
Biostatistics Case Studies Peter D. Christenson Biostatistician Session 6: Control of Confounding...
22
Biostatistics Case Studies Peter D. Christenson Biostatistician http://gcrc.humc.edu/Biostat Session 6: Control of Confounding Bias Using Propensity Scoring
-
Upload
marshall-morris -
Category
Documents
-
view
216 -
download
0
Transcript of Biostatistics Case Studies Peter D. Christenson Biostatistician Session 6: Control of Confounding...

Biostatistics Case Studies
Peter D. Christenson
Biostatistician
http://gcrc.humc.edu/Biostat
Session 6: Control of Confounding Bias Using Propensity Scoring

Case Study
Impact of Valve Surgery on 6-Month Mortality in Adults With Complicated,
Left-Sided Native Valve Endocarditis A Propensity Analysis
Holenarasipur R. Vikram, MD; Joan Buenconsejo, MPH; Rodrigo Hasbun, MD; Vincent J. Quagliarello, MD
JAMA. 2003;290:3207-3214.

Subjects
• N=513 from records at 7 hospitals : Jan 1990 - Jan 2000.
• Definite (3%) or probable (97%) endocarditis.
• Left-sided infection of native valve.
• Have a complication for which surgery is considered:
• CHF
• New valvular regurgitation.
• Refractory infection.
• Systemic embolism to vital organs.
• Echocardiographic evidence of vegetation.

Measured Characteristics
Exposure:Surgery or no surgery for valve repair or replacement. Outcome:All-cause mortality within 6 months of baseline = date of surgery or date of decision to not operate.
Other factors:Hospital, baseline demographics, comorbidity, previous heart disease, symptoms, physical findings, blood cultures, EKG, echo, type of surgery, operative findings.

Analysis #1: Typical Survival Analysis
Step 1:Individually determine factors related to mortality with Cox regression (survival analysis). Surgery is one. Step 2:Include factors related to mortality in step 1, and surgery, in a multivariable survival analysis that adjusts the effect of mortality for these other factors.

Analysis #1: ResultsTable 3 and p. 3209 top center
Step 1:Factors significantly associated with greater mortality are: female, older, immunocompromised, fever, intracardiac abscess, comorbidity on standard scale, CHF, abnormal mental status, bacteria other than viridans strep, elevated serum creatinine, and refractory infection.
Surgery: 37/230=16% died, non-surgery: 94/160=33% died in six months. Hazard ratio = 0.43 (95%CI: 0.29 – 0.63). Step 2:Adjustment for “heterogeneity factors” gives a slightly greater surgical effect: Hazard ratio = 0.35 (95%CI: 0.23 – 0.54).But, why are these factors in * of Table 3 not the same as those in step 1?
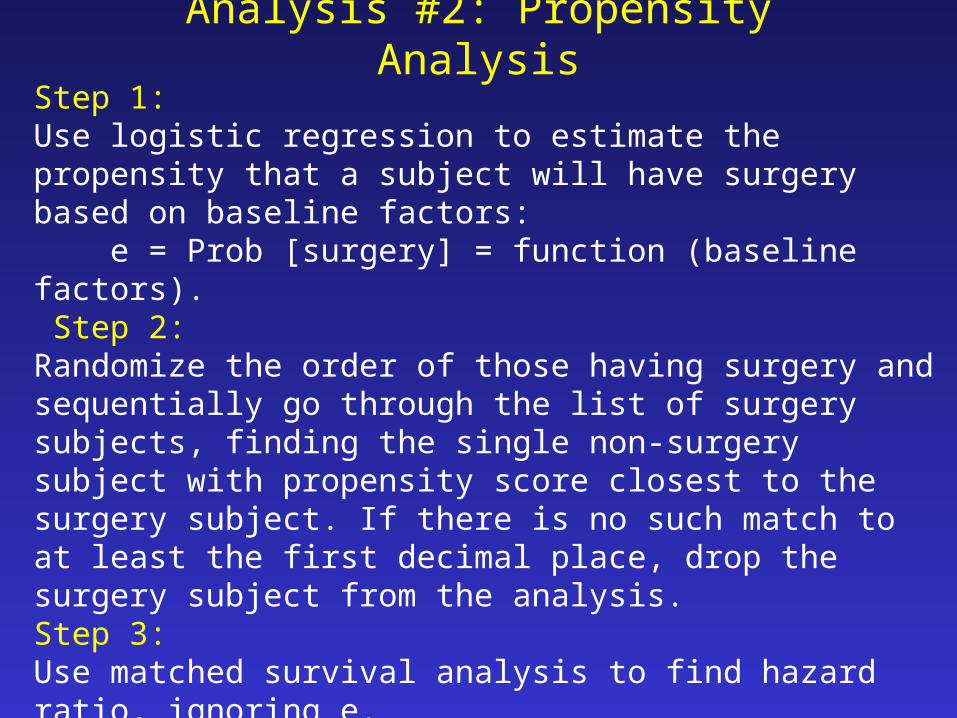
Analysis #2: Propensity Analysis
Step 1:Use logistic regression to estimate the propensity that a subject will have surgery based on baseline factors: e = Prob [surgery] = function (baseline factors). Step 2:Randomize the order of those having surgery and sequentially go through the list of surgery subjects, finding the single non-surgery subject with propensity score closest to the surgery subject. If there is no such match to at least the first decimal place, drop the surgery subject from the analysis.Step 3:Use matched survival analysis to find hazard ratio, ignoring e.Step 4:Use matched survival analysis to find hazard ratio, also adjusting for heterogeneity or confounding factors.

