
Transforming Wikipedia into an Ontology-based Information ...
Upload
amarnath-guptaCategory
view
213download
1
Data & Knowledge Engineering 69 (2010) 1084–1102
Contents lists available at ScienceDirect
Data & Knowledge Engineering
j ourna l homepage: www.e lsev ie r.com/ locate /datak
Editorial
BioDB: An ontology-enhanced information system for heterogeneousbiological information
Amarnath Gupta⁎, Christopher Condit, Xufei QianSan Diego Supercomputer Center, University of California San Diego, La Jolla, CA 92093, USA
a r t i c l e i n f o
⁎ Corresponding author.E-mail addresses: [email protected] (A. Gupta), con
0169-023X/$ – see front matter © 2010 Elsevier B.V.doi:10.1016/j.datak.2010.07.003
a b s t r a c t
Available online 27 July 2010
This paper presents BIODB, an ontology-enhanced information system to manage heterogeneousdata. An ontology-enhanced system is a system where ad hoc data is imported into the systemby a user, annotated by the user to connect the data to an ontology or other data sources, andthen all data connected through the ontology can be queried in a federated manner. The BIODBsystem enables multi-model data federation, i.e., it federate data that can be in different datamodels including, relational, XML and RDF, sequence data and so on. It uses an ontologicallyenhanced system catalog, an ontological data index, an association index to facilitate cross-model data mapping, and a new algorithm for ontology-assisted keyword queries with ranking.The paper describes these components in detail, and presents an evaluation of the architecturein the context of an actual application.© 2010 Elsevier B.V. All rights reserved.
Keywords:OntologyData modelData integrationBiological information system
1. Introduction
In [1,2] Jean et al. defined an ontology-based database system (OBDB) as a class of database systems for which the conceptualmodel of the database is created by extending an ontologywhich captures the primary knowledge of the application domain. Theyargue that an ontology-based database system enables a user to query the database not only through the logical schema, butthrough the concepts of the ontology from which its conceptual model is derived. Consequently, a user can retrieve data in thecontext of its semantics, which includes the ontological terms related to the data, the associations among these terms, theirdefinitions, and so forth. The basic principle of explicitly encoding data semantics by associating a database schema and data itemsto ontologies is now widely practiced in the domain of biological sciences. The broad goal of our paper is to present BIODB, abiological information system designed based on a deep ontological underpinning.
While BIODB explicitly encodes semantics, its motivational setting is different from that of the OBDB advocated by [1,2]. Unlikethe OntoDB system, BIODB is not developed by starting from a domain ontology and then extending it with the schema needed forthe application domain. Instead, it reflects the way a typical user, in our case, a systems biologist named Joe, actually works. Let usassume that Joe is starting to work in a new research area like skin cancer (malignant melanoma), and is interested in exploringwhat role a biological entity, such as the human microRNA (miRNA), plays in the disease process. He explores and finds out that asite called miRBase (microrna.sanger.ac.uk) has a publicly accessible database of human miRNA, and downloads two relationaltables, microRNAs and miRNATargets into BIODB. The first table contains information about basic properties of the microRNAsthemselves, while the second table records which microRNA interacts with (regulates) which gene (more accurately, the mRNAtranscript produced from the gene). Next, Joe determines that some biological pathways (which are node and edge-labeled graphsof molecular interactions) are important to understand the molecular mechanism of the microRNAs — so he goes to a number ofdata sources (like KEGG at www.genome.ad.jp/kegg/pathway.html) and downloads a set of molecular network instances intoBIODB. Finally, Joe asks his postdoctoral student to upload a set of gene expression data (which can be represented as correlation
[email protected] (C. Condit), [email protected] (X. Qian).
All rights reserved.

1085A. Gupta et al. / Data & Knowledge Engineering 69 (2010) 1084–1102
graphs, containing XML metadata), from his wet lab experiments into BIODB. His intention is to correlate and combine these databy querying them, running bioinformatics algorithms on them, storing the results of these computations (which could be relationswith ranked records, edge-weighted graphs, hierarchically grouped sets and so forth) back into BIODB. After this, he would returnto BIODB and perform the next round of query, analysis and biological experiments. Notice that by the end of the first round, BIODBcontains relational tables, XML data, graph data and so on, collected from various domain contributors. Each of these data elementscome from different sources, have different data types and each type of data carries some specific semantics with it. Specifically,the data contains both biological semantics that represents the domain significance of the data, and in some cases, experimentalsemantics that specifies the experimental context in which the data was recorded or computationally produced. Thus, the datacontent of BIODB is structurally and semantically heterogeneous, although thematically related by the research discourse forwhich they were collected. Philosophically, the ontology plays the role of a semantic type system as well as that of a semanticcorrelator. The biological semantics may be specified through ontologies in the OBO (Open Biomedical Ontologies — www.obofoundry.org) repository, including the Gene Ontology, the Sequence Ontology, and the Cell Ontology. The experimentalsemantics may come from ontologies like the Open Biomedical Investigations (OBI) ontology. Using ontologies as these provides aviable way to realize the thematic relationships across these diverse, multi-model data elements so that they can be semanticallyqueried, navigated and interlinked to bring out the scientific connections that Joe wishes to explore. To reflect this post-factoutilization of ontologies, as opposed to an ontologically-driven database development, we call systems like BIODB ontology-enhanced rather than ontology-based information systems.
Through the design of the BIODB system, we have developed a number of generic design principles for ontology-enhanceddatabase systems. The goal of this paper is to present the design, architecture, and functional details of a practical ontology-enhanced information system for our domain. Many of the techniques presented in this paper are adapted from existing literature,but combined together in a novel way to achieve our goals. In this vein, the contributions of this paper are as follows.
1. We present the functional architecture of BIODB, that is distinct from many other information system because it managesheterogeneous information models (relational, graphs, trees), extended with and connected through their ontologicalannotations. In developing this system for our end users, we made the conscious choice of keeping the user-provided data setsin their native models because the native forms are what the users are familiar with. In this regard, our system is distinct fromsystems like D2R (http://www4.wiwiss.fu-berlin.de/bizer/d2rmap/D2Rmap.htm) that explicitly converts all data into acommon data model (in this case RDF).
2. As part of the above, we present the detailed functionality of the OntoQuest subsystem [3] that manages multiple ontologies bytreating them as a special class of graphs. This paper presents several enhancements to the OntoQuest system not reportedearlier.
3. We present the design of an ontology-aware system catalog that extends standard system catalogs by (a) mapping schemaelements to ontologies and (b) accommodating multiple information models within the same catalog structure.
4. We detail the query formulation and evaluation process for (a) general keyword queries, (b) ontological keyword queries, and(c) ontological keyword queries combinedwith predicate-based queries overmultiplemodels of data. To our knowledge, this isthe first ontology-enhanced information system that has these capabilities.
