
Bottleneck Elimination from Stream Graphs S. M. Farhad The University of Sydney Joint work with...
24
Bottleneck Elimination from Stream Graphs S. M. Farhad The University of Sydney Joint work with Yousun Ko Bernd Burgstaller Bernhard Scholz
-
Upload
london-mille -
Category
Documents
-
view
213 -
download
0
Transcript of Bottleneck Elimination from Stream Graphs S. M. Farhad The University of Sydney Joint work with...

Bottleneck Elimination from Stream Graphs
S. M. Farhad
The University of Sydney
Joint work with
Yousun Ko
Bernd Burgstaller
Bernhard Scholz

2
Outline
Motivation Multicore Stream programming
Research question Our work Summary
2
3
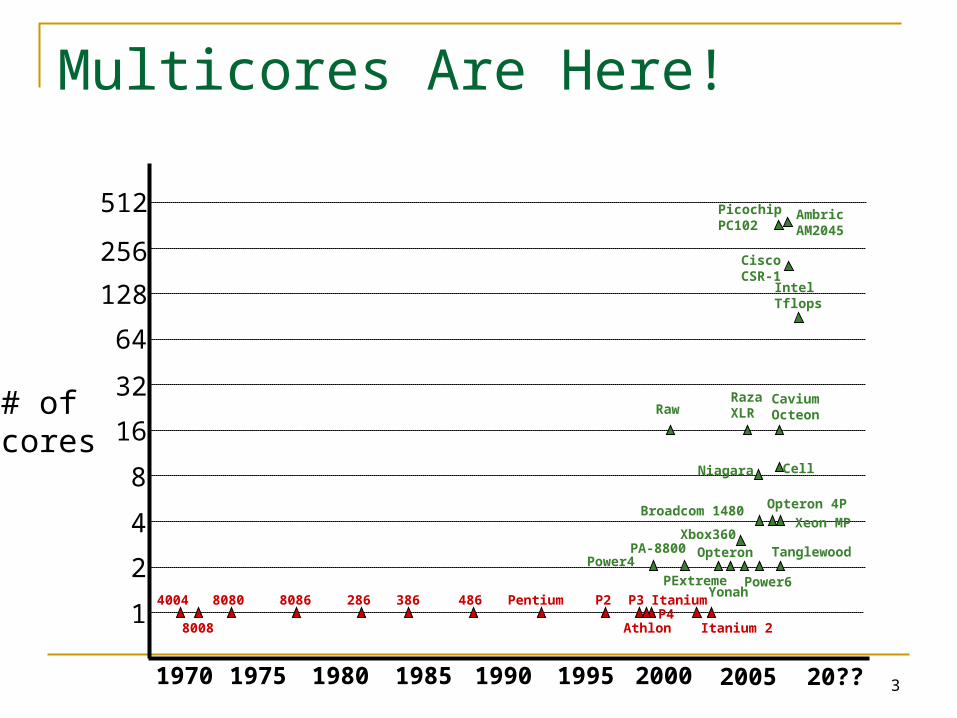
Multicores Are Here!
1985 199019801970 1975 1995 2000
4004
8008
80868080 286 386 486 Pentium P2 P3P4Itanium
Itanium 2
2005 20??
# ofcores
1
2
4
8
16
32
64
128
256
512
Athlon
Raw
Power4Opteron
Power6
Niagara
YonahPExtreme
Tanglewood
Cell
IntelTflops
Xbox360
CaviumOcteon
RazaXLR
PA-8800
CiscoCSR-1
PicochipPC102
Broadcom 1480 Opteron 4P
Xeon MP
AmbricAM2045

4
Multicores Are Here!
Uniprocessors:C is the commonmachine language
1985 199019801970 1975 1995 2000
4004
8008
80868080 286 386 486 Pentium P2 P3P4Itanium
Itanium 2
2005
Raw
Power4Opteron
Power6
Niagara
YonahPExtreme
Tanglewood
Cell
IntelTflops
Xbox360
CaviumOcteon
RazaXLR
PA-8800
CiscoCSR-1
PicochipPC102
Broadcom 1480
20??
# ofcores
1
2
4
8
16
32
64
128
256
512
Opteron 4P
Xeon MP
Athlon
AmbricAM2045

5
Multicores Are Here!
What is the commonmachine languagefor multicores?
1985 199019801970 1975 1995 2000
4004
8008
80868080 286 386 486 Pentium P2 P3P4Itanium
Itanium 2
2005
Raw
Power4Opteron
Power6
Niagara
YonahPExtreme
Tanglewood
Cell
IntelTflops
Xbox360
CaviumOcteon
RazaXLR
PA-8800
CiscoCSR-1
PicochipPC102
Broadcom 1480
20??
# ofcores
1
2
4
8
16
32
64
128
256
512
Opteron 4P
Xeon MP
Athlon
AmbricAM2045

6
Stream Programming Paradigm Research topic in parallel programming Various forms of parallelism
Pipeline, task, and data Applications
Signal Processing Multi-media High-Performance Computing
Programs expressed as stream graphs Streams
Infinite sequence of data elements (aka. Tokens) Actor
Functions applied to streams
6
Actor
Stream
Stream

