaniem. W kapsułkowaniu możemy zakładać opcję ukrywania danych. Ukrywanie danych jest możliwością, dzięki której obiekt może być używany przez osobę nie posiadającą wiedzy o tym, w jaki sposób działa. Skoro możemy korzystać z lodówki bez znajomości zasad działania kompresora, możemy też użyć dobrze zaprojektowanego obiektu nie znając jego wewnętrznych danych składowych.
Sytuacja wygląda podobnie, gdy z rezystora korzysta inżynier: nie musi wiedzieć niczego o jego wewnętrznym stanie. Wszystkie właściwości rezystora są zakapsułkowane w obiekcie rezystora (nie są rozrzucone po całym układzie elektronicznym). Do efektywnego korzystania z rezystora nie jest potrzebna wiedza o sposobie jego działania. Można powiedzieć, że jego dane są ukryte wewnątrz obudowy.
C++ wspiera kapsułkowanie poprzez tworzenie typów zdefiniowanych przez użytkownika, zwanych klasami. O tym, jak tworzyć klasy, dowiesz się z rozdziału szóstego, „Programowanie zorientowane obiektowo.” Po stworzeniu, dobrze zdefiniowana klasa działa jako spójna całość — jest używana jako jednostka. Wewnętrzne działanie klasy powinno być ukryte. Użytkownicy dobrze zdefiniowanych klas nie muszą wiedzieć, w jaki sposób one działają; muszą jedynie wiedzieć, jak z nich korzystać.
Dziedziczenie i ponowne wykorzystanie Gdy inżynierowie z Acme Motors chcą zbudować nowy samochód, mają do wyboru dwie możliwości: mogą zacząć od początku lub zmodyfikować istniejący już model. Być może ich model, Gwiazda, jest prawie doskonały, ale chcą do niego dodać turbodoładowanie i sześciobiegową skrzynię biegów. Główny inżynier nie chciałby zaczynać od początku, zamiast tego wolałby zbudować nowy, podobny model, z tym dodatkowym wyposażeniem. Nowy model
5

ma nosić nazwę Kwazar. Kwazar jest rodzajem Gwiazdy, wyposażonym w nowe elementy (według NASA, kwazary są bardzo jasnymi ciałami, wydzielającymi ogromne ilości energii).
C++ wspiera dziedziczenie. Można dzięki niemu deklarować nowe typy, będące rozszerzeniem istniejących już typów. Mówi się, że nowa podklasa jest wyprowadzona z istniejącego typu i czasem nazywa się ją typem wyprowadzonym (pochodnym). Kwazar jest wyprowadzony z Gwiazdy i jako taki dziedziczy jej możliwości, ale w razie potrzeby może je uzupełnić lub zmodyfikować. Dziedziczenie i jego zastosowania w C++ zostaną omówione w rozdziale dwunastym, „Dziedziczenie” oraz szesnastym, „Zaawansowane dziedziczenie.”
Polimorfizm Nowy Kwazar może reagować na naciśnięcie pedału gazu inaczej niż Gwiazda. Kwazar może korzystać z wtrysku paliwa i turbodoładowania, natomiast w Gwieździe benzyna po prostu wpływa do gaźnika. Użytkownik jednak nie musi wiedzieć o tych różnicach, po prostu naciska na pedał gazu i samochód robi to, co do niego należy, bez względu na to, jakim jest pojazdem.
C++ sprawia że różne obiekty „robią odpowiednie rzeczy” poprzez mechanizm zwany polimorfizmem funkcji i polimorfizmem klas. „Poli” oznacza wiele, zaś „morfizm” oznacza w tym przypadku formę. Pojęcie „polimorfizm” oznacza, że ta sama nazwa może przybierać wiele form, zostanie ono szerzej omówione w rozdziale dziesiątym, „Funkcje zaawansowane” oraz czternastym, „Polimorfizm.”
Jak ewoluowało C++ Gdy powszechnie znane stały się analiza, projektowanie i programowanie zorientowane obiektowo, Bjarne Stroustrup sięgnął do najpopularniejszego języka przenaczonego do tworzenia komercyjnego oprogramowania, C, i rozszerzył go, uzupełniając o elementy umożliwiające programowanie zorientowane obiektowo.
Choć C++ stanowi nadzbiór języka C, a wszystkie poprawne programy C są także poprawnymi programami C++, różnica pomiędzy C a C++ jest bardzo znacząca. C++ przez wiele lat czerpało korzyści ze swego pokrewieństwa z C, gdyż programiści mogli łatwo przejść z C do tego nowego języka. Aby w pełni skorzystać z jego zalet, wielu programistów musiał pozbyć się swoich przyzwyczajeń i nauczyć nowego sposobu formułowania i rozwiązywania problemów programistycznych.
Czy należy najpierw poznać C? Natychmiast nasuwa się więc pytanie: skoro C++ jest nadzbiorem C, to czy powinienem najpierw nauczyć się C? Stroustrup i większość innych programistów C++ nie tylko zgadza się, że wcześniejsze poznanie języka C nie jest konieczne, ale także że brak jego znajomości może stanowić pewną zaletę.
6

Programowanie w C opiera się na programowaniu strukturalnym; natomiast C++ jest oparte na programowaniu zorientowanym obiektowo. Poznawanie języka C tylko po to, by „oduczyć” się niepożądanych nawyków nabytych podczas pracy z C, jest błędem.
Nie zakładamy że masz jakiekolwiek doświadczenie programistyczne. Jeśli jednak jesteś programistą C, kilka pierwszych rozdziałów tej książki będzie stanowić dla ciebie powtórzenie posiadanych już wiadomości. Prawdziwą pracę nad tworzeniem obiektowo zorientowanego oprogramowania zaczniemy dopiero od rozdziału szóstego.
C++ a Java i C# C++ jest obecnie dominującym językiem oprogramowania komercyjnego. W ostatnich latach pojawiła się dla niego silna konkurencja w postaci Javy, jednak „wahadło wróciło” i wielu programistów, którzy porzucili C++ dla Javy, zaczyna do niego powracać. Języki te są tak podobne, że opanowanie jednego jest równoznaczne z opanowaniem dziewięćdziesięciu procent drugiego.
C# jest nowym językiem, opracowanym przez Microsoft dla platformy .Net. C# stanowi w zasadzie podzbiór C++, i choć oba języki różnią się w kilku zasadniczych sprawach, poznanie C++ oznacza poznanie około dziewięćdziesięciu procent C#. Upłynie jeszcze wiele lat, zanim przekonamy się, czy C# będzie poważnym konkurentem dla C++; jednak nawet, gdy tak się stanie, praca włożona w poznanie C++ z pewnością okaże się doskonałą inwestycją.
Standard ANSI Międzynarodowy standard języka C++ został stworzony przez komitet ASC (Accredited Standards Committee), działający w ramach ANSI (American National Standards Institute).
Standard C++ jest nazywany standardem ISO (International Standards Organization), standardem NCITS (National Committee for Information Technology Standards), standardem X3 (starsza nazwa NCITS) oraz standardem ANSI/ISO. W tej książce będziemy odwoływali się do standardu ANSI, gdyż to określenie jest najbardziej popularne.
Standard ANSI próbuje zapewnić przenośność C++ — zapewnia na przykład to, że kod zgodny ze standardem ANSI napisany dla kompilatora Microsoftu skompiluje się bez błędów w kompilatorze innego producenta. Ponieważ kod w tej książce jest zgodny ze standardem ANSI, powinien kompilować się bez błędów na Macintoshu, w Windows lub w komputerze z procesorem Alpha.
Dla większości osób uczących się języka C++, standard ANSI będzie niewidoczny. Ten standard istnieje już od dłuższego czasu i obsługuje go większość głównych producentów. Włożyliśmy wiele trudu, by zapewnić że cały kod w tej książce jest zgodny z ANSI.
7

Przygotowanie do programowania C++, bardziej niż inne języki, wymaga od programisty zaprojektowania programu przed jego napisaniem. Banalne problemy, takie jak te przedstawiane w kilku pierwszych rozdziałach książki, nie wymagają projektowania. Jednak złożone problemy, z którymi profesjonalni programiści zmagają się każdego dnia, wymagają projektowania; zaś im dokładniejszy i pełniejszy projekt, tym większe prawdopodobieństwo, że program rozwiąże problemy w zaplanowanym czasie, nie przekraczając budżetu. Dobry projekt sprawia także, że program jest w dużym stopniu pozbawiony błędów i łatwy w konserwacji. Obliczono, że połączony koszt debuggowania i konserwacji stanowi co najmniej dziewięćdziesiąt procent kosztów tworzenia oprogramowania. Ponieważ dobry projekt może te koszty zredukować, staje się ważnym czynnikiem wpływającym na ostateczne wydatki związane z tworzenia programu.
Pierwszym pytaniem, jakie powinniśmy zadać, przygotowując się do projektowania programu jest: jaki problem ma zostać rozwiązany? Każdy program powinien ustanawiać jasny, dobrze określony celem – przekonasz się, że w tej książce nawet najprostszy program spełnia ten postulat.
Drugie pytanie, stawiane przez każdego dobrego programistę, to: czy można to osiągnąć bez konieczności pisania własnego oprogramowania? Ponowne wykorzystanie starego programu, użycie pióra i papieru lub zakup istniejącego oprogramowania, jest często lepszym rozwiązaniem problemu niż pisanie nowego programu. Programista znajdujący takie alternatywy nigdy nie będzie narzekał na brak pracy; znajdowanie najtańszych rozwiązań dzisiejszych problemów otwiera nowe możliwości na przyszłość.
Zakładając, że rozumiesz problem, i że wymaga on napisania nowego programu, jesteś gotów do rozpoczęcia projektowania.
Proces pełnego zrozumienia problemu (analiza) i znajdowania jego rozwiązania (projekt) stanowi niezbędną podstawę dla pisania komercyjnych aplikacji na najwyższym, profesjonalnym poziomie.
Twoje środowisko programowania Zakładamy, że twój kompilator posiada tryb, w którym może wypisywać tekst bezpośrednio na ekranie, bez konieczności wykorzystania środowiska graficznego, na przykład Windows czy Macintosh. Poszukaj opcji takiej, jak console, console wizard czy easy window lub przejrzyj dokumentację kompilatora.
Kompilator może posiadać własny, wbudowany edytor tekstów, lub do tworzenia plików programów możesz użyć komercyjnego edytora lub procesora tekstów. Ważne jest, by bez względu na to, jaki program stosujemy, miał on możliwość zapisywania zwykłych plików tekstowych, nie zawierających osadzonych w tekście kodów i poleceń formatowania. Bezpiecznymi pod tym względem edytorami są na przykład Notatnik w Windows, program Edit w DOS-ie, Brief, Epsilon, Emacs i vi. Wiele komercyjnych procesorów tekstu, takich jak WordPerfect, Word czy tuziny innych, także oferuje możliwość zapisywania zwykłych plików tekstowych.
8

Pliki tworzone za pomocą edytora tekstów są nazywane plikami źródłowymi, w przypadku języka C++ zwykle posiadają nazwy z rozszerzeniem .cpp, .cp .c lub . W tej książce wszystkie pliki źródłowe posiadają rozszerzenie .cpp, ale sprawdź w swoim kompilatorze, jakich plików oczekuje.
UWAGA Większość kompilatorów C++ nie „zwraca uwagi” na rozszerzenia nadawane nazwom plików źródłowych, ale jeśli nie określisz tych plików, wiele z nich domyślnie korzysta z rozszerzenia .cpp. Należy jednak zachować ostrożność, gdyż niektóre kompilatory traktują pliki .c jako pliki języka C, zaś pliki .cpp jako pliki języka C++. Sprawdź koniecznie dokumentację kompilatora.
Tak Nie
Nie używaj procesora tekstów zapisującego wraz z tekstem specjalne znaki formatujące. Jeśli korzystasz z takiego procesora, zapisuj pliki jako tekst ASCII.
Do tworzenia plików źródłowych używaj prostego edytora tekstów lub skorzystaj z edytora wbudowanego w kompilator.
Zapisuj pliki, nadając im rozszerzenie .c, .cp lub .cpp.
Sprawdź w dokumentacji kompilatora i linkera, w jaki sposób należy kompilować i budować programy.
Tworzenie programu Choć kod źródłowy w pliku wygląda na niezrozumiały i każdy, kto nie zna C++, będzie miał trudności ze zrozumieniem jego przeznaczenia, kod ten przyjmuje czytelną dla człowieka postać. Plik kodu źródłowego nie jest programem i, w odróżnieniu od pliku wykonywalnego, nie może zostać wykonany (uruchomiony).
Tworzenie pliku obiektowego za pomocą kompilatora Do zamiany kodu źródłowego w program używamy kompilatora. Sposób uruchomienia go i wskazania mu plików źródłowych zależy od konkretnego kompilatora; sprawdź w tym celu posiadaną przez ciebie dokumentację.
9

Gdy kod źródłowy zostanie skompilowany, tworzony jest plik obiektowy. Ten plik ma często rozszerzenie 1.obj – jednak w dalszym ciągu nie jest to program wykonywalny. Aby zmienić go w program wykonywalny, należy użyć tzw. linkera, czyli programu łączącego.
Tworzenie pliku wykonywalnego za pomocą linkera .objProgramy C++ zwykle powstają w wyniku łączenia jednego lub więcej plików z jedną lub
więcej bibliotekami. Biblioteka (ang. library) jest zbiorem połączonych plików, dostarczanym wraz z kompilatorem. Może też zostać nabyta osobno lub stworzona i skompilowana samodzielnie. Wszystkie kompilatory C++ są dostarczane wraz z bibliotekami użytecznych funkcji (lub procedur) oraz klas, które można zastosować w programie. O klasach i funkcjach porozmawiamy szczegółowo w następnych rozdziałach.
Kroki konieczne do stworzenia pliku wykonywalnego to:
1. Stworzenie pliku kodu źródłowego z rozszerzeniem .cpp.
2. Skompilowanie kodu źródłowego do pliku z rozszerzeniem .obj.
.obj3. Połączenie pliku z wymaganymi bibliotekami w celu stworzenia programu wykonywalnego.
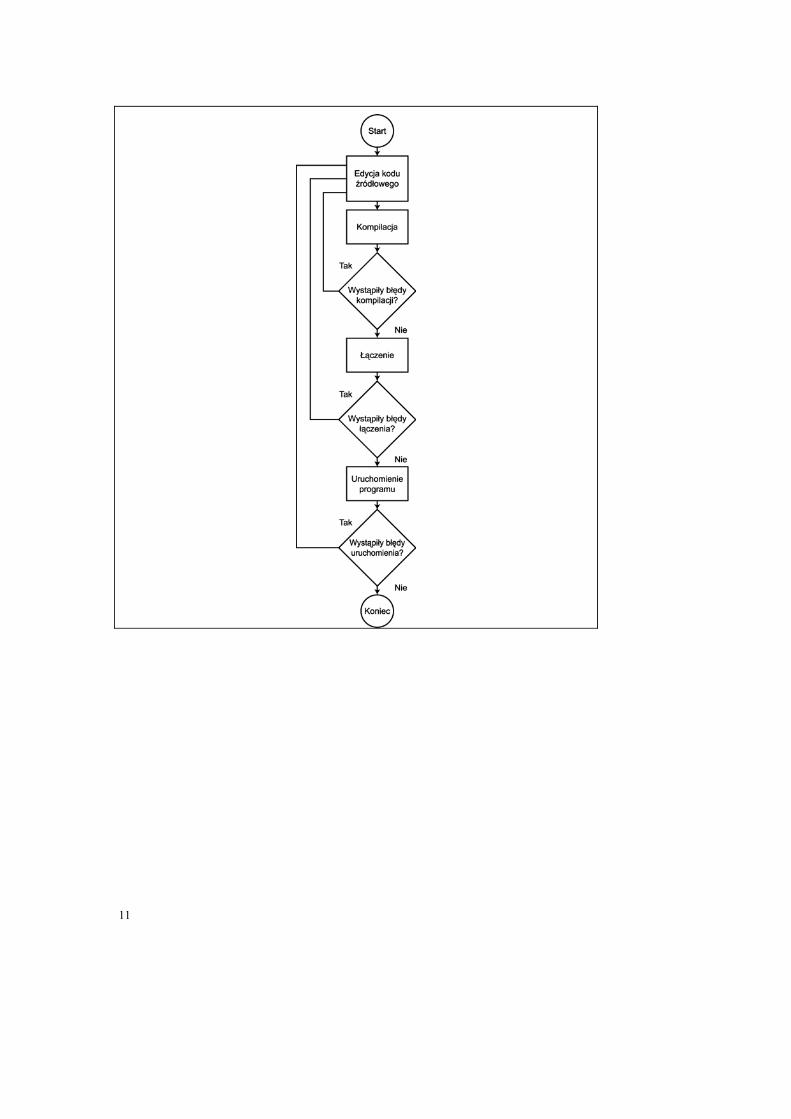
Cykl tworzenia programu Gdyby każdy program zadziałał już przy pierwszej próbie uruchomienia, wtedy pełny cykl tworzenia wyglądałby następująco: pisanie programu, kompilowanie kodu źródłowego, łączenie plików .obj, uruchomienie programu wykonywalnego. Niestety, prawie każdy program (nawet najbardziej trywialny) może zawierać błędy, często nazywane „pluskwami”. Niektóre błędy uniemożliwiają kompilację, inne uniemożliwiają łączenie, zaś jeszcze inne objawiają się dopiero podczas działania programu.
Bez względu na rodzaj błędu, należy go poprawić – oznacza to edycję kodu źródłowego, ponowną kompilacja i łączenie, oraz ponowne uruchomienie programu. Cały ten cykl został przedstawiony na rysunku 1.1, schematycznie obrazuje on kolejne kroki w cyklu tworzenia programu wykonywalnego.
Rys. 1.1. Kroki wykonywane podczas tworzenia programu w języku C++ C
1 Plik .obj jest kodem wynikowym programu (ang. object code). Stanowi translację (przekład) tekstu źródłowego na język zrozumiały dla komputera. Kod wynikowy jest zawsze wczytywany przez linker (konsolidator) — przyp.tłum.
Komentarz [D1]: Do boxu „Edycja kodu źródłowego” powinny prowadzić strzałki zwrotne od rąbów: „Błędów kompilacji”, „Błędów łączenia” oraz „błędów uruchomienia”. Absolutnie nie mogę dostać się do tego rysunku w miom Wordzie, zatem czynność tą pozostawiam Redakcji.
10
11

HELLO.cpp — twój pierwszy program w C++ 2Tradycyjne książki o programowaniu zaczynają od wypisania na ekranie słów „Witaj Świecie”
lub od innej „wariacji na ten temat”. Ta uświecona tradycją formuła zostanie zachowana także i tu.
Wpisz swój pierwszy program bezpośrednio do edytora, dokładnie przepisując jego treść. Gdy będziesz pewien, że został wpisany poprawnie, zapisz go do pliku, skompiluj, połącz i uruchom. Program wypisze na ekranie słowa „Witaj Świecie”. Nie martw się na razie tym, jak działa; teraz powinieneś jedynie poznać cykl tworzenia programu. Każdy element programu zostanie omówiony w kilku następnych rozdziałach.
OSTRZEŻENIE Na przedstawionym poniżej listingu po lewej stronie umieszczone zostały numery linii. Te numery służą jedynie jako punkty odniesienia dla opisu w tekście. Nie należy ich wpisywać do kodu programu. Na przykład, w linii 1. listingu 1.1 należy wpisać:
#include <iostream>
HELLO.cppListing 1.1. , program „Witaj Świecie”. 0: #include <iostream> 1: 2: int main() 3: { 4: std::cout << "Witaj Swiecie!\n"; 5: return 0; 6: }
Upewnij się, czy wpisałeś kod dokładnie tak, jak na listingu. Zwróć szczególną uwagę na znaki przestankowe. Znaki << w linii 4. są symbolem przekierowania, który na większości klawiatur uzyskuje się wciskając klawisz Shift, po czym dwukrotnie naciskając klawisz przecinka. Pomiędzy słowami i w linii 4. występują dwa dwukropki (std cout :). Linie 4. i 5. kończą się średnikiem ( ). ;
Upewnij się także, czy postępujesz zgodnie z zaleceniami kompilatora. Większość kompilatorów potrafi połączyć (zbudować) program wykonywalny automatycznie, ale sprawdź to w dokumentacji. Jeśli pojawią się błędy, dokładnie przejrzyj kod i sprawdź, czym różni się od kodu z listingu. Gdy zauważysz błąd w pierwszej linii, na przykład cannot find file iostream (nie można znaleźć pliku iostream), sprawdź w dokumentacji kompilatora, w jaki sposób należy ustawić ścieżkę do dołączanych plików lub zmienne środowiskowe. Gdy otrzymasz błąd informujący o braku prototypu dla , tuż przed linią 2. dopisz linię main int main();. W takim przypadku musisz dopisać tę linię przed początkiem funkcji w każdym programie main
2 Jak zwykle w takich przypadkach, pojawia się problem polskich znaków diakrytycznych. Wpisanie w kodzie programu słów „Witaj Świecie” w dosłownym brzmieniu, spowodowałoby pojawianie się na ekranie dziwnego znaczka (w miejscu litery Ś). W związku z tym w treści listingów, w tekstach wypisywanych przez program, zrezygnowałem ze stosowania polskich znaków diakrytycznych, zastępując je odpowiednikami łacińskimi. — przyp.tłum.
12

pojawiającym się w tej książce. Większość kompilatorów tego nie wymaga, ale istnieje kilka wyjątków.
Pełny program będzie wyglądał następująco:
1: #include <iostream> 2: 3: int main(); // większość kompilatorów nie wymaga tej linii 4: int main() 5: { 6: std::cout << "Witaj Swiecie!\n"; 7: return 0; 8: }
UWAGA Trudno jest czytać program samemu, nie wiedząc jak są wymawiane specjalne znaki i słowa kluczowe. Pierwszą linię odczytujemy jako : „hasz-inklad ajoustrim”. Linia 6. to „es-ti-di-si-aut Witaj Świecie.”
Spróbuj uruchomić plik HELLO.exe; program powinien wypisać:
Witaj Swiecie!
bezpośrednio na ekranie. Jeśli tak się stało, gratulacje! Właśnie wpisałeś, skompilowałeś i uruchomiłeś swój pierwszy program w C++. Być może nie wygląda to efektownie, ale każdy profesjonalny programista C++ zaczynał dokładnie od tego właśnie programu.
Korzystanie z bibliotek standardowych
Jeśli masz bardzo stary kompilator, przedstawiony powyżej program nie będzie działał — nie zostaną odnalezione nowe biblioteki standardu ANSI. W takim przypadku zmień kod programu na:
0: #include <iostream.h> 1: 2: int main() 3: { 4: cout << "Witaj Swiecie!\n"; 5: return 0; 6: }
13

Zwróć uwagę, że tym razem nazwa biblioteki kończy się na .h (kropka-h) i że nie korzystamy już z std:: na początku linii 4. Jest to stary, poprzedzający ANSI styl plików nagłówkowych. Jeśli twój kompilator zadziała z tym programem, lecz nie poradzi sobie z wersją przedstawioną wcześniej, oznacza to, że jest prawdziwym antykiem. Nadaje się jedynie do wykorzystania w trakcie czytania kilku pierwszych rozdziałów, ale gdy przejdziemy do wzorców i wyjątków, taki kompilator już nie wystarczy.
Zaczynamy pracę z kompilatorem Ta książka nie jest związana z określonym kompilatorem. Oznacza to, że zawarte w niej programy powinny działać z każdym zgodnym z ANSI kompilatorem C++, na każdej dostępnej platformie (Windows, Mac, UNIX, Linux, itd.).
Większość programistów pracuje jednak w Windows, zaś większość profesjonalnych programistów używa kompilatorów Microsoftu. Nie jestem w stanie opisać szczegółów kompilowania i łączenia za pomocą każdego istniejącego kompilatora, ale mogę jedynie pokazać od czego zacząć w kompilatorze Visual C++ 6. Inne kompilatory działają podobne, zatem będziesz wiedział, od czego rozpocząć.
Kompilatory mimo wszystko różnią się od siebie, więc pamiętaj o przejrzeniu dokumentacji3.
Budowanie projektu Hello World Aby stworzyć i przetestować program Hello World, wykonaj następujące kroki:
1. Uruchom kompilator.
2. W menu File (plik) wybierz polecenie New (nowy).
3. Wybierz pozycję Win32 Console Application (aplikacja konsoli Win32) i w polu Project name wpisz nazwę projektu, taką jak Przyklad 1. Następnie kliknij na przycisku OK.
Komentarz [D2]: Nie wiem, czy tego rodzaju samocytowanie jest dopuszczalne (ale jest to chyba jedyna obecnie na rynku nowsza książka opisująca to „zjawisko”), jednak trzeba pamiętać, że w odróżnieniu od USA, gdzie być może (osobiście nie jestem przekonany) dominuje Visual C++ Microsoftu – to w Europie jednak chyba większymi względami wśród programistów cieszą się kompilatory Borlanda. Cytowana książka zawiera kompletny opis zagadnienia. Wbrew temu, co twierdzi autor proces budowania projektu w tych dwóch kompilatorach wcale nie jest tak bardzo podobny.
4. W oknie dialogowym wybierz opcję An Empty Project (pusty projekt) i kliknij na przycisku OK.
File5. W menu wybierz polecenie New.
6. Wybierz pozycję C++ Source File (plik źródłowy C++) i nadaj jej nazwę . prz1
7. Wpisz kod programu, w sposób opisany nieco wcześniej.
Build (buduj) wybierz polecenie Build Przyklad1.exe. 8. W menu
9. Sprawdź, czy nie pojawiły się błędy kompilacji lub łączenia.
10. Naciśnij Ctrl+F5, aby uruchomić program.
3 Szczegółowy opis tworzenia projektu za pomocą kompilatorów Borlanda można znaleźć w książce Andrzeja Daniluka „C++Builder 5. Ćwiczenia praktyczne,” Helion 2001. — przyp.redakcji.
14

11. Naciśnij spację, aby zakończyć program.
Często zadawane pytanie
Mogę uruchomić program, ale znika on tak szybko, że nie mogę odczytać wypisywanego tekstu. Co się dzieje?
Odpowiedź
Sprawdź w dokumentacji kompilatora; powinna ona zawierać informacje na temat sposobu zachowania na ekranie wyników działania programu. W przypadku kompilatorów Microsoftu najprościej jest użyć kombinacji Ctrl+F5.
W przypadku starszych kompilatorów Borlanda należy kliknąć prawym przyciskiem myszy w oknie edycji kodu, kliknąć na poleceniu Target Export Platform Win 3.1 (16), zmienić opcję na , po czym ponownie przekompilować i uruchomić program. Okno wyników pozostanie otwarte do momentu, w którym sam je zamkniesz.
returnNa zkończenie, w każdym kompilatorze, bezpośrednio przed instrukcją (tj. pomiędzy liniami 4. i 5. na listingu 1.1), możesz dodać przedstawione poniżej linie:
int x; std::cin >> x;
Spowodują one wstrzymanie działania programu i oczekiwanie na wprowadzenie jakiejś wartości. Aby zakończyć działanie programu, wpisz liczbę (na przykład 1), po czym naciśnij klawisz Enter.
std::cin i std::coutZnaczenie zostanie omówione w następnych rozdziałach. Na razie uznaj je za swego rodzaju magiczne zaklęcia.
Prawdopodobnie bardzo wielu czytelników posiada kompilator Borlanda (np. C++Builder). Pisząc programy dla Windows w środowisku Buildera, należy zwrócić uwagę na pewne charakterystyczne dla tego środowiska cechy.
15

1. Dobrym zwyczajem jest poinformowanie kompilatora o zakończeniu listy plików nagłówkowych, tj. plików zapisanych w ostrych nawiasach (absolutnie nie dotyczy to tzw. modułów z rozszerzeniem .h). Dokonujemy tego, korzystając z dyrektywy prekompilatora #pragma hdrstop (ang. header stop). Zapis ten znacznie przyśpieszy proces konsolidacji projektu.
2. Jeżeli tworzymy aplikacje konsolowe za pomocą Borland C++Buildera w celu „przytrzymania” ekranu (w tym wypadku normalnego tekstowego okienka DOS), zawsze możemy użyć funkcji
przynależnej do prototypu getch() conio.h. Należy jednak pamiętać, że funkcja ta podtrzymywana jest obecnie jedynie w Win32 i nie należy już do szerokiego standardu ANSI C/C++.
3. Przestrzeń strumieni wejścia-wyjścia w C++Builder jest dostatecznie dobrze zdefiniowana, dlatego w tym wypadku nie jest konieczne jawne wskazywanie kompilatorowi miejsca ich pochodzenia.
Poniższy przykład ilustruje te cechy.
0: #include <iostream.h> 1: #include <conio> 2: #pragma hdrstop 3: int main() 4: { 5: cout << "Witaj Swiecie "<< endl; 6: cout << "Nacisnij klawisz..."; 7: getch(); 8: return 0; 9: }
Należy zwrócić uwagę, iż przy następującym zapisie, wykorzystującym jawne wskazanie przestrzeni strumieni wejścia-wyjścia, działanie programu będzie również poprawne:
0: #include <iostream> 1: #include <conio> 2: #pragma hdrstop 3: int main() 4: { 5: std::cout << "Witaj Swiecie "<< std::endl; 6: std::cout << "Nacisnij klawisz..."; 7: getch(); 8: return 0; 9: }
Błędy kompilacji Błędy kompilacji mogą pojawić się z wielu powodów. Zwykle są rezultatem pomyłki przy wpisywaniu lub innych, mniej istotnych przyczyn. Dobry kompilator nie tylko poinformuje, co
16

jest nie tak, ale także wskaże dokładnie miejsce kodu, w którym został popełniony błąd. Najlepsze kompilatory sugerują nawet, co należy z tym zrobić!
Możesz zobaczyć, co się stanie gdy celowo umieścimy w programie błąd. Jeśli program HELLO.cpp działa poprawnie, zmodyfikuj go teraz i usuń zamykający nawias klamrowy z linii 6. Teraz program będzie wyglądał tak, jak na listingu 1.2.
Listing 1.2. Demonstracja błędu kompilacji. 0: #include <iostream> 1: 2: int main() 3: { 4: std::cout << "Witaj Swiecie!\n"; 5: return 0;
Ponownie skompiluj program; powinieneś zauważyć błąd podobny do tego:
4Hello.cpp(7) : fatal error C1004: unexpected end of file found
Ten błąd informuje o nazwie pliku i numerze linii, w której wystąpił problem, oraz o przyczynie pojawienia się problemu (przyznam jednak, że ten komunikat jest nieco tajemniczy).
Czasem błędy informują jedynie o ogólnej przyczynie problemu. Gdyby kompilator mógł idealnie zidentyfikować każdy z problemów, mógłby poprawiać kod samodzielnie.
4 W kompilatorach najnowszej generacji firmy Borland komunikat o ww. błędzie jest wyświetlony w formie nie wymagającej głębszego zastanowiania się nad jego znaczeniem:
[C++ Error] Hello.cpp(6): E2134 Compound statement missing } — przyp.redakcji.
17

Rozdział 2. Anatomia programu C++ Programy C++ składają się z obiektów, funkcji, zmiennych i innych elementów. Większość tej książki stanowi obszerny opis tych elementów, jednakże w celu zrozumienia zasad ich współdziałania, musisz najpierw poznać cały działający program.
W tym rozdziale:
• poznasz elementy programu C++,
• dowiesz się, jak te elementy ze sobą współpracują,
• dowiesz się, czym jest funkcja i do czego służy.
Prosty program Nawet prosty program HELLO.cpp z rozdziału pierwszego, „Zaczynamy”, miał wiele interesujących elementów. W tym podrozdziale omówimy go bardziej szczegółowo. Listing 2.1 przypomina treść programu HELLO.cpp z poprzedniego rozdziału.
Listing 2.1. HELLO.cpp demonstruje elementy programu C++ 0: #include <iostream> 1: 2: int main() 3: { 4: std::cout << "Witaj Swiecie!\n"; 5: return 0; 6: }
Wynik działania Witaj Swiecie! 1
1 W środowisku programowania takim, jak np. Visual, pod napisem Witaj Swiecie! pojawi się dodatkowo napis: Press any key to continue. Naciśnięcie jakiegokolwiek klawisza zamknie działanie programu HELLO.exe i usunie z ekranu jego okno (ramkę). — przyp.redakcji.
Usunięto: składowych
Usunięto: jest poświęcona dogłębnemu
Usunięto: owi
Usunięto: ale by
Usunięto: ć
Usunięto: jak one do siebie pasują,
Usunięto: pełny
Usunięto: P
Usunięto: .
Usunięto: D
Usunięto: .
Usunięto: D
Usunięto: zawiera
Usunięto: n
Usunięto: enie
Usunięto: ci
Usunięto: .
Usunięto: :
Usunięto: ,
Usunięto: jeszcze

Analiza:
W linii 0. do bieżącego pliku jest dołączany plik iostream.
Oto sposób jego działania: pierwszy znak jest symbolem #, który stanowi sygnał dla preprocesora. Za każdym razem gdy uruchamiasz kompilację, uruchamiany jest preprocesor. Preprocesor odczytuje kod źródłowy, wyszukując linii zaczynających się od znaku # (hasz) i operuje na nich jeszcze przed uruchomieniem właściwego kompilatora. Preprocesor zostanie szczegółowo opisany w rozdziale 21., „Co dalej.”
Polecenie #include jest instrukcją preprocesora, mówiącą mu: „Po mnie następuje nazwa pliku. Znajdź ten plik i wstaw go w to miejsce.” Nawiasy kątowe dookoła nazwy pliku informują preprocesor, by szukał pliku w standardowych miejscach dla tego typu plików. Jeśli twój kompilator jest odpowiednio skonfigurowany, nawiasy kątowe powodują, że preprocesor szuka pliku iostream w kartotece zawierającej wszystkie pliki nagłówkowe dostarczane wraz z kompilatorem. Plik iostream (Input Output Stream — strumień wejścia-wyjścia) jest używany przez obiekt cout, asystujący przy wypisywaniu tekstu na ekranie. Efektem działania linii 0. jest wstawienie zawartości pliku iostream do kodu programu, tak jakby został on wpisany przez ciebie. Preprocesor działa przed każdym rozpoczęciem kompilacji, poprzedzając jej właściwą fazę. Ponadto zamienia wszystkie linie rozpoczynające się od znaku hasz (#) na specjalne polecenia, przygotowując ostateczny kod źródłowy dla kompilatora.
Linia 2. rozpoczyna rzeczywisty program od funkcji o nazwie main(). Funkcję tę posiada każdy program C++. Funkcja jest blokiem kodu wykonującym jedną lub więcej operacji. Zwykle funkcje są wywoływane przez inne funkcje, lecz funkcja main()pod tym względem odbiega od standardu. Gdy program rozpoczyna działanie, jest ona wywoływana automatycznie.
Funkcja main (), podobnie jak inne funkcje, musi określić rodzaj zwracanej przez siebie wartości. Typem zwracanej przez nią w programie HELLO.cpp wartości jest typ int, to oznacza że po zakończeniu działania funkcja ta zwraca systemowi operacyjnemu wartość całkowitą (ang. integer). W tym przypadku zwracaną wartością jest 0, tak jak to widzimy w linii 5. Zwrócenie wartości systemowi operacyjnemu jest stosunkowo mało ważną i rzadko wykorzystywaną możliwością, ale standard C++ wymaga, by funkcja main() została zadeklarowana tak jak pokazano.
UWAGA Niektóre kompilatory pozwalają na deklarację main(), jeśli funkcja main ma zwracać typ void. Nie jest to zgodne ze standardem C++ i nie powinieneś się do tego przyzwyczajać. Niech funkcja main() zwraca wartość typu int, zaś w ostatniej linii tej funkcji po prostu zwracaj wartość 0.
UWAGA Niektóre systemy operacyjne umożliwiają sprawdzanie (testowanie), jaka wartość została zwrócona przez program. Zgodnie z konwencją, zwrócenie wartości 0 oznacza, że program zakończył działanie normalnie.
Usunięto: jak to
Usunięto: omówiony
Usunięto: w
Usunięto: Preprocesor tłumaczy
Usunięto: jest
Usunięto: specjalna
Usunięto: funkcja main()
Usunięto: zwracanej przez funkcję main() w programie HELLO.cpp
Usunięto: c
Usunięto: ta
Usunięto: była
Usunięto:
Usunięto: normalnie

Wszystkie funkcje rozpoczynają się od nawiasu otwierającego ({) i kończą nawiasem zamykającym (}). Nawiasy dla funkcji main() znajdują się w liniach 3. i 6. Wszystko, co znajduje się pomiędzy nawiasem otwierającym a zamykającym, jest uważane za treść funkcji.
Prawdziwa treść programu znajduje się w linii 4. Obiekt cout jest używany do wypisywania komunikatów na ekranie. Obiektami zajmiemy się w rozdziale 6., „Programowanie zorientowane obiektowo”, zaś obiekt cout i powiązany z nim obiekt cin omówimy szczegółowo w rozdziale 17., „Strumienie.” Te dwa obiekty, cin i cout, są w C++ używane, odpowiednio: do obsługi wejścia (na przykład z klawiatury) oraz wyjścia (na przykład na ekran).
Obiekt cout jest dostarczany przez bibliotekę standardową. Biblioteka jest kolekcją klas. Standardowa biblioteka jest standardową kolekcją dostarczaną wraz z każdym kompilatorem zgodnym z ANSI.
Używając specyfikatora przestrzeni nazw, std, informujemy kompilator, że obiekt cout jest częścią biblioteki standardowej. Ponieważ możesz mieć kilka, pochodzących od różnych dostawców, obiektów o tych samych nazwach, C++ dzieli „świat” na „przestrzenie nazw”. Przestrzeń nazw jest sposobem na powiedzenie, że: „gdy mówię cout, mam na myśli to, że cout jest częścią standardowej przestrzeni nazw, a nie jakiejś innej przestrzeni nazw.” Mówimy to kompilatorowi poprzez umieszczenie przed nazwą cout znaków sdt i podwójnego dwukropka. Więcej na temat różnych przestrzeni nazw powiemy w następnych rozdziałach.
Oto sposób użycia obiektu cout: wpisz słowo cout, a po nim operator przekierowania wyjścia (<<). To, co następuje po operatorze przekierowania wyjścia, zostanie wypisane na ekranie. Jeśli chcesz, by został wypisany łańcuch znaków, pamiętaj o ujęciu go w cudzysłowy (tak jak widzimy w linii 4.)
Łańcuch tekstowy jest serią znaków drukowalnych.
Dwa ostatnie znaki, \n, informują obiekt cout, by po słowach „Witaj Świecie!” umieścił nową linię. Ten specjalny kod zostanie opisany szczegółowo podczas omawiania obiektu cout w rozdziale 18., „Przestrzenie nazw.”
Funkcja main() kończy się w linii 6. nawiasem zamykającym.
Rzut oka na klasę cout W rozdziale 17. zobaczysz, w jaki sposób używa się obiektu cout do wypisywania danych na ekranie. Na razie możesz z niego korzystać, nie wiedząc, jak działa. Aby wypisać wartość na ekranie, napisz słowo cout, po nim operator wstawiania (<<), uzyskiwany w wyniku dwukrotnego wpisania znaku mniejszości (<). Choć w rzeczywistości są to dwa znaki, C++ traktuje je jako pojedynczy symbol.
Po znaku wstawiania wpisz przeznaczone do wypisania dane. Listing 2.2 ilustruje sposób użycia tego obiektu. Wpisz w tym przykładzie dokładnie to, co pokazano na listingu, z tym, że zamiast nazwiska Jesse Liberty wpisz swoje własne (chyba, że rzeczywiście nazywasz się Jesse Liberty).
Listing 2.2. Użycie cout
Usunięto: zawartość
Usunięto: ogólnie
Usunięto: ,
Usunięto: bibliotekę
Usunięto: .
Usunięto:
Usunięto: sobie
Usunięto: jak
Usunięto: wany
Usunięto: jest
Usunięto: ,
Usunięto:
Usunięto: znaków
Usunięto:
Usunięto: wyjaśniony
Usunięto: właściwie
Usunięto: dane
Usunięto: wyjątkiem tego
Usunięto: .

0: // Listing 2.2 użycie std::cout 1: #include <iostream> 2: int main() 3: { 4: std::cout << "Hej tam.\n"; 5: std::cout << "To jest 5: " << 5 << "\n"; 6: std::cout << "Manipulator std::endl "; 7: std::cout << "wypisuje nowa linie na ekranie."; 8: std::cout << std::endl; 9: std::cout << "To jest bardzo duza liczba:\t" << 70000; 10: std::cout << std::endl; 11: std::cout << "To jest suma 8 i 5:\t"; 12: std::cout << 8+5 << std::endl; 13: std::cout << "To jest ulamek:\t\t"; 14: std::cout << (float) 5/8 << std::endl; 15: std::cout << "I bardzo, bardzo duza liczba:\t"; 16: std::cout << (double) 7000 * 7000 << std::endl; 17: std::cout << "Nie zapomnij zamienic Jesse Liberty "; 18: std::cout << "na swoje nazwisko...\n"; 19: std::cout << "Jesse Liberty jest programista C++!\n"; 20: return 0; 21: }
Wynik działania Hej tam. To jest 5: 5 Manipulator std::endl wypisuje nowa linie na ekranie. To jest bardzo duza liczba: 70000 To jest suma 8 i 5: 13 To jest ulamek: 0.625 I bardzo, bardzo duza liczba: 4.9e+007 Nie zapomnij zamienic Jesse Liberty na swoje nazwisko... Jesse Liberty jest programista C++!
UWAGA Niektóre kompilatory zawierają błąd; przed przekazaniem sumy do obiektu cout należy umieścić ją w nawiasach. Tak więc linia 12. powinna być zmieniona na:
12 std::cout << (8+5) << std::endl;
Analiza:
W linii 1., instrukcja #include <iostream> powoduje włączenie zawartości pliku iostream do kodu źródłowego. Jest ona wymagana, jeśli używasz obiektu cout i powiązanych z nim funkcji.
W linii 4. znajduje się najprostsze zastosowanie obiektu cout, do wypisania ciągu znaków. Symbol \n jest specjalnym znakiem formatującym. Informuje on cout by wypisał na ekranie znak nowej linii (tzn. aby dalsze wypisywanie rozpoczął od następnej linii ekranu).
W linii 5. przekazujemy do cout trzy wartości, oddzielone operatorem wstawiania. Pierwszą z tych wartości jest łańcuch "To jest 5: ". Zwróć uwagę na odstęp po dwukropku. Ten odstęp (spacja) jest częścią łańcucha. Następnie do operatora wstawiania jest przekazywana wartość 5 oraz znak nowej linii (zawsze w cudzysłowach lub apostrofach), co powoduje wypisanie na ekranie linii
Usunięto: :
Usunięto: ,
Usunięto: wymagający by
Usunięto: zawartości pliku iostream
Usunięto: . To

To jest 5: 5
Ponieważ po pierwszym łańcuchu nie występuje znak nowej linii, następna wartość jest wypisywana tuż za nim. Nazywa się to konkatenacją (łączeniem) dwóch wartości.
W linii 6. wypisywany jest komunikat informacyjny, po czym (w linii 8.) użyty zostaje manipulator endl. Przeznaczeniem endl jest wypisanie nowej linii na ekranie. (Inne zastosowania dla endl zostaną omówione w rozdziale 16.). Zwróć uwagę, że endl także pochodzi z biblioteki standardowej.
UWAGA endl pochodzi od słów „end line” (zakończ linię) i w rzeczywistości jest to „end-L”, a nie „end-jeden”.
W linii 9. został wprowadzony nowy znak formatujący, \t. Powoduje on wstawienie znaku tabulacji i jest używany w celu wyrównywania wydruków wyników w liniach od 9. do 15. Linia 9. pokazuje, że wypisywane mogą być nie tylko liczby całkowite, ale także długie liczby całkowite. Linia 12. demonstruje, że cout potrafi wykonać proste dodawanie. Do obiektu jest przekazywana wartość 8+5, lecz wypisywana jest suma 13.
W linii 14. do cout jest wstawiana wartość 5/8. Symbol (float) informuje cout, że chcemy aby ta wartość została obliczona jako rozwinięcie dziesiętne, więc wypisywany jest ułamek. W linii 16. cout otrzymuje wartość 7000 * 7000, zaś symbol (double) służy do poinformowania cout, że jest to wartość zmiennoprzecinkowa. Wszystko to zostanie wyjaśnione w rozdziale 3., „Zmienne i stałe,” przy okazji omawiania typów danych.
W linii 16. podstawiłeś swoje nazwisko, zaś wynik potwierdza, że naprawdę jesteś programistą C++. Musi być to prawda, skoro tak uważa komputer!
Używanie przestrzeni nazw standardowych Z pewnością zauważyłeś, że przed każdym cout i endl występuje std::, co po jakimś czasie może być irytujące. Choć korzystanie z odnośnika do przestrzeni nazw jest poprawne, jednak okazuje się dosyć żmudne przy wpisywaniu. Standard ANSI oferuje dwa rozwiązania tego niewielkiego problemu.
Pierwszym z nich jest poinformowanie kompilatora (na początku listingu kodu) że będziemy używać cout i endl z biblioteki standardowej, tak jak pokazano na listingu 2.3.
Listing 2.3. Użycie słowa kluczowego using 0: // Listing 2.3 - użycie słowa kluczowego "using" 1: #include <iostream> 2: int main() 3: {
Usunięto: informacyjny
Usunięto: następuje
Usunięto: cie
Usunięto: a
Usunięto: w celu wyrównywania wydruków wyników
Usunięto: wypisywane
Usunięto:
Usunięto:
Usunięto: tak uważa
Usunięto: ą form
Usunięto: ą
Usunięto: jest
Usunięto: j
Usunięto: j
Usunięto: niedogodności
Usunięto: ,
Usunięto:
Usunięto: ,
Usunięto: .

4: using std::cout; 5: using std::endl; 6: 7: cout << "Hej tam.\n"; 8: cout << "To jest 5: " << 5 << "\n"; 9: cout << "Manipulator endl "; 10: cout << "wypisuje nowa linie na ekranie."; 11: cout << endl; 12: cout << "To jest bardzo duza liczba:\t" << 70000; 13: cout << endl; 14: cout << "To jest suma 8 i 5:\t"; 15: cout << 8+5 << endl; 16: cout << "To jest ulamek:\t\t"; 17: cout << (float) 5/8 << endl; 18: cout << "I bardzo, bardzo duza liczba:\t"; 19: cout << (double) 7000 * 7000 << endl; 20: cout << "Nie zapomnij zamienic Jesse Liberty "; 21: cout << "na swoje nazwisko...\n"; 22: cout << "Jesse Liberty jest programista C++!\n"; 23: return 0; 24: }
Wynik działania Hej tam. To jest 5: 5 Manipulator endl wypisuje nowa linie na ekranie. To jest bardzo duza liczba: 70000 To jest suma 8 i 5: 13 To jest ulamek: 0.625 I bardzo, bardzo duza liczba: 4.9e+007 Nie zapomnij zamienic Jesse Liberty na swoje nazwisko... Jesse Liberty jest programista C++!
Analiza
Zauważ, że wynik jest identyczny. Jedyną różnicą pomiędzy listingiem 2.3 a 2.2 jest to, że w liniach 4. i 5. informujemy kompilator, że będziemy używać dwóch obiektów ze standardowej biblioteki. Używamy do tego słowa kluczowego using. Gdy to zrobimy, nie musimy już kwalifikować obiektów cout i endl.
Drugim sposobem uniknięcia pisania std:: przed cout i endl jest po prostu poinformowanie kompilatora, że będziemy używać całej przestrzeni nazw standardowych, tj, że każdy obiekt, który nie zostanie oznaczony, z założenia będzie pochodził z przestrzeni nazw standardowych. W tym przypadku, zamiast pisać using std::cout; napiszemy po prostu using namespace std;, tak jak pokazano na listingu 2.4.
Listing 2.4. Użycie słowa kluczowego namespace 0: // Listing 2.3 - użycie przestrzeni nazw standardowych 1: #include <iostream> 2: int main() 3: { 4: using namespace std; 5: 6: cout << "Hej tam.\n"; 7: cout << "To jest 5: " << 5 << "\n"; 8: cout << "Manipulator endl "; 9: cout << "wypisuje nowa linie na ekranie."; 10: cout << endl;
Usunięto: :
Usunięto: :
Usunięto: i
Usunięto: niedogodności
Usunięto: ;
Usunięto: .
Usunięto: .

11: cout << "To jest bardzo duza liczba:\t" << 70000; 12: cout << endl; 13: cout << "To jest suma 8 i 5:\t"; 14: cout << 8+5 << endl; 15: cout << "To jest ulamek:\t\t"; 16: cout << (float) 5/8 << endl; 17: cout << "I bardzo, bardzo duza liczba:\t"; 18: cout << (double) 7000 * 7000 << endl; 19: cout << "Nie zapomnij zamienic Jesse Liberty ", 20: cout << "na swoje nazwisko...\n", 21: cou << "Jesse Liberty jest programista C++!\n"; 22: return 0; 23: }
Analiza
Także tym razem wynik jest identyczny z wynikami uzyskiwanymi we wcześniejszych wersjach programu. Zaletą zapisu using namespace std; jest to, że nie musimy określać obiektów, z których chcemy korzystać (na przykład cout oraz endl). Wadą jest ryzyko niezamierzonego użycia obiektów z niewłaściwej biblioteki.
Puryści preferują zapisywanie std:: przed każdym wystąpieniem cout i endl. Osoby bardziej leniwe wolą używać using namespace std; Na tym zakończmy temat. W tej książce w większości przypadków będziemy pisać, z jakich obiektów korzystamy, ale od czasu do czasu, dla odmiany, wypróbujemy także pozostałe style.
Komentarze Gdy piszesz program, to, co chcesz osiągnąć, zawsze jest jasne i oczywiste. Jednak miesiąc gdy do niego wracasz później, kod może okazać się całkiem niezrozumiały. Nie jestem w stanie przewidzieć, co może być niezrozumiałego w twoim programie, ale zdarza się to zawsze.
Aby sobie z tym poradzić, a także, by pomóc innym w zrozumieniu twojego kodu, powinieneś używać komentarzy. Komentarze są tekstem całkowicie ignorowanym przez kompilator, mogą natomiast informować czytającego o tym, co robisz w danym punkcie programu.
Rodzaje komentarzy Komentarze w C++ występują w dwóch odmianach: jako komentarze podwójnego ukośnika (//) oraz jako komentarze ukośnika i gwiazdki (/*). Komentarz podwójnego ukośnika, nazywany komentarzem w stylu C++, informuje kompilator, by zignorował wszystko, co po nim następuje, aż do końca linii.
Komentarz ukośnika i gwiazdki informuje kompilator, by zignorował wszystko to, co jest zawarte pomiędzy znakami /* oraz */. Te znaki są nazywane komentarzami w stylu C. Każdemu znakowi /* musi odpowiadać zamykający komentarz znak */.
Jak można się domyślać, komentarze w stylu C są używane także w programach C; jednakże komentarze C++ nie są częścią oficjalnej definicji języka C.
Usunięto: :
Usunięto: mi
Usunięto: mi
Usunięto: to, że
Usunięto: ujemy
Usunięto: e
Usunięto: i n
Usunięto: samej
Usunięto: sp
Usunięto: ych
Usunięto: stylów
Usunięto: to, co chcesz osiągnąć
Usunięto: co zabawne,
Usunięto: gdy do niego wracasz, k
Usunięto: tak jest
Usunięto: lecz
Usunięto: , lecz

Większość programistów używa przeważnie komentarzy w stylu C++, rezerwując komentarze w stylu C do wyłączania z kompilacji większych bloków kodu. Komentarze w stylu C++ mogą występować w blokach kodu „skomentowanych” komentarzami w stylu C. Ignorowana jest zawartość całego „skomentowanego” bloku, łącznie z komentarzami w stylu C++.
Używanie komentarzy Niektórzy programiści zalecają stosowanie komentarzy przed każdą funkcją (w celu wyjaśnienia, jakie czynności funkcja wykonuje i jakie wartości zwraca)
Osobiście nie zgadzam się z tym, uważam, że komentarze w nagłówkach funkcji zwykle są nieaktualne, bo prawie nikt nie pamięta o tym, by zaktualizować je po modyfikacji kodu. Funkcje powinny przyjmować takie nazwy, na podstawie których można jasno określić, do czego służą. Z kolei niejasne i skomplikowane fragmenty kodu powinny zostać przeprojektowane i przepisane tak, aby same się objaśniały. Dość często zdarza się, że komentarze stanowią dla leniwego programisty pretekst dla niedbałości.
Nie sugeruję żeby w ogóle nie korzystać z komentarzy, choć oczywiście nie powinny służyć do wyjaśniania niejasnego kodu. W takim przypadku należy poprawić sam kod. Mówiąc krótko, pisz swoje programy dobrze, zaś komentarzy używaj w celu zwiększenia ich zrozumiałości.
Listing 2.5 demonstruje użycie komentarzy i pokazuje, że nie wpływają one na działanie programu i na otrzymywane wyniki.
Listing 2.5. HELP.cpp demonstruje komentarze 0: #include <iostream> 1: 2: int main() 3: { 4: using std::cout; 5: 6: /* to jest komentarz w stylu C 7: i rozciąga się on aż do zamykającego 8: znaku gwiazdki i ukośnika */ 9: cout << "Witaj Swiecie!\n"; 10: // ten komentarz kończy się wraz z końcem tej linii 11: cout << "Ten komentarz sie zakonczyl!\n"; 12: 13: // komentarze podwójnego ukośnika mogą występować w linii same 14: /* podobnie jak komentarze ukośnika i gwiazdki */ 15: return 0; 16: }
Wynik Witaj Swiecie! Ten komentarz sie zakonczyl!
Analiza
Komentarze w liniach od 6. do 8. są całkowicie ignorowane przez kompilator, podobnie jak komentarze w liniach 10., 13. oraz 14. Komentarz w linii 10. kończy się wraz z końcem linii, lecz komentarze w liniach 6. i 14. wymagają użycia zamykającego znaku komentarza.
Usunięto: w większości przypadków
Usunięto: rezerwując dla
Usunięto: wy
Usunięto: wy
Usunięto: w
Usunięto: ,
Usunięto:
Usunięto: co ta
Usunięto: robi
Usunięto: .
Usunięto: gdyż
Usunięto: je zaktualizować
Usunięto: mieć takie
Usunięto: by
Usunięto: ich
Usunięto: było
Usunięto: ,
Usunięto: wymówkę
Usunięto: oczywiście by nigdy
Usunięto: Zamiast tego
Usunięto: poprawy jego
Usunięto: ,
Usunięto: ąc
Usunięto: an
Usunięto: .
Usunięto: :
Usunięto: :

Jeszcze jedna uwaga na temat komentarzy Komentarze, które informują o czymś oczywistym, są bezużyteczne. Mogą być wręcz szkodliwe, np. gdy kod ulegnie zmianie, a programista zapomni o aktualizacji komentarza. Jednak to, co jest oczywiste dla jednej osoby, może być niezrozumiałe dla innej, zatem musisz samodzielnie ocenić użyteczność komentarza.
Ogólnie rzecz biorąc, komentarze powinny informować nie o tym, co się dzieje, ale o tym, dlaczego tak się dzieje.
Funkcje Funkcja main() nie jest zwykłą funkcją. Normalnie funkcja musi być wywołana w czasie działania programu. Funkcja main() jest wywoływana przez system operacyjny.
Program jest wykonywany „linia po linii” – w kolejności, w jakiej występują w kodzie źródłowym, aż do napotkania wywołania funkcji. Wtedy działanie programu „rozgałęzia” się w celu wykonania funkcji. Gdy funkcja zakończy działanie, zwraca sterowanie do linii kodu następującej bezpośrednio po linii, w której funkcja została wywołana.
Dobrym przykłądem jest ostrzenie ołówka. Jeśli rysujesz obrazek a w ołówku złamie się grafit, przestajesz rysować, idziesz naostrzyć ołówek, po czym wracasz do tego miejsca rysunku, w którym przerwałeś rysowanie. Gdy program wymaga wykonania usługi, może w tym celu wywołać funkcję, po czym po zakończeniu jej działanie podjąć działanie w tym miejscu, w którym je przerwał. Przebieg tego procesu demonstruje listing 2.6.
Listing 2.6. Przykład wywołania funkcji 0: #include <iostream> 1: 2: // funkcja DemonstrationFunction 3: // wypisuje informacyjny komunikat 4: void DemonstrationFunction() 5: { 6: std::cout << "Wewnatrz funkcji DemonstrationFunction\n"; 7: } 8: 9: // funkcja main - wypisuje komunikat, następnie 10: // wywołuje funkcję DemonstrationFunction, po czym wypisuje 11: // drugi komunikat. 12: int main() 13: { 14: std::cout << "Wewnatrz funkcji main\n" ; 15: DemonstrationFunction(); 16: std::cout << "Ponownie w funkcji main\n"; 17: return 0; 18: }
Wynik Wewnatrz funkcji main Wewnatrz funkcji DemonstrationFunction Ponownie w funkcji main
Analiza
Usunięto: I j
Usunięto: W rzeczywistości, m
Usunięto: gdyż
Usunięto: może
Usunięto: c
Usunięto: lecz
Usunięto: może
Usunięto: eć
Usunięto: więc
Usunięto: to osądzić
Usunięto: Mówiąc o
Usunięto: Choć
Usunięto: , jednak jest to funkcja niezwykła
Usunięto: Aby być użyteczną,
Usunięto: ich
Usunięto: owania
Usunięto: się
Usunięto: ą
Usunięto: analogią jest
Usunięto: i
Usunięto: zakończeniu
Usunięto: działanie
Usunięto: Tę ideę
Usunięto: Demonstracja
Usunięto: .
Usunięto: :
Usunięto: :

Funkcja DemonstrationFunction() jest zdefiniowana w liniach od 5. do 7. Gdy zostanie wywołana, wypisuje na ekranie komunikat, po czym wraca.
Linia 12. stanowi początek rzeczywistego programu. W linii 14. funkcja main() wypisuje komunikat informujący, że program znajduje się wewnątrz funkcji main(). Po wypisaniu tego komunikatu, wywołuje funkcję DemonstrateFunction() w linii 15. To wywołanie powoduje że wykonane zostają instrukcje zawarte wewnątrz funkcji DemonstrationFunction (). W tym przypadku, cała funkcja składa się z kodu w linii 6., kod ten wypisuje kolejny komunikat. Gdy funkcja DemonstrateFunction() kończy działanie (linia 7.), program powraca do linii, z której ta funkcja została wywołana. W tym przypadku program wraca do linii 16., w której funkcja main() wypisuje ostatnią linię komunikatu.
UWAGA Zwróć uwagę, że nie ma sensu stosować instrukcji using w funkcji DemonstrationFunction, gdyż z obiektu cout korzystamy tylko raz, w związku z czym w zupełności wystarczy zastosowanie zapisu std::cout. Mógłbym zdecydować się na skorzystanie z instrukcji using w funkcji main(), ale także tym razem po prostu użyłem obiektu wraz z nazwą przestrzeni nazw, tak jak pokazano w liniach 14. i 16.
Korzystanie z funkcji Funkcje zwracają albo wartość, albo typ void, który oznacza, że nie zwracają niczego. Funkcja dodająca dwie liczby całkowite może zwracać ich sumę, funkcja taka będzie zdefiniowana jako zwracająca wartość całkowitą. Funkcja, która jedynie wypisuje komunikat, nie musi niczego zwracać i może zostać zadeklarowana jako zwracająca typ void.
Funkcja składa się z nagłówka oraz ciała. Nagłówek składa się ze zwracanego typu, nazwy funkcji oraz parametrów funkcji. Parametry funkcji umożliwiają przekazywanie wartości do funkcji. Zatem, jeśli funkcja ma dodawać dwie liczby, będą one parametrami funkcji. Oto typowy nagłówek funkcji:
int Sum(int a, int b)
Parametr jest deklaracją typu wartości, jaka zostanie przekazana funkcji; wartość przekazywana w wywołaniu funkcji jest nazywana argumentem. Wielu programistów używa określeń parametr i argument jako synonimów. Inni zwracają uwagę na to rozróżnienie. W tej książce obu terminów będziemy używać zamiennie.
Ciało funkcji składa się z otwierającego nawiasu klamrowego, pewnej liczby instrukcji lub ich braku, oraz klamrowego nawiasu zamykającego. Instrukcje określają działanie funkcji. Funkcja może zwracać wartość, używając instrukcji return. Ta instrukcja powoduje również wyjście z funkcji. Jeśli nie umieścisz instrukcji return wewnątrz funkcji, funkcja automatycznie zwróci wartość typu void. Zwracana wartość musi mieć typ zgodny z typem zadeklarowanym w nagłówku funkcji.
UWAGA Funkcje zostaną omówione bardziej szczegółowo w rozdziale 5., „Funkcje.” Typy, jakie mogą być przez funkcje zwracane, zostaną dokładniej omówione w rozdziale 3., „Zmienne i
Usunięto: w
Usunięto: wywołuje funkcję DemonstrateFunction()
Usunięto: który
Usunięto: w funkcji DemonstrationFunction
Usunięto: ,
Usunięto: W funkcji main() m
Usunięto: ,
Usunięto: albo
Usunięto: zwracają
Usunięto: i jako
Usunięto: ąca
Usunięto: jako taka
Usunięto: Z kolei n
Usunięto: Tak więc
Usunięto: sama
Usunięto: techniczne
Usunięto: braku lub
Usunięto: jednocześnie
Usunięto: nie umieścisz instrukcji return
Usunięto: na koniec
Usunięto: przez funkcje

stałe.” Informacje zamieszczone w tym rozdziale mają na celu jedynie ogólne zaprezentowanie funkcji, gdyż są one używane w praktycznie wszystkich programach C++.
Listing 2.7 przedstawia funkcję, która otrzymuje dwa parametry całkowite i zwraca wartość całkowitą. Nie martw się na razie o składnię i sposób posługiwania się wartościami całkowitymi (na przykład int x); zostaną one dokładnie omówione w rozdziale 3.
Listing 2.7. FUNC.cpp demonstruje prostą funkcję 0: #include <iostream> 1: int Add (int x, int y) 2: { 3: std::cout << "Funkcja Add() otrzymala " << x << " oraz " << y << "\n"; 4: return (x+y); 5: } 6: 7: int main() 8: { 9: using std::cout; 10: using std::cin; 11: 12: 13: cout << "Jestem w funkcji main()!\n"; 14: int a, b, c; 15: cout << "Wpisz dwie liczby: "; 16: cin >> a; 17: cin >> b; 18: cout << "\nWywoluje funkcje Add()\n"; 19: c=Add(a,b); 20: cout << "\nPonownie w funkcji main().\n"; 21: cout << "c zostalo ustawione na " << c; 22: cout << "\nOpuszczam program...\n\n"; 23: return 0; 24: }
Wynik Jestem w funkcji main()! Wpisz dwie liczby: 3 5 Wywoluje funkcje Add() Funkcja Add() otrzymala 3 oraz 5 Ponownie w funkcji main(). c zostalo ustawione na 8 Opuszczam program...
Analiza
Funkcja Add() jest zdefiniowana w linii 1. Otrzymuje dwa parametry w postaci liczb całkowitych i zwraca wartość całkowitą. Sam program zaczyna się w linii 7. Program prosi użytkownika o dwie liczby (linie od 15. do 17.). Użytkownik wpisuje liczby, oddzielając je spacją, po czym naciska klawisz Enter. Funkcja main() w linii 19. przekazuje funkcji Add()wartości wpisane przez użytkownika.
Przetwarzanie przechodzi do funkcji Add(), która rozpoczyna się od linii 1. Parametry a i b są wypisywane, po czym sumowane. Rezultat sumowania jest zwracany w linii 4., po czym następuje wyjście z funkcji.
Usunięto: podane
Usunięto: pobieżne
Usunięto: lub
Usunięto: ie
Usunięto: to
Usunięto: .
Usunięto: :
Usunięto: :
Usunięto: wciska

Znajdujący się w liniach 16. i 17. obiekt cin służy do uzyskania liczb dla zmiennych a i b, zaś obiekt cout jest używany do wypisania tych wartości na ekranie. Zmienne i inne aspekty tego programu zostaną szerzej omówione w kilku następnych rozdziałach.
Usunięto: W
Usunięto: dogłębnie

Rozdział 3. Zmienne i stałe Program musi mieć możliwość przechowywania danych, z których korzysta. Dzięki zmiennym i stałym mamy możliwość reprezentowania, przechowywania i manipulowania tymi danymi.
Z tego rozdziału dowiesz się
• jak deklarować i definiować zmienne oraz stałe,
• jak przypisywać wartości zmiennym oraz jak nimi manipulować,
• jak wypisywać wartość zmiennej na ekranie.
Czym jest zmienna? W C++ zmienna służy do przechowywania informacji – jest to miejsce w pamięci komputera, w którym możesz umieścić wartość, i z którego możesz ją później odczytać.
Zwróć uwagę, że jest to tymczasowe miejsce przechowywania. Gdy wyłączysz komputer, wszystkie zmienne zostają utracone. Przechowywanie trwałe przebiega zupełnie inaczej. Zwykle zmienne są przechowywane trwale dzięki umieszczeniu ich w bazie danych lub w pliku na dysku. Przechowywanie w pliku na dysku zostanie omówione w rozdziale 16., „Zaawansowane dziedziczenie.”
Dane są przechowywane w pamięci Pamięć komputera można traktować jako szereg pojemników, ułożonych jeden za drugim. Każdy pojemnik — czyli miejsce w pamięci — jest oznaczony kolejnym numerem. Te numery są nazywane adresami pamięci. Zmienna rezerwuje jeden lub więcej pojemników, w których może przechowywać wartość.
Nazwa zmiennej (na przykład myVariable) stanowi etykietkę jednego z tych pojemników; dzięki niej można go łatwo zlokalizować nie znając rzeczywistego adresu pamięci. Rysunek 3.1 przedstawia schemat przebiegu tego procesu. Jak widać, zmienna myVariable rozpoczyna się od
Usunięto: używanych przez siebie
Usunięto: Z
Usunięto: e
Usunięto: e
Usunięto: oferują różne sposoby
Usunięto: W tym rozdziale dowiesz się
Usunięto: J
Usunięto: .
Usunięto: J
Usunięto: tymi wartościami.
Usunięto: J
Usunięto: jest miejscem do
Usunięto: .
Usunięto: Zmienna
Usunięto: jest
Usunięto: m
Usunięto: jedynie
Usunięto: Trwałe p
Usunięto: jest zupełnie innym zagadnieniem
Usunięto: w wyniku
Usunięto: a
Usunięto: jest
Usunięto: a
Usunięto: a
Usunięto: . Każdy pojemnik jest jednym z bardzo wielu takich samych pojemników
Usunięto: jest
Usunięto: ą
Usunięto: ,
Usunięto: której
Usunięto: bez znajomości
Usunięto: yczną reprezentację tej idei
Usunięto: na nim

adresu 103. W zależności od rozmiaru tej zmiennej, może ona zająć w pamięci jeden lub więcej adresów.
Rysunek 3.1. Schematyczna reprezentacja pamięci
UWAGA Skrót RAM oznacza Random Access Memory (pamięć o dostępie swobodnym). Gdy uruchamiasz program, jest on ładowany z pliku na dysku do pamięci RAM. W pamięci RAM tworzone są wszystkie zmienne. Gdy programiści używają terminu „pamięć”, zwykle mają na myśli pamięć RAM, do której się odwołują.
Przydzielanie pamięci Gdy definiujesz zmienną w C++, musisz poinformować kompilator o jej rodzaju: czy jest to liczba całkowita, znak, czy coś innego. Ta informacja mówi kompilatorowi, ile miejsca ma zarezerwować dla zmiennej oraz jaki rodzaj wartości będzie w niej przechowywany.
Każdy pojemnik ma rozmiar jednego bajtu. Jeśli tworzona zmienna ma rozmiar czterech bajtów, to wymaga czterech bajtów pamięci, czyli czterech pojemników. Typ zmiennej (na przykład liczba całkowita) mówi kompilatorowi, ile pamięci (pojemników) ma przygotować dla zmiennej.
Swojego czasu programiści musieli znać się na bitach i bajtach, gdyż stanowią one podstawowe jednostki przechowywania wszelkiego rodzaju danych. Programy komputerowe pozwalają na ucieczkę od tych szczegółów, ale jest w dalszym ciągu pomocna wiedza o przechowywaniu danych. Krótki przegląd podstaw matematyki dwójkowej możesz znaleźć w dodatku A, „Binarnie i szesnastkowo.”
UWAGA Jeśli przeraża cię matematyka, nie przejmuj się dodatkiem A; tak naprawdę nie jest ci potrzebny. Programiści nie muszą już być równocześnie matematykami, choć umiejętność logicznego i racjonalnego myślenia jest zawsze pożądana.
Usunięto: w pamięci
Usunięto: to
Usunięto: z pliku na dysku
Usunięto: są także
Usunięto: mówią o
Usunięto: ci
Usunięto: tej zmiennej
Usunięto: tej zmiennej
Usunięto: ile
Usunięto: koniecznie
Usunięto: dla
Usunięto: uzyskanie lepszej abstrakcji
Usunięto: jest
Usunięto: tym, jak dane są
Usunięto: e
Usunięto: .
Usunięto: Szybki
Usunięto: koncepcji stanowiących
Usunięto: ę
Usunięto: sprawia że z krzykiem wybiegasz z pokoju
Usunięto: wtedy
Usunięto: rawdą jest, że p
Usunięto: zawsze pożądana jest

Rozmiar liczb całkowitych W danym komputerze każdy typ zmiennych zajmuje stałą ilość miejsca. Oznacza to, że liczba całkowita może mieć w jednym komputerze dwa bajty, w innym cztery, lecz w danym komputerze ma zawsze ten sam, niezmienny rozmiar.
Zmienna typu char (używana do przechowywania znaków) ma najczęściej rozmiar jednego bajtu.
Krótka liczba całkowita (short) ma w większości komputerów rozmiar dwóch bajtów, zaś długa liczba całkowita (long) ma zwykle cztery bajty. Natomiast liczba całkowita (bez słowa kluczowego short lub long) może mieć dwa lub cztery bajty. Można przypuszczać, że język powinien to określać precyzyjnie, ale tak nie jest. Ustalono jedynie, że typ short musi mieć rozmiar mniejszy lub równy typowi int (integer, liczba całkowita), który z kolei musi mieć rozmiar mniejszy lub równy typowi long.
Najprawdopodobniej jednak pracujesz z komputerem, w którym typ short ma dwa bajty, zaś typy int i long mają po cztery bajty.
Rozmiar liczb całkowitych jest wyznaczany przez procesor (16 lub 32 bity) oraz kompilator. W nowoczesnych, 32-bitowych procesorach Pentium z najnowszymi kompilatorami (na przykład Visual C++4 lub nowsze), liczby całkowite mają cztery bajty. W tej książce zakładamy, że liczby całkowite (typ int) mają cztery bajty, choć w twoim przypadku może być inaczej.
Znak jest pojedynczą literą, cyfrą lub symbolem i zajmuje pojedynczy bajt pamięci.
Skompiluj i uruchom w swoim komputerze listing 3.1; pokaże on dokładny rozmiar każdego z tych typów.
Listing 3.1. Sprawdzanie rozmiarów typów zmiennych istniejących w twoim komputerze 0: #include <iostream> 1: 2: int main() 3: { 4: using std::cout; 5: 6: cout << "Rozmiar zmiennej typu int to:\t\t" 7: << sizeof(int) << " bajty.\n"; 8: cout << "Rozmiar zmiennej typu short int to:\t" 9: << sizeof(short) << " bajty.\n"; 10: cout << "Rozmiar zmiennej typu long int to:\t" 11: << sizeof(long) << " bajty.\n"; 12: cout << "Rozmiar zmiennej typu char to:\t\t" 13: << sizeof(char) << " bajty.\n"; 14: cout << "Rozmiar zmiennej typu float to:\t\t" 15: << sizeof(float) << " bajty.\n"; 16: cout << "Rozmiar zmiennej typu double to:\t" 17: << sizeof(double) << " bajty.\n"; 18: cout << "Rozmiar zmiennej typu bool to:\t" 19: << sizeof(bool) << " bajty.\n"; 20: 21: return 0; 22: }
Wynik Rozmiar zmiennej typu int to: 4 bajty. Rozmiar zmiennej typu short int to: 2 bajty. Rozmiar zmiennej typu long int to: 4 bajty.
Usunięto: W każdym komputerze każdy typ zmiennych zajmuje
Usunięto: , niezmienną
Usunięto: To
Usunięto: y
Usunięto: zaś
Usunięto: ego
Usunięto: by sądzić
Usunięto: precyzyjnie
Usunięto: J
Usunięto: co musi zostać zapewnione, to to
Usunięto: niż
Usunięto: nowoczesnymi
Usunięto: .
Usunięto: :

Rozmiar zmiennej typu char to: 1 bajty. Rozmiar zmiennej typu float to: 4 bajty. Rozmiar zmiennej typu double to: 8 bajty. Rozmiar zmiennej typu bool to: 1 bajty.
UWAGA W twoim komputerze rozmiary zmiennych mogą być inne.
Większość listingu 3.1 powinna być ci znana. Podzieliłem linie tak, aby mieściły się na całej stronie książki. W rzeczywistości linie 6. i 7. powinny stanowić linię pojedynczą. Kompilator ignoruje tak zwane białe spacje (spacje, tabulatory, przejścia do nowej linii), więc traktuje linie 6. i 7. jak jedną całość.
Nowym elementem w tym programie jest użycie w liniach od 6. do 19. operatora (funkcji) sizeof(). Ten operator jest dostarczany przez kompilator; informuje on o rozmiarze obiektu przekazywanego mu jako parametr. Na przykład w linii 7., do operatora sizeof() jest przekazywane słowo kluczowe int. Za pomocą tego operatora byłem w stanie sprawdzić że w moim komputerze zmienne typu int mają ten sam rozmiar, co zmienne typu long, czyli cztery bajty.
Zapis ze znakiem i bez znaku Wszystkie typy całkowite występują w dwóch odmianach: signed (ze znakiem) oraz unsigned (bez znaku). Czasem potrzebna jest liczba ujemna, a czasem dodatnia. Liczby całkowite (krótkie i długie) bez słowa kluczowego unsigned są traktowane jako liczby ze znakiem. Liczby całkowite signed są albo dodatnie albo ujemne, zaś liczby całkowite unsigned są zawsze dodatnie.
Liczby ze znakiem i liczby bez znaku mają po tyle samo bajtów, więc największa liczba, jaką można przechować w zmiennej całkowitej bez znaku jest dwa razy większa niż największa liczba dodatnia jaką można przechować w zmiennej całkowitej ze znakiem. Zmienna typu unsigned short może pomieścić wartości od 0 do 65 535. Połowa tych wartości (reprezentowana przez zmienną typu signed short) jest ujemna, więc zmienna tego typu może przechowywać jedynie wartości od –32 768 do 32 767. Jeśli wydaje ci się to skomplikowane, zajrzyj do dodatku A.
Podstawowe typy zmiennych Język C++ posiada jeszcze kilka innych wbudowanych typów zmiennych. Można je wygodnie podzielić na typy całkowite, typy zmiennopozycyjne oraz typy znakowe.
Zmienne zmiennoprzecinkowe zawierają wartości, które można wyrazić w postaci ułamków dziesiętnych — stanowią obszerny podzbiór liczb rzeczywistych. Zmienne znakowe mają rozmiar jednego bajtu i są używane do przechowywania 256 znaków i symboli pochodzących z zestawów znaków ASCII i rozszerzonego ASCII.
Zestaw ASCII jest standardowym zestawem znaków używanych w komputerach. ASCII stanowi skrót od American Standard Code for Information Interchange. Prawie każdy komputerowy system operacyjny obsługuje zestaw ASCII, choć wiele systemów obsługuje także inne, międzynarodowe zestawy znaków.
Usunięto: już
Usunięto: znajoma
Usunięto: w szerokości
Usunięto: strony
Usunięto: , tak w
Usunięto: ięc w
Usunięto: linię
Usunięto: linie 6 i 7
Usunięto: i
Usunięto: Używając
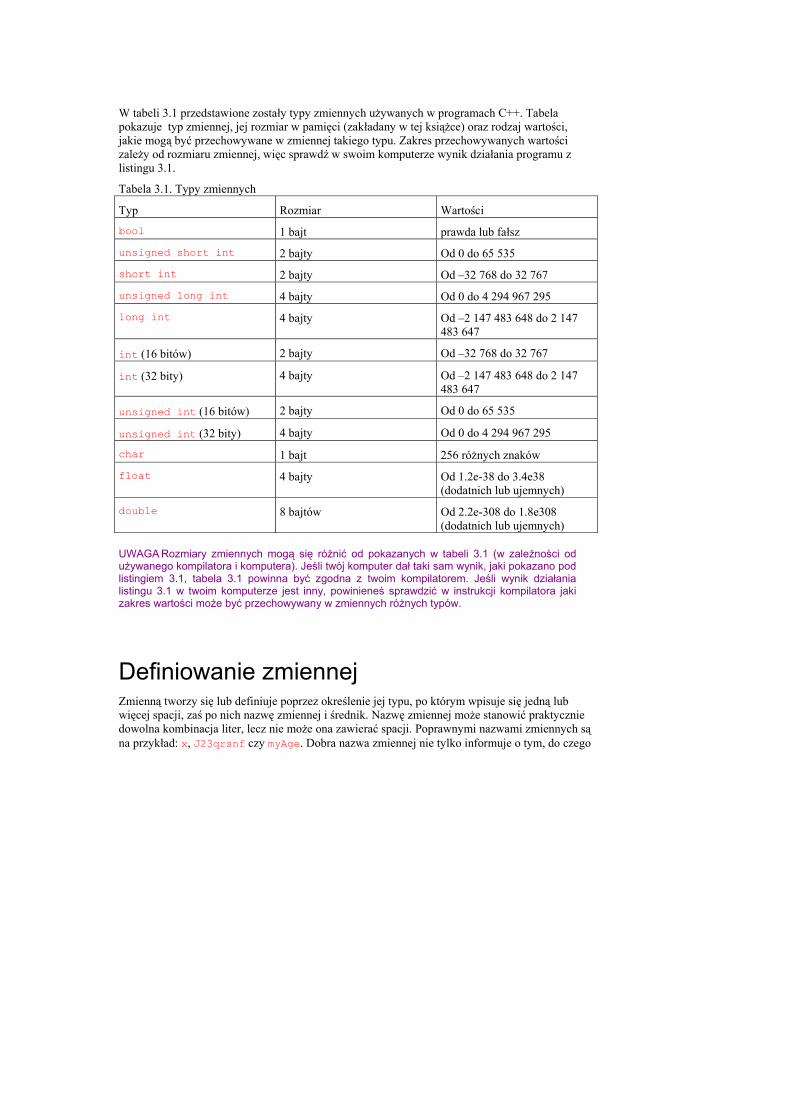
W tabeli 3.1 przedstawione zostały typy zmiennych używanych w programach C++. Tabela pokazuje typ zmiennej, jej rozmiar w pamięci (zakładany w tej książce) oraz rodzaj wartości, jakie mogą być przechowywane w zmiennej takiego typu. Zakres przechowywanych wartości zależy od rozmiaru zmiennej, więc sprawdź w swoim komputerze wynik działania programu z listingu 3.1.
Tabela 3.1. Typy zmiennych
Typ Rozmiar Wartości
bool 1 bajt prawda lub fałsz
unsigned short int 2 bajty Od 0 do 65 535
short int 2 bajty Od –32 768 do 32 767
unsigned long int 4 bajty Od 0 do 4 294 967 295
long int 4 bajty Od –2 147 483 648 do 2 147 483 647
int (16 bitów) 2 bajty Od –32 768 do 32 767
int (32 bity) 4 bajty Od –2 147 483 648 do 2 147 483 647
unsigned int (16 bitów) 2 bajty Od 0 do 65 535
unsigned int (32 bity) 4 bajty Od 0 do 4 294 967 295
char 1 bajt 256 różnych znaków
float 4 bajty Od 1.2e-38 do 3.4e38 (dodatnich lub ujemnych)
double 8 bajtów Od 2.2e-308 do 1.8e308 (dodatnich lub ujemnych)
UWAGA Rozmiary zmiennych mogą się różnić od pokazanych w tabeli 3.1 (w zależności od używanego kompilatora i komputera). Jeśli twój komputer dał taki sam wynik, jaki pokazano pod listingiem 3.1, tabela 3.1 powinna być zgodna z twoim kompilatorem. Jeśli wynik działania listingu 3.1 w twoim komputerze jest inny, powinieneś sprawdzić w instrukcji kompilatora jaki zakres wartości może być przechowywany w zmiennych różnych typów.
Definiowanie zmiennej Zmienną tworzy się lub definiuje poprzez określenie jej typu, po którym wpisuje się jedną lub więcej spacji, zaś po nich nazwę zmiennej i średnik. Nazwę zmiennej może stanowić praktycznie dowolna kombinacja liter, lecz nie może ona zawierać spacji. Poprawnymi nazwami zmiennych są na przykład: x, J23qrsnf czy myAge. Dobra nazwa zmiennej nie tylko informuje o tym, do czego

jest ona przeznaczona, ale także znacznie ułatwia zrozumienie działania programu. Przedstawiona poniżej instrukcja definiuje zmienną całkowitą o nazwie myAge:
int myAge;
UWAGA Gdy deklarujesz zmienną, jest dla niej alokowana (przygotowywana i rezerwowana) pamięć. Wartość zmiennej stanowi to, co w danej chwili znajduje się w tym miejscu pamięci. Za chwilę zobaczysz, jak można przypisać nowej zmiennej określoną wartość.
W praktyce należy unikać tak przerażających nazw, jak J23qrsnf oraz ograniczyć użycie nazw jednoliterowych (takich jak x czy i) do zmiennych stosowanych jedynie pomocniczo. Postaraj się używać nazw opisowych, takich jak myAge (mój wiek) czy howMany (jak dużo). Są one łatwiejsze do zrozumienia trzy tygodnie po ich napisaniu i nie będziesz łamać sobie głowy nad tym, co chciałeś osiągnąć pisząc, tę linię kodu.
Przeprowadź taki eksperyment: w oparciu o znajmość kilku pierwszych linii kodu, spróbuj odgadnąć do, czego on służy:
Przykład 1: int main() { unsigned short x; unsigned short y; unsigned short z; z = x * y; return 0; };
Przykład 2: int main() { unsigned short Szerokosc; unsigned short Dlugosc; unsigned short Obszar; Obszar = Szerokosc * Dlugosc; return 0; };
UWAGA Jeśli skompilujesz ten program, kompilator ostrzeże cię, że te wartości nie zostały zainicjalizowane. Wkrótce dowiesz się, jak sobie poradzić z tym problemem.
Oczywiście, łatwiejsze do odgadnięcia jest przeznaczenie drugiego programu, a niedogodność polegająca wpisywaniu dłuższych nazw zmiennych zostaje z nawiązką nagrodzona (przez łatwość konserwacji drugiego programu).
Uwzględnianie wielkości liter Język C++ uwzględnia wielkość liter. Innymi słowy, odróżnia małe i duże litery. Zmienna o nazwie age różni się od zmiennej Age, która z kolei jest uważana za różną od zmiennej AGE.

UWAGA Niektóre kompilatory umożliwiają wyłączenie rozróżniania dużych i małych liter. Nie daj się jednak skusić – twoje programy nie będą wtedy działać z innymi kompilatorami, zaś inni programiści C++ będą mieli wiele problemów z twoim kodem.
Istnieją różne konwencje nazywania zmiennych, i choć nie ma znaczenia, którą z nich przyjmiesz, ważne jest, by zachować ją w całym kodzie programu. Niespójne nazewnictwo może znacznie utrudnić zrozumienie twojego kodu przez innych programistów.
Wielu programistów decyduje się na używanie dla swoich zmiennych nazw składających się wyłącznie z małych liter. Jeśli nazwa wymaga użycia dwóch słów (na przykład „moje auto”), można zastosować dwie popularne konwencje: moje_auto lub mojeAuto. Druga forma jest nazywana zapisem wielbłąda, gdyż duża litera w jego środku przypomina nieco garb tego zwierzęcia.
Niektórzy uważają, że znak podkreślenia (moje_auto) jest łatwiejszy do odczytania, jednak inni wolą go unikać, gdyż trudniej się go wpisuje. W tej książce będziemy stosować zapis wielbłąda, w którym wszystkie kolejne słowa będą zaczynać się od wielkiej litery: myCar (mojeAuto), theQuickBrownFox (szybkiRudyLis), itd.
UWAGA Wielu zaawansowanych programistów korzysta ze stylu zapisu nazywanego notacją węgierską. Polega ona na poprzedzaniu każdej nazwy zmiennej zestawem znaków opisującym jej typ. Zmienne całkowite (integer) mogą rozpoczynać się od małej litery „i”, a zmienne typu long mogą zaczynać się od małej litery „l”. Inne litery oznaczają stałe, zmienne globalne, wskaźniki, itd. Taki zapis ma dużo większe znaczenie w przypadku języka C, dlatego nie będzie stosowany w tej książce.
Ten zapis jest nazywany notacją węgierską, ponieważ człowiek, który go wymyślił, Charles Simonyi z Microsoftu, jest Węgrem. Jego monografię można znaleźć pod adresem http://www.strangecreations.com/library/c/naming.txt.
Microsoft ostatnio zrezygnował z notacji węgierskiej, zaś zalecenia projektowe dla języka C# wyraźnie odradzają jej wykorzystanie. Strategię tę stosujemy również w języku C++.
Słowa kluczowe Niektóre słowa są zarezerwowane przez C++ i nie można używać ich jako nazw zmiennych. Są to słowa kluczowe, używane do sterowania działaniem programu. Należą do nich if, while, for czy main. Dokumentacja kompilatora powinna zawierać pełną listę słów kluczowych, ale słowem kluczowym prawie na pewno nie jest każda sensowna nazwa zmiennej. Lista słów kluczowych języka C++ znajduje się w dodatku B.
Tak Nie
Definiuj zmienną, zapisując jej typ, a następnie jej nazwę.
Nie używaj słów kluczowych języka C++ jako nazw zmiennych.

Używaj znaczących nazw dla zmiennych.
Pamiętaj, że język C++ uwzględnia wielkość znaków.
Zapamiętaj ilość bajtów, jaką każdy typ zmiennej zajmuje w pamięci oraz jakie wartości można przechowywać w zmiennych danego typu.
Nie używaj zmiennych bez znaku dla wartości ujemnych.
Tworzenie kilku zmienych jednocześnie W jednej instrukcji możesz tworzyć kilka zmiennych tego samego typu; w tym celu powinieneś zapisać typ, a po nim nazwy zmiennych, oddzielone przecinkami. Na przykład:
unsigned int myAge, myWeight; // dwie zmienne typu unsigned int long int area, width, length; // trzy zmienne typu long
Jak widać, myAge i myWeight są zadeklarowane jako zmienne typu unsigned int. Druga linia deklaruje trzy osobne zmienne typu long; ich nazwy to area (obszar), width (szerokość) oraz length (długość). W obrębie jednej instrukcji nie można deklarować zmiennych o różnych typach.
Przypisywanie zmiennym wartości Do przypisywania zmiennej wartości służy operator przypisania (=). Na przykład zmiennej Width przypisujemy wartość 5, zapisując:
unsigned short Width; Width = 5;
UWAGA Typ long jest skróconym zapisem dla long int, zaś short jest skróconym zapisem dla short int.
Możesz połączyć te kroki i zainicjalizować zmienną w chwili jej definiowania, zapisując:
unsigned short Width = 5;

Inicjalizacja jest podobna do przypisania, a w przypadku zmiennych całkowitych różnica między nimi jest niewielka. Później, gdy poznasz stałe, przekonasz się, że pewne wartości muszą być zainicjalizowane, gdyż nie można im niczego przypisywać. Zasadniczą różnicą między inicjalizacją a przypisaniem jest to, że inicjalizacja odbywa się w chwili tworzenia zmiennej.
Ponieważ można definiować kilka zmienych jednocześnie, podczas tworzenia można również inicjalizować więcej niż jedną zmienną. Na przykład:
// Tworzymy dwie zmienne typu long i inicjalizujemy je long width = 5, length = 7;
W tym przykładzie inicjalizujemy zmienną width typu long, nadając jej wartość 5 oraz zmienną length tego samego typu, nadając jej wartość 7. Można także mieszać definicje i inicjalizacje:
int myAge = 39, yourAge, hisAge = 40;
W tym przykładzie stworzyliśmy trzy zmienne typu int, inicjalizując pierwszą i trzecią z nich.
Listing 3.2 przedstawia pełny, gotowy do kompilacji program, który oblicza obszar prostokąta i wypisuje wynik na ekranie.
Listing 3.2. Przykład użycia zmiennych 0: // Demonstracja zmiennych 1: #include <iostream> 2: 3: int main() 4: { 5: using std::cout; 6: using std::endl; 7: 8: unsigned short int Width = 5, Length; 9: Length = 10; 10: 11: // tworzymy zmienną typu unsigned short i inicjalizujemy 12: // ją iloczynem szerokości (Width) i długości (Length) 13: unsigned short int Area = (Width * Length); 14: 15: cout << "Szerokosc:" << Width << "\n"; 16: cout << "Dlugosc: " << Length << endl; 17: cout << "Obszar: " << Area << endl; 18: return 0; 19: }
Wynik Szerokosc:5 Dlugosc: 10 Obszar: 50
Analiza
Linia 1. dołącza wymagany plik nagłówkowy dla biblioteki iostream, dzięki czemu możemy korzystać z obiektu cout. Linia 3. rozpoczyna program. Linie 5. i 6. definiują cout i endl jako część przestrzeni nazw standardowych (std).

W linii 8. zdefiniowana jest zmienna całkowita Width typu unsigned sort, która zostaje zainicjalizowana wartością 5. Definiowana jest także inna zmienna typu unsigned short, zmienna Length, lecz nie jest ona inicjalizowana. W linii 9. zmiennej Length przypisywana jest wartość 10.
W linii 13. jest definiowana zmienna całkowita Area typu unsigned short, która jest inicjalizowana przez wartość uzyskaną w wyniku mnożenia wartości zawartej w zmiennej Width przez wartość zawartą w zmiennej Length. W liniach od 15. do 17. wartości zmiennych są wypisywane na ekranie. Zwróć uwagę, że słowo endl powoduje przejście do nowej linii.
typedef Ciągłe wpisywanie unsigned short int może być żmudne, a co gorsza, może spowodować wystąpienie błędu. C++ umożliwia użycie słowa kluczowego typedef (od type definition, definicja typu), dzięki któremu możesz stworzyć skróconą formę takiego zapisu.
Dzięki skróconemu zapisowi tworzysz synonim, lecz zwróć uwagę, że nie jest to nowy typ (będziesz go tworzyć w rozdziale 6., „Programowanie zorientowane obiektowo”). Przy zapisywaniu synonimu typu używa się słowa kluczowego typedef, po którym wpisuje się istniejący typ, zaś po nim nową nazwę typu. Całość kończy się średnikiem. Na przykład:
typedef unsigned short int USHORT;
tworzy nową nazwę typu, USHORT, której można użyć wszędzie tam, gdzie mógłbyś użyć zapisu unsigned short int. Listing 3.3 jest powtórzeniem listingu 3.2, jednak zamiast typu unsigned short int została w nim użyta definicja USHORT.
Listing 3.3. Przykład użycia typedef 0: // ***************** 1: // Demonstruje użycie słowa kluczowego typedef 2: #include <iostream> 3: 4: typedef unsigned short int USHORT; //definiowane poprzez typedef 5: 6: int main() 7: { 8: 9: using std::cout; 10: using std::endl; 11: 12: USHORT Width = 5; 13: USHORT Length; 14: Length = 10; 15: USHORT Area = Width * Length; 16: cout << "Szerokosc:" << Width << "\n"; 17: cout << "Dlugosc: " << Length << endl; 18: cout << "Obszar: " << Area <<endl; 19: return 0; 20: }
Wynik Szerokosc:5 Dlugosc: 10 Obszar: 50
UWAGA * oznacza mnożenie.
Analiza
W linii 4. definiowany jest synonim USHORT dla typu unsigned short int. Poza tym program jest bardzo podobny do programu z listingu 3.2, a wyniki jego działania są takie same.
Kiedy używać typu short, a kiedy typu long? Jedną z przyczyn kłopotów początkujących programistów C++ jest konieczność wyboru pomiędzy zadeklarowaniem zmiennej jako wartości typu long lub jako wartości typu short. Reguła jest bardzo prosta: jeśli istnieje możliwość, że jakakolwiek wartość, która może zostać umieszczona w zmiennej, przekroczy dozwolony zakres wartości dla danego typu, należy użyć typu o większym zakresie.
Jak pokazano w tabeli 3.1, zmienne typu unsigned short (zakładając że zajmują dwa bajty) mogą przechowywać wartości z zakresu od 0 do 65 535, zaś zmienne całkowite signed short dzielą ten zakres pomiędzy liczby dodatnie a ujemne; stąd maksymalne wartości stanowią w tym przypadku połowę maksymalnej wartości dla typu unsigned.
Choć zmienne całkowite unsigned long mieszczą bardzo duże liczby (4 294 967 295), w dalszym ciągu są one znacznie ograniczone. Jeśli potrzebujesz większej liczby, musisz użyć typu float lub double, zmniejszając jednak precyzję ich przechowywania. Zmienne typu float i double mogą przechowywać naprawdę bardzo duże wartości, ale w większości komputerów ich precyzja ogranicza się do 7 lub 9 pierwszych cyfr. Oznacza to, że po tych kilku cyfrach liczba jest zaokrąglana.
Krótsze zmienne zajmują mniej pamięci. Obecnie pamięć jest tania, więc nie wahaj się używać typu int, który w twoim komputerze zajmuje najprawdopodobniej cztery bajty.
Zawinięcie liczby całkowitej bez znaku Zmienne całkowite typu unsigned long mogą pomieścić duże wartości, ale co się stanie, gdy rzeczywiście zabraknie w nich miejsca?
Gdy typ unsigned int osiągnie swoją maksymalną wartość, „przewija się” i zaczyna od zera, podobnie jak licznik kilometrów w samochodzie. Listing 3.4 pokazuje, co się dzieje, gdy w krótkiej zmiennej całkowitej spróbujesz umieścić zbyt dużą wartość.
Listing 3.4. Przykład umieszczenia zbyt dużej wartości w zmiennej całkowitej bez znaku 0: #include <iostream> 1: int main() 2: { 3:

4: using std::cout; 5: using std::endl; 6: 7: unsigned short int smallNumber; 8: smallNumber = 65535; 9: cout << "krotka liczba:" << smallNumber << endl; 10: smallNumber++; 11: cout << "krotka liczba:" << smallNumber << endl; 12: smallNumber++; 13: cout << "krotka liczba:" << smallNumber << endl; 14: return 0; 15: }
Wynik krotka liczba:65535 krotka liczba:0 krotka liczba:1
Analiza
W linii 7. zmienna smallNumber deklarowana jest jako zmienna typu unsigned short int. W moim komputerze zmienne tego typu mają dwa bajty i mogą pomieścić wartości od 0 do 65 535. W linii 8. zmiennej tej jest przypisywana maksymalna wartość, która jest następnie wypisywana w linii 9.
W linii 10. zmienna smallNumber jest inkrementowana, czyli zwiększana o 1. Symbolem inkrementacji jest podwójny znak plus (++) (tak jak w nazwie języka C++, co symbolizuje inkrementację języka C). Tak więc wartością zmiennej smallNumber powinno być teraz 65 536. Ponieważ jednak zmienne typu unsigned short nie mogą przechowywać wartości większych od 65 535, wartość ta jest przewijana do 0, które jest wypisywane w linii 11.
W linii 12. zmienna smallNumber jest inkrementowana ponownie, po czym wypisywana jest jej nowa wartość, czyli 1.
Zawinięcie liczby całkowitej ze znakiem Liczby całkowite ze znakiem różnią się od liczb całkowitych bez znaku, gdyż połowa wartości, jakie mogą reprezentować, jest ujemna. Zamiast tradycyjnego samochodowego licznika kilometrów, możesz wyobrazić sobie zegar podobny do pokazanego na rysunku 3.2. Liczby na tym zegarze rosną zgodnie z ruchem wskazówek zegara i maleją w kierunku przeciwnym. Spotykają się na dole tarczy (czyli na godzinie szóstej).
Rys. 3.2. Gdyby zegary stosowały liczby ze znakiem...

W odległości jednej liczby od zera istnieje albo 1 (w kierunku zgodnym z ruchem wskazówek) albo –1 (w kierunku przeciwnym). Gdy skończą się liczby dodatnie, przejdziesz do największej liczby ujemnej, a potem z powrotem do zera. Listing 3.5 pokazuje, co się stanie gdy do maksymalnej liczby dodatniej w zmiennej całkowitej typu short int dodasz 1.
Listing 3.5. Przykład zwiększenia maksymalnej wartości dodatniej w licznie całkowitej ze znakiem.
0: #include <iostream> 1: int main() 2: { 3: short int smallNumber; 4: smallNumber = 32767; 5: std::cout << "krotka liczba:" << smallNumber << std::endl; 6: smallNumber++; 7: std::cout << "krotka liczba:" << smallNumber << std::endl; 8: smallNumber++; 9: std::cout << "krotka liczba:" << smallNumber << std::endl; 10: return 0; 11: }
Wynik krotka liczba:32767 krotka liczba:-32768 krotka liczba:-32767

Analiza
W linii 3. zmienna smallNumber deklarowana jest jako zmienna typu signed short int (jeśli nie wskażemy jawnie, że zmienna jest unsigned, bez znaku, zakłada się że jest signed, ze znakiem). Program działa bardzo podobnie do poprzedniego, jednak osiągany przez niego wynik jest całkiem inny. Aby w pełni zrozumieć jego działanie, musisz wiedzieć w jaki sposób liczby całkowite ze znakiem są reprezentowane bitowo w dwubajtowych zmiennych całkowitych.
Podobnie jak w przypadku liczb całkowitych bez znaku, liczby całkowite ze znakiem po najwyższej wartości dodatniej przewijają się do najwyższej wartości ujemnej.
Znaki Zmienne znakowe (typu char) zwykle mają rozmiar jednego bajtu, co wystarczy do przechowania jednej z 256 wartości (patrz dodatek C). Typ char może być interpretowany jako mała liczba (od 0 do 255) lub jako element zestawu kodów ASCII. Skrót ASCII pochodzi od słów American Standard Code for Information Interchange. Zestaw znaków ASCII oraz jego odpowiednik ISO (International Standards Organization) służą do kodowania wszystkich liter (alfabetu łacińskiego), cyfr oraz znaków przestankowych.
UWAGA Komputery nie mają pojęcia o literach, znakach przestankowych i zdaniach. Rozpoznają tylko liczby. Zauważają tylko odpowiedni poziom napięcia na określonym złączu przewodów. Jeśli występuje napięcie, jest ono symbolicznie oznaczane jako jedynka, zaś gdy nie występuje, jest oznaczane jako zero. Poprzez grupowanie zer i jedynek, komputer jest w stanie generować wzory, które mogą być interpretowane jako liczby, które z kolei można przypisywać literom i znakom przestankowym.
W kodzie ASCII mała litera „a” ma przypisaną wartość 97. Wszystkie duże i małe litery, wszystkie cyfry oraz wszystkie znaki przestankowe mają przypisane wartości pomiędzy 0 a 127. Dodatkowe 128 znaków i symboli jest zarezerwowanych dla „wykorzystania” przez producenta komputera, choć standard kodowania stosowany przez firmę IBM stał się niejako „obowiązkowy”.
UWAGA ASCII wymawia się jako „eski.”
Znaki i liczby Gdy w zmiennej typu char umieszczasz znak, na przykład „a”, w rzeczywistości jest on liczbą pochodzącą z zakresu od 0 do 255. Kompilator wie jednak, w jaki sposób odwzorować znaki (umieszczone wewnątrz apostrofów) na jedną z wartości kodu ASCII.
Odwzorowanie litery na liczbę jest umowne; nie ma szczególnego powodu, dla którego mała litera „a” ma wartość 97. Dopóki zgadzają się na to klawiatura, kompilator i ekran, nie ma żadnych problemów. Należy jednak zdawać sobie sprawę z dużej różnicy pomiędzy wartością 5 a znakiem „5.” Ten ostatni ma w rzeczywistości wartość 53, podobnie jak litera „a,” która ma wartość 97. Ilustruje to listing 3.6.

Listing 3.6. Wypisywanie znaków na podstawie ich kodów 0: #include <iostream> 1: int main() 2: { 3: for (int i = 32; i<128; i++) 4: std::cout << (char) i; 5: return 0; 6: }
Wynik !"#$%&'()*+,-./0123456789:;<=>?@ABCDEF GHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijkl mnopqrstuvwxyz{|}~_
Ten prosty program wypisuje znaki o wartościach od 32 do 127.
Znaki specjalne Kompilator C++ rozpoznaje pewne specjalne znaki formatujące. Najpopularniejsze z nich przedstawia tabela 3.2. Kody te umieszcza się w kodzie programu, wpisując znak odwrotnego ukośnika, a po nim znak specjalny. Aby umieścić w kodzie znak tabulacji, należy wpisać apostrof, odwrotny ukośnik, literę „t” oraz zamykający apostrof:
char tabCharacter = '\t';
Ten przykład deklaruje zmienną typu char (o nazwie tabCharacter) oraz inicjalizuje ją wartością \t, która jest rozpoznawana jako tabulator. Specjalne znaki formatujące używane są do wypisywania tekstu na ekranie, do zapisu tekstu do pliku lub do innego urządzenia wyjściowego.
Znak specjalny \ zmienia znaczenie znaku, który po nim następuje. Na przykład, normalnie znak n oznacza po prostu literę n, lecz gdy jest poprzedzony znakiem specjalnym \, oznacza przejście do nowej linii.
Tabela 3.2. Znaki specjalne
Znak Oznacza
\a Bell (dzwonek)
\b Backspace (znak wstecz)
\f Form feed (koniec strony)
\n New line (nowa linia)
\r Carriage return (powrót „karetki”; powrót na początek linii)
\t Tab (tabulator)
\v Vertical tab (tabulator pionowy)
\' Single quote (apostrof)
\" Double quote (cudzysłów)
\? Question mark (znak zapytania)
\\ Backslash (lewy ukośnik)
\0oo Zapis ósemkowy
\xhhh Zapis szesnastkowy
Stałe Do przechowywania danych służą także stałe. Jednak w odróżnieniu od zmiennej, jak sama nazwa sugeruje, wartość stałej nie ulega zmianie. Podczas tworzenia stałej trzeba ją zainicjalizować; później nie można już przypisywać jej innej wartości.
Literały C++ posiada dwa rodzaje stałych: literały i stałe symboliczne.
Literał jest wartością wpisywaną bezpośrednio w danym miejscu programu. Na przykład:
int myAge = 39;
myAge jest zmienną typu int; z kolei 39 jest literałem. Literałowi 39 nie można przypisać wartości, zaś jego wartość nie może ulec zmianie.
Stałe symboliczne Stała symboliczna jest reprezentowana poprzez swoją nazwę (podobnie jak w przypadku zmiennych). Jednak w odróżnieniu od zmiennej, po zainicjalizowaniu stałej, nie można później zmieniać jej wartości.
Jeśli w programie występuje zmienna całkowita o nazwie students (studenci) oraz inna zmienna o nazwie classes (klasy), możemy obliczyć ilość studentów znając ilość klas (przy zakładając że w każdej klasie jest piętnastu studentów):
students = classess * 15;
W tym przykładzie, 15 jest literałem. Kod będzie jednak łatwiejszy w czytaniu i w konserwacji, jeśli zastąpimy literał stałą symboliczną:
students = classess * studentsPerClass;

Jeśli zdecydujesz się zmienić ilość studentów przypadającą na każdą z klas, możesz to zrobić w definicji stałej studentsPerClass (studentów na klasę), bez konieczności zmiany tej wartości w każdym miejscu jej wystąpienia.
W języku C++ istnieją dwa sposoby deklarowania stałych symbolicznych. Starszy, tradycyjny (obecnie uważany za przestarzały) polega na wykorzystaniu dyrektywy preprocesora, #define.
Definiowanie stałych za pomocą #define Aby zdefiniować stałą w tradycyjny sposób, możesz napisać:
#define studentsPerClass 15
Zwróć uwagę, że stała studentsPerClass nie ma określonego typu (int, char, itd.). Dyrektywa #define umożliwia jedynie proste podstawianie tekstu. Za każdym razem, gdy preprocesor natrafia na słowo studentsPerClass, zastępuje je napisem 15.
Ponieważ działanie preprocesora poprzedza działanie kompilatora, kompilator nigdy nie „widzi” takich stałych; zamiast tego „widzi” po prostu liczbę 15.
Definiowanie stałych za pomocą const Mimo, że działa instrukcja #define, do definiowania stałych w C++ używa się nowszego, lepszego sposobu:
const unsigned short int studentsPerClass = 15;
Ten przykład także deklaruje stałą symboliczną o nazwie studentsPerClass, ale tym razem ta stała ma typ, którym jest unsigned short int. Metoda ta ma kilka zalet, dzięki którym kod programu jest łatwiejszy w konserwacji i jest bardziej odporny na błędy. Natomiast zdefiniowana w ten sposób stała posiada typ; dzięki temu kompilator może wymusić użycie jej zgodnie z tym typem.
UWAGA Stałe nie mogą być zmieniane podczas działania programu. Jeśli chcesz na przykład zmienić wartość stałej studentsPerClass, musisz zmodyfikować kod źródłowy, po czym skompilować program ponownie.
TAK NIE
Sprawdzaj, czy liczby nie przekraczają maksymalnego rozmiaru dopuszczalnego dla zmiennych całkowitych i czy nie zawijają się do niewłaściwych wartości.
Nadawaj zmiennym nazwy znaczące, dobrze odzwierciedlające ich zastosowanie.
Nie używaj słów kluczowych jako nazw zmiennych.

Stałe wyliczeniowe Stałe wyliczeniowe umożliwiają tworzenie nowych typów, a następnie definiowanie ich zmiennych. Wartości takich zmiennych ograniczają się do wartości określonych w definicji typu. Na przykład, możesz zadeklarować typ COLOR (kolor) jako wyliczenie, dla którego możesz zdefiniować pięć wartości: RED, BLUE, GREEN, WHITE oraz BLACK.
Składnię definicji wyliczenia stanowią słowo kluczowe enum, nazwa typu, otwierający nawias klamrowy, lista wartości oddzielonych przecinkami, zamykający nawias klamrowy oraz średnik. Oto przykład:
enum COLOR { RED, BLUE, GREEN, WHITE, BLACK };
Ta instrukcja wykonuje dwa zadania:
1. Sprawia, że nowe wyliczenie otrzymuje nazwę COLOR, tj. tworzony jest nowy typ.
2. Powoduje, że RED (czerwony) jest stałą symboliczną o wartości 0, BLUE (niebieski) jest stałą symboliczną o wartości 1, GREEN (zielony) jest stałą symboliczną o wartości 2, itd.
Każda wyliczana stała posiada wartość całkowitą. Jeśli tego nie określisz, zakłada się że pierwsza stała ma wartość 0, następna 1, itd. Każda ze stałych może zostać zainicjalizowana dowolną wartością. Stałe, które nie zostaną zainicjalizowane, będą miały wartości naliczane począwszy od wartości od jeden większej od wartości stałych zainicjalizowanych. Zatem, jeśli napiszesz:
enum COLOR { RED=100, BLUE, GREEN=500, WHITE, BLACK=700 };
RED będzie mieć wartość 100, BLUE będzie mieć wartość 101; GREEN wartość 500, WHITE (biały) wartość 501, zaś BLACK (czarny) wartość 700.
Możesz definiować zmienne typu COLOR, ale mogą one przyjmować tylko którąś z wyliczonych wartości (w tym przypadku RED, BLUE, GREEN, WHITE lub BLACK, albo 100, 101, 500, 501 lub 700). Zmiennej typu COLOR możesz przypisać dowolną wartość koloru. W rzeczywistości możesz przypisać jej dowolną wartość całkowitą, nawet jeśli nie odpowiada ona dozwolonemu kolorowi; dobry kompilator powinien w takim przypadku wypisać ostrzeżenie. Należy zdawać sobie sprawę, że stałe wyliczeniowe to w rzeczywistości zmienne typu unsigned int oraz że te stałe odpowiadają zmiennym całkowitym. Możliwość nazywania wartości okazuje się bardzo pomocna, na przykład podczas pracy z kolorami, dniami tygodnia czy podobnymi zestawami. Program używający typu wyliczeniowego został przedstawiony na listingu 3.7.
Listing 3.7. Przykład stałych wyliczeniowych 0: #include <iostream> 1: int main() 2: { 3: enum Days { Sunday, Monday, Tuesday,

4: Wednesday, Thursday, Friday, Saturday }; 5: 6: Days today; 7: today = Monday; 8: 9: if (today == Sunday || today == Saturday) 10: std::cout << "\nUwielbiam weekendy!\n"; 11: else 12: std::cout << "\nWracaj do pracy.\n"; 13: 14: return 0; 15: }
Wynik Wracaj do pracy.
Analiza
W linii 3. definiowana jest stała wyliczeniowa Days (dni), posiadająca siedem, odpowiadających dniom tygodnia, wartości. Każda z tych wartości jest wartością całkowitą, numerowaną od 0 w górę (tak więc Monday — poniedziałek — ma wartość 1)1.
Tworzymy też zmienną typu Days — tj. zmienną, która będzie przyjmować wartość z listy wyliczonych stałych. W linii 7. przypisujemy jej wartość wyliczeniową Monday, którą następnie sprawdzamy w linii 9.
Stała wyliczeniowa zawarta w linii 3. może być zastąpiona serią stałych całkowitych, tak jak pokazano na listingu 3.8.
Listing 3.8. Ten sam program wykorzystujący stałe całkowite 0: #include <iostream> 1: int main() 2: { 3: const int Sunday = 0; 4: const int Monday = 1; 5: const int Tuesday = 2; 6: const int Wednesday = 3; 7: const int Thursday = 4; 8: const int Friday = 5; 9: const int Saturday = 6; 10: 11: int today; 12: today = Monday; 13: 14: if (today == Sunday || today == Saturday) 15: std::cout << "\nUwielbiam weekendy!\n"; 16: else 17: std::cout << "\nWracaj do pracy.\n"; 18: 19: return 0; 20: }
Wynik Wracaj do pracy.
Analiza
1 Amerykanie liczą dni tygodnia zaczynając od niedzieli. — przyp.tłum.

Wynik działania tego programu jest identyczny z wynikiem programu z listingu 3.7. W tym programie każda ze stałych (Sunday, Monday, itd.) została zdefiniowana jawnie i nie istnieje typ wyliczeniowy Days. Stałe wyliczeniowe mają tę zaletę, że się same dokumentują — przeznaczenie typu wyliczeniowego Days jest oczywiste.

Rozdział 4. Wyrażenia i instrukcje Program stanowi zestaw kolejno wykonywanych instrukcji. Jakość działania programu zależy od możliwości wykonywania określonego zestawu instrukcji w danych warunkach.
Z tego rozdziału dowiesz się:
• czym są instrukcje,
• czym są bloki,
• czym są wyrażenia,
• jak, w zależności od warunków, kierować wykonaniem programu,
• czym jest prawda i jak działać na jej podstawie.
Instrukcje W C++ instrukcje kontrolują kolejność działania programu, obliczają wyrażenia lub nie robią nic (instrukcja pusta). Wszystkie instrukcje C++ kończą się średnikiem (nawet instrukcja pusta, która składa się wyłącznie ze średnika). Jedną z najczęściej występujących instrukcji jest instrukcja przypisania:
x = a + b;
W przeciwieństwie do znaczenia, jakie ma w algebrze, ta instrukcja nie oznacza tutaj, że x równa się a+b. Należy ją traktować jako „przypisz wartość sumy a i b do x” lub „przypisz a+b do x” lub „niech x równa się a+b.” Choć ta instrukcja wykonuje dwie czynności, nadal jest pojedynczą instrukcją (stąd tylko jeden średnik). Operator przypisania przypisuje to, co znajduje się po prawej stronie znaku równości elementowi znajdującemu się po lewej stronie.

Białe spacje Białe spacje (tabulatory, spacje i znaki nowej linii) są w instrukcjach ignorowane. Omawiana poprzednio instrukcja przypisania może zostać zapisana jako:
x=a+b;
lub jako:
x =a + b ;
Choć ostatni zapis jest poprawny, jest równocześnie niemądry. Białe spacje mogą być używane w celu poprawienia czytelności programu lub stworzenia okropnego, niemożliwego do rozszyfrowania kodu. C++ daje do wyboru wiele możliwości, ale ich rozważne użycie zależy od ciebie.
Znaki białych spacji nie są widoczne. Gdy zostaną wydrukowane, na papierze będą widoczne jako odstępy.
Bloki i instrukcje złożone Wszędzie tam, gdzie może znaleźć się instrukcja pojedyncza, może znaleźć się także instrukcja złożona, zwana także blokiem. Blok rozpoczyna się od otwierającego nawiasu klamrowego ({) i kończy nawiasem zamykającym (}). Choć każda instrukcja w bloku musi kończyć się średnikiem, sam blok nie wymaga jego zastosowania (jak pokazano w poniższym przykładzie):
{ temp = a; a = b; b = temp; }
Ten blok kodu działa jak pojedyncza instrukcja i zamienia wartości w zmiennych a i b.
TAK
Jeśli użyłeś otwierającego nawiasu klamrowego, pamiętaj także o nawiasie zamykającym.
Kończ instrukcje średnikiem.
Używaj rozważnie białych spacji, tak aby kod był czytelny.

Wyrażenia Wszystko, co staje się wartością, w C++ jest uważane za wyrażenie. Mówi się, że wyrażenie zwraca wartość. Skoro instrukcja 3+2; zwraca wartość 5, więc jest wyrażeniem. Wszystkie wyrażenia są jednocześnie instrukcjami.
Możesz zdziwić się, ile miejsc w kodzie kwalifikuje się jako wyrażenia. Oto trzy przykłady:
3.2 // zwraca wartość 3.2 PI // stała typu float zwracająca wartość 3.14 SecondsPerMinute // stała typu int zwracająca 60
Gdy założymy, że PI jest stałą, którą zainicjalizowałem wartością 3.14 i że SecondsPerMinute (sekund na minutę) jest stałą wynoszącą 60, wtedy wszystkie te trzy instrukcje są wyrażeniami.
Nieco bardziej skomplikowane wyrażenie
x = a + b;
nie tylko dodaje do siebie a oraz b, a wynik umieszcza w x, ale także zwraca wartość tego przypisania (nową wartość x). Zatem instrukcja przypisania także jest wyrażeniem. Ponieważ jest wyrażeniem, może wystąpić po prawej stronie operatora przypisania:
y = x = a + b;
Ta linia jest przetwarzana w następującym porządku:
Dodaj a do b.
Przypisz wynik wyrażenia a + b do x.
Przypisz rezultat wyrażenia przypisania, x = a + b, do y.
Jeśli a, b, x oraz y byłyby zmiennymi całkowitymi, zaś a miałoby wartość 2, a b miałoby wartość 5, wtedy zarówno zmiennej x, jak i y zostałaby przypisana wartość 7. Ilustruje to listing 4.1.
Listing 4.1. Obliczanie wyrażeń złożonych 0: #include <iostream> 1: int main() 2: { 3: using std::cout; 4: using std::endl; 5: 6: int a=0, b=0, x=0, y=35; 7: cout << "a: " << a << " b: " << b; 8: cout << " x: " << x << " y: " << y << endl;

9: a = 9; 10: b = 7; 11: y = x = a+b; 12: cout << "a: " << a << " b: " << b; 13: cout << " x: " << x << " y: " << y << endl; 14: return 0; 15: }
Wynik a: 0 b: 0 x: 0 y: 35 a: 0 b: 7 x: 16 y: 16
Analiza
W linii 6. deklarowane i inicjalizowane są cztery zmienne. Ich wartości są wypisywane w liniach 7. i 8. W linii 9. zmiennej a jest przypisywana wartość 9. W linii 10., zmiennej b jest przypisywana wartość 7. W linii 11. zmienne a i b są sumowane, zaś wynik sumowania jest przypisywany zmiennej x. To wyrażenie (x = a+b) powoduje obliczenie sumy a oraz b i przypisanie jej do zmiennej x, wartość tego przypisania jest następnie przypisywana zmiennej y.
Operatory Operator jest symbolem, który powoduje, że kompilator rozpoczyna działanie. Operatory działają na operandach, zaś wszystkie operandy w C++ są wyrażeniami. W C++ istnieje kilka kategorii operatorów. Dwie z tych kategorii to:
• operatory przypisania,
• operatory matematyczne.
Operator przypisania Operator przypisania (=) powoduje, że operand znajdujący się po lewej stronie operatora przypisania zmienia wartość na wartość operandu znajdującego się po prawej stronie operatora. Wyrażenie:
x = a + b;
przypisuje operandowi x wynik dodawania wartości a i b.
Operand, który może wystąpić po lewej stronie operatora przypisania jest nazywany l-wartością (l-value). Natomiast ten, który może znaleźć się po prawej stronie, jest nazywany (jak można się domyślić), r-wartością (r-value).
Stałe są r-wartościami. Nie mogą być l-wartościami. Zatem możesz napisać:
x = 35; // OK
Usunięto: To w
Usunięto: To, co
Usunięto: e

lecz nie możesz napisać:
35 = x; // błąd, 35 nie może być l-wartością!
L-wartość jest operandem, który może znaleźć się po lewej stronie wyrażenia. R-wartość jest operandem, który może występować po prawej stronie wyrażenia. Zwróć uwagę, że wszystkie l-wartości mogą być r-wartościami, ale nie wszystkie r-wartości mogą być l-wartościami. Przykładem r-wartości, która nie jest l-wartością, może być literał. Zatem możesz napisać x = 5;, lecz nie możesz napisać 5 = x; (x może być l- lub r-wartością, lecz 5 może być tylko r-wartością).
Operatory matematyczne Piątka operatorów matematycznych to: dodawanie (+), odejmowanie (–), mnożenie (*), dzielenie (/) oraz reszta z dzielenia (%).
Dodawanie i odejmowanie działają rutynowo, choć odejmowanie liczb całkowitych bez znaku może prowadzić do zadziwiających rezultatów gdy wynik będzie ujemny. Z czymś takim spotkałeś się w poprzednim rozdziale, kiedy opisywaliśmy przepełnienie (przewinięcie wartości). Listing 4.2 pokazuje, co się stanie gdy odejmiesz dużą liczbę całkowitą bez znaku od małej liczby całkowitej bez znaku.
Listing 4.2. Przykład odejmowania i przepełnienia wartości całkowitej 0: // Listing 4.2 - Demonstracja odejmowania 1: // i przepełnienia wartości całkowitej. 2: #include <iostream> 3: 4: int main() 5: { 6: using std::cout; 7: using std::endl; 8: 9: unsigned int difference; 10: unsigned int bigNumber = 100; 11: unsigned int smallNumber = 50; 12: difference = bigNumber - smallNumber; 13: cout << "Roznica to: " << difference; 14: difference = smallNumber - bigNumber; 15: cout << "\nTeraz roznica to: " << difference <<endl; 16: return 0; 17: }
Wynik Roznica to: 50 Teraz roznica to: 4294967246
Analiza
Operator odejmowania jest wywoływany w linii 12., zaś wynik jest wypisywany w linii 13. (taki, jakiego mogliśmy oczekiwać). Operator odejmowania jest ponownie wywoływany w linii 14., jednak tym razem od małej liczby całkowitej bez znaku jest odejmowana duża liczba całkowita bez znaku. Wynik powinien być ujemny, ale ponieważ wartości są obliczane (i wypisywane) jako liczby całkowite bez znaku, efektem tej operacji jest przepełnienie, tak jak opisywaliśmy w
Usunięto: że
poprzednim rozdziale. Ten temat jest szczegółowo omawiany w dodatku C, „Kolejność operatorów.”
Dzielenie całkowite i reszta z dzielenia Dzielenie całkowite poznałeś w drugiej klasie szkoły podstawowej. Gdy w dzieleniu całkowitym podzielisz 21 przez 4 (21/4), otrzymasz w wyniku 5 (oraz pewną resztę).
Resztę z dzielenia całkowitego zwraca operator reszty z dzielenia (tzw. operator modulo). Aby otrzymać resztę, oblicz 21 modulo 4 (21 % 4). W wyniku otrzymasz 1.
Obliczanie reszty z dzielenia może być bardzo przydatne. Możesz na przykład zechcieć wypisywać komunikat po każdej dziesiątej akcji. Każda liczba, dla której wynikiem reszty z dzielenia przez 10 jest zero, stanowi pełną wielokrotność dziesięciu. Tak więc 1 % 10 wynosi 1, 2 % 10 wynosi 2, itd., aż do 10 % 10, które ponownie wynosi 0. 11 % 10 to znów 1, wzór ten powtarza się aż do następnej wielokrotności dziesięciu, którą jest liczba 20. 20 % 0 to ponownie 0. Tę technikę wykorzystujemy wewnątrz pętli, które zostaną omówione w rozdziale 7.
Często zadawane pytanie
Gdy dzielę 5/3, otrzymuję w wyniku 1. Czy coś robię nie tak?
Odpowiedź
Gdy dzielisz jedną liczbę całkowitą przez inną, w wyniku otrzymujesz także liczbę całkowitą. Zatem 5/3 wyniesie 1. (W rzeczywistości wynikiem jest 1 i reszta 2. Aby otrzymać resztę, spróbuj napisać 5%3, uzyskasz w ten sposób wartość 2.)
Aby uzyskać ułamkową wartość z dzielenia, musisz użyć zmiennych zmiennoprzecinkowych.
5.0/3.0 da wartość zmiennoprzecinkową 1.66667.
Jeśli zmiennoprzecinkowa jest dzielna lub dzielnik, kompilator wygeneruje zmiennoprzecinkowy iloraz.
Usunięto: ozycyjnych
Usunięto: ozycyjną
Usunięto: ozycyjna
Usunięto: ozycyjny

Łączenie operatora przypisania z operatorem matematycznym Często zdarza się, że chcemy do zmiennej dodać wartość, zaś wynik umieścić z powrotem w tej zmiennej. Jeśli masz zmienną myAge (mój wiek) i chcesz zwiększyć jej wartość o dwa, możesz napisać:
int myAge = 5; int temp; temp = myAge + 2; // czyli 5 + 2 jest umieszczane w zmiennej temp myAge = temp; // wynik umieszczamy z powrotem w myAge
Ta metoda jest jednak bardzo żmudna i nieefektywna. W C++ istnieje możliwość umieszczenia tej samej zmiennej po obu stronach operatora przypisania; w takim przypadku poprzedni przykład można zapisać jako:
myAge = myAge + 2;
Jest to dużo lepsza metoda. W algebrze to wyrażenie nie miałoby sensu, ale w C++ jest traktowane jako „dodaj dwa do wartości zawartej w zmiennej myAge, zaś wynik umieść ponownie w tej zmiennej”.
Jeszcze prostsze w zapisie, choć może nieco trudniejsze do odczytania, jest:
myAge += 2;
Operator += sumuje r-wartość z l-wartością, zaś wynik umieszcza ponownie w l-wartości. Ten operator wymawia się jako „plus-równa się”, zatem cała instrukcja powinna zostać odczytana jako „myAge plus-równa się dwa”. Jeśli zmienna myAge miałaby początkowo wartość 4, to po wykonaniu tej instrukcji przyjęłaby wartość 6.
Oprócz operatora += istnieją także operatory -= (odejmowania), /= (dzielenia), *= (mnożenia), %= (reszty z dzielenia) i inne.
Inkrementacja i dekrementacja Najczęściej dodawaną (i odejmowaną), z ponownym przypisaniem wyniku zmiennej, wartością jest 1. W C++ zwiększenie wartości o jeden jest nazywane inkrementacją, zaś zmniejszenie o jeden — dekrementacją. Służą do tego specjalne operatory.

Operator inkrementacji (++) zwiększa wartość zmiennej o jeden, zaś operator dekrementacji (--) zmniejsza ją o jeden. Jeśli chcemy inkrementować zmienną C, możemy użyć następującej instrukcji:
C++; // zaczynamy od C i inkrementujemy
Ta instrukcja stanowi odpowiednik bardziej jawnie zapisanej operacji:
C = C + 1;
którą, jak wiemy, możemy zapisać w nieco prostszy sposób:
C += 1;
UWAGA Jak można się domyślić, język C++ otrzymał swoją nazwę dzięki zastosowaniu operatora inkrementacji do nazwy języka, od którego pochodzi (C). C++ jest kolejną, poprawioną wersją języka C.
Przedrostki i przyrostki Zarówno operator inkrementacji (++), jak i dekrementacji (--) występuje w dwóch odmianach: przedrostkowej i przyrostkowej. Odmiana przedrostkowa jest zapisywana przed nazwą zmiennej (++myAge), zaś odmiana przyrostkowa — po niej (myAge++).
W przypadku instrukcji prostej nie ma znaczenia, której wersji użyjesz, jednak w wyrażeniach złożonych, gdy inkrementujesz (lub dekrementujesz) zmienną, a następnie przypisujesz rezultat innej zmiennej, różnica jest bardzo ważna. Operator przedrostkowy jest obliczany przed przypisaniem, zaś operator przyrostkowy — po przypisaniu.
Operator przedrostkowy działa następująco: zwiększ wartość zmiennej i zapamiętaj ją. Operator przyrostkowy działa inaczej: zapamiętaj pierwotną wartość zmiennej, po czym zwiększ wartość w zmiennej.
Na początku może to wydawać się dość niezrozumiałe, ale jeśli x jest zmienną całkowitą o wartości 5, to gdy napiszesz
int a = ++x;
poinformujesz kompilator, by inkrementował zmienną x (nadając jej wartość 6), po czym pobrał tę wartość i przypisał ją zmiennej a. Zatem po wykonaniu tej instrukcji zarówno zmienna x, jak i zmienna a mają wartość 6.

Jeśli następnie napiszesz
int b = x++;
to poinformujesz kompilator, by pobrał wartość zmiennej x (wynoszącą 6) i przypisał ją zmiennej b, po czym powrócił do zmiennej x i inkrementował ją. W tym momencie zmienna b ma wartość 6, a zmienna x ma wartość 7. Zastosowanie i działanie obu wersji operatora przedstawia listing 4.3.
Listing 4.3. Przykład działania operatora przedrostkowego i przyrostkowego 0: // Listing 4.3 - demonstruje użycie 1: // przedrostkowych i przyrostkowych operatorów 2: // inkrementacji i dekrementacji 3: #include <iostream> 4: int main() 5: { 6: using std::cout; 7: 8: int myAge = 39; // inicjalizujemy dwie zmienne całkowite 9: int yourAge = 39; 10: cout << "Ja mam: " << myAge << " lat.\n"; 11: cout << "Ty masz: " << yourAge << " lat\n"; 12: myAge++; // inkrementacja przyrostkowa 13: ++yourAge; // inkrementacja przedrostkowa 14: cout << "Minal rok...\n"; 15: cout << "Ja mam: " << myAge << " lat.\n"; 16: cout << "Ty masz: " << yourAge << " lat\n"; 17: cout << "Minal kolejny rok\n"; 18: cout << "Ja mam: " << myAge++ << " lat.\n"; 19: cout << "Ty masz: " << ++yourAge << " lat\n"; 20: cout << "Wypiszmy to jeszcze raz.\n"; 21: cout << "Ja mam: " << myAge << " lat.\n"; 22: cout << "Ty masz: " << yourAge << " lat\n"; 23: return 0; 24: }
Wynik Ja mam: 39 lat. Ty masz: 39 lat Minal rok... Ja mam: 40 lat. Ty masz: 40 lat Minal kolejny rok Ja mam: 40 lat. Ty masz: 41 lat Wypiszmy to jeszcze raz. Ja mam: 41 lat. Ty masz: 41 lat
Analiza
W liniach 8. i 9. deklarujemy dwie zmienne całkowite i inicjalizujemy je wartością 39. Ich wartości są wypisywane w liniach 10. i 11.
W linii 12. zmienna myAge (mój wiek) jest inkrementowana za pomocą operatora przyrostkowego, zaś w linii 13. zmienna yourAge (twój wiek) jest inkrementowana za pomocą operatora przedrostkowego. Wyniki wypisywane w liniach 15. i 16. są identyczne (40).
W linii 18. zmienna myAge jest inkrementowana jako część instrukcji wypisywania danych, za pomocą operatora przyrostkowego. Ponieważ jest to operator przyrostkowy, inkrementacja odbywa się już po wypisaniu tekstu, dlatego ponownie wypisywana jest wartość 40. Dla odróżnienia od linii 18., w linii 19. zmienna yourAge jest inkrementowana za pomocą operatora przedrostkowego. Ponieważ w takim przypadku inkrementacja odbywa się przed wypisaniem tekstu, zostaje wypisana wartość 41.
Na zakończenie, w liniach 21. i 22., ponownie wypisywane są wartości zmiennych. Ponieważ instrukcje inkrementacji zostały dokończone, zmienna myAge, podobnie jak zmienna yourAge przyjmuje wartość 41.
Kolejność działań Które działanie instrukcji złożonej, takiej jak ta
x = 5 + 3 * 8;
jest wykonywane jako pierwsze: dodawanie czy mnożenie? Gdyby najpierw wykonywane było dodawanie, wynik wynosiłby 8 * 8, czyli 64. Gdyby najpierw wykonywane było mnożenie, uzyskalibyśmy wynik 5 + 24, czyli 29.
Każdy operator posiada swój priorytet, który określa kolejność wykonywania działań. Pełną listę priorytetów operatorów można znaleźć w dodatku C.
Mnożenie ma priorytet nad dodawaniem, więc w tym przypadku wartością wyrażenia jest 29.
Gdy dwa operatory matematyczne osiągają ten sam priorytet, są obliczane w kolejności od lewej do prawej. Zatem w wyrażeniu
x = 5 + 3 + 8 * 9 + 6 * 4;
mnożenia są wykonywane jako pierwsze (najpierw lewe, potem prawe). Otrzymujemy 8*9 = 72 oraz 6*4 = 24. Teraz wyrażenie można zapisać jako
x = 5 + 3 + 72 + 24.
Następnie obliczane są dodawania, od lewej do prawej: 5 + 3 = 8; 8 + 72 = 80; 80 + 24 = 104.
Bądź ostrożny. Niektóre operatory, takie jak operator przypisania, są obliczane w kolejności od prawej do lewej!

Co zrobić gdy kolejność wykonywania działań nie odpowiada naszym potrzebom? Weźmy na przykład takie wyrażenie:
TotalSeconds = NumMinutesToThink + NumMinutesToType * 60
W tym wyrażeniu nie chcemy mnożyć zmiennej NumMinutesToType (ilość minut wpisywania) przez 60, a następnie dodawać otrzymanej wartości do zmiennej NumMinutesToThink (ilość minut namysłu). Chcemy zsumować obie zmienne, aby otrzymać łączną ilość minut, a dopiero potem przemnożyć ją przez ilość sekund w minucie, w celu otrzymania łącznej ilości sekund (TotalSeconds).
W tym przypadku, w celu zmiany kolejności działań użyjemy nawiasów. Działania na elementach w nawiasach są zawsze wykonywane przed innymi operacjami matematycznymi. Zatem zamierzony wynik uzyskamy dopiero wtedy, gdy napiszemy:
TotalSeconds = (NumMinutesToThink + NumMinutesToType) * 60
Zagnieżdżanie nawiasów W przypadku złożonych wyrażeń można zagnieżdżać nawiasy jeden wewnątrz drugiego. Na przykład, przed obliczeniem łącznej ilości „osobosekund” (TotalPersonSeconds) możesz zechcieć obliczyć łączną ilość sekund oraz łączną ilość osób zajętych pracą:
TotalPersonSeconds = ( ( (NumMinutesToThink+NumMinutesToType) * 60) * (PeopleInTheOffice + PeopleOnVacation) )
To złożone wyrażenie jest odczytywane od wewnątrz na zewnątrz. Najpierw sumowane są zmienne NumMinutesToThink oraz NumMinutesToType, gdyż znajdują się w wewnętrznych nawiasach. Potem ta suma jest mnożona przez 60. Następnie sumowane są zmienne PeopleInTheOffice (osoby w biurze) oraz PeopleOnVacation (osoby na urlopie). Na koniec łączna ilość osób jest przemnażana przez łączną ilość sekund.
Z tym przykładem wiąże się jeszcze jedno ważne zagadnienie. To wyrażenie jest łatwe do zrozumienia przez komputer, lecz jest bardzo trudne do odczytania, zrozumienia lub zmodyfikowania przez człowieka. Oto to samo wyrażenie, przepisane z użyciem kilku tymczasowych zmiennych całkowitych:
TotalMinutes = NumMinutesToThink + NumMinutesToType; TotalSeconds = TotalMinutes * 60; TotalPeople = PeopleInTheOffice + PeopleOnVacation; TotalPersonSeconds = TotalPeople * TotalSeconds;
Usunięto: *

Napisanie tego przykładu wymaga więcej czasu do napisania i skorzystania z większej ilości tymczasowych zmiennych, lecz sprawi, że będzie on dużo łatwiejszy do zrozumienia. Gdy dodasz do niego komentarz, opisujący, do czego służy ten kod oraz gdy zamienisz wartość 60 na stałą symboliczną, otrzymasz łatwy do zrozumienia i modyfikacji kod.
TAK NIE
Pamiętaj, że wyrażenia mają wartość.
Używaj operatora przedrostkowego (++zmienna) do inkrementacji lub dekrementacji zmiennej przed jej użyciem w wyrażeniu.
Używaj operatora przyrostkowego (zmienna++) do inkrementacji lub dekrementacji zmiennej po jej użyciu w wyrażeniu.
W celu zmiany kolejności działań używaj nawiasów.
Nie zagnieżdżaj nawiasów zbyt głęboko, gdyż wyrażenie stanie się zbyt trudne do zrozumienia i modyfikacji.
Prawda i fałsz W poprzednich wersjach C++, prawda i fałsz były reprezentowane jako liczby całkowite; w standardzie ANSI wprowadzono nowy typ: bool. Typ ten może mieć tylko dwie wartości, true (prawda) oraz false (fałsz).
Można sprawdzić prawdziwość każdego wyrażenia. Wyrażenia, których matematycznym wynikiem jest zero, zwracają wartość false. Wszystkie inne wyrażenia zwracają wartość true.
UWAGA Wiele kompilatorów oferowało typ bool już wcześniej, był on wewnętrznie reprezentowany jako typ long int i miał rozmiar czterech bajtów. Nowe, zgodne z ANSI kompilatory często korzystają z jednobajtowych zmiennych typu bool.
Operatory relacji Operatory relacji są używane do sprawdzania, czy dwie liczby są równe, albo czy jedna z nich jest większa lub mniejsza od drugiej. Każdy operator relacji zwraca prawdę lub fałsz. Operatory relacji zostaną przedstawione nieco dalej, w tabeli 4.1.
UWAGA Wszystkie operatory relacji zwracają wartość typu bool, czyli wartość true albo false. W poprzednich wersjach C++ operatory te zwracały albo wartość 0 dla fałszu, albo wartość różną od zera (zwykle 1) dla prawdy.
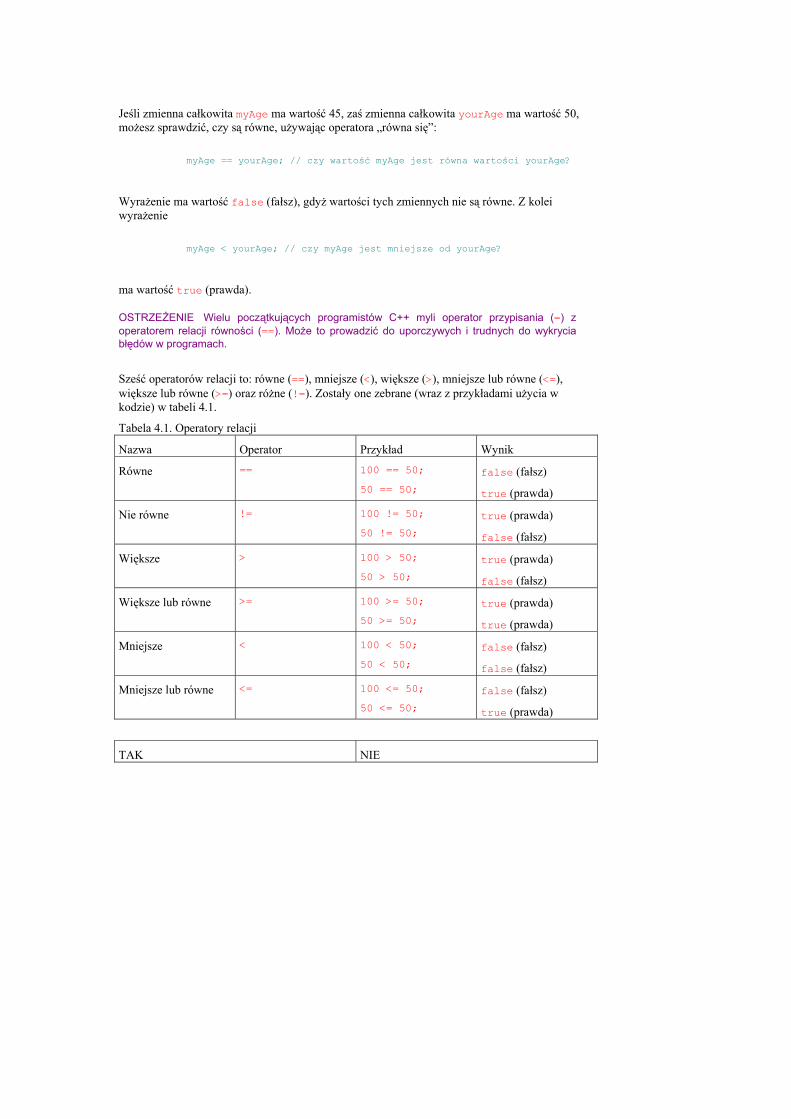
Jeśli zmienna całkowita myAge ma wartość 45, zaś zmienna całkowita yourAge ma wartość 50, możesz sprawdzić, czy są równe, używając operatora „równa się”:
myAge == yourAge; // czy wartość myAge jest równa wartości yourAge?
Wyrażenie ma wartość false (fałsz), gdyż wartości tych zmiennych nie są równe. Z kolei wyrażenie
myAge < yourAge; // czy myAge jest mniejsze od yourAge?
ma wartość true (prawda).
OSTRZEŻENIE Wielu początkujących programistów C++ myli operator przypisania (=) z operatorem relacji równości (==). Może to prowadzić do uporczywych i trudnych do wykrycia błędów w programach.
Sześć operatorów relacji to: równe (==), mniejsze (<), większe (>), mniejsze lub równe (<=), większe lub równe (>=) oraz różne (!=). Zostały one zebrane (wraz z przykładami użycia w kodzie) w tabeli 4.1.
Tabela 4.1. Operatory relacji
Nazwa Operator Przykład Wynik
Równe == 100 == 50;
50 == 50;
false (fałsz)
true (prawda)
Nie równe != 100 != 50;
50 != 50;
true (prawda)
false (fałsz)
Większe > 100 > 50;
50 > 50;
true (prawda)
false (fałsz)
Większe lub równe >= 100 >= 50;
50 >= 50;
true (prawda)
true (prawda)
Mniejsze < 100 < 50;
50 < 50;
false (fałsz)
false (fałsz)
Mniejsze lub równe <= 100 <= 50;
50 <= 50;
false (fałsz)
true (prawda)
TAK NIE
Pamiętaj, że operatory relacji zwracają wartość true (prawda) lub false (fałsz).
Nie myl operatora przypisania (=) z operatorem relacji równości (==). Jest to jeden z najczęstszych błędów popełnianych przez programistów C++. Strzeż się go.
Instrukcja if Program jest wykonywany linia po linii, w takiej kolejności, w jakiej linie te występują w tekście kodu źródłowego. Instrukcja if umożliwia sprawdzenie spełnienia warunku (na przykład, czy dwie zmienne są równe) i przejście do wykonania innej części kodu.
Najprostsza forma instrukcji if jest następująca:
if (wyrażenie) instrukcja;
Wyrażenie w nawiasach może być całkowicie dowolne, ale najczęściej jest to jedno z wyrażeń relacji. Jeśli wyrażenie to ma wartość false, wtedy instrukcja jest pomijana. Jeśli wyrażenie jest prawdziwe (ma wartość true), wtedy instrukcja jest wykonywana. Weźmy poniższy przykład:
if (bigNumber > smallNumber) bigNumber = smallNumber;
Ten kod porównuje zmienną bigNumber (duża liczba) ze zmienną smallNumber (mała liczba). Jeśli wartość zmiennej bigNumber jest większa, w drugiej linii tej zmiennej jest przypisywana wartość zmiennej smallNumber.
Ponieważ blok instrukcji ujętych w nawiasy klamrowe stanowi odpowiednik instrukcji pojedynczej, warunkowo wykonywany fragment kodu może być dość rozbudowany:
if (wyrażenie) { instrukcja1; instrukcja2; instrukcja3; }
Oto prosty przykład wykorzystania tej możliwości:
if (bigNumber > smallNumber) {

bigNumber = smallNumber; std::cout << "duza liczba: " << bigNumber << "\n"; std::cout << "mala liczba: " << smallNumber << "\n"; }
Tym razem, jeśli zmienna bigNumber jest większa od zmiennej smallNumber, przypisywana jest jej wartość zmiennej smallNumber, a ponadto wypisywany jest informacyjny komunikat. Listing 4.4 przedstawia szczegółowo przykład warunkowego wykonywania kodu (z zastosowaniem operatorów relacji).
Listing 4.4. Przykład warunkowego wykonania kodu (z zastosowaniem operatorów relacji) 0: // Listing 4.5 - demonstruje instrukcje if 1: // używane z operatorami relacji 2: #include <iostream> 3: int main() 4: { 5: using std::cout; 6: using std::cin; 7: 8: int MetsScore, YankeesScore; 9: cout << "Wpisz wynik dla Metsow: "; 10: cin >> MetsScore; 11: 12: cout << "\nWpisz wynik dla Yankees: "; 13: cin >> YankeesScore; 14: 15: cout << "\n"; 16: 17: if (MetsScore > YankeesScore) 18: cout << "Let's Go Mets!\n"; 19: 20: if (MetsScore < YankeesScore) 21: { 22: cout << "Go Yankees!\n"; 23: } 24: 25: if (MetsScore == YankeesScore) 26: { 27: cout << "Remis? Eeee, nie moze byc...\n"; 28: cout << "Podaj mi prawdziwy wynik dla Yanks: "; 29: cin >> YankeesScore; 30: 31: if (MetsScore > YankeesScore) 32: cout << "Wiedzialem! Let's Go Mets!"; 33: 34: if (YankeesScore > MetsScore) 35: cout << "Wiedzialem! Go Yanks!"; 36: 37: if (YankeesScore == MetsScore) 38: cout << "Coz, rzeczywiscie byl remis!"; 39: } 40: 41: cout << "\nDzieki za informacje.\n"; 42: return 0; 43: }
Wynik

Wpisz wynik dla Metsow: 10 Wpisz wynik dla Yankees: 10 Remis? Eeee, nie moze byc... Podaj mi prawdziwy wynik dla Yanks: 8 Wiedzialem! Let's Go Mets! Dzieki za informacje.
Analiza
Ten program pyta użytkownika o wyniki spotkań dwóch drużyn baseballowych; wyniki są przechowywane w zmiennych całkowitych. Te zmienne są porównywane w instrukcjach if w liniach 17., 20. i 25. (W poprzednich wydaniach książki Yankees występowali przeciw Red Sox. W tym roku mamy inną serię, więc zaktualizowałem przykład!)
Jeśli jeden z wyników jest wyższy niż drugi, wypisywany jest komunikat informacyjny. Jeśli wyniki są równe, wtedy program przechodzi do bloku kodu zaczynającego się w linii 25. i kończącego w linii 39. Pojawia się w nim prośba o ponowne podanie drugiego wyniku, po czym wyniki są porównywane jeszcze raz.
Zwróć uwagę, że gdyby początkowy wynik Yankees był większy niż wynik Metsów, wtedy w instrukcji if w linii 17. otrzymalibyśmy wynik false, co spowodowałoby że linia 18. nie zostałaby wykonana. Test w linii 20. miałby wartość true, więc wykonana zostałaby instrukcja w linii 22.. Następnie zostałaby wykonana instrukcja if w linii 25. i jej wynikiem byłoby false (jeśli wynikiem w linii 17. była prawda). Tak więc program pominąłby cały blok, aż do linii 39.
Ten przykład ilustruje że otrzymanie wyniku true w jednej z instrukcji if nie powoduje zaprzestania sprawdzania pozostałych instrukcji if.
Zauważ, że wykonywaną zawartością dwóch pierwszych instrukcji if są pojedyncze linie (wypisujące „Let’s Go Mets!” lub „Go Yankees!”). W pierwszym przykładzie (w linii 18.) nie umieściłem linii w nawiasach klamrowych, gdyż pojedyncza instrukcja nie wymaga ich zastosowania. Nawiasy klamrowe są jednak dozwolone, więc użyłem ich w liniach 21. i 23.
OSTRZEŻENIE Wielu początkujących programistów C++ nieświadomie umieszcza średnik za nawiasem zamykającym instrukcję if:
if(SomeValue < 10); SomeValue = 10;
Zamiarem programisty było tu sprawdzenie, czy zmienna SomeValue (jakaś wartość) jest mniejsza niż 10, i gdy warunek ten zostałby spełniony, przypisalibyśmy tej zmiennej minimalną wartość 10. Uruchomienie tego fragmentu kodu pokazuje, że zmienna SomeValue jest zawsze ustawiana na 10! Dlaczego? Ponieważ instrukcja if kończy się średnikiem (czyli instrukcją pustą).
Pamiętaj, że wcięcia w kodzie źródłowym nie mają dla kompilatora żadnego znaczenia. Ten fragment mógłby zostać zapisany (bardziej poprawnie) jako:
if(SomeValue < 10) // sprawdzenie ; // nic nie rób
Usunięto: 9
SomeValue = 10; // przypisz
Usunięcie średnika występującego w pierwszym przykładzie spowoduje, że druga linia stanie się częścią instrukcji if i kod zadziała zgodnie z planem.
Styl wcięć Listing 4.3 pokazuje jeden ze stylów „wcinania” instrukcji if. Nie ma chyba jednak lepszego sposobu na wszczęcie wojny religijnej niż zapytanie grupy programistów, jaki jest najlepszy styl wyrównywania nawiasów klamrowych. Choć dostępne są tuziny ich odmian, wygląda na to, że najczęściej stosowane są trzy z nich:
• umieszczenie otwierającego nawiasu klamrowego po warunku i wyrównanie nawiasu klamrowego zamykającego blok zawierający początek instrukcji if:
if (wyrażenie){ instrukcje }
• wyrównanie nawiasów klamrowych z instrukcją if i wcięcie jedynie bloku instrukcji:
if (wyrażenie) { instrukcje }
• wcięcie zarówno instrukcji, jak i nawiasów klamrowych:
if (wyrażenie) { instrukcje }
W tej książce stosujemy drugą z podanych wyżej wersji, gdyż uważam, że najlepiej pokazuje gdzie zaczyna się, a gdzie się kończy blok instrukcji. Pamiętaj jednak, że nie ma znaczenia który styl sam wybierzesz, o ile tylko będziesz go konsekwentnie stosował.
else Często zdarza się, że w swoim programie chcesz wykonać jakiś fragment kodu, jeżeli spełniony zostanie pewien warunek, oraz inny fragment kodu, gdy warunek ten nie zostanie spełniony. Na listingu 4.4 chcieliśmy wypisać komunikat (Let’s Go Mets!), pod warunkiem, że pierwszy test
Usunięto: powodu

(MetsScore > YankeesScore) da wartość true, lub inny komunikat (Go Yankees!), gdy ten test da wartość false.
Pokazana już wcześniej metoda — sprawdzenie najpierw pierwszego warunku, a potem drugiego — działa poprawnie, lecz jest nieco żmudna. Dzięki zastosowaniu słowa kluczowego else możemy to zamienić na bardziej czytelny fragment kodu:
if (wyrażenie) instrukcja; else instrukcja;
Użycie słowa kluczowego else demonstruje listing 4.5.
Listing 4.5. Użycie słowa kluczowego else 0: // Listing 4.5 - demonstruje instrukcję if 1: // z klauzulą else 2: #include <iostream> 3: int main() 4: { 5: using std::cout; 6: using std::cin; 7: 8: int firstNumber, secondNumber; 9: cout << "Prosze wpisac wieksza liczbe: "; 10: cin >> firstNumber; 11: cout << "\nProsze wpisac mniejsza liczbe: "; 12: cin >> secondNumber; 13: if (firstNumber > secondNumber) 14: cout << "\nDzieki!\n"; 15: else 16: cout << "\nPomylka! Druga liczba jest wieksza!"; 17: 18: return 0; 19: }
Wynik Prosze wpisac wieksza liczbe: 10 Prosze wpisac mniejsza liczbe: 12 Pomylka! Druga liczba jest wieksza!
Analiza
Obliczany jest warunek w instrukcji if w linii 13. Jeśli warunek jest spełniony (prawdziwy), wykonywana jest instrukcja w linii 14.; jeśli nie jest spełniony (jest fałszywy), wykonywana jest instrukcja w linii 16. Gdyby klauzula else w linii 15. została usunięta, wtedy instrukcja w linii 16. byłaby wykonywana zawsze, bez względu na to, czy warunek instrukcji if byłby spełniony, czy nie. Pamiętaj że instrukcja if kończy się po linii 14. Gdyby nie było else, linia 16. byłaby po prostu kolejną linią programu.
Usunięto: by

Pamiętaj, że obie instrukcje wykonywane warunkowo można zastąpić blokami kodu ujętymi w nawiasy klamrowe.
Instrukcja if
Składnia instrukcji if jest następująca:
Forma 1
if (wyrażenie) instrukcja; następna instrukcja;
Jeśli wyrażenie ma wartość true, to instrukcja jest wykonywana i program przechodzi do wykonania następnej instrukcji. Jeśli wyrażenie nie jest prawdziwe, instrukcja jest ignorowana i program przechodzi bezpośrednio do następnej instrukcji.
Pamiętaj, że instrukcja może być pojedynczą instrukcją zakończoną średnikiem lub blokiem instrukcji ujętym w nawiasy klamrowe.
Forma 2
if (wyrażenie) instrukcja1; else instrukcja2; następna instrukcja;
Jeśli wyrażenie ma wartość true, wykonywana jest instrukcja1; w przeciwnym razie wykonywana jest instrukcja2. Następnie program przechodzi do wykonania następnej instrukcji.
Przykład 1
if (SomeValue < 10) cout << "SomeValue jest mniejsze niż 10"; else cout << "SomeValue nie jest mniejsze niż 10"; cout << "Gotowe." << endl;
Zaawansowane instrukcje if Warto zauważyć, że w klauzuli if lub else może być zastosowana dowolna instrukcja, nawet inna instrukcja if lub else. Z tego powodu możemy natrafić na złożone instrukcje if, przyjmujące postać:

if (wyrażenie1) { if (wyrażenie2) instrukcja1; else { if (wyrażenie3) instrukcja2; else instrukcja3; } } else instrukcja4;
Ta rozbudowana instrukcja if działa następująco: jeśli wyrażenie1 ma wartość true i wyrażenie2 ma wartość true, wykonaj instrukcję1. Jeśli wyrażenie1 ma wartość true, lecz wyrażenie2 ma wartość false, wtedy, jeśli wyrażenie3 ma wartość true, wykonaj instrukcję2. Jeśli wyrażenie1 ma wartość true, lecz wyrażenie2 i wyrażenie3 mają wartość false, wtedy wykonaj instrukcję3. Na zakończenie, jeśli wyrażenie1 ma wartość false, wykonaj instrukcję4. Jak widać, złożone instrukcje if mogą wprawiać w zakłopotanie!
Przykład takiej złożonej instrukcji if zawiera listing 4.6.
Listing 4.6. Złożona, zagnieżdżona instrukcja if 0: // Listing 4.6 - a złożona zagnieżdżona 1: // instrukcja if 2: #include <iostream> 3: int main() 4: { 5: // Poproś o dwie liczby. 6: // Przypisz je zmiennym bigNumber i littleNumber 7: // Jeśli bigNumber jest większe niż littleNumber, 8: // sprawdź, czy się dzielą bez reszty. 9: // Jeśli tak, sprawdź, czy są to te same liczby. 10: 11: using namespace std; 12: 13: int firstNumber, secondNumber; 14: cout << "Wpisz dwie liczby.\nPierwsza: "; 15: cin >> firstNumber; 16: cout << "\nDruga: "; 17: cin >> secondNumber; 18: cout << "\n\n"; 19: 20: if (firstNumber >= secondNumber) 21: { 22: if ((firstNumber%secondNumber) == 0) // dziela sie bez reszty? 23: { 24: if (firstNumber == secondNumber) 25: cout << "One sa takie same!\n"; 26: else 27: cout << "One dziela sie bez reszty!\n"; 28: }

29: else 30: cout << "One nie dziela sie bez reszty!\n"; 31: } 32: else 33: cout << "Hej! Druga liczba jest wieksza!\n"; 34: return 0; 35: }
Wynik Wpisz dwie liczby. Pierwsza: 10 Druga: 2 One dziela sie bez reszty!
Analiza
Program prosi o wpisanie dwóch liczb, jednej po drugiej. Następnie są one porównywane. Pierwsza instrukcja if, w linii 20., sprawdza, czy pierwsza liczba jest większa lub równa drugiej. Jeśli nie, wykonywana jest klauzula else w linii 32.
Jeśli pierwsza instrukcja if jest prawdziwa, wykonywany jest blok kodu zaczynający się w linii 21., po czym w linii 22. przeprowadzany jest kolejny test w instrukcji if. W tym przypadku sprawdzamy, czy reszta z dzielenia pierwszej liczby przez drugą wynosi zero, to jest czy obie liczby są przez siebie podzielne. Jeśli tak, liczby te mogą być takie same lub mogą być podzielne przez siebie. Instrukcja if w linii 24. sprawdza, czy te liczby są równe i w obu przypadkach wyświetla odpowiedni komunikat.
Jeśli warunek instrukcji if w linii 22. nie zostanie spełniony, wtedy wykonywana jest instrukcja else w linii 29.
Użycie nawiasów klamrowych w zagnieżdżonych instrukcjach if Choć dozwolone jest pomijanie nawiasów klamrowych w instrukcjach if zawierających tylko pojedyncze instrukcje, i choć dozwolone jest zagnieżdżanie instrukcji if:
if (x > y) // gdy x jest większe od y if (x < z) // oraz gdy x jest mniejsze od z x = y; // wtedy przypisz zmiennej x wartość zmiennej y
może to powodować zbyt dużo problemów ze zrozumieniem struktury kodu w przypadku, gdy piszesz duże zagnieżdżone instrukcje. Pamiętaj, białe spacje i wcięcia są ułatwieniem dla programisty, lecz nie stanowią żadnej różnicy dla kompilatora. Łatwo jest się pomylić i błędnie wstawić instrukcję else do niewłaściwej instrukcji if. Problem ten ilustruje listing 4.7.
Usunięto: lecz

Listing 4.7. Przykład: nawiasy klamrowe ułatwiają zorientowanie się, które instrukcje else należą do których instrukcji if.
0: // Listing 4.7 – demonstruje, dlaczego nawiasy klamrowe 1: // mają duże znaczenie w zagnieżdżonych instrukcjach if 2: #include <iostream> 3: int main() 4: { 5: int x; 6: std::cout << "Wpisz liczbe mniejsza niz 10 lub wieksza niz 100: "; 7: std::cin >> x; 8: std::cout << "\n"; 9: 10: if (x >= 10) 11: if (x > 100) 12: std::cout << "Wieksza niz 100, Dzieki!\n"; 13: else // nie tego else chcieliśmy! 14: std::cout << "Mniejsza niz 10, Dzieki!\n"; 15: 16: return 0; 17: }
Wynik Wpisz liczbe mniejsza niz 10 lub wieksza niz 100: 20 Mniejsza niz 10, Dzieki!
Analiza
Programista miał zamiar poprosić o liczbę mniejszą niż 10 lub większą od 100, sprawdzić czy wartość jest poprawna, po czym wypisać podziękowanie.
Jeśli instrukcja if w linii 10. jest prawdziwa, zostaje wykonana następna instrukcja (w linii 11.). W tym przypadku linia 11. jest wykonywana, gdy wprowadzona liczba jest większa niż 10. Linia 11. także zawiera instrukcję if. Ta instrukcja jest prawdziwa, gdy wprowadzona liczba jest większa od 100. Jeśli liczba jest większa niż 100, wtedy wykonywana jest instrukcja w linii 12.
Jeśli wprowadzona liczba jest mniejsza od 10, wtedy instrukcja if w linii 10. daje wynik false i program przechodzi do następnej linii po instrukcji if, czyli w tym przypadku do linii 16. Jeśli wpiszesz liczbę mniejszą niż 10, otrzymasz wynik:
Wpisz liczbe mniejsza niz 10 lub wieksza niz 100: 9
Klauzula else w linii 13. miała być dołączona do instrukcji if w linii 10., i w związku z tym została odpowiednio wcięta. Jednak w rzeczywistości ta instrukcja else jest dołączona do instrukcji if w linii 11., co powoduje, że w programie występuje subtelny błąd.
Błąd jest subtelny, gdyż kompilator go nie zauważy i nie zgłosi. Jest to w pełni poprawny program języka C++, lecz nie wykonuje tego, do czego został stworzony. Na dodatek, w większości testów przeprowadzanych przez programistę będzie działał poprawnie. Dopóki wprowadzane będą liczby większe od 100, program będzie działał poprawnie.
Usunięto: 7

Listing 4.8 przedstawia rozwiązanie tego problemu – wstawienie koniecznych nawiasów klamrowych.
Listing 4.8. Przykład właściwego użycia nawiasów klamrowych w instrukcji if 0: // Listing 4.8 - demonstruje właściwe użycie nawiasów 1: // klamrowych w zagnieżdżonych instrukcjach if 2: #include <iostream> 3: int main() 4: { 5: int x; 6: std::cout << "Wpisz liczbe mniejsza niz 10 lub wieksza niz 100: "; 7: std::cin >> x; 8: std::cout << "\n"; 9: 10: if (x >= 10) 11: { 12: if (x > 100) 13: std::cout << "Wieksza niz 100, Dzieki!\n"; 14: } 15: else // poprawione! 16: std::cout << "Mniejsza niz 10, Dzieki!\n"; 17: return 0; 18: }
Wynik Wpisz liczbe mniejsza niz 10 lub wieksza niz 100: 9 Mniejsza niz 10, Dzieki!
Analiza
Nawiasy klamrowe w liniach 11. i 14. powodują, że cały zawarty między nimi kod jest traktowany jak pojedyncza instrukcja, dzięki czemu instrukcja else w linii 15. odnosi się teraz do instrukcji if w linii 10., czyli tak, jak zamierzono.
UWAGA Programy przedstawione w tej książce zostały napisane w celu zilustrowania omawianych zagadnień. Są więc z założenia uproszczone i nie zawierają żadnych mechanizmów kontroli błędów wpisywanych przez użytkownika danych. W profesjonalnym kodzie należy przewidzieć każdy błąd i odpowiednio na niego zareagować.
Operatory logiczne Często zdarza się, że chcemy zadać więcej niż jedno relacyjne pytanie na raz. „Czy jest prawdą że x jest większe od y i czy jest jednocześnie prawdą, że y jest większe od z?” Aby móc podjąć działanie, program musi mieć możliwość sprawdzenia, czy oba te warunki są prawdziwe — lub czy przynajmniej któryś z nich jest prawdziwy.
Wyobraźmy sobie skomplikowany system alarmowy, działający zgodnie z następującą zasadą: „gdy zabrzmi alarm przy drzwiach I jest już po szóstej po południu I NIE ma świąt LUB jest

weekend, wtedy zadzwoń po policję”. Do tego rodzaju obliczeń stosowane są trzy operatory logiczne języka C++. Zostały one przedstawione w tabeli 4.2.
Tabela 4.2. Operatory logiczne
Operator Symbol Przykład
I (AND) && wyrażenie1 && wyrażenie2
LUB (OR) || wyrażenie1 || wyrażenie2
NIE (NOT) ! !wyrażenie
Logiczne I Instrukcja logicznego I (AND) oblicza dwa wyrażenia, jeżeli oba mają wartość true, wartością całego wyrażenia I także jest true. Jeśli prawdą jest, że jesteś głodny I prawdą jest, że masz pieniądze, WTEDY możesz kupić obiad. Zatem
if ( (x == 5) && (y == 5) )
będzie prawdziwe, gdy zarówno x, jak i y ma wartość 5, zaś będzie nieprawdziwe, gdy któraś z tych zmiennych będzie miała wartość różną od 5. Zapamiętaj, że aby całe wyrażenie było prawdziwe, prawdziwe muszą być oba wyrażenia.
Zauważ, że logiczne I to podwójny symbol, &&. Pojedynczy symbol, &, jest zupełnie innym operatorem, który opiszemy w rozdziale 21., „Co dalej.”
Logiczne LUB Instrukcja logicznego LUB (OR) oblicza dwa wyrażenia, gdy któreś z nich ma wartość true, wtedy wartością całego wyrażenia LUB także jest true. Jeśli prawdą jest, że masz gotówkę LUB prawdą jest że, masz kartę kredytową, WTEDY możesz zapłacić rachunek. Nie potrzebujesz jednocześnie gotówki i karty kredytowej, choć posiadanie obu jednocześnie nie przeszkadza. Zatem
if ( (x == 5) || (y == 5) )
będzie prawdziwe, gdy x lub y ma wartość 5, lub gdy obie zmienne mają wartość 5.
Zauważ, że logiczne LUB to podwójny symbol ||. Pojedynczy symbol | jest zupełnie innym operatorem, który opiszemy w rozdziale 21., „Co dalej.”
Usunięto: ,
Usunięto: ,
Usunięto: ,
Logiczne NIE Instrukcja logicznego NIE (NOT) ma wartość true, gdy sprawdzane wyrażenie ma wartość false. Jeżeli sprawdzane wyrażenie ma wartość true, operator logiczny NIE zwraca wartość false. Zatem
if ( !(x == 5) )
jest prawdziwe tylko wtedy, gdy x jest różne od 5. Identycznie działa zapis:
if (x != 5)
Skrócone obliczanie wyrażeń logicznych Gdy kompilator oblicza instrukcję I, na przykład taką, jak:
if ( (x == 5) && (y == 5) )
wtedy najpierw sprawdza prawdziwość pierwszego wyrażenia (x == 5). Gdy jest ono nieprawdziwe, POMIJA sprawdzanie prawdziwości drugiego wyrażenia (y == 5), gdyż instrukcja I wymaga, aby oba wyrażenia były prawdziwe.
Gdy kompilator oblicza instrukcję LUB, na przykład taką, jak:
if ( (x == 5) || (y == 5) )
wtedy w przypadku prawdziwości pierwszego wyrażenia (x == 5), nigdy NIE JEST sprawdzane drugie wyrażenie (y == 5), gdyż w instrukcji LUB wystarczy prawdziwość któregokolwiek z wyrażeń.
Kolejność operatorów logicznych Operatory logiczne, podobnie jak operatory relacji, są w języku C++ wyrażeniami, więc zwracają wartości; w tym przypadku wartość true lub false. Tak jak wszystkie wyrażenia, posiadają priorytet (patrz dodatek C), określający kolejność ich obliczania. Ma on znaczenie podczas wyznaczania wartości instrukcji
if ( x > 5 && y > 5 || z > 5)
Usunięto: ego
Być może programista chciał, by to wyrażenie miało wartość true, gdy zarówno x, jak i y są większe od 5 lub gdy z jest większe od 5. Z drugiej strony, programista mógł chcieć, by to wyrażenie było prawdziwe tylko wtedy, gdy x jest większe od 5 i gdy y lub z jest większe od 5.
Jeśli x ma wartość 3, zaś y i z mają wartość 10, wtedy prawdziwa jest pierwsza interpretacja (z jest większe od 5, więc x i y są ignorowane). Jednak w drugiej interpretacji otrzymujemy wartość false (x nie jest większe od 5, więc nie ma znaczenia, co jest po prawej stronie symbolu &&, gdyż obie jego strony muszą być prawdziwe).
Choć o kolejności obliczeń decydują priorytety operatorów, jednak do zmiany ich kolejności i jasnego wyrażenia naszych zamiarów możemy użyć nawiasów:
if ( (x > 5) && (y > 5 || z > 5) )
Używając poprzednio opisanych wartości otrzymujemy dla tego wyrażenia wartość false. Ponieważ x nie jest większe od 5, lewa strona instrukcji I jest nieprawdziwa, więc całe wyrażenie jest traktowane jako nieprawdziwe. Pamiętaj, że instrukcja I wymaga, by obie strony były prawdziwe.
UWAGA Dobrym pomysłem jest używanie dodatkowych nawiasów – pomagają one lepiej oznaczyć operatory, które chcesz pogrupować. Pamiętaj, że twoim celem jest pisanie programów, które nie tylko działają, ale są także łatwe do odczytania i zrozumienia.
Kilka słów na temat prawdy i fałszu W języku C++ wartość zero jest traktowana jako logiczna wartość false, zaś wszystkie inne wartości są traktowane jako logiczna wartość true. Ponieważ wyrażenie zawsze posiada jakąś wartość, wielu programistów wykorzystuje ją w swoich instrukcjach if. Instrukcja taka jak
if(x) // jeśli x ma wartość true (różną od zera) x = 0;
może być odczytywana jako “jeśli x ma wartość różną od zera, ustaw x na 0”. Jest to efektowna sztuczka; zamiast tego lepiej będzie, gdy napiszesz:
if (x != 0) // jeśli x ma wartość różną od zera x = 0;
Obie instrukcje są dozwolone, ale druga z nich lepiej wyraża intencje programisty. Do dobrych obyczajów programistów należy pozostawienie pierwszej z form dla prawdziwych testów logicznych (a nie dla sprawdzania czy wartość jest różna od zera).

Te dwie instrukcje także są równoważne: if (!x) // jeśli x ma wartość false (równą zeru) if (x == 0) // jeśli x ma wartość zero
Druga z nich jest nieco łatwiejsza do zrozumienia i wyraźniej sugeruje, że sprawdzamy matematyczną wartość zmiennej x, a nie jej stan logiczny.
TAK NIE
Aby lepiej wyrazić kolejność obliczeń, umieszczaj nawiasy wokół wyrażeń logicznych.
Aby uniknąć błędów i lepiej wyrazić przynależność instrukcji else, używaj nawiasów klamrowych w zagnieżdżonych instrukcjach if.
Nie używaj if(x) jako synonimu dla if(x != 0); druga z tych form jest bardziej czytelna.
Nie używaj if(!x) jako synonimu dla if(x == 0); druga z tych form jest bardziej czytelna.
Operator warunkowy (trójelementowy) Operator warunkowy (?:) jest w języku C++ jedynym operatorem trójelementowym, tj. operatorem korzystającym z trzech wyrażeń.
Operator warunkowy składa się z trzech wyrażeń i zwraca wartość:
(wyrażenie1) ? (wyrażenie2) : (wyrażenie3)
Tę linię odczytuje się jako: „jeśli wyrażenie1 jest prawdziwe, zwróć wartość wyrażenia2; w przeciwnym razie zwróć wartość wyrażenia3”. Zwracana wartość jest zwykle przypisywana zmiennej.
Listing 4.9 przedstawia instrukcję if przepisaną z użyciem operatora warunkowego.
Listing 4.9. Przykład użycia operatora warunkowego 0: // Listing 4.9 - demonstruje operator warunkowy 1: // 2: #include <iostream> 3: int main() 4: { 5: using namespace std; 6: 7: int x, y, z; 8: cout << "Wpisz dwie liczby.\n"; 9: cout << "Pierwsza: "; 10: cin >> x; 11: cout << "\nDruga: "; 12: cin >> y;

13: cout << "\n"; 14: 15: if (x > y) 16: z = x; 17: else 18: z = y; 19: 20: cout << "z: " << z; 21: cout << "\n"; 22: 23: z = (x > y) ? x : y; 24: 25: cout << "z: " << z; 26: cout << "\n"; 27: return 0; 28: }
Wynik Wpisz dwie liczby. Pierwsza: 5 Druga: 8 z: 8 z: 8
Analiza
Tworzone są trzy zmienne całkowite: x, y oraz z. Wartości dwóch pierwszych są nadawane przez użytkownika. Instrukcja if w linii 15. sprawdza, która wartość jest większa i przypisuje ją zmiennej z. Ta wartość jest wypisywana w linii 20.
Operator warunkowy w linii 23. przeprowadza ten sam test i przypisuje zmiennej z większą z wartości. Można go odczytać jako: jeśli x jest większe od y, zwróć wartość x; w przeciwnym razie zwróć wartość y”. Zwracana wartość jest przypisywana zmiennej z, zaś jej wartość jest wypisywana w linii 25. Jak widać, instrukcja warunkowa stanowi krótszy odpowiednik instrukcji if...else.

Rozdział 5. Funkcje Choć w programowaniu zorientowanym obiektowo zainteresowanie użytkowników zaczęło koncentrować się na obiektach, jednak mimo to funkcje w dalszym ciągu pozostają głównym komponentem każdego programu. Funkcje globalne występują poza obiektami, zaś funkcje składowe (zwane także metodami składowymi) występują wewnątrz obiektów, wykonując ich pracę.
Z tego rozdziału dowiesz się:
• czym jest funkcja i z jakich części się składa,
• jak deklarować i definiować funkcje,
• jak przekazywać argumenty do funkcji,
• jak zwracać wartość z funkcji.
Zaczniemy od funkcji globalnych; w następnym rozdziale dowiesz się, w jaki sposób funkcje działają wewnątrz obiektów.
Czym jest funkcja? Ogólnie, funkcja jest podprogramem, operującym na danych i zwracającym wartość. Każdy program C++ posiada przynajmniej jedną funkcję, main(). Gdy program rozpoczyna działanie, funkcja main() jest wywoływana automatycznie. Może ona wywoływać inne funkcje, które z kolei mogą wywoływać kolejne funkcje.
Ponieważ funkcje te nie stanowią części jakiegoś obiektu, są nazywane „globalnymi” — mogą być dostępne z dowolnego miejsca programu. W tym rozdziale, gdy będziemy mówić o funkcjach, będziemy mieli na myśli właśnie funkcje globalne (chyba, że postanowimy inaczej).
Każda funkcja posiada nazwę; gdy ta nazwa zostanie napotkana przez program, przechodzi on do wykonywania kodu zawartego wewnątrz ciała tej funkcji. Nazywa się to wywołaniem funkcji. Gdy funkcja wraca, wykonanie programu jest wznawiane od instrukcji następującej po wywołaniu tej funkcji. Ten przepływ sterowania został pokazany na rysunku 5.1.

Rysunek 5.1. Gdy program wywołuje funkcję, sterowanie przechodzi do jej ciała, po czym jest wznawiane od instrukcji występującej po wywołaniu tej funkcji
Dobrze zaprojektowane funkcje wykonują określone, łatwo zrozumiałe zadania. Złożone zadania powinny być dzielone na kilka, odpowiednio wywoływanych funkcji.
Funkcje występują w dwóch odmianach: zdefiniowane przez użytkownika (programistę) oraz wbudowane. Funkcje wbudowane stanowią część pakietu dostarczanego wraz z kompilatorem — zostały one stworzone przez producenta kompilatora, z którego korzystasz. Funkcje zdefiniowane przez użytkownika są funkcjami, które piszesz samodzielnie.
Zwracane wartości, parametry i argumenty Funkcja może zwracać wartość. Gdy wywołujesz funkcję, może ona wykonać swoją pracę, po czym zwrócić wartość stanowiącą rezultat tej pracy. Ta wartość jest nazywana wartością zwracaną, zaś jej typ musi być zadeklarowany. Zatem, gdy piszesz:
int myFunction();
deklarujesz, że funkcja myFunction zwraca wartość całkowitą.
Możesz także przekazywać wartości do funkcji. Te wartości pełnią rolę zmiennych, którymi możesz manipulować wewnątrz funkcji.
Opis przekazywanych wartości jest nazywany listą parametrów.
int myFunction(int someValue, float someFloat);

Ta deklaracja wskazuje, że funkcja myFunction nie tylko zwraca liczbę całkowitą, ale także, że jej parametrami są: wartość całkowita oraz wartość typu float.
Parametr opisuje typ wartości, jaka jest przekazywana funkcji podczas jej wywołania. Wartości przekazywane funkcji są nazywane argumentami.
int theValueReturned = myFunction(5, 6.7);
W tej deklaracji widzimy, że zmienna całkowita theValueReturned (zwracana wartość) jest inicjalizowana wartością zwracaną przez funkcję myFunction, której zostały przekazane wartości 5 oraz 6.7 (jako argumenty). Typy argumentów muszą odpowiadać zadeklarowanym typom parametrów.
Deklarowanie i definiowanie funkcji Aby użyć funkcji w programie, należy najpierw zadeklarować funkcję, a następnie ją zdefiniować. Deklaracja informuje kompilator o nazwie funkcji, typie zwracanej przez nią wartości, oraz o jej parametrach. Z kolei definicja informuje, w jaki sposób dana funkcja działa. Żadna funkcja nie może zostać wywołana z jakiejkolwiek innej funkcji, jeśli nie zostanie wcześniej zadeklarowana. Deklaracja funkcji jest nazywana prototypem.
Deklarowanie funkcji Istnieją trzy sposoby deklarowania funkcji:
• zapisanie prototypu funkcji w pliku, a następnie użycie dyrektywy #include w celu dołączenia go do swojego programu,
• zapisanie prototypu w pliku, w którym dana funkcja jest używana,
• zdefiniowanie funkcji zanim zostanie wywołana przez inne funkcje. Jeśli tego nie dokonasz, definicja będzie pełnić jednocześnie rolę deklaracji funkcji.
Choć możesz zdefiniować funkcję przed jej użyciem i uniknąć w ten sposób konieczności tworzenia jej prototypu, nie należy to do dobrych obyczajów programistycznych z trzech powodów.
Po pierwsze, niedobrze jest, gdy funkcje muszą występować w pliku źródłowym w określonej kolejności. Powoduje to, że w razie wprowadzenia zmian trudno jest zmodyfikować taki program.
Po drugie, istnieje możliwość, że w pewnych warunkach funkcja A() musi być w stanie wywołać funkcję B(), a funkcja B() także musi być w stanie wywołać funkcję A(). Nie jest możliwe zdefiniowanie funkcji A() przed zdefiniowaniem funkcji B() i jednoczesne zdefiniowanie funkcji B() przed zdefiniowaniem funkcji A(), dlatego przynajmniej jedna z nich zawsze musi zostać zadeklarowana.
Usunięto: W
Usunięto: tutaj

Po trzecie, prototypy funkcji stanowią wydajną technikę debuggowania (usuwania błędów w programach). Jeśli z prototypu wynika, że funkcja otrzymuje określony zestaw parametrów lub że zwraca określony typ wartości, to w przypadku gdy funkcja nie jest zgodna z tym prototypem, kompilator, zamiast czekać na wystąpienie błędu podczas działania programu, może wskazać tę niezgodność. Przypomina to dwustronną księgowość. Prototyp i definicja sprawdzają się wzajemnie, redukując prawdopodobieństwo, że zwykła literówka spowoduje błąd w programie.
Prototypy funkcji Wiele z wbudowanych funkcji posiada już gotowe prototypy. Występują one w plikach, które są dołączane do programu za pomocą dyrektywy #include. W przypadku funkcji pisanych samodzielnie, musisz stworzyć samodzielnie także ich prototypy.
Prototyp funkcji jest instrukcją, co oznacza, że kończy się on średnikiem. Składa się ze zwracanego przez funkcję typu oraz tzw. sygnatury funkcji. Sygnatura funkcji to jej nazwa oraz lista parametrów.
Lista parametrów jest listą wszystkich parametrów oraz ich typów, oddzielonych od siebie przecinkami. Elementy prototypu funkcji przedstawia rysunek 5.2.
Rysunek 5.2. Elementy prototypu funkcji
Zwracany typ oraz sygnatura prototypu i definicji funkcji muszą zgadzać się dokładnie. Jeśli nie są one zgodne, wystąpi błąd kompilacji. Zauważ jednak, że prototyp funkcji nie musi zawierać nazw parametrów, a jedynie ich typy. Poniższy prototyp jest poprawny:
long Area(int, int);
Ten prototyp deklaruje funkcję o nazwie Area (obszar), która zwraca wartość typu long i posiada dwa parametry, będące wartościami całkowitymi. Choć ten zapis jest poprawny, jednak jego stosowanie nie jest dobrym pomysłem. Dodanie nazw parametrów powoduje, że prototyp staje się bardziej czytelny. Ta sama funkcja z nazwanymi parametrami mogłaby być zadeklarowana następująco:
long Area(int length, int width );
W tym przypadku jest oczywiste, do czego służy ta funkcja oraz jakie są jej parametry.

Zwróć uwagę, że wszystkie funkcje zwracają wartość pewnego typu. Jeśli ten typ nie zostanie podany jawnie, zakłada się, że jest wartością całkowitą, a konkretnie typem int. Twoje programy będą jednak łatwiejsze do zrozumienia, jeśli we wszystkich funkcjach, włącznie z funkcją main(), będziesz deklarował zwracany typ.
Definiowanie funkcji Definicja funkcji składa się z nagłówka funkcji oraz z jej ciała. Nagłówek przypomina prototyp funkcji, w którym wszystkie parametry muszą być nazwane a na końcu nagłówka nie występuje średnik.
Ciało funkcji jest ujętym w nawiasy klamrowe zestawem instrukcji. Rysunek 5.3 przedstawia nagłówek i ciało funkcji.
Rysunek 5.3. Nagłówek i ciało funkcji
Listing 5.1 demonstruje program zawierający prototyp oraz deklarację funkcji Area().
Listing 5.1. Deklaracja i definicja funkcji oraz ich wykorzystanie w programie 0: // Listing 5.1 - demonstruje użycie prototypów funkcji 1: 2: #include <iostream> 3: int Area(int length, int width); //prototyp funkcji 4: 5: int main() 6: { 7: using std::cout; 8: using std::cin; 9: 10: int lengthOfYard; 11: int widthOfYard; 12: int areaOfYard; 13:

14: cout << "\nJak szerokie jest twoje podworko? "; 15: cin >> widthOfYard; 16: cout << "\nJak dlugie jest twoje podworko? "; 17: cin >> lengthOfYard; 18: 19: areaOfYard= Area(lengthOfYard,widthOfYard); 20: 21: cout << "\nTwoje podworko ma "; 22: cout << areaOfYard; 23: cout << " metrow kwadratowych\n\n"; 24: return 0; 25: } 26: 27: int Area(int l, int w) 28: { 29: return l * w; 30: }
Wynik Jak szerokie jest twoje podworko? 100 Jak dlugie jest twoje podworko? 200 Twoje podworko ma 20000 metrow kwadratowych
Analiza
Prototyp funkcji Area() znajduje się w linii 3. Porównaj ten prototyp z definicją funkcji, zaczynającą się od linii 27. Zwróć uwagę, że nazwa, zwracany typ oraz typy parametrów są takie same. Gdyby były różne, wystąpiłby błąd kompilacji. W rzeczywistości jedyną różnicę stanowi fakt, że prototyp funkcji kończy się średnikiem i nie posiada ciała.
Zwróć także uwagę, że nazwy parametrów w prototypie to length (długość) oraz width (szerokość), ale nazwy parametrów w definicji to l oraz w. Jak wspomniano wcześniej, nazwy w prototypie nie są używane i służą wyłącznie jako informacja dla programisty. Do dobrych obyczajów programistycznych należy dopasowanie nazw parametrów prototypu do nazw parametrów definicji (nie jest to wymaganie języka).
Argumenty są przekazywane funkcji w takiej kolejności, w jakiej zostały zadeklarowane i zdefiniowane parametry, lecz ich nazwy nie muszą do siebie pasować. Gdy przekażesz zmienną widthOfYard (szerokość podwórka), a po niej lengthOfYard (długość podwórka), wtedy funkcja FindArea (znajdź obszar) użyje wartości widthOfYard jako długości oraz wartości lengthOfYard jako szerokości. Ciało funkcji jest zawsze ujęte w nawiasy klamrowe, nawet jeśli (tak jak w tym przypadku) składa się z jednej tylko instrukcji.
Wykonywanie funkcji Gdy wywołujesz funkcję, jej wykonanie rozpoczyna się od pierwszej instrukcji następującej po otwierającym nawiasie klamrowym ({). Rozgałęzienie działania można uzyskać za pomocą instrukcji if. (Instrukcja if oraz instrukcje z nią związane zostaną omówione w rozdziale 7.).

