
By: Jeffrey Dean & Sanjay Ghemawat Presented by: Warunika Ranaweera Supervised by: Dr. Nalin...
34
MapReduce By: Jeffrey Dean & Sanjay Ghemawat Presented by: Warunika Ranaweera Supervised by: Dr. Nalin Ranasinghe
-
Upload
louisa-parsons -
Category
Documents
-
view
226 -
download
0
Transcript of By: Jeffrey Dean & Sanjay Ghemawat Presented by: Warunika Ranaweera Supervised by: Dr. Nalin...

MapReduceBy: Jeffrey Dean & Sanjay Ghemawat
Presented by: Warunika Ranaweera
Supervised by: Dr. Nalin Ranasinghe

Paper
MapReduce: Simplified Data Processing on Large Clusters
In Proceedings of the 6th Symposium on Operating SystemsDesign and Implementation (OSDI' 04)
Also appears in the Communications of the ACM (2008)

Authors – Jeffrey Dean
Ph.D. in Computer Science – University of Washington
Google Fellow in Systems and Infrastructure Group
ACM Fellow
Research Areas: Distributed Systems and Parallel Computing

Authors – Sanjay Ghemawat
Ph.D. in Computer Science – Massachusetts Institute of Technology
Google Fellow
Research Areas: Distributed Systems and Parallel Computing

Large Computations
Calculate 30*50Easy?
30*50 + 31*51 + 32*52 + 33*52 + .... + 40*60Little bit hard?

Large Computations
Simple computation, but huge data set
Real world example for large computations 20+ billion web pages * 20kB webpage One computer reads 30/35 MB/sec from
disc Nearly four months to read the web

Good News: Distributed Computation
Parallelize tasks in a distributed computing environment
Web page problem solved in 3 hours with 1000 machines

o How to parallelize the computation?o Coordinate with other nodes
o Handling failures
o Preserve bandwidtho Load balancing
Though, the bad news is...
Complexities in Distributed Computing