In the rest of the paper, we describe four components of the BIODB information system. Section 2 presents the overallarchitecture of the system. Section 3 describes how ontologies are imported, managed and operated on. The work reported hereextends our previous system called OntoQuest [3,4] by including ontologies that represent non-binary relationships [5]. Section 4presents the data management architecture— it describes the internal cataloging facilities and generic operators for manipulatingintra-type and cross-type data. It also describes a subset of the "hooks" that help associate data terms to ontologies. Section 5presents the mechanism used within BIODB to create associations between data and ontologies, different data sets, as well asbetween ontologies themselves. We discuss a number of common operations that are used to navigate between ontologies andsome common types of data supported by BIODB. In Section 6, we show the basic query processingmachinery developed on top ofthe framework defined in the previous three sections. We present query operations through a set of commonly used functionsinstead of a full query language. Section 8 presents a briefly survey of related literature to situate our work in the context of thecurrent state of the art in four areas of information systems research. In Section 9, we briefly state how BIODB can be used by asystems biologist like Joe, and then conclude the paper with an outlook of future work.
2. An architectural overview of BIODB
Fig. 1 shows the basic building blocks of the BIODB system. In this section we present a brief description of the architecturalelements of the system, and present more details of the ontology-related aspects in the following sections.
2.1. Data readers
BIODB uses a number of data readers for common forms of data, like data exported from relational databases, BioPAX files forgraph-structured pathways, and so forth.

Fig. 1. The overall architecture of the BIODB system.
1086 A. Gupta et al. / Data & Knowledge Engineering 69 (2010) 1084–1102
2.2. Data ingestion and transformation
As described in Section 4, the BIODB system has its own internal model for different types of data (trees, graphs, sequences,…).A primary characteristic of all models is that they are inherently annotatable, typically through an ontology reference. That means,if the input data is a tree, this module augments a canonical tree representation into a new data structure where the nodes and theedges of the tree can be associated with additional information through additional user input. The data ingestion process alsopopulates the semantic catalogs, a structure that not only records the newly registered data set, but also records schema levelannotations that a user may supply during or after ingestion.
2.3. Type-partitioned data store
Since the system needs to deal with heterogeneous kinds of data, it uses a common relational backend, but creates separateindex structures and access routines for different types of data. Thus, the annotated tree structure stores the tree-nodes in theRDBMS, but uses auxiliary structures (e.g., Dewey indices) to facilitate hierarchical data access. Many of these index structures(e.g., the relational interval tree) are implemented over the same relational system, while some (e.g., suffix tree) are handledseparately.
2.4. Query processor array
BIODB is essentially a multi-model system where the heterogeneous data are held together mainly by their ontology. This isenabled by having different query processing routines for different categories of data. For annotated relational data, the processoris a standard relational processor (postgreSQL), augmented by additional routines to handle row, column, and value-levelannotation. For annotated graph data, the node and edge properties as well as the connectivity structure are stored in relations,together with additional graph properties such as centrality measures, and degree distribution that are used by the processorduring query evaluation. Aside from structured data, the system also supports keyword query processing because it is the mostcommonway for biologists to find starting data sets that they can use for further querying and for analysis. As detailed in Section 6,keyword query processing using ontologies is one of the primary mode of use for the system.
2.5. Ontology transformation and ingestion
As detailed in Section 3, the BIODB system accepts OWL, OBO and RDFS ontologies. These ontologies are converted into acommon graph structure, so that OntoQuest, the ontology management subsystem elaborately discussed in the next section, cansearch and manipulate the data.
2.6. Semantic and association catalogs
Every time a new data set is registered with the system, the semantic and the association catalogs get updated. Both catalogsare built on a relational backend. The semantic catalog not only preserves the metadata for every data set, but preserves specific

1087A. Gupta et al. / Data & Knowledge Engineering 69 (2010) 1084–1102
mappings between each data set and the ontology. The association catalog preservesmapping across different data sets, and acrossontologies. They are detailed in Sections 4 and 5, respectively.
2.7. Index structures
In addition to the relationally implemented index structures, BIODB employs a set of indices for different categories ofinformation. A standard but important index structure not covered in the rest of the paper is an inverted index over all string dataover both data and ontology sources stored within the system, and is implemented using the Lucene system from Apache (http://lucene.apache.org/). The index plays a crucial role in query planning to determine which sources are relevant for a specific query.This process is detailed in Section 6.
2.8. Upper-level query processing units
Although bioinformatics and information systems users also access the BIODB system, the prototypical user of the system is abiologist. This means that the general purpose retrieval task (e.g., find all data sets that satisfy condition C) has to be very simple. Onthe other hand, when the data sets are actually detected, the operations to be performed are finely detailed (e.g., merge graph-1with graph-2 and eliminate all edges of type mphX; call this graph G; then find all gene expression arrays corresponding to genenodes in G) and almost like an algebraic procedure. Our strategy is to expose mid-level algebraic operations for all processorsincluding OntoQuest, such that the query planner views them as the base operators of the system. The query planner and evaluationengine keeps the state of queries and results in an entire session so that any intermediate data retrieved as part of one stage ofuser request can be reused for an operation coming later in the session. This stateful mode of operation distinguishes BIODB from astandard DBMS. As with any datamanagement system, the query planner and executor makes heavy use of the catalogs. However, inthis system, query formulation is often incremental; hence the planning process often uses the ontology, the catalogs and the textindex to figure out which sources to access to formulate the next part of the query. This is elaborated in Section 6. In the followingsections, we provide amore detailed and functional view of the system components, highlighting on the use of the ontology in BIODB.
3. The BIODB ontology framework
Just as the BIODB framework allows different data sets to be dropped into the data store, the system allows qualified users toadd ontologies to the ontology repository under the control of an ontology management system called OntoQuest, initiallyreported in [3]. At present the OntoQuest system can accept both OWL ontologies and OBO ontologies; it also accepts simplertaxonomies, expressed for instance in RDFS, to be represented in the ontology repository underlying the OntoQuest system.Further, OntoQuest allows one to specify inter-ontologymappings as a set of axioms (described later). OntoQuest is not a reasoner(see later in this section), but provides an efficient navigation and query facility on ontologies by treating them as graphs. At theback end, OntoQuest builds on a relational schema motivated by the IODT system from IBM [6], that shreds OWL and OBOontologies into this relational schema. Next, we discuss the data model of OntoQuest, and then in Section 6 we discuss how userqueries make use of the data access functions of OntoQuest.
3.1. A graph model for ontologies
OntoQuest models the class-level ontologies as a pair of rooted graphs — the concept graph C and the property tree P. Aproperty tree is shown in Fig. 2.