Funkcje mogą także wywoływać inne funkcje, a nawet wywoływać siebie same (patrz podrozdział „Rekurencja” w dalszej części tego rozdziału).
Zmienne lokalne Zmienne można przekazywać funkcjom; można również deklarować zmienne wewnątrz ciała funkcji. Zmienne deklarowane wewnątrz ciała funkcji są nazywane „lokalnymi”, gdyż istnieją tylko lokalnie wewnątrz danej funkcji. Gdy funkcja wraca (kończy działanie), zmienne lokalne przestają być dostępne i zostają zniszczone przez kompilator.
Zmienne lokalne są definiowane tak samo, jak wszystkie inne zmienne. Parametry przekazywane do funkcji także są uważane za zmienne lokalne i mogą być używane identycznie, jak zmienne zadeklarowane wewnątrz ciała funkcji. Przykład użycia parametrów oraz zmiennych zadeklarowanych lokalnie wewnątrz funkcji przedstawia listing 5.2.
Listing 5.2. Użycie zmiennych lokalnych oraz parametrów 0: #include <iostream> 1: 2: float Convert(float); 3: int main() 4: { 5: using namespace std; 6: 7: float TempFer; 8: float TempCel; 9: 10: cout << "Podaj prosze temperature w stopniach Fahrenheita: "; 11: cin >> TempFer; 12: TempCel = Convert(TempFer); 13: cout << "\nOdpowiadajaca jej temperatura w stopniach Celsjusza: "; 14: cout << TempCel << endl; 15: return 0; 16: } 17: 18: float Convert(float TempFer) 19: { 20: float TempCel; 21: TempCel = ((TempFer - 32) * 5) / 9; 22: return TempCel; 23: }
Wynik Podaj prosze temperature w stopniach Fahrenheita: 212 Odpowiadajaca jej temperatura w stopniach Celsjusza: 100 Podaj prosze temperature w stopniach Fahrenheita: 32 Odpowiadajaca jej temperatura w stopniach Celsjusza: 0

Podaj prosze temperature w stopniach Fahrenheita: 85 Odpowiadajaca jej temperatura w stopniach Celsjusza: 29.4444
Analiza
W liniach 7. i 8. są deklarowane dwie zmienne typu float, z których jedna przechowuje temperaturę w stopniach Fahrenheita, zaś druga w stopniach Celsjusza. W linii 10. użytkownik jest proszony o podanie temperatury w stopniach Fahrenheita, zaś uzyskana wartość jest przekazywana funkcji Convert() (konwertuj).
Wykonanie programu przechodzi do pierwszej linii funkcji Convert() w linii 20., w której jest deklarowana zmienna lokalna, także o nazwie TempCel (temperatura w stopniach Celsjusza). Zwróć uwagę, że ta zmienna lokalna nie jest równoważna zmiennej TempCel w linii 8. Ta zmienna istnieje tylko wewnątrz funkcji Convert(). Wartość przekazywana jako parametr, TempFer (temperatura w stopniach Fahrenheita), także jest tylko lokalną kopią zmiennej przekazywanej przez funkcję main().
Ta funkcja mogłaby posiadać parametr o nazwie FerTemp i zmienną lokalną CelTemp, a program działałby równie dobrze. Aby przekonać się że program działa, możesz wpisać te nazwy i ponownie go skompilować.
Lokalnej zmiennej funkcji, TempCel, jest przypisywana wartość, będąca wynikiem odjęcia 32 od parametru TempFer, pomnożenia przez 5, a następnie podzielenia przez 9. Ta wartość jest następnie zwracana jako wartość funkcji, która w linii 12. jest przypisywana zmiennej TempCel wewnątrz funkcji main(). Ta wartość jest wypisywana w linii 14.
Program został uruchomiony trzykrotnie. Za pierwszym razem została podana wartość 212, w celu upewnienia się, czy punkt wrzenia wody w stopniach Fahrenheita (212) daje właściwy wynik w stopniach Celsjusza (100). Drugi test sprawdza temperaturę zamarzania wody. Trzeci test to przypadkowa wartość, wybrana w celu wygenerowania wyniku ułamkowego.
Zakres Zmienna posiada zakres, który określa, jak długo i w których miejscach programu jest ona dostępna. Zmienne zadeklarowane wewnątrz bloku mają zakres obejmujący ten blok; mogą być dostępne tylko wewnątrz tego bloku i „przestają istnieć” po wyjściu programu z tego bloku. Zmienne globalne mają zakres globalny i są dostępne w każdym miejscu programu.
Zmienne globalne Zmienne zdefiniowane poza funkcją mają zakres globalny i są dostępne z każdej funkcji w programie, włącznie z funkcją main().
Zmienne lokalne o takich samych nazwach, jak zmienne globalne nie zmieniają zmiennych globalnych. Jednak zmienna lokalna o takiej samej nazwie, jak zmienna globalna przesłania „ukrywa” zmienną globalną. Jeśli funkcja posiada zmienną o takiej samej nazwie jak zmienna
Usunięto: k
Usunięto: a

globalna, to nazwa użyta wewnątrz funkcji odnosi się do zmiennej lokalnej, a nie do globalnej. Ilustruje to listing 5.3.
Listing 5.3. Przykład zmiennych lokalnych i globalnych 0: #include <iostream> 1: void myFunction(); // prototyp 2: 3: int x = 5, y = 7; // zmienne globalne 4: int main() 5: { 6: using std::cout; 7: 8: cout << "x z funkcji main: " << x << "\n"; 9: cout << "y z funkcji main: " << y << "\n\n"; 10: myFunction(); 11: cout << "Wrocilem z myFunction!\n\n"; 12: cout << "x z funkcji main: " << x << "\n"; 13: cout << "y z funkcji main: " << y << "\n"; 14: return 0; 15: } 16: 17: void myFunction() 18: { 19: using std::cout; 20: 21: int y = 10; 22: 23: cout << "x z funkcji myFunction: " << x << "\n"; 24: cout << "y z funkcji myFunction: " << y << "\n\n"; 25: }
Wynik x z funkcji main: 5 y z funkcji main: 7 x z funkcji myFunction: 5 y z funkcji myFunction: 10 Wrocilem z myFunction! x z funkcji main: 5 y z funkcji main: 7
Analiza
Ten prosty program ilustruje kilka kluczowych i potencjalnie niezrozumiałych zagadnień, dotyczących zmiennych lokalnych i globalnych. W linii 3. są deklarowane dwie zmienne globalne, x oraz y. Zmienna globalna x jest inicjalizowana wartością 5, zaś zmienna globalna y jest inicjalizowana wartością 7.
W liniach 8. i 9. w funkcji main() te wartości są wypisywane na ekranie. Zauważ, że funkcja main() nie definiuje tych zmiennych; ponieważ są one globalne, są one dostępne w funkcji main().
Gdy w linii 10. zostaje wywołana funkcja myFunction(), działanie programu przechodzi do linii 17. a w linii 21. jest definiowana lokalna zmienna y, inicjalizowana wartością 10. W linii 23.
Usunięto: ta

funkcja myFunction() wypisuje wartość zmiennej x; w tym przypadku zostaje użyta wartość globalnej zmiennej x, tak jak w funkcji main(). Jednak w linii 24., w której zostaje użyta nazwa zmiennej y, wykorzystywana jest lokalna zmienna y, gdyż przesłoniła (ukryła) ona zmienną globalną o tej samej nazwie.
Funkcja kończy swoje działanie i zwraca sterowanie do funkcji main(), która ponownie wypisuje wartości zmiennych globalnych. Zauważ, że przypisanie wartości do zmiennej lokalnej y w funkcji myFunction() w żaden sposób nie wpłynęło na wartość globalnej zmiennej y.
Zmienne globalne: ostrzeżenie W C++ dozwolone są zmienne globalne, ale prawie nigdy nie są one używane. C++ wyrosło z języka C, zaś w tym języku zmienne globalne były niebezpiecznym, choć niezbędnym narzędziem. Zmienne globalne są konieczne, gdyż zdarzają się sytuacje, w których dane muszą być łatwo dostępne dla wielu funkcji i nie chcemy ich przekazywać z funkcji do funkcji w postaci parametrów.
Zmienne globalne są niebezpieczne, gdyż zawierają wspólne dane, które mogą być zmienione przez którąś z funkcji w sposób niewidoczny dla innych. Może to powodować bardzo trudne do odszukania błędy.
W rozdziale 15., „Specjalne klasy i funkcje,” poznasz alternatywę dla zmiennych globalnych, stanowią ją statyczne zmienne składowe.
Kilka słów na temat zmiennych lokalnych Zmienne można definiować w dowolnym miejscu funkcji, nie tylko na jej początku. Zakresem zmiennej jest blok, w którym została zdefiniowana. Dlatego, jeśli zdefiniujesz zmienną wewnątrz nawiasów klamrowych wewnątrz funkcji, będzie ona dostępna tylko wewnątrz tego bloku. Ilustruje to listing 5.4.
Listing 5.4. Zakres zmiennych ogranicza się do bloku, w którym zostały zadeklarowane 0: // Listing 5.4 - demonstruje że zakres zmiennej 1: // ogranicza się do bloku, w którym została zadeklarowana 2: 3: #include <iostream> 4: 5: void myFunc(); 6: 7: int main() 8: { 9: int x = 5; 10: std::cout << "\nW main x ma wartosc: " << x; 11: 12: myFunc(); 13: 14: std::cout << "\nPonownie w main, x ma wartosc: " << x; 15: return 0; 16: } 17:

18: void myFunc() 19: { 20: int x = 8; 21: std::cout << "\nW myFunc, lokalne x: " << x << std::endl; 22: 23: { 24: std::cout << "\nW bloku w myFunc, x ma wartosc: " << x; 25: 26: int x = 9; 27: 28: std::cout << "\nBardzo lokalne x: " << x; 29: } 30: 31: std::cout << "\nPoza blokiem, w myFunc, x: " << x << std::endl; 32: }
Wynik W main x ma wartosc: 5 W myFunc, lokalne x: 8 W bloku w myFunc, x ma wartosc: 8 Bardzo lokalne x: 9 Poza blokiem, w myFunc, x: 8 Ponownie w main, x ma wartosc: 5
Analiza
Ten program zaczyna działanie od inicjalizacji lokalnej zmiennej x w linii 9., w funkcji main(). Komunikat wypisywany w linii 10. potwierdza, że x zostało zainicjalizowane wartością 5.
Wywoływana jest funkcja myFunc(), w której, w linii 20., wartością 8 jest inicjalizowana lokalna zmienna, także o nazwie x. Jej wartość jest wypisywana w linii 21.
W linii 23. rozpoczyna się blok, a w linii 24. ponownie wypisywana jest wartość zmiennej x z funkcji. Wewnątrz bloku, w linii 26., tworzona jest nowa zmienna, także o nazwie x, która jednak jest lokalna dla bloku. Jest ona inicjalizowana wartością 9.
Wartość najnowszej zmiennej jest wypisywana w linii 28. Lokalny blok kończy się w linii 29., gdzie zmienna stworzona w linii 26. „wychodzi” z zakresu i nie jest już widoczna.
Gdy w linii 31. jest wypisywana wartość x, jest to wartość zmiennej x zadeklarowanej w linii 20. Na tę zmienną nie miała wpływu deklaracja zmiennej x w linii 26.; jej wartość wynosi wciąż 8.
W linii 32., funkcja myFunc() wychodzi z zakresu, a jej zmienna lokalna x staje się niedostępna. Wykonanie wraca do linii 14., w której jest wypisywana wartość lokalnej zmiennej x, stworzonej w linii 9. Nie ma na nią wpływu żadna ze zmiennych zdefiniowanych w funkcji myFunc().
Mimo wszystko, program ten sprawiałby dużo mniej kłopotów, gdyby te trzy zmienne posiadały różne nazwy!
Usunięto: lokalnej zmiennej x

Instrukcje funkcji Praktycznie ilość rodzajów instrukcji, które mogą być umieszczone wewnątrz ciała funkcji, jest nieograniczona. Choć wewnątrz danej funkcji nie można definiować innych funkcji, jednak można je wywoływać, z czego korzysta oczywiście funkcja main() w większości programów C++. Funkcje mogą nawet wywoływać same siebie (co zostanie wkrótce omówione w podrozdziale poświęconym rekurencji).
Chociaż rozmiar funkcji w języku C++ nie jest ograniczony, jednak dobrze zaprojektowane funkcje są zwykle niewielkie. Wielu programistów radzi, by funkcja mieściła się na pojedynczym ekranie tak, aby można ją było widzieć w całości. Ta reguła jest często łamana, także przez bardzo dobrych programistów. Jednakże mniejsze funkcje są łatwiejsze do zrozumienia i utrzymania.
Każda funkcja powinna spełniać pojedyncze, dobrze określone zadanie. Jeśli funkcja zbytnio się rozrasta, poszukaj miejsc, w których możesz podzielić ją na mniejsze podzadania.
Kilka słów na temat argumentów funkcji Argumenty funkcji nie muszą być tego samego typu. Najzupełniej poprawne i sensowne jest na przykład posiadanie funkcji, której argumentami są liczba całkowita, dwie liczby typu long oraz znak (char).
Argumentem funkcji może być każde poprawne wyrażenie języka C++, łącznie ze stałymi, wyrażeniami matematycznymi i logicznymi, a także innymi funkcjami zwracającymi wartość.
Użycie funkcji jako parametrów funkcji Choć jest dozwolone, by parametrem funkcji była inna zwracająca wartość funkcja, może to spowodować trudności w debuggowaniu kodu i jego nieczytelność.
Na przykład, przypuśćmy, że masz funkcje: myDouble() (podwojenie), triple() (potrojenie), square() (do kwadratu) oraz cube() (do trzeciej potęgi), z których każda zwraca wartość. Mógłbyś napisać:
Answer = (myDouble(triple(square(cube(myValue)))));
Ta instrukcja pobiera zmienną, myValue i przekazuje ją jako argument do funkcji cube(), której zwracana wartość jest przekazywana jako argument do funkcji square(), której zwracana wartość jest przekazywana z kolei jako argument do funkcji triple(), zaś jej zwracana wartość jest przekazywana do funkcji myDouble(). Ostatecznie zwracana wartość tej funkcji jest przypisywana zmiennej Answer (odpowiedź).
Trudno jest przewidzieć, do czego służy ten kod (wartość jest potrajana przed, czy po podniesieniu do kwadratu?), a gdy odpowiedź jest niepoprawna, trudno będzie sprawdzić, która z funkcji działa niewłaściwie.

Alternatywą jest użycie w każdym kroku oddzielnej, pośredniej zmiennej:
unsigned long myValue = 2; unsigned long cubed = cube(myValue); // cubed = 8 unsigned long squared = square(cubed); // squared = 64 unsigned long tripled = triple(squared); // tripled = 192 unsigned long Answer = myDouble(tripled); // Answer = 384
Teraz każdy pośredni wynik może zostać sprawdzony, zaś kolejność wykonywania jest bardzo dobrze widoczna.
Parametry są zmiennymi lokalnymi Argumenty przekazywane funkcji są lokalne dla tej funkcji. Zmiany dokonane w argumentach nie wpływają na wartości w funkcji wywołującej. Nazywa się to przekazywaniem przez wartość, co oznacza, że wewnątrz funkcji jest tworzona lokalna kopia każdego z argumentów. Te lokalne kopie są traktowane tak samo, jak każda inna zmienna lokalna. Ilustruje to listing 5.5.
Listing 5.5. Przykład przekazywania przez wartość 0: // Listing 5.5 - demonstracja przekazywania przez wartość. 1: 2: #include <iostream> 3: 4: void swap(int x, int y); 5: 6: int main() 7: { 8: int x = 5, y = 10; 9: 10: std::cout << "Funkcja Main. Przed funkcja Swap, x: " << x << " y: " << y << "\n"; 11: swap(x,y); 12: std::cout << "Funkcja Main. Po funkcji Swap, x: " << x << " y: " << y << "\n"; 13: return 0; 14: } 15: 16: void swap (int x, int y) 17: { 18: int temp; 19: 20: std::cout << "Funkcja Swap. Przed zamiana, x: " << x << " y: " << y << "\n"; 21: 22: temp = x; 23: x = y; 24: y = temp; 25: 26: std::cout << "Funkcja Swap. Po zamianie, x: " << x << " y: " << y << "\n"; 27: }
Wynik Funkcja Main. Przed funkcja Swap, x: 5 y: 10

Funkcja Swap. Przed zamiana, x: 5 y: 10 Funkcja Swap. Po zamianie, x: 10 y: 5 Funkcja Main. Po funkcji Swap, x: 5 y: 10
Analiza
Program inicjalizuje w funkcji main() dwie zmienne, po czym przekazuje je do funkcji swap() (zamień), która wydaje się wzajemnie wymieniać ich wartości. Jednak gdy ponownie sprawdzimy ich wartość w funkcji main(), okazuje się, że pozostały niezmienione!
Zmienne są inicjalizowane w linii 8., a ich wartości są pokazywane w linii 10. Następnie wywoływana jest funkcja swap(), do której przekazywane są zmienne.
Działanie programu przechodzi do funkcji swap(), gdzie w linii 20 wartości są wypisywane ponownie. Mają tę samą kolejność, jak w funkcji main(), czego zresztą oczekiwaliśmy. W liniach od 22. do 24. wartości są zamieniane, co potwierdza komunikat wypisywany w linii 26. Rzeczywiście, wewnątrz funkcji swap() wartości zostały zamienione.
Wykonanie programu powraca następnie do linii 12., z powrotem do funkcji main(), gdzie okazuje się, że wartości nie są już zamienione.
Jak zapewne się domyślasz, wartości przekazane funkcji swap() zostały przekazane przez wartość, co oznacza, że w tej funkcji zostały utworzone ich lokalne kopie. Właśnie te zmienne lokalne są zamieniane w liniach od 22. do 24., bez odwoływania się do zmiennych funkcji main().
W rozdziale 8., „Wskaźniki,” oraz rozdziale 10., „Funkcje zaawansowane,” poznasz alternatywne sposoby przekazywania przez wartość, które umożliwią zmianę wartości w funkcji main().
Kilka słów na temat zwracanych wartości Funkcja zwraca albo wartość, albo typ void (pusty). Typ void jest dla kompilatora sygnałem, że funkcja nie zwraca żadnej wartości.
Aby zwrócić wartość z funkcji, użyj słowa kluczowego return, a po nim wartości, którą chcesz zwrócić. Wartość ta może być wyrażeniem zwracającym wartość. Na przykład:
return 5; return (x > 5); return (MyFunction());
Wszystkie te instrukcje są poprawne, pod warunkiem, że funkcja MyFunction() także zwraca wartość. Wartością w drugiej instrukcji, return (x > 5); będzie false, gdy x nie jest większe od 5, lub true w odwrotnej sytuacji. Zwracana jest wartość wyrażenia, false lub true, a nie wartość x.
Gdy program natrafia na słowo kluczowe return, następująca po nim wartość jest zwracana jako wartość funkcji. Wykonanie programu powraca natychmiast do funkcji wywołującej, zaś instrukcje występujące po instrukcji return nie są już wykonywane.
Usunięto: ę
Usunięto: a
Usunięto: łaby
Usunięto: przekazanych przez
Usunięto: ę

Pojedyncza funkcja może zawierać więcej niż jedną instrukcję return. Ilustruje to listing 5.6.
Listing 5.6. Przykład kilku instrukcji return zawartych w tej samej funkcji 0: // Listing 5.6 - Demonstracja kilku instrukcji return 1: // zawartych w tej samej funkcji. 2: 3: #include <iostream> 4: 5: int Doubler(int AmountToDouble); 6: 7: int main() 8: { 9: using std::cout; 10: 11: int result = 0; 12: int input; 13: 14: cout << "Wpisz liczbe do podwojenia (od 0 do 10 000): "; 15: std::cin >> input; 16: 17: cout << "\nPrzed wywolaniem funkcji Doubler... "; 18: cout << "\nwejscie: " << input << " podwojone: " << result << "\n"; 19: 20: result = Doubler(input); 21: 22: cout << "\nPo powrocie z funkcji Doubler...\n"; 23: cout << "\nwejscie: " << input << " podwojone: " << result << "\n"; 24: 25: return 0; 26: } 27: 28: int Doubler(int original) 29: { 30: if (original <= 10000) 31: return original * 2; 32: else 33: return -1; 34: std::cout << "Nie mozesz tu byc!\n"; 35: }
Wynik Wpisz liczbe do podwojenia (od 0 do 10 000): 9000 Przed wywolaniem funkcji Doubler... wejscie: 9000 podwojone: 0 Po powrocie z funkcji Doubler... wejscie: 9000 podwojone: 18000 Wpisz liczbe do podwojenia (od 0 do 10 000): 11000 Przed wywolaniem funkcji Doubler... wejscie: 11000 podwojone: 0

Po powrocie z funkcji Doubler... wejscie: 11000 podwojone: -1
Analiza
W liniach 14. i 15. program prosi o podanie liczby, która jest wypisywana w linii 18., razem z wynikiem w zmiennej lokalnej. Następnie w linii 20. jest wywoływana funkcja Doubler() (podwojenie), której argumentem jest zmienna input (wejście). Rezultat jest przypisywany lokalnej zmiennej result (wynik), a w linii 23. ponownie wypisywane są wartości.
W linii 30., w funkcji Doubler(), następuje sprawdzenie, czy parametr jest większy od 10000. Jeśli nie, funkcja zwraca podwojoną liczbę pierwotną. Jeśli jest większy od 10000, funkcja zwraca –1 jako wartość błędu.
Instrukcja w linii 34. nigdy nie jest wykonywana, ponieważ bez względu na to, czy wartość jest większa od 10000, czy nie, funkcja wraca (do main) w linii 31. lub 33. — czyli przed przejściem do linii 34. Dobry kompilator ostrzeże, że ta instrukcja nie może zostać wykonana, a dobry programista ją usunie!
Często zadawane pytanie
Jaka jest różnica pomiędzy int main() a void main(); której formy powinienem użyć? Używałem obu i obie działają poprawnie, dlaczego więc powinienem używać int main(){ return 0;}?
Odpowiedź: W większości kompilatorów działają obie formy, ale zgodna z ANSI jest tylko forma int main() i tylko jej użycie gwarantuje, że program będzie mógł być bez zmian kompilowany także w przyszłości.
Oto różnica: int main() zwraca wartość do systemu operacyjnego. Gdy program kończy działanie, ta wartość może być odczytana przez, na przykład, program wsadowy.
Nie będziemy używać tej zwracanej wartości (rzadko się z niej korzysta), ale wymaga jej standard ANSI.
Parametry domyślne Funkcja wywołująca musi przekazać wartość dla każdego parametru zadeklarowanego w prototypie i definicji funkcji. Przekazywana wartość musi być zgodna z zadeklarowanym typem. Zatem, gdy masz funkcję zadeklarowaną jako
Usunięto: zaś
Usunięto: powinien się tym zająć!

long myFunction(int);
wtedy funkcja ta musi otrzymać wartość całkowitą. Jeśli definicja funkcji jest inna lub nie przekażesz jej wartości całkowitej, wystąpi błąd kompilacji.
Jedyny wyjątek od tej reguły obowiązuje, gdy prototyp funkcji deklaruje domyślną wartość parametru. Ta domyślna wartość jest używana wtedy, gdy nie zostanie przekazany argument funkcji. Poprzednią deklarację można przepisać jako
long myFunction (int x = 50);
Ten prototyp informuje, że funkcja myFunction() zwraca wartość typu long i otrzymuje parametr będący wartością całkowitą. Jeśli argument nie zostanie podany, użyta zostanie domyślna wartość 50. Ponieważ nazwy parametrów nie są wymagane w prototypach funkcji, tę deklarację można zapisać następująco:
long myFunction (int = 50);
Definicja funkcji nie zmienia się w wyniku zadeklarowania parametru domyślnego. W tym przypadku nagłówek definicji funkcji przyjmie postać:
long myFunction (int x)
Jeśli funkcja wywołująca nie przekaże parametru, kompilator wypełni parametr x domyślną wartością 50. Nazwa domyślnego parametru w prototypie nie musi być tak sama, jak nazwa w nagłówku funkcji; domyślna wartość jest przypisywana na podstawie pozycji, a nie nazwy.
Wartość domyślna może zostać przypisana każdemu parametrowi funkcji. Istnieje tylko jedno ograniczenie: jeśli któryś z parametrów nie ma wartości domyślnej, nie może jej mieć także żaden z wcześniejszych parametrów.
Jeśli prototyp funkcji ma postać:
long myFunction (int Param1, int Param2, int Param3);
to parametrowi Param1 możesz przypisać domyślną wartość tylko wtedy, gdy przypiszesz ją również parametrom Param2 i Param3. Użycie parametrów domyślnych ilustruje listing 5.7.
Listing 5.7. Użycie parametrów domyślnych 0: // Listing 5.7 - demonstruje użycie 1: // domyślnych wartości parametrów 2: 3: #include <iostream> 4: 5: int VolumeCube(int length, int width = 25, int height = 1);

6: 7: int main() 8: { 9: int length = 100; 10: int width = 50; 11: int height = 2; 12: int area; 13: 14: area = VolumeCube(length, width, height); 15: std::cout << "Za pierwszym razem objetosc wynosi: " << area << "\n"; 16: 17: area = VolumeCube(length, width); 18: std::cout << "Za drugim razem objetosc wynosi: " << area << "\n"; 19: 20: area = VolumeCube(length); 21: std::cout << "Za trzecim razem objetosc wynosi: " << area << "\n"; 22: return 0; 23: } 24: 25: int VolumeCube(int length, int width, int height) 26: { 27: 28: return (length * width * height); 29: }
Wynik Za pierwszym razem objetosc wynosi: 10000 Za drugim razem objetosc wynosi: 5000 Za trzecim razem objetosc wynosi: 2500
Analiza
W linii 5., prototyp funkcji VolumeCube() (objętość sześcianu) określa, że ta funkcja posiada trzy parametry, będące wartościami całkowitymi. Dwa ostatnie posiadają wartości domyślne.
Ta funkcja oblicza objętość sześcianu, którego wymiary zostały jej przekazane. Jeśli nie zostanie podana szerokość (width), funkcja użyje szerokości równej 25 i wysokości (height) równej 1. Jeśli zostanie podana szerokość, lecz nie zostanie podana wysokość, funkcja użyje wysokości równej 1. Nie ma możliwości przekazania wysokości bez przekazania szerokości.
W liniach od 9. do 11. inicjalizowane są wymiary, a w linii 14. są one przekazywane funkcji VolumeCube(). Obliczana jest objętość, zaś wynik jest wypisywany w linii 15.
Wykonanie przechodzi do linii 17., w której ponownie wywoływana jest funkcja VolumeCube() (lecz tym razem bez podawania wysokości). Używana jest wartość domyślna, a objętość jest ponownie obliczana i wypisywana.
Wykonanie przechodzi do linii 20., lecz tym razem nie jest przekazywana ani szerokość, ani wysokość. Wykonanie po raz trzeci przechodzi do linii 25. Użyte zostają domyślne wartości. Obliczana i wypisywana jest objętość.
TAK NIE
Pamiętaj, że parametry funkcji pełnią wewnątrz Nie próbuj tworzyć domyślnej wartości dla
Usunięto: powraca
Usunięto: powraca
Usunięto: powraca

tej funkcji rolę zmiennych lokalnych. pierwszego parametru, jeśli nie istnieje domyślna wartość dla drugiego.
Nie zapominaj, że argumenty przekazywane przez wartość nie wpływają na zmienne w funkcji wywołującej.
Nie zapominaj, że zmiana zmiennej globalnej w jednej z funkcji zmienia jej wartość we wszystkich funkcjach.
Przeciążanie funkcji C++ umożliwia tworzenie większej ilości funkcji o tej samej nazwie. Nazywa się to przeciążaniem lub przeładowaniem funkcji (ang. function overloading). Listy parametrów funkcji przeciążonych muszą się różnić od siebie albo typami parametrów, albo ich ilością, albo jednocześnie typami i ilością. Oto przykład:
int myFunction (int, int); int myFunction (long, long); int myFunction (long);
Funkcja myFunction() jest przeciążona trzema listami parametrów. Pierwsza i druga wersja różnią się od siebie typem parametrów, zaś trzecia wersja różni się od nich ilością parametrów.
Typy wartości zwracanych przez funkcje przeciążone mogą być takie same lub różne.
UWAGA Dwie funkcje o tych samych nazwach i listach parametrów, różniące się tylko typem zwracanej wartości, powodują wystąpienie błędu kompilacji. Aby zmienić zwracany typ, musisz zmienić także sygnaturę funkcji (tj. jej nazwę i (lub) listę parametrów).
Przeciążanie funkcji zwane jest także polimorfizmem funkcji. „Poli” oznacza „wiele”, zaś „morf” oznacza „formę”; tak więc „polimorfizm” oznacza „wiele form”.
Polimorfizm funkcji oznacza możliwość „przeciążenia” funkcji więcej niż jednym znaczeniem. Zmieniając ilość lub typ parametrów, możemy nadawać jednej lub więcej funkcjom tę samą nazwę, a mimo to, na podstawie użytych parametrów, zostanie wywołana właściwa funkcja. Dzięki temu można na przykład tworzyć funkcje uśredniające liczby całkowite, zmiennoprzecinkowe i inne wartości bez konieczności tworzenia osobnych nazw dla każdej funkcji, np. AverageInts() (uśredniaj wartości całkowite), AverageDoubles() (uśredniaj wartości typu double), itd.
Przypuśćmy, że piszesz funkcję, która podwaja każdą wartość, którą jej przekażesz. Chciałbyś mieć możliwość przekazywania jej wartości typu int, long, float oraz double. Bez przeciążania funkcji musiałbyś wymyślić cztery jej nazwy:
Usunięto: funkcji
Usunięto: się
Usunięto: z
Usunięto: funkcje

int DoubleInt(int); long DoubleLong(long); float DoubleFloat(float); double DoubleDouble(double);
Dzięki przeciążaniu funkcji możesz zastosować deklaracje:
int Double(int); long Double(long); float Double(float); double Double(double);
Są one łatwiejsze do odczytania i wykorzystania. Nie musisz pamiętać, którą funkcję należy wywołać; po prostu przekazujesz jej zmienną, a właściwa funkcja zostaje wywołana automatycznie. Takie zastosowanie przeciążania funkcji przedstawia listing 5.8.
Listing 5.8. Przykład polimorfizmu funkcji 0: // Listing 5.8 - demonstruje 1: // polimorfizm funkcji 2: 3: #include <iostream> 4: 5: int Double(int); 6: long Double(long); 7: float Double(float); 8: double Double(double); 9: 10: using namespace std; 11: 12: int main() 13: { 14: int myInt = 6500; 15: long myLong = 65000; 16: float myFloat = 6.5F; 17: double myDouble = 6.5e20; 18: 19: int doubledInt; 20: long doubledLong; 21: float doubledFloat; 22: double doubledDouble; 23: 24: cout << "myInt: " << myInt << "\n"; 25: cout << "myLong: " << myLong << "\n"; 26: cout << "myFloat: " << myFloat << "\n"; 27: cout << "myDouble: " << myDouble << "\n"; 28: 29: doubledInt = Double(myInt); 30: doubledLong = Double(myLong); 31: doubledFloat = Double(myFloat); 32: doubledDouble = Double(myDouble); 33: 34: cout << "doubledInt: " << doubledInt << "\n"; 35: cout << "doubledLong: " << doubledLong << "\n"; 36: cout << "doubledFloat: " << doubledFloat << "\n"; 37: cout << "doubledDouble: " << doubledDouble << "\n";

38: 39: return 0; 40: } 41: 42: int Double(int original) 43: { 44: cout << "Wewnatrz Double(int)\n"; 45: return 2 * original; 46: } 47: 48: long Double(long original) 49: { 50: cout << "Wewnatrz Double(long)\n"; 51: return 2 * original; 52: } 53: 54: float Double(float original) 55: { 56: cout << "Wewnatrz Double(float)\n"; 57: return 2 * original; 58: } 59: 60: double Double(double original) 61: { 62: cout << "Wewnatrz Double(double)\n"; 63: return 2 * original; 64: }
Wynik myInt: 6500 myLong: 65000 myFloat: 6.5 myDouble: 6.5e+020 Wewnatrz Double(int) Wewnatrz Double(long) Wewnatrz Double(float) Wewnatrz Double(double) doubledInt: 13000 doubledLong: 130000 doubledFloat: 13 doubledDouble: 1.3e+021
Analiza
Funkcja MyDouble() jest przeciążona dla parametrów typu int, long, float oraz double. Ich prototypy znajdują się w liniach od 5. do 8., zaś definicje w liniach od 42. do 64.
Zwróć uwagę, że w tym przykładzie, w linii 10., użyłem instrukcji using namespace std; poza jakąkolwiek funkcją. Sprawia to, że ta instrukcja stała się dla tego pliku globalną i że przestrzeń nazw std jest używana we wszystkich zdefiniowanych w tym pliku funkcjach.
W ciele głównego programu jest deklarowanych osiem zmiennych lokalnych. W liniach od 14. do 17. są inicjalizowane cztery z tych zmiennych, zaś w liniach od 29. do 32. pozostałym czterem zmiennym są przypisywane wyniki przekazania każdej z pierwszych czterech zmiennych do funkcji MyDouble(). Zauważ, że w chwili wywoływania tej funkcji, funkcja wywołująca nie

rozróżnia, która wersja ma zostać wywołana; po prostu przekazuje argument, i to już zapewnia wywołanie właściwej wersji.
Kompilator sprawdza argumenty i na tej podstawię wybiera właściwą wersję funkcji MyDouble(). Z wypisywanych komunikatów wynika, że wywoływane są kolejno poszczególne wersje funkcji (tak jak mogliśmy się spodziewać).
Zagadnienia związane z funkcjami Ponieważ funkcje są istotną częścią programowania, omówimy teraz kilka zagadnień, które mogą się okazać przydatne przy rozwiązywaniu pewnych problemów. Właściwe wykorzystanie funkcji typu inline może pomóc w zwiększeniu wydajności programu. Natomiast rekurencyjne wywoływanie funkcji jest jednym z tych cudownych elementów programowania, które mogą łatwo rozwiązać skomplikowane problemy, trudne do rozwiązania w inny sposób.
Funkcje typu inline Gdy definiujesz funkcję, kompilator zwykle tworzy w pamięci osobny zestaw instrukcji. Gdy wywołujesz funkcję, wykonanie programu przechodzi (wykonuje skok) do tego zestawu instrukcji, zaś gdy funkcja skończy działanie, wykonanie wraca do instrukcji następnej po wywołaniu funkcji. Jeśli wywołujesz funkcję dziesięć razy, program za każdym razem „skacze” do tego samego zestawu instrukcji. Oznacza to, że istnieje tylko jedna kopia funkcji, a nie dziesięć.
Z wchodzeniem do funkcji i wychodzeniem z niej wiąże się pewien niewielki narzut. Okazuje się, że pewne funkcje są bardzo małe, zawierają tylko jedną czy dwie linie kodu, więc istnieje możliwość poprawienia efektywności działania programu przez rezygnację z wykonywania skoków w celu wykonania jednej czy dwóch krótkich instrukcji. Gdy programiści mówią o efektywności, zwykle mają na myśli szybkość działania programu; jeśli unikniemy wywoływania funkcji, program będzie działał szybciej.
Jeśli funkcja zostanie zadeklarowana ze słowem kluczowym inline, kompilator nie tworzy prawdziwej funkcji tylko kopiuje kod z funkcji typu inline bezpośrednio do kodu funkcji wywołującej (w miejscu wywołania funkcji inline). Nie odbywa się żaden skok; program działa tak, jakbyś zamiast wywołania funkcji wpisał instrukcje tej funkcji ręcznie.
Zauważ, że funkcje typu inline mogą oznaczać duże koszty (w sensie czasu procesora). Gdy funkcja jest wywoływana w dziesięciu różnych miejscach programu, jej kod jest kopiowany do każdego z tych dziesięciu miejsc. Niewielkie zwiększenie szybkości może zostać zniwelowane przez znaczny wzrost objętości pliku wykonywalnego, co w efekcie może doprowadzić do spowolnienia działania programu!
Współczesne kompilatory prawie zawsze lepiej radzą sobie z podjęciem takiej decyzji niż programista, dlatego dobrym pomysłem jest rezygnacja z deklarowania funkcji jako inline, chyba że faktycznie składa się ona z jednej czy dwóch linii. Jeśli masz jakiekolwiek wątpliwości, zrezygnuj z użycia słowa kluczowego inline.
Funkcja typu inline została przedstawiona na listingu 5.9.
Usunięto: a kompilator zajmuje się resztą.
Usunięto: z
Usunięto: cię zainteresować w momencie natrafienia na rzadko występujące problemy.
Usunięto: rekurencja
Usunięto: zagadnień

Listing 5.9. Przykład funkcji typu inline 0: // Listing 5.9 - demonstruje funkcje typu inline 1: 2: #include <iostream> 3: 4: inline int Double(int); 5: 6: int main() 7: { 8: int target; 9: using std::cout; 10: using std::cin; 11: using std::endl; 12: 13: cout << "Wpisz liczbe: "; 14: cin >> target; 15: cout << "\n"; 16: 17: target = Double(target); 18: cout << "Wynik: " << target << endl; 19: 20: target = Double(target); 21: cout << "Wynik: " << target << endl; 22: 23: 24: target = Double(target); 25: cout << "Wynik: " << target << endl; 26: return 0; 27: } 28: 29: int Double(int target) 30: { 31: return 2*target; 32: }
Wynik Wpisz liczbe: 20 Wynik: 40 Wynik: 80 Wynik: 160
Analiza
W linii 4. funkcja MyDouble() jest deklarowana jako funkcja typu inline, otrzymująca parametr typu int i zwracająca wartość całkowitą. Ta deklaracja jest taka sama, jak w przypadku innych prototypów, jednak tuż przed typem zwracanej wartości zastosowano słowo kluczowe inline.
Program kompiluje się do kodu, który ma postać taką, jakby w każdym miejscu wystąpienia instrukcji
target = Double(target);
ręcznie wpisano

target = 2 * target;
W czasie działania programu instrukcje są już na miejscu, wkompilowane do pliku .obj. Dzięki temu unika się „skoków” w wykonaniu kodu (kosztem nieco obszerniejszego pliku wykonywalnego).
UWAGA Słowo kluczowe inline jest wskazówką dla kompilatora, że dana funkcja może być funkcją kopiowaną do kodu. Kompilator może jednak zignorować tę wskazówkę i stworzyć zwyczajną, wywoływaną funkcję.
Rekurencja Funkcja może wywoływać samą siebie. Nazywa się to rekurencją (lub rekursją). Rekurencja może być bezpośrednia lub pośrednia. Rekurencja bezpośrednia ma miejsce, gdy funkcja wywołuje samą siebie; rekurencja pośrednia następuje wtedy, gdy funkcja wywołuje inną funkcję, która z kolei (być może także pośrednio) wywołuje funkcję pierwotną.
Niektóre problemy najłatwiej rozwiązuje się stosując właśnie rekurencję. Zwykle są to czynności, w trakcie których operuje się na danych, a potem w podobny sposób operuje się na wyniku. Oba rodzaje rekurencji, pośrednia i bezpośrednia, występują w dwóch wersjach: takiej, która się kończy i zwraca wynik, oraz takiej, która się nigdy nie kończy i zwraca błąd czasu działania. Programiści uważają, że ta druga jest bardzo zabawna (gdy przytrafia się komuś innemu).
Należy pamiętać, że gdy funkcja wywołuje siebie samą, tworzona jest nowa kopia lokalnych zmiennych tej funkcji. Zmienne lokalne w wersji wywoływanej są zupełnie niezależne od zmiennych lokalnych w wersji wywołującej i w żaden sposób nie mogą na siebie wpływać. Zmienne lokalne w funkcji main() również nie są związane ze zmiennymi lokalnymi w wywoływanej przez nią funkcji (ilustrował to listing 5.4).
Aby zilustrować zastosowanie rekurencji, wykorzystajmy obliczanie ciągu Fibonacciego:
1, 1, 2, 3, 5, 8, 13, 21, 34...
Każda wartość, począwszy od trzeciej, stanowi sumę dwóch poprzednich elementów. Zadaniem Fibonacciego może być na przykład wyznaczenie dwunastego elementu takiego ciągu.
Aby rozwiązać to zadanie, musimy dokładnie sprawdzać ciąg. Pierwsze dwa elementy mają wartość jeden. Każdy kolejny element stanowi sumę dwóch poprzednich elementów. Np., siódmy element jest sumą elementu piątego i szóstego. Przyjmujemy regułę, że n-ty element jest sumą n-2 i n-1 elementu (przy założeniu, że n jest większe od dwóch).
Funkcje rekurencyjne wymagają istnienia warunku zatrzymania (tzw. warunku stopu). Musi wydarzyć się coś, co powoduje zatrzymanie rekurencji, gdyż w przeciwnym razie nigdy się ona nie skończy (tzn. zakończy się błędem działania programu). W ciągu Fibonacciego warunkiem

stopu jest n < 3 (tzn. gdy n stanie się mniejsze od trzech, możemy przestać pracować nad zadaniem).
Algorytm jest to zestaw kroków podejmowanych w celu rozwiązania zadania. Jeden z algorytmów obliczania elementów ciągu Fibonacciego jest następujący:
1. Poproś użytkownika o podanie numeru elementu ciągu.
2. Wywołaj funkcję fib(), przekazując jej uzyskany od użytkownika numer elementu.
3. Funkcja fib() sprawdza argument (n). Jeśli n < 3, zwraca wartość 1; w przeciwnym razie wywołuje (rekurencyjnie) samą siebie, przekazując jako argument wartość n-2. Następnie wywołuje się ponownie, przekazując wartość n-1, po czym zwraca sumę pierwszego i drugiego wywołania.
Gdy wywołasz fib(1), zwróci ona wartość 1. Gdy wywołasz fib(2), także zwróci 1. Jeśli wywołasz fib(3), to zwróci ona sumę z wywołań fib(2) oraz fib(1). Ponieważ fib(2) zwraca 1 a fib(1) też zwraca 1, fib(3) zwróci 2 (sumę 1+1). Jeżeli wywołasz fib(4), to zwróci ona sumę z wywołań fib(3) oraz fib(2). Już wiesz, że fib(3) zwraca 2 (z wywołań fib(2) i fib(1)) oraz, że fib(2) zwraca 1. fib(4) zsumuje te liczby i zwróci 3 (co stanowi czwarty element szeregu). Gdy wywołasz fib(5), zwróci ona sumę fib(4) oraz fib(3). Sprawdziliśmy, że fib(4) zwraca 3, zaś fib(3) zwraca 2, więc zwróconą sumą będzie 5.
Ta metoda nie jest najbardziej efektywnym sposobem rozwiązywania tego problemu (w fib(20) funkcja fib() jest wywoływana 13 529 razy!), ale działa. Bądź ostrożny — jeśli podasz zbyt dużą liczbę, w komputerze zabraknie pamięci potrzebnej do działania programu. Przy każdym wywołaniu funkcji fib() rezerwowany jest fragment pamięci. Gdy funkcja wraca, pamięć jest zwalniana. W przypadku rekurencji pamięć jest wciąż rezerwowana przed zwolnieniem, więc może się bardzo szybko skończyć. Listing 5.10 przedstawia implementację funkcji fib().
OSTRZEŻENIE Gdy uruchomisz listing 5.10, użyj niewielkiej liczby (mniejszej niż 15). Ponieważ program używa rekurencji, może zużyć mnóstwo pamięci.
Listing 5.10. Rekurencyjne obliczanie elementów ciągu Fibonacciego 0: // Obliczanie ciągu Fibonacciego z użyciem rekurencji 1: #include <iostream> 2: 3: int fib (int n); 4: 5: int main() 6: { 7: 8: int n, answer; 9: std::cout << "Podaj numer elementu ciagu: "; 10: std::cin >> n; 11: 12: std::cout << "\n\n"; 13: 14: answer = fib(n); 15: 16: std::cout << "Wartoscia " << n << "-go elementu ciagu "; 17: std::cout << "Fibonacciego jest " << answer << "\n"; 18: return 0;
Komentarz [PaG1]: Poniżej brak jednego akapitu - str. 118.
Usunięto: Wiemy więc że fib(3) zwraca wartość 2 (w wyniku wywołania fib(1) i fib(2)) oraz że fib(2) zwraca wartość 1, więc fib(4) zsumuje te wartości i zwróci 3, czyli wartość czwartego elementu ciągu.¶

19: } 20: 21: int fib (int n) 22: { 23: std::cout << "Przetwarzanie fib(" << n << ")... "; 24: 25: if (n < 3 ) 26: { 27: std::cout << "Zwraca 1!\n"; 28: return (1); 29: } 30: else 31: { 32: std::cout << "Wywoluje fib(" << n-2 << ") "; 33: std::cout << "oraz fib(" << n-1 << ").\n"; 34: return( fib(n-2) + fib(n-1)); 35: } 36: }
Wynik Podaj numer elementu ciagu: 6 Przetwarzanie fib(6)... Wywoluje fib(4) oraz fib(5). Przetwarzanie fib(4)... Wywoluje fib(2) oraz fib(3). Przetwarzanie fib(2)... Zwraca 1! Przetwarzanie fib(3)... Wywoluje fib(1) oraz fib(2). Przetwarzanie fib(1)... Zwraca 1! Przetwarzanie fib(2)... Zwraca 1! Przetwarzanie fib(5)... Wywoluje fib(3) oraz fib(4). Przetwarzanie fib(3)... Wywoluje fib(1) oraz fib(2). Przetwarzanie fib(1)... Zwraca 1! Przetwarzanie fib(2)... Zwraca 1! Przetwarzanie fib(4)... Wywoluje fib(2) oraz fib(3). Przetwarzanie fib(2)... Zwraca 1! Przetwarzanie fib(3)... Wywoluje fib(1) oraz fib(2). Przetwarzanie fib(1)... Zwraca 1! Przetwarzanie fib(2)... Zwraca 1! Wartoscia 6-go elementu ciagu Fibonacciego jest 8
UWAGA Niektóre kompilatory mają problem z użyciem operatorów w instrukcji zawierającej cout. Jeśli w linii 32. pojawi się ostrzeżenie, umieść nawiasy wokół operacji odejmowania tak, by linie 32. i 33. wyglądały następująco:
32: std::cout << "Wywoluje fib(" << (n-2) << ") "; 33: std::cout << "oraz fib(" << (n-1) << ").\n";
Analiza
W linii 9. program prosi o podanie numeru elementu ciągu i przypisuje ten numer zmiennej n. Następnie wywołuje funkcję fib(), przekazując jej tę wartość. Wykonanie przechodzi do funkcji fib(), która wypisuje wartość swojego argumentu w linii 23.
W linii 25. argument n jest sprawdzany w celu upewnienia się czy jest mniejszy od 3; jeśli tak, funkcja fib() zwraca wartość 1. W przeciwnym razie zwraca sumę wartości otrzymanych w wyniku wywołania funkcji fib() z argumentami n-2 oraz n-1.
Usunięto: wewnątrz
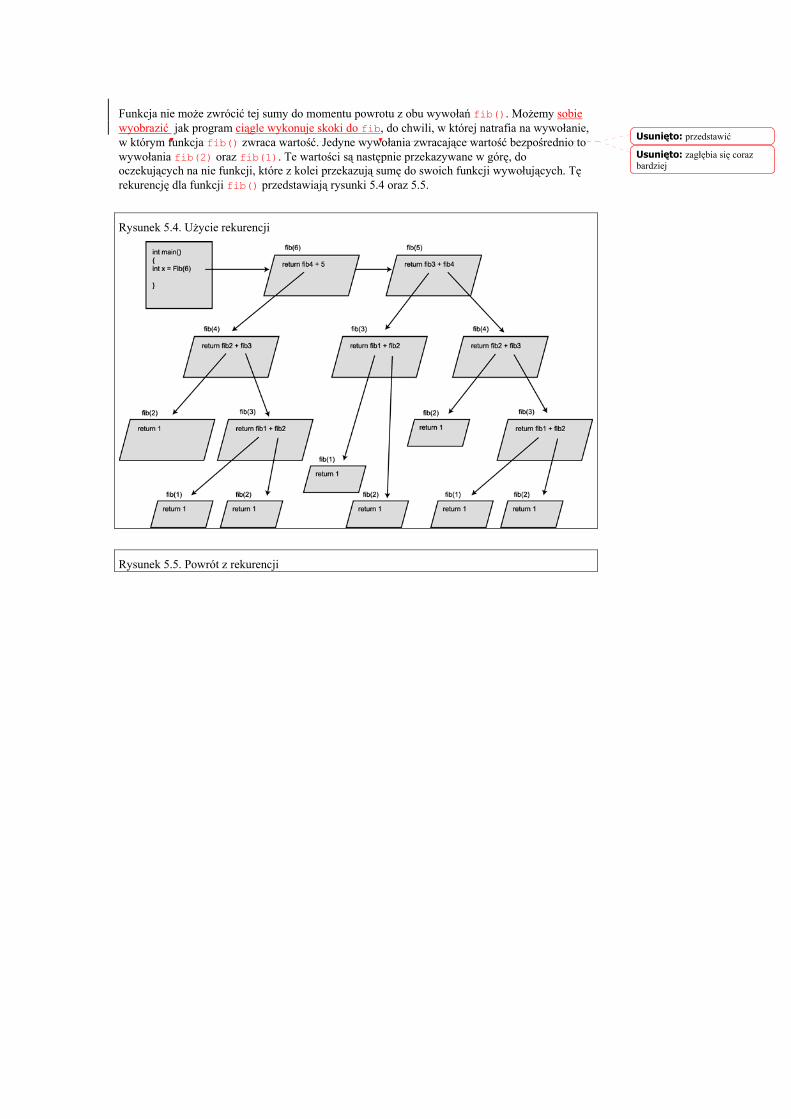
Funkcja nie może zwrócić tej sumy do momentu powrotu z obu wywołań fib(). Możemy sobie wyobrazić jak program ciągle wykonuje skoki do fib, do chwili, w której natrafia na wywołanie, w którym funkcja fib() zwraca wartość. Jedyne wywołania zwracające wartość bezpośrednio to wywołania fib(2) oraz fib(1). Te wartości są następnie przekazywane w górę, do oczekujących na nie funkcji, które z kolei przekazują sumę do swoich funkcji wywołujących. Tę rekurencję dla funkcji fib() przedstawiają rysunki 5.4 oraz 5.5.
Rysunek 5.4. Użycie rekurencji
Rysunek 5.5. Powrót z rekurencji
Usunięto: przedstawić
Usunięto: zagłębia się coraz bardziej

W tym przykładzie n ma wartość 6, dlatego w funkcji main() jest wywoływana funkcja fib(6). Wykonanie przechodzi do funkcji fib(), w której (w linii 25.) następuje sprawdzenie czy n jest mniejsze od 3. Wartość n jest większa od 3, więc funkcja fib(6) zwraca sumę wartości zwracanych przez funkcje fib(4) oraz fib(5).
34: return( fib(n-2) + fib(n-1));
Oznacza to, że odbywa się wywołanie fib(4) (ponieważ n == 6, więc fib(n-2) to w istocie fib(4)) oraz wywołanie fib(5) (czyli fib(n-1)), po czym funkcja, w której się znajdujemy (w tym przypadku fib(6)) czeka, aż te wywołania zwrócą wartości. Gdy wartości te zostaną zwrócone, funkcja ta zwraca rezultat sumowania tych wartości.
Ponieważ fib(5) otrzymuje argument większy od 3, funkcja fib() zostaje wywołana ponownie, tym razem z argumentami 3 i 4. Funkcja fib(4) wywołuje z kolei funkcje fib(2) oraz fib(3).
Wypisywane komunikaty pokazują te wywołania oraz zwracane wartości. Skompiluj, zbuduj i uruchom ten program, podając wartość 1, następnie 2, potem 3 i tak aż do 6. Uruchamiając program uważnie śledź komunikaty.
To doskonała okazja, aby rozpocząć samodzielne eksperymenty z debuggerem. Umieść punkt przerwania w linii 21., po czym obserwuj każde wywołanie funkcji fib(), śledząc wartość n w każdym rekurencyjnym wywołaniu tej funkcji.
W programach C++ rekurencja nie jest używana zbyt często, ale może stanowić wydajne i eleganckie narzędzie rozwiązywania pewnych problemów.
Usunięto: wchodź wewnątrz (into)
Usunięto: go
Usunięto: a

UWAGA Rekurencja jest elementem programowania zaawansowanego. Została tu zaprezentowana, ponieważ zrozumienie podstaw jej działania może okazać się przydatne, jednak nie przejmuj się zbytnio, jeśli nie zrozumiałeś w pełni wszystkich jej szczegółów.
Jak działają funkcje — rzut oka „pod maskę” Gdy wywołujesz daną funkcję, program przechodzi do tej funkcji, przekazywane są parametry i następuje wykonanie ciała funkcji. Gdy funkcja zakończy działanie, zwracana jest wartość (chyba, że zwracana jest wartość typu void) i sterowanie powraca do funkcji wywołującej.
Jak to się odbywa? Skąd kod wie, gdzie skoczyć? Gdzie są przechowywane przekazywane zmienne? Co się dzieje ze zmiennymi zadeklarowanymi w ciele funkcji? W jaki sposób jest przekazywana wartość zwracana przez funkcję? Skąd kod wie, w którym miejscu ma wznowić działanie po powrocie z funkcji?
Większość książek wprowadzających w zagadnienia programowania nie próbuje odpowiadać na te pytania, ale bez zrozumienia tych mechanizmów pisanie programów wciąż pozostaje „programowaniem z elementami magii.” Wyjaśnienie zasad działania funkcji wymaga poruszenia tematu pamięci komputera.
Poziomy abstrakcji Jednym z największych wyzwań dla początkujących programistów jest konieczność posługiwania się wieloma poziomami abstrakcji. Oczywiście, komputery są jedynie urządzeniami elektronicznymi. Nie mają pojęcia o oknach czy menu, nie znają programów ani instrukcji, a nawet nie wiedzą nic o zerach i jedynkach. W rzeczywistości jedyne zmiany, jakie zauważają, to zmiany napięcia mierzonego w odpowiednich punktach układów elektronicznych. Nawet to jest dla nich pewną abstrakcją: w rzeczywistości elektryczność jest tylko wygodną intelektualną koncepcją dla zaprezentowania działania cząstek subatomowych, które z kolei są abstrakcją dla czegoś innego (!).
Bardzo niewielu programistów zadaje sobie trud zejścia poniżej poziomu wartości w pamięci RAM. W końcu nie trzeba znać fizyki cząsteczkowej, aby prowadzić samochód, robić kanapki czy kopać piłkę; nie trzeba też znać się na elektronice, aby programować komputer.
Konieczne jest jednak zrozumienie, w jaki sposób jest zorganizowana pamięć komputera. Bez wyraźnego obrazu tego, gdzie znajdują się tworzone zmienne i w jaki sposób przekazywane są wartości między funkcjami, programowanie nadal pozostanie tajemnicą.
Podział pamięci Gdy uruchamiasz program, system operacyjny (taki jak DOS, Unix czy Microsoft Windows) przygotowuje różne obszary pamięci (w zależności od wymagań kompilatora). Jako programista C++, często będziesz miał do czynienia z globalną przestrzenią nazw, stertą, rejestrami, przestrzenią kodu oraz stosem.
Usunięto: Dzielenie
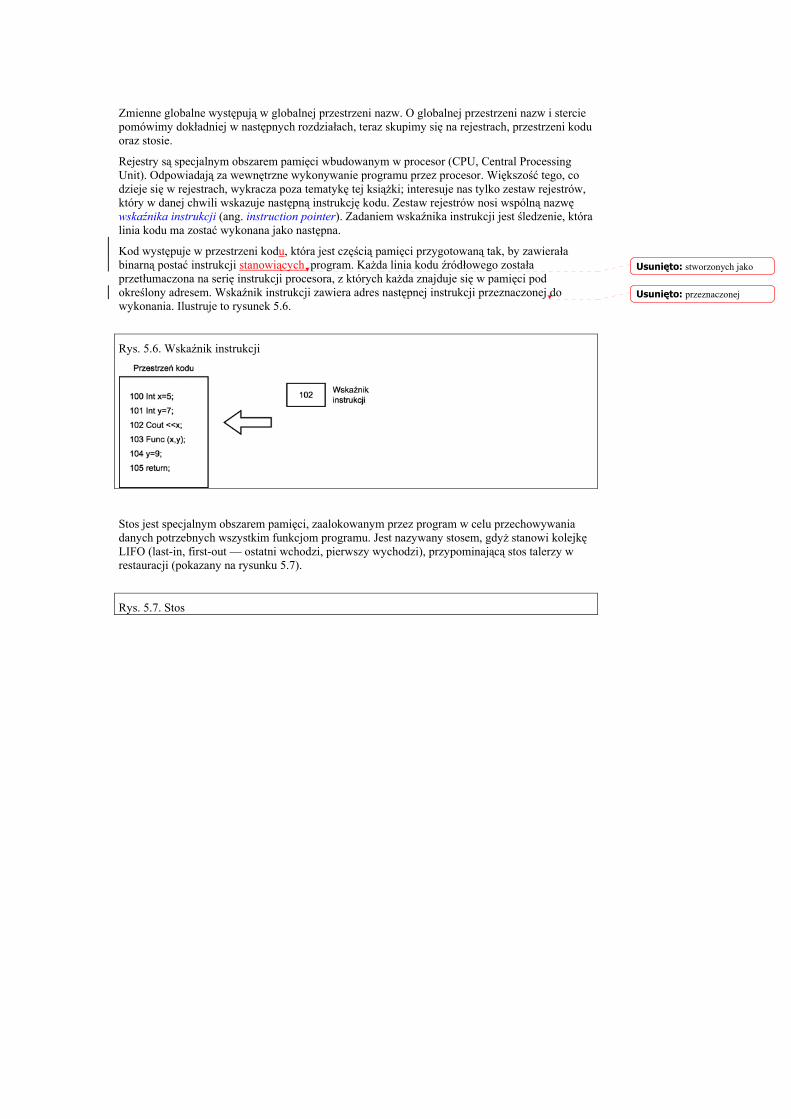
Zmienne globalne występują w globalnej przestrzeni nazw. O globalnej przestrzeni nazw i stercie pomówimy dokładniej w następnych rozdziałach, teraz skupimy się na rejestrach, przestrzeni kodu oraz stosie.
Rejestry są specjalnym obszarem pamięci wbudowanym w procesor (CPU, Central Processing Unit). Odpowiadają za wewnętrzne wykonywanie programu przez procesor. Większość tego, co dzieje się w rejestrach, wykracza poza tematykę tej książki; interesuje nas tylko zestaw rejestrów, który w danej chwili wskazuje następną instrukcję kodu. Zestaw rejestrów nosi wspólną nazwę wskaźnika instrukcji (ang. instruction pointer). Zadaniem wskaźnika instrukcji jest śledzenie, która linia kodu ma zostać wykonana jako następna.
Kod występuje w przestrzeni kodu, która jest częścią pamięci przygotowaną tak, by zawierała binarną postać instrukcji stanowiących program. Każda linia kodu źródłowego została przetłumaczona na serię instrukcji procesora, z których każda znajduje się w pamięci pod określony adresem. Wskaźnik instrukcji zawiera adres następnej instrukcji przeznaczonej do wykonania. Ilustruje to rysunek 5.6.
Rys. 5.6. Wskaźnik instrukcji
Stos jest specjalnym obszarem pamięci, zaalokowanym przez program w celu przechowywania danych potrzebnych wszystkim funkcjom programu. Jest nazywany stosem, gdyż stanowi kolejkę LIFO (last-in, first-out — ostatni wchodzi, pierwszy wychodzi), przypominającą stos talerzy w restauracji (pokazany na rysunku 5.7).
Rys. 5.7. Stos
Usunięto: stworzonych jako
Usunięto: przeznaczonej
„Ostatni wchodzi, pierwszy wychodzi” – oznacza, że to, co zostanie umieszczone na stosie jako ostatnie, zostanie z niego zdjęte jako pierwsze. Większość kolejek przypomina kolejki w sklepie: pierwsza osoba w kolejce jest obsługiwana jako pierwsza. Stos przypomina stos monet: gdy ułożysz na stole dziesięć monet, jedna na drugiej, a następnie część z nich zabierasz, zabierasz najpierw te monety, które ułożyłeś jako ostatnie.
Gdy dane są umieszczane (ang. push) na stosie, stos rośnie; gdy są zdejmowane ze stosu (ang. pop), stos maleje. Nie ma możliwości wyjęcia talerza ze stosu bez zdjęcia wszystkich talerzy, które zostały umieszczone na nim później.
Stos talerzy jest najczęściej przedstawianą analogią. Jest ona poprawna, ale działanie pamięci wygląda nieco inaczej. Bardziej odpowiednie jest wyobrażenie sobie szeregu pojemników ułożonych jeden na drugim. Szczytem stosu jest ten pojemnik, na który w danej chwili wskazuje wskaźnik stosu (ang. stack pointer), będący jeszcze jednym rejestrem.
Każdy z pojemników ma kolejny adres, a jeden z tych adresów jest przechowywany w rejestrze wskaźnika stosu. Wszystko, co znajduje się poniżej tego magicznego adresu, znanego jako szczyt stosu, jest uważane za zawartość stosu. Wszystko, co znajduje się powyżej szczytu stosu, jest uważane za znajdujące się poza stosem, a co za tym idzie, niepoprawne. Ilustruje to rysunek 5.8.
Rys. 5.8. Wskaźnik stosu

Gdy odkładasz daną na stos, jest ona umieszczana w pojemniku znajdującym się powyżej wskaźnika stosu, a następnie wskaźnik stosu jest przesuwany o jeden pojemnik w górę. Gdy zdejmujesz daną ze stosu, jedyną czynnością odbywającą się w rzeczywistości jest przesunięcie wskaźnika stosu o jeden pojemnik w dół. Pokazuje to rysunek 5.9.
Rys. 5.9. Przesunięcie wskaźnika stosu
Dane powyżej wskaźnika stosu (czyli poza stosem) mogą (ale nie muszą) ulec zmianie w dowolnej chwili. Wartości te nazywamy „odpadami” (aby lepiej uświadomić sobie, że nie powinniśmy na nie liczyć).

Stos i funkcje Poniżej przedstawiono przybliżony opis tego, co się dzieje, gdy program przechodzi do wykonania funkcji. (Poszczególne rozwiązania różnią się, w zależności od systemu operacyjnego i kompilatora).
1. Zwiększany jest adres we wskaźniku instrukcji i wskazuje on instrukcję następną po tej, która wywołuje funkcję. Ten adres jest następnie umieszczany na stosie; stanowi adres powrotu z funkcji.
2. Na stosie jest tworzone miejsce dla zadeklarowanego typu wartości zwracanej przez funkcję. Gdy zwracany typ jest zadeklarowany jako int, w przypadku systemu z dwubajtowymi liczbami całkowitymi, na stos są odkładane dwa kolejne bajty, ale nie jest w nich umieszczana żadna wartość („odpady”, które się w nich dotąd znajdowały, pozostają tam nadal).
3. Do wskaźnika instrukcji jest ładowany adres wywoływanej funkcji (ten adres jest zawarty w kodzie aktualnie wykonywanej instrukcji wywołania funkcji), dzięki czemu następna wykonywana instrukcja będzie już instrukcją funkcji.
4. Odczytywany jest adres bieżącego szczytu stosu, następnie zostaje on umieszczony w specjalnym wskaźniku nazywanym ramką stosu (ang. stack frame). Wszystko, co zostanie umieszczone na stosie od tego momentu, jest uważane za „lokalne” dla funkcji.
5. Na stosie umieszczane są argumenty funkcji.
6. Wykonywana jest instrukcja wskazywana przez wskaźnik instrukcji (następuje wykonanie pierwszej instrukcji w funkcji).
7. W trakcie ich definiowania, lokalne zmienne zostają umieszczane na stosie.
Gdy funkcja jest gotowa do powrotu, zwracana wartość jest umieszczana w miejscu stosu zarezerwowanym w kroku 2. Następnie stos jest zwijany (tzn. wskaźnik stosu przesuwa się) aż do wskaźnika ramki stosu, co oznacza odrzucenie wszystkich lokalnych zmiennych i argumentów funkcji.
Zwracana wartość jest zdejmowana ze stosu i przypisywana jako wartość instrukcji wywołania funkcji. Następnie ze stosu zdejmowana jest wartość odłożona w kroku 1.; wartość ta zostaje umieszczona we wskaźniku instrukcji. Program, posiadając wartość zwróconą przez funkcję, wznawia działanie od instrukcji następującej bezpośrednio po instrukcji wywołania funkcji.
Niektóre ze szczegółów tego procesu zmieniają się w zależności od kompilatora i komputera, ale podstawowy jego przebieg jest niezmienny. Gdy wywołujesz funkcję, na stosie odkładany jest adres powrotu i argumenty. W trakcie działania tych funkcji, na stos są odkładane zmienne lokalne. Gdy funkcja wraca, ze stosu zostaje usunięte wszystko.
W następnych rozdziałach poznamy inne miejsca pamięci, używane do przechowywania danych, które muszą istnieć dłużej niż czas życia funkcji.
Usunięto: aniu
Usunięto: i

Rozdział 6. Programowanie zorientowane obiektowo Klasy rozszerzają wbudowane w C++ możliwości, ułatwiające rozwiązywanie złożonych, „rzeczywistych” problemów.
Z tego rozdziału dowiesz się:
• czym są klasy i obiekty,
• jak definiować nową klasę oraz tworzyć obiekty tej klasy,
• czym są funkcje i dane składowe,
• czym są konstruktory i jak z nich korzystać.
Czy C++ jest zorientowane obiektowo? Język C++ stanowi pomost pomiędzy programowaniem zorientowanym obiektowo a językiem C, najpopularniejszym językiem programowania aplikacji komercyjnych. Celem jego autorów było stworzenie obiektowo zorientowanego języka dla tej szybkiej i efektywnej platformy.
Język C jest etapem pośrednim pomiędzy wysokopoziomowymi językami aplikacji „firmowych”, takimi jak COBOL, a niskopoziomowym, wysokowydajnym, lecz trudnym do użycia asemblerem. C wymusza programowanie „strukturalne”, w którym poszczególne zagadnienia są dzielone na mniejsze jednostki powtarzalnych działań, zwanych funkcjami.
Programy, które piszemy na początku dwudziestego pierwszego wieku, są dużo bardziej złożone niż te, które były pisane pod koniec wieku dwudziestego. Programy stworzone w językach proceduralnych są trudne w zarządzaniu i konserwacji, a ich rozbudowa jest niemożliwa. Graficzne interfejsy użytkownika, Internet, telefonia cyfrowa i bezprzewodowa oraz wiele innych technologii, znacznie zwiększyły poziom skomplikowania nowych projektów, a wymagania konsumentów dotyczące jakości interfejsu użytkownika wzrosły.
Usunięto: u

W obliczu rosnących wymagań, programiści bacznie przyjrzeli się przemysłowi informatycznemu. Wnioski, do jakich doszli, były co najmniej przygnębiające. Oprogramowanie powstawało z opóźnieniem, posiadało błędy, działało niestabilnie i było drogie. Projekty regularnie przekraczały budżet i trafiały na rynek z opóźnieniem. Koszt obsługi tych projektów był znaczny, zmarnowano ogromne ilości pieniędzy.
Jedynym wyjściem z tej sytuacji okazało się tworzenie oprogramowania zorientowanego obiektowo. Języki programowania obiektowego stworzyły silne więzy pomiędzy strukturami danych a metodami manipulowania tymi danymi. A co najważniejsze, w programowaniu zorientowanym obiektowo nie już musisz myśleć o strukturach danych i manipulujących nimi funkcjami; myślisz o obiektach. Rzeczach.
Świat jest wypełniony przedmiotami: samochodami, psami, drzewami, chmurami, kwiatami. Rzeczy. Każda rzecz ma charakterystykę (szybki, przyjazny, brązowy, puszysty, ładny). Większość rzeczy cechuje jakieś zachowanie (ruch, szczekanie, wzrost, deszcz, uwiąd). Nie myślimy o danych psa i o tym, jak moglibyśmy nimi manipulować — myślimy o psie jako o rzeczy: do czego jest podobny i co robi.
Tworzenie nowych typów Poznałeś już kilka typów zmiennych, m.in. liczby całkowite i znaki. Typ zmiennej dostarcza nam kilka informacji o niej. Na przykład, jeśli zadeklarujesz zmienne Height (wysokość) i Width (szerokość) jako liczby całkowite typu unsigned short int, wiesz, że w każdej z nich możesz przechować wartość z przedziału od 0 do 65 535 (przy założeniu że typ unsigned short int zajmuje dwa bajty pamięci). Są to liczby całkowite bez znaku; próba przechowania w nich czegokolwiek innego powoduje błąd. W zmiennej typu unsigned short nie możesz umieścić swojego imienia, nie powinieneś nawet próbować.
Deklarując te zmienne jako unsigned short int, wiesz, że możesz dodać do siebie wysokość i szerokość oraz przypisać tę wartość innej zmiennej.
Typ zmiennych informuje:
• o ich rozmiarze w pamięci,
• jaki rodzaj informacji mogą zawierać,
• jakie działania można na nich wykonywać.
W tradycyjnych językach, takich jak C, typy były wbudowane w język. W C++ programista może rozszerzyć język, tworząc potrzebne mu typy, zaś każdy z tych nowych typów może być w pełni funkcjonalny i dysponować tą samą siłą, co typy wbudowane.
Po co tworzyć nowy typ? Programy są zwykle pisane w celu rozwiązania jakiegoś realnego problemu, takiego jak prowadzenie rejestru pracowników czy symulacja działania systemu grzewczego. Choć istnieje możliwość rozwiązywania tych problemów za pomocą programów napisanych wyłącznie przy użyciu liczb całkowitych i znaków, jednak w przypadku większych, bardziej rozbudowanych
Usunięto: 6
problemów, dużo łatwiej jest stworzyć reprezentacje obiektów, o których się mówi. Innymi słowy, symulowanie działania systemu grzewczego będzie łatwiejsze, gdy stworzymy zmienne reprezentujące pomieszczenia, czujniki ciepła, termostaty i bojlery. Im bardziej te zmienne odpowiadają rzeczywistości, tym łatwiejsze jest napisanie programu.
Klasy i składowe Nowy typ zmiennych tworzy się, deklarując klasę. Klasa jest właściwie grupą zmiennych — często o różnych typach — skojarzonych z zestawem odnoszących się do nich funkcji.
Jedną z możliwości myślenia o samochodzie jest potraktowanie go jako zbioru kół, drzwi, foteli, okien, itd. Inna możliwość to wyobrażenie sobie, co samochód może zrobić: jeździć, przyspieszać, zwalniać, zatrzymywać się, parkować, itd. Klasa umożliwia kapsułkowanie, czyli upakowanie, tych różnych części oraz różnych działań w jeden zbiór, który jest nazywana obiektem.
Upakowanie wszystkiego, co wiesz o samochodzie, w jedną klasę przynosi programiście liczne korzyści. Wszystko jest na miejscu, ułatwia to odwoływanie się, kopiowanie i manipulowanie danymi. Klienty twojej klasy — tj. te części programu, które z niej korzystają — mogą używać twojego obiektu bez zastanawiania się, co znajduje się w środku i jak on działa.
Klasa może składać się z dowolnej kombinacji zmiennych prostych oraz zmiennych innych klas. Zmienna wewnątrz klasy jest nazywana zmienną składową lub daną składową. Klasa Car (samochód) może posiadać składowe reprezentujące siedzenia, typ radia, opony, itd.
Zmienne składowe są zmiennymi w danej klasie. Stanowią one część klasy, tak jak koła i silnik stanowią część samochodu.
Funkcje w danej klasie zwykle manipulują zmiennymi składowymi. Funkcje klasy nazywa się funkcjami składowymi lub metodami klasy. Metodami klasy Car mogą być Start() (uruchom) oraz Brake() (hamuj). Klasa Cat (kot) może posiadać zmienne składowe, reprezentujące wiek i wagę; jej metodami mogą być Sleep() (śpij), Meow() (miaucz) czy ChaseMice() (łap myszy).
Funkcje składowe (metody) są funkcjami w klasie. Podobnie jak zmienne składowe, stanowią część klasy i określają, co dana klasa może zrobić.
Deklarowanie klasy Aby zadeklarować klasę, użyj słowa kluczowego class, po którym następuje otwierający nawias klamrowy, a następnie lista danych składowych i metod tej klasy. Deklaracja kończy się zamykającym nawiasem klamrowym i średnikiem. Oto deklaracja klasy o nazwie Cat (kot):
class Cat { unsigned int itsAge; unsigned int itsWeight; void Meow(); };
Usunięto: połączonych
Usunięto: powiązanych

Zadeklarowanie takiej klasy nie powoduje zaalokowania pamięci dla obiektu Cat. Informuje jedynie kompilator, czym jest typ Cat, jakie dane zawiera (itsAge — jego wiek oraz itsWeight — jego waga) oraz co może robić (Meow() — miaucz). Informuje także kompilator, jak duża jest zmienna typu Cat — to jest, jak dużo miejsca w pamięci ma przygotować w przypadku tworzenia zmiennej typu Cat. W tym przykładzie, o ile typ int ma cztery bajty, zmienna typu Cat zajmuje osiem bajtów: cztery bajty dla zmiennej itsAge i cztery dla zmiennej itsWeight. Funkcja Meow() nie zajmuje miejsca, gdyż dla funkcji składowych (metod) miejsce nie jest rezerwowane.
Kilka słów o konwencji nazw Jako programista, musisz nazwać wszystkie swoje zmienne składowe, funkcje składowe oraz klasy. Jak przeczytałeś w rozdziale 3., „Stałe i zmienne,” nazwy te powinny być zrozumiałe i znaczące. Dobrymi nazwami klas mogą być wspomniana Cat, Rectangle (prostokąt) czy Employee (pracownik). Meow(), ChaseMice() czy StopEngine() (zatrzymaj silnik) również są dobrymi nazwami funkcji, gdyż informują, co robią te funkcje. Wielu programistów nadaje nazwom zmiennych składowych przedrostek „its” (jego), tak jak w zmiennych itsAge, itsWeight czy itsSpeed (jego szybkość). Pomaga to w odróżnieniu zmiennych składowych od innych zmiennych.
Niektórzy programiści wolą przedrostek „my” (mój), tak jak w nazwach myAge, myWeight czy mySpeed. Jeszcze inni używają po prostu litery m (od słowa member — składowa), czasem wraz ze znakiem podkreślenia (_): mAge i m_age, mWeight i m_weight czy mSpeed i m_speed.
Język C++ uwzględnia wielkość liter, dlatego wszystkie nazwy klas powinny przestrzegać tej samej konwencji. Dzięki temu nigdy nie będziesz musiał sprawdzać pisowni nazwy klasy (czy to było Rectangle, rectangle czy RECTANGLE?).
Niektórzy programiści lubią poprzedzić każdą nazwę klasy określoną literą — na przykład cCat czy cPerson — podczas, gdy inni używają wyłącznie dużych lub małych liter. Ja sam korzystam z konwencji, w której wszystkie nazwy klas rozpoczynają się od dużej litery, tak jak Cat czy Person (osoba).
Wielu programistów rozpoczyna wszystkie nazwy funkcji od dużej litery, zaś wszystkie nazwy zmiennych — od małej. Słowa zwykle rozdzielane są znakiem podkreślenia — tak jak w Chase_Mice — lub poprzez zastosowanie dużej litery dla każdego słowa — na przykład ChaseMice czy DrawCircle (rysuj okrąg).
Ważne jest, by wybrać określony styl i trzymać się go w każdym programie. Z czasem rozwiniesz swój styl nie tylko na konwencje nazw, ale także na wcięcia, wyrównanie nawiasów klamrowych oraz styl komentarzy.
UWAGA W firmach programistycznych powszechne jest określenie standardu wielu elementów stylu zapisu kodu źródłowego. Sprawia on, że wszyscy programiści mogą łatwo odczytywać wzajemnie swój kod.
Definiowanie obiektu Definiowanie obiektu nowego typu przypomina definiowanie zmiennej całkowitej:
Usunięto: a
unsigned int GrossWeight; // definicja zmiennej typu unsigned int Cat Mruczek; // definicja zmiennej typu Cat
Ten kod definiuje zmienną o nazwie GrossWeight (łączna waga), której typem jest unsigned int. Oprócz tego definiuje zmienną o nazwie Mruczek, która jest obiektem klasy (typu) Cat.
Klasy a obiekty Nigdy nie karmi się definicji kota, lecz konkretnego kota. Należy dokonać rozróżnienia pomiędzy ideą kota a konkretnym kotem, który właśnie ociera się o twoje nogi. C++ również dokonuje rozróżnienia pomiędzy klasą Cat, będącą ideą kota, a poszczególnymi obiektami typu Cat. Tak więc Mruczek jest obiektem typu Cat, tak jak GrossWeight jest zmienną typu unsigned int.
Obiekt jest indywidualnym egzemplarzem klasy.
Dostęp do składowych klasy Gdy zdefiniujesz już faktyczny obiekt Cat — na przykład Mruczek — w celu uzyskania dostępu do jego składowych możesz użyć operatora kropki (.). Aby zmiennej składowej itsWeight obiektu Mruczek przypisać wartość 50, powinieneś napisać:
Mruczek.itsWeight = 50;
Aby wywołać funkcję Meow(), możesz napisać:
Mruczek.Meow();
Gdy używasz metody klasy, oznacza to, że wywołujesz tę metodę. W tym przykładzie wywołałeś metodę Meow() obiektu Mruczek.
Przypisywać należy obiektom, nie klasom W C++ nie przypisuje się wartości typom; przypisuje się je zmiennym. Na przykład, nie można napisać:
int = 5; // źle
Kompilator uzna to za błąd, gdyż nie można przypisać wartości pięć typowi całkowitemu. Zamiast tego musisz zdefiniować zmienną typu całkowitego i przypisać jej wartość 5. Na przykład:

int x ; // definicja zmiennej typu int x = 5; // ustawienie wartości zmiennej x na 5
Jest to skrócony zapis stwierdzenia: „Przypisz wartość 5 zmiennej x, która jest zmienną typu int.” Nie można również napisać:
Cat.itsAge = 5; // źle
Kompilator uzna to za błąd, gdyż nie możesz przypisać wartości 5 do elementu itsAge klasy Cat. Zamiast tego musisz zdefiniować egzemplarz obiektu klasy Cat i dopiero wtedy przypisać wartość jego składowej. Na przykład:
Cat Mruczek; // podobnie jak int x; Mruczek.itsAge = 5; // podobnie jak x = 5;
Czego nie zadeklarujesz, tego klasa nie będzie miała Przeprowadź taki eksperyment: podejdź do trzylatka i pokaż mu kota. Następnie powiedz: To jest Mruczek. Mruczek zna sztuczkę. Mruczek, zaszczekaj! Dziecko roześmieje się i powie: „Nie, głuptasie, koty nie szczekają!”
Jeśli napisałeś:
Cat Mruczek; // tworzy obiekt Cat o nazwie Mruczek Mruczek.Bark(); // nakazuje Mruczkowi szczekać
Kompilator wypisze: „Nie, głuptasie, koty (cats) nie szczekają!” (Być może w twoim kompilatorze ten komunikat będzie brzmiał nieco inaczej.) Kompilator wie, że Mruczek nie może szczekać, gdyż klasa Cat nie posiada metody Bark() (szczekaj). Kompilator nie pozwoli Mruczkowi nawet zamiauczeć, jeśli nie zdefiniujesz dla niego funkcji Meow() (miaucz).
TAK NIE
Do deklarowania klasy używaj słowa kluczowego class.
W celu uzyskania dostępu do zmiennych i funkcji składowych klasy używaj operatora kropki (.).
Nie myl deklaracji z definicją. Deklaracja mówi czym jest klasa, a definicja przygotowuje pamięć dla obiektu.
Nie myl klasy z obiektem.
Nie przypisuj klasie wartości. Wartości przypisuj danym składowym obiektu.

Prywatne i publiczne W deklaracji klasy używanych jest także kilka innych słów kluczowych. Dwa najważniejsze z nich to: public (publiczny) i private (prywatny).
Wszystkie składowe klasy — dane i metody — są domyślnie prywatne. Prywatne składowe mogą być używane tylko przez metody należące do danej klasy. Składowe publiczne są dostępne dla innych funkcji i klas. To rozróżnienie jest ważne, choć na początku może sprawiać kłopot. Aby to lepiej wyjaśnić, spójrzmy na poprzedni przykład:
class Cat { unsigned int itsAge; unsigned int itsWeight; viod Meow(); };
W tej deklaracji, składowe itsAge, itsWeight oraz Meow() są prywatne, gdyż wszystkie składowe klasy są prywatne domyślnie. Oznacza to, że dopóki nie postanowisz inaczej, pozostaną one prywatne.
Jeśli jednak w funkcji main() napiszesz na przykład:
Cat Bobas; Bobas.itsAge = 5; // błąd! nie można używać prywatnych danych!
kompilator uzna to za błąd. We wcześniejszej deklaracji powiedziałeś kompilatorowi, że składowych itsAge, itsWeight oraz Meow() będziesz używał tylko w funkcjach składowych klasy Cat. W powyższym fragmencie kodu próbujesz odwołać się do zmiennej składowej obiektu Bobas spoza metody klasy Cat. To, że Bobas jest obiektem klasy Cat, nie oznacza, że możesz korzystać z tych elementów obiektu Bobas, które są prywatne.
Właśnie to jest źródłem niekończących się kłopotów początkujących programistów C++. Już słyszę, jak narzekasz: „Hej! Właśnie napisałem, że Bobas jest kotem, tj. obiektem klasy Cat. Dlaczego Bobas nie ma dostępu do swojego własnego wieku?” Odpowiedź brzmi: Bobas ma dostęp, ale ty nie masz. Bobas, w swoich własnych metodach, ma dostęp do wszystkich swoich składowych, zarówno publicznych, jak i prywatnych. Nawet, jeśli to ty tworzysz obiekt klasy Cat, nie możesz przeglądać ani zmieniać tych jego składowych, które są prywatne.
Aby mieć dostęp do składowych obiektu Cat, powinieneś napisać:
class Cat { public:
Usunięto: ę

unsigned int itsAge; unsigned int itsWeight; void Meow(); };
Teraz składowe itsAge, itsWeight oraz Meow() są publiczne. Bobas.itsAge = 5; kompiluje się bez problemów.
Listing 6.1 przedstawia deklarację klasy Cat z publicznymi zmiennymi składowymi.
Listing 6.1. Dostęp do publicznych składowych w prostej klasie 0: // Demonstruje deklaracje klasy oraz 1: // definicje obiektu tej klasy. 2: 3: #include <iostream> 4: 5: class Cat // deklaruje klasę Cat (kot) 6: { 7: public: // następujące po tym składowe są publiczne 8: int itsAge; // zmienna składowa 9: int itsWeight; // zmienna składowa 10: }; // zwróć uwagę na średnik 11: 12: 13: int main() 14: { 15: Cat Mruczek; 16: Mruczek.itsAge = 5; // przypisanie do zmiennej składowej 17: std::cout << "Mruczek jest kotem i ma " ; 18: std::cout << Mruczek.itsAge << " lat.\n"; 19: return 0; 20: }
Wynik Mruczek jest kotem i ma 5 lat.
Analiza
Linia 5. zawiera słowo kluczowe class. Informuje ono kompilator, że następuje po nim deklaracja klasy. Nazwa nowej klasy następuje bezpośrednio po słowie kluczowym class. W tym przypadku nazwą klasy jest Cat (kot).
Ciało deklaracji rozpoczyna się w linii 6. od otwierającego nawiasu klamrowego i kończy się zamykającym nawiasem klamrowym i średnikiem w linii 10. Linia 7. zawiera słowo kluczowe public, które wskazuje, że wszystko, co po nim nastąpi, będzie publiczne, aż do natrafienia na słowo kluczowe private lub koniec deklaracji klasy.
Linie 8. i 9. zawierają deklaracje składowych klasy, itsAge (jego wiek) oraz itsWeight (jego waga).
W linii 13. rozpoczyna się funkcja main(). W linii 15. Mruczek jest definiowany jako egzemplarz klasy Cat — tj. jako obiekt klasy Cat. W linii 16. wiek Mruczka jest ustawiany na 5. W liniach 17. i 18. zmienna składowa itsAge zostaje użyta do wypisania informacji o kocie Mruczku.
UWAGA Spróbuj wykomentować linię 7., po czym skompiluj program ponownie. W linii 16. wystąpi błąd, gdyż zmienna składowa itsAge nie będzie już składową publiczną. Domyślnie, wszystkie składowe klasy są prywatne.
Oznaczanie danych składowych jako prywatnych Powinieneś przyjąć jako ogólną regułę, że dane składowe klasy należy utrzymywać jako prywatne. W związku z tym musisz stworzyć publiczne funkcje składowe, zwane funkcjami dostępowymi lub akcesorami. Funkcje te umożliwią odczyt zmiennych składowych i przypisywanie im wartości. Te funkcje dostępowe (akcesory) są funkcjami składowymi, używanymi przez inne części programu w celu odczytywania i ustawiania prywatnych zmiennych składowych.
Publiczny akcesor jest funkcją składową klasy, używaną albo do odczytu wartości prywatnej zmiennej składowej klasy, albo do ustawiania wartości tej zmiennej.
Dlaczego miałbyś utrudniać sobie życie dodatkowym poziomem pośredniego dostępu? Łatwiej niż posługiwać się akcesorami jest używać danych,.
Akcesory umożliwiają oddzielenie szczegółów przechowywania danych klasy od szczegółów jej używania. Dzięki temu możesz zmieniać sposób przechowywania danych klasy bez konieczności przepisywania funkcji, które z tych danych korzystają.
Jeśli funkcja, która chce poznać wiek kota, odwoła się bezpośrednio do zmiennej itsAge klasy Cat, będzie musiała zostać przepisana, jeżeli ty, jako autor klasy Cat, zdecydujesz się na zmianę sposobu przechowywania tej zmiennej. Jednak posiadając funkcję składową GetAge() (pobierz wiek), klasa Cat może łatwo zwrócić właściwą wartość bez względu na to, w jaki sposób przechowywany będzie wiek. Funkcja wywołująca nie musi wiedzieć, czy jest on przechowywany jako zmienna typu unsigned int czy long, lub czy wiek jest obliczany w miarę potrzeb.
Ta technika ułatwia zapanowanie nad programem. Przedłuża istnienie kodu, gdyż zmiany projektowe nie powodują, że program staje się przestarzały.
Listing 6.2 przedstawia klasę Cat zmodyfikowaną tak, by zawierała prywatne dane składowe i publiczne akcesory. Zwróć uwagę, że ten listing przedstawia wyłącznie deklarację klasy, nie ma w nim kodu wykonywalnego.
Listing 6.2. Klasa z akcesorami 0: // Deklaracja klasy Cat 1: // Dane składowe są prywatne, publiczne akcesory pośredniczą 2: // w ustawianiu i odczytywaniu wartości składowych prywatnych 3: 4: class Cat 5: { 6: public: 7: // publiczne akcesory 8: unsigned int GetAge(); 9: void SetAge(unsigned int Age); 10: 11: unsigned int GetWeight(); 12: void SetWeight(unsigned int Weight); 13: 14: // publiczna funkcja składowa 15: void Meow();
Usunięto: A
Usunięto: zmienną

16: 17: // prywatne dane składowe 18: private: 19: unsigned int itsAge; 20: unsigned int itsWeight; 21: 22: };
Analiza
Ta klasa posiada pięć metod publicznych. Linie 8. i 9. zawierają akcesory dla składowej itsAge. Linie 11. i 12. zawierają akcesory dla składowej itsWeight. Te akcesory ustawiają zmienne składowe i zwracają ich wartości.
W linii 15. jest zadeklarowana publiczna funkcja składowa Meow(). Ta funkcja nie jest akcesorem. Nie zwraca wartości ani ich nie ustawia; wykonuje inną usługę dla klasy – wypisuje słowo Miau.
Zmienne składowe są zadeklarowane w liniach 19. i 20.
Aby ustawić wiek Mruczka, powinieneś przekazać wartość metodzie SetAge() (ustaw wiek), na przykład:
Cat Mruczek; Mruczek.SetAge(5); // ustawia wiek Mruczka // używając publicznego akcesora
Prywatność a ochrona Zadeklarowanie metod lub danych jako prywatnych umożliwia kompilatorowi wyszukanie w programach pomyłek, zanim staną się one błędami. Każdy szanujący się programista potrafi znaleźć sposób na obejście prywatności składowych. Stroustrup, autor języka C++, stwierdza że „...mechanizmy ochrony z poziomu języka chronią przed pomyłką, a nie przed świadomym oszustwem.” (WNT, 1995).
Słowo kluczowe class
Składnia słowa kluczowego class jest następująca:
class nazwa_klasy { // słowa kluczowe kontroli dostępu // zadeklarowane zmienne i składowe klasy };
Słowo kluczowe class służy do deklarowania nowych typów. Klasa stanowi zbiór danych składowych klasy, które są zmiennymi różnych typów, także innych klas. Klasa zawiera także funkcje klasy — tzw. metody — które są funkcjami używanymi do manipulowania danymi w danej klasie i wykonywania innych usług dla klasy.
Usunięto: danych

Obiekty nowego typu definiuje się w taki sam sposób, w jaki definiuje się inne zmienne. Należy określić typ (klasę), a po nim nazwę zmiennej (obiektu). Do uzyskania dostępu do funkcji i danych klasy służy operator kropki (.).
Słowa kluczowe kontroli dostępu określają, które sekcje klasy są prywatne, a które publiczne. Domyślnie wszystkie składowe klasy są prywatne. Każde słowo kluczowe zmienia kontrolę dostępu od danego miejsca aż do końca klasy, lub kontrolę wystąpienia następnego słowa kluczowego kontroli dostępu. Deklaracja klasy kończy się zamykającym nawiasem klamrowym i średnikiem.
Przykład 1
class Cat { public: unsigned int Age; unsigned int Weight; void Meow(); }; Cat Mruczek; Mruczek.Age = 8; Mruczek.Weight = 18; Mruczek.Meow();
Przykład 2
class Car { public: // pięć następnych składowych jest publicznych void Start(); void Accelerate(); void Brake(); void SetYear(int year); int GetYear(); private: // pozostała część jest prywatna int Year; char Model [255]; }; // koniec deklaracji klasy Car OldFaithful; // tworzy egzemplarz klasy int bought; // lokalna zmienna typu int OldFaithful.SetYear(84); // ustawia składową Year na 84 bought = OldFaithful.GetYear(); // ustawia zmienną bought na 84 OldFaithful.Start(); //wywołuje metodę Start
TAK NIE
Deklaruj zmienne składowe jako prywatne.
Używaj publicznych akcesorów, czyli publicznych funkcji dostępowych.
Nie używaj prywatnych zmiennych składowych klasy poza tą klasą. Usunięto: .
Odwołuj się do prywatnych zmiennych składowych z funkcji składowych klasy.
Implementowanie metod klasy Akcesory stanowią publiczny interfejs do prywatnych danych klasy. Każdy akcesor musi posiadać, wraz z innymi zadeklarowanymi metodami klasy, implementację. Implementacja jest nazywana definicją funkcji.
Definicja funkcji składowej rozpoczyna się od nazwy klasy, po której występują dwa dwukropki, nazwa funkcji i jej parametry. Listing 6.3 przedstawia pełną deklarację prostej klasy Cat, wraz z implementacją jej akcesorów i jednej ogólnej funkcji tej klasy.
Listing 6.3. Implementacja metod prostej klasy 0: // Demonstruje deklarowanie klasy oraz 1: // definiowanie jej metod 2: 3: #include <iostream> // dla cout 4: 5: class Cat // początek deklaracji klasy 6: { 7: public: // początek sekcji publicznej 8: int GetAge(); // akcesor 9: void SetAge (int age); // akcesor 10: void Meow(); // ogólna funkcja 11: private: // początek sekcji prywatnej 12: int itsAge; // zmienna składowa 13: }; 14: 15: // GetAge, publiczny akcesor 16: // zwracający wartość składowej itsAge 17: int Cat::GetAge() 18: { 19: return itsAge; 20: } 21: 22: // definicja SetAge, akcesora 23: // publicznego 24: // ustawiającego składową itsAge 25: void Cat::SetAge(int age) 26: { 27: // ustawia zmienną składową itsAge 28: // zgodnie z wartością przekazaną w parametrze age 29: itsAge = age; 30: } 31: 32: // definicja metody Meow 33: // zwraca: void 34: // parametery: brak 35: // działanie: wypisuje na ekranie słowo "miauczy" 36: void Cat::Meow() 37: { 38: std::cout << "Miauczy.\n";
Usunięto: e
Usunięto: składowych
Usunięto: klasy

39: } 40: 41: // tworzy kota, ustawia jego wiek, sprawia, 42: // że miauczy, wypisuje jego wiek i ponownie miauczy. 43: int main() 44: { 45: Cat Mruczek; 46: Mruczek.SetAge(5); 47: Mruczek.Meow(); 48: std::cout << "Mruczek jest kotem i ma " ; 49: std::cout << Mruczek.GetAge() << " lat.\n"; 50: Mruczek.Meow(); 51: return 0; 52: }
Wynik Miauczy. Mruczek jest kotem i ma 5 lat. Miauczy.
Analiza
Linie od 5. do 13. zawierają definicję klasy Cat (kot). Linia 7. zawiera słowo kluczowe public, które informuje kompilator, że to, co po nim następuje, jest zestawem publicznych składowych. Linia 8. zawiera deklarację publicznego akcesora GetAge() (pobierz wiek). GetAge() zapewnia dostęp do prywatnej zmiennej składowej itsAge (jego wiek), zadeklarowanej w linii 12. Linia 9. zawiera publiczny akcesor SetAge() (ustaw wiek). Funkcja SetAge() otrzymuje parametr typu int, który następnie przypisuje składowej itsAge.
Linia 10. zawiera deklarację metody Meow() (miaucz). Funkcja Meow() nie jest akcesorem. Jest to ogólna metoda klasy, wypisująca na ekranie słowo „Miauczy.”
Linia 11. rozpoczyna sekcję prywatną, która obejmuje jedynie zadeklarowaną w linii 12. prywatną składową itsAge. Deklaracja klasy kończy się zamykającym nawiasem klamrowym i średnikiem.
Linie od 17. do 20. zawierają definicję składowej funkcji GetAge(). Ta metoda nie ma parametrów i zwraca wartość całkowitą. Zauważ, że ta metoda klasy zawiera nazwę klasy, dwa dwukropki oraz nazwę funkcji (linia 17.). Ta składnia informuje kompilator, że definiowana funkcja GetAge() jest właśnie tą funkcją, która została zadeklarowana w klasie Cat. Poza formatem tego nagłówka, definiowanie funkcji własnej GetAge() niczym nie różni się od definiowania innych (zwykłych) funkcji.
Funkcja GetAge() posiada tylko jedną linię i zwraca po prostu wartość zmiennej składowej itsAge. Zauważ, że funkcja main() nie ma dostępu do tej zmiennej składowej, gdyż jest ona prywatna dla klasy Cat. Funkcja main() ma za to dostęp do publicznej metody GetAge(). Ponieważ ta metoda jest składową klasy Cat, ma pełny dostęp do zmiennej itsAge. Dzięki temu może zwrócić funkcji main() wartość zmiennej itsAge.
Linia 25. zawiera definicję funkcji składowej SetAge(). Ta funkcja posiada parametr w postaci wartości całkowitej i przypisuje składowej itsAge jego wartość (linia 29.). Ponieważ jest składową klasy Cat, ma bezpośredni dostęp do jej zmiennych prywatnych i publicznych.
Usunięto: deklaracja
Usunięto: innych klas.

Linia 36. rozpoczyna definicję (czyli implementację) metody Meow() klasy Cat. Jest to jednoliniowa funkcja wypisująca na ekranie słowo „Miaucz”, zakończone znakiem nowej linii. Pamiętaj, że znak \n powoduje przejście do nowej linii.
Linia 43. rozpoczyna ciało funkcji main(), czyli właściwy program. W tym przypadku funkcja main() nie posiada argumentów. W linii 45., funkcja main() deklaruje obiekt Cat o nazwie Mruczek. W linii 46. zmiennej itsAge tego obiektu jest przypisywana wartość 5 (poprzez użycie akcesora SetAge()). Zauważ, że wywołanie tej metody następuje dzięki użyciu nazwy obiektu (Mruczek), po której zastosowano operator kropki (.) i nazwę metody (SetAge()). W podobny sposób wywoływane są wszystkie inne metody wszystkich klas.
Linia 47. wywołuje funkcję składową Meow(), zaś w linii 48. za pomocą akcesora GetAge(),wypisywany jest komunikat. Linia 50. ponownie wywołuje funkcję Meow().
Konstruktory i destruktory Istnieją dwa sposoby definiowania zmiennej całkowitej. Można zdefiniować zmienną, a następnie, w dalszej części programu, przypisać jej wartość. Na przykład:
int Weight; // definiujemy zmienną ... // tu inny kod Weight = 7; // przypisujemy jej wartość
Możemy też zdefiniować zmienną i jednocześnie zainicjalizować ją. Na przykład:
int Weight = 7; // definiujemy i inicjalizujemy wartością 7
Inicjalizacja łączy w sobie definiowanie zmiennej oraz początkowe przypisanie wartości. Nic nie stoi na przeszkodzie temu, by zmienić później wartość zmiennej. Inicjalizacja powoduje tylko że zmienna nigdy nie będzie pozbawiona sensownej wartości.
W jaki sposób zainicjalizować składowe klasy? Klasy posiadają specjalne funkcje składowe, zwane konstruktorami. Konstruktor (ang. constructor) może w razie potrzeby posiadać parametry, ale nie może zwracać wartości — nawet typu void. Konstruktor jest metodą klasy o takiej samej nazwie, jak nazwa klasy.
Gdy zadeklarujesz konstruktor, powinieneś także zadeklarować destruktor (ang. destructor). Konstruktor tworzy i inicjalizuje obiekt danej klasy, zaś destruktor porządkuje obiekt i zwalnia pamięć, którą mogłeś w niej zaalokować. Destruktor zawsze nosi nazwę klasy, poprzedzoną znakiem tyldy (~). Destruktory nie mają argumentów i nie zwracają wartości. Dlatego deklaracja destruktora klasy Cat ma następującą postać:
~Cat();
Usunięto: wypisuje
Usunięto: ą
Usunięto: ę
Domyślne konstruktory i destruktory Jeśli nie zadeklarujesz konstruktora lub destruktora, zrobi to za ciebie kompilator.
Istnieje wiele rodzajów konstruktorów; niektóre z nich posiadają argumenty, inne nie. Konstruktor, którego można wywołać bez żadnych argumentów, jest nazywany konstruktorem domyślnym. Istnieje tylko jeden rodzaj destruktora. On także nie posiada argumentów.
Jeśli nie stworzysz konstruktora lub destruktora, kompilator stworzy je za ciebie. Konstruktor dostarczany przez kompilator jest konstruktorem domyślnym — czyli konstruktorem bez argumentów. Taki konstruktor domyślny możesz stworzyć samodzielnie.
Stworzone przez kompilator domyślny konstruktor i destruktor nie mają żadnych argumentów, a na dodatek w ogóle nic nie robią!
Użycie domyślnego konstruktora Do czego może przydać się konstruktor, który nic nie robi? Jest to problem techniczny: wszystkie obiekty muszą być konstruowane i niszczone, dlatego w odpowiednich momentach wywoływane są te nic nie robiące funkcje. Aby móc zadeklarować obiekt bez przekazywania parametrów, na przykład
Cat Filemon; // Filemon nie ma parametrów
musisz posiadać konstruktor w postaci
Cat();
Gdy definiujesz obiekt klasy, wywoływany jest konstruktor. Gdyby konstruktor klasy Cat miał dwa parametry, mógłbyś zdefiniować obiekt Cat, pisząc
Cat Mruczek (5, 7);
Gdyby konstruktor miał jeden parametr, napisałbyś
Cat Mruczek (3);
W przypadku, gdy konstruktor nie ma żadnych parametrów (gdy jest konstruktorem domyślnym), możesz opuścić nawiasy i napisać
Cat Mruczek;
Usunięto: nie posiadający

Jest to wyjątek od reguły, zgodnie z którą wszystkie funkcje wymagają zastosowania nawiasów, nawet jeśli nie mają parametrów. Właśnie dlatego możesz napisać:
Cat Mruczek;
Jest to interpretowane jako wywołanie konstruktora domyślnego. Nie dostarczamy mu parametrów i pomijamy nawiasy.
Zwróć uwagę, że nie musisz używać domyślnego konstruktora dostarczanego przez kompilator. Zawsze możesz napisać własny konstruktor domyślny — tj. konstruktor bez parametrów. Możesz zastosować w nim ciało funkcji, w którym możesz zainicjalizować obiekt.
Zgodnie z konwencją, gdy deklarujesz konstruktor, powinieneś także zadeklarować destruktor, nawet jeśli nie robi on niczego. Nawet jeśli destruktor domyślny będzie działał poprawnie, nie zaszkodzi zadeklarować własnego. Dzięki niemu kod staje się bardziej przejrzysty.
Listing 6.4 zawiera nową wersję klasy Cat, w której do zainicjalizowania obiektu kota użyto konstruktora. Wiek kota został ustawiony zgodnie z wartością otrzymaną jako parametr konstruktora.
Listing 6.4. Użycie konstruktora i destruktora 0: // Demonstruje deklarowanie konstruktora 1: // i destruktora dla klasy Cat 2: // Domyślny konstruktor został stworzony przez programistę 3: 4: #include <iostream> // dla cout 5: 6: class Cat // początek deklaracji klasy 7: { 8: public: // początek sekcji publicznej 9: Cat(int initialAge); // konstruktor 10: ~Cat(); // destruktor 11: int GetAge(); // akcesor 12: void SetAge(int age); // akcesor 13: void Meow(); 14: private: // początek sekcji prywatnej 15: int itsAge; // zmienna składowa 16: }; 17: 18: // konstruktor klasy Cat 19: Cat::Cat(int initialAge) 20: { 21: itsAge = initialAge; 22: } 23: 24: Cat::~Cat() // destruktor, nic nie robi 25: { 26: } 27: 28: // GetAge, publiczny akcesor 29: // zwraca wartość składowej itsAge 30: int Cat::GetAge() 31: { 32: return itsAge; 33: } 34:
Usunięto:

35: // definicja SetAge, akcesora 36: // publicznego 37: 38: void Cat::SetAge(int age) 39: { 40: // ustawia zmienną składową itsAge 41: // zgodnie z wartością przekazaną w parametrze age 42: itsAge = age; 43: } 44: 45: // definicja metody Meow 46: // zwraca: void 47: // parametery: brak 48: // działanie: wypisuje na ekranie słowo "miauczy" 49: void Cat::Meow() 50: { 51: std::cout << "Miauczy.\n"; 52: } 53: 54: // tworzy kota, ustawia jego wiek, sprawia, 55: // że miauczy, wypisuje jego wiek i ponownie miauczy. 56: int main() 57: { 58: Cat Mruczek(5); 59: Mruczek.Meow(); 60: std::cout << "Mruczek jest kotem i ma " ; 61: std::cout << Mruczek.GetAge() << " lat.\n"; 62: Mruczek.Meow(); 63: Mruczek.SetAge(7); 64: std::cout << "Teraz Mruczek ma " ; 65: std::cout << Mruczek.GetAge() << " lat.\n"; 66: return 0; 67: }
Wynik Miauczy. Mruczek jest kotem i ma 5 lat. Miauczy. Teraz Mruczek ma 7 lat.
Analiza
Listing 6.4 przypomina listing 6.3, jednak w linii 9. dodano konstruktor, posiadający argument w postaci wartości całkowitej. Linia 10. deklaruje destruktor, który nie posiada parametrów. Destruktory nigdy nie mają parametrów, zaś destruktory i konstruktory nie zwracają żadnych wartości — nawet typu void.
Linie od 19. do 22. zawierają implementację konstruktora. Jest ona podobna do implementacji akcesora SetAge(). Konstruktor nie zwraca wartości.
Linie od 24. do 26. przedstawiają implementację destruktora ~Cat(). Ta funkcja nie robi nic, ale jeśli deklaracja klasy zawiera deklarację destruktora, zdefiniowany musi zostać wtedy także ten destruktor.
Linia 58. zawiera definicję obiektu Mruczek, stanowiącego egzemplarz klasy Cat. Do konstruktora obiektu Mruczek przekazywana jest wartość 5. Nie ma potrzeby wywoływania funkcji SetAge(), gdyż Mruczek został stworzony z wartością 5 znajdującą się w zmiennej

składowej itsAge, tak jak pokazano w linii 61. W linii 63. zmiennej itsAge obiektu Mruczek jest przypisywana wartość 7. Tę nową wartość wypisuje linia 65.
TAK NIE
W celu zainicjalizowania obiektów używaj konstruktorów.
Pamiętaj, że konstruktory i destruktory nie mogą zwracać wartości.
Pamiętaj, że destruktory nie mogą mieć parametrów.
Funkcje składowe const Jeśli zadeklarujesz metodę klasy jako const, obiecujesz w ten sposób, że metoda ta nie zmieni wartości żadnej ze składowych klasy. Aby zadeklarować metodę w ten sposób, umieść słowo kluczowe const za nawiasami, lecz przed średnikiem. Pokazana poniżej deklaracja funkcji składowej const o nazwie SomeFunction() nie posiada argumentów i zwraca typ void:
void SomeFunction() const;
Wraz z modyfikatorem const często deklarowane są akcesory. Klasa Cat posiada dwa akcesory:
void SetAge(int anAge); int GetAge();
Funkcja SetAge() nie może być funkcją const, gdyż modyfikuje wartość zmiennej składowej itsAge. Natomiast funkcja GetAge() może być const, gdyż nie modyfikuje wartości żadnej ze składowych klasy. Funkcja GetAge() po prostu zwraca bieżącą wartość składowej itsAge. Zatem deklaracje tych funkcji można przepisać następująco:
void SetAge(int anAge); int GetAge() const;
Gdy zadeklarujesz funkcję jako const, zaś implementacja tej funkcji modyfikuje obiekt poprzez modyfikację wartości którejkolwiek ze składowych, kompilator zgłosi błąd. Na przykład, gdy napiszesz funkcję GetAge() w taki sposób, że będziesz zapamiętywał ilość zapytań o wiek kota, spowodujesz błąd kompilacji. Jest to spowodowane tym, że wywołując tę metodę, modyfikujesz zawartość obiektu Cat.
UWAGA Deklaruj funkcje jako const wszędzie, gdzie to jest możliwe. Deklaruj je tam, gdzie nie przewidujesz modyfikowania obiektu. Kompilator może w ten sposób pomóc ci w wykryciu błędów w programie; tak jest szybciej i dokładniej.
Deklarowanie funkcji jako const wszędzie tam, gdzie jest to możliwe, należy do tradycji programistycznej. Za każdym razem, gdy to zrobisz, umożliwisz kompilatorowi wykrycie pomyłki zanim stanie się ona błędem, który ujawni się już podczas działania programu.
Interfejs a implementacja Jak wiesz, klienty są tymi elementami programu, które tworzą i wykorzystują obiekty twojej klasy. Publiczny interfejs swojej klasy — deklarację klasy — możesz traktować jako kontrakt z tymi klientami. Ten kontrakt informuje, jak zachowuje się dana klasa.
Na przykład, w deklaracji klasy Cat, stworzyłeś kontrakt informujący, że wiek każdego kota może być zainicjalizowany w jego konstruktorze, modyfikowany za pomocą akcesora SetAge() oraz odczytywany za pomocą akcesora GetAge(). Oprócz tego obiecujesz, że każdy kot może miauczeć (funkcją Meow()). Zwróć uwagę, że w publicznym interfejsie nie ma ani słowa o zmiennej składowej itsAge; jest to szczegół implementacji, który nie stanowi elementu kontraktu. Na żądanie dostarczysz wieku (GetAge()) i ustawisz go (SetAge()), ale sam mechanizm (itsAge) jest niewidoczny.
Gdy uczynisz funkcję GetAge()funkcją const — a powinieneś to zrobić — kontrakt obiecuje także, że funkcja GetAge() nie modyfikuje obiektu Cat, dla którego jest wywołana.
C++ jest językiem zapewniającym silną kontrolę typów, co oznacza, że kompilator wymusza przestrzeganie kontraktu, zgłaszając błędy kompilacji za każdym razem, gdy naruszysz reguły tego kontraktu. Listing 6.5 przedstawia program, który nie skompiluje się z powodu naruszenia ustaleń takiego kontraktu.
OSTRZEŻENIE Listing 6.5 nie skompiluje się!
Listing 6.5. Przykład naruszenia ustaleń interfejsu 0: // Demonstruje błędy kompilacji 1: // Ten program się nie kompiluje! 2: 3: #include <iostream> // dla cout 4: 5: class Cat 6: { 7: public: 8: Cat(int initialAge); 9: ~Cat(); 10: int GetAge() const; // akcesor typu const 11: void SetAge (int age); 12: void Meow(); 13: private: 14: int itsAge; 15: }; 16:
Usunięto: Używaj
Usunięto:

17: // konstruktor klasy Cat, 18: Cat::Cat(int initialAge) 19: { 20: itsAge = initialAge; 21: std::cout << "Konstruktor klasy Cat\n"; 22: } 23: 24: Cat::~Cat() // destruktor, nic nie robi 25: { 26: std::cout << "Destruktor klasy Cat\n"; 27: } 28: // GetAge, funkcja const, 29: // ale narusza zasadę const! 30: int Cat::GetAge() const 31: { 32: return (itsAge++); // narusza const! 33: } 34: 35: // definicja SetAge, publicznego 36: // akcesora 37: 38: void Cat::SetAge(int age) 39: { 40: // ustawia zmienną składową itsAge 41: // zgodnie z wartością przekazaną w parametrze age 42: itsAge = age; 43: } 44: 45: // definicja metody Meow 46: // zwraca: void 47: // parametery: brak 48: // działanie: wypisuje na ekranie słowo "miauczy" 49: void Cat::Meow() 50: { 51: std::cout << "Miauczy.\n"; 52: } 53: 54: // demonstruje różne naruszenia reguł interfejsu 55: // oraz wynikające z tego błędy kompilatora 56: int main() 57: { 58: Cat Mruczek; // nie pasuje do deklaracji 59: Mruczek.Meow(); 60: Mruczek.Bark(); // Nie, głuptasie, koty nie szczekają. 61: Mruczek.itsAge = 7; // itsAge jest składową prywatną 62: return 0; 63: }
Analiza
Program w przedstawionej powyżej postaci się nie kompiluje, więc nie ma wyników działania.
Pisanie go było dość zabawne, ponieważ zawiera tak dużo błędów.
Linia 10 deklaruje funkcję GetAge() jako akcesor typu const — i tak powinno być. Jednak w ciele funkcji GetAge(), w linii 32., inkrementowana jest zmienna składowa itsAge. Ponieważ ta metoda została zadeklarowana jako const, nie może zmieniać wartości tej zmiennej. Dlatego podczas kompilacji programu zostanie to zgłoszone jako błąd.

W linii 12., funkcja Meow() nie jest zadeklarowana jako const. Choć nie jest to błędem, stanowi zły obyczaj. Należałoby wziąć pod uwagę, że ta metoda nie modyfikuje zmiennych składowych klasy. Dlatego funkcja Meow() powinna być funkcją const.
Linia 58. pokazuje definicję obiektu Mruczek klasy Cat. W tym programie klasa Cat posiada konstruktor, który wymaga podania argumentu, będącego wartością całkowitą. Oznacza to, że musisz taki argument przekazać. Ponieważ w linii 58. nie występuje argument konstruktora, kompilator zgłosi błąd.
UWAGA Jeśli stworzysz jakikolwiek konstruktor, kompilator zrezygnuje z dostarczenia swojego konstruktora domyślnego. Gdy stworzysz konstruktor wymagający parametru, nie będziesz miał konstruktora domyślnego, chyba że stworzysz go sam.
Linia 60. zawiera wywołanie metody Bark() dla obiektu Mruczek. Metoda Bark() nie została zadeklarowana, więc jest niedozwolona.
Linia 61. zawiera przypisanie wartości 7 do zmiennej itsAge. Ponieważ itsAge jest składową prywatną, kompilator zgłosi błąd kompilacji.
Po co używać kompilatora do wykrywania błędów?
Gdyby można było tworzyć programy w stu procentach pozbawione błędów, byłoby cudowanie, jednak tylko bardzo niewielu programistów jest w stanie tego dokonać. Wielu programistów opracowało jednak system pozwalający zminimalizować ilość błędów przez wczesne ich wykrycie i poprawienie.
Choć błędy kompilatora są irytujące i stanowią dla programisty przekleństwo, jednak są czymś dużo lepszym niż opisana dalej alternatywa. Język o słabej kontroli typów umożliwia naruszanie zasad kontraktu bez słowa sprzeciwu ze strony kompilatora, jednak program może załamać się w trakcie działania — na przykład wtedy, gdy pracuje z nim twój szef.
Błędy czasu kompilacji — tj. błędy wykryte podczas kompilowania programu — są zdecydowanie lepsze niż błędy czasu działania — tj. błędy wykryte podczas działania programu. Są lepsze, gdyż dużo łatwiej i precyzyjniej można określić ich przyczynę. Może się zdarzyć że program zostanie wykonany wielokrotnie bez wykonania wszystkich istniejących ścieżek wykonania kodu. Dlatego błąd czasu działania może przez dłuższy czas pozostać niezauważony. Błędy kompilacji są wykrywane podczas każdej kompilacji, są więc dużo łatwiejsze do zidentyfikowania i poprawienia. Celem dobrego programowania jest ochrona przed pojawianiem się błędów czasu działania. Jedną ze znanych i sprawdzonych technik jest wykorzystanie kompilatora do wykrycia pomyłek już na wczesnym etapie tworzenia programu.

Gdzie umieszczać deklaracje klasy i definicje metod Każda funkcja, którą zadeklarujesz dla klasy, musi posiadać definicję. Definicja jest nazywana także implementacją funkcji. Podobnie jak w przypadku innych funkcji, definicja metody klasy posiada nagłówek i ciało.
Definicja musi znajdować się w pliku, który może zostać znaleziony przez kompilator. Większość kompilatorów C++ wymaga, by taki plik miał rozszerzenie .c lub .cpp. W tej książce korzystamy z rozszerzenia .cpp, ale aby mieć pewność, sprawdź, czego oczekuje twój kompilator.
UWAGA Wiele kompilatorów zakłada, że pliki z rozszerzeniem .c są programami C, zaś pliki z rozszerzeniem .cpp są programami C++. Możesz używać dowolnego rozszerzenia, ale rozszerzenie .cpp wyeliminuje ewentualne nieporozumienia.
W pliku, w którym umieszczasz implementację funkcji, możesz umieścić również jej deklarację, ale nie należy to do dobrych obyczajów. Zgodnie z konwencją zaadoptowaną przez większość programistów, deklaracje umieszcza się w tak zwanych plikach nagłówkowych, zwykle posiadających tę samą nazwę, lecz z rozszerzeniem .h, .hp lub .hpp. W tej książce dla plików nagłówkowych stosujemy rozszerzenie .hpp, ale sprawdź w swoim kompilatorze, jakie rozszerzenie powinieneś stosować.
Na przykład, deklarację klasy Cat powinieneś umieścić w pliku o nazwie CAT.hpp, zaś definicję metod tej klasy w pliku o nazwie CAT.cpp. Następnie powinieneś dołączyć do pliku .cpp plik nagłówkowy, poprzez umieszczenie na początku pliku CAT.cpp następującej dyrektywy:
#include "Cat.hpp"
Informuje ona kompilator, by wstawił w tym miejscu zawartość pliku CAT.hpp tak, jakbyś ją wpisał ręcznie. Uwaga: niektóre kompilatory nalegają, by wielkość liter w nazwie pliku w dyrektywie #include zgadzała się z wielkością liter w nazwie pliku na dysku.
Dlaczego masz się trudzić, rozdzielając program na pliki .hpp i .cpp, skoro i tak plik .hpp jest wstawiany do pliku .cpp? W większości przypadków klienty klasy nie dbają o szczegóły jej implementacji. Odczytanie pliku nagłówkowego daje im wystarczającą ilość informacji by zignorować plik implementacji. Poza tym, ten sam plik .hpp możesz dołączać do wielu różnych plików .cpp.
UWAGA Deklaracja klasy mówi kompilatorowi, czym jest ta klasa, jakie dane zawiera oraz jakie funkcje posiada. Deklaracja klasy jest nazywana jej interfejsem, gdyż informuje kompilator w jaki sposób ma z nią współdziałać. Ten interfejs jest zwykle przechowywany w pliku .hpp, często nazywanym plikiem nagłówkowym.
Definicja funkcji mówi kompilatorowi, jak działa dana funkcja. Definicja funkcji jest nazywana implementacją metody klasy i jest przechowywana w pliku .cpp. Szczegóły dotyczące implementacji klasy należą wyłącznie do jej autora. Klienty klasy — tj. części programu
Usunięto: tym
Usunięto: funkcji

używające tej klasy — nie muszą, ani nie powinny wiedzieć, jak zaimplementowane zostały funkcje.
Implementacja inline Możesz poprosić kompilator, by uczynił zwykłą funkcję funkcją inline, funkcjami inline mogą stać się również metody klasy. W tym celu należy umieścić słowo kluczowe inline przed typem zwracanej wartości. Na przykład, implementacja inline funkcji GetWeight() wygląda następująco:
inline int Cat::GetWeight() { return itsWeight; // zwraca daną składową itsWeight }
Definicję funkcji można także umieścić w deklaracji klasy, co automatycznie sprawia, że ta funkcja staje się funkcją inline. Na przykład:
class Cat { public: int GetWeight() { return itsWeight; } // inline void SetWeight(int aWeight); };
Zwróć uwagę na składnię definicji funkcji GetWeight(). Ciało funkcji inline zaczyna się natychmiast po deklaracji metody klasy; po nawiasach nie występuje średnik. Podobnie jak w innych funkcjach, definicja zaczyna się od otwierającego nawiasu klamrowego i kończy zamykającym nawiasem klamrowym. Jak zwykle, białe spacje nie mają znaczenia; możesz zapisać tę deklarację jako:
class Cat { public: int GetWeight() const { return itsWeight; } // inline void SetWeight(int aWeight); };
Listingi 6.6 i 6.7 odtwarzają klasę Cat, tym razem jednak deklaracja klasy została umieszczona w pliku CAT.hpp, zaś jej definicja w pliku CAT.cpp. Oprócz tego, na listingu 6.7 akcesor Meow() został zadeklarowany jako funkcja inline.

Listing 6.6. Deklaracja klasy Cat w pliku CAT.hpp 0: #include <iostream> 1: class Cat 2: { 3: public: 4: Cat (int initialAge); 5: ~Cat(); 6: int GetAge() const { return itsAge;} // inline! 7: void SetAge (int age) { itsAge = age;} // inline! 8: void Meow() const { std::cout << "Miauczy.\n";} // inline! 9: private: 10: int itsAge; 11: };
Listing 6.7. Implementacja klasy Cat w pliku CAT.cpp 0: // Demonstruje funkcje inline 1: // oraz dołączanie pliku nagłówkowego 2: 3: // pamiętaj o włączeniu plików nagłówkowych! 4: #include "cat.hpp" 5: 6: 7: Cat::Cat(int initialAge) //konstruktor 8: { 9: itsAge = initialAge; 10: } 11: 12: Cat::~Cat() //destruktor, nic nie robi 13: { 14: } 15: 16: // tworzy kota, ustawia jego wiek, sprawia 17: // że miauczy, wypisuje jego wiek i ponownie miauczy. 18: int main() 19: { 20: Cat Mruczek(5); 21: Mruczek.Meow(); 22: std::cout << "Mruczek jest kotem i ma " ; 23: std::cout << Mruczek.GetAge() << " lat.\n"; 24: Mruczek.Meow(); 25: Mruczek.SetAge(7); 26: std::cout << "Teraz Mruczek ma " ; 27: std::cout << Mruczek.GetAge() << " lat.\n"; 28: return 0; 29: }
Wynik Miauczy. Mruczek jest kotem i ma 5 lat. Miauczy. Teraz Mruczek ma 7 lat.
Analiza

Kod zaprezentowany na listingach 6.6 i 6.7 jest podobny do kodu z listingu 6.4, trzy metody zostały zadeklarowane w pliku deklaracji jako inline, a deklaracja została przeniesiona do pliku CAT.hpp (listing 6.6).
Funkcja GetAge() jest deklarowana w linii 6., gdzie znajduje się także jej implementacja. Linie 7. i 8. zawierają kolejne funkcje inline, jednak w stosunku do poprzednich, „zwykłych” implementacji, działanie tych funkcji nie zmienia się.
Linia 4. listingu 6.7 zawiera dyrektywę #include "cat.hpp", która powoduje wstawienie do pliku zawartości pliku CAT.hpp. Dołączając plik CAT.hpp, informujesz prekompilator, by odczytał zawartość tego pliku i wstawił ją w miejscu wystąpienia dyrektywy #include (tak jakbyś, począwszy od linii 5, sam wpisał tę zawartość).
Ta technika umożliwia umieszczenie deklaracji w pliku innym niż implementacja, a jednocześnie zapewnienie kompilatorowi dostępu do niej. W programach C++ technika ta jest powszechnie wykorzystywana. Zwykle deklaracje klas znajdują się w plikach .hpp, które są dołączane do powiązanych z nimi plików .cpp za pomocą dyrektyw #include.
Linie od 18. do 29. stanowią powtórzenie funkcji main() z listingu 6.4. Oznacza to, że funkcje inline działają tak samo jak zwykłe funkcje.
Klasy, których danymi składowymi są inne klasy Budowanie złożonych klas przez deklarowanie prostszych klas i dołączanie ich do deklaracji bardziej skomplikowanej klasy nie jest niczym niezwykłym. Na przykład, możesz zadeklarować klasę koła, klasę silnika, klasę skrzyni biegów, itd., a następnie połączyć je w klasę „samochód”. Deklaruje to relację posiadania. Samochód posiada silnik, koła i skrzynię biegów.
Weźmy inny przykład. Prostokąt składa się z odcinków. Odcinek jest zdefiniowany przez dwa punkty. Punkt jest zdefiniowany przez współrzędną x i współrzędną y. Listing 6.8 przedstawia pełną deklarację klasy Rectangle (prostokąt), która może wystąpić w pliku RECTANGLE.hpp. Ponieważ prostokąt jest zdefiniowany jako cztery odcinki łączące cztery punkty, zaś każdy punkt odnosi się do współrzędnej w układzie, najpierw zadeklarujemy klasę Point (punkt) jako przechowującą współrzędne x oraz y punktu. Listing 6.9 zawiera implementacje obu klas.
Listing 6.8. Deklarowanie kompletnej klasy 0: // początek Rect.hpp 1: 2: #include <iostream> 3: class Point // przechowuje współrzędne x,y 4: { 5: // bez konstruktora, używa domyślnego 6: public: 7: void SetX(int x) { itsX = x; } 8: void SetY(int y) { itsY = y; } 9: int GetX()const { return itsX;} 10: int GetY()const { return itsY;} 11: private: 12: int itsX; 13: int itsY;
Usunięto: Taka deklaracja posiada związek relacji.
Usunięto: ma

14: }; // koniec deklaracji klasy Point 15: 16: 17: class Rectangle 18: { 19: public: 20: Rectangle (int top, int left, int bottom, int right); 21: ~Rectangle () {} 22: 23: int GetTop() const { return itsTop; } 24: int GetLeft() const { return itsLeft; } 25: int GetBottom() const { return itsBottom; } 26: int GetRight() const { return itsRight; } 27: 28: Point GetUpperLeft() const { return itsUpperLeft; } 29: Point GetLowerLeft() const { return itsLowerLeft; } 30: Point GetUpperRight() const { return itsUpperRight; } 31: Point GetLowerRight() const { return itsLowerRight; } 32: 33: void SetUpperLeft(Point Location) {itsUpperLeft = Location;} 34: void SetLowerLeft(Point Location) {itsLowerLeft = Location;} 35: void SetUpperRight(Point Location) {itsUpperRight = Location;} 36: void SetLowerRight(Point Location) {itsLowerRight = Location;} 37: 38: void SetTop(int top) { itsTop = top; } 39: void SetLeft (int left) { itsLeft = left; } 40: void SetBottom (int bottom) { itsBottom = bottom; } 41: void SetRight (int right) { itsRight = right; } 42: 43: int GetArea() const; 44: 45: private: 46: Point itsUpperLeft; 47: Point itsUpperRight; 48: Point itsLowerLeft; 49: Point itsLowerRight; 50: int itsTop; 51: int itsLeft; 52: int itsBottom; 53: int itsRight; 54: }; 55: // koniec Rect.hpp
Listing 6.9. RECTANGLE.cpp 0: // początek rect.cpp 1: 2: #include "rect.hpp" 3: Rectangle::Rectangle(int top, int left, int bottom, int right) 4: { 5: itsTop = top; 6: itsLeft = left; 7: itsBottom = bottom; 8: itsRight = right; 9: 10: itsUpperLeft.SetX(left); 11: itsUpperLeft.SetY(top);

12: 13: itsUpperRight.SetX(right); 14: itsUpperRight.SetY(top); 15: 16: itsLowerLeft.SetX(left); 17: itsLowerLeft.SetY(bottom); 18: 19: itsLowerRight.SetX(right); 20: itsLowerRight.SetY(bottom); 21: } 22: 23: 24: // oblicza obszar prostokąta przez obliczenie 25: // i pomnożenie szerokości i wysokości 26: int Rectangle::GetArea() const 27: { 28: int Width = itsRight-itsLeft; 29: int Height = itsTop - itsBottom; 30: return (Width * Height); 31: } 32: 33: int main() 34: { 35: //inicjalizuje lokalną zmienną typu Rectangle 36: Rectangle MyRectangle (100, 20, 50, 80 ); 37: 38: int Area = MyRectangle.GetArea(); 39: 40: std::cout << "Obszar: " << Area << "\n"; 41: std::cout << "Wsp. X lewego gornego rogu: "; 42: std::cout << MyRectangle.GetUpperLeft().GetX(); 43: return 0; 44: }
Wynik Obszar: 3000 Wsp. X lewego gornego rogu: 20
Analiza
Linie od 3. do 14. listingu 6.8 deklarują klasę Point (punkt), która służy do przechowywania współrzędnych x i y określonego punktu rysunku. W tym programie nie wykorzystujemy należycie klasy Point. Jej zastosowania wymagają jednak inne metody rysunkowe.
UWAGA Gdy nadasz klasie nazwę Rectangle, niektóre kompilatory zgłoszą błąd, W takim przypadku po prostu zmień nazwę klasy na myRectangle.
W deklaracji klasy Point, w liniach 12. i 13., zadeklarowaliśmy dwie zmienne składowe (itsX oraz itsY). Te zmienne przechowują współrzędne punktu. Zakładamy, że współrzędna x rośnie w prawo, a współrzędna y w górę. Istnieją także inne systemy. W niektórych programach okienkowych współrzędna y rośnie „w dół” okna.
Klasa Point używa akcesorów inline, zwracających i ustawiających współrzędne X i Y punktu. Te akcesory zostały zadeklarowane w liniach od 7. do 10. Punkty używają konstruktora i destruktora domyślnego. W związku z tym ich współrzędne trzeba ustawiać jawnie.
Usunięto: swojej postaci,
Usunięto:
Usunięto:

Linia 17. rozpoczyna deklarację klasy Rectangle (prostokąt). Klasa ta kłada się z czterech punktów reprezentujących cztery narożniki prostokąta.
Konstruktor klasy Rectangle (linia 20.) otrzymuje cztery wartości całkowite, top (górna), left (lewa), bottom (dolna) oraz right (prawa). Do czterech zmiennych składowych (listing 6.9) kopiowane są cztery parametry konstruktora i tworzone są cztery punkty.
Oprócz standardowych akcesorów, klasa Rectangle posiada funkcję GetArea() (pobierz obszar), zadeklarowaną w linii 43. Zamiast przechowywać obszar w zmiennej, funkcja GetArea() oblicza go w liniach od 28. do 30. listingu 6.9. W tym celu oblicza szerokość i wysokość prostokąta, następnie mnoży je przez siebie.
Uzyskanie współrzędnej x lewego górnego wierzchołka prostokąta wymaga dostępu do punktu UpperLeft (lewy górny) i zapytania o jego współrzędną X. Ponieważ funkcja GetUpperLeft() jest funkcją klasy Rectangle, może ona bezpośrednio odwoływać się do prywatnych danych tej klasy, włącznie ze zmienną (itsUpperLeft). Ponieważ itsUpperLeft jest obiektem klasy Point, a zmienna itsX tej klasy jest prywatna, funkcja GetUpperLeft() nie może odwoływać się do niej bezpośrednio. Zamiast tego, w celu uzyskania tej wartości musi użyć publicznego akcesora GetX().
Linia 33. listingu 6.9 stanowi początek ciała programu. Pamięć nie jest alokowana aż do linii 36.; w obszarze tym nic się nie dzieje. Jedyna rzecz, jaką zrobiliśmy, to poinformowanie kompilatora, jak ma stworzyć punkt i prostokąt (gdyby były potrzebne w przyszłości).
W linii 36. definiujemy obiekt typu Rectangle, przekazując mu wartości Top, Left, Bottom oraz Right.
W linii 38. tworzymy lokalną zmienną Area (obszar) typu int. Ta zmienna przechowuje obszar stworzonego przez nas prostokąta. Zmienną Area inicjalizujemy za pomocą wartości zwróconej przez funkcję GetArea() klasy Rectangle.
Klient klasy Rectangle może stworzyć obiekt tej klasy i uzyskać jego obszar, nie znając nawet implementacji funkcji GetArea().
Plik RECT.hpp został przedstawiony na listingu 6.8. Obserwując plik nagłówkowy, który zawiera deklarację klasy Rectangle, programista może wysnuć wniosek, że funkcja GetArea() zwraca wartość typu int. Sposób, w jaki funkcja GetArea() uzyskuje tę wartość, nie interesuje klientów klasy Rectangle. Autor klasy Rectangle mógłby zmienić funkcję GetArea(); nie wpłynęłoby to na programy, które z niej korzystają.
Często zadawane pytanie
Jaka jest różnica pomiędzy deklaracją a definicją?
Odpowiedź: Deklaracja wprowadza nową nazwę, lecz nie alokuje pamięci; dokonuje tego definicja.
Wszystkie deklaracje (z kilkoma wyjątkami) są także definicjami. Najważniejszym wyjątkiem jest deklaracja funkcji globalnej (prototyp) oraz deklaracja klasy (zwykle w pliku nagłówkowym).
Usunięto: i 29
Struktury Bardzo bliskim kuzynem słowa kluczowego class jest słowo kluczowe struct, używane do deklarowania struktur. W C++ struktura jest odpowiednikiem klasy, ale wszystkie jej składowe są domyślnie publiczne. Możesz zadeklarować strukturę dokładnie tak, jak klasę; możesz zastosować w niej te same zmienne i funkcje składowe. Gdy przestrzegasz jawnego deklarowania publicznych i prywatnych sekcji klasy, nie ma żadnej różnicy pomiędzy klasą a strukturą.
Spróbuj wprowadzić do listingu 6.8 następujące zmiany:
• w linii 3., zmień class Point na struct Point,
• w linii 17., zmień class Rectangle na struct Rectangle.
Następnie skompiluj i uruchom program. Otrzymane wyniki nie powinny się od siebie różnić.
Dlaczego dwa słowa kluczowe spełniają tę samą funkcję Prawdopodobnie zastanawiasz się dlaczego dwa słowa kluczowe spełniają tę samą funkcję. Przyczyn należy szukać w historii języka. Język C++ powstawał jako rozszerzenie języka C. Język C posiada struktury, ale nie posiadają one metod. Bjarne Stroustrup, twórca języka C++, rozbudował struktury, ale zmienił ich nazwę na klasy, odzwierciedlając w ten sposób ich nowe, rozszerzone możliwości.
TAK
Umieszczaj deklarację klasy w pliku .hpp, zaś funkcje składowe definiuj w pliku .cpp.
Używaj const wszędzie tam, gdzie jest to możliwe.
Zanim przejdziesz dalej, postaraj się dokładnie zrozumieć zasady działania klasy.

Rozdział 7. Sterowanie przebiegiem działania programu Większość działań programu powiązanych jest z warunkowymi rozgałęzieniami i pętlami. W rozdziale 4., „Wyrażenia i instrukcje”, poznałeś sposób, w jaki należy rozgałęzić działanie programu za pomocą instrukcji if.
W tym rozdziale:
• dowiesz się, czym są pętle i jak się z nich korzysta,
• nauczysz się tworzyć różnorodne pętle,
• poznasz alternatywę dla głęboko zagnieżdżonych instrukcji if-else.
Pętle Wiele problemów programistycznych rozwiązywanych jest przez powtarzanie operacji wykonywanych na tych samych danych. Dwie podstawowe techniki to: rekurencja (omawiana w rozdziale 5., „Funkcje”) oraz iteracja. Iteracja oznacza ciągłe powtarzanie tych samych czynności. Podstawową metodą wykorzystywaną przy iteracji jest pętla.
Początki pętli: instrukcja goto W początkowym okresie rozwoju informatyki, programy były nieporadne, proste i krótkie. Pętle składały się z etykiety, zestawu wykonywanych instrukcji i skoku.
W C++ etykieta jest zakończoną dwukropkiem nazwą (:). Etykieta może być umieszczona po lewej stronie instrukcji języka C++, zaś skok odbywa się w wyniku wykonania instrukcji goto (idź do) z nazwą etykiety. Ilustruje to listing 7.1.
Listing 7.1. Pętla z użyciem słowa kluczowego goto 0: // Listing 7.1

1: // Pętla z instrukcją goto 2: 3: #include <iostream> 4: 5: int main() 6: { 7: int counter = 0; // inicjalizujemy licznik 8: loop: counter ++; // początek pętli 9: std::cout << "Licznik: " << counter << "\n"; 10: if (counter < 5) // sprawdzamy wartość 11: goto loop; // skok do początku 12: 13: std::cout << "Gotowe. Licznik: " << counter << ".\n"; 14: return 0; 15: }
Wynik Licznik: 1 Licznik: 2 Licznik: 3 Licznik: 4 Licznik: 5 Gotowe. Licznik: 5.
Analiza
W linii 7., zmienna counter (licznik) jest inicjalizowana wartością 0. W linii 8 występuje etykieta loop (pętla), oznaczająca początek pętli. Zmienna counter jest inkrementowana, następnie wypisywana jest jej nowa wartość. W linii 10. sprawdzana jest wartość zmiennej. Gdy jest ona mniejsza od 5, wtedy instrukcja if jest prawdziwa i wykonywana jest instrukcja goto. W efekcie wykonanie programu wraca do linii 8. Program działa w pętli do chwili, gdy, wartość zmiennej counter osiągnie 5; to powoduje że program wychodzi z pętli i wypisuje końcowy komunikat.
Dlaczego nie jest zalecane stosowanie instrukcji goto? Programiści unikają instrukcji goto, i mają ku temu znaczące powody. Instrukcja goto umożliwia wykonanie skoku do dowolnego miejsca w kodzie źródłowym, do przodu lub do tyłu. Nierozważne użycie tej instrukcji sprawia że kod źródłowy jest zagmatwany, nieestetyczny i trudny do przeanalizowania, kod taki nazywany „kodem spaghetti”.
Instrukcja goto
Aby użyć instrukcji goto, powinieneś napisać słowo kluczowe goto, a następnie nazwę etykiety. Spowoduje to wykonanie skoku bezwarunkowego.
Przykład
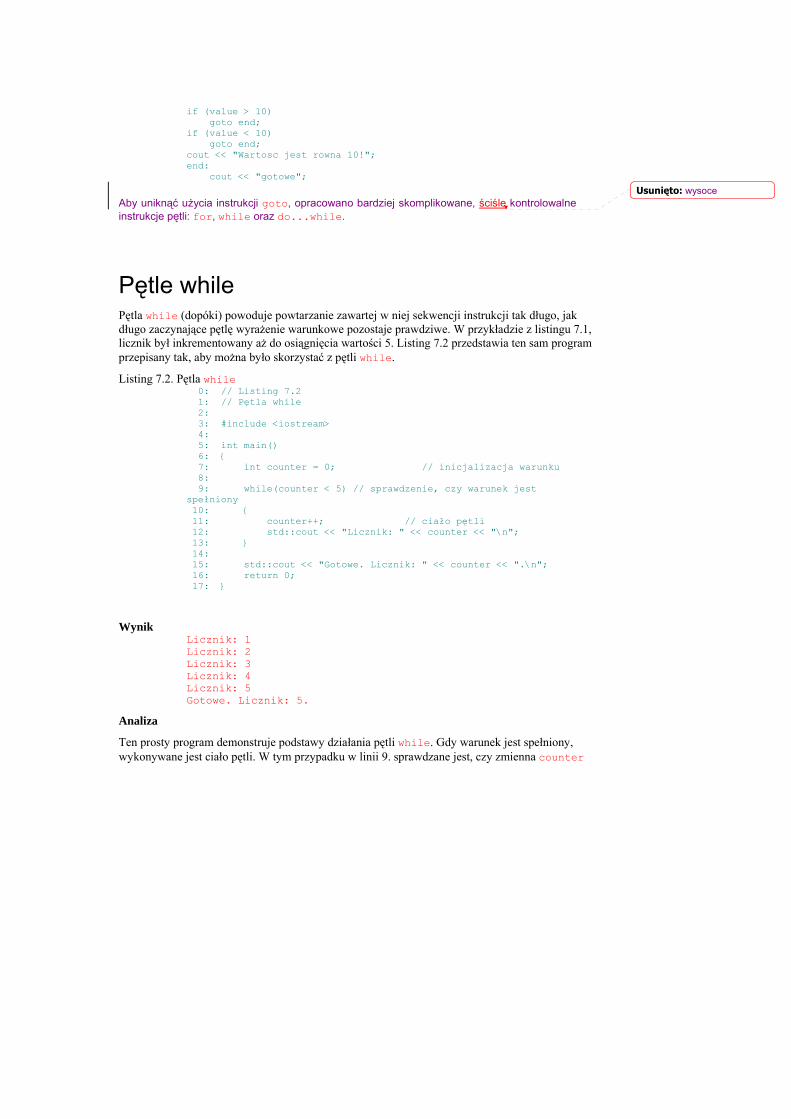
if (value > 10) goto end; if (value < 10) goto end; cout << "Wartosc jest rowna 10!"; end: cout << "gotowe";
Aby uniknąć użycia instrukcji goto, opracowano bardziej skomplikowane, ściśle kontrolowalne instrukcje pętli: for, while oraz do...while.
Pętle while Pętla while (dopóki) powoduje powtarzanie zawartej w niej sekwencji instrukcji tak długo, jak długo zaczynające pętlę wyrażenie warunkowe pozostaje prawdziwe. W przykładzie z listingu 7.1, licznik był inkrementowany aż do osiągnięcia wartości 5. Listing 7.2 przedstawia ten sam program przepisany tak, aby można było skorzystać z pętli while.
Listing 7.2. Pętla while 0: // Listing 7.2 1: // Pętla while 2: 3: #include <iostream> 4: 5: int main() 6: { 7: int counter = 0; // inicjalizacja warunku 8: 9: while(counter < 5) // sprawdzenie, czy warunek jest spełniony 10: { 11: counter++; // ciało pętli 12: std::cout << "Licznik: " << counter << "\n"; 13: } 14: 15: std::cout << "Gotowe. Licznik: " << counter << ".\n"; 16: return 0; 17: }
Wynik Licznik: 1 Licznik: 2 Licznik: 3 Licznik: 4 Licznik: 5 Gotowe. Licznik: 5.
Analiza
Ten prosty program demonstruje podstawy działania pętli while. Gdy warunek jest spełniony, wykonywane jest ciało pętli. W tym przypadku w linii 9. sprawdzane jest, czy zmienna counter
Usunięto: wysoce

(licznik) ma wartość mniejszą od 5. Jeśli ten warunek jest spełniony (prawdziwy), wykonywane jest ciało pętli: w linii 11. następuje inkrementacja licznika, zaś jego wartość jest wypisywana w linii 12. Gdy warunek w linii 9. nie został spełniony (tzn. gdy zmienna counter ma wartość większą lub równą 5), wtedy całe ciało pętli while (linie od 10. do 13.) jest pomijane i program przechodzi do następnej instrukcji, czyli w tym przypadku do linii 14.
Instrukcja while
Składnia instrukcji while jest następująca:
while ( warunek ) instrukcja;
warunek jest wyrażeniem języka C++, zaś instrukcja jest dowolną instrukcją lub blokiem instrukcji C++. Gdy wartością wyrażenia warunek jest true (prawda), wykonywana jest instrukcja, po czym następuje powrót do początku pętli i ponowne sprawdzenie warunku. Czynność ta powtarza się, dopóki warunek zwraca wartość true. Gdy wyrażenie warunek ma wartość false, działanie pętli while kończy się i program przechodzi do instrukcji następujących po pętli.
Przykład
// zliczanie do 10 int x = 0; while (x < 10) cout << "X: " << x++;
Bardziej skomplikowane instrukcje while Warunek sprawdzany w pętli while może być złożony, tak jak każde poprawne wyrażenie języka C++. Może zawierać wyrażenia tworzone za pomocą operatorów logicznych && (I), || (LUB) oraz ! (NIE). Taką nieco bardziej skomplikowaną instrukcję while przedstawia listing 7.3.
Listing 7.3. Warunek złożony w instrukcji while 0: // Listing 7.3 1: // Złożona instrukcja while 2: 3: #include <iostream> 4: using namespace std; 5: 6: int main() 7: { 8: unsigned short small; 9: unsigned long large; 10: const unsigned short MAXSMALL=65535; 11: 12: cout << "Wpisz mniejsza liczbe: "; 13: cin >> small; 14: cout << "Wpisz duza liczbe: "; 15: cin >> large; 16:

17: cout << "mala: " << small << "..."; 18: 19: // w każdej iteracji sprawdzamy trzy warunki 20: while (small < large && large > 0 && small < MAXSMALL) 21: { 22: if (small % 5000 == 0) // wypisuje kropkę co każde 5000 linii 23: cout << "."; 24: 25: small++; 26: 27: large-=2; 28: } 29: 30: cout << "\nMala: " << small << " Duza: " << large << endl; 31: return 0; 32: }
Wynik Wpisz mniejsza liczbe: 2 Wpisz duza liczbe: 100000 mala: 2......... Mala: 33335 Duza: 33334
Analiza
Ten program to gra. Podaj dwie liczby, mniejszą i większą. Mniejsza liczba jest zwiększana o jeden, a większa liczba jest zmniejszana o dwa. Celem gry jest odgadnięcie, kiedy się „spotkają”.
Linie od 12. do 15. służą do wprowadzania liczb. W linii 20. rozpoczyna się pętla while, której działanie będzie kontynuowane, dopóki spełnione są wszystkie trzy poniższe warunki:
1. Mniejsza liczba nie jest większa od większej liczby.
2. Większa liczba nie jest ujemna ani równa zeru.
3. Mniejsza liczba nie przekracza maksymalnej wartości dla małych liczb całkowitych (MAXSMALL).
W linii 23. wartość zmiennej small (mała) jest obliczana modulo 5 000. Nie powoduje to zmiany wartości tej zmiennej; chodzi jedynie o to, że wartość 0 jest wynikiem działania modulo 5 000 tylko wtedy, gdy wartość zmiennej small jest wielokrotnością pięciu tysięcy. Za każdym razem, gdy otrzymujemy wartość zero, na ekranie wypisywana jest kropka, przedstawiająca postęp działań. W linii 25. następuje inkrementacja zmiennej small, zaś w linii 27. zmniejszenie zmiennej large (duża) o dwa.
Jeżeli w pętli while nie zostanie spełniony któryś z trzech warunków, pętla kończy działanie, a wykonanie programu przechodzi do linii 29., za zamykający nawias klamrowy pętli while.
UWAGA Operator reszty z dzielenia (modulo) oraz warunki złożone zostały opisane w rozdziale 3, „Stałe i zmienne.”
Usunięto: 6
Usunięto: 8
Usunięto: d
Usunięto: ego
Usunięto: u
Usunięto: ego

continue oraz break Może się zdarzyć, że przed wykonaniem całego zestawu instrukcji w pętli będziesz chcieć powrócić do jej początku. Służy do tego instrukcja continue (kontynuuj).
Może zdarzyć się także, że będziesz chcieć wyjść z pętli jeszcze przed spełnieniem warunku końca. Instrukcja break (przerwij) powoduje natychmiastowe wyjście z pętli i przejście wykonywania do następnych instrukcji programu.
Listing 7.4 demonstruje użycie tych instrukcji. Tym razem gra jest nieco bardziej skomplikowana. Użytkownik jest proszony o podanie liczby mniejszej i większej, liczby pomijanej oraz liczby docelowej. Mniejsza liczba jest zwiększana o jeden, a większa liczba jest zmniejszana o dwa. Za każdym razem, gdy mniejsza liczba jest wielokrotnością liczby pomijanej, nie jest wykonywane zmniejszanie. Gra kończy się, gdy mniejsza liczba staje się większa od większej liczby. Gdy większa liczba dokładnie zrówna się z liczbą docelową. wypisywany jest komunikat i gra zatrzymuje się.
Listing 7.4. Instrukcje break i continue 0: // Listing 7.4 1: // Demonstruje instrukcje break i continue 2: 3: #include <iostream> 4: 5: int main() 6: { 7: using namespace std; 8: unsigned short small; 9: unsigned long large; 10: unsigned long skip; 11: unsigned long target; 12: const unsigned short MAXSMALL=65535; 13: 14: cout << "Wpisz mniejsza liczbe: "; 15: cin >> small; 16: cout << "Wpisz wieksza liczbe: "; 17: cin >> large; 18: cout << "Wpisz liczbe pomijana: "; 19: cin >> skip; 20: cout << "Wpisz liczbe docelowa: "; 21: cin >> target; 22: 23: cout << "\n"; 24: 25: // ustalamy dla pętli trzy warunki zatrzymania 26: while (small < large && large > 0 && small < MAXSMALL) 27: 28: { 29: 30: small++; 31: 32: if (small % skip == 0) // pomijamy zmniejszanie? 33: { 34: cout << "pominieto dla " << small << endl; 35: continue; 36: } 37: 38: if (large == target) // osiągnięto wartość docelową? 39: {

40: cout << "Osiagnieto wartosc docelowa!"; 41: break; 42: } 43: 44: large-=2; 45: } // koniec pętli while 46: 47: cout << "\nMniejsza: " << small << " Wieksza: " << large << endl; 48: return 0; 49: }
Wynik Wpisz mniejsza liczbe: 2 Wpisz wieksza liczbe: 20 Wpisz liczbe pomijana: 4 Wpisz liczbe docelowa: 6 pominieto dla 4 pominieto dla 8 Mniejsza: 10 Wieksza: 8
Analiza
W tej grze użytkownik przegrał; zmienna small (mała) stała się większa, zanim zmienna large (większa) zrównała się z liczbą docelową 6.
W linii 26. są sprawdzane warunki instrukcji while. Jeśli zmienna small jest mniejsza od zmiennej large, zmienna large jest większa od zera, a zmienna small nie przekroczyła maksymalnej wartości dla krótkich liczb całkowitych (short), program wchodzi do ciała pętli.
W linii 32. jest obliczana reszta z dzielenia (modulo) wartości zmiennej small przez wartość pomijaną. Jeśli zmienna small jest wielokrotnością zmiennej skip (pomiń), wtedy wykonywana jest instrukcja continue i program wraca do początku pętli, do linii 26. W efekcie pominięte zostają: sprawdzanie wartości docelowej i zmniejszanie zmiennej large.
W linii 38. następuje porównanie zmiennej target (docelowa) ze zmienną large. Jeśli są równe, wygrywa użytkownik. Wypisywany jest wtedy komunikat i wykonywana jest instrukcja break. Powoduje ona natychmiastowe wyjście z pętli i kontynuację wykonywania programu od linii 46.
UWAGA Instrukcje continue oraz break powinny być używane ostrożnie. Wraz z goto stanowią one dwie najbardziej niebezpieczne instrukcje języka (są one niebezpieczne z tych samych powodów co instrukcja goto). Programy zmieniające nagle kierunek działania są trudniejsze do zrozumienia, a używanie instrukcji continue i break według własnego uznania może uniemożliwić analizę nawet niewielkich pętli while.
Instrukcja continue
Usunięto: małych

continue;
Powoduje pominięcie pozostałych instrukcji pętli while lub for i powrót do początku pętli. Przykład użycia tej instrukcji znajduje się na listingu 7.4.
Instrukcja break
break;
Powoduje natychmiastowe wyjście z pętli while lub for. Wykonanie programu przechodzi do zamykającego nawiasu klamrowego.
Przykład
while (warunek) { if (warunek2) break; // instrukcje }
Pętla while(true) Sprawdzanym w pętli while warunkiem może być każde poprawne wyrażenie języka C++. Dopóki ten warunek pozostanie spełniony, działanie pętli while nie zostanie przerwane. Używając wartości true jako wyrażenia w instrukcji while, możesz stworzyć pętlę, która będzie wykonywana bez końca. Listing 7.5 przedstawia liczenie do 10 za pomocą takiej konstrukcji języka.
Listing 7.5. Pętla while 0: // Listing 7.5 1: // Demonstruje pętlę (true) 2: 3: #include <iostream> 4: 5: int main() 6: { 7: int counter = 0; 8: 9: while (true) 10: { 11: counter ++; 12: if (counter > 10) 13: break; 14: } 15: std::cout << "Licznik: " << counter << "\n";

16: return 0; 17: }
Wynik Licznik: 11
Analiza
W linii 9. rozpoczyna się pętla while z warunkiem, który zawsze jest spełniony. W linii 11. pętla inkrementuje wartość zmiennej licznikowej, po czym w linii 12. sprawdza, czy licznik przekroczył wartość 10. Jeśli nie, działanie pętli trwa. Jeśli licznik przekroczy wartość 10, wtedy instrukcja break w linii 13. powoduje wyjście z pętli, a działanie programu przechodzi do linii 15., w której wypisywany jest komunikat końcowy.
Program działa, lecz nie jest elegancki – stanowi dobry przykład użycia złego narzędzia. Ten sam efekt można osiągnąć, umieszczając funkcję sprawdzania wartości licznika tam, gdzie powinna się ona znaleźć — w warunku instrukcji while.
OSTRZEŻENIE Niekończące się pętle, takie jak while(true), mogą doprowadzić do zawieszenia się komputera gdy warunek wyjścia nie zostanie nigdy spełniony. Używaj ich ostrożnie i dokładnie testuj ich działanie.
C++ oferuje wiele sposobów wykonania danego zadania. Prawdziwa sztuka polega na wybraniu odpowiedniego narzędzia dla odpowiedniego zadania.
TAK NIE
W celu wykonywania pętli, dopóki spełniony jest warunek, używaj pętli while.
Bądź ostrożny używając instrukcji continue i break.
Upewnij się, czy pętla while w pewnym momencie kończy działanie.
Nie używaj instrukcji goto.
Pętla do...while Istnieje możliwość, że ciało pętli while nigdy nie zostanie wykonane. Instrukcja while sprawdza swój warunek przed wykonaniem którejkolwiek z zawartych w niej instrukcji, a gdy ten warunek nie jest spełniony, całe ciało pętli jest pomijane. Ilustruje to listing 7.6.
Listing 7.6. Pominięcie ciała pętli while 0: // Listing 7.6 1: // Demonstruje pominięcie ciała pętli while 2: // w momencie, gdy warunek nie jest spełniony.

3: 4: #include <iostream> 5: 6: int main() 7: { 8: 9: int counter; 10: std::cout << "Ile pozdrowien?: "; 11: std::cin >> counter; 12: while (counter > 0) 13: { 14: std::cout << "Hello!\n"; 15: counter--; 16: } 17: std::cout << "Wartosc licznika: " << counter; 18: return 0; 19: }
Wynik Ile pozdrowien?: 2 Hello! Hello! Wartosc licznika: 0 Ile pozdrowien?: 0 Wartosc licznika: 0
Analiza
W linii 10. użytkownik jest proszony o wpisanie wartości początkowej. Ta wartość jest umieszczana w zmiennej całkowitej counter (licznik). Wartość licznika jest sprawdzana w linii 12. i dekrementowana w ciele pętli while. Za pierwszym razem wartość licznika została ustawiona na 2, dlatego ciało pętli while zostało wykonane dwukrotnie. Jednak za drugim razem użytkownik wpisał 0. Wartość licznika została sprawdzona w linii 12. i tym razem warunek nie został spełniony; tj. zmienna counter nie była większa od zera. Zostało więc pominięte całe ciało pętli i komunikat „Hello” nie został wypisany ani razu.
Co zrobić komunikat „Hello” został wypisany co najmniej raz? Nie może tego zapewnić pętla while, gdyż jej warunek jest sprawdzany przed wypisywaniem komunikatu. Można to osiągnąć umieszczając instrukcję if przed pętlą while:
if (counter < 1) // wymuszamy minimalną wartość counter = 1;
ale to rozwiązanie nie jest zbyt eleganckie.

do...while Pętla do...while (wykonuj...dopóki) wykonuje ciało pętli przed sprawdzeniem warunku i sprawia że instrukcje w pętli zostaną wykonane co najmniej raz. Listing 7.7 stanowi zmodyfikowaną wersję listingu 7.6, w której została użyta pętla do...while.
Listing 7.7. Przykład pętli do...while. 0: // Listing 7.7 1: // Demonstruje pętlę do...while 2: 3: #include <iostream> 4: 5: int main() 6: { 7: using namespace std; 8: int counter; 9: cout << "Ile pozdrowien? "; 10: cin >> counter; 11: do 12: { 13: cout << "Hello\n"; 14: counter--; 15: } while (counter >0 ); 16: cout << "Licznik ma wartosc: " << counter << endl; 17: return 0; 18: }
Wynik Ile pozdrowien? 2 Hello Hello Licznik ma wartosc: 0
Analiza
W linii 9. użytkownik jest proszony o wpisanie początkowej wartości, która jest umieszczana w zmiennej counter. W pętli do...while, ciało pętli jest wykonywane przed sprawdzeniem warunku, dlatego w każdym przypadku zostanie wykonane co najmniej raz. W linii 13. wypisywany jest komunikat, w linii 14. dekrementowany jest licznik, zaś dopiero w linii 15. następuje sprawdzenie warunku. Jeśli warunek jest spełniony, wykonanie programu wraca do początku pętli w linii 13.; w przeciwnym razie przechodzi do linii 16.
Instrukcje break i continue w pętlach do...while działają tak jak w pętli loop. Jedyna różnica pomiędzy pętlą while a pętlą do...while pojawia się w chwili sprawdzania warunku.
Instrukcja do...while
Składnia instrukcji do...while jest następująca:
do instrukcja while (warunek);

Wykonywana jest instrukcja, po czym sprawdzany jest warunek. Jeśli warunek jest spełniony, pętla jest powtarzana; w przeciwnym razie jej działanie się kończy. Pod innymi względami instrukcje i warunki są identyczne, jak w pętli while.
Przykład 1
// liczymy do 10 int x = 0; do cout << "X: " << x++; while (x < 10);
Przykład 2
// wypisujemy małe litery alfabetu char ch = 'a'; do { cout << ch << ' '; ch++; } while ( ch <= 'z' );
TAK
Używaj pętli do...while, gdy chcesz mieć pewność że pętla zostanie wykonana co najmniej raz.
Używaj pętli while, gdy chcesz pominąć pętlę (gdy warunek nie jest spełniony).
Sprawdzaj wszystkie pętle, aby mieć pewność, że robią to, czego oczekujesz.
Pętle for Gdy korzystasz z pętli while, ustawiasz warunek początkowy, sprawdzasz, czy jest spełniony, po czym w każdym wykonaniu pętli inkrementujesz lub w inny sposób zmieniasz zmienną kontrolującą jej wykonanie. Demonstruje to listing 7.8.
Listing 7.8. Następna pętla while 0: // Listing 7.8 1: // Pętla while 2: 3: #include <iostream> 4: 5: int main() 6: { 7: 8: int counter = 0;

9: 10: while(counter < 5) 11: { 12: counter++; 13: std::cout << "Petla! "; 14: } 15: 16: std::cout << "\nLicznik: " << counter << ".\n"; 17: return 0; 18: }
Wynik Petla! Petla! Petla! Petla! Petla! Licznik: 5.
Analiza
W linii 8. ustawiany jest warunek: zmienna counter (licznik) ustawiana jest na zero. W linii 10. następuje sprawdzenie, czy licznik jest mniejszy od 5. Inkrementacja licznika odbywa się w linii 12. W linii 16. wypisywany jest prosty komunikat, ale można przypuszczać, że przy każdej inkrementacji licznika można wykonać bardziej konkretną pracę.
Pętla for (dla) łączy powyższe trzy etapy w jedną instrukcję. Są to: inicjalizacja, test i inkrementacja. Pętla for składa się ze słowa kluczowego for, po którym następuje para nawiasów. Wewnątrz nawiasów znajdują się trzy, oddzielone średnikami, instrukcje.
Pierwsza instrukcja służy do inicjalizacji. Można w niej umieścić każdą poprawną instrukcję języka C++, ale zwykle po prostu tworzy się i inicjalizuje zmienną licznikową. Drugą instrukcją jest test, którym może być każde poprawne wyrażenie języka. Pełni ono taką samą funkcję, jak warunek w pętli while. Trzecia instrukcja jest działaniem. Zwykle w jego wyniku wartość zmiennej licznikowej jest zwiększana lub zmniejszana, ale oczywiście można tu zastosować każdą poprawną instrukcję języka C++. Zwróć uwagę, że instrukcje pierwsza i trzecia mogą być dowolnymi instrukcjami, lecz druga instrukcja musi być wyrażeniem — czyli instrukcją języka C++, zwracającą wartość. Pętlę for demonstruje listing 7.9.
Listing 7.9. Przykład pętli for 0: // Listing 7.9 1: // Pętla for 2: 3: #include <iostream> 4: 5: int main() 6: { 7: 8: int counter; 9: for (counter = 0; counter < 5; counter++) 10: std::cout << "Petla! "; 11: 12: std::cout << "\nLicznik: " << counter << ".\n"; 13: return 0; 14: }
Wynik Petla! Petla! Petla! Petla! Petla!

Licznik: 5.
Analiza
Instrukcja for w linii 9. łączy w sobie inicjalizację zmiennej counter, sprawdzenie, czy jej wartość jest mniejsza od 5, oraz inkrementację tej zmiennej. Ciało pętli for znajduje się w linii 10. Oczywiście, w tym miejscu mógłby zostać użyty blok instrukcji.
Składnia pętli for
Składnia instrukcji for jest następująca:
for (inicjalizacja; test; akcja ) instrukcja;
Instrukcja inicjalizacja jest używana w celu zainicjalizowania stanu licznika lub innego przygotowania do wykonania pętli. Instrukcja test jest dowolnym wyrażeniem języka C++, które jest obliczane przed każdym wykonaniem zawartości pętli. Jeśli wyrażenie test ma wartość true, wykonywane jest ciało pętli, po czym wykonywana jest instrukcja akcja z nagłówka pętli (zwykle po prostu następuje inkrementacja zmiennej licznikowej).
Przykład 1
// dziesięć razy wpisuje napis "Hello" for (int i = 0; i < 10; i++) cout << "Hello! ";
Przykład 2
for (int i = 0; i < 10; i++) { cout << "Hello!" << endl; cout << "wartoscia i jest: " << i << endl; }
Zaawansowane pętle for Instrukcje for są wydajne i działają w sposób elastyczny. Trzy niezależne instrukcje (inicjalizacja, test i akcja) umożliwiają stosowanie różnorodnych rozwiązań.
Pętla for działa w następującej kolejności:
1. Przeprowadza inicjalizację.
2. Oblicza wartość warunku .
3. Jeśli warunek ma wartość true, wykonuje ciało pętli, a następnie wykonuje instrukcję akcji.
Przy każdym wykonaniu pętli powtarzane są kroki 2 i 3.
Usunięto: i
Usunięto: wyrażenie
Usunięto: wyrażenie

Wielokrotna inicjalizacja i inkrementacja Inicjalizowanie więcej niż jednej zmiennej, testowanie złożonego wyrażenia logicznego czy wykonywanie więcej niż jednej instrukcji nie są niczym niezwykłym. Inicjalizacja i akcja mogą być zastąpione kilkoma instrukcjami C++, oddzielonymi od siebie przecinkami. Listing 7.10 przedstawia inicjalizację i inkrementację dwóch zmiennych.
Listing 7.10. Przykład instrukcji wielokrotnych w pętli for 0: //listing 7.10 1: // demonstruje wielokrotne instrukcje 2: // w pętli for 3: 4: #include <iostream> 5: 6: int main() 7: { 8: 9: for (int i=0, j=0; i<3; i++, j++) 10: std::cout << "i: " << i << " j: " << j << std::endl; 11: return 0; 12: }
Wynik i: 0 j: 0 i: 1 j: 1 i: 2 j: 2
Analiza
W linii 9. dwie zmienne, i oraz j, są inicjalizowane wartością 0. Obliczany jest test (i < 3); ponieważ jest prawdziwy, wykonywane jest ciało pętli for, w którym wypisywane są wartości zmiennych. Na koniec wykonywana jest trzecia klauzula instrukcji for, w której są inkrementowane zmienne i oraz j.
Po wykonaniu linii 10., warunek jest sprawdzany ponownie, jeśli wciąż jest spełniony, działania się powtarzają (inkrementowane są zmienne i oraz j) i ponownie wykonywane jest ciało pętli. Dzieje się tak do momentu, w którym warunek nie będzie spełniony; wtedy nie jest wykonywana instrukcja akcji, a działanie programu wychodzi z pętli.
Puste instrukcje w pętli for Każdą z instrukcji w nagłówku pętli for można pominąć. W tym celu należy oznaczyć jej położenie średnikiem (;). Aby stworzyć pętlę for, która działa dokładnie tak, jak pętla while, pomiń pierwszą i trzecią instrukcję. Przedstawia to listing 7.11.
Listing 7.11. Puste instrukcje w nagłówku pętli for 0: // Listing 7.11 1: // Pętla for z pustymi instrukcjami 2: 3: #include <iostream> 4: 5: int main() 6: { 7: 8: int counter = 0;

9: 10: for( ; counter < 5; ) 11: { 12: counter++; 13: std::cout << "Petla! "; 14: } 15: 16: std::cout << "\nLicznik: " << counter << ".\n"; 17: return 0; 19: }
Wynik Petla! Petla! Petla! Petla! Petla! Licznik: 5.
Analiza
Być może poznajesz, że ta pętla wygląda dokładnie tak, jak pętla while z listingu 7.8. W linii 8. inicjalizowana jest zmienna counter. Instrukcja for w linii 10. nie inicjalizuje żadnych wartości, lecz zawiera test warunku counter < 5. Nie występuje także instrukcja inkrementacji, więc ta pętla działa dokładnie tak samo, gdybyśmy napisali:
while (counter < 5)
Jak już wiesz, C++ oferuje kilka sposobów osiągnięcia tego samego celu. Żaden doświadczony programista C++ nie użyłby pętli for w ten sposób, przykład ten ilustruje jedynie elastyczność instrukcji for. W rzeczywistości, dzięki zastosowaniu instrukcji break i continue, istnieje możliwość stworzenia pętli for bez żadnej instrukcji w nagłówku. Pokazuje to listing 7.12.
Listing 7.12. Instrukcja for z pustym nagłówkiem 0: //Listing 7.12 ilustruje 1: //instrukcję for z pustym nagłówkiem 2: 3: #include <iostream> 4: 5: int main() 6: { 7: 8: int counter=0; // inicjalizacja 9: int max; 10: std::cout << "Ile pozdrowień?"; 11: std::cin >> max; 12: for (;;) // pętla, która się nie kończy 13: { 14: if (counter < max) // test 15: { 16: std::cout << "Hello!\n"; 17: counter++; // inkrementacja 18: } 19: else 20: break; 21: } 22: return 0; 23: }

Wynik Ile pozdrowien?3 Hello! Hello! Hello!
Analiza
Z tej pętli usunęliśmy wszystko, co się dało. Inicjalizacja, test i akcja zostały przeniesione poza instrukcję for. Inicjalizacja odbywa się w linii 8., przed pętlą for. Test jest przeprowadzany w osobnej instrukcji if, w linii 14., i gdy się powiedzie, w linii 17. jest wykonywana akcja, czyli inkrementacja zmiennej counter. Jeśli warunek nie jest spełniony, w linii 20. następuje wyjście z pętli (spowodowane użyciem instrukcji break).
Choć program ten jest nieco absurdalny, jednak czasem pętle for(;;) lub while(true) są właśnie tym, czego nam potrzeba. Bardziej sensowny przykład wykorzystania takiej pętli zobaczysz w dalszej części rozdziału, przy okazji omawiania instrukcji switch.
Puste pętle for Ponieważ w samym nagłówku pętli for można wykonać tak wiele pracy, więc czasem ciało pętli może już niczego nie robić. Dlatego pamiętaj o zastosowaniu instrukcji pustej (;) jako ciała funkcji. Średnik może zostać umieszczony w tej samej linii, co nagłówek pętli, ale wtedy łatwo go przeoczyć. Użycie pętli for z pustym ciałem przedstawia listing 7.13.
Listing 7.13. Instrukcja pusta w ciele pętli for. 0: //Listing 7.13 1: //Demonstruje instrukcję pustą 2: // w ciele pętli for 3: 4: #include <iostream> 5: int main() 6: { 7: 8: for (int i = 0; i<5; std::cout << "i: " << i++ << std::endl) 9: ; 10: return 0; 11: }
Wynik i: 0 i: 1 i: 2 i: 3 i: 4
Analiza
Pętla for w linii 8. zawiera trzy instrukcje. Instrukcja inicjalizacji definiuje i inicjalizuje zmienną licznikową i wartością 0. Instrukcja warunku sprawdza, czy i < 5, zaś instrukcja akcji wypisuje wartość zmiennej i oraz inkrementuje ją.

Ponieważ ciało pętli nie wykonuje żadnych czynności, użyto w nim instrukcji pustej (;). Zwróć uwagę, że ta pętla for nie jest najlepiej zaprojektowana: instrukcja akcji wykonuje zbyt wiele pracy. Lepiej więc byłoby zmienić tę pętlę w następujący sposób:
8: for (int i = 0; i<5; i++) 9: std::cout << "i: " << i << std::endl;
Choć obie wersje działają tak samo, druga z nich jest łatwiejsza do zrozumienia.
Pętle zagnieżdżone Pętle mogą być zagnieżdżone, tj. pętla może znajdować się w ciele innej pętli. Pętla wewnętrzna jest wykonywana wielokrotnie, przy każdym wykonaniu pętli zewnętrznej. Listing 7.14 przedstawia zapisywanie znaczników do macierzy, za pomocą zagnieżdżonych pętli for.
Listing 7.14. Zagnieżdżone pętle for 0: //Listing 7.14 1: //Ilustruje zagnieżdżone pętle for 2: 3: #include <iostream> 4: 5: int main() 6: { 7: using namespace std; 8: int rows, columns; 9: char theChar; 10: cout << "Ile wierszy? "; 11: cin >> rows; 12: cout << "Ile kolumn? "; 13: cin >> columns; 14: cout << "Jaki znak? "; 15: cin >> theChar; 16: for (int i = 0; i<rows; i++) 17: { 18: for (int j = 0; j<columns; j++) 19: cout << theChar; 20: cout << "\n"; 21: } 22: return 0; 23: }
Wynik Ile wierszy? 4 Ile kolumn? 12 Jaki znak? x xxxxxxxxxxxx xxxxxxxxxxxx xxxxxxxxxxxx xxxxxxxxxxxx
Analiza
Użytkownik jest proszony o podanie ilości wierszy i kolumn oraz znaku, jaki ma zostać użyty do wydrukowania zarysu macierzy. Pierwsza pętla for, w linii 16., ustawia wartość początkową licznika (i) na 0, po czym przechodzi do wykonania ciała zewnętrznej pętli.
W linii 18., pierwszej linii ciała zewnętrznej pętli for, tworzona jest kolejna pętla for. Jest w niej inicjalizowany drugi licznik (j), także wartością 0, po czym program przechodzi do wykonania ciała pętli wewnętrznej. W linii 19. wypisywany jest wybrany znak, a program wraca do nagłówka wewnętrznej pętli. Zwróć uwagę, że wewnętrzna pętla for posiada tylko jedną instrukcję (wypisującą znak). Gdy sprawdzany warunek jest spełniony (j < columns), zmienna j jest inkrementowana i wypisywany jest następny znak. Czynność powtarzana jest tak długo, aż j zrówna się z ilością kolumn.
Gdy warunek w wewnętrznej pętli nie zostanie spełniony (w tym przypadku po wypisaniu dwunastu znaków), wykonanie programu przechodzi do linii 20., w której wypisywany jest znak nowej linii. Następuje powrót do nagłówka pętli zewnętrznej, w którym odbywa się sprawdzenie warunku (i < rows). Jeśli ten warunek zostaje spełniony, zmienna i jest inkrementowana i ponownie wykonywane jest ciało pętli.
W drugiej iteracji zewnętrznej pętli for ponownie rozpoczyna się wykonanie pętli wewnętrznej. Zmiennej j ponownie przypisywana jest wartość 0 i cała pętla wykonywana jest jeszcze raz.
Powinieneś zwrócić uwagę, że wewnętrzna pętla jest wykonywana w całości przy każdym wykonaniu pętli zewnętrznej. Dlatego wypisywanie znaku powtarza się (columns · rows) razy.
UWAGA Wielu programistów nadaje zmiennym licznikowym nazwy i oraz j. Ta tradycja sięga czasów języka FORTRAN, w którym jedynymi zmiennymi licznikowymi były zmienne i, j, k, l, m oraz n.
Inni programiści wolą używać dla zmiennych licznikowych bardziej opisowych nazw, takich jak licznik1 czy licznik2. Jednak zmienne i oraz j są tak popularne, że nie powodują żadnych nieporozumień, gdy zostaną użyte w nagłówkach pętli for.
Zakres zmiennych w pętlach for W przeszłości zakres zmiennych zadeklarowanych w pętlach for rozciągał się także na blok zewnętrzny. Standard ANSI ograniczył ten zakres do bloku pętli for (nie gwarantują tego jednak wszystkie kompilatory). Możesz sprawdzić swój kompilator za pomocą poniższego kodu:
#inlude <iostream> int main() { // czy i ogranicza się tylko do pętli for? for (int i = 0; i < 5; i++) { std::cout << "i: " << i << std::endl; } i = 7; // nie powinno być w tym zakresie! return 0;
Usunięto: wypisania
Usunięto: inicjalizuje
Usunięto: oznacza

}
Jeśli kod skompiluje się bez kłopotów, oznacza to, że twój kompilator nie obsługuje tego aspektu standardu ANSI.
Jeśli kompilator zaprotestuje, że i nie jest zdefiniowane (w linii i = 7), oznacza to, że obsługuje nowy standard. Aby stworzyć kod, który skompiluje się za każdym razem, możesz zmienić go następująco:
#inlude <iostream> int main() { int i; // zadeklarowane poza pętlą for (i = 0; i < 5; i++) { std::cout << "i: " << i << std::endl; } i = 7; // teraz jest w zakresie w każdym kompilatorze return 0; }
Podsumowanie pętli W rozdziale 5., „Funkcja,” nauczyłeś się, jak rozwiązywać problem ciągu Fibonacciego za pomocą rekurencji. Dla przypomnienia: ciąg Fibonacciego rozpoczyna się od wyrazów 1, 1, 2, 3..., zaś każde kolejne wyrazy stanowią sumę dwóch poprzednich:
1, 1, 2, 3, 5, 8, 13, 21, 34...
N-ty wyraz ciągu jest sumą wyrazów n-1 i n-2. Problemem rozwiązywanym w rozdziale piątym było obliczenie wartości n-tego wyrazu ciągu. W tym celu używaliśmy rekurencji. Tym razem, jak pokazuje listing 7.15, użyjemy iteracji.
Listing 7.15. Obliczanie wyrazów ciągu Fibonacciego za pomocą iteracji. 0: // Listing 7.15 1: // Demonstruje obliczanie wartości n-tego 2: // wyrazu ciągu Fibonacciego za pomocą iteracji 3: 4: #include <iostream> 5: 6: int fib(int position); 7: int main() 8: { 9: using namespace std; 10: int answer, position; 11: cout << "Ktory wyraz ciagu? ";

12: cin >> position; 13: cout << "\n"; 14: 15: answer = fib(position); 16: cout << position << " wyraz ciagu Fibonacciego "; 17: cout << "ma wartosc " << answer << ".\n"; 18: return 0; 19: } 20: 21: int fib(int n) 22: { 23: int minusTwo=1, minusOne=1, answer=2; 24: 25: if (n < 3) 26: return 1; 27: 28: for (n -= 3; n; n--) 29: { 30: minusTwo = minusOne; 31: minusOne = answer; 32: answer = minusOne + minusTwo; 33: } 34: 35: return answer; 36: }
Wynik Ktory wyraz ciagu? 4 4 wyraz ciagu Fibonacciego ma wartosc 3. Ktory wyraz ciagu? 5 5 wyraz ciagu Fibonacciego ma wartosc 5. Ktory wyraz ciagu? 20 20 wyraz ciagu Fibonacciego ma wartosc 6765. Ktory wyraz ciagu? 30 30 wyraz ciagu Fibonacciego ma wartosc 832040.
Analiza
W listingu 7.15 obliczyliśmy wartości wyrazów ciągu Fibonacciego, stosując iterację zamiast rekurencji. Ta metoda jest szybsza i zajmuje mniej pamięci niż rekurencja.
W linii 11. użytkownik jest proszony o podanie numeru wyrazu ciągu. Następuje wywołanie funkcji fib(), która oblicza wartość tego wyrazu. Jeśli numer wyrazu jest mniejszy od 3, funkcja zwraca wartość 1. Począwszy od trzeciego wyrazu, funkcja iteruje (działa w pętli), używając następującego algorytmu:
1. Ustawia pozycję wyjściową: przypisuje zmiennej answer (wynik) wartość 2, zaś zmiennym minusTwo (minus dwa) i minusOne (minus jeden) wartość 1. Zmniejsza numer wyrazu o trzy, gdyż pierwsze dwa wyrazy zostały już obsłużone przez pozycję wyjściową.
2. Dla każdego wyrazu, aż do wyrazu poszukiwanego, obliczana jest wartość ciągu Fibonacciego. Odbywa się to poprzez:
a. Przypisanie bieżącej wartości zmiennej minusOne do zmiennej minusTwo.
b. Przypisanie bieżącej wartości zmiennej answer do zmiennej minusOne.

c. Zsumowanie wartości zmiennych minusOne oraz minusTwo i przypisanie tej sumy zmiennej answer.
d. Dekrementację zmiennej licznikowej n.
3. Gdy zmienna n osiągnie zero, funkcja zwraca wartość zmiennej answer.
Dokładnie tak samo rozwiązywalibyśmy ten problem na papierze. Gdybyś został poproszony o podanie wartości piątego wyrazu ciągu Fibonacciego, napisałbyś:
1, 1, 2,
i pomyślałbyś: „jeszcze dwa wyrazy.” Następnie dodałbyś 2+1 i dopisałbyś 3, myśląc: „Jeszcze jeden.” Na koniec dodałbyś 3+2 i otrzymałbyś w wyniku 5. Rozwiązanie tego zadania polega na każdorazowym przesuwaniu operacji sumowania w prawo i zmniejszaniu ilości pozostałych do obliczenia wyrazów ciągu.
Zwróć uwagę na warunek sprawdzany w linii 28. (n). Jest to idiom języka C++, który stanowi odpowiednik n != 0. Ta pętla for jest wykonywana, dopóki wartość n nie osiągnie zera (które odpowiada wartości logicznej false). Zatem nagłówek tej pętli for mógłby zostać przepisany następująco:
for (n -=3; n != 0; n--)
dzięki temu pętla byłaby bardziej czytelna. Jednak ten idiom jest tak popularny, że nie ma sensu z nim walczyć.
Skompiluj, zbuduj i uruchom ten program, po czym porównaj jego działanie z korzystającym z rekurencji programem z rozdziału piątego. Spróbuj obliczyć wartość 25. wyrazu ciągu i porównaj czas działania obu programów. Rekurencja to elegancka metoda, ale ponieważ z wywołaniem funkcji wiąże się pewien narzut, i ponieważ jest ona wywoływana tak wiele razy, metoda ta jest wolniejsza od iteracji. Wykonywanie operacji arytmetycznych na mikrokomputerach zostało zoptymalizowane, dlatego rozwiązania iteracyjne powinny działać bardzo szybko.
Uważaj, by nie wpisać zbyt wysokiego numeru wyrazu ciągu. Ciąg Fibonacciego rośnie bardzo szybko i nawet przy niewielkich wartościach zmienne całkowite typu long zostają przepełnione.
Instrukcja Switch Z rozdziału 4. dowiedziałeś się jak korzystać z instrukcji if i else. Gdy zostaną one zbyt głęboko zagnieżdżone, stają się całkowicie niezrozumiałe. Na szczęście C++ oferuje pewną alternatywę. W odróżnieniu od instrukcji if, ,która sprawdza jedną wartość, instrukcja switch (przełącznik) umożliwia podjęcie działań na podstawie jednej z wielu różnych wartości. Ogólna postać instrukcji switch wygląda następująco:

switch (wyrażenie) { case wartośćJeden: instrukcja; break; case wartośćDwa: instrukcja; break; .... case wartośćN: instrukcja; break; default: instrukcja; }
wyrażenie jest dowolnym wyrażeniem języka C++, zaś jego instrukcje są dowolnymi instrukcjami lub blokami instrukcji, pod warunkiem jednak, że ich wynikiem jest liczba typu integer (lub jej wynik jest jednoznacznie konwertowalny do takiej liczby).. Należy również pamiętać, że instrukcja switch sprawdza jedynie równość wyrażenia; nie można stosować operatorów relacji ani operacji logicznych.
Jeśli któraś z wartości case jest równa wartości wyrażenia, program przechodzi do instrukcji tuż po tej wartości case i jego wykonanie jest kontynuowane aż do napotkania instrukcji break (przerwij). Jeśli wartość wyrażenia nie pasuje do żadnej z wartości case, wykonywana jest instrukcja default (domyślna). Jeśli nie występuje default i wartość wyrażenia nie pasuje do żadnej z wartości case, instrukcja switch nie spowoduje żadnej akcji i program przechodzi do następnych instrukcji w kodzie.
UWAGA Stosowanie w instrukcji switch przypadku default jest dobrym pomysłem. Jeśli nie znajdziesz dla niego innego zastosowania, użyj go do wykrycia sytuacji, której wystąpienie nie było przewidziane; wypisz wtedy odpowiedni komunikat błędu. Może to być bardzo pomocne podczas debuggowania programu.
Należy pamiętać, że w przypadku braku instrukcji break na końcu bloku instrukcji (po case), wykonanie przechodzi także do następnego przypadku case. Czasem takie działanie jest zamierzone, ale zwykle jest po prostu błędem. Jeśli zdecydujesz się na wykonanie instrukcji w kilku kolejnych przypadkach case, pamiętaj o umieszczeniu obok komentarza, który wyjaśni, że nie pominąłeś instrukcji break przypadkowo.
Listing 7.16 przedstawia użycie instrukcji switch.
Listing 7.16. Przykład instrukcji switch 0: //Listing 7.16 1: // Demonstruje instrukcję switch 2: 3: #include <iostream> 4: 5: int main() 6: { 7: using namespace std; 8: unsigned short int number; 9: cout << "Wpisz liczbe pomiedzy 1 i 5: "; 10: cin >> number; 11: switch (number) 12: { 13: case 0: cout << "Za mala, przykro mi!";
Usunięto: Wartości muszą być stałymi (literałami lub wyrażeniami o stałej wartości)
Usunięto: jednak
Usunięto: jedynie czy wartośća
Usunięto: odpowiada którejś z wartości
Usunięto: w związanej z nią klauzuli
Usunięto: klauzul
Usunięto: klauzula
Usunięto: y
Usunięto: klauzula
Usunięto: klauzul
Usunięto: a
Usunięto: jest pomijana
Usunięto: klauzuli
Usunięto: j
Usunięto: jej
Usunięto: w
Usunięto: klauzuli
Usunięto: j
Usunięto: klauzuli
Usunięto: klauzulach

14: break; 15: case 5: cout << "Dobra robota!\n"; // przejście dalej 16: case 4: cout << "Niezle!\n"; // przejście dalej 17: case 3: cout << "Wysmienicie!\n"; // przejście dalej 18: case 2: cout << "Cudownie!\n"; // przejście dalej 19: case 1: cout << "Niesamowicie!\n"; 20: break; 21: default: cout << "Zbyt duza!\n"; 22: break; 23: } 24: cout << "\n\n"; 25: return 0; 26: }
Wynik Wpisz liczbe pomiedzy 1 i 5: 3 Wysmienicie! Cudownie! Niesamowicie! Wpisz liczbe pomiedzy 1 i 5: 8 Zbyt duza!
Analiza
Użytkownik jest proszony o podanie liczby. Ta liczba jest przekazywana do instrukcji switch. Jeśli ma wartość 0, odpowiada klauzuli case w linii 13., dlatego jest wypisywany komunikat: „Za mala, przykro mi!”, po czym instrukcja break kończy działanie instrukcji switch. Jeśli liczba ma wartość 5, wykonanie przechodzi do linii 15., w której wypisywany jest odpowiedni komunikat, po czym przechodzi do linii 16., w której wypisywany jest kolejny komunikat, i tak dalej, aż do napotkania instrukcji break w linii 20.
Efektem działania tej instrukcji switch dla liczb pomiędzy 1 a 5 jest wypisanie odpowiadającej ilości komunikatów. Jeśli wartością liczby nie jest ani 0 ani 5, zakłada się, że jest ona zbyt duża i w takim przypadku w linii 21. wykonywana jest instrukcja klauzuli default.
Instrukcja switch
Składnia instrukcji switch jest następująca:
switch (wyrażenie) { case wartośćJeden: instrukcja; case wartośćDwa: instrukcja; .... case wartośćN: instrukcja; default: instrukcja; }

Instrukcja switch umożliwia rozgałęzienie programu (w zależności od wartości wyrażenia). Na początku wykonywania instrukcji następuje obliczenie wartości wyrażenia, gdy odpowiada ona którejś z wartości przypadku case, wykonanie programu przechodzi do tego właśnie przypadku. Wykonywanie instrukcji jest kontynuowane aż do końca ciała instrukcji switch lub do czasu napotkania instrukcji break.
Jeśli wartość wyrażenia nie odpowiada żadnej z wartości przypadków case i występuje przypadek default, wykonanie przechodzi do przypadku default. W przeciwnym razie wykonywanie instrukcji switch się kończy.
Przykład 1
switch (wybor) { case 0: cout << "Zero!" << endl; break; case 1: cout << "Jeden!" << endl; break; case 2: cout << "Dwa!" << endl; break; default: cout << "Domyślna!" << endl; }
Przykład 2
switch (wybor) { case 0: case 1: case 2: cout << "Mniejsza niż 3!"; break; case 3: cout << "Równa 3!"; break; default: cout << "Większa niż 3!"; }
Użycie instrukcji switch w menu Listing 7.17 wykorzystuje omawianą wcześniej pętli for(;;). Takie pętle są nazywane pętlami nieskończonymi, gdyż są wykonywane bez końca, aż do natrafienia na kończącą ich działanie instrukcję. Pętla nieskończona jest używana do tworzenia menu, pobrania polecenia od użytkownika, wykonania odpowiednich działań i powrót do menu. Jej działanie powtarza się dopóty, dopóki użytkownik nie zdecyduje się na wyjście z menu.
Usunięto: klauzul
Usunięto: danej klauzuli
Usunięto: i
Usunięto: klauzul
Usunięto: klauzula
Usunięto: klauzuli

UWAGA Niektórzy programiści wolą pisać:
#define EVER ;; for (EVER) { // instrukcje... }
Pętla nieskończona nie posiada warunku wyjścia. Aby opuścić taką pętlę, należy użyć instrukcji break. Pętle nieskończone są także zwane pętlami wiecznymi.
Listing 7.17. Przykład pętli nieskończonej 0: //Listing 7.17 1: //Używa nieskończonej pętli do 2: //interakcji z użytkownikiem 3: #include <iostream> 4: 5: // prototypy 6: int menu(); 7: void DoTaskOne(); 8: void DoTaskMany(int); 9: 10: using namespace std; 11: 12: int main() 13: { 14: bool exit = false; 15: for (;;) 16: { 17: int choice = menu(); 18: switch(choice) 19: { 20: case (1): 21: DoTaskOne(); 22: break; 23: case (2): 24: DoTaskMany(2); 25: break; 26: case (3): 27: DoTaskMany(3); 28: break; 29: case (4): 30: continue; // nadmiarowa! 31: break; 32: case (5): 33: exit=true; 34: break; 35: default: 36: cout << "Prosze wybrac ponownie!\n"; 37: break; 38: } // koniec instrukcji switch 39: 40: if (exit) 41: break; 42: } // koniec pętli for(;;) 43: return 0; 44: } // koniec main() 45: 46: int menu()

47: { 48: int choice; 49: 50: cout << " **** Menu ****\n\n"; 51: cout << "(1) Pierwsza opcja.\n"; 52: cout << "(2) Druga opcja.\n"; 53: cout << "(3) Trzecia opcja.\n"; 54: cout << "(4) Ponownie wyswietl menu.\n"; 55: cout << "(5) Wyjscie.\n\n"; 56: cout << ": "; 57: cin >> choice; 58: return choice; 59: } 60: 61: void DoTaskOne() 62: { 63: cout << "Opcja pierwsza!\n"; 64: } 65: 66: void DoTaskMany(int which) 67: { 68: if (which == 2) 69: cout << "Opcja druga!\n"; 70: else 71: cout << "Opcja trzecia!\n"; 72: }
Wynik **** Menu **** (1) Pierwsza opcja. (2) Druga opcja. (3) Trzecia opcja. (4) Ponownie wyswietl menu. (5) Wyjscie. : 1 Opcja pierwsza! **** Menu **** (1) Pierwsza opcja. (2) Druga opcja. (3) Trzecia opcja. (4) Ponownie wyswietl menu. (5) Wyjscie. : 3 Opcja trzecia! **** Menu **** (1) Pierwsza opcja. (2) Druga opcja. (3) Trzecia opcja. (4) Ponownie wyswietl menu. (5) Wyjscie.