MapReduce to the Rescue A platform to hide the messy details of
distributed computing Which are,
Parallelization Fault-tolerance Data distribution Load Balancing
A programming model An implementation
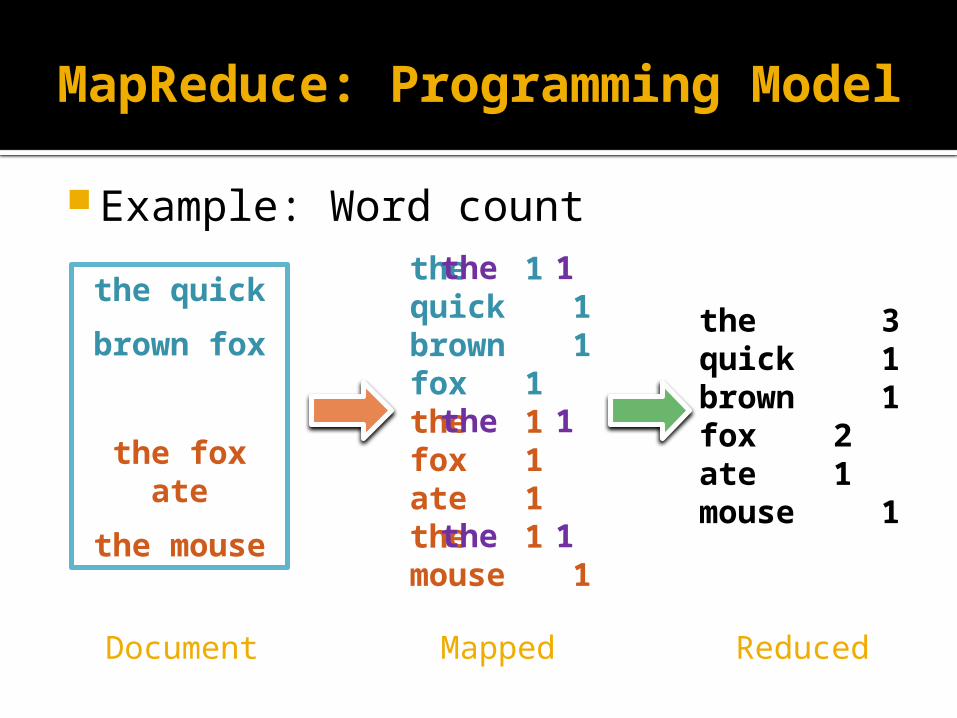
MapReduce: Programming Model
Example: Word count
the quick
brown fox
the fox ate
the mouse
the 1quick 1brown 1fox 1the 1fox 1ate 1the 1mouse 1
the 3quick 1brown 1fox 2ate 1mouse 1
Document Mapped Reduced
the 1
the 1
the 1
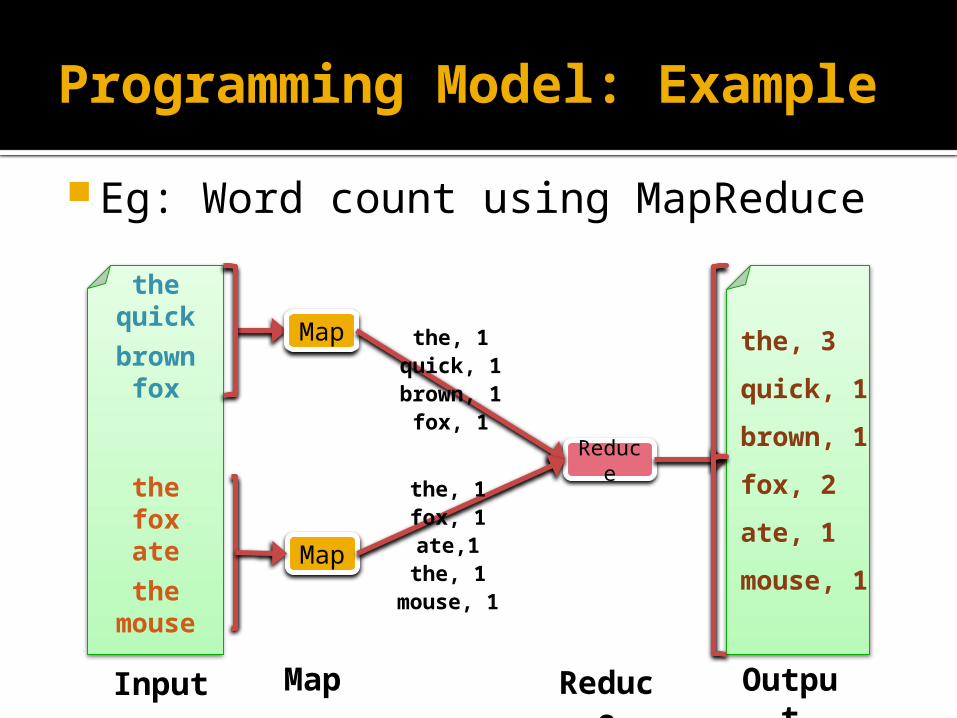
Programming Model: Example Eg: Word count using MapReduce
the quick
brown fox
the fox ate
the mous
e
Map
Map
Reduce
the, 1quick, 1brown, 1
fox, 1
the, 1fox, 1ate,1the, 1
mouse, 1
Input Map