Analysis #2: Results Part 1Tables 1 and 2
Propensity score is a function of: Hospital, HIV+, comorbidity, CHF, abnormal mental status, symptomatic or disabling emboli, refractory infection, intracardiac abscess, new valve regurgitation, microbial etiology, valve involved, number of embolic events.
The propensity score does what it is intended to do:
Most of the factors in Table 1 are different between surgery (N=230) and non-surgery (N=283) subjects.
All of these same factors in are not different between surgery (N=109) and their matched non-surgery (N=109) subjects in Table 2.

Analysis #2: Results Part 2Table 3 and Figure 1
Table 3: HR (95% CI) p
Propensity-matched only 0.45 (0.23-0.86) 0.02Include confounder* adjustment 0.45 (0.24-0.88) 0.02Add heterogeneity adjustment 0.40 (0.18-0.91) 0.03 *only for slight differences in propensity score within matched pairs.
Figure 1:
Does not assume proportional hazards. p=0.01

Logic for Propensity Score
Q: Why estimate the probability that a subject receives surgery, when we KNOW which subjects did?
A: This creates a “quasi-randomized” experiment. If one surgery subject and one non-surgery subject have the same probability that they would have received surgery, then the fact that one of them eventually did is random, a 50% chance for each.
Two issues:
(1) We assume that the set of covariates contains all of the characteristics related to both treatment and response, i.e., that all confounders are measured.
(2) Even if (1) is true, we don’t know true propensity, but need to estimate it from the data.

Basic Theory for Propensity ScoreThe two conditions:
(1) The propensity score is a balancing score, meaning that the statistical distribution of the covariates is the same for surgery or non-surgery subjects with the same propensity.
(2) Treatment assignment is strongly ignorable, meaning that the probability of treatment assignment and the distribution of response are independent for a given set of the covariates. [This is (1) from the previous slide.]
imply that: Average treatment effect can be measured unbiasedly for a specific propensity, as in a randomized experiment.
But, again, (2) is an assumption, and we only have an estimate in (1). In practice, approximately unbiased estimates are hoped for, but cannot be verified statistically.