: 5
Analiza
Ten program łączy w sobie kilka zagadnień omawianych w tym i poprzednich rozdziałach. Oprócz tego przedstawia popularne zastosowanie instrukcji switch.
W linii 15. zaczyna się pętla nieskończona. Wywoływana jest w niej funkcja menu(), wypisująca na ekranie menu i zwracająca numer polecenia wybranego przez użytkownika. Na podstawie tego numeru polecenia, instrukcja switch (zajmująca linie od 18. do 38.) wywołuje odpowiednią funkcję obsługi polecenia.
Gdy użytkownik wybierze polecenie 1., następuje „skok” do instrukcji case 1: w linii 20. W linii 21. wykonanie przechodzi do funkcji DoTaskOne() (wykonaj zadanie 1.), wypisującej komunikat i zwracającej sterowanie. Po powrocie z tej funkcji program wznawia działanie od linii 22., w której instrukcja break kończy działanie instrukcji switch, co powoduje przejście do linii 39. W linii 40. sprawdzana jest wartość zmiennej exit (wyjście). Jeśli wynosi true, w linii 41. wykonywana jest instrukcja break, powodująca wyjście z pętli for(;;); jeśli zmienna ma wartość false, program wraca do początku pętli w linii 15.
Zwróć uwagę, że instrukcja continue w linii 30. jest nadmiarowa. Gdybyśmy ją pominęli i napotkali instrukcję break, instrukcja switch zakończyłaby działanie, zmienna exit miałaby wartość false, pętla zostałaby wykonana ponownie, a menu zostałoby wypisane ponownie. Jednak dzięki tej instrukcji continue można pominąć sprawdzanie zmiennej exit.
TAK NIE
Aby uniknąć głęboko zagnieżdżonych instrukcji if, używaj instrukcji switch.
Pieczołowicie dokumentuj wszystkie zamierzone przejścia pomiędzy przypadkami case.
W instrukcjach switch stosuj przypadek default, choćby do wykrycia sytuacji pozornie niemożliwej.
Nie zapominaj o instrukcji break na końcu każdego przypadku case, chyba że celowo chcesz by program przeszedł bezpośrednio dalej.
Program podsumowujący wiadomości {uwaga skład: jest to zawartość rozdziału „Week 1 In Review” } Listing 7.18. Program podsumowujący wiadomości
0: #include <iostream> 1: using namespace std; 2: enum CHOICE { DrawRect = 1, GetArea, GetPerim, 3: ChangeDimensions, Quit}; 4:
Usunięto: może pominąć
Usunięto: j
Usunięto: klauzuli
Usunięto: klauzulami
Usunięto: klauzule

5: // Deklaracja klasy Rectangle 6: class Rectangle 7: { 8: public: 9: // konstruktory 10: Rectangle(int width, int height); 11: ~Rectangle(); 12: 13: // akcesory 14: int GetHeight() const { return itsHeight; } 15: int GetWidth() const { return itsWidth; } 16: int GetArea() const { return itsHeight * itsWidth; } 17: int GetPerim() const { return 2*itsHeight + 2*itsWidth; } 18: void SetSize(int newWidth, int newHeight); 19: 20: // Inne metody 21: 22: 23: private: 24: int itsWidth; 25: int itsHeight; 26: }; 27: 28: // Implementacja metod klasy 29: void Rectangle::SetSize(int newWidth, int newHeight) 30: { 31: itsWidth = newWidth; 32: itsHeight = newHeight; 33: } 34: 35: 36: Rectangle::Rectangle(int width, int height) 37: { 38: itsWidth = width; 39: itsHeight = height; 40: } 41: 42: Rectangle::~Rectangle() {} 43: 44: int DoMenu(); 45: void DoDrawRect(Rectangle); 46: void DoGetArea(Rectangle); 47: void DoGetPerim(Rectangle); 48: 49: int main () 50: { 51: // inicjalizujemy prostokąt jako 30,5 52: Rectangle theRect(30,5); 53: 54: int choice = DrawRect; 55: int fQuit = false; 56: 57: while (!fQuit) 58: { 59: choice = DoMenu(); 60: if (choice < DrawRect || choice > Quit) 61: { 62: cout << "\nBledny wybor, prosze sprobowac ponownie.\n\n"; 63: continue; 64: } 65: switch (choice)

66: { 67: case DrawRect: 68: DoDrawRect(theRect); 69: break; 70: case GetArea: 71: DoGetArea(theRect); 72: break; 73: case GetPerim: 74: DoGetPerim(theRect); 75: break; 76: case ChangeDimensions: 77: int newLength, newWidth; 78: cout << "\nNowa szerokosc: "; 79: cin >> newWidth; 80: cout << "Nowa wysokosc: "; 81: cin >> newLength; 82: theRect.SetSize(newWidth, newLength); 83: DoDrawRect(theRect); 84: break; 85: case Quit: 86: fQuit = true; 87: cout << "\nWyjscie...\n\n"; 88: break; 89: default: 90: cout << "Blad wyboru!\n"; 91: fQuit = true; 92: break; 93: } // koniec instrukcji switch 94: } // koniec petli while 95: return 0; 96: } // koniec funkcji main 97: 98: int DoMenu() 99: { 100: int choice; 101: cout << "\n\n *** Menu *** \n"; 102: cout << "(1) Rysuj prostokat\n"; 103: cout << "(2) Obszar\n"; 104: cout << "(3) Obwod\n"; 105: cout << "(4) Zmien rozmiar\n"; 106: cout << "(5) Wyjscie\n"; 107: 108: cin >> choice; 109: return choice; 110: } 111: 112: void DoDrawRect(Rectangle theRect) 113: { 114: int height = theRect.GetHeight(); 115: int width = theRect.GetWidth(); 116: 117: for (int i = 0; i<height; i++) 118: { 119: for (int j = 0; j< width; j++) 120: cout << "*"; 121: cout << "\n"; 122: } 123: } 124: 125: 126: void DoGetArea(Rectangle theRect)

127: { 128: cout << "Obszar: " << theRect.GetArea() << endl; 129: } 130: 131: void DoGetPerim(Rectangle theRect) 132: { 133: cout << "Obwod: " << theRect.GetPerim() << endl; 134: }
Wynik *** Menu *** (1) Rysuj prostokat (2) Obszar (3) Obwod (4) Zmien rozmiar (5) Wyjscie 1 ****************************** ****************************** ****************************** ****************************** ****************************** *** Menu *** (1) Rysuj prostokat (2) Obszar (3) Obwod (4) Zmien rozmiar (5) Wyjscie 2 Obszar: 150 *** Menu *** (1) Rysuj prostokat (2) Obszar (3) Obwod (4) Zmien rozmiar (5) Wyjscie 3 Obwod: 70 *** Menu *** (1) Rysuj prostokat (2) Obszar (3) Obwod (4) Zmien rozmiar (5) Wyjscie 4 Nowa szerokosc: 10 Nowa wysokosc: 8

********** ********** ********** ********** ********** ********** ********** ********** *** Menu *** (1) Rysuj prostokat (2) Obszar (3) Obwod (4) Zmien rozmiar (5) Wyjscie 2 Obszar: 80 *** Menu *** (1) Rysuj prostokat (2) Obszar (3) Obwod (4) Zmien rozmiar (5) Wyjscie 3 Obwod: 36 *** Menu *** (1) Rysuj prostokat (2) Obszar (3) Obwod (4) Zmien rozmiar (5) Wyjscie 5 Wyjscie...
Analiza
Ten program wykorzystuje większość wiadomości, jakie zdobyłeś czytając poprzednie rozdziały. Powinieneś umieć wpisać, skompilować, połączyć i uruchomić program, a ponadto zrozumieć w jaki sposób działa (pod warunkiem że uważnie czytałeś dotychczasowe rozdziały).
Sześć pierwszych linii przygotowuje nowe typy i definicje, które będą używane w programie.
W liniach od 6. do 26. jest zadeklarowana klasa Rectangle (prostokąt). Zawiera ona publiczne akcesory przeznaczone do odczytywania i ustawiania wysokości i szerokości prostokąta, a także metody obliczania jego obszaru i obwodu. Linie od 29. do 40. zawierają definicje tych funkcji klasy, które nie zostały zdefiniowane inline.
Prototypy funkcji dla funkcji globalnych znajdują się w liniach od 44. do 47., zaś sam program zaczyna się w linii 49. Działanie programu polega na wygenerowaniu prostokąta, a następnie

wypisaniu menu, zawierającego pięć opcji: rysowanie prostokąta, obliczanie jego obszaru, obliczanie jego obwodu, zmiana rozmiarów prostokąta oraz wyjście.
W linii 55. ustawiany jest znacznik (flaga); jeśli wartością tego znacznika jest false, działanie pętli jest kontynuowane. Wartość true jest przypisywana do tego znacznika tylko wtedy, gdy użytkownik wybierze z menu polecenie Wyjście.
Inne opcje, z wyjątkiem Zmień rozmiar, wywołują odpowiednie funkcje. Dzięki temu działanie instrukcji switch jest bardziej przejrzyste. Opcja Zmień rozmiar nie może wywoływać funkcji, gdyż zmieniłoby to rozmiary prostokąta. Jeśli prostokąt zostałby przekazany (przez wartość) do funkcji takiej, jak na przykład DoChangeDimensions() (zmień rozmiary), wtedy rozmiary zostałyby zmienione jedynie w lokalnej kopii prostokąta w tej funkcji i nie zostałyby odzwierciedlone w prostokącie w funkcji main(). Z rozdziału 8., „Wskaźniki,” oraz rozdziału 10., „Funkcje zaawansowane,” dowiesz się, w jaki sposób ominąć to ograniczenie. Na razie jednak zmiana rozmiarów odbywa się bezpośrednio w funkcji main().
Zwróć uwagę, że użycie typu wyliczeniowego sprawiło, że instrukcja switch jest bardziej przejrzysta i łatwiejsza do zrozumienia. Gdyby przełączanie zależało od liczb (1 – 5) wybranych przez użytkownika, musiałbyś stale zaglądać do opisu menu, aby dowiedzieć się, do czego służy dana opcja.
W linii 60. następuje sprawdzenie, czy opcja wybrana przez użytkownika mieści się w dozwolonym zakresie. Jeśli nie, jest wypisywany komunikat błędu i następuje odświeżenie (czyli ponowne wypisanie) menu. Zauważ, że instrukcja switch posiada „niemożliwy” przypadek default. Stanowi on pomoc przy debuggowaniu. Gdy program działa, instrukcja ta nigdy nie powinna zostać wykonana.
Usunięto: wyliczenia
Usunięto: ą
Usunięto: klauzulę
Usunięto: a

Rozdział 8. Wskaźniki Jedną z najbardziej przydatnych dla programisty C++ rzeczy jest możliwość bezpośredniego manipulowania pamięcią za pomocą wskaźników.
Z tego rozdziału dowiesz się:
• czym są wskaźniki,
• jak deklarować wskaźniki i używać ich,
• czym jest sterta i w jaki sposób można manipulować pamięcią.
Wskaźniki stanowią podwójne wyzwanie dla osoby uczącej się języka C++: po pierwsze, mogą być niezrozumiałe, a po drugie, na początku może nie być jasne, do czego mogą się przydać. W tym rozdziale krok po kroku wyjaśnimy działanie wskaźników. Aby w pełni zrozumieć potrzebę ich używania, musisz zapoznać się z zawartością kolejnych rozdziałów.
Czym jest wskaźnik? Wskaźnik (ang. pointer) jest zmienną, przechowującą adres pamięci. To wszystko. Jeśli rozumiesz to proste stwierdzenie, wiesz już wszystko o wskaźnikach. Jeszcze raz: wskaźnik jest zmienną przechowującą adres pamięci.
Kilka słów na temat pamięci Aby zrozumieć, do czego służą wskaźniki, musisz wiedzieć kilka rzeczy o pamięci komputera. Pamięć jest podzielona na kolejno numerowane lokalizacje. Każda zmienna umieszczona jest w danym miejscu pamięci, jednoznacznie określonym przez tzw. adres pamięci. Rysunek 8.1 przedstawia schemat miejsca przechowywania zmiennej typu unsigned long o nazwie theAge (wiek).
Rys. 8.1. Schemat przechowywania zmiennej theAge

Użycie operatora adresu (&) W każdym komputerze pamięć jest adresowana w inny sposób, za pomocą różnych, złożonych schematów. Zwykle programista nie musi znać konkretnego adresu danej zmiennej, tymi szczegółami zajmuje się kompilator. Jeśli jednak chcesz uzyskać tę informację, możesz użyć operatora adresu (&), który zwraca adres obiektu znajdującego się w pamięci. Jego wykorzystanie przedstawiono na listingu 8.1.
Listing 8.1. Przykład użycia operatora adresu 0: // Listing 8.1 Demonstruje operator adresu 1: // oraz adresy zmiennych lokalnych 2: 3: #include <iostream> 4: 5: int main() 6: { 7: using namespace std; 8: unsigned short shortVar=5; 9: unsigned long longVar=65535; 10: long sVar = -65535; 11: 12: cout << "shortVar:\t" << shortVar; 13: cout << "\tAdres zmiennej shortVar:\t"; 14: cout << &shortVar << "\n"; 15: 16: cout << "longVar:\t" << longVar; 17: cout << "\tAdres zmiennej longVar:\t" ; 18: cout << &longVar << "\n"; 19: 20: cout << "sVar:\t\t" << sVar; 21: cout << "\tAdres zmiennej sVar:\t" ; 22: cout << &sVar << "\n"; 23: 24: return 0;

25: }
Wynik shortVar: 5 Adres zmiennej shortVar: 0012FF7C longVar: 65535 Adres zmiennej longVar: 0012FF78 sVar: -65535 Adres zmiennej sVar: 0012FF74
Analiza
Tworzone i inicjalizowane są trzy zmienne: typu unsigned short w linii 8., typu unsigned long w linii 9. oraz long w linii 10. Ich wartości i adresy są wypisywane w liniach od 12 do 16. Adresy zmiennych uzyskiwane są za pomocą operatora adresu (&).
Wartością zmiennej shortVar (krótka zmienna) jest 5 (tak jak można było oczekiwać). W moim komputerze Pentium (32-bitowym) ta zmienna ma adres 0012FF7C. Adres zależy od komputera i może być nieco inny przy każdym uruchomieniu programu. W twoim komputerze adresy tych zmiennych także mogą się różnić.
Deklarując typ zmiennej, informujesz kompilator, ile miejsca w pamięci powinien dla niej zarezerwować, jednak adres jest przydzielany zmiennej automatycznie. Na przykład długie (long) zmienne całkowite zajmują zwykle cztery bajty, co oznacza, że zmienna posiada adres dla czterech bajtów pamięci.
Zwróć uwagę, że twój kompilator, podobnie jak mój, może nalegać na to, by zmienne otrzymywały adresy będące wielokrotnością 4 (tj. zmienna longVar otrzymuje adres położony cztery bajty za zmienną shortVar, mimo iż zmienna shortVar potrzebuje tylko dwóch bajtów!)
Przechowywanie adresu we wskaźniku Każda zmienna posiada adres. Możesz umieścić go we wskaźniku nawet bez znajomości adresu danej zmiennej.
Przypuśćmy na przykład, że zmienna howOld jest całkowita. Aby zadeklarować wskaźnik o nazwie pAge, mogący zawierać adres tej zmiennej, możesz napisać:
int *pAge = 0;
Spowoduje to zadeklarowanie zmiennej pAge jako wskaźnika do typu int. Innymi słowy, zmienna pAge jest zadeklarowana jako przechowująca adresy wartości całkowitych.
Zwróć uwagę, że pAge jest zmienną. Gdy deklarujesz zmienną całkowitą (typu int), kompilator rezerwuje tyle pamięci, ile jest potrzebne do przechowania wartości całkowitej. Gdy deklarujesz zmienną wskaźnikową taką jak pAge, kompilator rezerwuje ilość pamięci wystarczającą do przechowania adresu (w większości komputerów zajmuje on cztery bajty). pAge jest po prostu kolejnym typem zmiennej.

Puste i błędne wskaźniki W tym przykładzie wskaźnik pAge jest inicjalizowany wartością zero. Wskaźnik, którego wartością jest zero, jest nazywany wskaźnikiem pustym (ang. null pointer). Podczas tworzenia wskaźników, powinny być one zainicjalizowane jakąś wartością. Jeśli nie wiesz, jaką wartość przypisać wskaźnikowi, przypisz mu wartość 0. Wskaźnik, który nie jest zainicjalizowany, jest nazywany wskaźnikiem błędnym (ang. wild pointer). Błędne wskaźniki są bardzo niebezpieczne.
UWAGA Pamiętaj o zasadzie bezpiecznego programowania: inicjalizuj swoje wskaźniki!
Musisz jawnie przypisać wskaźnikowi adres zmiennej howOld. Poniższy przykład pokazuje, jak to zrobić:
unsigned short int howOld = 50; // tworzymy zmienną unsigned short int * pAge = 0; // tworzymy wskaźnik pAge = &howOld; // umieszczamy adres zmiennej hOld w zmiennej pAge
Pierwsza linia tworzy zmienną — howOld typu unsigned short int — oraz inicjalizuje ją wartością 50. Druga linia deklaruje zmienną pAge jako wskaźnik do typu unsigned short int i ustawia ją na zero. To, że zmienna pAge jest wskaźnikiem, można poznać po gwiazdce (*) umieszczonej pomiędzy typem zmiennej a jej nazwą.
Trzecia, ostatnia linia, przypisuje wskaźnikowi pAge adres zmiennej howOld. Przypisywanie adresu można poznać po użyciu operatora adresu (&). Gdyby operator adresu został pominięty, wskaźnikowi pAge zostałaby przypisana wartość zmiennej howOld. Oczywiście, wartość ta mogłaby być poprawnym adresem.
Teraz wskaźnik pAge zawiera adres zmiennej howOld. Ta zmienna ma wartość 50. Można uzyskać ten rezultat wykonując o jeden krok mniej, na przykład:
unsigned short int howOld = 50; // tworzymy zmienną unsigned short int * pAge = &howOld; // tworzymy wskaźnik do howOld
pAge jest wskaźnikiem, zawierającym teraz adres zmiennej howOld. Używając wskaźnika pAge, możesz sprawdzić wartość zmiennej howOld, która w tym przypadku wynosi 50. Dostęp do zmiennej howOld poprzez wskaźnik pAge jest nazywany dostępem pośrednim (dostęp do niej rzeczywiście odbywa się poprzez ten wskaźnik). Z dalszej części rozdziału dowiesz się, jak w ten sposób odwoływać się do wartości zmiennej.
Dostęp pośredni oznacza dostęp do zmiennej o adresie przechowywanym we wskaźniku. Użycie wskaźników stanowi pośredni sposób uzyskania wartości przechowywanej pod danym adresem.
UWAGA W przypadku zwykłej zmiennej, jej typ informuje kompilator, ile potrzebuje pamięci do przechowania jej wartości. W przypadku wskaźników sytuacja wygląda inaczej: każdy wskaźnik zajmuje cztery bajty. Typ wskaźnika informuje kompilator, ile potrzeba miejsca w pamięci do przechowania obiektu, którego adres zawiera wskaźnik!
W deklaracji
unsigned shot int * pAge = 0; // tworzymy wskaźnik
zmienna pAge jest zadeklarowana jako wskaźnik do typu unsigned short int. Mówi ona kompilatorowi, że wskaźnik ten (który do przechowania adresu wymaga czterech bajtów) będzie przechowywał adres obiektu typu unsigned short int, który zajmuje dwa bajty.
Nazwy wskaźników Podobnie jak inne zmienne, wskaźniki mogą mieć dowolne nazwy. Wielu programistów przestrzega konwencji, w której nazwy wszystkich wskaźników poprzedza się literką p (pointer), np. pAge czy pNumber.
Operator wyłuskania Operator wyłuskania (*) jest zwany także operatorem dostępu pośredniego albo dereferencją. Podczas wyłuskiwania wskaźnika otrzymywana jest wartość wskazywana przez adres zawarty w tym wskaźniku.
Zwykłe zmienne zapewniają bezpośredni dostęp do swoich wartości. Gdy tworzysz nową zmienną typu unsigned short int o nazwie yourAge i chcesz jej przypisać wartość zmiennej howOld, możesz napisać:
unsigned short int yourAge; yourAge = howOld;
Wskaźnik umożliwia pośredni dostęp do wartości zmiennej, której adres zawiera. Aby przypisać wartość zmiennej howOld do zmiennej yourAge za pomocą wskaźnika pAge, powinieneś napisać:
unsigned short int yourAge; yourAge = *pAge;
Operator wyłuskania (*) znajdujący się przed zmienną pAge oznacza „wartość przechowywana pod adresem.” To przypisanie można potraktować jako: „Weź wartość przechowywaną pod adresem zawartym w pAge i przypisz ją do zmiennej yourAge”.
UWAGA W przypadku wskaźników gwiazdka (*) może posiadać dwa znaczenia (może symbolizować część deklaracji wskaźnika albo operator wyłuskania).
Usunięto: e

Gdy deklarujesz wskaźnik, * jest częścią deklaracji i następuje po typie wskazywanego obiektu. Na przykład:
// tworzymy wskaźnik do typu unsigned short unsigned short * page = 0;
Gdy wskaźnik jest wyłuskiwany, operator wyłuskiwania wskazuje, że odwołujemy się do wartości, znajdującej się w miejscu pamięci określonym przez adres zawarty we wskaźniku, a nie do tego adresu.
// wartości wskazywanej przez pAge przypisujemy wartość 5 *pAge = 5;
Zwróć także uwagę, że ten sam znak (*) jest używany jako operator mnożenia. Kompilator wie z kontekstu, o który operator chodzi w danym miejscu programu.
Wskaźniki, adresy i zmienne Należy dokonać rozróżnienia pomiędzy wskaźnikiem, adresem zawartym w tym wskaźniku, a zmienną o adresie zawartym w tym wskaźniku. Nieumiejętność rozróżnienia ich jest najczęstszym powodem nieporozumień ze wskaźnikami.
Weźmy następujący fragment kodu:
int theVariable = 5; int * pPointer = &theVariable;
Zmienna theVariable jest zadeklarowana jako zmienna typu int i jest inicjalizowana wartością 5. Zmienna pPointer jest zadeklarowana jako wskaźnik do typu int i jest inicjalizowana adresem zmiennej theVariable. pPointer jest wskaźnikiem. Adres zawarty w pPointer jest adresem zmiennej theVariable. Wartością znajdującą się pod adresem zawartym w pPointer jest 5. Schemat zmiennych theVariable i pPointer przedstawia rysunek 8.2.
Rys. 8.2. Schematyczna reprezentacja pamięci

Na tym rysunku wartość 5 została umieszczona pod adresem 101. Jest on podany jako liczba dwójkowa
0000 0000 0000 0101
Jest to dwubajtowa (16-bitowa) wartość, której wartością dziesiętną jest 5.
Zmienna wskaźnikowa ma adres 106. Jej wartość to
0000 0000 0000 0000 0000 0000 0110 0101
Jest to binarna reprezentacja wartości 101 (dziesiętnie), stanowiącej adres zmiennej theVariable, która zawiera wartość 5.
Przedstawiony powyżej układ pamięci jest uproszczony, ale ilustruje przeznaczenie wskaźników zawierających adresy pamięci.
Operowanie danymi poprzez wskaźniki Gdy przypiszesz wskaźnikowi adres zmiennej, możesz użyć tego wskaźnika w celu uzyskania dostępu do danych zawartych w tej zmiennej. Listing 8.2 pokazuje, w jaki sposób adres lokalnej zmiennej jest przypisywany wskaźnikowi i w jaki sposób ten wskaźnik może operować wartością w tej zmiennej.
Listing 8.2. Operowanie danymi poprzez wskaźnik 0: // Listing 8.2 Użycie wskaźnika 1: 2: #include <iostream> 3: 4: typedef unsigned short int USHORT; 5: 6: int main() 7: { 8: 9: using std::cout; 10: 11: USHORT myAge; // zmienna 12: USHORT * pAge = 0; // wskaźnik 13: 14: myAge = 5; 15: 16: cout << "myAge: " << myAge << "\n"; 17: pAge = &myAge; // wskaźnikowi pAge przypisuje adres zmiennej myAge 18: cout << "*pAge: " << *pAge << "\n\n"; 19: 20: cout << "Ustawiam *pAge = 7...\n"; 21: *pAge = 7; // ustawia myAge na 7 22: 23: cout << "*pAge: " << *pAge << "\n";

24: cout << "myAge: " << myAge << "\n\n"; 25: 26: cout << "Ustawiam myAge = 9...\n"; 27: myAge = 9; 28: 29: cout << "myAge: " << myAge << "\n"; 30: cout << "*pAge: " << *pAge << "\n"; 31: 32: return 0; 33: }
Wynik myAge: 5 *pAge: 5 Ustawiam *pAge = 7... *pAge: 7 myAge: 7 Ustawiam myAge = 9... myAge: 9 *pAge: 9
Analiza
Program deklaruje dwie zmienne: myAge typu unsigned short oraz wskaźnik do typu unsigned short, zmienną pAge. W linii 14. zmiennej myAge jest przypisywana wartość 5; potwierdza to komunikat wypisywany w linii 16.
W linii 17. wskaźnikowi pAge jest przypisywany adres zmiennej myAge. W linii 18 następuje wyłuskanie wskaźnika pAge i wypisanie otrzymanej wartości (to pokazuje, że wartość o adresie zawartym w pAge jest wartością 5, czyli wartością zmiennej myAge). W linii 21. zmiennej o adresie zawartym w pAge jest przypisywana wartość 7. Powoduje to przypisanie tej wartości zmiennej myAge, co potwierdzają komunikaty wypisywane w liniach 23. i 24.
W linii 29. zmiennej myAge jest przypisywana wartość 9. Ta wartość jest pobierana bezpośrednio w linii 29., zaś w linii 30. pośrednio (poprzez wyłuskanie wskaźnika pAge).
Sprawdzanie adresu Wskaźniki umożliwiają operowanie adresami nawet bez znajomości ich faktycznych wartości. Do tej pory musiałeś przyjmować jako oczywiste, że gdy przypisujesz wskaźnikowi adres zmiennej, to wartością wskaźnika staje się rzeczywiście adres tej zmiennej. Dlaczego nie miałbyś się teraz co do tego upewnić? Przedstawia to listing 8.3.
Listing 8.3. Sprawdzanie zawartości wskaźnika 0: // Listing 8.3 Co zawiera wskaźnik?. 1: 2: #include <iostream> 3: 4: 5: int main() 6: { 7: using std::cout;

8: 9: unsigned short int myAge = 5, yourAge = 10; 10: 11: // wskaźnik 12: unsigned short int * pAge = &myAge; 13: 14: cout << "myAge:\t" << myAge 15: << "\t\tyourAge:\t" << yourAge << "\n"; 16: 17: cout << "&myAge:\t" << &myAge 18: << "\t&yourAge:\t" << &yourAge <<"\n"; 19: 20: cout << "pAge:\t" << pAge << "\n"; 21: cout << "*pAge:\t" << *pAge << "\n"; 22: 23: 24: cout << "\nPonowne przypisanie: pAge = &yourAge...\n\n"; 25: pAge = &yourAge; // ponowne przypisanie do wskaźnika 26: 27: cout << "myAge:\t" << myAge << 28: "\t\tyourAge:\t" << yourAge << "\n"; 29: 30: cout << "&myAge:\t" << &myAge 31: << "\t&yourAge:\t" << &yourAge <<"\n"; 32: 33: cout << "pAge:\t" << pAge << "\n"; 34: cout << "*pAge:\t" << *pAge << "\n"; 35: 36: cout << "\n&pAge:\t" << &pAge << "\n"; 37: 38: return 0; 39: }
Wynik myAge: 5 yourAge: 10 &myAge: 0012FF7C &yourAge: 0012FF78 pAge: 0012FF7C *pAge: 5 Ponowne przypisanie: pAge = &yourAge... myAge: 5 yourAge: 10 &myAge: 0012FF7C &yourAge: 0012FF78 pAge: 0012FF78 *pAge: 10 &pAge: 0012FF74
(Twoje wyniki mogą być inne.)
Analiza

W linii 9. deklarowane są dwie zmienne, myAge oraz yourAge, obie typu unsigned short. W linii 12. deklarowana jest zmienna pAge, będąca wskaźnikiem do typu unsigned short; ten wskaźnik jest inicjalizowany adresem zmiennej myAge.
W liniach od 14. do 18. następuje wypisanie wartości i adresów zmiennych myAge i yourAge. Linia 20. wypisuje zawartość wskaźnika pAge, którą jest adres zmiennej myAge. Linia 21. wypisuje rezultat wyłuskania wskaźnika pAge, czyli wypisuje wartość zmiennej wskazywanej przez ten wskaźnik (wartość zmiennej myAge, wynoszącą 5).
W taki właśnie sposób działają wskaźniki. Linia 20. pokazuje, że wskaźnik pAge zawiera adres zmiennej myAge, zaś linia 21. pokazuje, w jaki sposób wartość przechowywana w zmiennej myAge może zostać uzyskana w wyniku wyłuskania wskaźnika pAge. Zanim przejdziesz dalej, upewnij się, czy to rozumiesz. Przestudiuj kod i porównaj z wynikiem.
W linii 25. zmiennej pAge jest przypisywany nowy adres, tym razem adres zmiennej yourAge. Ponownie wypisywane są wartości i adresy. Wyniki pokazują, że wskaźnik pAge zawiera teraz adres zmiennej yourAge i że jako efekt wyłuskania uzyskujemy wartość przechowywaną w tej zmiennej.
Linia 36. wypisuje adres zmiennej pAge. Tak jak wszystkie inne zmienne, swój adres posiada także wskaźnik. Adres ten także może być umieszczony we wskaźniku. (Przypisywanie adresu wskaźnika do innego wskaźnika zostanie omówione wkrótce.)
TAK
W celu uzyskania dostępu do danych przechowywanych pod adresem zawartym we wskaźniku używaj operatora wyłuskania (*).
Inicjalizuj wszystkie wskaźniki albo adresem poprawnym, albo adresem pustym (0).
Pamiętaj o różnicy pomiędzy adresem we wskaźniku, a wartością pod tym adresem.
Użycie wskaźników
Aby zadeklarować wskaźnik, napisz typ zmiennej lub obiektu, którego adres będzie przechowywany w tym wskaźniku, gwiazdkę (*) oraz nazwę wskaźnika. Na przykład:
unsigned short int * pPointer = 0;
Aby zainicjalizować wskaźnik (przypisać mu adres), poprzedź nazwę zmiennej, której adres chcesz przypisać, operatorem adresu (&). Na przykład;
unsigned short int theVariable = 5; unsigned short int * pPointer = & theVariable;
Aby wyłuskać wskaźnik, poprzedź nazwę wskaźnika operatorem wyłuskania (*). Na przykład:
unsigned short int theValue = *pPointer;
Usunięto: i

Do czego służą wskaźniki? Jak dotąd, poznałeś krok po kroku proces przypisywania wskaźnikowi adresu zmiennej. W praktyce jednak nie będziesz tego robił nigdy. Po co miałbyś utrudniać sobie życie używaniem wskaźników, skoro masz do dyspozycji zmienną, do której masz pełny dostęp? Jedynym powodem, dla którego operujemy wskaźnikami na zmiennych automatycznych (tj. lokalnych), jest zademonstrowanie sposobu działania wskaźników. Teraz, gdy poznałeś już składnię wskaźników, możesz poznać ich praktyczne zastosowania. Wskaźniki są najczęściej używane do wykonywania trzech zadań:
• zarządzania danymi na stercie,
• uzyskiwania dostępu do danych i funkcji składowych klasy.
• przekazywania zmiennych do funkcji poprzez referencję.
W pozostałej części rozdziału skupimy się na zarządzaniu danymi na stercie oraz dostępie do danych i funkcji składowych klasy. Przekazywanie zmiennych przez referencję omówimy w następnym rozdziale.
Stos i sterta W rozdziale 5., w podrozdziale „Jak działają funkcje — rzut oka <<pod maskę>>” wspomniano o pięciu obszarach pamięci:
• globalnej przestrzeni nazw,
• stercie,
• rejestrach,
• przestrzeni kodu,
• stosie.
Zmienne lokalne znajdują się na stosie (podobnie jak parametry funkcji). Kod występuje, oczywiście, w przestrzeni kodu, zaś zmienne globalne w globalnej przestrzeni nazw. Rejestry są używane do kontrolowania wewnętrznych zadań procesora, takich jak śledzenie szczytu stosu czy miejsca wykonania programu. Cała pozostała pamięć jest prawie w całości przeznaczona na tak zwaną stertę (ang. heap).
Problem ze zmiennymi lokalnymi polega na tym, że nie są one trwałe: gdy funkcja kończy działanie, zmienne te są niszczone. Rozwiązują ten problem zmienne globalne, nie są one jednak dostępne bez ograniczeń w całym programie; powoduje to, kod jest trudny do zrozumienia i zmodyfikowania. Umieszczanie danych na stercie uwalnia od obu tych niedogodności.
Usunięto: składowych
Usunięto: j

Możesz uznawać stertę za obszerny blok pamięci, zawierający dziesiątki tysięcy kolejno ponumerowanych pojemników, oczekujących na twoje dane. Jednak w odróżnieniu od stosu, nie możesz nadawać tym pojemnikom etykietek. Musisz poprosić o adres pojemnika, który rezerwujesz, a następnie przechować ten adres we wskaźniku.
Można także znaleźć inną analogię: wyobraź sobie, że przyjaciel dał ci numer telefonu do firmy kurierskiej. Wracasz do domu, programujesz ten numer w swoim aparacie telefonicznym pod określonym przyciskiem, po czym wyrzucasz kartkę z numerem. Gdy naciśniesz przycisk, telefon wybierze jakiś numer i połączy cię z firmą kurierską. Nie pamiętasz numeru i nie wiesz, gdzie znajduje się firma, ale przycisk umożliwia ci dostęp do niej. Firma to twoje dane na stercie. Nie wiesz gdzie jest, ale wiesz jak się z nią skontaktować. Służy do tego jej adres — w tym przypadku jest nim numer telefonu. Nie musisz znać tego numeru; wystarczy, że masz go we wskaźniku (przycisku w telefonie). Wskaźnik umożliwia ci dostęp do danych, bez konieczności przeprowadzania szczegółowych, dodatkowych działań.
Gdy funkcja kończy działanie, stos jest czyszczony automatycznie. Wszystkie zmienne lokalne wychodzą poza zakres i są usuwane ze stosu. Sterta nie jest czyszczona aż do chwili zakończenia działania programu, dlatego to ty jesteś odpowiedzialny za zwolnienie wszelkiej zaalokowanej przez siebie pamięci.
Zaletą sterty jest to, że zaalokowana (zarezerwowana) na niej pamięć pozostaje dostępna aż do momentu, w którym ją zwolnisz. Jeśli pamięć na stercie zaalokujesz w funkcji, po wyjściu z tej funkcji pamięć pozostanie nadal dostępna.
Zaletą tej metody korzystania z pamięci (w przeciwieństwie do zmiennych globalnych) jest to, że dostęp do tej pamięci mają tylko te funkcje, które posiadają do niej wskaźnik. Dzięki temu można ściśle kontrolować interfejs do danych – eliminuje to potencjalny problem nieoczekiwanej i niezauważalnej zmiany danych przez inną funkcję.
Aby ten mechanizm działał, musisz mieć możliwość tworzenia wskaźnika do obszaru pamięci na stercie oraz przekazywania tego wskaźnika pomiędzy funkcjami. Proces ten opisują następne podrozdziały.
Operator new W języku C++, do alokowania pamięci na stercie służy słowo kluczowe new (nowy). Po tym słowie kluczowym następuje typ obiektu, jaki chcesz zaalokować – dzięki temu kompilator wie, ile miejsca powinien zarezerwować. Instrukcja new unsigned short int alokuje na stercie dwa bajty, a instrukcja new long alokuje cztery bajty.
Zwracaną wartością jest adres pamięci. Musi on zostać przypisany do wskaźnika. Aby stworzyć na stercie obiekt typu unsigned short, możesz napisać:
unsigned short int * pPointer; pPointer = new unsigned short int;
Można oczywiście zainicjalizować wskaźnik w trakcie jego tworzenia:
unsigned short int * pPointer = new unsigned short int;

W obu przypadkach, wskaźnik pPointer wskazuje teraz położony na stercie obiekt typu unsigned short int. Możesz użyć tego wskaźnika tak, jak każdego innego wskaźnika do zmiennej i przypisać obiektowi na stercie dowolną wartość:
*pPointer = 72;
Oznacza to: „Umieść 72 jako wartość obiektu wskazywanego przez pPointer” lub „Przypisz obszarowi sterty wskazywanemu przez wskaźnik pPointer wartość 72”.
UWAGA Gdy operator new nie jest w stanie zarezerwować pamięci na stercie (w końcu pamięć ma ograniczoną objętość), zgłasza wyjątek (patrz rozdział 20., „Wyjątki i obsługa błędów”).
delete Gdy skończysz korzystać z obszaru pamięci na stercie, musisz użyć słowa kluczowego delete (usuń) z właściwym wskaźnikiem. Instrukcja delete zwalnia pamięć zaalokowaną na stercie, tj. zwraca ją stercie. Pamiętaj, że sam wskaźnik — w przeciwieństwie do pamięci, na którą wskazuje — jest zmienną lokalną. Gdy funkcja, w której został zadeklarowany, kończy działanie, wskaźnik wychodzi poza zakres i jest niszczony. Pamięć zaalokowana operatorem new nie jest zwalniana automatycznie; staje się niedostępna — taka sytuacja jest nazywana wyciekiem pamięci (ang. memory leak). Nazwa wzięła się stąd, że pamięć nie może być odzyskana, aż do momentu zakończenia działania programu (z punktu widzenia programu, pamięć „wycieka” z komputera).
Aby zwrócić stercie pamięć, użyj słowa kluczowego delete. Na przykład:
delete pPointer;
Gdy zwalniasz wskaźnik, w rzeczywistości zwalniasz jedynie pamięć, której adres jest zawarty w tym wskaźniku. Mówisz: „Zwróć stercie pamięć, na którą wskazuje ten wskaźnik”. Wskaźnik nadal pozostaje wskaźnikiem i można mu ponownie przypisać adres. Listing 8.4 przedstawia alokowanie zmiennej na stercie, użycie tej zmiennej, a następnie zwolnienie jej.
OSTRZEŻENIE Gdy używasz słowa kluczowego delete dla wskaźnika, zwalniana jest pamięć, na którą on wskazuje. Ponowne wywołanie delete dla tego wskaźnika spowoduje załamanie programu! Gdy zwalniasz wskaźnik, ustaw go na zero (null, wskaźnik pusty). Kompilator gwarantuje, że wywołanie delete z pustym wskaźnikiem jest bezpieczne. Na przykład:
Animal *pDog = new Animal; delete pDog; // zwalnia pamięć pDog = 0; // ustawia wskaźnik na null // ... delete pDog; // nieszkodliwe

Listing 8.4. Alokowanie, użycie i zwolnienie wskaźnika 0: // Listing 8.4 1: // Alokowanie i zwalnianie wskaźnika 2: 3: #include <iostream> 4: int main() 5: { 6: using std::cout; 7: int localVariable = 5; 8: int * pLocal= &localVariable; 9: int * pHeap = new int; 10: *pHeap = 7; 11: cout << "localVariable: " << localVariable << "\n"; 12: cout << "*pLocal: " << *pLocal << "\n"; 13: cout << "*pHeap: " << *pHeap << "\n"; 14: delete pHeap; 15: pHeap = new int; 16: *pHeap = 9; 17: cout << "*pHeap: " << *pHeap << "\n"; 18: delete pHeap; 19: return 0; 20: }
Wynik localVariable: 5 *pLocal: 5 *pHeap: 7 *pHeap: 9
Analiza
W linii 7. program deklaruje i inicjalizuje lokalną zmienną. W linii 8. deklaruje i inicjalizuje wskaźnik, przypisując mu adres tej zmiennej. W linii 9. deklaruje wskaźnik, lecz inicjalizuje go wartością uzyskaną w wyniku wywołania operatora new int. Powoduje to zaalokowanie na stercie miejsca dla wartości typu int.
Linia 10. przypisuje wartość 7 do nowo zaalokowanej pamięci. Linia 11. wypisuje wartość zmiennej lokalnej, a linia 12. wypisuje wartość wskazywaną przez pLocal (lokalna) Jak należało oczekiwać, są one takie same. Linia 13. wypisuje wartość wskazywaną przez pHeap (sterta) i pokazuje, że rzeczywiście mamy dostęp do wartości zaalokowanej w linii 10.
W linii 14. pamięć zaalokowana w linii 9. jest zwracana na stertę (w wyniku wywołania delete). Czynność ta zwalnia pamięć i odłącza od niej wskaźnik. Teraz pHeap może wskazywać inne miejsce w pamięci. Nowy adres i wartość przypisujemy mu w liniach 15. i 16., zaś w linii 17. wypisujemy wynik. Linia 18. zwalnia pamięć i zwraca ją stercie.
Choć linia 18. jest nadmiarowa (zakończenie programu automatycznie powoduje zwolnienie pamięci), do dobrych obyczajów należy jawne zwalnianie wskaźników. Gdy program będzie modyfikowany lub rozbudowywany, zapamiętanie tego kroku może okazać się bardzo przydatne.

Wycieki pamięci Inną sytuacją, która może doprowadzić do wycieku pamięci, jest ponowne przypisanie wskaźnikowi adresu, bez wcześniejszego zwolnienia pamięci, na którą w danym momencie wskazuje. Spójrzmy na poniższy fragment kodu:
0: unsigned short int * pPointer = new unsigned short int; 1: *pPointer = 72; 2: pPointer = new unsigned short int; 3: pPointer = 84;
Linia 0 tworzy pPointer i przypisuje mu adres rezerwowanego na stercie obszaru. Linia 1. umieszcza w tym obszarze wartość 72. Linia 2. ponownie przypisuje wskaźnikowi pPointer adres innego obszaru pamięci. Linia 3. umieszcza w tym obszarze wartość 84. Pierwotny obszar — w którym jest zawarta wartość 72 — jest niedostępny, gdyż wskaźnik do tej pamięci został wypełniony innym adresem. Nie ma sposobu na odzyskanie pierwotnego obszaru, nie ma też sposobu na zwolnienie go przed zakończeniem działania programu.
Ten kod powinien zostać napisany następująco:
0: unsigned short int * pPointer = new unsigned short int; 1: *pPointer = 72; 2: delete pPointer; 3: pPointer = new unsigned short int; 4: pPointer = 84;
Teraz pamięć, wskazywana pierwotnie przez pPointer, jest zwalniana w linii 2.
UWAGA Za każdym razem, gdy użyjesz w programie słowa kluczowego new, powinieneś użyć także odpowiadającego mu słowa kluczowego delete. Należy pamiętać, na co wskazuje dany wskaźnik (aby mieć pewność, że zostanie to zwolnione, gdy przestanie potrzebne).
Tworzenie obiektów na stercie Możesz stworzyć nie tylko wskaźnik do zmiennej całkowitej, ale i wskaźnik do dowolnego obiektu. Jeśli zadeklarowałeś obiekt typu Cat (kot), możesz zadeklarować wskaźnik do tej klasy i stworzyć na stercie egzemplarz obiektu tej klasy (tak jak mogłeś stworzyć go na stosie). Składnia jest taka sama, jak w przypadku innych zmiennych:
Cat *pCat = new Cat;

Powoduje to wywołanie domyślnego konstruktora klasy — czyli konstruktora, który nie ma parametrów. Konstruktor jest wywoływany za każdym razem, gdy tworzony jest obiekt klasy (na stosie lub na stercie).
Usuwanie obiektów Gdy wywołujesz delete ze wskaźnikiem do obiektu na stercie, przed zwolnieniem pamięci obiektu wywoływany jest jego destruktor. Dzięki temu klasa ma szansę „posprzątania po sobie,” tak jak w przypadku obiektów niszczonych na stosie. Tworzenie i usuwanie obiektów na stercie przedstawia listing 8.5.
Listing 8.5. Tworzenie i usuwanie obiektów na stercie 0: // Listing 8.5 1: // Tworzenie obiektów na stercie 2: // z użyciem new oraz delete 3: 4: #include <iostream> 5: 6: class SimpleCat 7: { 8: public: 9: SimpleCat(); 10: ~SimpleCat(); 11: private: 12: int itsAge; 13: }; 14: 15: SimpleCat::SimpleCat() 16: { 17: std::cout << "Wywolano konstruktor.\n"; 18: itsAge = 1; 19: } 20: 21: SimpleCat::~SimpleCat() 22: { 23: std::cout << "Wywolano destruktor.\n"; 24: } 25: 26: int main() 27: { 28: std::cout << "SimpleCat Mruczek...\n"; 29: SimpleCat Mruczek; 30: std::cout << "SimpleCat *pFilemon = new SimpleCat...\n"; 31: SimpleCat * pFilemon = new SimpleCat; 32: std::cout << "delete pFilemon...\n"; 33: delete pFilemon; 34: std::cout << "Wyjscie, czekaj na Mruczka...\n"; 35: return 0; 36: }
Wynik SimpleCat Mruczek... Wywolano konstruktor. SimpleCat *pFilemon = new SimpleCat...
Usunięto: t

Wywolano konstruktor. delete pFilemon... Wywolano destruktor. Wyjscie, czekaj na Mruczka... Wywolano destruktor.
Analiza
Linie od 6. do 13. deklarują okrojoną klasę SimpleCat (prosty kot). Linia 9. deklaruje konstruktor tej klasy, zaś linie od 15. do 19. zawierają jego definicję. Linia 10 deklaruje destruktor klasy, a linie od 21. do 24. zawierają jego definicję.
W linii 29. na stosie tworzony jest obiekt Mruczek, powoduje to wywołanie konstruktora klasy. W linii 31. na stercie tworzony jest egzemplarz obiektu SimpleCat, wskazywany przez zmienną pFilemon; w wyniku tego działania następuje ponowne wywołanie konstruktora. W linii 33. znajduje się słowo kluczowe delete ze wskaźnikiem pFilemon, dlatego wywoływany jest destruktor. Gdy funkcja main() kończy działanie, obiekt Mruczek wychodzi z zakresu i ponownie wywoływany jest destruktor.
Dostęp do składowych klasy W przypadku obiektów Cat stworzonych lokalnie, dostęp do składowych funkcji i danych odbywa się za pomocą operatora kropki (.). Aby odwołać się do składowych utworzonego na stercie obiektu Cat, musisz wyłuskać wskaźnik i wywołać operator kropki dla obiektu wskazywanego przez ten wskaźnik. Aby odwołać się do funkcji składowej GetAge(), możesz napisać:
(*pFilemon).GetAge();
Aby zapewnić, wyłuskanie wskaźnika pFilemon przed odwołaniem się do metody GetAge(), użyte zostały nawiasy.
Ponieważ taki zapis jest dość skomplikowany, C++ oferuje skrótowy operator dostępu pośredniego: operator wskazywania (->). Składa się on z ze znaku minus (-) i znaku większości (>), zapisanych razem. Kompilator traktuje je jako pojedynczy symbol. Dostęp do składowych funkcji i danych utworzonego na stercie obiektu przedstawia listing 8.6.
Listing 8.6. Dostęp do składowych funkcji i danych utworzonego na stercie obiektu. 0: // Listing 8.6 1: // Dostęp do składowych funkcji i danych obiektu 2: // utworzonego na stercie, z użyciem operatora -> 3: 4: #include <iostream> 5: 6: class SimpleCat 7: { 8: public: 9: SimpleCat() {itsAge = 5; } 10: ~SimpleCat() {} 11: int GetAge() const { return itsAge; } 12: void SetAge(int age) { itsAge = age; }

13: private: 14: int itsAge; 15: }; 16: 17: int main() 18: { 19: SimpleCat * Mruczek = new SimpleCat; 20: std::cout << "Mruczek ma " << Mruczek->GetAge() << " lat\n"; 21: Mruczek->SetAge(7); 22: std::cout << "Mruczek ma " << Mruczek->GetAge() << " lat\n"; 23: delete Mruczek; 24: return 0; 25: }
Wynik Mruczek ma 5 lat Mruczek ma 7 lat
Analiza
W linii 19. na stercie tworzony jest egzemplarz obiektu klasy SimpleCat. Domyślny konstruktor ustawia jego zmienną składową itsAge (jego wiek) na 5, zaś w linii 20. wywoływana jest metoda GetAge(). Ponieważ zmienna Mruczek jest wskaźnikiem, w celu uzyskania dostępu do danych i funkcji składowych został użyty operator wskazania (->). W linii 21. zostaje wywołana metoda SetAge(), po czym w linii 22. ponownie wywoływana jest metoda GetAge().
Dane składowe na stercie Wskaźnikami do obiektów znajdujących się na stercie może być jedna lub więcej danych składowych klasy. Pamięć może być alokowana w konstruktorze klasy lub w którejś z jej metod, zaś do jej zwolnienia można wykorzystać destruktor. Przedstawia to listing 8.7.
Listing 8.7. Wskaźniki jako dane składowe 0: // Listing 8.7 1: // Wskaźniki jako dane składowe 2: // dostępne poprzez operator -> 3: 4: #include <iostream> 5: 6: class SimpleCat 7: { 8: public: 9: SimpleCat(); 10: ~SimpleCat(); 11: int GetAge() const { return *itsAge; } 12: void SetAge(int age) { *itsAge = age; } 13: 14: int GetWeight() const { return *itsWeight; } 15: void setWeight (int weight) { *itsWeight = weight; } 16: 17: private: 18: int * itsAge; 19: int * itsWeight; 20: };

21: 22: SimpleCat::SimpleCat() 23: { 24: itsAge = new int(5); 25: itsWeight = new int(2); 26: } 27: 28: SimpleCat::~SimpleCat() 29: { 30: delete itsAge; 31: delete itsWeight; 32: } 33: 34: int main() 35: { 36: SimpleCat *Mruczek = new SimpleCat; 37: std::cout << "Mruczek ma " << Mruczek->GetAge() << " lat\n"; 38: Mruczek->SetAge(7); 39: std::cout << "Mruczek ma " << Mruczek->GetAge() << " lat\n"; 40: delete Mruczek; 41: return 0; 42: }
Wynik Mruczek ma 5 lat Mruczek ma 7 lat
Analiza
Klasa SimpleCat (prosty kot) deklaruje (w liniach 18. i 19.) dwie zmienne składowe; obie te zmienne są wskaźnikami do wartości całkowitych. Konstruktor (linie od 22. do 26.) inicjalizuje na stercie pamięć dla tych wskaźników i przypisuje obiektom wartości domyślne.
Zwróć uwagę, że dla tworzonych obiektów int możemy wywołać pseudo-konstruktor, przekazując mu domyślną wartość obiektu. Umożliwia to stworzenie obiektu na stercie i zainicjalizowanie jego wartości (w linii 24. jest to wartość 5, zaś w linii 25., wartość 2).
Destruktor (linie od 28. do 32.) zwalnia zaalokowaną pamięć. Nie ma sensu przypisywać wskaźnikom wartości pustej (null), gdyż po opuszczeniu destruktora i tak nie będą już dostępne. Jest to jedna z okazji, przy których można bezpiecznie złamać regułę mówiącą, że usuwanym wskaźnikom należy przypisać wartość pustą (choć oczywiście nie zaszkodzi postępować zgodnie z tą regułą).
Funkcja wywołująca (w tym przypadku funkcja main()) nie jest świadoma, że zmienne składowe itsAge i itsWeight (jego waga) są wskaźnikami do pamięci na stercie. Funkcja main()tak samo odwołuje się do akcesorów GetAge() i SetAge(), zaś szczegóły zarządzania pamięcią są ukryte w implementacji klasy — i tak właśnie powinno być.
Gdy w linii 40. zwalniany jest obiekt Mruczek, następuje wywołanie jego destruktora. Destruktor zwalnia wszystkie wskaźniki składowe. Gdyby wskaźniki te wskazywały na obiekty innych klas (lub być może tej samej klasy), zostałyby wywołane także destruktory tych klas.
Przechowywanie własnych zmiennych składowych jako referencji jest całkiem nierozsądne, chyba że istnieje ku temu ważny powód. W tym przypadku nie ma takiego powodu, ale być może w innej sytuacji przechowywanie zmiennych okaże się bardzo przydatne.

Nasuwa się oczywiste pytanie: co próbujesz uzyskać? Musisz zacząć od projektu. Jeśli zaprojektujesz obiekt, który odwołuje się do innego obiektu, a ten drugi obiekt może zaistnieć przed zaistnieniem pierwszego obiektu i trwać jeszcze po jego zniszczeniu, wtedy pierwszy obiekt musi odwoływać się do drugiego obiektu poprzez referencję.
Na przykład: pierwszy obiekt może być oknem, a drugi dokumentem. Okno potrzebuje dostępu do dokumentu, ale nie kontroluje czasu jego życia. Dlatego okno musi odwoływać się do obiektu poprzez referencję.
W C++ można to osiągnąć poprzez użycie wskaźników lub referencji. Referencje zostaną opisane w rozdziale 9.
Często zadawane pytanie
Gdy zadeklaruję na stosie obiekt, którego dane składowe tworzone są na stercie, co znajdzie się na stosie, a co na stercie? Na przykład:
#include <iostream> class SimpleCat { public: SimpleCat(); ~SimpleCat(); int GetAge() const { return *itsAge; } // inne metody private: int * itsAge; int * itsWeight; }; SimpleCat::SimpleCat() { itsAge = new int(5); itsWeight = new int(2); } SimpleCat::~SimpleCat() { delete itsAge; delete itsWeight; } int main() { SimpleCat Mruczek; std::cout << "Mruczek ma " << Mruczek.GetAge() << " lat\n"; Mruczek.SetAge(7); std::cout << "Mruczek ma " << Mruczek.GetAge() << " lat\n"; return 0; }
Odpowiedź: Na stosie znajdzie się lokalny obiekt Mruczek. Ten obiekt zawiera dwa wskaźniki, z których każdy zajmuje cztery bajty stosu i zawiera adres zmiennej całkowitej zaalokowanej na stercie. W tym przykładzie, na stosie i na stercie zajętych zostanie po osiem bajtów.
Usunięto: na

Wskaźnik this Każda funkcja składowa klasy posiada ukryty parametr, jest nim wskaźnik this (to). Wskaźnik this wskazuje na ten egzemplarz obiektu klasy, dla którego wywołana została dana funkcja składowa. W każdym wywołaniu funkcji GetAge() lub SetAge() występuje ukryty parametr w postaci wskaźnika this.
Wskaźnika this można użyć jawnie; pokazuje to listing 8.8.
Listing 8.8. Użycie wskaźnika this 0: // Listing 8.8 1: // Użycie wskaźnika this 2: 3: 4: #include <iostream.h> 5: 6: class Rectangle 7: { 8: public: 9: Rectangle(); 10: ~Rectangle(); 11: void SetLength(int length) 12: { this->itsLength = length; } 13: int GetLength() const 14: { return this->itsLength; } 15: 16: void SetWidth(int width) 17: { itsWidth = width; } 18: int GetWidth() const 19: { return itsWidth; } 20: 21: private: 22: int itsLength; 23: int itsWidth; 24: }; 25: 26: Rectangle::Rectangle() 27: { 28: itsWidth = 5; 29: itsLength = 10; 30: } 31: Rectangle::~Rectangle() 32: {} 33: 34: int main() 35: { 36: Rectangle theRect; 37: cout << "theRect ma dlugosc " << theRect.GetLength() 38: << " metrow.\n"; 39: cout << "theRect ma szerokosc " << theRect.GetWidth() 40: << " metrow.\n"; 41: theRect.SetLength(20); 42: theRect.SetWidth(10); 43: cout << "theRect ma dlugosc " << theRect.GetLength() 44: << " metrow.\n"; 45: cout << "theRect ma szerokosc " << theRect.GetWidth() 46: << " metrow.\n"; 47: return 0; 48: }

Wynik theRect ma dlugosc 10 metrow. theRect ma szerokosc 5 metrow. theRect ma dlugosc 20 metrow. theRect ma szerokosc 10 metrow.
Analiza
Akcesory SetLength() (ustaw długość) oraz GetLength() (pobierz długość) w jawny sposób korzystają ze wskaźnika this przy dostępie do zmiennych składowych obiektu Rectangle (prostokąt). Akcesory SetWidth() (ustaw szerokość) oraz GetWidth() (pobierz szerokość) nie korzystają z tego wskaźnika jawnie. Nie ma żadnej różnicy pomiędzy działaniami tych akcesorów, choć składnia z użyciem wskaźnika this jest łatwiejsza do zrozumienia.
Gdyby tutaj kończyły się wiadomości na temat wskaźnika this, wspominanie o nim nie miałoby sensu. Należy pamiętać że wskaźnik this jest wskaźnikiem; oznacza to, że zawiera adres obiektu. Może zatem okazać się bardzo przydatny.
Praktyczne zastosowanie wskaźnika this poznasz w rozdziale 10., „Funkcje zaawansowane”; zostanie w nim omówione zagadnienie przeciążania operatorów. Na razie pamiętaj tylko o istnieniu wskaźnika this oraz jego przeznaczeniu: wskazywaniu na swój obiekt klasy.
Nie musisz martwić się tworzeniem i usuwaniem wskaźnika this – wszystkim zajmuje się kompilator.
Utracone wskaźniki Utracone wskaźniki są jednym ze źródeł trudnych do zlokalizowania błędów. Wskaźnik zostaje utracony, gdy wywołasz dla niego delete — a więc zwolnisz pamięć, na którą wskazuje — a następnie nie przypiszesz mu wartości pustej. Jeśli spróbujesz później użyć wskaźnika bez ponownego przypisania mu adresu obiektu, wynik będzie nieprzewidywalny i, o ile masz szczęście, program się załamie.
Przypomina to sytuację, w której firma kurierska zmieniła adres, a ty użyłeś zaprogramowanego przycisku w telefonie. Może nie zdarzyłoby się nic strasznego — telefon zadzwoniłby gdzieś w magazynie na którejś z pustyń. Może się jednak zdarzyć, że numer tego telefonu został przydzielony fabryce amunicji, a twój telefon doprowadziłby do wybuchu, który wysadziłby w powietrze całe miasto!
Innymi słowy, nie używaj wskaźników po ich zwolnieniu. Wskaźnik nadal wskazuje to samo miejsce w pamięci, ale kompilator może umieścić w nim zupełnie nowe dane; użycie wskaźnika może spowodować załamanie programu. Co gorsza, program może działać pozornie normalnie i załamać się kilka minut później. Można to nazwać bombą z opóźnionym zapłonem, co wcale nie jest zabawne. W celu zachowania bezpieczeństwa, po zwolnieniu wskaźnika przypisz mu wartość pustą (0). To spowoduje rozbrojenie wskaźnika.
Listing 8.9 przedstawia tworzenie utraconego wskaźnika.

OSTRZEŻENIE Przedstawiony poniżej program celowo tworzy utracony wskaźnik. NIE uruchamiaj go. Jeśli będziesz miał szczęście, program załamie się sam.
Listing 8.9. Tworzenie utraconego wskaźnika 0: // Listing 8.9 1: // Demonstruje utracony wskaźnik 2: 3: typedef unsigned short int USHORT; 4: #include <iostream> 5: 6: int main() 7: { 8: USHORT * pInt = new USHORT; 9: *pInt = 10; 10: std::cout << "*pInt: " << *pInt << std::endl; 11: delete pInt; 12: 13: long * pLong = new long; 14: *pLong = 90000; 15: std::cout << "*pLong: " << *pLong << std::endl; 16: 17: *pInt = 20; // o, nie! on był usunięty! 18: 19: std::cout << "*pInt: " << *pInt << std::endl; 20: std::cout << "*pLong: " << *pLong << std::endl; 21: delete pLong; 22: return 0; 23: }
Wynik *pInt: 10 *pLong: 90000 *pInt: 20 *pLong: 65556
(Nie próbuj odtworzyć tego wyniku; jeśli masz szczęście, w twoim komputerze uzyskasz inny wynik, jeśli nie masz szczęścia, komputer ci się zawiesi.)
Analiza
Linia 8. deklaruje zmienną pInt jako wskaźnik do typu USHORT; zmienna ta wskazuje nowo zaalokowaną pamięć. Linia 9. umieszcza w tej pamięci wartość 10, zaś linia 10. wypisuje jej wartość. Po wypisaniu wartości wskaźnik jest zwalniany za pomocą instrukcji delete. W tym momencie utracony został wskaźnik pInt.
Linia 13. deklaruje nowy wskaźnik, pLong, wskazujący pamięć zaalokowaną operatorem new. W linii 14. obiektowi wskazywanemu przez pLong jest przypisywana wartość 9000, zaś w linii 15. wypisywana jest wartość tego obiektu.
Linia 17. przypisuje wartość 20 do miejsca w pamięci, na które wskazuje pInt, ale wskaźnik ten nie wskazuje na poprawny wynik. Pamięć wskazywana przez pInt została zwolniona w wyniku wywołania delete, więc przypisanie jej wartości może okazać się katastrofą.
Usunięto: masz
Usunięto: załamie się sam
Usunięto: .

Linia 19. wypisuje wartość wskazywaną przez pInt. Oczywiście, jest nią 20. Linia 20. powinna wypisać wartość wskazywaną przez pLong, powinna ona wynosić 90000, jednak w tajemniczy sposób ta wartość zmieniła się na 65556. Nasuwają się dwa pytania:
1. Jak mogła zmienić się wartość wskazywana przez pLong, skoro nie był wykorzystywany wskaźnik pLong?
2. Gdzie została umieszczona wartość 20, która w linii 17. została przypisana obiektowi wskazywanemu przez pInt?
Jak można się domyślić, pytania te są ze sobą powiązane. Gdy w linii 17., w pamięci wskazywanej przez pInt umieszczana była wartość, w miejscu wskazywanym dotąd przez pInt kompilator ufnie umieścił 20. Jednak ponieważ w linii 11. ta pamięć została zwolniona, kompilator mógł ją przydzielić czemuś innemu. Gdy w linii 13. został stworzony wskaźnik pLong, otrzymał on poprzedni adres pamięci wskazywanej przez pInt. (Proces ten różni się w poszczególnych komputerach, w zależności od pamięci, w której przechowywane są wartości.) Gdy do miejsca wskazywanego uprzednio przez pInt zostało przypisane 20, zastąpiło ono wartość wskazywaną przez pLong. Proces ten nazywa się nadpisaniem wartości i często występuje w przypadku użycia utraconego wskaźnika.
Jest to szczególnie uciążliwy błąd, gdyż zmieniona wartość nie była związana z utraconym wskaźnikiem. Zmiana wartości wskazywanej przez pLong była jedynie efektem ubocznym użycia utraconego wskaźnika pInt. W obszernym programie taki błąd jest bardzo trudny do wykrycia.
Dla zabawy, zastanówmy się, jak mogła znaleźć się w pamięci wartość 65 556:
1. Wskaźnik pInt wskazywał określone miejsce w pamięci, w którym została umieszczona wartość 10.
2. Instrukcja delete zwolniła wskaźnik pInt, dzięki czemu zwolniło się miejsce do przechowania innej wartości. Następnie to samo miejsce w pamięci zostało przydzielone wskaźnikowi pLong.
3. W miejscu wskazywanym przez pLong została umieszczona wartość 90000. W komputerze, w którym uruchomiono ten przykładowy program, do przechowania tej wartości użyto czterech bajtów (00 01 5F 90), przechowywanych w odwróconej kolejności. Ta wartość była przechowywana jako 5F 90 00 01.
4. W pamięci wskazywanej przez pInt została umieszczona wartość 20 (czyli w zapisie szesnastkowym: 00 14). Ponieważ pInt przez cały czas wskazywało ten sam adres, zastąpione zostały pierwsze dwa bajty pamięci wskazywanej przez pLong, co dało wartość 00 14 00 01.
5. Gdy wartość wskazywana przez pLong została wypisana, odwrócenie bajtów dało wynik 00 01 00 14, co odpowiada wartości dziesiętnej 65556.
Często zadawane pytanie
Jaka jest różnica pomiędzy wskaźnikiem pustym a wskaźnikiem utraconym?
Usunięto: została

Odpowiedź: Gdy zwalniasz wskaźnik, informujesz kompilator, by zwolnił pamięć. Wskaźnik istnieje nadal i zawiera ten sam adres. Jest jedynie wskaźnikiem utraconym.
Gdy napiszesz myPtr = 0; zmieniasz go ze wskaźnika utraconego na wskaźnik pusty.
Normalnie, gdy usuniesz (zwolnisz) wskaźnik, po czym usuniesz go ponownie, wynik będzie nieprzewidywalny. Oznacza to, że może zdarzyć się dosłownie wszystko — jeśli masz szczęście, program się załamie. Natomiast przy zwalnianiu pustego wskaźnika nie dzieje się nic; jest to bezpieczne.
Użycie utraconego lub pustego wskaźnika (na przykład napisanie myPtr = 5;) jest niedozwolone i może spowodować załamanie programu. Jeśli wskaźnik jest pusty, program musi się załamać – stanowi to kolejną przewagę wskaźnika pustego nad wskaźnikiem utraconym. Programiści zdecydowanie wolą, gdy program załamuje się w sposób przewidywalny, znacznie ułatwia to usuwanie błędów.
Wskaźniki const W przypadku wskaźników, słowo kluczowe const możesz umieścić przed typem, po nim lub w obu tych miejscach. Wszystkie poniższe deklaracje są poprawne:
const int *pOne; int * const pTwo; const int * const pThree;
pOne jest wskaźnikiem do stałej wartości całkowitej. Wskazywana przez niego wartość nie może być zmieniana.
pTwo jest stałym wskaźnikiem do wartości całkowitej. Wartość może być zmieniana, ale pTwo nie może wskazywać na nic innego.
pThree jest stałym wskaźnikiem do stałej wartości całkowitej. Wskazywana przez niego wartość nie może być zmieniana, pThree nie może również wskazywać na nic innego.
Aby dowiedzieć się, która wartość jest stała, wystarczy spojrzeć na prawo od słowa kluczowego const. Jeśli znajduje się tam typ, stała jest wartość. Jeśli znajduje się zmienna, wtedy stały jest wskaźnik.
const int * p1; // wskazywana wartość typu int jest stała int * const p2; // p2 jest stałe i nie może wskazywać na nic innego

Wskaźniki const i funkcje składowe const Z rozdziału 6., „Programowanie zorientowane obiektowo”, dowiedziałeś się, że funkcja składowa może być zadeklarowana za pomocą słowa kluczowego const. Gdy funkcja zostanie zadeklarowana w taki właśnie sposób, przy każdej próbie zmiany danych obiektu wewnątrz tej funkcji kompilator zgłosi błąd.
Jeśli zadeklarujesz wskaźnik do obiektu const, za pomocą pomocy tego wskaźnika możesz wywoływać tylko metody const. Ilustruje to listing 8.10.
Listing 8.10. Użycie wskaźnika do obiektu const 0: // Listing 8.10 1: // Użycie wskaźników z metodami const 2: 3: #include <iostream> 4: using namespace std; 5: 6: class Rectangle 7: { 8: public: 9: Rectangle(); 10: ~Rectangle(); 11: void SetLength(int length) { itsLength = length; } 12: int GetLength() const { return itsLength; } 13: void SetWidth(int width) { itsWidth = width; } 14: int GetWidth() const { return itsWidth; } 15: 16: private: 17: int itsLength; 18: int itsWidth; 19: }; 20: 21: Rectangle::Rectangle() 22: { 23: itsWidth = 5; 24: itsLength = 10; 25: } 26: 27: Rectangle::~Rectangle() 28: {} 29: 30: int main() 31: { 32: Rectangle* pRect = new Rectangle; 33: const Rectangle * pConstRect = new Rectangle; 34: Rectangle * const pConstPtr = new Rectangle; 35: 36: cout << "szerokosc pRect: " << pRect->GetWidth() 37: << " metrow\n"; 38: cout << "szerokosc pConstRect: " << pConstRect->GetWidth() 39: << " metrow\n"; 40: cout << "szerokosc pConstPtr: " << pConstPtr->GetWidth() 41: << " metrow\n"; 42: 43: pRect->SetWidth(10); 44: // pConstRect->SetWidth(10); 45: pConstPtr->SetWidth(10); 46: 47: cout << "szerokosc pRect: " << pRect->GetWidth()

48: << " metrow\n"; 49: cout << "szerokosc pConstRect: " << pConstRect->GetWidth() 50: << " metrow\n"; 51: cout << "szerokosc pConstPtr: " << pConstPtr->GetWidth() 52: << " metrow\n"; 53: return 0; 54: }
Wynik szerokosc pRect: 5 metrow szerokosc pConstRect: 5 metrow szerokosc pConstPtr: 5 metrow szerokosc pRect: 10 metrow szerokosc pConstRect: 5 metrow szerokosc pConstPtr: 10 metrow
Analiza
Linie od 6. do 19. deklarują klasę Rectangle (prostokąt). Linia 14. deklaruje metodę GetWidth() (pobierz szerokość) jako funkcję składową const. Linia 32. deklaruje wskaźnik do obiektu typu Rectangle. Linia 33. deklaruje pConstRect, który jest wskaźnikiem do stałego obiektu typu Rectangle. Linia 34. deklaruje pConstPtr, który jest stałym wskaźnikiem do obiektu typu Rectangle.
Linie od 36. do 41. wypisują ich wartości.
W linii 43. wskaźnik pRect jest używany do ustawienia szerokości prostokąta na 10. W linii 44. zostałby użyty wskaźnik pConstRect, ale został on zadeklarowany jako wskazujący na stały obiekt typu Rectangle. W związku z tym nie może legalnie wywoływać funkcji składowej, nie będącej funkcją const, dlatego został wykomentowany. W linii 45. wskaźnik pConstPtr wywołuje metodę SetWidth() (ustaw szerokość). Wskaźnik pConstPtr został zadeklarowany jako stały wskaźnik do obiektu typu Rectangle. Innymi słowy, zawartość wskaźnika jest stała i nie może wskazywać na nic innego, natomiast wskazywany prostokąt nie jest stały.
Wskaźniki const this Gdy deklarujesz obiekt jako const, deklarujesz jednocześnie, że wskaźnik this jest wskaźnikiem do obiektu const. Wskaźnik const this może być używany tylko z funkcjami składowymi const.
Stałe obiekty i stałe wskaźniki omówimy szerzej w następnym rozdziale, przy okazji omawiania referencji do stałych obiektów.
TAK NIE
Jeśli nie chcesz, by obiekty przekazywane przez referencję były zmieniane, chroń je słowem kluczowym const.
Jeśli obiekt może być zmieniany, przekazuj go
Nie usuwaj wskaźnika więcej niż jeden raz.
Usunięto: Width

przez referencję.
Jeśli nie chcesz, by zmieniany był mały obiekt, przekazuj go przez wartość.
Działania arytmetyczne na wskaźnikach — temat dla zaawansowanych Wskaźniki można od siebie odejmować. Jedną z użytecznych technik jest przypisanie dwóm wskaźnikom różnych elementów tablicy, a następnie odjęcie wskaźników od siebie (w celu obliczenia ilości elementów rozdzielających dwa wskazywane elementy). Może to być bardzo użyteczne w przypadku przetwarzania tablic znaków. Pokazuje to listing 8.11.
Listing 8.11. Wydzielanie słów z łańcucha znaków 0: #include <iostream> 1: #include <ctype.h> 2: #include <string.h> 3: 4: bool GetWord(char* theString, 5: char* word, int& wordOffset); 6: 7: // program sterujący 8: int main() 9: { 10: const int bufferSize = 255; 11: char buffer[bufferSize+1]; // zawiera cały łańcuch 12: char word[bufferSize+1]; // zawiera słowo 13: int wordOffset = 0; // zaczynamy od początku 14: 15: std::cout << "Wpisz lancuch znakow:\n"; 16: std::cin.getline(buffer,bufferSize); 17: 18: while (GetWord(buffer,word,wordOffset)) 19: { 20: std::cout << "Wydzielono slowo: " << word << std::endl; 21: } 22: 23: return 0; 24: 25: } 26: 27: 28: // funkcja wydzielająca słowa z łańcucha. 29: bool GetWord(char* theString, char* word, int& wordOffset) 30: { 31: 32: if (!theString[wordOffset]) // koniec łańcucha? 33: return false; 34: 35: char *p1, *p2; 36: p1 = p2 = theString+wordOffset; // wskazuje następne słow 37: 38: // pomijamy wiodące spacje

39: for (int i = 0; i<(int)strlen(p1) && !isalnum(p1[0]); i++) 40: p1++; 41: 42: // sprawdzamy, czy mamy słowo 43: if (!isalnum(p1[0])) 44: return false; 45: 46: // p1 wskazuje teraz na początek następnego słowa; 47: // niech na nie wskazuje także p2 48: p2 = p1; 49: 50: // przesuwamy p2 na koniec słowa 51: while (isalnum(p2[0])) 52: p2++; 53: 54: // teraz p2 wskazuje na koniec słowa 55: // p1 wskazuje na początek słowa 56: // różnicą jest długość słowa 57: int len = int (p2 - p1); 58: 59: // kopiujemy słowo do bufora 60: strncpy (word,p1,len); 61: 62: // kończymy je bajtem zerowym 63: word[len]='\0'; 64: 65: // szukamy początku następnego słowa 66: for (int j = int(p2-theString); j<(int)strlen(theString) 67: && !isalnum(p2[0]); j++) 68: { 69: p2++; 70: } 71: 72: wordOffset = int(p2-theString); 73: 74: return true; 75: }
Wynik Wpisz lancuch znakow: Ten kod po raz pierwszy pojawil sie w raporcie jezyka C++ Wydzielono slowo: Ten Wydzielono slowo: kod Wydzielono slowo: po Wydzielono slowo: raz Wydzielono slowo: pierwszy Wydzielono slowo: pojawil Wydzielono slowo: sie Wydzielono slowo: w Wydzielono slowo: raporcie Wydzielono slowo: jezyka Wydzielono slowo: C
Analiza
W linii 15. użytkownik jest proszony o wpisanie łańcucha znaków. Otrzymany łańcuch jest przekazywany funkcji GetWord() (pobierz słowo) w linii 18., wraz z buforem do przechowania

pierwszego słowa i zmienną wordOffset (przesunięcie słowa), inicjalizowaną w linii 13. wartością zero. Słowa zwracane przez funkcję GetWord() są wypisywane do chwili, w której funkcja ta zwróci wartość false.
Każde wywołanie funkcji GetWord() powoduje skok do linii 29. W linii 32. sprawdzamy, czy wartością theString[wordOffset] jest zero – to będzie oznaczać, że doszliśmy do końca łańcucha; w takim przypadku funkcja GetWord() zwróci wartość false.
Zwróć uwagę na fakt, że C++ uważa zero za wartość false. Moglibyśmy przepisać tę linię następująco:
32: if (theString[wordOffset] == 0) // koniec łańcucha?
W linii 35. są deklarowane dwa wskaźniki do znaków, p1 i p2, które w linii 36. są inicjalizowane tak, aby wskazywały na miejsce łańcucha o przesunięciu wordOffset względem jego początku. Początkowo zmienna wordOffset ma wartość zero, więc oba wskaźniki wskazują początek łańcucha.
Linie 39. i 40. przechodzą poprzez łańcuch, do chwili, w której wskaźnik p1 wskaże pierwszy znak alfanumeryczny. Linie 43. i 44. zapewniają, że faktycznie znaleźliśmy znak alfanumeryczny; jeśli tak nie jest, zwracamy wartość false.
Wskaźnik p1 wskazuje teraz na następne słowo, a linia 48. ustawia wskaźnik p2 tak, aby wskazywał na to samo miejsce.
Następnie linie 51. i 52. powodują, że wskaźnik p2 przechodzi poprzez słowo, zatrzymując się na pierwszym znaku nie będącym znakiem alfanumerycznym. W tym momencie wskaźnik p2 wskazuje na koniec słowa, na którego początek wskazuje wskaźnik p1. Odejmując wskaźnik p1 od wskaźnika p2 w linii 55. i rzutując rezultat do wartości całkowitej, możemy obliczyć długość słowa. Następnie kopiujemy słowo do bufora word (słowo), przekazując wskaźnik (wskazujący początkowy znak – p1) oraz obliczoną długość słowa.
W linii 63. na końcu słowa w buforze dopisujemy wartość null (zero). Wskaźnik p2 jest inkrementowany tak, by wskazywał na początek następnego słowa, następnie przesunięcie tego słowa (względem początku łańcucha) jest umieszczane w zmiennej referencyjnej wordOffset. Na koniec, funkcja zwraca wartość true, aby wskazać, że znaleziono następne słowo.
Jest to klasyczny przykład kodu, który najlepiej analizować uruchamiając w debuggerze, śledząc jego działanie krok po kroku.
Usunięto: l

Rozdział 9. Referencje W poprzednim rozdziale poznałeś wskaźniki i dowiedziałeś się, jak za ich pomocą można operować obiektami na stercie oraz jak odwoływać się do obiektów pośrednio. Referencje mają prawie te same możliwości, co wskaźniki, ale posiadają przy tym dużo prostszą składnię.
Z tego rozdziału dowiesz się:
• czym są referencje,
• czym różnią się od wskaźników,
• jak się je tworzy i wykorzystuje,
• jakie są ich ograniczenia,
• w jaki sposób przekazywać obiekty i wartości do i z funkcji za pomocą referencji.
Czym jest referencja? Referencja jest aliasem (inną nazwą); gdy tworzysz referencję, inicjalizujesz ją nazwą innego obiektu, będącego celem referencji. Od tego momentu referencja działa jak alternatywna nazwa celu. Wszystko, co robisz z referencją, w rzeczywistości dotyczy jej obiektu docelowego.
Referencję tworzy się, zapisując typ obiektu docelowego, operator referencji (&) oraz nazwę referencji.
Nazwy referencji mogą być dowolne, ale wielu programistów woli poprzedzać jej nazwę literą „r”. Jeśli masz zmienną całkowitą o nazwie someInt, możesz stworzyć referencję do niej pisząc:
int &rSomeRef = someInt;
Odczytuje się to jako: „rSomeRef jest referencją do zmiennej typu int. Ta referencja została zainicjalizowana tak, aby odnosiła się do zmiennej someInt.” Sposób tworzenia referencji i korzystania z niej przedstawia listing 9.1.
Usunięto: u
Usunięto: jest robione
Usunięto: z
Usunięto: em
Usunięto: wartości

UWAGA Operator referencji (&) ma taki sam symbol, jak operator adresu. Nie są to jednak te same operatory (choć oczywiście są ze sobą powiązane).
Zastosowanie spacji przed operatorem referencji jest obowiązkowe, użycie spacji pomiędzy operatorem referencji a nazwą zmiennej referencyjnej jest opcjonalne. Tak więc:
int &rSomeRef = someInt; // ok int & rSomeRef = someInt; // ok
Listing 9.1. Tworzenie referencji i jej użycie 0: //Listing 9.1 1: // Demonstruje użycie referencji 2: 3: #include <iostream> 4: 5: int main() 6: { 7: using namespace std; 8: int intOne; 9: int &rSomeRef = intOne; 10: 11: intOne = 5; 12: cout << "intOne: " << intOne << endl; 13: cout << "rSomeRef: " << rSomeRef << endl; 14: 15: rSomeRef = 7; 16: cout << "intOne: " << intOne << endl; 17: cout << "rSomeRef: " << rSomeRef << endl; 18: 19: return 0; 20: }
Wynik intOne: 5 rSomeRef: 5 intOne: 7 rSomeRef: 7
Analiza
W linii 8. jest deklarowana lokalna zmienna intOne. W linii 9. referencja rSomeRef (jakaś referencja) jest deklarowana i inicjalizowana tak, by odnosiła się do zmiennej intOne. Jeśli zadeklarujesz referencję, lecz jej nie zainicjalizujesz, kompilator zgłosi błąd powstały podczas kompilacji. Referencje muszą być zainicjalizowane.
W linii 11. zmiennej intOne jest przypisywana wartość 5. W liniach 12. i 13. są wypisywane wartości zmiennej intOne i referencji rSomeRef; są one oczywiście takie same.
W linii 17. referencji rSomeRef jest przypisywana wartość 7. Ponieważ jest to referencja, czyli inna nazwa zmiennej intOne, w rzeczywistości wartość ta jest przypisywana tej zmiennej (co potwierdzają komunikaty wypisywane w liniach 16. i 17.).

Użycie operatora adresu z referencją Gdy pobierzesz adres referencji, uzyskasz adres jej celu. Wynika to z natury referencji (są one aliasami dla obiektów docelowych). Pokazuje to listing 9.2.
Listing 9.2. Odczytywanie adresu referencji 0: //Listing 9.2 1: // Demonstruje użycie referencji 2: 3: #include <iostream> 4: 5: int main() 6: { 7: using namespace std; 8: int intOne; 9: int &rSomeRef = intOne; 10: 11: intOne = 5; 12: cout << "intOne: " << intOne << endl; 13: cout << "rSomeRef: " << rSomeRef << endl; 14: 15: cout << "&intOne: " << &intOne << endl; 16: cout << "&rSomeRef: " << &rSomeRef << endl; 17: 18: return 0; 19: }
Wynik intOne: 5 rSomeRef: 5 &intOne: 0012FF7C &rSomeRef: 0012FF7C
UWAGA W twoim komputerze dwie ostatnie linie mogą wyglądać inaczej.
Analiza
W tym przykładzie referencja rSomeRef ponownie odnosi się do zmiennej intOne. Tym razem jednak wypisywane są adresy obu zmiennych; są one identyczne. C++ nie umożliwia dostępu do adresu samej referencji, gdyż jego użycie, w odróżnieniu od użycia adresu zmiennej, nie miałoby sensu. Referencje są inicjalizowane podczas tworzenia i zawsze stanowią synonim dla swojego obiektu docelowego (nawet gdy zostanie zastosowany operator adresu).
Na przykład, jeśli masz klasę o nazwie President, jej egzemplarz możesz zadeklarować następująco:
President George_Washington;
Możesz wtedy zadeklarować referencję do klasy President i zainicjalizować ją tym obiektem:
President &FatherOfOurCountry = George_Washington;
Istnieje tylko jeden obiekt klasy President; oba identyfikatory odnoszą się do tego samego egzemplarza obiektu tej samej klasy. Wszelkie operacje, jakie wykonasz na zmiennej FatherOfOurCountry (ojciec naszego kraju), będą odnosić się do obiektu George_Washington.
Należy odróżnić symbol & w linii 9. listingu 9.2 (deklarujący referencję o nazwie rSomeRef) od symboli & w liniach 15. i 16., które zwracają adresy zmiennej całkowitej intOne i referencji rSomeRef.
Zwykle w trakcie używania referencji nie używa się operatora adresu. Referencji używa się tak, jak jej zmiennej docelowej. Pokazuje to linia 13.
Nie można zmieniać przypisania referencji Nawet doświadczonym programistom C++, którzy wiedzą, że nie można zmieniać przypisania referencji, gdyż jest ona aliasem swojego obiektu docelowego, zdarza się próba zmiany jej przypisania. To, co wygląda w takiej sytuacji na ponowne przypisanie referencji, w rzeczywistości jest przypisaniem nowej wartości obiektowi docelowemu. Przedstawia to listing 9.3.
Listing 9.3. Przypisanie do referencji 0: //Listing 9.3 1: //Ponowne przypisanie referencji 2: 3: #include <iostream> 4: 5: int main() 6: { 7: using namespace std; 8: int intOne; 9: int &rSomeRef = intOne; 10: 11: intOne = 5; 12: cout << "intOne:\t" << intOne << endl; 13: cout << "rSomeRef:\t" << rSomeRef << endl; 14: cout << "&intOne:\t" << &intOne << endl; 15: cout << "&rSomeRef:\t" << &rSomeRef << endl; 16: 17: int intTwo = 8; 18: rSomeRef = intTwo; // to nie to o czym myślisz! 19: cout << "\nintOne:\t" << intOne << endl; 20: cout << "intTwo:\t" << intTwo << endl; 21: cout << "rSomeRef:\t" << rSomeRef << endl; 22: cout << "&intOne:\t" << &intOne << endl; 23: cout << "&intTwo:\t" << &intTwo << endl; 24: cout << "&rSomeRef:\t" << &rSomeRef << endl; 25: return 0; 26: }
Wynik intOne: 5

rSomeRef: 5 &intOne: 0012FF7C &rSomeRef: 0012FF7C intOne: 8 intTwo: 8 rSomeRef: 8 &intOne: 0012FF7C &intTwo: 0012FF74 &rSomeRef: 0012FF7C
Analiza
Także w tym programie zostały zadeklarowane (w liniach 8. i 9.) zmienna całkowita i referencja do niej. W linii 11. zmiennej jest przypisywana wartość 5, po czym w liniach od 12. do 15. wypisywane są wartości i ich adresy.
W linii 17. tworzona jest nowa zmienna, intTwo, inicjalizowana wartością 8. W linii 18. programista próbuje zmienić przypisanie referencji rSomeRef tak, aby odnosiła się do zmiennej intTwo, lecz mu się to nie udaje. W rzeczywistości referencja rSomeRef w dalszym ciągu jest aliasem dla zmiennej intOne, więc to przypisanie stanowi ekwiwalent dla:
intOne = intTwo;
Potwierdzają to wypisywane w liniach 19. do 21. komunikaty, pokazujące wartości zmiennej intOne i referencji rSomeRef. Ich wartości są takie same, jak wartość zmiennej intTwo. W rzeczywistości, gdy w liniach od 22. do 24. są wypisywane adresy, okazuje się, że rSomeRef w dalszym ciągu odnosi się do zmiennej intOne, a nie do zmiennej intTwo.
TAK NIE
W celu stworzenia aliasu do obiektu używaj referencji.
Inicjalizuj wszystkie referencje.
Nie zmieniaj przypisania referencji.
Nie myl operatora adresu z operatorem referencji.
Do czego mogą odnosić się referencje? Referencje mogą odnosić się do każdego z obiektów, także do obiektów zdefiniowanych przez użytkownika. Zwróć uwagę, że referencja odnosi się do obiektu, a nie do klasy, do której ten obiekt należy. Nie możesz napisać:
int & rIntRef = int; // źle
Musisz zainicjalizować referencję rIntRef tak, aby odnosiła się do konkretnej zmiennej całkowitej, na przykład:
int howBig = 200; int & rIntRef = howBig;
Nie możesz zainicjalizować też referencji do klasy CAT:
CAT & rCatRef = CAT; // źle
Musisz zainicjalizować referencję rCatRef tak, aby odnosiła się do konkretnego egzemplarza tej klasy:
CAT mruczek; CAT & rCatRef = mruczek;
Referencje do obiektów są używane w taki sam sposób, jak obiekty. Dane i funkcje składowe są dostępne poprzez ten sam operator dostępu do składowych (.) i, podobnie jak w typach wbudowanych, referencja działa jak inna nazwa obiektu. Ilustruje to listing 9.4.
Listing 9.4. Referencje do obiektów 0: // Listing 9.4 1: // Referencje do obiektów klas 2: 3: #include <iostream> 4: 5: class SimpleCat 6: { 7: public: 8: SimpleCat (int age, int weight); 9: ~SimpleCat() {} 10: int GetAge() { return itsAge; } 11: int GetWeight() { return itsWeight; } 12: private: 13: int itsAge; 14: int itsWeight; 15: }; 16: 17: SimpleCat::SimpleCat(int age, int weight) 18: { 19: itsAge = age; 20: itsWeight = weight; 21: } 22: 23: int main() 24: { 25: SimpleCat Mruczek(5,8); 26: SimpleCat & rCat = Mruczek; 27: 28: std::cout << "Mruczek ma: "; 29: std::cout << Mruczek.GetAge() << " lat. \n"; 30: std::cout << "i wazy: ";
Usunięto: W ten sam sposób
Usunięto: Int
31: std::cout << rCat.GetWeight() << " funtow. \n"; 32: return 0; 33: }
Wynik Mruczek ma: 5 lat. i wazy: 8 funtow.
Analiza
W linii 25. zmienna Mruczek jest deklarowana jako obiekt klasy SimpleCat (zwykły kot). W linii 26. jest deklarowana referencja rCat do obiektu klasy SimpleCat, która odnosi się do obiektu Mruczek. W liniach 29. i 31. są wykorzystywane akcesory klasy SimpleCat, najpierw poprzez obiekt klasy, a potem poprzez referencję. Zwróć uwagę, że dostęp do nich jest identyczny. Także w tym przypadku referencja jest inną nazwą (aliasem) rzeczywistego obiektu.
Referencje
Referencję deklaruje się, zapisując typ, operator referencji (&) oraz nazwę referencji. Referencje muszą być inicjalizowane w trakcie ich tworzenia.
Przykład 1
int hisAge; int &rAge = hisAge;
Przykład 2
CAT Filemon; CAT &rCatRef = Filemon;
Zerowe wskaźniki i zerowe referencje Gdy wskaźniki nie są inicjalizowane lub zostaną zwolnione, powinno się im przypisać wartość zerową null (0). W przypadku referencji sytuacja wygląda inaczej. Referencja nie może być zerowa, a program zawierający referencję do nie istniejącego (czyli pustego) obiektu, jest uważany za niewłaściwy. Gdy program jest niewłaściwy, może zdarzyć się prawie wszystko. Może się zdarzyć, że taki program działa, ale równie dobrze może też usunąć wszystkie pliki z dysku.
Większość kompilatorów obsługuje puste obiekty, powodując załamanie programu tylko wtedy, gdy spróbujesz użyć takiego obiektu. Obsługa pustych obiektów nie jest dobrym pomysłem. Gdy przeniesiesz program do innego komputera lub kompilatora, puste obiekty mogą spowodować tajemnicze błędy w działaniu programu.
Usunięto: prosty
Usunięto: Puste
Usunięto: puste
Usunięto: pusta

Przekazywanie argumentów funkcji przez referencję Z rozdziału 5., „Funkcje”, dowiedziałeś się, że funkcje mają dwa ograniczenia: argumenty są przekazywane przez wartość, a funkcja może zwrócić tylko jedną wartość.
Przekazywanie argumentów funkcji poprzez referencję może zlikwidować oba te ograniczenia. W C++, przekazywanie przez referencję odbywa się na dwa sposoby: z wykorzystaniem wskaźników i z wykorzystaniem referencji. Zauważ różnicę: przekazujesz poprzez referencję, używając wskaźnika lub przekazujesz poprzez referencję, używając referencji.
Składnia użycia wskaźnika jest inna niż użycia referencji, ale ogólny efekt jest taki sam. W dużym uproszczeniu można powiedzieć, że zamiast tworzyć w funkcji kopię przekazywanego obiektu, program przekazuje jej obiekt oryginalny.
Z rozdziału 5. dowiedziałeś się, że argumenty funkcji są im przekazywane poprzez stos. Gdy funkcja otrzymuje wartość poprzez referencję (z użyciem wskaźnika lub referencji), na stosie umieszczany jest adres obiektu, a nie cały obiekt.
W niektórych komputerach adres jest przechowywany w rejestrze i nie jest umieszczany na stosie. Kompilator wie, jak odwołać się do oryginalnego obiektu, więc zmiany są dokonywane w tym obiekcie, a nie w jego kopii.
Przekazanie obiektu przez referencję umożliwia funkcji dokonywanie zmian w tym obiekcie.
Przypomnij sobie, że listing 5.5 z rozdziału piątego pokazywał, że wywołanie funkcji swap() nie miało wpływu na wartości w funkcji wywołującej. Listing 5.5 został tu dla wygody powtórzony jako listing 9.5.
Listing 9.5. Przykład przekazywania przez wartość 0: //Listing 9.5 Demonstruje przekazywanie przez wartość 1: 2: #include <iostream> 3: 4: using namespace std; 5: void swap(int x, int y); 6: 7: int main() 8: { 9: int x = 5, y = 10; 10: 11: cout << "Funkcja main(). Przed funkcja swap(), x: " << x << " y: " << y << "\n"; 12: swap(x,y); 13: cout << "Funkcja main(). Po funkcji swap(), x: " << x << " y: " << y << "\n"; 14: return 0; 15: } 16: 17: void swap (int x, int y) 18: { 19: int temp; 20: 21: cout << "Funkcja swap(). Przed zamiana, x: " << x << " y: " << y << "\n";
Usunięto: odtworzony

22: 23: temp = x; 24: x = y; 25: y = temp; 26: 27: cout << "Funkcja swap(). Po zamianie, x: " << x << " y: " << y << "\n"; 28: 29: }
Wynik Funkcja main(). Przed funkcja swap(), x: 5 y: 10 Funkcja swap(). Przed zamiana, x: 5 y: 10 Funkcja swap(). Po zamianie, x: 10 y: 5 Funkcja main(). Po funkcji swap(), x: 5 y: 10
Analiza
Wewnątrz funkcji main() program inicjalizuje dwie zmienne i przekazuje je funkcji swap() (zamień), która wydaje się je zamieniać. Jednak gdy ponownie sprawdzimy ich wartości w funkcji main(), okaże się, że nie uległy one zmianie!
Problem polega na tym, że zmienne x i y są przekazywane funkcji swap() poprzez wartość. Oznacza to, że wewnątrz tej funkcji są tworzone ich lokalne kopie. Nam potrzebne jest przekazanie zmiennych x i y przez referencję.
W C++ istnieją dwie możliwości rozwiązania tego problemu: parametry funkcji swap() możesz zamienić na wskaźniki do oryginalnych wartości, lub przekazać referencje do pierwotnych wartości.
Tworzenie funkcji swap() otrzymującej wskaźniki Przekazując wskaźnik, przekazujesz adres obiektu, dlatego funkcja może manipulować wartością znajdującą się pod tym adresem. Aby za pomocą wskaźników umożliwić funkcji swap() zamianę wartości swoich argumentów, powinieneś zadeklarować ją jako przyjmującą dwa wskaźniki do zmiennych całkowitych. Następnie, poprzez wyłuskanie wskaźników (czyli dereferencję), możesz zamienić wartości zmiennych miejscami . Demonstruje to listing 9.6.
Listing 9.6. Przekazywanie przez referencję za pomocą wskaźników 0: //Listing 9.6 Demonstruje przekazywanie przez referencję 1: 2: #include <iostream> 3: 4: using namespace std; 5: void swap(int *x, int *y); 6: 7: int main() 8: { 9: int x = 5, y = 10; 10: 11: cout << "Funkcja main(). Przed funkcja swap(), x: " << x << " y: " << y << "\n"; 12: swap(&x,&y);
Usunięto: miejscami

13: cout << "Funkcja main(). Po funkcji swap(), x: " << x << " y: " << y << "\n"; 14: return 0; 15: } 16: 17: void swap (int *px, int *py) 18: { 19: int temp; 20: 21: cout << "Funkcja swap(). Przed zamiana, *px: " << *px << 22: " *py: " << *py << "\n"; 23: 24: temp = *px; 25: *px = *py; 26: *py = temp; 27: 28: cout << "Funkcja swap(). Po zamianie, *px: " << *px << 29: " *py: " << *py << "\n"; 30: 31: }
Wynik Funkcja main(). Przed funkcja swap(), x: 5 y: 10 Funkcja swap(). Przed zamiana, *px: 5 *py: 10 Funkcja swap(). Po zamianie, *px: 10 *py: 5 Funkcja main(). Po funkcji swap(), x: 10 y: 5
Analiza
Udało się! W linii 5. został zmieniony prototyp funkcji swap(), w którym zadeklarowano że oba parametry funkcji są wskaźnikami do zmiennych typu int, a nie zmiennymi tego typu. Gdy w linii 12. następuje wywołanie funkcji swap(), jako argumenty są jej przekazywane adresy zmiennych x i y.
W linii 19., w funkcji swap(),deklarowana jest lokalna zmienna temp1. Ta zmienna nie musi być wskaźnikiem; w czasie życia funkcji swap() przechowuje ona wartość *px (tj. wartość zmiennej x zadeklarowanej w funkcji wywołującej). Gdy funkcja swap() zakończy działanie, zmienna temp nie będzie już potrzebna.
W linii 24. zmiennej temp przypisywana jest wartość wskazywana przez px. W linii 25. zmiennej wskazywanej przez px przypisywana jest wartość wskazywana przez py. W linii 26. wartość przechowywana w zmiennej temp (tj. oryginalna wartość wskazywana przez px) jest umieszczana w zmiennej wskazywanej przez py.
Efektem przeprowadzonych przez nas działań jest zamiana wartości tych zmiennych, których adresy zostały przekazane do funkcji swap().
1 Ta nazwa jest skrótem od słowa temporary (tymczasowa) i bardzo często występuje w programach. — przyp.tłum.
Usunięto: zmiennej
Usunięto: umieszczona

Implementacja funkcji swap() za pomocą referencji Przedstawiony wcześniej program działa, ale składnia pokazanej w nim funkcji swap() ma dwie wady. Po pierwsze, konieczność wyłuskiwania wskaźników wewnątrz funkcji swap() ułatwia popełnieni błędów i zmniejsza czytelność programu. Po drugie, konieczność przekazania adresów zmiennych przez funkcję wywołującą zdradza użytkownikom sposób działania funkcji swap().
W języku C++ użytkownik funkcji nie ma możliwości poznania sposobu jej działania. Przekazywanie wskaźników do parametrów oznacza konieczność odpowiednich przygotowań w funkcji wywołującej, a przecież przygotowania te powinny należeć do obowiązków funkcji wywoływanej. W listingu 9.7 funkcja swap() została ponownie przepisana, tym razem z zastosowaniem referencji, a nie wskaźników.
Listing 9.7. Funkcja swap() przepisana z zastosowaniem referencji 0: //Listing 9.7 Demonstruje przekazywanie przez referencję 1: // z zastosowaniem referencji! 2: 3: #include <iostream> 4: 5: using namespace std; 6: void swap(int &x, int &y); 7: 8: int main() 9: { 10: int x = 5, y = 10; 11: 12: cout << "Funkcja main(). Przed funkcja swap(), x: " << x << " y: " 13: << y << "\n"; 14: 15: swap(x,y); 16: 17: cout << "Funkcja main(). Po funkcji swap(), x: " << x << " y: " 18: << y << "\n"; 19: 20: return 0; 21: } 22: 23: void swap (int &rx, int &ry) 24: { 25: int temp; 26: 27: cout << "Funkcja swap(). Przed zamiana, rx: " << rx << " ry: " 28: << ry << "\n"; 29: 30: temp = rx; 31: rx = ry; 32: ry = temp; 33: 34: 35: cout << "Funkcja swap(). Po zamianie, rx: " << rx << " ry: " 36: << ry << "\n"; 37: 38: }
Usunięto: argumentów

Wynik Funkcja main(). Przed funkcja swap(), x: 5 y: 10 Funkcja swap(). Przed zamiana, rx: 5 ry: 10 Funkcja swap(). Po zamianie, rx: 10 ry: 5 Funkcja main(). Po funkcji swap(), x: 10 y: 5
Analiza
Podobnie, jak w przykładzie ze wskaźnikami, także i tu (w linii 10.) deklarowane są dwie zmienne, których wartości wypisywane są w linii 12. W linii 15. następuje wywołanie funkcji swap(), ale zwróć uwagę, że tym razem nie są przekazywane adresy zmiennych x i y, lecz same zmienne. Funkcja wywołująca po prostu przekazuje zmienne.
Gdy wywoływana jest funkcja swap(), działanie programu przechodzi do linii 23., w której zmienne zostają zidentyfikowane jako referencje. Ich wartości są wypisywane w linii 27., zwróć uwagę, że nie wymagają one przeprowadzania żadnych dodatkowych operacji. Są to aliasy oryginalnych wartości, które mogą zostać użyte jako te wartości.
W liniach od 30. do 32. wartości są zamieniane, a następnie ponownie wypisywane w linii 35. Wykonanie programu wraca do funkcji wywołującej, zatem funkcja main() (w linii 17.) ponownie wypisuje wartości zmiennych. Ponieważ parametry funkcji swap() zostały zadeklarowane jako referencje, wartości w funkcji main() zostały przekazane przez referencję, dlatego są zamienione również w tej funkcji.
Referencje ułatwiają korzystanie z normalnych zmiennych, zachowując przy tym możliwość przekazywania argumentów poprzez referencję.
Nagłówki i prototypy funkcji Listing 9.6 zawierał funkcję swap(), używającą wskaźników, zaś listing 9.7 zawierał tę samą funkcję używającą referencji. Stosowanie funkcji korzystającej z referencji jest łatwiejsze; łatwiejsze jest także zrozumienie kodu, ale skąd funkcja wywołująca wie, czy wartości są przekazywane poprzez wartość, czy poprzez referencję? Jako klient (czyli użytkownik) funkcji swap(), programista musi mieć pewność, że funkcja ta faktycznie zamieni swoje parametry.
Oto kolejne zastosowanie prototypów funkcji. Sprawdzając parametry zadeklarowane w prototypie, który zwykle znajduje się w pliku nagłówkowym wraz z innymi prototypami, programista wie, że wartości przekazywane do funkcji swap() są przekazywane poprzez referencję i wie, jak powinien ich użyć.
Gdyby funkcja swap() była częścią klasy, informacji tych dostarczyłaby deklaracja klasy, także umieszczana zwykle w pliku nagłówkowym.
W języku C++ wszystkich informacji potrzebnych klientom klas i funkcji mogą dostarczyć pliki nagłówkowe; pełnią one rolę interfejsu dla klasy lub funkcji. Implementacja jest natomiast ukrywana przed klientem. Dzięki temu programista może skupić się na analizowanym aktualnie problemie i korzystać z klasy lub funkcji bez zastanawiania się, w jaki sposób ona działa.
Gdy John Roebling projektował Most Brookliński, zajmował się takimi szczegółami, jak sposób wylewania betonu czy metoda produkcji drutu do kabli nośnych. Znał każdy fizyczny i chemiczny proces związany z tworzeniem materiałów przeznaczonych do budowy mostu. Obecnie

inżynierowie oszczędzają czas, używając dobrze znanych materiałów budowlanych, nie zastanawiając się, w jaki sposób są one tworzone przez producenta.
Języka C++ umożliwia programistom korzystanie z „dobrze znanych” klas i funkcji, bez konieczności zajmowania się szczegółami ich działania. Te „części składowe” mogą zostać połączone w celu stworzenia programu (podobnie jak łączone są kable, rury, klamry i inne części w celu stworzenia mostu czy budynku).
Inżynier przegląda specyfikację betonu w celu poznania jego wytrzymałości, ciężaru własnego, czasu krzepnięcia, itd., a programista przegląda interfejs funkcji lub klasy w celu poznania usług, jakich ona dostarcza, parametrów, których potrzebuje i wartości, jakie zwraca.
Zwracanie kilku wartości Jak wspominaliśmy wcześniej, funkcja może zwracać (bezpośrednio) tylko jedną wartość. Co zrobić, gdy chcesz otrzymać od funkcji dwie wartości? Jednym ze sposobów rozwiązania tego problemu jest przekazanie funkcji dwóch obiektów poprzez referencje. Funkcja może wtedy wypełnić te obiekty właściwymi wartościami. Ponieważ przekazywanie przez referencję umożliwia funkcji zmianę pierwotnego obiektu, może ona zwrócić dwie oddzielne informacje. Dzięki temu wartość zwracana przez funkcję bezpośrednio może zostać wykorzystana w inny sposób, na przykład do zgłoszenia informacji o błędach.
Także w tym przypadku do zwracania wartości w ten sposób można użyć wskaźników lub referencji. Listing 9.8 przedstawia funkcję zwracającą trzy wartości: dwie zwracane jako parametry mające postać wskaźników i jedną jako wartość zwracaną funkcji.
Listing 9.8. Zwracanie wartości poprzez wskaźniki 0: //Listing 9.8 1: // Zwracanie kilku wartości z funkcji 2: 3: #include <iostream> 4: 5: using namespace std; 6: short Factor(int n, int* pSquared, int* pCubed); 7: 8: int main() 9: { 10: int number, squared, cubed; 11: short error; 12: 13: cout << "Wpisz liczbe (0 - 20): "; 14: cin >> number; 15: 16: error = Factor(number, &squared, &cubed); 17: 18: if (!error) 19: { 20: cout << "liczba: " << number << "\n"; 21: cout << "do kwadratu: " << squared << "\n"; 22: cout << "do trzeciej potegi: " << cubed << "\n"; 23: } 24: else 25: cout << "Napotkano blad!!\n"; 26: return 0;
Usunięto: zostały złożone
Usunięto: jący
Usunięto: ten
Usunięto: przekazywane przez
Usunięto: otną

27: } 28: 29: short Factor(int n, int *pSquared, int *pCubed) 30: { 31: short Value = 0; 32: if (n > 20) 33: Value = 1; 34: else 35: { 36: *pSquared = n*n; 37: *pCubed = n*n*n; 38: Value = 0; 39: } 40: return Value; 41: }
Wynik Wpisz liczbe (0 - 20): 3 liczba: 3 do kwadratu: 9 do trzeciej potegi: 27
Analiza
W linii 10. zostały zadeklarowane trzy krótkie zmienne całkowite: number (liczba), squared (do kwadratu) oraz cubed (do trzeciej potęgi). Wartość zmiennej number jest wpisywana przez użytkownika. Ta liczba oraz adresy zmiennych squared i cubed są przekazywane do funkcji Factor() (czynnik).
Funkcja Factor() sprawdza pierwszy parametr, który jest przekazywany przez wartość. Jeśli jest większy od 20 (maksymalnej wartości, jaką może obsłużyć funkcja), zwracanej wartości Value (wartość) przypisywany jest prosty kod błędu. Zwróć uwagę, że wartość zwracana funkcji Factor() jest zarezerwowana dla zwrotu albo tej wartości błędu albo wartości 0, oznaczającej, że wszystko poszło dobrze; wartość tę funkcja zwraca w linii 40.
Obliczane w funkcji wartości, czyli podniesiona do potęgi drugiej i do trzeciej liczba, są zwracane nie poprzez instrukcję return, ale bezpośrednio poprzez zmianę wartości zmiennych wskazywanych przez wskaźniki przekazane do funkcji.
W liniach 36. i 37. zmiennym wskazywanym poprzez wskaźniki przypisywane są obliczone wartości wcześniej. W linii 38. zmiennej Value jest przypisywany kod sukcesu, który jest zwracany w linii 40.
Jednym z ulepszeń wprowadzonych do tej funkcji mogłaby być deklaracja:
enum ERROR_VALUE { SUCCESS, FAILURE};
Dzięki temu, zamiast zwracać wartości 0 lub 1, program mógłby zwracać odpowiednią wartość typu wyliczeniowego ERROR_VALUE (wartość błędu), czyli albo SUCCESS (sukces) albo FAILURE (porażka).
Usunięto: a
Usunięto: może
Usunięto: ócić
Usunięto: tę
Usunięto: ć
Usunięto: lub
Usunięto: ć
Usunięto: ą
Usunięto: potęgi
Usunięto: wartościom
Usunięto: wy
Usunięto: o
Usunięto: napisanie
Usunięto: stałą
Usunięto: a
Usunięto: lub

Zwracanie wartości przez referencję Choć program z listingu 9.8 działa poprawnie, byłby łatwiejszy w użyciu i modyfikacji, gdyby zamiast wskaźników zastosowano w nim referencje. Listing 9.9 przedstawia ten sam program przepisany tak, aby wykorzystywał referencje i typ wyliczeniowy ERR_CODE (kod błędu).
Listing 9.9. Listing 9.8 przepisany z zastosowaniem referencji 0: //Listing 9.9 1: // Zwracanie kilku wartości z funkcji 2: // z zastosowaniem referencji 3: 4: #include <iostream> 5: 6: using namespace std; 7: typedef unsigned short USHORT; 8: enum ERR_CODE { SUCCESS, ERROR }; 9: 10: ERR_CODE Factor(USHORT, USHORT&, USHORT&); 11: 12: int main() 13: { 14: USHORT number, squared, cubed; 15: ERR_CODE result; 16: 17: cout << "Wpisz liczbe (0 - 20): "; 18: cin >> number; 19: 20: result = Factor(number, squared, cubed); 21: 22: if (result == SUCCESS) 23: { 24: cout << "liczba: " << number << "\n"; 25: cout << "do kwadratu: " << squared << "\n"; 26: cout << "do trzeciej potegi: " << cubed << "\n"; 27: } 28: else 29: cout << "Napotkano blad!!\n"; 30: return 0; 31: } 32: 33: ERR_CODE Factor(USHORT n, USHORT &rSquared, USHORT &rCubed) 34: { 35: if (n > 20) 36: return ERROR; // prosty kod błędu 37: else 38: { 39: rSquared = n*n; 40: rCubed = n*n*n; 41: return SUCCESS; 42: } 43: }
Wynik Wpisz liczbe (0 - 20): 3 liczba: 3 do kwadratu: 9 do trzeciej potegi: 27
Usunięto: e

Analiza
Listing 9.9 jest prawie identyczny z listingiem 9.8, z dwiema różnicami. Dzięki zastosowaniu wyliczenia ERR_CODE zgłaszanie błędów w liniach 36. i 41., a także ich obsługa w linii 22., są bardziej przejrzyste.
Istotną zmianą jest to, że tym razem funkcja Factor() została zadeklarowana jako przyjmująca referencje, a nie wskaźniki, do zmiennych squared i cubed. Dzięki temu operowanie tymi parametrami jest prostsze i bardziej zrozumiałe.
Przekazywanie przez referencję zwiększa efektywność działania programu Za każdym razem, gdy przekazujesz obiekt do funkcji poprzez wartość, tworzona jest kopia tego obiektu. Za każdym razem, gdy zwracasz z funkcji obiekt poprzez wartość, tworzona jest kolejna kopia.
Z rozdziału 5. dowiedziałeś się, że obiekty te są kopiowane na stos. Wymaga to sporej ilości czasu i pamięci. W przypadku niewielkich obiektów, takich jak wbudowane typy całkowite, koszt ten jest niewielki.
Jednak w przypadku większych, zdefiniowanych przez użytkownika obiektów, ten koszt staje się dużo większy. Rozmiar zdefiniowanego przez użytkownika obiektu umieszczonego na stosie jest sumą rozmiarów wszystkich jego zmiennych składowych. Każda z tych zmiennych także może być obiektem zdefiniowanym przez użytkownika, a przekazywanie takich rozbudowanych struktur przez kopiowanie ich na stos może być mało wydajne i zużywać dużo pamięci.
Pojawiają się także dodatkowe koszty. W przypadku tworzonych przez ciebie klas, za każdym razem gdy kompilator tworzy kopię tymczasową, wywoływany jest specjalny konstruktor: konstruktor kopiujący. Działanie konstruktorów kopiujących i metody ich tworzenia zostaną omówione w następnym rozdziale, na razie wystarczy, że będziesz wiedział, że konstruktor taki jest wywoływany za każdym razem, gdy na stosie jest umieszczana tymczasowa kopia obiektu.
Gdy niszczony jest obiekt tymczasowy (na zakończenie działania funkcji), wywoływany jest destruktor obiektu. Jeśli obiekt jest zwracany z funkcji poprzez wartość, konieczne jest stworzenie i zniszczenie kopii także i tego obiektu.
W przypadku dużych obiektów, takie wywołania konstruktorów i destruktorów mogą być kosztowne ze względu na szybkość i zużycie pamięci. Aby to zilustrować, listing 9.9 tworzy okrojony, zdefiniowany przez użytkownika obiekt klasy SimpleCat. Prawdziwy obiekt byłby większy i droższy, ale nasz obiekt wystarczy do pokazania, jak często wywoływany jest konstruktor kopiujący oraz destruktor.
Listing 9.10 tworzy obiekt typu SimpleCat, po czym wywołuje dwie funkcje. Pierwsza z nich otrzymuje obiekt poprzez wartość i zwraca go również poprzez wartość. Druga funkcja otrzymuje wskaźnik do obiektu i zwraca także wskaźnik, bez przekazywania samego obiektu.
Listing 9.10. Przekazywanie obiektów poprzez referencję, za pomocą wskaźników 0: //Listing 9.10 1: // Przekazywanie wskaźników do obiektów
Usunięto: e
Usunięto: i
Usunięto: i
Usunięto: :
Usunięto: i

2: 3: #include <iostream> 4: 5: using namespace std; 6: class SimpleCat 7: { 8: public: 9: SimpleCat (); // konstruktor 10: SimpleCat(SimpleCat&); // konstruktor kopiujący 11: ~SimpleCat(); // destruktor 12: }; 13: 14: SimpleCat::SimpleCat() 15: { 16: cout << "Konstruktor klasy SimpleCat...\n"; 17: } 18: 19: SimpleCat::SimpleCat(SimpleCat&) 20: { 21: cout << "Konstruktor kopiujący klasy SimpleCat...\n"; 22: } 23: 24: SimpleCat::~SimpleCat() 25: { 26: cout << "Destruktor klasy SimpleCat...\n"; 27: } 28: 29: SimpleCat FunctionOne (SimpleCat theCat); 30: SimpleCat* FunctionTwo (SimpleCat *theCat); 31: 32: int main() 33: { 34: cout << "Tworze obiekt...\n"; 35: SimpleCat Mruczek; 36: cout << "Wywoluje funkcje FunctionOne...\n"; 37: FunctionOne(Mruczek); 38: cout << "Wywoluje funkcje FunctionTwo...\n"; 39: FunctionTwo(&Mruczek); 40: return 0; 41: } 42: 43: // FunctionOne, parametr przekazywany poprzez wartość 44: SimpleCat FunctionOne(SimpleCat theCat) 45: { 46: cout << "FunctionOne. Wracam...\n"; 47: return theCat; 48: } 49: 50: // FunctionTwo, parametr przekazywany poprzez wskaźnik 51: SimpleCat* FunctionTwo (SimpleCat *theCat) 52: { 53: cout << "FunctionTwo. Wracam...\n"; 54: return theCat; 55: }
Wynik Tworze obiekt... Konstruktor klasy SimpleCat... Wywoluje funkcje FunctionOne...
Usunięto: i
Usunięto: i

Konstruktor kopiujący klasy SimpleCat... FunctionOne. Wracam... Konstruktor kopiujący klasy SimpleCat... Destruktor klasy SimpleCat... Destruktor klasy SimpleCat... Wywoluje funkcje FunctionTwo... FunctionTwo. Wracam... Destruktor klasy SimpleCat...
Analiza
W liniach od 6. do 12. została zadeklarowana bardzo uproszczona klasa SimpleCat. Zarówno konstruktor, jak i konstruktor kopiujący oraz destruktor wypisują odpowiednie dla siebie komunikaty, dzięki którym wiadomo, w którym momencie zostały wywołane.
W linii 34. funkcja main() wypisuje komunikat widoczny w pierwszej linii wyniku. W linii 35. tworzony jest egzemplarz obiektu klasy SimpleCat. Powoduje to wywołanie konstruktora tej klasy, co potwierdza druga linia wyniku.
W linii 36. funkcja main() zgłasza (poprzez wypisanie komunikatu w trzeciej linii wydruku), że wywołuje funkcję FunctionOne.. Ponieważ ta funkcja otrzymuje obiekt typu SimpleCat przekazywany poprzez wartość, na stosie tworzona jest lokalna dla tej funkcji kopia obiektu klasy SimpleCat. To powoduje wywołanie konstruktora kopiującego, który wypisuje czwartą linię wyniku.
Wykonanie programu przechodzi do wywoływanej funkcji, do linii 46., w której wypisywany jest komunikat informacyjny, stanowiący piątą linię wyniku. Następnie funkcja wraca i zwraca obiekt typu SimpleCat poprzez wartość. To powoduje utworzenie kolejnej kopii obiektu (poprzez wywołanie konstruktora kopiującego, wypisującego też szóstą linię wyniku).
Wartość zwracana przez funkcję FunctionOne() nie jest niczemu przypisywana, więc tymczasowy obiekt utworzony na stosie jest odrzucany, co powoduje wywołanie destruktora, który wypisuje siódmą linię wyniku. Ponieważ działanie funkcji FunctionOne() się zakończyło, jej lokalna kopia obiektu wychodzi z zakresu i jest niszczona; powoduje to wywołanie destruktora i wypisanie ósmej linii wyniku.
Program wraca do funkcji main(), w której zostaje teraz wywołana funkcja FunctionTwo(), lecz tym razem jej parametr jest przekazywany przez referencję. Nie jest tworzona żadna kopia, dlatego nie jest wypisywany żaden komunikat konstruktora. Funkcja FunctionTwo() wypisuje jedynie własny komunikat w dziesiątej linii wyniku, po czym zwraca obiekt typu SimpleCat, także poprzez wskaźnik, zatem także tym razem nie jest wywoływany konstruktor ani destruktor.
Program kończy swoje działanie i obiekt Mruczek wychodzi z zakresu, powodując jeszcze jedno wywołanie destruktora, wypisującego komunikat w jedenastej linii wyniku.
Ponieważ parametr funkcji FunctionOne() jest przekazywany i zwracany przez wartość, jej wywołanie wiąże się z dwoma wywołaniami konstruktora kopiującego i dwoma wywołaniami destruktora; natomiast wywołanie funkcji FunctionTwo() nie wymagało wywołania ani konstruktora, ani destruktora.
Usunięto: i
Usunięto: i
Usunięto: i
Usunięto: , która wypisuje komunikat w trzeciej linii wyniku
Usunięto: i
Usunięto: łącznie z
Usunięto: m
Usunięto: i
Usunięto: i

Przekazywanie wskaźnika const Choć przekazywanie wskaźnika jest dużo bardziej efektywne w funkcji FunctionTwo(), jednak jest także bardziej niebezpieczne. Funkcja FunctionTwo() nie powinna mieć możliwości zmiany otrzymanego obiektu SimpleCat, mimo, że otrzymuje wskaźnik do tego obiektu. Ten wskaźnik daje jej jednak możliwość zmiany wartości obiektu, co nie jest możliwe w przypadku przekazywania obiektu przez wartość.
Przekazywanie poprzez wartość przypomina przekazanie do muzeum reprodukcji arcydzieła, zamiast prawdziwego obrazu. Nawet, gdy do muzeum zakradnie się wandal, oryginał nie poniesie uszczerbku. Przekazywanie poprzez referencję przypomina przesłanie do muzeum swojego adresu domowego i zaproszenie gości do oglądania oryginałów.
Rozwiązaniem tego problemu jest przekazanie wskaźnika do stałego (const) obiektu typu SimpleCat. W ten sposób zabezpieczamy ten obiekt przed wywoływaniem metod tej klasy innych niż metody typu const, chroniąc go tym samym przed zmianami.
Przekazanie referencji typu const umożliwia gościom oglądanie oryginału, ale nie umożliwia jego modyfikacji. Demonstruje to listing 9.11.
Listing 9.11. Przekazywanie wskaźnika do obiektu const 0: //Listing 9.11 1: // Przekazywanie wskaźników do obiektów 2: 3: #include <iostream> 4: 5: using namespace std; 6: class SimpleCat 7: { 8: public: 9: SimpleCat(); 10: SimpleCat(SimpleCat&); 11: ~SimpleCat(); 12: 13: int GetAge() const { return itsAge; } 14: void SetAge(int age) { itsAge = age; } 15: 16: private: 17: int itsAge; 18: }; 19: 20: SimpleCat::SimpleCat() 21: { 22: cout << "Konstruktor klasy SimpleCat...\n"; 23: itsAge = 1; 24: } 25: 26: SimpleCat::SimpleCat(SimpleCat&) 27: { 28: cout << "Konstruktor kopiujący klasy SimpleCat...\n"; 29: } 30: 31: SimpleCat::~SimpleCat() 32: { 33: cout << "Destruktor klasy SimpleCat...\n"; 34: } 35: 36: const SimpleCat * const FunctionTwo
Usunięto: ale
Usunięto: To
Usunięto: tego
Usunięto: niż
Usunięto:
Usunięto: metod tej klasy, czyli chronimy go
Usunięto: i

37: (const SimpleCat * const theCat); 38: 39: int main() 40: { 41: cout << "Tworze obiekt...\n"; 42: SimpleCat Mruczek; 43: cout << "Mruczek ma " ; 44: cout << Mruczek.GetAge(); 45: cout << " lat\n"; 46: int age = 5; 47: Mruczek.SetAge(age); 48: cout << "Mruczek ma " ; 49: cout << Mruczek.GetAge(); 50: cout << " lat\n"; 51: cout << "Wywoluje funkcje FunctionTwo...\n"; 52: FunctionTwo(&Mruczek); 53: cout << "Mruczek ma " ; 54: cout << Mruczek.GetAge(); 55: cout << " lat\n"; 56: return 0; 57: } 58: 59: // functionTwo, otrzymuje wskaźnik const 60: const SimpleCat * const FunctionTwo 61: (const SimpleCat * const theCat) 62: { 63: cout << "FunctionTwo. Wracam...\n"; 64: cout << "Mruczek ma teraz " << theCat->GetAge(); 65: cout << " lat \n"; 66: // theCat->SetAge(8); const! 67: return theCat; 68: }
Wynik Tworze obiekt... Konstruktor klasy SimpleCat... Mruczek ma 1 lat Mruczek ma 5 lat Wywoluje funkcje FunctionTwo... FunctionTwo. Wracam... Mruczek ma teraz 5 lat Mruczek ma 5 lat Destruktor klasy SimpleCat...
Analiza
Klasa SimpleCat zawiera dwa akcesory: GetAge() w linii 13., będący funkcją const oraz SetAge() w linii 14., nie będący funkcją const. Oprócz tego posiada zmienną składową itsAge, deklarowaną w linii 17.
Konstruktor, konstruktor kopiujący oraz destruktor wypisują odpowiednie komunikaty. Jednak konstruktor kopiujący nie jest wywoływany, gdyż obiekt przekazywany jest poprzez referencję i nie jest tworzona żadna kopia. Na początku programu, w linii 42., tworzony jest obiekt, a w liniach od 43. do 45. jest wypisywany wiek początkowy.
W linii 47. zmienna składowa itsAge jest ustawiana za pomocą akcesora SetAge(), zaś wynik jest wypisywany w liniach od 48. do 50. W tym programie nie jest używana funkcja
Usunięto: i
Usunięto: i
Usunięto: i
Usunięto: i
FunctionOne(). Posługujemy się tylko funkcją FunctionTwo(). Uległa ona jednak niewielkiej zmianie; jej nagłówek został zmodyfikowany tak, że funkcja przyjmuje teraz stały wskaźnik do stałego obiektu i zwraca stały wskaźnik do stałego obiektu.
Ponieważ parametr i wartość zwracana wciąż są przekazywane poprzez referencje, nie są tworzone żadne kopie, nie jest zatem wywoływany konstruktor kopiujący. Jednak obecnie obiekt wskazywany w funkcji FunctionTwo() jest obiektem const, więc nie można wywoływać jego metod, nie będących metodami const, czyli nie można wywołać jego metody SetAge(). Gdyby wywołanie tej metody w linii 66. nie zostało umieszczone w komentarzu, program nie skompilowałby się.
Zwróć uwagę, że obiekt tworzony w funkcji main() nie jest const, więc możemy dla niego wywołać funkcję SetAge(). Do funkcji FunctionTwo()przekazywany jest adres tego zwykłego obiektu, ale ponieważ deklaracja tej funkcji określa, że ten parametr jest wskaźnikiem const do obiektu const, obiekt ten jest traktowany, jakby był stały!
Referencje jako metoda alternatywna Listing 9.11 rozwiązuje problem tworzenia dodatkowych kopii i w ten sposób zmniejsza ilość wywołań konstruktora kopiującego i destruktora. Używa stałych wskaźników do stałych obiektów, rozwiązując w ten sposób problem zmiany obiektu przez funkcję. Jednak w dalszym ciągu jest dość nieczytelny, gdyż obiekty przekazywane do funkcji są wskaźnikami.
Ponieważ wiemy, że ten obiekt nie jest pusty, możemy ułatwić sobie pracę w funkcji, stosując przekazanie przez referencję, a nie przez wskaźnik. Pokazuje to listing 9.12.
Listing 9.12. Przekazywanie referencji do obiektów 0: //Listing 9.12 1: // Przekazywanie wskaźników do obiektów 2: 3: #include <iostream> 4: 5: using namespace std; 6: class SimpleCat 7: { 8: public: 9: SimpleCat(); 10: SimpleCat(SimpleCat&); 11: ~SimpleCat(); 12: 13: int GetAge() const { return itsAge; } 14: void SetAge(int age) { itsAge = age; } 15: 16: private: 17: int itsAge; 18: }; 19: 20: SimpleCat::SimpleCat() 21: { 22: cout << "Konstruktor klasy SimpleCat...\n"; 23: itsAge = 1; 24: } 25: 26: SimpleCat::SimpleCat(SimpleCat&) 27: {
Usunięto: i
Usunięto: p
Usunięto: otna
Usunięto: i
Usunięto: i

28: cout << "Konstruktor kopiujący klasy SimpleCat...\n"; 29: } 30: 31: SimpleCat::~SimpleCat() 32: { 33: cout << "Destruktor klasy SimpleCat...\n"; 34: } 35: 36: const SimpleCat & FunctionTwo (const SimpleCat & theCat); 37: 38: int main() 39: { 40: cout << "Tworze obiekt...\n"; 41: SimpleCat Mruczek; 42: cout << "Mruczek ma " ; 43: cout << Mruczek.GetAge(); 44: cout << " lat\n"; 45: int age = 5; 46: Mruczek.SetAge(age); 47: cout << "Mruczek ma " ; 48: cout << Mruczek.GetAge(); 49: cout << " lat\n"; 50: cout << "Wywoluje funkcje FunctionTwo...\n"; 51: FunctionTwo(Mruczek); 52: cout << "Mruczek ma " ; 53: cout << Mruczek.GetAge(); 54: cout << " lat\n"; 55: return 0; 56: } 57: 58: // functionTwo, otrzymuje referencję do obiektu const 59: const SimpleCat & FunctionTwo (const SimpleCat & theCat) 60: { 61: cout << "FunctionTwo. Wracam...\n"; 62: cout << "Mruczek ma teraz " << theCat.GetAge(); 63: cout << " lat \n"; 64: // theCat.SetAge(8); const! 65: return theCat; 66: }
Wynik Tworze obiekt... Konstruktor klasy SimpleCat... Mruczek ma 1 lat Mruczek ma 5 lat Wywoluje funkcje FunctionTwo... FunctionTwo. Wracam... Mruczek ma teraz 5 lat Mruczek ma 5 lat Destruktor klasy SimpleCat...
Analiza
Wynik jest identyczny z wynikiem z listingu 9.11. Jedyną istotną różnicą w programie jest to, że obecnie funkcja FunctionTwo() otrzymuje i zwraca referencję do stałego obiektu. Także tym razem praca z referencjami jest nieco prostsza od pracy ze wskaźnikami, a na dodatek zapewnia tę samą efektywność oraz bezpieczeństwo obiektu const.
Referencje const
Usunięto: i

Programiści C++ zwykle nie uznają różnicy pomiędzy „stałą referencją do obiektu typu SimpleCat” a „referencją do stałego obiektu typu SimpleCat”. Referencje nigdy nie mogą otrzymać ponownego przypisania i odnosić się do innego obiektu, więc są zawsze stałe. Jeśli słowo kluczowe const zostanie zastosowane w odniesieniu do referencji, sprawi, że to obiekt związany z referencją staje się stały.
Kiedy używać wskaźników, a kiedy referencji Programiści C++ zdecydowanie przedkładają referencje nad wskaźniki. Referencje są bardziej przejrzyste i łatwiejsze w użyciu, ponadto lepiej ukrywają szczegóły implementacji, co mogliśmy zobaczyć w poprzednim przykładzie.
Nie można zmieniać obiektu docelowego referencji. Jeśli chcesz najpierw wskazać na jeden obiekt, a potem na inny, musisz użyć wskaźnika. Referencje nie mogą być zerowe , więc jeśli istnieje jakakolwiek możliwość, że dany obiekt będzie pusty (tzn., że może przestać istnieć), nie możesz użyć referencji. Musisz użyć wskaźnika.
To ostatnie zagadnienie dotyczy operatora new. Gdy new nie może zaalokować pamięci na stercie, zwraca wskaźnik null (wskaźnik zerowy, czyli pusty). Ponieważ referencje nie mogą być puste, nie wolno ci przypisać referencji do tej pamięci, dopóki nie upewnisz się, że nie jest pusta. Właściwy sposób przypisania pokazuje poniższy przykład:
int *pInt = new int; if (pInt != NULL) int &rInt = *pInt;
W tym przykładzie deklarowany jest wskaźnik pInt do typu int; jest on inicjalizowany adresem pamięci zwracanym przez operator new. Następnie jest sprawdzany adres w pInt i jeśli nie jest on pusty, wyłuskiwany jest wskaźnik. Rezultatem wyłuskania wskaźnika do typu int jest obiekt int, więc referencja rInt jest inicjalizowana jako odnosząca się do tego obiektu. W efekcie, referencja rInt staje się aliasem do wartości int o adresie zwróconym przez operator new.
TAK NIE
Jeśli jest to możliwe, przekazuj parametry przez referencję.
Jeśli jest to możliwe, przekazuj przez referencję wartość zwracaną przez funkcję.
Jeśli jest to możliwe, używaj const do ochrony referencji i wskaźników.
Nie używaj wskaźników tam, gdzie można użyć referencji.
Usunięto: puste
Usunięto: e
Usunięto: wartość
Usunięto: otną

Łączenie referencji i wskaźników Dozwolone jest jednoczesne deklarowanie wskaźników oraz referencji na tej samej liście parametrów funkcji, a także obiektów przekazywanych przez wartość. Na przykład:
CAT * SomeFunction (Person &theOwner, House *theHouse, int age);
Ta deklaracja informuje, że funkcja SomeFunction ma trzy parametry. Pierwszy z nich jest referencją do obiektu klasy Person (osoba), drugim jest wskaźnik do obiektu klasy House (dom), zaś trzecim jest wartość typu int. Funkcja zwraca wskaźnik do obiektu klasy CAT.
Pytanie, gdzie powinien zostać umieszczony operator referencji (&) lub wskaźnika (*), jest bardzo kontrowersyjne. Możesz zastosować któryś z poniższych zapisów:
1: CAT& rMruczek; 2: CAT & rMruczek; 3: CAT &rMruczek;
UWAGA Białe spacje są całkowicie ignorowane, dlatego wszędzie tam, gdzie można umieścić spację, można także umieścić dowolną ilość innych spacji, tabulatorów czy nowych linii.
Jeśli powyższe zapisy są równoważne, który z nich jest najlepszy? Oto argumenty przemawiające za wszystkimi trzema:
Argumentem przemawiającym za przypadkiem 1. jest to, że rMruczek jest zmienną, której nazwą jest rMruczek, zaś typ może być traktowany jako „referencja do obiektu klasy CAT”. Zgodnie z tą argumentacją, & powinno znaleźć się przy typie.
Argumentem przeciwko przypadkowi 1. jest to, że typem jest klasa CAT. Symbol & jest częścią „deklaratora” zawierającego nazwę klasy i znak ampersand (&). Jednak umieszczenie & przy CAT może spowodować wystąpienie poniższego błędu:
CAT& rMruczek, rFilemon;
Szybkie sprawdzenie tej linii może doprowadzić cię do odkrycia, że zarówno rMruczek, jak i rFilemon są referencjami do obiektów klasy CAT, ale w rzeczywistości tak nie jest. Ta deklaracja informuje, że rMruczek jest referencją do klasy CAT, zaś rFilemon (mimo zastosowanego przedrostka) nie jest referencją, lecz zwykłym obiektem klasy CAT. Tę deklarację należy przepisać następująco:
CAT &rMruczek, rFilemon;
Usunięto: a
Usunięto: Pozostawiając zagadnienia wyrażeń
Usunięto: zapisów
Wniosek płynący z powyższych rozważań brzmi następująco: deklaracje referencji i zmiennych nigdy nie powinny występować w tej samej linii. Oto poprawny zapis:
CAT& rMruczek; CAT Filemon;
Wielu programistów optuje za zastosowaniem operatora pośrodku, tak jak pokazuje przypadek 2.
Oczywiście, wszystko, co powiedziano dotąd na temat operatora referencji (&), odnosi się także do operatora wskaźnika (*). Należy zdawać sobie sprawę, że styl zapisu zależy od programisty. Wybierz więc styl, który ci odpowiada i konsekwentnie stosuj go w programach; przejrzystość kodu jest w końcu jednym z twoich głównych celów.
Deklarując referencje i wskaźniki, wielu programistów przestrzega następujących konwencji:
1. Umieszczaj znak ampersand lub gwiazdkę pośrodku, ze spacją po obu stronach.
2. Nigdy nie deklaruj w tej samej linii referencji, wskaźników i zmiennych.
Nie pozwól funkcji zwracać referencji do obiektu, którego nie ma w zakresie! Gdy programiści C++ nauczą się korzystać z referencji, przejawiają tendencję do używania ich bez zastanowienia, wszędzie, gdzie tylko się da. Można z tym przesadzić. Pamiętaj, że referencja jest zawsze aliasem do innego obiektu. Gdy przekazujesz referencje do lub z funkcji, pamiętaj, by zadać sobie pytanie: „Czym jest obiekt, do którego odnosi się referencja, i czy będzie istniał przez cały czas, gdy będę z niego korzystał?”
Listing 9.13 pokazuje niebezpieczeństwo zwrócenia referencji do obiektu, który już nie istnieje.
Listing 9.13. Zwracanie referencji do nieistniejącego obiektu 0: // Listing 9.13 1: // Zwracanie referencji do obiektu 2: // który już nie istnieje 3: 4: #include <iostream> 5: 6: 7: class SimpleCat 8: { 9: public: 10: SimpleCat (int age, int weight);

11: ~SimpleCat() {} 12: int GetAge() { return itsAge; } 13: int GetWeight() { return itsWeight; } 14: private: 15: int itsAge; 16: int itsWeight; 17: }; 18: 19: SimpleCat::SimpleCat(int age, int weight) 20: { 21: itsAge = age; 22: itsWeight = weight; 23: } 24: 25: SimpleCat &TheFunction(); 26: 27: int main() 28: { 29: SimpleCat &rCat = TheFunction(); 30: int age = rCat.GetAge(); 31: std::cout << "rCat ma " << age << " lat!\n"; 32: return 0; 33: } 34: 35: SimpleCat &TheFunction() 36: { 37: SimpleCat Mruczek(5,9); 38: return Mruczek; 39: }
Wynik Błąd kompilacji: próba zwrócenia referencji do lokalnego obiektu!
OSTRZEŻENIE Ten program nie skompiluje się z kompilatorem firmy Borland. Skompiluje się jednak z kompilatorem firmy Microsoft, co mimo wszystko powinno to być uważane za błąd.
Analiza
W liniach od 7. do 17. deklarowana jest klasa SimpleCat. W linii 29. referencja do klasy SimpleCat jest inicjalizowana rezultatem wywołania funkcji TheFunction(), zadeklarowanej w linii 25. jako zwracająca referencję do obiektów klasy SimpleCat.
W ciele funkcji TheFunction() jest deklarowany lokalny obiekt typu SimpleCat; konstruktor inicjalizuje jego wiek i wagę. Następnie ten obiekt lokalny jest zwracany poprzez referencję. Niektóre kompilatory są na tyle inteligentne, by wychwycić ten błąd i nie pozwolić na uruchomienie programu. Inne pozwolą na jego skompilowanie i uruchomienie, co może spowodować nieprzewidywalne zachowanie komputera.
Gdy funkcja TheFunction() kończy działanie, jej obiekt lokalny, Mruczek, jest niszczony (zapewniam, że bezboleśnie). Referencja zwracana przez tę funkcję staje się aliasem do nieistniejącego obiektu, a to poważny błąd.
Usunięto: jednak

Zwracanie referencji do obiektu na stercie Być może kusi cię rozwiązanie problemu z listingu 9.13 – modyfikacja funkcji TheFunction() tak, by tworzyła Mruczka na stercie. Dzięki temu, gdy funkcja zakończy działanie, Mruczek będzie nadal istniał.
W tym miejscu pojawia się następujący problem: co zrobisz z pamięcią zaalokowaną dla obiektu Mruczek, gdy nie będzie już potrzebny? To zagadnienie ilustruje listing 9.14.
Listing 9.14. Wycieki pamięci 0: // Listing 9.14 1: // Unikanie wycieków pamięci 2: 3: #include <iostream> 4: 5: class SimpleCat 6: { 7: public: 8: SimpleCat (int age, int weight); 9: ~SimpleCat() {} 10: int GetAge() { return itsAge; } 11: int GetWeight() { return itsWeight; } 12: 13: private: 14: int itsAge; 15: int itsWeight; 16: }; 17: 18: SimpleCat::SimpleCat(int age, int weight) 19: { 20: itsAge = age; 21: itsWeight = weight; 22: } 23: 24: SimpleCat & TheFunction(); 25: 26: int main() 27: { 28: SimpleCat & rCat = TheFunction(); 29: int age = rCat.GetAge(); 30: std::cout << "rCat ma " << age << " lat!\n"; 31: std::cout << "&rCat: " << &rCat << std::endl; 32: // jak się go pozbędziesz z pamięci? 33: SimpleCat * pCat = &rCat; 34: delete pCat; 35: // a do czego teraz odnosi się rCat?? 36: return 0; 37: } 38: 39: SimpleCat &TheFunction() 40: { 41: SimpleCat * pMruczek = new SimpleCat(5,9); 42: std::cout << "pMruczek: " << pMruczek << std::endl; 43: return *pMruczek; 44: }
Wynik

pMruczek: 004800F0 rCat ma 5 lat! &rCat: 004800F0
OSTRZEŻENIE Ten program kompiluje się, uruchamia i sprawia wrażenie, że działa poprawnie. Jest jednak swego rodzaju bombą zegarową, która może w każdej chwili wybuchnąć.
Funkcja TheFunction() została zmieniona tak, że już nie zwraca referencji do lokalnej zmiennej. W linii 41. funkcja alokuje pamięć na stercie i przypisuje jej adres do wskaźnika. Adres zawarty w tym wskaźniku jest wypisywany w następnej linii, po czym wskaźnik jest wyłuskiwany, a wskazywany przez niego obiekt typu SimpleCat jest zwracany przez referencję.
W linii 28. wynik funkcji TheFunction() jest przypisywany referencji do obiektu klasy SimpleCat, po czym ta referencja jest używana w celu uzyskania wieku kota, wypisywanego w linii 30.
Aby udowodnić, że referencja zadeklarowana w funkcji main() odnosi się do obiektu umieszczonego na stercie przez funkcję TheFunction(), do referencji rCat został zastosowany operator adresu. Oczywiście, wyświetla on adres obiektu, do którego odnosi się referencja, zgodny z adresem pamięci na stercie.
Jak dotąd wszystko jest w porządku. Ale w jaki sposób możemy zwolnić tę pamięć? Nie można wywołać operatora delete dla referencji. Sprytnym rozwiązaniem jest utworzenie kolejnego wskaźnika i zainicjalizowanie go adresem uzyskanym od referencji rCat. Dzięki temu można zwolnić pamięć i „powstrzymać” jej wyciek. Powstaje jednak pewien problem: do czego odnosi się referencja rCat po wykonaniu linii 34.? Jak już wspomnieliśmy, referencja zawsze musi stanowić alias rzeczywistego obiektu; jeśli odnosi się do obiektu pustego (tak, jak w tym przypadku), program jest błędny.
UWAGA Jeszcze raz należy przypomnieć, że program z referencją do pustego obiektu może się skompilować, ale jest błędny i jego działanie jest nieprzewidywalne.
Istnieją trzy rozwiązania tego problemu. Pierwszym jest zadeklarowanie obiektu typu SimpleCat w linii 28. i zwrot tego obiektu z funkcji TheFunction() poprzez wartość. Drugim jest zadeklarowanie w funkcji TheFunction() obiektu SimpleCat na stercie, lecz ze zwróceniem wskaźnika. Wtedy funkcja wywołująca może sama usunąć ten wskaźnik gdy, nie będzie już potrzebować obiektu.
Trzecim rozwiązaniem, tym właściwym, jest zadeklarowanie obiektu w funkcji wywołującej i przekazanie go funkcji TheFunction() przez referencję.
Wskaźnik, wskaźnik, kto ma wskaźnik? Gdy program alokuje pamięć na stercie, otrzymuje wskaźnik. Przechowywanie tego wskaźnika jest koniecznością, gdy zostanie on utracony, pamięć nie będzie mogła zostać zwolniona i powiększy tzw. wyciek pamięci.
Usunięto: na
Usunięto: stanie się
Usunięto: iem

W czasie przekazywania bloku pamięci pomiędzy funkcjami, ktoś przez cały czas „posiada” ten wskaźnik. Zwykle wartości w bloku są przekazywane poprzez referencje, zaś funkcja, która stworzyła pamięć, zajmuje się jej zwolnieniem. Jest to jednak reguła poparta doświadczeniem, a nie zasada wyryta w kamieniu.
Tworzenie pamięci w jednej funkcji i zwalnianie jej w innej może być niebezpieczne. Nieporozumienia co do tego, kto posiada wskaźnik, mogą spowodować dwa następujące problemy: zapomnienie o zwolnieniu wskaźnika lub dwukrotnie zwolnienie go. W obu przypadkach jest to poważny błąd programu. Bezpieczniej jest budować funkcje tak, by usuwały pamięć, którą stworzyły.
Jeśli piszesz funkcję, która musi stworzyć pamięć, po czym przekazać ją funkcji wywołującej, zastanów się nad zmianą jej interfejsu. Niech funkcja wywołująca sama alokuje pamięć i przekazuje ją innej funkcji przez referencję. Dzięki temu zarządzanie pamięcią pozostaje w tej funkcji, która jest przygotowana do jej usunięcia.
TAK NIE
Gdy jesteś do tego zmuszony, przekazuj parametry przez wartość.
Gdy jesteś do tego zmuszony, zwracaj wynik funkcji przez wartość.
Nie przekazuj referencji, jeśli obiekt, do którego się ona odnosi, może znaleźć się poza zakresem.
Nie używaj referencji do pustych obiektów.
Usunięto: ę

Rozdział 10. Funkcje zaawansowane W rozdziale 5., „Funkcje”, poznałeś podstawy pracy z funkcjami. Teraz, gdy wiesz także, jak działają wskaźniki i referencje, możesz zgłębić zagadnienia dotyczące funkcji.
Z tego rozdziału dowiesz się, w jaki sposób:
• przeciążać funkcje składowe,
• przeciążać operatory,
• pisać funkcje, mając na celu tworzenie klas z dynamicznie alokowanymi zmiennymi.
Przeciążone funkcje składowe Z rozdziału 5. dowiedziałeś się jak implementować polimorfizm funkcji, czyli ich przeciążanie, przez tworzenie dwóch lub więcej funkcji o tych samych nazwach, lecz innych parametrach. Funkcje składowe klas mogą być przeciążane w dokładnie ten sam sposób.
Klasa Rectangle (prostokąt), zademonstrowana na listingu 10.1, posiada dwie funkcje DrawShape() (rysuj kształt). Pierwsza z nich, nie posiadająca parametrów, rysuje prostokąt na podstawie bieżących wartości składowych danego egzemplarza klasy. Druga funkcja otrzymuje dwie wartości (szerokość i długość) i rysuje na ich podstawie prostokąt, ignorując bieżące wartości zmiennych składowych.
Listing 10.1. Przeciążone funkcje składowe 0: //Listing 10.1 Przeciążanie funkcji składowych klasy 1: 2: #include <iostream> 3: 4: // Deklaracja klasy Rectangle 5: class Rectangle 6: { 7: public: 8: // konstruktory 9: Rectangle(int width, int height); 10: ~Rectangle(){} 11:

12: // przeciążona funkcja składowa klasy 13: void DrawShape() const; 14: void DrawShape(int aWidth, int aHeight) const; 15: 16: private: 17: int itsWidth; 18: int itsHeight; 19: }; 20: 21: // implementacja konstruktora 22: Rectangle::Rectangle(int width, int height) 23: { 24: itsWidth = width; 25: itsHeight = height; 26: } 27: 28: 29: // Przeciążona funkcja DrawShape - nie ma parametrów 30: // Rysuje kształt w oparciu o bieżące wartości zmiennych składowych 31: void Rectangle::DrawShape() const 32: { 33: DrawShape( itsWidth, itsHeight); 34: } 35: 36: 37: // Przeciążona funkcja DrawShape - z dwoma parametrami 38: // Rysuje kształt w oparciu o podane wartości 39: void Rectangle::DrawShape(int width, int height) const 40: { 41: for (int i = 0; i<height; i++) 42: { 43: for (int j = 0; j< width; j++) 44: { 45: std::cout << "*"; 46: } 47: std::cout << "\n"; 48: } 49: } 50: 51: // Główna funkcja demonstrująca przeciążone funkcje 52: int main() 53: { 54: // inicjalizujemy prostokąt 30 na 5 55: Rectangle theRect(30,5); 56: std::cout << "DrawShape(): \n"; 57: theRect.DrawShape(); 58: std::cout << "\nDrawShape(40,2): \n"; 59: theRect.DrawShape(40,2); 60: return 0; 61: }
Wynik DrawShape(): ****************************** ****************************** ****************************** ****************************** ******************************

DrawShape(40,2): **************************************** ****************************************
Analiza
Listing 10.1 prezentuje okrojoną wersję programu, zamieszczonego w podsumowaniu wiadomości po rozdziale 7. Aby zaoszczędzić miejsce, z programu usunięto sprawdzanie niepoprawnych wartości, a także niektóre z akcesorów. Główny program został sprowadzony do dużo prostszej postaci, w której nie ma już menu.
Najważniejszy kod znajduje się w liniach 13. i 14., gdzie przeciążona została funkcja DrawShape(). Implementacja tych przeciążonych funkcji składowych znajduje się w liniach od 29. do 49. Zwróć uwagę, że funkcja w wersji bez parametrów po prostu wywołuje funkcję z parametrami, przekazując jej bieżące zmienne składowe. Postaraj się nigdy nie powtarzać tego samego kodu w dwóch funkcjach, może to spowodować wiele problemów z zachowaniem ich w zgodności w trakcie wprowadzaniu poprawek (może stać się to przyczyną błędów).
Główna funkcja tworzy w liniach od 51. do 61. obiekt prostokąta, po czym wywołuje funkcję DrawShape(), najpierw bez parametrów, a potem z dwoma parametrami typu int.
Kompilator na podstawie ilości i typu podanych parametrów wybiera metodę. Można sobie wyobrazić także trzecią przeciążoną funkcję o nazwie DrawShape(), która otrzymywałaby jeden wymiar oraz wartość wyliczeniową, określającą, czy jest on wysokością czy szerokością (wybór należałby do użytkownika).
Użycie wartości domyślnych Podobnie, jak w przypadku funkcji składowych klasy, funkcje globalne również mogą mieć jedną lub więcej wartości domyślnych. W przypadku deklaracji wartości domyślnych w funkcjach składowych stosujemy takie same reguły, jak w funkcjach globalnych, co ilustruje listing 10.2.
Listing 10.2. Użycie wartości domyślnych 0: //Listing 10.2 Domyślne wartości w funkcjach składowych 1: 2: #include <iostream> 3: 4: using namespace std; 5: 6: // Deklaracja klasy Rectangle 7: class Rectangle 8: { 9: public: 10: // konstruktory 11: Rectangle(int width, int height); 12: ~Rectangle(){} 13: void DrawShape(int aWidth, int aHeight, 14: bool UseCurrentVals = false) const; 15: 16: private: 17: int itsWidth; 18: int itsHeight; 19: };
Usunięto: kilku
Usunięto: go w synchronizacji

20: 21: // implementacja konstruktora 22: Rectangle::Rectangle(int width, int height): 23: itsWidth(width), // inicjalizacje 24: itsHeight(height) 25: {} // puste ciało konstruktora 26: 27: 28: // dla trzeciego parametru jest używana domyślna wartość 29: void Rectangle::DrawShape( 30: int width, 31: int height, 32: bool UseCurrentValue 33: ) const 34: { 35: int printWidth; 36: int printHeight; 37: 38: if (UseCurrentValue == true) 39: { 40: printWidth = itsWidth; // używa bieżących wartości klasy 41: printHeight = itsHeight; 42: } 43: else 44: { 45: printWidth = width; // używa wartości z parametrów 46: printHeight = height; 47: } 48: 49: 50: for (int i = 0; i<printHeight; i++) 51: { 52: for (int j = 0; j< printWidth; j++) 53: { 54: cout << "*"; 55: } 56: cout << "\n"; 57: } 58: } 59: 60: // Główna funkcja demonstrująca przeciążone funkcje 61: int main() 62: { 63: // inicjalizujemy prostokąt 30 na 5 64: Rectangle theRect(30,5); 65: cout << "DrawShape(0,0,true)...\n"; 66: theRect.DrawShape(0,0,true); 67: cout <<"DrawShape(40,2)...\n"; 68: theRect.DrawShape(40,2); 69: return 0; 70: }
Wynik DrawShape(0,0,true)... ****************************** ****************************** ******************************

****************************** ****************************** DrawShape(40,2)... **************************************** ****************************************
Analiza
Listing 10.2 zastępuje przeciążone funkcje DrawShape() pojedynczą funkcją z domyślnym parametrem. Ta funkcja, zadeklarowana w linii 13., posiada trzy parametry. Dwa pierwsze, aWidth (szerokość) i aHeight (wysokość) są typu int, zaś trzeci, UseCurrentVals (użyj bieżących wartości), jest zmienną typu bool o domyślnej wartości false.
Implementacja tej nieco udziwnionej funkcji rozpoczyna się w linii 28. Sprawdzany jest w niej trzeci parametr, UseCurrentValue. Jeśli ma on wartość true, wtedy do ustawienia lokalnych zmiennych printWidth (wypisywana szerokość) i printHeight (wypisywana wysokość) są używane zmienne składowe klasy, itsWidth oraz itsHeight.
Jeśli parametr UseCurrentValue ma wartość false, podaną przez użytkownika, lub ustawioną domyślnie, wtedy zmiennym printWidth i printHeight są przypisywane wartości dwóch pierwszych argumentów funkcji.
Zwróć uwagę, że gdy parametr UseCurrentValue ma wartość true, wartości dwóch pierwszych parametrów są całkowicie ignorowane.
Wybór pomiędzy wartościami domyślnymi a przeciążaniem funkcji Listingi 10.1 i 10.2 dają ten sam wynik, lecz przeciążone funkcje z listingu 10.1 są łatwiejsze do zrozumienia i wygodniejsze w użyciu. Poza tym, gdy jest potrzebna trzecia wersja — na przykład, gdy użytkownik chce dostarczyć szerokości albo wysokości osobno — można łatwo stworzyć kolejną przeciążoną funkcję. Z drugiej strony, w miarę dodawania kolejnych wersji, wartości domyślne mogą szybko stać się zbyt skomplikowane.
W jaki sposób podjąć decyzję, czy użyć przeciążania funkcji, czy wartości domyślnych? Oto ogólna reguła:
Przeciążania funkcji używaj, gdy:
• nie istnieje sensowna wartość domyślna,
• używasz różnych algorytmów,
• chcesz korzystać z różnych rodzajów parametrów funkcji.
Usunięto: wartością logiczną
Usunięto: s
Usunięto: s
Usunięto: s

Konstruktor domyślny Jak mówiliśmy w rozdziale 6., „Programowanie zorientowane obiektowo”, jeśli nie zadeklarujesz konstruktora klasy jawnie, zostanie dla niej stworzony konstruktor domyślny, który nie ma żadnych parametrów i nic nie robi. Możesz jednak stworzyć własny konstruktor domyślny, który także nie posiada parametrów, ale odpowiednio „przygotowuje” obiekt do działania.
Taki konstruktor także jest nazywany konstruktorem „domyślnym”, bo zgodnie z konwencją, jest nim konstruktor nie posiadający parametrów. Może to budzić wątpliwości, ale zwykle jasno wynika z kontekstu danego miejsca w programie.
Zwróć uwagę, że gdy stworzysz jakikolwiek konstruktor, kompilator nie dostarcza już konstruktora domyślnego. Gdy potrzebujesz konstruktora nie posiadającego parametrów i stworzysz jakikolwiek inny konstruktor, musisz stworzyć także konstruktor domyślny!
Przeciążanie konstruktorów Przeznaczeniem konstruktora jest przygotowanie obiektu; na przykład, celem konstruktora Rectangle jest stworzenie poprawnego obiektu prostokąta. Przed wykonaniem konstruktora nie istnieje żaden prostokąt, a jedynie miejsce w pamięci. Gdy konstruktor kończy działanie, w pamięci istnieje kompletny, gotowy do użycia obiekt prostokąta.
Konstruktory, tak jak wszystkie inne funkcje składowe, mogą być przeciążane. Możliwość przeciążania ich jest bardzo przydatna.
Na przykład: możesz mieć obiekt prostokąta posiadający dwa konstruktory. Pierwszy z nich otrzymuje szerokość oraz długość i tworzy prostokąt o podanych rozmiarach. Drugi nie ma żadnych parametrów i tworzy prostokąt o rozmiarach domyślnych. Ten pomysł wykorzystano na listingu 10.3.
Listing 10.3. Przeciążanie konstruktora 0: // Listing 10.3 1: // Przeciążanie konstruktorów 2: 3: #include <iostream> 4: using namespace std; 5: 6: class Rectangle 7: { 8: public: 9: Rectangle(); 10: Rectangle(int width, int length); 11: ~Rectangle() {} 12: int GetWidth() const { return itsWidth; } 13: int GetLength() const { return itsLength; } 14: private: 15: int itsWidth; 16: int itsLength; 17: }; 18: 19: Rectangle::Rectangle() 20: {

21: itsWidth = 5; 22: itsLength = 10; 23: } 24: 25: Rectangle::Rectangle (int width, int length) 26: { 27: itsWidth = width; 28: itsLength = length; 29: } 30: 31: int main() 32: { 33: Rectangle Rect1; 34: cout << "Rect1 szerokosc: " << Rect1.GetWidth() << endl; 35: cout << "Rect1 dlugosc: " << Rect1.GetLength() << endl; 36: 37: int aWidth, aLength; 38: cout << "Podaj szerokosc: "; 39: cin >> aWidth; 40: cout << "\nPodaj dlugosc: "; 41: cin >> aLength; 42: 43: Rectangle Rect2(aWidth, aLength); 44: cout << "\nRect2 szerokosc: " << Rect2.GetWidth() << endl; 45: cout << "Rect2 dlugosc: " << Rect2.GetLength() << endl; 46: return 0; 47: }
Wynik Rect1 szerokosc: 5 Rect1 dlugosc: 10 Podaj szerokosc: 20 Podaj dlugosc: 50 Rect2 szerokosc: 20 Rect2 dlugosc: 50
Analiza
Klasa Rectangle jest zadeklarowana w liniach od 6. do 17. Posiada dwa konstruktory: „domyślny” konstruktor w linii 9. oraz drugi konstruktor w linii 10., przyjmujący dwie liczby całkowite.
W linii 33. za pomocą domyślnego konstruktora tworzony jest prostokąt; jego rozmiary są wypisywane w liniach 34. i 35. W liniach od 38. do 41. użytkownik jest proszony o podanie szerokości i długości, po czym w linii 43. wywoływany jest konstruktor, który otrzymuje dwa parametry. Na koniec, w liniach 44. i 45. wypisywane są rozmiary drugiego prostokąta.
Tak jak w przypadku innych funkcji przeciążonych, kompilator wybiera właściwy konstruktor na podstawie typów i ilości parametrów.
Inicjalizowanie obiektów Do tej pory ustawiałeś zmienne składowe wewnątrz ciała konstruktora. Konstruktory są jednak wywoływane w dwóch fazach: inicjalizacji i ciała.
Większość zmiennych może być ustawiana w dowolnej z tych faz, podczas inicjalizacji lub w wyniku przypisania w ciele konstruktora. Lepiej zrozumiałe, i często bardziej efektywne, jest inicjalizowanie zmiennych składowych w fazie inicjalizacji konstruktora. Sposób inicjalizowania zmiennych składowych przedstawia poniższy przykład:
CAT(): // nazwa konstruktora i parametry itsAge(5), // lista inicjalizacyjna itsWeight(8) { } // ciało konstruktora
Po nawiasie zamykającym listę parametrów wpisz dwukropek. Następnie wpisz nazwę zmiennej składowej oraz parę nawiasów. Wewnątrz nawiasów wpisz wyrażenie, którego wartość ma zainicjalizować zmienną składową. Jeśli chcesz zainicjalizować kilka zmiennych, każdą z inicjalizacji oddziel przecinkiem. Listing 10.4 przedstawia definicję konstruktora z listingu 10.3, w której zamiast przypisania w ciele konstruktora zastosowano inicjalizację zmiennych.
Listing 10.4. Fragment kodu, przedstawiający inicjalizację zmiennych składowych
0: //Listing 10.4 - Inicjalizacja zmiennych składowych 1: Rectangle::Rectangle(): 2: itsWidth(5), 3: itsLength(10) 4: { 5: } 6: 7: Rectangle::Rectangle (int width, int length): 8: itsWidth(width), 9: itsLength(length) 10: { 11: }
Bez wyniku.
Niektóre zmienne muszą być inicjalizowane i nie można im niczego przypisywać; dotyczy to referencji i stałych. Wewnątrz ciała konstruktora można zawrzeć także inne przypisania i działania, jednak najlepiej maksymalnie wykorzystać fazę inicjalizacji.
Usunięto: ji

Konstruktor kopiujący Oprócz domyślnego konstruktora i destruktora, kompilator dostarcza także domyślnego konstruktora kopiującego. Konstruktor kopiujący jest wywoływany za każdym razem, gdy tworzona jest kopia obiektu.
Gdy przekazujesz obiekt przez wartość, czy to jako parametr funkcji czy też jako jej wartość zwracaną , tworzona jest tymczasowa kopia tego obiektu. Jeśli obiekt jest obiektem zdefiniowanym przez użytkownika, wywoływany jest konstruktor kopiujący danej klasy, taki mogłeś zobaczyć w poprzednim rozdziale na listingu 9.6.
Wszystkie konstruktory kopiujące posiadają jeden parametr; jest nim referencja do obiektu tej samej klasy. Dobrym pomysłem jest oznaczenie tej referencji jako const, gdyż wtedy konstruktor nie ma możliwości modyfikacji otrzymanego obiektu. Na przykład:
CAT(const CAT & theCat);
W tym przypadku konstruktor CAT otrzymuje stałą referencję do istniejącego obiektu klasy CAT. Celem konstruktora kopiującego jest utworzenie kopii obiektu theCat.
Domyślny konstruktor kopiujący po prostu kopiuje każdą zmienną składową z obiektu otrzymanego jako parametr do odpowiedniej zmiennej składowej obiektu tymczasowego. Nazywa się to kopiowaniem składowych (czyli kopiowaniem płytkim), i choć w przypadku większości składowych nie jest potrzebne nic więcej, proces ten jednak nie sprawdza się w przypadku zmiennych będących wskaźnikami do obiektów na stercie.
W płytkiej kopii (czyli bezpośredniej kopii składowych) kopiowane są dokładne wartości składowych jednego obiektu do składowych drugiego obiektu. Wskaźniki zawarte w obu obiektach wskazują wtedy na to samo miejsce w pamięci. W przypadku głębokiej kopii, wartości zaalokowane na stercie są kopiowane do nowo alokowanej pamięci.
Gdyby klasa CAT zawierała zmienną składową itsAge, będącą wskaźnikiem do zmiennej całkowitej zaalokowanej na stercie, wtedy domyślny konstruktor kopiujący skopiowałby wartość zmiennej itsAge otrzymanego obiektu do zmiennej itsAge nowego obiektu. Oba obiekty wskazywałyby więc to samo miejsce w pamięci, co ilustruje rysunek 10.1.
Rys. 10.1. Użycie domyślnego konstruktora kopiującego
Usunięto: i
Usunięto: y
Usunięto: i
Usunięto: i
Usunięto: zwrotną
Usunięto: i
Usunięto: i
Usunięto: i
Usunięto: i
Usunięto: ą
Usunięto: ą
Usunięto: ą
Usunięto: i
Usunięto: i

Gdy któryś z obiektów CAT znajdzie się poza zakresem, nastąpi katastrofa. Jak opisano w rozdziale 8., „Wskaźniki”, zadaniem destruktora jest uporządkowanie i zwolnienie pamięci po obiekcie. Jeśli destruktor pierwotnego obiektu CAT zwolni tę pamięć, zaś wskaźnik w nowym obiekcie CAT nadal będzie na nią wskazywał, oznaczać to będzie pojawienie się błędnego (zagubionego) wskaźnika, a program znajdzie się w śmiertelnym niebezpieczeństwie. Ten problem ilustruje rysunek 10.2.
Rys. 10.2. Powstawanie zagubionego wskaźnika
Rozwiązaniem tego problemu jest stworzenie własnego konstruktora kopiującego, alokującego wymaganą pamięć. Po zaalokowaniu pamięci, stare wartości mogą być skopiowane do nowej pamięci. Pokazuje to listing 10.5.
Listing 10.5. Konstruktor kopii 0: // Listing 10.5 1: // Konstruktory kopii 2: 3: #include <iostream> 4: using namespace std; 5: 6: class CAT 7: { 8: public: 9: CAT(); // domyślny konstruktor 10: CAT (const CAT &); // konstruktor kopiujący 11: ~CAT(); // destruktor 12: int GetAge() const { return *itsAge; } 13: int GetWeight() const { return *itsWeight; } 14: void SetAge(int age) { *itsAge = age; } 15: 16: private: 17: int *itsAge; 18: int *itsWeight; 19: }; 20: 21: CAT::CAT() 22: { 23: itsAge = new int; 24: itsWeight = new int; 25: *itsAge = 5; 26: *itsWeight = 9; 27: } 28: 29: CAT::CAT(const CAT & rhs)
Usunięto: t
Usunięto: i
Usunięto: i

30: { 31: itsAge = new int; 32: itsWeight = new int; 33: *itsAge = rhs.GetAge(); // dostęp publiczny 34: *itsWeight = *(rhs.itsWeight); // dostęp prywatny 35: } 36: 37: CAT::~CAT() 38: { 39: delete itsAge; 40: itsAge = 0; 41: delete itsWeight; 42: itsWeight = 0; 43: } 44: 45: int main() 46: { 47: CAT mruczek; 48: cout << "Wiek Mruczka: " << mruczek.GetAge() << endl; 49: cout << "Ustawiam wiek Mruczka na 6 lat...\n"; 50: mruczek.SetAge(6); 51: cout << "Tworze Filemona z Mruczka\n"; 52: CAT filemon(mruczek); 53: cout << "Wiek Mruczka: " << mruczek.GetAge() << endl; 54: cout << "Wiek Filemona: " << filemon.GetAge() << endl; 55: cout << "Ustawiam wiek Mruczka na 7 lat...\n"; 56: mruczek.SetAge(7); 57: cout << "Wiek Mruczka: " << mruczek.GetAge() << endl; 58: cout << "Wiek Filemona: " << filemon.GetAge() << endl; 59: return 0; 60: }
Wynik Wiek Mruczka: 5 Ustawiam wiek Mruczka na 6 lat... Tworze Filemona z Mruczka Wiek Mruczka: 6 Wiek Filemona: 6 Ustawiam wiek Mruczka na 7 lat... Wiek Mruczka: 7 Wiek Filemona: 6
Analiza
W liniach od 6. do 19. deklarowana jest klasa CAT. Zwróć uwagę, że w linii 9. został zadeklarowany konstruktor domyślny, a w linii 10. został zadeklarowany konstruktor kopiujący.
W liniach 17. i 18. są deklarowane dwie zmienne składowe, będące wskaźnikami do zmiennych typu int. Zwykle klasa nie ma powodów do przechowywania danych składowych typu int w postaci wskaźników, ale w tym przypadku służy to do zilustrowania operowania zmiennymi składowymi na stercie.
Domyślny konstruktor, zdefiniowany w liniach od 21. do 27. alokuje miejsce na stercie dla dwóch zmiennych typu int, po czym przypisuje im wartości.
Definicja konstruktora kopiującego rozpoczyna się w linii 29. Zwróć uwagę, że jego parametrem jest rhs. Jest to często stosowana nazwa dla parametru konstruktora kopiującego, stanowiąca skrót
Usunięto: i
Usunięto: i
Usunięto: i

od wyrażenia right-hand side (prawa strona). Gdy spojrzysz na przypisania w liniach 33. i 34., przekonasz się, że obiekt przekazywany jako parametr znajduje się po prawej stronie znaku równości. Oto sposób, w jaki działa:
W liniach 31. i 32. alokowana jest pamięć na stercie. Następnie, w liniach 33. i 34., wartościom w nowej pamięci są przypisywane wartości danych z istniejącego obiektu CAT.
Parametr rhs jest obiektem CAT przekazanym do konstruktora kopiującego jako stała referencja. Jako obiekt klasy CAT, parametr rhs posiada wszystkie składowe tej klasy.
Każdy obiekt CAT może odwoływać się do wszystkich (także prywatnych) składowych innych obiektów tej samej klasy; jednak do tradycji programistycznej należy korzystanie z akcesorów wszędzie tam, gdzie jest to możliwe. Funkcja składowa rhs.GetAge() zwraca wartość przechowywaną w pamięci wskazywanej przez zmienną składową itsAge obiektu rhs.
Rysunek 10.3 przedstawia, co dzieje się w programie. Wartości wskazywane przez zmienne składowe istniejącego obiektu CAT są kopiowane do pamięci zaalokowanej dla nowego obiektu CAT.
Rys. 10.3. Przykład kopiowania głębokiego
W linii 47. tworzony jest obiekt CAT o nazwie mruczek. Wypisywany jest jego wiek, po czym w linii 50. wiek Mruczka jest ustawiany na 6 lat. W linii 52. tworzony jest nowy obiekt klasy CAT, tym razem o nazwie filemon. Jest on tworzony za pomocą konstruktora kopiującego, któremu przekazano obiekt mruczek. Gdyby mruczek został przekazany do funkcji przez wartość (nie przez referencję), wtedy kompilator użyłby tego samego konstruktora kopii.
W liniach 53. i 54. jest wypisywany wiek Mruczka i Filemona. Oczywiście, wiek Filemona jest taki sam, jak wiek Mruczka i wynosi 6 lat, a nie domyślne 5. W linii 56. wiek Mruczka jest ustawiany na 7 lat, po czym wiek obu obiektów jest wypisywany ponownie. Tym razem Mruczek ma 7 lat, ale Filemon wciąż ma 6, co dowodzi, że dane tych obiektów są przechowywane w osobnych miejscach pamięci.
Gdy obiekt klasy CAT wychodzi z zakresu, automatycznie wywoływany jest jego destruktor. Implementacja destruktora klasy CAT została przedstawiona w liniach od 37. do 43. Dla obu wskaźników, itsAge oraz itsWeight, wywoływany jest operator delete, zwalniający
Usunięto: i
Usunięto: głębokiej
Usunięto: i
Usunięto: i

zaalokowaną dla nich pamięć sterty. Oprócz tego, dla bezpieczeństwa, obu wskaźnikom jest przypisywana wartość NULL.
Przeciążanie operatorów C++ posiada liczne typy wbudowane, takie jak int, float, char, itd. Każdy z nich posiada własne wbudowane operatory, takie jak dodawanie (+) czy mnożenie (*). C++ umożliwia stworzenie takich operatorów także dla klas definiowanych przez użytkownika.
Aby umożliwić pełne poznanie procesu przeciążania operatorów, na listingu 10.6 stworzono nową klasę o nazwie Counter (licznik). Obiekt typu Counter będzie używany do (uwaga!) zliczania pętli oraz innych zadań, w których wartość musi być inkrementowana, dekrementowana czy śledzona w inny sposób.
Listing 10.6. Klasa Counter 0: // Listing 10.6 1: // Klasa Counter 2: 3: #include <iostream> 4: using namespace std; 5: 6: class Counter 7: { 8: public: 9: Counter(); 10: ~Counter(){} 11: int GetItsVal()const { return itsVal; } 12: void SetItsVal(int x) {itsVal = x; } 13: 14: private: 15: int itsVal; 16: 17: }; 18: 19: Counter::Counter(): 20: itsVal(0) 21: {} 22: 23: int main() 24: { 25: Counter i; 26: cout << "Wartoscia i jest " << i.GetItsVal() << endl; 27: return 0; 28: }
Wynik Wartoscia i jest 0
Analiza
W obecnej postaci klasa Counter jest raczej bezużyteczna. Sama klasa jest zdefiniowana w liniach od 6. do 17. Jej jedyną zmienną składową jest wartość typu int. Domyślny konstruktor,

zadeklarowany w linii 9. i zaimplementowany w linii 19., inicjalizuje jedyną zmienną składową, itsVal (jego wartość), wartością zero.
W odróżnieniu od wbudowanego typu int, obiekt klasy Counter nie może być inkrementowany, dekrementowany, dodawany, przypisywany, nie można też nim operować w inny sposób. Sprawia za to, że wypisywanie jego wartości staje się jeszcze bardziej skomplikowane!
Pisanie funkcji inkrementacji Dzięki przeciążeniu operatorów możemy odzyskać większość działań, których klasa ta została pozbawiona. Istnieją na przykład dwa sposoby uzupełnienia obiektu Counter o inkrementację. Pierwszy z nich polega na napisaniu metody do inkrementacji, zobaczymy to na listingu 10.7.
Listing 10.7. Dodawanie operatora inkrementacji 0: // Listing 10.7 1: // Klasa Counter 2: 3: #include <iostream> 4: using namespace std; 5: 6: class Counter 7: { 8: public: 9: Counter(); 10: ~Counter(){} 11: int GetItsVal()const { return itsVal; } 12: void SetItsVal(int x) {itsVal = x; } 13: void Increment() { ++itsVal; } 14: 15: private: 16: int itsVal; 17: 18: }; 19: 20: Counter::Counter(): 21: itsVal(0) 22: {} 23: 24: int main() 25: { 26: Counter i; 27: cout << "Wartoscia i jest " << i.GetItsVal() << endl; 28: i.Increment(); 29: cout << "Wartoscia i jest " << i.GetItsVal() << endl; 30: return 0; 31: }
Wynik Wartoscia i jest 0 Wartoscia i jest 1
Analiza
Usunięto: na

Listing 10.7 zawiera nową funkcję Increment() (inkrementuj), zdefiniowaną w linii 13. Choć ta funkcja działa poprawnie, jest jednak nieco kłopotliwa w użyciu. Program aż prosi się o uzupełnienie go o operator ++, co oczywiście możemy zrobić.
Przeciążanie operatora przedrostkowego Operatory przedrostkowe można przeciążyć, deklarując funkcję o postaci:
zwracanyTyp operator op()
gdzie op jest przeciążanym operatorem. Operator ++ można przeciążyć, pisząc:
void operator++ ()
Tę alternatywę demonstruje listing 10.8.
Listing 10.8. Przeciążanie operatora++ 0: // Listing 10.8 1: // Klasa Counter 2: // przedrostkowy operator inkrementacji 3: 4: #include <iostream> 5: using namespace std; 6: 7: class Counter 8: { 9: public: 10: Counter(); 11: ~Counter(){} 12: int GetItsVal()const { return itsVal; } 13: void SetItsVal(int x) {itsVal = x; } 14: void Increment() { ++itsVal; } 15: void operator++ () { ++itsVal; } 16: 17: private: 18: int itsVal; 19: 20: }; 21: 22: Counter::Counter(): 23: itsVal(0) 24: {} 25: 26: int main() 27: { 28: Counter i; 29: cout << "Wartoscia i jest " << i.GetItsVal() << endl; 30: i.Increment(); 31: cout << "Wartoscia i jest " << i.GetItsVal() << endl; 32: ++i; 33: cout << "Wartoscia i jest " << i.GetItsVal() << endl;

34: return 0; 35: }
Wynik Wartoscia i jest 0 Wartoscia i jest 1 Wartoscia i jest 2
Analiza
W linii 15. został przeciążony operator++, który jest używany w linii 32. Jego składnia jest już zbliżona do składni typów wbudowanych, takich jak int. Teraz możesz wziąć pod uwagę wykonywanie podstawowych zadań, dla których została stworzona klasa Counter (na przykład wykrywanie sytuacji, w której licznik przekracza największą wartość).
Jednak w zapisie operatora inkrementacji tkwi poważny defekt. Jeśli umieścisz obiekt typu Counter po prawej stronie przypisania, kompilator zgłosi błąd. Na przykład:
Counter a = ++i;
W tym przykładzie mieliśmy zamiar stworzyć nowy obiekt a należący do klasy Counter, a następnie, po inkrementacji tej zmiennej, przypisać mu wartość i. To przypisanie obsłużyłby wbudowany konstruktor kopiujący, ale wykorzystywany obecnie operator inkrementacji nie zwraca obiektu typu Counter. Zamiast tego zwraca typ void. Nie można przypisywać obiektów void obiektom Counter. (Z pustego i Salomon nie naleje!)
Zwracanie typów w przeciążonych funkcjach operatorów To, czego nam teraz potrzeba, to zwrócenie obiektu klasy Counter, który mógłby być przypisany innemu obiektowi tej klasy. Który z obiektów powinien zostać zwrócony? Jednym z rozwiązań jest stworzenie obiektu tymczasowego i zwrócenie go. Pokazuje to listing 10.9.
Listing 10.9. Zwracanie obiektu tymczasowego 0: // Listing 10.9 1: // operator++ zwraca tymczasowy obiekt 2: 3: #include <iostream> 4: 5: using namespace std; 6: 7: class Counter 8: { 9: public: 10: Counter(); 11: ~Counter(){} 12: int GetItsVal()const { return itsVal; } 13: void SetItsVal(int x) {itsVal = x; } 14: void Increment() { ++itsVal; } 15: Counter operator++ ();
Usunięto: i

16: 17: private: 18: int itsVal; 19: 20: }; 21: 22: Counter::Counter(): 23: itsVal(0) 24: {} 25: 26: Counter Counter::operator++() 27: { 28: ++itsVal; 29: Counter temp; 30: temp.SetItsVal(itsVal); 31: return temp; 32: } 33: 34: int main() 35: { 36: Counter i; 37: cout << "Wartoscia i jest " << i.GetItsVal() << endl; 38: i.Increment(); 39: cout << "Wartoscia i jest " << i.GetItsVal() << endl; 40: ++i; 41: cout << "Wartoscia i jest " << i.GetItsVal() << endl; 42: Counter a = ++i; 43: cout << "Wartoscia a jest: " << a.GetItsVal(); 44: cout << " , a wartosc i to: " << i.GetItsVal() << endl; 45: return 0; 46: }
Wynik Wartoscia i jest 0 Wartoscia i jest 1 Wartoscia i jest 2 Wartoscia a jest: 3 , a wartosc i to: 3
Analiza
W tej wersji operator++ został zadeklarowany w linii 15. jako zwracający obiekt typu Counter. W linii 29. jest tworzona zmienna tymczasowa temp, której wartość jest ustawiana zgodnie z wartością bieżącego obiektu. Ta tymczasowa wartość jest zwracana i natychmiast przypisywana zmiennej a w linii 42.
Zwracanie obiektów tymczasowych bez nadawania im nazw Nie ma potrzeby nadawania nazwy obiektowi tymczasowemu tworzonemu w linii 29. Gdyby klasa Counter miała konstruktor przyjmujący wartość, jako wartość zwrotną operatora inkrementacji moglibyśmy po prostu zwrócić wynik tego konstruktora. Pokazuje to listing 10.10.
Listing 10.10. Zwracanie obiektu tymczasowego bez nadawania mu nazwy 0: // Listing 10.10 1: // operator++ zwraca tymczasowy obiekt bez nazwy

2: 3: #include <iostream> 4: 5: using namespace std; 6: 7: class Counter 8: { 9: public: 10: Counter(); 11: Counter(int val); 12: ~Counter(){} 13: int GetItsVal()const { return itsVal; } 14: void SetItsVal(int x) {itsVal = x; } 15: void Increment() { ++itsVal; } 16: Counter operator++ (); 17: 18: private: 19: int itsVal; 20: 21: }; 22: 23: Counter::Counter(): 24: itsVal(0) 25: {} 26: 27: Counter::Counter(int val): 28: itsVal(val) 29: {} 30: 31: Counter Counter::operator++() 32: { 33: ++itsVal; 34: return Counter (itsVal); 35: } 36: 37: int main() 38: { 39: Counter i; 40: cout << "Wartoscia i jest " << i.GetItsVal() << endl; 41: i.Increment(); 42: cout << "Wartoscia i jest " << i.GetItsVal() << endl; 43: ++i; 44: cout << "Wartoscia i jest " << i.GetItsVal() << endl; 45: Counter a = ++i; 46: cout << "Wartoscia a jest: " << a.GetItsVal(); 47: cout << ", zas wartosc i to: " << i.GetItsVal() << endl; 48: return 0; 49: }
Wynik Wartoscia i jest 0 Wartoscia i jest 1 Wartoscia i jest 2 Wartoscia a jest: 3, zas wartosc i to: 3
Analiza
W linii 11. został zadeklarowany nowy konstruktor, przyjmujący wartość typu int. Jego implementacja znajduje się w liniach od 27. do 29.; inicjalizuje ona zmienną składową itsVal za pomocą wartości otrzymanej jako argument konstruktora.
Implementacja operatora++ może zostać teraz uproszczona. W linii 33. wartość itsVal jest inkrementowana. Następnie, w linii 34., tworzony jest tymczasowy obiekt klasy Counter, który jest inicjalizowany wartością zmiennej itsVal, po czym zwracany jako rezultat operatora++.
To rozwiązanie jest bardziej eleganckie, ale powoduje, że musimy zadać następne pytanie: dlaczego w ogólne musimy tworzyć obiekt tymczasowy? Pamiętajmy, że każdy obiekt tymczasowy musi zostać najpierw skonstruowany, a później zniszczony — te operacje mogą być potencjalnie dość kosztowne. Poza tym, obiekt już istnieje i posiada właściwą wartość, więc dlaczego nie mielibyśmy zwrócić właśnie jego? Rozwiążemy ten problem, używając wskaźnika this.
Użycie wskaźnika this Wskaźnik this jest przekazywany wszystkim funkcjom składowym, nawet przeciążonym operatorom, takim jak operator++(). Wskaźnik this wskazuje na i, więc gdy zostanie wyłuskany, zwróci tylko obiekt i, który w swojej zmiennej itsVal zawiera już właściwą wartość. Zwracanie wyłuskanego wskaźnika this i zaniechanie tworzenia niepotrzebnego obiektu tymczasowego przedstawia listing 10.11.
Listing 10.11. Zwracanie wskaźnika this 0: // Listing 10.11 1: // Zwracanie wyłuskanego wskaźnika this 2: 3: #include <iostream> 4: 5: using namespace std; 6: 7: class Counter 8: { 9: public: 10: Counter(); 11: ~Counter(){} 12: int GetItsVal()const { return itsVal; } 13: void SetItsVal(int x) {itsVal = x; } 14: void Increment() { ++itsVal; } 15: const Counter& operator++ (); 16: 17: private: 18: int itsVal; 19: 20: }; 21: 22: Counter::Counter(): 23: itsVal(0) 24: {}; 25: 26: const Counter& Counter::operator++() 27: { 28: ++itsVal; 29: return *this; 30: }
Usunięto:

31: 32: int main() 33: { 34: Counter i; 35: cout << "Wartoscia i jest " << i.GetItsVal() << endl; 36: i.Increment(); 37: cout << "Wartoscia i jest " << i.GetItsVal() << endl; 38: ++i; 39: cout << "Wartoscia i jest " << i.GetItsVal() << endl; 40: Counter a = ++i; 41: cout << "Wartoscia a jest: " << a.GetItsVal(); 42: cout << ", zas wartosc i to: " << i.GetItsVal() << endl; 43: return 0; 44: }
Wynik Wartoscia i jest 0 Wartoscia i jest 1 Wartoscia i jest 2 Wartoscia a jest: 3, zas wartosc i to: 3
Analiza
Implementacja operatora++, zawarta w liniach od 26. do 30., została zmieniona w taki sposób, aby wyłuskiwała wskaźnik this i zwracała bieżący obiekt. Dzięki temu zmiennej a może być przypisany bieżący egzemplarz klasy Counter. Jak wspomnieliśmy wcześniej, gdyby obiekt klasy Counter alokował pamięć, należałoby przysłonić domyślny konstruktor kopiujący. Jednak w tym przypadku domyślny konstruktor kopiujący działa poprawnie.
Zwróć uwagę, że zwracaną wartością jest referencja do obiektu klasy Counter, dzięki czemu unikamy tworzenia dodatkowego obiektu tymczasowego. Jest to zmienna const, ponieważ nie powinna być modyfikowana przez funkcję wykorzystującą zwracany obiekt klasy Counter.
Dlaczego stała referencja? Zwracany obiekt Counter musi być obiektem const. Gdyby nim nie był, można by wykonać na zwracanym obiekcie operacje, które mogłyby zmienić jego dane składowe. Na przykład, gdyby zwracana wartość nie była stała, mógłbyś napisać:
40: Counter a = ++++i;
Można to rozumieć jako wywołanie operatora inkrementacji (++) na wyniku wywołania operatora inkrementacji, opcja ta powinno być zablokowane.
Spróbuj wykonać taki eksperyment: zarówno w deklaracji, jak i w implementacji (linie 15. i 26.) zmień zwracaną wartość na wartość nie będącą const, po czym zmień linię 40. na pokazaną powyżej (++++i). Umieść punkt przerwania w debuggerze na linii 40. i wejdź do funkcji. Zobaczysz, że do operatora inkrementacji wejdziesz dwa razy. Inkrementacja zostanie zastosowana do (teraz nie będącej stałą) wartości zwracanej.
Usunięto: i
Usunięto: i

Aby się przed tym zabezpieczyć, deklarujemy wartość zwracaną jako const. Gdy zmienisz linie 15. i 26. z powrotem na stałe, zaś linię 40. pozostawisz bez zmian (++++i), kompilator zaprotestuje przeciwko wywołaniu operatora inkrementacji dla obiektu stałego.
Przeciążanie operatora przyrostkowego Jak dotąd, udało się nam przeciążyć operator przedrostkowy. A co zrobić, gdy chcemy przeciążyć operator przyrostkowy? Kompilator nie potrafi odróżnić przedrostka od przyrostka. Zgodnie z konwencją, jako parametr deklaracji operatora dostarczana jest zmienna całkowita. Wartość parametru jest ignorowana; sygnalizuje on tylko, że jest to operator przyrostkowy.
Różnica pomiędzy przedrostkiem a przyrostkiem Zanim będziemy mogli napisać operator przyrostkowy, musimy zrozumieć, czym różni się on od operatora przedrostkowego. Omawialiśmy to szczegółowo w rozdziale 4., „Wyrażenia i instrukcje”. (Patrz listing 4.3.).
Przypomnijmy: przedrostek mówi: „Inkrementuj, po czym pobierz”, zaś przyrostek mówi: „Pobierz, a następnie inkrementuj”.
Operator przedrostkowy może po prostu inkrementować wartość, a następnie zwrócić sam obiekt, zaś operator przyrostkowy musi zwracać wartość istniejącą przed dokonaniem inkrementacji. W tym celu musimy stworzyć obiekt tymczasowy, który będzie zawierał pierwotną wartość, następnie inkrementować wartość pierwotnego obiektu, po czy, zwrócić obiekt tymczasowy.
Przyjrzyjmy się temu procesowi od początku. Weźmy następującą linię kodu:
a = x++;
Jeśli x miało wartość 5, wtedy po wykonaniu tej instrukcji a ma wartość 5, zaś x ma wartość 6. Zwracamy wartość w x i przypisujemy ją zmiennej a, po czym inkrementujemy wartość x. Jeśli x jest obiektem, jego przyrostkowy operator inkrementacji musi zachować pierwotną wartość (5) w obiekcie tymczasowym, inkrementować wartość x do 6, po czym zwrócić obiekt tymczasowy w celu przypisania oryginalnej wartości do zmiennej a.
Zwróć uwagę, że skoro zwracamy obiekt tymczasowy, musimy zwracać go poprzez wartość, a nie poprzez referencję (w przeciwnym razie obiekt ten znajdzie się poza zakresem natychmiast po wyjściu programu z funkcji).
Listing 10.12 przedstawia użycie operatora przedrostkowego i przyrostkowego.
Listing 10.12. Operator przedrostkowy i przyrostkowy 0: // Listing 10.12 1: // Operator przedrostkowy i przyrostkowy 2: 3: #include <iostream> 4: 5: using namespace std; 6: 7: class Counter

8: { 9: public: 10: Counter(); 11: ~Counter(){} 12: int GetItsVal()const { return itsVal; } 13: void SetItsVal(int x) {itsVal = x; } 14: const Counter& operator++ (); // przedrostkowy 15: const Counter operator++ (int); // przyrostkowy 16: 17: private: 18: int itsVal; 19: }; 20: 21: Counter::Counter(): 22: itsVal(0) 23: {} 24: 25: const Counter& Counter::operator++() 26: { 27: ++itsVal; 28: return *this; 29: } 30: 31: const Counter Counter::operator++(int theFlag) 32: { 33: Counter temp(*this); 34: ++itsVal; 35: return temp; 36: } 37: 38: int main() 39: { 40: Counter i; 41: cout << "Wartoscia i jest " << i.GetItsVal() << endl; 42: i++; 43: cout << "Wartoscia i jest " << i.GetItsVal() << endl; 44: ++i; 45: cout << "Wartoscia i jest " << i.GetItsVal() << endl; 46: Counter a = ++i; 47: cout << "Wartoscia a jest: " << a.GetItsVal(); 48: cout << ", zas wartosc i to: " << i.GetItsVal() << endl; 49: a = i++; 50: cout << "Wartoscia a jest: " << a.GetItsVal(); 51: cout << ", zas wartosc i to: " << i.GetItsVal() << endl; 52: return 0; 53: }
Wynik Wartoscia i jest 0 Wartoscia i jest 1 Wartoscia i jest 2 Wartoscia a jest: 3, zas wartosc i to: 3 Wartoscia a jest: 3, zas wartosc i to: 4
Analiza
Operator przyrostkowy jest deklarowany w linii 15. i implementowany w liniach od 31. do 36. Operator przedrostkowy jest deklarowany w linii 14.