Reduce
Output
the, 3
quick, 1
brown, 1
fox, 2
ate, 1
mouse, 1
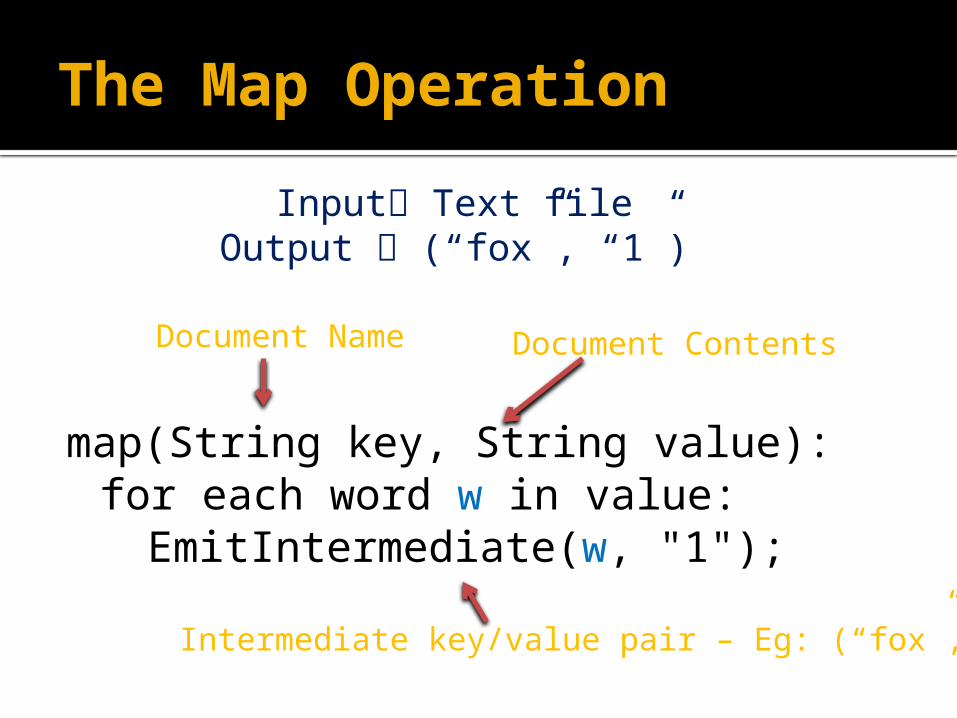
The Map Operation
map(String key, String value):for each word w in value:
EmitIntermediate(w, "1");
Intermediate key/value pair – Eg: (“fox”, “1”)
Document Name Document Contents
Input Text fileOutput (“fox”, “1”)
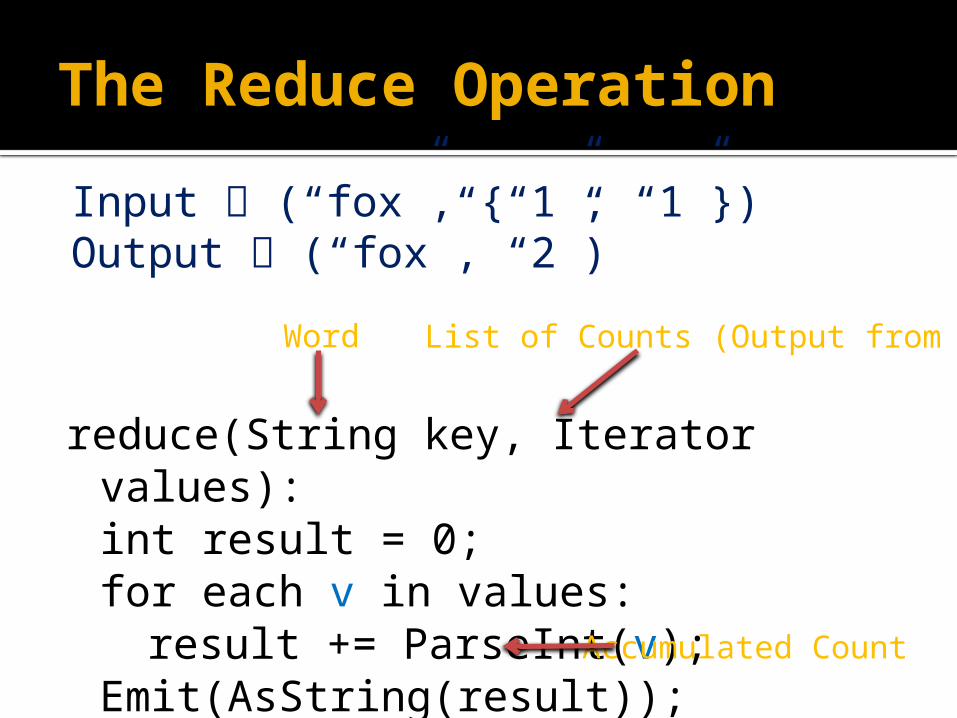
The Reduce Operation
reduce(String key, Iterator values):int result = 0;for each v in values:
result += ParseInt(v);Emit(AsString(result));
Word List of Counts (Output from Map)
Input (“fox”, {“1”, “1”})Output (“fox”, “2”)
Accumulated Count
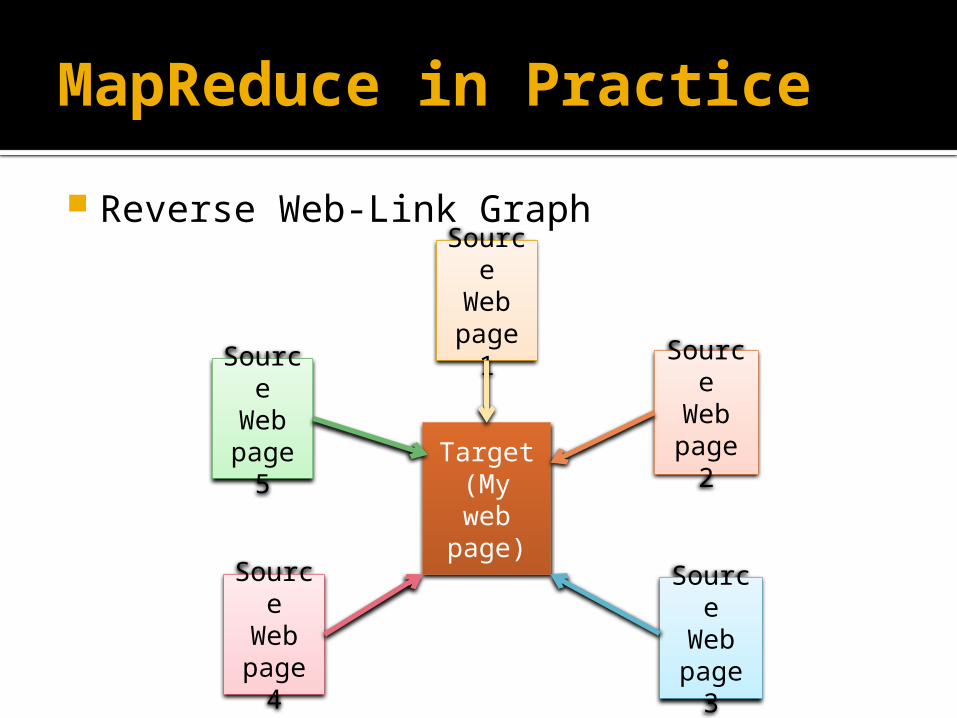
MapReduce in Practice
Reverse Web-Link Graph
Target(My web