The nodes of a property tree are typed. The leaf nodes may have the type class or literal with obvious semantics. All class nodesin P must occur in C. All literal nodes in P must be type-matched with the corresponding relationships in C.
An internal node of the property tree can either be a node of type propertyName or an operator node within an incoming edge-labeled domain or range, representing the domain and range of the property respectively. The correctness of the property tree isnot ascertained by OntoQuest, but an external reasoner like Pellet before being ingested into OntoQuest. In Fig. 2 , the property treewill be rendered correct if C3 ⊏ C1. In addition, propertyName nodes also have outbound edges labeled transitive, reflexive,symmetric incident on literal nodes valued true or false respectively.
Fig. 2. All properties in one ontology is represented by a single property tree.

1088 A. Gupta et al. / Data & Knowledge Engineering 69 (2010) 1084–1102
The concept graph C is more complicated. The nodes of a concept graph are typed where the basic types are class, literal andquality. The notion of quality is inspired by upper ontologies like DOLCE (www.loa-cnr.it/DOLCE.html), where it representsconcepts like color or shape that are not objects but observable conceptual properties. Unlike a literal which represents a value of abasic type (e.g., string) and is not related to any other value, a quality is a kind of value whose domain can have namedsubdomains. For example, shape is a quality, and elongated is a "subdomain quality" of shape, and significantly elongated is aquality that specializes elongated. Similar to P, some class nodes are defined using operators; the class C3⊓ C1 is represented as anintersection class withmembers C1,C2. If C1 is a class, ¬C1 is also a class designated as :neg:C1, such that the system can treat such a:neg:−prefixed class appropriately. The edges of the concept graph are labeledwith a relationship name, and optionally decoratedwith quantifiers. By default, an edge is represented as triples like (miRNA subclass-of X), (X :exists:downregulates mRNA).The first triple uses the distinguished edge label subclass-of, and represents the sentence miRNA ⊏ X. The second triple usesan application-defined edge-label that is explicitly decorated with the existential quantifier. Similarly, we use decorationsfor universal quantification (gene :forall:transcribes-to mRNA), and cardinality constraints (pre-miRNA :[card=1]:produces mature-miRNA).
While OntoQuest is agnostic about the way an ontology is constructed, it does allow some conventions an ontology creatormay choose to follow. For instance, if there are multiple axes along which a concept can be classified, OntoQuest would allowthe concept nodes to be "colored". For example, according to genetic classification, an miRNA can be intronic or extronic, andaccording to the structural classification an miRNA can be symmetric or asymmetric. If the ontology creator so chooses, she cancreate subclasses of miRNA as genetic::intronic_miRNA, structural::symmetric_miRNA and so forth, where thestring before the :: symbol serves as the classification axis or "color". OntoQuest also allows the expression of property chainrules advocated by the proposed OWL 2.0 standard. This enables non-recursive first order rules like (A subclass -of B), (C part -ofB)⇒(C part -of A). When such rules are specified, OntoQuest may be instructed to materialize them or to evaluate them duringquery processing. Finally, OntoQuest also accepts bridge ontologies that provide mappings between multiple existing ontologiesthrough rules specified in OWL. This is particularly important for BIODB because most biomedical ontologies in the OBOconsortium (www.obofoundry.org/) significantly cross reference each other. In [7,8], we have made extensive use of inter-ontology mappings.
3.2. OntoQuest operators
Table 1 lists the operators used by OntoQuest. Many of these operators are quite straightforward. Here we explain some of themore involved aspects of the more complex operators.
scangraph(p): The scangraph operation is similar to a relational scan operation used in a DBMS, and is used when it is morecost-effective compared to using indices. A typical case is ontology browsing, where the user just navigates through theontology and then would like to find instances of classes they browse over.selectEdges(p): The canonical use of this operation to find all instances of domain-specific relationships like regulates orany subproperties (e.g., positively regulates) and then perform a merge operation to compute a set of subgraphs, and then askfor data instances for the class nodes in the subgraph. A more advanced user would use regular expressions in the predicate tofind, for instance, all the universally quantified relationships.
Table 1Currently implemented OntoQuest operators to manipulate the ontology graph stored in the ontology repository. Node and edge IDs are unique in the system overall stored ontologies.
scangraph(p) Performs a scan operation over the edges that are evaluated to satisfy predicate p.selectNodeLabels(p) Selects a set of node labels satisfying predicate p.selectNodes(p) Selects a subset of nodes based on predicate p.selectEdges(p) Selects a subset of edges based on predicate p.project(pat) Projects a set of subgraphs that satisfy a graph pattern pat.label(g) Accepts a graph g and returns a copy of it by replacing the node-ids by node labels,
and edge-ids by edge-labels.merge(g1,g2) Performs a node and edge union of graphs g1, g2.flattenPropTree(pLabel) Accept a property label pLabel and return a set of subproperties of label pLabel.flattenQuality(qValue) Accept a quality value qValue and return a set of subdomain quality names under qValue.induce(N) Given a node set N, returns the graph induced by Nreachable(n1, n2, ei) Whether node n2 is reachable n1 by traversing edges satisfying regular expression ei.getTransitiveAncestors(n, Label, k) Get k levels of ancestors of node n, by following the transitive edge label Label.getTransitiveDescendants(n, Label, k) Get k levels of descendants of node n, by following the transitive edge label Label.neighbors(N, k, ei, ex) Given nodes N, returns the k-neighborhoods of each node in N, such that the edges satisfy
the regular expression ei, and do not satisfy the regular expression ex.LCA(N, Label) Find the least common ancestor of node set N by traversing the transitive edge label Label.dagPath(n1, n2, Label) Find the paths connecting nodes n1 to n2 along transitive edge label Label.centerpiece(N) Given a node set N, compute the centerpiece subgraph intervening the nodes in N.unfoldPropertyChain(chID) Compute and materialize derived edges by unfolding OWL2 property chains identified by
property chain ID chID.instantiate(N) Find instances of the nodes N, where N can be only class nodes.