Parametr przekazywany do operatora przyrostkowego w linii 32. (theFlag) sygnalizuje jedynie kompilatorowi, że chodzi tu o operator przyrostkowy; wartość tego parametru nigdy nie jest wykorzytywana.
Operator dodawania Operator inkrementacji jest operatorem unarnym, tj. operatorem działającym na tylko jednym obiekcie. Operator dodawania (+) jest operatorem binarnym, co oznacza, że do działania potrzebuje dwóch obiektów. W jaki więc sposób można zaimplementować przeciążenie operatora + dla klasy Counter?
Naszym celem jest zadeklarowanie dwóch zmiennych typu Counter, a następnie dodanie ich, tak jak w poniższym przykładzie:
Counter varOne, varTwo, varThree; varThree = varOne + varTwo;
Także w tym przypadku mógłbyś zacząć od napisania funkcji Add() (dodaj), która jako argument przyjmowałaby obiekt klasy Counter, dodawałaby wartości, po czym zwracałaby obiekt klasy Counter jako wynik. Takie postępowanie ilustruje listing 10.13.
Listing 10.13. Funkcja Add() 0: // Listing 10.13 1: // Funkcja Add 2: 3: #include <iostream> 4: 5: using namespace std; 6: 7: class Counter 8: { 9: public: 10: Counter(); 11: Counter(int initialValue); 12: ~Counter(){} 13: int GetItsVal()const { return itsVal; } 14: void SetItsVal(int x) {itsVal = x; } 15: Counter Add(const Counter &); 16: 17: private: 18: int itsVal; 19: 20: }; 21: 22: Counter::Counter(int initialValue): 23: itsVal(initialValue) 24: {} 25: 26: Counter::Counter(): 27: itsVal(0) 28: {} 29: 30: Counter Counter::Add(const Counter & rhs) 31: {
Usunięto: jest to

32: return Counter(itsVal+ rhs.GetItsVal()); 33: } 34: 35: int main() 36: { 37: Counter varOne(2), varTwo(4), varThree; 38: varThree = varOne.Add(varTwo); 39: cout << "varOne: " << varOne.GetItsVal()<< endl; 40: cout << "varTwo: " << varTwo.GetItsVal() << endl; 41: cout << "varThree: " << varThree.GetItsVal() << endl; 42: 43: return 0; 44: }
Wynik varOne: 2 varTwo: 4 varThree: 6
Analiza
Funkcja Add() została zadeklarowana w linii 15. Otrzymuje ona stałą referencję do obiektu klasy Counter, który zawiera wartość przeznaczoną do dodania do wartości w bieżącym obiekcie. Zwraca obiekt klasy Counter, który jest przypisywany lewej stronie instrukcji przypisania w linii 38. Innymi słowy, varOne jest obiektem, varTwo jest parametrem funkcji Add(), zaś wynik tej funkcji jest przypisywany do varThree.
Aby stworzyć varThree bez inicjalizowania wartości tego obiektu, potrzebny jest konstruktor domyślny. Ten konstruktor inicjalizuje zmienną składową itsVal jako zero, co pokazują linie od 26. do 28. Ponieważ zmienne varOne i varTwo powinny być zainicjalizowane wartościami różnymi od zera, został stworzony kolejny konstruktor, znajdujący się w liniach od 22. do 24. Innym rozwiązaniem tego problemu jest zastosowanie wartości domyślnej 0 w konstruktorze zadeklarowanym w linii 11.
Przeciążanie operatora dodawania Funkcja Add() znajduje się w liniach od 30. do 33. listingu 10.13. Funkcja działa poprawnie, ale jej użycie jest mało naturalne. Przeciążenie operatora + spowoduje, że użycie klasy Counter będzie mogło przebiegać bardziej naturalnie. Pokazuje to listing 10.14.
Listing 10.14. operator+ 0: // Listing 10.14 1: //Przeciążony operator dodawania (+) 2: 3: #include <iostream> 4: 5: using namespace std; 6: 7: class Counter 8: {

9: public: 10: Counter(); 11: Counter(int initialValue); 12: ~Counter(){} 13: int GetItsVal()const { return itsVal; } 14: void SetItsVal(int x) {itsVal = x; } 15: Counter operator+ (const Counter &); 16: private: 17: int itsVal; 18: }; 19: 20: Counter::Counter(int initialValue): 21: itsVal(initialValue) 22: {} 23: 24: Counter::Counter(): 25: itsVal(0) 26: {} 27: 28: Counter Counter::operator+ (const Counter & rhs) 29: { 30: return Counter(itsVal + rhs.GetItsVal()); 31: } 32: 33: int main() 34: { 35: Counter varOne(2), varTwo(4), varThree; 36: varThree = varOne + varTwo; 37: cout << "varOne: " << varOne.GetItsVal()<< endl; 38: cout << "varTwo: " << varTwo.GetItsVal() << endl; 39: cout << "varThree: " << varThree.GetItsVal() << endl; 40: 41: return 0; 42: }
Wynik varOne: 2 varTwo: 4 varThree: 6
Analiza
operator+ został zadeklarowany w linii 15., a jego implementacja znajduje się w liniach od 28. do 31.
Porównaj go z deklaracją i definicją funkcji Add() w poprzednim listingu: są prawie identyczne. Jednak ich składnia jest całkiem inna. Bardziej naturalny jest zapis:
varThree = varOne + varTwo;
niż zapis:
varThree = varOne.Add(varTwo);
Nie jest to duża zmiana, ale na tyle ważna, by program stał się łatwiejszy do odczytania i zrozumienia.
Operator jest wykorzystywany w linii 36:
36: varThree = varOne + varTwo;
Kompilator tłumaczy ten zapis na:
varThree = varOne.operator+(varTwo);
Mógłbyś oczywiście napisać tę linię sam, a kompilator zaakceptowałby to bez zastrzeżeń.
Metoda operator+ jest wywoływana dla operandu po lewej stronie, a jako argument otrzymuje operand po prawej stronie.
Zagadnienia związane z przeciążaniem operatorów Przeciążane operatory mogą być funkcjami składowymi, takimi, jak opisane w tym rozdziale, lub funkcjami globalnymi. Te ostatnie zostaną opisane w rozdziale 15., „Specjalne klasy i funkcje”, przy okazji omawiania funkcji zaprzyjaźnionych.
Jedynymi operatorami, które muszą być funkcjami składowymi klasy, są operator: przypisania (=), indeksu tablicy ([]), wywołania funkcji (()) oraz wskaźnika (->).
Operator [] zostanie omówiony w rozdziale 13., przy okazji omawiania tablic. Przeciążanie operatora -> zostanie omówione w rozdziale 15., przy okazji omawiania wskaźników inteligentnych.
Ograniczenia w przeciążaniu operatorów Operatory dla typów wbudowanych (takich jak int) nie mogą być przeciążane. Nie można zmieniać priorytetu operatorów ani ilości operandów operatora, tj. operator unarny nie może stać się operatorem binarnym i na odwrót. Nie można także tworzyć nowych operatorów, dlatego niemożliwe jest zadeklarowanie symbolu ** jako operatora „podnoszenia do potęgi.”
Niektóre operatory C++ są operatorami unarnymi i wymagają tylko jednego operandu (na przykład myValue++). Inne operatory są binarne, czyli wymagają dwóch operandów (na przykład a+b). W C++ istnieje tylko jeden operator trójargumentowy: operator ? (na przykład a > b ? x : y).

Co przeciążać? Przeciążanie operatorów jest jednym z najczęściej nadużywanych przez początkujących programistów aspektów języka C++. Tworzenie nowych zastosowań dla niektórych z mniej znanych operatorów jest bardzo kuszące, ale niezmiennie prowadzi do tworzenia nieczytelnego kodu.
Oczywiście, doprowadzenie to tego, by operator + odejmował, a operator * dodawał może być zabawne, ale żaden profesjonalny programista tego nie zrobi. Duże niebezpieczeństwo kryje się także w machinalnym użyciu operatora + do łączenia ciągów liter czy operatora / do dzielenia łańcuchów. Oczywiście, istnieją powody, dla których stosujemy te operatory, ale istnieje jeszcze więcej powodów, by zachować przy tym dużą ostrożność. Pamiętaj że celem przeciążania operatorów jest zwiększenie użyteczności i przejrzystości obiektów.
TAK NIE
Stosuj przeciążanie operatorów wtedy, gdy zwiększa to przejrzystość programu.
Zwracaj z przeciążanego operatora obiekt jego klasy.
Nie twórz operatorów działających niezgodnie z przeznaczeniem.
Operator przypisania Czwartą, ostatnią funkcją, która jest dostarczana przez kompilator (gdy nie stworzysz jej sam) jest operator przypisania (operator=()). Ten operator jest wywoływany za każdym razem, gdy przypisujesz coś do obiektu. Na przykład:
CAT catOne(5,7); CAT catTwo(3,4); // ... tutaj inny kod catTwo = catOne;
W tym fragmencie tworzony jest obiekt catOne; jego zmienna składowa itsAge jest inicjalizowana wartością 5, a zmienna składowa itsWeight wartością 7. W następnej linii tworzony jest obiekt catTwo, którego zmienne składowe są inicjalizowane wartościami 3 i 4.
Po jakimś czasie obiektowi catTwo jest przypisywany obiekt catOne. Pojawiają się więc dwa problemy: co się stanie, gdy zmienna składowa itsAge jest wskaźnikiem i co się dzieje z pierwotnymi wartościami w obiekcie catTwo?
Posługiwanie się zmiennymi składowymi, przechowującymi swoje wartości na stercie, zostało omówione już wcześniej, podczas omawiania działania konstruktora kopiującego. Te same zagadnienia odnoszą się także do przedstawionego tutaj przypadku, tak jak pokazano na rysunkach 10.1 i 10.2.
Usunięto: i
Programiści C++ dokonują rozróżnienia pomiędzy kopiowaniem płytkim, czyli kopiowaniem składowych klasy, a kopiowaniem głębokim. Przy kopiowaniu płytkim kopiowane są jedynie składowe, więc oba obiekty wskazują to samo miejsce na stercie. Przy kopiowaniu głębokim na stercie alokowany jest nowy obszar pamięci. Ilustrował to rysunek 10.3.
Jednak w przypadku operatora przypisania pojawia się kolejny problem. Obiekt catTwo już istnieje i posiada zaalokowaną pamięć. Jeśli nie chcemy doprowadzić do wycieku pamięci, pamięć musi zostać zwolniona. Ale co zrobić, gdy przypiszemy obiekt catTwo samemu sobie?
catTwo = catTwo;
Nikt nie ma oczywiście zamiaru tego robić, ale może się to zdarzyć przypadkiem, gdy referencje i wyłuskane wskaźniki ukryją fakt, że przypisanie odnosi się do tego samego obiektu.
Jeśli nie rozwiążesz tego problemu, obiekt catTwo może usunąć swoją zaalokowaną pamięć, po czym, gdy już będzie gotów do skopiowania pamięci z obiektu po prawej stronie operatora przypisania, znajdzie się w ogromnym kłopocie: tej wartości już nie będzie!
Aby się przed tym zabezpieczyć, operator przypisania musi sprawdzać, czy operand po prawej stronie operatora nie jest tym samym obiektem. W tym celu może sprawdzić wskaźnik this. Klasę z przeciążonym operatorem przypisania przedstawia listing 10.15.
Listing 10.15. Operator przypisania 0: // Listing 10.15 1: // Operator przypisania 2: 3: #include <iostream> 4: 5: using namespace std; 6: 7: class CAT 8: { 9: public: 10: CAT(); // domyślny konstruktor 11: // konstruktor kopiujący oraz destruktor zostały usunięte! 12: int GetAge() const { return *itsAge; } 13: int GetWeight() const { return *itsWeight; } 14: void SetAge(int age) { *itsAge = age; } 15: CAT & operator=(const CAT &); 16: 17: private: 18: int *itsAge; 19: int *itsWeight; 20: }; 21: 22: CAT::CAT() 23: { 24: itsAge = new int; 25: itsWeight = new int; 26: *itsAge = 5; 27: *itsWeight = 9; 28: } 29: 30: 31: CAT & CAT::operator=(const CAT & rhs) 32: {
Usunięto: ą
Usunięto: ą
Usunięto: ą
Usunięto: ą
Usunięto: ą
Usunięto: W
Usunięto: i
Usunięto: ej
Usunięto: W
Usunięto: ej kopii
Usunięto: i
33: if (this == &rhs) 34: return *this; 35: *itsAge = rhs.GetAge(); 36: *itsWeight = rhs.GetWeight(); 37: return *this; 38: } 39: 40: 41: int main() 42: { 43: CAT mruczek; 44: cout << "Wiek Mruczka: " << mruczek.GetAge() << endl; 45: cout << "Ustawiam wiek Mruczka na 6...\n"; 46: mruczek.SetAge(6); 47: CAT filemon; 48: cout << "Wiek Filemona: " << filemon.GetAge() << endl; 49: cout << "Kopiuje Mruczka do Filemona...\n"; 50: filemon = mruczek; 51: cout << "Wiek Filemona: " << filemon.GetAge() << endl; 52: return 0; 53: }
Wynik Wiek Mruczka: 5 Ustawiam wiek Mruczka na 6... Wiek Filemona: 5 Kopiuje Mruczka do Filemona... Wiek Filemona: 6
Analiza
Listing 10.15 stanowi powrót do klasy CAT, z której (dla zaoszczędzenia miejsca) usunięto konstruktor kopiujący oraz destruktor. Operator przypisania jest deklarowany w linii 15., zaś jego definicja znajduje się w liniach od 31. do 38.
W linii 33. następuje sprawdzenie, czy bieżący obiekt (obiekt CAT, do którego następuje przypisanie), jest tym samym obiektem, co przypisywany obiekt CAT. Odbywa się to poprzez sprawdzenie, czy adres rhs jest taki sam, jak adres zawarty we wskaźniku this.
Oczywiście, można przeciążyć także operator równości (==), dzięki czemu możesz sam określić co oznacza „równość” twoich obiektów.
Obsługa konwersji typów danych Co się stanie, gdy spróbujesz przypisać zmienną typu wbudowanego, takiego jak int czy unsigned short, do obiektu klasy zdefiniowanej przez użytkownika? Na listingu 10.16 ponownie skorzystamy z klasy Counter, próbując przypisać obiektowi tej klasy zmienną typu int.
OSTRZEŻENIE Listing 10.16 nie skompiluje się!
Usunięto: i

Listing 10.16. Próba przypisania obiektowi typu Counter zmiennej typu int 0: // Listing 10.16 1: // Ten kod nie skompiluje się! 2: 3: #include <iostream> 4: 5: using namespace std; 6: 7: class Counter 8: { 9: public: 10: Counter(); 11: ~Counter(){} 12: int GetItsVal()const { return itsVal; } 13: void SetItsVal(int x) {itsVal = x; } 14: private: 15: int itsVal; 16: 17: }; 18: 19: Counter::Counter(): 20: itsVal(0) 21: {} 22: 23: int main() 24: { 25: int theShort = 5; 26: Counter theCtr = theShort; 27: cout << "theCtr: " << theCtr.GetItsVal() << endl; 28: return 0; 29: }
Wynik Błąd kompilacji! Nie można dokonać konwersji z typu int do typu Counter.
Analiza
Klasa Counter zadeklarowana w liniach od 7. do 17. posiada jedynie konstruktor domyślny. Nie deklaruje żadnej konkretnej metody zamiany zmiennych typu int w obiekty klasy Counter, więc linia 26. powoduje błąd kompilacji. Kompilator nie wie, dopóki go o tym nie poinformujesz, że mając zmienną typu int, powinien przypisać jej wartość do zmiennej składowej itsVal.
Listing 10.17 poprawia ten błąd, tworząc operator konwersji: konstruktor przyjmuje wartość typu int i tworzy obiekt klasy Counter.
Listing 10.17. Konwersja typu int na typ Counter 0: // Listing 10.17 1: // Konstruktor jako operator konwersji 2: 3: #include <iostream> 4: 5: using namespace std; 6: 7: class Counter 8: { 9: public: 10: Counter();

11: Counter(int val); 12: ~Counter(){} 13: int GetItsVal()const { return itsVal; } 14: void SetItsVal(int x) {itsVal = x; } 15: private: 16: int itsVal; 17: 18: }; 19: 20: Counter::Counter(): 21: itsVal(0) 22: {} 23: 24: Counter::Counter(int val): 25: itsVal(val) 26: {} 27: 28: 29: int main() 30: { 31: int theShort = 5; 32: Counter theCtr = theShort; 33: cout << "theCtr: " << theCtr.GetItsVal() << endl; 34: return 0; 35: }
Wynik theCtr: 5
Analiza
Ważna zmiana pojawia się w linii 11., gdzie deklarowany jest przeciążony konstruktor, przyjmujący wartość typu int, oraz w liniach od 24. do 26., gdzie konstruktor ten jest implementowany. Efektem jego działania jest stworzenie z obiektu typu int obiektu typu Counter.
Na tej podstawie kompilator może wywołać konstruktor, którego argumentem jest wartość int.
Krok 1: Tworzymy licznik o nazwie theCtr.
Odpowiada to zapisowi x = 5;, który tworzy zmienną całkowitą x i inicjalizuje ją wartością 5. W naszym przypadku tworzymy obiekt klasy Counter o nazwie theCtr i inicjalizujemy go zmienną całkowitą theShort.
Krok 2: Przypisujemy obiektowi theCtr wartość zmiennej theShort.
Zmienna theShort jest zmienną całkowitą, a nie zmienną typu Counter! Najpierw musimy przekonwertować ją do typu Counter. Kompilator spróbuje dokonać dla nas pewnych konwersji automatycznie, ale musimy go tego nauczyć. Osiągniemy to poprzez stworzenie dla klasy Counter konstruktora, którego jedynym parametrem jest wartość całkowita:
class Counter
{ Counter(int val); // ... };
Konstruktor tworzy obiekty typu Counter na podstawie wartości typu int. Aby tego dokonać, tworzy tymczasowy, pozbawiony nazwy obiekt klasy Counter. Dla zilustrowania tego przykładu przypuśćmy, że ten tymczasowy obiekt typu Counter, tworzony ze zmiennej typu int, ma nazwę wasShort.
Krok 3: Przypisujemy wasShort do theCtr, co odpowiada zapisowi:
*theCtr = wasShort;
W tym kroku wasShort (tymczasowy obiekt stworzony podczas działania konstruktora) jest zastępowany zapisem znajdującym się po prawej stronie operatora przypisania. Teraz, gdy kompilator potrafi stworzyć dla nas obiekt tymczasowy, może zainicjalizować nim zmienną theCtr.
Aby zrozumieć ten proces, musisz uświadomić sobie, że wszystkie przeciążenia operatorów działają w ten sam sposób — deklarujesz przeciążony operator, używając słowa kluczowego operator. W przypadku operatorów binarnych (takich jak = czy +), parametrem operatora staje się zmienna położona po jego prawej stronie. Jest to zapewniane przez kompilator. Tak więc:
a = b;
staje się
a.operator=(b);
Co się jednak stanie, gdy spróbujesz odwrócić przypisanie:
0: Counter theCtr(5); 1: int theShort = theCtr; 2: cout << "theShort: " << theShort << endl;
Znów wystąpi błąd kompilacji. Choć kompilator wie już, w jaki sposób stworzyć obiekt typu Counter z wartości typu int, nie ma pojęcia, jak odwrócić ten proces.
Usunięto: Także w tym przypadku

Operatory konwersji Aby rozwiązać ten i podobne problemy, język C++ dostarcza operatorów konwersji, które mogą być dodawane do tworzonych klas. Dzięki temu klasa może jawnie określić, w jaki sposób ma być dokonywana konwersja do typów wbudowanych. Pokazuje to listing 10.18. Zwróć uwagę, że operatory konwersji nie określają zwracanej wartości, mimo, iż w efekcie zwracają wartość przekonwertowaną.
Listing 10.18. Konwersja z typu Counter na typ unsigned short() 0: // Listing 10.18 - Operatory konwersji 1: 2: #include <iostream> 3: 4: class Counter 5: { 6: public: 7: Counter(); 8: Counter(int val); 9: ~Counter(){} 10: int GetItsVal()const { return itsVal; } 11: void SetItsVal(int x) {itsVal = x; } 12: operator unsigned short(); 13: private: 14: int itsVal; 15: 16: }; 17: 18: Counter::Counter(): 19: itsVal(0) 20: {} 21: 22: Counter::Counter(int val): 23: itsVal(val) 24: {} 25: 26: Counter::operator unsigned short () 27: { 28: return ( int (itsVal) ); 29: } 30: 31: int main() 32: { 33: Counter ctr(5); 34: int theShort = ctr; 35: std::cout << "theShort: " << theShort << std::endl; 36: return 0; 37: }
Wynik theShort: 5
Analiza
W linii 12. deklarowany jest operator konwersji. Zwróć uwagę, że nie posiada on wartości zwrotnej. Implementacja tej funkcji znajduje się w liniach od 26. do 29. Linia 28. zwraca wartość itsVal, przekonwertowaną na wartość typu int.

Teraz kompilator wie już, w jaki sposób zamieniać wartości typu int w obiekty typu Counter i odwrotnie. Dzięki temu można je sobie wzajemnie przypisywać.

Rozdział 11.
Analiza i projektowanie zorientowane obiektowo Gdy skoncentrujesz się wyłącznie na składni języka C++, łatwo zapomnisz, dlaczego techniki te są używane do tworzenia programów.
Z tego rozdziału dowiesz się, jak:
- używać analizy zorientowanej obiektowo w celu zrozumienia problemów, które próbujesz rozwiązać,
- używać modelowania zorientowanego obiektowo do tworzenia stabilnych, pewnych i możliwych do rozbudowania rozwiązań,
- używać zunifikowanego języka modelowania (UML, Unified Modeling Language) do dokumentowania analizy i projektu.
1

Budowanie modeli Jeśli chcemy ogarnąć złożony problem, musimy stworzyć „model świata”. Zadaniem tego modelu jest symboliczne przedstawienie świata rzeczywistego. Taki abstrakcyjny model powinien być prostszy niż świat rzeczywisty, ale powinien poprawnie go odzwierciedlać, tak, aby na podstawie modelu można było przewidzieć zachowanie przedmiotów istniejących w realnym świecie.
Klasycznym modelem świata jest dziecięcy globus. Model ten nie jest tylko rzeczą; choć nigdy nie mylimy go z Ziemią, odwzorowuje on Ziemię na tyle dobrze, że możemy poznać jej budowę oglądając powierzchnię globusa.
W modelu występują oczywiście znaczne uproszczenia. Na globusie mojej córki nigdy nie pada deszcz, nie ma powodzi, trzęsień ziemi, itd., ale mogę go użyć, aby przewidzieć, ile czasu zajmie mi podróż z domu do Indianapolis, gdybym musiał osobiście stawić się w wydawnictwie i usprawiedliwić się, dlaczego rękopis się opóźnia („Wiesz, wszystko szło dobrze, ale nagle pogubiłem się w metaforach i przez kilka godzin nie mogłem się z nich wydostać”).
Metoda, która nie jest prostsza od modelowanej rzeczy, nie jest przydatna. Komik Steve Wright zażartował kiedyś: „Mam mapę, na której jeden cal równa się jednemu calowi. Mieszkam na E5.”
Projektowanie oprogramowania zorientowane obiektowo zajmuje się budowaniem dobrych modeli. Składa się z dwóch ważnych elementów: języka modelowania oraz procesu.
Projektowanie oprogramowania: język modelowania Język modelowania jest najmniej znaczącym aspektem obiektowo zorientowanej analizy i projektowania; niestety, przyciąga on najwięcej uwagi. Język modelowania nie jest tylko niż konwencją, określającą sposób rysowania modelu na papierze. Możemy zdecydować, że trójkąty będą reprezentować klasy, a przerywane linie będą symbolizować dziedziczenie. Przy takich założeniach możemy stworzyć model geranium tak, jak pokazano na rysunku 11.1.
Rys. 11.1. Generalizacja – specjalizacja
2

Na tym rysunku widać, że Geranium jest szczególnym rodzajem Kwiatu. Jeśli zarówno ty, jak i ja zgodzimy się na rysowanie diagramów dziedziczenia (generalizacji – specjalizacji) w ten sposób, wtedy wzajemnie się zrozumiemy. Prawdopodobnie wkrótce zechcemy stworzyć model mnóstwa złożonych zależności, w tym celu opracujemy nasz złożony zestaw konwencji i reguł rysowania.
Oczywiście, musimy przedstawić nasze konwencje wszystkim osobom, z którymi pracujemy; będzie je musiał poznać każdy nowy pracownik lub współpracownik. Możemy współpracować z innymi firmami, posiadającymi własne konwencje, w związku z czym będziemy potrzebować czasu na wynegocjowanie wspólnej konwencji i wyeliminowanie ewentualnych nieporozumień.
Dużo wygodniej byłoby, gdyby wszyscy zgodzili się na wspólny język modelowania. (Wygodnie byłoby, gdyby wszyscy mieszkańcy Ziemi zgodzili się na używanie wspólnego języka, ale to już inne zagadnienie.) Takim lingua franca w projektowaniu oprogramowania jest UML – Unified Modeling Language (zunifikowany język modelowania)1. Zadaniem UML jest udzielenie odpowiedzi na pytania w rodzaju: „Jak rysować relację dziedziczenia?” Model geranium z rysunku 11.1 w UML mógłby zostać przedstawiony tak, jak na rysunku 11.2.
Rys. 11.2. Specjalizacja narysowana w UML
1 Często określenie „język UML” utożsamia się z bardziej ogólnym pojęciem, jakim jest metodyka (projektowania) UML — przyp.red.
3

W UML klasy są rysowane w postaci prostokątów, zaś dziedziczenie jest przedstawiane jako linia zakończona strzałką. Strzałka przebiega w kierunku od klasy bardziej wyspecjalizowanej do klasy bardziej ogólnej. Dla większości osób taki kierunek strzałki jest niezgodny ze zdrowym rozsądkiem, ale nie ma to większego znaczenia; gdy wszyscy się na to zgodzimy, cały system zadziała poprawnie.
Szczegóły działania UML są raczej proste. Diagramy nie są trudne w użyciu i zrozumieniu; zostaną opisane w trakcie ich wykorzystywania. Choć na temat UML można napisać całą książkę, jednak w 90 procentach przypadków będziesz korzystał jedynie z małego podzbioru tego języka; podzbiór ten jest bardzo łatwy do zrozumienia.
Projektowanie oprogramowania: proces Proces obiektowo zorientowanej analizy i projektowania jest dużo bardziej złożony i ważniejszy niż język modelowania. Oczywiście, słyszy się o nim dużo mniej. Dzieje się tak dlatego, że niezgodności dotyczące języka modelowania zostały już w dużym stopniu wyeliminowane; przemysł informatyczny zdecydował się na używanie UML. Debata na temat procesu wciąż trwa.
Metodolog jest osobą, która opracowuje lub studiuje jedną lub więcej metod. Zwykle metodolodzy opracowują i publikują własne metody. Metoda jest językiem modelowania i procesem. Trzech wiodących w branży metodologów to: Grady Booch, który opracował metodę Boocha, Ivar Jacobson, który opracował obiektowo zorientowaną inżynierię oprogramowania oraz James Rumbaugh, który opracował technologię OMT (Object Modeling Technology). Ci trzej mężczyźni stworzyli wspólnie tzw. Rational Unified Process (dawniej znany jako Objectory), metodę oraz komercyjny produkt firmy Rational Software Inc. Wszyscy trzej są
4

zatrudnieni we wspomnianej wyżej firmie, gdzie są znani jako trzej przyjaciele (Three Amigos)2.
Ten rozdział przedstawia w ogólnym zarysie stworzony przez nich procesem. Nie będę szczegółowo go przedstawiał, gdyż nie wierzę w niewolnicze przywiązanie do akademickiej teorii – dużo bardziej niż postępowanie zgodne z metodą interesuje mnie sprzedanie produktu. Inne metody również dostarczają ciekawych rozwiązań, więc będę starał się wybierać z nich to, co wydaje mi się najlepsze i łączyć to użyteczną całość.
Proces projektowania oprogramowania jest iteracyjny. Oznacza to, że opracowując program „przechodzimy” przez cały proces wielokrotnie, coraz lepiej rozumiejąc jego wymagania. Projekt ukierunkowuje implementację, ale szczegóły, na które zwracamy uwagę podczas implementacji, wpływają z kolei na projekt. Nie próbujemy opracować jakiegokolwiek niebanalnego projektu w pojedynczym, uporządkowanym procesie liniowym; zamiast tego rozwijamy fragmenty projektu, wciąż poprawiając jego założenia oraz ulepszając szczegóły implementacji.
Opracowywanie iteracyjne można odróżnić od opracowywania kaskadowego. W opracowywaniu kaskadowym wynik jednego etapu staje się wejściem dla następnego, przy czym nie istnieje możliwość powrotu (patrz rysunek 11.3). W procesie opracowywania kaskadowego wymagania są szczegółowo przedstawione klientowi i podpisane przez niego („Tak, właśnie tego potrzebuję”); następnie wymagania te są przekazywane projektantowi. Projektant tworzy projekt, po czym przekazuje go programiście, w celu implementacji. Z kolei programista
2 Każdy z tych panów był autorem odrębnej metodyki projektowania.
J. Rumbaugh opracował Object Modelling Technique (OMT), która jest wystarczająca w przypadku modelowania dziedziny zagadnienia (problem domain). Nie odzwierciedla jednak dokładnie ani wymagań użytkowników systemów, ani wymagań implementacji.
I. Jacobson rozwinął Object-Oriented System Engineering (OOSE), który w sposób zadowalający uwzględnia aspekty modelowania użytkowników i cyklu życia systemu jako całości. Nie odzwierciedla jednak w sposób wystarczający sposobu modelowania dziedziny oraz aspektu implementacji.
G. Booch jest autorem Object-Oriented Analysis and Design Methods (OOAD), spełniającej wszelkie wymogi w dziedzinie projektowania, konstrukcji i związków ze środowiskiem implementacji. Nie uwzględnia jednak w sposób dostateczny fazy rozpoznania i analizy wymagań użytkowników.
UML ma stanowić syntezę wymienionych metodyk. Ma jednak wielu krytyków. W wielu publikacjach można przeczytać, że jest to rzecz przereklamowana i w niewystarczający sposób zdefiniowana. Konkurencją dla ciągle uzupełnianej metodyki UML jest m.in. metodyka i notacja oparta na tzw. technice “design by contracts”. — przyp.red
5

wręcza kod osobie zajmującej się kontrolą jakości, która sprawdza jego działanie i przekazuje go klientowi. Wspaniałe w teorii, katastrofalne w praktyce.
Rys. 11.3. Model kaskadowy
Przy opracowywaniu iteracyjnym zaczynamy od koncepcji; pomysłu, jak moglibyśmy to zbudować. W miarę poznawania szczegółów nasza wizja może rozrastać się i ewoluować.
Gdy już dobrze znamy wymagania, możemy rozpocząć projektowanie, doskonale zdając sobie sprawę, że pytania, które się wtedy pojawią, mogą wprowadzić zmiany w wymaganiach. Pracując nad projektem, zaczynamy tworzyć prototyp, a następnie implementację produktu. Zagadnienia pojawiające się podczas opracowywania programu wpływają na zmiany w projekcie i mogą nawet wpłynąć na zrozumienie wymagań. Projektujemy i implementujemy tylko części produktu, powtarzając za każdym razem fazy projektowania i implementacji.
Choć poszczególne etapy tego procesu są powtarzane, jednak opisanie ich w sposób cykliczny jest prawie niemożliwe. Dlatego opiszę je w następującej kolejności: koncepcja początkowa, analiza, projekt, implementacja, testowanie, prezentacja. Nie zrozum mnie źle — w rzeczywistości, podczas tworzenia pojedynczego produktu przechodzimy przez każdy z tych kroków wielokrotnie. Po prostu proces iteracyjny byłby trudny do przedstawienia, gdybyśmy chcieli pokazać cykliczne wykonywanie każdego z kroków.
Oto kolejne kroki iteracyjnego procesu projektowania:
1. Konceptualizacja.
2. Analiza.
3. Projektowanie.
4. Implementacja.
5. Testowanie
6. Prezentacja.
6

Konceptualizacja to „tworzenie wizji”. Jest pojedynczym zdaniem, opisującym dany pomysł.
Analiza jest procesem zrozumienia wymagań.
Projektowanie jest procesem tworzenia modelu klas, na podstawie którego wygenerujemy kod.
Implementacja jest pisaniem kodu (na przykład w C++).
Testowanie jest upewnianiem się, czy wykonaliśmy wszystko poprawnie.
Prezentacja to pokazanie produktu klientom.
Bułka z masłem. Cała reszta to detale.
Kontrowersje
Pojawia się mnóstwo kontrowersji na temat tego, co dzieje się na każdym etapie procesu projektowania iteracyjnego, a nawet na temat nazw poszczególnych etapów. Zdradzę ci sekret: to nie ma znaczenia. Podstawowe kroki są w każdym obiektowo zorientowanym procesie takie same: dowiedz się, co chcesz zbudować, zaprojektuj rozwiązanie i zaimplementuj projekt.
Choć w grupach dyskusyjnych i listach mailingowych dyskutujących o technologii obiektowej dzieli się włos na czworo, podstawowa analiza i projektowanie obiektowe są niezmienne. W tym rozdziale przedstawię pewien punkt widzenia na ten temat, mając nadzieję, że utworzę w ten sposób fundament, na którym będziesz mógł stworzyć architekturę swojej aplikacji.
Celem tej pracy jest stworzenie kodu, który spełnia założone wymagania i który jest stabilny, możliwy do rozbudowania i łatwy do modyfikacji. Najważniejsze jest stworzenie kodu o wysokiej jakości (w określonym czasie i przy założonym funduszu).
Programowanie ekstremalne Ostatnio pojawiła się nowa koncepcja analizy i projektowania, zwana programowaniem ekstremalnym. Programowanie to zostało omówione przez Kena Becka w książce Extreme Programming Expanded: Embrace Change (Addison-Wesley, 1999 ISBN 0201616416).
7

W tej książce Beck przedstawia kilka radykalnych i cudownych pomysłów, np. by nie kodować niczego, dopóki nie będzie można sprawdzić, czy to działa, a także programowanie w parach (dwóch programistów przy jednym komputerze). Jednak z naszego punktu widzenia, najważniejszym jego stwierdzeniem jest to, że zmianom ulegają wymagania. Należy więc sprawić, by program działał i utrzymywać to działanie; należy projektować dla wymagań, które się zna i nie tworzyć projektów „na wyrost”.
Jest to, oczywiście, ogromne uproszczenie wypowiedzi Becka i sądzę, że mógłby uznać je za przeinaczenie, jednak w każdym razie wierzę w jego sedno: spraw by program działał, tworząc go dla wymagań, które rozumiesz i staraj się nie doprowadzić do sytuacji, w której, programu nie można już zmienić.
Bez zrozumienia wymagań (analiz) i planowania (projekt), trudno jest stworzyć stabilny i łatwy do modyfikacji program, jednak staraj się nie kontrolować zbyt wielu czynności.
Pomysł Wszystkie wspaniałe programy powstają z jakiegoś pomysłu. Ktoś ma wizję produktu, który uważa za warty wdrożenia. Pożyteczne pomysły rzadko kiedy powstają w wyniku pracy zbiorowej. Pierwszą fazą obiektowo zorientowanej analizy i projektowania jest zapisanie takiego pomysłu w pojedynczym zdaniu (a przynajmniej krótkim akapicie). Pomysł ten staje się myślą przewodnią tworzonego programu, zaś zespół, który zbiera się w celu zaimplementowania tego pomysłu, powinien podczas pracy odwoływać się do tej myśli przewodniej — w razie potrzeby nawet ją modyfikując.
Nawet jeśli pomysł narodził się w wyniku zespołowej pracy działu marketingu, „wizjonerem” powinna zostać jedna osoba. Jej zadaniem jest utrzymywanie „czystości idei”. W miarę rozwoju projektu wymagania będą ewoluować. Harmonogram pracy może (i powinien) modyfikować to, co próbujesz osiągnąć w pierwszej iteracji programowania, jednak wizjoner musi zapewnić, że wszystko to, co zostanie stworzone, odzwierciedli pierwotny pomysł. Właśnie jego bezwzględne poświęcenie i żarliwe zaangażowanie doprowadza do ukończenia projektu. Gdy stracisz z oczu pierwotny zamysł, twój produkt jest skazany na niepowodzenie.
8

Analiza wymagań Faza konceptualizacji, w której precyzowany jest pomysł, jest bardzo krótka. Może trwać krócej niż błysk olśnienia połączony z czasem wymaganym do zapisania pomysłu na kartce. Często zdarza się, że dołączasz do projektu jako ekspert zorientowany obiektowo wtedy, gdy wizja została już sprecyzowana.
Niektóre firmy mylą pomysł z wymaganiami. Wyraźna wizja jest potrzebna, lecz sama w sobie nie jest wystarczająca. Aby przejść do analizy, musisz zrozumieć, w jaki sposób produkt będzie używany i jak musi działać. Celem fazy analizy jest sprecyzowanie tych wymagań. Efektem końcowym tej fazy jest stworzenie dokumentu zawierającego opracowane wymagania. Pierwszą częścią tego dokumentu jest analiza przypadków użycia produktu.
Przypadki użycia Istotną częścią analizy, projektowania i implementacji są przypadki użycia. Przypadek użycia jest ogólnym opisem sposobu, w jaki produkt będzie używany. Przypadki użycia nie tylko ukierunkowują analizę, ale także pomagają w określeniu klas i są szczególnie ważne podczas testowania produktu.
Tworzenie stabilnego i wyczerpującego zestawu przypadków użycia może być najważniejszym zadaniem całej analizy. Właśnie wtedy jesteś najbardziej uzależniony od ekspertów w danej dziedzinie, to oni wiedzą najwięcej o dziedzinie pracy, której wymagania próbujesz określić.
Przypadki użycia są w niewielkim stopniu związane z interfejsem użytkownika, nie są natomiast związane z wnętrzem budowanego systemu. Każda osoba (lub system) współpracująca z projektowanym systemem jest nazywana aktorem.
Dokonajmy krótkiego podsumowania:
- przypadek użycia – opis sposobu, w jaki używane będzie oprogramowanie,
- eksperci – osoby znające się na dziedzinie, dla której tworzysz produkt,
- aktor – każda osoba (lub system) współpracująca z projektowanym systemem.
Przypadek użycia jest opisem interakcji zachodzących pomiędzy aktorem a samym systemem. W trakcie analizy przypadku użycia system jest traktowany
9

jako „czarna skrzynka.” Aktor „wysyła komunikat” do systemu, po czym zwracana jest informacja, zmienia się stan systemu, statek kosmiczny zmienia kierunek, itd.
Identyfikacja aktorów Należy pamiętać, że nie wszyscy aktorzy są ludźmi. Systemy współpracujące z budowanym systemem także są aktorami. Gdy budujesz na przykład bankomat, aktorami mogą być urzędnik bankowy i klient – a także inny system współpracujący z aktualnie tworzonym systemem, na przykład system śledzenia pożyczek czy udzielania kredytów studenckich. Oto podstawowa charakterystyki aktorów:
- są oni na zewnątrz dla systemu,
- współpracują z systemem.
Często najtrudniejszą częścią analizy przypadków użycia jest jej początek. Zwykle najlepszą metodą „ruszenia z miejsca” jest sesja burzy mózgów. Po prostu spisz listę osób i systemów, które będą pracować z nowym systemem. Pamiętaj, że mówiąc o ludziach, w rzeczywistości mamy na myśli role – urzędnika bankowego, kasjera, klienta, itd. Jedna osoba może pełnić więcej niż jedną rolę.
We wspomnianym przykładzie z bankomatem, na naszej liście mogą wystąpić następujące role:
- klient
- personel banku
- system bankowy
- osoba wypełniająca bankomat pieniędzmi i materiałami
Na początku nie ma potrzeby wychodzenia poza tę listę. Wygenerowanie trzech czy czterech aktorów może wystarczyć do rozpoczęcia generowania przypadków użycia. Każdy z tych aktorów pracuje z systemem w inny sposób; chcemy wykryć te interakcje w naszych sposobach użycia.
10

Wyznaczanie pierwszych przypadków użycia Zacznijmy od roli klienta. Podczas burzy mózgów możemy określić następujące przypadki użycia dla klienta:
- klient sprawdza stan swojego rachunku,
- klient wpłaca pieniądze na swój rachunek,
- klient wypłaca pieniądze ze swojego rachunku,
- klient przelewa pieniądze z rachunku na rachunek,
- klient otwiera rachunek,
- klient zamyka rachunek.
Czy powinniśmy dokonać rozróżnienia pomiędzy „klient wpłaca pieniądze na swój rachunek bieżący” a „klient wpłaca pieniądze na lokatę”, czy też powinniśmy te działania połączyć (tak jak na powyższej liście) w „klient wpłaca pieniądze na swój rachunek?” Odpowiedź na to pytanie zależy od tego, czy takie rozróżnienie ma znaczenie dla danej dziedziny (dziedzina jest rzeczywistym środowiskiem, które modelujemy – w tym przypadku jest nią bankowość).
Aby sprawdzić, czy te działania są jednym przypadkiem użycia, czy też dwoma, musisz zapytać, czy ich mechanizmy są różne (czy klient w każdym z przypadków robi coś innego) i czy różne są wyniki (czy system odpowiada na różne sposoby). W naszym przykładzie, w obu przypadkach odpowiedź brzmi „nie”: klient składa pieniądze na każdy z rachunków w ten sam sposób, przy czym wynik także jest podobny, gdyż bankomat odpowiada, zwiększając stan odpowiedniego rachunku.
Zakładając, że aktor i system działają i odpowiadają mniej więcej identycznie, bez względu na to, na jaki rachunek dokonuje wpłaty, te dwa przypadki użycia są w rzeczywistości jednym sposobem. Później, gdy opracujemy scenariusze przypadków użycia, możemy wypróbować obie wariacje i sprawdzić, czy ich rezultatem są jakiekolwiek różnice.
Odpowiadając na poniższe pytania, możesz odkryć dodatkowe przypadki użycia:
1. Dlaczego aktor używa tego systemu?
11

Klient używa tego systemu, aby zdobyć gotówkę, złożyć depozyt lub sprawdzić bieżący stan rachunku.
2. Jakiego wyniku oczekuje aktor po każdym żądaniu?
Zwiększenia stanu rachunku lub uzyskania gotówki na zakupy.
3. Co spowodowało, że aktor używa w tym momencie systemu?
Być może ostatnio otrzymał wypłatę lub jest na zakupach.
4. Co aktor musi zrobić, aby użyć systemu?
Włożyć kartę do szczeliny w bankomacie.
Aha! Potrzebujemy przypadku użycia dla logowania się klienta do systemu.
5. Jakie informacje aktor musi dostarczyć systemowi?
Musi wprowadzić kod PIN.
Aha! Potrzebujemy przypadków użycia dla uzyskania i edycji kodu PIN.
6. Jakich informacji aktor oczekuje od systemu?
Stanu rachunku itd.
Często dodatkowe przypadki użycia możemy znaleźć, skupiając się na atrybutach obiektów w danej dziedzinie. Klient posiada nazwisko, kod PIN oraz numer rachunku; czy występują przypadki użycia dla zarządzania tymi obiektami? Rachunek posiada swój numer, stan oraz historię transakcji; czy wykryliśmy te elementy w przypadkach użycia?
Po szczegółowym przeanalizowaniu przypadków użycia dla klienta, następnym krokiem w opracowywaniu listy przypadków użycia jest opracowanie przypadków użycia dla wszystkich pozostałych aktorów. Poniższa lista przedstawia pierwszy zestaw przypadków użycia dla naszego przykładu z bankomatem:
- klient sprawdza stan swojego rachunku,
- klient wpłaca pieniądze na swój rachunek,
- klient wypłaca pieniądze ze swojego rachunku,
- klient przekazuje pieniądze z rachunku na rachunek,
- klient otwiera rachunek,
12

- klient zamyka rachunek,
- klient loguje się do swojego rachunku,
- klient sprawdza ostatnie transakcje,
- urzędnik bankowy loguje się do specjalnego konta przeznaczonego do zarządzania,
- urzędnik bankowy dokonuje zmian w rachunku klienta,
- system bankowy aktualizuje stan rachunku klienta na podstawie działań zewnętrznych,
- zmiany rachunku użytkownika są odzwierciedlane w systemie bankowym,
- bankomat sygnalizuje niedobór pieniędzy,
- technik uzupełnia w bankomacie gotówkę i materiały.
Tworzenie modelu dziedziny Gdy masz już pierwszą wersję przypadków użycia, możesz zacząć wypełniać dokument wymagań szczegółowym modelem dziedziny. Model dziedziny jest dokumentem zawierającym wszystko to, co wiesz o danej dziedzinie (zagadnieniu, nad którym pracujesz). Jako część modelu dziedziny tworzysz obiekty dziedziny, opisujące wszystkie obiekty wymienione w przypadkach użycia. Przykład z bankomatem zawiera następujące obiekty: klient, personel banku, system bankowy, rachunek bieżący, lokata, itd.
Dla każdego z tych obiektów dziedziny chcemy uzyskać tak ważne dane, jak nazwa obiektu (na przykład klient, rachunek, itd.), czy obiekt jest aktorem, podstawowe atrybuty i zachowanie obiektu, itd. Wiele narzędzi do modelowania wspiera zbieranie tych informacji w opisach „klas.” Na przykład, rysunek 11.4 przedstawia sposób, w jaki te informacje są zbierane w systemie Rational Rose.
Rys. 11.4. Rational Rose
13

Należy zdawać sobie sprawę, że to, co opisujemy, nie jest obiektem projektu, ale obiektem dziedziny. Odzwierciedla sposób funkcjonowania świata, a nie sposób działania naszego systemu.
Możemy określić relacje pomiędzy obiektami dziedziny pojawiającymi się w przykładzie z bankomatem, używając UML – korzystając z takich samych konwencji rysowania, jakich użyjemy później do opisania relacji pomiędzy klasami w dziedzinie. Jest to jedna z ważniejszych zalet UML: możemy używać tych samych narzędzi na każdym etapie projektu.
Na przykład, używając konwencji UML dla klas i powiązań generalizacji, możemy przedstawić rachunki bieżące i rachunki lokat jako specjalizacje bardziej ogólnej koncepcji rachunku bankowego, tak jak pokazano na rysunku 11.5.
Rys. 11.5. Specjalizacje
14

Na diagramie z rysunku 11.5 prostokąty reprezentują różne obiekty dziedziny; zaś strzałki wskazują generalizację. UML zakłada, że linie są rysowane w kierunku od klasy wyspecjalizowanej do bardziej ogólnej klasy „bazowej.” Dlatego, zarówno Rachunek bieżący, jak i Rachunek lokaty, wskazują na Rachunek bankowy, informując że każdy z nich jest wyspecjalizowaną formą Rachunku bankowego.
UWAGA Pamiętajmy, że w tym momencie widzimy tylko zależności pomiędzy obiektami w dziedzinie. Później być może zdecydujesz się na zastosowanie w projekcie obiektów o nazwach RachunekBiezacy RachunekBankowy oraz i może odwzorujesz te zależności, używając dziedziczenia, ale będą to decyzje podjęte w czasie projektowania. W czasie analizy dokumentujemy jedynie obiekty istniejące w danej dziedzinie.
UML jest bogatym językiem modelowania i można w nim umieścić dowolną ilość relacji. Jednak podstawowe relacje wykrywane podczas analizy to: generalizacja (lub specjalizacja), zawieranie i powiązanie.
Generalizacja Generalizacja jest często porównywana z „dziedziczeniem,” lecz istnieje pomiędzy nimi wyraźna, istotna różnica. Generalizacja opisuje relację; dziedziczenie jest programową implementacją generalizacji – jest sposobem przedstawienia generalizacji w kodzie. Odwrotnością generalizacji jest specjalizacja. Kot jest wyspecjalizowaną formą zwierzęcia, zaś zwierzę jest generalną formą kota lub psa.
Specjalizacja określa, że obiekt wyprowadzony jest podtypem obiektu bazowego. Zatem rachunek bieżący jest rachunkiem bankowym. Ta relacja jest symetryczna: rachunek bankowy generalizuje ogólne zachowanie i atrybuty rachunku bieżącego i rachunku lokaty.
Podczas analizowania dziedziny chcemy przedstawić te zależności dokładnie tak, jak występują w realnym świecie.
Zawieranie Często obiekt składa się z wielu podobiektów. Na przykład samochód składa się z kierownicy, kół, drzwi, radia, itd. Rachunek bieżący składa się ze stanu, historii transakcji, identyfikatora klienta, itd. Mówimy, że rachunek bieżący posiada te
15

elementy; zawieranie modeluje właśnie takie relacje posiadania. UML ilustruje relację zawierania za pomocą strzałki z rombem, wskazującej obiekt zawierany (patrz rysunek 11.6).
Rys. 11.6. Zawieranie
Diagram z rysunku 11.6 sugeruje, że rachunek osobisty posiada stan. Można połączyć oba diagramy, przedstawiając w ten sposób dość złożony zestaw relacji (patrz rysunek 11.7).
Rys. 11.7. Relacje pomiędzy obiektami
16

Diagram z rysunku 11.7 informuje, że rachunek bieżący i rachunek lokaty są rachunkami bankowymi oraz, że rachunki bankowe posiadają zarówno stan, jak i historię transakcji.
Powiązania Trzecią relacją, wykrywaną zwykle podczas analizowania dziedziny, jest proste powiązanie. Powiązanie sugeruje, że dwa obiekty w jakiś sposób ze sobą współpracują. Ta definicja staje się dużo bardziej precyzyjna w fazie projektowania, ale w fazie analizy sugerujemy jedynie, że obiekt A współpracuje z obiektem B, i że jeden obiekt nie zawiera drugiego; a także, że żaden z nich nie jest specjalizacją drugiego. W UML powiązania między obiektami są przedstawiane jako zwykła prosta linia pomiędzy obiektami, co pokazuje rysunek 11.8.
Diagram z rysunku 11.8 wskazuje, że obiekt A w jakiś sposób współpracuje z obiektem B.
Rys. 11.8.
17

Tworzenie scenariuszy Gdy mamy już gotowy wstępny zestaw przypadków użycia oraz narzędzi, dzięki którym możemy przedstawić relacje pomiędzy obiektami w dziedzinie, jesteśmy gotowi do uporządkowania przypadków użycia i zdefiniowania ich przeznaczenia.
Każdy przypadek użycia można „rozbić” na serie scenariuszy. Scenariusz jest opisem określonego zestawu okoliczności towarzyszących danemu przypadkowi użycia. Na przykład, przypadek użycia „klient wypłaca pieniądze ze swojego rachunku” może posiadać następujące scenariusze:
- klient żąda trzystu dolarów z rachunku bieżącego, otrzymuje gotówkę, po czym system drukuje kwit,
- klient żąda trzystu dolarów z rachunku bieżącego, lecz na rachunku znajduje się tylko dwieście dolarów. Klient jest informowany, że na koncie znajduje się zbyt mało środków, aby spełnić jego żądanie,
- klient żąda trzystu dolarów z rachunku bieżącego, ale tego dnia pobrał już sto dolarów, a limit dzienny wynosi trzysta dolarów. Klient jest informowany o problemie i może się zdecydować na pobranie jedynie dwustu dolarów,
- klient żąda trzystu dolarów z rachunku bieżącego, ale skończył się papier w drukarce kwitów. Klient jest informowany o problemie i może się zdecydować na pobranie pieniędzy bez potwierdzenia w postaci kwitu.
I tak dalej. Każdy scenariusz przedstawia wariant tego samego przypadku użycia. Często te sytuacje są sytuacjami wyjątkowymi (zbyt mało środków na rachunku, zbyt mało gotówki w bankomacie, itd.). Czasem warianty dotyczą niuansów w podejmowaniu decyzji w samym sposobie użycia (na przykład, czy przed podjęciem gotówki klient chce dokonać transferu środków).
18

Nie musimy analizować każdego ewentualnego scenariusza. Szukamy tych scenariuszy, które prezentują wymagania systemu lub szczegóły interakcji z aktorem.
Tworzenie wytycznych Teraz, jako część metodologii, będziemy tworzyć wytyczne dla udokumentowania każdego ze scenariuszy. Te wytyczne znajdą się w dokumentacji wymagań. Zwykle chcemy, by każdy scenariusz zawierał:
- warunki wstępne – jakie warunki muszą być spełnione, aby scenariusz się rozpoczął,
- włączniki – co powoduje, że scenariusz się rozpoczyna,
- akcje, jakie podejmuje aktor,
- wyniki lub zmiany powodowane przez system,
- informację zwrotną otrzymywaną przez aktora,
- informacje o występowaniu cyklicznych operacji i o przyczynach ich wykonywania,
- schematyczny opis przebiegu scenariusza,
- okoliczności powodujące zakończenie scenariusza,
- warunki końcowe – jakie warunki muszą być spełnione w momencie zakończenia scenariusza.
Ponadto, każdemu sposobowi użycia i każdemu scenariuszowi powinno się nadać nazwę. Możesz spotkać się z następującą sytuacją:
Przypadek użycia: Klient wypłaca pieniądze.
Scenariusz: Pomyślne pobranie gotówki z rachunku bieżącego.
Warunki wstępne: Klient jest już zalogowany do systemu.
Włącznik: Klient żąda gotówki.
Opis: Klient decyduje się na wypłacenie gotówki z rachunku
19

bieżącego. Na rachunku znajduje się wystarczająca ilość środków, w bankomacie jest wystarczająco dużo pieniędzy i papieru na kwity, a sieć działa. Bankomat prosi klienta o podanie wysokości wypłaty, klient prosi o trzysta dolarów, co w tym momencie jest kwotą dozwoloną. Maszyna wydaje trzysta dolarów i wypisuje kwit; klient odbiera pieniądze i kwit.
Warunki końcowe: Rachunek klienta jest obciążany kwotą trzystu dolarów, zaś klient otrzymuje trzysta dolarów w gotówce.
Ten przypadek użycia może zostać przedstawiony za pomocą prostego diagramu, pokazanego na rysunku 11.9.
Rys. 11.9. Diagram przypadku użycia
Ten diagram nie dostarcza zbyt wielu informacji, poza wysokopoziomową abstrakcją interakcji pomiędzy aktorem (klientem) a systemem. Diagram stanie się nieco bardziej użyteczny, gdy przedstawimy interakcję pomiędzy sposobami użycia. Tylko nieco bardziej użyteczny, gdyż możliwe są tylko dwie interakcje:
( ) i ( ). Stereotyp <<korzysta z>> <<uses>> <<rozszerza>> <<extends>> <<korzysta
z>> wskazuje, że jeden przypadek użycia jest nadzestawem innego. Na przykład, nie jest możliwa wypłata gotówki bez wcześniejszego zalogowania się. Tę relację przedstawiamy za pomocą diagramu, pokazanego na rysunku 11.10.
Rys. 11.10. Stereotyp <<korzysta z>>
20

Rysunek 11.10 pokazuje, że przypadek użycia Wypłata Gotówki „korzysta z” przypadku użycia Logowanie i w pełni implementuje Logowanie jako część Wypłaty Gotówki.
Przypadek użycia <<rozszerza>> został opracowany w celu wskazania relacji warunkowych i częściowo odnosił się do dziedziczenia, ale wywoływał tyle nieporozumień wśród projektantów obiektowych (związanych z odróżnieniem go od <<korzysta z>>), że wielu z nich odrzuca go, uważając że nie jest wystarczająco dobrze zrozumiany. Ja używam <<korzysta z>> aby uniknąć kopiowania i wklejania całego przypadku użycia, a <<rozszerza>> używam wtedy, gdy korzystam z przypadku użycia tylko w określonych warunkach.
Diagramy interakcji Choć diagram przypadku użycia może mieć ograniczoną wartość, można powiązać go z przypadkiem użycia, który może znacznie wzbogacić dokumentację i ułatwić zrozumienie interakcji. Na przykład wiemy, że scenariusz Wypłata Gotówki reprezentuje interakcję pomiędzy następującymi obiektami dziedziny: klientem, rachunkiem bieżącym oraz interfejsem użytkownika. Możemy przedstawić tę interakcję na diagramie interakcji, widocznym na rysunku 11.11.
Rys. 11.11. Diagram interakcji w języku UML
21

Diagram interakcji z rysunku 11.11 przedstawia te szczegóły scenariusza, które mogą nie zostać zauważane podczas czytania tekstu. Współdziałające ze sobą obiekty są obiektami dziedziny, a cały bankomat (ATM) wraz z interfejsem użytkownika traktowany jest jako pojedynczy obiekt, wywoływany szczegółowo jest tylko określony rachunek bankowy.
Ten prosty przykład bankomatu pokazuje jedynie ograniczony zestaw interakcji, ale szczegółowe ich przeanalizowanie może okazać się bardzo pomocne w zrozumieniu zarówno dziedziny problemu, jak i wymagań nowego systemu.
Tworzenie pakietów Ponieważ dla każdego problemu o znacznej złożoności generuje się wiele przypadków użycia, UML umożliwia grupowanie ich w pakiety.
Pakiet przypomina kartotekę lub folder – jest zbiorem obiektów modelowania (klas, aktorów, itd.). Aby opanować złożoność przypadków użycia, możemy tworzyć pakiety pogrupowane według charakterystyk, mających znaczenie dla danego projektu. Możesz więc pogrupować swoje przypadki użycia według rodzaju rachunku (wszystko, co odnosi się do rachunku bieżącego albo do lokaty), według wpływów albo obciążeń, według rodzaju klienta czy według jakiejkolwiek innej charakterystyki, która ma sens w danym przypadku.
22

Pojedynczy przypadek użycia może występować w kilku różnych pakietach, ułatwiając w ten sposób projektowanie.
Analiza aplikacji Oprócz tworzenia przypadków użycia, dokument wymagań powinien zawierać założenia i ograniczenia twojego klienta, a także wymagania wobec sprzętu i systemu operacyjnego. Wymagania aplikacji są założeniami pochodzącymi od konkretnego klienta – zwykle określiłbyś je podczas projektowania i implementacji, ale klient zadecydował o nich za ciebie.
Wymagania aplikacji są często narzucane przez konieczność współpracy z istniejącymi systemami. W takim przypadku kluczowym elementem analizy jest zrozumienie sposobów działania istniejących systemów.
W idealnych warunkach analizujesz problem, projektujesz rozwiązanie, po czym decydujesz, jaka platforma i system operacyjny najlepiej odpowiadają potrzebom twojego projektu. Taka sytuacja jest nie tylko idealna, ale i rzadka. Dużo częściej zdarza się, że klient zainwestował już w określony sprzęt lub system operacyjny. Plany jego firmy opierają się na działaniu twojego oprogramowania w istniejącym już systemie, więc musisz poznać te wymagania jak najwcześniej i odpowiednio się do nich dostosować.
Analiza systemów Czasem oprogramowanie jest zaprojektowane jako samodzielne; współpracuje ono jedynie z końcowym użytkownikiem. Często jednak twoim zadaniem będzie współpraca z istniejącym systemem. Analiza systemów to proces zbierania wszystkich informacji na temat systemów, z którymi będziesz współpracował. Czy twój nowy system będzie serwerem, dostarczającym usługi istniejącym systemom, czy też będzie ich klientem? Czy będziesz mógł negocjować interfejs pomiędzy systemami, czy też musisz się dostosować do istniejącego standardu? Czy inne systemy pozostaną niezmienne, czy też przez cały czas będziesz śledził zachodzące w nich zmiany?
Na te i inne pytania należy odpowiedzieć podczas fazy analizowania, jeszcze przed przystąpieniem do projektowania nowego systemu. Oprócz tego, powinieneś poznać ograniczenia wynikające ze współpracy z innymi systemami.
23

Czy spowolnią one szybkość odpowiedzi twojego systemu? Czy nakładają one na twój system wysokie wymagania, zajmując zasoby i czas procesora?
Tworzenie dokumentacji Gdy już określisz zadania systemu i sposób jego działania, nadchodzi czas, aby podjąć pierwszą próbę stworzenia dokumentu, określającego czas i budżet produkcji. Często termin jest narzucony przez klienta z góry: „Masz na to osiemnaście miesięcy.” Byłoby wspaniale, gdybyś mógł przeanalizować wymagania i oszacować czas, jaki zajmie ci zaprojektowanie i zaimplementowanie rozwiązania. W praktyce większość systemów powstaje w bardzo krótkim terminie i przy niskich kosztach, zaś prawdziwa sztuka polega na określeniu, jak duża część założeń może zostać spełniona w zadanym czasie — oraz przy założonym budżecie.
Oto wytyczne, o których powinieneś pamiętać, określając harmonogram i budżet projektu:
- jeśli musisz zmieścić się w pewnym przedziale, wtedy założeniem optymistycznym jest najprawdopodobniej jego ograniczenie zewnętrzne,
- zgodnie z prawem Liberty’ego, wszystko będzie trwać dłużej niż tego oczekujesz – nawet jeśli uwzględnisz to prawo.
Konieczne będzie też określenie priorytetów. Nie skończysz w wyznaczonym terminie – po prostu. Zadbaj, by system działał w momencie, gdy kończy się czas ukończenia prac i by był wystarczający sprawny dla pierwszego wydania. Gdy budujesz most zbliża się termin ukończenia prac, a nie została jeszcze wykonana ścieżka rowerowa, to niedobrze; możesz jednak otworzyć już most i zacząć pobierać myto. Jeśli jednak most sięga dopiero połowy rzeki, to już bardzo źle.
Dokumentów planowania przeważnie są błędne. Na tak wczesnym etapie projektu praktycznie nie jest możliwe właściwe oszacowanie czasu jego trwania. Gdy już znasz wymagania, możesz w przybliżeniu określić ilość czasu, jaką zajmie projektowanie systemu, jego implementacja i testowanie. Do tego musisz zaplanować dodatkowo od dwudziestu do dwudziestu pięciu procent „zapasu”, który możesz zmniejszać w trakcie wykonywania zlecenia (gdy dowiadujesz się coraz więcej).
24

UWAGA Uwzględnienie „zapasu” czasu nie może być wymówką dla uniknięcia tworzenia planu. Jest jedynie ostrzeżeniem, że nie można na nim do końca polegać. W trakcie prac nad projektem lepiej poznasz działanie systemu, a obliczenia staną się bardziej dokładne.
Wizualizacje Ostatnim elementem dokumentu wymagań jest wizualizacja. Jest to nazwa wszystkich diagramów, rysunków, zrzutów ekranu, prototypów i wszelkich innych wizualnych reprezentacji, przeznaczonych do wsparcia analizy i projektu graficznego interfejsu użytkownika dla produktu.
W przypadku dużych projektów możesz opracować pełny prototyp, który pomoże tobie (i twoim klientom) zrozumieć jak będzie działał system. W niektórych przypadkach prototyp staje się odzwierciedleniem wymagań; prawdziwy system jest projektowany tak, by implementował funkcje zademonstrowane w prototypie.
Dokumentacja produktu Na koniec każdej fazy analizy i projektowania stworzysz serię dokumentów produktu. Tabela 11.1 pokazuje kilka z takich dokumentów dla fazy analizy. Są one używane przez klienta w celu upewnienia się, czy rozumiesz jego potrzeby, przez końcowego użytkownika jako wsparcie i wytyczne dla projektu, zaś przez zespół projektowy do zaprojektowania i zaimplementowania kodu. Wiele z tych dokumentów dostarcza także materiału istotnego zarówno dla zespołu zajmującego się dokumentacją, jak i zespołu kontroli jakości, informując ,w jaki sposób powinien zachowywać się system.
Tabela 11.1. Dokumenty produktu tworzone podczas fazy analizy
Dokument Opis
Raport przypadków użycia Dokument opisujący szczegółowo przypadki użycia, scenariusze, stereotypy, warunki wstępne, warunki końcowe oraz wizualizacje.
Analiza dziedziny Dokument i diagramy, opisujące powiązania
25

pomiędzy obiektami dziedziny.
Diagramy analizy współpracy Diagramy współpracy, opisujące interakcje pomiędzy obiektami dziedziny.
Diagramy analizy działań Diagramy działań, opisujące interakcje pomiędzy obiektami dziedziny.
Analiza systemu Raport i diagramy, opisujące na niższym poziomie system i sprzęt, dla którego będzie tworzony projekt.
Dokument analizy zastosowań Raport i diagramy, opisujące wymagania klienta wobec konkretnego produktu.
Raport ograniczeń działania Raport charakteryzujący wydajność oraz ograniczenia narzucone przez klienta.
Dokument kosztów i harmonogramu
Raport z wykresami Ganta i Perta, opisującymi zakładany harmonogram, etapy i koszty.
Projektowanie Analiza skupia się na dziedzinie problemu, natomiast projektowanie zajmuje się stworzeniem rozwiązania. Projektowanie jest procesem przekształcenia wymagań w model, który może być zaimplementowany w postaci oprogramowania. Rezultatem tego procesu jest stworzenie dokumentu projektowego.
Dokument projektowy jest podzielony na dwie części: projekt klas oraz mechanizmy architektury. Część projektu klas dzieli się z kolei na projekt statyczny (szczegółowo określający poszczególne klasy, ich powiązania i charakterystyki) oraz projekt dynamiczny (określający, jak te klasy ze sobą współpracują).
Część mechanizmów architektury zawiera informacje na temat implementacji przechowywania obiektów, rozproszonego systemu obiektów, konkurencji pomiędzy elementami, itd. W następnej części rozdziału skupimy się na aspekcie projektowania klas; zaś do projektowania mechanizmów architektury wykorzystamy wiadomości zawarte w następnych rozdziałach tej książki.
26

Czym są klasy? Jako programista C++, przywykłeś do tworzenia klas. Metodologia projektowania wymaga operowania klasami C++ poprzez klasy projektu, mimo, iż są one dość ściśle powiązane. Klasa C++ zapisana w kodzie programu stanowi implementację klasy zaprojektowanej. Każda klasa stworzona w kodzie będzie stanowić odzwierciedlenie klasy w projekcie, ale nie należy mylić jednej z drugą. Oczywiście, klasy projektu można zaimplementować także w innym języku, jednak składnia definicji klasy może być inna.
Z tego powodu przez większość czasu będziemy mówić o klasach bez dokonywania takiego rozróżnienia, gdyż różnice między nimi są zbyt abstrakcyjne. Gdy mówimy, że w naszym modelu klasa posiada metodę Cat
, naszym zdaniem oznacza to, że metodę Meow() Meow() umieścimy także w naszej klasie C++.
Klasy modelu przedstawia się w postaci diagramów UML, zaś klasy C++ jako kod, który może zostać skompilowany. Rozróżnienie, choć subtelne, jest jednak istotne.
Największym wyzwaniem dla wielu nowicjuszy jest określenie początkowego zestawu klas i zrozumienie, z czego składa się dobrze zaprojektowana klasa. Jedną z technik jest wypisanie scenariuszy przypadków użycia, a następnie stworzenie osobnej klasy dla każdego rzeczownika. Spójrzmy na poniższy scenariusz przypadku użycia:
Klient decyduje się na wypłatę gotówki z rachunku osobistego. Na rachunku znajduje się wystarczająca ilość środków, w bankomacie jest wystarczająca ilość gotówki i papieru, działa także sieć. Bankomat prosi klienta o podanie kwoty wypłaty, zaś klient prosi o wypłatę trzystu dolarów, co w tym momencie jest możliwe. Maszyna wydaje trzysta dolarów i drukuje kwit, po czym klient bierze pieniądze i odbiera kwit.
Z tego scenariusza możesz wybrać następujące klasy:
- klient
- gotówka
- rachunek bieżący
- rachunek
27

- kwity
- bankomat
- sieć
- kwota
- wypłata
- maszyna
- pieniądze
Możesz następnie usunąć z listy synonimy, po czym stworzyć klasy dla każdego z następujących rzeczowników:
- klient
- gotówka (pieniądze, kwota, wypłata)
- rachunek bieżący
- rachunek
- kwity
- bankomat (maszyna)
- sieć
Jak na razie, to niezły początek. Możesz następnie przedstawić na diagramie relacje pomiędzy niektórymi z tych klas (patrz rysunek 11.12).
Rysunek 11.12. Wstępnie zdefiniowane klasy
28

Przekształcenia Proces, który zaczął się w poprzednim podrozdziale, jest nie tyle wybieraniem rzeczowników ze scenariusza, ile początkiem przekształcania obiektów z analizy dziedziny w obiekty projektowe. To ważny, pierwszy krok. Wiele obiektów dziedziny będzie posiadało w projekcie reprezentacje. Obiekt jest nazywany reprezentacją w celu odróżnienia, na przykład, rzeczywistego papierowego kwitu wydawanego przez bankomat od obiektu w projekcie, który jest jedynie zaimplementowaną w kodzie abstrakcją.
Najprawdopodobniej odkryjesz, że większość obiektów dziedziny posiada izomorficzną reprezentację w projekcie – tj. pomiędzy obiektem dziedziny a obiektem projektu istnieje relacja „jeden do jednego”. Zdarza się jednak, że pojedynczy obiekt dziedziny jest reprezentowany w projekcie przez całą serię obiektów. Kiedy indziej seria obiektów dziedziny może być reprezentowana przez pojedynczy obiekt projektowy.
Zwróć uwagę, że w rysunku 11.12 już zauważyliśmy fakt, iż RachunekBieżący jest specjalizacją Rachunku. Nie przygotowywaliśmy się do wyszukiwania relacji generalizacji, ale ta była tak oczywista, że od razu ją zauważyliśmy. Z analizy dziedziny wiemy, że wydaje Bankomat Gotówkę i Kwity, więc natychmiast wyszukaliśmy tę informację w projekcie.
29

Relacja pomiędzy a Klientem RachunkiemBieżacym jest już mniej oczywista. Wiemy, że taka relacja istnieje, ale ponieważ jej szczegóły nie są oczywiste, na razie nie będziemy się nią zajmować.
Inne przekształcenia Gdy przekształcimy już obiekty dziedziny, możemy zacząć szukać innych użytecznych obiektów projektowych. Mogą być nimi np. interfejsy. Każdy interfejs pomiędzy nowym systemem a systemami już istniejącymi, powinien zostać ujęty w klasie interfejsu. Jeśli współpracujesz z bazą danych (obojętne, jakiego rodzaju), baza ta także jest dobrym kandydatem na klasę interfejsu.
Klasy interfejsów umożliwiają ukrycie szczegółów interfejsu i w ten sposób chronią nas przed zmianami w innych systemach. Klasy interfejsów pozwalają na zmianę własnego projektu lub dostosowywanie się do zmian w projekcie innych systemów, bez zmian w pozostałej części kodu. Dopóki dwa systemy współpracują ze sobą poprzez uzgodniony interfejs, mogą się zmieniać niezależnie od siebie.
Manipulowanie danymi Gdy stworzysz klasy dla manipulowania danymi, a musisz przekształcać dane z formatu do formatu (na przykład ze skali Celsjusza do Fahrenheita lub z systemu angielskiego na metryczny), możesz ukryć szczegóły takiej transformacji w klasie. Możesz użyć tej techniki, przekazując dane w żądanym formacie do innego systemu lub transmitując je poprzez Internet. Gdy musisz manipulować danymi w określonym formacie, możesz ukryć szczegóły protokołu w klasie manipulowania danymi.
Widoki Każdy „widok” lub „raport” generowany przez system (lub w przypadku, gdy generujesz wiele raportów, każdy zestaw raportów) jest kandydatem na klasę. Reguły tworzenia raportu – sposób gromadzenia informacji i ich przedstawiania – można ukryć wewnątrz klasy.
30

Urządzenia Gdy twój system współpracuje z urządzeniami (takimi jak drukarki, modemy, skanery, itd.) lub operuje nimi, specyfika protokołu komunikacji z urządzeniem także powinna zostać ukryta w klasie. Także w tym przypadku, przez stworzenie klas dla interfejsu urządzenia, możesz podłączać nowe urządzenia z nowymi protokołami, nie naruszając przy tym żadnych pozostałych części swojego kodu; po prostu tworzysz nową klasę interfejsu, obsługującą ten sam (lub wyprowadzony) interfejs. I gotowe!
Model statyczny Gdy określisz już wstępny zestaw klas, pora rozpocząć modelowanie powiązań i interakcji pomiędzy nimi. W tym rozdziale najpierw opiszemy model statyczny, a dopiero potem model dynamiczny. W rzeczywistym procesie projektowania będziesz swobodnie przechodził pomiędzy tymi modelami, dodając nowe klasy i, szkicując je w miarę postępu prac.
Model statyczny skupia się na trzech obszarach: odpowiedzialności, atrybutach i powiązaniach. Najważniejszy z nich – i na nim skupisz się najpierw – jest zestaw odpowiedzialności dla każdej z klas. Najważniejszą wytyczną będzie teraz: Każda klasa powinna być odpowiedzialna za jedną rzecz.
Nie chcę przez to powiedzieć, że każda klasa ma tylko jedną metodę; wiele klas będzie miało tuziny metod. Jednak wszystkie te metody muszą być spójne i wzajemnie do siebie przystające; tj. wszystkie muszą być ze sobą powiązane i zapewniać klasie zdolność osiągnięcia określonego obszaru odpowiedzialności.
W dobrze zaprojektowanym systemie, każdy obiekt jest egzemplarzem dobrze zdefiniowanej i dobrze zrozumianej klasy, odpowiedzialnej za określony obszar. Klasy zwykle delegują zewnętrzne odpowiedzialności na inne, powiązane z nimi klasy. Dzięki stworzeniu klas, które zajmują się tylko jednym obszarem, umożliwiasz tworzenie kodu łatwego do konserwacji i rozbudowy.
Aby określić obszar odpowiedzialności swoich klas, możesz zacząć projektowanie od użycia kart CRC.
Karty CRC CRC oznacza Class, Responsibility i Collaboration (klasa, odpowiedzialność, współpraca). Karta CRC jest tylko zwykłą kartką z notatnika. To proste
31

urządzenie umożliwia nawiązanie współpracy z innymi osobami w celu określenia podstawowych odpowiedzialności dla początkowego zestawu klas. W tym celu ułóż na stole stos pustych kart CRC, a przy stole zorganizuj serię sesji CRC.
W jaki sposób przeprowadzać sesję CRC Każda sesja CRC powinna odbywać się w grupie od trzech do sześciu osób; przy większej ich ilości staje się nieefektywna. Powinieneś wyznaczyć koordynatora, którego zadaniem będzie zapewnienie właściwego przebiegu sesji i pomaganie jej uczestnikom w zidentyfikowaniu najważniejszych zagadnień. Powinien być obecny co najmniej jeden doświadczony architekt oprogramowania, najlepiej ktoś z dużym doświadczeniem w obiektowo zorientowanej analizie i projektowaniu. Oprócz tego, w sesji powinien wziąć udział co najmniej jeden ekspert w danej dziedzinie, rozumiejący wymagania systemu i mogący udzielić fachowej porady na temat działania systemu.
Najważniejszym elementem sesji CRC jest nieobecność menedżerów. Sprawia ona, że sesja jest kreatywnym, swobodnie toczącym się spotkaniem, na przebieg którego nie może mieć wpływu chęć zrobienia wrażenia na czyimś szefie. Celem jej jest eksperyment, podjęcie ryzyka, odkrycie wymagań klas oraz zrozumienie, w jaki sposób mogą one ze sobą współpracować.
Sesję CRC rozpoczyna się od zebrania grupy przy stole, na którym znajduje się niewielki stos kartek. Na górze każdej karty CRC wypisuje się nazwę pojedynczej klasy. Poniżej narysuj pionową linię biegnącą w poprzez kartki, następnie opisz rubrykę po lewej stronie jako Odpowiedzialności, zaś po prawej stronie jako Współpraca.
Zacznij od wypełnienia kart dla najważniejszych zidentyfikowanych dotąd klas. Na odwrocie każdej karty zapisz jedno lub dwuzdaniową definicję. Możesz także wskazać, jaką klasę specjalizuje dana klasa (o ile jest to wiadome w czasie posługiwania się kartą CRC). Poniżej nazwy klasy napisz po prostu Superklasa: oraz nazwę klasy, od której ta klasa pochodzi.
Skup się na odpowiedzialnościach Celem sesji CRC jest zidentyfikowanie odpowiedzialności każdej z klas. Nie zwracaj większej uwagi na atrybuty, wychwytuj tylko te najważniejsze. Najważniejszym zadaniem jest zidentyfikowanie odpowiedzialności. Jeśli w celu
32

wypełnienia odpowiedzialności klasa musi delegować pracę na inną klasę, zapisz tę informację w rubryce Współpraca.
W miarę postępu prac zwracaj uwagę na listę odpowiedzialności. Gdy na karcie CRC zabraknie miejsca, zadaj sobie pytanie, czy nie żądasz od klasy zbyt wiele. Pamiętaj, każda klasa powinna być odpowiedzialna za jeden ogólny obszar pracy, zaś wymienione na karcie odpowiedzialności powinny być spójne i przystające – tj. powinny współgrać ze sobą w celu zapewnienia ogólnej odpowiedzialności klasy.
Nie powinieneś teraz skupiać się na powiązaniach ani na interfejsie klasy lub na tym, która metoda będzie publiczna, a która prywatna. Postaraj się jedynie zrozumieć, co robi każda z klas.
Antropomorfizacja i ukierunkowanie na przypadki użycia Kluczową cechą kart CRC jest ich antropomorfizacja – tj. przypisywanie każdej z klas ludzkich atrybutów. Oto sposób jej działania: gdy masz już wstępny zestaw klas, wróć do scenariuszy użycia. Rozdziel karty wśród uczestników sesji i razem prześledźcie scenariusz. Na przykład, zastanówmy się nad następującym scenariuszem:
Klient decyduje się na wypłatę gotówki z rachunku osobistego. Na rachunku znajduje się wystarczająca ilość środków, w bankomacie jest wystarczająca ilość gotówki i papieru, działa także sieć. Bankomat prosi klienta o podanie kwoty wypłaty, zaś klient prosi o wypłatę trzystu dolarów, co jest w tym momencie możliwe. Maszyna wydaje trzysta dolarów i drukuje kwit, klient odbiera pieniądze i kwit.
Załóżmy, że w sesji uczestniczy pięć osób: Amy, koordynator i projektant obiektowo zorientowanego oprogramowania; Barry, główny programista; Charlie, klient; Dorris, ekspert w danej dziedzinie oraz Ed, programista.
Amy trzyma kartę CRC reprezentującą RachunekBieżący i mówi: „Mówię klientowi, ile pieniędzy jest dostępnych. Klient prosi mnie o wypłacenie trzystu dolarów. Wysyłam do dystrybutora polecenie wypłacenia trzystu dolarów w gotówce.” Barry podnosi swoją kartę i mówi: „Jestem dystrybutorem; wydaję trzysta dolarów i wysyłam do Amy komunikat nakazujący jej zmniejszenie stanu rachunku o trzysta dolarów. Komu mam powiedzieć, że maszyna zawiera teraz o trzysta dolarów mniej? Czy też ja to śledzę?” Charlie odpowiada: „Myślę, że
33

potrzebujemy obiektu do śledzenia ilości gotówki w maszynie.” Ed mówi: „Nie, dystrybutor powinien wiedzieć, ile ma gotówki; to należy do jego zadań.” Amy nie zgadza się z tym i mówi: „Nie, ktoś powinien koordynować wydawanie pieniędzy. Dystrybutor musi wiedzieć, czy gotówka jest dostępna i czy klient posiada wystarczającą ilość środków na koncie, powinien wypłacić pieniądze i w odpowiednim momencie zamknąć szufladę. Powinien delegować na kogoś innego odpowiedzialność za śledzenie ilości dostępnej gotówki – na pewien rodzaj wewnętrznego rachunku. osoba, która zna ilość dostępnej gotówki, może także poinformować biuro o tym, że zasoby bankomatu powinny zostać uzupełnione. W przeciwnym razie dystrybutor miałby zbyt wiele zadań.”
Dyskusja trwa dalej. Trzymając karty i współpracując z innymi, odkrywa się wymagania i możliwości delegacji; każda klasa „ożywa” i „odkrywa” swoje odpowiedzialności. Gdy grupa zbytnio zagłębi się w projekt, koordynator może podjąć decyzję o przejściu do następnego zagadnienia.
Ograniczenia kart CRC Choć karty CRC mogą stanowić dobre narzędzie dla rozpoczęcia projektowania, posiadają one duże ograniczenia. Podstawowym problemem jest to, że nie zapewniają dobrego skalowania. W bardzo skomplikowanym projekcie posługiwanie się kartami CRC może być trudne.
Karty CRC nie odzwierciedlają także wzajemnych relacji pomiędzy klasami. Choć można zapisać na nich zakres współpracy, jednak nie da się nimi wymodelować tej współpracy. Patrząc na kartę CRC, nie jesteś w stanie powiedzieć, czy klasa agreguje inną klasę, kto kogo tworzy itd. Karty CRC nie wychwytują także atrybutów, więc trudno jest z nich przejść bezpośrednio do kodu. Karty CRC są statyczne; choć możesz za ich pomocą ustalić interakcje między klasami, same karty CRC nie wychwytują tej informacji.
Karty CRC są dobre na początek, ale jeśli chcesz stworzyć stabilny i kompletny model swojego projektu, powinieneś przedstawić klasy w języku UML. Choć przejście do UML nie jest zbyt trudne, jest jednak operacją jednokierunkową. Gdy przeniesiesz swoje klasy do diagramów UML, nie będzie już odwrotu; nie wrócisz do kart CRC. Po prostu synchronizacji obu modeli jest zbyt trudna.
Przekształcanie kart CRC na UML Każda karta CRC może zostać przekształcona bezpośrednio w klasę wymodelowaną w UML. Odpowiedzialności są przekształcane na metody klasy,
34

ewentualnie dodawane są także wychwycone atrybuty. Definicja klasy z odwrotnej strony karty jest umieszczana w dokumentacji klasy. Rysunek 11.13 przedstawia relację pomiędzy kartą CRC RachunekBieżący, a stworzoną na podstawie tej karty klasą UML.
Rys. 11.13. Karta CRC
Klasa: RachunekBieżący
Superklasa: Rachunek
Odpowiedzialności:
śledzenie stanu bieżącego
przyjmowanie depozytów i transfery na rachunek
wypisywanie czeków
transfery z rachunku
śledzenie dziennego limitu wypłaty gotówki z bankomatu
Współpraca:
inne rachunki
system bankowy
dystrybutor gotówki
35

Relacje pomiędzy klasami Gdy klasy zostaną już przedstawione w UML, możesz zwrócić uwagę na relacje pomiędzy różnymi klasami. Podstawowe modelowane relacje to:
- generalizacja
- powiązania
- agregacja
- kompozycja
Relacja generalizacji jest w C++ implementowana poprzez publiczne dziedziczenie. Pamiętając jednak że najważniejszy jest projekt, nie skupimy się mechanizmie działania relacji, ale na semantyce: co z takiej relacji wynika.
Relacje sprawdziliśmy już w fazie analizy, teraz skupimy się nie tylko na obiektach dziedziny, ale także na obiektach w naszym projekcie. Naszym zadaniem jest określenie „wspólnej funkcjonalności” w powiązanych ze sobą klasach i wydzielenie z nich klas bazowych, obejmujących te wspólne właściwości.
Gdy określisz „wspólną funkcjonalność”, powinieneś przenieść ją z klas specjalizowanych do klasy bardziej ogólnej. Gdy zauważymy, że oba rachunki, bieżący i lokaty, potrzebują metod do transferu pieniędzy do i z rachunku, metodę
przeniesiemy do klasy bazowej TransferŚrodków() Rachunek. Im więcej funkcji przeniesiemy z klas potomnych, tym bardziej polimorficzny stanie się projekt.
Jedną z możliwości dostępnych w C++, lecz niedostępnych w Javie, jest wielokrotne dziedziczenie (Java ma podobną, choć ograniczoną, możliwość posiadania wielu interfejsów). Wielokrotne dziedziczenie pozwala klasie na dziedziczenie po więcej niż jednej klasie bazowej, wprowadzając składowe i metody z dwóch lub więcej klas.
Doświadczenie wykazało, że wielokrotne dziedziczenie powinno być używane rozważnie, gdyż może skomplikować zarówno projekt, jak i implementację. Wiele problemów rozwiązywanych dawniej poprzez wielokrotne dziedziczenie obecnie rozwiązuje się poprzez agregację. Należy jednak pamiętać, że wielokrotne dziedziczenie jest użytecznym narzędziem, zaś projekt może
36

wymagać, by pojedyncza klasa specjalizowała zachowanie dwóch lub więcej innych klas.
Wielokrotne dziedziczenie a zawieranie Czy obiekt jest sumą swoich części? Czy ma sens modelowanie obiektu Samochód jako specjalizacji , i Kierownicy Drzwi Kół, tak jak pokazano na rysunku 11.14?
Rys. 11.14. Fałszywe dziedziczenie
Trzeba powrócić do źródeł: publiczne dziedziczenie powinno zawsze modelować generalizację. Ogólnie przyjętym wyrażeniem tej reguły jest stwierdzenie, że dziedziczenie powinno modelować relację jest czymś. Jeśli chcesz wymodelować relację posiada (na przykład samochód posiada kierownicę), powinieneś użyć agregacji, jak pokazano na rysunku 11.15.
Rys. 11.15. Agregacja
37

Diagram z rysunku 11.15 wskazuje, że samochód posiada kierownicę, cztery koła oraz od dwóch do pięciu drzwi. Jest to właściwy model relacji pomiędzy samochodem a jego elementami. Zwróć uwagę, że romby na rysunku nie są wypełnione; rysujemy je w ten sposób, aby wskazać, że modelujemy agregację, a nie kompozycję. Kompozycja implikuje kontrolę czasu życia obiektu. Choć samochód posiada koła i drzwi, mogą one istnieć jako elementy samochodu, a także jako samodzielne obiekty.
Rysunek 11.16 modeluje kompozycję. Ten model pokazuje, że ciało jest nie tylko agregacją głowy, dwóch rąk i dwóch nóg, ale także, że obiekty te (głowa, ręce, nogi) są tworzone w momencie tworzenia ciała i znikają w chwili, gdy znika ciało. Nie mogą istnieć niezależnie; ciało jest złożone z tych rzeczy, a czas ich istnienia jest powiązany.
Rys. 11.16. Kompozycja
38

Cechy i główne typy Jak zaprojektować klasy potrzebne do zaprezentowania różnych linii modelowych typowego producenta samochodów? Przypuśćmy, że zostałeś wynajęty do zaprojektowania systemu dla Acme Motors, który aktualnie produkuje pięć modeli: Pluto (powolny, kompaktowy samochód z niewielkim silnikiem), Venus (czterodrzwiowy sedan ze średnim silnikiem), Mars (sportowe coupe z największym silnikiem, opracowanym w celu uzyskiwania rekordowych szybkości), Jupiter (minwan z takim samym silnikiem, jak w sportowym coupe, lecz z możliwością zmiany biegów przy niższych obrotach oraz dostosowaniemm do napędzania większej masy) oraz Earth (furgonetka z niewielkim silnikiem o wysokich obrotach).
Możesz zacząć od stworzenia podtypów samochodów, odzwierciedlających różne modele, po czym tworzyć egzemplarze każdego z modelu w miarę ich schodzenia z linii montażowej, tak jak pokazano na rysunku 11.17.
Rys. 11.17. Modelowanie podtypów
Czym różnią się te modele? Typem nadwozia oraz rozmiarem i charakterystykami silnika. Te elementy mogą być łączone i dopasowywane w celu stworzenia różnych modeli. Możemy to wymodelować w UML za pomocą stereotypu cecha, tak jak pokazano na rysunku 11.18.
Rys. 11.18. Modelowanie cech
39

Diagram z rysunku 11.18 wskazuje, że klasy mogą być wyprowadzone z klasy „samochód” dzięki mieszaniu i dopasowaniu trzech atrybutów cech. Rozmiar silnika określa siłę pojazdu, zaś charakterystyka wydajności określa, czy samochód jest pojazdem sportowym, czy rodzinnym. Dzięki temu możemy stworzyć silną, sportową furgonetkę, słaby rodzinny sedan, itd.
Każdy atrybut może być zaimplementowany za pomocą zwykłego wyliczenia. Typ nadwozia można zaimplementować w kodzie za pomocą poniższego wyliczenia:
enum TypNadwozia = { sedan, coupe, minivan, furgonetka };
Może się jednak okazać, że pojedyncza wartość nie wystarcza do wymodelowania określonej cechy. Na przykład, charakterystyka wydajności może być raczej złożona. W takim przypadku cecha może zostać wymodelowana jako klasa, zaś określona cecha obiektu może istnieć jako konkretny egzemplarz tej klasy.
Model samochodu może modelować charakterystykę wydajności, np. typ wydajność, zawierający informacje o tym, w którym momencie silnik zmienia bieg i jak wysokie obroty może osiągnąć. Stereotyp UML dla klasy obejmującej cechę — klasa ta może służyć do tworzenia egzemplarzy klasy (Samochód) należącej logicznie do innego typu (np. i SamochódSportowy SamochódLuksusowy) — to . W tym przypadku, klasa <<typ główny>> Wydajność jest typem głównym dla klasy . Gdy tworzymy egzemplarz klasy Samochód Samochód, jednocześnie tworzymy obiekt , wiążąc go z danym obiektem Wydajność Samochód, jak pokazano na rysunku 11.19.
40

Rys. 11.19. Cecha jako typ główny
Typy główne umożliwiają tworzenie różnorodnych typów logicznych, bez potrzeby używania dziedziczenia. Dzięki temu można obsłużyć duży i złożony zestaw typów, bez gwałtownego wzrostu złożoności klas, jaki mógłby nastąpić przy używaniu samego dziedziczenia.
W C++ typy główne są najczęściej implementowane za pomocą wskaźników. W tym przypadku klasa zawiera wskaźnik do egzemplarza klasy Samochód
CharakterystykaWydajności (patrz rysunek 11.20). Zamianę cech nadwozia i silnika w typy główne pozostawię ambitnym czytelnikom.
Rys. 11.20. Relacja pomiędzy obiektem a jego typem głównym Samochód
41

Class Samochod : public Pojazd { public: Samochod(); ~Samochod(); // inne publiczne metody private: CharakterystykaWydajnosci * pWydajnosc; };
I jeszcze jedna uwaga. Typy główne umożliwiają tworzenie nowych typów (a nie tylko egzemplarzy) w czasie działania programu. Ponieważ typy logiczne różnią się od siebie jedynie atrybutami powiązanego z nim typu głównego, atrybuty te mogą być parametrami konstruktora typu głównego. Oznacza to, że w czasie działania programu możesz na bieżąco tworzyć nowe typy samochodów. Przekazując różne rozmiary silnika i różne punkty zmiany biegów do typu głównego, możesz efektywnie tworzyć nowe charakterystyki wydajności. Przypisując te charakterystyki różnym samochodom, możesz zwiększać zestaw typów samochodów w czasie działania programu.
Model dynamiczny Oprócz modelowania relacji pomiędzy klasami, bardzo ważne jest także wymodelowanie sposobu współpracy pomiędzy klasami. Na przykład, klasy
, oraz mogą współpracować z klasą RachunekBieżący Bankomat Kwit Klient, wypełniając przypadek użycia „Wypłata gotówki.” Wkrótce wrócimy do diagramów sekwencji używanych wcześniej w fazie analizy, ale tym razem, na podstawie metod opracowanych dla klas, wypełnimy je szczegółami, tak jak na rysunku 11.21.
Rys. 11.21. Diagram sekwencji
42

Ten prosty diagram interakcji pokazuje współdziałanie pomiędzy klasami projektowymi oraz ich następstwo w czasie. Sugeruje, że klasa Bankomat deleguje na klasę RachunekBieżący całą odpowiedzialność za zarządzanie stanem rachunku, zaś klasa przenosi na klasę RachunekBieżący Bankomat zadanie wyświetlania informacji dla użytkownika.
Diagramy interakcji występują w dwóch odmianach. Odmiana pokazana na rysunku 11.21 jest nazywana diagramem sekwencji. Diagramy współpracy dostarczają innego widoku tych samych informacji. Diagramy sekwencji kładą nacisk na kolejność zdarzeń, zaś diagramy współpracy obrazują współdziałanie pomiędzy klasami. Diagram współpracy można stworzyć bezpośrednio z diagramu sekwencji; programy takie jak Rational Rose potrafią stworzyć taki diagram po jednym kliknięciu na przycisku (patrz rysunek 11.22).
Rys. 11.22. Diagram współpracy
43

Diagramy zmian stanu Przechodząc do zagadnienia interakcji pomiędzy obiektami, musimy poznać różne możliwe stany każdego z obiektów. Przejścia pomiędzy stanami możemy wymodelować na diagramie stanu (lub diagramie zmian stanów). Rysunek 12.23 przedstawia różne stany obiektu RachunekBieżący w czasie, gdy klient jest zalogowany do systemu.
Rys. 11.23. Stan rachunku klienta
44

Każdy diagram stanu rozpoczyna się od stanu , a kończy na stanie start koniec. Poszczególne stany posiadają nazwy, zaś zmiany stanów mogą być opisane za pomocą etykiet. Strażnik wskazuje warunek, który musi być spełniony, aby obiekt mógł przejść ze stanu do stanu.
Superstany Klient może w każdej chwili zmienić zamiar i zrezygnować z logowania się. Może to uczynić po włożeniu karty w celu zidentyfikowania swojego rachunku lub już po wprowadzeniu kodu PIN. W obu przypadkach system musi zaakceptować jego żądanie anulowania operacji i powrócić do stanu „nie zalogowany” (patrz rysunek 11.24).
Rys. 11.24. Użytkownik może zrezygnować
45

Jak widać, w bardziej skomplikowanych diagramach, stan Anulowany szybko zaczyna przeszkadzać. Jest to szczególnie irytujące, gdyż anulowanie jest stanem wyjątkowym, który nie powinien dominować w diagramie. Możemy uprościć ten diagram, używając superstanu, tak jak pokazano na rysunku 11.25.
Rys. 11.25. Superstan
46
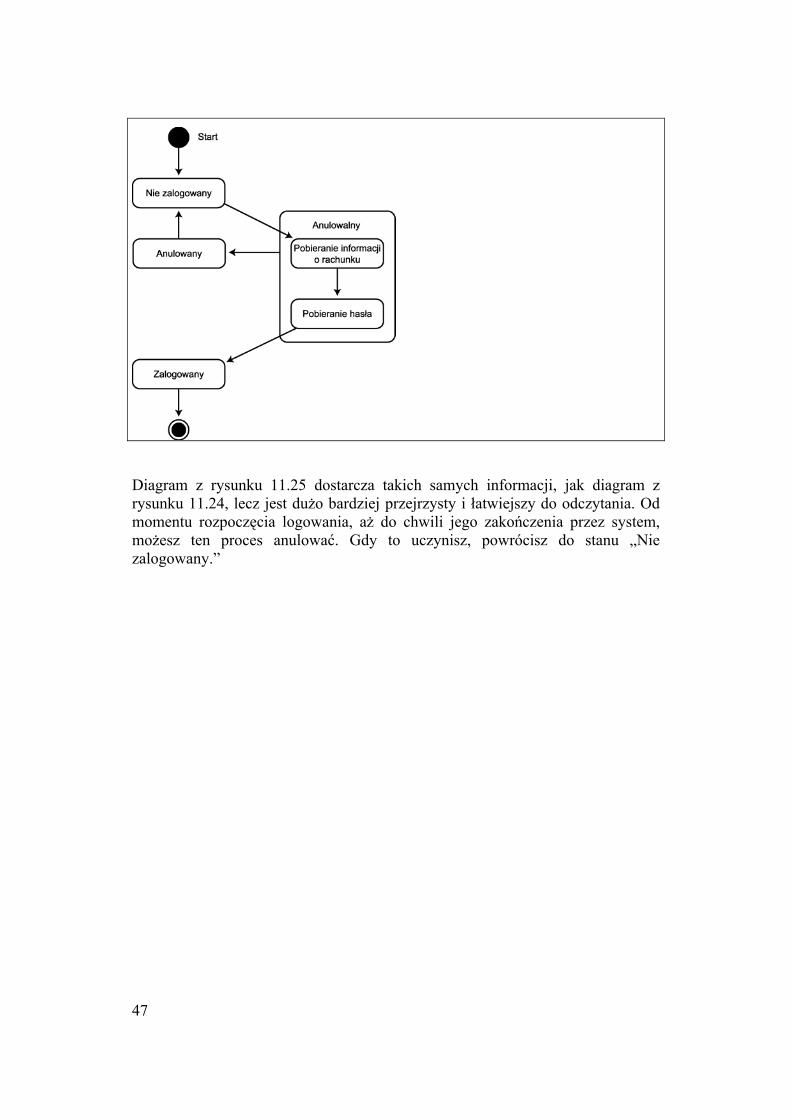
Diagram z rysunku 11.25 dostarcza takich samych informacji, jak diagram z rysunku 11.24, lecz jest dużo bardziej przejrzysty i łatwiejszy do odczytania. Od momentu rozpoczęcia logowania, aż do chwili jego zakończenia przez system, możesz ten proces anulować. Gdy to uczynisz, powrócisz do stanu „Nie zalogowany.”
47

Rozdział 12. Dziedziczenie W poprzednim rozdziale poznałeś wiele relacji związanych z projektowaniem obiektowym, m.in. relację specjalizacji/generalizacji. Język C++ implementuje ją poprzez dziedziczenie.
Z tego rozdziału dowiesz się:
• czym jest dziedziczenie,
• w jaki sposób wyprowadzać klasę z innej klasy,
• czym jest dostęp chroniony i jak z niego korzystać,
• czym są funkcje wirtualne.
Czym jest dziedziczenie? Czym jest pies? Co widzisz, gdy patrzysz na swoje zwierzę? Ja widzę cztery łapy i pysk. Biolodzy widzą sieć interesujących organów, fizycy — atomy i różnorodne siły, zaś taksonom widzi przedstawiciela gatunku canine domesticus.
Skupmy się na tym ostatnim przypadku. Pies jest przedstawicielem psowatych, psowate są przedstawicielami ssaków, i tak dalej. Taksonomowie dzielą świat żywych stworzeń na królestwa, typy, klasy, rzędy, rodziny, rodzaje i gatunki.
Hierarchia specjalizacji/generalizacji ustanawia relację typu jest-czymś. Homo sapiens jest przedstawicielem naczelnych. Taką relację widzimy wszędzie: wóz kempingowy jest rodzajem samochodu, który z kolei jest rodzajem pojazdu. Budyń jest rodzajem deseru, który jest rodzajem pożywienia.
Gdy mówimy, że coś jest rodzajem czegoś innego, zakładamym że stanowi to specjalizację tej rzeczy. Samochód jest zatemspecjalnym rodzajem pojazdu.
Usunięto: zagadnień
Usunięto: włącznie
Usunięto: z
Usunięto: e
Usunięto:
Usunięto: ą
Usunięto: ą i
Usunięto: ą
Usunięto: e
Usunięto: W
Usunięto: ym
Usunięto: le
Usunięto: C
Usunięto: .
Usunięto: W
Usunięto: .
Usunięto: C
Usunięto: chroniony
Usunięto: .
Usunięto: C
Usunięto: na służbie
Usunięto: a
Usunięto: działające
Usunięto: Właśnie ten ostatni przypadek interesuje nas w tym momencie
Usunięto: -
Usunięto: wokół
Usunięto: Tak więc s
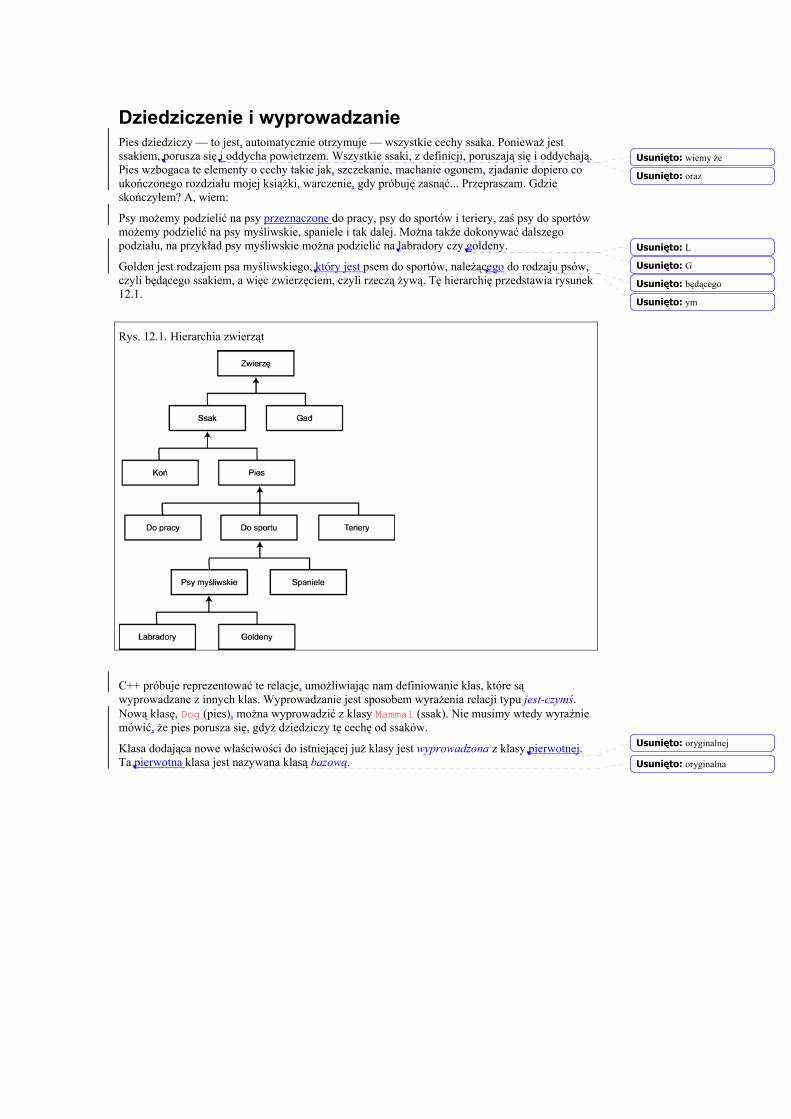
Dziedziczenie i wyprowadzanie Pies dziedziczy — to jest, automatycznie otrzymuje — wszystkie cechy ssaka. Ponieważ jest ssakiem, porusza się i oddycha powietrzem. Wszystkie ssaki, z definicji, poruszają się i oddychają. Pies wzbogaca te elementy o cechy takie jak, szczekanie, machanie ogonem, zjadanie dopiero co ukończonego rozdziału mojej książki, warczenie, gdy próbuję zasnąć... Przepraszam. Gdzie skończyłem? A, wiem:
Psy możemy podzielić na psy przeznaczone do pracy, psy do sportów i teriery, zaś psy do sportów możemy podzielić na psy myśliwskie, spaniele i tak dalej. Można także dokonywać dalszego podziału, na przykład psy myśliwskie można podzielić na labradory czy goldeny.
Golden jest rodzajem psa myśliwskiego, który jest psem do sportów, należącego do rodzaju psów, czyli będącego ssakiem, a więc zwierzęciem, czyli rzeczą żywą. Tę hierarchię przedstawia rysunek 12.1.
Rys. 12.1. Hierarchia zwierząt
C++ próbuje reprezentować te relacje, umożliwiając nam definiowanie klas, które są wyprowadzane z innych klas. Wyprowadzanie jest sposobem wyrażenia relacji typu jest-czymś. Nową klasę, Dog (pies), można wyprowadzić z klasy Mammal (ssak). Nie musimy wtedy wyraźnie mówić, że pies porusza się, gdyż dziedziczy tę cechę od ssaków.
Klasa dodająca nowe właściwości do istniejącej już klasy jest wyprowadzona z klasy pierwotnej. Ta pierwotna klasa jest nazywana klasą bazową.
Usunięto: wiemy że
Usunięto: oraz
Usunięto: L
Usunięto: G
Usunięto: będącego
Usunięto: ym
Usunięto: oryginalnej
Usunięto: oryginalna
Jeśli klasa Dog jest wyprowadzona z klasy Mammal, oznacza to, że klasa Mammal jest klasą bazową (nadrzędną) klasy Dog. Klasy wyprowadzone (pochodne) stanową nadzbiór swoich klas bazowych. Pies przejmuje swoje cechy od ssaków, tak klasa Dog przejmie pewne metody lub dane klasy Mammal.
Zwykle klasa bazowa posiada więcej niż jedną klasę pochodną. Ponieważ zarówno psy, jak i koty oraz konie są ssakami, więc ich zostały były wyprowadzone z klasy Mammal.
Królestwo zwierząt Aby ułatwić przedstawienie procesu dziedziczenia i wyprowadzania, w tym rozdziale skupimy się na związkach pomiędzy różnymi klasami reprezentującymi zwierzęta. Możesz sobie wyobrazić, że bawimy się w dziecięcą grę — symulację farmy.
Opracujemy cały zestaw zwierząt, obejmujący konie, krowy, psy, koty, owce, itd. Stworzymy metody dla tych klas, aby zwierzęta mogły funkcjonować tak, jak oczekiwałoby tego dziecko, ale na razie każdą z tych metod zastąpimy zwykłą instrukcją wydruku.
Minimalizowanie funkcji (czyli pozostawienie tylko jej szkieletu) oznacza, że napiszemy tylko tyle kodu, ile wystarczy do pokazania, że funkcja została wywołana. Szczegóły pozostawimy na później, gdy będziemy mieć więcej czasu. Jeśli tylko masz ochotę, możesz wzbogacić minimalny kod zaprezentowany w tym rozdziale i sprawić, by zwierzęta zachowywały się bardziej realistycznie.
Składnia wyprowadzania Gdy deklarujesz klasę, możesz wskazać klasę, od której pochodzi, zapisując po nazwie tworzonej klasy dwukropek, rodzaj wyprowadzania (publiczny lub inny) oraz klasę bazową. Oto przykład:
class Dog : public Mammal
Rodzaj wyprowadzania opiszemy w dalszej części rozdziału. Na razie będziemy używać wyprowadzania publicznego (oznaczonego słowem kluczowym public). Klasa bazowa musi być zdefiniowana wcześniej, gdyż w przeciwnym razie kompilator zgłosi błąd. Listing 12.1 ilustruje sposób deklarowania klasy Dog, wyprowadzonej z klasy Mammal.
Listing 12.1. Proste dziedziczenie 0: //Listing 12.1 Proste dziedziczenie 1: 2: #include <iostream> 3: using namespace std; 4: 5: enum BREED { GOLDEN, CAIRN, DANDIE, SHETLAND, DOBERMAN, LAB }; 6: 7: class Mammal 8: { 9: public: 10: // konstruktory 11: Mammal(); 12: ~Mammal();
Usunięto: Tak jak p
Usunięto: klasy
Usunięto: Z czasem o
Usunięto: tak
Usunięto: Zastępowanie
Usunięto: Zminimalizowanie
Usunięto: pnia
Usunięto:
Usunięto: aby
Usunięto: ć
Usunięto: ,
Usunięto: pozostawiając s
Usunięto: ,
Usunięto: ając
Usunięto: omówimy
Usunięto: zawsze
Usunięto: wcześniej
Usunięto:

13: 14: //akcesory 15: int GetAge() const; 16: void SetAge(int); 17: int GetWeight() const; 18: void SetWeight(); 19: 20: //inne metody 21: void Speak() const; 22: void Sleep() const; 23: 24: 25: protected: 26: int itsAge; 27: int itsWeight; 28: }; 29: 30: class Dog : public Mammal 31: { 32: public: 33: 34: // konstruktory 35: Dog(); 36: ~Dog(); 37: 38: // akcesory 39: BREED GetBreed() const; 40: void SetBreed(BREED); 41: 42: // inne metody 43: WagTail(); 44: BegForFood(); 45: 46: protected: 47: BREED itsBreed; 48: };
Ten kod nie wyświetla wyników, gdyż zawiera jedynie zestaw deklaracji klas (bez ich implementacji). Mimo to można w nim wiele zobaczyć.
Analiza
W liniach od 7. do 28. deklarowana jest klasa Mammal (ssak). Zwróć uwagę, że w tym przykładzie klasa Mammal nie jest wyprowadzana z żadnej innej klasy. W realnym świecie ssaki pochodzą od (to znaczy, że są rodzajem) zwierząt. W programie C++ możesz zaprezentować jedynie część informacji, które posiadasz na temat danego obiektu. Rzeczywistość jest zdecydowanie zbyt skomplikowana, aby uchwycić ją w całości, więc każda hierarchia w C++ jest umowną reprezentacją dostępnych danych. Sztuka dobrego projektowania polega na reprezentowaniu interesujących nas obszarów tak, aby reprezentowały rzeczywistość w możliwie najlepszy sposób.
Hierarchia musi się gdzieś zaczynać; w tym programie rozpoczyna się od klasy Mammal. Z powodu tego, pewne zmienne składowe, które mogły należeć do wyższej klasy, nie są tu reprezentowane. Wszystkie zwierzęta z pewnością posiadają na przykład wagę i wiek, więc jeśli klasa Mammal byłaby wyprowadzona z klasy Animal (zwierzę), moglibyśmy oczekiwać, że dziedziczy te atrybuty. Jednak w naszym przykładzie atrybuty te występują w klasie Mammal.
Usunięto: jest
Usunięto: do
Usunięto: enia
Usunięto: :
Usunięto: rzeczywistym
Usunięto: wystarczająco dobry
Usunięto: reprezentowały rzeczywistość
Usunięto: j decyzji
Usunięto: atrybuty
Aby zachować niewielką i spójną postać programu, w klasie Mammal zostało umieszczonych jedynie sześć metod — cztery akcesory oraz metody Speak() (mówienie) i Sleep() (spanie).
Klasa Dog (pies) dziedziczy po klasie Mammal, co wskazuje linia 30. Każdy obiekt typu Dog będzie posiadał trzy zmienne składowe: itsAge (wiek), itsWeight (waga) oraz itsBread (rasa). Zwróć uwagę, że deklaracja klasy Dog nie obejmuje zmiennych składowych itsAge oraz itsWeight. Obiekty klasy Dog dziedziczą te zmienne od klasy Mammal, razem z metodami tej klasy (z wyjątkiem operatora kopiującego oraz destruktora i konstruktora).
Prywatne kontra chronione Być może w liniach 25. i 46. listingu 12.1 zauważyłeś nowe słowo kluczowe dostępu, protected (chronione). Wcześniej dane klasy były deklarowane jako prywatne. Jednak prywatne składowe nie są dostępne dla klas pochodnych. Moglibyśmy uczynić zmienne itsAge i itsWeight składowymi publicznymi, ale nie byłoby to pożądane. Nie chcemy, by inne klasy mogły bezpośrednio odwoływać się do tych danych składowych.
UWAGA Istnieje powód, by wszystkie dane składowe klasy oznaczać jako prywatne, a nie jako chronione. Powód ten przedstawił Stroustrup (twórca języka C++) w swojej książce The Design and Evolution of C++, ISBN 0-201-543330-3, Addison Wesley, 1994. Metody chronione nie są jednak uważane za kłopotliwe i mogą być bardzo użyteczne.
Potrzebujemy teraz oznaczenia, które mówi: „Uczyń te zmienne widocznymi dla tej klasy i dla klas z niej wyprowadzonych”. Takim oznaczeniem jest właśnie słowo kluczowe protected — chroniony. Chronione funkcje i dane składowe są w pełni widoczne dla klas pochodnych i nie są dostępne dla innych klas.
Istnieją trzy specyfikatory dostępu: publiczny (public), chroniony (protected) oraz private (prywatny). Jeśli funkcja posiada obiekt twojej klasy, może odwoływać się do wszystkich jej publicznych funkcji i danych składowych. Z kolei funkcje składowe klasy mogą odwoływać się do wszystkich prywatnych funkcji i danych składowych swojej własnej klasy, oraz do wszystkich chronionych funkcji i danych składowych wszystkich klas, z których ich klasa jest wyprowadzona.
Tak więc, funkcja Dog::WagTail() (macha ogonem) może odwoływać się do prywatnej danej itsBreed oraz do prywatnych danych klasy Mammal.
Nawet gdyby pomiędzy klasą Mammal, a klasą Dog występowały inne klasy (na przykład DomesticAnimals — zwierzęta domowe), klasa Dog w dalszym ciągu mogłaby się odwoływać do prywatnych składowych klasy Mammal, zakładając że wszystkie inne klasy używałyby dziedziczenia publicznego. Dziedziczenie prywatne zostanie omówione w rozdziale 16., „Dziedziczenie zaawansowane”.
Listing 12.2 przedstawia sposób tworzenia obiektów typu Dog oraz dostępu do danych i funkcji zawartych w tym typie.
Listing 12.2. Użycie klasy wyprowadzonej 0: //Listing 12.2 Użycie klasy wyprowadzonej 1: 2: #include <iostream>
Usunięto: utrzymać
Usunięto: i
Usunięto: argument
Usunięto: i
Usunięto: gdy
Usunięto: Argument
Usunięto: problematyczne
Usunięto: C
Usunięto: metody
Usunięto: To, czego p
Usunięto: ,
Usunięto: to
Usunięto: e
Usunięto: y
Usunięto: Ogólnie, i
Usunięto: a
Usunięto: jeśli
Usunięto:
Usunięto: by
Usunięto: te
Usunięto: Z
Usunięto: dziedziczenie
Usunięto: do
Usunięto: klasy
Usunięto: klasy¶

3: using std::cout; 4: 5: enum BREED { GOLDEN, CAIRN, DANDIE, SHETLAND, DOBERMAN, LAB }; 6: 7: class Mammal 8: { 9: public: 10: // konstruktory 11: Mammal():itsAge(2), itsWeight(5){} 12: ~Mammal(){} 13: 14: //akcesory 15: int GetAge() const { return itsAge; } 16: void SetAge(int age) { itsAge = age; } 17: int GetWeight() const { return itsWeight; } 18: void SetWeight(int weight) { itsWeight = weight; } 19: 20: //inne metody 21: void Speak()const { cout << "Dzwiek ssaka!\n"; } 22: void Sleep()const { cout << "Ciiiicho. Wlasnie spie.\n"; } 23: 24: 25: protected: 26: int itsAge; 27: int itsWeight; 28: }; 29: 30: class Dog : public Mammal 31: { 32: public: 33: 34: // konstruktory 35: Dog():itsBreed(GOLDEN){} 36: ~Dog(){} 37: 38: // akcesory 39: BREED GetBreed() const { return itsBreed; } 40: void SetBreed(BREED breed) { itsBreed = breed; } 41: 42: // inne metody 43: void WagTail() const { cout << "Macham ogonem...\n"; } 44: void BegForFood() const {cout << "Prosze o jedzenie...\n"; } 45: 46: private: 47: BREED itsBreed; 48: }; 49: 50: int main() 51: { 52: Dog fido; 53: fido.Speak(); 54: fido.WagTail(); 55: cout << "Fido ma " << fido.GetAge() << " lat(a)\n"; 56: return 0; 57: }
Wynik Dzwiek ssaka! Macham ogonem...
Usunięto: :
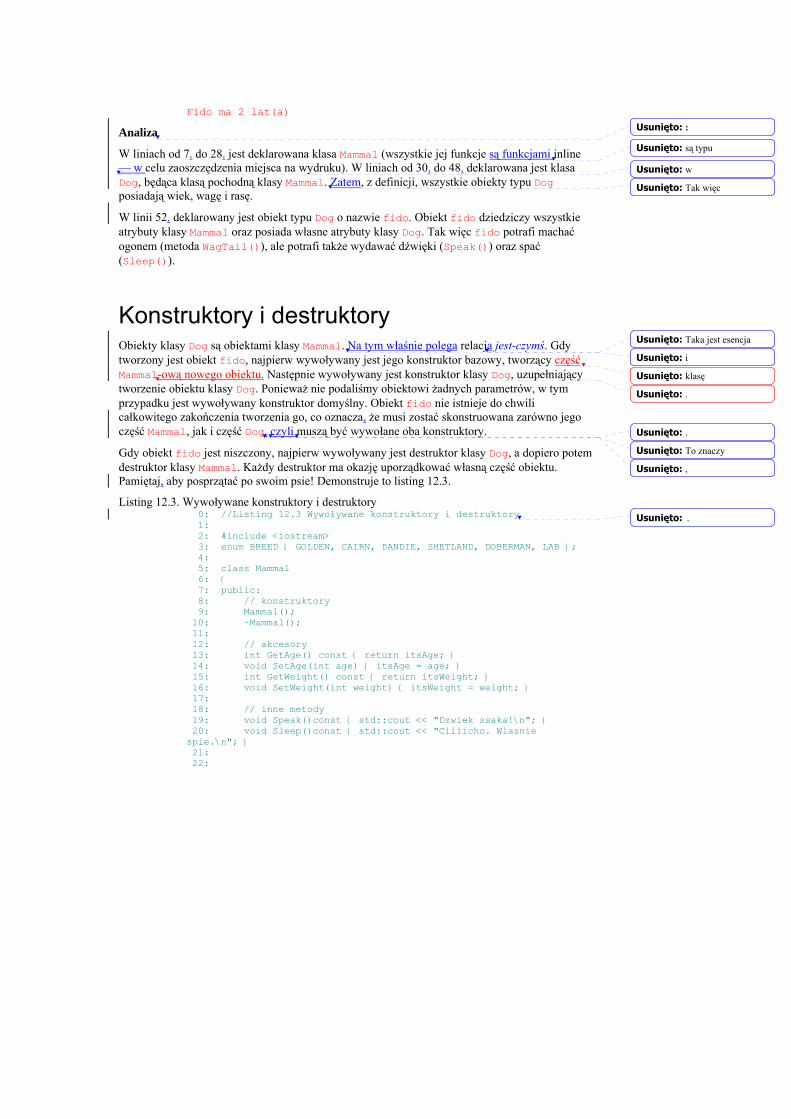
Fido ma 2 lat(a)
Analiza
W liniach od 7. do 28. jest deklarowana klasa Mammal (wszystkie jej funkcje są funkcjami inline — w celu zaoszczędzenia miejsca na wydruku). W liniach od 30. do 48. deklarowana jest klasa Dog, będąca klasą pochodną klasy Mammal. Zatem, z definicji, wszystkie obiekty typu Dog posiadają wiek, wagę i rasę.
W linii 52. deklarowany jest obiekt typu Dog o nazwie fido. Obiekt fido dziedziczy wszystkie atrybuty klasy Mammal oraz posiada własne atrybuty klasy Dog. Tak więc fido potrafi machać ogonem (metoda WagTail()), ale potrafi także wydawać dźwięki (Speak()) oraz spać (Sleep()).
Konstruktory i destruktory Obiekty klasy Dog są obiektami klasy Mammal. Na tym właśnie polega relacja jest-czymś. Gdy tworzony jest obiekt fido, najpierw wywoływany jest jego konstruktor bazowy, tworzący część Mammal-ową nowego obiektu. Następnie wywoływany jest konstruktor klasy Dog, uzupełniający tworzenie obiektu klasy Dog. Ponieważ nie podaliśmy obiektowi żadnych parametrów, w tym przypadku jest wywoływany konstruktor domyślny. Obiekt fido nie istnieje do chwili całkowitego zakończenia tworzenia go, co oznacza, że musi zostać skonstruowana zarówno jego część Mammal, jak i część Dog, czyli muszą być wywołane oba konstruktory.
Gdy obiekt fido jest niszczony, najpierw wywoływany jest destruktor klasy Dog, a dopiero potem destruktor klasy Mammal. Każdy destruktor ma okazję uporządkować własną część obiektu. Pamiętaj, aby posprzątać po swoim psie! Demonstruje to listing 12.3.
Listing 12.3. Wywoływane konstruktory i destruktory 0: //Listing 12.3 Wywoływane konstruktory i destruktory 1: 2: #include <iostream> 3: enum BREED { GOLDEN, CAIRN, DANDIE, SHETLAND, DOBERMAN, LAB }; 4: 5: class Mammal 6: { 7: public: 8: // konstruktory 9: Mammal(); 10: ~Mammal(); 11: 12: // akcesory 13: int GetAge() const { return itsAge; } 14: void SetAge(int age) { itsAge = age; } 15: int GetWeight() const { return itsWeight; } 16: void SetWeight(int weight) { itsWeight = weight; } 17: 18: // inne metody 19: void Speak()const { std::cout << "Dzwiek ssaka!\n"; } 20: void Sleep()const { std::cout << "Ciiiicho. Wlasnie spie.\n"; } 21: 22:
Usunięto: :
Usunięto: są typu
Usunięto: w
Usunięto: Tak więc
Usunięto: Taka jest esencja
Usunięto: i
Usunięto: klasę
Usunięto: .
Usunięto: .
Usunięto: To znaczy
Usunięto: ,
Usunięto: .
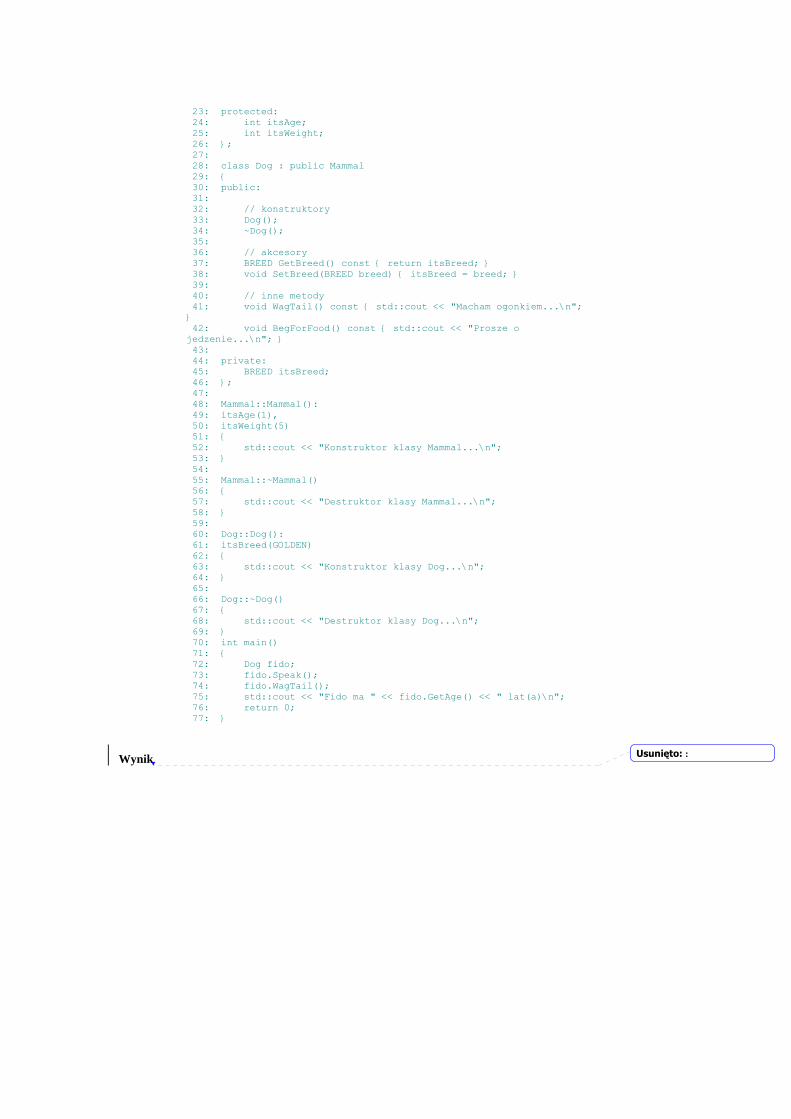
23: protected: 24: int itsAge; 25: int itsWeight; 26: }; 27: 28: class Dog : public Mammal 29: { 30: public: 31: 32: // konstruktory 33: Dog(); 34: ~Dog(); 35: 36: // akcesory 37: BREED GetBreed() const { return itsBreed; } 38: void SetBreed(BREED breed) { itsBreed = breed; } 39: 40: // inne metody 41: void WagTail() const { std::cout << "Macham ogonkiem...\n"; } 42: void BegForFood() const { std::cout << "Prosze o jedzenie...\n"; } 43: 44: private: 45: BREED itsBreed; 46: }; 47: 48: Mammal::Mammal(): 49: itsAge(1), 50: itsWeight(5) 51: { 52: std::cout << "Konstruktor klasy Mammal...\n"; 53: } 54: 55: Mammal::~Mammal() 56: { 57: std::cout << "Destruktor klasy Mammal...\n"; 58: } 59: 60: Dog::Dog(): 61: itsBreed(GOLDEN) 62: { 63: std::cout << "Konstruktor klasy Dog...\n"; 64: } 65: 66: Dog::~Dog() 67: { 68: std::cout << "Destruktor klasy Dog...\n"; 69: } 70: int main() 71: { 72: Dog fido; 73: fido.Speak(); 74: fido.WagTail(); 75: std::cout << "Fido ma " << fido.GetAge() << " lat(a)\n"; 76: return 0; 77: }
Wynik Usunięto: :

Konstruktor klasy Mammal... Konstruktor klasy Dog... Dzwiek ssaka! Macham ogonkiem... Fido ma 1 lat(a) Destruktor klasy Dog... Destruktor klasy Mammal...
Analiza
Listing 12.3 jest podobny do listingu 12.2, z tą różnicą, że konstruktory i destruktory wypisują teraz komunikaty na ekranie. Wywoływany jest najpierw konstruktor klasy Mammal, następnie konstruktor klasy Dog. W tym momencie obiekt klasy Dog już istnieje i można wywoływać jego metody. Gdy fido wychodzi z zakresu, wywoływany jest jego destruktor klasy Dog, a następnie destruktor klasy Mammal.
Przekazywanie argumentów do konstruktorów bazowych Może się zdarzyć, że zechcemy przeciążyć konstruktor klasy Mammal tak, aby przyjmował określony wiek, oraz że zechcemy przeciążyć konstruktor klasy Dog tak, aby przyjmował rasę. W jaki sposób możemy przesłać właściwe parametry wieku i wagi do odpowiedniego konstruktora klasy Mammal? Co zrobić, gdy obiekty klasy Dog chcą inicjalizować swoją wagę, a obiekty klasy Mammal nie?
Inicjalizacja klasy bazowej może być wykonana podczas inicjalizacji klasy pochodnej, przez zapisanie nazwy klasy bazowej, po której następują parametry oczekiwane przez tę klasę. Demonstruje to listing 12.4.
Listing 12.4. Przeciążone konstruktory w wyprowadzonych klasach 0: //Listing 12.4 Przeciążone konstruktory w wyprowadzonych klasach 1: 2: #include <iostream> 3: using namespace std; 4: 5: enum BREED { GOLDEN, CAIRN, DANDIE, SHETLAND, DOBERMAN, LAB }; 6: 7: class Mammal 8: { 9: public: 10: // konstruktory 11: Mammal(); 12: Mammal(int age); 13: ~Mammal(); 14: 15: //akcesory 16: int GetAge() const { return itsAge; } 17: void SetAge(int age) { itsAge = age; } 18: int GetWeight() const { return itsWeight; } 19: void SetWeight(int weight) { itsWeight = weight; } 20: 21: // inne metody 22: void Speak()const { cout << "Dzwiek ssaka!\n"; } 23: void Sleep()const { cout << "Ciiiicho. Wlasnie spie.\n"; } 24:
Usunięto: :
Usunięto: tym
Usunięto: w pełni
Usunięto: Istnieje możliwość

25: 26: protected: 27: int itsAge; 28: int itsWeight; 29: }; 30: 31: class Dog : public Mammal 32: { 33: public: 34: 35: // konstruktory 36: Dog(); 37: Dog(int age); 38: Dog(int age, int weight); 39: Dog(int age, BREED breed); 40: Dog(int age, int weight, BREED breed); 41: ~Dog(); 42: 43: // akcesory 44: BREED GetBreed() const { return itsBreed; } 45: void SetBreed(BREED breed) { itsBreed = breed; } 46: 47: // inne metody 48: void WagTail() const { cout << "Macham ogonem...\n"; } 49: void BegForFood() const { cout << "Prosze o jedzenie...\n"; } 50: 51: private: 52: BREED itsBreed; 53: }; 54: 55: Mammal::Mammal(): 56: itsAge(1), 57: itsWeight(5) 58: { 59: cout << "Konstruktor klasy Mammal...\n"; 60: } 61: 62: Mammal::Mammal(int age): 63: itsAge(age), 64: itsWeight(5) 65: { 66: cout << "Konstruktor klasy Mammal(int)...\n"; 67: } 68: 69: Mammal::~Mammal() 70: { 71: cout << "Destruktor klasy Mammal...\n"; 72: } 73: 74: Dog::Dog(): 75: Mammal(), 76: itsBreed(GOLDEN) 77: { 78: cout << "Konstruktor klasy Dog...\n"; 79: } 80: 81: Dog::Dog(int age): 82: Mammal(age), 83: itsBreed(GOLDEN) 84: {
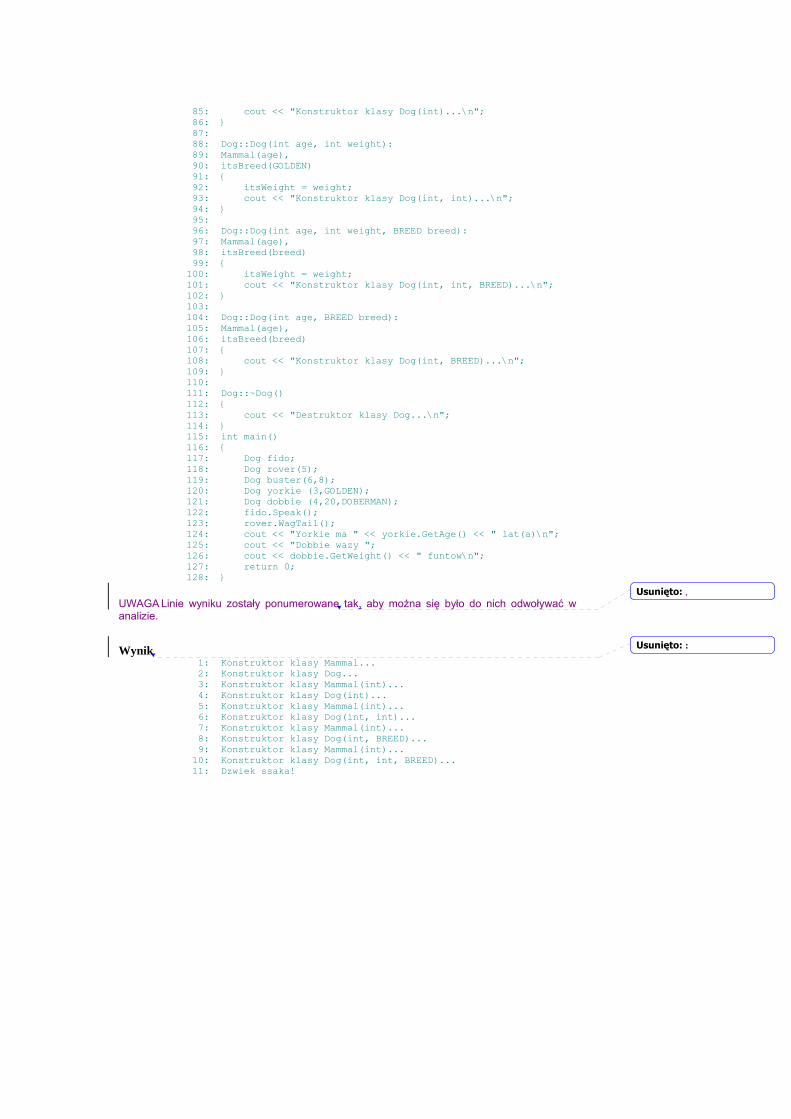
85: cout << "Konstruktor klasy Dog(int)...\n"; 86: } 87: 88: Dog::Dog(int age, int weight): 89: Mammal(age), 90: itsBreed(GOLDEN) 91: { 92: itsWeight = weight; 93: cout << "Konstruktor klasy Dog(int, int)...\n"; 94: } 95: 96: Dog::Dog(int age, int weight, BREED breed): 97: Mammal(age), 98: itsBreed(breed) 99: { 100: itsWeight = weight; 101: cout << "Konstruktor klasy Dog(int, int, BREED)...\n"; 102: } 103: 104: Dog::Dog(int age, BREED breed): 105: Mammal(age), 106: itsBreed(breed) 107: { 108: cout << "Konstruktor klasy Dog(int, BREED)...\n"; 109: } 110: 111: Dog::~Dog() 112: { 113: cout << "Destruktor klasy Dog...\n"; 114: } 115: int main() 116: { 117: Dog fido; 118: Dog rover(5); 119: Dog buster(6,8); 120: Dog yorkie (3,GOLDEN); 121: Dog dobbie (4,20,DOBERMAN); 122: fido.Speak(); 123: rover.WagTail(); 124: cout << "Yorkie ma " << yorkie.GetAge() << " lat(a)\n"; 125: cout << "Dobbie wazy "; 126: cout << dobbie.GetWeight() << " funtow\n"; 127: return 0; 128: }
UWAGA Linie wyniku zostały ponumerowane tak, aby można się było do nich odwoływać w analizie.
Wynik 1: Konstruktor klasy Mammal... 2: Konstruktor klasy Dog... 3: Konstruktor klasy Mammal(int)... 4: Konstruktor klasy Dog(int)... 5: Konstruktor klasy Mammal(int)... 6: Konstruktor klasy Dog(int, int)... 7: Konstruktor klasy Mammal(int)... 8: Konstruktor klasy Dog(int, BREED)... 9: Konstruktor klasy Mammal(int)... 10: Konstruktor klasy Dog(int, int, BREED)... 11: Dzwiek ssaka!
Usunięto: ,
Usunięto: :
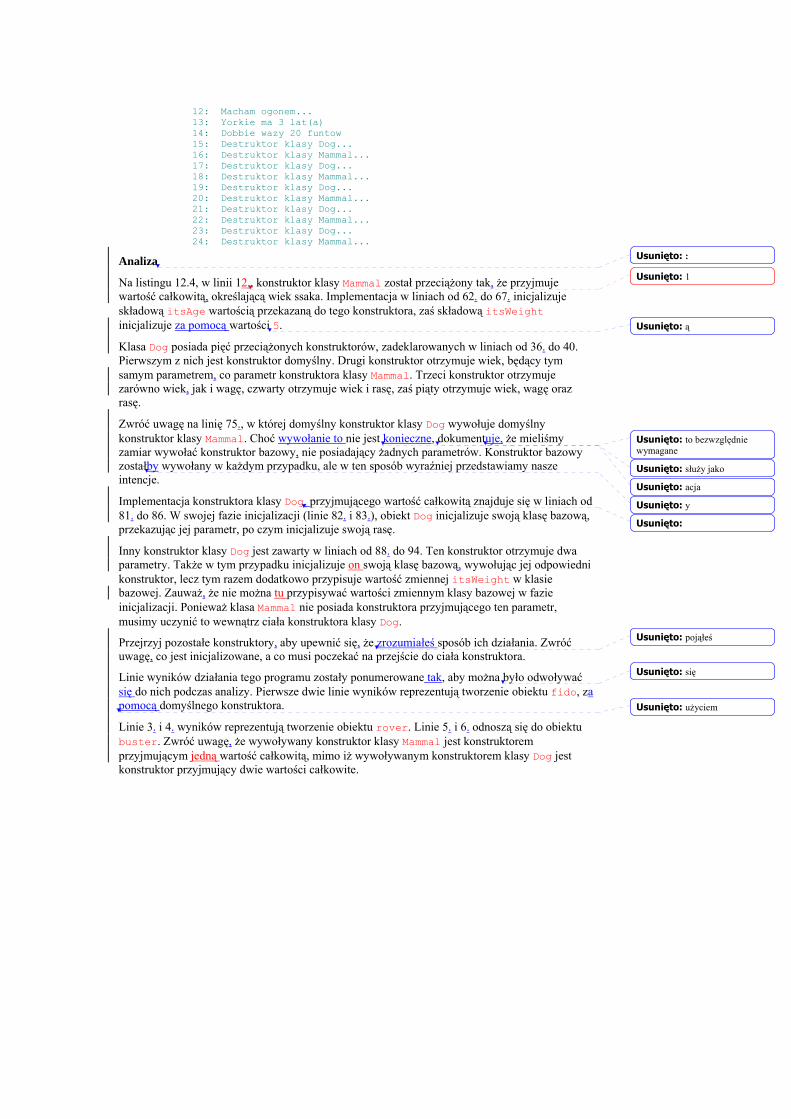
12: Macham ogonem... 13: Yorkie ma 3 lat(a) 14: Dobbie wazy 20 funtow 15: Destruktor klasy Dog... 16: Destruktor klasy Mammal... 17: Destruktor klasy Dog... 18: Destruktor klasy Mammal... 19: Destruktor klasy Dog... 20: Destruktor klasy Mammal... 21: Destruktor klasy Dog... 22: Destruktor klasy Mammal... 23: Destruktor klasy Dog... 24: Destruktor klasy Mammal...
Analiza
Na listingu 12.4, w linii 12., konstruktor klasy Mammal został przeciążony tak, że przyjmuje wartość całkowitą, określającą wiek ssaka. Implementacja w liniach od 62. do 67. inicjalizuje składową itsAge wartością przekazaną do tego konstruktora, zaś składową itsWeight inicjalizuje za pomocą wartości 5.
Klasa Dog posiada pięć przeciążonych konstruktorów, zadeklarowanych w liniach od 36. do 40. Pierwszym z nich jest konstruktor domyślny. Drugi konstruktor otrzymuje wiek, będący tym samym parametrem, co parametr konstruktora klasy Mammal. Trzeci konstruktor otrzymuje zarówno wiek, jak i wagę, czwarty otrzymuje wiek i rasę, zaś piąty otrzymuje wiek, wagę oraz rasę.
Zwróć uwagę na linię 75., w której domyślny konstruktor klasy Dog wywołuje domyślny konstruktor klasy Mammal. Choć wywołanie to nie jest konieczne, dokumentuje, że mieliśmy zamiar wywołać konstruktor bazowy, nie posiadający żadnych parametrów. Konstruktor bazowy zostałby wywołany w każdym przypadku, ale w ten sposób wyraźniej przedstawiamy nasze intencje.
Implementacja konstruktora klasy Dog, przyjmującego wartość całkowitą znajduje się w liniach od 81. do 86. W swojej fazie inicjalizacji (linie 82. i 83.), obiekt Dog inicjalizuje swoją klasę bazową, przekazując jej parametr, po czym inicjalizuje swoją rasę.
Inny konstruktor klasy Dog jest zawarty w liniach od 88. do 94. Ten konstruktor otrzymuje dwa parametry. Także w tym przypadku inicjalizuje on swoją klasę bazową, wywołując jej odpowiedni konstruktor, lecz tym razem dodatkowo przypisuje wartość zmiennej itsWeight w klasie bazowej. Zauważ, że nie można tu przypisywać wartości zmiennym klasy bazowej w fazie inicjalizacji. Ponieważ klasa Mammal nie posiada konstruktora przyjmującego ten parametr, musimy uczynić to wewnątrz ciała konstruktora klasy Dog.
Przejrzyj pozostałe konstruktory, aby upewnić się, że zrozumiałeś sposób ich działania. Zwróć uwagę, co jest inicjalizowane, a co musi poczekać na przejście do ciała konstruktora.
Linie wyników działania tego programu zostały ponumerowane tak, aby można było odwoływać się do nich podczas analizy. Pierwsze dwie linie wyników reprezentują tworzenie obiektu fido, za pomocą domyślnego konstruktora.
Linie 3. i 4. wyników reprezentują tworzenie obiektu rover. Linie 5. i 6. odnoszą się do obiektu buster. Zwróć uwagę, że wywoływany konstruktor klasy Mammal jest konstruktorem przyjmującym jedną wartość całkowitą, mimo iż wywoływanym konstruktorem klasy Dog jest konstruktor przyjmujący dwie wartości całkowite.
Usunięto: :
Usunięto: 1
Usunięto: ą
Usunięto: to bezwzględnie wymagane
Usunięto: służy jako
Usunięto: acja
Usunięto: y
Usunięto:
Usunięto: pojąłeś
Usunięto: się
Usunięto: użyciem
Wszystkie stworzone obiekty są używane w programie, po czym wychodzą poza zakres. Podczas niszczenia każdego obiektu najpierw wywoływany jest destruktor klasy Dog, a następnie destruktor klasy Mammal (łącznie po pięć razy).
Przesłanianie funkcji Obiekt klasy Dog posiada dostęp do wszystkich funkcji składowych klasy Mammal, a także do wszystkich funkcji składowych, na przykład takich jak WagTail(), które mogłyby zostać dodane w deklaracji klasy Dog. Może także przesłaniać funkcje klasy bazowej. Przesłonięcie (ang. override) funkcji oznacza zmianę implementacji funkcji klasy bazowej w klasie z niej wyprowadzonej. Gdy tworzysz obiekt klasy wyprowadzonej, wywoływana jest właściwa funkcja.
Gdy klasa wyprowadzona tworzy funkcję o tym samym zwracanym typie i sygnaturze, co funkcja składowa w klasie bazowej, ale z inną implementacją, mówimy, że funkcja klasy bazowej została przesłonięta.
Gdy przesłaniasz funkcję, jej sygnatura musi się zgadzać z sygnaturą tej funkcji w klasie bazowej. Sygnatura jest innym prototypem funkcji niż typ zwracany; zawiera nazwę, listę parametrów oraz słowo kluczowe const (o ile jest używane). Zwracane typy mogą się od siebie różnić.
Listing 12.5 pokazuje, co się stanie, gdy w klasie Dog przesłonimy metodę Speak() klasy Mammal. Dla zaoszczędzenia miejsca, z tych klas zostały usunięte akcesory.
Listing 12.5. Przesłanianie metod klasy bazowej w klasie potomnej 0: //Listing 12.5 Przesłanianie metod klasy bazowej w klasie potomnej 1: 2: #include <iostream> 3: using std::cout; 4: 5: enum BREED { GOLDEN, CAIRN, DANDIE, SHETLAND, DOBERMAN, LAB }; 6: 7: class Mammal 8: { 9: public: 10: // konstruktory 11: Mammal() { cout << "Konstruktor klasy Mammal...\n"; } 12: ~Mammal() { cout << "Destruktor klasy Mammal...\n"; } 13: 14: // inne metody 15: void Speak()const { cout << "Dzwiek ssaka!\n"; } 16: void Sleep()const { cout << "Ciiiicho. Wlasnie spie.\n"; } 17: 18: 19: protected: 20: int itsAge; 21: int itsWeight; 22: }; 23: 24: class Dog : public Mammal 25: { 26: public: 27: 28: // konstruktory
Usunięto: Po stworzeniu w
Usunięto: ch
Usunięto: zostają
Usunięto: te
Usunięto: i
Usunięto: przez
Usunięto: ę
Usunięto: ta

29: Dog(){ cout << "Konstruktor klasy Dog...\n"; } 30: ~Dog(){ cout << "Destruktor klasy Dog...\n"; } 31: 32: // inne metody 33: void WagTail() const { cout << "Macham ogonkiem...\n"; } 34: void BegForFood() const { cout << "Prosze o jedzenie...\n"; } 35: void Speak() const { cout << "Hau!\n"; } 36: 37: private: 38: BREED itsBreed; 39: }; 40: 41: int main() 42: { 43: Mammal bigAnimal; 44: Dog fido; 45: bigAnimal.Speak(); 46: fido.Speak(); 47: return 0; 48: }
Wynik Konstruktor klasy Mammal... Konstruktor klasy Mammal... Konstruktor klasy Dog... Dzwiek ssaka! Hau! Destruktor klasy Dog... Destruktor klasy Mammal... Destruktor klasy Mammal...
Analiza
W linii 35., klasa Dog przesłania metodę Speak() z klasy Mammal, co powoduje, że obiekty klasy Dog w momencie wywołania tej metody wypisują komunikat Hau!. W linii 43. tworzony jest obiekt klasy Mammal, o nazwie bigAnimal (duże zwierzę), powodując wypisanie pierwszej linii wyników (w efekcie wywołania konstruktora klasy Mammal). W linii 44. tworzony jest obiekt klasy Dog, o nazwie fido, powodując wypisanie dwóch następnych linii wyników (powstających w efekcie wywołania konstruktora klasy Mammal, a następnie konstruktora klasy Dog).
W linii 45. obiekt klasy Mammal wywołuje swoją metodę Speak(), zaś w linii 46. swoją metodę Speak() wywołuje obiekt klasy Dog. Jak widać na wydruku, wywołane zostały odpowiednie metody z obu klas. Na zakończenie, oba obiekty wychodzą z zakresu, więc są wywoływane ich destruktory.
Przesłanianie a przeciążanie
Te określenia są do siebie podobne i odnoszą się do podobnych rzeczy. Gdy przeciążasz metodę, tworzysz kilka funkcji o tej samej nazwie, ale z innymi sygnaturami. Gdy przesłaniasz metodę, tworzysz metodę w klasie wyprowadzonej; posiada ona taką samą nazwę i sygnaturę, jak przesłaniana metoda w klasie bazowej.
Usunięto: w
Usunięto: ie
Usunięto: zostaje
Usunięto: onięta
Usunięto: a
Usunięto: ,
Usunięto: w wyniku
Usunięto: yw
Usunięto: są

Ukrywanie metod klasy bazowej W poprzednim listingu metoda Speak() klasy Dog ukryła metodę klasy bazowej. Właśnie tego wtedy potrzebowaliśmy, ale w innych sytuacjach metoda ta może dawać nieoczekiwane rezultaty. Gdyby klasa Mammal posiadała przeciążoną metodę Move() (ruszaj), zaś klasa Dog przesłoniłaby tę metodę, wtedy metoda klasy Dog ukryłaby w klasie Mammal wszystkie metody o tej nazwie.
Jeśli klasa Mammal posiada trzy przeciążone metody o nazwie Move() — jedną bez parametrów, drugą z parametrem w postaci liczby całkowitej oraz trzecią z parametrem całkowitym i kierunkowym — zaś klasa Dog przesłania jedynie metodę Move() bez parametrów, wtedy dostęp do pozostałych dwóch metod poprzez obiekt klasy Dog nie będzie łatwy. Problem ten ilustruje listing 12.6.
Listing 12.6. Ukrywanie metod 0: //Listing 12.6 Ukrywanie metod 1: 2: #include <iostream> 3: 4: 5: class Mammal 6: { 7: public: 8: void Move() const { std::cout << "Mammal przeszedl jeden krok\n"; } 9: void Move(int distance) const 10: { 11: std::cout << "Mammal przeszedl "; 12: std::cout << distance <<" kroki.\n"; 13: } 14: protected: 15: int itsAge; 16: int itsWeight; 17: }; 18: 19: class Dog : public Mammal 20: { 21: public: 22: // Możesz zauważyć ostrzeżenie, że ukrywasz funkcję! 23: void Move() const { std::cout << "Dog przeszedl 5 krokow.\n"; } 24: }; 25: 26: int main() 27: { 28: Mammal bigAnimal; 29: Dog fido; 30: bigAnimal.Move(); 31: bigAnimal.Move(2); 32: fido.Move(); 33: // fido.Move(10); 34: return 0; 35: }
Wynik Mammal przeszedl jeden krok Mammal przeszedl 2 kroki.
Usunięto: wartości
Usunięto: iem
Usunięto: jest

Dog przeszedl 5 krokow.
Analiza
Z tych klas zostały usunięte wszystkie dodatkowe metody i dane. W liniach 8. i 9. klasa Mammal deklaruje przeciążone metody Move(). W linii 23. klasa Dog przesłania wersję metody Move(), która nie posiada żadnych parametrów. Metody te są wywoływane w liniach od 30. do 32., zaś w wynikach widzimy, że zostały one wykonane.
Linia 33. została jednak wykomentowana, gdyż powoduje powstanie błędu kompilacji. Klasa Dog mogłaby wywoływać metodę Move(int), gdyby nie przesłoniła wersji metody Move() bez parametrów. Ponieważ jednak metoda ta została przesłonięta, konieczne jest przesłonięcie obu wersji. W przeciwnym razie metody, które nie zostały przesłonięte, są ukrywane. Przypomina to regułę, według której w momencie dostarczenia przez nas jakiegokolwiek konstruktora, kompilator nie dostarcza już konstruktora domyślnego.
Oto obowiązująca reguła: Gdy przesłonisz jakąkolwiek z przeciążonych metod, wszystkie inne przeciążenia tej metody zostają ukryte. Jeśli nie chcesz ich ukrywać, musisz przesłonić je wszystkie.
Ukrycie metody klasy bazowej, gdy chcemy ją przesłonić, jest dość częstym błędem; wynika on z tego, że nie zastosowaliśmy słowa kluczowego const. Słowo kluczowe const stanowi część sygnatury i pominięcie go powoduje zmianę sygnatury, a więc ukrycie metody, a nie przesłonięcie jej.
Przesłanianie a ukrywanie
W następnym podrozdziale zajmiemy się metodami wirtualnymi. Przesłonięcie metody wirtualnej umożliwia uzyskanie polimorfizmu, zaś ukrycie jej uniemożliwia polimorfizm. Więcej informacji na ten temat uzyskasz już wkrótce.
Wywoływanie metod klasy bazowej Jeśli przesłoniłeś metodę klasy bazowej, wciąż możesz ją wywoływać, używając pełnej kwalifikowanej nazwy metody. W tym celu zapisuje się nazwę klasy bazowej, dwa dwukropki oraz nazwę metody. Na przykład: Mammal::Move().
Istnieje możliwość przepisania linii 33. z listingu 12.6 tak, aby można ją było skompilować:
33: fido.Mammal::Move(10);
Taka linia wywołuje metodę klasy Mammal w sposób jawny. Proces ten w pełni ilustruje listing 12.7.
Listing 12.7. Wywoływanie metody bazowej z metody przesłoniętej 0: //Listing 12.7 Wywoływanie metody bazowej z metody przesłoniętej 1: 2: #include <iostream> 3: using namespace std;
Usunięto: Choć
Usunięto: k
Usunięto: ,
Usunięto: jednak p
Usunięto: w tym celu

4: 5: class Mammal 6: { 7: public: 8: void Move() const { cout << "Mammal przeszedl jeden krok\n"; } 9: void Move(int distance) const 10: { 11: cout << "Mammal przeszedl " << distance; 12: cout << " kroki.\n"; 13: } 14: 15: protected: 16: int itsAge; 17: int itsWeight; 18: }; 19: 20: class Dog : public Mammal 21: { 22: public: 23: void Move()const; 24: 25: }; 26: 27: void Dog::Move() const 28: { 29: cout << "W metodzie Move klasy dog...\n"; 30: Mammal::Move(3); 31: } 32: 33: int main() 34: { 35: Mammal bigAnimal; 36: Dog fido; 37: bigAnimal.Move(2); 38: fido.Mammal::Move(6); 39: return 0; 40: }
Wynik Mammal przeszedl 2 kroki. Mammal przeszedl 6 kroki.
Analiza
W linii 35. tworzony jest obiekt bigAnimal klasy Mammal, zaś w linii 36. jest tworzony obiekt fido klasy Dog. Metoda wywoływana w linii 37. wykonuje metodę Move() klasy Mammal, przyjmującą pojedynczy argument typu int.
Programista chciał wywołać metodę Move(int) obiektu klasy Dog, ale miał problem. W klasie Dog została przesłonięta metoda Move(), lecz nie została przesłonięta wersja tej metody z parametrem typu int. Rozwiązał ten problem, jawnie wywołując metodę Move(int) klasy bazowej, w linii 38.
TAK NIE

Rozszerzaj funkcjonalność testowanych klas, stosując wyprowadzanie.
Zmieniaj zachowanie określonych funkcji w klasie wyprowadzonej przez przesłanianie metod klasy bazowej.
Nie ukrywaj metod klasy bazowej przez zmianę sygnatury metod w klasie pochodnej.
Metody wirtualne W tym rozdziale sygnalizujemy fakt, iż obiekt klasy Dog jest obiektem klasy Mammal. Jak dotąd oznaczało to jedynie, że obiekt Dog dziedziczy atrybuty (dane) oraz możliwości (metody) swojej klasy bazowej. Jednak w języku C++ relacja jest-czymś sięga nieco głębiej.
C++ rozszerza swój polimorfizm, pozwalając, by wskaźnikom do klas bazowych przypisywane były wskaźniki do obiektów klas pochodnych. Zatem można napisać:
Mammal* pMammal = new Dog;
W ten sposób tworzymy na stercie nowy obiekt klasy Dog, zaś otrzymany do niego wskaźnik przypisujemy wskaźnikowi do obiektów klasy Mammal. Jest to poprawne, gdyż pies (ang. dog) jest ssakiem (ang. mammal).
UWAGA Na tym właśnie polega polimorfizm. Na przykład, możesz stworzyć wiele rodzajów okien, np. okna dialogowe, okna przewijane lub listy, każdemu z nich przydzielając wirtualną metodę draw() (rysuj). Tworząc wskaźnik do okna i przypisując okna dialogowe i inne wyprowadzone typy temu wskaźnikowi, możesz wywoływać metodę draw(); bez względu na bieżący typ obiektu, na który on wskazuje. Za każdym zostanie wywołania właściwa funkcja draw().
Możesz użyć tego wskaźnika do wywołania dowolnej metody klasy Mammal. Z pewnością jednak bardziej spodoba ci się, że zostaną wywołane właściwe metody przesłaniające z klasy Dog. Proces ten umożliwiają funkcje wirtualne. Mechanizm ten ilustruje listing 12.8, pokazuje on także, co się dzieje z metodami, które nie są wirtualne.
Listing 12.8. Używanie metod wirtualnych 0: //Listing 12.8 Używanie metod wirtualnych 1: 2: #include <iostream> 3: using std::cout; 4: 5: class Mammal 6: { 7: public: 8: Mammal():itsAge(1) { cout << "Konstruktor klasy Mammal...\n"; }
Usunięto: onięte metody

9: virtual ~Mammal() { cout << "Destruktor klasy Mammal...\n"; } 10: void Move() const { cout << "Mammal przeszedl jeden krok\n"; } 11: virtual void Speak() const { cout << "Metoda Speak klasy Mammal\n"; } 12: protected: 13: int itsAge; 14: 15: }; 16: 17: class Dog : public Mammal 18: { 19: public: 20: Dog() { cout << "Konstruktor klasy Dog...\n"; } 21: virtual ~Dog() { cout << "Destruktor klasy Dog...\n"; } 22: void WagTail() { cout << "Macham ogonkiem...\n"; } 23: void Speak()const { cout << "Hau!\n"; } 24: void Move()const { cout << "Dog przeszedl 5 krokow...\n"; } 25: }; 26: 27: int main() 28: { 29: 30: Mammal *pDog = new Dog; 31: pDog->Move(); 32: pDog->Speak(); 33: 34: return 0; 35: }
Wynik Konstruktor klasy Mammal... Konstruktor klasy Dog... Mammal przeszedl jeden krok Hau!
Analiza
W linii 11. została zadeklarowana wirtualna metoda klasy Mammal — metoda Speak(). Projektant tej klasy sygnalizuje w ten sposób, że oczekuje, iż ta klasa może być typem bazowym innej klasy. Klasa pochodna najprawdopodobniej zechce przesłonić tę funkcję.
W linii 30. tworzony jest wskaźnik (pDog) do klasy Mammal, lecz jest mu przypisywany adres nowego obiektu klasy Dog. Ponieważ obiekt klasy Dog jest obiektem klasy Mammal, przypisanie to jest poprawne. Następnie wskaźnik ten jest używany do wywołania funkcji Move(). Ponieważ kompilator wie tylko, że pDog jest wskaźnikiem do klasy Mammal, zagląda do obiektu tej klasy w celu znalezienia metody Move().
W linii 32. za pomocą tego wskaźnika zostaje wywołana metoda Speak(). Ponieważ metoda ta jest metodą wirtualną, wywołana zostaje przesłonięta metoda Speak() z klasy Dog.
To prawie magia. Funkcja wywołująca wie tylko, iż posiada wskaźnik do obiektu klasy Mammal, a mimo to zostaje wywołana metoda klasy Dog. W rzeczywistości, gdybyśmy mieli tablicę wskaźników do klasy Mammal, a każdy z nich wskazywałby obiekt klasy wyprowadzonej z tej
Usunięto: przesłonięta w
Usunięto: ie

klasy, moglibyśmy wywoływać je po kolei, a wywoływane funkcje byłyby właściwe. Proces ten ilustruje listing 12.9.
Listing 12.9. Wywoływanie wielu funkcji wirtualnych 0: //Listing 12.9 Wywoływanie wielu funkcji wirtualnych 1: 2: #include <iostream> 3: using namespace std; 4: 5: class Mammal 6: { 7: public: 8: Mammal():itsAge(1) { } 9: virtual ~Mammal() { } 10: virtual void Speak() const { cout << "Ssak mowi!\n"; } 11: protected: 12: int itsAge; 13: }; 14: 15: class Dog : public Mammal 16: { 17: public: 18: void Speak()const { cout << "Hau!\n"; } 19: }; 20: 21: 22: class Cat : public Mammal 23: { 24: public: 25: void Speak()const { cout << "Miau!\n"; } 26: }; 27: 28: 29: class Horse : public Mammal 30: { 31: public: 32: void Speak()const { cout << "Ihaaa!\n"; } 33: }; 34: 35: class Pig : public Mammal 36: { 37: public: 38: void Speak()const { cout << "Kwik!\n"; } 39: }; 40: 41: int main() 42: { 43: Mammal* theArray[5]; 44: Mammal* ptr; 45: int choice, i; 46: for ( i = 0; i<5; i++) 47: { 48: cout << "(1)pies (2)kot (3)kon (4)swinia: "; 49: cin >> choice; 50: switch (choice) 51: { 52: case 1: ptr = new Dog; 53: break; 54: case 2: ptr = new Cat; 55: break; 56: case 3: ptr = new Horse;
Usunięto: j
Usunięto: zostałyby

57: break; 58: case 4: ptr = new Pig; 59: break; 60: default: ptr = new Mammal; 61: break; 62: } 63: theArray[i] = ptr; 64: } 65: for (i=0;i<5;i++) 66: theArray[i]->Speak(); 67: return 0; 68: }
Wynik (1)pies (2)kot (3)kon (4)swinia: 1 (1)pies (2)kot (3)kon (4)swinia: 2 (1)pies (2)kot (3)kon (4)swinia: 3 (1)pies (2)kot (3)kon (4)swinia: 4 (1)pies (2)kot (3)kon (4)swinia: 5 Hau! Miau! Ihaaa! Kwik! Ssak mowi!
Analiza
Ten skrócony program, w którym pozostawiono jedynie najistotniejsze części każdej z klas, przedstawia funkcje wirtualne w ich najczystszej postaci. Zadeklarowane zostały cztery klasy: Dog, Cat, Horse (koń) oraz Pig (świnia), wszystkie wyprowadzone z klasy Mammal.
W linii 10. funkcja Speak() klasy Mammal została zadeklarowana jako metoda wirtualna. Metoda ta zostaje przesłonięta we wszystkich czterech klasach pochodnych, w liniach 18., 25., 32. i 38. Użytkownik jest proszony o wybranie obiektu, który ma zostać stworzony, po czym w liniach od 47. do 64. do tablicy zostają dodane wskaźniki.
UWAGA W czasie kompilacji nie ma możliwości sprawdzenia, które obiekty zostaną stworzone i które wersje metody Speak() zostaną wywołane. Wskaźnik ptr jest przypisywany do obiektu już podczas wykonywania programu. Nazywa się to wiązaniem dynamicznym (dokonywanym podczas działania programu), w przeciwieństwie do wiązania statycznego (dokonywanego podczas kompilacji).
Często zadawane pytanie
Jeśli oznaczę metodę składową jako wirtualną w klasie bazowej, to czy muszę oznaczać ją jako wirtualną także w klasach pochodnych?
Usunięto: 5
Usunięto: y
Usunięto: mają być

Odpowiedź: Nie, jeśli oznaczysz metodę jako wirtualną, a potem przesłonisz ją w klasie pochodnej, pozostanie ona w dalszym ciągu wirtualna. Jednak warto oznaczyć ją jako wirtualną (choć nie jest to konieczne) — dzięki temu kod jest łatwiejszy do zrozumienia.
Jak działają funkcje wirtualne Gdy tworzony jest obiekt klasy pochodnej, na przykład obiekt klasy Dog, najpierw wywoływany jest konstruktor klasy bazowej, a następnie konstruktor klasy pochodnej. Rysunek 12.2 pokazuje, jak wygląda obiekt klasy Dog po utworzeniu go. Zwróć uwagę, że część Mammal obiektu jest w pamięci spójna z częścią Dog.
Rys. 12.2. Obiekt klasy Dog po utworzeniu
Gdy w obiekcie tworzona jest funkcja wirtualna, jest ona śledzona przez ten obiekt. Wiele kompilatorów buduje tablicę funkcji wirtualnych, nazywaną v-table. Dla każdego typu przechowywana jest jedna taka tablica, zaś każdy obiekt tego typu przechowuje do niej wskaźnik (nazywany vptr lub v-pointer).
Choć implementacje różnią się od siebie, wszystkie kompilatory muszą wykonywać te same czynności, dlatego przedstawiony poniżej opis nie będzie odbiegał od rzeczywistości.
Wskaźnik vptr każdego z obiektów wskazuje na tablicę v-table, która z kolei zawiera wskaźniki do każdej z funkcji wirtualnych. (Uwaga: wskaźniki do funkcji zostaną szerzej omówione w rozdziale 15., „Specjalne klasy i funkcje”). Gdy tworzona jest część Mammal klasy Dog, wskaźnik vptr jest inicjalizowany tak, by wskazywał właściwą część tablicy v-table, jak pokazano na rysunku 12.3.
Rys. 12.3. V-table klasy Mammal

Gdy zostaje wywołany konstruktor klasy Dog i dodawana jest część Dog tego obiektu, wskaźnik vptr jest modyfikowany tak, by wskazywał na przesłonięcia funkcji wirtualnych (o ile istnieją) w klasie Dog (patrz rysunek 12.4).
Rys. 12.4. V-table klasy Dog
Gdy używany jest wskaźnik do klasy Mammal, wskaźnik vptr cały czas wskazuje właściwą funkcję, w zależności od „rzeczywistego” typu obiektu. W chwili wywołania metody Speak() wywoływana jest właściwa funkcja.
Nie możesz przejść stąd dotąd Gdyby obiekt klasy Dog miał metodę (na przykład WagTail()), która nie występowałaby w klasie Mammal, w celu odwołania się do tej metody nie mógłbyś użyć wskaźnika do klasy Mammal (chyba że jawnie rzutowałbyś ten wskaźnik do klasy Dog). Ponieważ WagTail() nie jest funkcją wirtualną i ponieważ nie występuje ona w klasie Mammal, nie możesz jej użyć, nie posiadając obiektu klasy Dog lub wskaźnika do klasy Dog.
Choć możesz przekształcić wskaźnik do klasy Mammal we wskaźnik do klasy Dog, istnieją dużo lepsze i bezpieczniejsze sposoby wywołania metody WagTail(). C++ odradza jawne rzutowanie (konwersję) typów, gdyż jest ono podatne na błędy. Ten problem zostanie omówiony przy okazji rozważań na temat wielokrotnego dziedziczenia w rozdziale 15. oraz przy omawianiu szablonów w rozdziale 20., „Wyjątki i obsługa błędów”.
Okrajanie Zwróć uwagę, że funkcje wirtualne działają tylko w przypadku wskaźników i referencji. Przekazanie obiektu przez wartość uniemożliwia wywołanie funkcji wirtualnych. Problem ten ilustruje listing 12.10.
Listing 12.10. Okrajanie (przycięcie) danych podczas przekazywania przez wartość 0: //Listing 12.10 Okrajanie danych podczas przekazywania przez wartość 1: 2: #include <iostream> 3: 4: class Mammal 5: { 6: public:
Usunięto: amt
Usunięto: tu
Usunięto: w

7: Mammal():itsAge(1) { } 8: virtual ~Mammal() { } 9: virtual void Speak() const { std::cout << "Ssak mowi!\n"; } 10: protected: 11: int itsAge; 12: }; 13: 14: class Dog : public Mammal 15: { 16: public: 17: void Speak()const { std::cout << "Hau!\n"; } 18: }; 19: 20: class Cat : public Mammal 21: { 22: public: 23: void Speak()const { std::cout << "Miau!\n"; } 24: }; 25: 26: void ValueFunction (Mammal); 27: void PtrFunction (Mammal*); 28: void RefFunction (Mammal&); 29: int main() 30: { 31: Mammal* ptr=0; 32: int choice; 33: while (1) 34: { 35: bool fQuit = false; 36: std::cout << "(1)pies (2)kot (0)Wyjscie: "; 37: std::cin >> choice; 38: switch (choice) 39: { 40: case 0: fQuit = true; 41: break; 42: case 1: ptr = new Dog; 43: break; 44: case 2: ptr = new Cat; 45: break; 46: default: ptr = new Mammal; 47: break; 48: } 49: if (fQuit) 50: break; 51: PtrFunction(ptr); 52: RefFunction(*ptr); 53: ValueFunction(*ptr); 54: } 55: return 0; 56: } 57: 58: void ValueFunction (Mammal MammalValue) 59: { 60: MammalValue.Speak(); 61: } 62: 63: void PtrFunction (Mammal * pMammal) 64: { 65: pMammal->Speak(); 66: } 67:

68: void RefFunction (Mammal & rMammal) 69: { 70: rMammal.Speak(); 71: }
Wynik (1)pies (2)kot (0)Wyjscie: 1 Hau! Hau! Ssak mowi! (1)pies (2)kot (0)Wyjscie: 2 Miau! Miau! Ssak mowi! (1)pies (2)kot (0)Wyjscie: 0
Analiza
W liniach od 4. do 24. są deklarowane okrojone klasy Mammal, Dog oraz Cat. Deklarowane są trzy funkcje — PtrFunction(), RefFunction() oraz ValueFunction(). Przyjmują one, odpowiednio, wskaźnik do obiektu klasy Mammal, referencję do takiego obiektu oraz sam obiekt Mammal. Wszystkie trzy funkcje robią to samo: wywołują metodę Speak().
Użytkownik jest proszony o wybranie albo Pies albo Kot i, w zależności od tego wyboru, w liniach od 42. do 45. tworzony jest wskaźnik do odpowiedniego typu (Dog lub Cat).
W pierwszej linii wydruku użytkownik wybrał klasę Dog. Obiekt klasy Dog został utworzony na stercie (w linii 42.). Następnie nowo utworzony obiekt jest przekazywany wspomnianym wyżej trzem funkcjom poprzez wskaźnik, referencję i wartość.
Wskaźnik i referencje wywołują funkcje wirtualne, zatem zostaje wywołana funkcja składowa Dog::Speak(). Obrazują to następne dwie linie wydruku (po wyborze dokonanym przez użytkownika).
Wyłuskany wskaźnik jest jednak przekazywany poprzez wartość. Funkcja oczekuje obiektu klasy Mammal, więc kompilator „okraja” obiekt klasy Dog, pozostawiając jedynie część stanowiącą obiekt klasy Mammal. W tym momencie wywoływana jest więc metoda Speak() klasy Mammal, co odzwierciedla trzecia linia wydruku (po wyborze dokonanym przez użytkownika).
Ten eksperyment zostaje następnie powtórzony dla klasy Cat; uzyskaliśmy podobne rezultaty.
Destruktory wirtualne Dozwolone, i dość często stosowane, jest przekazywanie wskaźnika do wyprowadzonego obiektu tam, gdzie oczekiwany jest wskaźnik do klasy bazowej. Co się dzieje, gdy taki wskaźnik do wyprowadzonej klasy zostaje usunięty? Jeśli destruktor jest wirtualny, a taki powinien być, następuje to, co powinno : zostaje wywoływany destruktor klasy wyprowadzonej. Ponieważ destruktor klasy wyprowadzonej automatycznie wywołuje destruktor klasy bazowej, cały obiekt zostanie zniszczony.
Obowiązuje tu następująca zasada: jeśli jakiekolwiek funkcje w klasie są wirtualne, destruktor także powinien być wirtualny.
Usunięto: klasy Dog
Usunięto: lub Cat
Usunięto:
Usunięto: niku
Usunięto: ników
Usunięto: niku
Usunięto: dzieją
Usunięto: się właściwe rzeczy

Wirtualne konstruktory kopiujące Konstruktory nie mogą być wirtualne, więc nie istnieje coś takiego, jak wirtualny konstruktor kopiujący. Zdarza się jednak, że musimy przekazać wskaźnik do obiektu bazowego i otrzymać kopię właściwie utworzonego obiektu klasy wyprowadzonej. Powszechnie stosowanym rozwiązaniem tego problemu jest stworzenie metody o nazwie Clone() (klonuj) w klasie bazowej i uczynienie jej metodą wirtualną. Metoda Clone() tworzy i zwraca nową kopię obiektu bieżącej klasy.
Ponieważ metoda Clone() zostaje przesłonięta w każdej z klas pochodnych, tworzona jest kopia klasy wyprowadzonej. Ilustruje to listing 12.11.
Listing 12.11. Wirtualny konstruktor kopiujący 0: //Listing 12.11 Wirtualny konstruktor kopiujący 1: 2: #include <iostream> 3: using namespace std; 4: 5: class Mammal 6: { 7: public: 8: Mammal():itsAge(1) { cout << "Konstruktor klasy Mammal...\n"; } 9: virtual ~Mammal() { cout << "Destruktor klasy Mammal...\n"; } 10: Mammal (const Mammal & rhs); 11: virtual void Speak() const { cout << "Ssak mowi!\n"; } 12: virtual Mammal* Clone() { return new Mammal(*this); } 13: int GetAge()const { return itsAge; } 14: protected: 15: int itsAge; 16: }; 17: 18: Mammal::Mammal (const Mammal & rhs):itsAge(rhs.GetAge()) 19: { 20: cout << "Konstruktor kopiujacy klasy Mammal...\n"; 21: } 22: 23: class Dog : public Mammal 24: { 25: public: 26: Dog() { cout << "Konstruktor klasy Dog...\n"; } 27: virtual ~Dog() { cout << "Destruktor klasy Dog...\n"; } 28: Dog (const Dog & rhs); 29: void Speak()const { cout << "Hau!\n"; } 30: virtual Mammal* Clone() { return new Dog(*this); } 31: }; 32: 33: Dog::Dog(const Dog & rhs): 34: Mammal(rhs) 35: { 36: cout << "Konstruktor kopiujacy klasy Dog...\n"; 37: } 38: 39: class Cat : public Mammal 40: { 41: public: 42: Cat() { cout << "Konstruktor klasy Cat...\n"; } 43: ~Cat() { cout << "Destruktor klasy Cat...\n"; }
Usunięto: i
Usunięto: y
Usunięto: i
Usunięto: i
Usunięto: i
Usunięto: i
Usunięto: i

44: Cat (const Cat &); 45: void Speak()const { cout << "Miau!\n"; } 46: virtual Mammal* Clone() { return new Cat(*this); } 47: }; 48: 49: Cat::Cat(const Cat & rhs): 50: Mammal(rhs) 51: { 52: cout << "Konstruktor kopiujacy klasy Cat...\n"; 53: } 54: 55: enum ANIMALS { MAMMAL, DOG, CAT}; 56: const int NumAnimalTypes = 3; 57: int main() 58: { 59: Mammal *theArray[NumAnimalTypes]; 60: Mammal* ptr; 61: int choice, i; 62: for ( i = 0; i<NumAnimalTypes; i++) 63: { 64: cout << "(1)dog (2)cat (3)Mammal: "; 65: cin >> choice; 66: switch (choice) 67: { 68: case DOG: ptr = new Dog; 69: break; 70: case CAT: ptr = new Cat; 71: break; 72: default: ptr = new Mammal; 73: break; 74: } 75: theArray[i] = ptr; 76: } 77: Mammal *OtherArray[NumAnimalTypes]; 78: for (i=0;i<NumAnimalTypes;i++) 79: { 80: theArray[i]->Speak(); 81: OtherArray[i] = theArray[i]->Clone(); 82: } 83: for (i=0;i<NumAnimalTypes;i++) 84: OtherArray[i]->Speak(); 85: return 0; 86: }
Wynik 1: (1)dog (2)cat (3)Mammal: 1 2: Konstruktor klasy Mammal... 3: Konstruktor klasy Dog... 4: (1)dog (2)cat (3)Mammal: 2 5: Konstruktor klasy Mammal... 6: Konstruktor klasy Cat... 7: (1)dog (2)cat (3)Mammal: 3 8: Konstruktor klasy Mammal... 9: Hau! 10: Konstruktor kopiujacy klasy Mammal... 11: Konstruktor kopiujacy klasy Dog... 12: Miau! 13: Konstruktor kopiujacy klasy Mammal...
Usunięto: i
Usunięto: i
Usunięto: i
Usunięto: i

14: Konstruktor kopiujacy klasy Cat... 15: Ssak mowi! 16: Konstruktor kopiujacy klasy Mammal... 17: Hau! 18: Miau! 19: Ssak mowi!
Analiza
Listing 12.11 jest bardzo podobny do dwóch poprzednich listingów, z wyjątkiem tego, iż tym razem do klasy Mammal została dodana nowa wirtualna metoda, o nazwie Clone(). Ta metoda zwraca wskaźnik do nowego obiektu klasy Mammal poprzez wywołanie konstruktora kopiującego, przekazując samą siebie (*this) jako stałą (const) referencję.
Metoda Clone() została przeciążona zarówno w klasie Dog, jak i w klasie Cat, w których inicjalizuje dane tych klas i przekazuje kopie samych siebie do swoich własnych konstruktorów kopiujących. Ponieważ metoda Clone() jest wirtualna, w efekcie otrzymujemy wirtualny konstruktor kopiujący, co pokazano w linii 81.
Użytkownik jest proszony o wybranie klasy Dog, Cat lub Mammal, a w liniach od 62. do 74. tworzony jest odpowiedni obiekt. Wskaźnik dla każdego z wyborów jest umieszczany w tablicy w linii 75.
Gdy program „przechodzi” przez kolejne elementy tablicy, wywołuje metodę Speak() i Clone() każdego ze wskazywanych obiektów (w liniach 80. i 81.). Rezultatem wywołania metody Clone() jest wskaźnik do kopii obiektu, który w linii 81 jest przechowywany w drugiej tablicy.
W pierwszej linii wydruku użytkownik wybiera pierwszą opcję, tworząc klasę Dog. Wywoływane są konstruktory klasy Mammal oraz klasy Dog. Czynność tę powtarza się dla klas Cat oraz Mammal w liniach wyników od 4. do 8.
Linia 9. wyników reprezentuje wywołanie metody Speak() pierwszego obiektu, należącego do klasy Dog. Wywoływana jest wirtualna metoda Speak(), zatem zostaje wywołana metoda właściwej klasy. Następnie wywoływana jest metoda Clone(), a ponieważ ona także jest wirtualna, w efekcie zostaje wywołana metoda Clone() klasy Dog. Powoduje to wywołanie konstruktora klasy Mammal oraz konstruktora kopiującego klasy Dog.
Te same czynności powtarza się dla klasy Cat w liniach wyników od 12. do 14., a następnie dla klasy Mammal w liniach 15. i 16. Na zakończenie program „przechodzi” przez drugą tablicę, w której dla każdego z nowych obiektów zostaje wywołana metoda Speak().
Koszt metod wirtualnych Ponieważ obiekty zawierające metody wirtualne muszą przechowywać tablice funkcji wirtualnych (v-table), z posiadaniem metod wirtualnych wiąże się pewne obciążenie. Jeśli posiadasz bardzo małą klasę, z której nie zamierzasz wyprowadzać innych klas, być może nie ma powodu umieszczania w niej jakichkolwiek metod wirtualnych.
Gdy zadeklarujesz którąś z metod jako wirtualną, poniesiesz już większość kosztów posiadania tablicy funkcji wirtualnych (choć każda z kolejnych funkcji wirtualnych także powoduje pewne niewielkie obciążenie pamięci). Powinieneś także posiadać wirtualny destruktor (zakładając także,
Usunięto: i
Usunięto: i
Usunięto: i
Usunięto: i
Usunięto: i
Usunięto: niku
Usunięto: ników
Usunięto: i

że wszystkie inne metody również najprawdopodobniej będą wirtualne). Dokładnie przyjrzyj się każdej z niewirtualnych metod i upewnij się że, czy wiesz, dlaczego nie są one wirtualne.
TAK NIE
Gdy spodziewasz się, że będziesz wyprowadzał nowe klasy z klasy, którą właśnie tworzysz, użyj metod wirtualnych.
Jeśli którakolwiek z metod jest wirtualna, użyj także wirtualnego destruktora.
Nie oznaczaj konstruktora jako funkcji wirtualnej.