page)
Source
Web page
2
Source
Web page
3
Source
Web page
4
Source
Web page
5
Source
Web page
1
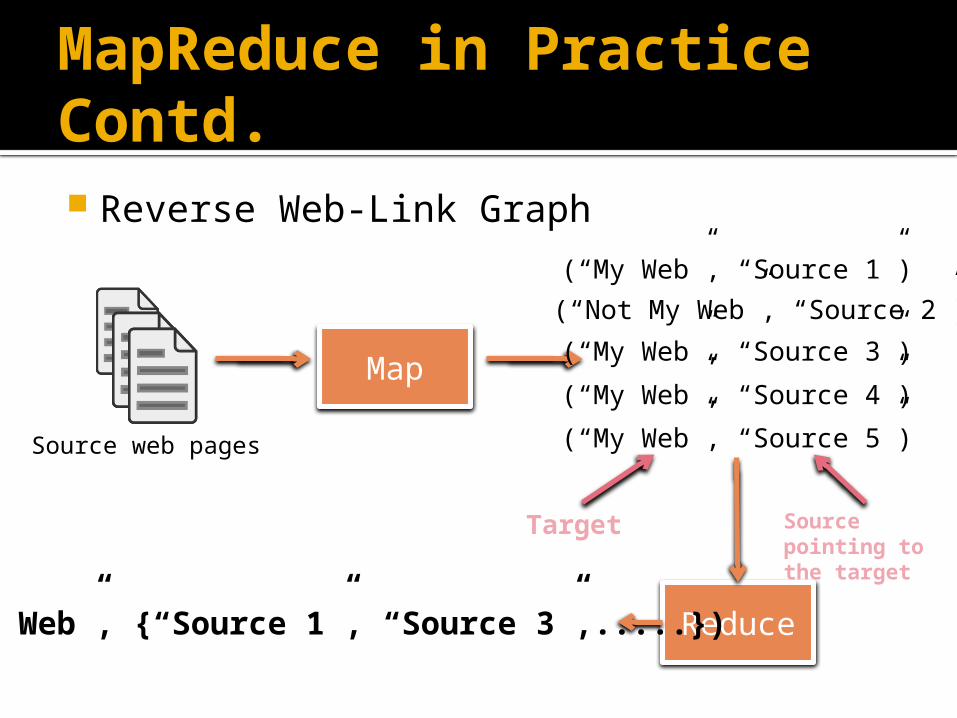
MapReduce in Practice Contd. Reverse Web-Link Graph
Map
(“My Web”, “Source 1”)
(“Not My Web”, “Source 2”)
(“My Web”, “Source 3”)
(“My Web”, “Source 4”)
(“My Web”, “Source 5”)
Reduce(“My Web”, {“Source 1”, “Source 3”,.....})
Target Source pointing to the target
Source web pages
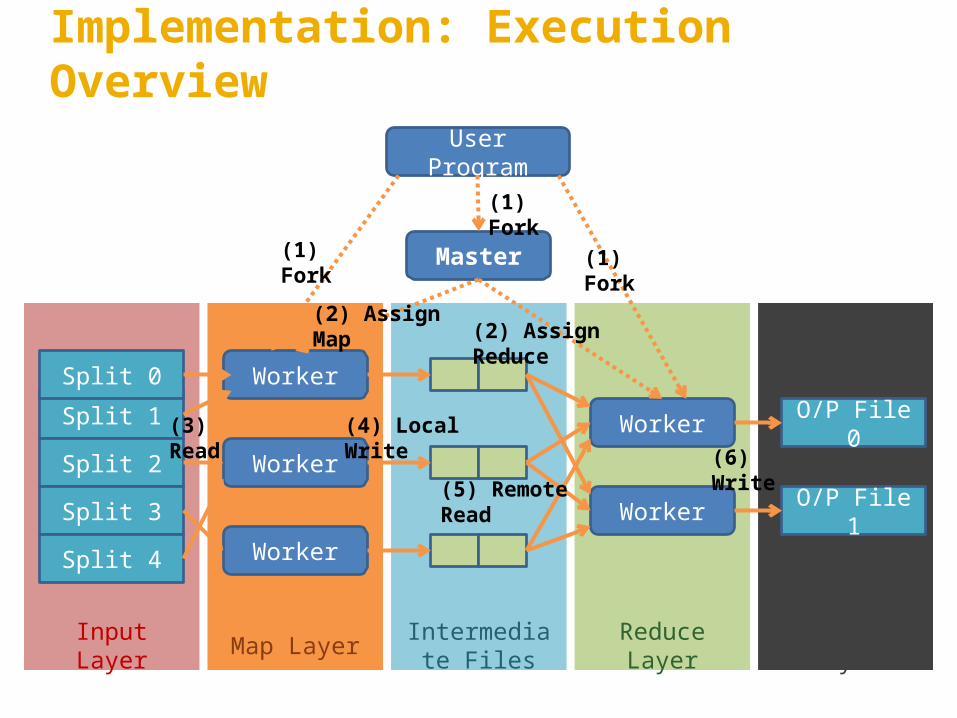
Implementation: Execution Overview
Map Layer Reduce Layer
User Program
Master
Worker
Worker
Worker
Worker
Worker
Input Layer Intermediate Files Output Layer
Split 1
Split 2
Split 3
Split 4
Split 0
(1) Fork
(1) Fork
(1) Fork