1089A. Gupta et al. / Data & Knowledge Engineering 69 (2010) 1084–1102
project(pat): This is one of the most used functions. A question like "find from Gene Ontology descendants of enzyme class'acetyltransferase' have a 'regulates' edge (or any subproperty) to a descendant of any 'histone' related node', and return thegraph connected these classes". This would be expressed by the pattern:
project(
(GO::'acetyltransferase',BioDB:descendant, X),
(X, BioDB:flattenPropTree('regulates'), Y),
(Y, BioDB:descendant, regexp(GO:'histone'*)),
merge(dagPath(GO::'acetyltransferase', X, *),
dagPath(X, *, Y), dagPath(regexp(GO:'histone'*), *, Y))
)
The predicates before the merge operation create variable bindings, the dagPath operations construct paths and the mergeoperation produces the graph that is projected out.
getTransitiveDescendants(n, Label, k): This operation uses the internal DAG index built for the transitive relation-ships. The index-based access produces significant benefits compared to graph traversal (see [9] for experimental results). Themost dominant use of this operation is for searches that collect subclasses and subparts of a set of terms, which is a verycommon query operation.LCA(N, Label): Computation of the least common ancestor uses the DAG indexes if the label is a transitive relation. For themore commonly used edge labels are path-indexed for k-long paths. Otherwise, the operation is performed through graphtraversal.Induce(N): Unlike the centerpiece subgraph computation described next, the induce operation constructs a minimal(potentially unconnected) graph that contains edges whose end points are both in the given node set N. This operation is usedwhen a node-selecting predicate selects some nodes in a query and the user wants to know the "region of the graph" fromwhich the nodes are selected. Typically, as the induced subgraph is presented to the user, he uses it as a seed graph to expandand explore neighboring parts of the ontology.centerpiece(N): The centerpiece subgraph, motivated by [10] defined by the authors as "Given Q query nodes in a …
network…find the node(s) and the resulting subgraph, that have strong connections to all ormost of theQ query nodes". The ideais tofind additional nodes and edges that are "in between" the nodes in the node set N.We have implemented the same algorithmin the context of the ontology, by adjusting node weights according to the criteria specified in [11]. Within the algorithm theseadjustments (a) increase the weight of more specific nodes in the subclass DAG, (b) increase the weights of properties of lesscommon properties compared to the more common ones, (c) increase the weights of nodes with higher centrality. This is anexpensive operation, but it is used for a version of query expansion with ontologies (described in more detail in Section 6).
It is important to note that the ontology repository under OntoQuest does not store instances, but only the classes and inter-class properties. The instance data is stored in the various databases, and are duly mapped to ontological concepts where possible.Therefore the instantiate operator in OntoQuest calls data access operations; this is the task of the BIODB data framework,described next.
4. The BIODB data framework
The BIODB data framework consists of two components — catalogs that carry meta-information about data sets, and the datasets that are submitted by users. Both these components make extensive use of the ontology framework.
4.1. Catalogs
To accommodate the users' practice of "dropping in" disparate types of data, BIODB uses an extended catalog structure for eachrecognized data type. Currently, the system recognizes different classes of unranked and ranked relations, annotated sequences,labeled trees and labeled graphs. As a data set is registered into the system, it gets cataloged and broadly associated with ontology.We first explain the catalog structure using the examples of relations and graphs.
4.1.1. The semantic relational catalogThe BIODB system uses a single master relation catalog (BMRC) for all relational tables registered into the system by users. The
BMRC is similar to the database catalog used in most commercial DBMS, with the following extensions.
A) A relation called All_Schemas is maintained to keep a record of every source/schema from which tables are imported intoBIODB. In our running example, a record is created to capture the fact that the mirBase contributes tables to the system.
B) All_Relations, the relation that keeps a record for every registered table is extended with a column Table_Ontology_R-eference. This column contains an ontology identifier that relates the basic "aboutness" information about the table. The

1090 A. Gupta et al. / Data & Knowledge Engineering 69 (2010) 1084–1102
Table_Ontology_Reference column corresponding to the microRNAs table record, contains the reference SO :0000276,indicating that it is a term from the Sequence Ontology (SO) and has the identifier 0000276. Suppose that the user had onlydownloaded the human microRNA information from the original microRNAs table. Then the semantic annotation of thetable would need to specialize the ontology reference to state that it is only a subset of the miRNAs where the organism isrestricted to human. Since the catalog entry only maintains an ontology identifier, the BIODB system stores thisspecialization a local bridge ontology (which has the name biodb : : lbo), which in turn, refers to the SO. Thoughbioinformatics users are encouraged to create a semantic reference for all imported or computationally generated tables, itis not mandatory.
While our focus is on ontologies, it is important to recognize that not all semantics of attribute has to relate to ontologies. Forexample, the recording the order-generating attribute of a ranked relation (e.g., gene-list ordered by statistical significance) is partof a relation's semantics.
C) For every table that has a non-null semantic record in All_Relations, it is mandatory to capture similar semantic informationat the column level for at least one column of a semantically annotated table. The All_Attributes relation keeps this informationin a column called Column_Ontology_Reference. If T(C1,C2…Ck) is a semantically referenced table, and T.Ci is the semanticallyannotated column recorded in the All_Attributes relation, Ciwould typically be a candidate key (often the primary key) of tableT. For example, for the table microRNAs, the column microRNA_name serves as the semantic reference column that referencesthe name attribute of theontology term SO :0000276. In general, the column-level semantic annotation may be an ontologyexpression rather than just a term identifier. An ontology expression is an expression that relates the domain of the attribute toa term in the ontology through a (potentially nested) restriction clause. For example, a simple ontological expression can bedom(C) ⊏ subclass(OntoTerm1)-subclass(OntoTerm2), thus designating that the domain of the column C is an ontologyfragment covering all subclasses of OntoTerm1 that are not subclasses of OntoTerm2.
However, defining the ontology expression for a column may be far from simple. Suppose a relation R has a column Gcontains a list of genes that are differentially expressed in an experimental condition EC. If we just annotate G with theexpression dom(G)⊏ SO :0000704 (where SO :0000704 stands for the term gene), it does not quite capture the semantics of thecolumn, primarily because the semantics of the column is not in the ontology but its dependence on EC which is another tablein the schema. Since it is difficult to formulate a precise statement of schema and ontology dependence for every case, we use ageneric relationships that depict the dependencies without needing the users to commit to deep ontological data modeling. Inthe example case, we use the expression:
domðGÞ⊏ S O : 0000704⊓ ðOBI : 0000118⊓∃:toward termðdifferential expression analysisÞÞ⊓∃:depends�on�schema�conditionsðR; EC;M2Þ
ðE1Þ
Here OBI :0000118 stands for "gene lists" created for experimental data, the relationship toward qualifies that the gene-list isfor differential expression analysis. The keyword term is to specify that the string-valued argument is not in any registeredontology, but should be treated as a semantic term. Finally, the relationship depends-on-schema-conditions is a genericrelationship to hint to a semantic schema dependency between relations R and EC, andspecifies M2 as pointer to where thiscondition is specified. In Section 5, show how M2 is defined in our Association Framework and describe how it is used duringexploration and query evaluation.