Rozdział 13. Tablice i listy połączone W poprzednich rozdziałach deklarowaliśmy pojedyncze obiekty typu int, char, i tym podobne. Często chcemy jednak deklarować zbiory obiektów, takie jak 20 wartości typu int czy kilka obiektów typu CAT.
Z tego rozdziału dowiesz się:
• czym są tablice i jak się je deklaruje,
• czym są łańcuchy i jak je tworzyć za pomocą tablic znaków,
• jaki jest związek pomiędzy tablicami a wskaźnikami,
• w jaki sposób posługiwać się arytmetyką na wskaźnikach odnoszących się do tablic.
Czym jest tablica? Tablica (ang. array) jest zbiorem miejsc przechowywania danych, w którym każde z tych miejsc zawiera dane tego samego typu. Każde miejsce przechowywania jest nazywane elementem tablicy.
Tablicę deklaruje się, zapisując typ, nazwę tablicy oraz jej rozmiar. Rozmiar tablicy jest zapisywany jako ujęta w nawiasy kwadratowe ilość elementów tablicy. Na przykład linia:
long LongArray[25];
deklaruje tablicę składającą się z dwudziestu pięciu wartości typu long, noszącą nazwę LongArray. Gdy kompilator natrafi na tę deklarację, zarezerwuje miejsce do przechowania wszystkich dwudziestu pięciu elementów. Ponieważ każda wartość typu long wymaga czterech bajtów pamięci, ta deklaracja rezerwuje sto bajtów ciągłego obszaru pamięci, tak jak pokazano na rysunku 13.1.
Rys. 13.1. Deklarowanie tablicy

Elementy tablicy Do każdego z elementów tablicy możemy się odwołać, podając przesunięcie (ang. offset) względem nazwy tablicy. Elementy tablicy są liczone od zera. Tak więc pierwszym elementem tablicy jest arrayName[0]. W przykładzie z tablicą LongArray, pierwszym elementem jest LongArray[0], drugim LongArray[1], itd.
Może to być nieco mylące. Tablica SomeArray[3] zawiera trzy elementy. Są to: SomeArray[0], SomeArray[1] oraz SomeArray[2]. Tablica SomeArray[n] zawiera n elementów ponumerowanych od SomeArray[0] do SomeArray[n-1].
Elementy tablicy LongArray[25] są ponumerowane od LongArray[0] do LongArray[24]. Listing 13.1 przedstawia sposób zadeklarowania tablicy pięciu wartości całkowitych i wypełnienia jej wartościami.
Listing 13.1. Użycie tablicy wartości całkowitych 0: //Listing 13.1 - Tablice 1: #include <iostream> 2: 3: int main() 4: { 5: int myArray[5]; 6: int i; 7: for ( i=0; i<5; i++) // 0-4 8: { 9: std::cout << "Wartosc elementu myArray[" << i << "]: "; 10: std::cin >> myArray[i]; 11: } 12: for (i = 0; i<5; i++) 13: std::cout << i << ": " << myArray[i] << "\n"; 14: return 0; 15: }
Wynik Wartosc elementu myArray[0]: 3 Wartosc elementu myArray[1]: 6 Wartosc elementu myArray[2]: 9
Usunięto: u

Wartosc elementu myArray[3]: 12 Wartosc elementu myArray[4]: 15 0: 3 1: 6 2: 9 3: 12 4: 15
Analiza
W linii 5. jest deklarowana tablica o nazwie myArray, zawierająca pięć zmiennych całkowitych. W linii 7. rozpoczyna się pętla zliczająca od 0 do 4, czyli przeznaczona dla wszystkich elementów pięcioelementowej tablicy. Użytkownik jest proszony o podanie kolejnych wartości, które są umieszczane w odpowiednich miejscach tablicy.
Pierwsza wartość jest umieszczana w elemencie myArray[0], druga w elemencie myArray[1] , i tak dalej. Druga pętla, for, służy do wypisania na ekranie wartości kolejnych elementów tablicy.
UWAGA Elementy tablic liczy się od 0, a nie od 1. Z tego powodu początkujący programiści języka C++ często popełniają błędy. Zawsze, gdy korzystasz z tablicy, pamiętaj, że tablica zawierająca 10 elementów jest liczona od ArrayName[0] do ArrayName[9]. Element ArrayName[10] nie jest używany.
Zapisywanie poza koniec tablicy Gdy zapisujesz wartość do elementu tablicy, kompilator na podstawie rozmiaru elementu oraz jego indeksu oblicza miejsce, w którym powinien ją umieścić. Przypuśćmy, że chcesz zapisać wartość do elementu LongArray[5], który jest szóstym elementem tablicy. Kompilator mnoży indeks (5) przez rozmiar elementu, który w tym przypadku wynosi 4. Następnie przemieszcza się od początku tablicy o otrzymaną liczbę bajtów (20) i zapisuje wartość w tym miejscu.
Gdy poprosisz o zapisanie wartości do pięćdziesiątego elementu tablicy LongArray, kompilator zignoruje fakt, iż taki element nie istnieje. Obliczy miejsce wstawienia wartości (200 bajtów od początku tablicy) i zapisze ją w otrzymanym miejscu pamięci. Miejsce to może zawierać praktycznie dowolne dane i zapisanie tam nowej wartości może dać zupełnie nieoczekiwane wyniki. Jeśli masz szczęście, program natychmiast się załamie. Jeśli nie, dziwne wyniki pojawią się dużo później i będziesz miał problem z ustaleniem, co jest ich przyczyną.
Kompilator przypomina ślepca mijającego kolejne domy. Zaczyna od pierwszego domu, MainStreet[0]. Gdy poprosisz go o przejście do szóstego domu na Main Street, mówi sobie: „Muszę minąć jeszcze pięć domów. Każdy dom to cztery duże kroki. Muszę więc przejść jeszcze dwadzieścia kroków. Gdy poprosisz go o przejście do MainStreet[100], mimo iż przy Main Street stoi tylko 25 domów, przejdzie 400 kroków. Z pewnością, zanim przejdzie ten dystans, wpadnie pod ciężarówkę. Uważaj więc, gdzie go wysyłasz.
Listing 13.2 pokazuje, co się dzieje, gdy zapiszesz coś za końcem tablicy.
OSTRZEŻENIE Nie uruchamiaj tego programu, może on załamać system!
Usunięto: poruszającego się

Listing 13.2. Zapis za końcem tablicy 0: //Listing 13.2 1: // Demonstruje, co się stanie, gdy zapiszesz 2: // wartość za końcem tablicy 3: 4: #include <iostream> 5: using namespace std; 6: 7: int main() 8: { 9: // wartownicy 10: long sentinelOne[3]; 11: long TargetArray[25]; // tablica do wypełnienia 12: long sentinelTwo[3]; 13: int i; 14: for (i=0; i<3; i++) 15: sentinelOne[i] = sentinelTwo[i] = 0; 16: 17: for (i=0; i<25; i++) 18: TargetArray[i] = 0; 19: 20: cout << "Test 1: \n"; // sprawdzamy bieżące wartości (powinny być 0) 21: cout << "TargetArray[0]: " << TargetArray[0] << "\n"; 22: cout << "TargetArray[24]: " << TargetArray[24] << "\n\n"; 23: 24: for (i = 0; i<3; i++) 25: { 26: cout << "sentinelOne[" << i << "]: "; 27: cout << sentinelOne[i] << "\n"; 28: cout << "sentinelTwo[" << i << "]: "; 29: cout << sentinelTwo[i]<< "\n"; 30: } 31: 32: cout << "\nPrzypisywanie..."; 33: for (i = 0; i<=25; i++) 34: TargetArray[i] = 20; 35: 36: cout << "\nTest 2: \n"; 37: cout << "TargetArray[0]: " << TargetArray[0] << "\n"; 38: cout << "TargetArray[24]: " << TargetArray[24] << "\n"; 39: cout << "TargetArray[25]: " << TargetArray[25] << "\n\n"; 40: for (i = 0; i<3; i++) 41: { 42: cout << "sentinelOne[" << i << "]: "; 43: cout << sentinelOne[i]<< "\n"; 44: cout << "sentinelTwo[" << i << "]: "; 45: cout << sentinelTwo[i]<< "\n"; 46: } 47: 48: return 0; 49: }
Wynik Test 1: TargetArray[0]: 0 TargetArray[24]: 0 sentinelOne[0]: 0 sentinelTwo[0]: 0

sentinelOne[1]: 0 sentinelTwo[1]: 0 sentinelOne[2]: 0 sentinelTwo[2]: 0 Przypisywanie... Test 2: TargetArray[0]: 20 TargetArray[24]: 20 TargetArray[25]: 20 sentinelOne[0]: 20 sentinelTwo[0]: 0 sentinelOne[1]: 0 sentinelTwo[1]: 0 sentinelOne[2]: 0 sentinelTwo[2]: 0
Analiza
W liniach 10. i 12. deklarowane są dwie tablice, zawierające po trzy zmienne całkowite, które pełnią rolę wartowników (ang. sentinel) wokół docelowej tablicy (TargetArray). Tablice wartowników są wypełniane zerami. Gdy dokonamy zapisu do pamięci poza tablicą TargetArray, najprawdopodobniej zmodyfikujemy zawartość wartowników. Niektóre kompilatory zliczają pamięć do góry, inne w dół. Z tego powodu umieściliśmy wartowników po obu stronach tablicy.
Linie od 20. do 30. potwierdzają wartości wartowników w teście 1. W linii 34. elementy tablicy są wypełniane wartością 20, ale licznik zlicza aż do elementu 25, który nie istnieje w tablicy TargetArray.
Linie od 37. do 39. wypisują wartości elementów tablicy TargetArray w drugim teście. Zwróć uwagę, że element TargetArray[25] wypisuje wartość 20. Jednak gdy wypisujemy wartości wartowników sentinelOne i sentinelTwo, okazuje się, że wartość elementu sentinelOne[0] uległa zmianie. Stało się tak, ponieważ pamięć położona o 25 elementów dalej od elementu TargetArray[0] zajmuje to samo miejsce, co element sentinelOne[0]. Gdy odwołujemy się do nieistniejącego elementu TargetArray[0], w rzeczywistości odwołujemy się do elementu sentinelOne[0].
Taki błąd może być bardzo trudny do wykrycia, gdyż wartość elementu sentinelOne[0] zostaje zmieniona w miejscu programu, które pozornie nie jest związane z zapisem wartości do tej tablicy.
W tym programie użyto „magicznych liczb”, takich jak 3 dla rozmiarów tablic wartowników i 25 dla rozmiaru tablicy TargetArray. Bezpieczniej jednak jest używać stałych tak, aby można było zmieniać te wartości w jednym miejscu.
Pamiętaj, że ponieważ kompilatory różnią się od siebie, otrzymany przez ciebie wynik może być nieco inny.

Błąd słupka w płocie Zapisanie wartości o jedną pozycję za końcem tablicy jest tak często popełnianym błędem, że otrzymał on nawet swoją własną nazwę. Nazywany jest błędem słupka w płocie. Nazwa ta nawiązuje do problemu, jaki wiele osób ma z obliczeniem ilości słupków potrzebnych do utrzymania dziesięciometrowego płotu, z słupkami rozmieszonymi co metr. Większość osób odpowie, że potrzeba dziesięciu słupków, ale oczywiście potrzebnych jest ich jedenaście. Wyjaśnia to rysunek 13.2.
Rys. 13.2. Błąd słupka w płocie
Typ zliczania „o jeden więcej” może być początkowo udręką programisty. Jednak z czasem przywykniesz do tego, że elementy w dwudziestopięcioelementowej tablicy zliczane są tylko do elementu numer dwadzieścia cztery, oraz do tego, że wszystko liczone jest począwszy od zera.
UWAGA Niektórzy programiści określają element ArrayName[0] jako element zerowy. Nie należy się na to zgadzać, gdyż jeśli ArrayName[0] jest elementem zerowym, to czym jest ArrayName[1]? Pierwszym? Jeśli tak, to czy będziesz pamiętał, gdy zobaczysz ArrayName[24], że nie jest to element dwudziesty czwarty, ale dwudziesty piąty? Lepiej jest powiedzieć, że element ArrayName[0] ma zerowy offset i jest pierwszym elementem.
Inicjalizowanie tablic Deklarując po raz pierwszy prostą tablicę wbudowanych typów, takich jak int czy char, możesz ją zainicjalizować. Po nazwie tablicy umieść znak równości (=) oraz ujętą w nawiasy klamrowe listę rozdzielonych przecinkami wartości. Na przykład
int IntegerArray[5] = { 10, 20, 30, 40, 50 };
deklaruje IntegerArray jako tablicę pięciu wartości całkowitych. Przypisuje elementowi IntegerArray[0] wartość 10, elementowi IntegerArray[1] wartość 20, i tak dalej.
Gdy pominiesz rozmiar tablicy, zostanie stworzona tablica na tyle duża, by mogła pomieścić inicjalizujące je elementy. Jeśli napiszesz:
int IntegerArray[] = { 10, 20, 30, 40, 50 };

stworzysz taką samą tablicę, jak w poprzednim przykładzie.
Jeśli chcesz znać rozmiar tablicy, możesz poprosić kompilator, aby go dla ciebie obliczył. Na przykład
const USHORT IntegerArrayLength = sizeof(IntegerArray) / sizeof(IntegerArray[0]);
przypisuje stałej IntegerArrayLength typu USHORT wynik dzielenia rozmiaru całej tablicy przez rozmiar pojedynczego jej elementu. Wynik ten odpowiada ilości elementów w tablicy.
Nie można inicjalizować więcej elementów niż wynosi rozmiar tablicy. Tak więc zapis
int IntegerArray[5] = { 10, 20, 30, 40, 50, 60 };
spowoduje błąd kompilacji, gdyż została zadeklarowana tablica pięcioelementowa, a my próbujemy zainicjalizować sześć elementów. Można natomiast napisać
int IntegerArray = {10, 20};
TAK NIE
Pozwól, by kompilator sam określał rozmiar inicjalizowanych tablic.
Nadawaj tablicom znaczące nazwy, tak jak wszystkim innym zmiennym.
Pamiętaj, że pierwszy element tablicy ma offset (przesunięcie) wynoszący zero.
Nie dokonuj zapisów za końcem tablicy.
Deklarowanie tablic Tablica może mieć dowolną nazwę, zgodną z zasadami nazywania zmiennych, ale nie może mieć takiej samej nazwy jak zmienna lub inna tablica wewnątrz danego zakresu. Dlatego nie można mieć jednocześnie tablicy o nazwie myCats[5] oraz zmiennej myCats.
Rozmiar tablicy można określić, używając stałej lub wyliczenia. Ilustruje to listing 13.3.
Listing 13.3. Użycie stałej i wyliczenia jako rozmiaru tablicy 0: // Listing 13.3 1: // Użycie stałej i wyliczenia jako rozmiaru tablicy 2: 3: #include <iostream> 4: int main()

5: { 6: enum WeekDays { Sun, Mon, Tue, 7: Wed, Thu, Fri, Sat, DaysInWeek }; 8: int ArrayWeek[DaysInWeek] = { 10, 20, 30, 40, 50, 60, 70 }; 9: 10: std::cout << "Wartoscia Wtorku jest: " << ArrayWeek[Tue]; 11: return 0; 12: }
Wynik Wartoscia Wtorku jest: 30
Analiza
Linia 6. tworzy typ wyliczeniowy o nazwie WeekDays (dni tygodnia). Zawiera ono osiem składowych. Stałej Sun (od sunday — niedziela) odpowiada wartość 0, zaś stałej DaysInWeek (dni w tygodniu) odpowiada wartość 7.
W linii 10. wyliczeniowa stała Tue (od tuesday — wtorek) pełni rolę offsetu tablicy. Ponieważ stała Tue odpowiada wartości dwa, w linii 10. zwracany i wypisywany jest trzeci element tablicy, ArrayWeek[2].
Tablice
Aby zadeklarować tablicę, zapisz typ przechowywanego w niej obiektu, nazwę tablicy oraz jej rozmiar, określający ilość obiektów, które powinny być przechowane w tej tablicy.
Przykład 1
int MyIntegerArray[90];
Przykład 2
long * ArrayOfPointersToLong[8];
Aby odwołać się do elementów tablicy, użyj operatora indeksu.
Przykład 1
int theNinethInteger = MyIntegerArray[8];
Przykład 2
long * pLong = ArrayOfPointersToLongs[8];
Usunięto: e

Elementy tablic są liczone od zera. Tablica n elementów zawiera elementy liczone od zera do n–1.
Tablice obiektów W tablicach można przechowywać dowolne obiekty, zarówno wbudowane, jak i te zdefiniowane przez użytkownika. Deklarując tablicę, informujesz kompilator o typie przechowywanych obiektów oraz ilości obiektów, dla jakiej ma zostać zaalokowane miejsce. Kompilator, na podstawie deklaracji klasy, zna ilość miejsca zajmowanego przez każdy z obiektów. Klasa musi posiadać domyślny konstruktor nie posiadający argumentów (aby obiekty mogły zostać stworzone podczas definiowania tablicy).
Na proces dostępu do danych składowych w tablicy obiektów składają się dwa kroki. Właściwy element tablicy jest wskazywany za pomocą operatora indeksu ([]), po czym dodawany jest operator składowej (.), wydzielający określoną zmienną składową obiektu. Listing 13.4 demonstruje sposób tworzenia i wykorzystania tablicy pięciu obiektów typu CAT.
Listing 13.4. Tworzenie tablicy obiektów 0: // Listing 13.4 - Tablica obiektów 1: 2: #include <iostream> 3: using namespace std; 4: 5: class CAT 6: { 7: public: 8: CAT() { itsAge = 1; itsWeight=5; } 9: ~CAT() {} 10: int GetAge() const { return itsAge; } 11: int GetWeight() const { return itsWeight; } 12: void SetAge(int age) { itsAge = age; } 13: 14: private: 15: int itsAge; 16: int itsWeight; 17: }; 18: 19: int main() 20: { 21: CAT Litter[5]; 22: int i; 23: for (i = 0; i < 5; i++) 24: Litter[i].SetAge(2*i +1); 25: 26: for (i = 0; i < 5; i++) 27: { 28: cout << "Kot nr " << i+1<< ": "; 29: cout << Litter[i].GetAge() << endl; 30: } 31: return 0;

32: }
Wynik Kot nr 1: 1 Kot nr 2: 3 Kot nr 3: 5 Kot nr 4: 7 Kot nr 5: 9
Analiza
Linie od 5. do 17. deklarują klasę CAT. Klasa CAT musi posiadać domyślny konstruktor, aby w tablicy mogły być tworzone jej obiekty. Pamiętaj, że jeśli stworzysz jakikolwiek inny konstruktor, domyślny konstruktor nie zostanie dostarczany przez kompilator; będziesz musiał stworzyć go sam.
Pierwsza pętla for (linie 23. i 24.) ustawia wiek dla każdego z pięciu obiektów CAT w tablicy. Druga pętla for (linie od 26. do 30.) odwołuje się do każdego z obiektów i wywołuje jego funkcję składową GetAge().
Metoda GetAge() każdego z poszczególnych obiektów jest wywoływana poprzez określenie elementu tablicy, Litter[i], po którym następuje operator kropki (.) oraz nazwa funkcji składowej.
Tablice wielowymiarowe Tablice mogą mieć więcej niż jeden wymiar. Każdy wymiar jest reprezentowany przez oddzielny indeks tablicy. Na przykład, tablica dwuwymiarowa posiada dwa indeksy; tablica trójwymiarowa posiada trzy indeksy, i tak dalej. Tablice mogą mieć dowolną ilość wymiarów, choć najprawdopodobniej większość tworzonych przez ciebie tablic będzie miała tylko jeden lub dwa wymiary.
Dobrym przykładem tablicy dwuwymiarowej jest szachownica. Jeden wymiar reprezentuje osiem rzędów, zaś drugi wymiar reprezentuje osiem kolumn. Ilustruje to rysunek 13.3.
Rys. 13.3. Szachownica oraz tablica dwuwymiarowa
Przypuśćmy że mamy klasę o nazwie SQUARE (kwadrat). Deklaracja tablicy o nazwie Board (plansza), która ją reprezentuje, mogłaby więc mieć postać:
SQUARE Board[8][8];
Te same dane moglibyśmy przechować w jednowymiarowej, 64-elementowej tablicy. Na przykład:
SQUARE Board[64];
Nie odpowiadałoby to jednak rzeczywistej, dwuwymiarowej planszy. Na początku gry król umieszczany jest na czwartej pozycji w pierwszym rzędzie; tej pozycji odpowiada:
Board[0][3];
przy założeniu, że pierwszy wymiar odnosi się do rzędów, a drugi do kolumn.
Inicjalizowanie tablic wielowymiarowych Tablice wielowymiarowe także mogą być inicjalizowane. Kolejnym elementom tablicy przypisywane są wartości, przy czym zmianie podlegają dane w ostatnim wymiarze tablicy (przy ustaleniu wszystkich poprzednich). Tak więc, gdy mamy tablicę:
int theArray[5][3];
pierwsze trzy elementy trafiają do theArray[0], następne trzy do theArray[1], i tak dalej.
Tablicę tę możemy zainicjalizować, pisząc:
int theArray[5][3] = { 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15 };
W celu uzyskania lepszej przejrzystości, możesz pogrupować wartości, używając nawiasów klamrowych. Na przykład:
int theArray[5][3] = { { 1, 2, 3}, { 4, 5, 6}, { 7, 8, 9}, {10,11,12}, {13,14,15} };
Usunięto: gdy wcześniejsze wymiary pozostają stały,
Usunięto: enia
Usunięto: się

Kompilator ignoruje wewnętrzne nawiasy klamrowe (choć ułatwiają one użytkownikowi zrozumienie sposobu ułożenia wartości).
Każda wartość musi być oddzielona przecinkiem, bez względu na stosowanie nawiasów klamrowych. Cały zestaw inicjalizacyjny musi być ujęty w nawiasy klamrowe i kończyć się średnikiem.
Listing 13.5 tworzy tablicę dwuwymiarową. Pierwszy wymiarem (czyli pierwszą kolumną) jest zestaw liczb od zera do cztery. Drugi wymiar (czyli drugą kolumnę) stanowią liczby o wartościach dwukrotnie większych niż wartości w kolumnie pierwszej.
Listing 13.5. Tworzenie tablicy wielowymiarowej 0: // Listing 13.5 - Tworzenie tablicy wielowymiarowej 1: 2: #include <iostream> 3: using namespace std; 4: 5: int main() 6: { 7: int SomeArray[5][2] = { {0,0}, {1,2}, {2,4}, {3,6}, {4,8}}; 8: for (int i = 0; i<5; i++) 9: for (int j=0; j<2; j++) 10: { 11: cout << "SomeArray[" << i << "][" << j << "]: "; 12: cout << SomeArray[i][j]<< endl; 13: } 14: 15: return 0; 16: }
Wynik SomeArray[0][0]: 0 SomeArray[0][1]: 0 SomeArray[1][0]: 1 SomeArray[1][1]: 2 SomeArray[2][0]: 2 SomeArray[2][1]: 4 SomeArray[3][0]: 3 SomeArray[3][1]: 6 SomeArray[4][0]: 4 SomeArray[4][1]: 8
Analiza
Linia 7. deklaruje SomeArray jako tablicę dwuwymiarową. Pierwszy wymiar składa się z pięciu liczb całkowitych, zaś drugi z dwóch liczb całkowitych. Powstaje więc siatka o rozmiarach 5×2, co ilustruje rysunek 13.4.
Rys. 13.4. Tablica 5 x 2
Usunięto: m
Usunięto: zawiera podwojoną
Usunięto: ć każdej z wartości w pierwszym wymiarze.¶

Wartości są inicjalizowane w parach, choć równie dobrze mogłyby zostać obliczone. Linie 8. i 9. tworzą zagnieżdżoną pętlę for. Pętla zewnętrzna „przechodzi” przez każdy element pierwszego wymiaru. Odpowiednio, dla każdego elementu w tym wymiarze, wewnętrzna pętla przechodzi przez każdy element drugiego wymiaru. Jest to zgodne z wydrukiem. Po elemencie SomeArray[0][0] następuje element SomeArray[0][1]. Pierwszy wymiar jest inkrementowany tylko wtedy, gdy drugi wymiar zostanie wcześniej zwiększony o jeden. Wtedy zaczyna się ponowne zliczanie drugiego wymiaru.
Kilka słów na temat pamięci Gdy deklarujesz tablicę, dokładnie informujesz kompilator o tym, ile obiektów chcesz w niej przechować. Kompilator rezerwuje pamięć dla wszystkich tych obiektów, nawet jeśli nigdy z nich nie skorzystasz. Nie stanowi to problemu w przypadku tych tablic, w których dokładnie znasz ilość potrzebnych ci elementów. Na przykład, szachownica zawiera 64 pola, zaś koty rodzą od jednego do dziesięciu kociąt. Jeśli jednak nie masz pojęcia, ilu obiektów potrzebujesz, musisz skorzystać z bardziej zaawansowanych struktur danych.
W tej książce przedstawimy tablice wskaźników, tablice tworzone na stercie oraz różne inne kolekcje. Poznamy też kilka zaawansowanych struktur danych, jednak więcej informacji na ten temat możesz znaleźć w mojej książce C++ Unleashed, wydanej przez Sams Publishing. Dwie najlepsze rzeczy w programowaniu to możliwość ciągłego uczenia się i to, że zawsze pojawiają się kolejne książki, z których można się uczyć.
Tablice wskaźników W przedstawianych dotąd tablicach wszystkie ich elementy były składowane na stosie. Zwykle pamięć stosu jest dość ograniczona, podczas gdy pamięć na stercie jest dużo bardziej obszerna. Istnieje możliwość zadeklarowania wszystkich obiektów na stercie i przechowania w tablicy tylko wskaźnika do każdego z obiektów. Powoduje to znaczne zmniejszenie ilości pamięci stosu zajmowanej przez tablicę. Listing 13.6 zawiera zmodyfikowaną wersję listingu 13.4, w której wszystkie obiekty przechowywane są na stercie. W celu podkreślenia faktu, że umożliwia ona

lepsze wykorzystanie pamięci, rozmiar tablicy został zwiększony z pięciu do pięciuset elementów, zaś jej nazwa została zmieniona z Litter (miot) na Family (rodzina).
Listing 13.6. Tablica wskaźników do obiektów 0: // Listing 13.6 - Tablica wskaźników do obiektów 1: 2: #include <iostream> 3: using namespace std; 4: 5: class CAT 6: { 7: public: 8: CAT() { itsAge = 1; itsWeight=5; } 9: ~CAT() {} // destruktor 10: int GetAge() const { return itsAge; } 11: int GetWeight() const { return itsWeight; } 12: void SetAge(int age) { itsAge = age; } 13: 14: private: 15: int itsAge; 16: int itsWeight; 17: }; 18: 19: int main() 20: { 21: CAT * Family[500]; 22: int i; 23: CAT * pCat; 24: for (i = 0; i < 500; i++) 25: { 26: pCat = new CAT; 27: pCat->SetAge(2*i +1); 28: Family[i] = pCat; 29: } 30: 31: for (i = 0; i < 500; i++) 32: { 33: cout << "Kot nr " << i+1 << ": "; 34: cout << Family[i]->GetAge() << endl; 35: } 36: return 0; 37: }
Wynik Kot nr 1: 1 Kot nr 2: 3 Kot nr 3: 5 ... Kot nr 499: 997 Kot nr 500: 999
Analiza
Obiekt CAT zadeklarowany w liniach od 5. do 17. jest identyczny z obiektem CAT zadeklarowanym na listingu 13.4. Tym razem jednak tablica zadeklarowana w linii 21. ma nazwę Family i zawiera 500 wskaźników do obiektów typu CAT.
W początkowej pętli for (linie od 24. do 29.) na stercie tworzonych jest pięćset nowych obiektów typu CAT; dla każdego z nich wiek jest ustawiany jako podwojony indeks plus jeden. Tak więc pierwszy CAT ma wiek 1, drugi ma wiek 3, trzeci ma 5, i tak dalej. Na zakończenie, w tablicy umieszczany jest wskaźnik kolejnego stworzonego obiektu.
Ponieważ tablica została zadeklarowana jako zawierająca wskaźniki, dodawany jest do niej wskaźnik — a nie obiekt wyłuskany spod tego wskaźnika.
Druga pętla for (linie od 31. do 35.) wypisuje każdą z wartości. Dostęp do wskaźnika uzyskuje się przez użycie indeksu elementu, Family[i]. Otrzymany adres umożliwia dostęp do metody GetAge().
W tym przykładzie tablica Family i wszystkie zawarte w niej wskaźniki są przechowywane na stosie, ale pięćset stworzonych przedtem obiektów CAT znajduje się na stercie.
Deklarowane tablic na stercie Istnieje możliwość umieszczenia na stercie całej tablicy. W tym celu należy wywołać new z operatorem indeksu. W rezultacie otrzymujemy wskaźnik do obszaru sterty zawierającego nowo utworzoną tablicę. Na przykład:
CAT *Family = new CAT[500];
deklaruje zmienną Family jako wskaźnik do pierwszego elementu w pięciusetelementowej tablicy obiektów typu CAT. Innymi słowy, Family wskazuje na — czyli zawiera adres — element Family[0].
Zaletą użycia zmiennej Family w ten sposób jest to, że możemy na wskaźnikach wykonać działania arytmetyczne odwołując się do elementów tablicy. Na przykład, możemy napisać:
CAT *Family = new CAT[500]; CAT *pCat = Family; // pCat wskazuje na Family[0] pCat->SetAge(10); // ustawia Family[0] na 10 pCat++; // przechodzi do Family[1] pCat->SetAge(20); // ustawia Family[1] na 20
Deklarujemy tu nową tablicę pięciuset obiektów typu CAT oraz wskaźnik wskazujący początek tej tablicy. Używając tego wskaźnika, wywołujemy funkcję SetAge() pierwszego obiektu, przekazując jej wartość 10. Następnie wskaźnik jest inkrementowany i automatycznie wskazuje następny obiekt w tablicy, po czym wywoływana jest metoda SetAge()następnego obiektu.
Usunięto: z

Wskaźnik do tablicy a tablica wskaźników Przyjrzyjmy się trzem poniższym deklaracjom:
1: CAT FamilyOne[500]; 2: CAT * FamilyTwo[500]; 3: CAT * FamilyThree = new CAT[500];
FamilyOne jest tablicą pięciuset obiektów typu CAT. FamilyTwo jest tablicą pięciuset wskaźników do obiektów typu CAT. FamilyThree jest wskaźnikiem do tablicy pięciuset obiektów typu CAT.
Różnice pomiędzy tymi trzema liniami kodu zasadniczo wpływają na działanie tych tablic. Jeszcze bardziej dziwi fakt, iż FamilyThree jest po prostu wariantem deklaracji FamilyOne (i bardzo się różni od FamilyTwo).
Mamy tu do czynienia ze złożonym zagadnieniem powiązań tablic ze wskaźnikami. W trzecim przypadku, FamilyThree jest wskaźnikiem do tablicy, czyli adres w zmiennej FamilyThree jest adresem pierwszego elementu w tej tablicy, co dokładnie odpowiada przypadkowi ze zmienną FamilyOne.
Wskaźniki a nazwy tablic W C++ nazwa tablicy jest stałym wskaźnikiem do pierwszego elementu tablicy. Tak więc, w deklaracji
CAT Family[50];
Family jest wskaźnikiem do &Family[0], które jest adresem pierwszego elementu w tablicy Family.
Używanie nazw tablic jako stałych wskaźników (i odwrotnie) jest dozwolone. Tak więc Family + 4 jest poprawnym sposobem odwołania się do danych w elemencie Family[4].
Podczas dodawania, inkrementowania lub dekrementowania wskaźników wszystkie działania arytmetyczne wykonuje kompilator. Adres, do którego odwołujemy się, pisząc Family + 4, nie jest adresem położonym o cztery bajty od adresu wskazywanego przez Family, lecz adresem położonym o cztery obiekty dalej. Gdyby każdy z obiektów zajmował cztery bajty, wtedy Family + 4 odnosiłoby się do miejsca położonego o szesnaście bajtów za początkiem tablicy. Gdyby każdy obiekt typu CAT zawierał cztery składowe typu long, zajmujące po cztery bajty każda, oraz dwie składowe typu short, po dwa bajty każda, wtedy każdy obiekt tego typu zajmowałby dwadzieścia bajtów, zaś Family + 4 odnosiłoby się do adresu położonego o osiemdziesiąt bajtów od początku tablicy.
Deklarowanie i wykorzystanie tablicy zadeklarowanej na stercie ilustruje listing 13.7.

Listing 13.7. Tworzenie tablicy za pomocą operatora new 0: // Listing 13.7 - Tablica utworzona na stercie 1: 2: #include <iostream> 3: 4: class CAT 5: { 6: public: 7: CAT() { itsAge = 1; itsWeight=5; } 8: ~CAT(); 9: int GetAge() const { return itsAge; } 10: int GetWeight() const { return itsWeight; } 11: void SetAge(int age) { itsAge = age; } 12: 13: private: 14: int itsAge; 15: int itsWeight; 16: }; 17: 18: CAT :: ~CAT() 19: { 20: // cout << "Wywolano destruktor!\n"; 21: } 22: 23: int main() 24: { 25: CAT * Family = new CAT[500]; 26: int i; 27: 28: for (i = 0; i < 500; i++) 29: { 30: Family[i].SetAge(2*i +1); 31: } 32: 33: for (i = 0; i < 500; i++) 34: { 35: std::cout << "Kot nr " << i+1 << ": "; 36: std::cout << Family[i].GetAge() << std::endl; 37: } 38: 39: delete [] Family; 40: 41: return 0; 42: }
Wynik Kot nr 1: 1 Kot nr 2: 3 Kot nr 3: 5 ... Kot nr 499: 997 Kot nr 500: 999
Analiza
Linia 25. deklaruje tablicę Family zawierającą pięćset obiektów typu CAT. Cała tablica jest tworzona na stercie, za pomocą wywołania new CAT[500].

Usuwanie tablic ze sterty Co się stanie z pamięcią zaalokowaną dla tych obiektów CAT, gdy tablica zostanie zniszczona? Czy istnieje możliwość wycieku pamięci? Usunięcie tablicy Family automatycznie zwróci całą pamięć przydzieloną tablicy wtedy, gdy użyjesz operatora delete[], pamiętając o nawiasach kwadratowych. Kompilator potrafi wtedy zniszczyć każdy z obiektów w tablicy i odpowiednio zwolnić pamięć sterty.
Aby to sprawdzić, zmień rozmiar tablicy z 500 na 10 w liniach 25., 28. oraz 36. Następnie usuń znak komentarza przy instrukcji cout w linii 20. Gdy program „dojedzie” do linii 39., w której tablica jest niszczona, zostanie wywołany destruktor każdego z obiektów CAT.
Gdy tworzysz element na stercie za pomocą operatora new, zawsze powinieneś usuwać go i zwalniać jego pamięć za pomocą operatora delete. Gdy tworzysz tablicę, używając operatora new <klasa>[rozmiar], do usunięcia tej tablicy i zwolnienia jej pamięci powinieneś użyć operatora delete[]. Nawiasy kwadratowe sygnalizują kompilatorowi, że chodzi o usunięcie tablicy.
Gdy pominiesz nawiasy kwadratowe, zostanie usunięty tylko pierwszy element w tablicy. Możesz to sprawdzić sam, usuwając nawiasy kwadratowe w linii 39. Jeśli zmodyfikowałeś linię 20. tak, by destruktor wypisywał komunikat, powinieneś zobaczyć na ekranie, że niszczony jest tylko jeden obiekt CAT. Gratulacje! Właśnie stworzyłeś wyciek pamięci!
TAK NIE
Pamiętaj, że tablica n elementów zawiera elementy liczone od zera do n–1.
W przypadku wskaźników wskazujących tablice, używaj indeksowania tablic.
Nie dokonuj zapisów ani odczytów poza końcem tablicy.
Nie myl tablicy wskaźników ze wskaźnikiem do tablicy.
Tablice znaków Łańcuch w języku C jest tablicą znaków, zakończoną znakiem null. Jedyne łańcuchy w stylu C, z jakimi mieliśmy dotąd do czynienia, to nienazwane stałe łańcuchowe, używane w instrukcjach cout, takie jak:
cout << "hello world.\n";
Łańcuchy w stylu C możesz deklarować i inicjalizować tak samo, jak wszystkie inne tablice. Na przykład:
char Greeting[] =

{ 'H', 'e', 'l', 'l', 'o', ' ', 'W', 'o', 'r', 'l', 'd', '\0' };
Ostatni znak, '\0', jest znakiem null, który jest rozpoznawany przez wiele funkcji C++ jako znak kończący łańcuch w stylu C. Choć inicjalizowanie „znak po znaku” przynosi efekty, jest jednak dość żmudne i daje wiele okazji do błędów. C++ pozwala więc na używanie dla poprzedniej deklaracji formy skrótowej:
char Greeting[] = "Hello World";
Powinieneś zwrócić uwagę na dwa elementy w tej konstrukcji:
• zamiast pojedynczych znaków ujętych w apostrofy, oddzielonych przecinkami i ujętych w nawiasy klamrowe, wpisuje się ujęty w cudzysłowy łańcuch w stylu C, bez przecinków i bez nawiasów klamrowych,
• nie ma potrzeby dołączania znaku null, gdyż kompilator dołącza go automatycznie.
Łańcuch Hello World, przechowywany w stylu C, ma dwanaście znaków. Słowo Hello zajmuje pięć bajtów, spacja jeden bajt, słowo World pięć bajtów, zaś kończący znak null zajmuje jeden bajt.
Możesz także tworzyć nie zainicjalizowane tablice znaków. Tak jak w przypadku wszystkich tablic, należy upewnić się, czy w buforze nie zostanie umieszczone więcej znaków, niż jest miejsca.
Listing 13.8 demonstruje użycie nie zainicjalizowanego bufora.
Listing 13.8. Wypełnianie tablicy 0: //Listing 13.8 bufory znakowe 1: 2: #include <iostream> 3: 4: int main() 5: { 6: char buffer[80]; 7: std::cout << "Wpisz lancuch: "; 8: std::cin >> buffer; 9: std::cout << "Oto zawartosc bufora: " << buffer << std::endl; 10: return 0; 11: }
Wynik Wpisz lancuch: Hello World Oto zawartosc bufora: Hello
Analiza
W linii 6. deklarowany jest bufor, mogący pomieścić osiemdziesiąt znaków. Wystarcza to do przechowania 79–znakowego łańcucha w stylu C oraz kończącego znaku null.

W linii 7. użytkownik jest proszony o wpisanie łańcucha w stylu C, który w linii 8. jest wprowadzany do bufora. Obiekt cin automatycznie dopisuje do łańcucha w buforze znak kończący null.
W przypadku programu z listingu 13.8 pojawiają się dwa problemy. Po pierwsze, jeśli użytkownik wpisze więcej niż 79 znaków, cin dokona zapisu poza końcem bufora. Po drugie, gdy użytkownik wpisze spację, cin potraktuje ją jako koniec łańcucha i przestanie zapisywać resztę znaków do bufora.
Aby rozwiązać te problemy, musisz wywołać specjalną metodę obiektu cin: metodę get(). Metoda cin.get() posiada trzy parametry:
• bufor do wypełnienia,
• maksymalną ilość znaków do pobrania,
• znak kończący wprowadzany łańcuch.
Domyślnym znakiem kończącym jest znak nowej linii. Użycie tej metody ilustruje listing 13.9.
Listing 13.9. Wypełnianie tablicy 0: //Listing 13.9 użycie cin.get() 1: 2: #include <iostream> 3: using namespace std; 4: 5: int main() 6: { 7: char buffer[80]; 8: cout << "Wpisz lancuch: "; 9: cin.get(buffer, 79); // pobiera do 79 znaków lub do znaku nowej linii 10: cout << "Oto zawartosc bufora: " << buffer << endl; 11: return 0; 12: }
Wynik Wpisz lancuch: Hello World Oto zawartosc bufora: Hello World
Analiza
Linia 9. wywołuje metodę get() obiektu cin. Bufor zadeklarowany w linii 7. jest przekazywany jako jej pierwszy argument. Drugim argumentem jest maksymalna ilość znaków do pobrania, w tym przypadku musi nią być 79 (tak, aby bufor mógł pomieścić także kończący znak null). Nie ma potrzeby podawania także znaku kończącego wpis, gdyż robi to wartość domyślna dla przejścia do nowej linii.
strcpy() oraz strncpy() C++ odziedziczyło od języka C bibliotekę funkcji operujących na łańcuchach w stylu C. Wśród wielu funkcji tego typu znajdziemy dwie funkcje służące do kopiowania jednego łańcucha do drugiego: strcpy() oraz strncpy(). Funkcja strcpy() kopiuje całą zawartość jednego łańcucha do wskazanego bufora. Jej użycie ilustruje listing 13.10.
Usunięto: jest
Usunięto: dodawania
Usunięto: wystarczy
Usunięto: ej

Listing 13.10. Użycie strcpy() 0: //Listing 13.10 Użycie strcpy() 1: 2: #include <iostream> 3: #include <string.h> 4: using namespace std; 5: 6: int main() 7: { 8: char String1[] = "Zaden czlowiek nie jest samoistna wyspa"; 9: char String2[80]; 10: 11: strcpy(String2,String1); 12: 13: cout << "String1: " << String1 << endl; 14: cout << "String2: " << String2 << endl; 15: return 0; 16: }
Wynik String1: Zaden czlowiek nie jest samoistna wyspa String2: Zaden czlowiek nie jest samoistna wyspa
Analiza
W linii 3. jest dołączany plik nagłówkowy string.h. Ten plik zawiera prototyp funkcji strcpy(). Funkcja otrzymuje dwie tablice znaków — docelową oraz źródłową. Gdyby tablica źródłowa była większa niż tablica docelowa, funkcja strcpy() dokonałaby zapisu poza koniec bufora.
Aby nas przed tym zabezpieczyć, biblioteka standardowa zawiera także funkcję strncpy(). Ta wersja funkcji posiada dodatkowy argument, określający maksymalną ilość znaków do skopiowania. Funkcja strncpy() kopiuje znaki, aż do napotkania pierwszego znaku null albo do osiągnięcia dozwolonej maksymalnej ilości znaków.
Listing 13.11 ilustruje użycie funkcji strncpy().
Listing 13.11. Użycie funkcji strncpy() 0: //Listing 13.11 Użycie strncpy() 1: 2: #include <iostream> 3: #include <string.h> 4: 5: int main() 6: { 7: const int MaxLength = 80; 8: char String1[] = "Zaden czlowiek nie jest samoistna wyspa"; 9: char String2[MaxLength+1]; 10: 11: 12: strncpy(String2,String1,MaxLength); 13: 14: std::cout << "String1: " << String1 << std::endl; 15: std::cout << "String2: " << String2 << std::endl; 16: return 0; 17: }

Wynik String1: Zaden czlowiek nie jest samoistna wyspa String2: Zaden czlowiek nie jest samoistna wyspa
Analiza
W linii 12. wywołanie funkcji strcpy() zostało zmienione na wywołanie funkcji strncpy(). Funkcja ta posiada także trzeci parametr, określający maksymalną ilość znaków do skopiowania. Bufor String2 ma długość MaxLength+1 (maksymalna długość + 1) znaków. Dodatkowy znak jest przeznaczony do przechowania znaku null, który jest automatycznie umieszczany na końcu łańcucha — zarówno przez funkcję strcpy(), jak i strncpy().
Klasy łańcuchów C++ przejęło z języka C zakończone znakiem null łańcuchy oraz bibliotekę funkcji, zawierającą także funkcję strcpy(), ale funkcje tej biblioteki nie są zintegrowane z bibliotekami zorientowanymi obiektowo. Biblioteka standardowa zawiera klasę String, obejmującą zestaw danych i funkcji przeznaczonych do manipulowania łańcuchami, oraz zestaw akcesorów, dzięki którym same dane są ukryte przed klientami tej klasy.
W ramach ćwiczenia potwierdzającego właściwe zrozumienie omawianych zagadnień, spróbujemy teraz stworzyć własną klasę String. Nasza klasa String powinna likwidować podstawowe ograniczenia tablic znaków. Podobnie jak wszystkie tablice, tablice znaków są statyczne. Sami definiujemy, jaki mają rozmiar. Tablice te zawsze zajmują określoną ilość pamięci, bez względu na to, czy jest to naprawdę potrzebne. Z kolei dokonanie zapisu za końcem tablicy może mieć katastrofalne skutki.
UWAGA Przedstawiona tu klasa String jest bardzo ograniczona i w żadnym przypadku nie może być uważana za nadającą się do poważnych zastosowań. Wystarczy jednak na potrzeby naszego ćwiczenia, gdyż biblioteka standardowa zawiera pełną i stabilną klasę String.
Dobra klasa String alokuje tylko tyle pamięci, ile potrzebuje (aby zawsze wystarczało na przechowanie tego, co powinna zawierać). Jeśli nie może zaalokować wystarczającej ilości pamięci, powinna poprawnie to zgłosić.
Pierwszą próbę utworzenia naszej klasy String przedstawia listing 13.12.
Listing 13.12. Użycie klasy String 0: //Listing 13.12 Użycie klasy String 1: 2: #include <iostream> 3: #include <string.h> 4: using namespace std; 5: 6: // zasadnicza klasa łańcucha 7: class String 8: { 9: public: 10: // konstruktory

11: String(); 12: String(const char *const); 13: String(const String &); 14: ~String(); 15: 16: // przeciążone operatory 17: char & operator[](unsigned short offset); 18: char operator[](unsigned short offset) const; 19: String operator+(const String&); 20: void operator+=(const String&); 21: String & operator= (const String &); 22: 23: // ogólne akcesory 24: unsigned short GetLen()const { return itsLen; } 25: const char * GetString() const { return itsString; } 26: 27: private: 28: String (unsigned short); // prywatny konstruktor 29: char * itsString; 30: unsigned short itsLen; 31: }; 32: 33: // domyślny konstruktor tworzy łańcuch o długości zera bajtów 34: String::String() 35: { 36: itsString = new char[1]; 37: itsString[0] = '\0'; 38: itsLen=0; 39: } 40: 41: // prywatny (pomocniczy) konstruktor, używany tylko przez 42: // metody klasy, do tworzenia nowego łańcucha o 43: // wymaganym rozmiarze, wypełnionym bajtami zerowymi 44: String::String(unsigned short len) 45: { 46: itsString = new char[len+1]; 47: for (unsigned short i = 0; i<=len; i++) 48: itsString[i] = '\0'; 49: itsLen=len; 50: } 51: 52: // zamienia tablicę znaków na String 53: String::String(const char * const cString) 54: { 55: itsLen = strlen(cString); 56: itsString = new char[itsLen+1]; 57: for (unsigned short i = 0; i<itsLen; i++) 58: itsString[i] = cString[i]; 59: itsString[itsLen]='\0'; 60: } 61: 62: // konstruktor kopiujący 63: String::String (const String & rhs) 64: { 65: itsLen=rhs.GetLen(); 66: itsString = new char[itsLen+1]; 67: for (unsigned short i = 0; i<itsLen;i++) 68: itsString[i] = rhs[i]; 69: itsString[itsLen] = '\0'; 70: } 71:
Usunięto: i

72: // destruktor, zwalnia zaalokowaną pamięć 73: String::~String () 74: { 75: delete [] itsString; 76: itsLen = 0; 77: } 78: 79: // operator równości, zwalnia istniejącą pamięć, 80: // po czym kopiuje łańcuch i rozmiar 81: String& String::operator=(const String & rhs) 82: { 83: if (this == &rhs) 84: return *this; 85: delete [] itsString; 86: itsLen=rhs.GetLen(); 87: itsString = new char[itsLen+1]; 88: for (unsigned short i = 0; i<itsLen;i++) 89: itsString[i] = rhs[i]; 90: itsString[itsLen] = '\0'; 91: return *this; 92: } 93: 94: // nie stały operator indeksu, zwraca 95: // referencję do znaku, dzięki czemu może on 96: // być zmieniony! 97: char & String::operator[](unsigned short offset) 98: { 99: if (offset > itsLen) 100: return itsString[itsLen-1]; 101: else 102: return itsString[offset]; 103: } 104: 105: // stały operator offsetu do użycia dla 106: // stałych obiektów (patrz konstruktor kopiujący!) 107: char String::operator[](unsigned short offset) const 108: { 109: if (offset > itsLen) 110: return itsString[itsLen-1]; 111: else 112: return itsString[offset]; 113: } 114: 115: // tworzy nowy łańcuch przez dodanie bieżącego 116: // łańcucha do rhs 117: String String::operator+(const String& rhs) 118: { 119: unsigned short totalLen = itsLen + rhs.GetLen(); 120: String temp(totalLen); 121: unsigned short i; 122: for ( i= 0; i<itsLen; i++) 123: temp[i] = itsString[i]; 124: for (unsigned short j = 0; j<rhs.GetLen(); j++, i++) 125: temp[i] = rhs[j]; 126: temp[totalLen]='\0'; 127: return temp; 128: } 129: 130: // zmienia bieżący łańcuch, nic nie zwraca 131: void String::operator+=(const String& rhs) 132: {
Usunięto: indeksu dla
Usunięto: i

133: unsigned short rhsLen = rhs.GetLen(); 134: unsigned short totalLen = itsLen + rhsLen; 135: String temp(totalLen); 136: unsigned short i; 137: for (i = 0; i<itsLen; i++) 138: temp[i] = itsString[i]; 139: for (unsigned short j = 0; j<rhs.GetLen(); j++, i++) 140: temp[i] = rhs[i-itsLen]; 141: temp[totalLen]='\0'; 142: *this = temp; 143: } 144: 145: int main() 146: { 147: String s1("poczatkowy test"); 148: cout << "S1:\t" << s1.GetString() << endl; 149: 150: char * temp = "Hello World"; 151: s1 = temp; 152: cout << "S1:\t" << s1.GetString() << endl; 153: 154: char tempTwo[20]; 155: strcpy(tempTwo,"; milo tu byc!"); 156: s1 += tempTwo; 157: cout << "tempTwo:\t" << tempTwo << endl; 158: cout << "S1:\t" << s1.GetString() << endl; 159: 160: cout << "S1[4]:\t" << s1[4] << endl; 161: s1[4]='x'; 162: cout << "S1:\t" << s1.GetString() << endl; 163: 164: cout << "S1[999]:\t" << s1[999] << endl; 165: 166: String s2(" Inny lancuch"); 167: String s3; 168: s3 = s1+s2; 169: cout << "S3:\t" << s3.GetString() << endl; 170: 171: String s4; 172: s4 = "Dlaczego to dziala?"; 173: cout << "S4:\t" << s4.GetString() << endl; 174: return 0; 175: }
Wynik S1: poczatkowy test S1: Hello World tempTwo: ; milo tu byc! S1: Hello World; milo tu byc! S1[4]: o S1: Hellx World; milo tu byc! S1[999]: ! S3: Hellx World; milo tu byc! Inny lancuch S4: Dlaczego to dziala?
Analiza

Linie od 7. do 31. zawierają deklarację prostej klasy String. Linie od 11. do 13. zawierają trzy konstruktory: konstruktor domyślny, konstruktor kopiujący oraz konstruktor otrzymujący istniejący łańcuch, zakończony znakiem null (w stylu C).
Klasa String przeciąża operator indeksu ([]), operator plus (+) oraz operator plus-równa się (+=). Operator indeksu jest przeciążony dwukrotnie: raz jako funkcja const zwracająca znak; drugi raz jako funkcja nie const zwracająca referencję do znaku. Wersja nie const jest używana w wyrażeniach takich, jak:
SomeString[4] = 'x';
tak, jak widać w linii 161. Dzięki temu mamy bezpośredni dostęp do każdego znaku w łańcuchu. Zwracana jest referencja do znaku, dzięki czemu funkcja wywołująca może nim manipulować.
Wersja const jest używana w przypadkach, gdy następuje odwołanie do stałego obiektu typu String, na przykład w implementacji konstruktora kopiującego (linia 63.). Zauważ, że następuje odwołanie do rhs[i]; jednakże rhs jest zadeklarowane jako const String &. Dostęp do tego obiektu za pomocą funkcji składowej, nie będącej funkcją const, jest zabroniony. Dlatego operator indeksu musi być przeciążony za pomocą akcesora const.
Jeśli zwracane obiekty byłyby bardzo duże, mógłbyś zechcieć zadeklarować zwracaną wartość jako referencję const. Jednak ponieważ znak zajmuje tylko jeden bajt, nie ma takiej potrzeby.
Domyślny konstruktor jest zaimplementowany w liniach od 33. do 39. Tworzy on łańcuch, którego długość wynosi zero znaków. Zgodnie z konwencją, klasa String zwraca długość łańcucha bez końcowego znaku null. Tworzony łańcuch domyślny zawiera więc jedynie końcowy znak null.
Konstruktor kopiujący został zaimplementowany w liniach od 63. do 70. Ustawia on długość nowego łańcucha zgodnie z długością łańcucha istniejącego, plus jeden bajt dla końcowego znaku null. Kopiuje każdy znak z istniejącego łańcucha do nowego łańcucha, po czym kończy nowy łańcuch znakiem null.
W liniach od 53. do 60. znajduje się implementacja konstruktora otrzymującego istniejący łańcuch w stylu C. Ten konstruktor jest podobny do konstruktora kopiującego. Długość istniejącego łańcucha wyznaczana jest w wyniku wywołania standardowej funkcji bibliotecznej strlen().
W linii 28. został zadeklarowany jeszcze jeden konstruktor, String(unsigned short), stanowiący prywatną funkcję składową. Odpowiada on zamierzeniom projektanta, zgodnie z którymi, żaden z klientów klasy nigdy nie powinien tworzyć łańcuchów typu String o określonej długości. Ten konstruktor istnieje tylko po to, by pomóc przy wewnętrznym tworzeniu egzemplarzy łańcuchów, na przykład w funkcji operator+= w linii 130. Opiszemy to dokładniej przy okazji omawiania działania funkcji operator+=.
Konstruktor String(unsigned short) wypełnia każdy element swojej tablicy wartością NULL. Dlatego w pętli dokonujemy sprawdzenia i <= len, a nie i < len.
Destruktor, zaimplementowany w liniach od 73. do 77., usuwa łańcuch znaków przechowywany przez klasę. Musimy pamiętać o użyciu nawiasów kwadratowych w wywołaniu operatora delete (aby usunięte zostały wszystkie elementy tablicy, a nie tylko pierwszy).
Usunięto: i
Usunięto: zieliśmy
Usunięto: i
Usunięto: ,
Usunięto: choć
Usunięto: i
Usunięto: i
Operator przypisania najpierw sprawdza, czy prawa strona przypisania jest taka sama, jak lewa strona. Jeśli tak nie jest, bieżący łańcuch jest usuwany, po czym w jego miejsce tworzony jest i kopiowany nowy łańcuch. W celu umożliwienia przypisań w rodzaju:
String1 = String2 = String3;
zwracana jest referencja. Operator indeksu jest przeciążany dwukrotnie. W obu przypadkach przeprowadzane jest podstawowe sprawdzanie zakresów. Jeśli użytkownik próbuje odwołać się do znaku położonego poza końcem tablicy, zwracany jest ostatni znak (znajdujący się na pozycji len-1).
Linie od 117. do 127. implementują operator plus (+) jako operator konkatenacji (łączenia łańcuchów). Dzięki temu możemy napisać:
String3 = String1 + String2;
przypisując łańcuchowi String3 połączenie dwóch pozostałych łańcuchów. W tym celu funkcja operatora plus oblicza połączoną długość obu łańcuchów i tworzy tymczasowy łańcuch temp. To powoduje wywołanie prywatnego konstruktora, który otrzymuje wartość całkowitą i tworzy łańcuch wypełniony znakami null. Następnie znaki null są zastępowane przez zawartość obu łańcuchów. Łańcuch po lewej stronie (*this) jest kopiowany jako pierwszy; łańcuch po prawej stronie (rhs) kopiowany jest później.
Pierwsza pętla for przechodzi przez łańcuch po lewej stronie i przenosi każdy jego znak do nowego łańcucha. Druga pętla for przetwarza łańcuch po prawej stronie. Zauważ, że zmienna i cały czas wskazuje miejsce w łańcuchu docelowym, nawet wtedy, gdy zmienna j zlicza znaki łańcucha rhs.
Operator plus zwraca łańcuch tymczasowy poprzez wartość, która jest przypisywana łańcuchowi po lewej stronie przypisania (string1). Operator += działa na istniejącym łańcuchu — tj. na łańcuchu po lewej stronie instrukcji string1 += string2. Działa on tak samo, jak operator plus, z tym, że wartość tymczasowa jest przypisywana do bieżącego łańcucha (*this = temp w linii 142.).
Funkcja main() (w liniach od 145. do 175.) służy jako program testujący tę klasę. Linia 147. tworzy obiekt String za pomocą konstruktora, otrzymującego łańcuch w stylu C zakończony znakiem null. Linia 148. wypisuje jego zawartość za pomocą funkcji akcesora GetString(). Linia 150. tworzy kolejny łańcuch w stylu C. Linia 151. sprawdza operator przypisania, zaś linia 152. wypisuje wyniki.
Linia 154. tworzy trzeci łańcuch w stylu C, tempTwo. Linia 155. wywołuje funkcję strcpy() (w celu wypełnienia bufora znakami ; milo tu byc!). Linia 156. wywołuje operator += i dołącza tempTwo do istniejącego łańcucha s1. Linia 158. wypisuje wyniki.
W linii 160. odczytywany jest i wypisywany piąty znak łańcucha s1. W linii 161. jest mu przypisywana nowa wartość. Powoduje to wywołanie operatora indeksu (operatora [] w wersji
Usunięto: znak
Usunięto: ;

nie const). Linia 162. wypisuje wynik, który pokazuje, że wartość znaku rzeczywiście uległa zmianie.
Linia 164. próbuje odwołać się do znaku za końcem tablicy. Ostatni znak w tablicy jest zwracany, zgodnie z projektem klasy.
Linie 166. i 167. tworzą kolejne dwa obiekty String, zaś linia 168. wywołuje operator dodawania. Wynik jest wypisywany w linii 169.
Linia 171. tworzy nowy obiekt String o nazwie s4. Linia 172. wywołuje operator przypisania. Linia 173. wypisuje wyniki. Być może zastanawiasz się: „Skoro operator przypisania jest zdefiniowany w linii 21. jako otrzymujący stałą referencję do obiektu String, to dlaczego w tym miejscu program przekazuje łańcuch w stylu C. Jak to możliwe?”
A oto odpowiedź na to pytanie: kompilator oczekuje obiektu String, lecz otrzymuje tablicę znaków. W związku z tym sprawdza, czy może stworzyć obiekt String z tego, co otrzymał. W linii 12. zadeklarowaliśmy konstruktor, który tworzy obiekt String z tablicy znaków. Kompilator tworzy tymczasowy obiekt String z tablicy znaków i przekazuje go do operatora przypisania. Proces ten nazywa się rzutowaniem niejawnym lub promocją. Gdyby nie został zadeklarowany i zaimplementowany konstruktor przyjmujący tablicę znaków, to takie przypisanie spowodowałoby błąd kompilacji.
Listy połączone i inne struktury Tablice przypominają kontenery służące do przeprowadzek. Są one bardzo przydatnymi pojemnikami, ale mają określony rozmiar. Jeśli wybierzesz zbyt duży pojemnik, niepotrzebnie zmarnujesz miejsce. Jeśli wybierze pojemnik zbyt mały, jego zawartość wysypie się i powstanie bałagan.
Jednym ze sposobów rozwiązania tego problemu jest użycie listy połączonej. Lista połączona jest to struktura danych składająca się z małych pojemników, przystosowanych do łączenia się ze sobą w miarę potrzeb. Naszym celem jest napisanie klasy zawierającej pojedynczy obiekt naszych danych — na przykład jeden obiekt CAT lub jeden obiekt Rectangle — która może wskazywać na następny pojemnik. Tworzymy jeden pojemnik dla każdego obiektu, który chcemy przechować i w miarę potrzeb łączymy je ze sobą.
Takie pojemniki są nazywane węzłami (ang. node). Pierwszy węzeł listy jest nazywany głową (ang. head), zaś ostatni — ogonem (ang. tail).
Listy występują w trzech podstawowych odmianach. W kolejności od najmniej do najbardziej złożonej, są to
• lista połączona pojedynczo,
• lista połączona podwójnie,
• drzewo.
W liście połączonej pojedynczo każdy węzeł wskazuje na węzeł następny (nie wskazuje poprzedniego). Aby odszukać określony węzeł, musimy zacząć od początku listy, tak jak w zabawie w poszukiwanie skarbów („Następny węzeł jest pod fotelem”). Lista połączona
Usunięto: ale

podwójnie umożliwia poruszenie się wzdłuż łańcucha węzłów do przodu i do tyłu. Drzewo jest złożoną strukturą zbudowaną z węzłów. Każdy węzeł może wskazywać w dwóch lub więcej kierunkach. Te trzy podstawowe struktury przedstawia rysunek 13.5.
Rys. 13.5. Listy połączone
Analiza listy połączonej W tym podrozdziale omówimy działanie listy połączonej. Lista ta posłuży nam nie tylko jako przykład tworzenia złożonych struktur, ale przede wszystkim jako przykład użycia dziedziczenia, polimorfizmu i kapsułkowania w celu zarządzania większymi projektami.

Przeniesienie odpowiedzialności Podstawowym celem programowania zorientowanego obiektowo jest to, by każdy obiekt wykonywał dobrze jedną rzecz, zaś wszystkie inne czynności przekazywał innym obiektom.
Doskonałym przykładem zastosowania tej idei w praktyce jest samochód: zadaniem silnika jest dostarczanie siły. Jej dystrybucja nie jest już zadaniem silnika, ale układu napędowego. Skręcanie nie jest zadaniem ani silnika, ani układu napędowego, tylko kół.
Dobrze zaprojektowana maszyna składa się z mnóstwa małych, dobrze przemyślanych części, z których każda wykonuje swoje zadanie i współpracuje z innymi częściami w celu osiągnięcia wspólnego celu. Dobrze zaprojektowany program działa bardzo podobnie: każda klasa wykonuje swoje niewielkie operacje, ale w połączeniu z innymi może wykonać naprawdę skomplikowane zadanie.
Części składowe Lista połączona składa się z węzłów. Pojęcie klasy węzła będzie abstrakcyjne; do wykonania zadania użyjemy trzech podtypów. Lista będzie też zawierała węzeł czołowy, którego zadaniem będzie zarządzanie głową listy, węzeł ogona (domyśl się, do czego posłuży!) oraz zero lub więcej węzłów wewnętrznych. Węzły wewnętrzne będą odpowiedzialne za dane przechowywane wewnątrz listy.
Zauważ, że dane i lista są od siebie zupełnie niezależne. Teoretycznie, możesz przechowywać w liście dane dowolnego rodzaju, ponieważ to nie dane są ze sobą połączone, ale węzły, które je przechowują.
Program sterujący nie wie niczego o węzłach, ponieważ operuje na liście. Jednak sama lista wykonuje niewiele pracy, delegując większość zadań na węzły.
Kod programu przedstawia listing 13.13; za moment omówimy jego szczegóły.
Listing 13.13. Lista połączona 0: // *********************************************** 1: // PLIK: Listing 13.13 2: // 3: // PRZEZNACZENIE: Demonstruje listę połączoną 4: // UWAGI: 5: // 6: // COPYRIGHT: Copyright (C) 1998 Liberty Associates, Inc. 7: // All Rights Reserved 8: // 9: // Demonstruje obiektowo zorientowane podejście do list 10: // połączonych. Lista deleguje pracę na węzły. 11: // Węzeł jest abstrakcyjnym typem danych. Używane są trzy 12: // typy węzłów: węzły głowy, węzły ogona oraz węzły 13: // wewnętrzne. Tylko węzły wewnętrzne przechowują dane. 14: // 15: // Klasa data została stworzona jako obiekt danych 16: // przechowywany na liście połączonej. 17: // 18: // *********************************************** 19:
Usunięto: określonych
Usunięto: B
Usunięto: o
Usunięto: głowy
20: 21: #include <iostream> 22: using namespace std; 23: 24: enum { kIsSmaller, kIsLarger, kIsSame}; 25: 26: // Klasa danych do umieszczania w liście połączonej. 27: // Każda klasa w tej połączonej liście musi posiadać dwie metody: 28: // Show (wyświetla wartość) a 29: // Compare (zwraca względną pozycję) 30: class Data 31: { 32: public: 33: Data(int val):myValue(val){} 34: ~Data(){} 35: int Compare(const Data &); 36: void Show() { cout << myValue << endl; } 37: private: 38: int myValue; 39: }; 40: 41: // Compare jest używane do podjęcia decyzji, w którym 42: // miejscu listy powinien znaleźć się dany obiekt. 43: int Data::Compare(const Data & theOtherData) 44: { 45: if (myValue < theOtherData.myValue) 46: return kIsSmaller; 47: if (myValue > theOtherData.myValue) 48: return kIsLarger; 49: else 50: return kIsSame; 51: } 52: 53: // wstępne deklaracje 54: class Node; 55: class HeadNode; 56: class TailNode; 57: class InternalNode; 58: 59: // ADT reprezentuje obiekt węzła listy 60: // Każda klasa potomna musi przesłonić metody Insert i Show 61: class Node 62: { 63: public: 64: Node(){} 65: virtual ~Node(){} 66: virtual Node * Insert(Data * theData)=0; 67: virtual void Show() = 0; 68: private: 69: }; 70: 71: // To jest węzeł przechowujący rzeczywisty obiekt. 72: // W tym przypadku obiekt jest typu Data. 73: // Gdy poznamy szablony, dowiemy się, jak można 74: // to uogólnić. 75: class InternalNode: public Node 76: { 77: public: 78: InternalNode(Data * theData, Node * next); 79: ~InternalNode(){ delete myNext; delete myData; }
Usunięto: oraz

80: virtual Node * Insert(Data * theData); 81: // delegujemy! 82: virtual void Show() { myData->Show(); myNext->Show(); } 83: 84: private: 85: Data * myData; // dane jako takie 86: Node * myNext; // wskazuje następny węzeł w liście połączonej 87: }; 88: 89: // Konstruktor dokonuje jedynie inicjalizacji 90: InternalNode::InternalNode(Data * theData, Node * next): 91: myData(theData),myNext(next) 92: { 93: } 94: 95: // Esencja listy 96: // Gdy umieścisz nowy obiekt na liście, jest on 97: // przekazywany do węzła, który stwierdza, gdzie 98: // powinien on zostać umieszczony i wstawia go do listy 99: Node * InternalNode::Insert(Data * theData) 100: { 101: 102: // czy nowy element jest większy czy mniejszy niż ja? 103: int result = myData->Compare(*theData); 104: 105: 106: switch(result) 107: { 108: // konwencja: gdy jest taki sam jak ja, wstawiamy wcześniej 109: case kIsSame: // przechodzimy dalej 110: case kIsLarger: // nowe dane trafiają przede mnie 111: { 112: InternalNode * dataNode = new InternalNode(theData, this); 113: return dataNode; 114: } 115: 116: // gdy jest większy niż ja, przekazuję go do następnego węzła 117: // i niech ON się tym zajmie. 118: case kIsSmaller: 119: myNext = myNext->Insert(theData); 120: return this; 121: } 122: return this; 123: } 124: 125: 126: // Węzeł ogona jest tylko wartownikiem. 127: 128: class TailNode : public Node 129: { 130: public: 131: TailNode(){} 132: ~TailNode(){} 133: virtual Node * Insert(Data * theData); 134: virtual void Show() { } 135: 136: private: 137: 138: };

139: 140: // Gdy dane trafiają do mnie, muszą być wstawione wcześniej, 141: // gdyż jestem ogonem i za mną NIC nie ma. 142: Node * TailNode::Insert(Data * theData) 143: { 144: InternalNode * dataNode = new InternalNode(theData, this); 145: return dataNode; 146: } 147: 148: // Węzeł głowy nie zawiera danych; wskazuje jedynie 149: // na sam początek listy. 150: class HeadNode : public Node 151: { 152: public: 153: HeadNode(); 154: ~HeadNode() { delete myNext; } 155: virtual Node * Insert(Data * theData); 156: virtual void Show() { myNext->Show(); } 157: private: 158: Node * myNext; 159: }; 160: 161: // Gdy tylko głowa zostanie stworzona, 162: // natychmiast tworzy ogon. 163: HeadNode::HeadNode() 164: { 165: myNext = new TailNode; 166: } 167: 168: // Przed głowę nic nie wstawiamy nic, zatem 169: // po prostu przekazujemy dane do następnego węzła. 170: Node * HeadNode::Insert(Data * theData) 171: { 172: myNext = myNext->Insert(theData); 173: return this; 174: } 175: 176: // Odbieram słowa uznania, a sama nic nie robię. 177: class LinkedList 178: { 179: public: 180: LinkedList(); 181: ~LinkedList() { delete myHead; } 182: void Insert(Data * theData); 183: void ShowAll() { myHead->Show(); } 184: private: 185: HeadNode * myHead; 186: }; 187: 188: // Przy narodzinach tworzę węzeł głowy. 189: // Tworzy on węzeł ogona. 190: // Tak więc pusta lista wskazuje na głowę, która 191: // wskazuje na ogon; pomiędzy nimi nie ma nic innego. 192: LinkedList::LinkedList() 193: { 194: myHead = new HeadNode; 195: } 196: 197: // Delegujemy, delegujemy, delegujemy 198: void LinkedList::Insert(Data * pData) 199: {

200: myHead->Insert(pData); 201: } 202: 203: // testowy program sterujący 204: int main() 205: { 206: Data * pData; 207: int val; 208: LinkedList ll; 209: 210: // prosimy użytkownika o wpisanie kilku wartości 211: // i umieszczamy je na liście 212: for (;;) 213: { 214: cout << "Jaka wartosc? (0 aby zakonczyc): "; 215: cin >> val; 216: if (!val) 217: break; 218: pData = new Data(val); 219: ll.Insert(pData); 220: } 221: 222: // teraz przechodzimy listę i wyświetlamy wartości 223: ll.ShowAll(); 224: return 0; // ll wychodzi poza zakres i zostaje zniszczone! 225: }
Wynik Jaka wartosc? (0 aby zakonczyc): 5 Jaka wartosc? (0 aby zakonczyc): 8 Jaka wartosc? (0 aby zakonczyc): 3 Jaka wartosc? (0 aby zakonczyc): 9 Jaka wartosc? (0 aby zakonczyc): 2 Jaka wartosc? (0 aby zakonczyc): 10 Jaka wartosc? (0 aby zakonczyc): 0 2 3 5 8 9 10
Analiza
Pierwszą rzeczą, jaką należy zauważyć, jest instrukcja wyliczeniowa definiująca trzy stałe: kIsSmaller (jest mniejsze), kIsLarger (jest większe) oraz kIsSame (jest takie same). Każdy obiekt, który może być przechowywany na tej liście połączonej, musi obsługiwać metodę Compare(). Te stałe są zwracane właśnie przez tę metodę.
Dla przykładu, w liniach od 30. do 39. została stworzona klasa Data (dane), zaś jej metoda Compare() została zaimplementowana w liniach od 41. do 51. Obiekt typu Data przechowuje wartość i może porównywać się z innymi obiektami Data. Oprócz tego obsługuje metodę Show(), która wyświetla wartość obiektu Data.
Najprostszym sposobem na zrozumienie działania listy połączonej jest przeanalizowanie ilustrującego ją przykładu. W linii 203. rozpoczyna się testowy program sterujący; w linii 206.
Usunięto: e
Usunięto: zawierające

deklarowany jest wskaźnik do obiektu Data, zaś w linii 208. definiowana jest lokalna lista połączona.
Gdy tworzona jest lista połączona, wywoływany jest jej konstruktor, zaczynający się w linii 192. Jedyną pracą wykonywaną w tym konstruktorze jest zaalokowanie obiektu HeadNode (węzeł głowy) i przypisanie jego adresu do wskaźnika przechowywanego w połączonej liście w linii 185.
Tworzenie obiektu HeadNode powoduje wywołanie konstruktora klasy HeadNode zawartego w liniach od 163. do 166. To z kolei powoduje zaalokowanie obiektu TailNode (węzeł głowy) i przypisanie jego adresu do wskaźnika myNext (mój następny) w węźle głowy. Tworzenie obiektu TailNode powoduje wywołanie konstruktora tej klasy zdefiniowanego w linii 131., który jest funkcją inline i nie robi nic.
Dzięki zwykłemu zaalokowaniu listy połączonej na stosie, tworzona jest sama lista, węzły głowy i ogona oraz ustanawiane są powiązania pomiędzy nimi. Ilustruje to rysunek 13.6.
Rys. 13.6. Lista połączona po jej utworzeniu
Linia 212. rozpoczyna pętlę nieskończoną. Użytkownik jest proszony o wpisanie wartości dodawanych do listy połączonej. Może on dodać dowolną ilość wartości ; wpisanie wartości 0 powoduje zakończenie pobierania danych. Kod w linii 216. sprawdza wprowadzaną wartość; po natrafianiu na wartość 0 powoduje on wyjście z pętli.
Jeśli wartość jest różna od zera, w linii 218. tworzony jest nowy obiekt typu Data, który w linii 219. jest wstawiany do listy. Dla zilustrowania tego przykładu załóżmy, że użytkownik wprowadził wartość 15. Powoduje to wywołanie metody Insert() (wstaw) w linii 198.
Lista połączona (klasa LinkedList) natychmiast przenosi odpowiedzialność za wstawienie obiektu na swój węzeł głowy. To wywołuje metodę Insert() z linii 170. Z kolei węzeł głowy natychmiast przekazuje odpowiedzialność za wstawienie obiektu do węzła wskazywanego przez składową myNext (mój następny). W tym (pierwszym) przypadku, składowa ta wskazuje na węzeł ogona (pamiętajmy, że podczas tworzenia węzła głowy zostało stworzone łącze do węzła ogona). Tak więc zostaje wywołana metoda Insert() z linii 142.
Metoda TailNode::Insert() wie, że obiekt, który otrzymała, musi być wstawiony bezpośrednio przed jej obiektem — tj. nowy obiekt znajdzie się na liście tuż przed węzłem ogona. Zatem, w linii 144. tworzy ona nowy obiekt InternalNode (węzeł wewnętrzny), przekazując mu dane oraz wskaźnik do siebie. To powoduje wywołanie konstruktora klasy InternalNode, zdefiniowanego w linii 90.
Usunięto: mu
Usunięto: tyle wartości, ile chce
Usunięto: W
Usunięto: ,
Usunięto: ona

Konstruktor klasy InternalNode inicjalizuje tylko swój wskaźnik Data za pomocą adresu otrzymanego obiektu Data oraz inicjalizuje swój wskaźnik myNext za pomocą otrzymanego adresu węzła. W tym przypadku nowy węzeł wewnętrzny będzie wskazywał na węzeł ogona (pamiętajmy, że węzeł ogona przekazał mu swój wskaźnik this).
Gdy utworzony zostanie nowy węzeł InternalNode, w linii 144. jego adres jest przypisywany do wskaźnika dataNode i właśnie ten adres jest zwracany z metody TailNode::Insert(). Wracamy więc do metody HeadNode::Insert(), w której adres węzła InternalNode jest przypisywany do wskaźnika myNext węzła głowy (w linii 172.). Na zakończenie, adres węzła głowy jest zwracany do listy połączonej, gdzie w linii 200. jest odrzucany (nie robimy z nim nic, ponieważ lista połączona znała adres swojego węzła głowy już wcześniej).
Dlaczego zawracamy sobie głowę zwracaniem adresu, który nie jest używany? Metoda Insert jest zadeklarowana w klasie bazowej, Node. Zwracana wartość jest potrzebna w innych implementacjach. Gdy zmienisz zwracaną wartość metody HeadNode::Insert(), spowodujesz błąd kompilacji; prościej jest więc po prostu zwrócić adres węzła głowy i pozwolić, by lista połączona go zignorowała.
Co się więc stało? Dane zostały wstawione do listy. Lista przekazała je do głowy. Głowa, „na ślepo”, przekazała dane do pierwszego wskazywanego przez siebie elementu. W tym (pierwszym) przypadku, głowa wskazywała na ogon. Ogon natychmiast stworzył nowy węzeł wewnętrzny, inicjalizując go tak, by wskazywał na ogon. Następnie ogon zwrócił głowie adres nowego węzła, która zmodyfikowała swój wskaźnik myNext tak, aby wskazywał na nowy węzeł. Gotowe! Dane na liście znajdują się we właściwym miejscu, co ilustruje rysunek 13.7.
Rys. 13.7. Lista połączona po wstawieniu pierwszego węzła
Po wstawieniu pierwszego węzła, sterowanie programu powraca do linii 214., gdzie wprowadzane są kolejne dane. Dla przykładu załóżmy, że użytkownik wpisał wartość 3. Powoduje to stworzenie w linii 218. nowego obiektu typu Data, który jest wstawiany do listy w linii 219.

W linii 200. lista ponownie przekazuje dane do swojego węzła głowy. Z kolei metoda HeadNode::Insert() przekazuje nową wartość do węzła wskazywanego przez swój wskaźnik myNext. Jak wiemy, w tym momencie wskaźnik ten wskazuje węzeł zawierający obiekt Data o wartości 15. Powoduje to wywołanie metody InternalNode::Insert() z linii 99.
W linii 103. obiekt InternalNode używa wskaźnika myData, aby dla własnego obiektu Data (tego o wartości 15) wywołać za pomocą otrzymanego nowego obiektu Data (tego o wartości 3) metodę Compare(). To powoduje wywołanie metody InternalNode::Compare() zdefiniowanej w linii 43.
Obie wartości zostają porównane, a ponieważ myValue ma wartość 15, zaś theOtherData.myValue ma wartość 3, zwróconą wartością jest kIsLarger. To powoduje, że program przechodzi do linii 112.
Dla nowego obiektu Data tworzony jest nowy węzeł InternalNode. Nowy węzeł będzie wskazywał na bieżący obiekt InternalNode, a metoda InternalNode::Insert() zwróci do obiektu HeadNode adres nowego węzła. Zatem nowy węzeł, którego wartość obiektu danych jest mniejsza od wartości obiektu danych węzła bieżącego, zostanie wstawiony do listy przed węzłem bieżącym. Cała lista wygląda w tym momencie tak, jak na rysunku 13.8.
Rys. 13.8. Lista połączona po wstawieniu drugiego węzła
W trakcie trzeciego wykonania pętli użytkownik wpisał wartość 8. Jest ona większa od 3, ale mniejsza od 15, więc powinna być wstawiona pomiędzy dwa istniejące już węzły. Działanie programu będzie podobne do przedstawionego w poprzednim przykładzie, z tą różnicą, że gdy dojdzie do porównania wartości danych z wartością 3, zamiast zwrócić stałą kIsLarger, funkcja zwróci wartość kIsSmaller (co oznacza, że obiekt o wartości 3 jest mniejszy od nowego obiektu, którego wartość wynosi 8).
To spowoduje, że metoda InternalNode::Insert() przejdzie do linii 119. Zamiast tworzyć nowy węzeł i wstawiać go, obiekt InternalNode po prostu przekaże nowe dane do metody Insert tego węzła, na który wskazuje akurat jego zmienna myNext. W tym przypadku zostanie więc wywołana metoda Insert() tego obiektu InternalNode, którego obiektem danych jest wartość 15.

Ponownie odbywa się porównanie i tworzony jest nowy obiekt InternalNode. Będzie wskazywał on na węzeł, którego wartością danych jest 15, zaś jego adres zostanie przekazany wstecz do węzła, którego wartością danych jest 3 (w linii 119.).
Spowoduje to, że nowy węzeł zostanie wstawiony we właściwe miejsce na liście.
Jeśli to możliwe, powinieneś prześledzić w swoim debuggerze proces wstawiania kolejnych węzłów. Powinieneś zobaczyć, jak te metody wzajemnie się wywołują i odpowiednio dostosowują wskaźniki.
Czego się nauczyłaś, Dorotko? „Jeśli kiedykolwiek pójdę za głosem serca, nie wyjdę poza swoje podwórko”. Nie ma to jak w domu i nie ma to jak programowanie proceduralne. W programowaniu proceduralnym metoda kontrolująca sprawdza dane i wywołuje funkcje.
W metodzie obiektowej każdy obiekt ma swoje ściśle określone zadanie. Lista połączona odpowiada za zarządzanie węzłem głowy. Węzeł głowy natychmiast przekazuje nowe dane do następnego wskazywanego przez siebie węzła, bez względu na to, czym jest ten węzeł.
Węzeł ogona tworzy nowy węzeł i wstawia go do listy za każdym razem, gdy otrzyma dane. Potrafi tylko jedno: jeśli coś do niego dotrze, wstawia to tuż przed sobą.
Węzły wewnętrzne są nieco bardziej skomplikowane; proszą swój istniejący obiekt o porównanie się z nowym obiektem. W zależności od wyniku tego porównania, wstawiają go przed sobą lub po prostu przekazują do następnego węzła na liście.
Zauważ, że węzeł InternalNode nie ma pojęcia o sposobie przeprowadzenia porównania; należy to wyłącznie do obiektu danych. InternalNode wie jedynie, że powinien poprosić obiekt danych o dokonanie porównania w celu otrzymania jednej z trzech odpowiedzi. Na podstawie otrzymanej odpowiedzi wstawia obiekt do listy; w przeciwnym razie przekazuje go dalej, nie dbając o to, gdzie w końcu dotrze.
Kto więc tu rządzi? W dobrze zaprojektowanym programie zorientowanym obiektowo nikt nie rządzi. Każdy obiekt wykonuje własną, ograniczoną pracę, zaś w ogólnym efekcie otrzymujemy sprawnie działającą maszynę.
Klasy tablic Napisanie własnej klasy tablicowej ma wiele zalet w porównaniem z korzystaniem z tablic wbudowanych. Jako początkujący programista, możesz zabezpieczyć program przed przepełnieniem tablicy. Możesz także wziąć pod uwagę stworzenie własnej klasy tablicowej, dynamicznie zmieniającej rozmiar: tuż po utworzeniu mogłaby ona zawierać tylko jeden element i zwiększać rozmiar w miarę potrzeb, podczas działania programu.
W przypadku, gdy zechcesz posortować lub uporządkować elementy tablicy w jakiś inny sposób, możesz wykorzystać kilka różnych przydatnych odmian tablic. Do najpopularniejszych z nich należą:
Usunięto: y
Usunięto: y

• zbiór uporządkowany (ordered collection): każdy element jest ułożony w odpowiedniej kolejności,
• zestaw (set): każdy element występuje tylko raz,
• słownik (dictionary): wykorzystuje on dopasowane do siebie pary, w których jedna wartość pełni rolę klucza służącego do pobierania drugiej wartości,
• rzadka tablica (sparse array): umożliwia używanie bardzo szerokiego zakresu indeksów, ale pamięć zajmują tylko te elementy, które rzeczywiście zostały dodane do tablicy. Możesz poprosić o element SparseArray[5] lub SparseArray[200], a mimo to pamięć zostanie zaalokowana tylko dla niewielkiej ilości elementów,
• torba (bag): nieuporządkowany zbiór, którego elementy są dodawane i zwracane w przypadkowej kolejności.
Przeciążając operator indeksu ([]), możesz zamienić listę połączoną w zbiór uporządkowany. Odrzucając duplikaty, możesz zamienić zbiór w zestaw. Jeśli każdy obiekt na liście posiada parę dopasowanych wartości, możesz użyć listy połączonej do zbudowania słownika lub rzadkiej tablicy.

Rozdział 14. Polimorfizm Z rozdziału 12. dowiedziałeś się, jak pisać funkcje wirtualne w klasach wyprowadzonych. Jest to jedna z podstawowych umiejętności potrzebnych przy posługiwaniu się polimorfizmem, czyli możliwością przypisywania — już podczas działania programu — specyficznych obiektów klas pochodnych do wskaźników wskazujących na obiekty klasy bazowej.
Z tego rozdziału dowiesz się:
• czym jest dziedziczenie wielokrotne i jak z niego korzystać,
• czym jest dziedziczenie wirtualne,
• czym są abstrakcyjne typy danych,
• czym są czyste funkcje wirtualne.
Problemy z pojedynczym dziedziczeniem Przypuśćmy, że od pewnego czasu pracujemy z naszymi klasami zwierząt i że podzieliliśmy hierarchię klas na ptaki (Bird) i ssaki (Mammal). Klasa Bird posiada funkcję składową Fly() (latanie). Klasa Mammal została podzielona na różne rodzaje ssaków, między innymi na klasę Horse (koń). Klasa Horse posiada funkcje składowe Whinny() (rżenie) oraz Gallop() (galopowanie).
Nagle okazuje się, że potrzebujemy obiektu pegaza (Pegasus): skrzyżowania konia z ptakiem. Pegasus może latać (metoda Fly()), ale także może rżeć (Whinny()) i galopować (Gallop()). Przy dziedziczeniu pojedynczym okazuje się, że jesteśmy w kropce.
Możemy uczynić z pegaza obiekt klasy Bird, ale wtedy nie będzie mógł rżeć ani galopować. Możemy zrobić z niego obiekt Horse, ale wtedy nie będzie mógł latać.
Pierwszą próbą rozwiązania tego problemu może być skopiowanie metody Fly() do klasy Pegasus i wyprowadzenie tej klasy z klasy Horse. Będzie to prawidłowa operacja, przeprowadzona jednak kosztem posiadania metody Fly() w dwóch miejscach (w klasach Bird i Pegasus). Gdy zmienisz ją w jednym miejscu, musisz pamiętać o wprowadzeniu modyfikacji

także w drugim. Oczywiście, programista, który kilka miesięcy czy lat później spróbuje zmodyfikować taki kod, także musi wiedzieć o obu miejscach.
Wkrótce jednak pojawia się nowy problem. Chcemy stworzyć listę obiektów typu Horse oraz listę obiektów typu Bird. Chcielibyśmy dodać obiekt klasy Pegasus do dowolnej z tych list, ale gdyby Pegasus został wyprowadzony z klasy Horse, nie moglibyśmy go dodać do listy obiektów klasy Bird.
Istnieje kilka rozwiązań tego problemu. Możemy zmienić nazwę metody Gallop() na Move() (ruch), a następnie przesłonić metodę Move() w klasie Pegasus tak, aby wykonywała pracę metody Fly(). Następnie przesłonilibyśmy metodę Move() innych koni tak, aby wykonywała pracę metody Gallop(). Być może pegaz byłby inteligentny na tyle, by galopować na krótkich dystansach, a latać tylko na dłuższych:
Pegasus::Move(long distance)
{
if (distance > veryFar)
Fly(distance);
else
Gallop(distance);
}
To rozwiązanie posiada jednak pewne ograniczenia. Być może któregoś dnia pegaz zechce latać na krótkich dystansach lub galopować na dłuższych. Następnym rozwiązaniem mogłoby być przeniesienie metody Fly() w górę, do klasy Horse, co zostało pokazane na listingu 14.1. Problem jednak polega na tym, iż zwykłe konie nie potrafią latać, więc w przypadku koni innych niż pegaz, ta metoda nie będzie nic robić.
Listing 14.1. Gdyby konie umiały latać... 0: // Listing 14.1. Gdyby konie umiały latać...
1: // Przeniesienie metody Fly() do klasy Horse
2:
3: #include <iostream>
4: using namespace std;
5:
6: class Horse
7: {
8: public:
9: void Gallop(){ cout << "Galopuje...\n"; }
10: virtual void Fly() { cout << "Konie nie potrafia latac.\n" ; }
11: private:
12: int itsAge;

13: };
14:
15: class Pegasus : public Horse
16: {
17: public:
18: virtual void Fly() {cout<<"Moge latac! Moge latac! Moge latac!\n";}
19: };
20:
21: const int NumberHorses = 5;
22: int main()
23: {
24: Horse* Ranch[NumberHorses];
25: Horse* pHorse;
26: int choice,i;
27: for (i=0; i<NumberHorses; i++)
28: {
29: cout << "(1)Horse (2)Pegasus: ";
30: cin >> choice;
31: if (choice == 2)
32: pHorse = new Pegasus;
33: else
34: pHorse = new Horse;
35: Ranch[i] = pHorse;
36: }
37: cout << "\n";
38: for (i=0; i<NumberHorses; i++)
39: {
40: Ranch[i]->Fly();
41: delete Ranch[i];
42: }
43: return 0;
44: }
Wynik (1)Horse (2)Pegasus: 1
(1)Horse (2)Pegasus: 2

(1)Horse (2)Pegasus: 1
(1)Horse (2)Pegasus: 2
(1)Horse (2)Pegasus: 1
Konie nie potrafia latac.
Moge latac! Moge latac! Moge latac!
Konie nie potrafia latac.
Moge latac! Moge latac! Moge latac!
Konie nie potrafia latac.
Analiza
Ten program oczywiście działa, ale kosztem posiadania przez klasę Horse metody Fly(). Metoda Fly() dla klasy Horse jest zdefiniowana w linii 10. W rzeczywistej klasie mogłaby po prostu wyświetlać komunikat błędu lub po cichu zakończyć działanie. W linii 18. klasa Pegasus przesłania metodę Fly() tak, aby wykonywała właściwą pracę, w tym przypadku polegającą na wypisywaniu radosnego komunikatu.
Tablica wskaźników do klasy Horse, zadeklarowana w linii 24., służy do zademonstrowania, że właściwa metoda Fly()zostaje wywołana w zależności od tego, czy został stworzony obiekt klasy Horse lub klasy Pegasus.
UWAGA Pokazany tutaj przykład został bardzo okrojony, do elementów niezbędych dla zrozumienia zasad jego działania. Konstruktory, wirtualne destruktory i tak dalej, zostały usunięte w celu ułatwienia analizy kodu.
Przenoszenie w górę Przenoszenie pożądanej funkcji w górę hierarchii klas jest powszechnym rozwiązaniem tego typu problemów; powoduje jednak, że w klasie bazowej występuje wiele funkcji „nadmiarowych”. Istnieje niebezpieczeństwo, że klasa bazowa stanie się globalną przestrzenią nazw dla wszystkich funkcji, które mogłyby być użyte w klasach potomnych. Może to znacznie wpłynąć na efektywność zarządzania typami w C++ i powodować zbytni rozrost i skomplikowanie klas bazowych.
Chcemy przenieść funkcjonalność w górę hierarchii, ale bez równoczesnego przenoszenia interfejsu każdej z klas. Oznacza to, że jeśli dwie klasy posiadają wspólną klasę bazową (na przykład klasy Horse i Bird pochodzą od klasy Animal) i posiadają wspólną funkcję (zarówno konie, jak i ptaki odżywiają się), powinniśmy przenieść tę cechę w górę, do klasy bazowej i stworzyć z niej funkcję wirtualną.
Powinniśmy unikać przy tym przenoszenia interfejsu (tak, jak przeniesienie metody Fly() tam, gdzie nie powinno jej być) tylko w celu wywoływania danej funkcji w niektórych z klas wyprowadzonych.

Rzutowanie w dół Alternatywą dla przedstawionego wcześniej rozwiązania (nie wykluczającą korzystania z pojedynczego dziedziczenia), jest zatrzymanie metody Fly() wewnątrz klasy Pegasus i wywoływanie jej tylko wtedy, gdy wskaźnik do obiektu rzeczywiście wskazuje obiekt klasy Pegasus. Aby sposób ten mógł działać, musimy mieć możliwość zapytania wskaźnika, jaki typ faktycznie wskazuje. Nazywa się to identyfikacją typów podczas wykonywania programu (RTTI, Run Time Type Identification). Korzystanie z RTTI stało się oficjalnym elementem języka C++ dopiero od niedawna.
Jeśli kompilator nie obsługuje RTTI, możemy symulować tę obsługę, umieszczając w każdej z klas metodę zwracającą jedną z wyliczeniowych stałych. Możemy następnie sprawdzać typ podczas działania programu i wywoływać metodę Fly() tylko wtedy, gdy ta metoda zwróci stałą dla typu Pegasus.
UWAGA Bądź ostrożny z RTTI. Korzystanie z tego mechanizmu może być oznaką słabości projektu programu. Zamiast tego użyj funkcji wirtualnych, wzorców lub wielokrotnego dziedziczenia.
Aby móc wywołać metodę Fly(), musimy dokonać rzutowania wskaźnika, informując kompilator, że wskazywany obiekt jest obiektem typu Pegasus, a nie obiektem typu Horse. Nazywa się to rzutowaniem w dół, gdyż obiekt Horse rzutujemy w dół hierarchii, do typu bardziej wyprowadzonego.
Dziś C++ już oficjalnie, choć dość niechętnie, obsługuje rzutowanie w dół za pomocą nowego operatora dynamic_cast. Oto sposób jego działania:
Jeśli mamy wskaźnik do klasy bazowej, takiej jak Horse, i przypiszemy mu adres obiektu klasy wyprowadzonej, takiej jak Pegasus, możemy używać wskaźnika do klasy Horse polimorficznie. Jeśli chcemy następnie odwołać się do obiektu klasy Pegasus, tworzymy wskaźnik do tej klasy i w celu dokonania konwersji używamy operatora dynamic_cast.
W czasie działania programu nastąpi sprawdzenie wskaźnika do klasy bazowej. Jeśli konwersja będzie właściwa, nowy wskaźnik do klasy Pegasus będzie poprawny. Jeśli konwersja będzie niewłaściwa (nie będzie to wskaźnik do klasy Pegasus), nowy wskaźnik będzie pusty (null). Ilustruje to listing 14.2.
Listing 14.2. Rzutowanie w dół 0: // Listing 14.2 Użycie operatora dynamic_cast.
1: // Using rtti
2:
3: #include <iostream>
4: using namespace std;
5:
6: enum TYPE { HORSE, PEGASUS };
7:
8: class Horse

9: {
10: public:
11: virtual void Gallop(){ cout << "Galopuje...\n"; }
12:
13: private:
14: int itsAge;
15: };
16:
17: class Pegasus : public Horse
18: {
19: public:
20:
21: virtual void Fly() {cout<<"Moge latac! Moge latac! Moge latac!\n";}
22: };
23:
24: const int NumberHorses = 5;
25: int main()
26: {
27: Horse* Ranch[NumberHorses];
28: Horse* pHorse;
29: int choice,i;
30: for (i=0; i<NumberHorses; i++)
31: {
32: cout << "(1)Horse (2)Pegasus: ";
33: cin >> choice;
34: if (choice == 2)
35: pHorse = new Pegasus;
36: else
37: pHorse = new Horse;
38: Ranch[i] = pHorse;
39: }
40: cout << "\n";
41: for (i=0; i<NumberHorses; i++)
42: {
43: Pegasus *pPeg = dynamic_cast< Pegasus *> (Ranch[i]);
44: if (pPeg)
45: pPeg->Fly();

46: else
47: cout << "Po prostu kon\n";
48:
49: delete Ranch[i];
50: }
51: return 0;
52: }
Wynik (1)Horse (2)Pegasus: 1
(1)Horse (2)Pegasus: 2
(1)Horse (2)Pegasus: 1
(1)Horse (2)Pegasus: 2
(1)Horse (2)Pegasus: 1
Po prostu kon
Moge latac! Moge latac! Moge latac!
Po prostu kon
Moge latac! Moge latac! Moge latac!
Po prostu kon
Analiza
Ten sposób również okazał się dobry. Metoda Fly() została utrzymana poza klasą Horse i nie jest wywoływana dla obiektów typu Horse. Jednak w przypadku wywoływania jej dla obiektów klasy Pegasus, musi być stosowane rzutowanie jawne; obiekty klasy Horse nie posiadają metody Fly(), więc musimy poinformować kompilator, że wskaźnik wskazuje na klasę Pegasus.
Potrzeba rzutowania obiektu klasy Pegasus jest ostrzeżeniem, że program może być źle zaprojektowany. Taki program znacznie obniża użyteczność polimorfizmu funkcji wirtualnych, gdyż podczas działania jest zależny od rzutowania obiektu do jego rzeczywistego typu.
Często zadawane pytanie
Podczas kompilacji za pomocą kompilatora Visual C++ Microsoftu otrzymują ostrzeżenie: „warning C4541: 'dynamic_cast' used on polymorphic type 'class Horse' with /GR-; unpredictable behavior may result”. Co powinienem zrobić?
Odpowiedź: Jest to jeden z najbardziej kłopotliwych komunikatów o błędach. Aby się go pozbyć, wykonaj następujące kroki:
Usunięto: ów

1. W swoim projekcie wybierz polecenie Project | Settings.
2. Przejdź na zakładkę C++.
3. Z listy rozwijanej wybierz pozycję C++ Language.
4. Włącz opcję Enable Runtime Type Information (RTTI).
5. Zbuduj cały projekt ponownie.
Połączenie dwóch list Inny problem z podanymi wyżej rozwiązaniami polega na tym, że zadeklarowaliśmy obiekt Pegasus jako obiekt typu Horse, więc nie możemy dodać obiektu Pegasus do listy obiektów Bird. Straciliśmy albo poprzez przeniesienie metody Fly() w górę albo poprzez rzutowanie wskaźnika w dół, a mimo to wciąż nie osiągnęliśmy pełnej funkcjonalności.
Pojawia się jeszcze jedno, ostatnie rozwiązanie, również wykorzystujące pojedyncze dziedziczenie. Możemy umieścić metody Fly(), Whinny() oraz Gallop() w klasie bazowej wspólnej zarówno dla klas Bird, jak i Horse: w klasie Animal. Teraz, zamiast osobnej listy ptaków i listy koni, możemy mieć jedną, zunifikowaną listę zwierząt. Sposób ten działa, ale powoduje jeszcze większe przeniesienie specjalnych funkcji w górę do klas bazowych.
Możemy również pozostawić te metody tam, gdzie są i rzutować w dół obiekty klas Horse, Bird i Pegasus, ale to jeszcze gorsze rozwiązanie!
TAK NIE
Przenoś funkcjonalność w górę hierarchii dziedziczenia.
Unikaj przełączania na podstawie typu obiektu sprawdzanego podczas działania programu — używaj metod wirtualnych, wzorców oraz wielokrotnego dziedziczenia.
Nie przenoś interfejsów w górę hierarchii dziedziczenia.
Nie rzutuj wskaźników do obiektów bazowych w dół, do obiektów wyprowadzonych.
Usunięto: tymi
Usunięto: osząc
Usunięto: ę
Usunięto: ując

Dziedziczenie Wielokrotne Istnieje możliwość wyprowadzenia nowej klasy z więcej niż jednej klasy bazowej. Nazywa się to dziedziczeniem wielokrotnym. Aby wyprowadzić klasę z więcej niż jednej klasy bazowej, w nagłówku klasy musimy oddzielić każdą z klas bazowych przecinkami. Listing 14.3 pokazuje sposób zadeklarowania klasy Pegasus jako pochodzącej zarówno od klasy Horse, jak i klasy Bird. Następnie program dodaje obiekty klasy Pegasus do list obu typów.
Listing 14.3. Dziedziczenie wielokrotne 0: // Listing 14.3. Dziedziczenie wielokrotne.
1: // Dziedziczenie wielokrotne
2:
3: #include <iostream>
4: using std::cout;
5: using std::cin;
6:
7: class Horse
8: {
9: public:
10: Horse() { cout << "Konstruktor klasy Horse... "; }
11: virtual ~Horse() { cout << "Destruktor klasy Horse... "; }
12: virtual void Whinny() const { cout << "Ihaaa!... "; }
13: private:
14: int itsAge;
15: };
16:
17: class Bird
18: {
19: public:
20: Bird() { cout << "Konstruktor klasy Bird... "; }
21: virtual ~Bird() { cout << "Destruktor klasy Bird... "; }
22: virtual void Chirp() const { cout << "Cwir, cwir... "; }
23: virtual void Fly() const
24: {
25: cout << "Moge latac! Moge latac! Moge latac! ";
26: }
27: private:
28: int itsWeight;
29: };

30:
31: class Pegasus : public Horse, public Bird
32: {
33: public:
34: void Chirp() const { Whinny(); }
35: Pegasus() { cout << "Konstruktor klasy Pegasus... "; }
36: ~Pegasus() { cout << "Destruktor klasy Pegasus... "; }
37: };
38:
39: const int MagicNumber = 2;
40: int main()
41: {
42: Horse* Ranch[MagicNumber];
43: Bird* Aviary[MagicNumber];
44: Horse * pHorse;
45: Bird * pBird;
46: int choice,i;
47: for (i=0; i<MagicNumber; i++)
48: {
49: cout << "\n(1)Horse (2)Pegasus: ";
50: cin >> choice;
51: if (choice == 2)
52: pHorse = new Pegasus;
53: else
54: pHorse = new Horse;
55: Ranch[i] = pHorse;
56: }
57: for (i=0; i<MagicNumber; i++)
58: {
59: cout << "\n(1)Bird (2)Pegasus: ";
60: cin >> choice;
61: if (choice == 2)
62: pBird = new Pegasus;
63: else
64: pBird = new Bird;
65: Aviary[i] = pBird;
66: }

67:
68: cout << "\n";
69: for (i=0; i<MagicNumber; i++)
70: {
71: cout << "\nRanch[" << i << "]: " ;
72: Ranch[i]->Whinny();
73: delete Ranch[i];
74: }
75:
76: for (i=0; i<MagicNumber; i++)
77: {
78: cout << "\nAviary[" << i << "]: " ;
79: Aviary[i]->Chirp();
80: Aviary[i]->Fly();
81: delete Aviary[i];
82: }
83: return 0;
84: }
Wynik (1)Horse (2)Pegasus: 1
Konstruktor klasy Horse...
(1)Horse (2)Pegasus: 2
Konstruktor klasy Horse... Konstruktor klasy Bird... Konstruktor klasy Pegasus...
(1)Bird (2)Pegasus: 1
Konstruktor klasy Bird...
(1)Bird (2)Pegasus: 2
Konstruktor klasy Horse... Konstruktor klasy Bird... Konstruktor klasy Pegasus...
Ranch[0]: Ihaaa!... Destruktor klasy Horse...
Ranch[1]: Ihaaa!... Destruktor klasy Pegasus... Destruktor klasy Bird... Destruktor klasy Horse...
Aviary[0]: Cwir, cwir... Moge latac! Moge latac! Moge latac! Destruktor klasy Bird...

Aviary[1]: Ihaaa!... Moge latac! Moge latac! Moge latac! Destruktor klasy Pegasus... Destruktor klasy Bird... Destruktor klasy Horse...
Analiza
W liniach od 7. do 15. została zadeklarowana klasa Horse. Jej konstruktor i destruktor wypisuje komunikat, zaś metoda Whinny() wypisuje komunikat Ihaaa!.
W liniach od 17. do 29. została zadeklarowana klasa Bird. Oprócz konstruktora i destruktora, ta klasa posiada dwie metody: Chirp() (ćwierkanie) oraz Fly(). Obie te metody wypisują odpowiednie komunikaty. W rzeczywistym programie mogłyby na przykład uaktywniać głośnik lub wyświetlać animowane sekwencje.
Na zakończenie, w liniach od 31. do 37. została zadeklarowana klasa Pegasus. Dziedziczy ona zarówno po klasie Horse, jak i klasie Bird. Klasa Pegasus przesłania metodę Chirp() tak, aby została wywołana metoda Whinny(), odziedziczona po klasie Horse.
Tworzone są dwie tablice: w linii 42. tablica Ranch (ranczo) ze wskaźnikami do klasy Horse oraz w linii 43. tablica Aviary (ptaszarnia) ze wskaźnikami do klasy Bird. W liniach od 47. do 56. do tablicy Ranch są dodawane obiekty klas Horse i Pegasus. W liniach od 57. do 66. do tablicy Aviary są dodawane obiekty klas Bird i Pegasus.
Wywołania metod wirtualnych zarówno dla wskaźników do obiektów klasy Bird, jak i obiektów klasy Horse, działają poprawnie także dla obiektów klasy Pegasus. Na przykład, w linii 79., elementy tablicy Aviary są używane do wywołania metody Chirp() wskazywanych przez nie obiektów. Klasa Bird deklaruje tę metodę jako wirtualną, więc dla każdego obiektu wywoływana jest właściwa funkcja.
Zwróć uwagę, że za każdym razem, gdy tworzony jest obiekt Pegasus, wyniki odzwierciedlają, że tworzone są także części tego obiektu należące tak do klasy Bird, jak i Horse. Gdy obiekt Pegasus jest niszczony, niszczone są także części obiektu należące do klas Bird oraz Horse, a to dzięki temu, że destruktor także został zamieniony na wirtualny.
Deklarowanie dziedziczenia wielokrotnego
Deklarowanie obiektu dziedziczącego z więcej niż jednej klasy bazowej polega na umieszczeniu po nazwie tworzonej klasy dwukropka i rozdzielonej przecinkami listy klas bazowych.
Przykład 1
class Pegasus : public Horse, public Bird
Przykład 2
class Schnoodle : Public Schnauzer, public Poodle
Usunięto: oraz

Części obiektu z dziedziczeniem wielokrotnym Gdy w pamięci tworzony jest obiekt Pegasus, na część tego obiektu składają się obie klasy bazowe, co ilustruje rysunek 14.1.
Rys. 14.1. Obiekt klasy z wielokrotnym dziedziczeniem
W przypadku obiektów posiadających kilka klas bazowych, pojawia się kilka zagadnień. Na przykład, co się stanie, gdy dwie klasy bazowe mają dane lub funkcje wirtualne o tych samych nazwach? Jak są inicjalizowane konstruktory klas bazowych? Co się dzieje, gdy różne klasy bazowe dziedziczą z tej samej klasy? Na te pytania odpowiemy w następnych podrozdziałach i pokażemy także, jak dziedziczenie wielokrotne można wykorzystać do pracy.
Konstruktory w obiektach dziedziczonych wielokrotnie Jeśli klasa Pegasus jest wyprowadzona z klas Horse oraz Bird, a każda z nich posiada konstruktory wymagające parametrów, klasa Pegasus inicjalizuje te konstruktory po kolei. Ilustruje to listing 14.4.
Listing 14.4. Wywoływanie wielu konstruktorów 0: // Listing 14.4
1: // Wywoływanie wielu konstruktorów
2:
3: #include <iostream>
4: using namespace std;
5:
6: typedef int HANDS;
7: enum COLOR { Red, Green, Blue, Yellow, White, Black, Brown } ;

8:
9: class Horse
10: {
11: public:
12: Horse(COLOR color, HANDS height);
13: virtual ~Horse() { cout << "Destruktor klasy Horse...\n"; }
14: virtual void Whinny()const { cout << "Ihaaa!... "; }
15: virtual HANDS GetHeight() const { return itsHeight; }
16: virtual COLOR GetColor() const { return itsColor; }
17: private:
18: HANDS itsHeight;
19: COLOR itsColor;
20: };
21:
22: Horse::Horse(COLOR color, HANDS height):
23: itsColor(color),itsHeight(height)
24: {
25: cout << "Konstruktor klasy Horse...\n";
26: }
27:
28: class Bird
29: {
30: public:
31: Bird(COLOR color, bool migrates);
32: virtual ~Bird() {cout << "Destruktor klasy Bird...\n"; }
33: virtual void Chirp()const { cout << "Cwir, cwir... "; }
34: virtual void Fly()const
35: {
36: cout << "Moge latac! Moge latac! Moge latac! ";
37: }
38: virtual COLOR GetColor()const { return itsColor; }
39: virtual bool GetMigration() const { return itsMigration; }
40:
41: private:
42: COLOR itsColor;
43: bool itsMigration;
44: };

45:
46: Bird::Bird(COLOR color, bool migrates):
47: itsColor(color), itsMigration(migrates)
48: {
49: cout << "Konstruktor klasy Bird...\n";
50: }
51:
52: class Pegasus : public Horse, public Bird
53: {
54: public:
55: void Chirp()const { Whinny(); }
56: Pegasus(COLOR, HANDS, bool,long);
57: ~Pegasus() {cout << "Destruktor klasy Pegasus...\n";}
58: virtual long GetNumberBelievers() const
59: {
60: return itsNumberBelievers;
61: }
62:
63: private:
64: long itsNumberBelievers;
65: };
66:
67: Pegasus::Pegasus(
68: COLOR aColor,
69: HANDS height,
70: bool migrates,
71: long NumBelieve):
72: Horse(aColor, height),
73: Bird(aColor, migrates),
74: itsNumberBelievers(NumBelieve)
75: {
76: cout << "Konstruktor klasy Pegasus...\n";
77: }
78:
79: int main()
80: {
81: Pegasus *pPeg = new Pegasus(Red, 5, true, 10);

82: pPeg->Fly();
83: pPeg->Whinny();
84: cout << "\nTwoj Pegaz ma " << pPeg->GetHeight();
85: cout << " dloni wysokosci i ";
86: if (pPeg->GetMigration())
87: cout << "migruje.";
88: else
89: cout << "nie migruje.";
90: cout << "\nLacznie " << pPeg->GetNumberBelievers();
91: cout << " osob wierzy ze on istnieje.\n";
92: delete pPeg;
93: return 0;
94: }
Wynik Konstruktor klasy Horse...
Konstruktor klasy Bird...
Konstruktor klasy Pegasus...
Moge latac! Moge latac! Moge latac! Ihaaa!...
Twoj Pegaz ma 5 dloni wysokosci i migruje.
Lacznie 10 osob wierzy ze on istnieje.
Destruktor klasy Pegasus...
Destruktor klasy Bird...
Destruktor klasy Horse...
Analiza
W liniach od 9. do 20. została zadeklarowana klasa Horse. Jej konstruktor wymaga dwóch parametrów: jednym z nich jest stała wyliczeniowa zadeklarowana w linii 7., a drugim typ zadeklarowany w linii 6. Implementacja konstruktora zawarta w liniach od 22. do 26. po prostu inicjalizuje zmienne składowe i wypisuje komunikat.
W liniach od 28. do 44. jest deklarowana klasa Bird, zaś implementacja jej konstruktora znajduje się w liniach od 46. do 50. Także konstruktor tej klasy wymaga podania dwóch parametrów. Co ciekawe, konstruktor klasy Horse wymaga podania koloru (dzięki czemu możemy reprezentować konie o różnych kolorach), tak jak wymaga go konstruktor klasy Bird (co pozwala mu na reprezentowanie ptaków o różnym kolorze upierzenia). W momencie zapytania pegaza o jego kolor powstaje problem, co zresztą zobaczymy w następnym przykładzie.
Sama klasa Pegasus została zadeklarowana w liniach od 52. do 56., zaś jej konstruktor znajduje się w liniach od 67. do 77. Inicjalizacja obiektu tej klasy składa się z trzech instrukcji. Po pierwsze, konstruktor klasy Horse jest inicjalizowany kolorem i wysokością. Po drugie,

konstruktor klasy Bird jest inicjalizowany kolorem i wartością logiczną. Na koniec inicjalizowana jest zmienna składowa klasy Pegasus, itsNumberBelievers (ilość wierzących). Gdy proces ten zostanie zakończony, wywoływane jest ciał konstruktora obiektu Pegasus.
W funkcji main() tworzony jest wskaźnik do obiektu klasy Pegasus i zostaje on użyty do wywołania funkcji składowych klas bazowych tego obiektu.
Eliminowanie niejednoznaczności Na listingu 14.4 zarówno klasa Horse, jak i klasa Bird posiadały metodę GetColor() (pobierz kolor). Możemy poprosić obiekt Pegasus o podanie swojego koloru, ale będziemy mieli wtedy problem — klasa Pegasus dziedziczy zarówno po klasie Bird, jak i klasie Horse. Obie te klasy posiadają kolor, zaś metody odczytywania koloru tych klas mają te same nazwy i sygnatury. To powoduje niejednoznaczność, niezrozumiałą dla kompilatora. Spróbujemy rozwiązać ten problem.
Jeśli napiszemy po prostu:
COLOR currentColor = pPeg->GetColor();
otrzymamy błąd kompilatora:
Member is ambiguous: 'Horse::GetColor' and 'Bird::GetColor'
(składowa jest niejednoznaczna: 'Horse::GetColor' i 'Bird::GetColor')
Możemy zlikwidować tę niejednoznaczność przez jawne wywołanie funkcji, której chcemy użyć:
COLOR currentColor = pPeg->Horse::GetColor();
Za każdym razem, gdy chcemy określić klasę używanej funkcji lub danej składowej, możemy użyć pełnej kwalifikowanej nazwy, poprzedzając nazwę składowej nazwą klasy bazowej.
Zwróć uwagę, że gdyby klasa Pegasus przesłoniła tę funkcję, pytanie o kolor zostałoby przesunięte tak, jak powinno, do funkcji składowej klasy Pegasus:
virtual COLOR GetColor()const { return Horse::GetColor(); }
To powoduje ukrycie problemu przed klientami klasy Pegasus i ukrywa wewnątrz tej klasy wiedzę o tym, z której klasy bazowej obiekt chce odczytać swój kolor. Klient jednak w dalszym ciągu może wymusić odczytanie koloru z żądanej klasy, pisząc:
Usunięto: problem
Usunięto: y
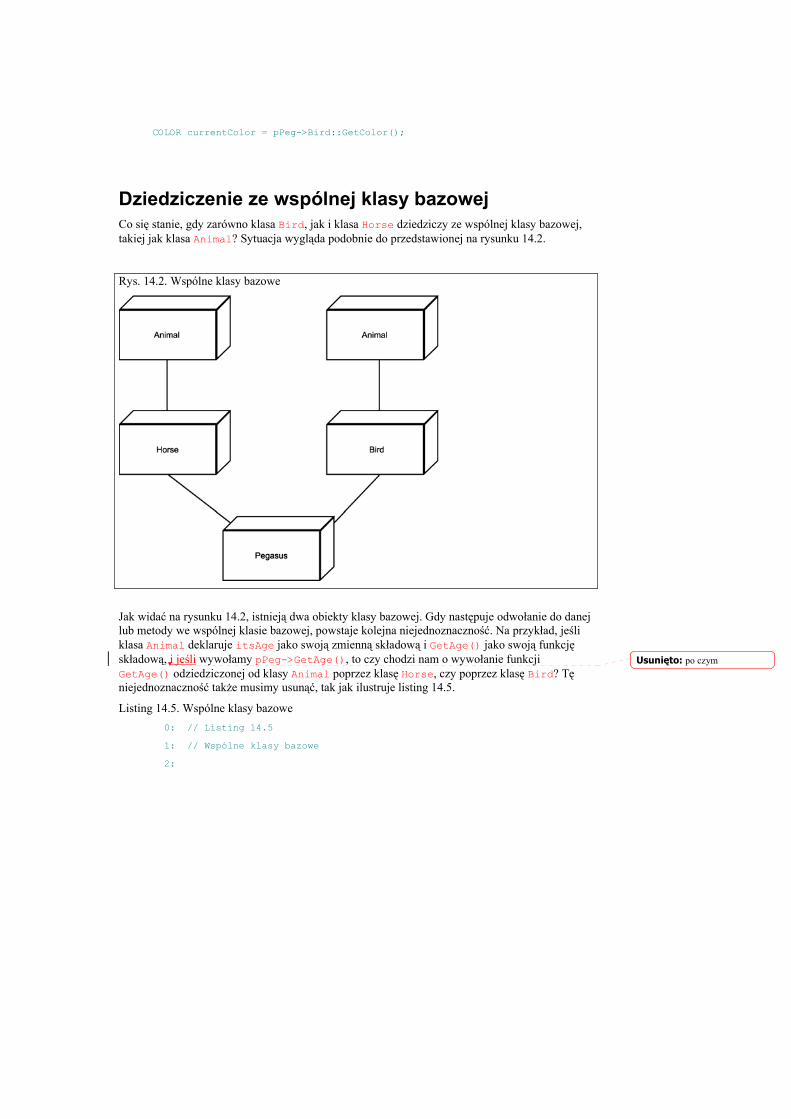
COLOR currentColor = pPeg->Bird::GetColor();
Dziedziczenie ze wspólnej klasy bazowej Co się stanie, gdy zarówno klasa Bird, jak i klasa Horse dziedziczy ze wspólnej klasy bazowej, takiej jak klasa Animal? Sytuacja wygląda podobnie do przedstawionej na rysunku 14.2.
Rys. 14.2. Wspólne klasy bazowe
Jak widać na rysunku 14.2, istnieją dwa obiekty klasy bazowej. Gdy następuje odwołanie do danej lub metody we wspólnej klasie bazowej, powstaje kolejna niejednoznaczność. Na przykład, jeśli klasa Animal deklaruje itsAge jako swoją zmienną składową i GetAge() jako swoją funkcję składową, i jeśli wywołamy pPeg->GetAge(), to czy chodzi nam o wywołanie funkcji GetAge() odziedziczonej od klasy Animal poprzez klasę Horse, czy poprzez klasę Bird? Tę niejednoznaczność także musimy usunąć, tak jak ilustruje listing 14.5.
Listing 14.5. Wspólne klasy bazowe 0: // Listing 14.5
1: // Wspólne klasy bazowe
2:
Usunięto: po czym

3: #include <iostream>
4: using namespace std;
5:
6: typedef int HANDS;
7: enum COLOR { Red, Green, Blue, Yellow, White, Black, Brown } ;
8:
9: class Animal // wspólna klasa dla klasy Bird i Horse
10: {
11: public:
12: Animal(int);
13: virtual ~Animal() { cout << "Destruktor klasy Animal...\n"; }
14: virtual int GetAge() const { return itsAge; }
15: virtual void SetAge(int age) { itsAge = age; }
16: private:
17: int itsAge;
18: };
19:
20: Animal::Animal(int age):
21: itsAge(age)
22: {
23: cout << "Konstruktor klasy Animal...\n";
24: }
25:
26: class Horse : public Animal
27: {
28: public:
29: Horse(COLOR color, HANDS height, int age);
30: virtual ~Horse() { cout << "Destruktor klasy Horse...\n"; }
31: virtual void Whinny()const { cout << "Ihaaa!... "; }
32: virtual HANDS GetHeight() const { return itsHeight; }
33: virtual COLOR GetColor() const { return itsColor; }
34: protected:
35: HANDS itsHeight;
36: COLOR itsColor;
37: };
38:
39: Horse::Horse(COLOR color, HANDS height, int age):

40: Animal(age),
41: itsColor(color),itsHeight(height)
42: {
43: cout << "Konstruktor klasy Horse...\n";
44: }
45:
46: class Bird : public Animal
47: {
48: public:
49: Bird(COLOR color, bool migrates, int age);
50: virtual ~Bird() {cout << "Destruktor klasy Bird...\n"; }
51: virtual void Chirp()const { cout << "Cwir, cwir... "; }
52: virtual void Fly()const
53: { cout << "Moge latac! Moge latac! Moge latac! "; }
54: virtual COLOR GetColor()const { return itsColor; }
55: virtual bool GetMigration() const { return itsMigration; }
56: protected:
57: COLOR itsColor;
58: bool itsMigration;
59: };
60:
61: Bird::Bird(COLOR color, bool migrates, int age):
62: Animal(age),
63: itsColor(color), itsMigration(migrates)
64: {
65: cout << "Konstruktor klasy Bird...\n";
66: }
67:
68: class Pegasus : public Horse, public Bird
69: {
70: public:
71: void Chirp()const { Whinny(); }
72: Pegasus(COLOR, HANDS, bool, long, int);
73: virtual ~Pegasus() {cout << "Destruktor klasy Pegasus...\n";}
74: virtual long GetNumberBelievers() const
75: { return itsNumberBelievers; }
76: virtual COLOR GetColor()const { return Horse::itsColor; }

77: virtual int GetAge() const { return Horse::GetAge(); }
78: private:
79: long itsNumberBelievers;
80: };
81:
82: Pegasus::Pegasus(
83: COLOR aColor,
84: HANDS height,
85: bool migrates,
86: long NumBelieve,
87: int age):
88: Horse(aColor, height,age),
89: Bird(aColor, migrates,age),
90: itsNumberBelievers(NumBelieve)
91: {
92: cout << "Konstruktor klasy Pegasus...\n";
93: }
94:
95: int main()
96: {
97: Pegasus *pPeg = new Pegasus(Red, 5, true, 10, 2);
98: int age = pPeg->GetAge();
99: cout << "Ten pegaz ma " << age << " lat.\n";
100: delete pPeg;
101: return 0;
102: }
Wynik Konstruktor klasy Animal...
Konstruktor klasy Horse...
Konstruktor klasy Animal...
Konstruktor klasy Bird...
Konstruktor klasy Pegasus...
Ten pegaz ma 2 lat.
Destruktor klasy Pegasus...
Destruktor klasy Bird...

Destruktor klasy Animal...
Destruktor klasy Horse...
Destruktor klasy Animal...
Analiza
Na tym listingu występuje kilka ciekawych elementów. W liniach od 9. do 18. została zadeklarowana klasa Animal. Klasa ta posiada własną zmienną składową, itsAge, oraz dwa akcesory przeznaczone do jej odczytywania i ustawiania: GetAge() i SetAge().
W linii 26. rozpoczyna się deklaracja klasy Horse, wyprowadzonej z klasy Animal. Obecnie konstruktor klasy Horse posiada trzeci parametr, age (wiek), który przekazuje do swojej klasy bazowej. Zwróćmy uwagę, że klasa Horse nie przesłania metody GetAge(), lecz po prostu ją dziedziczy.
W linii 46. rozpoczyna się deklaracja klasy Bird, także wyprowadzonej z klasy Animal. Jej konstruktor także otrzymuje wiek i używa go do inicjalizacji swojej klasy bazowej. Oprócz tego, także w tej klasie nie jest przesłaniana metoda GetAge().
Klasa Pegasus dziedziczy po klasach Bird i Horse, więc w swoim łańcuchu dziedziczenia posiada dwie klasy Animal. Gdybyśmy zechcieli wywołać funkcję GetAge() dla obiektu klasy Pegasus, musielibyśmy usunąć niejednoznaczność, czyli użyć pełnej kwalifikowanej nazwy metody, której chcielibyśmy użyć.
Problem ten zostaje rozwiązany w linii 77., w której klasa Pegasus przesłania metodę GetAge() tak, aby nie robiła niczego poza przekazaniem wywołania w górę, do którejś z metod w klasach bazowych.
Przekazywanie w górę odbywa się z dwóch powodów: albo w celu rozwiązania niejednoznaczności wywołania metody klasy bazowej, tak jak w tym przypadku, albo w celu wykonania pewnej pracy, a następnie pozwolenia, by klasa bazowa wykonała dodatkową pracę. Czasem zechcemy wykonać pracę i dopiero potem wywołać metodę klasy bazowej, a czasem zechcemy najpierw wywołać metodę klasy bazowej, a dopiero po powrocie z niej wykonać swoją pracę.
Konstruktor klasy Pegasus posiada pięć parametrów: jego kolor, wysokość (w DŁONIACH), zmienną określającą, czy migruje, ilość wierzących w niego osób oraz wiek. Konstruktor inicjalizuje część Horse obiektu kolorem, wysokością i wiekiem (w linii 89.). Część Bird inicjalizowana jest kolorem, określeniem, czy migruje oraz wiekiem (w linii 88.). Na zakończenie, w linii 90., konstruktor inicjalizuje swoją składową itsNumberBelievers.
Wywołanie konstruktora klasy Horse w linii 88. powoduje wywołanie jego implementacji zawartej w linii 39. Konstruktor klasy Horse używa parametru age do zainicjalizowania części Animal obiektu klasy Pagasus. Następnie inicjalizuje dwie składowe klasy Horse — itsColor oraz itsHeight.
Wywołanie konstruktora klasy Bird w linii 89. wywołuje jego implementację zawartą w linii 61. Także w tym przypadku parametr age jest używany do zainicjalizowania części Animal obiektu.
Zwróć uwagę, że parametr koloru przekazany konstruktorowi klasy Pegasus jest używany do zainicjalizowania zmiennych składowych zarówno w klasie Bird, jak i klasie Horse. Zauważ

także. że parametr age jest używany do zainicjalizowania wieku (zmiennej itsAge) w klasie Animal, otrzymanej od klasy Bird oraz w klasie Animal, otrzymanej od klasy Horse.
Dziedziczenie wirtualne Na listingu 14.5 pokazano, jak klasa Pegasus musiała usuwać pewne niejednoznaczności związane z tym, która z bazowych klas Animal miała być użyta. W większości przypadków taka decyzja może być dowolna — w końcu klasy Horse i Bird mają tę samą klasę bazową.
Istnieje możliwość poinformowania C++, że nie chcemy mieć dwóch kopii wspólnej klasy bazowej, tak jak widzieliśmy na rysunku 14.2, ale że chcemy mieć pojedynczą wspólną klasę bazową, tak jak pokazano na rysunku 14.3.
Rys. 14.3. Dziedziczenie wirtualne
Osiągniemy to, czyniąc z klasy Animal wirtualną klasę bazową zarówno dla klasy Horse, jak i klasy Bird. Klasa Animal nie ulega żadnej zmianie. W deklaracjach klas Horse i Bird przed nazwą klasy Animal dodawane jest jedynie słowo kluczowe virtual. Jednak klasa Pegasus podlega już większym modyfikacjom.
Normalnie konstruktor klasy inicjalizuje tylko swoje własne zmienne i swoją klasę bazową. Klasy bazowe dziedziczone wirtualnie są jednak wyjątkiem. Są one inicjalizowane przez swoje najbardziej wyprowadzone klasy. Tak więc klasa Animal nie będzie inicjalizowana przez klasy

Horse i Bird, ale przez klasę Pegasus. Klasy Horse i Bird muszą w swoich konstruktorach inicjalizować klasę Animal, ale w przypadku tworzenia obiektu klasy Pegasus te inicjalizacje są ignorowane.
Listing 14.6 zawiera zmodyfikowaną wersję listingu 14.5, wykorzystującą zalety dziedziczenia wirtualnego.
Listing 14.6. Przykład użycia dziedziczenia wirtualnego 0: // Listing 14.6
1: // Dziedziczenie wirtualne
2: #include <iostream>
3: using namespace std;
4:
5: typedef int HANDS;
6: enum COLOR { Red, Green, Blue, Yellow, White, Black, Brown } ;
7:
8: class Animal // wspólna klasa dla klasy Bird i Horse
9: {
10: public:
11: Animal(int);
12: virtual ~Animal() { cout << "Destruktor klasy Animal...\n"; }
13: virtual int GetAge() const { return itsAge; }
14: virtual void SetAge(int age) { itsAge = age; }
15: private:
16: int itsAge;
17: };
18:
19: Animal::Animal(int age):
20: itsAge(age)
21: {
22: cout << "Konstruktor klasy Animal...\n";
23: }
24:
25: class Horse : virtual public Animal
26: {
27: public:
28: Horse(COLOR color, HANDS height, int age);
29: virtual ~Horse() { cout << "Destruktor klasy Horse...\n"; }
30: virtual void Whinny()const { cout << "Ihaaa!... "; }

31: virtual HANDS GetHeight() const { return itsHeight; }
32: virtual COLOR GetColor() const { return itsColor; }
33: protected:
34: HANDS itsHeight;
35: COLOR itsColor;
36: };
37:
38: Horse::Horse(COLOR color, HANDS height, int age):
39: Animal(age),
40: itsColor(color),itsHeight(height)
41: {
42: cout << "Konstruktor klasy Horse...\n";
43: }
44:
45: class Bird : virtual public Animal
46: {
47: public:
48: Bird(COLOR color, bool migrates, int age);
49: virtual ~Bird() {cout << "Destruktor klasy Bird...\n"; }
50: virtual void Chirp()const { cout << "Cwir, cwir... "; }
51: virtual void Fly()const
52: { cout << "Moge latac! Moge latac! Moge latac! "; }
53: virtual COLOR GetColor()const { return itsColor; }
54: virtual bool GetMigration() const { return itsMigration; }
55: protected:
56: COLOR itsColor;
57: bool itsMigration;
58: };
59:
60: Bird::Bird(COLOR color, bool migrates, int age):
61: Animal(age),
62: itsColor(color), itsMigration(migrates)
63: {
64: cout << "Konstruktor klasy Bird...\n";
65: }
66:
67: class Pegasus : public Horse, public Bird

68: {
69: public:
70: void Chirp()const { Whinny(); }
71: Pegasus(COLOR, HANDS, bool, long, int);
72: virtual ~Pegasus() {cout << "Destruktor klasy Pegasus...\n";}
73: virtual long GetNumberBelievers() const
74: { return itsNumberBelievers; }
75: virtual COLOR GetColor()const { return Horse::itsColor; }
76: private:
77: long itsNumberBelievers;
78: };
79:
80: Pegasus::Pegasus(
81: COLOR aColor,
82: HANDS height,
83: bool migrates,
84: long NumBelieve,
85: int age):
86: Horse(aColor, height,age),
87: Bird(aColor, migrates,age),
88: Animal(age*2),
89: itsNumberBelievers(NumBelieve)
90: {
91: cout << "Konstruktor klasy Pegasus...\n";
92: }
93:
94: int main()
95: {
96: Pegasus *pPeg = new Pegasus(Red, 5, true, 10, 2);
97: int age = pPeg->GetAge();
98: cout << "Ten pegaz ma " << age << " lat.\n";
99: delete pPeg;
100: return 0;
101: }
Wynik Konstruktor klasy Animal...

Konstruktor klasy Horse...
Konstruktor klasy Bird...
Konstruktor klasy Pegasus...
Ten pegaz ma 4 lat.
Destruktor klasy Pegasus...
Destruktor klasy Bird...
Destruktor klasy Horse...
Destruktor klasy Animal...
Analiza
W linii 25. klasa Horse deklaruje, że dziedziczy wirtualnie po klasie Animal.Tę samą deklarację zgłasza klasa Bird w linii 45. Zauważ, że konstruktory obu tych klas nadal inicjalizują obiekt Animal.
Klasa Pegasus dziedziczy po klasach Bird i Horse, i z tej racji, jako najbardziej wyprowadzona klasa, musi inicjalizować klasę Animal. Podczas inicjalizacji obiektu klasy Pegasus, wywołania konstruktora klasy Animal w konstruktorach klas Bird i Horse są ignorowane. Możemy to zobaczyć, gdyż do konstruktora przekazywana jest wartość 2, która w klasach Horse i Bird byłaby przekazywana dalej (do Animal), natomiast w klasie Pegasus jest podwajana. Rezultat, wartość 4, został odzwierciedlony w komunikacie wypisywanym w linii 98. i widocznym w wynikach.
Klasa Pegasus nie musi już usuwać niejednoznaczności wywołania metody GetAge() i może po prostu odziedziczyć tę funkcję od klasy Animal. Zauważ jednak, że klasa Pegasus musi w dalszym ciągu usuwać niejednoznaczność wywołania metody GetColor(), gdyż ta funkcja występuje w obu klasach bazowych, a nie w klasie Animal.
Deklarowanie klas dla dziedziczenia wirtualnego
Aby zapewnić, że wyprowadzone klasy mają tylko jeden egzemplarz wspólnej klasy bazowej, zadeklaruj klasy pośrednie tak, aby dziedziczyły wirtualnie po klasie bazowej.
Przykład 1
class Horse : virtual public Animal
class Bird : virtual public Animal
class Pegasus : public Horse, public Bird
Przykład 2
class Schnauzer : virtual public Dog
class Poodle : virtual public Dog
Usunięto: , zaś w linii 45 klasa Bird zgłasza t
Usunięto: zaś
Usunięto: ów
Usunięto: jest
Usunięto: wirtualnie

class Schnoodle : public Schnauzer, public Poodle
Problemy z dziedziczeniem wielokrotnym Choć dziedziczenie wielokrotne w porówniu do dziedziczenia pojedynczego posiada kilka zalet, jednak wielu programistów C++ korzysta z niego niechętnie. Tłumaczą to faktem, iż wiele kompilatorów jeszcze go nie obsługuje, że utrudnia ono debuggowanie oraz że prawie wszystko to, co można uzyskać dzięki dziedziczeniu wielokrotnemu, da się uzyskać także bez niego.
Są to ważkie powody i sam powinieneś uważać, by nie komplikować niepotrzebnie swoich programów. Niektóre debuggery nie radzą sobie z dziedziczeniem wielokrotnym; zdarza się też, że wprowadzenie wielokrotnego dziedziczenia niepotrzebnie komplikuje projekt programu.
TAK NIE
Używaj dziedziczenia wielokrotnego, jeśli nowa klasa wymaga funkcji i cech pochodzących z więcej niż jednej klasy bazowej.
Używaj dziedziczenia wirtualnego wtedy, gdy najbardziej wyprowadzona klasa musi posiadać tylko jeden egzemplarz wspólnej klasy bazowej.
Używając wirtualnych klas bazowych, inicjalizuj wspólną klasę bazową w klasie najbardziej wyprowadzonej.
Nie używaj dziedziczenia wielokrotnego tam, gdzie wystarczy dziedziczenie pojedyncze.
Mixiny i klasy metod Jednym ze sposobów uzyskania efektu pośredniego pomiędzy dziedziczeniem wielokrotnym a pojedynczym jest użycie tak zwanych mixinów. Możemy więc wyprowadzić klasę Horse z klasy Animal oraz z klasy Displayable (możliwy do wyświetlenia). Klasa Displayable będzie posiadała jedynie kilka metod służących do wyświetlenia dowolnego obiektu na ekranie.
Mixin, czyli klasa metod, jest klasą zwiększającą funkcjonalność, ale nie posiadającą własnych danych lub posiadającą ich bardzo niewiele.
Klasy metod są łączone (miksowane — stąd nazwa) z klasami wyprowadzanymi w taki sam sposób, jak wszystkie inne klasy: przez zadeklarowanie klasy wyprowadzonej jako klasy publicznie po nich dziedziczącej. Jedyną różnicą między klasą metod a inną klasą jest to, że klasa metod zwykle nie zawiera danych. Jest to oczywiście rozróżnienie dość dowolne, które przypomina jedynie, że czasem jedyną rzeczą, jakiej potrzebujemy, jest dołączenie pewnych dodatkowych możliwości bez komplikowania klasy wyprowadzonej.
Usunięto: z klas.
Usunięto: dodającą
Usunięto: a
Usunięto: a
Usunięto: po

W przypadku pewnych debuggerów łatwiej jest pracować z mixinami niż z bardziej złożonymi obiektami dziedziczonymi wielokrotnie. Oprócz tego prawdopodobieństwo wystąpienia niejednoznaczności przy dostępie do danych w innych podstawowych klasach bazowych jest mniejsze.
Na przykład, gdyby klasa Horse dziedziczyła po klasach Animal i Displayable, wtedy klasa Displayable nie zawierałaby żadnych danych. Klasa Animal wyglądałaby tak jak zwykle, więc wszystkie dane w klasie Horse pochodziłyby z klasy Animal, zaś funkcje składowe pochodziłyby z obu klas bazowych.
Określenie mixin narodziło się w pewnej lodziarni w Sommerville w stanie Massachusetts, w której z podstawowymi smakami lodów miksowano różne ciastka i słodycze. Dla odwiedzających lodziarnię programistów zorientowanych obiektowo stanowiło to dobrą metaforę, szczególnie wtedy, gdy pracowali nad obiektowo zorientowanym językiem SCOOPS.
Abstrakcyjne typy danych Często hierarchie klas tworzone są wspólnie. Na przykład, możemy stworzyć klasę Shape (kształt), a z niej wyprowadzić klasy Rectangle (prostokąt) i Circle (okrąg). Z klasy Rectangle możemy wyprowadzić klasę Square (kwadrat), stanowiącą specjalny przypadek prostokąta.
W każdej z wyprowadzonych klas zostanie przesłonięta metoda Draw() (rysuj), GetArea() (pobierz obszar), i tak dalej. Listing 14.7 ilustruje podstawowy szkielet implementacji klasy Shape i wyprowadzonych z niej klas Circle i Rectangle.
Listing 14.7. Klasy kształtów 0: //Listing 14.7. Klasy kształtów
1:
2: #include <iostream>
3: using std::cout;
4: using std::cin;
5: using std::endl;
6:
7: class Shape
8: {
9: public:
10: Shape(){}
11: virtual ~Shape(){}
12: virtual long GetArea() { return -1; } // błąd
13: virtual long GetPerim() { return -1; }
14: virtual void Draw() {}

15: private:
16: };
17:
18: class Circle : public Shape
19: {
20: public:
21: Circle(int radius):itsRadius(radius){}
22: ~Circle(){}
23: long GetArea() { return 3 * itsRadius * itsRadius; }
24: long GetPerim() { return 6 * itsRadius; }
25: void Draw();
26: private:
27: int itsRadius;
28: int itsCircumference;
29: };
30:
31: void Circle::Draw()
32: {
33: cout << "Procedura rysowania okregu!\n";
34: }
35:
36:
37: class Rectangle : public Shape
38: {
39: public:
40: Rectangle(int len, int width):
41: itsLength(len), itsWidth(width){}
42: virtual ~Rectangle(){}
43: virtual long GetArea() { return itsLength * itsWidth; }
44: virtual long GetPerim() {return 2*itsLength + 2*itsWidth; }
45: virtual int GetLength() { return itsLength; }
46: virtual int GetWidth() { return itsWidth; }
47: virtual void Draw();
48: private:
49: int itsWidth;
50: int itsLength;
51: };

52:
53: void Rectangle::Draw()
54: {
55: for (int i = 0; i<itsLength; i++)
56: {
57: for (int j = 0; j<itsWidth; j++)
58: cout << "x ";
59:
60: cout << "\n";
61: }
62: }
63:
64: class Square : public Rectangle
65: {
66: public:
67: Square(int len);
68: Square(int len, int width);
69: ~Square(){}
70: long GetPerim() {return 4 * GetLength();}
71: };
72:
73: Square::Square(int len):
74: Rectangle(len,len)
75: {}
76:
77: Square::Square(int len, int width):
78: Rectangle(len,width)
79: {
80: if (GetLength() != GetWidth())
81: cout << "Blad, nie Square... Moze Rectangle??\n";
82: }
83:
84: int main()
85: {
86: int choice;
87: bool fQuit = false;
88: Shape * sp;

89:
90: while ( !fQuit )
91: {
92: cout << "(1)Circle (2)Rectangle (3)Square (0)Wyjscie: ";
93: cin >> choice;
94:
95: switch (choice)
96: {
97: case 0: fQuit = true;
98: break;
99: case 1: sp = new Circle(5);
100: break;
101: case 2: sp = new Rectangle(4,6);
102: break;
103: case 3: sp = new Square(5);
104: break;
105: default: cout<<"Wpisz liczbe pomiedzy 0 a 3"<<endl;
106: continue;
107: break;
108: }
109: if( !fQuit )
110: sp->Draw();
111: delete sp;
112: sp = 0;
113: cout << "\n";
114: }
115: return 0;
116: }
Wynik (1)Circle (2)Rectangle (3)Square (0)Wyjscie: 2
x x x x x x
x x x x x x
x x x x x x
x x x x x x

(1)Circle (2)Rectangle (3)Square (0)Wyjscie: 3
x x x x x
x x x x x
x x x x x
x x x x x
x x x x x
(1)Circle (2)Rectangle (3)Square (0)Wyjscie: 0
Analiza
W liniach od 7. do 16. tworzona jest klasa Shape. Metody GetArea() i GetPerim() (pobierz obwód) zwracają wartość, będącą kodem błędu, zaś metoda Draw() nie robi niczego. Właściwie, co to znaczy: narysować „kształt”? Można rysować jedynie rodzaje kształtów (okręgi, prostokąty, itd.); kształt jako taki jest abstrakcją, której nie można narysować.
Klasa Circle jest wyprowadzona z klasy Shape i przesłania jej trzy metody wirtualne. Zauważ, że nie ma powodu do stosowania słowa kluczowego virtual, gdyż jest to część ich dziedziczenia. Nie zaszkodzi jednak tego uczynić, tak jak pokazano w klasie Rectangle w liniach 43., 44. oraz 47. Dobrym nawykiem jest stosowanie słowa kluczowego virtual w celu przypomnienia (jako formy dokumentacji).
Klasa Square jest wyprowadzona z klasy Rectangle; została w niej przesłonięta metoda GetPerim(), zaś inne metody zostały odziedziczone od klasy Rectangle.
Kłopoty mogą pojawić się, gdy klient spróbuje stworzyć egzemplarz obiektu klasy Shape, należy mu to uniemożliwić. Klasa Shape istnieje tylko po to, by dostarczać interfejsu dla wyprowadzonych z niej klas; jako taka jest abstrakcyjnym typem danych, czyli ADT (abstract data type).
Abstrakcyjny typ danych reprezentuje koncepcję (taką jak kształt), a nie sam obiekt (na przykład okrąg). W C++ ADT jest zawsze klasą bazową innych klas; tworzenie egzemplarzy obiektów klas abstrakcyjnych nie jest możliwe.
Czyste funkcje wirtualne C++ obsługuje tworzenie abstrakcyjnych typów danych poprzez czyste funkcje wirtualne. Funkcja wirtualna staje się „czysta”, gdy zainicjalizujemy ją wartością zero, tak jak:
virtual void Draw() = 0;
Każda klasa, zawierająca jedną lub więcej czystych funkcji wirtualnych, staje się abstrakcyjnym typem danych i nie jest możliwe tworzenie jej obiektów. Próba stworzenia obiektu klasy abstrakcyjnej powoduje błąd kompilacji. Umieszczenie w klasie czystej funkcji wirtualnej sygnalizuje aplikacjom-klientom tej klasy dwie rzeczy:
Usunięto: y

• aby nie tworzyły obiektów tej klasy, a jedynie wyprowadzały z niej nowe klasy;
• aby zapewniły, że czysta funkcja wirtualna jest przesłaniana.
Każda klasa wyprowadzona z klasy abstrakcyjnej dziedziczy czystą funkcję wirtualną jako czystą, dlatego, aby móc tworzyć egzemplarze obiektów, musi przesłonić każdą czystą funkcję wirtualną. Zatem, gdyby klasa Rectangle dziedziczyła po klasie Shape i klasa Shape miała trzy czyste funkcje wirtualne, wtedy klasa Rectangle musiałaby przesłonić wszystkie trzy funkcje, gdyż w przeciwnym razie sama stałaby się klasą abstrakcyjną. Listing 14.8 został przepisany tak, aby klasa Shape stała się klasą abstrakcyjną. Aby zaoszczędzić miejsca, nie została tu pokazana pozostała część listingu 14.7. Zamień deklarację klasy Shape na listingu 14.7, linie od 7. do 16., deklaracją klasy Shape z listingu 14.8, po czym uruchom program ponownie.
Listing 14.8. Abstrakcyjne typy danych 0: //Listing 14.8 Abstrakcyjne typy danych
1:
2: class Shape
3: {
4: public:
5: Shape(){}
6: ~Shape(){}
7: virtual long GetArea() = 0;
8: virtual long GetPerim()= 0;
9: virtual void Draw() = 0;
10: private:
11: };
Wynik (1)Circle (2)Rectangle (3)Square (0)Wyjscie: 2
x x x x x x
x x x x x x
x x x x x x
x x x x x x
(1)Circle (2)Rectangle (3)Square (0)Wyjscie: 3
x x x x x
x x x x x
x x x x x
x x x x x
x x x x x
Usunięto: jeśli chce
Usunięto: y
Usunięto: // błąd
(1)Circle (2)Rectangle (3)Square (0)Wyjscie: 0
Analiza
Jak widać, działanie programu nie zmieniło się. Jedyną różnicą jest to, że teraz nie jest możliwe stworzenie obiektu klasy Shape.
Abstrakcyjne typy danych
Klasa abstrakcyjna powstaje wtedy, gdy w jej deklaracji znajdzie się jedna lub więcej czystych funkcji wirtualnych. Funkcja wirtualna staje się „czysta”, gdy do jej deklaracji dopiszemy = 0.
Przykład
class Shape
{
virtual void Draw() = 0; // czysta funkcja wirtualna
};
Implementowanie czystych funkcji wirtualnych Zwykle czyste funkcje wirtualne nie są implementowane w abstrakcyjnej klasie bazowej. Ponieważ nigdy nie są tworzone obiekty tego typu, nie ma powodu do dostarczania implementacji; klasa abstrakcyjna funkcjonuje wyłącznie jako definicja interfejsu dla obiektów z niej wyprowadzanych.
Czyste funkcje wirtualne mogą być jednak implementowane. Taka funkcja może być wywoływana przez klasy wyprowadzone z klasy abstrakcyjnej, na przykład w celu zapewnienia wspólnej funkcjoalności wszystkich funkcji przesłoniętych. Listing 14.9 stanowi reprodukcję listingu 14.7, w którym klasa Shape jest tym razem klasą abstrakcyjną, zawierającą implementację czystej funkcji wirtualnej Draw(). Klasa Circle przesłania funkcję Draw(), gdyż musi, ale potem przekazuje wywołanie do klasy bazowej, w celu skorzystania z dodatkowej funkcjonalności.
W tym przykładzie dodatkowa funkcjonalność polega po prostu na wypisaniu dodatkowego komunikatu, ale można sobie wyobrazić, że klasa bazowa mogłaby zawierać wspólny mechanizm rysowania, który mógłby pomóc w przygotowaniu okna używanego przez wszystkie wyprowadzone klasy.
Listing 14.9. Implementowanie czystych funkcji wirtualnych 0: //Listing 14.9 Implementowanie czystych funkcji wirtualnych
1:
2: #include <iostream>
Usunięto: funkcji
Usunięto: to

3: using namespace std;
4:
5: class Shape
6: {
7: public:
8: Shape(){}
9: virtual ~Shape(){}
10: virtual long GetArea() = 0; // błąd
11: virtual long GetPerim()= 0;
12: virtual void Draw() = 0;
13: private:
14: };
15:
16: void Shape::Draw()
17: {
18: cout << "Abstrakcyjny mechanizm rysowania!\n";
19: }
20:
21: class Circle : public Shape
22: {
23: public:
24: Circle(int radius):itsRadius(radius){}
25: virtual ~Circle(){}
26: long GetArea() { return 3 * itsRadius * itsRadius; }
27: long GetPerim() { return 9 * itsRadius; }
28: void Draw();
29: private:
30: int itsRadius;
31: int itsCircumference;
32: };
33:
34: void Circle::Draw()
35: {
36: cout << "Procedura rysowania okregu!\n";
37: Shape::Draw();
38: }
39:

40:
41: class Rectangle : public Shape
42: {
43: public:
44: Rectangle(int len, int width):
45: itsLength(len), itsWidth(width){}
46: virtual ~Rectangle(){}
47: long GetArea() { return itsLength * itsWidth; }
48: long GetPerim() {return 2*itsLength + 2*itsWidth; }
49: virtual int GetLength() { return itsLength; }
50: virtual int GetWidth() { return itsWidth; }
51: void Draw();
52: private:
53: int itsWidth;
54: int itsLength;
55: };
56:
57: void Rectangle::Draw()
58: {
59: for (int i = 0; i<itsLength; i++)
60: {
61: for (int j = 0; j<itsWidth; j++)
62: cout << "x ";
63:
64: cout << "\n";
65: }
66: Shape::Draw();
67: }
68:
69:
70: class Square : public Rectangle
71: {
72: public:
73: Square(int len);
74: Square(int len, int width);
75: virtual ~Square(){}
76: long GetPerim() {return 4 * GetLength();}

77: };
78:
79: Square::Square(int len):
80: Rectangle(len,len)
81: {}
82:
83: Square::Square(int len, int width):
84: Rectangle(len,width)
85:
86: {
87: if (GetLength() != GetWidth())
88: cout << "Blad, nie Square... moze Rectangle??\n";
89: }
90:
91: int main()
92: {
93: int choice;
94: bool fQuit = false;
95: Shape * sp;
96:
97: while (1)
98: {
99: cout << "(1)Circle (2)Rectangle (3)Square (0)Wyjscie: ";
100: cin >> choice;
101:
102: switch (choice)
103: {
104: case 1: sp = new Circle(5);
105: break;
106: case 2: sp = new Rectangle(4,6);
107: break;
108: case 3: sp = new Square (5);
109: break;
110: default: fQuit = true;
111: break;
112: }
113: if (fQuit)

114: break;
115:
116: sp->Draw();
117: delete sp;
118: cout << "\n";
119: }
120: return 0;
121: }
Wynik (1)Circle (2)Rectangle (3)Square (0)Wyjscie: 2
x x x x x x
x x x x x x
x x x x x x
x x x x x x
Abstrakcyjny mechanizm rysowania!
(1)Circle (2)Rectangle (3)Square (0)Wyjscie: 3
x x x x x
x x x x x
x x x x x
x x x x x
x x x x x
Abstrakcyjny mechanizm rysowania!
(1)Circle (2)Rectangle (3)Square (0)Wyjscie: 0
Analiza
W liniach od 5. do 14. została zadeklarowana abstrakcyjna klasa Shape, której wszystkie trzy metody użytkowe zostały zadeklarowane jako czyste funkcje wirtualne. Zwróć uwagę, że nie jest to konieczne. Gdyby którakolwiek z tych metod zostałaby zadeklarowana jako czysta, i tak cała klasa byłaby traktowana jako abstrakcyjna.
Metody GetArea() oraz GetPerim() nie zostały zaimplementowane (w przeciwieństwie do metody Draw()). W klasach Circle i Rectangle metoda Draw() została przesłonięta, jednakże w obu przypadkach, w przesłoniętych wersjach jest wywoływana także metoda klasy bazowej, w celu dodatkowego skorzystania ze wspólnej funkcjonalności.
Usunięto: i

Złożone hierarchie abstrakcji Czasem zdarza się, że wyprowadzamy klasy abstrakcyjne z innych klas abstrakcyjnych. Być może zechcemy zmienić niektóre z odziedziczonych czystych funkcji wirtualnych w zwykłe funkcje, zaś inne pozostawić jako czyste.
Jeśli stworzymy klasę Animal, to wszystkie metody typu Eat() (jedzenie), Sleep() (spanie), Move() (poruszanie się) i Reproduce() (rozmnażanie) możemy zmienić na czyste funkcje wirtualne. Być może, zechcesz następnie wyprowadzić z klasy Animal na przykład klasę Mammal (ssak) lub Fish (ryba).
Po dłuższej analizie hierarchii, możemy zdecydować, że każdy ssak będzie rozmnażał się w ten sam sposób, więc metodę Mammal::Reproduce() zamienimy w zwykłą funkcję, pozostawiając metody Eat(), Sleep() i Move() w postaci czystych funkcji wirtualnych.
Z klasy Mammal wyprowadzimy klasę Dog (pies), w której musimy przesłonić i zaimplementować trzy pozostałe czyste funkcje wirtualne tak, aby móc tworzyć egzemplarze obiektów tej klasy.
Jako projektanci klasy stwierdzamy fakt, że nie można tworzyć egzemplarzy klas Animal i Mammal, i że wszystkie obiekty klasy Mammal mogą dziedziczyć dostarczoną metodę Reproduce() bez konieczności jej przesłaniania.
Technikę tę ilustruje listing 14.10; zastosowano w nim jedynie szkieletową implementację omawianych klas.
Listing 14.10. Wyprowadzanie klas abstrakcyjnych z innych klas abstrakcyjnych 0: // Listing 14.10
1: // Wyprowadzanie klas abstrakcyjnych z innych klas abstrakcyjnych
2: #include <iostream>
3: using namespace std;
4:
5: enum COLOR { Red, Green, Blue, Yellow, White, Black, Brown } ;
6:
7: class Animal // wspólna klasa bazowa dla klas Mammal i Fish
8: {
9: public:
10: Animal(int);
11: virtual ~Animal() { cout << "Destruktor klasy Animal...\n"; }
12: virtual int GetAge() const { return itsAge; }
13: virtual void SetAge(int age) { itsAge = age; }
14: virtual void Sleep() const = 0;
15: virtual void Eat() const = 0;
16: virtual void Reproduce() const = 0;
17: virtual void Move() const = 0;
18: virtual void Speak() const = 0;
Usunięto: y
Usunięto: wszystkie
Usunięto: N
Usunięto: możemy
Usunięto: wyprowadzić
Usunięto: y

19: private:
20: int itsAge;
21: };
22:
23: Animal::Animal(int age):
24: itsAge(age)
25: {
26: cout << "Konstruktor klasy Animal...\n";
27: }
28:
29: class Mammal : public Animal
30: {
31: public:
32: Mammal(int age):Animal(age)
33: { cout << "Konstruktor klasy Mammal...\n";}
34: virtual ~Mammal() { cout << "Destruktor klasy Mammal...\n";}
35: virtual void Reproduce() const
36: { cout << "Rozmnazanie dla klasy Mammal...\n"; }
37: };
38:
39: class Fish : public Animal
40: {
41: public:
42: Fish(int age):Animal(age)
43: { cout << "Konstruktor klasy Fish...\n";}
44: virtual ~Fish() {cout << "Destruktor klasy Fish...\n"; }
45: virtual void Sleep() const { cout << "Ryba spi...\n"; }
46: virtual void Eat() const { cout << "Ryba zeruje...\n"; }
47: virtual void Reproduce() const
48: { cout << "Ryba sklada jaja...\n"; }
49: virtual void Move() const
50: { cout << "Ryba plywa...\n"; }
51: virtual void Speak() const { }
52: };
53:
54: class Horse : public Mammal
55: {

56: public:
57: Horse(int age, COLOR color ):
58: Mammal(age), itsColor(color)
59: { cout << "Konstruktor klasy Horse...\n"; }
60: virtual ~Horse() { cout << "Destruktor klasy Horse...\n"; }
61: virtual void Speak()const { cout << "Ihaaa!... \n"; }
62: virtual COLOR GetItsColor() const { return itsColor; }
63: virtual void Sleep() const
64: { cout << "Kon spi...\n"; }
65: virtual void Eat() const { cout << "Kon sie pasie...\n"; }
66: virtual void Move() const { cout << "Kon biegnie...\n";}
67:
68: protected:
69: COLOR itsColor;
70: };
71:
72: class Dog : public Mammal
73: {
74: public:
75: Dog(int age, COLOR color ):
76: Mammal(age), itsColor(color)
77: { cout << "Konstruktor klasy Dog...\n"; }
78: virtual ~Dog() { cout << "Destruktor klasy Dog...\n"; }
79: virtual void Speak()const { cout << "Hau, hau!... \n"; }
80: virtual void Sleep() const { cout << "Pies chrapie...\n"; }
81: virtual void Eat() const { cout << "Pies je...\n"; }
82: virtual void Move() const { cout << "Pies biegnie...\n"; }
83: virtual void Reproduce() const
84: { cout << "Pies sie rozmnaza...\n"; }
85:
86: protected:
87: COLOR itsColor;
88: };
89:
90: int main()
91: {
92: Animal *pAnimal=0;

93: int choice;
94: bool fQuit = false;
95:
96: while (1)
97: {
98: cout << "(1)Dog (2)Horse (3)Fish (0)Quit: ";
99: cin >> choice;
100:
101: switch (choice)
102: {
103: case 1: pAnimal = new Dog(5,Brown);
104: break;
105: case 2: pAnimal = new Horse(4,Black);
106: break;
107: case 3: pAnimal = new Fish (5);
108: break;
109: default: fQuit = true;
110: break;
111: }
112: if (fQuit)
113: break;
114:
115: pAnimal->Speak();
116: pAnimal->Eat();
117: pAnimal->Reproduce();
118: pAnimal->Move();
119: pAnimal->Sleep();
120: delete pAnimal;
121: cout << "\n";
122: }
123: return 0;
124: }
Wynik (1)Dog (2)Horse (3)Fish (0)Quit: 1
Konstruktor klasy Animal...
Konstruktor klasy Mammal...

Konstruktor klasy Dog...
Hau, hau!...
Pies je...
Pies sie rozmnaza...
Pies biegnie...
Pies chrapie...
Destruktor klasy Dog...
Destruktor klasy Mammal...
Destruktor klasy Animal...
(1)Dog (2)Horse (3)Fish (0)Quit: 0
Analiza
W liniach od 7. do 21. została zadeklarowana abstrakcyjna klasa Animal. Klasa ta posiada zwykłe wirtualne akcesory do swojej składowej itsAge, współuzytkowane przez wszystkie obiekty tej klasy. Oprócz tego posiada pięć czystych funkcji wirtualnych: Sleep(), Eat(), Reproduce(), Move() i Speak() (mówienie).
Klasa Mammal, zadeklarowana w liniach od 29. do 37., została wyprowadzona z klasy Animal. Nie posiada ona żadnych własnych danych. Przesłania jednak funkcję Reproduce(), zapewniając wspólną formę rozmnażania dla wszystkich ssaków. W klasie Fish funkcja Reproduce() musi zostać przesłonięta, gdyż ta klasa musi dziedziczyć bezpośrednio po klasie Animal i nie może skorzystać z rozmnażania na wzór ssaków (i dobrze!).
Klasy ssaków nie muszą już przesłaniać funkcji Reproduce(), ale jeśli chcą, mogą to zrobić, na przykład tak, jak klasa Dog w linii 83. Klasy Fish, Horse i Dog przesłaniają pozostałe czyste funkcje wirtualne, dzięki czemu można tworzyć specyficzne dla nich egzemplarze obiektów.
Znajdujący się w ciele programu wskaźnik do klasy Animal jest używany do kolejnego wskazywania obiektów różnych wyprowadzonych klas. Wywoływane są metody wirtualne i, w zależności od powiązań tworzonych dynamicznie, z właściwych klas pochodnych wywoływane są właściwe funkcje.
Próba stworzenia egzemplarza klasy Animal lub Mammal spowodowałaby błąd kompilacji, gdyż obie te klasy są klasami abstrakcyjnymi.
Które typy są abstrakcyjne? Klasa Animal jest abstrakcyjna w jednym programie, a w innym nie. Co decyduje o tym, że jakąś klasę czynimy abstrakcyjną?
Odpowiedź na to pytanie nie zależy od żadnego czynnika zewnętrznego, ale od tego, co ma sens dla danego programu. Jeśli piszesz program opisujący farmę lub ogród zoologiczny, możesz zdecydować, by klasa Animal była klasą abstrakcyjną, a klasa Dog była klasą, której obiekty mógłbyś samodzielnie tworzyć.
Usunięto: y
Usunięto: y
Usunięto: la
Usunięto: j
Usunięto: funkcji
Usunięto: wszystkie
Usunięto: ich
Usunięto: sprawia
Usunięto: a
Usunięto: jest
Usunięto: a
Usunięto: określonego

Z drugiej strony, gdybyś tworzył animowane schronisko dla psów, mógłbyś zdecydować, by klasa Dog była abstrakcyjnym typem danych i tworzyć jedynie egzemplarze ras psów: jamniki, teriery i tak dalej. Poziom abstrakcji zależy od tego, jak precyzyjnie chcesz rozróżniać swoje typy.
TAK NIE
W celu zapewnienia wspólnej funkcjonalności licznym powiązanym ze sobą klasom, używaj typów abstrakcyjnych.
Przesłaniaj wszystkie czyste funkcje wirtualne.
Jeśli funkcja musi zostać przesłonięta, zamień ją w czystą funkcję wirtualną.
Nie próbuj tworzyć egzemplarzy obiektów klas abstrakcyjnych.
Program podsumowujący wiadomości {uwaga korekta: to jest zawartość rozdziału „Week 2 In Review” }
W tym programie zebrano w w całość wiele omawianych w poprzednich rozdziałach zagadnień.
Przedstawiona poniżej demonstracja połączonych list wykorzystuje funkcje wirtualne, czyste funkcje wirtualne, przesłanianie funkcji, polimorfizm, dziedziczenie publiczne, przeciążanie funkcji, pętle nieskończone, wskaźniki, referencje i inne elementy. Należy zwrócić uwagę, że ta lista połączona różni się od listy opisywanej wcześniej; w C++ zwykle ten sam efekt można uzyskać na kilka sposobów.
Celem programu jest utworzenie listy połączonej. Węzły listy są zaprojektowane w celu przechowywania części samochodowych, takich, jakie mogłyby być używane w fabryce. Choć nie jest to ostateczna wersja programu, stanowi jednak dobry przykład dość zaawansowanej struktury danych. Kod ma prawie trzysta linii; zanim przystąpisz do przeczytania analizy przedstawionej po wynikach jego działania, spróbuj przeanalizować go samodzielnie.
Listing 14.11. Program podsumowujący wiadomości 0: // **************************************************
1: //
2: // Tytuł: Program podsumowujący numer 2
3: //
4: // Plik: 4eList1411
5: //
6: // Opis: Program demonstruje tworzenie listy połączonej
7: //

8: // Klasy: PART - zawiera numery części oraz ewentualnie inne
9: // informacje na ich temat
10: //
11: // PartNode - pełni rolę węzła w liście PartsList
12: //
13: // PartsList - dostarcza mechanizmu dla połączonej
14: // listy obiektów PartNode
15: //
16: //
17: // **************************************************
18:
19: #include <iostream>
20: using namespace std;
21:
22:
23:
24: // **************** Part ************
25:
26: // Abstrakcyjna klasa bazowa części
27: class Part
28: {
29: public:
30: Part():itsPartNumber(1) {}
31: Part(int PartNumber):itsPartNumber(PartNumber){}
32: virtual ~Part(){};
33: int GetPartNumber() const { return itsPartNumber; }
34: virtual void Display() const =0; // musi być przesłonięte
35: private:
36: int itsPartNumber;
37: };
38:
39: // implementacja czystej funkcji wirtualnej, dzięki czemu
40: // mogą z niej korzystać klasy pochodne
41: void Part::Display() const
42: {
43: cout << "\nNumer czesci: " << itsPartNumber << endl;
44: }

45:
46: // **************** Część samochodu ************
47:
48: class CarPart : public Part
49: {
50: public:
51: CarPart():itsModelYear(94){}
52: CarPart(int year, int partNumber);
53: virtual void Display() const
54: {
55: Part::Display(); cout << "Rok modelu: ";
56: cout << itsModelYear << endl;
57: }
58: private:
59: int itsModelYear;
60: };
61:
62: CarPart::CarPart(int year, int partNumber):
63: itsModelYear(year),
64: Part(partNumber)
65: {}
66:
67:
68: // **************** Część samolotu ************
69:
70: class AirPlanePart : public Part
71: {
72: public:
73: AirPlanePart():itsEngineNumber(1){};
74: AirPlanePart(int EngineNumber, int PartNumber);
75: virtual void Display() const
76: {
77: Part::Display(); cout << "Nr silnika.: ";
78: cout << itsEngineNumber << endl;
79: }
80: private:
81: int itsEngineNumber;

82: };
83:
84: AirPlanePart::AirPlanePart(int EngineNumber, int PartNumber):
85: itsEngineNumber(EngineNumber),
86: Part(PartNumber)
87: {}
88:
89: // **************** Węzeł części ************
90: class PartNode
91: {
92: public:
93: PartNode (Part*);
94: ~PartNode();
95: void SetNext(PartNode * node) { itsNext = node; }
96: PartNode * GetNext() const;
97: Part * GetPart() const;
98: private:
99: Part *itsPart;
100: PartNode * itsNext;
101: };
102:
103: // Implementacje klasy PartNode
104:
105: PartNode::PartNode(Part* pPart):
106: itsPart(pPart),
107: itsNext(0)
108: {}
109:
110: PartNode::~PartNode()
111: {
112: delete itsPart;
113: itsPart = 0;
114: delete itsNext;
115: itsNext = 0;
116: }
117:
118: // Gdy nie ma następnego węzła, zwraca NULL
119: PartNode * PartNode::GetNext() const
120: {
121: return itsNext;
122: }
123:
124: Part * PartNode::GetPart() const
125: {
126: if (itsPart)
127: return itsPart;
128: else
129: return NULL; //błąd
130: }
131:
132: // **************** Klasa PartList ************
133: class PartsList
134: {
135: public:
136: PartsList();
137: ~PartsList();
138: // wymaga konstruktora kopiujacego i operatora porównania!
139: Part* Find(int & position, int PartNumber) const;
140: int GetCount() const { return itsCount; }
141: Part* GetFirst() const;
142: void Insert(Part *);
143: void Iterate() const;
144: Part* operator[](int) const;
145: private:
146: PartNode * pHead;
147: int itsCount;
148: };
149:
150: // Implementacje dla list...
151:
152: PartsList::PartsList():
153: pHead(0),
154: itsCount(0)
155: {}
Usunięto: i
Usunięto: rzy

156:
157: PartsList::~PartsList()
158: {
159: delete pHead;
160: }
161:
162: Part* PartsList::GetFirst() const
163: {
164: if (pHead)
165: return pHead->GetPart();
166: else
167: return NULL; // w celu wykrycia błędu
168: }
169:
170: Part * PartsList::operator[](int offSet) const
171: {
172: PartNode* pNode = pHead;
173:
174: if (!pHead)
175: return NULL; // w celu wykrycia błędu
176:
177: if (offSet > itsCount)
178: return NULL; // błąd
179:
180: for (int i=0;i<offSet; i++)
181: pNode = pNode->GetNext();
182:
183: return pNode->GetPart();
184: }
185:
186: Part* PartsList::Find(int & position, int PartNumber) const
187: {
188: PartNode * pNode = 0;
189: for (pNode = pHead, position = 0;
190: pNode!=NULL;
191: pNode = pNode->GetNext(), position++)
192: {

193: if (pNode->GetPart()->GetPartNumber() == PartNumber)
194: break;
195: }
196: if (pNode == NULL)
197: return NULL;
198: else
199: return pNode->GetPart();
200: }
201:
202: void PartsList::Iterate() const
203: {
204: if (!pHead)
205: return;
206: PartNode* pNode = pHead;
207: do
208: pNode->GetPart()->Display();
209: while (pNode = pNode->GetNext());
210: }
211:
212: void PartsList::Insert(Part* pPart)
213: {
214: PartNode * pNode = new PartNode(pPart);
215: PartNode * pCurrent = pHead;
216: PartNode * pNext = 0;
217:
218: int New = pPart->GetPartNumber();
219: int Next = 0;
220: itsCount++;
221:
222: if (!pHead)
223: {
224: pHead = pNode;
225: return;
226: }
227:
228: // jeśli ten węzeł jest mniejszy niż głowa,
229: // wtedy staje się nową głową

230: if (pHead->GetPart()->GetPartNumber() > New)
231: {
232: pNode->SetNext(pHead);
233: pHead = pNode;
234: return;
235: }
236:
237: for (;;)
238: {
239: // jeśli nie ma następnego, dołączamy ten nowy
240: if (!pCurrent->GetNext())
241: {
242: pCurrent->SetNext(pNode);
243: return;
244: }
245:
246: // jeśli trafia pomiędzy bieżący a nastepny,
247: // wstawiamy go tu; w przeciwnym razie bierzemy następny
248: pNext = pCurrent->GetNext();
249: Next = pNext->GetPart()->GetPartNumber();
250: if (Next > New)
251: {
252: pCurrent->SetNext(pNode);
253: pNode->SetNext(pNext);
254: return;
255: }
256: pCurrent = pNext;
257: }
258: }
259:
260: int main()
261: {
262: PartsList pl;
263:
264: Part * pPart = 0;
265: int PartNumber;
266: int value;
Usunięto: o

267: int choice;
268:
269: while (1)
270: {
271: cout << "(0)Wyjscie (1)Samochod (2)Samolot: ";
272: cin >> choice;
273:
274: if (!choice)
275: break;
276:
277: cout << "Nowy numer czesci?: ";
278: cin >> PartNumber;
279:
280: if (choice == 1)
281: {
282: cout << "Model?: ";
283: cin >> value;
284: pPart = new CarPart(value,PartNumber);
285: }
286: else
287: {
288: cout << "Numer silnika?: ";
289: cin >> value;
290: pPart = new AirPlanePart(value,PartNumber);
291: }
292:
293: pl.Insert(pPart);
294: }
295: pl.Iterate();
296: return 0;
297: }
Wynik (0)Wyjscie (1)Samochod (2)Samolot: 1
Nowy numer czesci?: 2837
Model?: 90
(0)Wyjscie (1)Samochod (2)Samolot: 2

Nowy numer czesci?: 378
Numer silnika?: 4938
(0)Wyjscie (1)Samochod (2)Samolot: 1
Nowy numer czesci?: 4499
Model?: 94
(0)Wyjscie (1)Samochod (2)Samolot: 1
Nowy numer czesci?: 3000
Model?: 93
(0)Wyjscie (1)Samochod (2)Samolot: 0
Numer czesci: 378
Nr silnika.: 4938
Numer czesci: 2837
Rok modelu: 90
Numer czesci: 3000
Rok modelu: 93
Numer czesci: 4499
Rok modelu: 94
Analiza
Przedstawiony tu listing zawiera implementację listy połączonej, przechowującej obiekty klasy Part (część). Lista połączona jest dynamiczną strukturą danych, mogącą dostosowywać swoje rozmiary do potrzeb programu.
Ta konkretna lista połączona została zaprojektowana w celu przechowywania obiektów klasy Part, przy czym klasa Part jest klasą abstrakcyjną, pełniącą rolę klasy bazowej dla wszystkich obiektów posiadających numer części. W tym przykładzie z klasy Part zostały wydzielone dwie podklasy: CarPart (część samochodowa) oraz AirPlanePart (część samolotu).
Klasa Part jest deklarowana w liniach od 27. do 37. i składa się z numeru części oraz kilku akcesorów. W rzeczywistym programie klasa ta mogłaby zawierać dodatkowe informacje o częściach, na przykład na temat komponentów, z jakich się składają, ile takich części znajduje się w magazynie i tak dalej. Klasa Part jest abstrakcyjnym typem danych, wymuszonym przez czystą funkcję wirtualną Display() (wyświetl).
Zauważmy, że metoda Display() posiada w liniach od 41. do 44. swoją implementację. W ten sposób została wyrażona intencja projektanta kodu; chciał on by klasy pochodne tworzyły własne

implementacje metody Display(), a jednocześnie mogły w nich korzystać z metody Display() w klasie bazowej.
Dwie proste klasy pochodne, CarPart oraz AirPlanePart zostały zadeklarowane w liniach od 48. do 66. oraz od 70. do 88. Każda z nich zawiera przesłoniętą metodę Display(), która jednak w obu przypadkach wywołuje metodę Display() klasy bazowej.
Klasa PartNode (węzeł części) pełni rolę interfejsu pomiędzy klasą Part a klasą PartsList (lista części). Zawiera ona wskaźnik do części oraz wskaźnik do następnego węzła na liście. Jej jedynymi metodami są metody przeznaczone do ustawiania i odczytywania następnego węzła listy oraz do zwracania wskazywanego przez węzeł obiektu Part.
Cała tajemnica działania listy kryje się w klasie PartsList, zadeklarowanej w liniach od 133. do 148. Klasa PartsList przechowuje wskaźnik do pierwszego elementu listy (pHead) i używa go we wszystkich metodach przetwarzających tę listę. Przetworzenie listy oznacza odpytanie każdego z węzłów o następny węzeł, aż do czasu osiągnięcia węzła, którego wskaźnik itsNext wynosi NULL.
Jest to implementacja częściowa; w pełni zaprojektowana lista oferowywałaby albo lepszy dostęp do swojego pierwszego i ostatniego węzła, albo dostarczałaby obiektu iteratora, pozwalającego klientom na łatwe poruszanie się po liście.
Jednak klasa PartsList i tak posiada kilka interesujących metod, opisanych poniżej w kolejności alfabetycznej. Zwykle dobrze jest zachowywać taką kolejność, gdyż ułatwia ona odszukanie funkcji.
Metoda Find() otrzymuje numer części oraz referencję do typu int. Jeśli zostanie znaleziona część zgodna z PartNumber (numerem części), funkcja zwraca wskaźnik do obiektu Part i wypełnia referencję pozycją tej części na liście. Jeśli szukany numer części nie zostanie znaleziony, funkcja zwraca wartość NULL i numer pozycji nie ma znaczenia.
Metoda GetCount() zwraca ilość elementów na liście. Klasa PartsList przechowuje tę wartość jako swoją zmienną składową, itsCount, choć oczywiście mogłaby ją obliczać, przetwarzając listę.
Metoda GetFirst() zwraca wskaźnik do pierwszego obiektu Part na liście; w przypadku, gdy lista jest pusta, zwraca wartość NULL.
Metoda Insert() otrzymuje wskaźnik do obiektu klasy Part, tworzy dla niego obiekt PartNode, po czym dodaje go do listy, zgodnie z kolejnością wyznaczaną przez PartNumber.
Metoda Iterate() otrzymuje wskaźnik do funkcji składowej klasy Part, która nie posiada parametrów, zwraca void i jest funkcją const. Wywołuje tę funkcję dla każdego obiektu klasy Part na liście. W naszym przykładowym programie zostaje wywołana funkcja Display(), będąca funkcją wirtualną, więc w każdym przypadku zostaje wywołana metoda odpowiedniej podklasy klasy Part.
Operator[] umożliwia bezpośredni dostęp do obiektu Part, znajdującego się we wskazanym położeniu na liście. Wykonywane jest przy tym podstawowe sprawdzanie zakresów; jeśli lista jest pusta lub podane położenie wykracza poza rozmiar listy, jako wartość błędu zostaje zwrócona wartość NULL.
Usunięto: 0
Usunięto:

Zwróć uwagę, że w rzeczywistym programie takie opisy funkcji zostałyby zapisane w deklaracji klasy.
Program sterujący jest zawarty w liniach od 260. do 298. Obiekt PartsList jest tworzony w linii 263.
W linii 278. użytkownik jest proszony o wybranie, czy część powinna być wprowadzana dla samochodu, czy dla samolotu. W zależności od tego wyboru tworzona jest odpowiednia część, która następnie jest wstawiana do listy w linii 294.
Implementacja metody Insert() klasy PartsList znajduje się w liniach od 212. do 258. Gdy zostaje wprowadzony numer pierwszej części, 2837, zostaje stworzony obiekt CarPar o tym numerze części i modelu 90, który jest przekazywany do metody LinkedList::Insert().
W linii 214. dla tej części jest tworzony nowy obiekt PartNode, zaś zmienna New jest inicjalizowana numerem części. Zmienna itsCount klasy PartsList jest inkrementowana w linii 220.
W linii 222., w teście sprawdzającym, czy pHead ma wartość NULL, otrzymujemy wartość TRUE. Ponieważ jest to pierwszy węzeł, wskaźnik pHead listy na nic jeszcze nie wskazuje. Zatem w linii 224. wskaźnik pHead jest ustawiany tak, aby wskazywał nowy węzeł, po czym następuje powrót z funkcji.
Użytkownik jest proszony o wybranie kolejnej części; tym razem zostaje wybrana część do samolotu, o numerze części 378 i numerze silnika 4938. Ponownie jest wywoływana metoda PartsList::Insert(), a pNode jest ponownie inicjalizowane nowym węzłem. Statyczna zmienna składowa itsCount zostaje zwiększona do dwóch i następuje sprawdzenie wskaźnika pHead. Ponieważ ostatnim razem temu wskaźnikowi została przypisana wartość, nie zawiera on już wartości NULL i test zwraca wartość FALSE.
W linii 230. numer części wskazywanej przez pHead, 2837, jest porównywany z numerem bieżącej części, 378. Ponieważ numer nowej części jest mniejszy od numeru części wskazywanej przez pHead, nowa część musi stać się nowym pierwszym elementem listy, więc test w linii 230. zwraca wartość TRUE.
W linii 232. nowy węzeł jest ustawiany tak, by wskazywał na węzeł aktualnie wskazywany przez wskaźnik pHead. Zwróć uwagę, że nowy węzeł nie wskazuje na pHead, ale na węzeł wskazywany przez pHead! W linii 233. pHead jest ustawiany tak, by wskazywał na nowy węzeł.
Przy trzecim wykonaniu pętli użytkownik wybrał część samochodową o numerze 4499 i modelu 94. Następuje zwiększenie licznika i tym razem numer części nie jest mniejszy od numeru wskazywanego przez pHead, więc przechodzimy do pętli for, rozpoczynającej się w linii 237.
Wartością wskazywaną przez pHead jest 378. Wartością wskazywaną przez następny węzeł jest 2837. Bieżącą wartością jest 4499. Wskaźnik pCurrent wskazuje na ten sam węzeł, co pHead, więc posiada następną wartość; pCurrent wskazuje na drugi węzeł, więc test w linii 240 zwraca wartość FALSE.
Wskaźnik pCurrent jest ustawiany tak, by wskazywał następny węzeł, po czym następuje ponowne wykonanie pętli. Tym razem test w linii 240. zwraca wartość TRUE. Nie ma następnego elementu, więc w linii 242. bieżący węzeł zostaje ustawiony tak, by wskazywał nowy węzeł, po czym proces wstawiania się kończy.