(2) Assign Map (2) Assign Reduce
(3) Read (4) Local Write
(5) Remote ReadO/P File 1
O/P File 0(6) Write
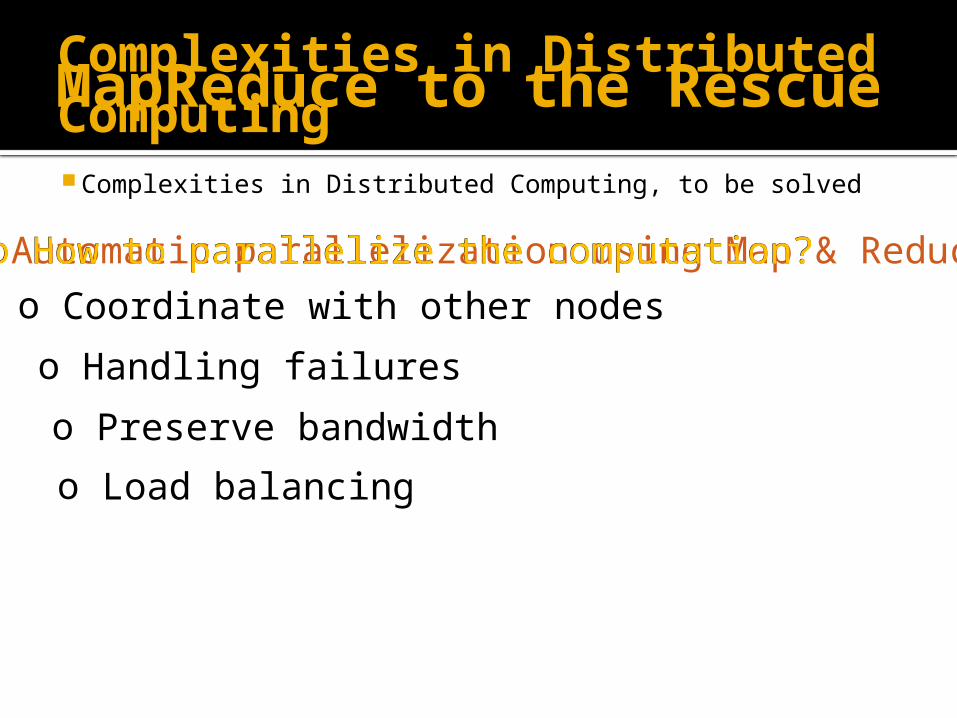
Complexities in Distributed Computing Complexities in Distributed Computing, to be solved
o How to parallelize the computation?o Coordinate with other nodes
o Handling failures
o Preserve bandwidtho Load balancing
o Automatic parallelization using Map & Reduceo How to parallelize the computation?
MapReduce to the Rescue
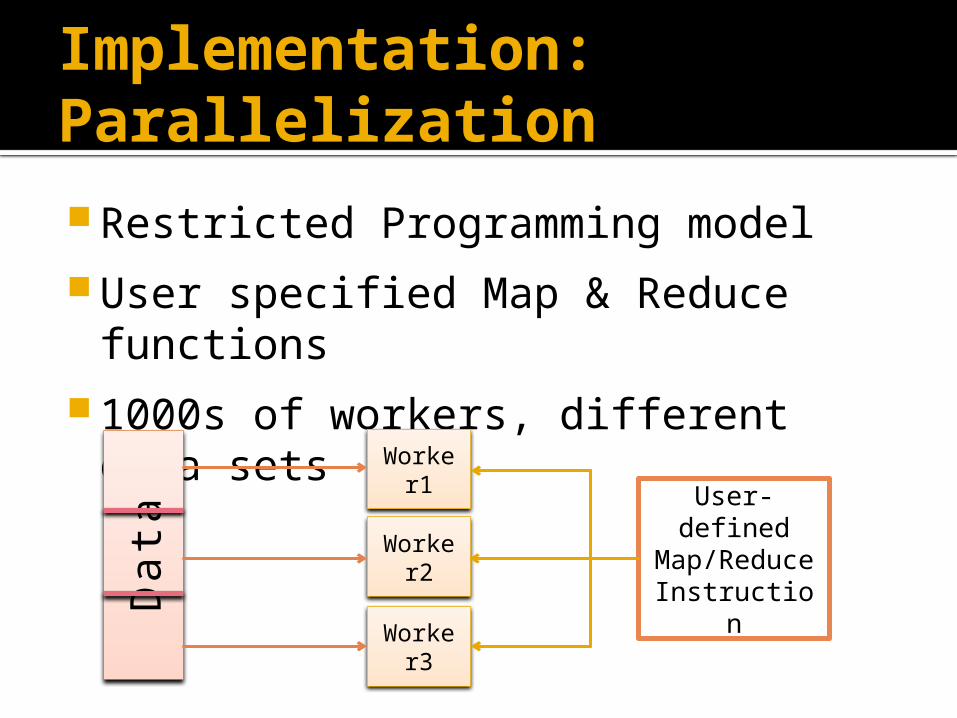
Implementation: Parallelization
Restricted Programming model User specified Map & Reduce
functions 1000s of workers, different data sets
Worker1
Worker2
Worker3
User-definedMap/ReduceInstructionD
ata