4.1.2. The semantic graph catalogIn the domain of BIODB applications, all graphs tend to have both node properties and edge properties, in addition to node-
edge connectivity. Since the number of properties for nodes and edges tend to vary across graphs in different applications, wemodel graphs in BIODB, to be an edge-centric data structure. In addition, we maintain a connectivity matrix when analysisalgorithms accept only this form of data. The master graph catalog (BMGC) has the following components.
A) The Graph_Types table keeps a record of the set of registered graphs, their structural and semantic types and their semanticassociations. The "structural graph type" refers to properties like whether the graphs are directed, weighted, whether theyallow group nodes (a set of nodes collectively treated as a single node), and so forth. The "semantic graph type" refers to: 1)whether graph represents a protein–protein interaction graph, a metabolic network, etc., and 2) whether the weightsrepresent correlations, number of evidences, and so forth. The semantic association of the graphs represents the set ofontologies that contribute to the node labels and edge labels. For example, the nodes of a regulatory may reference genes in theEntrez Gene vocabulary, whereas the interactionsmay reference both the Gene OntologyMolecular Functions, OBO Biomedicalrelationships ontology [12].B) A characteristic of our domain of applications is that the same objects (genes, miRNA, process names etc.) appear acrossmany different graphs that are authored or computed for different purposes. The SGO-Cross-Index is a data structure that keepsa master record of the Symbols (we adopt standard symbols for different classes of objects), the Graph-entities (node and edgeids) corresponding to these symbols, and Ontology entities corresponding to these symbols. This structure helps the query

1091A. Gupta et al. / Data & Knowledge Engineering 69 (2010) 1084–1102
processor to map between data graphs and ontologies. However, this structure only provides a partial cross mapping — a dataitem may not be accurately mapped to a specific ontology term. For example, a data item may contain the name of a cell typethat is not included in the cell ontology. In such a case, although the cell name is mapped to a higher level ontological termthrough a mapping, this mapping is not represented in the SGO-Cross-Index. Similar to these examples, catalogs for other datatypes have also been defined.
4.2. Data sets
Aside from the catalogs, the BIODB system maintains its own internal representation for each recognized data type. Some ofthese representations are novel while others aremore traditional. In either case, data from these data structures aremapped to theontology whenever possible. We take a simpler approach than modeling annotations as queries as done in [13], because in ourapplication domain, most annotation are user-defined semantic associations that can be encoded by simpler equivalence relations.As an illustration, we show the ontology-referencing data representations for two common cases — annotated relations andannotated sequences.
4.2.1. Annotated relationsAn annotated relation is a standard relation R(A1,A2,…Ak) together with a mapping relation μR(value, {ontologyExpression}).
The relation μR maps values from A1∪A2∪…pAk to a set of ontology expressions. For example, the value punctate nucleus may beassociated with the expression ≡GO :0005634 ⊓ ∃ PATO : inheres_in PATO_0000052 toward punctate — which translates to thosenucleus concepts (GO:0005634) that inheres in (a PATO [14] relationship) the quality called shape (PATO_0000052), toward thevalue punctate. This example shows an important reason for using ontology expressions. In this case, the mapping creates aspecialization of a term from one ontology using relationships and constructs from another ontology. The reason for associating aset of ontological expression to a single value is that often multiple associations need to be specified between one data value anddifferent ontologies.
4.2.2. Annotated sequencesAn annotated sequence A(a) is a pair (σ,τ) where sigma is a finite sequence of characters from the alphabet α, and τ is an
interval tree (implemented on top of a relational interval tree [15]) whose nodes define intervals on σ, and have a property calledannotation. The annotation content is produced by some combination of automated and manual analysis performed by scientists,and occurs outside the context of the BIODB system. BIODB imports the annotation content along with the sequence and intervalover which the annotation holds. This annotation content itself is a scientist-produced XML fragment; the only requirementimposed by BIODB is that any ontology reference made in the XML fragment has to use the distinguished XML element ontologyalong with the name of the ontology and the identifier of the ontology element(s) referred.
An example of this is shown in Fig. 3. The top part of the figure shows a fragment of a DNA sequence for a certain chromosome,along with layers of annotations of different types like CpG islands, genes, miRNAs, and fragments of conserved regions. Everynode of this tree contains details of the annotated object (e.g., a gene in Fig. 3), and states that the corresponding ontology is theGene Ontology, and the element "737" in it. In general, a single annotation may refer to multiple ontologies, each using a separateb ontology N tag.
As illustrated for relations and intervals, all data types handled by the BIODB system are "extended" by adding an annotationcomponent to establish the connection between a data element and the ontologies. Next, we consider the task of creatingmappings and indexes between data sets and ontologies.
Fig. 3. The structure of an annotated sequence. Notice the ontology references made by the annotation object, and therefore, indirectly by the interval onthe sequence.

1092 A. Gupta et al. / Data & Knowledge Engineering 69 (2010) 1084–1102
5. The BIODB association framework
There two ways in which two data sets can be related. The first occurs through the ontology. Consider the relational tablemiRNATargets from our motivating example.
miRNATargets(miRNA_ID, gene_symbol, transcript_ID, length, total_sites)
This relation may have domain annotations as follows:
mapping(miRNATargets.miRNA_ID, BioDB:maps_to, SO:microRNA.ID)
mapping(miRNATargets.gene_symbol, BioDB:maps_to SO::gene.gene_name)
Now, consider a different data set, such as a pathway graph expressed in BioPAX.
bbp:Pathway rdf:ID="MicroRNA_biogenesis"N
bbp:pathwayComponent rdf:resource="#Pol_II_mediated_transcription_of_microRNA_genes" /N
bbp:pathwayComponent rdf:resource="#Microprocessor_complex_cleaves_pri_miRNA_to_pre_miRNA" /N
bbp:pathwayComponent rdf:resource="#Exportin_5_recognizes_3__overhang_of_pre_miRNA_" /N
bbp:pathwayOrder rdf:resource="#Microprocessor_complex_cleaves_pri_miRNA_to_pre_miRNAStep" /N
bbp:pathwayOrder rdf:resource="#Pol_II_mediated_transcription_of_microRNA_genesStep" /N
This pathway description is annotated to refer to microRNA from the Sequence Ontology.
mapping(Reactome::bp:Pathway.rdf:ID="MicroRNA_biogenesis, BioDB:isAbout, SO:0000276")
The system can now relate this pathway object to the relational table because they refer to the same ontological concept. After adata set is deposited in BIODB and the annotations are performed through user interaction, the BIODB administrator runsacomputeAssociations procedure to populate tables in an Association Catalog that materializes these relationships. The ontology-based associations are maintained in a table called OntologyAssociations (data-object-1, data-object-2, ontology-id, ontology-term).