Za czwartym razem wprowadzona zostaje część o numerze 3000. Jej wstawianie jest bardzo podobne do przypadku opisanego powyżej, ale tym razem, gdy bieżący węzeł wskazuje numer 2837, a następny 4499, test w linii 250. zwraca wartość TRUE i nowy węzeł jest wstawiany właśnie w tej pozycji.
Gdy użytkownik w końcu wybierze zero, test w linii 275. zwraca wartość TRUE i następuje wyjście z pętli while(1). Wykonanie programu przechodzi do linii 296., w której wywoływana jest funkcja Iterate(). Wykonanie przechodzi do linii 202., a w linii 208. wskaźnik PNode jest wykorzystywany do uzyskania dostępu do obiektu Part i wywołania dla niego metody Display.

Rozdział 15. Specjalne klasy i funkcje C++ oferuje kilka sposobów na ograniczenie zakresu i oddziaływania zmiennych i wskaźników. Do tej pory, dowiedzieliśmy się, jak tworzyć zmienne globalne, lokalne zmienne funkcji, wskaźniki do zmiennych oraz zmienne składowe klas.
Z tego rozdziału dowiesz się:
• czym są zmienne statyczne i funkcje składowe,
• jak używać zmiennych statycznych i statycznych funkcji składowych,
• jak tworzyć i operować wskaźnikami do funkcji i wskaźnikami do funkcji składowych,
• jak pracować z tablicami wskaźników do funkcji.
Statyczne dane składowe Prawdopodobnie do tej pory uważałeś dane każdego obiektu za unikalne dla tego obiektu (i nie współużytkowane pomiędzy obiektami klasy). Gdybyś miał na przykład pięć obiektów klasy Cat, każdy z nich miałby swój wiek, wagę, itp. Wiek jednego kota nie wpływa na wiek innego.
Czasem zdarza się jednak, że chcemy śledzić pulę danych. Na przykład, możemy chcieć wiedzieć, ile obiektów danej klasy zostało stworzonych w programie, a także ile z nich istnieje nadal. Statyczne zmienne składowe są współużytkowane przez wszystkie egzemplarze obiektów klasy. Stanowią one kompromis pomiędzy danymi globalnymi, które są dostępne dla wszystkich części programu, a danymi składowymi, które zwykle są dostępne tylko dla konkretnego obiektu.
Statyczne składowe można traktować jako należące do całej klasy, a nie tylko do pojedynczego obiektu. Zwykła dana składowa odnosi się do pojedynczego obiektu, a dana składowa statyczna odnosi się do całej klasy. Listing 15.1 deklaruje obiekt Cat, zawierający statyczną składową HowManyCats (ile kotów). Ta zmienna śledzi, ile obiektów klasy Cat zostało utworzonych. Śledzenie odbywa się poprzez inkrementację statycznej zmiennej HowManyCats w konstruktorze klasy i dekrementowanie jej w destruktorze.
Listing 15.1. Statyczne dane składowe
Usunięto: e
Usunięto: e
Usunięto: e
Usunięto: przechowywane są po jednej dla każdego
Usunięto: e
Usunięto: e
Usunięto: są przechowywane po jednej dla

0: //Listing 15.1 Statyczne dane składowe
1:
2: #include <iostream>
3: using namespace std;
4:
5: class Cat
6: {
7: public:
8: Cat(int age):itsAge(age){HowManyCats++; }
9: virtual ~Cat() { HowManyCats--; }
10: virtual int GetAge() { return itsAge; }
11: virtual void SetAge(int age) { itsAge = age; }
12: static int HowManyCats;
13:
14: private:
15: int itsAge;
16:
17: };
18:
19: int Cat::HowManyCats = 0;
20:
21: int main()
22: {
23: const int MaxCats = 5; int i;
24: Cat *CatHouse[MaxCats];
25: for (i = 0; i<MaxCats; i++)
26: CatHouse[i] = new Cat(i);
27:
28: for (i = 0; i<MaxCats; i++)
29: {
30: cout << "Zostalo kotow: ";
31: cout << Cat::HowManyCats;
32: cout << "\n";
33: cout << "Usuwamy kota, ktory ma ";
34: cout << CatHouse[i]->GetAge();
35: cout << " lat\n";
36: delete CatHouse[i];

37: CatHouse[i] = 0;
38: }
39: return 0;
40: }
Wynik Zostalo kotow: 5
Usuwamy kota, ktory ma 0 lat
Zostalo kotow: 4
Usuwamy kota, ktory ma 1 lat
Zostalo kotow: 3
Usuwamy kota, ktory ma 2 lat
Zostalo kotow: 2
Usuwamy kota, ktory ma 3 lat
Zostalo kotow: 1
Usuwamy kota, ktory ma 4 lat
Analiza
W liniach od 5. do 17. została zadeklarowana uproszczona klasa Cat. W linii 12. zmienna HowManyCats została zadeklarowana jako statyczna zmienna składowa typu int.
Sama deklaracja zmiennej HowManyCats nie definiuje wartości całkowitej i nie jest dla niej rezerwowane miejsce w pamięci. W odróżnieniu od zwykłych zmiennych składowych, w momencie tworzenia egzemplarzy obiektów klasy Cat, nie jest tworzone miejsce dla tej zmiennej statycznej, gdyż nie znajduje się ona w obiekcie. W związku z tym musieliśmy zdefiniować i zainicjalizować tę zmienną w linii 19..
Programistom bardzo często zdarza się zapomnieć o zdefiniowaniu statycznych zmiennych składowych klasy. Nie pozwól, by przydarzało się to tobie! Oczywiście, gdy się przydarzy, linker zgłosi komunikat błędu, informujący o niezdefiniowanym symbolu, na przykład taki jak poniższy:
undefined symbol Cat::HowManyCats
(niezdefiniowany symbol Cat::HowManyCats)
Nie musimy definiować zmiennej itsAge, gdyż nie jest statyczną zmienną składową i w związku z tym jest definiowana za każdym razem, gdy tworzymy obiekt klasy Cat (w tym przypadku w linii 26. programu).
Konstruktor klasy Cat w linii 8. inkrementuje statyczną zmienną składową. Destruktor (zawarty w linii 9.) dekrementuje ją. Zatem zmienna HowManyCats przez cały czas zawiera właściwą ilość obiektów Cat, które zostały utworzone i jeszcze nie zniszczone.

Program sterujący. zawarty w liniach od 21. do 40., tworzy pięć egzemplarzy obiektów klasy Cat i umieszcza je w pamięci. Powoduje to pięciokrotne wywołanie konstruktora, w związku z czym następuje pięciokrotne inkrementowanie zmiennej HowManyCats od jej początkowej wartości 0.
Następnie program w pętli przechodzi przez wszystkie pięć elementów tablicy i przed usunięciem kolejnego wskaźnika do obiektu Cat wypisuje wartość zmiennej HowManyCats. Wydruk pokazuje to, że wartością początkową jest 5 (gdyż zostało skonstruowanych pięć obiektów) i że przy każdym wykonaniu pętli pozostaje o jeden obiekt Cat mniej.
Zwróć uwagę, że zmienna HowManyCats jest publiczna i jest używana bezpośrednio w funkcji main(). Nie ma powodu do udostępniania zmiennej składowej w ten sposób. Najlepszą metodą jest uczynienie z niej prywatnej składowej i udostępnienie publicznego akcesora (o ile ma być ona dostępna wyłącznie poprzez egzemplarze klasy Cat). Z drugiej strony, gdybyśmy chcieli korzystać z tej danej bezpośrednio, niekoniecznie posiadając obiekt klasy Cat, mamy do wyboru dwie opcje: możemy zadeklarować tę zmienną jako publiczną, tak jak pokazano na listingu 15.2, albo dostarczyć akcesor w postaci statycznej funkcji składowej, co zostanie omówione w dalszej części rozdziału.
Listing 15.2. Dostęp do statycznych danych składowych bez obiektu 0: //Listing 15.2 Statyczne dane składowe
1:
2: #include <iostream>
3: using namespace std;
4:
5: class Cat
6: {
7: public:
8: Cat(int age):itsAge(age){HowManyCats++; }
9: virtual ~Cat() { HowManyCats--; }
10: virtual int GetAge() { return itsAge; }
11: virtual void SetAge(int age) { itsAge = age; }
12: static int HowManyCats;
13:
14: private:
15: int itsAge;
16:
17: };
18:
19: int Cat::HowManyCats = 0;
20:
21: void TelepathicFunction();
22:
Usunięto: tablicy
Usunięto: des
Usunięto: bieżącego

23: int main()
24: {
25: const int MaxCats = 5; int i;
26: Cat *CatHouse[MaxCats];
27: for (i = 0; i<MaxCats; i++)
28: {
29: CatHouse[i] = new Cat(i);
30: TelepathicFunction();
31: }
32:
33: for ( i = 0; i<MaxCats; i++)
34: {
35: delete CatHouse[i];
36: TelepathicFunction();
37: }
38: return 0;
39: }
40:
41: void TelepathicFunction()
42: {
43: cout << "Zostalo jeszcze zywych kotow: ";
44: cout << Cat::HowManyCats << "\n";
45: }
Wynik Zostalo jeszcze zywych kotow: 1
Zostalo jeszcze zywych kotow: 2
Zostalo jeszcze zywych kotow: 3
Zostalo jeszcze zywych kotow: 4
Zostalo jeszcze zywych kotow: 5
Zostalo jeszcze zywych kotow: 4
Zostalo jeszcze zywych kotow: 3
Zostalo jeszcze zywych kotow: 2
Zostalo jeszcze zywych kotow: 1
Zostalo jeszcze zywych kotow: 0
Analiza

Listing 15.2 przypomina listing 15.1, z wyjątkiem nowej funkcji, TelepathicFunction() (funkcja telepatyczna). Ta funkcja nie tworzy obiektu Cat ani nie otrzymuje obiektu Cat jako parametru, a mimo to może odwoływać się do zmiennej składowej HowManyCats. Należy pamiętać, że ta zmienna składowa nie należy do żadnego konkretnego obiektu; znajduje się w klasie i, o ile jest publiczna, może być wykorzystywana przez każdą funkcję w programie.
Alternatywą dla tej zmiennej publicznej może być zmienna prywatna. Gdy skorzystamy z niej, możemy to uczynić poprzez funkcję składową, ale wtedy musimy posiadać obiekt tej klasy. Takie rozwiązanie przedstawia listing 15.3. Alternatywne rozwiązanie, z wykorzystaniem statycznej funkcji składowej, zostanie omówione bezpośrednio po analizie listingu 15.3.
Listing 15.3. Dostęp do statycznych składowych za pomocą zwykłych funkcji składowych 0: //Listing 15.3 prywatne statyczne dane składowe
1:
2: #include <iostream>
3: using std::cout;
4:
5: class Cat
6: {
7: public:
8: Cat(int age):itsAge(age){HowManyCats++; }
9: virtual ~Cat() { HowManyCats--; }
10: virtual int GetAge() { return itsAge; }
11: virtual void SetAge(int age) { itsAge = age; }
12: virtual int GetHowMany() { return HowManyCats; }
13:
14:
15: private:
16: int itsAge;
17: static int HowManyCats;
18: };
19:
20: int Cat::HowManyCats = 0;
21:
22: int main()
23: {
24: const int MaxCats = 5; int i;
25: Cat *CatHouse[MaxCats];
26: for (i = 0; i<MaxCats; i++)
27: CatHouse[i] = new Cat(i);

28:
29: for (i = 0; i<MaxCats; i++)
30: {
31: cout << "Zostalo jeszcze ";
32: cout << CatHouse[i]->GetHowMany();
33: cout << " kotow!\n";
34: cout << "Usuwamy kota, ktory ma ";
35: cout << CatHouse[i]->GetAge()+2;
36: cout << " lat\n";
37: delete CatHouse[i];
38: CatHouse[i] = 0;
39: }
40: return 0;
41: }
Wynik Zostalo jeszcze 5 kotow!
Usuwamy kota, ktory ma 2 lat
Zostalo jeszcze 4 kotow!
Usuwamy kota, ktory ma 3 lat
Zostalo jeszcze 3 kotow!
Usuwamy kota, ktory ma 4 lat
Zostalo jeszcze 2 kotow!
Usuwamy kota, ktory ma 5 lat
Zostalo jeszcze 1 kotow!
Usuwamy kota, ktory ma 6 lat
Analiza
W linii 17. statyczna zmienna składowa HowManyCats została zadeklarowana jako składowa prywatna. Nie możemy więc odwoływać się do niej z funkcji innych niż składowe, na przykład takich, jak TelepathicFunction() z poprzedniego listingu.
Jednak mimo, iż zmienna HowManyCats jest statyczna, nadal znajduje się w zakresie klasy. Może się do niej odwoływać dowolna funkcja składowa klasy, na przykład GetHowMany(), podobnie jak do wszystkich innych danych składowych. Jednak, aby zewnętrzna funkcja mogła wywołać metodę GetHowMany(), musi posiadać obiekt klasy Cat.
TAK NIE

W celu współużytkowania danych pomiędzy wszystkimi egzemplarzami klasy używaj statycznych zmiennych składowych
Jeśli chcesz ograniczyć dostęp do statycznych zmiennych składowych, uczyń je składowymi prywatnymi lub chronionymi.
Nie używaj statycznych zmiennych składowych do przechowywania danych należących do pojedynczego obiektu. Statyczne dane składowe są współużytkowane przez wszystkie obiekty klasy.
Statyczne funkcje składowe Statyczne funkcje składowe działają podobnie do statycznych zmiennych składowych: istnieją nie w obiekcie, ale w zakresie klasy. W związku z tym mogą być wywoływane bez posiadania obiektu swojej klasy, co ilustruje listing 15.4.
Listing 15.4. Statyczne funkcje składowe 0: //Listing 15.4 statyczne funkcje składowe
1:
2: #include <iostream>
3:
4: class Cat
5: {
6: public:
7: Cat(int age):itsAge(age){HowManyCats++; }
8: virtual ~Cat() { HowManyCats--; }
9: virtual int GetAge() { return itsAge; }
10: virtual void SetAge(int age) { itsAge = age; }
11: static int GetHowMany() { return HowManyCats; }
12: private:
13: int itsAge;
14: static int HowManyCats;
15: };
16:
17: int Cat::HowManyCats = 0;
18:
19: void TelepathicFunction();
20:
21: int main()
22: {

23: const int MaxCats = 5;
24: Cat *CatHouse[MaxCats]; int i;
25: for (i = 0; i<MaxCats; i++)
26: {
27: CatHouse[i] = new Cat(i);
28: TelepathicFunction();
29: }
30:
31: for ( i = 0; i<MaxCats; i++)
32: {
33: delete CatHouse[i];
34: TelepathicFunction();
35: }
36: return 0;
37: }
38:
39: void TelepathicFunction()
40: {
41: std::cout<<"Zostalo jeszcze "<< Cat::GetHowMany()<<" zywych kotow!\n";
42: }
Wynik Zostalo jeszcze 1 zywych kotow!
Zostalo jeszcze 2 zywych kotow!
Zostalo jeszcze 3 zywych kotow!
Zostalo jeszcze 4 zywych kotow!
Zostalo jeszcze 5 zywych kotow!
Zostalo jeszcze 4 zywych kotow!
Zostalo jeszcze 3 zywych kotow!
Zostalo jeszcze 2 zywych kotow!
Zostalo jeszcze 1 zywych kotow!
Zostalo jeszcze 0 zywych kotow!
Analiza
W linii 14., w klasie Cat została zadeklarowana statyczna prywatna zmienna składowa HowManyCats. Publiczny akcesor, GetHowMany(), został w linii 11. zadeklarowany zarówno jako metoda publiczna, jak i statyczna.

Ponieważ metoda GetHowMany() jest publiczna, może być używana w każdej funkcji zewnętrznej, a ponieważ jest też statyczna, może być wywołana bez obiektu klasy Cat. Zatem, w linii 41., funkcja TelepathicFunction() jest w stanie użyć publicznego statycznego akcesora, nie posiadając dostępu do obiektu klasy Cat. Oczywiście, moglibyśmy wywołać funkcję GetHowMany() dla obiektów klasy Cat dostępnych w funkcji main(), tak samo jak w przypadku innych akcesorów.
UWAGA Statyczne funkcje składowe nie posiadają wskaźnika this. W związku z tym nie mogą być deklarowane jako const. Ponadto, ponieważ zmienne składowe są dostępne w funkcjach składowych poprzez wskaźnik this, statyczne funkcje składowe nie mogą korzystać z żadnych zmiennych składowych, nie będących składowymi statycznymi!
Statyczne funkcje składowe
Możesz korzystać ze statycznych funkcji składowych, wywołując je dla obiektu klasy, tak samo jak w przypadku innych funkcji składowych, możesz też wywoływać je bez obiektu klasy, stosując pełną kwalifikowaną nazwę klasy i funkcji.
Przykład
class Cat
{
public:
static int GetHowMany() { return HowManyCats; }
private:
static int HowManyCats;
};
int Cat::HowManyCats = 0;
int main()
{
int howMany;
Cat theCat; // definiuje obiekt klasy Cat
howMany = theCat.GetHowMany(); // dostęp poprzez obiekt
howMany = Cat::GetHowMany(); // dostęp bez obiektu
}

Wskaźniki do funkcji Nazwa tablicy jest wskaźnikiem const do pierwszego elementu tej tablicy, a nazwa funkcji jest wskaźnikiem const do funkcji. Istnieje możliwość zadeklarowania zmiennej wskaźnikowej wskazującej na funkcję i wywoływania tej funkcji za pomocą tej zmiennej. Może to być bardzo przydatne; umożliwia tworzenie programów, które decydują (na podstawie wprowadzonych danych) o tym, która funkcja ma zostać wywołana.
Jedyny problem ze wskaźnikami do funkcji polega na zrozumieniu typu wskazywanego obiektu. Wskaźnik do int wskazuje zmienną całkowitą, zaś wskaźnik do funkcji musi wskazywać funkcję o określonym zwracanym typie i sygnaturze.
W deklaracji:
long (* funcPtr) (int);
funcPtr jest deklarowane jako wskaźnik (zwróć uwagę na gwiazdkę przed nazwą), wskazujący funkcję otrzymującą parametr typu int i zwracającą wartość typu long. Nawiasy wokół * funcPtr są konieczne, gdyż nawiasy wokół int wiążą ściślej; tj. mają priorytet nad operatorem dostępu pośredniego (*). Bez zastosowania pierwszych nawiasów zostałaby zadeklarowana funkcja otrzymująca parametr typu int i zwracająca wskaźnik do typu long. (Pamiętaj, że spacje nie mają tu znaczenia.)
Przyjrzyjmy się dwóm poniższym deklaracjom:
long * Function (int);
long (* funcPtr) (int);
Pierwsza, Function(), jest funkcją otrzymującą parametr typu int i zwracającą wskaźnik do zmiennej typu long. Druga, funcPtr, jest wskaźnikiem do funkcji otrzymującej wartość typu int i zwracającej zmienną typu long.
Deklaracja wskaźnika do funkcji zawsze zawiera zwracany typ oraz, w nawiasach, typ parametrów (o ile występują). Listing 15.5 ilustruje deklarowanie i używanie wskaźników do funkcji.
Listing 15.5. Wskaźniki do funkcji 0: // Listing 15.5 Użycie wskaźników do funkcji.
1:
2: #include <iostream>
3: using namespace std;
4:
5: void Square (int&,int&); // do kwadratu
6: void Cube (int&, int&); // do trzeciej potegi
Usunięto: bardziej

7: void Swap (int&, int &); // zamiana
8: void GetVals(int&, int&); // zmiana
9: void PrintVals(int, int);
10:
11: int main()
12: {
13: void (* pFunc) (int &, int &);
14: bool fQuit = false;
15:
16: int valOne=1, valTwo=2;
17: int choice;
18: while (fQuit == false)
19: {
20: cout << "(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: ";
21: cin >> choice;
22: switch (choice)
23: {
24: case 1: pFunc = GetVals; break;
25: case 2: pFunc = Square; break;
26: case 3: pFunc = Cube; break;
27: case 4: pFunc = Swap; break;
28: default : fQuit = true; break;
29: }
30:
31: if (fQuit)
32: break;
33:
34: PrintVals(valOne, valTwo);
35: pFunc(valOne, valTwo);
36: PrintVals(valOne, valTwo);
37: }
38: return 0;
39: }
40:
41: void PrintVals(int x, int y)
42: {
43: cout << "x: " << x << " y: " << y << endl;

44: }
45:
46: void Square (int & rX, int & rY)
47: {
48: rX *= rX;
49: rY *= rY;
50: }
51:
52: void Cube (int & rX, int & rY)
53: {
54: int tmp;
55:
56: tmp = rX;
57: rX *= rX;
58: rX = rX * tmp;
59:
60: tmp = rY;
61: rY *= rY;
62: rY = rY * tmp;
63: }
64:
65: void Swap(int & rX, int & rY)
66: {
67: int temp;
68: temp = rX;
69: rX = rY;
70: rY = temp;
71: }
72:
73: void GetVals (int & rValOne, int & rValTwo)
74: {
75: cout << "Nowa wartosc dla ValOne: ";
76: cin >> rValOne;
77: cout << "Nowa wartosc dla ValTwo: ";
78: cin >> rValTwo;
79: }

Wynik (0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 1
x: 1 y: 2
Nowa wartosc dla ValOne: 2
Nowa wartosc dla ValTwo: 3
x: 2 y: 3
(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 3
x: 2 y: 3
x: 8 y: 27
(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 2
x: 8 y: 27
x: 64 y: 729
(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 4
x: 64 y: 729
x: 729 y: 64
(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 0
Analiza
W liniach od 5. do 8. zostały zadeklarowane cztery funkcje, wszystkie o tych samych zwracanych typach i sygnaturach, zwracające void i przyjmujące referencje do dwóch zmiennych całkowitych.
W linii 13. zmienna pFunc jest deklarowana jako wskaźnik do funkcji zwracającej void i przyjmującej referencje do dwóch zmiennych całkowitych. Wskaźnik pFunc może więc wskazywać na dowolną z zadeklarowanych wcześniej czterech funkcji. Użytkownik ma możliwość wyboru funkcji, która powinna zostać wybrana, a wskaźnik pFunc jest ustawiany zgodnie z tym wyborem. W liniach od 34. do 36. są wypisywane bieżące wartości obu zmiennych całkowitych, wywoływana jest aktualnie przypisana funkcja, po czym ponownie wypisywane są wartości obu zmiennych.
Wskaźnik do funkcji
Wskaźnik do funkcji jest wywoływany tak samo jak funkcja, którą wskazuje, z wyjątkiem tego, że zamiast nazwy funkcji, używana jest nazwa wskaźnika do tej funkcji.

Przypisanie wskaźnikowi konkretnej funkcji odbywa się przez przypisanie mu nazwy funkcji bez nawiasów. Nazwa funkcji jest wskaźnikiem const do samej funkcji. Wskaźnika do funkcji można więc używać tak samo, jak nazwy funkcji. Zwracany typ oraz sygnatura wskaźnika do funkcji muszą być zgodne z przypisywaną mu funkcją.
Przykład
long (*pFuncOne) (int, int);
long SomeFunction (int, int);
pFuncOne = SomeFunction;
pFuncOne(5,7);
Dlaczego warto używać wskaźników do funkcji? Listing 15.5 z pewnością mógłby zostać napisany bez użycia wskaźników do funkcji, ale użycie takich wskaźników jawnie określa przeznaczenie programu: wybór funkcji z listy, a następnie jej wywołanie.
Listing 15.6 wykorzystuje prototypy i definicje funkcji z listingu 15.5, ale ciało programu nie korzysta ze wskaźników do funkcji. Przyjrzyj się różnicom dzielącym te dwa listingi.
Listing 15.6. Listing 15.5 przepisany bez używania wskaźników do funkcji 0: // Listing 15.6 bez wskaźników do funkcji
1:
2: #include <iostream>
3: using namespace std;
4:
5: void Square (int&,int&); // do kwadratu
6: void Cube (int&, int&); // do trzeciej potegi
7: void Swap (int&, int &); // zamiana
8: void GetVals(int&, int&); // zmiana
9: void PrintVals(int, int);
10:
11: int main()
12: {
13: bool fQuit = false;
14: int valOne=1, valTwo=2;
15: int choice;
16: while (fQuit == false)
17: {

18: cout << "(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: ";
19: cin >> choice;
20: switch (choice)
21: {
22: case 1:
23: PrintVals(valOne, valTwo);
24: GetVals(valOne, valTwo);
25: PrintVals(valOne, valTwo);
26: break;
27:
28: case 2:
29: PrintVals(valOne, valTwo);
30: Square(valOne,valTwo);
31: PrintVals(valOne, valTwo);
32: break;
33:
34: case 3:
35: PrintVals(valOne, valTwo);
36: Cube(valOne, valTwo);
37: PrintVals(valOne, valTwo);
38: break;
39:
40: case 4:
41: PrintVals(valOne, valTwo);
42: Swap(valOne, valTwo);
43: PrintVals(valOne, valTwo);
44: break;
45:
46: default :
47: fQuit = true;
48: break;
49: }
50:
51: if (fQuit)
52: break;
53: }
54: return 0;

55: }
56:
57: void PrintVals(int x, int y)
58: {
59: cout << "x: " << x << " y: " << y << endl;
60: }
61:
62: void Square (int & rX, int & rY)
63: {
64: rX *= rX;
65: rY *= rY;
66: }
67:
68: void Cube (int & rX, int & rY)
69: {
70: int tmp;
71:
72: tmp = rX;
73: rX *= rX;
74: rX = rX * tmp;
75:
76: tmp = rY;
77: rY *= rY;
78: rY = rY * tmp;
79: }
80:
81: void Swap(int & rX, int & rY)
82: {
83: int temp;
84: temp = rX;
85: rX = rY;
86: rY = temp;
87: }
88:
89: void GetVals (int & rValOne, int & rValTwo)
90: {
91: cout << "Nowa wartosc dla ValOne: ";

92: cin >> rValOne;
93: cout << "Nowa wartosc dla ValTwo: ";
94: cin >> rValTwo;
95: }
Wynik (0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 1
x: 1 y: 2
Nowa wartosc dla ValOne: 2
Nowa wartosc dla ValTwo: 3
x: 2 y: 3
(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 3
x: 2 y: 3
x: 8 y: 27
(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 2
x: 8 y: 27
x: 64 y: 729
(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 4
x: 64 y: 729
x: 729 y: 64
(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 0
Analiza
Kusiło mnie, by umieścić wywołanie funkcji PrintVals() na początku i na końcu pętli while, a nie w każdej z instrukcji case. Spowodowałoby to jednak wywołanie tej funkcji także dla opcji wyjścia z programu, co nie zgadzałoby się z jego specyfikacją.
Poza wzrostem objętości kodu i powtórzonych wywołań tej samej funkcji, znacznie zmniejszyła się także ogólna przejrzystość programu. Ten przypadek został jednak stworzony w celu zilustrowania działania wskaźników do funkcji. W rzeczywistości zalety wskaźników do funkcji są jeszcze większe: wskaźniki do funkcji mogą eliminować powtórzenia kodu, sprawiają, że program staje się bardziej przejrzysty i umożliwiają stosowanie tablic funkcji wywoływanych w zależności od sytuacji powstałych podczas działania programu.

Skrócone wywołanie
Wskaźnik do funkcji nie musi być wyłuskiwany, choć oczywiście można przeprowadzić tę operację. Zatem, jeśli pFunc jest wskaźnikiem do funkcji przyjmującej wartość całkowitą i zwracającej zmienną typu long, i gdy do pFunc przypiszemy odpowiednią dla niego funkcję, możemy wywołać tę funkcję, pisząc albo:
pFunc(x);
albo:
(*pFunc)(x);
Obie te formy działają identycznie. Pierwsza jest jedynie skróconą wersją drugiej.
Tablice wskaźników do funkcji Można deklarować nie tylko tablice wskaźników do wartości całkowitych, ale również tablice wskaźników do funkcji zwracających określony typ i posiadających określoną sygnaturę. Listing 15.7 stanowi zmodyfikowaną wersję listingu 15.5, tym razem wykorzystującą tablicę do wywoływania wszystkich opcji naraz.
Listing 15.7. Demonstruje użycie tablicy wskaźników do funkcji 0: // Listing 15.7
1: //Demonstruje użycie tablicy wskaźników do funkcji
2:
3: #include <iostream>
4: using namespace std;
5:
6: void Square (int&,int&); // do kwadratu
7: void Cube (int&, int&); // do trzeciej potegi
8: void Swap (int&, int &); // zamiana
9: void GetVals(int&, int&); // zmiana
10: void PrintVals(int, int);
11:
12: int main()
13: {
14: int valOne=1, valTwo=2;
15: int choice, i;
Usunięto: e

16: const MaxArray = 5;
17: void (*pFuncArray[MaxArray])(int&, int&);
18:
19: for (i=0;i<MaxArray;i++)
20: {
21: cout << "(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: ";
22: cin >> choice;
23: switch (choice)
24: {
25: case 1: pFuncArray[i] = GetVals; break;
26: case 2: pFuncArray[i] = Square; break;
27: case 3: pFuncArray[i] = Cube; break;
28: case 4: pFuncArray[i] = Swap; break;
29: default:pFuncArray[i] = 0;
30: }
31: }
32:
33: for (i=0;i<MaxArray; i++)
34: {
35: if ( pFuncArray[i] == 0 )
36: continue;
37: pFuncArray[i](valOne,valTwo);
38: PrintVals(valOne,valTwo);
39: }
40: return 0;
41: }
42:
43: void PrintVals(int x, int y)
44: {
45: cout << "x: " << x << " y: " << y << endl;
46: }
47:
48: void Square (int & rX, int & rY)
49: {
50: rX *= rX;
51: rY *= rY;
52: }

53:
54: void Cube (int & rX, int & rY)
55: {
56: int tmp;
57:
58: tmp = rX;
59: rX *= rX;
60: rX = rX * tmp;
61:
62: tmp = rY;
63: rY *= rY;
64: rY = rY * tmp;
65: }
66:
67: void Swap(int & rX, int & rY)
68: {
69: int temp;
70: temp = rX;
71: rX = rY;
72: rY = temp;
73: }
74:
75: void GetVals (int & rValOne, int & rValTwo)
76: {
77: cout << "Nowa wartosc dla ValOne: ";
78: cin >> rValOne;
79: cout << "Nowa wartosc dla ValTwo: ";
80: cin >> rValTwo;
81: }
Wynik (0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 1
(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 2
(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 3

(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 4
(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 2
Nowa wartosc dla ValOne: 2
Nowa wartosc dla ValTwo: 3
x: 2 y: 3
x: 4 y: 9
x: 64 y: 729
x: 729 y: 64
x: 531441 y: 4096
Analiza
W linii 17. tablica pFuncArray jest deklarowana jako tablica pięciu wskaźników do funkcji zwracających void i przyjmujących po dwie referencje do wartości całkowitych.
W liniach od 19. do 31. użytkownik jest proszony o wybranie funkcji przeznaczonej do wywołania, po czym każdemu elementowi tablicy jest przypisywany adres odpowiedniej funkcji. W liniach od 33. do 39. wywoływane są funkcje wskazywane przez kolejne elementy tablicy. Po każdym wywołaniu wypisywane są wyniki.
Przekazywanie wskaźników do funkcji innym funkcjom Wskaźniki do funkcji (a także tablice wskaźników do funkcji) mogą być przekazywane do innych funkcji, które mogą wykonywać obliczenia i na podstawie ich wyniku, dzięki otrzymanym wskaźnikom, wywoływać odpowiednie funkcje.
Możemy na przykład poprawić listing 15.5, przekazując wskaźnik do wybranej funkcji do innej funkcji (poza main()), która wypisuje wartości, wywołuje funkcję i ponownie wypisuje wartości. Ten wariant działania przedstawia listing 15.8.
Listing 15.8. Przekazywanie wskaźników do funkcji jako argumentów funkcji 0: // Listing 15.8 Przekazywanie wskaźników do funkcji
1:
2: #include <iostream>
3: using namespace std;
4:
5: void Square (int&,int&); // do kwadratu
6: void Cube (int&, int&); // do trzeciej potegi
7: void Swap (int&, int &); // zamiana
8: void GetVals(int&, int&); // zmiana
Usunięto: do innych funkcji

9: void PrintVals(void (*)(int&, int&),int&, int&);
10:
11: int main()
12: {
13: int valOne=1, valTwo=2;
14: int choice;
15: bool fQuit = false;
16:
17: void (*pFunc)(int&, int&);
18:
19: while (fQuit == false)
20: {
21: cout << "(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: ";
22: cin >> choice;
23: switch (choice)
24: {
25: case 1: pFunc = GetVals; break;
26: case 2: pFunc = Square; break;
27: case 3: pFunc = Cube; break;
28: case 4: pFunc = Swap; break;
29: default:fQuit = true; break;
30: }
31: if (fQuit == true)
32: break;
33: PrintVals ( pFunc, valOne, valTwo);
34: }
35:
36: return 0;
37: }
38:
39: void PrintVals( void (*pFunc)(int&, int&),int& x, int& y)
40: {
41: cout << "x: " << x << " y: " << y << endl;
42: pFunc(x,y);
43: cout << "x: " << x << " y: " << y << endl;
44: }
45:

46: void Square (int & rX, int & rY)
47: {
48: rX *= rX;
49: rY *= rY;
50: }
51:
52: void Cube (int & rX, int & rY)
53: {
54: int tmp;
55:
56: tmp = rX;
57: rX *= rX;
58: rX = rX * tmp;
59:
60: tmp = rY;
61: rY *= rY;
62: rY = rY * tmp;
63: }
64:
65: void Swap(int & rX, int & rY)
66: {
67: int temp;
68: temp = rX;
69: rX = rY;
70: rY = temp;
71: }
72:
73: void GetVals (int & rValOne, int & rValTwo)
74: {
75: cout << "Nowa wartosc dla ValOne: ";
76: cin >> rValOne;
77: cout << "Nowa wartosc dla ValTwo: ";
78: cin >> rValTwo;
79: }
Wynik

(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 1
x: 1 y: 2
Nowa wartosc dla ValOne: 2
Nowa wartosc dla ValTwo: 3
x: 2 y: 3
(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 3
x: 2 y: 3
x: 8 y: 27
(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 2
x: 8 y: 27
x: 64 y: 729
(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 4
x: 64 y: 729
x: 729 y: 64
(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 0
Analiza
W linii 17. zmienna pFunc zostaje zadeklarowana jako wskaźnik do funkcji zwracającej void i przyjmującej dwa parametry, będące referencjami do wartości typu int. W linii 9. została zadeklarowana funkcja PrintVals przyjmująca trzy parametry. Pierwszym z nich jest wskaźnik do funkcji zwracającej void i przyjmującej dwie referencje do typu int, a drugim i trzecim są referencje do zmiennych typu int. Także w tym programie użytkownik jest proszony o wybranie funkcji do wywołania, po czym w linii 33. wywoływana jest funkcja PrintVals.
Znajdź jakiegoś programistę C++ i zapytaj go, co oznacza poniższa deklaracja:
void PrintVals(void (*)(int&, int&), int&, int&);
Jest to niezbyt często używany rodzaj deklaracji; prawdopodobnie zajrzysz do książki za każdym razem, gdy spróbujesz z niej skorzystać. Może ona jednak ocalić twój program w tych rzadkich przypadkach, gdy niezbędna będzie taka właśnie konstrukcja.
Usunięto: ,
Usunięto: e
Usunięto: wartości
Usunięto: będzie dokładnie tą
Usunięto: ą
Usunięto: , jaka jest wymagana.

Użycie instrukcji typedef ze wskaźnikami do funkcji Konstrukcja void (*)(int&, int&) jest co najmniej niezrozumiała. Aby ją uprościć, możemy użyć instrukcji typedef, deklarując typ (w tym przypadku nazwiemy go VPF) jako wskaźnik do funkcji zwracającej void i przyjmującej dwie referencje do typu int. Listing 15.9 stanowi nieco zmodyfikowaną wersję listingu 15.8. w którym zastosowano instrukcję typedef.
Listing 15.9. Użycie instrukcji typedef w celu uproszczenia deklaracji wskaźnika do funkcji 0: // Listing 15.9.
1: // Użycie typedef w celu uproszczenia deklaracji wskaźnika do funkcji
2:
3: #include <iostream>
4: using namespace std;
5:
6: void Square (int&,int&); // do kwadratu
7: void Cube (int&, int&); // do trzeciej potegi
8: void Swap (int&, int &); // zamiana
9: void GetVals(int&, int&); // zmiana
10: typedef void (*VPF) (int&, int&) ;
11: void PrintVals(VPF,int&, int&);
12:
13: int main()
14: {
15: int valOne=1, valTwo=2;
16: int choice;
17: bool fQuit = false;
18:
19: VPF pFunc;
20:
21: while (fQuit == false)
22: {
23: cout << "(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: ";
24: cin >> choice;
25: switch (choice)
26: {
27: case 1: pFunc = GetVals; break;
28: case 2: pFunc = Square; break;
29: case 3: pFunc = Cube; break;

30: case 4: pFunc = Swap; break;
31: default:fQuit = true; break;
32: }
33: if (fQuit == true)
34: break;
35: PrintVals ( pFunc, valOne, valTwo);
36: }
37: return 0;
38: }
39:
40: void PrintVals( VPF pFunc,int& x, int& y)
41: {
42: cout << "x: " << x << " y: " << y << endl;
43: pFunc(x,y);
44: cout << "x: " << x << " y: " << y << endl;
45: }
46:
47: void Square (int & rX, int & rY)
48: {
49: rX *= rX;
50: rY *= rY;
51: }
52:
53: void Cube (int & rX, int & rY)
54: {
55: int tmp;
56:
57: tmp = rX;
58: rX *= rX;
59: rX = rX * tmp;
60:
61: tmp = rY;
62: rY *= rY;
63: rY = rY * tmp;
64: }
65:
66: void Swap(int & rX, int & rY)

67: {
68: int temp;
69: temp = rX;
70: rX = rY;
71: rY = temp;
72: }
73:
74: void GetVals (int & rValOne, int & rValTwo)
75: {
76: cout << "Nowa wartosc dla ValOne: ";
77: cin >> rValOne;
78: cout << "Nowa wartosc dla ValTwo: ";
79: cin >> rValTwo;
80: }
Wynik (0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 1
x: 1 y: 2
Nowa wartosc dla ValOne: 2
Nowa wartosc dla ValTwo: 3
x: 2 y: 3
(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 3
x: 2 y: 3
x: 8 y: 27
(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 2
x: 8 y: 27
x: 64 y: 729
(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 4
x: 64 y: 729
x: 729 y: 64
(0)Koniec (1)Zmiana (2)Do kwadratu (3)Do trzeciej potegi (4)Zamiana: 0

Analiza
W linii 10. instrukcja typedef została użyta do zadeklarowania VPF jako typu „wskaźnik do funkcji zwracającej void i przyjmującej dwa parametry w postaci referencji do wartości typu int”.
W linii 11. została zadeklarowana funkcja PrintVals() przyjmująca trzy parametry: VPF i dwie referencje do wartości typu int. W tym programie wskaźnik pFunc został zadeklarowany jako zmienna typu VPF (w linii 19.).
Po zdefiniowaniu typu VPF wszystkie następne konstrukcje z użyciem pFunc i PrintVals() stają się dużo bardziej przejrzyste. Jak widać, działanie programu nie ulega zmianie.
Wskaźniki do funkcji składowych Do tej pory wszystkie wskaźniki do funkcji odnosiły się do funkcji ogólnych, nie będących funkcjami składowymi. Istnieje jednak możliwość tworzenia wskaźników do funkcji, będących składowymi klas.
Aby stworzyć wskaźnik do funkcji składowej, musimy użyć tej samej składni, jak w przypadku zwykłego wskaźnika do funkcji, ale z zastosowaniem nazwy klasy i operatora zakresu (::). Jeśli pFunc ma wskazywać na funkcję składową klasy Shape zwracającą void i przyjmującą dwie wartości całkowite, wtedy deklaracja tej zmiennej powinna wyglądać następująco:
void (Shape::*pFunc) (int, int);
Wskaźniki do funkcji składowych są używane tak samo, jak wskaźniki do zwykłych funkcji, z tym że w celu wywołania ich potrzebny jest obiekt właściwej klasy. Listing 15.10 ilustruje użycie wskaźników do funkcji składowych.
Listing 15.10. Wskaźniki do funkcji składowych 0: //Listing 15.10 Wskaźniki do funkcji składowych
1:
2: #include <iostream>
3: using namespace std;
4:
5: class Mammal
6: {
7: public:
8: Mammal():itsAge(1) { }
9: virtual ~Mammal() { }
10: virtual void Speak() const = 0;
11: virtual void Move() const = 0;

12: protected:
13: int itsAge;
14: };
15:
16: class Dog : public Mammal
17: {
18: public:
19: void Speak()const { cout << "Hau!\n"; }
20: void Move() const { cout << "Gonie w pietke...\n"; }
21: };
22:
23:
24: class Cat : public Mammal
25: {
26: public:
27: void Speak()const { cout << "Miau!\n"; }
28: void Move() const { cout << "Skradam sie...\n"; }
29: };
30:
31:
32: class Horse : public Mammal
33: {
34: public:
35: void Speak()const { cout << "Ihaaa!\n"; }
36: void Move() const { cout << "Galopuje...\n"; }
37: };
38:
39:
40: int main()
41: {
42: void (Mammal::*pFunc)() const =0;
43: Mammal* ptr =0;
44: int Animal;
45: int Method;
46: bool fQuit = false;
47:
48: while (fQuit == false)

49: {
50: cout << "(0)Wyjscie (1)pies (2)kot (3)kon: ";
51: cin >> Animal;
52: switch (Animal)
53: {
54: case 1: ptr = new Dog; break;
55: case 2: ptr = new Cat; break;
56: case 3: ptr = new Horse; break;
57: default: fQuit = true; break;
58: }
59: if (fQuit)
60: break;
61:
62: cout << "(1)Speak! (2)Move: ";
63: cin >> Method;
64: switch (Method)
65: {
66: case 1: pFunc = Mammal::Speak; break;
67: default: pFunc = Mammal::Move; break;
68: }
69:
70: (ptr->*pFunc)();
71: delete ptr;
72: }
73: return 0;
74: }
Wynik (0)Wyjscie (1)pies (2)kot (3)kon: 1
(1)Speak (2)Move: 1
Hau!
(0)Wyjscie (1)pies (2)kot (3)kon: 2
(1)Speak (2)Move: 1
Miau!
(0)Wyjscie (1)pies (2)kot (3)kon: 3
(1)Speak (2)Move: 2

Galopuje...
(0)Wyjscie (1)pies (2)kot (3)kon: 0
Analiza
W liniach od 5. do 14. została zadeklarowana abstrakcyjna klasa Mammal, zawierająca dwie czyste metody wirtualne: Speak() (daj głos) oraz Move() (ruszaj się). Z klasy Mammal zostały wyprowadzone klasy Dog, Cat i Horse, z których każda przesłania metody Speak() i Move().
Program sterujący (funkcja main()) prosi użytkownika o wybranie zwierzęcia, które ma zostać stworzone, po czym w liniach od 54. do 56. na stercie tworzony jest nowy obiekt klasy pochodnej; jego adres zostaje przypisany wskaźnikowi ptr.
Następnie użytkownik jest proszony o wybranie metody, która ma zostać wywołana; wybrana metoda jest przypisywana do wskaźnika pFunc. W linii 70. wywoływana jest metoda wybrana dla stworzonego wcześniej obiektu. Wywoływana jest ona poprzez użycie wskaźnika ptr (w celu uzyskania dostępu do obiektu) i wskaźnika pFunc (w celu wywołania jego metody).
Na zakończenie, w linii 71., za pomocą operatora delete zostaje usunięty obiekt wskazywany przez ptr (w celu zwolnienia pamięci na stercie). Zauważ, że nie ma powodu wywoływania delete dla wskaźnika pFunc, gdyż jest to wskaźnik do kodu, a nie do obiektu na stercie. W rzeczywistości taka próba zakończyłaby się wypisaniem błędu kompilacji.
Tablice wskaźników do funkcji składowych Podobnie jak w przypadku wskaźników do zwykłych funkcji, w tablicach można przechowywać także wskaźniki do funkcji składowych. Tablica może zostać zainicjalizowana adresami różnych funkcji składowych, które potem mogą być wywoływane dla poszczególnych elementów tablicy. Technikę tę ilustruje listing 15.11.
Listing 15.11. Tablica wskaźników do funkcji składowych 0: //Listing 15.11 Tablica wskaźników do funkcji składowych
1:
2: #include <iostream>
3: using std::cout;
4:
5: class Dog
6: {
7: public:
8: void Speak()const { cout << "Hau!\n"; }
9: void Move() const { cout << "Gonie w pietke...\n"; }
10: void Eat() const { cout << "Jem...\n"; }
11: void Growl() const { cout << "Warcze\n"; }
12: void Whimper() const { cout << "Wyje...\n"; }
13: void RollOver() const { cout << "Tarzam sie...\n"; }

14: void PlayDead() const { cout << "Koniec Malego Cezara?\n"; }
15: };
16:
17: typedef void (Dog::*PDF)()const ;
18: int main()
19: {
20: const int MaxFuncs = 7;
21: PDF DogFunctions[MaxFuncs] =
22: {Dog::Speak,
23: Dog::Move,
24: Dog::Eat,
25: Dog::Growl,
26: Dog::Whimper,
27: Dog::RollOver,
28: Dog::PlayDead };
29:
30: Dog* pDog =0;
31: int Method;
32: bool fQuit = false;
33:
34: while (!fQuit)
35: {
36: cout << "(0)Wyjscie (1)Daj glos (2)Ruszaj sie (3)Jedz (4)Warcz";
37: cout << " (5)Wyj (6)Tarzaj sie (7)Zdechl pies: ";
38: std::cin >> Method;
39: if (Method == 0)
40: {
41: fQuit = true;
42: }
43: else
44: {
45: pDog = new Dog;
46: (pDog->*DogFunctions[Method-1])();
47: delete pDog;
48: }
49: }
50: return 0;

51: }
Wynik (0)Wyjscie (1)Daj glos (2)Ruszaj sie (3)Jedz (4)Warcz (5)Wyj (6)Tarzaj sie (7)Zdechl pies: 1
Hau!
(0)Wyjscie (1)Daj glos (2)Ruszaj sie (3)Jedz (4)Warcz (5)Wyj (6)Tarzaj sie (7)Zdechl pies: 4
Warcze
(0)Wyjscie (1)Daj glos (2)Ruszaj sie (3)Jedz (4)Warcz (5)Wyj (6)Tarzaj sie (7)Zdechl pies: 7
Koniec Malego Cezara?
(0)Wyjscie (1)Daj glos (2)Ruszaj sie (3)Jedz (4)Warcz (5)Wyj (6)Tarzaj sie (7)Zdechl pies: 0
Analiza
W liniach od 5. do 15. została stworzona klasa Dog, zawierająca siedem funkcji składowych, każdą o tym samym zwracanym typie i sygnaturze. W linii 17. instrukcja typedef deklaruje PDF jako wskaźnik do funkcji składowej klasy Dog, która nie przyjmuje żadnych parametrów i nie zwraca żadnej wartości, a ponadto jest funkcją const — typ ten jest zgodny z sygnaturą wszystkich siedmiu funkcji składowych klasy Dog.
W liniach od 21. do 28. została zadeklarowana tablica DogFunctions, przechowująca wskaźniki do siedmiu funkcji składowych; jest ona inicjalizowana adresami tych funkcji.
W liniach 36. i 37. użytkownik jest proszony o wybranie metody. Do momentu wybrania opcji Wyjście, na stercie za każdym razem jest tworzony obiekt klasy Dog, następnie w linii 46. jest dla niego wywoływana odpowiednia funkcja z tablicy. Oto kolejna linia, którą warto pokazać zarozumiałym programistom z twojej firmy; zapytaj ich, do czego służy:
(pDog->*DogFunctions[Method-1])();
Także ta konstrukcja może wydawać się niezrozumiała, ale zbudowana ze wskaźników do funkcji składowych tablica może znacznie ułatwić konstruowanie i analizę programu.
TAK NIE
Wywołuj wskaźniki do funkcji składowych dla konkretnych obiektów klasy.
W celu uproszczenia deklaracji wskaźników do funkcji składowych używaj instrukcji typedef.
Nie używaj wskaźników do funkcji składowych, gdy można zastosować prostsze rozwiązanie.
Usunięto: 7
Usunięto: 8
Usunięto:

Rozdział 16. Dziedziczenie zaawansowane Do tej pory używaliśmy dziedziczenia pojedynczego i wielokrotnego w celu stworzenia relacji typu jest-czymś.
Z tego rozdziału dowiesz się:
• czym jest zawieranie i jak je modelować,
• czym jest delegowanie i jak je modelować,
• jak zaimplementować daną klasę poprzez inną,
• jak używać dziedziczenia prywatnego.
Zawieranie Jak pokazaliśmy w poprzednich przykładach, możliwe jest, by dane składowe jednej klasy obejmowały obiekty innych klas. Programiści C++ mówią wtedy, że klasa zewnętrzna zawiera klasę wewnętrzną. Tak więc klasa Employee (pracownik) może zawierać na przykład obiekt typu łańcucha (przechowujący nazwisko pracownika) oraz składowe całkowite (zawierające jego pensję i inne dane).
Listing 16.1 opisuje niekompletną, jednak użyteczną klasę String, dość podobną do klasy String zadeklarowanej w rozdziale 13. Ten listing nie generuje żadnego wydruku. Będzie on jednak wykorzystywany razem z dalszymi listingami.
Listing 16.1. Klasa String 0: // Listing 16.1 Klasa String
1:
2: #include <iostream>
3: #include <string.h>
Usunięto: Z
Usunięto: dziedziczenie
Usunięto: Jak dotąd
Usunięto: korzystaliśmy z
Usunięto: pojedynczego i wielokrotnego
Usunięto: W
Usunięto: tym
Usunięto: le
Usunięto: C
Usunięto: za
Usunięto: .
Usunięto: C
Usunięto: za
Usunięto: .
Usunięto: J
Usunięto: .
Usunięto: J
Usunięto: dziedziczenia
Usunięto: widzieliśmy
Usunięto: choć wciąż
Usunięto: owoż
Usunięto: daje
Usunięto: wyniku
Usunięto: Zamiast tego zostanie
Usunięto: an

4: using namespace std;
5:
6: class String
7: {
8: public:
9: // konstruktory
10: String();
11: String(const char *const);
12: String(const String &);
13: ~String();
14:
15: // przeciążone operatory
16: char & operator[](int offset);
17: char operator[](int offset) const;
18: String operator+(const String&);
19: void operator+=(const String&);
20: String & operator= (const String &),
21:
22: // ogólne akcesory
23: int GetLen()const { return itsLen; }
24: const char * GetString() const { return itsString; }
25: static int ConstructorCount;
26:
27: private:
28: String (int); // prywatny konstruktor
29: char * itsString;
30: unsigned short itsLen;
31:
32: };
33:
34: // domyślny konstruktor tworzący ciąg pusty (0 bajtów)
35: String::String()
36: {
37: itsString = new char[1];
38: itsString[0] = '\0';
39: itsLen=0;
40: // cout << "\tDomyslny konstruktor lancucha\n";
Usunięto: zera

41: // ConstructorCount++;
42: }
43:
44: // prywatny (pomocniczy) konstruktor, używany tylko przez
45: // metody klasy przy tworzeniu nowego, wypełnionego zerowymi
46: // bajtami, łańcucha o zadanej długości
47: String::String(int len)
48: {
49: itsString = new char[len+1];
50: for (int i = 0; i<=len; i++)
51: itsString[i] = '\0';
52: itsLen=len;
53: // cout << "\tKonstruktor String(int)\n";
54: // ConstructorCount++;
55: }
56:
57: // Zamienia tablice znaków w typ String
58: String::String(const char * const cString)
59: {
60: itsLen = strlen(cString);
61: itsString = new char[itsLen+1];
62: for (int i = 0; i<itsLen; i++)
63: itsString[i] = cString[i];
64: itsString[itsLen]='\0';
65: // cout << "\tKonstruktor String(char*)\n";
66: // ConstructorCount++;
67: }
68:
69: // konstruktor kopiujący
70: String::String (const String & rhs)
71: {
72: itsLen=rhs.GetLen();
73: itsString = new char[itsLen+1];
74: for (int i = 0; i<itsLen;i++)
75: itsString[i] = rhs[i];
76: itsString[itsLen] = '\0';
77: // cout << "\tKonstruktor String(String&)\n";
Usunięto: i

78: // ConstructorCount++;
79: }
80:
81: // destruktor, zwalnia zaalokowaną pamięć
82: String::~String ()
83: {
84: delete [] itsString;
85: itsLen = 0;
86: // cout << "\tDestruktor klasy String\n";
87: }
88:
89: // operator równości, zwalnia istniejącą pamięć,
90: // po czym kopiuje łańcuch i rozmiar
91: String& String::operator=(const String & rhs)
92: {
93: if (this == &rhs)
94: return *this;
95: delete [] itsString;
96: itsLen=rhs.GetLen();
97: itsString = new char[itsLen+1];
98: for (int i = 0; i<itsLen;i++)
99: itsString[i] = rhs[i];
100: itsString[itsLen] = '\0';
101: return *this;
102: // cout << "\toperator= klasy String\n";
103: }
104:
105: //nie const operator indeksu, zwraca
106: // referencję do znaku, więc można go
107: // zmienić!
108: char & String::operator[](int offset)
109: {
110: if (offset > itsLen)
111: return itsString[itsLen-1];
112: else
113: return itsString[offset];
114: }

115:
116: // const operator indeksu do używania z obiektami
117: // const (patrz konstruktor kopiujący!)
118: char String::operator[](int offset) const
119: {
120: if (offset > itsLen)
121: return itsString[itsLen-1];
122: else
123: return itsString[offset];
124: }
125:
126: // tworzy nowy łańcuch przez dodanie do rhs
127: // bieżącego łańcucha
128: String String::operator+(const String& rhs)
129: {
130: int totalLen = itsLen + rhs.GetLen();
131: String temp(totalLen);
132: int i, j;
133: for (i = 0; i<itsLen; i++)
134: temp[i] = itsString[i];
135: for (j = 0; j<rhs.GetLen(); j++, i++)
136: temp[i] = rhs[j];
137: temp[totalLen]='\0';
138: return temp;
139: }
140:
141: // zmienia bieżący łańcuch, nie zwraca nic
142: void String::operator+=(const String& rhs)
143: {
144: unsigned short rhsLen = rhs.GetLen();
145: unsigned short totalLen = itsLen + rhsLen;
146: String temp(totalLen);
147: int i, j;
148: for (i = 0; i<itsLen; i++)
149: temp[i] = itsString[i];
150: for (j = 0; j<rhs.GetLen(); j++, i++)
151: temp[i] = rhs[i-itsLen];
Usunięto: i

152: temp[totalLen]='\0';
153: *this = temp;
154: }
155:
156: // int String::ConstructorCount = 0;
UWAGA Umieść kod z listingu 16.1 w pliku o nazwie String.hpp. Za każdym razem, gdy będziesz potrzebował klasy String, będziesz mógł dołączyć listing 16.1 (używając instrukcji #include "String.hpp";, tak jak to robimy w dalszych listingach przedstawionych w tym rozdziale).
Wynik
Brak
Analiza
Listing 16.1 zawiera klasę String, bardzo podobną do klasy String z listingu 13.12 przedstawionego w rozdziale trzynastym, „Tablice i listy połączone”. Jednakże konstruktory i inne funkcje z listingu 13.12 zawierały instrukcje wypisujące na ekranie komunikaty; w listingu 16.1 instrukcje te zostały wykomentowane. Z funkcji tych skorzystamy w następnych przykładach.
W linii 25. została zadeklarowana statyczna zmienna składowa ConstructorCount (licznik konstruktorów), która jest inicjalizowana w linii 156. Ta zmienna podlega inkrementacji w każdym konstruktorze klasy. Wszystko to zostało na razie wykomentowane; skorzystamy z tego dopiero w następnych listingach.
Listing 16.2 przedstawia klasę Employee (pracownik), zawierającą trzy obiekty typu String.
Listing 16.2. Klasa Employee i program sterujący 0: // Listing 16.2 Klasa Employee i program sterujący
1: #include "String.hpp"
2:
3: class Employee
4: {
5: public:
6: Employee();
7: Employee(char *, char *, char *, long);
8: ~Employee();
9: Employee(const Employee&);
10: Employee & operator= (const Employee &);
Usunięto: K
Usunięto: umieść
Usunięto: Wtedy z
Usunięto: :
Usunięto: :
Usunięto: Najważniejszą różnicą jest to, że
Usunięto: na ekranie
Usunięto: jest
Usunięto: inicjalizowana

11:
12: const String & GetFirstName() const
13: { return itsFirstName; }
14: const String & GetLastName() const { return itsLastName; }
15: const String & GetAddress() const { return itsAddress; }
16: long GetSalary() const { return itsSalary; }
17:
18: void SetFirstName(const String & fName)
19: { itsFirstName = fName; }
20: void SetLastName(const String & lName)
21: { itsLastName = lName; }
22: void SetAddress(const String & address)
23: { itsAddress = address; }
24: void SetSalary(long salary) { itsSalary = salary; }
25: private:
26: String itsFirstName;
27: String itsLastName;
28: String itsAddress;
29: long itsSalary;
30: };
31:
32: Employee::Employee():
33: itsFirstName(""),
34: itsLastName(""),
35: itsAddress(""),
36: itsSalary(0)
37: {}
38:
39: Employee::Employee(char * firstName, char * lastName,
40: char * address, long salary):
41: itsFirstName(firstName),
42: itsLastName(lastName),
43: itsAddress(address),
44: itsSalary(salary)
45: {}
46:
47: Employee::Employee(const Employee & rhs):

48: itsFirstName(rhs.GetFirstName()),
49: itsLastName(rhs.GetLastName()),
50: itsAddress(rhs.GetAddress()),
51: itsSalary(rhs.GetSalary())
52: {}
53:
54: Employee::~Employee() {}
55:
56: Employee & Employee::operator= (const Employee & rhs)
57: {
58: if (this == &rhs)
59: return *this;
60:
61: itsFirstName = rhs.GetFirstName();
62: itsLastName = rhs.GetLastName();
63: itsAddress = rhs.GetAddress();
64: itsSalary = rhs.GetSalary();
65:
66: return *this;
67: }
68:
69: int main()
70: {
71: Employee Edie("Jane","Doe","1461 Shore Parkway", 20000);
72: Edie.SetSalary(50000);
73: String LastName("Levine");
74: Edie.SetLastName(LastName);
75: Edie.SetFirstName("Edythe");
76:
77: cout << "Imie i nazwisko: ";
78: cout << Edie.GetFirstName().GetString();
79: cout << " " << Edie.GetLastName().GetString();
80: cout << ".\nAdres: ";
81: cout << Edie.GetAddress().GetString();
82: cout << ".\nPensja: " ;
83: cout << Edie.GetSalary();
84: return 0;

85: }
Dla wygody użytkownika, implementacja klasy String została umieszczona w pliku wraz z deklaracją. W rzeczywistym programie, deklaracja tej klasy zostałaby umieszczona w pliku String.hpp, zaś jej implementacja w pliku String.cpp. Wtedy moglibyśmy dodać do projektu plik String.cpp (za pomocą poleceń w menu kompilatora lub za pomocą pliku makefile). Na początku pliku String.cpp musiałaby się znaleźć instrukcja #include "String.hpp".
W rzeczywistym programie użylibyśmy klasy String ze standardowej biblioteki C++, a nie klasy stworzonej przez nas samych.
Wynik Imie i nazwisko: Edythe Levine.
Adres: 1461 Shore Parkway.
Pensja: 50000
Analiza
Listing 16.2 przedstawia klasę Employee zawierającą trzy obiekty łańcuchowe: itsFirstName (imię), itsLastName (nazwisko) oraz itsAddress (adres).
W linii 71. zostaje utworzony obiekt klasy Employee, a do jego inicjalizacji są wykorzystywane cztery wartości. W linii 72. zostaje wywołany akcesor SetSalary() (ustaw pensję), ze stałą wartością 50000. Zwróć uwagę że, w rzeczywistym programie byłaby to albo wartość dynamiczna (ustawiana podczas działania programu), albo zdefiniowana stała.
W linii 73. zostaje utworzony łańcuch, inicjalizowany za pomocą stałej łańcuchowej w stylu C++. Otrzymany obiekt łańcuchowy jest następnie używany jako argument funkcji SetLastName() (ustaw nazwisko) w linii 74.
W linii 75. wywołana zostaje funkcja SetFirstName() (ustaw imię) klasy Employee, której przekazywana jest inna stała łańcuchowa. Jeśli jednak bliżej się jej przyjrzysz, zauważysz, że klasa Employee nie posiada funkcji SetFirstName(), przyjmującej jako argument stałą łańcuchową w stylu C; zamiast tego funkcja SetFirstName() wymaga referencji do stałego łańcucha.
Kompilator potrafi rozwikłać to wywołanie, gdyż wie, w jaki sposób może stworzyć obiekt łańcuchowy ze stałej łańcuchowej.. Wie, gdyż poinformowaliśmy go o tym w linii 11. listingu 16.1.
Często zadawane pytanie
Dlaczego uciekamy się do wywołania funkcji GetString() w liniach 78., 79. i 81?
78: cout << Edie.GetFirstName().GetString();
Usunięto: plik String.cpp
Usunięto: przy
Usunięto: y
Usunięto: przy
Usunięto: y
Usunięto: Jednak przede wszystkim
Usunięto: Ale, oczywiście, w
Usunięto: łańcucha
Usunięto: siebie
Usunięto: :
Usunięto: :
Usunięto: ów
Usunięto: s
Usunięto: przy czym
Usunięto: zaś
Usunięto: zostają
Usunięto: ane
Usunięto: przy
Usunięto: y
Usunięto: a
Usunięto: się
Usunięto:
Usunięto: ej
Usunięto: ej
Usunięto: a
Usunięto: w stylu C
Usunięto: kłopoczemy
Usunięto: em
Odpowiedź: Metoda GetFirstName() obiektu Edie zwraca obiekt klasy String. Niestety, nasza klasa String jeszcze nie obsługuje operatora << dla cout. Aby więc usatysfakcjonować cout, musimy zwrócić łańcuch znaków w stylu C. Taki łańcuch zwraca metoda GetString() naszej klasy String. Problem ten rozwiążemy nieco później.
Dostęp do składowych klasy zawieranej Obiekty Employee nie posiadają specjalnych uprawnień dostępu do zmiennych składowych klasy String. Gdyby obiekt klasy Employee, Edie (Edyta) próbował odwołać się do składowej itsLen w swojej własnej zmiennej itsFirstName, wystąpiłby błąd kompilacji. Nie stanowi to jednak większego problemu, bowiem akcesory tworzą interfejs dla klasy String i klasa Employee nie musi się martwić o szczegóły implementacji obiektów łańcuchowych bardziej niż o szczegóły implementacji swojej składowej całkowitej itsSalary.
Filtrowany dostęp do składowych zawieranych Zwróć uwagę, że klasa String posiada operator+. Projektant klasy Employee zablokował dostęp do operatora+ wywoływanego dla obiektów Employee. Uczynił to, deklarując, że wszystkie akcesory zwracające łańcuch, takie jak GetFirstName(), zwracają stałą referencję. Ponieważ operator+ nie jest (i nie może być) funkcją const (gdyż zmienia obiekt, dla którego jest wywoływany), próba napisania poniższej linii zakończy się błędem kompilacji:
String buffer = Edie.GetFirstName() + Edie.GetLastName();
GetFirstName() zwraca stały obiekt String, a nie można używać operatora+ dla stałych obiektów.
Aby temu zaradzić, przeciążamy metodę GetFirstName() jako nie const:
const String & GetFirstName() const { return itsFirstName; }
String & GetFirstName() { return itsFirstName; }
Zwróć uwagę, że wartość zwracana nie jest const oraz, że sama funkcja nie jest już const. Zmiana samej wartości zwracanej nie wystarcza do przeciążenia nazwy funkcji; musimy także zmienić „stałość” samej funkcji.
Usunięto: klasy
Usunięto: Jeśli
Usunięto: by
Usunięto: jest
Usunięto: większym
Usunięto: problemem
Usunięto: .
Usunięto: Interfejs dla klasy String tworzą
Usunięto: B
Usunięto: ,
Usunięto: więc
Usunięto: ów
Usunięto: ,
Usunięto: ie
Usunięto: u
Usunięto: składowych
Usunięto: dla stałych obiektów
Usunięto: .
Usunięto: z
Usunięto: zarówno
Usunięto: wartość
Usunięto: jak i
Usunięto: oraz że
Usunięto: wartości

Koszt zawierania Należy zdawać sobie sprawę, że użytkownik klasy Employee ponosi koszty tworzenia i przechowywania obiektów String za każdym razem, gdy tworzony lub kopiowany jest obiekt klasy Employee.
Odkomentowanie kilku instrukcji cout w listingu 16.1 ujawni, jak często wywoływane są konstruktory klasy String. Listing 16.3 zawiera nową wersję programu sterującego, zawierającą komunikaty wskazujące momenty tworzenia obiektów i wywoływania dla nich metod.
UWAGA Aby skompilować ten listing, odkomentuj linie 40., 53., 65., 77., 86. oraz 102. na listingu 16.1.
Listing 16.3. Konstruktory klasy zawieranej 0: //Listing 16.3 Konstruktory klasy zawieranej
1: #include "String.hpp"
2:
3: class Employee
4: {
5: public:
6: Employee();
7: Employee(char *, char *, char *, long),
8: ~Employee();
9: Employee(const Employee&);
10: Employee & operator= (const Employee &);
11:
12: const String & GetFirstName() const
13: { return itsFirstName; }
14: const String & GetLastName() const { return itsLastName; }
15: const String & GetAddress() const { return itsAddress; }
16: long GetSalary() const { return itsSalary; }
17:
18: void SetFirstName(const String & fName)
19: { itsFirstName = fName; }
20: void SetLastName(const String & lName)
21: { itsLastName = lName; }
22: void SetAddress(const String & address)
23: { itsAddress = address; }
24: void SetSalary(long salary) { itsSalary = salary; }
25: private:
Usunięto: Ważne jest by
Usunięto: płaci cenę
Usunięto: jest tworzony lub kopiowany
Usunięto: pokazuje
Usunięto: przepisaną
Usunięto: na
Usunięto: o
Usunięto: napisaną
Usunięto: u
Usunięto: jego
Usunięto: klasy
Usunięto: klasy

26: String itsFirstName;
27: String itsLastName;
28: String itsAddress;
29: long itsSalary;
30: };
31:
32: Employee::Employee():
33: itsFirstName(""),
34: itsLastName(""),
35: itsAddress(""),
36: itsSalary(0)
37: {}
38:
39: Employee::Employee(char * firstName, char * lastName,
40: char * address, long salary):
41: itsFirstName(firstName),
42: itsLastName(lastName),
43: itsAddress(address),
44: itsSalary(salary)
45: {}
46:
47: Employee::Employee(const Employee & rhs):
48: itsFirstName(rhs.GetFirstName()),
49: itsLastName(rhs.GetLastName()),
50: itsAddress(rhs.GetAddress()),
51: itsSalary(rhs.GetSalary())
52: {}
53:
54: Employee::~Employee() {}
55:
56: Employee & Employee::operator= (const Employee & rhs)
57: {
58: if (this == &rhs)
59: return *this;
60:
61: itsFirstName = rhs.GetFirstName();
62: itsLastName = rhs.GetLastName();

63: itsAddress = rhs.GetAddress();
64: itsSalary = rhs.GetSalary();
65:
66: return *this;
67: }
68:
69: int main()
70: {
71: cout << "Tworzenie obiektu Edie...\n";
72: Employee Edie("Jane","Doe","1461 Shore Parkway", 20000);
73: Edie.SetSalary(20000);
74: cout << "Wywolanie SetFirstName z parametrem char *...\n";
75: Edie.SetFirstName("Edythe");
76: cout << "Tworzenie tymczasowego lancucha LastName...\n";
77: String LastName("Levine");
78: Edie.SetLastName(LastName);
79:
80: cout << "Imie i nazwisko: ";
81: cout << Edie.GetFirstName().GetString();
82: cout << " " << Edie.GetLastName().GetString();
83: cout << "\nAdres: ";
84: cout << Edie.GetAddress().GetString();
85: cout << "\nPensja: " ;
86: cout << Edie.GetSalary();
87: cout << endl;
88: return 0;
89: }
Wynik 1: Tworzenie obiektu Edie...
2: Konstruktor String(char*)
3: Konstruktor String(char*)
4: Konstruktor String(char*)
5: Wywolanie SetFirstName z parametrem char *...
6: Konstruktor String(char*)
7: Destruktor klasy String
Usunięto: :

8: Tworzenie tymczasowego lancucha LastName...
9: Konstruktor String(char*)
10: Imie i nazwisko: Edythe Levine
11: Adres: 1461 Shore Parkway
12: Pensja: 20000
13: Destruktor klasy String
14: Destruktor klasy String
15: Destruktor klasy String
16: Destruktor klasy String
Analiza
Listing 16.3 wykorzystuje tę samą deklarację klasy String, co listingi 16.1 i 16.2. Jednak tym razem instrukcje cout w implementacji klasy String zostały odkomentowane. Poza tym, dla ułatwienia analizy działania, linie wyników programu zostały ponumerowane.
W linii 71. listingu 16.3 zostaje wypisany komunikat Tworzenie obiektu Edie..., co pokazuje pierwsza linia wyników. W linii 72. zostaje utworzony obiekt klasy Employee o nazwie Edie; konstruktorowi zostają przekazane cztery parametry. Tak jak można było oczekiwać, konstruktor klasy String został wywołany trzykrotnie.
Linia 74. wypisuje informacyjny komunikat, po czym w linii 75. zostaje wykonana instrukcja Edie.SetFirstName("Edythe");. Ta instrukcja powoduje utworzenie z łańcucha znaków "Edythe" tymczasowego obiektu klasy String, co odzwierciedlają linie 5. i 6. wyników. Zwróć uwagę, że tymczasowy obiekt jest niszczony natychmiast po użyciu go w instrukcji przypisania.
W linii 77. w ciele programu zostaje utworzony obiekt klasy String. W tym przypadku programista wykonuje jawnie to, co kompilator zrobił w poprzedniej instrukcji niejawnie. Tym razem w ósmej linii wyników widzimy wywołanie konstruktora, nie ma jednak destruktora. Ten obiekt nie jest niszczony aż do chwili, kiedy wyjdzie poza zakres (czyli za koniec funkcji).
W liniach od 81. do 87. niszczone są obiekty łańcuchowe zawarte w klasie Employee, gdyż obiekt Edie wychodzi poza zakres funkcji main(). Z tego też powodu niszczony jest także obiekt łańcuchowy LastName, stworzony wcześniej w linii 77.
Kopiowanie przez wartość Listing 16.3 pokazuje, że stworzenie jednego obiektu Employee powoduje pięć wywołań konstruktora klasy String. Listing 16.4 zawiera kolejną wersję programu sterującego. Tym razem nie są wypisywane komunikaty o tworzeniu obiektu, lecz zostaje użyta (odkomentowana w linii 156.) statyczna zmienna składowa ConstructorCount klasy String.
Gdy przyjrzysz się listingowi 16.1, zauważysz, że zmienna ConstructorCount jest (po odkomentowaniu w konstruktorach) inkrementowana za każdym razem, gdy zostaje wywołany konstruktor. Program sterujący z listingu 16.4 wywołuje funkcje wypisujące, przekazując im obiekt Employee najpierw poprzez referencję, a następnie poprzez wartość. Zmienna
Usunięto: :
Usunięto:
Usunięto: Oprócz tego
Usunięto: odzwierciedla
Usunięto: Wyniki pokazują że, t
Usunięto: jawnie
Usunięto: niejawnie
Usunięto: kończący się wraz
Usunięto: końcem
Usunięto: ów
Usunięto: ych
Usunięto: a
ConstructorCount przechowuje aktualną liczbę obiektów String, tworzonych podczas przekazywania obiektu Employee jako parametru.
UWAGA Aby skompilować ten listing, pozostaw bez zmian linie, które odkomentowałeś w celu skompilowania listingu 16.3. Natomiast w listingu 16.1 odkomentuj linie 41., 54., 66., 78. oraz 156.
Listing 16.4. Przekazywanie przez wartość 0: // Listing 16.4 Przekazywanie przez wartość
1: #include "String.hpp"
2:
3: class Employee
4: {
5: public:
6: Employee();
7: Employee(char *, char *, char *, long);
8: ~Employee();
9: Employee(const Employee&);
10: Employee & operator= (const Employee &);
11:
12: const String & GetFirstName() const
13: { return itsFirstName; }
14: const String & GetLastName() const { return itsLastName; }
15: const String & GetAddress() const { return itsAddress; }
16: long GetSalary() const { return itsSalary; }
17:
18: void SetFirstName(const String & fName)
19: { itsFirstName = fName; }
20: void SetLastName(const String & lName)
21: { itsLastName = lName; }
22: void SetAddress(const String & address)
23: { itsAddress = address; }
24: void SetSalary(long salary) { itsSalary = salary; }
25: private:
26: String itsFirstName;
27: String itsLastName;
28: String itsAddress;
29: long itsSalary;
Usunięto:
Usunięto: s
Usunięto: Oprócz tego

30: };
31:
32: Employee::Employee():
33: itsFirstName(""),
34: itsLastName(""),
35: itsAddress(""),
36: itsSalary(0)
37: {}
38:
39: Employee::Employee(char * firstName, char * lastName,
40: char * address, long salary):
41: itsFirstName(firstName),
42: itsLastName(lastName),
43: itsAddress(address),
44: itsSalary(salary)
45: {}
46:
47: Employee::Employee(const Employee & rhs):
48: itsFirstName(rhs.GetFirstName()),
49: itsLastName(rhs.GetLastName()),
50: itsAddress(rhs.GetAddress()),
51: itsSalary(rhs.GetSalary())
52: {}
53:
54: Employee::~Employee() {}
55:
56: Employee & Employee::operator= (const Employee & rhs)
57: {
58: if (this == &rhs)
59: return *this;
60:
61: itsFirstName = rhs.GetFirstName();
62: itsLastName = rhs.GetLastName();
63: itsAddress = rhs.GetAddress();
64: itsSalary = rhs.GetSalary();
65:
66: return *this;

67: }
68:
69: void PrintFunc(Employee);
70: void rPrintFunc(const Employee&);
71:
72: int main()
73: {
74: Employee Edie("Jane","Doe","1461 Shore Parkway", 20000);
75: Edie.SetSalary(20000);
76: Edie.SetFirstName("Edythe");
77: String LastName("Levine");
78: Edie.SetLastName(LastName);
79:
80: cout << "Ilosc konstruktorow: " ;
81: cout << String::ConstructorCount << endl;
82: rPrintFunc(Edie);
83: cout << "Ilosc konstruktorow: ";
84: cout << String::ConstructorCount << endl;
85: PrintFunc(Edie);
86: cout << "Ilosc konstruktorow: ";
87: cout << String::ConstructorCount << endl;
88: return 0;
89: }
90: void PrintFunc (Employee Edie)
91: {
92: cout << "Imie i nazwisko: ";
93: cout << Edie.GetFirstName().GetString();
94: cout << " " << Edie.GetLastName().GetString();
95: cout << ".\nAdres: ";
96: cout << Edie.GetAddress().GetString();
97: cout << ".\nPensja: " ;
98: cout << Edie.GetSalary();
99: cout << endl;
100: }
101:
102: void rPrintFunc (const Employee& Edie)
103: {

104: cout << "Imie i nazwisko: ";
105: cout << Edie.GetFirstName().GetString();
106: cout << " " << Edie.GetLastName().GetString();
107: cout << "\nAdres: ";
108: cout << Edie.GetAddress().GetString();
109: cout << "\nPensja: " ;
110: cout << Edie.GetSalary();
111: cout << endl;
112: }
Wynik Konstruktor String(char*)
Konstruktor String(char*)
Konstruktor String(char*)
Konstruktor String(char*)
Destruktor klasy String
Konstruktor String(char*)
Ilosc konstruktorow: 5
Imie i nazwisko: Edythe Levine
Adres: 1461 Shore Parkway
Pensja: 20000
Ilosc konstruktorow: 5
Konstruktor String(String&)
Konstruktor String(String&)
Konstruktor String(String&)
Imie i nazwisko: Edythe Levine.
Adres: 1461 Shore Parkway.
Pensja: 20000
Destruktor klasy String
Destruktor klasy String
Destruktor klasy String
Ilosc konstruktorow: 8
Destruktor klasy String
Destruktor klasy String
Destruktor klasy String
Usunięto: :

Destruktor klasy String
Analiza
Wynik pokazuje, że przy okazji tworzenia jednego obiektu klasy Employee jest tworzonych pięć obiektów klasy String. Gdy obiekt klasy Employee jest przekazywany funkcji rPrintFunc() przez referencję, nie są tworzone żadne dodatkowe obiekty tej klasy, więc nie są tworzone także żadne dodatkowe obiekty klasy String (także przekazywane poprzez referencję).
Gdy w linii 85. obiekt klasy Employee jest przekazywany do funkcji PrintFunc() poprzez wartość, tworzona jest kopia obiektu, oznacza to, że powstają także trzy kolejne obiekty klasy String (w wyniku wywołania konstruktora kopiującego).
Implementowanie poprzez dziedziczenie i zawieranie oraz poprzez delegację Czasem zdarza się, że jedna klasa chce użyć jakichś atrybutów innej klasy. Na przykład, przypuśćmy, że musimy stworzyć klasę PartsCatalog (katalog części). Z otrzymanej specyfikacji wynika, że klasa PartsCatalog ma być zbiorem części; każda część posiada unikalny numer. Klasa PartsCatalog nie pozwala, by w zbiorze występowały takie same pozycje, natomiast umożliwia dostęp do części na podstawie jej numeru.
Podsumowujący wiadomości listing w rozdziale 14. zawierał klasę PartsList. Została dobrze przetestowana, więc możemy z niej skorzystać tworząc klasę PartsCatalog (bez konieczności wymyślania wszystkiego od początku).
Moglibyśmy stworzyć nową klasę PartsCatalog i umieścić w niej klasę PartsList. Klasa PartsCatalog mogłaby delegować (przekazać) zarządzanie połączoną listą do zawartego w niej obiektu klasy PartsList.
Alternatywnym rozwiązaniem mogłoby być wyprowadzenie klasy PartsCatalog z klasy PartsList i przejęcie w ten sposób właściwości klasy PartsList. Pamiętajmy jednak, że dziedziczenie publiczne przedstawia relację typu jest-czymś, więc powinniśmy sobie zadać pytanie, czy obiekt PartsCatalog rzeczywiście jest obiektem PartsList.
Jednym ze sposobów odpowiedzi na pytanie, czy obiekt PartsCatalog, jest obiektem PartsList jest założenie, że PartsList jest klasą bazową, a PartsCatalog jest klasą wyprowadzoną, i zadanie poniższych pytań:
1. Czy w klasie bazowej jest cokolwiek, co nie powinno być w klasie wyprowadzonej? Na przykład, czy klasa bazowa PartsList posiada funkcje nieodpowiednie dla klasy PartsCatalog? Jeśli tak, prawdopodobnie nie powinniśmy stosować dziedziczenia publicznego.
2. Czy klasa, którą tworzymy, ma więcej niż jedną bazę? Na przykład, czy klasa PartsCatalog wymaga dla każdego swojego obiektu dwóch obiektów PartsList? Jeśli tak, prawie z całą pewnością powinniśmy użyć zawierania.
Usunięto: :
Usunięto: u
Usunięto: one
Usunięto: są
Usunięto: Jednak g
Usunięto: więc
Usunięto: i
Usunięto: kolekcją
Usunięto: kolekcji
Usunięto: oraz
Usunięto: Listing p
Usunięto: Klasa PartsList z
Usunięto: i zrozumiana
Usunięto: chcemy z niej skorzystać,
Usunięto:
Usunięto: zawrzeć
Usunięto: na
Usunięto: y
Usunięto: ą
Usunięto: przejęcie
Usunięto: publiczne
Usunięto:
Usunięto: a
Usunięto: następnie
Usunięto: a
Usunięto: dziedziczenia
Usunięto: dwóch obiektów PartsList

3. Czy musimy dziedziczyć po klasie bazowej tak, aby móc skorzystać z funkcji wirtualnych lub z dostępu do składowych chronionych? Jeśli tak, musimy użyć dziedziczenia, publicznego lub prywatnego.
Uwzględniając odpowiedzi na te pytania, musimy dokonać wyboru pomiędzy dziedziczeniem publicznym (relacją jest-czymś) a dziedziczeniem prywatnym (którego zasady wyjaśnimy w dalszej części rozdziału) lub zawieraniem.
• Zawieranie — obiekt zadeklarowany jako składowa innej klasy zawartej w tej klasie.
• Delegacja — użycie atrybutów klasy zawieranej dla realizacji funkcji niedostępnych w klasie zawierającej.
• Implementacja poprzez — budowanie jednej klasy w oparciu o możliwości innej klasy, bez korzystania z publicznego dziedziczenia.
Delegacja Dlaczego nie powinniśmy wyprowadzać klasy PartsCatalog z klasy PartsList? Obiekt PartsCatlog nie jest obiektem PartsList ponieważ, obiekty PartsList są uporządkowanymi zbiorami, których elementy mogą się powtarzać. Klasa PartsCatalog ma zawierać unikalne pozycje, które nie muszą być uporządkowane. Piąty element obiektu PartsCatalog nie musi być częścią o numerze pięć.
Oczywiście, istnieje możliwości publicznego dziedziczenia po klasie PartsList, a następnie przesłonięcia metody Insert() i operatora indeksu ([]) tak, aby działały zgodnie z naszą specyfikacją, ale w ten sposób wpłynęlibyśmy na istotę działania tej klasy. Zamiast tego zbudujemy klasę PartsCatalog, która nie posiada operatora indeksu i nie pozwala na powtarzanie elementów, zaś w celu łączenia dwóch zestawów zdefiniujemy operator+.
W pierwszym przypadku wykorzystamy zawieranie. Klasa PartsCatalog będzie delegować zarządzanie listą na zawarty w niej obiekt klasy PartsList. To rozwiązanie ilustruje listing 16.5.
Listing 16.5. Delegowanie na zawierany obiekt klasy PartsList 0: // Listing 16.5 Delegowanie na zawierany obiekt klasy PartsList
1:
2: #include <iostream>
3: using namespace std;
4:
5: // **************** Część ************
6:
7: // Abstrakcyjna klasa bazowa części
8: class Part
9: {
10: public:
11: Part():itsPartNumber(1) {}
Usunięto: składowych
Usunięto: Na podstawie
Usunięto: albo
Usunięto: co
Usunięto: albo
Usunięto: O
Usunięto: jest zawierany przez tę klasę
Usunięto: Użycie
Usunięto: klasy w celu wykonania
Usunięto: B
Usunięto: kolekcjami
Usunięto:
Usunięto: samą esencję
Usunięto:
Usunięto: jącą
Usunięto: ,
Usunięto: jącą
Usunięto: órzone
Usunięto: y
Usunięto: do
Usunięto: podejściu

12: Part(int PartNumber):
13: itsPartNumber(PartNumber){}
14: virtual ~Part(){}
15: int GetPartNumber() const
16: { return itsPartNumber; }
17: virtual void Display() const =0;
18: private:
19: int itsPartNumber;
20: };
21:
22: // implementacja czystej funkcji wirtualnej, dzięki temu
23: // mogą z niej korzystać klasy pochodne
24: void Part::Display() const
25: {
26: cout << "\nNumer czesci: " << itsPartNumber << endl;
27: }
28:
29: // **************** Część samochodu ************
30:
31: class CarPart : public Part
32: {
33: public:
34: CarPart():itsModelYear(94){}
35: CarPart(int year, int partNumber);
36: virtual void Display() const
37: {
38: Part::Display();
39: cout << "Rok modelu: ";
40: cout << itsModelYear << endl;
41: }
42: private:
43: int itsModelYear;
44: };
45:
46: CarPart::CarPart(int year, int partNumber):
47: itsModelYear(year),
48: Part(partNumber)
Usunięto: czemu
Usunięto: mogą z niej korzystać¶

49: {}
50:
51:
52: // **************** Część samolotu ************
53:
54: class AirPlanePart : public Part
55: {
56: public:
57: AirPlanePart():itsEngineNumber(1){};
58: AirPlanePart
59: (int EngineNumber, int PartNumber);
60: virtual void Display() const
61: {
62: Part::Display();
63: cout << "Nr silnika: ";
64: cout << itsEngineNumber << endl;
65: }
66: private:
67: int itsEngineNumber;
68: };
69:
70: AirPlanePart::AirPlanePart
71: (int EngineNumber, int PartNumber):
72: itsEngineNumber(EngineNumber),
73: Part(PartNumber)
74: {}
75:
76: // **************** Węzeł części ************
77: class PartNode
78: {
79: public:
80: PartNode (Part*);
81: ~PartNode();
82: void SetNext(PartNode * node)
83: { itsNext = node; }
84: PartNode * GetNext() const;
85: Part * GetPart() const;

86: private:
87: Part *itsPart;
88: PartNode * itsNext;
89: };
90: // Implementacje klasy PartNode...
91:
92: PartNode::PartNode(Part* pPart):
93: itsPart(pPart),
94: itsNext(0)
95: {}
96:
97: PartNode::~PartNode()
98: {
99: delete itsPart;
100: itsPart = 0;
101: delete itsNext;
102: itsNext = 0;
103: }
104:
105: // Gdy nie ma następnego węzła części, zwraca NULL
106: PartNode * PartNode::GetNext() const
107: {
108: return itsNext;
109: }
110:
111: Part * PartNode::GetPart() const
112: {
113: if (itsPart)
114: return itsPart;
115: else
116: return NULL; //błąd
117: }
118:
119:
120:
121: // **************** Klasa PartList ************
122: class PartsList

123: {
124: public:
125: PartsList();
126: ~PartsList();
127: // wymaga konstruktora kopiującego i operatora porównania!
128: void Iterate(void (Part::*f)()const) const;
129: Part* Find(int & position, int PartNumber) const;
130: Part* GetFirst() const;
131: void Insert(Part *);
132: Part* operator[](int) const;
133: int GetCount() const { return itsCount; }
134: static PartsList& GetGlobalPartsList()
135: {
136: return GlobalPartsList;
137: }
138: private:
139: PartNode * pHead;
140: int itsCount;
141: static PartsList GlobalPartsList;
142: };
143:
144: PartsList PartsList::GlobalPartsList;
145:
146:
147: PartsList::PartsList():
148: pHead(0),
149: itsCount(0)
150: {}
151:
152: PartsList::~PartsList()
153: {
154: delete pHead;
155: }
156:
157: Part* PartsList::GetFirst() const
158: {
159: if (pHead)
Usunięto: i
Usunięto: rzy
Usunięto: rzy

160: return pHead->GetPart();
161: else
162: return NULL; // w celu wykrycia błędu
163: }
164:
165: Part * PartsList::operator[](int offSet) const
166: {
167: PartNode* pNode = pHead;
168:
169: if (!pHead)
170: return NULL; // w celu wykrycia błędu
171:
172: if (offSet > itsCount)
173: return NULL; // błąd
174:
175: for (int i=0;i<offSet; i++)
176: pNode = pNode->GetNext();
177:
178: return pNode->GetPart();
179: }
180:
181: Part* PartsList::Find(
182: int & position,
183: int PartNumber) const
184: {
185: PartNode * pNode = 0;
186: for (pNode = pHead, position = 0;
187: pNode!=NULL;
188: pNode = pNode->GetNext(), position++)
189: {
190: if (pNode->GetPart()->GetPartNumber() == PartNumber)
191: break;
192: }
193: if (pNode == NULL)
194: return NULL;
195: else
196: return pNode->GetPart();

197: }
198:
199: void PartsList::Iterate(void (Part::*func)()const) const
200: {
201: if (!pHead)
202: return;
203: PartNode* pNode = pHead;
204: do
205: (pNode->GetPart()->*func)();
206: while (pNode = pNode->GetNext());
207: }
208:
209: void PartsList::Insert(Part* pPart)
210: {
211: PartNode * pNode = new PartNode(pPart);
212: PartNode * pCurrent = pHead;
213: PartNode * pNext = 0;
214:
215: int New = pPart->GetPartNumber();
216: int Next = 0;
217: itsCount++;
218:
219: if (!pHead)
220: {
221: pHead = pNode;
222: return;
223: }
224:
225: // jeśli ten węzeł jest mniejszy niż głowa,
226: // staje się nową głową
227: if (pHead->GetPart()->GetPartNumber() > New)
228: {
229: pNode->SetNext(pHead);
230: pHead = pNode;
231: return;
232: }
233:

234: for (;;)
235: {
236: // jeśli nie ma następnego, dołączamy nowy
237: if (!pCurrent->GetNext())
238: {
239: pCurrent->SetNext(pNode);
240: return;
241: }
242:
243: // jeśli trafia pomiędzy bieżący a nastepny,
244: // wstawiamy go tu; w przeciwnym razie bierzemy następny
245: pNext = pCurrent->GetNext();
246: Next = pNext->GetPart()->GetPartNumber();
247: if (Next > New)
248: {
249: pCurrent->SetNext(pNode);
250: pNode->SetNext(pNext);
251: return;
252: }
253: pCurrent = pNext;
254: }
255: }
256:
257:
258:
259: class PartsCatalog
260: {
261: public:
262: void Insert(Part *);
263: int Exists(int PartNumber);
264: Part * Get(int PartNumber);
265: operator+(const PartsCatalog &);
266: void ShowAll() { thePartsList.Iterate(Part::Display); }
267: private:
268: PartsList thePartsList;
269: };
270:
Usunięto: o

271: void PartsCatalog::Insert(Part * newPart)
272: {
273: int partNumber = newPart->GetPartNumber();
274: int offset;
275:
276: if (!thePartsList.Find(offset, partNumber))
277: thePartsList.Insert(newPart);
278: else
279: {
280: cout << partNumber << " byl ";
281: switch (offset)
282: {
283: case 0: cout << "pierwsza "; break;
284: case 1: cout << "druga "; break;
285: case 2: cout << "trzecia "; break;
286: default: cout << offset+1 << "th ";
287: }
288: cout << "pozycja. Odrzucony!\n";
289: }
290: }
291:
292: int PartsCatalog::Exists(int PartNumber)
293: {
294: int offset;
295: thePartsList.Find(offset,PartNumber);
296: return offset;
297: }
298:
299: Part * PartsCatalog::Get(int PartNumber)
300: {
301: int offset;
302: Part * thePart = thePartsList.Find(offset, PartNumber);
303: return thePart;
304: }
305:
306:
307: int main()

308: {
309: PartsCatalog pc;
310: Part * pPart = 0;
311: int PartNumber;
312: int value;
313: int choice;
314:
315: while (1)
316: {
317: cout << "(0)Wyjscie (1)Samochod (2)Samolot: ";
318: cin >> choice;
319:
320: if (!choice)
321: break;
322:
323: cout << "Nowy numer czesci?: ";
324: cin >> PartNumber;
325:
326: if (choice == 1)
327: {
328: cout << "Model?: ";
329: cin >> value;
330: pPart = new CarPart(value,PartNumber);
331: }
332: else
333: {
334: cout << "Numer silnika?: ";
335: cin >> value;
336: pPart = new AirPlanePart(value,PartNumber);
337: }
338: pc.Insert(pPart);
339: }
340: pc.ShowAll();
341: return 0;
342: }
Wynik

(0)Wyjscie (1)Samochod (2)Samolot: 1
Nowy numer czesci?: 1234
Model?: 94
(0)Wyjscie (1)Samochod (2)Samolot: 1
Nowy numer czesci?: 4434
Model?: 93
(0)Wyjscie (1)Samochod (2)Samolot: 1
Nowy numer czesci?: 1234
Model?: 94
1234 byl pierwsza pozycja. Odrzucony!
(0)Wyjscie (1)Samochod (2)Samolot: 1
Nowy numer czesci?: 2345
Model?: 93
(0)Wyjscie (1)Samochod (2)Samolot: 0
Numer czesci: 1234
Rok modelu: 94
Numer czesci: 2345
Rok modelu: 93
Numer czesci: 4434
Rok modelu: 93
UWAGA Niektóre kompilatory nie potrafią skompilować linii 266., mimo iż w C++ jest ona poprawna. Jeśli zdarzy się to w przypadku twojego kompilatora, zmień tę linię na:
266: void ShowAll() { thePartsList.Iterate(&Part::Display); }
(Chodzi o dopisanie znaku ampersand (&) przed Part::Display.) Jeśli rozwiąże to problem, natychmiast zadzwoń do twórcy swojego kompilatora i poskarż się.
Analiza
Listing 16.5 zawiera klasy Part, PartNode oraz PartsList z listingu podsumowującego wiadomości (na końcu rozdziału czternastego).
W liniach od 259. do 269. została zadeklarowana nowa klasa, PartsCatalog (katalog części). Jedną ze składowych tej klasy jest obiekt klasy PartsList; właśnie do tej klasy jest delegowane
zarządzanie listą. Można także powiedzieć, że klasa PartsCatalog jest zaimplementowana poprzez klasę PartsList.
Zwróć uwagę, że klienci klasy PartsCatalog nie mają bezpośredniego dostępu do klasy PartsList. Interfejsem dla niej jest klasa PartsCatalog i w związku z tym działanie klasy PartsList uległo dużej zmianie. Na przykład, metoda PartsCatalog::Insert() nie pozwala, by w liście PartsList pojawiły się elementy powielone.
Implementacja metody PartsCatalog::Insert() rozpoczyna się w linii 271. Obiekt Part, który jest przekazywany jako parametr, jest pytany o wartość swojej zmiennej składowej itsPartNumber. Ta wartość jest przekazywana do metody PartsList::Find() (znajdź) i jeśli nie zostanie znaleziona pasująca część, element jest wstawiany do listy; w przeciwnym razie wypisywany jest komunikat informacyjny.
Zwróć uwagę, że klasa PartsCatalog wstawia elementy, wywołując metodę Insert() dla swojej zmiennej składowej thePartsList, która jest obiektem klasy PartsList. Mechanizm wstawiania i zarządzania listą połączoną, a także wyszukiwanie i pobieranie jej elementów, należy wyłącznie do obiektu klasy PartsList, zawartego w klasie PartsCatalog. Nie ma powodu, by klasa PartsCatalog powielała ten kod, gdyż może skorzystać z dobrze zdefiniowanego interfejsu.
Na tym właśnie polega idea ponownego wykorzystania klas w C++: klasa PartsCatalog może ponownie skorzystać z kodu klasy PartsList, a projektant klasy PartsCatalog może po prostu zignorować szczegóły implementacji klasy PartsList. Interfejs klasy PartsList (to jest deklaracja tej klasy) dostarcza wszystkich informacji potrzebnych projektantowi klasy PartsCatalog.
Dziedziczenie prywatne Gdyby klasa PartsCatalog musiała mieć dostęp do chronionych składowych klasy PartsList (w tym przypadku składowe te nie występują) lub musiała przesłaniać którąś z metod tej klasy, wtedy klasa PartsCatalog musiałaby zostać wyprowadzona z klasy PartsList.
Ponieważ klasa PartsCatalog nie jest obiektem PartsList i ponieważ nie chcemy udostępniać klientom klasy PartsCatalog całego zestawu funkcji klasy PartsList, musimy użyć dziedziczenia prywatnego.
Należy wiedzieć, iż wszystkie zmienne i funkcje składowe klasy bazowej są traktowane tak, jakby były zadeklarowane jako prywatne, bez względu na ich rzeczywiste deklaracje w klasie bazowej. Tak więc żadna funkcja, która nie jest funkcją składową klasy PartsCatalog, nie ma dostępu do żadnej składowej klasy PartsList. Obowiązuje tu następująca zasada: dziedziczenie prywatne nie wiąże się z dziedziczeniem interfejsu, a jedynie z implementacją.
Klasa PartsList jest niewidoczna dla klientów klasy PartsCatalog. Nie jest dla nich dostępny żaden z jej interfejsów: nie mogą wywoływać żadnych z jej metod. Mogą jednak wywoływać metody klasy PartsCatalog; metody tej klasy mogą z kolei odwoływać się do składowych klasy PartsList (gdyż klasa PartsCatalog jest z niej wyprowadzona). Ważny jest tu fakt, że klasa PartsCatalog nie jest klasą PartsList, tak jak w przypadku dziedziczenia publicznego. Klasa
Usunięto: Catalog
Usunięto: pl
Usunięto: j
Usunięto: prywatnego
Usunięto: nie
Usunięto: i

PartsCatalog jest zaimplementowana poprzez klasę PartsList, tak jak miało to miejsce w przypadku zawierania. Dziedziczenie prywatne stanowi jedynie ułatwienie.
Listing 16.6 demonstruje użycie dziedziczenia prywatnego; w tym przykładzie klasa PartsCatalog została przepisana jako dziedzicząca prywatnie po klasie PartsList.
Listing 16.6. Dziedziczenie prywatne 0: //Listing 16.6 demonstruje dziedziczenie prywatne
1: #include <iostream>
2: using namespace std;
3:
4: // **************** Część ************
5:
6: // Abstrakcyjna klasa bazowa części
7: class Part
8: {
9: public:
10: Part():itsPartNumber(1) {}
11: Part(int PartNumber):
12: itsPartNumber(PartNumber){}
13: virtual ~Part(){}
14: int GetPartNumber() const
15: { return itsPartNumber; }
16: virtual void Display() const =0;
17: private:
18: int itsPartNumber;
19: };
20:
21: // implementacja czystej funkcji wirtualnej, dzięki temu
22: // mogą z niej korzystać klasy pochodne
23: void Part::Display() const
24: {
25: cout << "\nNumer czesci: " << itsPartNumber << endl;
26: }
27:
28: // **************** Część samochodu ************
29:
30: class CarPart : public Part

31: {
32: public:
33: CarPart():itsModelYear(94){}
34: CarPart(int year, int partNumber);
35: virtual void Display() const
36: {
37: Part::Display();
38: cout << "Rok modelu: ";
39: cout << itsModelYear << endl;
40: }
41: private:
42: int itsModelYear;
43: };
44:
45: CarPart::CarPart(int year, int partNumber):
46: itsModelYear(year),
47: Part(partNumber)
48: {}
49:
50:
51: // **************** Część samolotu ************
52:
53: class AirPlanePart : public Part
54: {
55: public:
56: AirPlanePart():itsEngineNumber(1){};
57: AirPlanePart(int EngineNumber, int PartNumber);
58: virtual void Display() const
59: {
60: Part::Display();
61: cout << "Nr silnika: ";
62: cout << itsEngineNumber << endl;
63: }
64: private:
65: int itsEngineNumber;
66: };
67:

68: AirPlanePart::AirPlanePart
69: (int EngineNumber, int PartNumber):
70: itsEngineNumber(EngineNumber),
71: Part(PartNumber)
72: {}
73:
74: // **************** Węzeł części ************
75: class PartNode
76: {
77: public:
78: PartNode (Part*);
79: ~PartNode();
80: void SetNext(PartNode * node)
81: { itsNext = node; }
82: PartNode * GetNext() const;
83: Part * GetPart() const;
84: private:
85: Part *itsPart;
86: PartNode * itsNext;
87: };
88: // Implementacje klasy PartNode...
89:
90: PartNode::PartNode(Part* pPart):
91: itsPart(pPart),
92: itsNext(0)
93: {}
94:
95: PartNode::~PartNode()
96: {
97: delete itsPart;
98: itsPart = 0;
99: delete itsNext;
100: itsNext = 0;
101: }
102:
103: // Gdy nie ma następnego węzła części, zwraca NULL
104: PartNode * PartNode::GetNext() const
105: {
106: return itsNext;
107: }
108:
109: Part * PartNode::GetPart() const
110: {
111: if (itsPart)
112: return itsPart;
113: else
114: return NULL; //błąd
115: }
116:
117:
118:
119: // **************** Klasa PartList ************
120: class PartsList
121: {
122: public:
123: PartsList();
124: ~PartsList();
125: // wymaga konstruktora kopiującego i operatora porównania!
126: void Iterate(void (Part::*f)()const) const;
127: Part* Find(int & position, int PartNumber) const;
128: Part* GetFirst() const;
129: void Insert(Part *);
130: Part* operator[](int) const;
131: int GetCount() const { return itsCount; }
132: static PartsList& GetGlobalPartsList()
133: {
134: return GlobalPartsList;
135: }
136: private:
137: PartNode * pHead;
138: int itsCount;
139: static PartsList GlobalPartsList;
140: };
141:
Usunięto: i
Usunięto: rzy

142: PartsList PartsList::GlobalPartsList;
143:
144:
145: PartsList::PartsList():
146: pHead(0),
147: itsCount(0)
148: {}
149:
150: PartsList::~PartsList()
151: {
152: delete pHead;
153: }
154:
155: Part* PartsList::GetFirst() const
156: {
157: if (pHead)
158: return pHead->GetPart();
159: else
160: return NULL; // w celu wykrycia błędu
161: }
162:
163: Part * PartsList::operator[](int offSet) const
164: {
165: PartNode* pNode = pHead;
166:
167: if (!pHead)
168: return NULL; // w celu wykrycia błędu
169:
170: if (offSet > itsCount)
171: return NULL; // błąd
172:
173: for (int i=0;i<offSet; i++)
174: pNode = pNode->GetNext();
175:
176: return pNode->GetPart();
177: }
178:

179: Part* PartsList::Find(int & position, int PartNumber) const
180: {
181: PartNode * pNode = 0;
182: for (pNode = pHead, position = 0;
183: pNode!=NULL;
184: pNode = pNode->GetNext(), position++)
185: {
186: if (pNode->GetPart()->GetPartNumber() == PartNumber)
187: break;
188: }
189: if (pNode == NULL)
190: return NULL;
191: else
192: return pNode->GetPart();
193: }
194:
195: void PartsList::Iterate(void (Part::*func)()const) const
196: {
197: if (!pHead)
198: return;
199: PartNode* pNode = pHead;
200: do
201: (pNode->GetPart()->*func)();
202: while (pNode = pNode->GetNext());
203: }
204:
205: void PartsList::Insert(Part* pPart)
206: {
207: PartNode * pNode = new PartNode(pPart);
208: PartNode * pCurrent = pHead;
209: PartNode * pNext = 0;
210:
211: int New = pPart->GetPartNumber();
212: int Next = 0;
213: itsCount++;
214:
215: if (!pHead)

216: {
217: pHead = pNode;
218: return;
219: }
220:
221: // jeśli ten węzeł jest mniejszy niż głowa,
222: // staje się nową głową
223: if (pHead->GetPart()->GetPartNumber() > New)
224: {
225: pNode->SetNext(pHead);
226: pHead = pNode;
227: return;
228: }
229:
230: for (;;)
231: {
232: // jeśli nie ma następnego, dołączamy nowy
233: if (!pCurrent->GetNext())
234: {
235: pCurrent->SetNext(pNode);
236: return;
237: }
238:
239: // jeśli trafia pomiędzy bieżący a nastepny,
240: // wstawiamy go tu; w przeciwnym razie bierzemy następny
241: pNext = pCurrent->GetNext();
242: Next = pNext->GetPart()->GetPartNumber();
243: if (Next > New)
244: {
245: pCurrent->SetNext(pNode);
246: pNode->SetNext(pNext);
247: return;
248: }
249: pCurrent = pNext;
250: }
251: }
252:

253:
254:
255: class PartsCatalog : private PartsList
256: {
257: public:
258: void Insert(Part *);
259: int Exists(int PartNumber);
260: Part * Get(int PartNumber);
261: operator+(const PartsCatalog &);
262: void ShowAll() { Iterate(Part::Display); }
263: private:
264: };
265:
266: void PartsCatalog::Insert(Part * newPart)
267: {
268: int partNumber = newPart->GetPartNumber();
269: int offset;
270:
271: if (!Find(offset, partNumber))
272: PartsList::Insert(newPart);
273: else
274: {
275: cout << partNumber << " byl ";
276: switch (offset)
277: {
278: case 0: cout << "pierwsza "; break;
279: case 1: cout << "druga "; break;
280: case 2: cout << "trzecia "; break;
281: default: cout << offset+1 << "th ";
282: }
283: cout << "pozycja. Odrzucony!\n";
284: }
285: }
286:
287: int PartsCatalog::Exists(int PartNumber)
288: {
289: int offset;

290: Find(offset,PartNumber);
291: return offset;
292: }
293:
294: Part * PartsCatalog::Get(int PartNumber)
295: {
296: int offset;
297: return (Find(offset, PartNumber));
298:
299: }
300:
301: int main()
302: {
303: PartsCatalog pc;
304: Part * pPart = 0;
305: int PartNumber;
306: int value;
307: int choice;
308:
309: while (1)
310: {
311: cout << "(0)Wyjscie (1)Samochod (2)Samolot: ";
312: cin >> choice;
313:
314: if (!choice)
315: break;
316:
317: cout << "Nowy numer czesci?: ";
318: cin >> PartNumber;
319:
320: if (choice == 1)
321: {
322: cout << "Model?: ";
323: cin >> value;
324: pPart = new CarPart(value,PartNumber);
325: }
326: else

327: {
328: cout << "Numer silnika?: ";
329: cin >> value;
330: pPart = new AirPlanePart(value,PartNumber);
331: }
332: pc.Insert(pPart);
333: }
334: pc.ShowAll();
335: return 0;
336: }
Wynik (0)Wyjscie (1)Samochod (2)Samolot: 1
Nowy numer czesci?: 1234
Model?: 94
(0)Wyjscie (1)Samochod (2)Samolot: 1
Nowy numer czesci?: 4434
Model?: 93
(0)Wyjscie (1)Samochod (2)Samolot: 1
Nowy numer czesci?: 1234
Model?: 94
1234 byl pierwsza pozycja. Odrzucony!
(0)Wyjscie (1)Samochod (2)Samolot: 1
Nowy numer czesci?: 2345
Model?: 93
(0)Wyjscie (1)Samochod (2)Samolot: 0
Numer czesci: 1234
Rok modelu: 94
Numer czesci: 2345
Rok modelu: 93
Numer czesci: 4434
Rok modelu: 93

Analiza
Listing 16.6 pokazuje zmieniony interfejs klasy PartsCatalog oraz przepisany program sterujący. Interfejsy innych klas nie zmieniły się w stosunku do listingu 16.5.
W linii 255. listingu 16.6 klasa PartsCatalog została zadeklarowana jako dziedzicząca prywatnie po klasie PartsList. Interfejs klasy PartsCatalog pozostał taki sam jak na listingu 16.5, jednak obecnie w tej klasie nie korzystamy już z obiektu klasy PartsList jako zmiennej składowej.
Funkcja PartsCatalog::ShowAll() wywołuje metodę PartsList::Iterate(), przekazując jej odpowiedni wskaźnik do funkcji składowej klasy Part. Metoda ShowAll() pełni rolę publicznego interfejsu do metody Iterate(), dostarczając poprawnych informacji, ale nie pozwala klasom klientów na bezpośrednie wywoływanie tej metody. Choć klasa PartsList mogłaby pozwolić na przekazywanie innych funkcji do metody Iterate(), jednak nie pozwala na to klasa PartsCatalog.
Zmianie uległa także sama funkcja Insert(). Zauważ, że w linii 271. metoda Find() jest teraz wywoływana bezpośrednio, gdyż została odziedziczona po klasie bazowej. Wywołanie metody Insert() w linii 272. musi oczywiście korzystać z pełnej nazwy kwalifikowanej, gdyż w przeciwnym razie mielibyśmy do czynienia z rekurencją.
Podsumowując, gdy metody klasy PartsCatalog chcą wywołać metodę klasy PartsList, mogą uczynić to bezpośrednio. Jedyny wyjątek stanowi sytuacja, w której klasa PartsCatalog przesłania metodę, a potrzebna jest jej wersja z klasy PartsList. W takim przypadku konieczne jest użycie pełnej nazwy kwalifikowanej.
Dziedziczenie prywatne pozwala, by klasa PartsCatalog dziedziczyła to, czego może użyć i wciąż zapewniała klasom klientów pośredni dostęp do metody Insert() i innych metod, do których te klasy nie powinny mieć bezpośredniego dostępu.
TAK NIE
Używaj dziedziczenia publicznego, gdy wyprowadzany obiekt jest rodzajem obiektu bazowego.
Używaj zawierania wtedy, gdy chcesz delegować funkcjonalność na inną klasę i nie potrzebujesz dostępu do jej składowych chronionych.
Używaj dziedziczenia prywatnego wtedy, gdy musisz zaimplementować jedną klasę poprzez drugą i chcesz mieć dostęp do jej chronionych składowych.
Nie używaj dziedziczenia prywatnego, gdy musisz użyć więcej niż jednej klasy bazowej. W takiej sytuacji musisz użyć zawierania. Na przykład, gdyby klasa PartsCatalog potrzebowała dwóch obiektów PartsList, nie mógłbyś użyć dziedziczenia prywatnego.
Nie używaj dziedziczenia publicznego, gdy składowe klasy bazowej nie powinny być dostępne dla klientów klasy pochodnej.
Usunięto: oczywiście
Usunięto: zabezpieczając
Usunięto: y
Usunięto: przed
Usunięto: m
Usunięto: m
Usunięto: 3
Usunięto: chronionych
Usunięto: składowych

Klasy zaprzyjaźnione Czasem klasy tworzy się łącznie, jako zestaw. Na przykład, klasy PartNode i PartsList są ze sobą ściśle powiązane i byłoby wygodnie, gdyby klasa PartsList mogła bezpośrednio odczytywać wskaźnik do klasy Part z klasy PartNode, czyli mieć bezpośredni dostęp do jej zmiennej składowej itsPart.
Nie chcielibyśmy, by składowa itsPart była składową publiczną, ani nawet składową chronioną, gdyż jest ona szczegółem implementacji klasy PartNode, który powinien pozostać prywatny. Chcemy jednak udostępnić ją klasie PartsList.
Jeśli chcesz udostępnić swoje prywatne dane lub funkcje składowe innej klasie, musisz zadeklarować tę klasę jako zaprzyjaźnioną. To rozszerza interfejs twojej klasy o interfejs klasy zaprzyjaźnionej.
Gdy klasa PartNode zadeklaruje klasę PartsList jako zaprzyjaźnioną, wszystkie dane i funkcje składowe klasy PartNode są dla klasy PartsList dostępne jako składowe publiczne.
Należy pamiętać, że takie „zaprzyjaźnienie” nie może być przekazywane dalej. Choć ty jesteś moim przyjacielem, a Joe jest twoim przyjacielem, nie oznacza to, że Joe jest moim przyjacielem. Przyjaźń nie jest także dziedziczona. Choć jesteś moim przyjacielem i mam zamiar wyjawić ci swoją tajemnicę, nie oznacza to, że mam zamiar wyjawić ją twoim dzieciom.
„Zaprzyjaźnienie” nie działa zwrotnie. Zadeklarowanie klasy ClassOne jako klasy zaprzyjaźnionej klasy ClassTwo nie sprawia, że klasa ClassTwo jest klasą zaprzyjaźnioną klasy ClassOne. Być może chcesz wyjawić mi swoje sekrety, ale to nie oznacza, że ja chcę wyjawić ci moje.
Listing 16.7 ilustruje zastosowanie klasy zaprzyjaźnionej. Ten przykład to zmodyfikowana wersja listingu 16.6, w której klasa PartsList jest klasą zaprzyjaźnioną klasy PartNode. Zwróć uwagę, że to nie czyni z klasy PartNode klasy zaprzyjaźnionej klasy PartsList.
Listing 16.7. Przykład klasy zaprzyjaźnionej 0: //Listing 16.7 Przykład klasy zaprzyjaźnionej
1:
2: #include <iostream>
3: using namespace std;
4:
5: // **************** Część ************
6:
7: // Abstrakcyjna klasa bazowa części
8: class Part
9: {
10: public:
11: Part():itsPartNumber(1) {}
12: Part(int PartNumber):
Usunięto: Funkcje

13: itsPartNumber(PartNumber){}
14: virtual ~Part(){}
15: int GetPartNumber() const
16: { return itsPartNumber; }
17: virtual void Display() const =0;
18: private:
19: int itsPartNumber;
20: };
21:
22: // implementacja czystej funkcji wirtualnej, dzięki temu
23: // mogą z niej korzystać klasy pochodne
24: void Part::Display() const
25: {
26: cout << "\nNumer czesci: ";
27: cout << itsPartNumber << endl;
28: }
29:
30: // **************** Część samochodu ************
31:
32: class CarPart : public Part
33: {
34: public:
35: CarPart():itsModelYear(94){}
36: CarPart(int year, int partNumber);
37: virtual void Display() const
38: {
39: Part::Display();
40: cout << "Rok modelu: ";
41: cout << itsModelYear << endl;
42: }
43: private:
44: int itsModelYear;
45: };
46:
47: CarPart::CarPart(int year, int partNumber):
48: itsModelYear(year),
49: Part(partNumber)

50: {}
51:
52:
53: // **************** Część samolotu ************
54:
55: class AirPlanePart : public Part
56: {
57: public:
58: AirPlanePart():itsEngineNumber(1){};
59: AirPlanePart(int EngineNumber, int PartNumber);
60: virtual void Display() const
61: {
62: Part::Display();
63: cout << "Nr silnika: ";
64: cout << itsEngineNumber << endl;
65: }
66: private:
67: int itsEngineNumber;
68: };
69:
70: AirPlanePart::AirPlanePart(int EngineNumber, int PartNumber):
71: itsEngineNumber(EngineNumber),
72: Part(PartNumber)
73: {}
74:
75: // **************** Węzeł części ************
76: class PartNode
77: {
78: public:
79: friend class PartsList;
80: PartNode (Part*);
81: ~PartNode();
82: void SetNext(PartNode * node)
83: { itsNext = node; }
84: PartNode * GetNext() const;
85: Part * GetPart() const;
86: private:

87: Part *itsPart;
88: PartNode * itsNext;
89: };
90:
91:
92: PartNode::PartNode(Part* pPart):
93: itsPart(pPart),
94: itsNext(0)
95: {}
96:
97: PartNode::~PartNode()
98: {
99: delete itsPart;
100: itsPart = 0;
101: delete itsNext;
102: itsNext = 0;
103: }
104:
105: // Gdy nie ma następnego węzła części, zwraca NULL
106: PartNode * PartNode::GetNext() const
107: {
108: return itsNext;
109: }
110:
111: Part * PartNode::GetPart() const
112: {
113: if (itsPart)
114: return itsPart;
115: else
116: return NULL; //błąd
117: }
118:
119:
120: // **************** Klasa PartList ************
121: class PartsList
122: {
123: public:

124: PartsList();
125: ~PartsList();
126: // wymaga konstruktora kopiującego i operatora porównania!
127: void Iterate(void (Part::*f)()const) const;
128: Part* Find(int & position, int PartNumber) const;
129: Part* GetFirst() const;
130: void Insert(Part *);
131: Part* operator[](int) const;
132: int GetCount() const { return itsCount; }
133: static PartsList& GetGlobalPartsList()
134: {
135: return GlobalPartsList;
136: }
137: private:
138: PartNode * pHead;
139: int itsCount;
140: static PartsList GlobalPartsList;
141: };
142:
143: PartsList PartsList::GlobalPartsList;
144:
145: // Implementacje list...
146:
147: PartsList::PartsList():
148: pHead(0),
149: itsCount(0)
150: {}
151:
152: PartsList::~PartsList()
153: {
154: delete pHead;
155: }
156:
157: Part* PartsList::GetFirst() const
158: {
159: if (pHead)
160: return pHead->itsPart;
Usunięto: i

161: else
162: return NULL; // w celu wykrycia błędu
163: }
164:
165: Part * PartsList::operator[](int offSet) const
166: {
167: PartNode* pNode = pHead;
168:
169: if (!pHead)
170: return NULL; // w celu wykrycia błędu
171:
172: if (offSet > itsCount)
173: return NULL; // błąd
174:
175: for (int i=0;i<offSet; i++)
176: pNode = pNode->itsNext;
177:
178: return pNode->itsPart;
179: }
180:
181: Part* PartsList::Find(int & position, int PartNumber) const
182: {
183: PartNode * pNode = 0;
184: for (pNode = pHead, position = 0;
185: pNode!=NULL;
186: pNode = pNode->itsNext, position++)
187: {
188: if (pNode->itsPart->GetPartNumber() == PartNumber)
189: break;
190: }
191: if (pNode == NULL)
192: return NULL;
193: else
194: return pNode->itsPart;
195: }
196:
197: void PartsList::Iterate(void (Part::*func)()const) const

198: {
199: if (!pHead)
200: return;
201: PartNode* pNode = pHead;
202: do
203: (pNode->itsPart->*func)();
204: while (pNode = pNode->itsNext);
205: }
206:
207: void PartsList::Insert(Part* pPart)
208: {
209: PartNode * pNode = new PartNode(pPart);
210: PartNode * pCurrent = pHead;
211: PartNode * pNext = 0;
212:
213: int New = pPart->GetPartNumber();
214: int Next = 0;
215: itsCount++;
216:
217: if (!pHead)
218: {
219: pHead = pNode;
220: return;
221: }
222:
223: // jeśli ten węzeł jest mniejszy niż głowa,
224: // staje się nową głową
225: if (pHead->itsPart->GetPartNumber() > New)
226: {
227: pNode->itsNext = pHead;
228: pHead = pNode;
229: return;
230: }
231:
232: for (;;)
233: {
234: // jeśli nie ma następnego, dołączamy ten nowy

235: if (!pCurrent->itsNext)
236: {
237: pCurrent->itsNext = pNode;
238: return;
239: }
240:
241: // jeśli trafia pomiędzy bieżący a nastepny,
242: // wstawiamy go tu; w przeciwnym razie bierzemy następny
243: pNext = pCurrent->itsNext;
244: Next = pNext->itsPart->GetPartNumber();
245: if (Next > New)
246: {
247: pCurrent->itsNext = pNode;
248: pNode->itsNext = pNext;
249: return;
250: }
251: pCurrent = pNext;
252: }
253: }
254:
255: class PartsCatalog : private PartsList
256: {
257: public:
258: void Insert(Part *);
259: int Exists(int PartNumber);
260: Part * Get(int PartNumber);
261: operator+(const PartsCatalog &);
262: void ShowAll() { Iterate(Part::Display); }
263: private:
264: };
265:
266: void PartsCatalog::Insert(Part * newPart)
267: {
268: int partNumber = newPart->GetPartNumber();
269: int offset;
270:
271: if (!Find(offset, partNumber))

272: PartsList::Insert(newPart);
273: else
274: {
275: cout << partNumber << " byl ";
276: switch (offset)
277: {
278: case 0: cout << "pierwsza "; break;
279: case 1: cout << "druga "; break;
280: case 2: cout << "trzecia "; break;
281: default: cout << offset+1 << "-ta ";
282: }
283: cout << "pozycja. Odrzucony!\n";
284: }
285: }
286:
287: int PartsCatalog::Exists(int PartNumber)
288: {
289: int offset;
290: Find(offset,PartNumber);
291: return offset;
292: }
293:
294: Part * PartsCatalog::Get(int PartNumber)
295: {
296: int offset;
297: return (Find(offset, PartNumber));
298: }
299:
300: int main()
301: {
302: PartsCatalog pc;
303: Part * pPart = 0;
304: int PartNumber;
305: int value;
306: int choice;
307:
308: while (1)

309: {
310: cout << "(0)Wyjscie (1)Samochod (2)Samolot: ";
311: cin >> choice;
312:
313: if (!choice)
314: break;
315:
316: cout << "Nowy numer czesci?: ";
317: cin >> PartNumber;
318:
319: if (choice == 1)
320: {
321: cout << "Model?: ";
322: cin >> value;
323: pPart = new CarPart(value,PartNumber);
324: }
325: else
326: {
327: cout << "Numer silnika?: ";
328: cin >> value;
329: pPart = new AirPlanePart(value,PartNumber);
330: }
331: pc.Insert(pPart);
332: }
333: pc.ShowAll();
334: return 0;
335: }
Wynik (0)Wyjscie (1)Samochod (2)Samolot: 1
Nowy numer czesci?: 1234
Model?: 94
(0)Wyjscie (1)Samochod (2)Samolot: 1
Nowy numer czesci?: 4434
Model?: 93
(0)Wyjscie (1)Samochod (2)Samolot: 1

Nowy numer czesci?: 1234
Model?: 94
1234 byl pierwsza pozycja. Odrzucony!
(0)Wyjscie (1)Samochod (2)Samolot: 1
Nowy numer czesci?: 2345
Model?: 93
(0)Wyjscie (1)Samochod (2)Samolot: 0
Numer czesci: 1234
Rok modelu: 94
Numer czesci: 2345
Rok modelu: 93
Numer czesci: 4434
Rok modelu: 93
Analiza
W linii 79. klasa PartsList została zadeklarowana jako klasa zaprzyjaźniona klasy PartNode.
Na listingu deklarację klasy zaprzyjaźnionej umieszczono w sekcji publicznej, ale nie jest to niezbędne; klasa zaprzyjaźniona może być zadeklarowana w dowolnym miejscu deklaracji klasy, bez konieczności zmiany znaczenia instrukcji zaprzyjaźnienia (friend). Dzięki tej instrukcji wszystkie prywatne funkcje i dane składowe klasy PartNode stają się dostępne dla wszystkich funkcji składowych klasy PartsList.
Zmianę tę odzwierciedla w linii 157. implementacja funkcji GetFirst(). Zamiast zwracać pHead->GetPart, obecnie funkcja ta może zwrócić (wcześniej będącą prywatną) zmienną składową pHead->itsPart. Metoda Insert() może teraz użyć pNode->itsNext (zamiast wywoływać pNode->SetNext(pHead)).
Oczywiście, zmiany te są kosmetyczne i nie było istotnego powodu, by uczynić z klasy PartsList klasę zaprzyjaźnioną klasy PartNode, ale zmiany te posłużyły do zilustrowania działania słowa kluczowego friend (przyjaciel).
Klasy zaprzyjaźnione powinny być deklarowane z dużą rozwagą. Deklaracja taka przydaje się, gdy dwie klasy są ze sobą ściśle powiązane i często korzystają ze swoich składowych. Jednak używaj jej rozsądnie; często równie łatwe okazuje się zastosowanie publicznych akcesorów, dzięki którym można modyfikować jedną z klas bez konieczności modyfikowania drugiej.
UWAGA Często słyszy się, że początkujący programiści C++ narzekają, że deklaracja klasy zaprzyjaźnionej pomniejsza znaczenia kapsułkowania, tak ważnego dla obiektowo zorientowanego programowania. Mówiąc szczerze, to nonsens. Deklaracja friend czyni z
Usunięto: mogą
Usunięto: ć
Usunięto: la

zadeklarowanej klasy zaprzyjaźnionej część interfejsu klasy i nie pomniejsza znaczenia kapsułkowania bardziej niż publiczne dziedziczenie.
Klasa zaprzyjaźniona
Aby zadeklarować klasę zaprzyjaźnioną innej klasy, przed nazwą klasy, której chcesz przydzielić dostęp, umieść słowo kluczowe friend. W ten sposób ja mogę zadeklarować, że jesteś moim przyjacielem, ale ty sam nie możesz tego zadeklarować.
Przykład:
class PartNode {
public:
friend class PartsList; // deklaruje klasę PartsList jako zaprzyjaźnioną
};
Funkcje zaprzyjaźnione Czasem zdarza się, że chcemy nadać ten poziom dostępu nie całej klasie, ale tylko jednej czy dwóm jej funkcjom. Możemy to uczynić, deklarując jako zaprzyjaźnioną funkcję innej klasy (a nie całą tę klasę). W rzeczywistości, jako zaprzyjaźnioną możemy zadeklarować dowolną funkcję, nie tylko funkcję składową innej klasy.
Funkcje zaprzyjaźnione i przeciążanie operatorów Listing 16.1 zawierał klasę String, w której został przeciążony operator+. Oprócz tego, klasa ta zawierała konstruktor przyjmujący stały wskaźnik do znaków, dzięki czemu można było tworzyć obiekty łańcuchów z łańcuchów znaków w stylu C. Pozwalało to na tworzenie obiektu łańcucha i dodawanie do niego łańcucha w stylu C.
UWAGA Łańcuchy w stylu C są tablicami znaków zakończonymi znakiem null, takimi jak char myString[] = "Witaj Świecie".
Usunięto: podkopuje e

Nie mogliśmy jednak stworzyć łańcucha w stylu C (tablicy znaków) i dodać do niego obiektu łańcuchowego, tak jak w poniższym przykładzie:
char cString[] = {"Witaj"};
String sString(" Swiecie");
String sStringTwo = cString + sString; // błąd!
Łańcuchy w stylu C nie posiadają przeciążonego operatora+. Jak wspominaliśmy w rozdziale 10., „Funkcje zaawansowane”, gdy piszemy cString + sString;, w rzeczywistości wywołujemy cString.operator+(sString). Ponieważ łańcuchy w stylu C nie posiadają operatora+(), powoduje to błąd kompilacji.
Możemy rozwiązać ten problem, deklarując w klasie String funkcję zaprzyjaźnioną, która przeciąży operator+, lecz przyjmie dwa obiekty łańcuchów. Łańcuch w stylu C zostanie zamieniony przez odpowiedni konstruktor na obiekt łańcucha, po czym zostanie wywołany operator+ używający dwóch obiektów łańcuchów.
Listing 16.8. Zaprzyjaźniony operator+ 0: //Listing 16.8 - zaprzyjaźnione operatory
1:
2: #include <iostream>
3: #include <string.h>
4: using namespace std;
5:
6: // Zasadnicza klasa obiektu łańcuchowego
7: class String
8: {
9: public:
10: // konstruktory
11: String();
12: String(const char *const);
13: String(const String &);
14: ~String();
15:
16: // przeciążone operatory
17: char & operator[](int offset);
18: char operator[](int offset) const;
19: String operator+(const String&);
20: friend String operator+(const String&, const String&);
21: void operator+=(const String&);
Usunięto: u
Usunięto: a
Usunięto: ch
Usunięto: liniach
Usunięto: a

22: String & operator= (const String &);
23:
24: // ogólne akcesory
25: int GetLen()const { return itsLen; }
26: const char * GetString() const { return itsString; }
27:
28: private:
29: String (int); // prywatny konstruktor
30: char * itsString;
31: unsigned short itsLen;
32: };
33:
34: // domyślny konstruktor tworzący ciąg pusty (0 bajtów)
35: String::String()
36: {
37: itsString = new char[1];
38: itsString[0] = '\0';
39: itsLen=0;
40: // cout << "\tDomyslny konstruktor lancucha\n";
41: // ConstructorCount++;
42: }
43:
44: // prywatny (pomocniczy) konstruktor, używany tylko przez
45: // metody klasy przy tworzeniu nowego, wypełnionego zerowymi
46: // bajtami, łańcucha o żądanej długości
47: String::String(int len)
48: {
49: itsString = new char[len+1];
50: for (int i = 0; i<=len; i++)
51: itsString[i] = '\0';
52: itsLen=len;
53: // cout << "\tKonstruktor String(int)\n";
54: // ConstructorCount++;
55: }
56:
57: // Zamienia tablice znakow w typ String
58: String::String(const char * const cString)
Usunięto: zera

59: {
60: itsLen = strlen(cString);
61: itsString = new char[itsLen+1];
62: for (int i = 0; i<itsLen; i++)
63: itsString[i] = cString[i];
64: itsString[itsLen]='\0';
65: // cout << "\tKonstruktor String(char*)\n";
66: // ConstructorCount++;
67: }
68:
69: // konstruktor kopiujący
70: String::String (const String & rhs)
71: {
72: itsLen=rhs.GetLen();
73: itsString = new char[itsLen+1];
74: for (int i = 0; i<itsLen;i++)
75: itsString[i] = rhs[i];
76: itsString[itsLen] = '\0';
77: // cout << "\tKonstruktor String(String&)\n";
78: // ConstructorCount++;
79: }
80:
81: // destruktor, zwalnia zaalokowaną pamięć
82: String::~String ()
83: {
84: delete [] itsString;
85: itsLen = 0;
86: // cout << "\tDestruktor klasy String\n";
87: }
88:
89: // operator równości, zwalnia istniejącą pamięć,
90: // po czym kopiuje łańcuch i rozmiar
91: String& String::operator=(const String & rhs)
92: {
93: if (this == &rhs)
94: return *this;
95: delete [] itsString;
Usunięto: i

96: itsLen=rhs.GetLen();
97: itsString = new char[itsLen+1];
98: for (int i = 0; i<itsLen;i++)
99: itsString[i] = rhs[i];
100: itsString[itsLen] = '\0';
101: return *this;
102: // cout << "\toperator= klasy String\n";
103: }
104:
105: //nie const operator indeksu, zwraca
106: // referencję do znaku, więc można go
107: // zmienić!
108: char & String::operator[](int offset)
109: {
110: if (offset > itsLen)
111: return itsString[itsLen-1];
112: else
113: return itsString[offset];
114: }
115:
116: // const operator indeksu do używania z obiektami
117: // const (patrz konstruktor kopiujący!)
118: char String::operator[](int offset) const
119: {
120: if (offset > itsLen)
121: return itsString[itsLen-1];
122: else
123: return itsString[offset];
124: }
125:
126: // tworzy nowy łańcuch przez dodanie
127: // bieżącego łańcucha do rhs
128: String String::operator+(const String& rhs)
129: {
130: int totalLen = itsLen + rhs.GetLen();
131: String temp(totalLen);
132: int i, j;
Usunięto: i

133: for (i = 0; i<itsLen; i++)
134: temp[i] = itsString[i];
135: for (j = 0, i = itsLen; j<rhs.GetLen(); j++, i++)
136: temp[i] = rhs[j];
137: temp[totalLen]='\0';
138: return temp;
139: }
140:
141: // tworzy nowy łańcuch przez dodanie
142: // jednego łańcucha do drugiego
143: String operator+(const String& lhs, const String& rhs)
144: {
145: int totalLen = lhs.GetLen() + rhs.GetLen();
146: String temp(totalLen);
147: int i, j;
148: for (i = 0; i<lhs.GetLen(); i++)
149: temp[i] = lhs[i];
150: for (j = 0, i = lhs.GetLen(); j<rhs.GetLen(); j++, i++)
151: temp[i] = rhs[j];
152: temp[totalLen]='\0';
153: return temp;
154: }
155:
156: int main()
157: {
158: String s1("Lancuch Jeden ");
159: String s2("Lancuch Dwa ");
160: char *c1 = { "Lancuch-C Jeden " } ;
161: String s3;
162: String s4;
163: String s5;
164:
165: cout << "s1: " << s1.GetString() << endl;
166: cout << "s2: " << s2.GetString() << endl;
167: cout << "c1: " << c1 << endl;
168: s3 = s1 + s2;
169: cout << "s3: " << s3.GetString() << endl;
170: s4 = s1 + c1;
171: cout << "s4: " << s4.GetString() << endl;
172: s5 = c1 + s2;
173: cout << "s5: " << s5.GetString() << endl;
174: return 0;
175: }
Wynik s1: Lancuch Jeden
s2: Lancuch Dwa
c1: Lancuch-C Jeden
s3: Lancuch Jeden Lancuch Dwa
s4: Lancuch Jeden Lancuch-C Jeden
s5: Lancuch-C Jeden Lancuch Dwa
Analiza
Z wyjątkiem metody operator+, wszystkie inne metody pozostały takie same jak na listingu 16.1. W linii 21. nowy operator, operator+, został przeciążony tak, aby przyjmował dwie stałe referencje do łańcuchów i zwracał łańcuch; metoda ta została zadeklarowana jako zaprzyjaźniona.
Zwróć uwagę, że operator+ nie jest funkcją składową tej, ani żadnej innej klasy. W klasie String jest ona deklarowana tylko po to, aby uczynić ją zaprzyjaźnioną dla tej klasy, ale ponieważ jest zadeklarowana, nie potrzebujemy już innego prototypu.
Implementacja funkcji operator+ jest zawarta w liniach od 143. do 154. Zwróć uwagę, że jest ona podobna do wcześniejszej wersji operatora+, ale przyjmuje dwa łańcuchy i odwołuje się do nich poprzez publiczne akcesory.
Program sterujący demonstruje użycie tej funkcji w linii 172., w której operator+ może być teraz wywołany dla łańcucha w stylu C.
Funkcje zaprzyjaźnione
Funkcję zaprzyjaźnioną deklaruje się, używając słowa kluczowego friend oraz pełnej specyfikacji funkcji. Zadeklarowanie funkcji jako zaprzyjaźnionej nie umożliwia jej dostępu do wskaźnika this klasy, ale udostępnia jej wszystkie prywatne i chronione funkcje i dane składowe.
Przykład:
class PartNode
Usunięto: ujący
Usunięto: jący

{ // ...
// deklarujemy jako zaprzyjaźnioną funkcję innej klasy
friend void PartsList::Insert(Part *);
// deklarujemy jako zaprzyjaźnioną funkcję globalną
friend int SomeFunction();
// ...
};
Przeciążanie operatora wstawiania Jesteśmy już gotowi do nadania naszej klasie String możliwości korzystania z cout w taki sam sposób, w jaki czyni to każdy inny typ. Do tej pory, gdy chcieliśmy wypisać łańcuch, musieliśmy robić to następująco:
cout << theString.GetString();
My natomiast chcemy mieć możliwość pisania:
cout << theString;
Aby to osiągnąć, musimy przeciążyć operator<<(). W rozdziale 17. zajmiemy się plusami i minusami pracy z obiektem iostream; na razie jedynie zobaczmy, jak na listingu 16.9 został przeciążony operator<< z wykorzystaniem funkcji zaprzyjaźnionej.
Listing 16.9. Przeciążanie operatora<<() 0: // Listing 16.9 Przeciążanie operatora<<()
1:
2: #include <iostream>
3: #include <string.h>
4: using namespace std;
5:
6: class String
7: {
8: public:
9: // konstruktory
10: String();
Usunięto: o
Usunięto: e
Usunięto: y

11: String(const char *const);
12: String(const String &);
13: ~String();
14:
15: // przeciążone operatory
16: char & operator[](int offset);
17: char operator[](int offset) const;
18: String operator+(const String&);
19: void operator+=(const String&);
20: String & operator= (const String &);
21: friend ostream& operator<<
22: ( ostream& theStream,String& theString);
23: // ogólne akcesory
24: int GetLen()const { return itsLen; }
25: const char * GetString() const { return itsString; }
26:
27: private:
28: String (int); // prywatny konstruktor
29: char * itsString;
30: unsigned short itsLen;
31: };
32:
33:
34: // domyślny konstruktor tworzący ciąg zera bajtów
35: String::String()
36: {
37: itsString = new char[1];
38: itsString[0] = '\0';
39: itsLen=0;
40: // cout << "\tDomyslny konstruktor lancucha\n";
41: // ConstructorCount++;
42: }
43:
44: // prywatny (pomocniczy) konstruktor, używany tylko przez
45: // metody klasy przy tworzeniu nowego, wypełnionego zerowymi
46: // bajtami, łańcucha o żądanej długości
47: String::String(int len)

48: {
49: itsString = new char[len+1];
50: for (int i = 0; i<=len; i++)
51: itsString[i] = '\0';
52: itsLen=len;
53: // cout << "\tKonstruktor String(int)\n";
54: // ConstructorCount++;
55: }
56:
57: // Zamienia tablice znaków w typ String
58: String::String(const char * const cString)
59: {
60: itsLen = strlen(cString);
61: itsString = new char[itsLen+1];
62: for (int i = 0; i<itsLen; i++)
63: itsString[i] = cString[i];
64: itsString[itsLen]='\0';
65: // cout << "\tKonstruktor String(char*)\n";
66: // ConstructorCount++;
67: }
68:
69: // konstruktor kopiujący
70: String::String (const String & rhs)
71: {
72: itsLen=rhs.GetLen();
73: itsString = new char[itsLen+1];
74: for (int i = 0; i<itsLen;i++)
75: itsString[i] = rhs[i];
76: itsString[itsLen] = '\0';
77: // cout << "\tKonstruktor String(String&)\n";
78: // ConstructorCount++;
79: }
80:
81: // destruktor, zwalnia zaalokowaną pamięć
82: String::~String ()
83: {
84: delete [] itsString;
Usunięto: i
85: itsLen = 0;
86: // cout << "\tDestruktor klasy String\n";
87: }
88:
89: // operator równości, zwalnia istniejącą pamięć,
90: // po czym kopiuje łańcuch i rozmiar
91: String& String::operator=(const String & rhs)
92: {
93: if (this == &rhs)
94: return *this;
95: delete [] itsString;
96: itsLen=rhs.GetLen();
97: itsString = new char[itsLen+1];
98: for (int i = 0; i<itsLen;i++)
99: itsString[i] = rhs[i];
100: itsString[itsLen] = '\0';
101: return *this;
102: // cout << "\toperator= klasy String\n";
103: }
104:
105: // nie const operator indeksu, zwraca
106: // referencję do znaku, więc można go
107: // zmienić!
108: char & String::operator[](int offset)
109: {
110: if (offset > itsLen)
111: return itsString[itsLen-1];
112: else
113: return itsString[offset];
114: }
115:
116: // const operator indeksu do używania z obiektami
117: // const (patrz konstruktor kopiujący!)
118: char String::operator[](int offset) const
119: {
120: if (offset > itsLen)
121: return itsString[itsLen-1];
Usunięto: i

122: else
123: return itsString[offset];
124: }
125:
126: // tworzy nowy łańcuch przez dodanie
127: // bieżącego łańcucha do rhs
128: String String::operator+(const String& rhs)
129: {
130: int totalLen = itsLen + rhs.GetLen();
131: String temp(totalLen);
132: int i, j;
133: for (i = 0; i<itsLen; i++)
134: temp[i] = itsString[i];
135: for (j = 0; j<rhs.GetLen(); j++, i++)
136: temp[i] = rhs[j];
137: temp[totalLen]='\0';
138: return temp;
139: }
140:
141: // zmienia bieżący łańcuch, nie zwraca nic
142: void String::operator+=(const String& rhs)
143: {
144: unsigned short rhsLen = rhs.GetLen();
145: unsigned short totalLen = itsLen + rhsLen;
146: String temp(totalLen);
147: int i, j;
148: for (i = 0; i<itsLen; i++)
149: temp[i] = itsString[i];
150: for (j = 0, i = 0; j<rhs.GetLen(); j++, i++)
151: temp[i] = rhs[i-itsLen];
152: temp[totalLen]='\0';
153: *this = temp;
154: }
155:
156: // int String::ConstructorCount =
157: ostream& operator<< ( ostream& theStream,String& theString)
158: {

159: theStream << theString.itsString;
160: return theStream;
161: }
162:
163: int main()
164: {
165: String theString("Witaj swiecie.");
166: cout << theString;
167: return 0;
168: }
Wynik Witaj swiecie.
Analiza
W linii 21. operator<< został zadeklarowany jako funkcja zaprzyjaźniona, przyjmująca referencję do ostream oraz referencję do obiektu klasy String i zwracająca referencję do ostream. Zauważ, że nie jest to funkcja składowa klasy String. Zwraca ona referencję do ostream, więc możemy łączyć wywołania operatora<<, na przykład tak jak w poniższej linii:
cout << "Mam: " << itsAge << " lat.";
Implementacja samej funkcji zaprzyjaźnionej jest zawarta w liniach od 157. do 161. W rzeczywistości ukrywa ona tylko szczegóły przekazywania łańcucha do ostream (to właśnie powinna robić). Więcej informacji na temat przeciążania tego operatora oraz operatora>> znajdziesz w rozdziale 17.

Rozdział 17. Strumienie Do tej pory używaliśmy cout do wypisywania tekstu na ekranie, zaś cin do odczytywania klawiatury, wykorzystywaliśmy je bez pełnego zrozumienia ich działania.
Z tego rozdziału dowiesz się:
• czym są strumienie i jak się ich używa,
• jak zarządzać wejściem i wyjściem, wykorzystując strumienie,
• jak odczytywać i zapisywać pliki za pomocą strumieni.
Przegląd strumieni C++ nie określa, w jaki sposób dane są wypisywane na ekranie lub zapisywane do pliku, ani w jaki sposób są one odczytywane przez program. Operacje te stanowią jednak podstawową część pracy z C++, więc biblioteka standardowa C++ zawiera bibliotekę iostream, która obsługuje wejście i wyjście (I/O, input-output).
Zaletą oddzielenia funkcji wejścia-wyjścia od języka i obsługiwania ich w bibliotekach jest możliwość łatwiejszego przenoszenia programów pomiędzy różnymi platformami. Dzięki temu można napisać program na komputerze PC, a następnie przekompilować go i uruchomić na stacji roboczej Sun. Producent kompilatora dostarcza odpowiednią bibliotekę i wszystko działa. Przynajmniej w teorii.
UWAGA Biblioteka jest zbiorem plików .obj, które mogą być połączone z programem w celu zapewnienia dodatkowej funkcjonalności. Jest to najbardziej podstawowa forma wielokrotnego wykorzystywania kodu, i używana od czasów pierwszych programistów, ryjących zera i jedynki na ścianach jaskiń.
Usunięto: ponownego

Kapsułkowanie Klasy biblioteki iostream postrzegają przepływ danych z programu na ekran jako strumień, płynący bajt po bajcie. Jeśli punktem docelowym strumienia jest plik lub ekran, wtedy jego źródłem jest zwykle jakaś część programu. Gdy strumień jest odwrócony, dane mogą pochodzić z klawiatury lub z dysku i mogą „wypełniać” zmienne w programie.
Jednym z podstawowych zadań strumieni jest kapsułkowanie problemu pobierania danych z wejścia (na przykład dysku) i wysyłania ich do wyjścia (na przykład na ekran). Po stworzeniu strumienia program działa z tym strumieniem, przy czym strumień zajmuje się wszystkimi szczegółami. Tę podstawową ideę ilustruje rysunek 17.1.
Rys. 17.1. Kapsułkowanie poprzez strumienie
Buforowanie Zapis na dysk (i w mniejszym stopniu także na ekran) jest bardzo „kosztowny.” Zapis danych na dysk lub odczyt ich z dysku zajmuje (stosunkowo) dużo czasu, a podczas operacji zapisu i odczytu działanie programu zwykle jest zablokowane. Aby rozwiązać ten problem, strumienie oferują „buforowanie”. Dane są zapisywane do strumienia, ale nie są natychmiast zapisywane na dysk. Zamiast tego bufor strumienia wypełnia się danymi; gdy się całkowicie wypełni, dane są zapisywane na dysk w ramach pojedynczej operacji.
Wyobraźmy sobie wodę wpływającą do zbiornika przez górny zawór i wypełniającą go, lecz nie wypływającą z niego poprzez dolny zawór. Ilustruje to rysunek 17.2.
Rys. 17.2. Wypełnianie bufora
Usunięto: który
Gdy woda (dane) całkowicie wypełni zbiornik, zawór się otwiera i cała zawartość gwałtownie wypływa. Pokazuje to rysunek 17.3.
Rys. 17.3. Opróżnianie bufora
Gdy bufor się opróżni, dolny zawór zostaje zamknięty, otwiera się górny zawór i do zbiornika-bufora zaczyna napływać woda. Przedstawia to rysunek 17.4.
Rys. 17.4. Ponowne napełnianie bufora
Często zdarza się, że chcemy wypuścić wodę ze zbiornika jeszcze zanim całkowicie się wypełni. Nazywa się to „zrzucaniem bufora”. Ilustruje to rysunek 17.5.
Rys. 17.5. Zrzucanie bufora

Strumienie i bufory Jak można było oczekiwać, C++ implementuje strumienie i bufory w sposób obiektowy.
• Klasa streambuf zarządza buforem, zaś jej funkcje składowe oferują możliwość wypełniania, opróżniania, zrzucania i innych sposobów manipulowania buforem.
• Klasa ios jest bazową klasą dla klas wejścia-wyjścia z użyciem strumieni. Jedną ze zmiennych składowych tej klasy jest obiekt klasy streambuf.
• Klasy istream i ostream są wyprowadzone z klasy ios i specjalizują działanie strumieni wejściowych i wyjściowych.
• Klasa iostream jest wyprowadzona zarówno z klasy istream, jak i ostream i dostarcza metod wejścia-wyjścia do wypisywania danych na ekranie i odczytywania ich z klawiatury.
• Klasa fstream zapewnia wejście i wyjście z oraz do plików.
Standardowe obiekty wejścia-wyjścia Gdy program C++, zawierający klasę iostream, rozpoczyna działanie, tworzy i inicjalizuje cztery obiekty:
UWAGA Biblioteka klasy iostream jest dodawana przez kompilator do programu automatycznie. Aby użyć jej funkcji, musisz dołączyć do początku kodu swojego programu odpowiednią instrukcję #include.
• cin (wymawiane jako „si-in”) obsługuje wprowadzanie danych ze standardowego wejścia, czyli klawiatury.
• cout (wymawiane jako „si-aut”) obsługuje wyprowadzanie danych na standardowe wyjście, czyli ekran.
• cerr (wymawiane jako „si-err”) obsługuje niebuforowane wyprowadzanie danych na standardowe urządzenie wyjścia dla wydruku błędów, czyli ekran. Ponieważ wyjście błędów nie jest buforowane, wszystko co zostanie wysłane do cerr, jest wypisywane na standardowym urządzeniu błędów natychmiast, bez oczekiwania na wypełnienie bufora lub nadejście polecenia zrzutu.
• clog (wymawiane jako „si-log”) obsługuje buforowane wyprowadzanie danych na standardowe wyjście błędów, czyli ekran. Dość często to wyjście jest przekierowywane do pliku log dziennika, co zostanie opisane w następnym podrozdziale.
Usunięto:
Usunięto: e
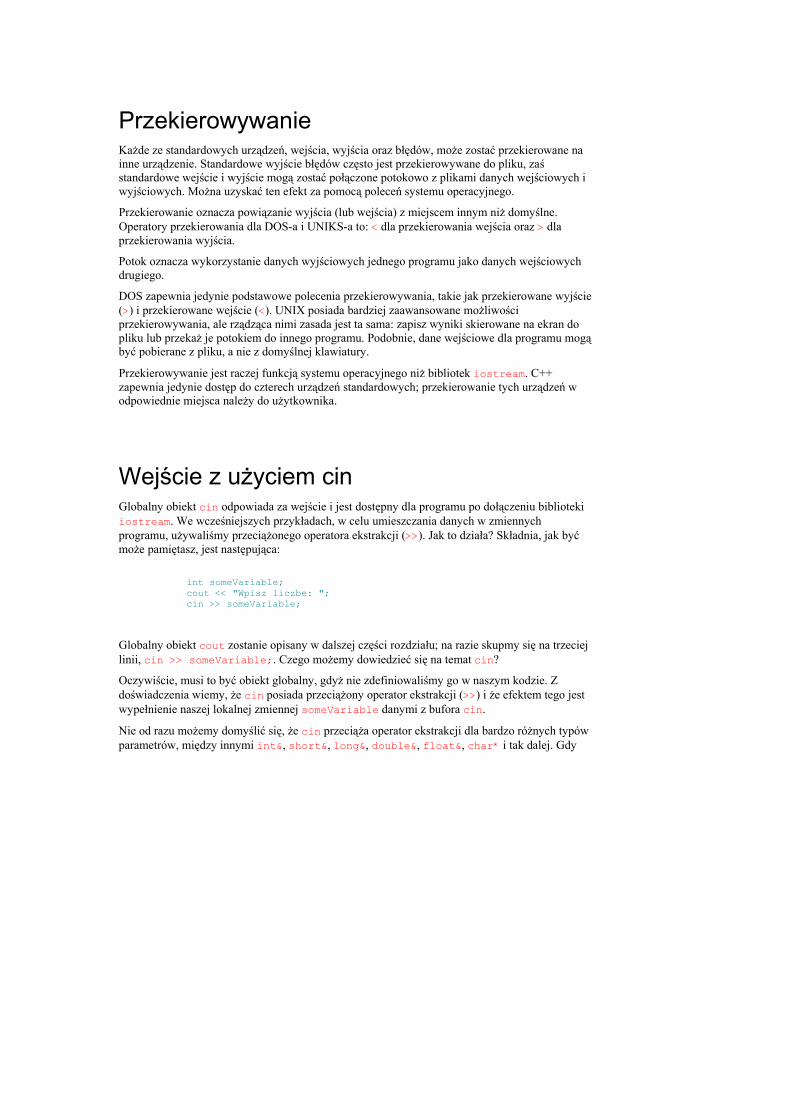
Przekierowywanie Każde ze standardowych urządzeń, wejścia, wyjścia oraz błędów, może zostać przekierowane na inne urządzenie. Standardowe wyjście błędów często jest przekierowywane do pliku, zaś standardowe wejście i wyjście mogą zostać połączone potokowo z plikami danych wejściowych i wyjściowych. Można uzyskać ten efekt za pomocą poleceń systemu operacyjnego.
Przekierowanie oznacza powiązanie wyjścia (lub wejścia) z miejscem innym niż domyślne. Operatory przekierowania dla DOS-a i UNIKS-a to: < dla przekierowania wejścia oraz > dla przekierowania wyjścia.
Potok oznacza wykorzystanie danych wyjściowych jednego programu jako danych wejściowych drugiego.
DOS zapewnia jedynie podstawowe polecenia przekierowywania, takie jak przekierowane wyjście (>) i przekierowane wejście (<). UNIX posiada bardziej zaawansowane możliwości przekierowywania, ale rządząca nimi zasada jest ta sama: zapisz wyniki skierowane na ekran do pliku lub przekaż je potokiem do innego programu. Podobnie, dane wejściowe dla programu mogą być pobierane z pliku, a nie z domyślnej klawiatury.
Przekierowywanie jest raczej funkcją systemu operacyjnego niż bibliotek iostream. C++ zapewnia jedynie dostęp do czterech urządzeń standardowych; przekierowanie tych urządzeń w odpowiednie miejsca należy do użytkownika.
Wejście z użyciem cin Globalny obiekt cin odpowiada za wejście i jest dostępny dla programu po dołączeniu biblioteki iostream. We wcześniejszych przykładach, w celu umieszczania danych w zmiennych programu, używaliśmy przeciążonego operatora ekstrakcji (>>). Jak to działa? Składnia, jak być może pamiętasz, jest następująca:
int someVariable; cout << "Wpisz liczbe: "; cin >> someVariable;
Globalny obiekt cout zostanie opisany w dalszej części rozdziału; na razie skupmy się na trzeciej linii, cin >> someVariable;. Czego możemy dowiedzieć się na temat cin?
Oczywiście, musi to być obiekt globalny, gdyż nie zdefiniowaliśmy go w naszym kodzie. Z doświadczenia wiemy, że cin posiada przeciążony operator ekstrakcji (>>) i że efektem tego jest wypełnienie naszej lokalnej zmiennej someVariable danymi z bufora cin.
Nie od razu możemy domyślić się, że cin przeciąża operator ekstrakcji dla bardzo różnych typów parametrów, między innymi int&, short&, long&, double&, float&, char* i tak dalej. Gdy
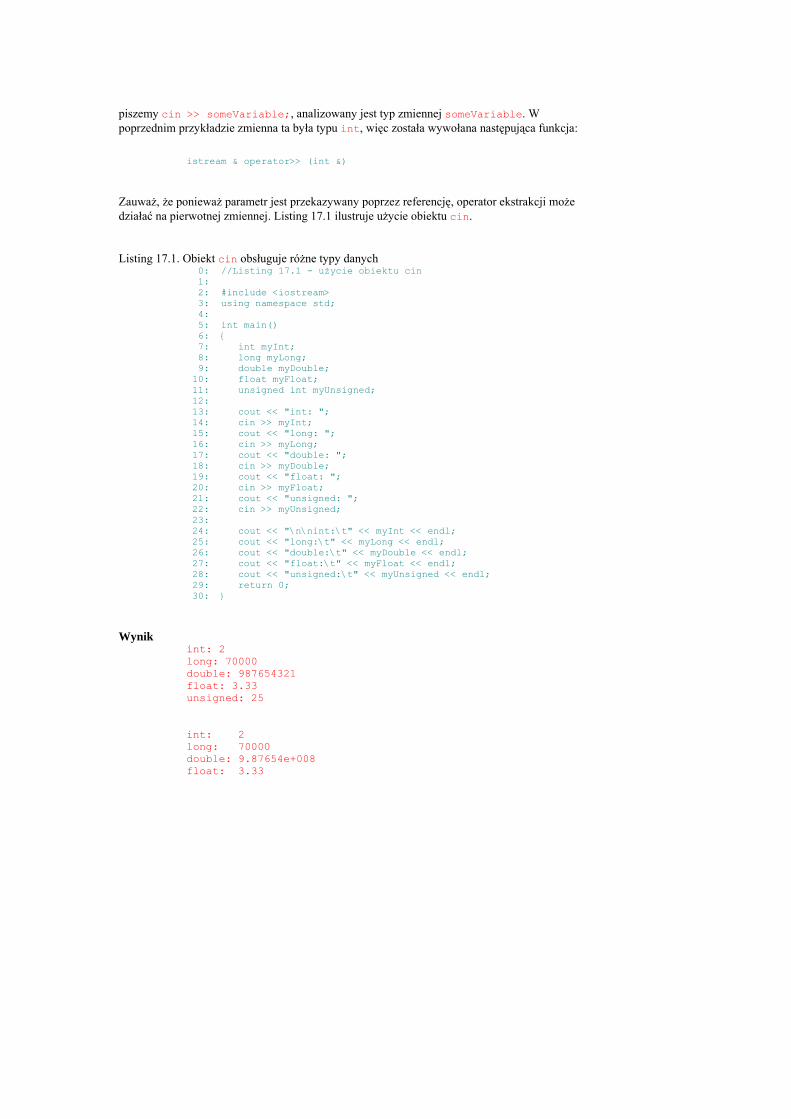
piszemy cin >> someVariable;, analizowany jest typ zmiennej someVariable. W poprzednim przykładzie zmienna ta była typu int, więc została wywołana następująca funkcja:
istream & operator>> (int &)
Zauważ, że ponieważ parametr jest przekazywany poprzez referencję, operator ekstrakcji może działać na pierwotnej zmiennej. Listing 17.1 ilustruje użycie obiektu cin.
Listing 17.1. Obiekt cin obsługuje różne typy danych 0: //Listing 17.1 - użycie obiektu cin 1: 2: #include <iostream> 3: using namespace std; 4: 5: int main() 6: { 7: int myInt; 8: long myLong; 9: double myDouble; 10: float myFloat; 11: unsigned int myUnsigned; 12: 13: cout << "int: "; 14: cin >> myInt; 15: cout << "long: "; 16: cin >> myLong; 17: cout << "double: "; 18: cin >> myDouble; 19: cout << "float: "; 20: cin >> myFloat; 21: cout << "unsigned: "; 22: cin >> myUnsigned; 23: 24: cout << "\n\nint:\t" << myInt << endl; 25: cout << "long:\t" << myLong << endl; 26: cout << "double:\t" << myDouble << endl; 27: cout << "float:\t" << myFloat << endl; 28: cout << "unsigned:\t" << myUnsigned << endl; 29: return 0; 30: }
Wynik int: 2 long: 70000 double: 987654321 float: 3.33 unsigned: 25 int: 2 long: 70000 double: 9.87654e+008 float: 3.33

unsigned: 25
Analiza
W liniach od 7. do 11. są deklarowane zmienne różnych typów. W liniach od 13. do 22. użytkownik jest proszony o wprowadzenie wartości dla tych zmiennych, po czym w liniach od 24. do 28. wypisywane są (z użyciem cout) wyniki.
Wynik odzwierciedla fakt, że dane zostały umieszczone w zmiennych odpowiedniego „rodzaju” i że program działa tak, jak mogliśmy tego oczekiwać.
Łańcuchy Obiekt cin może także obsługiwać argumenty w postaci łańcuchów do znaków (char*); tak więc możemy stworzyć bufor znaków i użyć cin do jego wypełnienia. Na przykład, możemy napisać:
char YourName[50]; cout << "Wpisz swoje imie: "; cin >> YourName;
Gdy wpiszesz Jesse, zmienna YourName zostanie wypełniona znakami J, e, s, s, \0. Ostatni znak to null; cin automatycznie kończy nim łańcuch, dlatego w buforze musi być wystarczająca ilość miejsca na pomieszczenie całego łańcucha oraz kończącego go znaku null. Dla funkcji biblioteki standardowej znak null oznacza koniec łańcucha. Funkcje biblioteki standardowej zostaną omówione w rozdziale 21., „Co dalej”.
Problemy z łańcuchami Pamiętając o wszystkich zaletach obiektu cin, możesz być zaskoczony, próbując wpisać do łańcucha swoje pełne imię i nazwisko. Obiekt cin traktuje białe spacje jako separatory. Gdy natrafia na spację lub znak nowej linii, zakłada, że dane wejściowe dla parametru są kompletne i, w przypadku łańcuchów, dodaje na ich końcu znak null. Problem ten ilustruje listing 17.2.
Listing 17.2. Próba wpisania do cin więcej niż jednego słowa 0: //Listing 17.2 - cin i łańcuchy znaków 1: 2: #include <iostream> 3: 4: int main() 5: { 6: char YourName[50]; 7: std::cout << "Podaj imie: "; 8: std::cin >> YourName; 9: std::cout << "Masz na imie: " << YourName << std::endl; 10: std::cout << "Podaj imie i nazwisko: "; 11: std::cin >> YourName;

12: std::cout << "Nazywasz sie: " << YourName << std::endl; 13: return 0; 14: }
Wynik Podaj imie: Jesse Masz na imie: Jesse Podaj imie i nazwisko: Jesse Liberty Nazywasz sie: Jesse
Analiza
W linii 6. została stworzona tablica znaków (w celu przechowania danych wprowadzanych przez użytkownika). W linii 7. użytkownik jest proszony o wpisanie jedynie imienia; imię to jest przechowywane prawidłowo, co odzwierciedla wynik.
W linii 10. użytkownik jest proszony o podanie całego nazwiska. Obiekt cin odczytuje dane wejściowe i gdy natrafia na spację pomiędzy wyrazami, umieszcza po pierwszym słowie znak null i kończy odczytywanie danych. Nie tego oczekiwaliśmy.
Aby zrozumieć, dlaczego działa to w ten sposób, przeanalizuj listing 17.3. Wyświetla on dane wprowadzone do kilku pól.
Listing 17.3 Wejście wielokrotne 0: //Listing 17.3 - działanie cin 1: 2: #include <iostream> 3: using namespace std; 4: 5: int main() 6: { 7: int myInt; 8: long myLong; 9: double myDouble; 10: float myFloat; 11: unsigned int myUnsigned; 12: char myWord[50]; 13: 14: cout << "int: "; 15: cin >> myInt; 16: cout << "long: "; 17: cin >> myLong; 18: cout << "double: "; 19: cin >> myDouble; 20: cout << "float: "; 21: cin >> myFloat; 22: cout << "slowo: "; 23: cin >> myWord; 24: cout << "unsigned: "; 25: cin >> myUnsigned; 26: 27: cout << "\n\nint:\t" << myInt << endl; 28: cout << "long:\t" << myLong << endl; 29: cout << "double:\t" << myDouble << endl;

30: cout << "float:\t" << myFloat << endl; 31: cout << "slowo: \t" << myWord << endl; 32: cout << "unsigned:\t" << myUnsigned << endl; 33: 34: cout << "\n\nint, long, double, float, slowo, unsigned: "; 35: cin >> myInt >> myLong >> myDouble; 36: cin >> myFloat >> myWord >> myUnsigned; 37: cout << "\n\nint:\t" << myInt << endl; 38: cout << "long:\t" << myLong << endl; 39: cout << "double:\t" << myDouble << endl; 40: cout << "float:\t" << myFloat << endl; 41: cout << "slowo: \t" << myWord << endl; 42: cout << "unsigned:\t" << myUnsigned << endl; 43: 44: 45: return 0; 46: }
Wynik int: 2 long: 30303 double: 393939397834 float: 3.33 slowo: Hello unsigned: 85 int: 2 long: 30303 double: 3.93939e+011 float: 3.33 slowo: Hello unsigned: 85 int, long, double, float, word, unsigned: 3 304938 393847473 6.66 bye -2 int: 3 long: 304938 double: 3.93847e+008 float: 6.66 slowo: bye unsigned: 4294967294
Analiza
Także w tym przykładzie zostało stworzonych kilka zmiennych, tym razem obejmujących także tablicę znaków. Użytkownik jest proszony o wprowadzenie danych, które następnie zostają wypisane.
W linii 34. użytkownik jest proszony i wpisanie wszystkich danych jednocześnie, po czym każde „słowo” danych wejściowych jest przypisywane odpowiedniej zmiennej. W przypadku takiego
wielokrotnego przypisania, obiekt cin musi potraktować każde słowo jako pełne dane dla każdej ze zmiennych. Gdyby obiekt cin potraktował wszystkie dane jako skierowane do jednej zmiennej, wtedy takie połączone wprowadzanie danych nie byłoby możliwe.
Zwróć uwagę, że w linii 42. ostatnim zażądanym obiektem była liczba całkowita bez znaku, lecz użytkownik wpisał wartość –2. Ponieważ cin wierzy, że odczytuje liczbę całkowitą bez znaku, wzorzec bitowy wartości –2 został odczytany jako liczba bez znaku. Wartość ta, wypisana przez cout, to 4294967294. Wartość całkowita bez znaku 4294967294 ma dokładnie ten sam wzór bitów, co wartość całkowita ze znakiem równa –2.
W dalszej części rozdziału zobaczymy, jak wpisać do bufora cały łańcuch z wieloma słowami. Na razie jednak pojawia się pytanie: w jaki sposób operator ekstrakcji daje sobie radę z łączeniem wartości?
operator>> zwraca referencję do obiektu istream Wartością zwracaną przez cin jest referencja do obiektu istream. Ponieważ samo cin jest obiektem klasy istream, więc zwracana wartość jednej ekstrakcji może być wejściem dla następnej.
int varOne, varTwo, varThree; cout << "Wpisz trzy liczby: "; cin >> varOne >> varTwo >> varThree;
Gdy piszemy cin >> varOne >> varTwo >> varThree;, wtedy pierwsza ekstrakcja jest obliczana jako (cin >> varOne). Otrzymana wartość jest kolejnym obiektem istream i operator ekstrakcji tego obiektu otrzymuje zmienną varTwo. Wygląda to tak, jakbyśmy napisali:
((cin >> varOne) >> varTwo) >> varThree;
Do techniki tej wrócimy później, przy omawianiu działania obiektu cout.
Inne funkcje składowe w dyspozycji cin W dyspozycji obiektu cin pozostaje nie tylko operator >>, ale także inne funkcje składowe. Są one używane wtedy, gdy jest wymagana bardziej precyzyjna kontrola wprowadzania danych.
Usunięto: klasy
Usunięto: Oprócz przeciążonego operatora>>, obiekt cin posiada

Wprowadzanie pojedynczych znaków operator>> przyjmujący referencję do znaku może być użyty do pobierania pojedynczego znaku ze standardowego wejścia. Do pobrania pojedynczego znaku można także użyć funkcji składowej get(), i to na dwa sposoby: funkcja get() może zostać wywołana bez parametrów(wtedy wykorzystywana jest wartość zwracana) lub z referencją do znaku.
Użycie get() bez parametrów Pierwsza forma funkcji get() nie przyjmuje żadnych parametrów. Zwraca ona odczytany znak lub znak EOF (znak końca pliku, end of file) w chwili dojścia do końca pliku. Funkcja get() bez parametrów nie jest używana zbyt często. Nie ma możliwości łączenia tej funkcji z wielokrotnym wprowadzaniem, gdyż zwracaną wartością nie jest obiekt klasy iostream. Dlatego nie zadziała poniższa linia kodu:
cin.get() >> myVarOne >> myVarTwo; // niedozwolone
Wartością zwracaną przez cin.get() >> myVarOne jest wartość całkowita, a nie obiekt klasy iostream.
Najczęstsze zastosowanie funkcji get() bez parametrów przedstawia listing 17.4.
Listing 17.4. Użycie funkcji get() bez parametrów 0: // Listing 17.4 - Using get() with no parameters 1: 2: #include <iostream> 3: 4: int main() 5: { 6: char ch; 7: while ( (ch = std::cin.get()) != EOF) 8: { 9: std::cout << "ch: " << ch << std::endl; 10: } 11: std::cout << "\nGotowe!\n"; 12: return 0; 13: }
Wynik Hello ch: H ch: e ch: l ch: l ch: o ch: World

ch: W ch: o ch: r ch: l ch: d ch: (ctrl+z) Gotowe!
Analiza
W linii 6. została zadeklarowana lokalna zmienna znakowa ch. Pętla while przypisuje dane otrzymane od funkcji get.cin() do ch, i gdy nie jest to znak końca pliku, wypisywany jest łańcuch.
Wypisywane dane są buforowane aż do chwili osiągnięcia końca linii. Gdy zostanie napotkany znak EOF (wprowadzony w wyniku naciśnięcia kombinacji klawiszy Ctrl+Z w DOS-ie lub Ctrl+D w UNIKS-ie), następuje wyjście z pętli.
Pamiętaj, że nie każda implementacja klasy istream obsługuje tę wersję funkcji get(), mimo iż obecnie stanowi ona część standardu ANSI/ISO.
Użycie funkcji get() z parametrem w postaci referencji do znaku Gdy jako parametr funkcji get() zostanie użyty znak, jest on wypełniany następnym znakiem ze strumienia wejściowego. Zwracaną wartością jest obiekt iostream, więc wywołanie tej funkcji get() może być łączone, co ilustruje listing 17.5.
Listing 17.5. Użycie funkcji get() z parametrem 0: // Listing 17.5 - Użycie funkcji get() z parametrem 1: 2: #include <iostream> 3: 4: int main() 5: { 6: char a, b, c; 7: 8: std::cout << "Wpisz trzy litery: "; 9: 10: std::cin.get(a).get(b).get(c); 11: 12: std::cout << "a: " << a << "\nb: "; 13: std::cout << b << "\nc: " << c << std::endl; 14: return 0; 15: }
Wynik Wpisz trzy litery: raz

a: r b: a c: z
Analiza
W linii 6. zostały zadeklarowane trzy zmienne znakowe. W linii 10. zostaje trzykrotnie wywołana, w sposób połączony, funkcja cin.get(). Najpierw jest wywoływana cin.get(a). To powoduje umieszczenie pierwszej litery w zmiennej a i zwrócenie obiektu cin. W rezultacie, po powrocie z wywołania, zostaje wywołane cin.get(b), a w zmiennej b jest umieszczana następna litera. Ostatecznie wywołane zostaje cin.get(c), a w zmiennej c zostaje umieszczona trzecia litera.
Ponieważ cin.get(a) zwraca obiekt cin, moglibyśmy napisać:
cin.gat(a) >> b;
W tej formie cin.get(a) zwraca obiekt cin, więc drugą frazą jest cin >> b;.
TAK NIE
Używaj operatora ekstrakcji (>>)wtedy, gdy chcesz pominąć białe spacje.
Używaj funkcji get() z parametrem wtedy, gdy chcesz sprawdzić każdy znak, włącznie z białymi spacjami.
Odczytywanie łańcuchów z wejścia standardowego Operator ekstrakcji (>>) może być używany do wypełniania tablicy znaków, podobnie jak funkcje get() i getline().
Ostatnia forma funkcji get() przyjmuje trzy parametry. Pierwszym z nich jest wskaźnik do tablicy znaków, drugim parametrem jest maksymalna ilość znaków do odczytania plus jeden, zaś trzecim parametrem jest znak kończący.
Gdy jako drugi parametr podasz wartość 20, funkcja get() odczyta dziewiętnaście znaków, doda znak null, po czym umieści całość w buforze wskazywanym przez pierwszy parametr. Trzeci parametr, znak kończący, jest domyślnie znakiem nowej linii ('\n'). Gdy znak kończący zostanie napotkany przed odczytaniem maksymalnej ilości znaków, do łańcucha zostaje dodany znak null, a znak kończący pozostaje w buforze wejściowym.
Sposób użycia tej formy funkcji get() przedstawia listing 17.6.