o Automatic parallelization using Map & Reduce
Complexities in Distributed Computing, solving..
o Coordinate with other nodes
o Handling failures
o Preserve bandwidtho Load balancing
o Coordinate nodes using a master node
MapReduce to the Rescue
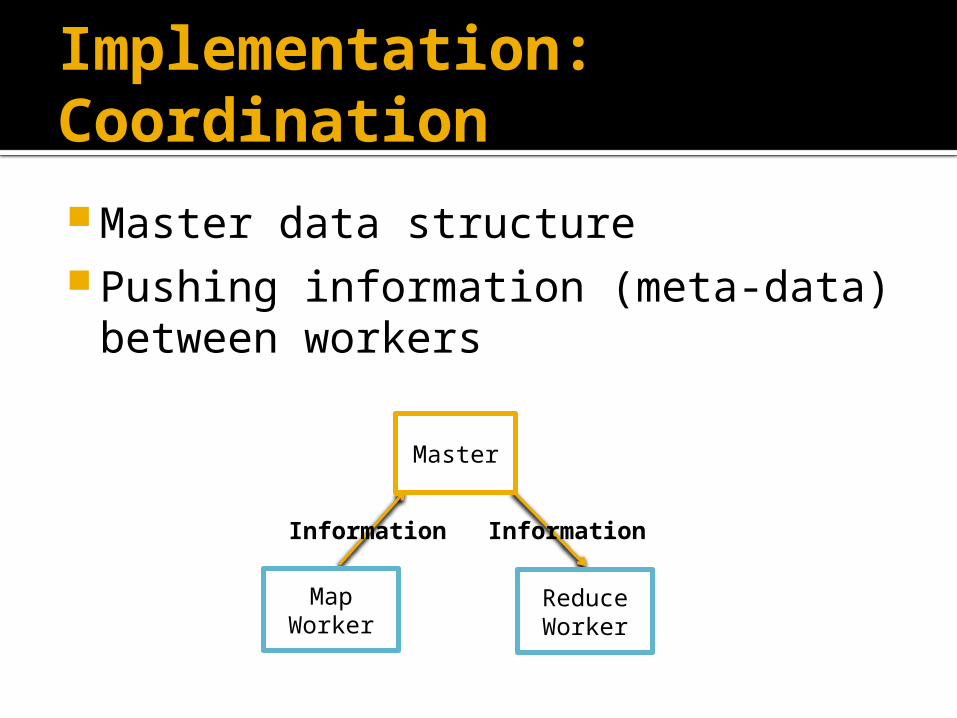
Implementation: Coordination
Master data structure Pushing information (meta-data)
between workers
Information Information
Master
MapWorker
ReduceWorker

