
Boyer more algorithm
19
BOYER MORE ALGORITHM
-
Upload
kritika-purohit -
Category
Engineering
-
view
27 -
download
1
Transcript of Boyer more algorithm

BOYER MORE ALGORITHM

String Searching Algorithms
•The goal of any string-searching algorithm is to determine whether or not a match of a particular string exists within another (typically much longer) string.
•Many such algorithms exist, with varying efficiencies.
•String-searching algorithms are important to a number of fields, including computational biology, computer science, and mathematics.

The Boyer-Moore String Search Algorithm•It is developed by Robert Boyer and J Strother Moore in 1977.
•The B-M string search algorithm is a particularly efficient algorithm, and has served as a standard benchmark for string search algorithm ever since.

How does it work?
•The B-M algorithm takes a ‘backward’ approach: the pattern string(P) is aligned with the start of the text string(T), and then it compares the characters of pattern from right to left, beginning with rightmost character.
•If a character is compared that is not within the pattern, no match can be found by comparing any further characters at this position so the pattern can be shifted completely past the mismatching character.

Continue…
For determining the possible shifts, B-M algorithm
uses 2 preprocessing strategies simultaneously.
Whenever a mismatch occurs, the algorithm computes
a shift using both strategies and selects the larger
shift. Thus, it makes use of the most efficient strategy
for each individual case.
The 2 strategies are called heuristics of B-M as they
are used to reduce the search. They are:
1. Bad Character Heuristic
2. Good suffix Heuristic

Bad Character Heuristic
This heuristic has 2 implications:
a) Suppose there is a character in text which does not occur in pattern at all. When a mismatch happens at this character (called as bad Character), whole pattern can be shifted, to begin matching form substring next to this ‘bad character’.
b) On the other hand, it might be that a bad character is present in the pattern; in this case align the character of pattern with a bad character in text.
Thus in any case shift may be greater than one.
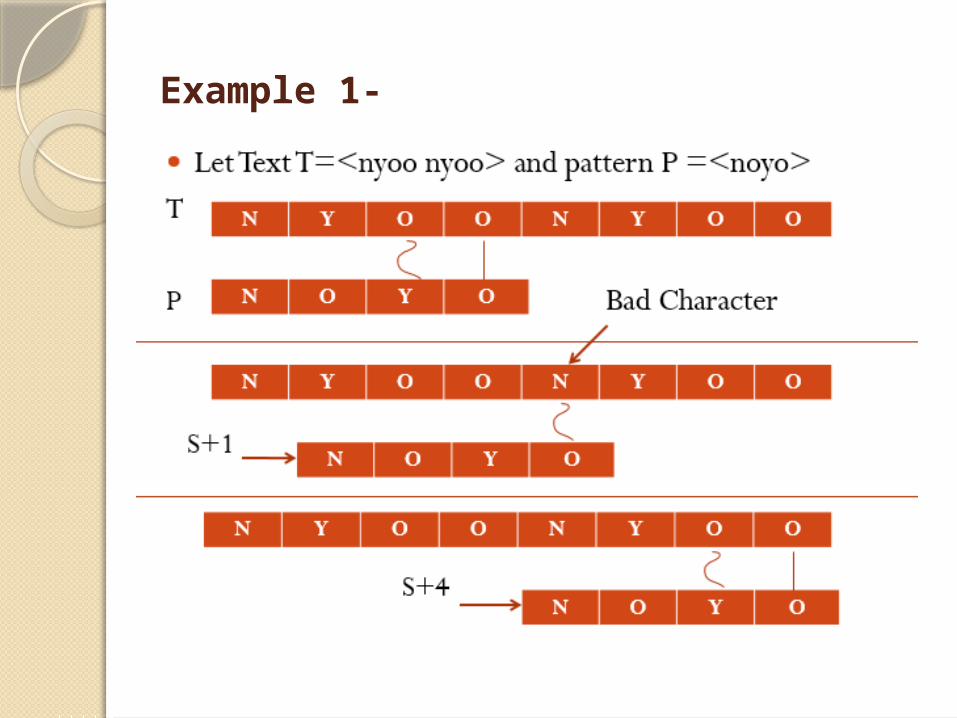
Example 1-
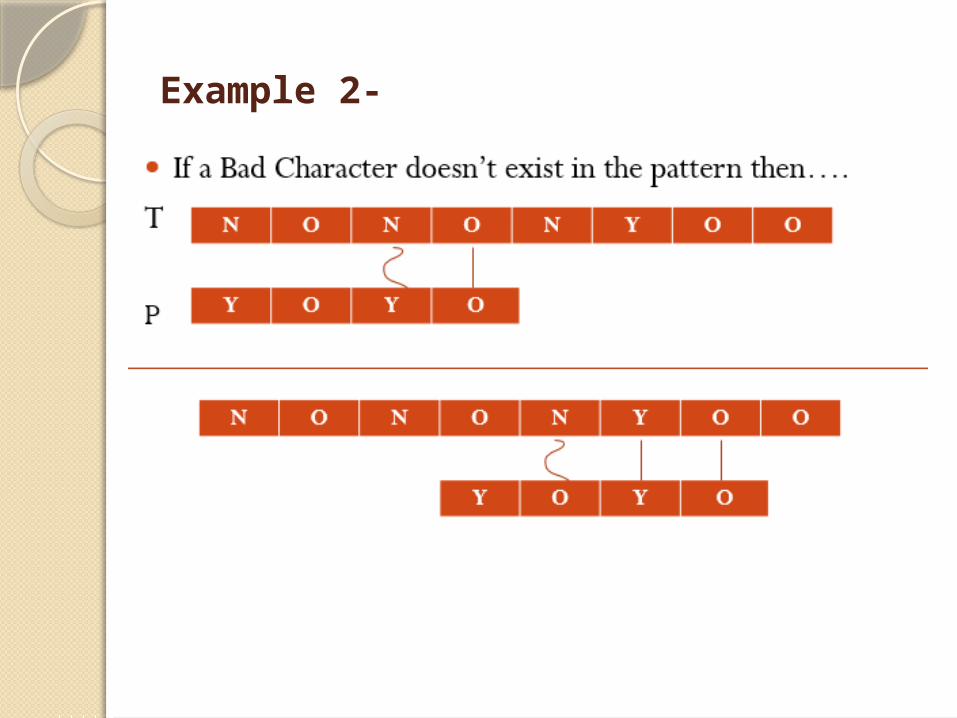
Example 2-