Listing 17.6. Użycie funkcji get() z tablicą znaków 0: // Listing 17.6 - Użycie funkcji get() z tablicą znaków 1: 2: #include <iostream> 3: using namespace std; 4: 5: int main() 6: { 7: char stringOne[256]; 8: char stringTwo[256]; 9: 10: cout << "Wpisz pierwszy lancuch: "; 11: cin.get(stringOne,256); 12: cout << "Pierwszy lancuch: " << stringOne << endl; 13: 14: cout << "Wpisz drugi lancuch: "; 15: cin >> stringTwo; 16: cout << "Drugi lancuch: " << stringTwo << endl; 17: return 0; 18: }
Wynik Wpisz pierwszy lancuch: Dobry zart Pierwszy lancuch: Dobry zart Wpisz drugi lancuch: tynfa wart Drugi lancuch: tynfa
Analiza
W liniach 7. i 8. zostały zadeklarowane dwie tablice znaków. W linii 10. użytkownik jest proszony o wprowadzenie łańcucha, po czym w linii 11. zostaje wywołana funkcja cin.get(). Pierwszym parametrem jest bufor do wypełnienia, zaś drugim jest zwiększona o jeden maksymalna ilość znaków, jaką funkcja get() może przyjąć (dodatkowa pozycja jest zarezerwowana dla znaku null, '\0'). Domyślnym, trzecim parametrem jest znak nowej linii.
Użytkownik wpisuje „Dobry żart”. Ponieważ fraza ta kończy się znakiem nowej linii, jest ona umieszczana wraz z kończącym znakiem null w buforze stringOne.
W linii 14. użytkownik jest proszony o wpisanie kolejnego łańcucha; tym razem do odczytania go został użyty operator ekstrakcji. Ponieważ operator ekstrakcji odczytuje znaki tylko do chwili napotkania białej spacji, w drugim buforze zostaje umieszczony wyraz „tynfa”, wraz z końcowym znakiem null. Oczywiście, nie tego chcieliśmy.
Innym sposobem rozwiązania tego problemu jest użycie funkcji getline(), co ilustruje listing 17.7.
Listing 17.7. Użycie funkcji getline() 0: // Listing 17.7 - Użycie funkcji getline() 1: 2: #include <iostream> 3: using namespace std; 4:
Usunięto: a

5: int main() 6: { 7: char stringOne[256]; 8: char stringTwo[256]; 9: char stringThree[256]; 10: 11: cout << "Wpisz pierwszy lancuch: "; 12: cin.getline(stringOne,256); 13: cout << "Pierwszy lancuch: " << stringOne << endl; 14: 15: cout << "Wpisz drugi lancuch: "; 16: cin >> stringTwo; 17: cout << "Drugi lancuch: " << stringTwo << endl; 18: 19: cout << "Wpisz trzeci lancuch: "; 20: cin.getline(stringThree,256); 21: cout << "Trzeci lancuch: " << stringThree << endl; 22: return 0; 23: }
Wynik Wpisz pierwszy lancuch: raz dwa trzy Pierwszy lancuch: raz dwa trzy Wpisz drugi lancuch: cztery piec szesc Drugi lancuch: cztery Wpisz trzeci lancuch: Trzeci lancuch: piec szesc
Analiza
Ten przykład wymaga dokładnego przeanalizowania, gdyż może sprawić kilka niespodzianek. W liniach od 7. do 9. zostały zadeklarowane trzy tablice znaków.
W linii 11. użytkownik jest proszony o wprowadzenie łańcucha; ten łańcuch jest odczytywany za pomocą funkcji getline(). Podobnie jak funkcja get(), funkcja getline() przyjmuje bufor i maksymalną liczbę znaków. Jednak w odróżnieniu od funkcji get(), końcowy znak nowej linii jest odczytywany i odrzucany. Funkcja get() nie odrzuca końcowego znaku nowej linii, ale pozostawia go w buforze wejściowym.
W linii 15. użytkownik jest ponownie proszony o wpisanie łańcucha; tym razem do jego odczytania zostaje użyty operator ekstrakcji. Użytkownik wpisuje cztery pięć sześć, a w tablicy stringTwo umieszczane jest pierwsze słowo cztery. Następnie wyświetlany jest komunikat Wpisz trzeci łańcuch: i ponownie zostaje wywołana funkcja getline(). Ponieważ w buforze wejściowym nadal znajdują się słowa pięć sześć, zostają one natychmiast odczytane, aż do znaku nowej linii; dopiero wtedy funkcja getline() kończy działanie i łańcuch z bufora stringThree zostaje wypisany na ekranie (w 21. linii kodu).
Użytkownik nie ma możliwości wpisania trzeciego łańcucha, gdyż drugie wywołanie funkcji getline() zostaje zaspokojone przez dane pozostające jeszcze w buforze wejściowym po wywołaniu operatora ekstrakcji w linii 16.
Operator ekstrakcji (>>) odczytuje znaki aż do chwili napotkania pierwszego białego znaku, wtedy umieszcza odczytane słowo w tablicy znaków.
Usunięto: buforze
Usunięto: spełnione

Funkcja składowa get() jest przeciążona. W pierwszej wersji nie przyjmuje żadnych parametrów i zwraca znak pobrany z bufora wejściowego. W drugiej wersji przyjmuje referencję do pojedynczego znaku i poprzez referencję zwraca obiekt klasy istream.
W trzeciej i ostatniej wersji funkcja get() przyjmuje tablicę znaków, ilość znaków do pobrania oraz znak kończący (którym domyślnie jest znak nowej linii). Ta wersja funkcji get() odczytuje znaki do tablicy aż do chwili odczytania maksymalnej ich ilości (mniejszej o jeden od wartości podanej jako jej parametr) lub do natrafienia na znak końcowy. Gdy funkcja get() natrafi na znak końcowy, przestaje odczytywać dalsze znaki, a znak końcowy pozostawia w buforze.
Funkcja składowa getline() także przyjmuje trzy parametry: bufor do wypełnienia, zwiększoną o jeden maksymalną ilość znaków, jaką może odczytać, oraz znak końcowy. Funkcja getline() działa tak samo, jak funkcja get() z takimi samymi parametrami, z wyjątkiem tego, że funkcja getline() odrzuca znak końcowy.
Użycie cin.ignore() Czasem zdarza się, że chcemy pominąć znaki, które pozostały na końcu linii (do znaku EOL, end of line) lub do końca pliku (EOF, end of file). Służy do tego funkcja składowa ignore(). Funkcja ta przyjmuje dwa parametry: maksymalną ilość znaków do pominięcia oraz znak końcowy. Gdybyśmy napisali ignore(80,'\n'), zostałoby odrzuconych do osiemdziesięciu znaków. Znaleziony znak nowej linii zostałby odrzucony i funkcja zakończyłaby działanie. Użycie funkcji ignore() ilustruje listing 17.8.
Listing 17.8. Użycie funkcji ignore() 0: // Listing 17.8 - Użycie funkcji ignore() 1: #include <iostream> 2: using namespace std; 3: 4: int main() 5: { 6: char stringOne[255]; 7: char stringTwo[255]; 8: 9: cout << "Wpisz pierwszy lancuch: "; 10: cin.get(stringOne,255); 11: cout << "Pierwszy lancuch: " << stringOne << endl; 12: 13: cout << "Wpisz drugi lancuch: "; 14: cin.getline(stringTwo,255); 15: cout << "Drugi lancuch: " << stringTwo << endl; 16: 17: cout << "\n\nA teraz sprobuj ponownie...\n"; 18: 19: cout << "Wpisz pierwszy lancuch: "; 20: cin.get(stringOne,255); 21: cout << "Pierwszy lancuch: " << stringOne<< endl; 22: 23: cin.ignore(255,'\n'); 24: 25: cout << "Wpisz drugi lancuch: ";
Usunięto: y
Usunięto: y
Usunięto: y

26: cin.getline(stringTwo,255); 27: cout << "Drugi lancuch: " << stringTwo<< endl; 28: return 0; 29: }
Wynik Wpisz pierwszy lancuch: dawno temu Pierwszy lancuch: dawno temu Wpisz drugi lancuch: Drugi lancuch: A teraz sprobuj ponownie... Wpisz pierwszy lancuch: dawno temu Pierwszy lancuch: dawno temu Wpisz drugi lancuch: byl sobie... Drugi lancuch: byl sobie...
Analiza
W liniach 6. i 7. zostały stworzone dwie tablice znaków. W linii 9. użytkownik jest proszony o wprowadzenie łańcucha, więc wpisuje słowa dawno temu, po których naciska klawisz Enter. Do odczytania łańcucha zostaje w linii 10. wywołana funkcja get(). Funkcja get() wypełnia tablicę stringOne i kończy działanie na znaku nowej linii, ale nie odrzuca go, lecz pozostawia w buforze wejściowym.
W linii 13. użytkownik jest ponownie proszony o wpisanie łańcucha znaków, ale funkcja getline() w linii 14. odczytuje pozostały w buforze znak nowej linii i natychmiast po tym kończy działanie (zanim użytkownik może wpisać jakikolwiek znak).
W linii 19. użytkownik jest jeszcze raz proszony o dokonanie wpisu i wpisuje te same słowa, co na początku. Jednak tym razem, w linii 23., zostaje użyta funkcja ignore(), która „zjada” pozostający znak nowej linii. W związku z tym, gdy w linii 26. zostaje wywołana funkcja getline(), bufor wejściowy jest już pusty i użytkownik może wprowadzić następną linię historyjki.
peek() oraz putback() Obiekt strumienia wejściowego cin posiada dwie dodatkowe metody, które mogą okazać się całkiem przydatne: funkcję peek(), która sprawdza, czy w buforze jest dostępny znak, lecz nie pobiera go, oraz funkcję putback(), która wstawia znak do strumienia wejściowego. Listing 17.9 pokazuje, w jaki sposób mogłyby zostać użyte te funkcje.
Listing 17.9. Użycie funkcji peek() i putback() 0: // Listing 17.9 - Użycie funkcji peek() i putback() 1: #include <iostream> 2: using namespace std; 3:
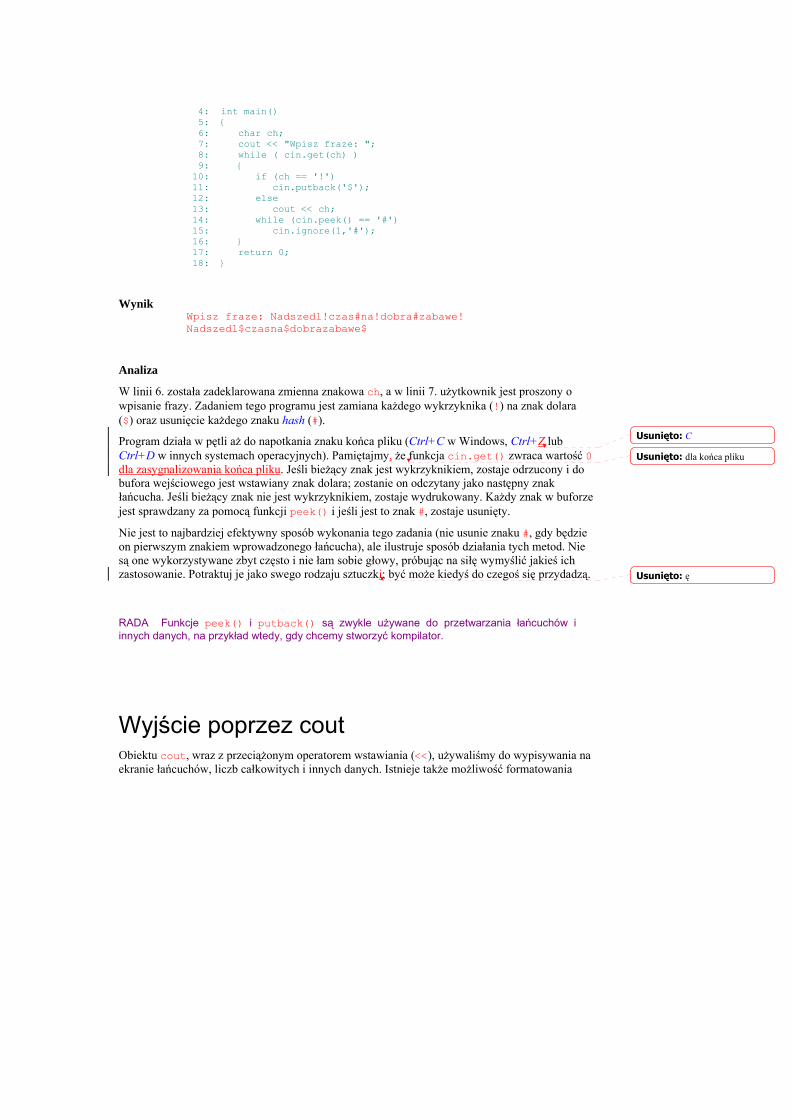
4: int main() 5: { 6: char ch; 7: cout << "Wpisz fraze: "; 8: while ( cin.get(ch) ) 9: { 10: if (ch == '!') 11: cin.putback('$'); 12: else 13: cout << ch; 14: while (cin.peek() == '#') 15: cin.ignore(1,'#'); 16: } 17: return 0; 18: }
Wynik Wpisz fraze: Nadszedl!czas#na!dobra#zabawe! Nadszedl$czasna$dobrazabawe$
Analiza
W linii 6. została zadeklarowana zmienna znakowa ch, a w linii 7. użytkownik jest proszony o wpisanie frazy. Zadaniem tego programu jest zamiana każdego wykrzyknika (!) na znak dolara ($) oraz usunięcie każdego znaku hash (#).
Program działa w pętli aż do napotkania znaku końca pliku (Ctrl+C w Windows, Ctrl+Z lub Ctrl+D w innych systemach operacyjnych). Pamiętajmy, że funkcja cin.get() zwraca wartość 0 dla zasygnalizowania końca pliku. Jeśli bieżący znak jest wykrzyknikiem, zostaje odrzucony i do bufora wejściowego jest wstawiany znak dolara; zostanie on odczytany jako następny znak łańcucha. Jeśli bieżący znak nie jest wykrzyknikiem, zostaje wydrukowany. Każdy znak w buforze jest sprawdzany za pomocą funkcji peek() i jeśli jest to znak #, zostaje usunięty.
Nie jest to najbardziej efektywny sposób wykonania tego zadania (nie usunie znaku #, gdy będzie on pierwszym znakiem wprowadzonego łańcucha), ale ilustruje sposób działania tych metod. Nie są one wykorzystywane zbyt często i nie łam sobie głowy, próbując na siłę wymyślić jakieś ich zastosowanie. Potraktuj je jako swego rodzaju sztuczki; być może kiedyś do czegoś się przydadzą.
RADA Funkcje peek() i putback() są zwykle używane do przetwarzania łańcuchów i innych danych, na przykład wtedy, gdy chcemy stworzyć kompilator.
Wyjście poprzez cout Obiektu cout, wraz z przeciążonym operatorem wstawiania (<<), używaliśmy do wypisywania na ekranie łańcuchów, liczb całkowitych i innych danych. Istnieje także możliwość formatowania
Usunięto: C
Usunięto: dla końca pliku
Usunięto: ę
wypisywanych danych, wyrównywania kolumn i wypisywania danych numerycznych w postaci dziesiętnej i szesnastkowej. Wszystkie te zagadnienia opiszemy w tym podrozdziale.
Zrzucanie zawartości bufora Przekonaliśmy się, że użycie endl powoduje zrzucenie zawartości bufora. endl wywołuje funkcję składową flush() obiektu cout, która wypisuje wszystkie dane znajdujące się w buforze. Funkcję flush() można wywoływać bezpośrednio, albo poprzez wywołanie metody obiektu, albo poprzez napisanie:
cout << flush
Przydaje się to wtedy, gdy chcemy mieć pewność, że bufor wyjściowy jest pusty i że jego zawartość została wypisana na ekranie.
Powiązane funkcje Działanie operatora ekstrakcji może być rozszerzone funkcjami get() i getline(); operator wstawiania także może być uzupełniony funkcjami put() oraz write().
Funkcja put() służy do wysyłania pojedynczego znaku do urządzenia wyjściowego. Ponieważ funkcja ta zwraca referencję do obiektu klasy ostream i ponieważ cout jest obiektem tej klasy, możemy łączyć wywołanie funkcji put() z wywołaniami operatora wstawiania. Ilustruje to listing 17.10.
Listing 17.10. Użycie funkcji put() 0: // Listing 17.10 - Użycie funkcji put() 1: 2: #include <iostream> 3: 4: int main() 5: { 6: std::cout.put('H').put('e').put('l').put('l').put('o').put('\n'); 7: return 0; 8: }
Wynik Hello

UWAGA Niektóre kompilatory mają problem z wypisywaniem znaków za pomocą powyższego kodu. Jeśli twój kompilator nie wypisze słowa Hello, możesz pominąć ten listing.
Analiza
Linia 6. jest przetwarzana w następujący sposób: std::cout.put('H') wypisuje na ekranie literę H i zwraca obiekt cout. To pozostawia nam:
cout.put('e').put('l').put('l').put('o').put('\n');
Wypisana zostaje litera e, pozostawiając cout.put('l'). Proces się powtarza: wypisane zostają litery i zwracany jest obiekt cout, aż do chwili wypisania końcowego znaku ('\n'), po czym funkcja kończy działanie.
Funkcja write() działa podobnie jak operator wstawiania (<<), ale przyjmuje parametr określający maksymalną ilość znaków, jaka może zostać wypisana. Jej użycie pokazuje listing 17.11.
Listing 17.11. Użycie funkcji write() 0: // Listing 17.11 - Użycie funkcji write() 1: #include <iostream> 2: #include <string.h> 3: using namespace std; 4: 5: int main() 6: { 7: char One[] = "O jeden most za daleko"; 8: 9: int fullLength = strlen(One); 10: int tooShort = fullLength -4; 11: int tooLong = fullLength + 6; 12: 13: cout.write(One,fullLength) << "\n"; 14: cout.write(One,tooShort) << "\n"; 15: cout.write(One,tooLong) << "\n"; 16: return 0; 17: }
Wynik O jeden most za daleko O jeden most za da O jeden most za daleko ╠└ ↕
UWAGA W twoim komputerze wynik może wyglądać nieco inaczej.
Analiza
Usunięto: a
W linii 7. jest tworzona pojedyncza fraza. W linii 9. zmienna fullLength (pełna długość) zostaje ustawiona na długość frazy, zmienna tooShort (zbyt krótka) zostaje ustawiona na długość pomniejszoną o cztery, zaś zmienna tooLong (zbyt długa) zostaje ustawiona na wartość fullLength plus sześć.
W linii 13., za pomocą funkcji write(), zostaje wypisana cała fraza. Długość została ustawiona zgodnie z faktyczną długością frazy, więc wydruk jest poprawny.
W linii 14. fraza jest wypisywana ponownie, lecz tym razem jest o cztery znaki krótsza niż pełna wersja, co odzwierciedla kolejna linia wyniku.
W linii 15. fraza jest wypisywana jeszcze raz, ale tym razem funkcja write() ma wypisać o sześć znaków za dużo. Po wypisaniu frazy wypisane zostają znaki odpowiadające wartościom sześciu bajtów z pamięci położonej bezpośrednio za frazą.
Manipulatory, znaczniki oraz instrukcje formatowania Strumień wyjściowy posiada kilka znaczników stanu, określających aktualnie używany system liczbowy (dziesiętny lub szesnastkowy), szerokość wypisywanych pól oraz znak używany do wypełniania pól. Znacznik stanu jest bajtem, którego poszczególne bity posiadają określone znaczenia. Sposób operowania bitami zostanie opisany w rozdziale 21. Każdy ze znaczników klasy ostream może być ustawiany za pomocą funkcji składowych i manipulatorów.
Użycie cout.width() Domyślna szerokość wydruku umożliwia zmieszczenie w jej obrębie wypisywanej liczby, znaku lub łańcucha znajdującego się w buforze wyjściowym. Można ją zmienić, używając funkcji width(). Ponieważ width() jest funkcją składową, musi być wywoływana z użyciem obiektu cout. Zmienia ona szerokość jedynie następnego wypisywanego pola, po czym natychmiast przywraca ustawienia domyślne. Jej użycie ilustruje listing 17.12.
Listing 17.12. Dostosowywanie szerokości wydruku 0: // Listing 17.12 - Dostosowywanie szerokości wydruku 1: #include <iostream> 2: using namespace std; 3: 4: int main() 5: { 6: cout << "Start >"; 7: cout.width(25); 8: cout << 123 << "< Koniec\n"; 9: 10: cout << "Start >";
Usunięto: niku
Usunięto: niku
11: cout.width(25); 12: cout << 123<< "< Nastepny >"; 13: cout << 456 << "< Koniec\n"; 14: 15: cout << "Start >"; 16: cout.width(4); 17: cout << 123456 << "< Koniec\n"; 18: 19: return 0; 20: }
Wynik Start > 123< Koniec Start > 123< Nastepny >456< Koniec Start >123456< Koniec
Analiza
Pierwsze wyjście (linie od 6. do 8. kodu) wypisuje liczbę 123 w polu, którego szerokość została ustawiona na 25 w linii 7.. Odzwierciedla to pierwsza linia wyniku.
Drugie wyjście najpierw wypisuje liczbę 123 w polu o szerokości ustawionej na 25 znaków, po czym wypisuje wartość 456. Zauważ, że wartość 456 jest wypisywana w polu o szerokości umożliwiającej precyzyjne zmieszczenie tej liczby; jak wspomniano, funkcja width() odnosi się wyłącznie do następnego wypisywanego pola.
Ostatnia linia wyniku pokazuje, iż ustawienie szerokości mniejszej niż wymagana oznacza ustawienie szerokości wystarczającej na zmieszczenie wypisywanego łańcucha.
Ustawianie znaków wypełnienia Zwykle obiekt cout wypełnia puste pola (powstałe w wyniku wywołania funkcji width()) spacjami, tak jak widzieliśmy w poprzednim przykładzie. Czasem zdarza się jednak, że chcemy wypełnić ten obszar innymi znakami, na przykład gwiazdkami. W tym celu możemy wywołać funkcję fill(), jako argument przekazując jej znak, którego chcemy użyć jako znaku wypełnienia. Pokazuje to listing 17.13.
Listing 17.13. Użycie funkcji fill() 0: // Listing 17.13 - Użycie funkcji fill() 1: 2: #include <iostream> 3: using namespace std; 4: 5: int main() 6: { 7: cout << "Start >"; 8: cout.width(25); 9: cout << 123 << "< Koniec\n"; 10:
Usunięto: u
Usunięto: a
Usunięto: a

11: 12: cout << "Start >"; 13: cout.width(25); 14: cout.fill('*'); 15: cout << 123 << "< Koniec\n"; 16: return 0; 17: }
Wynik Start > 123< Koniec Start >**********************123< Koniec
Analiza
Linie od 7. do 9. stanowią powtórzenie poprzedniego przykładu. Linie od 12. do 15. także stanowią powtórzenie, ale tym razem, w linii 14., jako znak wypełniania zostaje wybrana gwiazdka, co odzwierciedla druga linia wyniku.
Funkcja setf() Obiekt iostream pamięta swój stan dzięki przechowywanym znacznikom. Możemy je ustawiać, wywołując funkcję setf() i przekazując jej jedną z predefiniowanych stałych wyliczeniowych.
Obiekty posiadają stan wtedy, gdy któraś lub wszystkie z ich danych reprezentują warunki, które mogą ulegać zmianom podczas działania programu.
Na przykład, możemy określić, czy mają być wyświetlane zera końcowee (tak by 20.00 nie zostało obcięte do 20). Aby wyłączyć zera końcowe, wywołaj setf(ios::showpoint).
Stałe wyliczeniowe należą do zakresu klasy iostream (ios) i w związku z tym są stosowane z pełną kwalifikowaną nazwą w postaci ios::nazwa_znacznika, na przykład ios::showpoint.
Używając ios::showpos można włączyć wyświetlanie znaku plus (+) przed liczbami dodatnimi. Z kolei do wyrównywania wyniku służą stałe ios::left (do lewej strony), ios::right (do prawej) lub ios::internal (znak wypełnienia jest wstawiany między przedrostkiem oznaczającym system a liczbą).
Ustawiając znaczniki, możemy także ustawić system dla wypisywanych liczb jako dziesiętny (stała ios::dec), ósemkowy (o podstawie osiem, stała ios::oct) lub szesnastkowy (o podstawie szesnaście, stała ios::hex). Te znaczniki mogą być także łączone z operatorem wstawiania. Ustawienia te ilustruje listing 17.14. Dodatkowo, listing ten pokazuje także zastosowanie manipulatora setw, który ustawia szerokość pola, ale może być przy tym łączony z operatorem wstawiania.
Listing 17.14. Użycie funkcji setf() 0: // Listing 17.14 - Użycie funkcji setf() 1: #include <iostream> 2: #include <iomanip> 3: using namespace std; 4:
Usunięto: a
Usunięto: prze znakiem
Usunięto: wybrać

5: int main() 6: { 7: const int number = 185; 8: cout << "Liczba to " << number << endl; 9: 10: cout << "Liczba to " << hex << number << endl; 11: 12: cout.setf(ios::showbase); 13: cout << "Liczba to " << hex << number << endl; 14: 15: cout << "Liczba to " ; 16: cout.width(10); 17: cout << hex << number << endl; 18: 19: cout << "Liczba to " ; 20: cout.width(10); 21: cout.setf(ios::left); 22: cout << hex << number << endl; 23: 24: cout << "Liczba to " ; 25: cout.width(10); 26: cout.setf(ios::internal); 27: cout << hex << number << endl; 28: 29: cout << "Liczba to:" << setw(10) << hex << number << endl; 30: return 0; 31: }
Wynik Liczba to 185 Liczba to b9 Liczba to 0xb9 Liczba to 0xb9 Liczba to 0xb9 Liczba to 0x b9 Liczba to:0x b9
Analiza
W linii 7. stała typu int zostaje zainicjalizowana wartością 185. Ta wartość zostaje wypisana w linii 8.
Wartość jest wyświetlana ponownie w linii 10., ale tym razem w połączeniu z manipulatorem hex, który powoduje, że wartość ta jest wypisywana w systemie szesnastkowym (jako b9). (Szesnastkowa cyfra b odpowiada dziesiętnej liczbie 11. Jedenaście razy szesnaście równa się 176; po dodaniu 9 otrzymujemy wartość 185.)
W linii 12. zostaje ustawiony znacznik showbase. Powoduje on, że do wszystkich liczb szesnastkowych zostaje dodany przedrostek 0x (co widać w kolejnych liniach wyniku).
W linii 16. szerokość pola zostaje ustawiona na dziesięć znaków, a wypisywana wartość jest wyrównywana do prawej strony pola. W linii 20. szerokość także zostaje ustawiona na dziesięć znaków, ale tym razem wypisywana liczba zostaje wyrównana do lewej strony.

W linii 25. szerokość także zostaje ustawiona na dziesięć znaków, ale tym razem zostaje zastosowany znacznik internal. W związku z tym przedrostek (0x) jest wypisywany po lewej stronie, a sama wartość (b9) po prawej.
Na koniec, w linii 29. do ustawienia szerokości dziesięciu znaków zostaje użyty operator łączenia (konkatenacji) setw(), po czym wartość jest wypisywana ponownie.
Strumienie kontra funkcja printf() Większość implementacji C++ posiada standardowe biblioteki wejścia-wyjścia z języka C, zawierające między innymi funkcję printf(). Choć funkcja ta może być łatwiejsza w użyciu niż obiekt cout, jednak jej użycie nie jest zalecane.
Funkcja printf() nie zapewnia bezpieczeństwa typów, więc łatwo jest przypadkowo nakazać jej wypisanie wartości całkowitej jako znaku, i odwrotnie. Funkcja ta nie obsługuje klas, więc nie ma możliwości poinformowania jej jak ma wypisywać dane klasy; trzeba jej przekazywać kolejno wszystkie wartości, które mają zostać wypisane.
Ponieważ korzysta z tej funkcji duża ilość starszego kodu, w tym podrozdziale pokrótce omówimy jej działanie. Aby móc skorzystać z tej funkcji, musisz pamiętać o dołączeniu do kodu pliku nagłówkowego stdio.h. W swojej najprostszej formie funkcja printf() przyjmuje jako pierwszy parametr łańcuch formatujący, zaś jako następne parametry serię wartości.
Łańcuch formatujący jest ujętym w cudzysłowy łańcuchem znaków, zawierającym specyfikatory konwersji. Wszystkie specyfikatory konwersji muszą zaczynać się od symbolu procentów (%). Najczęściej stosowane specyfikatory zostały zebrane w tabeli 17.1.
Tabela 17.1. Powszechnie stosowane specyfikatory konwersji
Specyfikator Zastosowanie
%s Wypisywanie łańcuchów.
%d Wypisywanie liczb całkowitych.
%ld Wypisywanie długich liczb całkowitych.
%lg Wypisywanie wartości typu double.
%f Wypisywanie wartości typu float.
Każdy ze specyfikatorów konwersji może zawierać pole szerokości oraz pole precyzji, przedstawiane jako wartość zmiennoprzecinkowa, w której cyfry po lewej stronie kropki dziesiętnej oznaczają całkowitą szerokość pola, a cyfry po prawej stronie punktu dziesiętnego oznaczają dokładność zapisu liczb zmiennopozycyjnych. Tak więc specyfikator %5d określa szeroką na pięć cyfr liczbę całkowitą, a %15.5f jest specyfikatorem dla szerokiej na piętnaście
Usunięto: połączony
Usunięto: d

cyfr wartości typu float, w której na części dziesiętną ma zostać przeznaczone pięć ostatnich cyfr. Różne zastosowania funkcji printf() przedstawia listing 17.15.
Listing 17.15. Drukowanie z użyciem funkcji printf() 0: //17.15 Drukowanie z użyciem funkcji printf() 1: #include <stdio.h> 2: 3: int main() 4: { 5: printf("%s","Witaj swiecie\n"); 6: 7: char *phrase = "Witaj ponownie!\n"; 8: printf("%s",phrase); 9: 10: int x = 5; 11: printf("%d\n",x); 12: 13: char *phraseTwo = "Oto kilka wartosci: "; 14: char *phraseThree = " i jeszcze te: "; 15: int y = 7, z = 35; 16: long longVar = 98456; 17: float floatVar = 8.8f; 18: 19: printf("%s %d %d",phraseTwo,y,z); 20: printf("%s %ld %f\n",phraseThree,longVar,floatVar); 21: 22: char *phraseFour = "Sformatowane: "; 23: printf("%s %5d %10d %10.5f\n",phraseFour,y,z,floatVar); 24: 25: return 0; 26: }
Wynik Witaj swiecie Witaj ponownie! 5 Oto kilka wartosci: 7 35 i jeszcze te: 98456 8.800000 Sformatowane: 7 35 8.80000
Analiza
Pierwsza instrukcja printf(), zawarta w linii 5., używa formy standardowej: nazwy printf, po której następuje ujęty w cudzysłowy łańcuch ze specyfikatorem konwersji (w tym przypadku %s), a po nim wartość, która ma zostać wstawiona w miejsce specyfikatora konwersji.
Specyfikator %s wskazuje, że jest to łańcuch, a wartością łańcucha w tym przypadku jest ujęte w cudzysłowy "Witaj swiecie".
Druga instrukcja printf() jest podobna do pierwszej, ale tym razem jako drugi parametr funkcji został użyty wskaźnik do typu char, a nie stała łańcuchowa.
Trzecia instrukcja printf(), w linii 11., używa specyfikatora konwersji dla liczb całkowitych, zaś wstawianą wartością jest zmienna całkowita x. Czwarta instrukcja printf(), w linii 19., jest
już bardziej skomplikowana. Są w niej łączone trzy wartości. Dla każdej z nich istnieje specyfikator konwersji, a odpowiednie wartości są przekazywane jako rozdzielone przecinkami kolejne parametry funkcji.
Na koniec, w linii 23. specyfikatory konwersji zostają użyte do określenia szerokości i dokładności. Jak widać, jest to nieco łatwiejsze niż używanie manipulatorów.
Wspomnieliśmy wcześniej o ograniczenie funkcji printf(), które polega na braku kontroli typów. Oprócz tego, funkcji printf() nie można zadeklarować jako funkcji zaprzyjaźnionej lub funkcji składowej klasy. W związku z tym, gdy chcemy wypisywać różne dane składowe klasy, musimy jawnie przekazywać każdy z akcesorów klasy do funkcji printf().
Często zadawane pytanie
Czy możesz podsumować sposoby manipulowania wyjściem?
Odpowiedź (specjalne podziękowania dla Roberta Francisa) Aby sformatować wyjście w C++, należy użyć kombinacji znaków specjalnych, manipulatorów wyjścia oraz znaczników.
Poniższe znaki specjalne są dołączane do wyjściowego łańcucha wysyłanego do cout za pomocą operatora wstawiania:
\n – nowa linia
\r – powrót karetki
\t – tabulator
\\ – lewy ukośnik
\odd (liczba ósemkowa) – znak ASCII
\a – alarm (sygnał dźwiękowy).
Na przykład:
Usunięto: d

cout << "\aWystąpił błąd!\t"
powoduje powstanie sygnału dźwiękowego, wypisanie komunikatu błędu oraz przejście do następnego tabulatora. Manipulatory są używane z obiektem cout. Manipulatory przyjmujące argumenty wymagają dołączenia pliku nagłówkowego iomanip do pliku standardowego.
Oto lista manipulatorów, które nie wymagają pliku iomanip:
flush – zrzuca bufor wyjściowy
endl – wstawia znak nowej linii i zrzuca bufor wyjściowy
oct – ustawia system wypisywanych liczb na ósemkowy
dec – ustawia system wypisywanych liczb na dziesiętny
hex – ustawia system wypisywanych liczb na szesnastkowy.
Oto lista manipulatorów wymagających pliku iomanip:
setbase(base) – ustawia system liczbowy (0 = dziesiętny, 8 = ósemkowy, 10 = dziesiętny, 16 = szesnastkowy)
setw(width) – ustawia minimalną szerokość pola
setfill(ch) – ustawia znak wypełniania pustych obszarów pola
setprecision(p) – ustawia dokładność wypisywania liczb zmiennopozycyjnych
setiosflags(f) – ustawia jeden lub więcej znaczników ios
resetiosflags(f) – przywraca stan jednego lub więcej znaczników ios.
Usunięto: n
Usunięto: ś
Usunięto: e

Na przykład:
cout << setw(12) << setfill('#') << hex << x << endl;
ustawia szerokość pola na dwanaście znaków, ustawia znak wypełniania na '#', nakazuje wypisywanie liczb w systemie szesnastkowym, wypisuje wartość zmiennej x, umieszcza w buforze znak nowej linii i zrzuca zawartość bufora. Wszystkie manipulatory, z wyjątkiem flush, endl oraz setw, obowiązują aż do wprowadzenia jawnej zmiany lub końca programu. Domyślna wartość manipulatora setw jest przywracana po wykonaniu bieżącego cout.
Wraz z manipulatorami setiosflags oraz resetiosflags mogą być używane poniższe znaczniki ios:
ios::left – wyrównuje wynik do lewej strony pola
ios::right – wyrównuje wynik do prawej strony pola
ios::internal – znak lub przedrostek zostaje wyrównany do lewej, a liczba do prawej
ios::dec – dziesiętny system liczbowy
ios::oct – ósemkowy system liczbowy
ios::hex – szesnastkowy system liczbowy
ios::showbase – dodaje przedrostek 0x do liczb szesnastkowych i przedrostek 0 do liczb ósemkowych
ios::showpoint – dodaje zera końcowe, zgodnie z wymaganą dokładnością
ios::uppercase – litery w liczbach szesnastkowych i w wartościach wyświetlanych w zapisie wykładniczym są wyświetlane jako wielkie
ios::showpos – przed wartościami dodatnimi jest wyświetlany znak plus
ios::scientific – liczby zmiennoprzecinkowe są wyświetlane w zapisie wykładniczym
Usunięto: inżynierskim
Usunięto: ozycyjne
Usunięto: inżynierskim
ios::fixed – liczby zmiennoprzecinkowe są wyświetlane w zapisie dziesiętnym.
Dodatkowe informacje na ten temat można znaleźć w pliku ios oraz w dokumentacji kompilatora.
Wejście i wyjście z użyciem plików Strumienie zapewniają jednolity sposób obsługi danych przychodzących z klawiatury lub z twardego dysku oraz wychodzących na ekran lub do twardego dysku. W każdym z powyższych przypadków możemy korzystać z operatorów wstawiania i ekstrakcji lub innych, powiązanych z nimi funkcji i manipulatorów. Do otwarcia i zamknięcia pliku należy użyć obiektów typu ifstream i ofstream, których działanie omówimy w kilku następnych podrozdziałach.
ofstream Poszczególne obiekty używane do odczytu z pliku lub zapisu do pliku są nazywane obiektami ofstream. Są one wyprowadzone z używanych przez nas dotąd obiektów iostream.
Aby rozpocząć zapis do pliku, musimy najpierw stworzyć obiekt typu ofstream, a następnie powiązać go z konkretnym plikiem na dysku. Aby móc używać obiektów typu ofstream, do kodu należy dołączyć plik nagłówkowy fstream.h.
UWAGA Ponieważ plik fstream.h dołącza plik iostream.h, nie ma potrzeby jawnego dołączania tego drugiego pliku.
Stany strumieni Obiekty typu iostream przechowują znaczniki określające stan wejścia i wyjścia. Możemy je sprawdzać za pomocą logicznych funkcji eof(), bad(), fail() oraz good(). Funkcja eof() zwraca wartość true, gdy obiekt typu iostream napotkał koniec pliku. Funkcja bad() zwraca wartość true, gdy próbujemy wykonać niedozwoloną operację. Funkcja fail()zwraca wartość
Usunięto: ozycyjne
Usunięto: y

true, gdy funkcja bad() zwraca wartość true lub operacja się nie powiodła. Na koniec, funkcja good() zwraca wartość true, gdy wszystkie trzy pozostałe funkcje zwracają wartość false.
Otwieranie plików dla wejścia i wyjścia Aby otworzyć plik myfile.cpp z obiektem typu ofstream, deklarujemy egzemplarz obiektu typu ofstream i jako parametr przekazujemy mu nazwę pliku:
ofstream fout("myfile.cpp");
Otwarcie tego pliku do odczytu wygląda podobnie, ale wykorzystujemy w tym celu obiekt ifstream:
ifstream fin("myfile.cpp");
Zwróć uwagę na użyte nazwy, fout oraz fin; nazwa fout została użyta w celu zwrócenia uwagi na podobieństwo z cout, a nazwa fin w celu wykazania podobieństwa do nazwy cin.
Jedną z ważnych funkcji strumieni związanych z plikami, jest funkcja close(). Każdy tworzony obiekt strumienia otwiera plik albo do zapisu, albo do odczytu, albo do obu tych operacji. Po zakończeniu zapisywania lub odczytywania danych należy zamknąć plik funkcją close(); to zapewnia, że plik nie zostanie uszkodzony i że zawarte w buforze dane zostaną zrzucone na dysk.
Gdy obiekty strumieni plików zostaną już powiązane z plikami na dysku, mogą zostać użyte tak samo jak wszystkie inne obiekty strumieni. Ilustruje to listing 17.16.
Listing 17.16. Otwieranie plików do odczytu i zapisu 0: //Listing 17.16 Otwieranie plików do odczytu i zapisu 1: #include <fstream> 2: #include <iostream> 3: using namespace std; 4: 5: int main() 6: { 7: char fileName[80]; 8: char buffer[255]; // dla danych użytkownika 9: cout << "Nazwa pliku: "; 10: cin >> fileName; 11: 12: ofstream fout(fileName); // otwieramy do zapisu 13: fout << "Ta linia jest zapisana bezposrednio do pliku...\n"; 14: cout << "Wpisz tekst dla pliku: "; 15: cin.ignore(1,'\n'); // odrzucamy znak nowej linii po nazwie pliku 16: cin.getline(buffer,255); // odczytujemy dane wprowadzone przez użytkownika 17: fout << buffer << "\n"; // i zapisujemy je do pliku
Usunięto: e

18: fout.close(); // zamykamy plik; będzie gotów do ponownego otwarcia 19: 20: ifstream fin(fileName); // ponownie otwieramy plik do odczytu 21: cout << "Oto zawartosc pliku:\n"; 22: char ch; 23: while (fin.get(ch)) 24: cout << ch; 25: 26: cout << "\n***Koniec zawartosci pliku.***\n"; 27: 28: fin.close(); // dbałość zawsze popłaca 29: return 0; 30: }
Wynik Nazwa pliku: test1 Wpisz tekst dla pliku: Ten tekst zostal zapisany do pliku! Oto zawartosc pliku: Ta linia jest zapisana bezposrednio do pliku... Ten tekst zostal zapisany do pliku! ***Koniec zawartosci pliku.***
Analiza
W linii 7. zostaje przygotowany bufor przeznaczony na nazwę pliku, zaś w linii 8. został przygotowany bufor przeznaczony na dane wprowadzane przez użytkownika. W linii 9. użytkownik jest proszony o podanie nazwy pliku, a wprowadzona przez niego nazwa jest umieszczana w buforze fileName. W linii 12. zostaje stworzony obiekt typu ofstream o nazwie fout, który jest wiązany z nową nazwą pliku. To powoduje otwarcie pliku; jeśli plik istniał już wcześniej, jego zawartość zostaje usunięta.
W linii 13. do pliku zostaje bezpośrednio zapisany łańcuch znaków. W linii 14. użytkownik jest proszony o wpisanie danych. Znak końca linii pozostały po wpisaniu przez użytkownika nazwy pliku jest odrzucany w linii 15., po czym w linii 16. następne dane wpisane przez użytkownika są umieszczane w buforze. Dane te są w linii 17. zapisywane do pliku wraz ze znakiem nowej linii, po czym w linii 18. następuje zamknięcie pliku.
W linii 20. plik jest otwierany ponownie, tym razem w trybie do odczytu danych, po czym w liniach 23. i 24. jego zwartość jest odczytywana i wypisywana na ekranie (każdy znak wypisywany jest osobno).
Zmiana domyślnego zachowania obiektu ofstream w trakcie otwierania pliku

Domyślnym działaniem wykonywanym przy otwieraniu pliku jest stworzenie pliku, gdy jeszcze nie istnieje, lub obcięcie pliku (tj. usunięcie całej jego zawartości), gdy już istnieje. Gdy takie zachowanie domyślne nie jest pożądane, możemy jawnie przekazać drugi argument do konstruktora obiektu typu ofstream.
Dostępne argumenty to:
• ios::app — powoduje dołączenie danych do końca istniejącego pliku, bez usuwania istniejących w pliku danych.
• ios::ate — umieszcza nas na końcu pliku, ale możemy zapisywać dane w dowolnym miejscu pliku.
• ios::trunc — argument domyślny. Powoduje usunięcie zawartości istniejącego pliku.
• ios::nocreate — jeśli plik nie istnieje, otwarcie się nie powiedzie.
• ios::noreplace — jeśli plik już istnieje, otwarcie się nie powiedzie.
Dla ciekawych: nazwa app pochodzi od słowa append (dołącz), ate od at end (na końcu) oraz trunc od truncate (obetnij). Listing 17.17 ilustruje użycie dołączania (append) przez otwarcie pliku stworzonego w listingu 17.16 i dopisanie do niego dalszej treści.
Listing 17.17. Dopisywanie do końca pliku 0: //Listing 17.17 Dopisywanie do końca pliku 1: #include <fstream> 2: #include <iostream> 3: using namespace std; 4: 5: int main() // zwraca 1 w przypadku błędu 6: { 7: char fileName[80]; 8: char buffer[255]; 9: cout << "Prosze ponownie wpisac nazwe pliku: "; 10: cin >> fileName; 11: 12: ifstream fin(fileName); 13: if (fin) // czy już istnieje? 14: { 15: cout << "Biezaca zawartosc pliku:\n"; 16: char ch; 17: while (fin.get(ch)) 18: cout << ch; 19: cout << "\n***Koniec zawartosci pliku.***\n"; 20: } 21: fin.close(); 22: 23: cout << "\nOtwieranie " << fileName << " w trybie dopisywania...\n"; 24: 25: ofstream fout(fileName,ios::app); 26: if (!fout) 27: { 28: cout << "Nie mozna otworzyc " << fileName << " do dopisywania.\n";

29: return(1); 30: } 31: 32: cout << "\nWpisz tekst dla pliku: "; 33: cin.ignore(1,'\n'); 34: cin.getline(buffer,255); 35: fout << buffer << "\n"; 36: fout.close(); 37: 38: fin.open(fileName); // ponownie przypisujemy istniejacy obiekt fin! 39: if (!fin) 40: { 41: cout << "Nie mozna otworzyc " << fileName << " do odczytu.\n"; 42: return(1); 43: } 44: cout << "\nOto zawartosc pliku:\n"; 45: char ch; 46: while (fin.get(ch)) 47: cout << ch; 48: cout << "\n***Koniec zawartosci pliku.***\n"; 49: fin.close(); 50: return 0; 51: }
Wynik Prosze ponownie wpisac nazwe pliku: test1 Biezaca zawartosc pliku: Ta linia jest zapisana bezposrednio do pliku... Ten tekst zostal zapisany do pliku! ***Koniec zawartosci pliku.*** Otwieranie test1 w trybie dopisywania... Wpisz tekst dla pliku: Wiecej tekstu dla pliku! Oto zawartosc pliku: Ta linia jest zapisana bezposrednio do pliku... Ten tekst zostal zapisany do pliku! Wiecej tekstu dla pliku! ***Koniec zawartosci pliku.***
Analiza
Użytkownik jest proszony o ponowne wpisanie nazwy pliku. Tym razem w linii 12. jest tworzony obiekt strumienia wejściowego z pliku. Wynik otwierania jest sprawdzany w linii 13. i jeśli plik istnieje, jego zawartość jest wypisywana w liniach od 15. do 19. Zwróć uwagę, że if(fin) jest synonimem if(fin.good()).
Następnie zamykany jest plik wejściowy; ten sam plik zostaje otwarty ponownie w linii 25., tym razem w trybie dopisywania. Po tym otwarciu (i wszystkich innych) sprawdzamy, czy plik został otwarty poprawnie. Zwróć uwagę, że if(!fout) jest tym samym, co if(fout.fail()).

Użytkownik jest proszony o wpisanie tekstu, który jest dopisywany do pliku. W linii 36. plik zostaje ponownie zamknięty.
Na koniec, tak jak w listingu 17.16, plik zostaje ponownie otwarty w trybie do odczytu. Jednak tym razem obiekt fin nie musi być deklarowany ponownie, jest mu po prostu przypisywana ta sama nazwa pliku. W linii 39. ponownie następuje sprawdzenie poprawności otwarcia i gdy wszystko jest w porządku, zawartość pliku zostaje wypisana na ekranie, a sam plik jest ostatecznie zamykany.
TAK NIE
Sprawdzaj każde otwarcie pliku, aby mieć pewność że został on poprawnie otwarty.
Ponownie wykorzystuj istniejące obiekty ifstream lub ofstream.
Po wykorzystaniu obiektów ofstream zamykaj je
Nie próbuj zamykać lub ponownie przypisywać cin i cout.
Pliki binarne a pliki tekstowe Niektóre systemy operacyjne, takie jak DOS, dokonują rozróżnienia pomiędzy plikami tekstowymi a plikami binarnymi. Pliki tekstowe (jak można się domyślać) przechowują wszystko jako tekst, więc duże liczby, takie jak 54 325 są przechowywane jako łańcuchy cyfr (‘5’, ‘4’, ‘3’, ‘2’, ‘5’). To może być nieefektywne, ale ma tę zaletę, że tekst może zostać odczytany przez proste programy, takie jak DOS-owy program type.
Aby dopomóc systemowi plików w odróżnieniu pliku tekstowego od binarnego, C++ udostępnia znacznik ios::binary. W wielu systemach ten znacznik jest ignorowany, gdyż wszystkie dane są przechowywane w postaci binarnej. W jeszcze innych systemach znacznik ten jest niedozwolony i uniemożliwia skompilowanie programu!
Pliki binarne mogą przechowywać nie tylko liczby i łańcuchy, ale także całe struktury danych. Można do nich zapisywać wszystkie dane jednocześnie, używając metody write() klasy fstream.
Gdy użyjemy metody write(),do odczytania zapisanych danych możemy użyć funkcji read(). Każda z tych funkcji oczekuje wskaźnika do znaku, więc adres obiektu trzeba rzutować na wskaźnik do znaku.
Drugim argumentem obu funkcji jest ilość znaków do zapisu lub odczytu, którą można wyznaczyć za pomocą funkcji sizeof(). Pamiętaj, że zapisywane są tylko dane klasy, a nie jej metody. Odczytywane są także tylko dane. Zapis zawartości klasy do pliku ilustruje listing 17.18.
Listing 17.18. Zapis zawartości klasy do pliku
Usunięto: o
Usunięto: do
Usunięto: a

0: //Listing 17.18. Zapis zawartości klasy do pliku 1: #include <fstream> 2: #include <iostream.h> 3: using namespace std; 4: 5: class Animal 6: { 7: public: 8: Animal(int weight,long days):itsWeight(weight),DaysAlive(days){} 9: ~Animal(){} 10: 11: int GetWeight()const { return itsWeight; } 12: void SetWeight(int weight) { itsWeight = weight; } 13: 14: long GetDaysAlive()const { return DaysAlive; } 15: void SetDaysAlive(long days) { DaysAlive = days; } 16: 17: private: 18: int itsWeight; 19: long DaysAlive; 20: }; 21: 22: int main() // zwraca 1 w przypadku błędu 23: { 24: char fileName[80]; 25: 26: 27: cout << "Prosze wpisac nazwe pliku: "; 28: cin >> fileName; 29: ofstream fout(fileName,ios::binary); 30: if (!fout) 31: { 32: cout << "Nie mozna otworzyc " << fileName << " do zapisu.\n"; 33: return(1); 34: } 35: 36: Animal Bear(50,100); 37: fout.write((char*) &Bear,sizeof Bear); 38: 39: fout.close(); 40: 41: ifstream fin(fileName,ios::binary); 42: if (!fin) 43: { 44: cout << "Nie mozna otworzyc " << fileName << " do odczytu.\n"; 45: return(1); 46: } 47: 48: Animal BearTwo(1,1); 49: 50: cout << "BearTwo.GetWeight(): " << BearTwo.GetWeight() << endl; 51: cout << "BearTwo.GetDaysAlive(): " << BearTwo.GetDaysAlive() << endl; 52: 53: fin.read((char*) &BearTwo, sizeof BearTwo); 54:

55: cout << "BearTwo.GetWeight(): " << BearTwo.GetWeight() << endl; 56: cout << "BearTwo.GetDaysAlive(): " << BearTwo.GetDaysAlive() << endl; 57: fin.close(); 58: return 0; 59: }
Wynik Prosze wpisac nazwe pliku: Animals BearTwo.GetWeight(): 1 BearTwo.GetDaysAlive(): 1 BearTwo.GetWeight(): 50 BearTwo.GetDaysAlive(): 100
Analiza
W liniach od 5. do 20. została zadeklarowana okrojona klasa Animals. W liniach od 24. do 34. zostaje stworzony plik otwarty do zapisu w trybie binarnym. W linii 36. zostaje stworzony obiekt, którego waga zostaje ustawiona na 50, a wiek na 100 dni. Dane zawarte w tym obiekcie zostają w linii 37. zapisane do pliku.
W linii 39. plik jest zamykany, a w linii 41. ponownie otwierany do odczytu w trybie binarnym. W linii 48. tworzony jest drugi obiekt klasy Animal, o wadze 1 i wieku wynoszącym tylko jeden dzień. W linii 53. do nowego obiektu odczytywane są dane z pliku, zastępując istniejące dane obiektu danymi odczytanymi z pliku.
Przetwarzanie linii polecenia Wiele systemów operacyjnych, takich jak DOS czy UNIX, umożliwia użytkownikowi przekazywanie parametrów do programu podczas jego uruchamiania. Parametry te są nazywane opcjami linii polecenia i zwykle są oddzielone od siebie spacjami. Na przykład:
SomeProgram Param1 Param2 Param3
Te parametry nie są przekazywane bezpośrednio do funkcji main(), zamiast tego funkcja main() każdego programu otrzymuje dwa parametry. Pierwszym jest ilość parametrów w linii polecenia (parametr typu int). Nazwa pliku także jest wliczana do ilości parametrów, więc każdy program posiada co najmniej jeden parametr. Przedstawiona powyżej przykładowa linia poleceń zawiera cztery parametry (nazwa programu, SomeProgram, plus trzy parametry daje cztery argumenty wywołania programu).
Drugim parametrem przekazywanym do funkcji main() jest tablica wskaźników do łańcuchów znaków. Ponieważ nazwa tablicy jest stałym wskaźnikiem do pierwszego elementu tablicy,

możemy zadeklarować ten wskaźnik jako wskaźnik do wskaźnika do typu char, jako wskaźnik do tablicy elementów char lub jako wskaźnik do tablicy tablic elementów char.
Zwykle pierwszy argument ma nazwę argc (argument count, ilość argumentów), ale możesz nazwać go tak, jak chcesz. Drugi argument często nosi nazwę argv (argument vector, wektor argumentów), ale to także tylko konwencja.
Zwykle sprawdza się wartość parametru argc, aby upewnić się, czy program otrzymał oczekiwaną ilość argumentów, a następnie poprzez argv odwołuje się do samych łańcuchów parametrów. Pamiętaj, że argv[0] jest nazwą programu, a argv[1] jest jego pierwszym parametrem, reprezentowanym przez łańcuch. Jeśli argumentami programu mają być liczby, należy je zamienić z łańcuchów na wartości numeryczne. W rozdziale 21. zobaczymy, jak można wykorzystać w tym celu standardowe funkcje biblioteczne konwersji. Sposób korzystania z argumentów linii polecenia przedstawia listing 17.19.
Listing 17.19. Używanie argumentów linii polecenia 0: //Listing 17.19. Używanie argumentów linii polecenia 1: #include <iostream> 2: int main(int argc, char **argv) 3: { 4: std::cout << "Otrzymano " << argc << " argumentow...\n"; 5: for (int i=0; i<argc; i++) 6: std::cout << "argument " << i << ": " << argv[i] << std::endl; 7: return 0; 8: }
Wynik TestProgram Teach Yourself C++ In 21 Days Otrzymano 7 argumentow... argument 0: TestProgram.exe argument 1: Teach argument 2: Yourself argument 3: C++ argument 4: In argument 5: 21 argument 6: Days
UWAGA Musisz uruchomić ten kod albo z linii poleceń (tj. z okna DOS-a) lub ustawić parametry linii polecenia w kompilatorze (zajrzyj do dokumentacji swojego kompilatora).
Analiza
Funkcja main() deklaruje dwa argumenty: argc jest zmienną całkowitą zawierającą ilość argumentów linii polecenia, a argv jest wskaźnikiem do tablicy łańcuchów. Każdy łańcuch w tablicy wskazywanej przez argv jest jednym argumentem linii polecenia. Zauważ, że argv mogłoby równie łatwo zostać zadeklarowane jako char *argv[] lub char argv[][]. Jest to

zależne wyłącznie od stylu programowania. W tym programie, mimo iż argv zostało zadeklarowane jako wskaźnik do wskaźnika, to jednak do kolejnych łańcuchów (będących argumentami z linii poleceń) odwołujemy się jak do elementów tablicy.
W linii 4. argument argc zostaje wykorzystany przy wypisywaniu ilości argumentów linii polecenia: siedem, wliczając w to nazwę programu.
W liniach 5. i 6. zostaje wypisany każdy z argumentów linii polecenia; do cout przekazywane są zakończone zerem łańcuchy znaków pobierane z tablicy łańcuchów.
Bardziej popularne zastosowanie argumentów linii polecenia zostało przedstawione na listingu 17.20, powstałym w wyniku zmodyfikowania listingu 17.18 tak, by program odczytywał nazwę pliku z linii polecenia.
Listing 17.20. Użycie argumentów linii polecenia 0: //Listing 17.20. Użycie argumentów linii polecenia 1: #include <fstream> 2: #include <iostream> 3: using namespace std; 4: 5: class Animal 6: { 7: public: 8: Animal(int weight,long days):itsWeight(weight),DaysAlive(days){} 9: ~Animal(){} 10: 11: int GetWeight()const { return itsWeight; } 12: void SetWeight(int weight) { itsWeight = weight; } 13: 14: long GetDaysAlive()const { return DaysAlive; } 15: void SetDaysAlive(long days) { DaysAlive = days; } 16: 17: private: 18: int itsWeight; 19: long DaysAlive; 20: }; 21: 22: int main(int argc, char *argv[]) // zwraca 1 w przypadku błędu 23: { 24: if (argc != 2) 25: { 26: cout << "Uzycie: " << argv[0] << " <nazwa_pliku>" << endl; 27: return(1); 28: } 29: 30: ofstream fout(argv[1],ios::binary); 31: if (!fout) 32: { 33: cout << "Nie mozna otworzyc " << argv[1] << " do zapisu.\n"; 34: return(1); 35: } 36: 37: Animal Bear(50,100); 38: fout.write((char*) &Bear,sizeof Bear); 39: 40: fout.close();
Usunięto: nawet mimo iż w
Usunięto: do dostępu
Usunięto: poszczególnych
Usunięto: nadal są wykorzystywane
Usunięto: y

41: 42: ifstream fin(argv[1],ios::binary); 43: if (!fin) 44: { 45: cout << "Nie mozna otworzyc " << argv[1] << " do odczytu.\n"; 46: return(1); 47: } 48: 49: Animal BearTwo(1,1); 50: 51: cout << "BearTwo.GetWeight(): " << BearTwo.GetWeight() << endl; 52: cout << "BearTwo.GetDaysAlive(): " << BearTwo.GetDaysAlive() << endl; 53: 54: fin.read((char*) &BearTwo, sizeof BearTwo); 55: 56: cout << "BearTwo.GetWeight(): " << BearTwo.GetWeight() << endl; 57: cout << "BearTwo.GetDaysAlive(): " << BearTwo.GetDaysAlive() << endl; 58: fin.close(); 59: return 0; 60: }
Wynik BearTwo.GetWeight(): 1 BearTwo.GetDaysAlive(): 1 BearTwo.GetWeight(): 50 BearTwo.GetDaysAlive(): 100
Analiza
Deklaracja klasy Animal jest taka sama jak na listingu 17.18. Tym razem jednak zamiast prosić użytkownika o nazwę pliku, wykorzystujemy argument linii polecenia. W linii 22. funkcja main() została zadeklarowana jako przyjmująca dwa parametry: ilość argumentów linii polecenia oraz wskaźnik do tablicy łańcuchów tych argumentów.
W liniach od 24. do 28. program sprawdza, czy otrzymał wymaganą ilość argumentów (dokładnie dwa). Jeśli użytkownik nie poda pojedynczej nazwy pliku, zostanie wypisany komunikat błędu:
Uzycie TestProgram <nazwa_pliku>
Następnie program kończy działanie. Zwróć uwagę, że używając argv[0] zamiast sztywno określonej nazwy programu, możemy skompilować ten program tak, aby przyjmował dowolną nazwę i by była ona automatycznie wyświetlana w tym komunikacie.
W linii 30. program próbuje otworzyć wskazany plik do zapisu binarnego. Nie ma powodu, by kopiować nazwę pliku do tymczasowego bufora lokalnego, gdyż można bezpośrednio wykorzystać argument argv[1].

Ta technika zostaje powtórzona w linii 42., gdzie ten sam plik zostaje otwarty do odczytu; a także w liniach 33. i 45., w których wypisywane są komunikaty błędów otwarcia pliku.

Rozdział 18. Przestrzenie nazw Przestrzenie nazw pomagają programistom unikać konfliktów nazw powstających w trakcie korzystania z więcej niż jednej biblioteki.
Z tego rozdziału dowiesz się
• jak funkcje i klasy są rozpoznawane poprzez nazwy,
• jak stworzyć przestrzeń nazw,
• jak używać przestrzeni nazw,
• jak używać standardowej przestrzeni nazw std.
Zaczynamy Konflikty nazw są źródłem irytacji zarówno dla programistów C, jak i C++. Konflikt nazw powstaje wtedy, gdy w dwóch częściach programu, w tym samym zakresie, występuje kilka takich samych nazw. Najczęstszą przyczyną konfliktu jest wystąpienie tej samej nazwy w kilku różnych bibliotekach. Na przykład, biblioteka klasy kontenera prawie na pewno będzie deklarować i implementować klasę List (lista). Więcej na temat klas kontenerów dowiesz się z rozdziału 19., w którym będziemy omawiać szablony.
Nie powinno nas dziwić także występowanie klasy List w bibliotece związanej z okienkami. Przypuśćmy teraz, że chcemy stworzyć listę okien występujących w naszej aplikacji. Zakładamy także, że używamy klasy List z biblioteki klasy kontenera. Deklarujemy egzemplarz klasy List z biblioteki okienkowej (w celu przechowania okien) i okazuje się, że funkcja składowa, którą wywołujemy, jest niedostępna. Kompilator dopasował deklarację naszej klasy List do kontenera List w bibliotece standardowej, mimo iż w rzeczywistości chcieliśmy skorzystać z klasy List w bibliotece okienkowej, stworzonej przez kogoś innego.
Usunięto: wzorce

Przestrzenie nazw służą do podzielenia globalnej przestrzeni nazw i wyeliminowania (lub przynajmniej ograniczenia) konfliktów nazw. Przestrzenie nazw są nieco podobne do klas i posiadają bardzo podobną składnię.
Elementy zadeklarowane w przestrzeni nazw należą do tej przestrzeni. Wszystkie elementy w przestrzeni nazw są widoczne publicznie. Przestrzenie nazw mogą być zagnieżdżone. Funkcje mogą być definiowane w ciele przestrzeni nazw lub poza nim. Jeśli funkcja jest zdefiniowana poza ciałem przestrzeni nazw, musi być kwalifikowana nazwą tej przestrzeni.
Funkcje i klasy są rozpoznawane poprzez nazwy Podczas przetwarzania kodu źródłowego i budowania listy nazw funkcji i zmiennych, kompilator sprawdza także występowanie konfliktów nazw. Te konflikty, których kompilator nie potrafi rozwiązać sam, mogą być czasem rozwiązane przez program łączący (linker).
Kompilator nie potrafi wykryć konfliktu nazw pomiędzy jednostkami kompilacji (na przykład pomiędzy plikami object); jest to zadaniem programu łączącego (linkera). Dlatego kompilator nie zgłosi nawet ostrzeżenia.
Nie powinien nas dziwić komunikat linkera informujący o powielonym identyfikatorze, będącym jakimś nazwanym typem. Ten komunikat pojawia się, gdy zdefiniujemy tę samą nazwę w tym samym zakresie w różnych jednostkach kompilacji. Jeśli powielimy nazwę w tym samym zakresie w tym samym pojedynczym pliku, pojawi się błąd kompilacji. Poniższy kod powoduje wystąpienie błędu łączenia podczas kompilowania i łączenia:
// plik first.cpp int integerValue = 0; int main( ) { int integerValue = 0; // . . . return 0; }; // plik second.cpp int integerValue = 0; // koniec pliku second.cpp
Mój linker zgłasza komunikat: in second.obj: integerValue already defined in first.obj (w second.obj: integerValue już jest zdefiniowane w first.obj). Gdyby te nazwy występowały w innych zakresach, kompilator i linker przestałyby zgłaszać błędy.
Istnieje także możliwość, że kompilator zgłosi ostrzeżenie ukrywaniu identyfikatora. Kompilator powinien ostrzec, w pliku first.cpp, że integerValue w funkcji main() ukrywa zmienną globalną o tej samej nazwie.
Usunięto: obiektów
Usunięto: do tego służy
Usunięto: y
Aby użyć zmiennej integerValue zadeklarowanej poza funkcją main(), musisz jawnie przypisać tę zmienną do zakresu globalnego. Spójrzmy na poniższy przykład, w którym wartość 10 przypisujemy do zmiennej integerValue poza main(), a nie do zmiennej integerValue zadeklarowanej wewnątrz main():
// plik first.cpp int integerValue = 0; int main() { int integerValue = 0; ::integerValue = 10; // przypisanie do globalnej zmiennej // . . . return 0; }; // plik second.cpp int integerValue = 0; // koniec pliku second.cpp
UWAGA Zwróć uwagę na użycie operatora zakresu (::) wskazującego, że chodzi o zmienną globalną integerValue, a nie lokalną.
Problem z dwiema zmiennymi globalnymi zdefiniowanymi poza funkcjami polega na tym, że posiadają one takie same nazwy i tę samą widoczność, a tym samym powodują błąd linkera.
NOWE OKREŚLENIE
Określenie widoczność jest używane do oznaczenia zakresu zdefiniowanego obiektu, bez względu na to, czy jest to zmienna, klasa, czy funkcja. Na przykład, zmienna zadeklarowana i zdefiniowana poza funkcją posiada zakres pliku, czyli globalny. Zmienna ta jest widoczna od punktu jej zadeklarowania aż do końca pliku. Zmienna o zakresie bloku, czyli lokalna, występuje wewnątrz bloku kodu. Najczęstszymi przykładami takich zmiennych są zmienne zadeklarowane wewnątrz funkcji. Zakres zmiennych przedstawia poniższy przykład:
int globalScopeInt = 5; void f() { int localScopeInt = 10; } int main() { int localScopeInt = 15; { int anotherLocal = 20; int localScopeInt = 30; }
Usunięto: a
Usunięto: est zmienną globalną
Usunięto: globalnymi

return 0; }
Pierwsza definicja int, zmienna globalScopeInt, jest widoczna wewnątrz funkcji f() oraz main(). Następna definicja znajduje się wewnątrz funkcji f() i ma nazwę localScopeInt. Ta zmienna ma zakres lokalny, co oznacza, że jest widoczna tylko w bloku, w którym została zdefiniowana.
Funkcja main() nie może odwoływać się do zmiennej localScopeInt zdefiniowanej wewnątrz funkcji f(). Gdy funkcja f() kończy działanie, zmienna ta wychodzi poza zakres. Zmienna ta ma zakres blokowy.
Zwróć uwagę, że zmienna localScopeInt w funkcji main() nie koliduje ze zmienną localScopeInt w funkcji f(). Dwie następne definicje, anotherLocal oraz localScopeInt, mają zakres blokowy. Gdy dochodzimy do nawiasu klamrowego zamykającego, zmienne te stają się niewidoczne.
Zauważ, że zmienna localScopeInt ukrywa wewnątrz bloku zmienną localScopeInt zdefiniowaną tuż przed nawiasem klamrowym otwierającym blok (drugą zmienną localScopeInt zdefiniowaną w programie). Gdy program przechodzi poza nawias klamrowy zamykający blok, druga zdefiniowana zmienna localScopeInt znów staje się widoczna. Wszelkie zmiany dokonane w zmiennej localScopeInt zdefiniowanej wewnątrz bloku nie mają wpływu na zawartość innych zmiennych localScopeInt.
NOWE OKREŚLENIE
Nazwy mogą być łączone wewnętrznie i zewnętrznie. Te dwa terminy stosujemy określając dostępność nazwy w różnych jednostkach kompilacji lub wewnątrz pojedynczej jednostki kompilacji. Nazwa łączona wewnętrznie może być używana tylko w tej jednostce kompilacji, w której jest zdefiniowana. Na przykład, zmienna zdefiniowana jako łączona wewnętrznie może być wykorzystywana przez funkcje w tej samej jednostce kompilacji. Nazwy łączone zewnętrznie są dostępne także w innych jednostkach kompilacji. Poniższy przykład demonstruje łączenie wewnętrzne i zewnętrzne:
// plik first.cpp int externalInt = 5; const int j = 10; int main() { return 0; } // plik second.cpp extern int externalInt; int anExternalInt = 10; const int j = 10;
Usunięto: obie

Zmienna externalInt zdefiniowana w pliku first.cpp jest łączona zewnętrznie (ang. external). Choć jest zdefiniowana w pliku first.cpp, może z niej korzystać także plik second.cpp. Dwie zmienne j, występujące w obu plikach, są zmiennymi const, więc domyślnie są łączone wewnętrznie. Możemy przesłonić domyślne łączenie dla const, stosując jawną deklarację, taką jak ta:
// plik first.cp extern const int j = 10; // plik second.cpp extern const int j; #include <iostream> int main() { std::cout << "j ma wartosc " << j << std::endl; return 0; }
Zwróć uwagę, że wywołujemy cout z określeniem przestrzeni nazw std; w ten sposób możemy korzystać ze standardowej biblioteki ANSI. Po zbudowaniu i uruchomieniu, program ten wypisuje:
j ma wartosc 10
Komitet standaryzacji potępił przedstawione poniżej zastosowanie:
static int staticInt = 10; int main() { // ... }
Użycie modyfikatora static w celu ograniczenia zakresu zmiennych zewnętrznych nie jest już zalecane, a w przyszłości może stać się niedozwolone. Zamiast static powinieneś używać przestrzeni nazw.
TAK NIE
Zamiast statc używaj przestrzeni nazw. Nie używaj słowa kluczowego static w zmiennych zdefiniowanych w zakresie pliku.
Tworzenie przestrzeni nazw Składnia deklaracji przestrzeni nazw jest podobna do składni deklaracji struktury lub klasy: stosujemy słowo kluczowe namespace, po nim opcjonalną nazwę przestrzeni nazw, a następnie nawias klamrowy otwierający. Przestrzeń nazw kończy się nawiasem klamrowym zamykającym, bez średnika.
Na przykład:
namespace Window { void move( int x, int y); }
Nazwa Window identyfikuje przestrzeń nazw, która może wystąpić wielokrotnie. Wielokrotne wystąpienia mogą pojawić się w tym samym pliku lub w kilku różnych jednostkach kompilacji. Przykładem wielokrotnego wystąpienia jest przestrzeń nazw standardowej biblioteki C++, std. Wystąpienie to w tym przypadku ma sens, gdyż biblioteka standardowa grupuje funkcjonalność w logiczny sposób.
Głównym celem przestrzeni nazw jest grupowanie powiązanych elementów w określonym (nazwanym) obszarze. Oto prosty przykład przestrzeni nazw rozciągającej się na kilka plików nagłówkowych:
// header1.h namespace Window { void move( int x, int y); } // header2.h namespace Window { void resize( int x, int y); }
Deklarowanie i definiowanie typów W przestrzeni nazw można deklarować i definiować typy i funkcje. Oczywiście, jest to związane z projektem i konserwacją. W dobrym projekcie interfejsy powinny być oddzielone od implementacji. Powinieneś przestrzegać tej zasady nie tylko w przypadku klas, ale także w przypadku przestrzeni nazw. Poniższy przykład demonstruje „zaśmieconą” i kiepsko zdefiniowaną przestrzeń nazw:
namespace Window { // . . . inne deklaracje i definicje zmiennych. void move( int x, int y); // deklaracje void resize( int x, int y);
Usunięto: słabo

// . . . inne deklaracje i definicje zmiennych. void move( int x, int y ) { if( x < MAX_SCREEN_X && x > 0 ) if( y < MAX_SCREEN_Y && y > 0 ) platform.move( x, y ); // specyficzna funkcja } void resize( int x, int y ) { if( x < MAX_SCREEN_X && x > 0 ) if( y < MAX_SCREEN_Y && y > 0 ) platform.resize( x, y ); // specyficzna funkcja } // . . . dalsze definicje }
Widać tu, jak szybko „zaśmieca” się przestrzeń nazw! Ten przykład składa się z około dwudziestu linii; wyobraź sobie, jak by wyglądała cztery razy większa przestrzeń nazw.
Definiowanie funkcji poza przestrzenią nazw Funkcje danej przestrzeni nazw powinny być definiowane poza ciałem tej przestrzeni. W ten sposób jawnie separujemy deklaracje funkcji od ich definicji — a także utrzymujemy w porządku przestrzeń nazw. Oddzielenie definicji funkcji od przestrzeni nazw umożliwia także umieszczenie przestrzeni i zawartych w niej deklaracji w pliku nagłówkowym; definicje mogą zostać umieszczone w pliku implementacji.
Na przykład:
// plik header.h namespace Window { void move( int x, int y ); // . . . inne deklaracje } // plik impl.cpp void Window::move( int x, int y ) { // kod do przesuwania okna }
Dodawanie nowych składowych Nowe składowe mogą zostać dodane do przestrzeni nazw tylko w jej ciele. Nie można definiować nowych składowych, używając tylko kwalifikatorów. Jedyne, czego można oczekiwać od tego rodzaju definicji, to błąd kompilacji. Demonstruje to poniższy przykład:
namespace Window { // mnóstwo deklaracji } // ... jakiś kod int Window::newIntegerNamespace; // przykro mi, nie można tego zrobić
Powyższa linia kodu jest niedozwolona. Twój kompilator wypisze komunikat zgłaszający ten błąd. Aby go poprawić — czyli uniknąć — przenieś deklarację do ciała przestrzeni nazw.
Wszystkie składowe zawarte w przestrzeni nazw są publiczne. Poniższy kod nie skompiluje się:
namespace Window { private: void move( int x, int y ); }
Zagnieżdżanie przestrzeni nazw Przestrzenie nazw mogą być zagnieżdżane w innych przestrzeniach nazw. Jest to możliwe, gdyż definicja przestrzeni nazw jest także deklaracją. Tak jak w przypadku wszystkich innych przestrzeni nazw, należy wtedy kwalifikować nazwę zagnieżdżonej przestrzeni za pomocą nazwy przestrzeni zewnętrznej. Gdy mamy kilka kolejno zagnieżdżonych przestrzeni, musimy kwalifikować kolejno każdą z nich. Na przykład, poniższy kod przedstawia nazwaną przestrzeń nazw, zagnieżdżoną w innej nazwanej przestrzeni nazw:
namespace Window { namespace Pane { void size( int x, int y ); } }
Aby odwołać się do funkcji size() spoza przestrzeni nazw Window, musimy kwalifikować funkcję nazwami obu przestrzeni nazw. Demonstruje to poniższy kod:
int main() { Window::Pane::size( 10, 20 ); return 0; }

Używanie przestrzeni nazw Przyjrzyjmy się przykładowi użycia przestrzeni nazw i wynikającemu z niego przykładowi użycia operatora zakresu. Najpierw deklaruję wszystkie typy i funkcje używane w przestrzeni nazw Window. Po zdefiniowaniu wszystkiego, co jest wymagane, definiuję zadeklarowane funkcje składowe. Te funkcje składowe są definiowane poza przestrzenią nazw; nazwy są jawnie identyfikowane za pomocą operatora zakresu. Użycie przestrzeni nazw demonstruje listing 18.1.
Listing 18.1. Użycie przestrzeni nazw 0: #include <iostream> 1: // Użycie przestrzeni nazw 2: 3: namespace Window 4: { 5: const int MAX_X = 30 ; 6: const int MAX_Y = 40 ; 7: class Pane 8: { 9: public: 10: Pane() ; 11: ~Pane() ; 12: void size( int x, int y ) ; 13: void move( int x, int y ) ; 14: void show( ) ; 15: private: 16: static int cnt 17: int x ; 18: int y ; 19: } ; 20: } 21: 22: int Window::Pane::cnt = 0 ; 23: Window::Pane::Pane() : x(0), y(0) { } 24: Window::Pane::~Pane() { } 25: 26: void Window::Pane::size( int x, int y ) 27: { 28: if( x < Window::MAX_X && x > 0 ) 29: Pane::x = x ; 30: if( y < Window::MAX_Y && y > 0 ) 31: Pane::y = y ; 32: } 33: void Window::Pane::move( int x, int y ) 34: { 35: if( x < Window::MAX_X && x > 0 ) 36: Pane::x = x ; 37: if( y < Window::MAX_Y && y > 0 ) 38: Pane::y = y ; 39: } 40: void Window::Pane::show( ) 41: { 42: std::cout << "x " << Pane::x ; 43: std::cout << " y " << Pane::y << std::endl ; 44: } 45: 46: int main( ) 47: {

48: Window::Pane pane ; 49: 50: pane.move( 20, 20 ) ; 51: pane.show( ) ; 52: 53: return 0 ; 54: }
Wynik x 20 y 20
Analiza
Zwróć uwagę, że klasa Pane jest zagnieżdżona wewnątrz przestrzeni nazw Window. Dlatego musimy kwalifikować nazwę Pane kwalifikatorem, Window::.
Statyczna zmienna cnt, zadeklarowana w przestrzeni nazw Pane w linii 16., jest definiowana jak zwykle. Zauważ, że wewnątrz funkcji Pane::size(), w liniach od 26. do 32., stałe MAX_X i MAX_Y są w pełni kwalifikowane. Jest to konieczne, ponieważ jesteśmy tu w zakresie klasy Pane; w przeciwnym razie kompilator zgłosiłby błąd. To samo odnosi się do funkcji Pane::move().
Interesujące jest także kwalifikowanie Pane::x oraz Pane::y wewnątrz obu definicji funkcji. Do czego ono służy? Cóż, gdyby funkcja Pane::move() została zapisana tak, jak poniżej, pojawiłby się problem:
void Window::Pane::move( int x, int y ) { if( x < Window::MAX_X && x > 0 ) x = x ; if( y < Window::MAX_Y && y > 0 ) y = y ; Platform::move( x, y ); }
Czy widzisz błąd? Kompilator najprawdopodobniej nie okaże się w tej sytuacji pomocny; niektóre kompilatory nie zgłoszą żadnego komunikatu.
Źródłem problemu są argumenty funkcji. Argumenty x i y ukrywają prywatne zmienne x i y egzemplarza, zadeklarowane w klasie Pane. W efekcie instrukcje te przypisują zmienne x i y samym sobie:
x = x; y = y;
Usunięto: Wewnątrz funkcji Pane::size() w liniach od 26 do 32 z
Usunięto: ak
Usunięto: a
Usunięto: jest w zakresie

Słowo kluczowe using Słowo kluczowe using jest używane zarówno jako dyrektywa using, jak i deklaracja using. O tym, czy jest to dyrektywa, czy deklaracja, decyduje składnia tego słowa kluczowego.
Dyrektywa using Dyrektywa using powoduje wyeksponowanie wszystkich nazw zadeklarowanych w przestrzeni nazw tak, aby stały się dostępne w bieżącym zakresie. Wtedy możemy odwoływać się do nich bez konieczności kwalifikowania ich właściwą nazwą przestrzeni nazw. Poniższy przykład pokazuje użycie dyrektywy using:
namespace Window { int value1 = 20; int value2 = 40; } . . . Window::value1 = 10; using namespace Window; value2 = 30;
Zakres działania dyrektywy using zaczyna się w miejscu jej deklaracji i kończy się wraz z bieżącym zakresem. Zauważ, że zmienna value1 musiała być kwalifikowana. Z kolei zmienna value2 nie wymagała kwalifikowania, gdyż dyrektywa using spowodowała wprowadzenie do bieżącego zakresu wszystkich nazw ze wskazanej przestrzeni nazw.
Dyrektywa using może być używana na dowolnym poziomie zakresu. Dzięki temu możemy używać jej w zakresie bloku; gdy blok znajdzie się poza zakresem, wszystkie nazwy z przestrzeni nazw staną się niedostępne. To zachowanie przedstawia następny przykład:
namespace Window { int value1 = 20; int value2 = 40; } // . . . void f() { { using namespace Window; value2 = 30; } value2 = 20; // błąd! }
Ostatnia linia w funkcji f(), value2 = 20; jest błędna, gdyż nazwa value2 nie jest zdefiniowana. Jest ona dostępna w poprzednim bloku, gdyż została w nim użyta dyrektywa

using, udostępniająca nazwę zmiennej value2 w ramach tego bloku. Gdy wychodzimy poza zakres bloku, nazwy w przestrzeni nazw Window stają się niedostępne.
Nazwy zmiennych zadeklarowanych w lokalnym zakresie ukrywają nazwy wprowadzone do tego zakresu z przestrzeni nazw. To zachowanie przypomina ukrywanie zmiennych globalnych przez zmienne lokalne. Ta zasada obowiązuje nawet wtedy, gdy przestrzeń nazw zostanie wprowadzona już po zadeklarowaniu zmiennej lokalnej; zmienna lokalna w każdym przypadku ukrywa zmienną z przestrzeni nazw. Pokazuje to poniższy przykład:
namespace Window { int value1 = 20; int value2 = 40; } // . . . void f() { value2 = 10; using namespace Window; std::cout << value2 << std::endl; }
Wynikiem działanie tej funkcji jest 10, a nie 40. To potwierdza, iż zmienna value2 w przestrzeni nazw Window zostaje ukryta przez zmienną value2 funkcji f(). Gdybyśmy musieli użyć nazwy z przestrzeni nazw, musielibyśmy kwalifikować ją nazwą tej przestrzeni.
W przypadku użycia nazwy zdefiniowanej zarówno globalnie, jak i w przestrzeni nazw, może wystąpić niejednoznaczność. Ta niejednoznaczność objawia się tylko w przypadku użycia nazwy, a nie w przypadku wprowadzenia przestrzeni nazw. Ilustruje to poniższy fragment kodu:
namespace Window { int value1 = 20; } // . . . using namespace Window; int valu1 = 10; void f() { value1 = 10; }
Niejednoznaczność występuje wewnątrz funkcji f(). Dyrektywa using wprowadza do globalnej przestrzeni nazw nazwę Window::value1. Ponieważ nazwa value1 jest już globalnie zdefiniowana, użycie nazwy value1 w funkcji f() jest błędem. Zwróć jednak uwagę, że gdyby z tej funkcji została usunięta linia kodu, nie pojawiłby się błąd.
Usunięto: 4

Deklaracja using Deklaracja using jest podobna do dyrektywy o tej samej nazwie, lecz umożliwia bardziej precyzyjną kontrolę. Deklaracja using służy do wprowadzania do bieżącego zakresu określonej nazwy z przestrzeni nazw. Do wskazanego obiektu można się wtedy odwoływać poprzez samą jego nazwę. Następny przykład demonstruje zastosowanie deklaracji using:
namespace Window { int value1 = 20; int value2 = 40; int value3 = 60; } // . . . using Window::value2; // wprowadza nazwę value2 do bieżącego zakresu Window::value1 = 10; // nazwa value1 musi być kwalifikowana value2 = 30; Window::value3 = 10; // nazwa value3 musi być kwalifikowana
Deklaracja using wprowadza wskazaną nazwę do bieżącego zakresu. Deklaracja nie wpływa na widoczność innych nazw w przestrzeni nazw. W powyższym przykładzie do zmiennej value2 możemy odwoływać się bez korzystania z kwalifikacji, lecz zmienne value1 i value3 muszą być kwalifikowane. Deklaracja using zapewnia większą kontrolę nad wprowadzanymi do zakresu nazwami przestrzeni nazw. Tym właśnie deklaracja using różni się od dyrektywy using, która wprowadza do bieżącego zakresu wszystkie nazwy z przestrzeni nazw.
Gdy nazwa zostanie wprowadzona do zakresu, pozostaje widoczna aż do jego końca (czyli tak samo, jak w przypadku wszystkich innych deklaracji). Deklaracja using może zostać użyta w globalnej przestrzeni nazw lub w dowolnym zakresie lokalnym.
Wprowadzenie duplikatu nazwy do lokalnego zakresu, w którym została zadeklarowana nazwa z przestrzeni nazw, jest błędem. Błędna jest także sytuacja odwrotna. Pokazuje to poniższy przykład:
namespace Window { int value1 = 20; int value2 = 40; } // . . . void f() { int value2 = 10; using Window::value2; // wielokrotna deklaracja std::cout << value2 << std::endl; }
Druga linia w funkcji f() powoduje błąd kompilacji, gdyż nazwa value2 została już zdefiniowana. Ten sam błąd występuje, gdy deklaracja using zostanie wstawiona przed definicją lokalnej zmiennej value2.
Usunięto: przednim
Usunięto: powielonej
Każda nazwa, wprowadzona do zakresu lokalnego za pomocą deklaracji using, powoduje ukrycie nazwy poza tym zakresem. Demonstruje to następny fragment kodu:
namespace Window { int value1 = 20; int value2 = 40; } int value2 = 10; // . . . void f() { using Window::value2; std::cout << value2 << std::endl; }
Deklaracja using w funkcji f() ukrywa nazwę value2, zdefiniowaną w globalnej przestrzeni nazw.
Jak już wspomniałem, deklaracja using umożliwia bardziej precyzyjną kontrolę nazw wprowadzanych z przestrzeni nazw. Dyrektywa using wprowadza do bieżącego zakresu wszystkie nazwy z przestrzeni nazw. Zaleca się używanie deklaracji, a nie dyrektywy, gdyż dyrektywa anuluje mechanizm przestrzeni nazw. Deklaracja jest bardziej definitywna: jawnie identyfikujemy nazwy, które chcemy wprowadzić do zakresu. Deklaracja using nie „zaśmieca” globalnej przestrzeni nazw, tak jak dzieje się w przypadku dyrektywy using (chyba, że zadeklarujemy wszystkie nazwy znajdujące się w przestrzeni nazw). Dzięki użyciu deklaracji using likwidowane są takie problemy, jak ukrywanie nazw, „zaśmiecanie” globalnej przestrzeni nazw, czy też występowanie niejednoznaczności.
Alias przestrzeni nazw Alias przestrzeni nazw został zaprojektowany w celu nadania innej nazwy nazwanej już wcześniej przestrzeni nazw. Alias stanowi skrócone, określenie używane przy odwoływaniu się do przestrzeni nazw i przydaje się, gdy nazwa przestrzeni nazw jest bardzo długa. Stworzenie aliasu pomaga uniknąć ciągłego wpisywania tych samych, długich nazw. Spójrzmy na przykład:
namespace the_software_company { int value; // . . . } the_software_company::value = 10; . . . namespace TSC = the_software_company; TSC::value = 20;
Oczywiście, może się okazać, że alias koliduje z istniejącą nazwą. W takim przypadku kompilator wykryje konflikt i będziemy musieli zmienić nazwę aliasu.
Usunięto: oraz

Nienazwana przestrzeń nazw Nienazwana przestrzeń nazw jest po prostu pozbawiona nazwy. Takie przestrzenie zwykle są używane w celu ochrony globalnych danych przed potencjalnym konfliktem nazw występującym w różnych jednostkach kompilacji. Każda jednostka kompilacji posiada własną, unikalną, nienazwaną przestrzeń nazw. Wszystkie nazwy zdefiniowane w przestrzeni nienazwanej (w każdej z jednostek kompilacji) mogą być używane bez jawnego kwalifikowania. Oto przykład dwóch nienazwanych przestrzeni nazw, występujących w dwóch oddzielnych plikach:
// plik one.cpp namespace { int value; char p( char *p ); // . . . } // plik two.cpp namespace { int value; char p( char *p ); // . . . } int main() { char c = p( ptr ); }
Każda z nazw, zmiennej value oraz funkcji p(), należy do właściwego sobie pliku. Aby odwołać się do nazwy (z nienazwanej przestrzeni nazw) w jednostce kompilacji, używamy tej nazwy bez kwalifikowania. To użycie zostało zademonstrowane w powyższym przykładzie, w wywołaniu funkcji p(). Takie odwołanie jest równoważne z użyciem dyrektywy using dla obiektów zawartych w nienazwanej przestrzeni nazw. Z tego powodu nie można odwoływać się do składowych nienazwanej przestrzeni nazw w innej jednostce kompilacji. Zachowanie nienazwanej przestrzeni nazw jest takie samo, jak zachowanie obiektu posiadającego łączność zewnętrzną, ale zadeklarowanego jako static. Spójrzmy na poniższy przykład:
static int value = 10;
Pamiętaj, że użycie słowa kluczowego static zostało potępione przez komitet standaryzacji. Obecnie istnieją już przestrzenie nazw, które powinny zastąpić pokazany tu kod. Innym sposobem radzenia sobie z nienazwanymi przestrzeniami nazw jest potraktowanie ich jako łączonych wewnętrznie zmiennych globalnych.
Usunięto: przednim
Usunięto: zakłada
Usunięto: e
Usunięto:
Usunięto: zadeklarowanego jako zewnętrzny (external).

Standardowa przestrzeń nazw std Najlepsze przykłady zastosowań przestrzeni nazw znajdują się w bibliotece standardowej C++. Biblioteka ta jest w całości ujęta w przestrzeni nazw o nazwie std. W tej przestrzeni są zadeklarowane wszystkie funkcje, klasy, obiekty i wzorce.
Bez wątpienia widziałeś już kod podobny do poniższego:
#include <iostream> using namespace std;
Pamiętaj, że dyrektywa using umieszcza w bieżącym zakresie wszystkie nazwy z nazwanej przestrzeni nazw. W przypadku biblioteki standardowej użycie tej dyrektywy jest niewłaściwe. Dlaczego? Ponieważ używając jej negujemy cel, w jakim stworzono przestrzeń nazw; globalna przestrzeń nazw zostaje „zaśmiecona” wszystkimi nazwami występującymi w pliku nagłówkowym. Pamiętaj, że wszystkie pliki nagłówkowe w bibliotece standardowej korzystają z mechanizmu przestrzeni nazw, więc gdy dołączysz kilka standardowych plików nagłówkowych i użyjesz dyrektywy using, w globalnej przestrzeni nazw znajdzie się wszystko to, co znajduje się w tych plikach. Zauważ proszę, że w większości przykładów w tej książce naruszamy tę regułę; nie chciałem w ten sposób zachęcać do naruszania zasad, a jedynie zachować przejrzystość przykładów. W przeciwieństwie do mnie, powinieneś używać deklaracji using, tak jak w poniższym przykładzie:
#include <iostream> using std::cin; using std::cout; using std::endl; int main() { int value = 0; cout << "Ile wiec jajek sobie zyczysz?" << endl; cin >> value; cout << value << " jajka sadzone, raz!" << endl; return( 0 ); }
Oto wynik działania tego programu:
Ile wiec jajek sobie zyczysz? 4 4 jajka sadzone, raz!
Możesz również w pełni kwalifikować używane nazwy, tak jak w poniższym fragmencie kodu:
#include <iostream>

int main() { int value = 0; std::cout << "Ile wiec jajek sobie zyczysz?" << std::endl; std::cin >> value; std::cout << value << " jajka sadzone, raz!" << std::endl; return( 0 ); }
Wynik działania tego programu jest taki sam, jak poprzednio:
Ile wiec jajek sobie zyczysz? 4 4 jajka sadzone, raz!
Ta metoda nadaje się do krótszych programów, ale w przypadku większej ilości kodu może być kłopotliwa. Wyobraź sobie poprzedzanie przedrostkiem std:: każdej nazwy pochodzącej z biblioteki standardowej!

Rozdział 19. Wzorce Przydatnym dla programistów C++ nowym narzędziem są „typy sparametryzowane”, czyli wzorce. Są one tak użytecznym narzędziem, że do definicji języka C++ została wprowadzona standardowa biblioteka wzorców (STL, Standard Template Library).
Z tego rozdziału dowiesz się:
• czym są wzorce i jak ich używać,
• jak tworzyć wzorce klas,
• jak tworzyć wzorce funkcji,
• czym jest standardowa biblioteka wzorców i jak z niej korzystać.
Czym są wzorce? Pod koniec czternastego rozdziału stworzyliśmy obiekt PartsList i wykorzystaliśmy go do stworzenia katalogu części, klasy PartsCatalog. Jeśli jednak chcielibyśmy na obiekcie PartsList oprzeć listę kotów, pojawiłby się problem: klasa PartsList wie tylko o częściach.
Aby rozwiązać ten problem, moglibyśmy stworzyć klasę bazową List. Wtedy moglibyśmy wyciąć i wkleić większość kodu z klasy PartsList do nowej deklaracji klasy CatsList. Tydzień później, gdybyśmy zechcieli stworzyć listę obiektów Car, musielibyśmy stworzyć nową klasę i znów kopiować i wklejać kod.
Nie jest to dobre rozwiązanie. Z czasem mogłoby się okazać, że klasa List oraz klasy z niej wyprowadzone muszą być rozszerzone. Rozprowadzenie wszystkich zmian po wszystkich powiązanych z nią klasach byłoby koszmarem.
Problem ten rozwiązują wzorce, które po zaadoptowaniu standardu ANSI stały się integralną częścią języka. Podobnie jak wszystkie elementy w C++, są one bardzo elastyczne, a przy tym bezpieczne (pod względem typów).
Komentarz [MP1]: „Template” w odniesieniu do języka C++ to „wzorzec”, a nie „szablon”. (Za: Bjorne Stroustrup, Język C++, PWN).
Usunięto: Wzorce
Usunięto: Szablony
Usunięto: wzorce
Usunięto: Wzorce
Usunięto: wzorce
Usunięto: wzorce
Usunięto: wzorce
Usunięto: wzorców
Usunięto: wzorce

Typy parametryzowane Wzorce pozwalają na nauczenie kompilatora, w jaki sposób ma tworzyć listę rzeczy dowolnego typu (zamiast tworzenia zestawu list specyficznego typu) — PartsList jest listą części, CatsList jest listą kotów. Listy te różnią się tylko rodzajem przechowywanych w nich rzeczy. W trakcie korzystania z wzorców typ rzeczy zawartej w liście staje się parametrem definicji klasy.
Standardowym komponentem w prawie wszystkich bibliotekach C++ jest klasa tablicy. Jak widzieliśmy w przypadku klasy List, tworzenie osobnych tablic dla liczb całkowitych, liczb zmiennoprzecinkowych czy dla obiektów jest żmudne i nieefektywne. Wzorce umożliwiają zadeklarowanie sparametryzowanej klasy tablicy, a następnie określenie, jaki typ obiektu będzie zawierał każdy jej egzemplarz. Zauważ, że standardowa biblioteka wzorców zawiera standardowy zestaw klas kontenerów, obejmujący tablice, listy i tak dalej. W tym rozdziale sami stworzymy klasę kontenera, aby przekonać się, jak działają wzorce, ale w komercyjnych aplikacjach prawie z pewnością użyjesz klas standardowych (zamiast tworzyć własne).
Tworzenie egzemplarza wzorca Tworzenie egzemplarza wzorca oznacza tworzenie określonego typu na podstawie tego wzorca. Poszczególne, tworzone aktualnie klasy są nazywane egzemplarzami wzorca.
Parametryzowane wzorce pozwalają na tworzenie klasy ogólnej i przekazywanie jej typów jako parametrów, w celu stworzenia konkretnego egzemplarza wzorca.
Definicja wzorca Parametryzowany obiekt Array (wzorzec dla tablic) deklarujemy, pisząc:
1: template <class T> // deklaruje wzorzec i parametr 2: class Array // parametryzowana klasa 3: { 4: public: 5: Array(); 6: // w tym miejscu pełna deklaracja klasy 7: };
Słowo kluczowe template (wzorzec) jest używane na początku każdej deklaracji i definicji klasy wzorcowej. Parametry wzorca występują po słowie kluczowym template. Parametry są zmieniane (uaktualniane) w każdym egzemplarzu. Na przykład, w pokazanym tu wzorcu tablicy
Usunięto: ozycyjnych
Usunięto: Wzorce
Usunięto: wzorców
Usunięto: wzorce
Usunięto: wzorca
Usunięto: wzorce
Usunięto: wzorca
Usunięto: wzorca
Usunięto: wzorzec
Usunięto: wzorzec
Usunięto: wzorzec
Usunięto: wzorca
Usunięto: wzorca
Usunięto: rzeczami
Usunięto: wzorcu
zmienia się typ przechowywanych w niej obiektów. Jeden egzemplarz może być tablicą liczb całkowitych, a inny może być tablicą obiektów typu Animal.
W tym przykładzie zostało użyte słowo kluczowe class, po którym następuje identyfikator T. Słowo kluczowe class wskazuje że ten parametr (identyfikator) jest typem. Identyfikator T jest używany w pozostałej części definicji wzorca i odnosi się do typu parametryzowanego. W jednym z egzemplarzy tej klasy w miejscu wszystkich identyfikatorów T zostanie podstawiony na przykład typ int, a w innym egzemplarzu zostanie podstawiony typ Cat.
Aby zadeklarować egzemplarze wzorca typu int i Cat parametryzowanej klasy Array, moglibyśmy napisać:
Array<int> anIntArray; Array<Cat> aCatArray;
Obiekt anIntArray to obiekt typu tablica liczb całkowitych; obiekt aCatArray to obiekt typu tablica kotów. Od tego momentu możemy używać typu Array<int> wszędzie tam, gdzie normalnie używalibyśmy jakiegoś typu (np. dla wartości zwracanej przez funkcję, jako parametru funkcji i tak dalej). Pełną deklarację tej okrojonej klasy Array przedstawia listing 19.1.
UWAGA Listing 19.1 nie jest kompletnym programem!
Listing 19.1. Wzorzec klasy tablicy 0: //Listing 19.1 Wzorzec klasy tablicy 1: #include <iostream> 2: using namespace std; 3: const int DefaultSize = 10; 4: 5: template <class T> // deklaruje wzorzec i parametr 6: class Array // parametryzowana klasa 7: { 8: public: 9: // konstruktory 10: Array(int itsSize = DefaultSize); 11: Array(const Array &rhs); 12: ~Array() { delete [] pType; } 13: 14: // operatory 15: Array& operator=(const Array&); 16: T& operator[](int offSet) { return pType[offSet]; } 17: 18: // akcesory 19: int getSize() { return itsSize; } 20: 21: private: 22: T *pType; 23: int itsSize; 24: };
Usunięto: wzorca
Usunięto: wzorca
Usunięto: moglibyśmy użyć typu — jako
Usunięto: Wzorzec

Wynik
Brak. Program nie jest kompletny.
Analiza
Definicja wzorca rozpoczyna się w linii 5. od słowa kluczowego template, po którym występuje parametr. W tym przypadku parametr jest identyfikowany przez słowo kluczowe class, zaś do reprezentowania parametryzowanego typu został użyty identyfikator T.
Od linii 6. aż do końca wzorca w linii 24., pozostała część deklaracji wygląda tak samo jak deklaracja każdej innej klasy. Jedyną różnicą jest to, że tam, gdzie normalnie występowałby typ obiektu, występuje identyfikator T. Na przykład, można oczekiwać, że operator[] będzie zwracał referencję do obiektu zawartego w tablicy — rzeczywiście, jest zadeklarowany jako zwracający referencję do T.
Gdy deklarowany jest egzemplarz tablicy liczb całkowitych, to zdefiniowany dla tej tablicy operator= zwróci referencję do liczby całkowitej. Gdy jest deklarowany egzemplarz tablicy obiektów klasy Animal, to zdefiniowany dla tej tablicy operator= zwróci referencję do obiektu Animal.
Użycie nazwy Słowo Array może być użyte bez kwalifikowania wewnątrz deklaracji klasy. We wszystkich innych miejscach programu do klasy tej trzeba się odwoływać jako do Array<T>. Na przykład, jeśli nie wpiszemy konstruktora wewnątrz deklaracji klasy, to musimy napisać:
template <class T> Array<T>::Array(int size): itsSize = size { pType = new T[size]; for (int i = 0; i < size; i++) pType[i] = 0; }
Deklaracja w pierwszej linii tego fragmentu kodu jest wymagana do zidentyfikowania typu (class T). Nazwą wzorca jest Array<T>, a nazwą funkcji jest Array(int size). Pozostała część funkcji jest taka sama, jak w przypadku zwykłej funkcji. Powszechną i zalecaną praktyką jest przetestowanie działania klasy i jej funkcji jako zwykłych deklaracji przed zamienieniem ich we wzorzec. To rozwiązanie upraszcza tworzenie wzorca, umożliwiając skoncentrowanie się na celu programowania; rozwiązanie, poprzez stworzenie wzorca, uogólniamy dopiero później.
Usunięto: wzorca
Usunięto: wzorca
Usunięto: dostarczony
Usunięto: dostarczony
Usunięto: za
Usunięto: wzorca
Usunięto: e
Usunięto: wzorzec
Usunięto: wzorca
Usunięto: a
Usunięto: wzorca
Usunięto: enie

Implementowanie wzorca Pełna implementacja klasy wzorca Array wymaga zaimplementowania konstruktora kopiującego, operatora= i tak dalej. Prosty program sterujący, przenaczony do testowania tej klasy wzorcowej przedstawia listing 19.2.
UWAGA Niektóre starsze kompilatory nie obsługują wzorców. Wzorce są jednak częścią standardu ANSI C++ i są obsługiwane w obecnych wersjach kompilatorów wiodących producentów. Jeśli masz bardzo stary kompilator, nie będziesz mógł skompilować i uruchomić przykładowych programów przedstawionych w tym rozdziale. Jednak mimo to, powinieneś go w całości i wrócić do niego później, gdy zdobędziesz nowszy kompilator.
Listing 19.2. Implementacja wzorca klasy tablicy 0: //Listing 19.2 Implementacja wzorca klasy tablicy 1: #include <iostream> 2: 3: const int DefaultSize = 10; 4: 5: // deklaruje prostą klasę Animal tak, abyśmy 6: // mogli tworzyć tablice obiektów typu Animal 7: 8: class Animal 9: { 10: public: 11: Animal(int); 12: Animal(); 13: ~Animal() {} 14: int GetWeight() const { return itsWeight; } 15: void Display() const { std::cout << itsWeight; } 16: private: 17: int itsWeight; 18: }; 19: 20: Animal::Animal(int weight): 21: itsWeight(weight) 22: {} 23: 24: Animal::Animal(): 25: itsWeight(0) 26: {} 27: 28: 29: template <class T> // deklaruje wzorzec i parametr 30: class Array // parametryzowana klasa 31: { 32: public: 33: // konstruktory 34: Array(int itsSize = DefaultSize); 35: Array(const Array &rhs); 36: ~Array() { delete [] pType; } 37: 38: // operatory 39: Array& operator=(const Array&); 40: T& operator[](int offSet) { return pType[offSet]; }
Usunięto: wzorca
Usunięto: i
Usunięto: wzorca
Usunięto: wzorców
Usunięto: Wzorce
Usunięto: wzorca
Usunięto: wzorca
Usunięto: wzorzec

41: const T& operator[](int offSet) const 42: { return pType[offSet]; } 43: // akcesory 44: int GetSize() const { return itsSize; } 45: 46: private: 47: T *pType; 48: int itsSize; 49: }; 50: 51: // oraz implementacje... 52: 53: // implementacja konstruktora 54: template <class T> 55: Array<T>::Array(int size): 56: itsSize(size) 57: { 58: pType = new T[size]; 59: for (int i = 0; i<size; i++) 60: pType[i] = 0; 61: } 62: 63: // konstruktor kopiujący 64: template <class T> 65: Array<T>::Array(const Array &rhs) 66: { 67: itsSize = rhs.GetSize(); 68: pType = new T[itsSize]; 69: for (int i = 0; i<itsSize; i++) 70: pType[i] = rhs[i]; 71: } 72: 73: // operator= 74: template <class T> 75: Array<T>& Array<T>::operator=(const Array &rhs) 76: { 77: if (this == &rhs) 78: return *this; 79: delete [] pType; 80: itsSize = rhs.GetSize(); 81: pType = new T[itsSize]; 82: for (int i = 0; i<itsSize; i++) 83: pType[i] = rhs[i]; 84: return *this; 85: } 86: 87: // program sterujący 88: int main() 89: { 90: Array<int> theArray; // tablica liczb całkowitych 91: Array<Animal> theZoo; // tablica obiektów typu Animal 92: Animal *pAnimal; 93: 94: // wypełniamy tablice 95: for (int i = 0; i < theArray.GetSize(); i++) 96: { 97: theArray[i] = i*2; 98: pAnimal = new Animal(i*3); 99: theZoo[i] = *pAnimal; 100: delete pAnimal; 101: }
Usunięto: i

102: // wypisujemy zawartość tablic 103: for (int j = 0; j < theArray.GetSize(); j++) 104: { 105: std::cout << "theArray[" << j << "]:\t"; 106: std::cout << theArray[j] << "\t\t"; 107: std::cout << "theZoo[" << j << "]:\t"; 108: theZoo[j].Display(); 109: std::cout << std::endl; 110: } 111: 112: return 0; 113: }
Wynik theArray[0]: 0 theZoo[0]: 0 theArray[1]: 2 theZoo[1]: 3 theArray[2]: 4 theZoo[2]: 6 theArray[3]: 6 theZoo[3]: 9 theArray[4]: 8 theZoo[4]: 12 theArray[5]: 10 theZoo[5]: 15 theArray[6]: 12 theZoo[6]: 18 theArray[7]: 14 theZoo[7]: 21 theArray[8]: 16 theZoo[8]: 24 theArray[9]: 18 theZoo[9]: 27
Analiza
Linie od 8. do 26. zawierają okrojoną klasę Animal, stworzoną tu po to, by w tablicy mógł zostać umieszczony także typ definiowany przez użytkownika.
Linia 29. deklaruje, że to, co następuje po niej, jest wzorcem, i że parametrem tego wzorca jest typ oznaczony jako T. Klasa Array posiada dwa konstruktory; pierwszy z nich otrzymuje rozmiar, który domyślnie ustawiany jest zgodnie ze stałą DefaultSize (rozmiar domyślny).
Deklarowane są operatory przypisania i indeksu, przy czym ten drugi deklarowany jest zarówno w wariancie const jak i zwykłym. Jedynym zdefiniowanym akcesorem jest funkcja GetSize(), zwracająca rozmiar tablicy.
Z pewnością można sobie wyobrazić lepszy interfejs; zdefiniowany tu interfejs byłby nieodpowiedni w każdym poważnym programie korzystającym z klasy Array. Jako minimum wymagane są operatory do usuwania elementów, zwiększania i pakowania tablicy i tak dalej. Wszystko to jest dostarczane przez klasy kontenerów w STL, które opiszemy w dalszej części rozdziału.
Prywatne dane to: rozmiar tablicy oraz wskaźnik do rzeczywistej, zawartej w pamięci tablicy obiektów.
Usunięto: wzorcem
Usunięto: wzorca
Usunięto: dostarczonym
Usunięto: dostarczony

Funkcje wzorcowe Gdy chcemy przekazać obiekt tablicy do funkcji, musimy przekazać jej określony egzemplarz tej tablicy, a nie wzorzec. Tak więc, jeśli funkcja SomeFunction()przyjmuje jako parametr tablicę liczb całkowitych, możemy napisać:
void SomeFunction(Array<int>&); // ok
nie możemy jednak napisać:
void SomeFunction(Array<T>&); // błąd!
gdyż kompilator nie wie, jakim typem jest T&. Nie możemy także napisać:
void SomeFunction(Array &); // błąd
gdyż klasa Array nie istnieje — istnieje jedynie wzorzec i jego egzemplarze.
Aby uzyskać bardziej ogólny pogląd, musimy zadeklarować funkcję wzorcową.
template <class T> void MyTemplateFunction(Array<T>&); // ok
Funkcja MyTemplateFunction() jest zadeklarowana jako funkcja wzorcowa (poprzez deklarację w poprzedzającej ją linii). Zauważ, że funkcja wzorcowa może mieć dowolną nazwę, podobnie jak każda inna funkcja.
Funkcje wzorcowe mogą także przyjmować egzemplarze wzorca, a nie tylko jego sparametryzowane formy. Na przykład:
template <class T> void MyOtherFunction(Array<T>&, Array<int>&); // ok
Zwróć uwagę, że ta funkcja otrzymuje dwie tablice: tablicę parametryzowaną oraz tablicę liczb całkowitych. Pierwsza może być tablicą dowolnych obiektów, lecz druga musi być zawsze tablicą liczb całkowitych.
Usunięto: wzorca
Usunięto: wzorzec
Usunięto: jest
Usunięto: wzorzec
Usunięto: wzorca
Usunięto: wzorca
Usunięto: ej
Usunięto: wzorca
Usunięto: wzorców
Usunięto: wzorca

Wzorce i przyjaciele Klasy wzorcowe mogą deklarować trzy rodzaje przyjaciół:
• niewzorcowe zaprzyjaźnione klasy i funkcje,
• ogólne wzorcowe zaprzyjaźnione klasy i funkcje,
• specyficzne dla typu wzorca zaprzyjaźnione klasy i funkcje.
Niewzorcowe zaprzyjaźnione klasy i funkcje. Istnieje możliwość zadeklarowania dowolnej klasy lub funkcji jako zaprzyjaźnionej z klasą wzorcową . Każdy egzemplarz klasy będzie traktował klasę lub funkcję zaprzyjaźnioną tak, jakby deklaracja przyjaźni została zawarta z tym konkretnym egzemplarzem. Listing 19.3 dodaje definicję funkcji zaprzyjaźnionej, Intrude(), do definicji wzorca klasy Array. Funkcja ta zostaje wywołana przez program sterujący. Ponieważ jest zaprzyjaźniona, funkcja Intrude() może odwoływać się do prywatnych danych klasy Array. Jednak ponieważ nie jest funkcją wzorcową, może być wywoływana jedynie dla klas Array zawierających zmienne typu int.
Listing 19.3. Niewzorcowa funkcja zaprzyjaźniona 0: // Listing 19.3 - Specyficzne dla typu funkcje zaprzyjaźnione we wzorcu 1: 2: #include <iostream> 3: using namespace std; 4: 5: const int DefaultSize = 10; 6: 7: // deklaruje prostą klasę Animal tak abyśmy 8: // mogli tworzyć tablice obiektów typu Animal 9: 10: class Animal 11: { 12: public: 13: Animal(int); 14: Animal(); 15: ~Animal() {} 16: int GetWeight() const { return itsWeight; } 17: void Display() const { cout << itsWeight; } 18: private: 19: int itsWeight; 20: }; 21: 22: Animal::Animal(int weight): 23: itsWeight(weight) 24: {} 25: 26: Animal::Animal(): 27: itsWeight(0) 28: {} 29:
Usunięto: Wzorce
Usunięto: wzorców
Usunięto: wzorcowe
Usunięto: wzorcowe
Usunięto: wzorcowe
Usunięto: wzorcowe
Usunięto: wzorca
Usunięto: wzorca
Usunięto: wzorca
Usunięto: wzorcowa
Usunięto: e
Usunięto: wzorcu

30: template <class T> // deklaruje wzorzec i parametr 31: class Array // klasa parametryzowana 32: { 33: public: 34: // konstruktory 35: Array(int itsSize = DefaultSize); 36: Array(const Array &rhs); 37: ~Array() { delete [] pType; } 38: 39: // operatory 40: Array& operator=(const Array&); 41: T& operator[](int offSet) { return pType[offSet]; } 42: const T& operator[](int offSet) const 43: { return pType[offSet]; } 44: // akcesory 45: int GetSize() const { return itsSize; } 46: 47: // funkcja zaprzyjaźniona 48: friend void Intrude(Array<int>); 49: 50: private: 51: T *pType; 52: int itsSize; 53: }; 54: 55: // funkcja zaprzyjaźniona. Nie jest wzorcowa, więc może być 56: // użyta tylko z tablicami wartości int! Wnika w prywatne dane. 57: void Intrude(Array<int> theArray) 58: { 59: cout << "\n*** Funkcja Intrude() ***\n"; 60: for (int i = 0; i < theArray.itsSize; i++) 61: cout << "i: " << theArray.pType[i] << endl; 62: cout << "\n"; 63: } 64: 65: // oraz implementacje... 66: 67: // implementacja konstruktora 68: template <class T> 69: Array<T>::Array(int size): 70: itsSize(size) 71: { 72: pType = new T[size]; 73: for (int i = 0; i<size; i++) 74: pType[i] = 0; 75: } 76: 77: // konstruktor kopiujący 78: template <class T> 79: Array<T>::Array(const Array &rhs) 80: { 81: itsSize = rhs.GetSize(); 82: pType = new T[itsSize]; 83: for (int i = 0; i<itsSize; i++) 84: pType[i] = rhs[i]; 85: } 86: 87: // operator= 88: template <class T> 89: Array<T>& Array<T>::operator=(const Array &rhs) 90: {
Usunięto: wzorzec
Usunięto: wzorcowa
Usunięto: i

91: if (this == &rhs) 92: return *this; 93: delete [] pType; 94: itsSize = rhs.GetSize(); 95: pType = new T[itsSize]; 96: for (int i = 0; i<itsSize; i++) 97: pType[i] = rhs[i]; 98: return *this; 99: } 100: 101: // program sterujący 102: int main() 103: { 104: Array<int> theArray; // tablica liczb całkowitych 105: Array<Animal> theZoo; // tablica obiektów typu Animal 106: Animal *pAnimal; 107: 108: // wypełniamy tablice 109: for (int i = 0; i < theArray.GetSize(); i++) 110: { 111: theArray[i] = i*2; 112: pAnimal = new Animal(i*3); 113: theZoo[i] = *pAnimal; 114: } 115: 116: int j; 117: for (j = 0; j < theArray.GetSize(); j++) 118: { 119: cout << "theZoo[" << j << "]:\t"; 120: theZoo[j].Display(); 121: cout << endl; 122: } 123: cout << "Teraz uzywamy funkcji zaprzyjaznionej do \n"; 124: cout << "wypisania elementow tablicy Array<int>"; 125: Intrude(theArray); 126: 127: cout << "\n\nGotowe.\n"; 128: return 0; 129: }
Wynik theZoo[2]: 6 theZoo[3]: 9 theZoo[4]: 12 theZoo[5]: 15 theZoo[6]: 18 theZoo[7]: 21 theZoo[8]: 24 theZoo[9]: 27 Teraz uzywamy funkcji zaprzyjaznionej do wypisania elementow tablicy Array<int> *** Funkcja Intrude() *** i: 0 i: 2 i: 4 i: 6 i: 8

i: 10 i: 12 i: 14 i: 16 i: 18 Gotowe.
Analiza
Deklaracja wzorca Array została rozszerzona o zaprzyjaźnioną funkcję Intrude(). Deklarujemy, że każdy egzemplarz tablicy typów int będzie traktował funkcję Intrude() jak funkcję zaprzyjaźnioną, więc będzie ona miała dostęp do prywatnych danych i funkcji składowych egzemplarza tablicy.
W linii 60. funkcja Intrude() bezpośrednio odwołuje się do składowej itsSize, a w linii 61. do wskaźnika pType. Standardowe użycie tych składowych nie było konieczne, gdyż klasa Array zapewnia akcesory publiczne, służy ono jednak zilustrowaniu, w jaki sposób można deklarować funkcje zaprzyjaźnione dla wzorców.
Ogólne wzorcowe zaprzyjaźnione klasy i funkcje Dodanie operatora wyświetlania do klasy Array byłoby pomocne. Operator wyświetlania można zadeklarować dla każdego możliwego typu wzorca Array, ale w ten sposób cały wysiłek włożony w zmianę klasy Array na wzorzec stałby się bezcelowy.
My potrzebujemy operatora wstawiania działającego w przypadku zastosowania każdego typu wzorca Array:
ostream& operator<< (ostream&, Array<T>&);
Aby uzyskać zamierzony efekt, musimy zadeklarować operator<< jako funkcję wzorca:
template <class T> ostream& operator<< (ostream&, Array<T>&)
Teraz, gdy operator<< jest funkcją wzorcową, musimy jedynie podać jego implementację. Listing 19.4 przedstawia wzorzec Array rozszerzony o tę deklarację oraz implementację operatora<<.
Listing 19.4. Użycie operatora ostream 0: //Listing 19.4 Użycie operatora ostream 1: #include <iostream>
Usunięto: wzorca
Usunięto: wzorcowe
Usunięto: wzorca
Usunięto: wzorca
Usunięto: wzorca
Usunięto: dostarczyć
Usunięto: wzorzec

2: using namespace std; 3: 4: const int DefaultSize = 10; 5: 6: class Animal 7: { 8: public: 9: Animal(int); 10: Animal(); 11: ~Animal() {} 12: int GetWeight() const { return itsWeight; } 13: void Display() const { cout << itsWeight; } 14: private: 15: int itsWeight; 16: }; 17: 18: Animal::Animal(int weight): 19: itsWeight(weight) 20: {} 21: 22: Animal::Animal(): 23: itsWeight(0) 24: {} 25: 26: template <class T> // deklaruje wzorzec i parametr 27: class Array // parametryzowana klasa 28: { 29: public: 30: // konstruktory 31: Array(int itsSize = DefaultSize); 32: Array(const Array &rhs); 33: ~Array() { delete [] pType; } 34: 35: // operatory 36: Array& operator=(const Array&); 37: T& operator[](int offSet) { return pType[offSet]; } 38: const T& operator[](int offSet) const 39: { return pType[offSet]; } 40: // akcesory 41: int GetSize() const { return itsSize; } 42: 43: friend ostream& operator<< (ostream&, Array<T>&); 44: 45: private: 46: T *pType; 47: int itsSize; 48: }; 49: 50: template <class T> 51: ostream& operator<< (ostream& output, Array<T>& theArray) 52: { 53: for (int i = 0; i<theArray.GetSize(); i++) 54: output << "[" << i << "] " << theArray[i] << endl; 55: return output; 56: } 57: 58: // oraz implementacje... 59: 60: // implementacja konstruktora 61: template <class T> 62: Array<T>::Array(int size):
63: itsSize(size) 64: { 65: pType = new T[size]; 66: for (int i = 0; i<size; i++) 67: pType[i] = 0; 68: } 69: 70: // konstruktor kopiujący 71: template <class T> 72: Array<T>::Array(const Array &rhs) 73: { 74: itsSize = rhs.GetSize(); 75: pType = new T[itsSize]; 76: for (int i = 0; i<itsSize; i++) 77: pType[i] = rhs[i]; 78: } 79: 80: // operator= 81: template <class T> 82: Array<T>& Array<T>::operator=(const Array &rhs) 83: { 84: if (this == &rhs) 85: return *this; 86: delete [] pType; 87: itsSize = rhs.GetSize(); 88: pType = new T[itsSize]; 89: for (int i = 0; i<itsSize; i++) 90: pType[i] = rhs[i]; 91: return *this; 92: } 93: 94: int main() 95: { 96: bool Stop = false; // znacznik dla pętli 97: int offset, value; 98: Array<int> theArray; 99: 100: while (!Stop) 101: { 102: cout << "Podaj indeks (0-9) "; 103: cout << "oraz wartosc. (-1 aby skonczyc): " ; 104: cin >> offset >> value; 105: 106: if (offset < 0) 107: break; 108: 109: if (offset > 9) 110: { 111: cout << "***Prosze uzywac wartosci pomiedzy 0 i 9.***\n"; 112: continue; 113: } 114: 115: theArray[offset] = value; 116: } 117: 118: cout << "\nOto cala tablica:\n"; 119: cout << theArray << endl; 120: return 0; 121: }
Usunięto: i

Wynik Podaj indeks (0-9) oraz wartosc. (-1 aby skonczyc): 1 10 Podaj indeks (0-9) oraz wartosc. (-1 aby skonczyc): 2 20 Podaj indeks (0-9) oraz wartosc. (-1 aby skonczyc): 3 30 Podaj indeks (0-9) oraz wartosc. (-1 aby skonczyc): 4 40 Podaj indeks (0-9) oraz wartosc. (-1 aby skonczyc): 5 50 Podaj indeks (0-9) oraz wartosc. (-1 aby skonczyc): 6 60 Podaj indeks (0-9) oraz wartosc. (-1 aby skonczyc): 7 70 Podaj indeks (0-9) oraz wartosc. (-1 aby skonczyc): 8 80 Podaj indeks (0-9) oraz wartosc. (-1 aby skonczyc): 9 90 Podaj indeks (0-9) oraz wartosc. (-1 aby skonczyc): 10 10 ***Prosze uzywac wartosci pomiedzy 0 i 9.*** Podaj indeks (0-9) oraz wartosc. (-1 aby skonczyc): -1 -1 Oto cala tablica: [0] 0 [1] 10 [2] 20 [3] 30 [4] 40 [5] 50 [6] 60 [7] 70 [8] 80 [9] 90
Analiza
W linii 43. funkcja wzorcowa operator<<() została zadeklarowana jako funkcja zaprzyjaźniona klasy wzorcowej Array. Ponieważ operator<<() jest implementowany jako funkcja wzorcowa, każdy egzemplarz tej parametryzowanej klasy tablicy automatycznie będzie posiadał operator<<(). Implementacja tego operatora rozpoczyna się w linii 50. Wywoływany jest kolejno każdy element tablicy. Możemy uzyskać zamierzony efekt tylko wtedy, gdy dla każdego typu obiektów przechowywanych w tablicy będzie zdefiniowany operator<<().
Użycie elementów wzorca Elementy wzorca mogą być traktowane tak jak każdy inny typ. Można przekazywać je jako parametry, poprzez wartość lub poprzez referencję, można je także zwracać jako wartości zwrotne funkcji, również poprzez wartość lub poprzez referencję. Listing 19.5 przedstawia sposób przekazywania obiektów wzorca.
Listing 19.5. Przekazywanie obiektów wzorca do i z funkcji 0: //Listing 19.5 Przekazywanie obiektów wzorca do i z funkcji 1: #include <iostream> 2: using namespace std;
Usunięto: wzorca
Usunięto: wzorca
Usunięto: wzorca
Usunięto: wzorca
Usunięto: wzorca
Usunięto: wzorca
Usunięto: wzorca
3: 4: const int DefaultSize = 10; 5: 6: // Standardowa klasa do umieszczania w tablicach 7: class Animal 8: { 9: public: 10: // konstruktory 11: Animal(int); 12: Animal(); 13: ~Animal(); 14: 15: // akcesory 16: int GetWeight() const { return itsWeight; } 17: void SetWeight(int theWeight) { itsWeight = theWeight; } 18: 19: // zaprzyjaźnione operatory 20: friend ostream& operator<< (ostream&, const Animal&); 21: 22: private: 23: int itsWeight; 24: }; 25: 26: // operator ekstrakcji dla wypisywania wartości obiektu klasy Animals 27: ostream& operator<< 28: (ostream& theStream, const Animal& theAnimal) 29: { 30: theStream << theAnimal.GetWeight(); 31: return theStream; 32: } 33: 34: Animal::Animal(int weight): 35: itsWeight(weight) 36: { 37: // cout << "Animal(int)\n"; 38: } 39: 40: Animal::Animal(): 41: itsWeight(0) 42: { 43: // cout << "Animal()\n"; 44: } 45: 46: Animal::~Animal() 47: { 48: // cout << "Destruktor klasy Animal...\n"; 49: } 50: 51: template <class T> // deklaruje wzorzec i parametr 52: class Array // klasa parametryzowana 53: { 54: public: 55: Array(int itsSize = DefaultSize); 56: Array(const Array &rhs); 57: ~Array() { delete [] pType; } 58: 59: Array& operator=(const Array&); 60: T& operator[](int offSet) { return pType[offSet]; } 61: const T& operator[](int offSet) const 62: { return pType[offSet]; }
Usunięto: wzorzec
63: int GetSize() const { return itsSize; } 64: 65: // funkcja zaprzyjaźniona 66: friend ostream& operator<< (ostream&, const Array<T>&); 67: 68: private: 69: T *pType; 70: int itsSize; 71: }; 72: 73: template <class T> 74: ostream& operator<< (ostream& output, const Array<T>& theArray) 75: { 76: for (int i = 0; i<theArray.GetSize(); i++) 77: output << "[" << i << "] " << theArray[i] << endl; 78: return output; 79: } 80: 81: // oraz implementacje... 82: 83: // implementacja konstruktora 84: template <class T> 85: Array<T>::Array(int size): 86: itsSize(size) 87: { 88: pType = new T[size]; 89: for (int i = 0; i<size; i++) 90: pType[i] = 0; 91: } 92: 93: // konstruktor kopiujący 94: template <class T> 95: Array<T>::Array(const Array &rhs) 96: { 97: itsSize = rhs.GetSize(); 98: pType = new T[itsSize]; 99: for (int i = 0; i<itsSize; i++) 100: pType[i] = rhs[i]; 101: } 102: 103: void IntFillFunction(Array<int>& theArray); 104: void AnimalFillFunction(Array<Animal>& theArray); 105: 106: int main() 107: { 108: Array<int> intArray; 109: Array<Animal> animalArray; 110: IntFillFunction(intArray); 111: AnimalFillFunction(animalArray); 112: cout << "intArray...\n" << intArray; 113: cout << "\nanimalArray...\n" << animalArray << endl; 114: return 0; 115: } 116: 117: void IntFillFunction(Array<int>& theArray) 118: { 119: bool Stop = false; 120: int offset, value; 121: while (!Stop) 122: { 123: cout << "Podaj indeks (0-9) ";
Usunięto: i

124: cout << "oraz wartosc. (-1 aby skonczyc): " ; 125: cin >> offset >> value; 126: if (offset < 0) 127: break; 128: if (offset > 9) 129: { 130: cout << "***Prosze uzywac wartosci pomiedzy 0 i 9.***\n"; 131: continue; 132: } 133: theArray[offset] = value; 134: } 135: } 136: 137: 138: void AnimalFillFunction(Array<Animal>& theArray) 139: { 140: Animal * pAnimal; 141: for (int i = 0; i<theArray.GetSize(); i++) 142: { 143: pAnimal = new Animal; 144: pAnimal->SetWeight(i*100); 145: theArray[i] = *pAnimal; 146: delete pAnimal; // kopia została umieszczona w tablicy 147: } 148: }
Wynik Podaj indeks (0-9) oraz wartosc. (-1 aby skonczyc): 1 10 Podaj indeks (0-9) oraz wartosc. (-1 aby skonczyc): 2 20 Podaj indeks (0-9) oraz wartosc. (-1 aby skonczyc): 3 30 Podaj indeks (0-9) oraz wartosc. (-1 aby skonczyc): 4 40 Podaj indeks (0-9) oraz wartosc. (-1 aby skonczyc): 5 50 Podaj indeks (0-9) oraz wartosc. (-1 aby skonczyc): 6 60 Podaj indeks (0-9) oraz wartosc. (-1 aby skonczyc): 7 70 Podaj indeks (0-9) oraz wartosc. (-1 aby skonczyc): 8 80 Podaj indeks (0-9) oraz wartosc. (-1 aby skonczyc): 9 90 Podaj indeks (0-9) oraz wartosc. (-1 aby skonczyc): 10 10 ***Prosze uzywac wartosci pomiedzy 0 i 9.*** Podaj indeks (0-9) oraz wartosc. (-1 aby skonczyc): -1 –1 intArray... [0] 0 [1] 10 [2] 20 [3] 30 [4] 40 [5] 50 [6] 60 [7] 70 [8] 80 [9] 90 animalArray... [0] 0 [1] 100

[2] 200 [3] 300 [4] 400 [5] 500 [6] 600 [7] 700 [8] 800 [9] 900
Analiza
W celu zaoszczędzenia miejsca, w programie zrezygnowano z większości implementacji klasy Array. Klasa Animal została zadeklarowana w liniach od 7. do 24. Choć jest ona okrojona i uproszczona, posiada własny operator wstawiania (<<), umożliwiający wypisywanie wartości obiektów typu Animal. W tym przypadku wypisywanie wartości polega po prostu na wypisaniu wagi zwierzęcia.
Zauważ, że klasa Animal posiada konstruktor domyślny. Jest to konieczne, ponieważ gdy dodajemy do tablicy obiekt, w celu jego stworzenia używany jest domyślny konstruktor jego klasy. Jak wkrótce zobaczymy, wynikają z tego pewne trudności.
W linii 103. została zadeklarowana funkcja IntFillFunction(). Jej prototyp wskazuje, że ta funkcja przyjmuje tablicę liczb całkowitych. Zwróć też uwagę, że nie jest to funkcja wzorcowa. IntFillFunction() oczekuje tylko jednego typu tablicy — tablicy wartości całkowitych. W linii 104. funkcja AnimalFillFunction() przyjmuje tablicę Array obiektów Animal.
Implementacje tych funkcji różnią się od siebie, gdyż wypełnianie tablicy wartości całkowitych nie musi odbywać się w ten sam sposób, co wypełnianie tablicy obiektów Animal.
Funkcje specjalizowane Gdy w listingu 19.5 usuniesz znaki komentarza z instrukcji wypisujących komunikaty w konstruktorach i destruktorach klasy Animal, odkryjesz nowe, dodatkowe wywołania tych konstruktorów i destruktorów.
Gdy obiekt jest dodawany do tablicy, wywoływany jest jego konstruktor domyślny. Jednak konstruktor klasy Array przypisuje wartość 0 każdemu elementowi tablicy (co widzieliśmy w liniach 59. i 60. listingu 19.2).
Gdy piszemy someAnimal = (Animal) 0;, wywołujemy dla obiektu Animal domyślny operator=. To powoduje utworzenie tymczasowego obiektu Animal z użyciem konstruktora przyjmującego wartość całkowitą (zero). Ten obiekt tymczasowy jest używany po prawej stronie operatora=, a następnie jest niszczony.
Jest to niepotrzebne marnotrawstwo czasu, gdyż obiekt Animal jest już odpowiednio zainicjalizowany. Nie możemy jednak usunąć tej linii, gdyż zmienne całkowite nie są automatycznie inicjalizowane wartością zero. W tej sytuacji należy nakzać wzorcowi, by nie używał tego konstruktora dla klasy Animal, a zamiast niego użył specjalnego konstruktora tej klasy.
Usunięto: wzorca
Usunięto: wzorca

Na listingu 19.6 pokazano, jak możemy dostarczyć jawnej implementacji dla klasy Animal.
Listing 19.6. Specjalne implementacje wzorca 0: #include <iostream> 1: using namespace std; 2: 3: const int DefaultSize = 3; 4: 5: // Standardowa klasa do umieszczania w tablicach 6: class Animal 7: { 8: public: 9: // konstruktory 10: Animal(int); 11: Animal(); 12: ~Animal(); 13: 14: // akcesory 15: int GetWeight() const { return itsWeight; } 16: void SetWeight(int theWeight) { itsWeight = theWeight; } 17: 18: // zaprzyjaźnione operatory 19: friend ostream& operator<< (ostream&, const Animal&); 20: 21: private: 22: int itsWeight; 23: }; 24: 25: // operator ekstrakcji dla wypisywania wartości obiektu klasy Animals 26: ostream& operator<< 27: (ostream& theStream, const Animal& theAnimal) 28: { 29: theStream << theAnimal.GetWeight(); 30: return theStream; 31: } 32: 33: Animal::Animal(int weight): 34: itsWeight(weight) 35: { 36: cout << "Animal(int) "; 37: } 38: 39: Animal::Animal(): 40: itsWeight(0) 41: { 42: cout << "Animal() "; 43: } 44: 45: Animal::~Animal() 46: { 47: cout << "Destruktor klasy Animal..."; 48: } 49: 50: template <class T> // deklaruje wzorzec i parametr 51: class Array // klasa parametryzowana 52: { 53: public: 54: Array(int itsSize = DefaultSize);
Usunięto: o
Usunięto: wzorzec

55: Array(const Array &rhs); 56: ~Array() { delete [] pType; } 57: 58: // operatory 59: Array& operator=(const Array&); 60: T& operator[](int offSet) { return pType[offSet]; } 61: const T& operator[](int offSet) const 62: { return pType[offSet]; } 63: 64: // akcesory 65: int GetSize() const { return itsSize; } 66: 67: // funkcja zaprzyjaźniona 68: friend ostream& operator<< (ostream&, const Array<T>&); 69: 70: private: 71: T *pType; 72: int itsSize; 73: }; 74: 75: template <class T> 76: Array<T>::Array(int size = DefaultSize): 77: itsSize(size) 78: { 79: pType = new T[size]; 80: for (int i = 0; i<size; i++) 81: pType[i] = (T)0; 82: } 83: 84: template <class T> 85: Array<T>& Array<T>::operator=(const Array &rhs) 86: { 87: if (this == &rhs) 88: return *this; 89: delete [] pType; 90: itsSize = rhs.GetSize(); 91: pType = new T[itsSize]; 92: for (int i = 0; i<itsSize; i++) 93: pType[i] = rhs[i]; 94: return *this; 95: } 96: 97: template <class T> 98: Array<T>::Array(const Array &rhs) 99: { 100: itsSize = rhs.GetSize(); 101: pType = new T[itsSize]; 102: for (int i = 0; i<itsSize; i++) 103: pType[i] = rhs[i]; 104: } 105: 106: 107: template <class T> 108: ostream& operator<< (ostream& output, const Array<T>& theArray) 109: { 110: for (int i = 0; i<theArray.GetSize(); i++) 111: output << "[" << i << "] " << theArray[i] << endl; 112: return output; 113: } 114: 115:

116: Array<Animal>::Array(int AnimalArraySize): 117: itsSize(AnimalArraySize) 118: { 119: pType = new Animal[AnimalArraySize]; 120: } 121: 122: 123: void IntFillFunction(Array<int>& theArray); 124: void AnimalFillFunction(Array<Animal>& theArray); 125: 126: int main() 127: { 128: Array<int> intArray; 129: Array<Animal> animalArray; 130: IntFillFunction(intArray); 131: AnimalFillFunction(animalArray); 132: cout << "intArray...\n" << intArray; 133: cout << "\nanimalArray...\n" << animalArray << endl; 134: return 0; 135: } 136: 137: void IntFillFunction(Array<int>& theArray) 138: { 139: bool Stop = false; 140: int offset, value; 141: while (!Stop) 142: { 143: cout << "Podaj indeks (0-2) "; 144: cout << "oraz wartosc. (-1 aby skonczyc): " ; 145: cin >> offset >> value; 146: if (offset < 0) 147: break; 148: if (offset > 2) 149: { 150: cout << "***Prosze uzywac wartosci pomiedzy 0 i 2.***\n"; 151: continue; 152: } 153: theArray[offset] = value; 154: } 155: } 156: 157: 158: void AnimalFillFunction(Array<Animal>& theArray) 159: { 160: Animal * pAnimal; 161: for (int i = 0; i<theArray.GetSize(); i++) 162: { 163: pAnimal = new Animal(i*10); 164: theArray[i] = *pAnimal; 165: delete pAnimal; 166: } 167: }
UWAGA W celu ułatwienia analizy, do wyniku zostały dodane numery linii. Numery te nie są wypisywane przez program.
Wynik

1: Animal() Animal() Animal() Podaj indeks (0-2) oraz wartosc. (-1 aby skonczyc): 0 0 2: Podaj indeks (0-2) oraz wartosc. (-1 aby skonczyc): 1 1 3: Podaj indeks (0-2) oraz wartosc. (-1 aby skonczyc): 2 2 4: Podaj indeks (0-2) oraz wartosc. (-1 aby skonczyc): -1 -1 5: Animal(int) Destruktor klasy Animal...Animal(int) Destruktor klasy Animal...Animal(int) Destruktor klasy Animal...intArray... 6: [0] 0 7: [1] 1 8: [2] 2 9: 10: animalArray... 11: [0] 0 12: [1] 10 13: [2] 20 14: 15: Destruktor klasy Animal...Destruktor klasy Animal...Destruktor klasy Animal... 16: <<< Drugie uruchomienie >>> 17: Animal() Destruktor klasy Animal... 18: Animal() Destruktor klasy Animal... 19: Animal() Destruktor klasy Animal... 20: Podaj indeks (0-2) oraz wartosc. (-1 aby skonczyc): 0 0 21: Podaj indeks (0-2) oraz wartosc. (-1 aby skonczyc): 1 1 22: Podaj indeks (0-2) oraz wartosc. (-1 aby skonczyc): 2 2 23: Podaj indeks (0-2) oraz wartosc. (-1 aby skonczyc): -1 -1 24: Animal(int) 25: Destruktor klasy Animal... 26: Animal(int) 27: Destruktor klasy Animal... 28: Animal(int) 29: Destruktor klasy Animal... 30: intArray... 31: [0] 0 32: [1] 1 33: [2] 2 34: 35: animalArray... 36: [0] 0 37: [1] 10 38: [2] 20 39: 40: Destruktor klasy Animal... 41: Destruktor klasy Animal... 42: Destruktor klasy Animal...
Analiza

Na listingu 19.6, z wywołań wypisujących komunikaty, zostały usunięte znaki komentarza, dzięki czemu widać, kiedy są tworzone tymczasowe obiekty Animal. W celu skrócenia zapisu wyników, wartość DefaultSize została zmniejszona do trzech.
Konstruktory i destruktor klasy Animal, zawarte w liniach od 33. do 48., wypisują komunikaty wskazujące moment, kiedy zostały wywołane.
W liniach od 75. do 82. zostaje zadeklarowane działanie konstruktora klasy Array. W liniach od 116. do 120. został zademonstrowany wyspecjalizowany konstruktor dla tablicy Array obiektów typu Animal. Zwróć uwagę, że w tym wyspecjalizowanym konstruktorze do ustawiania domyślnej wartości każdego obiektu Animal jest używany jego konstruktor domyślny i nie jest dokonywane żadne jawne przypisanie.
Przy pierwszym uruchomieniu programu zostaje wypisany pierwszy zestaw wyników. Pierwsza linia wyniku pokazuje, że w wyniku tworzenia tablicy są wywoływane trzy konstruktory domyślne. Użytkownik wpisuje cztery liczby, z których trzy są umieszczane w tablicy wartości całkowitych.
Wykonanie programu przechodzi do funkcji AniamFillFunction(). W linii 163. na stercie jest tworzony nowy obiekt tymczasowy, a jego wartość jest w linii 164. używana do zmodyfikowania obiektu Animal w tablicy. W linii 165. ten obiekt tymczasowy jest niszczony. Czynność tę powtarza się dla każdego elementu tablicy, co odzwierciedla piąta linia wyniku.
Pod koniec programu tablice są niszczone i gdy są wywoływane ich destruktory, zostają zniszczone także zawarte w nich obiekty. Odzwierciedla to piętnasta linia wyniku.
Przed drugim uruchomieniem programu (linie wyniku od 17. do 42.) została wykomentowana specjalna implementacja konstruktora tablicy, zawarta w liniach od 116. do 120. Gdy program został uruchomiony ponownie, podczas konstruowania tablicy obiektów Animal nastąpiło więc wywołanie konstruktora wzorca, zawartego w liniach od 74. do 81.
To spowodowało, że w liniach 79. i 80. programu, dla każdego elementu tablicy był tworzony obiekt tymczasowy Animal. Pokazują to linie od 18. do 20. wyniku.
Jak można było oczekiwać, poza tym wyniki obu uruchomień programu nie uległy zmianie.
Wzorce i składowe statyczne Wzorzec może deklarować statyczne dane składowe. Każdy egzemplarz wzorca ma wtedy własny zestaw danych statycznych, po jednym dla każdego typu klasy. Tak więc, gdy dodamy składową statyczną do klasy Array (na przykład licznik określający, ile tablic zostało utworzonych), będziemy mieli jedną taką składową dla każdego typu: jedną dla wszystkich tablic Animal i inną dla wszystkich tablic wartości całkowitych. Na listingu 19.7 do klasy Array dodano daną statyczną i statyczną funkcję składową.
Listing 19.7. Użycie danych statycznych i funkcji składowych we wzorcach 0: #include <iostream> 1: using namespace std; 2:
Usunięto: wzorca
Usunięto: Wzorce
Usunięto: wzorca
Usunięto: e
Usunięto: wzorcach

3: const int DefaultSize = 3; 4: 5: // Standardowa klasa do umieszczania w tablicach 6: class Animal 7: { 8: public: 9: // konstruktory 10: Animal(int); 11: Animal(); 12: ~Animal(); 13: 14: // akcesory 15: int GetWeight() const { return itsWeight; } 16: void SetWeight(int theWeight) { itsWeight = theWeight; } 17: 18: // zaprzyjaźnione operatory 19: friend ostream& operator<< (ostream&, const Animal&); 20: 21: private: 22: int itsWeight; 23: }; 24: 25: // operator ekstrakcji dla wypisywania wartości obiektu klasy Animals 26: ostream& operator<< 27: (ostream& theStream, const Animal& theAnimal) 28: { 29: theStream << theAnimal.GetWeight(); 30: return theStream; 31: } 32: 33: Animal::Animal(int weight): 34: itsWeight(weight) 35: { 36: //cout << "Animal(int) "; 37: } 38: 39: Animal::Animal(): 40: itsWeight(0) 41: { 42: //cout << "Animal() "; 43: } 44: 45: Animal::~Animal() 46: { 47: //cout << "Destruktor klasy Animal..."; 48: } 49: 50: template <class T> // deklaruje wzorzec i parametr 51: class Array // parametryzowana klasa 52: { 53: public: 54: // konstruktory 55: Array(int itsSize = DefaultSize); 56: Array(const Array &rhs); 57: ~Array() { delete [] pType; itsNumberArrays--; } 58: 59: // operatory 60: Array& operator=(const Array&); 61: T& operator[](int offSet) { return pType[offSet]; } 62: const T& operator[](int offSet) const

63: { return pType[offSet]; } 64: // akcesory 65: int GetSize() const { return itsSize; } 66: static int GetNumberArrays() { return itsNumberArrays; } 67: 68: // funkcja zaprzyjaźniona 69: friend ostream& operator<< (ostream&, const Array<T>&); 70: 71: private: 72: T *pType; 73: int itsSize; 74: static int itsNumberArrays; 75: }; 76: 77: template <class T> 78: int Array<T>::itsNumberArrays = 0; 79: 80: template <class T> 81: Array<T>::Array(int size = DefaultSize): 82: itsSize(size) 83: { 84: pType = new T[size]; 85: for (int i = 0; i<size; i++) 86: pType[i] = (T)0; 87: itsNumberArrays++; 88: } 89: 90: template <class T> 91: Array<T>& Array<T>::operator=(const Array &rhs) 92: { 93: if (this == &rhs) 94: return *this; 95: delete [] pType; 96: itsSize = rhs.GetSize(); 97: pType = new T[itsSize]; 98: for (int i = 0; i<itsSize; i++) 99: pType[i] = rhs[i]; 100: } 101: 102: template <class T> 103: Array<T>::Array(const Array &rhs) 104: { 105: itsSize = rhs.GetSize(); 106: pType = new T[itsSize]; 107: for (int i = 0; i<itsSize; i++) 108: pType[i] = rhs[i]; 109: itsNumberArrays++; 110: } 111: 112: template <class T> 113: ostream& operator<< (ostream& output, const Array<T>& theArray) 114: { 115: for (int i = 0; i<theArray.GetSize(); i++) 116: output << "[" << i << "] " << theArray[i] << endl; 117: return output; 118: } 119: 120: int main() 121: { 122: cout << Array<int>::GetNumberArrays() << " tablic typu int\n";

123: cout << Array<Animal>::GetNumberArrays(); 124: cout << " tablic typu Animal\n\n"; 125: Array<int> intArray; 126: Array<Animal> animalArray; 127: 128: cout << intArray.GetNumberArrays() << " tablic typu int\n"; 129: cout << animalArray.GetNumberArrays(); 130: cout << " tablic typu Animal\n\n"; 131: 132: Array<int> *pIntArray = new Array<int>; 133: 134: cout << Array<int>::GetNumberArrays() << " tablic typu int\n"; 135: cout << Array<Animal>::GetNumberArrays(); 136: cout << " tablic typu Animal\n\n"; 137: 138: delete pIntArray; 139: 140: cout << Array<int>::GetNumberArrays() << " tablic typu int\n"; 141: cout << Array<Animal>::GetNumberArrays(); 142: cout << " tablic typu Animal\n\n"; 143: return 0; 144: }
Wynik 0 tablic typu int 0 tablic typu Animal 1 tablic typu int 1 tablic typu Animal 2 tablic typu int 1 tablic typu Animal 1 tablic typu int 1 tablic typu Animal
Analiza
Do klasy Array dodano w linii 74. statyczną zmienną tsNumberArrays, a ponieważ ta dana jest prywatna, w linii 66. dodano także publiczny akcesor GetNumberArrays().
Inicjalizacja tej danej statycznej odbywa się z użyciem pełnej kwalifikacji wzorca, co pokazują linie 77. i 78. Konstruktory oraz destruktor klasy Array modyfikują wartość tej zmiennej tak aby zawsze zawierała poprawną ilość istniejących tablic.
Dostęp do składowych statycznych we wzorcu odbywa się tak samo, jak dostęp do składowych statycznych we wszystkich innych klasach: poprzez istniejący obiekt (jak pokazano w liniach 134. i 135.) lub z użyciem pełnej specyfikacji klasy (co pokazano w liniach 128. i 129.). Zwróć uwagę, że odwołując się do statycznej danej musisz użyć tablicy właściwego typu. Dla każdego typu tablicy istnieje jedna zmienna statyczna.
Usunięto: wzorca
Usunięto: e
Usunięto: wzorcu

TAK NIE
W razie potrzeby możesz użyć składowych statycznych we wzorcach.
Specjalizuj działanie wzorca, przesłaniając funkcje wzorcowe określonym typem.
Używaj parametrów w funkcjach wzorcowych, aby zawęzić ich egzemplarze tak, aby były bezpieczne (ze względu na typy).
Standardowa biblioteka wzorców Nowością w języku C++ jest zaadoptowanie Standardowej Biblioteki Typów (STL, Standard Template Library). Obecnie biblioteka ta jest obsługiwana we wszystkich ważniejszych kompilatorach. STL jest biblioteką klas kontenerów opartych na wzorcach, obejmuje ona wektory, listy, kolejki i stosy. STL zawiera także kilka standardowych algorytmów, takich jak sortowanie i wyszukiwanie.
STL jest alternatywą dla „ponownego wymyślania koła”, przynajmniej w przypadku wymienionych tu standardowych zastosowań. Biblioteka STL jest dokładnie przetestowana, zapewnia wysoką wydajność i jest darmowa. Ponadto, STL nadaje się do ponownego wykorzystania. Gdy zrozumiesz już, jak działa kontener STL, możesz go wykorzystywać we wszystkich swoich programach, nie trudząc się za każdym razem nad tworzeniem go od nowa.
Kontenery Kontener jest obiektem przechowującym inne obiekty. Biblioteka standardowa C++ zawiera serię klas kontenerów stanowiących wydajne narzędzie, pomagające programistom C++ w obsłudze standardowych zadań programu. Klasy kontenerów zawarte w STL dzielą się na sekwencyjne i asocjacyjne. Kontenery sekwencyjne zostały zaprojektowane w celu zapewnienia sekwencyjnego oraz swobodnego dostępu do swoich elementów. Kontenery asocjacyjne są zoptymalizowane do dostępu do swoich elementów poprzez tak zwane klucze. Tak jak w przypadku wszystkich innych komponentów biblioteki standardowej C++, bibliotekę STL można przenosić pomiędzy różnymi systemami operacyjnymi. Wszystkie klasy kontenerów STL są zdefiniowane w przestrzeni nazw std.
Usunięto: e wzorcach
Usunięto: wzorca
Usunięto: wzorca
Usunięto: dla
Usunięto: ego
Usunięto: u
Usunięto: wzorca
Usunięto: typów
Usunięto: Type
Usunięto: wzorcach
Usunięto: ; g
Usunięto: zastanawiając
Usunięto: jak go użyć
Usunięto: tyw
Kontenery sekwencyjne Kontenery sekwencyjne, znajdujące się w standardowej bibliotece wzorców, zapewniają efektywny sekwencyjny dostęp do listy obiektów. Biblioteka standardowa C++ zawiera trzy kontenery sekwencyjne: vector, list oraz deque.
Kontener vector Do przechowywania elementów często wykorzystuje się tablice. Wszystkie elementy w tablicy mają ten sam typ i są dostępne poprzez swoje indeksy. STL zawiera klasę kontenera vector (wektor), która zachowuje się jak tablica, lecz jest bardziej elastyczna i bezpieczniejsza w użyciu niż standardowa tablica C++.
vector jest kontenerem zoptymalizowanym w celu zapewnienia szybkiego dostępu do elementu na podstawie jego indeksu. Klasa kontenera vector jest zdefiniowana w pliku nagłówkowym <vector> w przestrzeni nazw <std> (więcej informacji na temat przestrzeni nazw znajdziesz w rozdziale 18., „Przestrzenie nazw”). Wektor może, w miarę potrzeby, zwiększać objętość. Przypuśćmy, że stworzyliśmy wektor mogący zmieścić dziesięć elementów. Gdy wypełnimy go dziesięcioma obiektami, będzie pełny. Gdy następnie dodamy do niego kolejny obiekt, wektor automatycznie zwiększy swoją objętość tak, aby zmieścić jedenasty element. Klasa vector jest zdefiniowana następująco:
template <class T, class A = allocator<T>> class vector { // składowe klasy };
Pierwszy argument (class T) jest typem elementów w wektorze. Drugi argument (class A) jest klasą alokatora. Alokatory są menedżerami pamięci odpowiedzialnymi za alokację i dealokację pamięci dla elementów przechowywanych w kontenerze. Koncepcja alokatorów i ich implementacja są bardziej skomplikowanymi zagadnieniami i wykraczają poza zakres tej książki.
Domyślnie, elementy są tworzone za pomocą operatora new() i są zwalniane za pomocą operatora delete(). Oznacza to, że do stworzenia nowego elementu jest wywoływany domyślny konstruktor klasy T. To kolejny argument przemawiający za tym, by jawnie definiować domyślne konstruktory dla własnych klas. Gdy tego nie uczynimy, nie będziemy mogli przechowywać egzemplarzy obiektów swojej klasy w standardowych kontenerach.
Wektory zawierające wartości całkowite i wartości zmiennoprzecinkowe można zdefiniować następująco:
vector<int> vInts; // wektor zawierający elementy typu int vector<float> vFloat; // wektor zawierający elementy typu float
Usunięto: typów
Usunięto: ozycyjne

Zwykle mamy pewne pojęcie o tym, ile elementów może zawierać wektor. Na przykład, przypuśćmy, że w naszej szkole maksymalna ilość uczniów w klasie nie przekracza pięćdziesięciu. Aby stworzyć wektor uczniów w klasie, chcemy, aby był on na tyle duży, by zmieścił pięćdziesiąt elementów. Klasa standardowego wektora posiada konstruktor pozwalający na określenie początkowej ilości elementów. Tak więc wektor dla pięćdziesięciu uczniów w klasie możemy zdefiniować następująco:
vector<Student> MathClass(50);
Kompilator zaalokuje pamięć wystarczającą dla zmieszczenia pięćdziesięciu uczniów; każdy element zostanie stworzony za pomocą domyślnego konstruktora Student:: Student().
Aktualna ilość przechowywanych w wektorze elementów może zostać odczytana funkcją size() (rozmiar). W tym przykładzie vStudent.size() zwróci wartość 50.
Inna funkcja składowa, capacity() (pojemność), informuje nas dokładnie, ile elementów może zostać zmieszczonych w tablicy, zanim konieczne będzie zwiększenie jej rozmiaru. Zajmiemy się tym później.
Mówimy, że wektor jest pusty, gdy nie zawiera on żadnego elementu, tj. gdy jego rozmiar wynosi zero. Aby ułatwić sprawdzenie, czy wektor jest pusty, klasa vector posiada funkcję składową empty(), która zwraca wartość true wtedy, gdy wektor jest pusty.
Aby przypisać obiekt typu Student o nazwie Harry do elementu wektora MathClass, możemy użyć operatora indeksu []:
MathClass[5] = Harry;
Indeksy są liczone od zera. Jak być może zauważyłeś, do przypisania obiektu Harry do szóstego elementu wektora został użyty przeciążony operator= klasy Student. Aby sprawdzić wiek Harryego, możemy odwołać się do jego danych, używając:
MathClass[5].GetAge();
Jak już wspominałem, gdy do wektora zostanie dodanych więcej elementów niż może zmieścić, wektor automatycznie zwiększa swoją pojemność. Przypuśćmy na przykład, że jedna z klas stała się tak popularna, że ilość jej uczniów przekroczyła pięćdziesiąt. Cóż, może w przypadku klasy o profilu matematycznym jest to mało prawdopodobne, ale kto wie, wszystko może się zdarzyć. Gdy do klasy MathClass zostanie dodana pięćdziesiąta pierwsza osoba, Sally, kompilator rozszerzy tablicę.
Element może zostać dodany do wektora na kilka sposobów; jednym z nich jest użycie funkcji push_back():
MathClass.push_back(Sally);
Ta funkcja składowa dołącza nowy obiekt Student::Sally do końca wektora MathClass. W tym momencie w wektorze MathClass mamy pięćdziesiąt jeden elementów, a Sally znajduje się w elemencie MathClass[50].
Aby ta funkcja mogła działać, nasza klasa Student musi posiadać zdefiniowany konstruktor kopiujący. W przeciwnym razie funkcja push_back() nie będzie mogła stworzyć kopii obiektu Sally.
STL nie określa maksymalnej ilość elementów w wektorze; decyzję tę może podjąć producent kompilatora. Klasa vector posiada jednak specjalną funkcję, zwracającą wartość tej „magicznej” dla twojego kompilatora liczby; jest nią funkcja max_size().
Listing 19.8 demonstruje omówione dotąd składowe klasy vector. W listingu tym została użyta standardowa klasa string, ułatwiająca posługiwanie się łańcuchami znaków. Więcej informacji na temat tej klasy znajdziesz w dokumentacji swojego kompilatora.
Listing 19.8. Tworzenie wektora i dostęp do jego elementów 0: #include <iostream> 1: #include <string> 2: #include <vector> 3: using namespace std; 4: 5: class Student 6: { 7: public: 8: Student(); 9: Student(const string& name, const int age); 10: Student(const Student& rhs); 11: ~Student(); 12: 13: void SetName(const string& name); 14: string GetName() const; 15: void SetAge(const int age); 16: int GetAge() const; 17: 18: Student& operator=(const Student& rhs); 19: 20: private: 21: string itsName; 22: int itsAge; 23: }; 24: 25: Student::Student() 26: : itsName("Nowy uczen"), itsAge(16) 27: {} 28: 29: Student::Student(const string& name, const int age) 30: : itsName(name), itsAge(age) 31: {} 32: 33: Student::Student(const Student& rhs) 34: : itsName(rhs.GetName()), itsAge(rhs.GetAge()) 35: {} 36: 37: Student::~Student()
Usunięto: i
Usunięto: ą

38: {} 39: 40: void Student::SetName(const string& name) 41: { 42: itsName = name; 43: } 44: 45: string Student::GetName() const 46: { 47: return itsName; 48: } 49: 50: void Student::SetAge(const int age) 51: { 52: itsAge = age; 53: } 54: 55: int Student::GetAge() const 56: { 57: return itsAge; 58: } 59: 60: Student& Student::operator=(const Student& rhs) 61: { 62: itsName = rhs.GetName(); 63: itsAge = rhs.GetAge(); 64: return *this; 65: } 66: 67: ostream& operator<<(ostream& os, const Student& rhs) 68: { 69: os << rhs.GetName() << " ma " << rhs.GetAge() << " lat(a)"; 70: return os; 71: } 72: 73: template<class T> 74: // wyświetla właściwości wektora 75: void ShowVector(const vector<T>& v); 76: 77: typedef vector<Student> SchoolClass; 78: 79: int main() 80: { 81: Student Harry; 82: Student Sally("Sally", 15); 83: Student Bill("Bill", 17); 84: Student Peter("Peter", 16); 85: 86: SchoolClass EmptyClass; 87: cout << "EmptyClass:\n"; 88: ShowVector(EmptyClass); 89: 90: SchoolClass GrowingClass(3); 91: cout << "GrowingClass(3):\n"; 92: ShowVector(GrowingClass); 93: 94: GrowingClass[0] = Harry; 95: GrowingClass[1] = Sally; 96: GrowingClass[2] = Bill; 97: cout << "GrowingClass(3) po przypisaniu uczniow:\n"; 98: ShowVector(GrowingClass);

99: 100: GrowingClass.push_back(Peter); 101: cout << "GrowingClass() po dodaniu czwartego ucznia:\n"; 102: ShowVector(GrowingClass); 103: 104: GrowingClass[0].SetName("Harry"); 105: GrowingClass[0].SetAge(18); 106: cout << "GrowingClass() po wywolaniu funkcji Set\n:"; 107: ShowVector(GrowingClass); 108: 109: return 0; 110: } 111: 112: // 113: // Wyświetla właściwości wektora 114: // 115: template<class T> 116: void ShowVector(const vector<T>& v) 117: { 118: cout << "max_size() = " << v.max_size(); 119: cout << "\tsize() = " << v.size(); 120: cout << "\tcapacity() = " << v.capacity(); 121: cout << "\t" << (v.empty()? "pusta": "nie pusta"); 122: cout << "\n"; 123: 124: for (int i = 0; i < v.size(); ++i) 125: cout << v[i] << "\n"; 126: 127: cout << endl; 128: }
Wynik EmptyClass: max_size() = 214748364 size() = 0 capacity() = 0 pusta GrowingClass(3): max_size() = 214748364 size() = 3 capacity() = 3 nie pusta Nowy uczen ma 16 lat Nowy uczen ma 16 lat Nowy uczen ma 16 lat GrowingClass(3) po przypisaniu uczniow: max_size() = 214748364 size() = 3 capacity() = 3 nie pusta Nowy uczen ma 16 lat Sally ma 15 lat Bill ma 17 lat GrowingClass() po dodaniu czwartego ucznia: max_size() = 214748364 size() = 4 capacity() = 6 nie pusta Nowy uczen ma 16 lat Sally ma 15 lat Bill ma 17 lat Peter ma 16 lat

GrowingClass() po wywolaniu funkcji Set max_size() = 214748364 size() = 4 capacity() = 6 nie pusta Harry ma 18 lat Sally ma 15 lat Bill ma 17 lat Peter ma 16 lat
Analiza
Klasa Student jest zdefiniowana w liniach od 5. do 23. Implementacje jej funkcji składowych są zawarte w liniach od 25. do 65. Klasa ta jest prosta i przyjazna dla kontenerów. Z powodów omawianych wcześniej, zdefiniowaliśmy w niej domyślny konstruktor, konstruktor kopiujący oraz przeciążony operator przypisania. Zwróć uwagę, że jej zmienna składowa itsName została zdefiniowana jako egzemplarz klasy string języka C++. Jak widać, z łańcuchami C++ pracuje się dużo łatwiej niż z łańcuchami char* w stylu języka C.
W liniach 73. i 75. jest zadeklarowana funkcja wzorcowa ShowVector(); jej definicja znajduje się w liniach od 115. do 128. Demonstruje ona użycie niektórych funkcji składowych wektora: max_size(), size(), capacity() oraz empty(). Jak widać w wynikach, maksymalna ilość obiektów typu Student, jaką może pomieścić wektor w Visual C++, wynosi 214 748 364. Dla elementów innego typu wartość ta może być inna. Na przykład, wektor wartości typu int może zawierać do 1 073 741 823 elementów. Jeśli używasz innych kompilatorów, wartości te mogą być inne.
W liniach 124. i 125. „przechodzimy” przez każdy element w wektorze i wyświetlamy jego wartość, używając przeciążonego operatora wstawiania <<, zdefiniowanego w liniach od 67. do 71.
W liniach od 81. do 84. tworzonych jest czterech uczniów. W linii 86. zostaje zdefiniowany pusty wektor o nazwie EmptyClass (pusta klasa). Jest on tworzony za pomocą domyślnego konstruktora klasy vector. Gdy wektor jest tworzony w ten sposób, kompilator nie alokuje dla niego żadnej pamięci. Jak widać w wynikach wypisywanych przez funkcję ShowVector(EmptyClass), jego rozmiar i pojemność wynoszą zero.
W linii 90. zostaje zdefiniowany wektor mogący zmieścić trzech uczniów. Jak można było oczekiwać, zarówno jego rozmiar, jak i pojemność mają wartość 3. Elementy tego wektora (GrowingClass) są wypełniane obiektami w liniach od 94. do 96.; wykorzystujemy do tego operator [].
W linii 100. do wektora jest dodawany czwarty uczeń, Peter. To powoduje zwiększenie rozmiaru wektora do czterech. Co ciekawe, jego objętość faktycznie zwiększa się do sześciu. To oznacza, że kompilator zaalokował miejsce wystarczające do zmieszczenia sześciu obiektów typu Student. Ponieważ wektory muszą być alokowane w ciągłym bloku pamięci, rozszerzanie ich wymaga wykonania całego zestawu operacji. Najpierw alokowany jest nowy blok pamięci, wystarczający do zmieszczenia wszystkich czterech obiektów Student. Następnie do nowo zaalokowanej pamięci są kopiowane trzy elementy; po trzecim elemencie zostaje dołączony czwarty element. Na koniec zostaje zwolniony blok pamięci zajmowany pierwotnie. Gdy w wektorze znajduje się wiele elementów, ten proces alokacji i dealokacji może zajmować dużo czasu. W związku z tym
Usunięto: i
Usunięto: wzorca
Usunięto: n

kompilator przyjmuje strategię redukującą częstotliwość przeprowadzania tak kosztownych operacji. W tym przykładzie, gdy dodamy do wektora jeden czy dwa nowe obiekty, nie będzie potrzeby dealokowania i ponownego alokowania pamięci.
W liniach 104. i 105. ponownie używamy operatora indeksu [] w celu zmiany zmiennych składowych pierwszego elementu w wektorze GrowingClass.
TAK NIE
Jeśli zechcesz przechowywać egzemplarze klasy w wektorze, zdefiniuj dla tej klasy domyślny konstruktor.
Zdefiniuj też konstruktor kopiujący dla takiej klasy.
Zdefiniuj dla niej także przeciążony operator przypisania.
Klasa kontenera vector posiada jeszcze inne funkcje składowe. Funkcja front() zwraca referencję do pierwszego elementu wektora. Funkcja back() zwraca referencję do ostatniego elementu. Funkcja at() działa jak operator indeksu []. Jest jednak bardziej bezpieczna, gdyż sprawdza, czy przekazany jej indeks pasuje do zakresu dostępnych elementów. Jeśli indeks jest poza zakresem, funkcja zgłasza wyjątek out_of_range (poza zakresem; wyjątki zostaną omówione w następnym rozdziale).
Funkcja insert() wstawia jeden lub więcej elementów we wskazane miejsce w wektorze. Funkcja pop_back() usuwa z wektora ostatni element. Na koniec, funkcja remove() usuwa z wektora jeden lub więcej elementów.
Kontener list Lista (list) jest kontenerem przeznaczonym do zoptymalizowania częstych operacji wstawiania i usuwania elementów.
Klasa kontenera list w STL jest zdefiniowana w pliku nagłówkowym <list> w przestrzeni nazw std. Klasa list jest zaimplementowana jako lista połączona podwójnie, w której każdy węzeł posiada dowiązania do poprzedniego i następnego węzła listy.
Klasa list posiada wszystkie funkcje składowe oferowane przez klasę vector. Jak widzieliśmy w programie podsumowującym wiadomości w rozdziale 14., po liście możemy poruszać się podążając za łączami zawartymi w każdym z węzłów. Zwykle takie łącza są zaimplementowane za pomocą wskaźników. Standardowy kontener list wykorzystuje w tym celu mechanizm zwany iteratorem.
Usunięto: będą
Usunięto: ne
Usunięto: e
Usunięto: i

Iterator jest uogólnieniem wskaźnika. Aby uzyskać węzeł wskazywany przez iterator, możemy wyłuskać go z tego iteratora. Listing 19.9 przedstawia użycie iteratorów w celu uzyskania dostępu do węzłów listy.
Listing 19.9. „Przejście” przez listę za pomocą iteratora 0: #include <iostream> 1: #include <list> 2: using namespace std; 3: 4: typedef list<int> IntegerList; 5: 6: int main() 7: { 8: IntegerList intList; 9: 10: for (int i = 1; i <= 10; ++i) 11: intList.push_back(i * 2); 12: 13: for (IntegerList::const_iterator ci = intList.begin(); 14: ci != intList.end(); ++ci) 15: cout << *ci << " "; 16: 17: return 0; 18: }
Wynik 2 4 6 8 10 12 14 16 18 20
Analiza
W linii 8. zmienna intList zostaje zdefiniowana jako lista elementów typu int. W liniach 10. i 11., za pomocą funkcji push_back(), do listy zostaje dodanych dziesięć dodatnich, parzystych wartości.
W liniach od 13. do 15. odwołujemy się do każdego węzła listy, używając iteratora const_iterator. Oznacza to, że poprzez ten iterator nie chcemy zmieniać węzłów. Gdybyśmy chcieli zmienić węzeł wskazywany przez iterator, musielibyśmy zamiast tego użyć operatora nie const:
intList::iterator
Funkcja składowa begin() zwraca iterator wskazujący na pierwszy węzeł listy. Jak widać, do przeniesienia iteratora na następny węzeł możemy użyć operatora ++. Funkcja składowa end() jest dość niezwykła — zwraca iterator wskazujący o jeden węzeł za koniec listy. Musimy więc dopilnować, by nasz iterator nie osiągał węzła wskazywanego prze end().
Iterator jest wyłuskiwany tak samo jak wskaźnik i zwraca wskazywany przez siebie węzeł, co widzimy w linii 15.
Usunięto: chodzenie
Usunięto: y

Choć iteratory zostały tu przedstawione wraz z klasą list, są one jednak dostarczane także przez klasę vector. Oprócz funkcji przedstawionych dla klasy vector, klasa list posiada także funkcje push_front() oraz pop_front(), które działają podobnie jak funkcje push_back() i pop_back(), z tym że nie dodają i nie usuwają elementu na końcu listy, ale na jej początku.
Kontener deque Kontener deque przypomina podwójnie zakończony wektor — podobnie jak klasa vector, zapewnia on efektywność operacji sekwencyjnego zapisu i odczytu. Jednak oprócz tego, klasa kontenera deque optymalizuje operacje na końcach wektora. Te operacje są zaimplementowane podobnie jak w klasie kontenera list, w której alokacje pamięci odbywają się tylko w przypadku nowych elementów. Ta właściwość klasy deque eliminuje potrzebę realokowania całego kontenera do nowego bloku pamięci, co jest jedną z wad klasy vector. W związku z tym kontenery tego typu doskonale nadają się do aplikacji, w których wstawianie i usuwanie elementów dotyczy któregoś z końców wektora i w których ważny jest sekwencyjny dostęp do elementów. Przykładem takiej aplikacji może być symulator zestawiania składów pociągów, w którym wagony mogą być dołączane na początku lub na końcu składu.
Stosy Stos jest jedną ze struktur najczęściej wykorzystywanych przy programowaniu komputerów. Nie został on jednak zaimplementowany jako osobna klasa kontenera, ale jako klasa pośrednia dla klasy kontenera. Klasa wzorcowa stack (stos) jest zdefiniowana w pliku nagłówkowym <stack> w przestrzeni nazw std.
Stos jest ciągłym, zaalokowanym blokiem, który może się rozszerzać i kurczyć na jednym końcu. Elementy znajdujące się na stosie są dostępne tylko poprzez jego koniec. Podobne właściwości zauważyliśmy w kontenerach sekwencyjnych, a mianowicie w kontenerach vector i deque. W rzeczywistości, do zaimplementowania stosu może zostać użyty każdy kontener sekwencyjny, obsługujący operacje back(), push_back() oraz pop_back(). W przypadku stosu większość innych metod kontenerów nie jest potrzebna i w związku z tym klasa stack ich nie udostępnia.
Klasa wzorca stack w STL jest zaprojektowana tak, by mogła przechowywać dowolny typ obiektów, jednak by wszystkie elementy na stosie muszą być tego samego typu.
Stos jest strukturą LIFO (last in — first out, pierwszy wchodzi — ostatni wychodzi). Przypomina nieco zatłoczoną windę: pierwsza osoba wchodząca do windy przesuwa się w stronę ściany, zaś ostatnia osoba stoi tuż przy drzwiach. Gdy winda dotrze na dane piętro, wtedy ostatnią wychodzącą osobą jest ta, która weszła do windy pierwsza. Jeśli któraś z osób chce wysiąść na którymś z wcześniejszych pięter, muszą wyjść wszystkie te osoby, które stoją pomiędzy nią a drzwiami windy i dopiero potem mogą wejść z powrotem.
Usunięto: wzorca

Zgodnie z konwencją, otwarty koniec nazywa się szczytem stosu, zaś operacje wykonywane na stosie nazywane są odkładaniem (push) i zdejmowaniem (pop). Te konwencjonalne określenia przejęła klasa stack.
UWAGA Klasa stack w STL nie przypomina mechanizmu stosu używanego przez kompilatory i systemy operacyjne, w których stosy mogą zawierać obiekty różnych rodzajów. Jednak sama zasada działania stosu jest bardzo podobna.
Kolejki Kolejka jest kolejną, powszechnie wykorzystywaną w programowaniu strukturą. Elementy są dodawane do jednego końca kolejki, a pobierane są z drugiego. Możemy zastosować prostą analogię: stos przypomina stos talerzy w restauracji. Talerze dodaje się do stosu, kładąc je zawsze na górze; zabiera się je także z góry (tzn. pierwszy zostaje zabrany talerz odłożony na stos ostatnio).
Kolejka przypomina kolejkę w sklepie. Stajesz na końcu kolejki i wychodzisz na jej początku. Nazywa się to strukturą FIFO (first in — first out, pierwszy wchodzi — pierwszy wychodzi); stos jest strukturą LIFO.
Podobnie jak stos, kolejka jest zaimplementowana jako klasa pośrednia dla kontenera. Kontener musi obsługiwać operacje front(), back(), push_back() oraz pop_front().
Kontenery asocjacyjne O ile kontenery sekwencyjne są zaprojektowane do sekwencyjnego i swobodnego dostępu do elementów z użyciem indeksu lub operatora, o tyle kontenery asocjacyjne są zaprojektowane dla szybkiego swobodnego dostępu z wykorzystaniem kluczy. Biblioteka standardowa C++ zawiera cztery kontenery asocjacyjne: map, multimap, set oraz multiset.
Kontener map Widzieliśmy że wektor jest jakby rozszerzoną wersją tablicy. Posiada wszystkie charakterystyki tablicy oraz kilka dodatkowych właściwości. Niestety, wektory przejęły także jedną z poważniejszych wad tablic, a mianowicie brak mechanizmu swobodnego dostępu z użyciem kluczy innych niż indeksy lub iteratory. Z drugiej strony, kontenery asocjacyjne zapewniają właśnie szybki swobodny dostęp z wykorzystaniem kluczy.

Biblioteka standardowa C++ zawiera cztery kontenery asocjacyjne: map (mapa), multimap (multimapa), set (zestaw) oraz multiset (multizestaw). Następny listing pokazuje sposób zaimplementowania przy pomocy mapy naszego szkolnego przykładu z listingu 19.8.
Listing 19.8. Klasa kontenera mapy 0: #include <iostream> 1: #include <string> 2: #include <map> 3: using namespace std; 4: 5: class Student 6: { 7: public: 8: Student(); 9: Student(const string& name, const int age); 10: Student(const Student& rhs); 11: ~Student(); 12: 13: void SetName(const string& name); 14: string GetName() const; 15: void SetAge(const int age); 16: int GetAge() const; 17: 18: Student& operator=(const Student& rhs); 19: 20: private: 21: string itsName; 22: int itsAge; 23: }; 24: 25: Student::Student() 26: : itsName("Nowy uczen"), itsAge(16) 27: {} 28: 29: Student::Student(const string& name, const int age) 30: : itsName(name), itsAge(age) 31: {} 32: 33: Student::Student(const Student& rhs) 34: : itsName(rhs.GetName()), itsAge(rhs.GetAge()) 35: {} 36: 37: Student::~Student() 38: {} 39: 40: void Student::SetName(const string& name) 41: { 42: itsName = name; 43: } 44: 45: string Student::GetName() const 46: { 47: return itsName; 48: } 49: 50: void Student::SetAge(const int age) 51: { 52: itsAge = age; 53: }

54: 55: int Student::GetAge() const 56: { 57: return itsAge; 58: } 59: 60: Student& Student::operator=(const Student& rhs) 61: { 62: itsName = rhs.GetName(); 63: itsAge = rhs.GetAge(); 64: return *this; 65: } 66: 67: ostream& operator<<(ostream& os, const Student& rhs) 68: { 69: os << rhs.GetName() << " ma " << rhs.GetAge() << " lat"; 70: return os; 71: } 72: 73: template<class T, class A> 74: void ShowMap(const map<T, A>& v); // wyświetla właściwości mapy 75: 76: typedef map<string, Student> SchoolClass; 77: 78: int main() 79: { 80: Student Harry("Harry", 18); 81: Student Sally("Sally", 15); 82: Student Bill("Bill", 17); 83: Student Peter("Peter", 16); 84: 85: SchoolClass MathClass; 86: MathClass[Harry.GetName()] = Harry; 87: MathClass[Sally.GetName()] = Sally; 88: MathClass[Bill.GetName()] = Bill; 89: MathClass[Peter.GetName()] = Peter; 90: 91: cout << "MathClass:\n"; 92: ShowMap(MathClass); 93: 94: cout << "Wiemy ze " << MathClass["Bill"].GetName() 95: << " ma " << MathClass["Bill"].GetAge() << " lat\n"; 96: 97: return 0; 98: } 99: 100: // 101: // wyświetla właściwości mapy 102: // 103: template<class T, class A> 104: void ShowMap(const map<T, A>& v) 105: { 106: for (map<T, A>::const_iterator ci = v.begin(); 107: ci != v.end(); ++ci) 108: cout << ci->first << ": " << ci->second << "\n"; 109: 110: cout << endl; 111: }

Wynik MathClass: Bill: Bill ma 17 lat Harry: Harry ma 18 lat Peter: Peter ma 16 lat Sally: Sally ma 15 lat Wiemy ze Bill ma 17 lat
Analiza
W linii 2. dołączyliśmy plik nagłówkowy <map>, gdyż będziemy używać standardowej klasy kontenera map. W związku z tym definiujemy funkcję wzorcową ShowMap, wyświetlającą elementy w mapie. W linii 76. typ SchoolClass jest definiowany jako mapa elementów; każdy z nich stanowi parę składającą się z klucza i wartości. Pierwsza wartość w parze jest kluczem. W naszej klasie SchoolClass jako nazw kluczy użyliśmy imion uczniów, które są łańcuchami znaków. Klucze elementów w kontenerze mapy muszą być unikalne, tzn. dwa elementy nie mogą mieć tego samego klucza. Drugą wartością w parze jest sam obiekt; w tym przykładzie jest to obiekt klasy Student. Typ pary danych jest w STL zaimplementowany jako struktura zawierająca dwie składowe, mianowicie first (pierwsza) oraz second (druga). Możemy używać tych składowych w celu uzyskania dostępu do klucza i wartości zawartych w węźle.
Pominiemy funkcję main() i najpierw przyjrzymy się funkcji ShowMap(). Ta funkcja, odwołując się do obiektu mapy, używa iteratora const. W linii 108. ci->first wskazuje klucz (nazwę ucznia), a ci->second wskazuje wartość (obiekt klasy Student).
Wróćmy do linii od 80. do 83. Są w nich tworzone cztery obiekty klasy Student. W linii 85. zostaje zdefiniowany obiekt MathClass, będący egzemplarzem naszego kontenera SchoolClass. W liniach od 86. do 89. dodajemy do kontenera MathClass czterech uczniów, korzystając przy tym z następującej składni:
obiekt_mapy[wartość_klucza] = wartość_obiektu;
W celu dodania pary (klucz, wartość) do mapy moglibyśmy także użyć funkcji push_back() lub insert(); więcej szczegółów na ten temat znajdziesz w dokumentacji swojego kompilatora.
Po dodaniu do mapy wszystkich uczniów, możemy odwoływać się do nich poprzez ich wartości kluczy. W liniach 94. i 95. używamy MathClass["Bill"], aby odwołać się do danych Billa.
Inne kontenery asocjacyjne Klasa kontenera multimap jest klasą map, która nie wymaga, by klucze były unikalne. Tę samą wartość klucza może mieć więcej niż jeden element.
Klasa kontenera set także przypomina klasę mapy; jednak jej elementami nie są pary (klucz, wartość), lecz same klucze.
Usunięto: wzorca
Usunięto: o
Llasa kontenera multiset jest klasą set pozwalającą na występowanie powielonych kluczy.
Klasy algorytmów Kontener to dobre miejsce do przechowywania sekwencji elementów. Wszystkie kontenery standardowe definiują operacje manipulowania kontenerami i ich elementami. Implementowanie wszystkich tych operacji we własnych sekwencjach może być pracochłonne i podatne na błędy. Ponieważ w przypadku większości sekwencji wykonywane operacje są takie same, zastosowanie zestawu ogólnych algorytmów może zredukować potrzebę tworzenia własnych operacji dla każdego nowego kontenera. Biblioteka standardowa zawiera około sześćdziesięciu standardowych algorytmów wykonujących większość podstawowych i powszechnie używanych operacji na kontenerach.
Te standardowe algorytmy są zdefiniowane w pliku nagłówkowym <algorithm> w przestrzeni nazw std.
Aby zrozumieć, jak działają standardowe algorytmy, musimy poznać pojęcie obiektów funkcyjnych. Obiekt funkcyjny jest egzemplarzem klasy definiującej przeciążony operator (). W związku z tym może on być wywołany jako funkcja. Listing 19.11 demonstruje obiekt funkcyjny.
Listing 19.11. Obiekt funkcji 0: #include <iostream> 1: using namespace std; 2: 3: template<class T> 4: class Print { 5: public: 6: void operator()(const T& t) 7: { 8: cout << t << " "; 9: } 10: }; 11: 12: int main() 13: { 14: Print<int> DoPrint; 15: for (int i = 0; i < 5; ++i) 16: DoPrint(i); 17: return 0; 18: }
Wynik 0 1 2 3 4
Analiza
Usunięto: koncept
Usunięto: ji
Usunięto: ji
Usunięto: ji

W liniach od 3. do 10. została zdefiniowana klasa wzorcowa Print. Przeciążony operator () zdefiniowany w liniach od 6. do 9. przyjmuje obiekt i wypisuje go na standardowym wyjściu. W linii 14. obiekt DoPrint jest definiowany jako egzemplarz klasy Print. Możemy więc użyć obiektu DoPrint w celu wypisania dowolnej wartości całkowitej tak, jak użylibyśmy funkcji, co pokazano w linii 16.
Bezmutacyjne operacje sekwencyjne Algorytmy nie zmieniające sekwencji to operacje, które nie zmieniają elementów w sekwencji. Obejmują one operatory takie, jak for_each() (dla każdego) oraz find() (znajdź), search() (szukaj), count() (policz) itd. Listing 19.12 przedstawia sposób użycia obiektu funkcyjnego oraz algorytmu for_each() w celu wypisania elementów wektora.
Listing 19.12. Użycie algorytmu for_each() 0: #include <iostream> 1: #include <vector> 2: #include <algorithm> 3: using namespace std; 4: 5: template<class T> 6: class Print 7: { 8: public: 9: void operator()(const T& t) 10: { 11: cout << t << " "; 12: } 13: }; 14: 15: int main() 16: { 17: Print<int> DoPrint; 18: vector<int> vInt(5); 19: 20: for (int i = 0; i < 5; ++i) 21: vInt[i] = i * 3; 22: 23: cout << "for_each()\n"; 24: for_each(vInt.begin(), vInt.end(), DoPrint); 25: cout << "\n"; 26: 27: return 0; 28: }
Wynik for_each() 0 3 6 9 12
Analiza
Usunięto: wzorca
Usunięto: Algorytmy nie zmieniające
Usunięto: ji
Usunięto: ji

Zwróć uwagę, że algorytmy standardowe w C++ są zdefiniowane w pliku nagłówkowym <algorithm>, więc musimy dołączyć go do kodu programu. Większość programu powinna być łatwo zrozumiała. W linii 24. zostaje wywołana funkcja for_each() „przechodząca” przez wszystkie elementy w wektorze vInt. Dla każdego elementu wywołuje ona obiekt funkcji DoPrint i przekazuje element do funkcji DoPrint.operator(). To powoduje, że wartość elementu zostaje wypisana na ekranie.
Mutacyjne algorytmy sekwencyjne Mutacyjne algorytmy sekwencyjne wykonują operacje zmieniające elementy w sekwencji. Należą do nich operacje wypełniające sekwencje lub zmieniające kolejność zawartych w nich elementów. Listing 19.13 przedstawia algorytm fill() (wypełnij).
Listing 19.13. Algorytm zmieniający sekwencję 0: #include <iostream> 1: #include <vector> 2: #include <algorithm> 3: using namespace std; 4: 5: template<class T> 6: class Print 7: { 8: public: 9: void operator()(const T& t) 10: { 11: cout << t << " "; 12: } 13: }; 14: 15: int main() 16: { 17: Print<int> DoPrint; 18: vector<int> vInt(10); 19: 20: fill(vInt.begin(), vInt.begin() + 5, 1); 21: fill(vInt.begin() + 5, vInt.end(), 2); 22: 23: for_each(vInt.begin(), vInt.end(), DoPrint); 24: cout << "\n\n"; 25: 26: return 0; 27: }
Wynik 1 1 1 1 1 2 2 2 2 2
Analiza
Usunięto: A
Usunięto: zmieniające
Usunięto: A
Usunięto: zmieniające

Jedyną nową zawartością tego listingu są linie 20. i 21., w których jest używany algrytm fill(). Algorytm ten wypełnia elementy sekwencji żądaną wartością. W linii 20. przypisuje wartość całkowitą 1 do pięciu pierwszych elementów wektora vInt. W linii 21. pięciu ostatnim elementom wektora jest przypisywana wartość 2.