7
Properties of Stream Program Regular and repeating
computation Independent actors with explicit
communication Producer / Consumer
dependencies
7
Adder
Speaker
AtoD
FMDemod
LPF1
Splitter
Joiner
LPF2 LPF3
HPF1 HPF2 HPF3

8
StreamIt Language [ASPLOS’2&6, PLDI’3]
An implementation of stream prog.
Each construct has single input/output stream
Hierarchical structure
Filters can be stateful/stateless
parallel computation
may be any StreamIt language construct
joinersplitter
pipeline
feedback loop
joiner splitter
splitjoin
filter
8

9
Research Question: How to Eliminate Bottlenecks (Hot Actors) from Stream Graphs?
9

10
Mapping Actors
Core 1
B 60
C 60
D 5
5ACore 2 Core 3
5A
D 5
B 60 C 60
T =10s T = 60s T = 60s
Make span = 60s, Speedup = 130/60 = 2.17
10

11
Bottleneck Actors Limit the Performance
B 60
C 60
D 5
5A
D 5
5A
B_1 20
2s1
2j1
B_2 20 B_3 20
C_1 20
2s2
2j2
C_2 20 C_3 20
Hot actor duplication
Core 1 Core 2 Core 3
5A
s1 2
B_1 20
C_1 20
B_2 20
j1 2
s2 2
C_2 20
j2 2
B_3 20
C_3 20
D 5
T = 47s T = 46s T = 45s
Make span = 47s, Speedup = 130/47 = 2.77
11

12
Bottleneck Resolving of Stream Program Contd. Current state of the art
Integer Linear Programming Intractable
How to find a fast and good solution? Heuristics Optimal
12

Our Work
A data rate transfer model to detect and eliminate bottlenecks
We separate the bottleneck elimination from the actor allocation
Heuristics to solve bottleneck problem efficiently
13

14
Our Data Transfer Model
Throughput depends on the data rate of the actors (maximize)
Data transfer model forms a system of sim. functional linear equation
Compute a closed form of the output data rate We also consider a processor utilization
function for each actor
A B C1 5 1 1
z
zxA AB xx 2.0 BC xx
zxA zxB 2.0 zxC 2.0
14

15
Bottleneck Analysis
The throughput is limited by Processor capacity of the cores Memory bandwidth
A quantitative analysis determines An upper bound of the throughput imposed by an
actor An upper bound of the throughput imposed by the
parallel system Hot actor
Upper bound (actor) < upper bound (system)
15

h2
h1
Hot Region
Maximal connected subgraph where and each is hot and stateless
16
EEVV , EVh ,Vi
B
C
D
A
E
F
G

17
Resolving Bottleneck Options
17
B 60
C 60
D 5
5A
D 5
5A
B_1 20
2s1
B_2 20 B_3 20
C_1 20
2j1
C_2 20 C_3 20
Hot region duplication
D 5
5A
B_1 20
2s1
2j1
B_2 20 B_3 20
C_1 20
2s2
2j2
C_2 20 C_3 20
Hot actor duplication
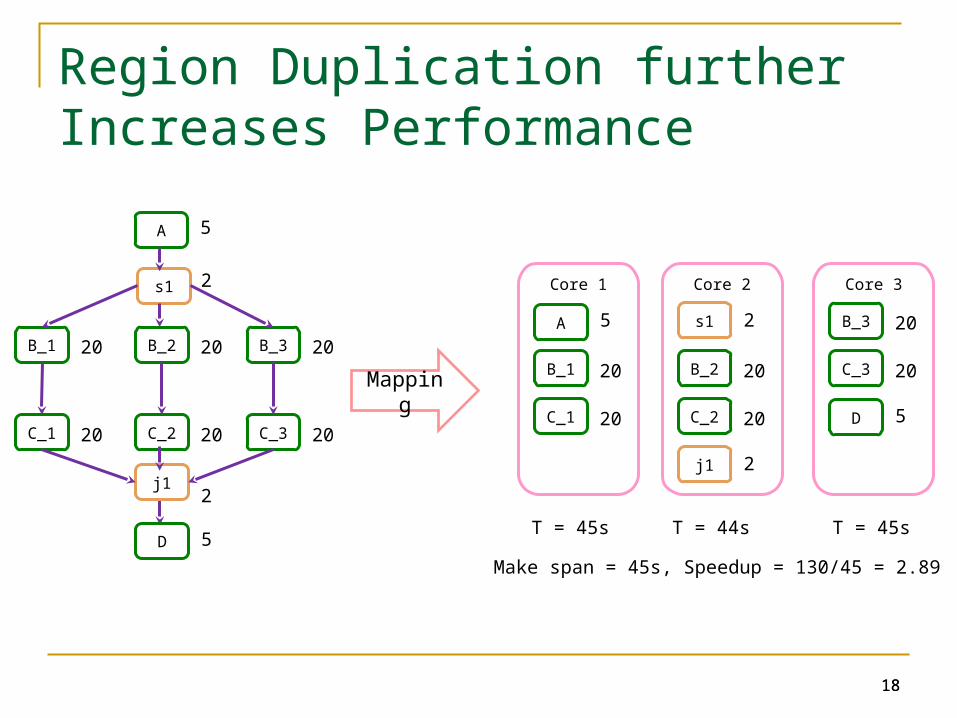
18
Region Duplication further Increases Performance
18
D 5
5A
B_1 20
2s1
B_2 20 B_3 20
C_1 20
2j1
C_2 20 C_3 20
Core 1
5A
B_1 20
C_1 20
Core 2
s1 2
B_2 20
j1 2
C_2 20
Core 3
B_3 20
C_3 20
D 5
T = 45s T = 44s T = 45s
Make span = 45s, Speedup = 130/45 = 2.89
Mapping