The Association Catalog also contains other tables to maintain relationships among data objects themselves. For example,consider again relationsmicroRNAs andmiRNATargets obtained from themiRBase database, and a computed data structure such asthe result of a hierarchical clustering algorithm. The clustering product, called ExpressionBasedCluster can be represented as a treewhose leaves represent gene symbols, and every internal node represents a grouping over the nodes below it. An internal nodemay also have other children representing other cluster properties like the variance of values within a cluster. TheSchemaBasedAssociation table relates microRNAs and miRNATargets as:
SchemaBasedAssociation(miroRNAs.miRNAID pk-fk miRNATargets.miRNA-ID)
where pf-fk is a known relationship to biodb. Similarly, the DataAssociation table relates table miRNATargets withExpressionBasedCluster as:
DataAssociation(miRNATargets.miRNA-ID joins-with leaves(ExpressionBasedCluster))
where leaves() is a known tree function, and joins-with is a known relationship that can be interpreted by the system to correlatethe heterogeneous data. As a more complex example, recall expression (E1) from Section 4, where the semantic catalog had theexpression:
domðGÞ⊏ SO : 0000704⊓ ðOBI : 0000118⊓∃:toward termðdifferential expression analysisÞÞ⊓∃:depends−on−schema−conditionsðR; EC;M2Þ
ðE1Þ
cify that a set of genes G (a column in relation R) is actually a gene-list for "differential expression analysis", such that the
to spegenes in G satisfies schema-dependent condition M2 between relations R and EC. Now, in the association catalog, we want tocapture this condition, which can be stated in English as: "for each gene in G, there must be a row in the experimental conditiontable EC, that can be identified by the attribute pair hGene". In other wordsmapping(M2, R.G, biodb:maps_to EC.Gene)
This creates a one-to-manymapping between the genes in R and those in EC, giving the set of experimental conditions in whicheach gene in G is expressed. If we wanted to make a one-to-one mapping between a gene in R and a specific tuple in EC, we mayneed to specify amore complex join condition overmultiple relations. This is donewith themap_rule keyword that specifies a rulewill be used to define the mapping.

1093A. Gupta et al. / Data & Knowledge Engineering 69 (2010) 1084–1102
mapping(M4, R.G biodb:map_rulebiodb:rule(Geneb− ECR(G,ExpID), EC(ExpID,Condition,Gene)))
where the rule is a simple positive conjunctive query over relations ECR and EC that produces the mapped term Gene.The final category of associations is the mapping between ontologies. There are two approaches to mapping or aligning
ontologies — one way is to map and merge constituent ontologies, and a second way is to create bridge ontologies which areessentially ontological statements (expressed, for instance, in OWL) that specify the relationships between two ontologies. Wetake the second approach in BIODB. There are two forms of bridges — concept bridges, that specify the relationship betweentwo concept (or class) nodes in two different ontologies, and relation bridges that induce a subproperty relationship betweentwo edge labels in two different ontologies. At this point, we handle only the former. [16] observes that there can be twelveinter-concept relationships (e.g., equivalence, hypernym, …) captured in bridge ontologies. In the current system we onlyconsider equivalence mappings, and store them as a simple table bridge(ontology-id1, concept-id1, relationship, ontology-id2,concept-id2) under the control of OntoQuest. The Association Catalog has a table that maintains a list of bridge ontologies andthe primary ontologies they reference.
6. Query processing in BIODB
To support the needs of biologist users, the BIODB system uses a query "language" inspired by current search engines likeGoogle. In this "language", the simplest option is to ask a keyword query, but one can optionally add predicates on metadata anddata attributes, specify return structures, and make references to ontologies. A detailed treatment of the full query specificationwith all options, and the evaluation strategy is beyond the scope of this paper. Here we discuss simpler constructs, but focus onhow the ontologies and ontology references described earlier are evaluated.
6.1. Processing keyword queries
A keyword query in BIODB is an Boolean expression with wildcards (PARK* stands for PARKIN, PARK2,…). There are two partsto the query evaluation process. The first part, called candidate generation, is standard.
1. The query is first sent to a query analysis unit to identify terms that are known to the ontology sources. (C1)2. The analyzed query goes through query expansion unit that uses the ontology to find synonyms and related terms stored with
the ontology. (C2)3. The terms in the expanded query are looked up from an inverted index to locate records that are in different data stores (graph
store, relation store etc.). (C3)4. Then the Boolean conditions are evaluated to generate a candidate list of data items (of heterogeneous types) that would form
the result. (C4)
We use the expression candidate term to refer to the actual term that matched, and the expression candidate record to refer tothe containing data structure that has the candidate term. For relational data, a candidate term is the matching attribute valuewhile the candidate record is the tuple containing that value. For tree and graph data, thematching term is the literal that matchedand the candidate record is the node that holds the identifier of the term. For sequence fragments, the candidate term is not in thesequence itself, but in the relational metadata of the sequence fragment. The candidate record is the metadata together with thesequence itself and the node of the interval tree for the sequence. The second part of query evaluation, performs an ontologicalremapping of the results instead of result ranking performed by most other keyword search engines.
The goal of the ontological remapping is to present the results with reference to all ontologies that relevant for the result, sothat for each relevant ontology the user can view the returned records in the context of the ontology.
• getIRC: The first step of query remapping is to compute the immediate result context (IRC(r)) of every unique candidate record r.For relational data, the IRC is the total record for which one or more attributes matched the query. For tree data, the IRC is asubtree consisting of the parent, children and siblings of thematching nodes. For graph data, the IRC is the 1-neighborhood of thematching terms. For all cases, the IRC includes the annotations of thematched nodes, but not for the rest of the data the IRC. Thus,if the record Rel(A1, A2, A3, A4) is the IRC, and A2 is the matching attribute, the annotations on A2 are included but those on A1,A3, A4 are not included. If the data is annotated and the query terms match the annotation, the IRC is defined as the IRC of thedata to which the annotation is attached. The resulting IRCs are checked for duplicates and cached in a temporary store calledIRC-cache.
• ontoMap: Once the IRCs are computed, data elements of each IRC is mapped to terms in each ontology. This is expedited by usingthe data-ontologies indices like the SGO cross-index and inter-ontology indices specified in previous sections.Notice that sincethese indices go across ontologies, we can directly map IRC terms to the ontologies without having to traverse them individually,although it is possible to restrict the ontologies to be used for the purpose. The result of themapping process is a set of ontologieseach containing a list of mapped nodes. These ontologies are then ranked by the number of mapped nodes. Optionally, only thetop-k ontologies are chosen for the next step.