Problem In Bad Character Heuristic-In some cases Bad Character He uristic produces some negative shifts.
For Example:
This means we need some extra information to produce a shift on encountering a bad character. The information is about last position of every character in the pattern and also the set of characters used in the pattern(often called the alphabet ∑ of pattern).

Algorithm-
Last_Occurence(P, ∑)//P is Pattern
// ∑ is alphabet of patternStep 1: Length of the pattern is computed.
m length[P]Step 2: For each alphabet a in ∑
Ł[a]:=0 // array Ł stores the last occurrence value of each
alphabet.Step 3: Find out the last occurrence of each character
for j 1 to mdo Ł [P[j]]=j
Step 4: return Ł

Good Suffix Heuristic
A good suffix is a suffix that had matched successfully.
After a mismatch which has negative shift in bad character heuristic, look if a substring of pattern matched till bad character has a good suffix in it; if it is so then we have a forward jump equal to length of suffix found.
Example:

Algorithm-
Good_Suffix(P)//P is a patternStep 1: m:=length(P)Step 2: ∏:=Compute_Prefix(P)Step 3: P’=reverse(P)Step 4: ∏ ‘=Compute_Prefix(P’)Step 5: for j:=0 to mStep 6: ¥[j]:= m- ∏ [m]Step 7: for k=1 to mStep 8: j:= m- ∏ ‘[k]Step 9: if (¥[j]>k- ∏’[k])Step 10: ¥[j]:=k- ∏’[k]Step 11: return ¥

Boyer Moore Algorithm
BM_Matcher(T,P)// T is a text// P is a patternStep 1: m:= length(P)Step 2: n:=length(T)Step 3: Ł:=Last_Occurence(P, ∑)Step 4: ¥=Good_Suffix(P)Step 5: s:=0Step 6: while(s<=n-m)Step 7: j:=mStep 8: while(j>0 and P[j]=T[s + j]Step 9: j:=j-1Step 10: if j=0

Continue…..
Step 11: print “pattern occurs at shift” sStep 12: s:=s+ ¥[0]Step 13: else s:=s+max{¥[j],j- Ł[T[s+j]]}Step 14: end ifStep 15: end while

Summary-
B-M is a String Searching Algorithm.
The algorithm preprocesses the pattern string that is
being searched for, but not the string being searched in,
which is T.
This algorithm’s execution time can be sub-linear, as
not every character of the string to be searched needs
to be checked.
Generally the algorithm gets faster as the target
string(pattern) becomes larger.

Continue…..
◦Complexity of Algorithm:
This algorithm takes O(mn) time in the worst case
and O(nlog(m)/m) on average case, which is sub-linear in
the sense that not all characters are inspected.
◦Applications:
This algorithm is highly useful in tasks like
recursively searching files for virus patterns, searching
databases for keys or data, text and word processing
and any other task that requires handling large amounts
of data at very high speed.

References-
Boyer-Moore String Searching Algorithm By: Matthew Brown
Boyer-Moore Algorithm by: Idan Szpektor
Boyer-Moore by: Charles Yan(2007)
Boyer-Moore Algorithm by : H.M. Chen

ANY QUERIES….!!!

Thank You


