Rozdział 20. Wyjątki i obsługa błędów Kod zawartych w tej książce przykładów został stworzony w celach ilustracji. Aby nie odwracać twojej uwagi od prezentowanych tutaj zagadnień, nie zastosowano w nich żadnych mechanizmów obsługi błędów. Jednak w prawdziwych programach obsługa błędów jest ważna.
Z tego rozdziału dowiesz się:
• czym są wyjątki,
• jak używać wyjątków i jakie są rezultaty ich działania,
• jak budować hierarchie wyjątków,
• Jak traktować wyjątki w stosunku do obsługi błędów,
• czym jest debugger.
Pluskwy, błędy, pomyłki i „psujący” się kod Wszystkie programy zawierają pluskwy (czyli błędy). Im większy program, tym więcej pluskiew i wiele z nich „przedostaje” się do ostatecznej jego wersji. Tworzenie stabilnych, wolnych od pluskiew programów powinno być priorytetem każdego, kto poważnie myśli o programowaniu.
Najważniejszym problemem przy tworzeniu oprogramowania jest błędny, niestabilny kod. W wielu poważnych przedsięwzięciach informatycznych największym wydatkiem jest jego testowanie i poprawianie. Ktoś, kto wpadnie na pomysł, jak tworzyć niskim kosztem i na czas dobre, solidne i odporne programy, zrewolucjonizuje przemysł oprogramowania.
Kłopoty z programem mogą być powodowane przez kilka różnych rodzajów błędów. Pierwszym z nich jest błędna logika: program robi to, co ma robić, ale algorytm nie został właściwie przemyślany. Drugim rodzajem błędów jest syntaktyka: niewłaściwa konstrukcja, funkcja, czy struktura. Te dwa rodzaje błędów występują najczęściej i szuka ich większość programistów.

Badania i doświadczenie programistów wykazały, że im później zostanie wykryty błąd, tym bardziej kosztowne staje się jego usunięcie. Najmniej kosztowne błędy i pomyłki to te, których uda się uniknąć. Kolejne mało kosztowne błędy to błędy wykrywane przez kompilator. Standardy języka C++ wymuszają na kompilatorze wychwytywanie coraz większej ilości błędów już podczas kompilacji.
Błędy, które zostały wkompilowane i zostały wychwycone przy pierwszym teście — tj. te, które niezmiennie powodują załamanie programu — są mniej kosztowne w wyszukaniu i poprawieniu niż błędy, które powodują załamanie programu dopiero po pewnym czasie.
Częstszym problemem niż błędy logiczne lub syntaktyczne jest wrażliwość programu: działa on poprawnie, gdy użytkownik wpisuje liczbę tam, gdzie powinien ją wpisać, lecz załamuje się, gdy użytkownik wpisze litery (zamiast liczby). Inne programy załamują się po wyczerpaniu się pamięci, gdy dyskietka zostanie wyjęta ze stacji lub gdy modem zerwie połączenie.
Aby walczyć z tego rodzaju błędami, programiści starają się „uodpornić” swoje programy. Odporny program potrafi obsłużyć wszystko, co może się wydarzyć podczas jego działania, od dziwnych danych wprowadzanych przez użytkownika po nagły brak pamięci.
Należy dokonać rozróżnienia pomiędzy pluskwami, które powstały, ponieważ pomylił się programista; błędami logicznymi, które powstały, ponieważ programista nie zrozumiał zagadnienia lub nie wie, jak sobie z nim poradzić, oraz wyjątkami, które powstają, gdyż wystąpił niezwykły, choć przewidywalny problem, taki jak wyczerpanie się zasobów (pamięci czy miejsca na dysku).
Wyjątki Sytuacji wyjątkowych nie da się wyeliminować; można się jedynie na nie przygotować. Użytkownikom programów od czasu do czasu kończy się pamięć i jedynym zagadnieniem pozostaje to, co twój program zrobi w takim przypadku. Masz wtedy do wyboru:
• załamanie programu,
• poinformowanie użytkownika i zamknięcie programu,
• poinformowanie użytkownika i pozwolenie mu na zwolnienie dodatkowej pamięci i podjęcie ponownej próby,
• podjęcie odpowiednich działań i kontynuowanie pracy bez niepokojenia użytkownika.
Choć nie zawsze jest konieczne (a czasem nawet niewskazane) automatyczne i niewidoczne obsługiwanie wszystkich wyjątkowych sytuacji, jednak trzeba coś zrobić, aby nie pozwolić na załamanie się programu.
Obsługa wyjątków w C++ dostarcza bezpiecznej (ze względu na typ), zintegrowanej metody reagowania na niezwykłe, choć przewidywalne sytuacje, które pojawiają się podczas działania programu.
Usunięto: a

Wyjątki W C++ wyjątek jest obiektem, który jest przekazywany z obszaru kodu, w którym wystąpił problem, do tej części kodu, która odpowiada za jego obsłużenie. Typ wyjątku określa obszar kodu, który ma obsłużyć problem, zaś zawartość zgłoszonego obiektu, o ile istnieje, może posłużyć do dokładniejszego poinformowania użytkownika.
Reguły rządzące wyjątkami są bardzo proste:
• rzeczywista alokacja zasobów (na przykład alokacja pamięci czy blokowanie pliku) zwykle odbywa się na bardzo niskim poziomie programu,
• logika określająca, co należy zrobić, gdy operacja się nie powiedzie, pamięć nie może zostać zaalokowana czy plik nie może zostać zablokowany, zwykle znajduje się na dużo wyższym poziomie programu, wraz z kodem współpracującym z użytkownikiem,
• wyjątki stanowią ekspresową ścieżkę od kodu alokującego zasoby do kodu mogącego obsłużyć sytuację wyjątkową. Gdy pomiędzy nimi występują warstwy funkcji interwencyjnych, daje im się możliwość uporządkowania zaalokowanej pamięci. Nie wymaga się od nich jednak, aby zawierały wyłącznie kod, którego przeznaczeniem jest przekazywanie informacji o błędzie dalej.
Jak używane są wyjątki Obszary kodu, które mogą powodować problem, ujmowane są w bloki try (spróbuj). Na przykład:
try { SomeDangerousFunction(); // potencjalnie niebezpieczna funkcja }
Z kolei bloki catch (wychwyć) obsługują wyjątki zgłoszone w bloku try. Na przykład:
try { SomeDangerousFunction(); } catch(OutOfMemory) { // podejmij jakieś działania przeciwdziałające brakowi pamięci } catch(FileNotFound)
Usunięto: inne
Usunięto: mają
Usunięto: muszą jednak
Usunięto: ć
Usunięto: u
Usunięto: jedynym
Usunięto: wyżej

{ // podejmij czynności przeciwdziałające brakowi pliku na dysku }
Podstawowe etapy obsługiwania wyjątków to:
1. Zidentyfikowanie tych obszarów programu, w których zaczynają się operacje mogące powodować wyjątek i umieszczenie ich w blokach try.
2. Stworzenie bloków catch wychwytujących zgłaszane wyjątki, porządkujące zaalokowaną pamięć i ewentualnie informujące użytkownika. Listing 20.1 przedstawia użycie zarówno bloków try, jak i catch.
Wyjątki są obiektami używanymi do przekazywania informacji o problemie.
Blok try jest blokiem ujętym w nawiasy klamrowe, wewnątrz którego mogą być zgłaszane wyjątki.
Blok catch jest blokiem występującym bezpośrednio po bloku try; są w nim obsługiwane zgłoszone wyjątki.
Gdy zostanie zgłoszony wyjątek, sterowanie przechodzi do właściwego bloku catch następującego po bieżącym bloku try.
UWAGA Niektóre bardzo stare kompilatory nie obsługują wyjątków. Wyjątki są jednak częścią standardu ANSI C++ i wszystkie najnowsze wersje kompilatorów w pełni je obsługują. Jeśli posiadasz starszy kompilator, nie będziesz mógł skompilować i uruchomić przykładów zawartych w tym rozdziale. Jednak mimo to powinieneś przeczytać całą jego zawartość i wrócić do tego materiału później, gdy zdobędziesz nowszą wersję kompilatora.
Listing 20.1. Zgłaszanie wyjątku 0: #include <iostream> 1: using namespace std; 2: 3: const int DefaultSize = 10; 4: 5: class Array 6: { 7: public: 8: // konstruktory 9: Array(int itsSize = DefaultSize); 10: Array(const Array &rhs); 11: ~Array() { delete [] pType;} 12: 13: // operatory 14: Array& operator=(const Array&); 15: int& operator[](int offSet); 16: const int& operator[](int offSet) const; 17: 18: // akcesory

19: int GetitsSize() const { return itsSize; } 20: 21: // funkcja zaprzyjaźniona 22: friend ostream& operator<< (ostream&, const Array&); 23: 24: class xBoundary {}; // definiuje klasę wyjątku 25: 26: private: 27: int *pType; 28: int itsSize; 29: }; 30: 31: 32: Array::Array(int size): 33: itsSize(size) 34: { 35: pType = new int[size]; 36: for (int i = 0; i<size; i++) 37: pType[i] = 0; 38: } 39: 40: 41: Array& Array::operator=(const Array &rhs) 42: { 43: if (this == &rhs) 44: return *this; 45: delete [] pType; 46: itsSize = rhs.GetitsSize(); 47: pType = new int[itsSize]; 48: for (int i = 0; i<itsSize; i++) 49: pType[i] = rhs[i]; 50: return *this; 51: } 52: 53: Array::Array(const Array &rhs) 54: { 55: itsSize = rhs.GetitsSize(); 56: pType = new int[itsSize]; 57: for (int i = 0; i<itsSize; i++) 58: pType[i] = rhs[i]; 59: } 60: 61: 62: int& Array::operator[](int offSet) 63: { 64: int size = GetitsSize(); 65: if (offSet >= 0 && offSet < GetitsSize()) 66: return pType[offSet]; 67: throw xBoundary(); 68: return pType[0]; // ucisza MSC 69: } 70: 71: 72: const int& Array::operator[](int offSet) const 73: { 74: int mysize = GetitsSize(); 75: if (offSet >= 0 && offSet < GetitsSize()) 76: return pType[offSet]; 77: throw xBoundary(); 78: return pType[0]; // ucisza MSC 79: }

80: 81: ostream& operator<< (ostream& output, const Array& theArray) 82: { 83: for (int i = 0; i<theArray.GetitsSize(); i++) 84: output << "[" << i << "] " << theArray[i] << endl; 85: return output; 86: } 87: 88: int main() 89: { 90: Array intArray(20); 91: try 92: { 93: for (int j = 0; j< 100; j++) 94: { 95: intArray[j] = j; 96: cout << "intArray[" << j << "] w porzadku..." << endl; 97: } 98: } 99: catch (Array::xBoundary) 100: { 101: cout << "Nie moglem przetworzyc tych danych!\n"; 102: } 103: cout << "Gotowe.\n"; 104: return 0; 105: }
Wynik intArray[0] w porzadku... intArray[1] w porzadku... intArray[2] w porzadku... intArray[3] w porzadku... intArray[4] w porzadku... intArray[5] w porzadku... intArray[6] w porzadku... intArray[7] w porzadku... intArray[8] w porzadku... intArray[9] w porzadku... intArray[10] w porzadku... intArray[11] w porzadku... intArray[12] w porzadku... intArray[13] w porzadku... intArray[14] w porzadku... intArray[15] w porzadku... intArray[16] w porzadku... intArray[17] w porzadku... intArray[18] w porzadku... intArray[19] w porzadku... Nie moglem przetworzyc tych danych! Gotowe.
Analiza
Listing 20.1 przedstawia nieco okrojoną klasę Array, opartą na szablonie opracowanym w rozdziale 19., „Szablony”.
Usunięto: wzorcu
Usunięto: Wzorce
W linii 24., wewnątrz deklaracji zewnętrznej klasy Array zostaje zadeklarowana nowa klasa, xBoundary.
Ta nowa klasa w żaden sposób nie jest wyróżniana jako klasa wyjątku. Jest po prostu taką samą klasą, jak każda inna. Jest ona bardzo prosta; nie zawiera żadnych danych ani funkcji składowych. Mimo to ,jest jednak najzupełniej poprawną klasą.
W rzeczywistości, stwierdzenie, że nie posiada ona żadnych metod, jest błędne, gdyż kompilator automatycznie przypisuje jej konstruktor domyślny, destruktor, konstruktor kopiujący oraz operator przypisania. Naprawdę klasa ta posiada cztery funkcje, przy braku jakichkolwiek własnych danych.
Zwróć uwagę, że zadeklarowanie jej wewnątrz klasy Array służy jedynie do wzajemnego powiązania tych klas. Jak mówiliśmy w rozdziale 16., „Dziedziczenie zaawansowane”, ani klasa Array nie ma specjalnych uprawnień dostępu do klasy xBoundary, ani klasa xBoundary nie ma preferencyjnego dostępu do składowych klasy Array.
W liniach od 62. do 69. oraz od 72. do 79. operatory indeksu zostały zmodyfikowane tak, by sprawdzały żądany indeks i, gdy znajduje się on poza zakresem, zgłaszały klasę xBoundary jako wyjątek. Nawiasy są wymagane dla odróżnienia tego wywołania konstruktora klasy xBoundary od użycia stałej wyliczeniowej. Zauważ, że niektóre kompilatory Microsoftu wymagają dostarczenia instrukcji return, adekwatnej do deklaracji funkcji (w tym przypadku referencji do typu int), mimo, iż gdy w linii 67. zostanie zgłoszony wyjątek, to wykonanie kodu nigdy nie dotrze do linii 68. Jest to błąd kompilatora, wskazujący że nawet Microsoft miał problemy z tym zagadnieniem!
W linii 91. słowo kluczowe try rozpoczyna blok try, który kończy się na linii 98. Wewnątrz tego bloku, do tablicy zadeklarowanej w linii 90. zostaje wpisanych 101 elementów.
W linii 99. rozpoczyna się blok catch, wychwytujący wyjątki typu xBoundary.
W programie sterującym, w liniach od 88. do 105, występuje blok try, w którym jest inicjalizowany każdy element tablicy. Gdy zmienna j (linia 93.) dojdzie do wartości 20, następuje odwołanie do elementu tablicy o indeksie 20. To powoduje, że test przeprowadzany w linii 65. nie udaje się i w linii 67. operator[] zgłasza wyjątek xBoundary.
Sterowanie programem przechodzi do bloku catch, zaczynającego się w linii 99., w którym wyjątek zostaje obsłużony (w tym przypadku przez wypisanie komunikatu błędu). Wykonanie programu przechodzi przez koniec bloku catch w linii 102.
Bloki try
Blok try jest serią instrukcji, zaczynającą się od słowa kluczowego try, po którym następuje nawias klamrowy otwierający. Blok kończy się nawiasem klamrowym zamykającym.
Przykład
try
Usunięto: i
Usunięto: , więc w
Usunięto: za
Usunięto: ten
Usunięto: dodanych dwadzieścia
Usunięto: 6

{ Funkcja(); }
Bloki catch
Blok catch jest serią instrukcji, z których każda zaczyna się od słowa kluczowego catch, po którym następuje ujęty w nawiasy okrągłe typ wyjątku oraz nawias klamrowy otwierający i zamykający.
Przykład
try { Funkcja(); } catch (OutOfMemory) { // obsługa braku pamięci }
Użycie bloków try oraz bloków catch Określenie, w którym miejscu należy umieścić bloki try, nie jest łatwe: nie zawsze oczywiste jest, które działania mogą powodować wyjątki. Następną zagadką jest to, gdzie wyjątek ma zostać wychwycony. Być może zechcemy zgłaszać wszystkie wyjątki pamięci podczas operacji alokowania pamięci, ale może też będziemy chcieć wyłapywać je na wyższym poziomie programu (tym współpracującym z interfejsem użytkownika).
Próbując wyznaczyć lokalizacje dla bloków try, poszukaj tych miejsc, w których alokujesz pamięć lub używasz zasobów. Inne błędy, które możesz wyłapywać, to błędy zakresu, niewłaściwych danych wejściowych, itd.
Wychwytywanie wyjątków Gdy zostaje zgłoszony wyjątek, sprawdzany jest stos wywołań. Stos wywołań jest listą wywołań funkcji tworzoną w momencie, gdy któraś z części programu wywołuje tę funkcję.
Usunięto: ;
Usunięto: ;

Stos wywołań śledzi ścieżkę wykonania. Jeśli funkcja main() wywołuje funkcję Animal::GetFavoriteFood(), a funkcja GetFavoriteFood() wywołuje funkcję Animal::LookupPreferences(), która z kolei wywołuje fstream::operator>>(), wszystkie te wywołania znajdą się na stosie. Funkcja wywoływana rekurencyjnie może wystąpić na stosie wielokrotnie.
Wyjątek jest przekazywany w górę stosu, do każdego obejmującego bloku. Nazywa się to „rozwijaniem stosu”. Gdy stos jest rozwijany, wywoływane są destruktory lokalnych obiektów na stosie i obiekty te są niszczone.
Po każdym bloku try występuje jedna lub więcej instrukcji catch. Gdy wyjątek pasuje do jednej z instrukcji catch, zakłada się, że zostaje on obsłużony przez wykonanie tej instrukcji. Jeśli nie pasuje do żadnej instrukcji catch, rozwijanie stosu przebiega dalej.
Gdy wyjątek przebędzie całą drogę aż do początku programu (funkcji main()) i wciąż nie jest wychwycony, jest wywoływana wbudowana procedura obsługi, która kończy działanie programu.
Należy zdawać sobie sprawę, że rozwijanie stosu jest działaniem jednokierunkowym. W miarę rozwijania stosu, zawarte na nim obiekty są niszczone. Nie ma więc powrotu: gdy wyjątek zostanie obsłużony, program kontynuuje działanie po bloku try tej instrukcji catch, która obsłużyła wyjątek.
Na listingu 20.1 wykonanie programu zostanie wznowione od linii 101., czyli pierwszej linii po bloku try instrukcji catch, która obsłużyła wyjątek xBoundary. Pamiętaj, że po zgłoszeniu wyjątku działanie programu jest kontynuowane za blokiem catch, a nie w punkcie, w którym został zgłoszony wyjątek.
Wychwytywanie więcej niż jednego rodzaju wyjątków Istnieje możliwość, że wyjątek może zostać spowodowany przez więcej niż jedną sytuację wyjątkową. W takim przypadku instrukcje catch mogą być układane jedna za drugą, podobnie jak bloki case w instrukcji switch. Odpowiednikiem bloku default jest instrukcja „wychwyć wszystko”, zapisywana jako catch(...). Listing 20.2 przedstawia wychwytywanie więcej niż jednego rodzaju wyjątków.
Listing 20.2. Wyjątki wielokrotne 0: #include <iostream> 1: using namespace std; 2: 3: const int DefaultSize = 10; 4: 5: class Array 6: { 7: public: 8: // konstruktory 9: Array(int itsSize = DefaultSize); 10: Array(const Array &rhs); 11: ~Array() { delete [] pType;}

12: 13: // operatory 14: Array& operator=(const Array&); 15: int& operator[](int offSet); 16: const int& operator[](int offSet) const; 17: 18: // akcesory 19: int GetitsSize() const { return itsSize; } 20: 21: // funkcja zaprzyjaźniona 22: friend ostream& operator<< (ostream&, const Array&); 23: 24: // definiujemy klasy wyjątków 25: class xBoundary {}; 26: class xTooBig {}; 27: class xTooSmall{}; 28: class xZero {}; 29: class xNegative {}; 30: private: 31: int *pType; 32: int itsSize; 33: }; 34: 35: int& Array::operator[](int offSet) 36: { 37: int size = GetitsSize(); 38: if (offSet >= 0 && offSet < GetitsSize()) 39: return pType[offSet]; 40: throw xBoundary(); 41: return pType[0]; // ucisza MSC 42: } 43: 44: 45: const int& Array::operator[](int offSet) const 46: { 47: int mysize = GetitsSize(); 48: if (offSet >= 0 && offSet < GetitsSize()) 49: return pType[offSet]; 50: throw xBoundary(); 51: 52: return pType[0]; // ucisza MSC 53: } 54: 55: 56: Array::Array(int size): 57: itsSize(size) 58: { 59: if (size == 0) 60: throw xZero(); 61: if (size < 10) 62: throw xTooSmall(); 63: if (size > 30000) 64: throw xTooBig(); 65: if (size < 1) 66: throw xNegative(); 67: 68: pType = new int[size]; 69: for (int i = 0; i<size; i++) 70: pType[i] = 0; 71: } 72:

73: int main() 74: { 75: try 76: { 77: Array intArray(0); 78: for (int j = 0; j< 100; j++) 79: { 80: intArray[j] = j; 81: cout << "intArray[" << j << "] w porzadku...\n"; 82: } 83: } 84: catch (Array::xBoundary) 85: { 86: cout << "Nie moglem przetworzyc tych danych!\n"; 87: } 88: catch (Array::xTooBig) 89: { 90: cout << "Ta tablica jest zbyt duza...\n"; 91: } 92: catch (Array::xTooSmall) 93: { 94: cout << "Ta tablica jest zbyt mala...\n"; 95: } 96: catch (Array::xZero) 97: { 98: cout << "Poprosiles o tablice"; 99: cout << " zawierajaca zero obiektow!\n"; 100: } 101: catch (...) 102: { 103: cout << "Cos poszlo nie tak!\n"; 104: } 105: cout << "Gotowe.\n"; 106: return 0; 107: }
Wynik Poprosiles o tablice zawierajaca zero obiektow! Gotowe.
Analiza
W liniach od 25. do 29. zostały utworzone cztery nowe klasy: xTooBig, xTooSmall, xZero oraz xNegative. W konstruktorze, zawartym w liniach do 56. do 71., sprawdzany jest rozmiar przekazywany jako parametr tego konstruktora. Gdy jest zbyt duży, zbyt mały, ujemny lub zerowy, zostaje zgłoszony wyjątek.
Blok try został zmodyfikowany i zawiera teraz instrukcje catch dla każdego warunku innego niż rozmiar ujemny. Warunek ten zostaje wychwycony (rozpoznany) przez „wychwytującą wszystko” instrukcję catch(...), zawartą w linii 101.
Wypróbuj działanie tego programu, stosując różne wartości rozmiaru tablicy. Następnie spróbuj zastosować rozmiar wynoszący –5. Mogłeś oczekiwać, że zostanie zgłoszony wyjątek xNegative, ale uniemożliwia to kolejność testów przeprowadzanych w konstruktorze: size <
Usunięto: se
Usunięto: ć

10 jest obliczane wcześniej niż size < 1. Aby to poprawić, zamień miejscami linie 61. i 62. z liniami 65. i 66., po czym ponownie skompiluj program.
Hierarchie wyjątków Wyjątki są klasami, więc można z nich wyprowadzać klasy pochodne. Być może przydatne byłoby stworzenie klasy xSize i wyprowadzenie z niej klas xZero, xTooSmall, xTooBig oraz xNegative. Niektóre funkcje mogłyby wtedy wyłapywać po prostu wyjątki xSize, a inne mogłyby wyłapywać bardziej specyficzne typy błędów. Listing 20.3 ilustruje ten pomysł.
Listing 20.3. Hierarchie klas i wyjątki 0: #include <iostream> 1: using namespace std; 2: 3: const int DefaultSize = 10; 4: 5: class Array 6: { 7: public: 8: // konstruktory 9: Array(int itsSize = DefaultSize); 10: Array(const Array &rhs); 11: ~Array() { delete [] pType;} 12: 13: // operatory 14: Array& operator=(const Array&); 15: int& operator[](int offSet); 16: const int& operator[](int offSet) const; 17: 18: // akcesory 19: int GetitsSize() const { return itsSize; } 20: 21: // funkcja zaprzyjaźniona 22: friend ostream& operator<< (ostream&, const Array&); 23: 24: // definiujemy klasy wyjątków 25: class xBoundary {}; 26: class xSize {}; 27: class xTooBig : public xSize {}; 28: class xTooSmall : public xSize {}; 29: class xZero : public xTooSmall {}; 30: class xNegative : public xSize {}; 31: private: 32: int *pType; 33: int itsSize; 34: }; 35: 36: 37: Array::Array(int size): 38: itsSize(size) 39: { 40: if (size == 0) 41: throw xZero(); 42: if (size > 30000)

43: throw xTooBig(); 44: if (size <1) 45: throw xNegative(); 46: if (size < 10) 47: throw xTooSmall(); 48: 49: pType = new int[size]; 50: for (int i = 0; i<size; i++) 51: pType[i] = 0; 52: } 53: 54: int& Array::operator[](int offSet) 55: { 56: int size = GetitsSize(); 57: if (offSet >= 0 && offSet < GetitsSize()) 58: return pType[offSet]; 59: throw xBoundary(); 60: return pType[0]; // ucisza MSC 61: } 62: 63: 64: const int& Array::operator[](int offSet) const 65: { 66: int mysize = GetitsSize(); 67: if (offSet >= 0 && offSet < GetitsSize()) 68: return pType[offSet]; 69: throw xBoundary(); 70: 71: return pType[0]; // ucisza MSC 72: } 73: 74: int main() 75: { 76: try 77: { 78: Array intArray(0); 79: for (int j = 0; j< 100; j++) 80: { 81: intArray[j] = j; 82: cout << "intArray[" << j << "] w porzadku...\n"; 83: } 84: } 85: catch (Array::xBoundary) 86: { 87: cout << "Nie moglem przetworzyc tych danych!\n"; 88: } 89: catch (Array::xTooBig) 90: { 91: cout << "Ta tablica jest zbyt duza...\n"; 92: } 93: 94: catch (Array::xTooSmall) 95: { 96: cout << "Ta tablica jest zbyt mala...\n"; 97: } 98: catch (Array::xZero) 99: { 100: cout << "Poprosiles o tablice"; 101: cout << " zawierajaca zero obiektow!\n"; 102: } 103: catch (...)

104: { 105: cout << "Cos poszlo nie tak!\n"; 106: } 107: cout << "Gotowe.\n"; 108: return 0; 109: }
Wynik Ta tablica jest zbyt mala... Gotowe.
Analiza
Jedyne znaczące zmiany pojawiają się w liniach od 27. do 30., gdzie ustanawiana jest hierarchia klas. Klasy xTooBig, xTooSmall oraz xNegative są wyprowadzone z klasy xSize, zaś klasa xZero jest wyprowadzona z klasy xTooSmall.
Stworzona została tablica Array o zerowym rozmiarze, ale co się stało? Wygląda na to, że został wychwycony niewłaściwy wyjątek! Sprawdź dokładnie blok catch — okaże się, że wyjątek typu xTooSmall jest wychwytywany przed wyjątkiem typu xZero. Ponieważ zgłaszany jest wyjątek typu xZero, a obiekt klasy xZero jest obiektem klasy xTooSmall, zostaje on wychwycony przez blok catch wyjątku typu xTooSmall. Po obsłużeniu, wyjątek nie jest przekazywany dalej, do kolejnych bloków wychwytywania, dlatego nigdy nie zostaje wywołany blok catch dla wyjątku typu xZero.
Rozwiązaniem tego problemu jest uważny dobór kolejności bloków catch (tak, aby najbardziej specyficzne wyjątki były wychwytywane w pierwszej kolejności, a mniej specyficzne w dalszej). W tym konkretnym przykładzie problem ten można rozwiązać, zamieniając miejscami bloki catch dla wyjątków xZero i xTooSmall.
Dane w wyjątkach oraz nazwane obiekty wyjątków Aby móc odpowiednio zareagować na błąd, często chcemy wiedzieć więcej; nie tylko znać typ zgłoszonego wyjątku. Klasy wyjątków są takie same jak inne klasy, więc można w nich umieszczać dane, inicjalizować je w konstruktorze i w dowolnym momencie odczytywać. Ilustruje to listing 20.4.
Listing 20.4. Odczytywanie danych z obiektu wyjątku 0: #include <iostream> 1: using namespace std; 2: 3: const int DefaultSize = 10; 4:

5: class Array 6: { 7: public: 8: // konstruktory 9: Array(int itsSize = DefaultSize); 10: Array(const Array &rhs); 11: ~Array() { delete [] pType;} 12: 13: // operatory 14: Array& operator=(const Array&); 15: int& operator[](int offSet); 16: const int& operator[](int offSet) const; 17: 18: // akcesory 19: int GetitsSize() const { return itsSize; } 20: 21: // funkcja zaprzyjaźniona 22: friend ostream& operator<< (ostream&, const Array&); 23: 24: // definiujemy klasy wyjątków 25: class xBoundary {}; 26: class xSize 27: { 28: public: 29: xSize(int size):itsSize(size) {} 30: ~xSize(){} 31: int GetSize() { return itsSize; } 32: private: 33: int itsSize; 34: }; 35: 36: class xTooBig : public xSize 37: { 38: public: 39: xTooBig(int size):xSize(size){} 40: }; 41: 42: class xTooSmall : public xSize 43: { 44: public: 45: xTooSmall(int size):xSize(size){} 46: }; 47: 48: class xZero : public xTooSmall 49: { 50: public: 51: xZero(int size):xTooSmall(size){} 52: }; 53: 54: class xNegative : public xSize 55: { 56: public: 57: xNegative(int size):xSize(size){} 58: }; 59: 60: private: 61: int *pType; 62: int itsSize; 63: }; 64: 65:

66: Array::Array(int size): 67: itsSize(size) 68: { 69: if (size == 0) 70: throw xZero(size); 71: if (size > 30000) 72: throw xTooBig(size); 73: if (size <1) 74: throw xNegative(size); 75: if (size < 10) 76: throw xTooSmall(size); 77: 78: pType = new int[size]; 79: for (int i = 0; i<size; i++) 80: pType[i] = 0; 81: } 82: 83: 84: int& Array::operator[] (int offSet) 85: { 86: int size = GetitsSize(); 87: if (offSet >= 0 && offSet < GetitsSize()) 88: return pType[offSet]; 89: throw xBoundary(); 90: return pType[0]; 91: } 92: 93: const int& Array::operator[] (int offSet) const 94: { 95: int size = GetitsSize(); 96: if (offSet >= 0 && offSet < GetitsSize()) 97: return pType[offSet]; 98: throw xBoundary(); 99: return pType[0]; 100: } 101: 102: int main() 103: { 104: try 105: { 106: Array intArray(9); 107: for (int j = 0; j< 100; j++) 108: { 109: intArray[j] = j; 110: cout << "intArray[" << j << "] w porzadku..." << endl; 111: } 112: } 113: catch (Array::xBoundary) 114: { 115: cout << "Nie moglem przetworzyc tych danych!\n"; 116: } 117: catch (Array::xZero theException) 118: { 119: cout << "Poprosiles o tablice Array zawierajaca zero elementow" << endl; 120: cout << "Otrzymano " << theException.GetSize() << endl; 121: } 122: catch (Array::xTooBig theException) 123: { 124: cout << "Ta tablica jest zbyt duza...\n"; 125: cout << "Otrzymano " << theException.GetSize() << endl;

126: } 127: catch (Array::xTooSmall theException) 128: { 129: cout << "Ta tablica jest zbyt mala...\n"; 130: cout << "Otrzymano " << theException.GetSize() << endl; 131: } 132: catch (...) 133: { 134: cout << "Cos poszlo nie tak, ale nie mam pojecia co!\n"; 135: } 136: cout << "Gotowe.\n"; 137: return 0; 138: }
Wynik Ta tablica jest zbyt mala... Otrzymano 9 Gotowe.
Analiza
Deklaracja klasy xSize zawiera teraz w linii 33. zmienną składową itsSize, a w linii 31. funkcję składową GetSize(). Oprócz tego, został dla niej stworzony konstruktor przyjmujący wartość całkowitą i inicjalizujący tę zmienną składową, co zostało pokazane w linii 29.
Klasy pochodne deklarują konstruktory, które tylko inicjalizują klasę bazową. Nie zostały zadeklarowane żadne inne funkcje (między innymi po to, by skrócić objętość listingu).
Instrukcje catch w liniach od 113. do 135. posiadają teraz nazwany obiekt xException wychwytywanego wyjątku i używają go w celu uzyskania dostępu do danej zawartej w jego zmiennej składowej itsSize.
UWAGA Pamiętaj o tym, że obiekt wyjątku jest tworzony w wyniku wystąpienia wyjątkowej sytuacji, więc powinieneś uważać, żeby nie spowodować takiej samej sytuacji w konstruktorze. Gdy tworzysz wyjątek braku pamięci (OutOfMemory), nie powinieneś alokować pamięci w konstruktorze.
Indywidualne wypisywanie odpowiednich komunikatów przez poszczególne instrukcje catch jest kłopotliwe i podatne na błędy. To zadanie należy do obiektu, który zna swój typ i zawarte w nim wartości. Listing 20.5 przedstawia bardziej obiektowo zorientowane podejście do tego problemu, w którym każdy wyjątek sam wykonuje odpowiednią pracę.
Listing 20.5. Przekazywanie przez referencję i użycie funkcji wirtualnych w wyjątkach 0: #include <iostream> 1: using namespace std; 2: 3: const int DefaultSize = 10;

4: 5: class Array 6: { 7: public: 8: // konstruktory 9: Array(int itsSize = DefaultSize); 10: Array(const Array &rhs); 11: ~Array() { delete [] pType;} 12: 13: // operatory 14: Array& operator=(const Array&); 15: int& operator[](int offSet); 16: const int& operator[](int offSet) const; 17: 18: // akcesory 19: int GetitsSize() const { return itsSize; } 20: 21: // funkcja zaprzyjaźniona 22: friend ostream& operator<< 23: (ostream&, const Array&); 24: 25: // definiujemy klasy wyjątków 26: class xBoundary {}; 27: class xSize 28: { 29: public: 30: xSize(int size):itsSize(size) {} 31: ~xSize(){} 32: virtual int GetSize() { return itsSize; } 33: virtual void PrintError() 34: { 35: cout << "Blad rozmiaru. Otrzymano: "; 36: cout << itsSize << endl; 37: } 38: protected: 39: int itsSize; 40: }; 41: 42: class xTooBig : public xSize 43: { 44: public: 45: xTooBig(int size):xSize(size){} 46: virtual void PrintError() 47: { 48: cout << "Zbyt duza! Otrzymano: "; 49: cout << xSize::itsSize << endl; 50: } 51: }; 52: 53: class xTooSmall : public xSize 54: { 55: public: 56: xTooSmall(int size):xSize(size){} 57: virtual void PrintError() 58: { 59: cout << "Zbyt mala! Otrzymano: "; 60: cout << xSize::itsSize << endl; 61: } 62: }; 63: 64: class xZero : public xTooSmall

65: { 66: public: 67: xZero(int size):xTooSmall(size){} 68: virtual void PrintError() 69: { 70: cout << "Zerowa!!. Otrzymano: " ; 71: cout << xSize::itsSize << endl; 72: } 73: }; 74: 75: class xNegative : public xSize 76: { 77: public: 78: xNegative(int size):xSize(size){} 79: virtual void PrintError() 80: { 81: cout << "Ujemna! Otrzymano: "; 82: cout << xSize::itsSize << endl; 83: } 84: }; 85: 86: private: 87: int *pType; 88: int itsSize; 89: }; 90: 91: Array::Array(int size): 92: itsSize(size) 93: { 94: if (size == 0) 95: throw xZero(size); 96: if (size > 30000) 97: throw xTooBig(size); 98: if (size <1) 99: throw xNegative(size); 100: if (size < 10) 101: throw xTooSmall(size); 102: 103: pType = new int[size]; 104: for (int i = 0; i<size; i++) 105: pType[i] = 0; 106: } 107: 108: int& Array::operator[] (int offSet) 109: { 110: int size = GetitsSize(); 111: if (offSet >= 0 && offSet < GetitsSize()) 112: return pType[offSet]; 113: throw xBoundary(); 114: return pType[0]; 115: } 116: 117: const int& Array::operator[] (int offSet) const 118: { 119: int size = GetitsSize(); 120: if (offSet >= 0 && offSet < GetitsSize()) 121: return pType[offSet]; 122: throw xBoundary(); 123: return pType[0]; 124: } 125:

126: int main() 127: { 128: try 129: { 130: Array intArray(9); 131: for (int j = 0; j< 100; j++) 132: { 133: intArray[j] = j; 134: cout << "intArray[" << j << "] w porzadku...\n"; 135: } 136: } 137: catch (Array::xBoundary) 138: { 139: cout << "Nie moglem przetworzyc tych danych!\n"; 140: } 141: catch (Array::xSize& theException) 142: { 143: theException.PrintError(); 144: } 145: catch (...) 146: { 147: cout << "Cos poszlo nie tak!\n"; 148: } 149: cout << "Gotowe.\n"; 150: return 0; 151: }
Wynik Zbyt mala! Otrzymano: 9 Gotowe.
Analiza
Listing 20.5 deklaruje w klasie xSize wirtualną metodę o nazwie PrintError(). Ta metoda wypisuje komunikat błędu oraz aktualny rozmiar klasy. Jest przesłonięta w każdej z klas pochodnych.
W linii 141. obiekt wyjątku jest deklarowany jako referencja. Gdy zostaje wywołana funkcja PrintError() dla referencji do obiektu, polimorfizm powoduje, że zostaje wywołana metoda właściwej klasy. Dzięki temu kod jest bardziej przejrzysty, łatwiejszy do zrozumienia i dużo łatwiejszy w konserwacji.
Wyjątki i wzorce Tworząc współdziałające z wzorcami wyjątki, masz do wyboru: tworzenie wyjątku dla każdego egzemplarza wzorca lub użycie klas wyjątków zadeklarowanych poza deklaracją szablonu. Listing 20.6 ilustruje obie możliwości.
Usunięto: wzorcami
Usunięto: wzorca
Usunięto: wzorca

Listing 20.6. Użycie wyjątków z wzorcami 0: #include <iostream> 1: using namespace std; 2: 3: const int DefaultSize = 10; 4: class xBoundary {}; 5: 6: template <class T> 7: class Array 8: { 9: public: 10: // konstruktory 11: Array(int itsSize = DefaultSize); 12: Array(const Array &rhs); 13: ~Array() { delete [] pType;} 14: 15: // operatory 16: Array& operator=(const Array<T>&); 17: T& operator[](int offSet); 18: const T& operator[](int offSet) const; 19: 20: // akcesory 21: int GetitsSize() const { return itsSize; } 22: 23: // funkcja zaprzyjaźniona 24: friend ostream& operator<< (ostream&, const Array<T>&); 25: 26: // definiujemy klasy wyjątków 27: 28: class xSize {}; 29: 30: private: 31: int *pType; 32: int itsSize; 33: }; 34: 35: template <class T> 36: Array<T>::Array(int size): 37: itsSize(size) 38: { 39: if (size <10 || size > 30000) 40: throw xSize(); 41: pType = new T[size]; 42: for (int i = 0; i<size; i++) 43: pType[i] = 0; 44: } 45: 46: template <class T> 47: Array<T>& Array<T>::operator=(const Array<T> &rhs) 48: { 49: if (this == &rhs) 50: return *this; 51: delete [] pType; 52: itsSize = rhs.GetitsSize(); 53: pType = new T[itsSize]; 54: for (int i = 0; i<itsSize; i++) 55: pType[i] = rhs[i]; 56: } 57: template <class T> 58: Array<T>::Array(const Array<T> &rhs) 59: {

60: itsSize = rhs.GetitsSize(); 61: pType = new T[itsSize]; 62: for (int i = 0; i<itsSize; i++) 63: pType[i] = rhs[i]; 64: } 65: 66: template <class T> 67: T& Array<T>::operator[](int offSet) 68: { 69: int size = GetitsSize(); 70: if (offSet >= 0 && offSet < GetitsSize()) 71: return pType[offSet]; 72: throw xBoundary(); 73: return pType[0]; 74: } 75: 76: template <class T> 77: const T& Array<T>::operator[](int offSet) const 78: { 79: int mysize = GetitsSize(); 80: if (offSet >= 0 && offSet < GetitsSize()) 81: return pType[offSet]; 82: throw xBoundary(); 83: } 84: 85: template <class T> 86: ostream& operator<< (ostream& output, const Array<T>& theArray) 87: { 88: for (int i = 0; i<theArray.GetitsSize(); i++) 89: output << "[" << i << "] " << theArray[i] << endl; 90: return output; 91: } 92: 93: 94: int main() 95: { 96: try 97: { 98: Array<int> intArray(9); 99: for (int j = 0; j< 100; j++) 100: { 101: intArray[j] = j; 102: cout << "intArray[" << j << "] w porzadku..." << endl; 103: } 104: } 105: catch (xBoundary) 106: { 107: cout << "Nie moglem przetworzyc tych danych!\n"; 108: } 109: catch (Array<int>::xSize) 110: { 111: cout << "Zly rozmiar!\n"; 112: } 113: 114: cout << "Gotowe.\n"; 115: return 0; 116: }
Wynik

Zly rozmiar! Gotowe.
Analiza
Pierwszy wyjątek, xBoundary, jest zadeklarowany w linii 4., poza definicją szablonu. Drugi wyjątek, xSize, jest zadeklarowany w linii 28., wewnątrz definicji szablonu.
Wyjątek xBoundary nie jest powiązany z klasą szablonu, ale może być używany tak samo, jak inne klasy. Wyjątek xSize jest związany z szablonem i musi być wywoływany w oparciu o egzemplarz klasy Array. Różnicę widać w składni dwóch instrukcji catch. Linia 105. zawiera instrukcję catch(xBoundary), a linia 109. zawiera instrukcję catch(Array<int>::xSize). Ta druga instrukcja jest powiązana z klasą Array przechowującą wartości typu int.
Wyjątki bez błędów Gdy programiści C++ spotykają się po pracy w cyberprzestrzennym barze przy wirtualnym piwie, często rozmawiają o tym, czy w rutynowych sytuacjach powinny być używane wyjątki. Niektórzy utrzymują, że z racji swojej natury, wyjątki powinny być zarezerwowane dla tych wyjątkowych (stąd nazwa!), lecz przewidywalnych sytuacji, które programista musi wziąć pod uwagę i nie powinny być częścią rutynowego działania kodu.
Inni wskazują, że wyjątki oferują wygodny i przejrzysty sposób powrotu poprzez wiele poziomów wywołań funkcji bez ryzyka powstawania wycieków pamięci. Często przytaczany jest następujący przykład: użytkownik żąda działania w środowisku GUI. Przechwytująca żądanie część kodu musi wywołać funkcję składową w menedżerze dialogów, który z kolei wywołuje kod przetwarzający żądanie, który wywołuje kod decydujący o tym, które okno dialogowe ma być użyte; ten kod z kolei wywołuje kod tworzący okno dialogowe, które następnie wywołuje kod obsługujący działania użytkownika w oknie. Gdy użytkownik kliknie przycisk Anuluj, kod musi powrócić do pierwszej metody wywołującej, w której było obsługiwane pierwotne żądanie.
Jednym z rozwiązań tego problemu jest umieszczenie bloku try wokół wywołania pierwotnego i wychwycenie CancelDialog (anuluj okno dialogowe) jako wyjątku, który może zostać zgłoszony przez procedurę obsługi przycisku Anuluj. To rozwiązanie jest bezpieczne i efektywne. Klikanie przycisku Anuluj nie jest błędem, lecz standardową operacją w interfejsie użytkownika.
Taka dyskusja często przeradza się w zacięty spór, ale najbardziej sensownym sposobem podjęcia decyzji jest zadanie sobie następujących pytań: czy użycie wyjątków ułatwi, czy utrudni zrozumienie kodu? Czy ryzyko powstania błędów i wycieków pamięci zwiększy się, czy zmniejszy? Czy modernizacja kodu będzie łatwiejsza, czy trudniejsza? Te decyzje, podobnie jak wiele innych, wymagają analizy wad i zalet; nie ma jednej, właściwej odpowiedzi.
Usunięto: wzorca
Usunięto: wzorca
Usunięto: wzorca
Usunięto: wzorcem
Usunięto: utrzymanie
Usunięto: e
Usunięto: e

Kilka słów na temat „psującego” się kodu „Psucie” się kodu jest powszechnie znanym zjawiskiem, w którym, z powodu zaniedbania pogarsza się jakość oprogramowania. Doskonale napisany, w pełni przetestowany program zmienia się w błędny już po kilku tygodniach od dostarczenia go do klienta. Po kilku miesiącach klient zauważy, że programowi brakuje logiki i że wiele obiektów zaczyna się rozsypywać.
Oprócz dostarczania kodu źródłowego w opakowaniach próżniowych, twoją jedyną ochroną jest pisanie programów w taki sposób, by móc szybko i łatwo zidentyfikować problem, gdy wrócisz do nich w celu poprawienia jakiegoś elementu.
UWAGA „Psucie” się kodu to żart programistów, z którego płynie ważna lekcja. Programy są bardzo złożone: pluskwy, błędy i pomyłki mogą się ukrywać przez dłuższy czas. Chroń sam siebie, pisząc łatwy w utrzymaniu kod.
To oznacza, że kod musi być napisany zrozumiale i uzupełniony komentarzami tam, gdzie korzystasz z jakichś „sztuczek”. Sześć miesięcy po dostarczeniu kodu będziesz go czytał jak ktoś zupełnie obcy, zastanawiając się ze zgrozą, jak ktoś mógł stworzyć tak udziwnioną składnię.
Pluskwy i odpluskwianie Prawie wszystkie nowoczesne środowiska programowania zawierają jeden lub więcej wysokowydajnych debuggerów. Podstawowa zasada korzystania z debuggera (nazwa pochodzi od słowa debug, odpluskwiać) jest następująca: uruchamiasz debugger, który ładuje kod źródłowy programu, po czym uruchamiasz swój program w debuggerze. Dzięki temu możesz śledzić wykonanie każdej instrukcji w programie oraz sprawdzać wartości zmiennych, które zmieniają się podczas jego działania.
Wszystkie kompilatory umożliwiają kompilację z symbolami lub bez. Kompilowanie z symbolami informuje kompilator, by tworzył konieczne odwzorowanie pomiędzy kodem źródłowym programu a generowanym kodem wykonywalnym; debugger używa tego odwzorowania do wskazania linii kodu źródłowego, która odpowiada następnemu działaniu w programie.
Pełnoekranowe symboliczne debuggery bardzo ułatwiają odpluskwianie kodu. Gdy ładujesz debugger, odczytuje on cały kod źródłowy i wyświetla go w oknie. Możesz „przechodzić” przez wywołania funkcji lub nakazać wejście do poszczególnych funkcji, wykonując kod linia po linii.
W większości debuggerów można przełączać się pomiędzy kodem źródłowym a wynikami programu tak, aby móc zobaczyć wynik wykonania poszczególnych instrukcji. Można sprawdzać bieżący stan każdej zmiennej, przeglądać złożone struktury danych oraz przeglądać pamięć wskazywaną przez wskaźniki lub zajmowaną przez obiekty. W debuggerze można wykonywać także różne operacje, takie jak ustawianie punktów wstrzymania, śledzenie wartości zmiennych, sprawdzanie pamięci i przeglądanie kodu maszynowego.
Punkty wstrzymania Punkty wstrzymania (ang. breakpoint) są instrukcją dla debuggera nakazującą mu, by wstrzymał wykonanie programu w momencie dotarcia do określonej linii kodu. Dzięki temu możesz uruchomić program tak, aby działał normalnie aż do chwili dotarcia do obszaru kodu, który cię interesuje. Punkty wstrzymania pomagają w analizowaniu bieżących wartości zmiennych tuż przed wykonaniem krytycznych linii kodu.
Śledzenie wartości zmiennych Istnieje możliwość poinstruowania debuggera, by wyświetlił wartość określonej zmiennej lub by wstrzymał działanie kodu w momencie, gdy następuje zapis lub odczyt zmiennej. Punkty śledzenia (ang. watch points) pozwalają na określenie tych warunków, a czasem nawet na modyfikowanie wartości zmiennej podczas działania programu.
Sprawdzanie pamięci Czasem użytkownik musi przejrzeć rzeczywiste wartości przechowywane w pamięci. Nowoczesne debuggery mogą wyświetlać wartości w postaci odpowiadającej typowi zmiennej, tj. łańcuchy mogą być wyświetlane jako napisy złożone ze znaków, zmienne typu long jako liczby, a nie cztery bajty, i tak dalej. Wymyślne debuggery C++ mogą nawet pokazywać pełne klasy i wyświetlać bieżące wartości wszystkich ich zmiennych składowych, łącznie ze wskaźnikiem this.
Asembler Choć czytanie kodu źródłowego może być wystarczające do znalezienia błędu, jednak gdy zawiodą inne sposoby, istnieje możliwość poinstruowania debuggera, by wyświetlił kod maszynowy wygenerowany dla poszczególnych linii programu. Można sprawdzać wartości rejestrów i znaczników procesora i analizować działanie programu dosłownie do „gołego metalu”.
Naucz się korzystać ze swojego debuggera. Może być on najlepszą bronią w świętej wojnie przeciwko pluskwom. Błędy czasu działania są najtrudniejsze do znalezienia i usunięcia, a wydajny debugger może umożliwić (nie tylko ułatwić) wyszukanie prawie wszystkich z nich.
Usunięto: z
Usunięto: y
Usunięto: rzeczywistej
Usunięto: są
Usunięto: ć

Rozdział 21. Co dalej Gratulacje! Przebrnąłeś już prawie przez całe wprowadzenie do C++. W tym momencie powinieneś już dobrze go rozumieć, ale w nowoczesnym programowaniu zawsze jest coś, czego jeszcze można się nauczyć. W tym rozdziale uzupełnimy brakujące szczegóły i wskażemy ci dalsze kierunki rozwoju.
Większość kodu, który zapisuje się w plikach kodu źródłowego, to C++. Ten kod jest interpretowany przez kompilator i zamieniany w program. Jednak przed uruchomieniem kompilatora zostaje uruchomiony preprocesor, który umożliwia kompilację warunkową.
Z tego rozdziału dowiesz się:
• czym jest kompilacja warunkowa i jak nią zarządzać,
• jak pisać makra preprocesora,
• jak używać preprocesora do wyszukiwania błędów,
• jak manipulować poszczególnymi bitami i używać ich jako znaczników,
• jakie są następne kroki w efektywnej nauce C++.
Preprocesor i kompilator Za każdym razem, gdy uruchamiasz kompilator, jako pierwszy rusza preprocesor. Preprocesor szuka swoich dyrektyw, z których każda zaczyna się od znaku hash (#). Efektem działania każdej z takich instrukcji jest zmiana tekstu kodu źródłowego. Rezultatem tej zmiany jest nowy plik kodu źródłowego — tymczasowy plik, którego zwykle nie widzisz, choć możesz poinstruować kompilator, aby zapisał go tak, abyś mógł go przeanalizować.
Kompilator nie odczytuje oryginalnego pliku kodu źródłowego; zamiast tego odczytuje i kompiluje plik będący wynikiem pracy preprocesora. Wykorzystywaliśmy ten mechanizm już wcześniej, dołączając pliki nagłówkowe za pomocą dyrektywy #include. Ta dyrektywa powoduje odszukanie pliku o wskazanej w instrukcji nazwie i dołączenie go w bieżącym miejscu

do pliku pośredniego. Odpowiada to wpisaniu całego pliku nagłówkowego do kodu źródłowego; w momencie, gdy plik trafia do kompilatora, plik nagłówkowy już znajduje się w kodzie.
Przeglądanie formy pośredniej Prawie każdy kompilator posiada przełącznik powodujący zapisanie pliku pośredniego na dysku; przełącznik ten można ustawiać albo w zintegrowanym środowisku programistycznym (IDE) albo w linii poleceń kompilatora. Jeśli chcesz przejrzeć plik pośredni, poszukaj odpowiedniego przełącznika w podręczniku dla swojego kompilatora.
Użycie dyrektywy #define Dyrektywa #define definiuje podstawienie symbolu. Jeśli napiszemy:
#define BIG 512
to poinstruujemy preprocesor, by podstawił łańcuch 512 w każde miejsce, w którym napotka symbol BIG. Nie jest to jednak łańcuch w rozumieniu C++. Znaki 512 są wstawiane do kodu źródłowego w każdym miejscu, w którym zostanie napotkany symbol BIG. Symbol jest łańcuchem znaków, który może być użyty tam, gdzie może być użyty łańcuch, stała lub inny spójny zestaw znaków. Tak więc, jeśli napiszemy:
#define BIG 512 int myArray[BIG];
wtedy stworzony przez preprocesor plik pośredni będzie wyglądał następująco:
int myArray[512];
Zwróć uwagę na brak instrukcji #define. Instrukcje preprocesora są usuwane z pliku pośredniego i w ogóle nie występują w ostatecznym kodzie źródłowym.

Użycie #define dla stałych Jednym z zadań dyrektywy #define jest podstawianie stałych. Jednak nie należy jej w tym celu wykorzystywać, gdyż dyrektyw ta jedynie podstawia łańcuch i nie dokonuje sprawdzenia typu. Jak wyjaśniono w podrozdziale dotyczącym stałych, użycie słowa kluczowego const ma o wiele więcej zalet niż użycie dyrektywy #define.
Użycie #define do definiowania symboli Drugim zastosowaniem #define jest po prostu definiowanie określonych symboli. W związku z tym możemy napisać:
#define BIG
Później możemy sprawdzić, czy symbol BIG został zdefiniowany i jeśli tak, podjąć odpowiednie działania. Dyrektywami preprocesora, które sprawdzają, czy symbol został zdefiniowany, są dyrektywy #ifdef (if defined, jeśli zdefiniowany) oraz #ifndef (if not defined, jeśli nie zdefiniowany). Po obu z nich musi wystąpić dyrektywa #endif, kończąca blok kompilowany warunkowo.
Dyrektywa #ifdef jest prawdziwa, jeśli sprawdzany w niej symbol jest już zdefiniowany. Możemy więc napisać:
#ifdef DEBUG cout << "Debug defined"; #endif
Gdy kompilator odczyta dyrektywę #ifdef, sprawdzi we wbudowanej wewnątrz siebie tablicy, czy zdefiniowany został symbol DEBUG. Jeśli tak, to warunek dyrektywy #ifdef jest spełniony i w pliku pośrednim znajdzie się wszystko, aż do następnej dyrektywy #else lub #endif. Jeśli warunek dyrektywy #ifdef nie zostanie spełniony, to w pliku źródłowym nie znajdzie się żadna linia zawarta pomiędzy tymi dyrektywami; efektem będzie zupełne pominięcie kodu znajdującego się w tym miejscu.
Zwróć uwagę, że #ifndef stanowi logiczną odwrotność dyrektywy #ifdef. Warunek dyrektywy #ifndef jest spełniony, gdy w danym miejscu pliku nie został jeszcze zdefiniowany symbol.
Dyrektywa #else preprocesora Jak można się domyślać, dyrektywa #else może być wstawiona pomiędzy dyrektywę #ifdef (lub #ifndef) a dyrektywę #endif. Sposób użycia tych dyrektyw ilustruje listing 21.1.
Usunięto: ,
Usunięto: a
Usunięto: zostanie
Usunięto: a
Usunięto: a
Usunięto: a
Usunięto: D
Usunięto: a

Listing 21.1. Użycie #define 0: #define DemoVersion 1: #define NT_VERSION 5 2: #include <iostream> 3: 4: 5: int main() 6: { 7: std::cout << "Sprawdzanie definicji DemoVersion,"; 8: std::cout << "NT_VERSION oraz WINDOWS_VERSION...\n"; 9: 10: #ifdef DemoVersion 11: std::cout << "Symbol DemoVersion zdefiniowany.\n"; 12: #else 13: std::cout << "Symbol DemoVersion nie zdefiniowany.\n"; 14: #endif 15: 16: #ifndef NT_VERSION 17: std::cout << "Symbol NT_VERSION nie zdefiniowany!\n"; 18: #else 19: std::cout<<"Symbol NT_VERSION zdefiniowany jako: "<<NT_VERSION<<std::endl; 20: #endif 21: 22: #ifdef WINDOWS_VERSION 23: std::cout << "Symbol WINDOWS_VERSION zdefiniowany!\n"; 24: #else 25: std::cout << "Symbol WINDOWS_VERSION nie zostal zdefiniowany.\n"; 26: #endif 27: 28: std::cout << "Gotowe.\n"; 29: return 0; 30: }
Wynik Sprawdzanie definicji DemoVersion,NT_VERSION oraz WINDOWS_VERSION... Symbol DemoVersion zdefiniowany. Symbol NT_VERSION zdefiniowany jako: 5 Symbol WINDOWS_VERSION nie zostal zdefiniowany. Gotowe.
Analiza
W liniach 0. i 1. zostały zdefiniowane symbole DemoVersion oraz NT_VERSION, przy czym symbol NT_VERSION został zdefiniowany jako łańcuch 5. W linii 10. sprawdzana jest definicja DemoVersion, a ponieważ została zdefiniowana (mimo, iż nie ma wartości), warunek został spełniony, dlatego wypisany zostaje łańcuch z linii 11.
W linii 16. dyrektywa #ifndef sprawdza, czy symbol NT_VERSION nie został zdefiniowany. Ponieważ został zdefiniowany, warunek nie jest spełniony i wykonanie programu przeskakuje do

linii 19. W tej linii, w miejscu symbolu NT_VERSION, jest podstawiany łańcuch 5, więc dla kompilatora cała linia ma postać:
std::cout<<"Symbol NT_VERSION zdefiniowany jako: "<<5<<std::endl;
Zwróć uwagę, że w miejscu pierwszego słowa NT_VERSION nic nie zostało podstawione, gdyż znajduje się ono w łańcuchu ujętym w cudzysłowy. Drugie NT_VERSION zostało jednak podstawione, więc kompilator widzi wartość 5, tak jakbyśmy ją sami wpisali.
Na koniec, w linii 22., program sprawdza symbol WINDOWS_VERSION. Ponieważ nie zdefiniowaliśmy tego symbolu, warunek nie jest spełniony i wypisany zostaje komunikat z linii 25.
Dołączanie i wartowniki dołączania W przyszłości będziesz tworzył projekty zawierające wiele różnych plików. Prawdopodobnie zorganizujesz swoje kartoteki tak, aby każda klasa posiadała swój własny plik nagłówkowy (na przykład .hpp), zawierający deklarację klasy oraz własny plik implementacji (na przykład .cpp), zawierający kod źródłowy dla metod tej klasy.
Funkcja main() znajdzie się we własnym pliku .cpp, a wszystkie pliki .cpp będą kompilowane do plików .obj, które z kolei zostaną połączone przez linker w pojedynczy program.
Ponieważ twoje programy będą używać metod z wielu klas, więc do każdego pliku będzie dołączanych wiele plików nagłówkowych. Poza tym, pliki nagłówkowe często muszą dołączać następne pliki. Na przykład, plik nagłówkowy dla deklaracji klasy pochodnej musi dołączyć plik nagłówkowy dla jej klasy bazowej.
Wyobraźmy sobie, że klasa Animal jest zadeklarowana w pliku ANIMAL.hpp. Klasa Dog (pochodząca od klasy Animal) musi w pliku DOG.hpp dołączać plik ANIMAL.hpp, gdyż w przeciwnym razie klasa Dog nie będzie mogła zostać wyprowadzona z klasy Animal. Plik nagłówkowy klasy Cat z tego samego powodu także dołącza plik ANIMAL.hpp.
Gdy stworzysz metodę używającą zarówno klas Cat, jak i Dog, oznacza to niebezpieczeństwo dwukrotnego dołączenia pliku ANIMAL.hpp. To spowoduje błąd kompilacji, gdyż dwukrotne zadeklarowanie klasy (Animal) nie jest dozwolone, nawet jeśli obie deklaracje są identyczne. Możesz rozwiązać ten problem, stosując wartowniki dołączania. Na początku pliku nagłówkowego ANIMAL.hpp dopisz poniższe linie:
#ifndef ANIMAL_HPP #define ANIMAL_HPP ... // w tym miejscu cała zawartość pliku #endif // ANIMAL_HPP
W ten sposób informujemy preprocesor, że jeśli symbol ANIMAL_HPP nie jest zdefiniowany, ma go zdefiniować i dołączyć całą zawartość pliku występującą pomiędzy dyrektywami #define a #endif.
Za pierwszym razem, gdy program dołącza ten plik, odczytuje pierwszą linię i sprawdza, czy symbol ANIMAL_HPP nie jest zdefiniowany. Ponieważ nie jest on jeszcze zdefiniowany, zostaje zdefiniowany w następnej linii, a do pliku pośredniego zostaje dołączona cała zawartość pliku nagłówkowego.
Za drugim razem, gdy preprocesor dołącza plik ANIMAL.hpp, także testuje symbol ANIMAL_HPP, lecz tym razem jest on już zdefiniowany, więc preprocesor pomija cały blok kodu, aż do dyrektywy #else (która w tym przypadku nie występuje) lub #endif (na końcu naszego pliku). Tak więc pomija całą zawartość pliku nagłówkowego, a klasa nie zostaje zadeklarowana ponownie.
Sama nazwa definiowanego symbolu (ANIMAL_HPP) nie ma znaczenia, ale przyjęło się stosowanie nazwy pliku zapisanej dużymi literami, w której znak kropki (.) zostaje zamieniony na znak podkreślenia (_). Jest to jednak jedynie konwencja.
UWAGA Stosowanie wartowników dołączania zawsze jest przydatne. Mogą one oszczędzić ci wielu godzin debuggowania.
Funkcje makro Dyrektywa #define może być używana także w celu tworzenia funkcji makro (tzw. makr). Funkcja makro jest symbolem stworzonym za pomocą dyrektywy #define; przyjmuje ona argument, podobnie jak zwykłe funkcje. Preprocesor podstawi przekazany łańcuch w każdym miejscu definicji, w którym występuje argument makra. Na przykład, makro TWICE (dwakroć) możemy zdefiniować jako:
#define TWICE(x) ( (x) * 2 )
a następnie napisać w kodzie:
TWICE(4)
Cały łańcuch TWICE(4) zostanie usunięty, a w jego miejscu zostanie podstawiona wartość 8! Gdy preprocesor natrafi na to makro z argumentem 4, w jego miejscu podstawi ( (4) * 2), co z kolei zostanie obliczone jako 4*2, czyli 8.
Usunięto: one
Makro może mieć więcej niż jeden parametr; każdy parametr może występować w tekście definicji wielokrotnie. Dwa powszechnie używane makra to MAX oraz MIN:
#define MAX(x,y) ( (x) > (y) ? (x) : (y) ) #define MIN(x,y) ( (x) < (y) ? (x) : (y) )
Zwróć uwagę, że w definicji makra nawiasy otwierające listę parametrów muszą występować bezpośrednio po nazwie makra bez występującej pomiędzy nimi spacji. Preprocesor nie pozwala na tak liberalne używanie spacji, jak robi to kompilator.
Jeśli napiszemy:
#define MAX (x,y) ( (x) > (y) ? (x) : (y) )
a następnie spróbujemy użyć tak zdefiniowanego makra MAX:
int x = 5, y = 7, z; z = MAX(x,y);
wtedy kod pośredni przyjmie postać:
int x = 5, y = 7, z; z = (x,y) ( (x) > (y) ? (x) : (y) )(x,y);
Zostałby jedynie podstawiony prosty tekst; nie nastąpiłoby wywołanie funkcji makro. Symbol MAX zostałby zastąpiony przez (x,y) ( (x) > (y) ? (x) : (y) ), po którym występuje łańcuch (x,y), który miał pełnić rolę parametrów makra.
Po usunięciu spacji pomiędzy MAX a (x,y) kod pośredni przyjąłby postać:
int x =5, y = 7, z; z =7;
Po co te wszystkie nawiasy? Być może zastanawiasz się, po co w przedstawianych dotąd makrach stosowaliśmy tak wiele nawiasów. Preprocesor nie wymaga, by wokół argumentów w łańcuchu podstawiania były umieszczane nawiasy, ale nawiasy te pomagają unikać niepożądanych efektów ubocznych w przypadkach, gdy do makra przekazujemy skomplikowane wyrażenia. Na przykład, jeśli zdefiniujemy makro MAX jako:
#define MAX(x,y) x > y ? x : y

i przekażemy mu wartości 5 oraz 7, wtedy to makro będzie działało tak, jak oczekujemy. Jeśli jednak przekażemy mu bardziej skomplikowane wyrażenia, otrzymamy niepożądane rezultaty, tak jak ilustruje listing 21.2.
Listing 21.2. Użycie nawiasów w makrach 0: // Listing 21.2 Rozwijanie makr 1: #include <iostream> 2: using namespace std; 3: 4: #define CUBE(a) ( (a) * (a) * (a) ) 5: #define THREE(a) a * a * a 6: 7: int main() 8: { 9: long x = 5; 10: long y = CUBE(x); 11: long z = THREE(x); 12: 13: cout << "y: " << y << endl; 14: cout << "z: " << z << endl; 15: 16: long a = 5, b = 7; 17: y = CUBE(a+b); 18: z = THREE(a+b); 19: 20: cout << "y: " << y << endl; 21: cout << "z: " << z << endl; 22: return 0; 23: }
Wynik y: 125 z: 125 y: 1728 z: 82
Analiza
W linii 4. zostało zdefiniowane makro CUBE, w którym przy każdym użyciu x argumenty zostały umieszczone w nawiasach. W linii 5. zostało zdefiniowane makro THREE, w którym parametry są używane bez nawiasów.
W pierwszym zastosowaniu obu makr jako parametr przekazujemy wartość 5; oba makra działają tak, jak oczekujemy. CUBE(5) zostaje rozwinięte do ( (5) * (5) * (5) ), co daje wartość 125, zaś THREE(5) zostaje rozwinięte do 5 * 5 * 5, co także daje wartość 125.
Jednak przy drugim użyciu, w liniach od 16. do 18., parametrem jest 5 + 7. W tym przypadku CUBE(5+7) jest rozwijane jako:
( (5+7) * (5+7) * (5+7) )
co jest obliczane jako:
( (12) * (12) * (12) )
co z kolei daje wynik 1728. Jednak makro THREE(5+7) zostaje rozwinięte jako:
5 + 7 * 5 + 7 * 5 + 7
co jest obliczane jako:
5 + (35) + (35) + 7
co ostatecznie daje wynik 82.
Makra a funkcje i wzorce Makra w C++ oznaczają cztery problemy. Pierwszym jest to, że rozrastające się makro staje się bardzo skomplikowane, gdyż musi być zdefiniowane w pojedynczej linii. Co prawda, można tę linię przedłużyć, stosując lewy ukośnik (\), ale duże makra szybko stają się zbyt trudne w zarządzaniu.
Drugi problem polega na tym, iż makro jest rozwijane w kod w każdym miejscu, w którym zostaje użyte. To oznacza, że jeśli makro zostaje użyte w tuzinie miejsc, zostanie podstawione w dwunastu miejscach kodu, nie wystąpi tylko raz, tak jak w przypadku funkcji wywoływanej. Z drugiej strony, makra są zwykle szybsze niż funkcje, gdyż unikają narzutu związanego z wywołaniem.
Fakt, iż makra są rozwijane w kodzie, prowadzi do trzeciego problemu: kod makra nie pojawia się w pośrednim kodzie źródłowym, więc większość kompilatorów (analizujących kod pośredni) go nie widzi. To powoduje, że debuggowanie makr jest bardzo trudne.
Jednak ostatni problem jest najpoważniejszy: makra nie są bezpieczne ze względu na typy. W makrze może zostać użyty absolutnie dowolny argument, co jest sprzeczne z ideą silnej kontroli typów w języku C++ i jest karą dla programistów tego języka. Oczywiście, jak mówiliśmy w rozdziale 19., poprawnym sposobem rozwiązania tego problemu jest użycie wzorców.
Usunięto: wzorce
Usunięto: dopiero
Usunięto: oryginalny
Usunięto: wzorców

Funkcje inline Często zamiast użycia makra istnieje możliwość zadeklarowania funkcji inline. Na przykład, listing 21.3 zawiera funkcję Cube(), która wykonuje to samo, co makro CUBE z listingu 21.2, lecz jednocześnie jest bezpieczna ze względu na typ.
Listing 21.3. Użycie funkcji inline zamiast makra 0: #include <iostream> 1: using namespace std; 2: 3: inline unsigned long Square(unsigned long a) { return a * a; } 4: inline unsigned long Cube(unsigned long a) 5: { return a * a * a; } 6: int main() 7: { 8: unsigned long x=1 ; 9: for (;;) 10: { 11: cout << "Wpisz liczbe (0 by zakonczyc): "; 12: cin >> x; 13: if (x == 0) 14: break; 15: cout << "Wpisales: " << x; 16: cout << ". Square(" << x << "): "; 17: cout << Square(x); 18: cout<< ". Cube(" << x << "): "; 19: cout << Cube(x) << "." << endl; 20: } 21: return 0; 22: }
Wynik Wpisz liczbe (0 by zakonczyc): 1 Wpisales: 1. Square(1): 1. Cube(1): 1. Wpisz liczbe (0 by zakonczyc): 2 Wpisales: 2. Square(2): 4. Cube(2): 8. Wpisz liczbe (0 by zakonczyc): 3 Wpisales: 3. Square(3): 9. Cube(3): 27. Wpisz liczbe (0 by zakonczyc): 4 Wpisales: 4. Square(4): 16. Cube(4): 64. Wpisz liczbe (0 by zakonczyc): 5 Wpisales: 5. Square(5): 25. Cube(5): 125. Wpisz liczbe (0 by zakonczyc): 6 Wpisales: 6. Square(6): 36. Cube(6): 216. Wpisz liczbe (0 by zakonczyc): 0
Analiza
W liniach 3. i 4. zostały zdefiniowane dwie funkcje inline: Square() oraz Cube(). Każda z nich jest zadeklarowana jako inline, więc podobnie jak makra, zostaną rozwinięte w miejscu użycia, a związany z ich wywołaniem narzut nie pojawi się.
Przypomnijmy, że rozwijanie funkcji inline oznacza, że zawartość funkcji zostaje umieszczana w miejscu, w którym funkcja ma być wywołana (w tym przykładzie w liniach 17. i 19.). Ponieważ nie następuje wywołanie funkcji, nie występuje także narzut spowodowany umieszczaniem na stosie parametrów funkcji i jej powrotnego adresu.
W linii 17. zostaje wywołana funkcja Square(), a w linii 19. funkcja Cube(). Ponieważ są to funkcje inline, zostaje wygenerowany program skompilowany tak, jak poniższy kod:
16: cout << ". Square(" << x << "): "; 17: cout << x * x; 18: cout<< ". Cube(" << x << "): "; 19: cout << x * x * x << "." << endl;
Manipulacje łańcuchami Preprocesor oferuje dwa specjalne operatory przeznaczone do manipulowania łańcuchami w makrach. Operator zamiany na łańcuch (#) podstawia ujęty w nawiasy łańcuch zamiast argumentu występującego po tym operatorze. Natomiast operator konkatenacji łączy ze sobą dwa łańcuchy.
Zamiana w łańcuch Operator zamiany w łańcuch umieszcza cudzysłowy dookoła wszelkich znaków tworzących operator, aż do miejsca wystąpienia następnej białej spacji. Zatem, jeśli napiszemy:
#define WRITESTRING(x) cout << #x
a następnie wywołamy:
WRITESTRING(To jest lancuch);
to preprocesor zmieni to w:
cout << "To jest lancuch";
Zwróć uwagę, że łańcuch To jest lancuch został ujęty w cudzysłowy, tak jak wymaga tego cout.
Usunięto: O

Konkatenacja Operator konkatenacji pozwala na łączenie kilku fraz w pojedyncze słowo. Nowe słowo jest w rzeczywistości symbolem, który może być użyty jako nazwa klasy, nazwa zmiennej, indeks tablicy, czy inna forma, jaką może przyjąć ciąg znaków.
Załóżmy przez moment, że mamy pięć funkcji o nazwach fOnePrint, fTwoPrint, fThreePrint, fFourPrint oraz fFivePrint. Możemy wtedy zadeklarować:
#define fPRINT(x) f ## x ## Print
a następnie użyć makra fPRINT(Two), aby wygenerować fTwoPrint oraz fPRINT(Three) aby wygenerować fThreePrint.
W programie podsumowującym, zawartym w rozdziale 14., została opracowana klasa PartsList. Ta klasa listy mogła obsługiwać jedynie obiekty typu List. Przypuśćmy, że ta lista działała bardzo dobrze i chcielibyśmy za jej pomocą tworzyć listy zwierząt, samochodów, komputerów i tak dalej.
Jedną z możliwości jest tworzenie klas AnimalList, CarList, ComputerList i tak dalej, poprzez wycinanie i wklejanie kod. Ta zabawa szybko stałoby się koszmarem, gdyż każda zmiana w liście wymagałaby uwzględnienia jej we wszystkich innych klasach.
Alternatywą może być użycie makr i operatora konkatenacji. Na przykład, moglibyśmy napisać:
#define Listof(Type) class Type##List \ { \ public: \ Type##List(){} \ private: \ int itsLength; \ };
Ten przykład jest bardzo ogólnikowy, ale pokazuje umieszczenie w takiej definicji wszystkich niezbędnych metod i danych. Gdy będziemy gotowi do stworzenia klasy AnimalList, napiszemy:
Listof(Animal)
co zostanie zamienione na deklarację klasy AnimalList. Z takim postępowaniem wiążą się pewne problemy, które zostały wyczerpująco opisane w rozdziale 19., „Wzorce”.
Usunięto: Wzorce

Makra predefiniowane Wiele kompilatorów predefiniuje wiele użytecznych makr, do których należą __DATE__, __TIME__, __LINE__ oraz __FILE__. Każda z tych nazw jest otoczona dwoma znakami podkreślenia (w celu zmniejszenia prawdopodobieństwa wystąpienia konfliktu z nazwami których mógłbyś użyć w swoim programie).
Gdy preprocesor natrafia na któreś z takich makr, dokonuje odpowiedniego podstawienia. Dla makra __DATE__ zostaje podstawiona bieżąca data. Dla makra __TIME__ zostaje podstawiony bieżący czas. Makra __LINE__ i __FILE__ są zastępowane bieżącym numerem linii w kodzie źródłowym oraz bieżącą nazwą pliku źródłowego. Należy pamiętać, że to podstawianie odbywa się w momencie prekompilacji kodu, a nie podczas działania programu. Gdy poprosisz program o wypisanie makra __DATE__, nie otrzymasz bieżącej daty, lecz datę kompilacji programu. Makra predefiniowane bardzo przydają się podczas debuggowania.
Makro assert() Wiele kompilatorów oferuje makro assert(). To makro zwraca wartość TRUE, jeśli jego parametr ma wartość TRUE i podejmuje pewną akcję w przypadku, gdy jego parametr ma wartość FALSE. Wiele kompilatorów przerywa działanie programu w przypadku, gdy argument tego makra nie jest spełniony; inne zgłaszają wtedy wyjątek (patrz rozdział 20., „Wyjątki i obsługa błędów”).
Jedną z przydatnych możliwości makra assert() jest to, że w przypadku niezdefiniowania symbolu DEBUG nie jest pod nie podstawiany żaden kod. Może ono bardzo pomóc podczas tworzenia programu, a w ostatecznym programie nie wpływa na wydajność i rozmiar kodu wynikowego.
Zamiast polegać na dostarczanym przez kompilator makrze assert(), możemy napisać własne makro. Listing 21.4 przedstawia proste makro ASSERT() wraz z jego zastosowaniem.
Listing 21.4. Proste makro ASSERT() 0: // Listing 21.4 makro ASSERT 1: #define DEBUG 2: #include <iostream> 3: using namespace std; 4: 5: #ifndef DEBUG 6: #define ASSERT(x) 7: #else 8: #define ASSERT(x) \ 9: if (! (x)) \ 10: { \ 11: cout << "BLAD!! Asercja " << #x << " nie jest spelniona.\n"; \ 12: cout << " W linii " << __LINE__ << "\n"; \ 13: cout << " pliku " << __FILE__ << "\n"; \ 14: }
Usunięto: 0

15: #endif 16: 17: int main() 18: { 19: int x = 5; 20: cout << "Pierwsza asercja: \n"; 21: ASSERT(x==5); 22: cout << "\nDruga asercja: \n"; 23: ASSERT(x != 5); 24: cout << "\nGotowe.\n"; 25: return 0; 26: }
Wynik Pierwsza asercja: Druga asercja: BLAD!! Asercja x != 5 nie jest spelniona. W linii 24 pliku C:\WC\test1\test1.cpp Gotowe.
Analiza
W linii 1. zostaje zdefiniowany symbol DEBUG. Zwykle definicji tej dokonuje się w linii polecenia kompilatora lub definiuje się ją jako opcję środowiska IDE, dzięki czemu można tę definicję dowolnie włączać i wyłączać. W liniach od. 8 do 14. zostało zdefiniowane makro ASSERT(). Zwykle taka definicja znalazłaby się w pliku nagłówkowym (na przykład ASSERT.hpp), który zostałby dołączony w pliku implementacji.
W linii 5. sprawdzany jest symbol DEBUG. Jeśli nie jest zdefiniowany, makro ASSERT() jest definiowane jako nie generujące żadnego kodu. Jeśli symbol DEBUG jest zdefiniowany, zostają wygenerowane linie od 8. do 14.
Samo makro ASSERT() jest z punktu widzenia preprocesora długą instrukcją, rozbitą na kilka linii kodu. W linii 9. zostaje sprawdzona wartość przekazywana jako parametr; jeśli da wartość FALSE, zostają wywołane instrukcje zawarte w liniach od 11. do 13., powodujące wypisanie komunikatu błędu. Jeśli przekazana wartość zostanie obliczona jako TRUE, nie są podejmowane żadne działania.
Debuggowanie za pomocą makra assert() Podczas pisania programu często będziesz miał całkowitą pewność, że coś jest prawdziwe: funkcja ma pewną wartość, wskaźnik jest poprawny i tak dalej. Istotą błędów jest jednak to, że coś, co uważasz za prawdziwe, w pewnych warunkach takie nie jest. Na przykład, możesz mieć pewność, że wskaźnik jest poprawny, a mimo to program się załamuje. Makro assert() może pomóc w znajdowaniu tego rodzaju błędów, ale tylko wtedy, gdy będziesz regularnie stosował to makro w swoim kodzie. Za każdym razem, gdy przypisujesz wartość do wskaźnika lub przekazujesz
Usunięto: uje
Usunięto: m

wskaźnik jako argument lub wartość zwrotną funkcji, pamiętaj o sprawdzeniu makrem assert(), czy ten wskaźnik jest poprawny. Za każdym razem, gdy twój kod jest zależny od tego, czy w zmiennej znajduje się odpowiednia wartość, upewnij się za pomocą makra assert(), że faktycznie jest w niej ta wartość.
Z korzystaniem z makra assert() nie wiąże się żaden narzut, gdyż w ostatecznej wersji programu jest ono usuwane. Przypomina ono czytelnikowi kodu o tym, co uważałeś za prawdziwe w danym momencie działania kodu.
Makro assert() a wyjątki W poprzednim rozdziale przekonałeś się, jak można obsługiwać błędy, korzystając z wyjątków. Należy zdawać sobie sprawę, że makro assert() nie jest przeznaczone do obsługi błędów czasu działania programu, takich jak błędne dane, brak pamięci, niemożność otwarcia pliku i tak dalej. Makro to jest tworzone wyłącznie w celu wychwycenia błędów programisty. Tak więc, jeśli makro assert() „zadziała”, wiesz, że w twoim kodzie tkwi błąd.
Jest to ważne, ponieważ gdy dostarczasz kod swoim klientom, nie zawiera on rozwiniętych makr assert(). Nie możesz więc oczekiwać, że obsłużą problemy pojawiające się podczas działania programu, gdyż po prostu tych makr nie będzie.
Częstym błędem jest użycie makra assert() w celu sprawdzania wartości zwracanej z przypisania pamięci:
Animal *pCat = new Cat; Assert(pCat); // złe użycie makra assert() pCat->SomeFunction();
Jest to klasyczny błąd programisty; za każdym razem, gdy uruchamia on program, dostępna jest wystarczająca ilość pamięci i makro assert() nigdy się nie uaktualnia. W końcu programista ma nowoczesny komputer z mnóstwem dodatkowej pamięci RAM, zoptymalizowany tak, by przyspieszyć działanie kompilatora, debuggera i tak dalej. Następnie programista dostarcza klientom plik wykonywalny, a biedny użytkownik, posiadający dużo mniej pamięci RAM, dochodzi do miejsca, w którym wywołanie new się nie udaje i zostaje zwrócona wartość NULL. Jednak makra assert() nie ma już w kodzie i nic nie wskazuje na to, że wskaźnik ma wartość NULL. Gdy tylko zostanie podjęta próba wykonania instrukcji pCat->SomeFunction(), program się załamie.
Otrzymanie wartości NULL z operatora przypisania pamięci nie jest błędem programistycznym, choć jest sytuacją wyjątkową. Twój program musi być w stanie poradzić sobie z taką sytuacją, choćby tylko poprzez zgłoszenie wyjątku. Pamiętaj: gdy symbol DEBUG nie jest zdefiniowany, cała instrukcja makra assert() znika. Wyjątki zostały szczegółowo opisane w rozdziale 20.

Efekty uboczne Dość często zdarza się, że błąd występuje tylko wtedy, gdy egzemplarze makra assert() zostaną usunięte. Dzieje się tak prawie zawsze, gdy działanie programu zależy od efektów ubocznych wynikających ze stosowania makra assert() i innego kodu związanego wyłącznie z debuggowaniem. Na przykład, jeśli napiszesz:
ASSERT(x = 5)
(gdy miałeś na myśli sprawdzenie czy x == 5), stworzysz szczególnie nieprzyjemny błąd.
Przypuśćmy, że tuż przed makrem assert() wywołujesz funkcję, która ustawia x na zero. Przy takiej asercji możesz uważać, że sprawdzasz, czy x jest równe 5, jednak w rzeczywistości przypisujesz wartość do tej zmiennej 5. Test zwraca wartość TRUE, gdyż x = 5 nie tylko ustawia zmienną x, ale także zwraca wartość 5, a ponieważ ta wartość jest różna od zera, więc całe wyrażenie ma wartość odpowiadającą wartości TRUE.
Gdy wykonujesz makro assert(), x rzeczywiście ma wartość 5 (w końcu to ty dokonałeś tego przypisania!). Program działa poprawnie. Jesteś gotów do rozpowszechnienia go, więc wyłączasz opcję debuggowania. W tym momencie makro assert() znika i zmiennej x nie jest już przypisywana wartość 5. Ponieważ tuż przed tym zmienna x była ustawiana na zero, ta wartość w niej pozostaje i program się załamuje.
Wtedy ponownie włączasz debuggowanie i staje się cud! Błąd zniknął. To bardzo zabawna sytuacja, ale tylko dla kogoś, kto nie musi sam sobie z nią radzić, więc bardzo uważaj na efekty uboczne w kodzie dla debuggowania. Jeśli napotkasz błąd występujący tylko przy wyłączonym debuggowaniu, dokładnie przejrzyj swój kod debuggowania — czy nie ma w nim niepożądanych efektów ubocznych.
Niezmienniki klas Większość klas posiada pewne warunki, które, gdy już zostanie zakończona jakaś metoda klasy, powinny być zawsze prawdziwe. Te niezmienniki klasy są warunkami sine qua non klasy. Na przykład, możemy założyć, że obiekt CIRCLE nigdy nie ma promienia o wartości ujemnej lub że obiekt klasy ANIMAL zawsze powinien mieć wiek większy od zera i mniejszy od stu.
Bardzo pomocne może okazać się zadeklarowanie metody Invariants() (niezmienniki) zwracającej wartość TRUE tylko wtedy, gdy każdy z niezmienników klasy jest spełniony. Wtedy na początku i końcu każdej metody możesz użyć konstrukcji ASSERT(Invariants()). Nie dotyczy to sytuacji, w której metoda Invariants() może nie zwrócić wartości TRUE, np. przed wykonaniem konstruktora lub po wykonaniu destruktora. Listing 21.5 demonstruje użycie metody Invariants() w standardowej klasie.
Listing 21.5. Użycie metody Invariants() 0: #define DEBUG
Usunięto: ją
Usunięto: łeś
Usunięto: z
Usunięto: ą
Usunięto: do
Usunięto: e
Usunięto: y
Usunięto: zawsze
Usunięto: Wyjątkiem będzie

1: #define SHOW_INVARIANTS 2: #include <iostream> 3: #include <string.h> 4: using namespace std; 5: 6: #ifndef DEBUG 7: #define ASSERT(x) 8: #else 9: #define ASSERT(x) \ 10: if (! (x)) \ 11: { \ 12: cout << "BLAD!! Asercja " << #x << " nie jest spelniona.\n"; \ 13: cout << " W linii " << __LINE__ << "\n"; \ 14: cout << " w pliku " << __FILE__ << "\n"; \ 15: } 16: #endif 17: 18: 19: const int FALSE = 0; 20: const int TRUE = 1; 21: typedef int BOOL; 22: 23: 24: class String 25: { 26: public: 27: // konstruktory 28: String(); 29: String(const char *const); 30: String(const String &); 31: ~String(); 32: 33: char & operator[](int offset); 34: char operator[](int offset) const; 35: 36: String & operator= (const String &); 37: int GetLen()const { return itsLen; } 38: const char * GetString() const { return itsString; } 39: BOOL Invariants() const; 40: 41: private: 42: String (int); // prywatny konstruktor 43: char * itsString; 44: // unsigned short itsLen; 45: int itsLen; 46: }; 47: 48: // domyślny konstruktor tworzy łańcuch o długości zera bajtów 49: String::String() 50: { 51: itsString = new char[1]; 52: itsString[0] = '\0'; 53: itsLen=0; 54: ASSERT(Invariants()); 55: } 56: 57: // prywatny (pomocniczy) konstruktor, używany tylko przez 58: // metody klasy do tworzenia nowego łańcucha 59: // o żądanej długości, wypełnionego znakami null. 60: String::String(int len)

61: { 62: itsString = new char[len+1]; 63: for (int i = 0; i<=len; i++) 64: itsString[i] = '\0'; 65: itsLen=len; 66: ASSERT(Invariants()); 67: } 68: 69: // Konwertuje tablicę znaków w obiekt String 70: String::String(const char * const cString) 71: { 72: itsLen = strlen(cString); 73: itsString = new char[itsLen+1]; 74: for (int i = 0; i<itsLen; i++) 75: itsString[i] = cString[i]; 76: itsString[itsLen]='\0'; 77: ASSERT(Invariants()); 78: } 79: 80: // konstruktor kopiujący 81: String::String (const String & rhs) 82: { 83: itsLen=rhs.GetLen(); 84: itsString = new char[itsLen+1]; 85: for (int i = 0; i<itsLen;i++) 86: itsString[i] = rhs[i]; 87: itsString[itsLen] = '\0'; 88: ASSERT(Invariants()); 89: } 90: 91: // destruktor, zwalnia zaalokowaną pamięć 92: String::~String () 93: { 94: ASSERT(Invariants()); 95: delete [] itsString; 96: itsLen = 0; 97: } 98: 99: // operator przypisania, zwalnia istniejącą pamięć, 100: // po czym kopiuje łańcuch i rozmiar 101: String& String::operator=(const String & rhs) 102: { 103: ASSERT(Invariants()); 104: if (this == &rhs) 105: return *this; 106: delete [] itsString; 107: itsLen=rhs.GetLen(); 108: itsString = new char[itsLen+1]; 109: for (int i = 0; i<itsLen;i++) 110: itsString[i] = rhs[i]; 111: itsString[itsLen] = '\0'; 112: ASSERT(Invariants()); 113: return *this; 114: } 115: 116: // nie const operator indeksu 117: char & String::operator[](int offset) 118: { 119: ASSERT(Invariants()); 120: if (offset > itsLen) 121: {
Usunięto: i

122: ASSERT(Invariants()); 123: return itsString[itsLen-1]; 124: } 125: else 126: { 127: ASSERT(Invariants()); 128: return itsString[offset]; 129: } 130: } 131: 132: // const operator indeksu 133: char String::operator[](int offset) const 134: { 135: ASSERT(Invariants()); 136: char retVal; 137: if (offset > itsLen) 138: retVal = itsString[itsLen-1]; 139: else 140: retVal = itsString[offset]; 141: ASSERT(Invariants()); 142: return retVal; 143: } 144: 145: BOOL String::Invariants() const 146: { 147: #ifdef SHOW_INVARIANTS 148: cout << "String OK "; 149: #endif 150: return ( (itsLen && itsString) || (!itsLen && !itsString) ); 151: } 152: 153: class Animal 154: { 155: public: 156: Animal():itsAge(1),itsName("John Q. Animal") 157: {ASSERT(Invariants());} 158: Animal(int, const String&); 159: ~Animal(){} 160: int GetAge() { ASSERT(Invariants()); return itsAge;} 161: void SetAge(int Age) 162: { 163: ASSERT(Invariants()); 164: itsAge = Age; 165: ASSERT(Invariants()); 166: } 167: String& GetName() 168: { 169: ASSERT(Invariants()); 170: return itsName; 171: } 172: void SetName(const String& name) 173: { 174: ASSERT(Invariants()); 175: itsName = name; 176: ASSERT(Invariants()); 177: } 178: BOOL Invariants(); 179: private: 180: int itsAge; 181: String itsName; 182: };

183: 184: Animal::Animal(int age, const String& name): 185: itsAge(age), 186: itsName(name) 187: { 188: ASSERT(Invariants()); 189: } 190: 191: BOOL Animal::Invariants() 192: { 193: #ifdef SHOW_INVARIANTS 194: cout << "Animal OK "; 195: #endif 196: return (itsAge > 0 && itsName.GetLen()); 197: } 198: 199: int main() 200: { 201: Animal sparky(5,"Sparky"); 202: cout << "\n" << sparky.GetName().GetString() << " ma "; 203: cout << sparky.GetAge() << " lat."; 204: sparky.SetAge(8); 205: cout << "\n" << sparky.GetName().GetString() << " ma "; 206: cout << sparky.GetAge() << " lat."; 207: return 0; 208: }
Wynik String OK String OK String OK String OK String OK String OK String OK String OK String OK String OK String OK String OK String OK String OK Animal OK String OK Animal OK Sparky ma Animal OK 5 lat.Animal OK Animal OK Animal OK Sparky ma Animal OK 8 lat.String OK
Analiza
W liniach od 9. do 15. zostało zdefiniowane makro ASSERT(). Gdy jest zdefiniowany symbol DEBUG, i gdy argument makra assert() przyjmie wartość FALSE, wypisany zostanie komunikat błędu.
W linii 30. została zadeklarowana metoda Invariants() klasy String; jej definicja znajduje się w liniach od 145. do 151. Konstruktor jest zdefiniowany w liniach od 49. do 55.; w linii 54., po pełnym skonstruowaniu obiektu (w celu potwierdzenia poprawnego konstruowania) zostaje wywołana metoda Invariants().
Ten wzór powtarza się także dla innych konstruktorów, lecz destruktor wywołuje metodę Invariants() tylko przed zniszczeniem obiektu. Pozostałe funkcje klasy wywołują tę metodę przed podjęciem jakichś działań i ponownie przed powrotem z funkcji. To zapewnia nam zgodność z fundamentalną zasadą języka C++: funkcje składowe inne niż konstruktory i destruktory powinny operować na poprawnie skonstruowanych obiektach i powinny pozostawiać je w poprawnym stanie.
Usunięto: to w przypadku nie spełnienia warunku,
Usunięto: uje
Usunięto: 3
Usunięto: 0

W linii 178. klasa Animal deklaruje własną metodę Invariants(), zaimplementowaną w liniach od 191. do 197. Zwróć uwagę, że w liniach 157., 160., 163. oraz 165. funkcje inline także mogą wywoływać metodę Invariants().
Wypisywanie wartości tymczasowych Po sprawdzeniu za pomocą makra assert(), czy wszystkie warunki zostały spełnione, możemy zechcieć także wypisać bieżące wartości znaczników, zmiennych i łańcuchów. To może być bardzo przydatne przy sprawdzaniu naszych założeń co do postępowania programu i lokalizowaniu błędów przekroczenia zakresów w pętlach. Ideę tę ilustruje listing 21.6.
Listing 21.6. Wypisywanie wartości w trybie debuggowania 0: // Listing 21.6 - Wypisywanie wartości w trybie debuggowania 1: #include <iostream> 2: using namespace std; 3: #define DEBUG 4: 5: #ifndef DEBUG 6: #define PRINT(x) 7: #else 8: #define PRINT(x) \ 9: cout << #x << ":\t" << x << endl; 10: #endif 11: 12: enum BOOL { FALSE, TRUE } ; 13: 14: int main() 15: { 16: int x = 5; 17: long y = 73898l; 18: PRINT(x); 19: for (int i = 0; i < x; i++) 20: { 21: PRINT(i); 22: } 23: 24: PRINT (y); 25: PRINT("Hi."); 26: int *px = &x; 27: PRINT(px); 28: PRINT (*px); 29: return 0; 30: }
Wynik x: 5 i: 0 i: 1 i: 2 i: 3 i: 4
Usunięto: 6
Usunięto: 89
Usunięto: 5
Usunięto: 5
Usunięto: 58
Usunięto: 1
Usunięto: 3
Usunięto: że

y: 73898 "Hi.": Hi. px: 0x2100 *px: 5
Analiza
Makro w liniach od 5. do 10. zapewnia wypisanie bieżącej wartości dostarczonego mu parametru. Zwróć uwagę, że najpierw dostarczana jest zamieniona na łańcuch wersja parametru, tj. jeśli dostarczymy x, otrzymujemy "x".
Następnie cout otrzymuje ujęty w cudzysłowy łańcuch, ":\t", który powoduje wypisanie dwukropka oraz odsunięcie odpowiadające wielkością znakowi tabulacji. Po trzecie, cout otrzymuje wartość parametru (x) oraz ostatecznie endl, które powoduje przejście do nowej linii i opróżnienie bufora.
W swoich wynikach możesz mieć otrzymać inną niż 0x2100.
Poziomy debuggowania W dużych, złożonych projektach możemy zażądać większej kontroli, nie tylko włączania lub wyłączania trybu debuggowania. Możemy definiować poziomy debuggowania i sprawdzać je decydując, którego makra użyć, a które pominąć.
Aby zdefiniować poziom, po prostu wpisz liczbę po instrukcji #define DEBUG. Choć można dysponować dowolną ilością poziomów, jednak najczęściej stosuje się cztery: HIGH (wysoki), MEDIUM (pośredni), LOW (niski) oraz NONE (bez debuggowania). Sposób zastosowania tych poziomów ilustruje listing 21.7, wykorzystane zostały w tym celu klasy String i Animal z listingu 21.5.
Listing 21.7. Poziomy debuggowania 0: enum LEVEL { NONE, LOW, MEDIUM, HIGH }; 1: const int FALSE = 0; 2: const int TRUE = 1; 3: typedef int BOOL; 4: 5: #define DEBUGLEVEL HIGH 6: 7: #include <iostream.h> 8: #include <string.h> 9: 10: #if DEBUGLEVEL < LOW // musi być MEDIUM lub HIGH 11: #define ASSERT(x) 12: #else 13: #define ASSERT(x) \ 14: if (! (x)) \ 15: { \ 16: cout << "BLAD!! Asercja " << #x << " nie jest spelniona.\n"; \ 17: cout << " W linii " << __LINE__ << "\n"; \
Usunięto: u
18: cout << " w pliku " << __FILE__ << "\n"; \ 19: } 20: #endif 21: 22: #if DEBUGLEVEL < MEDIUM 23: #define EVAL(x) 24: #else 25: #define EVAL(x) \ 26: cout << #x << ":\t" << x << endl; 27: #endif 28: 29: #if DEBUGLEVEL < HIGH 30: #define PRINT(x) 31: #else 32: #define PRINT(x) \ 33: cout << x << endl; 34: #endif 35: 36: 37: class String 38: { 39: public: 40: // konstruktory 41: String(); 42: String(const char *const); 43: String(const String &); 44: ~String(); 45: 46: char & operator[](int offset); 47: char operator[](int offset) const; 48: 49: String & operator= (const String &); 50: int GetLen()const { return itsLen; } 51: const char * GetString() const 52: { return itsString; } 53: BOOL Invariants() const; 54: 55: private: 56: String (int); // prywatny konstruktor 57: char * itsString; 58: unsigned short itsLen; 59: }; 60: 61: // domyślny konstruktor tworzy łańcuch pusty (o długości 0 bajtów) 62: String::String() 63: { 64: itsString = new char[1]; 65: itsString[0] = '\0'; 66: itsLen=0; 67: ASSERT(Invariants()); 68: } 69: 70: // prywatny (pomocniczy) konstruktor, używany tylko przez 71: // metody klasy do tworzenia nowego łańcucha 72: // o żądanej długości, wypełnionego znakami null. 73: String::String(int len) 74: { 75: itsString = new char[len+1]; 76: for (int i = 0; i<=len; i++) 77: itsString[i] = '\0';
Usunięto: zera

78: itsLen=len; 79: ASSERT(Invariants()); 80: } 81: 82: // Konwertuje tablicę znaków w obiekt String 83: String::String(const char * const cString) 84: { 85: itsLen = strlen(cString); 86: itsString = new char[itsLen+1]; 87: for (int i = 0; i<itsLen; i++) 88: itsString[i] = cString[i]; 89: itsString[itsLen]='\0'; 90: ASSERT(Invariants()); 91: } 92: 93: // konstruktor kopiujący 94: String::String (const String & rhs) 95: { 96: itsLen=rhs.GetLen(); 97: itsString = new char[itsLen+1]; 98: for (int i = 0; i<itsLen;i++) 99: itsString[i] = rhs[i]; 100: itsString[itsLen] = '\0'; 101: ASSERT(Invariants()); 102: } 103: 104: // destruktor, zwalnia zaalokowaną pamięć 105: String::~String () 106: { 107: ASSERT(Invariants()); 108: delete [] itsString; 109: itsLen = 0; 110: } 111: 112: // operator przypisania, zwalnia istniejącą pamięć, 113: // po czym kopiuje łańcuch i rozmiar 114: String& String::operator=(const String & rhs) 115: { 116: ASSERT(Invariants()); 117: if (this == &rhs) 118: return *this; 119: delete [] itsString; 120: itsLen=rhs.GetLen(); 121: itsString = new char[itsLen+1]; 122: for (int i = 0; i<itsLen;i++) 123: itsString[i] = rhs[i]; 124: itsString[itsLen] = '\0'; 125: ASSERT(Invariants()); 126: return *this; 127: } 128: 129: // nie const operator indeksu 130: char & String::operator[](int offset) 131: { 132: ASSERT(Invariants()); 133: if (offset > itsLen) 134: { 135: ASSERT(Invariants()); 136: return itsString[itsLen-1]; 137: } 138: else
Usunięto: i

139: { 140: ASSERT(Invariants()); 141: return itsString[offset]; 142: } 143: } 144: 145: // const operator indeksu 146: char String::operator[](int offset) const 147: { 148: ASSERT(Invariants()); 149: char retVal; 150: if (offset > itsLen) 151: retVal = itsString[itsLen-1]; 152: else 153: retVal = itsString[offset]; 154: ASSERT(Invariants()); 155: return retVal; 156: } 157: 158: BOOL String::Invariants() const 159: { 160: PRINT("(Niezmienniki klasy String sprawdzone)"); 161: return ((BOOL)(itsLen&&itsString)||(!itsLen&&!itsString)); 162: } 163: 164: class Animal 165: { 166: public: 167: Animal():itsAge(1),itsName("John Q. Animal") 168: {ASSERT(Invariants());} 169: 170: Animal(int, const String&); 171: ~Animal(){} 172: 173: int GetAge() 174: { 175: ASSERT(Invariants()); 176: return itsAge; 177: } 178: 179: void SetAge(int Age) 180: { 181: ASSERT(Invariants()); 182: itsAge = Age; 183: ASSERT(Invariants()); 184: } 185: String& GetName() 186: { 187: ASSERT(Invariants()); 188: return itsName; 189: } 190: 191: void SetName(const String& name) 192: { 193: ASSERT(Invariants()); 194: itsName = name; 195: ASSERT(Invariants()); 196: } 197: 198: BOOL Invariants(); 199: private:

200: int itsAge; 201: String itsName; 202: }; 203: 204: Animal::Animal(int age, const String& name): 205: itsAge(age), 206: itsName(name) 207: { 208: ASSERT(Invariants()); 209: } 210: 211: BOOL Animal::Invariants() 212: { 213: PRINT("(Niezmienniki klasy Animal sprawdzone)"); 214: return (itsAge > 0 && itsName.GetLen()); 215: } 216: 217: int main() 218: { 219: const int AGE = 5; 220: EVAL(AGE); 221: Animal sparky(AGE,"Sparky"); 222: cout << "\n" << sparky.GetName().GetString(); 223: cout << " ma "; 224: cout << sparky.GetAge() << " lat."; 225: sparky.SetAge(8); 226: cout << "\n" << sparky.GetName().GetString(); 227: cout << " ma "; 228: cout << sparky.GetAge() << " lat."; 229: return 0; 230: }
Wynik AGE: 5 (Niezmienniki klasy String sprawdzone) (Niezmienniki klasy String sprawdzone) (Niezmienniki klasy String sprawdzone) (Niezmienniki klasy String sprawdzone) (Niezmienniki klasy String sprawdzone) (Niezmienniki klasy String sprawdzone) (Niezmienniki klasy String sprawdzone) (Niezmienniki klasy String sprawdzone) (Niezmienniki klasy String sprawdzone) (Niezmienniki klasy String sprawdzone) (Niezmienniki klasy String sprawdzone) (Niezmienniki klasy String sprawdzone) (Niezmienniki klasy String sprawdzone) (Niezmienniki klasy String sprawdzone) (Niezmienniki klasy Animal sprawdzone) (Niezmienniki klasy String sprawdzone) (Niezmienniki klasy Animal sprawdzone) Sparky ma (Niezmienniki klasy Animal sprawdzone) 5 lat.(Niezmienniki klasy Animal sprawdzone) (Niezmienniki klasy Animal sprawdzone) (Niezmienniki klasy Animal sprawdzone)

Sparky ma (Niezmienniki klasy Animal sprawdzone) 8 lat.(Niezmienniki klasy String sprawdzone) // Uruchomiony ponownie z DEBUG = MEDIUM AGE: 5 Sparky ma 5 lat. Sparky ma 8 lat.
Analiza
W liniach od 10. do 20. makro ASSERT() zostało zdefiniowane tak, by w sytuacji, w której symbol DEBUGLEVEL jest mniejszy od LOW (tj. gdy jest zdefiniowany jako NONE), nie generowało żadnego kodu. Gdy jest włączony jakikolwiek wyższy poziom debuggowania, makro ASSERT() działa. W linii 22. makro EVAL() jest zdefiniowane jako nie generujące żadnego kodu, gdy symbol DEBUGLEVEL jest mniejszy od MEDIUM; gdy DEBUGLEVEL ma wartość NONE lub LOW, makro EVAL() jest pomijane.
Na koniec, w liniach od 29. do 34. makro PRINT() jest deklarowane jako pomijane, gdy DEBUGLEVEL ma wartość mniejszą niż HIGH. Makro PRINT() jest używane tylko wtedy, gdy symbol DEBUGLEVEL jest zdefiniowany jako HIGH; możemy je wyeliminować i jednocześnie korzystać z makr EVAL() i ASSERT(), definiując symbol DEBUGLEVEL jako MEDIUM.
Makro PRINT() jest używane w metodach Invariants() do wypisywania komunikatu informacyjnego. Makro EVAL() zostało użyte w linii 220. do obliczenia bieżącej wartości stałej całkowitej AGE.
TAK NIE
W nazwach makr używaj WIELKICH LITER. To powszechnie stosowana konwencja i jeśli nie będziesz jej przestrzegał, wprowadzisz w błąd innych programistów.
W funkcjach makro umieszczaj wszystkie argumenty w okrągłych nawiasach.
Nie pozwalaj, by twoje makra debuggowania powodowały efekty uboczne. Nie inkrementuj w nich zmiennych, ani nie przypisuj im wartości.
Operacje na bitach Często zdarza się, że musimy ustawić znaczniki w obiekcie, aby na bieżąco znać stan tego obiektu. (Czy jest w stanie alarmu? Czy został już zainicjalizowany?)
Można to osiągnąć, korzystając z własnych zmiennych logicznych, ale przy dużej ilości znaczników i w przypadkach, gdy ilość zajmowanej pamięci ma duże znaczenie, wygodne jest używanie jako znaczników poszczególnych bitów.
Usunięto: 1
Usunięto: 1
Usunięto: 30
Usunięto: 5

Każdy bajt zawiera osiem bitów, więc czterobajtowy typ long może zmieścić trzydzieści dwa osobne znaczniki. Mówimy, że bit jest „ustawiony”, gdy ma wartość 1, a wyzerowany gdy ma — jak można się domyślić — wartość 0. Bity możemy ustawiać i zerować zmieniając wartość typu long, ale może to być żmudna i podatna na błędy operacja.
UWAGA Dodatkowe informacje na temat systemu dwójkowego i szesnastkowego znajdziesz w dodatku A.
C++ dostarcza operatorów bitowych, które działają na poszczególnych bitach. Wyglądają one podobnie (choć są czymś innym) , jak operatory logiczne, więc wielu początkujących programistów myli je ze sobą. Operatory bitowe zostały przedstawione w tabeli 21.1.
Tabela 21.1. Operatory bitowe
Symbol Operator
& AND
| OR
^ XOR
~ Negacja bitowa
Operator AND Operator bitowy AND (I) to pojedynczy znak ampersand (&) — w odróżnieniu od logicznego AND, którego symbol składa się z dwóch takich znaków. Gdy wykonujemy operację AND na dwóch bitach, wynikiem jest 1, gdy oba bity są ustawione, a w przeciwnym przypadku zero. Gdy jeden lub oba bity są wyzerowane, wynikiem operatora AND jest zero.
Operator OR Drugim operatorem bitowym jest operator OR (LUB). Także ten operator składa się z pojedynczego znaku (|) — w odróżnieniu od operatora logicznego, który składa się z dwóch znaków (||). Gdy wykonujemy operację OR na dwóch bitach, wynikiem jest 1, gdy jeden lub oba bity są ustawione. Wynik zero otrzymujemy tylko wtedy, gdy oba bity są wyzerowane.
Usunięto: w

Operator XOR Trzeci operator bitowy to XOR (WYŁĄCZNIE-LUB), którego symbolem jest tzw. daszek (^). Gdy XOR-ujemy dwa bity, otrzymujemy wynik 1wtedy, gdy oba bity mają różne od siebie stany. Gdy stan obu bitów jest jednakowy, otrzymujemy wynik zero.
Operator negacji Operator negacji, oznaczony znakiem tyldy (~), zmienia stan każdego z bitów w swoim argumencie na przeciwny. Jeśli bieżącą wartością argumentu jest 1010 0011, to po negacji wartością tą będzie 0101 1100.
Ustawianie bitów Gdy chcemy ustawić lub wyzerować określony bit, używamy maski bitowej. Gdy mamy czterobajtowy znacznik i chcemy ustawić bit 8, musimy wykonać operację OR z wartością maski wynoszącą 128. Dlaczego? 128 to binarnie 1000 0000, więc wartość ósmego bitu wynosi 128. Bez względu na bieżącą wartość tego bitu, gdy wykonamy operację OR z wartością 128, ustawimy ten bit, nie zmieniając stanu żadnego innego bitu. Załóżmy, że bieżącą wartością bitową naszego argumentu jest 1010 0110 0010 0110. Wykonanie operacji OR z wartością 128 będzie wtedy wyglądać następująco:
8765 4321 1010 0110 0010 0110 // bit 8 jest wyzerowany | 0000 0000 1000 0000 // wartość 128 ====================== 1010 0110 1010 0110 // bit 8 jest ustawiony
Zwróć uwagę na kilka rzeczy. Po pierwsze, jak zwykle, bity są liczone od strony prawej do lewej. Po drugie, wartość 128 ma ustawiony tylko jeden bit, ósmy, czyli ten, który chcieliśmy ustawić w argumencie. Po trzecie, wartość bitów w argumencie 1010 0110 0010 0110, z wyjątkiem ustawienia ósmego bitu, nie zmienia się w wyniku przeprowadzenia operacji OR. Gdyby bit ósmy był już wcześniej ustawiony, wtedy pozostałby ustawiony tak, jakbyśmy sobie tego życzyli.
Zerowanie bitów Gdy zechcemy wyzerować bit ósmy, możemy użyć operacji AND z zanegowaną wartością 128. Negacją wartości 128 jest wartość, którą otrzymamy, zmieniając stan wszystkich bitów tej wartości (1000 0000) na przeciwny, tj. na wartość 0111 1111. Gdy użyjemy tej maski w operacji AND z argumentem, pozostawimy bez zmian wszystkie bity, poza bitem ósmym, który zostanie wyzerowany.

8765 4321 1010 0110 1010 0110 // bit 8 jest ustawiony & 1111 1111 0111 1111 // wartość ~128 ====================== 1010 0110 0010 0110 // bit 8 jest wyzerowany
Aby w pełni zrozumieć ten proces, wykonaj obliczenia sam. Za każdym razem, gdy oba bity są jedynkami, zapisz w wyniku jedynkę. Porównaj wynik z pierwotnym argumentem. Powinien być taki sam, lecz z wyzerowanym ósmym bitem. Zwróć także uwagę na rozmiary argumentów. Aby uzyskać ten wynik, musieliśmy użyć szesnastobitowej maski.
Zmiana stanu bitów na przeciwny Na koniec, gdy chcemy jedynie zmienić stan bitu ósmego, musimy wykonać operację XOR z argumentem 128. Tak więc:
8765 4321 1010 0110 1010 0110 // argument ^ 0000 0000 1000 0000 // wartość 128 ================= 1010 0110 0010 0110 // bit 8 zmieniony ^ 0000 0000 1000 0000 // wartość 128 ================= 1010 0110 1010 0110 // bit 8 ponownie zmieniony
TAK NIE
Do ustawiania bitów używaj maski i operatora OR.
Do zerowania bitów używaj maski i operatora AND.
Do negowania stanu bitów używaj maski i operatora XOR.
Pola bitowe W pewnych warunkach może liczyć się każdy bit i zaoszczędzenie sześciu czy ośmiu bitów w klasie może stanowić dla użytkownika zasadniczą różnicę. Jeśli klasa lub struktura zawiera serię zmiennych logicznych lub zmiennych przechowujących tylko kilka możliwych wartości, możemy zaoszczędzić nieco miejsca, używając pól bitowych.
Kiedy używamy standardowych typów danych w C++, najmniejszym typem, jaki możemy umieścić w klasie, jest typ char, składający się z pojedynczego bajtu. Zwykle jednak używamy
Usunięto: ustawiania
Usunięto: zmiany

typu int, który może składać się z dwóch lub częściej czterech bajtów. Używając pól bitowych możemy zmieścić w typie char osiem wartości bitowych, a w typie long trzydzieści dwie wartości.
Oto sposób działania pola bitowego: pole bitowe zostaje nazwane i jest dostępne tak samo, jak inne składowe klasy. Ich typem jest zawsze unsigned int. Po nazwie pola bitowego zapisujemy dwukropek oraz liczbę. Ta liczba informuje kompilator, ile bitów ma przydzielić zmiennej. Jeśli napiszemy 1, pole będzie reprezentowało wartość zero lub jeden. Jeśli napiszemy 2, będzie mogło zawierać łącznie cztery wartości: 0, 1, 2 lub 3. Trzybitowe pole może zawierać osiem wartości i tak dalej. Wartości binarne zostaną przedstawione w dodatku A. Użycie pól bitowych ilustruje listing 21.8.
Listing 21.8. Użycie pól bitowych 0: #include <iostream> 1: using namespace std; 2: #include <string.h> 3: 4: enum STATUS { FullTime, PartTime } ; 5: enum GRADLEVEL { UnderGrad, Grad } ; 6: enum HOUSING { Dorm, OffCampus }; 7: enum FOODPLAN { OneMeal, AllMeals, WeekEnds, NoMeals }; 8: 9: class student 10: { 11: public: 12: student(): 13: myStatus(FullTime), 14: myGradLevel(UnderGrad), 15: myHousing(Dorm), 16: myFoodPlan(NoMeals) 17: {} 18: ~student(){} 19: STATUS GetStatus(); 20: void SetStatus(STATUS); 21: unsigned GetPlan() { return myFoodPlan; } 22: 23: private: 24: unsigned myStatus : 1; 25: unsigned myGradLevel: 1; 26: unsigned myHousing : 1; 27: unsigned myFoodPlan : 2; 28: }; 29: 30: STATUS student::GetStatus() 31: { 32: if (myStatus) 33: return FullTime; 34: else 35: return PartTime; 36: } 37: 38: void student::SetStatus(STATUS theStatus) 39: { 40: myStatus = theStatus; 41: } 42: 43: int main()

44: { 45: student Jim; 46: 47: if (Jim.GetStatus()== PartTime) 48: cout << "Jim pracuje na pol etatu" << endl; 49: else 50: cout << "Jim pracuje na caly etat" << endl; 51: 52: Jim.SetStatus(PartTime); 53: 54: if (Jim.GetStatus()) 55: cout << "Jim pracuje na pol etatu" << endl; 56: else 57: cout << "Jim pracuje na caly etat" << endl; 58: 59: cout << "Jim " ; 60: 61: char Plan[80]; 62: switch (Jim.GetPlan()) 63: { 64: case OneMeal: strcpy(Plan,"oplacil jeden posilek."); break; 65: case AllMeals: strcpy(Plan,"oplacil wszystkie posilki."); break; 66: case WeekEnds: strcpy(Plan,"oplacil posilki w weekend."); break; 67: case NoMeals: strcpy(Plan,"nie oplacil posilkow.");break; 68: default : cout << "Cos poszlo zle!\n"; break; 69: } 70: cout << Plan << endl; 71: return 0; 72: }
Wynik Jim pracuje na pol etatu Jim pracuje na caly etat Jim nie oplacil posilkow.
Analiza
W liniach od 4. do 7. zostało zdefiniowanych kilka typów wyliczeniowych. Służą one do definiowania wartości dla pól bitowych w klasie student.
Klasa student jest zadeklarowana w liniach od 9. do 28. Choć sama klasa jest dość banalna, jednak interesujący jest fakt, iż wszystkie dane zostały „upakowane” w pięciu bitach. Pierwszy bit reprezentuje pracę studenta, na pół etatu lub na cały etat. Drugi bit określa, czy są to studia podyplomowe. Trzeci bit określa, czy student mieszka w akademiku. Dwa ostatnie bity reprezentują cztery możliwe sposoby korzystania z posiłków.
Metody klasy są zapisane tak, jak w każdej innej klasie i nie zmienia tego fakt, że dane klasy są polami bitowymi, a nie zmiennymi całkowitymi czy typami wyliczeniowymi.
Funkcja składowa GetStatus() odczytuje stan bitu i zwraca typ wyliczeniowy, ale nie jest to konieczne. Równie dobrze mogłaby zwracać wartość tego bitu bezpośrednio. Kompilator dokonałby odpowiedniej translacji automatycznie.
Aby to sprawdzić, zastąp implementację funkcji GetStatus() następującym kodem:

STATUS student::GetStatus() { return myStatus; }
W działaniu programu nie powinna nastąpić żadna zmiana. Jest to zagadnienie przejrzystości programu i nie sprawia kompilatorowi żadnej różnicy.
Zwróć uwagę, że kod w linii 47. musi sprawdzić stan, a następnie wypisać sensowny komunikat. Chciałoby się teraz napisać:
cout << "Jim pracuje na " << Jim.GetStatus() << endl;
ale w ten sposób wypiszemy po prostu:
Jim pracuje na 0
Kompilator nie ma sposobu na translację stałej wyliczeniowej PartTime na odpowiedni tekst komunikatu.
W linii 62. program przełącza się (w zależności od sposobu opłacania posiłków) i dla każdej możliwej wartości umieszcza w buforze odpowiedni komunikat, wypisywany dalej w linii 70. Zwróć uwagę, że instrukcja switch mogłaby zostać zapisana następująco:
case 0: strcpy(Plan,"oplacil jeden posilek."); break; case 1: strcpy(Plan,"oplacil wszystkie posilki."); break; case 2: strcpy(Plan,"oplacil posilki w weekend."); break; case 3: strcpy(Plan,"nie oplacil posilkow.");break;
Najważniejszą zaletą używania pól bitowych w klasie jest to, że klient klasy nie musi interesować się szczegółami implementacji przechowywania danych. Ponieważ pola bitowe mogą być prywatne, możemy je później dowolnie modyfikować, bez potrzeby zmiany samego interfejsu.
Styl Jak już wcześniej wspominałem, należy przyjąć spójny styl kodowania. W większości przypadków nie ma znaczenia jaki to będzie styl. Jednolity styl ułatwia odgadnięcie, do czego ma służyć określony fragment kodu i uniknięcie sprawdzania za każdym razem, czy nazwa funkcja rozpoczyna się od dużej, czy od małej litery.

Przedstawione tu zalecenia nie są obowiązkowe; zostały one oparte na wytycznych używanych w projektach, nad którymi pracowałem w przeszłości i które się sprawdziły. Możesz stworzyć własny styl zapisu, ale styl opisany tutaj może stanowić pewien punkt wyjścia.
Jak wiadomo, uporczywe trzymanie się reguł jest cechą małych umysłów, ale utrzymywanie spójności kodu jest rzeczą godną pochwały. Stwórz własny styl, ale potem traktuj go, jakby został zesłany przez boga programistów.
Wcięcia Rozmiar tabulatorów powinien być ustawiony na cztery spacje. Upewnij się, czy twój edytor stosuje dla tabulatorów cztery spacje.
Nawiasy klamrowe Sposób ułożenia nawiasów klamrowych może powodować najwięcej kontrowersji pomiędzy programistami C i C++. Oto kilka moich rad:
• odpowiadające sobie nawiasy klamrowe powinny być wyrównane w pionie;
• najbardziej zewnętrzna para nawiasów klamrowych w definicji lub deklaracji powinna występować przy lewym marginesie. Zawarte wewnątrz niej instrukcje powinny być wcięte. Wszystkie inne pary nawiasów klamrowych powinny być zrównane z ich wiodącymi instrukcjami;
• żaden kod nie powinien występować w tej samej linii, co nawias klamrowy. Na przykład:
if (warunek == true) { j = k; SomeFunction(); } m++;
Długość linii Staraj się utrzymać długość linii tak, aby mieściły się w szerokości ekranu. Kod znajdujący się poza prawą krawędzią ekranu zwykle zostaje przeoczony, a przesuwanie w poziomie jest irytujące. Gdy linia zostanie podzielona, dla następnych części zastosuj wcięcia. Spróbuj dzielić linię w sensownym miejscu i postaraj się pozostawiać operator na końcu poprzedniej linii (a nie na początku następnej), tak, aby zaznaczyć, że nie jest to jej koniec i że dalej pojawi się coś jeszcze.
Usunięto: Pasujące
Usunięto: do sie
Usunięto: oz
Usunięto: m
Usunięto: jest

W C++ funkcje zwykle są dużo krótsze niż w C, ale stare zalecenia wciąż są aktualne. Staraj się by funkcje były krótkie, a także by pojedyncza funkcja nie zajmowała więcej niż jedną stronę wydruku.
Instrukcje switch W celu zaoszczędzenia miejsca „w poziomie”, instrukcje switch wcinaj w następujący sposób:
switch(zmienna) { case ValueOne: ActionOne(); break; case ValueTwo: ActionTwo(); break; default: assert("zla Akcja"); break; }
Tekst programu Możesz skorzystać z kilku rad, które ułatwią ci tworzenie kodu łatwego w czytaniu. Kod łatwy w czytaniu jest równocześnie łatwy w utrzymaniu.
• W celu poprawienia czytelności kodu używaj białych spacji.
• Obiekty i tablice odnoszą się do tego samego. Nie używaj spacji w odwołaniach do obiektu (., ->, []).
• Operatory unarne (jednoargumentowe) są powiązane ze swoimi operandami, więc nie umieszczaj pomiędzy nimi spacji. Umieszczaj spację po drugiej stronie operandu. Do operatorów unarnych należą !, ~, ++, ––, –, * (dla wskaźników), & (adresu), sizeof.
• Operatory binarne powinny mieć po obu stronach spacje: +, =, *, /, %, >>, <<, <, >, ==, !=, &, |, &&, ||, ?:, =, += i tak dalej.
• Nie używaj spacji do wskazania kolejności działań (4+ 3*2).
• Umieszczaj spacje po przecinkach i średnikach, a nie przed nimi.
• Po obu stronach nawiasów nie powinno być spacji.
• Słowa kluczowe, takie jak if, powinny być oddzielone spacjami: if (a == b).
Usunięto: rzeczy
• Ciało komentarza powinno być oddzielone od znaków // spacją.
• Umieszczaj symbol wskaźnika lub referencji przy nazwie typu, a nie przy nazwie zmiennej:
char* foo; int& theInt;
zamiast
char *foo; int &theInt;
• Nie deklaruj w tej samej linii więcej niż jednej zmiennej.
Nazwy identyfikatorów Oto zalecenia dotyczące pracy z identyfikatorami.
• Nazwy identyfikatorów powinny być opisowe.
• Unikaj zaszyfrowanych skrótów.
• Poświęć czas i energię na nadawanie rzeczom nazw.
• Nie używaj notacji węgierskiej. C++ jest językiem o silnej kontroli typów i nie ma powodu, by umieszczać typ w nazwie zmiennej. Przy typach zdefiniowanych przez użytkownika (klasach), notacja węgierska przestaje się sprawdzać. Wyjątkiem może być użycie przedrostków dla wskaźników (p), referencji (r) oraz dla zmiennych składowych klasy (its).
• Krótkie nazwy (i, p, x itd.) powinny być używane tylko tam, gdzie ich skrótowość zwiększa czytelność kodu i gdzie ich przeznaczenie jest tak oczywiste, że nazwa opisowa jest zbędna.
• Długość nazwy zmiennej powinna być proporcjonalna do jej zakresu.
• Spraw, by identyfikatory znacznie różniły się od siebie, tak, aby nie można było ich pomylić.
• Nazwy funkcji (lub metod) stanowią zwykle czasowniki lub połączenia czasowników z rzeczownikiem: Search(), Reset(), FindParagraph(), ShowCursor(). Nazwy zmiennych są zwykle rzeczownikami abstrakcyjnymi, być może z dodatkowym rzeczownikiem: count, state, windSpeed, windowHeight. Zmienne logiczne powinny być odpowiednio nazywane: windowIconized, fileIsOpen.
Usunięto: e

Pisownia nazw i zastosowanie w nich wielkich liter W trakcie tworzenia własnego stylu nie można zapomnieć o pisowni i stosowaniu wielkich liter. Oto kilka rad.
• Używaj wielkich liter i znaków podkreślenia do oddzielenia słów w symbolach definiowanych za pomocą dyrektywy #define, takich jak SOURCE_FILE_TEMPLATE. Zauważ jednak, że w C++ stosuje się je rzadko. W większości przypadków powinieneś stosować stałe i wzorce.
• Wszystkie inne identyfikatory powinny zawierać litery różnej wielkości i nie powinny zawierać podkreśleń. Nazwy funkcji, metod, klas, typedef i nazwy struktur powinny zaczynać się od wielkiej litery. Elementy takie, jak dane składowe lub zmienne lokalne powinny zaczynać się od małej litery.
• Stałe wyliczeniowe powinny zaczynać się od kilku małych liter, będących skrótem nazwy wyliczenia. Na przykład:
enum TextStyle { tsPlain, tsBold, tsItalic, tsUnderscore };
Komentarze Komentarze mogą bardzo pomóc w zrozumieniu programu. Czasami praca nad programem zostaje wstrzymana na kilka dni czy miesięcy. W tym czasie możesz zapomnieć, do czego służył dany kod lub dlaczego został zamieszczony. Problemy ze zrozumieniem kodu mogą wystąpić także wtedy, gdy czyta go ktoś inny. Komentarze w spójnym, dobrze przemyślanym stylu mogą być bardzo cenne dla użytkownika. Oto kilka porad.
• O ile to możliwe, używaj komentarzy w stylu C++ //, a nie w stylu /* */. Komentarze w stylu C (/* */) zarezerwuj dla wykomentowywania tych bloków kodu, które mogą zawierać komentarze w stylu C++.
• Komentarze bardziej ogólne są dużo ważniejsze niż komentarze opisujące szczegóły procesu. Dodawaj wartościowe informacje, a nie podsumowuj kodu.
n++; // n jest zwiększane o jeden
Ten komentarz nie jest wart nawet czasu, jaki zajmuje jego wpisanie. Skoncentruj się na semantyce funkcji i bloków kodu. Powiedz, co robi funkcja. Wskaż efekty uboczne, typ parametrów oraz zwracaną wartość. Opisz wszystkie dokonane założenia (lub nie dokonane),
Usunięto: wzorce
Usunięto: wyższego poziomu
Usunięto: ć
Usunięto: y

takie jak „zakłada się, że n nie jest ujemne” lub „zwraca –1, gdy x nie jest poprawne”. Przy złożonej logice, używaj komentarzy do wskazania warunków, które występują w danym miejscu kodu.
• Używaj pełnych zdań ze znakami przestankowymi i wielkimi literami. Dodatkowy wysiłek się opłaca. Nie stosuj szyfru i nie rozpisuj się. To, co wydaje się oczywiste w momencie pisania kodu, po kilku miesiącach może być zadziwiająco niezrozumiałe.
• Używaj wielu pustych linii, aby pomóc czytelnikowi w zrozumieniu, co się dzieje. Dziel instrukcje na logiczne grupy.
Dostęp Sposób, w jaki odwołujesz się do części programu, także powinien być spójny. Oto moje rady.
• Zawsze używaj etykiet public:, private: oraz protected:; nie polegaj na dostępie domyślnym.
• Na początku umieszczaj składowe publiczne, potem chronione, a następnie prywatne. Dane składowe umieszczaj w grupach, po metodach.
• Konstruktory umieszczaj jako pierwsze, w odpowiedniej sekcji, a po nich umieść destruktor. Przeciążone metody o tych samych nazwach umieszczaj obok siebie. O ile to możliwe, grupuj także funkcje akcesorów.
• Weź pod uwagę alfabetyczny układ metod w każdej z grup, postaraj się też ułożyć zmienne składowe alfabetycznie. Pamiętaj o alfabetycznym ułożeniu nazw plików w instrukcjach #include.
• Choć przy przesłanianiu metody słowo kluczowe virtual jest opcjonalne, używaj go zawsze; pomoże ci to w zapamiętaniu, że metoda jest wirtualna oraz w utrzymaniu spójności deklaracji.
Definicje klas Postaraj się utrzymać definicje metod w tej samej kolejności, w jakiej występują w klasie. Dzięki temu będziesz mógł je łatwiej znaleźć.
Przy definiowaniu funkcji umieść zwracany typ i wszystkie modyfikatory we wcześniejszej linii, tak, aby nazwa klasy i nazwa funkcji rozpoczynały się od lewego marginesu. To znacznie ułatwia odszukiwanie funkcji.
Dołączanie plików O ile to możliwe, staraj się unikać dołączania plików w plikach nagłówkowych. Idealnym minimum jest plik nagłówkowy klasy, z której została wyprowadzona klasa bieżąca. Innymi obowiązkowymi plikami nagłówkowymi są pliki zawierające deklaracje klas stanowiących obiekty składowe klasy bieżącej. Klasy, których obiekty są jedynie wskazywane lub używane poprzez referencje, wymagają jedynie deklaracji nazwy.
Nie rezygnuj z dołączenia pliku w pliku nagłówkowym tylko dlatego, że zakładasz, że każdy plik .cpp dołączający ten nagłówek będzie dołączał także wszystkie potrzebne pliki.
RADA Wszystkie pliki nagłówkowe powinny stosować wartowniki dołączania.
assert() Używaj często makra assert(). Pomaga ono w znajdowaniu błędów, ale także ułatwia czytelnikowi zorientowanie się w dokonywanych założeniach. Oprócz tego pomaga skoncentrować się na tym, co jest prawdziwe, a co nie.
const Używaj modyfikatora const wszędzie tam, gdzie powinien się znaleźć: przy parametrach, zmiennych i metodach. Często trzeba użyć metody występującej w dwóch wersjach: z modyfikatorem const oraz bez niego; nie traktuj tego jako wymówki, by zrezygnować z jednej z nich. Bądź bardzo uważny przy jawnym rzutowaniu z const do nie const i odwrotnie (czasem jest to jedyna metoda, aby coś zrobić) i miej pewność, że to ma sens. Opisz to także komentarzem.
Następne kroki Przeczytałeś już ponad dwadzieścia długich rozdziałów, pracując z C++ i jesteś już kompetentnym programistą tego języka. Nie myśl jednak, że na tym zakończyłeś edukację. Jest jeszcze wiele miejsc, w których możesz zyskać cenne informacje, mogące pomóc ci w przebyciu drogi od nowicjusza do eksperta w programowaniu.
Następne podrozdziały przedstawią ci kilka specyficznych źródeł informacji; zalecam tu jedynie te źródła, z których sam korzystałem. Na każdy z tych tematów napisano jednak tuziny książek, więc zanim je kupisz, postaraj się zasięgnąć opinii.
Usunięto: ego
Usunięto:
Usunięto: dowoli
Gdzie uzyskać pomoc i poradę Pierwszą rzeczą, jaką powinieneś zrobić jako programista C++, jest dołączenie do jednej z grup dyskusyjnych w Internecie. Te grupy umożliwiają natychmiastowy kontakt z setkami lub tysiącami programistów C++, którzy mogą odpowiedzieć na twoje pytanie, zaoferować radę lub ocenić twoje pomysły.
Uczestniczę w internetowych grupach dyskusyjnych C++ (comp.lang.c++ oraz comp.lang.c++.moderated) i polecam je jako wyśmienite źródło informacji i porad.
Oprócz tego, możesz poszukać lokalnych grup użytkowników. W wielu miastach istnieją grupy osób zainteresowanych C++, możesz spotkać tam innych programistów i wymieniać z nimi poglądy.
Przejść do C#? Nowa platforma .Net Microsoftu radykalnie zmienia sposób, w jaki wielu z nas tworzy programy dla Internetu. Kluczowym komponentem .Net jest nowy język C#.
C# jest naturalnym rozszerzeniem C++, więc dla programistów C++ przejście do tego języka nie stanowi większego problemu. Istnieje kilka dobrych książek o C#, lecz mam nadzieję, że sięgniesz do mojej najnowszej książki: Programming C# (O’Reilly press).
Bądź w kontakcie Jeśli masz komentarze, sugestie lub pomysły dotyczące tej lub innych książek, bardzo chciałbym się o nich dowiedzieć. Skontaktuj się ze mną poprzez moją witrynę WWW www.libertyassociates.com. Czekam na twoje wiadomości.
TAK NIE
Zaglądaj do innych książek. Jedna książka nie nauczy cię wszystkiego, co powinieneś wiedzieć.
Przyłącz się do dobrej grupy dyskusyjnej związanej z C++.
Samo czytanie kodu nie wystarcza! Najlepszą metodą nauczenia się C++ jest pisanie programów w tym języku.
Usunięto: ji
Usunięto: Nie czytaj w

Program podsumowujący wiadomości {uwaga korekta: to jest zawartość rozdziału „Week 3 In Review” }
W tym programie podsumowującym zostało zebranych w całość wiele zagadnień omawianych w poprzednich rozdziałach. Program zawiera opartą na wzorcach listę połączoną, w której zastosowano także obsługę wyjątków. Przejrzyj go dokładnie; jeśli w pełni go zrozumiesz, oznacza to, że jesteś programistą C++.
OSTRZEŻENIE Jeśli twój kompilator nie obsługuje wzorców lub nie obsługuje bloków try i catch, nie będziesz mógł skompilować i uruchomić tego programu.
Listing 21.9. Program podsumowujący wiadomości 0: // ************************************************** 1: // 2: // Tytuł: Program podsumowujący numer 3 3: // 4: // Plik: 4eList2109 5: // 6: // Opis: Program demonstruje tworzenie listy połączonej 7: // oraz obsługę wyjątków 8: // 9: // Klasy: PART - zawiera numery części oraz ewentualnie inne 10: // informacje o częściach. Jest to przykładowa 11: // klasa przechowywana w liście. 12: // Zwróć uwagę na użycie operatora<< do wypisywania 13: // informacji o części w oparciu o jej typ, 14: // sprawdzany podczas działania programu. 15: // 16: // Node - pełni rolę węzła listy 17: // 18: // List - oparta na wzorcu lista, która zapewnia 19: // mechanizm dla listy połączonej 20: // 21: // 22: // Autor: Jesse Liberty (jl) 23: // 24: // Opracowane na: Pentium 200 Pro. 128MB RAM MVC 5.0 25: // 26: // Cel: Niezależne od platformy 27: // 28: // Historia wersji: 9/94 - pierwsze wydanie (jl) 29: // 4/97 - aktualizacja (jl) 30: // ************************************************** 31: 32: #include <iostream>
Usunięto: wzorcach
Usunięto: wzorców
Usunięto: wzorcu

33: using namespace std; 34: 35: // klasy wyjątków 36: class Exception {}; 37: class OutOfMemory : public Exception{}; 38: class NullNode : public Exception{}; 39: class EmptyList : public Exception {}; 40: class BoundsError : public Exception {}; 41: 42: 43: // **************** Part ************ 44: // Abstrakcyjna klasa bazowa części 45: class Part 46: { 47: public: 48: Part():itsObjectNumber(1) {} 49: Part(int ObjectNumber):itsObjectNumber(ObjectNumber){} 50: virtual ~Part(){}; 51: int GetObjectNumber() const { return itsObjectNumber; } 52: virtual void Display() const =0; // musi być przesłonięte 53: 54: private: 55: int itsObjectNumber; 56: }; 57: 58: // implementacja czystej funkcji wirtualnej, dzięki czemu 59: // mogą z niej korzystać klasy pochodne 60: void Part::Display() const 61: { 62: cout << "\nNumer czesci: " << itsObjectNumber << endl; 63: } 64: 65: // Ten operator<< będzie wywoływany dla wszystkich obiektów części. 66: // Nie musi być funkcją zaprzyjaźnioną, gdyż nie odwołuje się do 67: // prywatnych danych. Wywołuje Display(), która używa 68: // polimorfizmu. Chcielibyśmy móc przesłonić go w oparciu o rzeczywisty 69: // typ zmiennej thePart, ale C++ nie obsługuje kontrawariancji. 70: ostream& operator<<( ostream& theStream,Part& thePart) 71: { 72: thePart.Display(); // wirtualna kontrawariancja! 73: return theStream; 74: } 75: 76: // **************** Część samochodu ************ 77: class CarPart : public Part 78: { 79: public: 80: CarPart():itsModelYear(94){} 81: CarPart(int year, int partNumber); 82: int GetModelYear() const { return itsModelYear; } 83: virtual void Display() const; 84: private: 85: int itsModelYear; 86: }; 87: 88: CarPart::CarPart(int year, int partNumber): 89: itsModelYear(year), 90: Part(partNumber) 91: {}
Usunięto: c

92: 93: void CarPart::Display() const 94: { 95: Part::Display(); 96: cout << "Rok modelu: " << itsModelYear << endl; 97: } 98: 99: // **************** Część samolotu ************ 100: class AirPlanePart : public Part 101: { 102: public: 103: AirPlanePart():itsEngineNumber(1){}; 104: AirPlanePart(int EngineNumber, int PartNumber); 105: virtual void Display() const; 106: int GetEngineNumber()const { return itsEngineNumber; } 107: private: 108: int itsEngineNumber; 109: }; 110: 111: AirPlanePart::AirPlanePart(int EngineNumber, int PartNumber): 112: itsEngineNumber(EngineNumber), 113: Part(PartNumber) 114: {} 115: 116: void AirPlanePart::Display() const 117: { 118: Part::Display(); 119: cout << "Nr silnika: " << itsEngineNumber << endl; 120: } 121: 122: // wstępna deklaracja klasy List 123: template <class T> 124: class List; 125: 126: // **************** Node ************ 127: // Węzeł ogólny, może być dodawany do listy 128: // ************************************ 129: 130: template <class T> 131: class Node 132: { 133: public: 134: friend class List<T>; 135: Node (T*); 136: ~Node(); 137: void SetNext(Node * node) { itsNext = node; } 138: Node * GetNext() const; 139: T * GetObject() const; 140: private: 141: T* itsObject; 142: Node * itsNext; 143: }; 144: 145: // Implamentacje klasy Node... 146: 147: template <class T> 148: Node<T>::Node(T* pOjbect): 149: itsObject(pOjbect), 150: itsNext(0) 151: {} 152:

153: template <class T> 154: Node<T>::~Node() 155: { 156: delete itsObject; 157: itsObject = 0; 158: delete itsNext; 159: itsNext = 0; 160: } 161: 162: // Gdy nie ma następnego węzła, zwraca NULL 163: template <class T> 164: Node<T> * Node<T>::GetNext() const 165: { 166: return itsNext; 167: } 168: 169: template <class T> 170: T * Node<T>::GetObject() const 171: { 172: if (itsObject) 173: return itsObject; 174: else 175: throw NullNode(); 176: } 177: 178: // **************** List ************ 179: // Ogólny wzorzec listy 180: // Działa z każdym obiektem numerowanym 181: // *********************************** 182: template <class T> 183: class List 184: { 185: public: 186: List(); 187: ~List(); 188: 189: T* Find(int & position, int ObjectNumber) const; 190: T* GetFirst() const; 191: void Insert(T *); 192: T* operator[](int) const; 193: int GetCount() const { return itsCount; } 194: private: 195: Node<T> * pHead; 196: int itsCount; 197: }; 198: 199: // Implementacje dla list... 200: template <class T> 201: List<T>::List(): 202: pHead(0), 203: itsCount(0) 204: {} 205: 206: template <class T> 207: List<T>::~List() 208: { 209: delete pHead; 210: } 211: 212: template <class T> 213: T* List<T>::GetFirst() const
Usunięto: wzorzec

214: { 215: if (pHead) 216: return pHead->itsObject; 217: else 218: throw EmptyList(); 219: } 220: 221: template <class T> 222: T * List<T>::operator[](int offSet) const 223: { 224: Node<T>* pNode = pHead; 225: 226: if (!pHead) 227: throw EmptyList(); 228: 229: if (offSet > itsCount) 230: throw BoundsError(); 231: 232: for (int i=0;i<offSet; i++) 233: pNode = pNode->itsNext; 234: 235: return pNode->itsObject; 236: } 237: 238: // wyszukuje w liście dany obiekt w oparciu o jego unikalny numer (id) 239: template <class T> 240: T* List<T>::Find(int & position, int ObjectNumber) const 241: { 242: Node<T> * pNode = 0; 243: for (pNode = pHead, position = 0; 244: pNode!=NULL; 245: pNode = pNode->itsNext, position++) 246: { 247: if (pNode->itsObject->GetObjectNumber() == ObjectNumber) 248: break; 249: } 250: if (pNode == NULL) 251: return NULL; 252: else 253: return pNode->itsObject; 254: } 255: 256: // wstawia, gdy numer obiektu jest unikalny 257: template <class T> 258: void List<T>::Insert(T* pObject) 259: { 260: Node<T> * pNode = new Node<T>(pObject); 261: Node<T> * pCurrent = pHead; 262: Node<T> * pNext = 0; 263: 264: int New = pObject->GetObjectNumber(); 265: int Next = 0; 266: itsCount++; 267: 268: if (!pHead) 269: { 270: pHead = pNode; 271: return; 272: } 273:
274: // jeśli ten węzeł jest mniejszy niż głowa, 275: // staje się nową głową 276: if (pHead->itsObject->GetObjectNumber() > New) 277: { 278: pNode->itsNext = pHead; 279: pHead = pNode; 280: return; 281: } 282: 283: for (;;) 284: { 285: // jeśli nie ma następnego, dołączamy nowy 286: if (!pCurrent->itsNext) 287: { 288: pCurrent->itsNext = pNode; 289: return; 290: } 291: 292: // jeśli trafia pomiędzy bieżący a następny, 293: // wstawiamy go tu; w przeciwnym razie bierzemy następny 294: pNext = pCurrent->itsNext; 295: Next = pNext->itsObject->GetObjectNumber(); 296: if (Next > New) 297: { 298: pCurrent->itsNext = pNode; 299: pNode->itsNext = pNext; 300: return; 301: } 302: pCurrent = pNext; 303: } 304: } 305: 306: 307: int main() 308: { 309: List<Part> theList; 310: int choice; 311: int ObjectNumber; 312: int value; 313: Part * pPart; 314: while (1) 315: { 316: cout << "(0)Wyjscie (1)Samochod (2)Samolot: "; 317: cin >> choice; 318: 319: if (!choice) 320: break; 321: 322: cout << "Nowy numer czesci?: "; 323: cin >> ObjectNumber; 324: 325: if (choice == 1) 326: { 327: cout << "Model?: "; 328: cin >> value; 329: try 330: { 331: pPart = new CarPart(value,ObjectNumber); 332: } 333: catch (OutOfMemory) 334: {
Usunięto: o

335: cout << "Brak pamieci; Wyjscie..." << endl; 336: return 1; 337: } 338: } 339: else 340: { 341: cout << "Numer silnika?: "; 342: cin >> value; 343: try 344: { 345: pPart = new AirPlanePart(value,ObjectNumber); 346: } 347: catch (OutOfMemory) 348: { 349: cout << "Brak pamieci; Wyjscie..." << endl; 350: return 1; 351: } 352: } 353: try 354: { 355: theList.Insert(pPart); 356: } 357: catch (NullNode) 358: { 359: cout << "Lista jest uszkodzona i wezel jest pusty!" << endl; 360: return 1; 361: } 362: catch (EmptyList) 363: { 364: cout << "Lista jest pusta!" << endl; 365: return 1; 366: } 367: } 368: try 369: { 370: for (int i = 0; i < theList.GetCount(); i++ ) 371: cout << *(theList[i]); 372: } 373: catch (NullNode) 374: { 375: cout << "Lista jest uszkodzona i wezel jest pusty!" << endl; 376: return 1; 377: } 378: catch (EmptyList) 379: { 380: cout << "Lista jest pusta!" << endl; 381: return 1; 382: } 383: catch (BoundsError) 384: { 385: cout << "Proba odczytu poza koncem listy!" << endl; 386: return 1; 387: } 388: return 0; 389: }
Wynik

(0)Wyjscie (1)Samochod (2)Samolot: 1 Nowy numer czesci?: 2837 Model?: 90 (0)Wyjscie (1)Samochod (2)Samolot: 2 Nowy numer czesci?: 378 Numer silnika?: 4938 (0)Wyjscie (1)Samochod (2)Samolot: 1 Nowy numer czesci?: 4499 Model?: 94 (0)Wyjscie (1)Samochod (2)Samolot: 1 Nowy numer czesci?: 3000 Model?: 93 (0)Wyjscie (1)Samochod (2)Samolot: 0 Numer czesci: 378 Nr silnika: 4938 Numer czesci: 2837 Rok modelu: 90 Numer czesci: 3000 Rok modelu: 93 Numer czesci: 4499 Rok modelu: 94
Analiza
Listing tego programu stanowi modyfikację programu podsumowującego wiadomości w rozdziale 14. i uzupełnia go o wzorce, przetwarzanie za pomocą obiektu ostream oraz obsługę wyjątków. Wynik działania jest identyczny.
W liniach od 36. do 40. zostało zadeklarowanych kilka klas wyjątków. W zastosowanej w tym programie nieco prymitywnej obsłudze wyjątków, dla wyjątków nie są wymagane żadne dane ani metody; obiekty wyjątków służą jako znaczniki w instrukcjach catch, które wypisują bardzo prosty komunikat i wychodzą. Bardziej stabilny program mógłby przekazywać te wyjątki poprzez referencje, a następnie wydzielać z nich kontekst lub inne dane obiektu wyjątku w celu podjęcia próby rozwiązania problemu.
W linii 45. abstrakcyjna klasa bazowa Part została zadeklarowana dokładnie tak samo, jak w poprzednim programie podsumowującym wiadomości. Jedyną interesującą zmianą jest wystąpienie nie należącego do klasy operatora<<(), zadeklarowanego w liniach od 70. do 74. Zwróć uwagę, że nie jest to ani funkcja składowa klasy Part, ani funkcja zaprzyjaźniona tej klasy. Otrzymuje on jedynie w jednym ze swoich argumentów referencję do obiektu Part.
Możesz kiedyś zechcieć, by operator<< przyjmował klasy CarPart i AirPlanePart (w nadziei, że zostanie wywołany właściwy operator<<, w zależności od tego, czy przekazana została część samochodu czy samolotu). Ponieważ program przekazuje wskaźnik do części, a nie wskaźnik do części samochodu i części samolotu, więc C++ musiałoby wywoływać właściwą metodę w oparciu o rzeczywisty typ jednego z argumentów funkcji. Nazywa się to kontrawariancją i nie jest obsługiwane w C++.
Usunięto: wzorce
Usunięto: i klasę Part
Usunięto: jedynie jako referencję
Usunięto: ę
Usunięto: j
Usunięto: ły
Usunięto: jaki obiekt zostałby
Usunięto: y
Usunięto: na
Usunięto: m
Usunięto: ie

W C++ istnieją tylko dwa sposoby uzyskania polimorfizmu: polimorfizm funkcji oraz funkcje wirtualne. Polimorfizm funkcji tutaj nie zadziała, gdyż w każdym przypadku dopasowujemy tę samą sygnaturę: sygnaturę przyjmującą referencję do klasy Part.
Funkcje wirtualne także nie zadziałają, gdyż operator<< nie jest funkcją składową klasy Part. Nie możemy uczynić z tej funkcji funkcji składowej, gdyż chcemy wywoływać:
cout << thePart
a to oznacza, że rzeczywistym wywołaniem będzie cout.operator<<(Part&), a cout nie posiada wersji operatora<< przyjmującego referencję do klasy Part!
Aby ominąć to ograniczenie, w tym programie używamy tylko jednego operatora<<, przyjmującego referencję do klasy Part. Funkcja ta wywołuje następnie metodę Display(), która jest wirtualną funkcją składową. W ten sposób zostaje wywołana właściwa metoda.
W liniach od 130. do 143. klasa Node jest zadeklarowana jako wzorzec. Służy do tego samego celu, co klasa Node w poprzednim programie podsumowującym wiadomości, ale ta wersja klasy nie jest związana z obiektem Part. W rzeczywistości może być węzłem o dowolnym typie obiektu.
Zauważ, że jeśli chcesz uzyskać obiekt z klasy Node, w której nie ma obiektu, będzie to uznane za wyjątek, który jest zgłaszany w linii 175.
W liniach 182. i 183. został zdefiniowany wzorzec ogólnej klasy List. Klas ta może przechowywać węzły będące dowolnymi obiektami, posiadającymi unikalne numery identyfikacyjne, utrzymując je posortowane w kolejności od najmniejszego do największego. Każda z funkcji listy sprawdza, czy nie wystąpiła sytuacja wyjątkowa i w razie potrzeby zgłasza odpowiedni wyjątek.
W linii 309. program sterujący tworzy listę dwóch typów obiektów Part, po czym, korzystając ze standardowego mechanizmu strumieni, wypisuje wartości obiektów z listy.
Często zadawane pytanie
W komentarzu powyżej linii 70. wspominasz, że C++ nie obsługuje kontrawariancji. Czym jest kontrawariancja?
Odpowiedź: Kontrawariancja jest zdolnością przypisania wskaźnika do klasy bazowej wskaźnikowi do klasy pochodnej.
Gdyby C++ obsługiwało kontrawariancję, moglibyśmy w czasie działania programu przeciążać funkcję w oparciu o faktyczny typ obiektu. Listing 21.10 nie skompiluje się w języku C++, ale skompilowałby się, gdyby język ten obsługiwał kontrawariancję.
Usunięto: wzorzec
Usunięto: jest
Usunięto: wzorzec
Usunięto: ach 307 i
Usunięto: 8
Usunięto: w liście

OSTRZEŻENIE Ten listing się nie skompiluje!
Listing 21.10. #include <iostream.h> class Animal { public: virtual void Speak() { cout "Animal Speaks\n"; } }; class Dog : public Animal { public: void Speak() { cout "Dog Speaks\n"; } }; class Cat : public Animal { public: void Speak() { cout "Cat Speaks\n"; } }; void DoIt(Cat*); void DoIt(Dog*); int main() { Animal * pA = new Dog; DoIt(pA); return 0; } void DoIt(Cat * c) { cout << "Otrzymalem obiekt Cat!\n" << endl; c->Speak(); } void DoIt(Dog * d) { cout << "Otrzymalem obiekt Dog!\n" << endl; d->Speak(); }
Oczywiście, moglibyśmy użyć funkcji wirtualnej, co częściowo rozwiązałoby problem.
#include <iostream.h> class Animal { public: virtual void Speak() { cout "Animal Speaks\n"; } };

class Dog : public Animal { public: void Speak() { cout "Dog Speaks\n"; } }; class Cat : public Animal { public: void Speak() { cout "Cat Speaks\n"; } }; void DoIt(Animal*); int main() { Animal * pA = new Dog; DoIt(pA); return 0; } void DoIt(Animal * c) { cout << "Otrzymalem jakis rodzaj obiektu Animal\n" << endl; c->Speak(); }

Dodatek A. Dwójkowo i szesnastkowo Podstawy arytmetyki poznaliśmy w tak zamierzchłej przeszłości, że trudno sobie wyobrazić co by było, gdybyśmy nie posiadali tej wiedzy. Gdy patrzymy na znaki 145, to natychmiast wiemy, że chodzi o liczbę „sto czterdzieści pięć”.
Zrozumienie sposobu funkcjonowania systemu dwójkowego i szesnastkowego wymaga innego spojrzenia na liczbę 145, a mianowicie postrzegania jej nie jako liczby, ale jako jej kodu.
Na początku wyobraź sobie powiązanie pomiędzy liczbą trzy a „3”. Cyfra „3” jest znaczkiem na papierze; liczba trzy jest ideą. Cyfra służy do reprezentowania liczby.
To rozróżnienie może być łatwiejsze do zrozumienia, jeśli uświadomimy sobie, że zarówno trzy jak i 3, |||, III oraz *** reprezentują tę samą ideę liczby trzy.
W systemie dziesiętnym (czyli, jak mówią matematycy, o podstawie 10) do reprezentowania wszystkich liczb używamy cyfr 0, 1, 2, 3, 4, 5, 6, 7, 8 oraz 9. Jak jest reprezentowana liczba 10?
Można sobie wyobrazić, że do reprezentowania liczby dziesięć używamy litery A, lub że używamy zapisu IIIIIIIIII. Rzymianie używali znaku X. W systemie arabskim, z którego obecnie korzystamy, do reprezentowania wartości wykorzystujemy cyfry i ich pozycje. Pierwsza (położona najbardziej na prawo) kolumna jest używana dla jedynek, a druga (w lewą stronę) jest używana dla dziesiątek. Tak więc liczba piętnaście jest reprezentowana jako 15 (czytaj: „jeden, pięć”), czyli jedna dziesiątka i pięć jedynek.
Pojawia się regularność, dzięki której można dokonać pewnej generalizacji:
1. System o podstawie 10 używa cyfr od 0 do 9.
2. Kolumny są potęgami dziesięciu: 1, 10, 100, itd.
3. Jeśli trzecia kolumna reprezentuje setki, to największą liczbą, jaką można zapisać w dwóch kolumnach, jest 99. Innymi słowy, w n kolumnach możemy reprezentować liczby od 0 do (10n–1). Tak więc, w trzech kolumnach możemy reprezentować liczby od 0 do (103–1), czyli od 0 do 999.

Inne podstawy To, że korzystamy z podstawy 10, nie jest przypadkiem: w końcu mamy po dziesięć palców. Można sobie jednak wyobrazić inną podstawę. Używając reguł określonych dla podstawy 10, możemy opisać podstawę 8:
1. System o podstawie 8 używa cyfr od 0 do 7.
2. Kolumny są potęgami ośmiu: 1, 8, 64, itd.
3. W n kolumnach możemy zapisywać liczby od 0 do 8n–1.
W celu rozróżniania liczb o różnych podstawach, podstawy zapisujemy jako indeks dolny tuż za ostatnią cyfrą liczby. Liczba piętnaście przy podstawie 10 jest zapisywana jako 1510 i odczytywana jako „jeden, pięć, dziesiętnie”.
Tak więc, reprezentując liczbę 1510 w systemie o podstawie 8, napisalibyśmy 178. Należy ją odczytywać jako „jeden, siedem, ósemkowo”. Zwróć uwagę, że można to odczytywać jako „piętnaście”, gdyż tę wartość reprezentuje.
Dlaczego 17? Jedynka oznacza jedną ósemkę, a siódemka oznacza siedem jedynek. Jedna ósemka plus siedem jedynek daje piętnaście. Weźmy piętnaście gwiazdek:
***** ***** *****
Naturalnym działaniem będzie utworzenie dwóch grup: grupy dziesięciu gwiazdek i grupy pięciu gwiazdek. Dziesiętnie byłyby one reprezentowane jako 15 (jedna dziesiątka i pięć jedynek). Można także pogrupować gwiazdki następująco:
**** ******* ****
to jest, jako osiem gwiazdek i siedem. W systemie ósemkowym zapisalibyśmy to jako 178, czyli jako jedną ósemkę i siedem jedynek.
Wokół podstaw Liczbę piętnaście możemy w systemie dziesiętnym zapisywać jako 15, w systemie dziewiątkowym jako 169, w systemie ósemkowym jako 178, a czy w systemie siódemkowym jako 217. Dlaczego 217? W systemie siódemkowym nie ma cyfry 8. Aby wyrazić liczbę piętnaście, potrzebujemy dwóch siódemek i jednej jedynki.

Jak można to uogólnić? Aby zamienić liczbę o podstawie 10 na liczbę o podstawie 7, pomyśl o kolumnach: w systemie siódemkowym występują kolumny dla jedynek, siódemek, czterdziestek dziewiątek, trzysta czterdziestek trójek i tak dalej. Dlaczego takie kolumny? Ponieważ reprezentują 70, 71, 72, 74 i tak dalej.
Pamiętajmy, że dowolna liczba podniesiona do zerowej potęgi (na przykład 70) równa się 1, każda liczba podniesiona do pierwszej potęgi (na przykład 71) równa się samej sobie, każda liczba podniesiona do drugiej potęgi równa się wynikowi przemnożenia jej przez siebie (72 = 7*7 = 49), a każda liczba podniesiona do trzeciej potęgi odpowiada trzykrotnemu przemnożeniu jej przez siebie (73 = 7*7*7 = 343).
Wykonaj tabelę:
Kolumna 4 3 2 1
Potęga 73 72 71 70
Wartość 343 49 7 1
Pierwszy wiersz reprezentuje numer kolumny. Drugi wiersz reprezentuje potęgę siódemki. Trzeci wiersz reprezentuje wartość dziesiętną każdej liczby w drugim wierszu.
Aby zamienić wartości dziesiętne na liczby siódemkowe, postępuj zgodnie z poniższą procedurą: sprawdź liczbę i zdecyduj, której kolumny użyć jako pierwszej. Jeśli liczbą jest na przykład 200, wiemy, że kolumna 4 (343) będzie zawierała 0 i nie musimy się nią martwić.
Aby dowiedzieć się, ile 49-ek jest w liczbie 200, podzielimy 200 przez 49. Otrzymujemy 4, więc w kolumnie trzeciej umieszczamy cyfrę 4 i sprawdzamy resztę z dzielenia: 4. W liczbie 4 nie ma żadnej siódemki, więc w kolumnie siódemek umieszczamy cyfrę 0. W liczbie cztery są cztery jedynki, więc w kolumnie jedynek umieszczamy cyfrę 4. Odpowiedzią jest 4047.
Kolumna 4 3 2 1
Potęga 73 72 71 70
Wartość 343 49 7 1
200 siódemkowo 0 4 0 4
Wartość dziesiętna
0 4*49 = 196 0 4*1 = 4
W tym przykładzie cyfra 4 w trzeciej kolumnie reprezentuje wartość dziesiętną 196, a cyfra 4 w pierwszej kolumnie reprezentuje wartość 4. 196+4 = 200. Tak więc 4047 = 20010.
Przejdźmy następnego przykładu.
Aby zamienić liczbę 968 na liczbę szóstkową:
Kolumna 5 4 3 2 1
Usunięto: dwu
Potęga 64 63 62 61 60
Wartość 1296 216 36 6 1
Sprawdź, czy wiesz, dlaczego kolumny reprezentują takie wartości. Pamiętaj, że 63 = 6*6*6 = 216.
Aby wyznaczyć reprezentację liczby 986 w systemie szóstkowym, zaczniemy od kolumny 5. Ile 1296-tek mieści się w 986? Żadna, więc w kolumnie 5. zapisujemy 0. Jeśli podzielimy 968 przez 216, to otrzymamy 4 z resztą 104. W kolumnie 4. znajdzie się cyfra 4. To jest, ta kolumna będzie reprezentować 4*216 (864).
Musimy teraz wyrazić pozostałą wartość (968-864 = 104). Podzielenie 104 przez 36 daje 2 z resztą 32. Kolumna trzy będzie zawierać cyfrę 2. Podzielenie 32 przez 6 daje 5 z resztą 2. Tak więc otrzymujemy liczbę 42526.
Kolumna 5 4 3 2 1
Potęga 64 63 62 61 60
Wartość 1296 216 36 6 1
986 szóstkowo 0 4 2 5 2
Wartość dziesiętna
0 4*216=864 2*36=72 5*6=30 2*1=2
864+72+30+2 = 968
Dwójkowo Ostatecznym etapem tego systemu jest system o podstawie 2. Są w nim tylko dwie cyfry: 0 i 1. Kolumny to
Kolumna 8 7 6 5 4 3 2 1
Potęga 27 26 25 24 23 22 21 20
Wartość 128 64 32 16 8 4 2 1
Aby zamienić liczbę 88 na liczbę dwójkową, postępujemy zgodnie z tą samą procedurą: w 88 nie ma 128-ek, więc w kolumnie ósmej wpisujemy cyfrę 0.
W 88 jest jedna sześćdziesiątka czwórka, więc do kolumny 7 wpisujemy cyfrę 1. Zostaje nam reszta wynosząca 24. W 24 nie ma trzydziestek dwójek, więc kolumna 6 zawiera cyfrę 0.
Usunięto: P
Usunięto: enie
Usunięto: daje

W 24 mieści się jedna szesnastka, więc kolumna pięć zawiera cyfrę 1. Pozostaje nam reszta 8. W 8 jest jedna ósemka, więc kolumna 4. będzie zawierać cyfrę 1. Nie ma już żadnej reszty, więc pozostałe kolumny będą zawierać zera.
Kolumna 8 7 6 5 4 3 2 1
Potęga 27 26 25 24 23 22 21 20
Wartość 128 64 32 16 8 4 2 1
88 dwójkowo
0 1 0 1 1 0 0 0
Wartość 0 64 0 16 8 0 0 0
Aby sprawdzić wynik, zamieńmy to z powrotem na liczbę o podstawie dziesięć: 1 * 64 = 64 0 * 32 = 0 1 * 16 = 16 1 * 8 = 8 0 * 4 = 0 0 * 2 = 0 0 * 1 = 0 88
Dlaczego podstawa 2? Podstawa 2 pełni ważną rolę w programowaniu, gdyż dokładnie odpowiada temu, co może być w komputerze reprezentowane. Komputery w rzeczywistości nie wiedzą nic o literach, cyfrach, instrukcjach czy programach. W swoim rdzeniu są jedynie układami elektronicznymi, w których w danym punkcie może występować większe albo bardzo małe napięcie.
Aby zachować prostotę konstrukcji, inżynierowie nie traktują napięcia jako skali relatywnej (niskie napięcie, wyższe napięcie, bardzo wysokie napięcie czy ogromne napięcie), ale raczej jako skalę o dwóch stanach („napięcie wystarczające” lub „napięcie niewystarczające”). Zamiast jednak mówić „wystarczające” lub „niewystarczające”, mówią po prostu „tak” lub „nie”. Tak lub nie, czyli prawda lub fałsz, może być reprezentowane jako 1 lub 0. Zgodnie z konwencją, 1 oznacza prawdę lub Tak, ale to tylko konwencja; równie dobrze mogłoby oznaczać fałsz lub Nie.
Gdy zauważysz tę regułę, potęga systemu dwójkowego objawi się w całej okazałości: za pomocą zer i jedynek można oddać stan każdego układu (jest napięcie lub go nie ma). Wszystkie komputery znają tylko dwa stany: włączony = 1 oraz wyłączony = 0.

Bity, bajty, nible Gdy podjęto decyzjęm by reprezentować prawdę i fałsz jedynkami i zerami, bardzo ważne stało się pojęcie bitu (od binary digit, cyfra binarna1). Ponieważ pierwsze komputery mogły przesłać jednocześnie osiem bitów, więc naturalnie pierwszy kod zapisywano, używając liczb 8-bitowych — nazywanych bajtami (ang. byte).
UWAGA W gwarze programistycznej połówka bajtu (4 bity) jest nazywana niblem (ang. nybble).
Za pomocą ośmiu bitów można reprezentować do 256 różnych wartości. Dlaczego? Sprawdź kolumny: gdy wszystkie osiem bitów jest ustawionych (1), wartością jest 255 (128+64+32+16+8+4+2+1). Jeśli nie jest ustawiony żaden (wszystkie bity są wyzerowane, czyli mają wartość 0), wtedy wartością jest 0. Od 0 do 255 to 256 możliwych stanów.
Co to jest KB? Okazuje się, że 210 (1024) to w przybliżeniu 103 (1 000). Ten związek był zbyt dobry, aby go nie zauważyć, więc komputerowi specjaliści zaczęli nazywać 210 bajtów kilobajtem, czyli KB, zapożyczając przedrostek kilo (k) oznaczający tysiąc. Dla wskazania, że chodzi o wartość 1024, a nie 1000, „komputerowe kilo” oznacza się dużą literą K.
Również 1024*1024 (1 048 576) jest na tyle bliskie miliona, że otrzymało oznaczenie 1 MB, czyli megabajt, zaś 1 024 megabajtów jest nazywanych gigabajtem (giga to przedrostek oznaczający tysiąc milionów, czyli miliard).
Liczby dwójkowe Komputery kodują każdą wartość za pomocą zer i jedynek. Instrukcje maszynowe są zakodowane jako serie jedynek i zer, następnie są interpretowane przez układy procesora. Zestawy zer i jedynek mogą być zamienione na liczby, ale traktowanie tych liczb jako posiadających jakieś specyficzne znaczenie byłoby błędem.
Na przykład, procesor Intel 8086 interpretuje wzorzec bitów 1001 0101 jako instrukcję. Oczywiście, możemy zamienić te bity na liczbę dziesiętną 149, ale ta wartość sama w sobie nie ma dla nas żadnego znaczenia.
Czasem liczby są instrukcjami, czasem wartościami, a czasem kodami. Jednym z ważnych, standardowych zestawów kodów jest zestaw ASCII. W zestawie tym każda litera, cyfra i znak przestankowy ma przydzieloną siedmiobitową reprezentację. Na przykład, mała litera „a” jest
1 A także od „kawałka” informacji, gdyż bit to po angielsku także „kawałek.” — przyp. tłum.
Usunięto: wewnętrzne

reprezentowana jako 0110 0001. Nie jest to liczba, choć można ją zamienić na liczbę 97 w systemie dziesiętnym (64+32+1). Właśnie w tym sensie mówi się, że litera „a” to 97 w ASCII, choć w rzeczywistości kodem litery „a” jest dwójkowa reprezentacja wartości 97 (0110 0001), a wartość dziesiętna 97 stanowi tylko ułatwienie dla ludzi.
Szesnastkowo Ponieważ liczby dwójkowe są trudne do odczytania, stworzono prostszy sposób ich reprezentowania. Przejście z systemu dwójkowego na dziesiętny wymaga sporo przeprowadzenia skomplikowanych operacji na liczbach, ale okazuje się, że przejście z podstawy 2 do podstawy 16 jest proste, gdyż istnieje bardzo dobry skrót.
Aby zrozumieć ten proces, musisz najpierw zrozumieć system o podstawie 16, zwany systemem szesnastkowym lub heksadecymalnym. Przy podstawie 16 mamy do dyspozycji szesnaście cyfr: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E oraz F. Ostatnie sześć znaków, litery od A do F, zostały wybrane, ponieważ łatwo można je wpisać z klawiatury (i wyświetlić na wyświetlaczu siedmiosegmentowym). Kolumny w systemie szesnastkowym to:
Kolumna 4 3 2 1
Potęga 163 162 161 160
Wartość 4096 256 16 1
Aby zamienić liczbę z systemu szesnastkowego na dziesiętny, możemy mnożyć. Tak więc liczba F8C reprezentuje:
F * 256 = 15 * 256 = 3840 8 * 16 = 128 C * 1 = 12 * 1 = 12 3980
(Pamiętaj, że F16 to 1510)
Najlepiej przeprowadzić zamianę liczby FC na dwójkową, zamieniając ją najpierw na liczbę dziesiętną, a następnie na dwójkową:
F * 16 = 15 * 16 = 240 C * 1 = 12 * 1 = 12 252

Zamiana 252 na liczbę dwójkową wymaga użycia tablicy:
Kolumna 9 8 7 6 5 4 3 2 1
Potęga 28 27 26 25 24 23 22 21 20
Wartość 256 128 64 32 16 8 4 2 1
Nie ma 256-ek.
1*128 = 128. 252–128 = 124
1*64 = 64. 124–64 = 60
1*32 = 32. 60–32 = 28
1*16 = 16. 28–16=12
1*8 = 8. 12–8 = 4
1*4 = 4. 4–4 = 0
0*2 = 0
0*1 = 0
124+60+28+12+4 = 252.
Tak więc FC16 w systemie dwójkowym to 1111 1100.
Okazuje się, że gdy potraktujemy tę liczbę dwójkową jako dwa zestawy czterech cyfr (1111 1100), możemy dokonać „magicznego” przekształcenia.
Prawy zestaw to 1100. Dziesiętnie to 12, a szesnastkowo C. (1*8 + 1*4 + 0*2 + 0*1).
Lewy zestaw to 1111, czyli dziesiętnie 15, a szesnastkowo F.
Tak więc mamy:
1111 1100 F C
Umieśćmy dwie cyfry szesnastkowe razem i otrzymamy FC, które jest wartością szesnastkową binarnej liczby 1111 1100. Ten skrót działa! Możemy wziąć liczbę binarną o dowolnej długości, podzielić ją na zestawy po cztery bity, zamienić każdy z zestawów na cyfrę szesnastkową i połączyć otrzymane cyfry tak, aby otrzymać wynik w systemie szesnastkowym. Oto dużo większa liczba:
1011 0001 1101 0111
Aby sprawdzić, czy nasze założenia są właściwe, najpierw zamieńmy tę liczbę na dziesiętną.

Wartości kolumn możemy obliczyć poprzez ich podwajanie. Kolumna położona najbardziej na prawo ma wartość 1, następna 2, następne 4, 8, 16 i tak dalej.
Zaczniemy od kolumny położonej najbardziej na prawo, która, licząc dziesiętnie, ma wagę 1. Mamy jedynkę, więc ta kolumna jest warta 1. Następna kolumna ma wagę 2. W tej kolumnie także mamy jedynkę, więc dodajemy 2 i otrzymujemy sumę wynoszącą 3.
Następna kolumna ma wagę 4 (podwajamy wagę poprzedniej kolumny). W związku z tym otrzymujemy 4+2+1=7.
Kontynuujemy tę procedurę dla kolejnych kolumn:
1x1 1 1x2 2 1x4 4 0x8 0 1x16 16 0x32 0 1x64 64 1x128 128 1x256 256 0x512 0 0x1024 0 0x2048 0 1x4096 4 096 1x8192 8 192 0x16384 0 1x32768 32 768 Razem 45 527
Zamiana na liczbę szesnastkową wymaga zastosowania tablicy z wartościami szesnastkowymi.
Kolumna 4 3 2 1
Potęga 163 162 161 160
Wartość 4096 256 16 1
Mamy jedenaście 4096-ek (45 056) z resztą 471. W 471 jest jedna 256-ka z resztą 215. W 215 jest trzynaście 16-ek (208) z resztą 7. Tak więc szukana liczba szesnastkowa to B1D7.
Sprawdzamy obliczenia:
B (11) * 4096 = 45 056 1 * 256 = 256 D (13) * 16 = 208 7 * 1 = 7 Razem 45 527
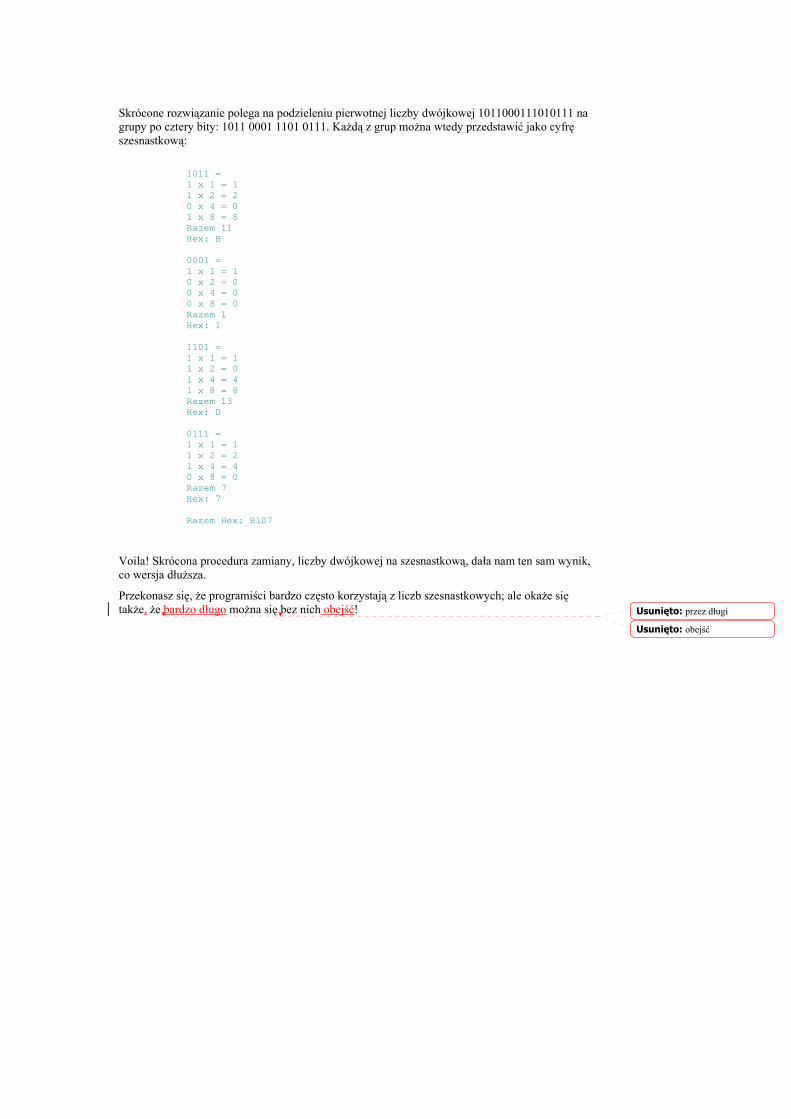
Skrócone rozwiązanie polega na podzieleniu pierwotnej liczby dwójkowej 1011000111010111 na grupy po cztery bity: 1011 0001 1101 0111. Każdą z grup można wtedy przedstawić jako cyfrę szesnastkową:
1011 = 1 x 1 = 1 1 x 2 = 2 0 x 4 = 0 1 x 8 = 8 Razem 11 Hex: B 0001 = 1 x 1 = 1 0 x 2 = 0 0 x 4 = 0 0 x 8 = 0 Razem 1 Hex: 1 1101 = 1 x 1 = 1 1 x 2 = 0 1 x 4 = 4 1 x 8 = 8 Razem 13 Hex: D 0111 = 1 x 1 = 1 1 x 2 = 2 1 x 4 = 4 0 x 8 = 0 Razem 7 Hex: 7 Razem Hex: B1D7
Voila! Skrócona procedura zamiany, liczby dwójkowej na szesnastkową, dała nam ten sam wynik, co wersja dłuższa.
Przekonasz się, że programiści bardzo często korzystają z liczb szesnastkowych; ale okaże się także, że bardzo długo można się bez nich obejść!
Usunięto: przez długi
Usunięto: obejść

Dodatek B. Słowa kluczowe C++ Słowa kluczowe są zarezerwowane jako symbole języka. Nie można ich używać jako nazw klas, zmiennych czy funkcji.
asm auto bool break case catch char class const const_cast continue default delete do double dynamic_cast else enum explicit extern false float for friend goto if inline int long mutable namespace new operator private protected public register

reinterpret_cast return short signed sizeof static static_cast struct switch template this throw true try typedef typeid typename union unsigned using virtual void volatile while
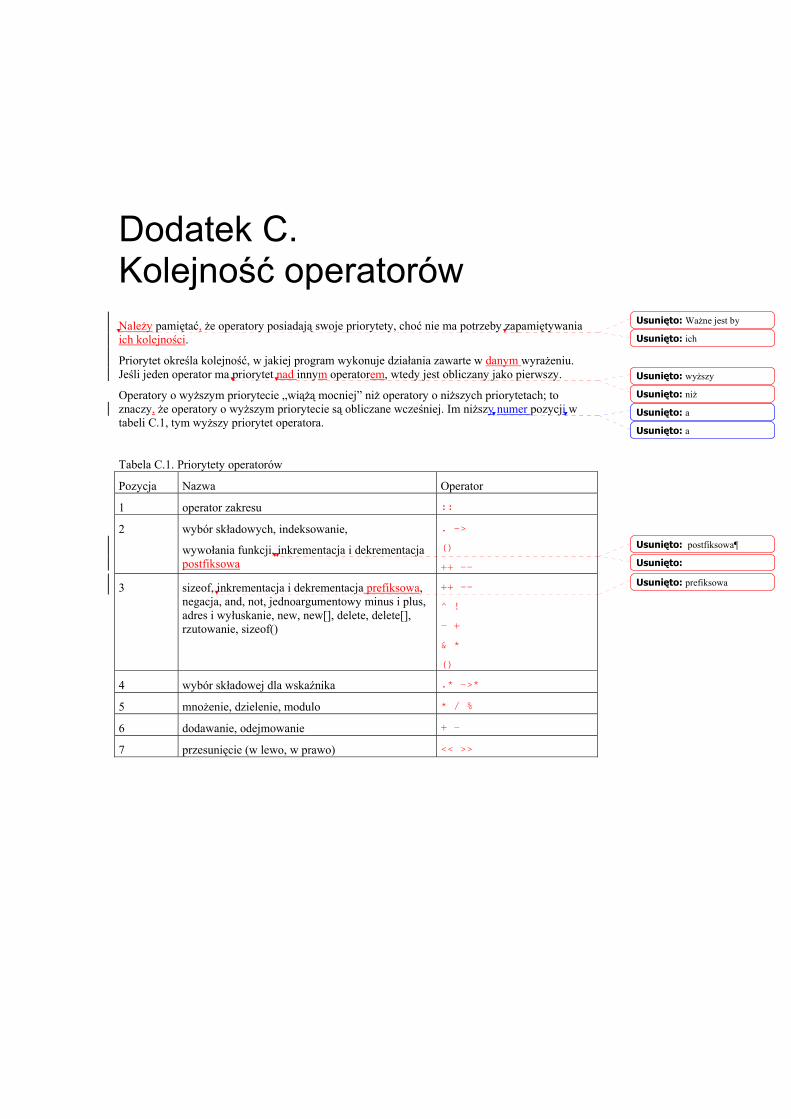
Dodatek C. Kolejność operatorów Należy pamiętać, że operatory posiadają swoje priorytety, choć nie ma potrzeby zapamiętywania ich kolejności.
Priorytet określa kolejność, w jakiej program wykonuje działania zawarte w danym wyrażeniu. Jeśli jeden operator ma priorytet nad innym operatorem, wtedy jest obliczany jako pierwszy.
Operatory o wyższym priorytecie „wiążą mocniej” niż operatory o niższych priorytetach; to znaczy, że operatory o wyższym priorytecie są obliczane wcześniej. Im niższy numer pozycji w tabeli C.1, tym wyższy priorytet operatora.
Tabela C.1. Priorytety operatorów
Pozycja Nazwa Operator
1 operator zakresu ::
2 wybór składowych, indeksowanie,
wywołania funkcji, inkrementacja i dekrementacja postfiksowa
. ->
()
++ --
3 sizeof, inkrementacja i dekrementacja prefiksowa, negacja, and, not, jednoargumentowy minus i plus, adres i wyłuskanie, new, new[], delete, delete[], rzutowanie, sizeof()
++ --
^ !
- +
& *
()
4 wybór składowej dla wskaźnika .* ->*
5 mnożenie, dzielenie, modulo * / %
6 dodawanie, odejmowanie + -
7 przesunięcie (w lewo, w prawo) << >>
Usunięto: Ważne jest by
Usunięto: ich
Usunięto: wyższy
Usunięto: niż
Usunięto: a
Usunięto: a
Usunięto: postfiksowa¶
Usunięto:
Usunięto: prefiksowa
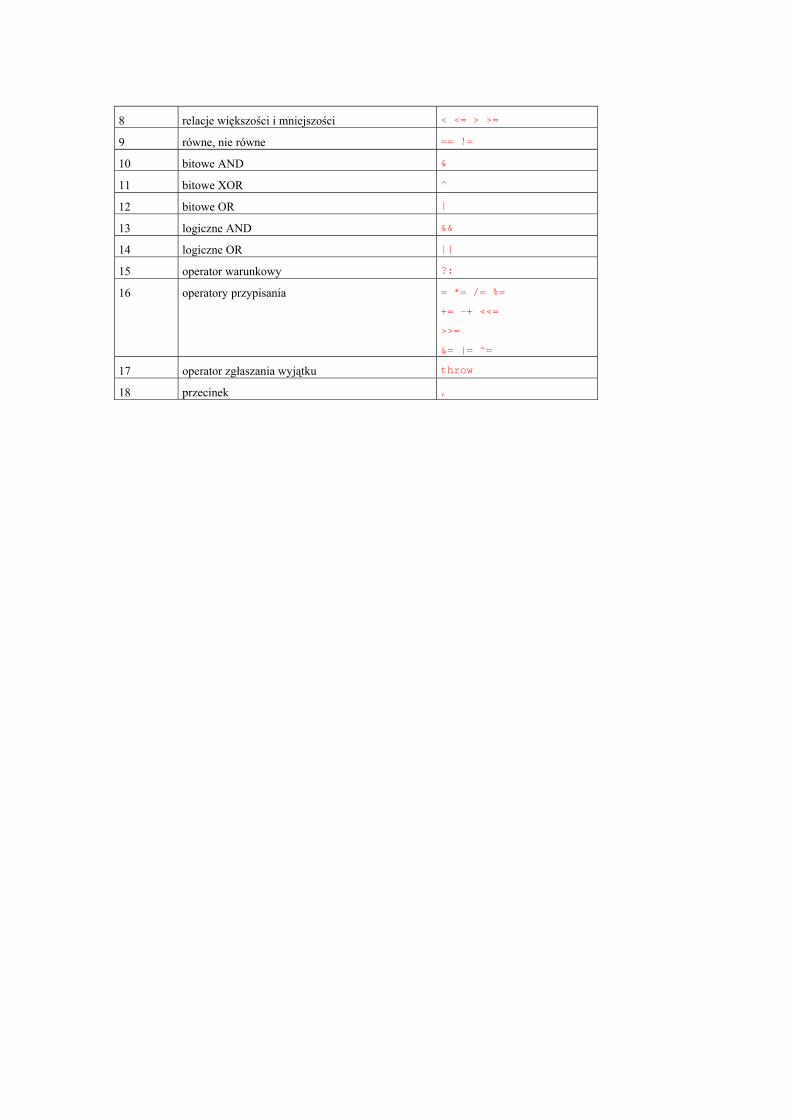
8 relacje większości i mniejszości < <= > >=
9 równe, nie równe == !=
10 bitowe AND &
11 bitowe XOR ^
12 bitowe OR |
13 logiczne AND &&
14 logiczne OR ||
15 operator warunkowy ?:
16 operatory przypisania = *= /= %=
+= -+ <<=
>>=
&= |= ^=
17 operator zgłaszania wyjątku throw
18 przecinek ,