• computeLCAPathDAG: Note that all ontologies, the subclass-of is a DAG, and for most of, the combination of the subclass-of andpart-of ontologies induce an acyclic subgraph. For each ontology from the ontoMap,we construct a reduced substructure called

Fig. 4. The right side represents the LCAPathDAG of the DAG on the left given the selected nodes C and F marked in circle. The dashed lines represent ancestor–descendant relationships. By definition, D and G are LCAs of C and F andmust be in the result graph. Both root-H and root-J are included in the result graph becausethey represent two paths from the root to the node F.
1094 A. Gupta et al. / Data & Knowledge Engineering 69 (2010) 1084–1102
LCAPathDAG. If D is a DAG, andm1,m2,…mk are matched nodes of D, an LCAPathDAG is defined as a DAG D′ such that (i) the rootof D′ corresponds to the root of D, the nodes of D′ correspond to the nodes of D and the edges of D′ correspond to the edges orpaths in D, (ii)m1,m2,…mk are leaves of D′, (iii) If n is a non-leaf node in D′, then the corresponding node emphn in D is either aparent or an ancestor of nodes inm1,m2,…mk in D′, (iv) if a node k is selected from D to D′, the parent of k is is also selected in D′,(v) If two nodes mi,mj havean LCA l in D, then l appears in D′, (vi) D′ is the minimal DAG that satisfy the above conditions.
An LCAPathDAG over a set of matched nodes of a DAG is illustrated in Fig. 4. Notice that an LCAPathDAG need not be unique.Weuse a variant of the subgraph indexing technique described in [9] to compute ancestor–descendant relationships in DAGs.
• createLinks: For all selected ontologies, the final result shown to the user is the combination of the LCAPathDAG and the actualIRC data computed at an earlier step. Since the data are dissimilar, it does notmake sense to create a physical join of the two data.Instead, the data are "virtually joined" by creating a link from every matched node in the ontology (m1,m2…), to the IRCelements. This is accomplished by creating a temporary URL for each IRC in the IRC-cache, and augmenting the LCAPathDAG byadding a virtual node for each IRC connected to the m nodes through an edge-labeled result.
6.2. Augmenting keyword search by ontology conditions
The keyword query described before can be made more expressive by qualifying the ontology conditions they should satisfy.Consider the following query fragment:
keyword($k1 AND ($k2 OR "microtubule"))
where $k1 REACHABLE FROM GO::"Cellular process disassembly" VIA (subclass-of)
AND
$k1 NOT REACHABLE FROM GO::"equatorial microtubule organizing center disassembly"
VIA (subclass-of) AND
$k2 SATISFIES (GO::0007026 GO::"negatively_regulates" $k2)
This keyword query uses variables $k1, $k2 that are further qualified in the where clause. The first two predicates structurallyposition $k1 as a term that is in the subclass-of DAG below "Cellular process disassembly" but not below the subclass-of DAGbelow "equatorial microtubule organizing center disassembly". The VIA construct can take a regular expression on edge labels ofthe form label1|label2 (either label1 or label2), (label1)+;(label2)+ (one ormore of label1 followed by one ormore of label2) and soon. The third predicate states the variable $k2 has a direct or inferred incoming edge labeled "negatively_regulates" from the node0007026 of the gene ontology. Currently, the query will:

1095A. Gupta et al. / Data & Knowledge Engineering 69 (2010) 1084–1102
1. evaluate the variables $k1, $k2 by searching the ontology by using OntoQuest search functions. (S1)2. construct an equivalent keyword query. (S2)3. evaluate the query as a regular keyword query as described in the previous section. (S3)
More efficient search strategies are under investigation.
6.3. Combining ontological keyword search with data queries
In the previous cases, the queries (i) did not put any constraints on the data other than that the result data sets should matchthe keywords, and (ii) did not put any conditions onwhat parts of thematching data should be returned as results. In this scenario,the query maker does not need to know anything about the schema or structure of the data sources. However, this apparentsimplicity also limits the expressiveness and specificity of the queries that a more advanced user wants. Our solution makes use ofthe Association Framework to guide the users' query formulation.
Recall from Section 5 that an outcome of the assisted model mapping operation is the creation of Association Catalogs. A BIODBuser first formulates an ontological keyword query as in the previous case with one additional construct called ANALYZE…AS asshown below.
ANALYZE( keyword($k1 AND ($k2 OR "microtubule"))
where $k1 REACHABLE FROM GO::"Cellular process disassembly" VIA (subclass-of)
AND
$k1 NOT REACHABLE FROM GO::"equatorial microtubule organizing center disassembly"
VIA (subclass-of) AND
$k2 SATISFIES (GO::0007026 GO::"negatively_regulates" $k2) ) AS Q1
This construct performs steps S1,S2 (see above) and then steps C1,C2,C3 to find the data objects that constitute the result, but itdoes not execute step C4 to retrieve the actual data objects. After step C3, the system has alist of catalog entries (for relations,interval trees, graphs, etc.) that satisfy the keyword part of the query. The next phase of query formulation would occur onelements of this list.
Let us assume that the ontological keyword query identifies four sources: the previously described tables microRNAs,miRNATargets, a gene expression table geneExpress (downloaded from the GEO database at www.ncbi.nlm.nih.gov/geo/)and the ExpressionBasedCluster tree. At this point, BIODB consults the Semantic Data Catalog and the Association Catalog toretrieve the schema of these data sources and the associations between them. Since the joining information from the sourcesis known from the Association Catalog, the system uses a "join-chasing" algorithm to construct integrated relational viewover these sources and presents a query form that contains searchable fields corresponding to this view. For example, themiRNATargets table has a column for "genes". Let us assume, that this table finds an association mapping like M4 fromSection 5.
mapping(M4, miRNATargets.gene_symbol biodb:map_rulebiodb:rule(Geneb− ECR(G,ExpID), EC(ExpID,Condition,Gene)))
The algorithm would use this mapping rule to include tables ECR and EC into the integrated view. A similar approach has alsobeen used by researchers who perform keyword queries on relational [17] and XML databases [18]. The primary distinction oursystem from these is that we operate on multiple information models. In the case of multiple models, we currently take a verysimplistic approach to construct the integrated view — we just take the first order neighbors of the mapped schema elements asthe portion of the schema that needs to participate in join-chasing. Let us consider two examples. In the first case, we have therelation miRNATargets, and the following XML schema fragment:
bxs:sequenceN
bxs:element name="recommendedName" minOccurs="0"N
bxs:complexTypeN
bxs:sequenceN
bxs:element name="fullName"
type="evidencedStringType"/N
bxs:element name="shortName"
type="evidencedStringType"
minOccurs="0" maxOccurs="unbounded"/N
b/xs:sequenceN
bxs:attribute name="ref"
type="xs:string" use="optional"/N
b/xs:complexTypeN
b/xs:elementN

1096 A. Gupta et al. / Data & Knowledge Engineering 69 (2010) 1084–1102
If miRNATargets.gene_symbol is mapped to the XML element shortName, the integrated view presented to the user will be:
view(miRNA_ID, gene_symbol, transcript_ID, length, total_sites, fullName, ref)
where the last two items are picked from the first order neighbors of the shortName element. In the second example, weconsider the same miRNATargets relation and the following fragment of an RDFS schema.