Cascading Effect of Duplication Actors may become hot due to duplication of
other actors
B
C
D
A
E
A
B_1
s1
B_2 B_3
C_1
j1
C_2 C_3
E
D

dB=2 dh1=2
dD=3
dE=2
dF=3
dh2=3
Duplication Factor of an Actor and a Hot Region The # of times the actor needs
to be duplicated Maximum duplication factor of
the actors of the hot region
20
B
C
D
A
E
F
G
1id
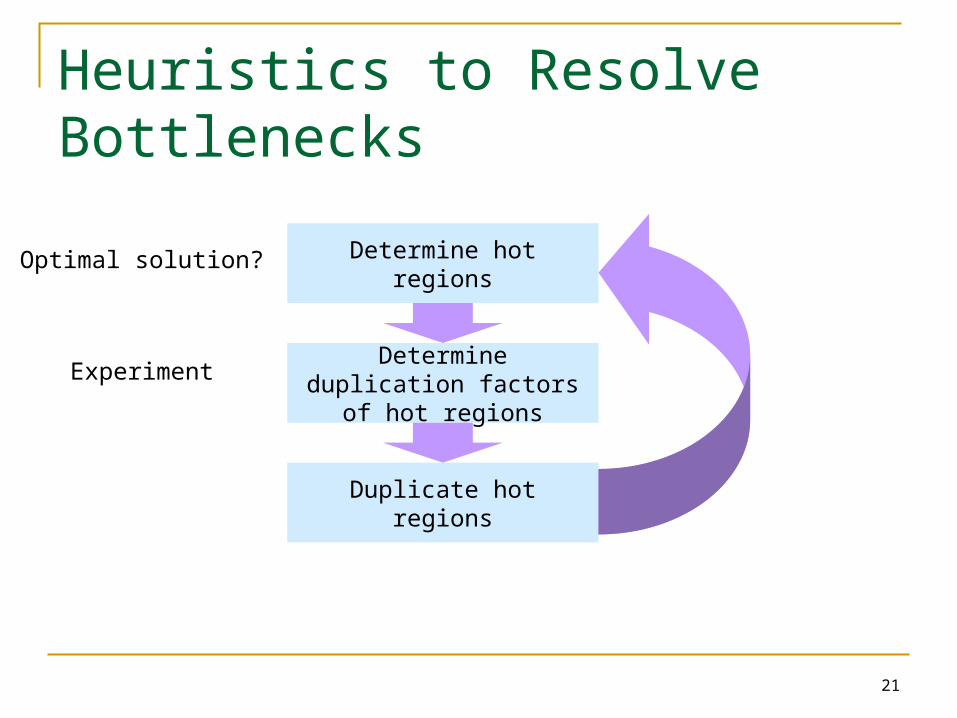
Heuristics to Resolve Bottlenecks
21
Determine hot regions
Determine duplication factors of hot regions
Duplicate hot regions
Optimal solution?
Experiment

22
Summary
A simple quantitative analysis to detect and
eliminate bottlenecks
We separate the bottleneck elimination from
the actor allocation
Heuristics to eliminate bottlenecks
22

23
Related Works
[1] Static Scheduling of SDF Programs for DSP [Lee ‘87]
[2] StreamIt: A language for streaming applications [Thies ‘02]
[3] Phased Scheduling of Stream Programs [Thies ’03]
[4] Exploiting Coarse Grained Task, Data, and Pipeline Parallelism in
Stream Programs [Thies ‘06]
[5] Orchestrating the Execution of Stream Programs on Cell [Scott ’08]
[6] Software Pipelined Execution of Stream Programs on GPUs
[Udupa‘09]
[7] Synergistic Execution of Stream Programs on Multicores with
Accelerators [Udupa ‘09]
23

Questions?
![Final Shilpabank-Farhad[1].doc](https://static.fdocuments.net/doc/165x107/577cc0091a28aba7118ea31d/final-shilpabank-farhad1doc.jpg)










![LW Claude Monet Attunement (Farhad Najafi)[1]](https://static.fdocuments.net/doc/165x107/577d21031a28ab4e1e9444f0/lw-claude-monet-attunement-farhad-najafi1.jpg)