o Fault tolerance (Re-execution) & back up tasks
o Coordinate nodes using a master node
o Automatic parallelization using Map & Reduce
Complexities in Distributed Computing , solving..
o Handling failures
o Preserve bandwidtho Load balancing
MapReduce to the Rescue

Implementation: Fault Tolerance
No response from a worker task? If an ongoing Map or Reduce task: Re-
execute If a completed Map task: Re-execute If a completed Reduce task: Remain
untouched
Master failure (unlikely) Restart

Implementation: Back Up Tasks “Straggler”: machine that takes a
long time to complete the last steps in the computation
Solution: Redundant Execution Near end of phase, spawn backup copies
Task that finishes first "wins"

o Saves bandwidth through locality
o Fault tolerance (Re-execution) & back up tasks
o Coordinate nodes using a master node
o Automatic parallelization using Map & Reduce
Complexities in Distributed Computing , solving..
o Preserve bandwidtho Load balancing
MapReduce to the Rescue

Same data set in different machines
If a task has data locally, no need to access other nodes
Implementation: Optimize Locality

o Saves bandwidth through locality
o Fault tolerance & back up tasks
o Coordinate nodes using a master node
o Automatic parallelization using Map & Reduce
Complexities in Distributed Computing , solving..
o Load balancingo Load balancing through granularity
MapReduce to the Rescue
Complexities in Distributed Computing , solved

Implementation: Load Balancing
Fine granularity tasks: map tasks > machines
1 worker several tasks Idle workers are quickly assigned to
work