Alternative Analysis A“Standard” adjusted survival analysis using a set of actual
confounder values.
Advantage:
Uses all subjects (provided data is available). Here, we dropped 513-218 = 295 subjects, although some due to missing data.
Disadvantages:
1. Adjusting for many confounders makes model stability difficult: choosing interactions, multicollinearity, overfitting, many categorical levels, etc. See slide after next one, cf.
2. If the range for just one confounder is very different for surgery and non-surgery subjects, the adjustment is at an interpolated value, which may not occur in practice or make clinical sense, as in example on next slide.

Example of Poor Confounder Adjustment
From Gerard Dallal, www.StatisticalPractice.com.
This problem exists in any regression adjustment, but is more likely when adjustment for many factors is made.

Confounder Adjustment Simulations: Set of many confounders vs. Propensity score
Cepeda, et al, American J Epidemiology 2003;158:280-287:
• Uses logistic regression, rather than survival analysis as here, but probably (?) similar conclusions.
• Compares the two methods on bias, CI coverage, power, and precision.
• Concludes: Use propensity score if # deaths per # of parameters for confounders is small, less than 7.
• Next three slides give reasons for this recommendation.
• In this study, have 113 deaths, so propensity score method is preferable if at least ~ 113/7 ~ 16 confounding parameters. There are 18 parameters for association with surgery (but not all are confounders?), not including interactions.

Confounder Adjustment Simulations: Set of many confounders vs. Propensity score
Precision

Confounder Adjustment Simulations: Set of many confounders vs. Propensity score
Confidence Interval: True Probability Level

Confounder Adjustment Simulations: Set of many confounders vs. Propensity score
Bias

Borrowing from Peter to Pay Paul?
Q: Isn’t this two-step process in propensity analysis just removing the problem of “many confounders” in the survival estimation, as in Alternative A, to the estimation of the propensity, and the problem still remains there?
A: Using many confounders in the equation for estimation of treatment effect may lead to over-fitting, specific for the data in the sample, and not generalizable, and to imprecision in the treatment effect.
We are not as concerned about over-fitting the equation for propensity scores, since the prediction from it will be less biased, and the imprecision is not as serious, as the simulations in the last few slides show.

Alternative Analysis B
“Standard” stratified survival analysis with strata defined by a set of actual confounder values.
Advantages:
1. Uses all subjects (provided data is available, and strata are not too numerous).
2. Assumptions and fitting difficulties of regression modeling as in alternative A are not issues.
Disadvantage:
Too many strata will be required. Thus, small Ns in strata, or some subjects dropped due to no non-surgery subjects in a strata.

Alternative Analysis C
Use techniques other than the propensity score for choosing a single summary confounding measure.
• Most popular method: Mahalanobis metric matching.
• This was the method of choice prior to propensity scores.
• Similar to clustering analyses.
• Approximately visualized for just 2 confounders by plotting each confounder as x or y on a plot, for all non-surgery subjects only. Then, for each surgery subject, add him/her to the plot, and choose the closest non-surgery subject as the match.
• Disadvantage: difficult to find close matches when there are many confounders.

Other Propensity-type Scores
Current Development: Drop-out in clinical trials
Propensity = Prob[ completing trial] =
function of baseline characteristics
Concept: Attempt to reduce the bias due to differential drop out between treated and non-treated groups, by matching on propensity to drop out.
Difficulty: This still will require the assumption that reasons for drop out are included in the measured characteristics.

Conclusions
The two analyses in the paper are extreme in their handling of potential confounding:
Analysis (1) ignores confounding, although it adjusts for some covariates.
Analysis (2) strongly corrects for confounding. It ignores subjects who don’t have a matched subject with similar confounders receiving the opposite treatment, and may over-match.
Similar conclusions, i.e., a 55% to 65% efficacy of surgery for the different analyses, adds robustness to the conclusion.
![Borko Jovanovic, MS, PhD Biostatistician [email protected]](https://static.fdocuments.net/doc/165x107/61fb98b72e268c58cd600e97/borko-jovanovic-ms-phd-biostatistician-emailprotected.jpg)

