Extensions
Partitioning
Combining
Skipping bad records
Debuggers – local execution
Counters
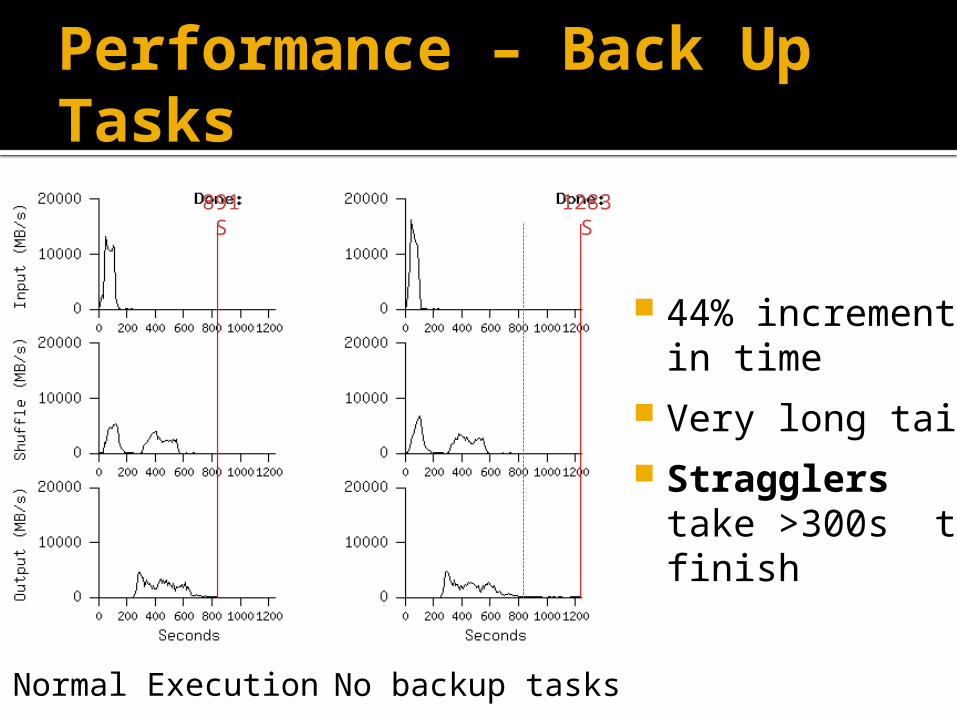
Performance – Back Up Tasks
Normal Execution No backup tasks
891 S 1283 S
44% increment in time
Very long tail Stragglers take
>300s to finish
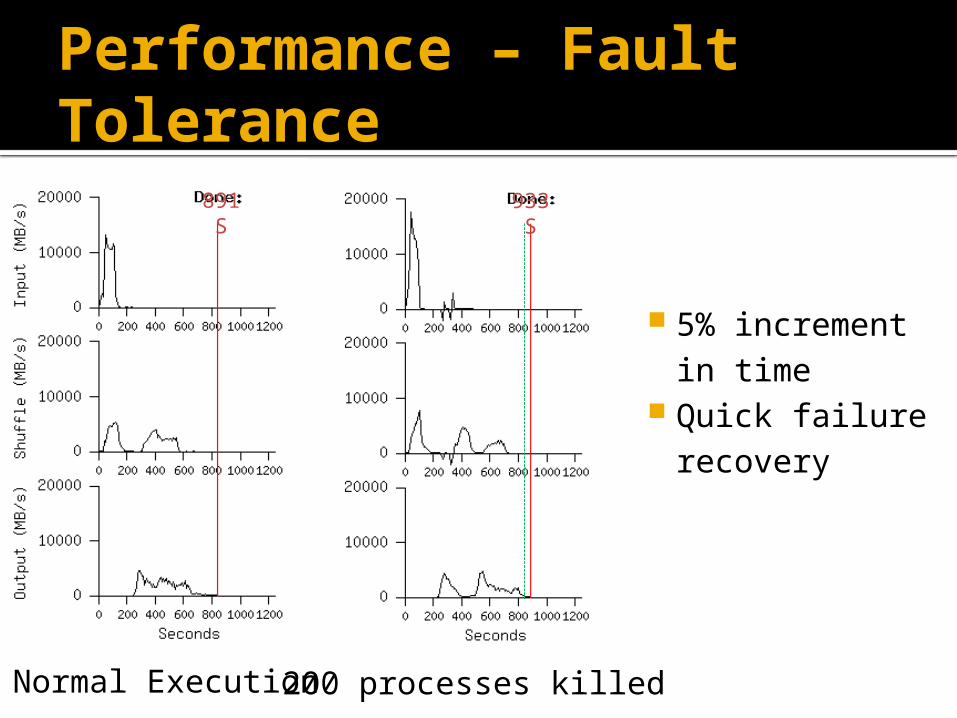
Performance – Fault Tolerance
Normal Execution200 processes killed
891 S 933 S
5% increment in time
Quick failure recovery
MapReduce at Google
Clustering for Google News and Google Product Search
Google Maps Locating addresses Map tiles rendering
Google PageRank Localized Search

Current Trends – Hadoop MapReduce Apache Hadoop MapReduce Hadoop Distributed File System (HDFS) Used in,
Yahoo! Search Facebook Amazon Twitter Google

Current Trends – Hadoop MapReduce
Higher level languages/systems based on Hadoop
Amazon Elastic MapReduce Available for general public Process data in the cloud
Pig and Hive

Conclusion
Large variety of problems can be expressed as Map & Reduce
Restricted programming model
Easy to hide details of distributed computing
Achieved scalability & programming efficiency














![ECON480 HY International Business Varela [Fall 2015]...Ghemawat,!Harvard!Business!Review,!September!2001!! Pankaj Ghemawat is Global Professor of Management and Strategy and Director](https://static.fdocuments.net/doc/165x107/5eceb802ac8f391609197e5e/econ480-hy-international-business-varela-fall-2015-ghemawatharvardbusinessreviewseptember2001.jpg)