bClass rdf:ID="gene"N
bsubClassOf rdf:resource="#DNASequence"/N
blabel xml:lang="en"Ngeneb/labelN
b/ClassN
bClass rdf:ID="DNASequence"N
bsubClassOf rdf:resource="#genomicSequence"/N
blabel xml:lang="en"Ngeneb/labelN
b/ClassN
brdf:Property rdf:ID="hasSymbol"N
brange rdf:resource="&xsd;string/N
bdomain rdf:resource="#gene"/N
blabel xml:lang="en"Nlocationb/labelN
b/rdf:PropertyN
brdf:Property rdf:ID="hasChromosomalLocation"N
bsubPropertyOf rdf:resource="#hasLocation"/N
brange rdf:resource="#chromosomalInterval"/N
bdomain rdf:resource="#genomicSequence"/N
blabel xml:lang="en"Nlocationb/labelN
b/rdf:PropertyN
brdf:Property rdf:ID="startsAt"N
bdomain rdf:resource="#chromosomalInterval"/N
brange rdf:resource="&xsd;integer"/N
blabel xml:lang="en"NstartsAtb/labelN
b/rdf:PropertyN
brdf:Property rdf:ID="endsAt"N
bdomain rdf:resource="#chromosomalInterval"/N
brange rdf:resource="&xsd;integer"/N
blabel xml:lang="en"NendsAtb/labelN
b/rdf:PropertyN
where miRNATargets.gene_symbol is mapped to the range of the property hasSymbol for the class gene. Before defining theview, we need to use the nature of RDF. It is easily inferred that the RDF Class gene has the property hasChromosomalLocationwhose range is the class chromosomalInterval. However, classes like chromosomalInterval are not directly associated withconcrete values. As the schema fragment shows, class chromosomalInterval has integer-valued properties startsAt and endsAt.One has to navigate along these two properties RDFS graph to get to concrete integer values corresponding to these two properties.Similarly, suppose DNASequence has a string-valued property called hasSequence that gives the actual character sequence of theDNA. Thus, after all inferences are complete by finding the data type properties of the first neighbors of the class gene in this toyexample, we willget the properties has_symbol, startsAt, endsAt and hasSequence. These will appear in the integrated view alongwith the attributes of miRNATargets. As the user issues a query against these views, the query is decomposed and relevantsubqueries are dispatched to appropriate data sources using a refined version of our view-based framework reported initiallyin [19].
Some potential problems may arise if the number of qualified sources identified after the ontological keyword query is largeand the inter-relationship between these sources is dense. In that case, forming an appropriate view as well as efficiently scalingup the integrated query evaluation become a harder problem. A proper solution to this problem is currently under investigation.Similarly, we are also exploring the effectiveness of our first neighbor based join-chasing approach.
7. Evaluation
The Neuroscience Information Framework (NIF at www.neuinfo.org) is an application system built upon the heterogeneousdata management infrastructure of BIODB. Since NIF is a user-facing software, we have hidden the complexity of the querylanguagewithin the elements of the user interface. Specifically, user presents only keyword and ontological keyword queries— theontology-based expansion and predicate search happens by user interaction. In this short evaluation we present a set of test

120 2500
100
80
2000
150060
401000
20 500
0Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8
0Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8
Queries
Tim
e in
ms.
Eff
ecti
ve Q
uer
y S
ize
Queries
Fig. 5. The figure on the left shows the number of effective terms produced after the ontology search. The figure on the right shows the execution time of locatingthe data including the catalog query, the ontology search and index search. These times do not include the actual time to fetch the data from the tables, XMLrecords etc.
1097A. Gupta et al. / Data & Knowledge Engineering 69 (2010) 1084–1102
queries and their performance results. The data set for these queries uses 57 different data sources. In some cases, the user hascopied an entire database table, or an entire XML document. In other cases, only a small part of the database is imported.Theontology, called NIFSTD [8], is an OWL/RDF graph with about 35,000 terms and about 25 edge labels. The subclassOf propertyinduces a spanning DAG over all ontology nodes. The partOf property is transitive, and has a tree of subproperties. All reachabilitycomputations use an improved version of the DAG indices from our prior work [9] that performs reachability queries in thepresence of subproperty hierarchies.
Q1. A single term ontological query synonyms(Hippocampus) is expanded through the ontology to Hippocampus OR "Cornuammonis" OR "Ammon's horn" OR "hippocampus proper"
Q2. transcription AND gene AND pathway — a conjunctive query with 3 terms.Q3. (gene) AND (pathway) AND (regulation OR "biological regulation") AND (transcription) AND (recombinant) — a 6-term
AND/OR queryQ4. synonyms(zebrafish AND descendants(promoter,subclassOf)), where zebrafish is expanded by synonym search and the
second term transitively expands to all subclasses of promoter as well as their synonyms.Q5. synonyms(descendants(Hippocampus,partOf)) expands to all parts of hippocampus and all their synonymsQ6. synonyms(Hippocampus) AND equivalent(synonyms(memory))— the second term uses the ontology to find all terms that
are equivalent to the term memory by ontological assertion, and their synonyms.Q7. synonyms(x:descendants(neuron,subclassOf) where x.neurotransmitter='GABA') AND synonyms(gene where gene.
name='IGF') — the x is an internal variable.Q8. synonyms(x:descendants(neuron,subclassOf) where x.soma.location=descendants(Hippocampus,partOf)) — the query
seeks all subclasses of neuron the location of whose soma is in any transitive part of the hippocampus.
Fig. 5 shows the results of these queries. The effective query size is counted by taking the number of terms produced afterthe ontological predicates are executed. Two factors influencing the execution time shown in the figure are the time toevaluate the ontology predicates and the time to locate the data by searching the catalog and the indices. Q1 takes longerbecause the result size is about 2 M records. Q2 and Q3 have very high selectivity. For Q4–Q8, the execution time is splitbetween the ontology predicate evaluation (60%) and the catalog+index searching (40%). The ontology search part is almostlinear with the number of results returned. For Q4, the subclass expansion of promoter is very large, although the result size issmall (261 items). For Q7, in contrast, both the ontology predicate evaluation time and the result size (2.2 M) are significant. Inthis query the ontology predicate evaluation dominates because it needs to evaluate the has_neurotransmitter edge forasubstantial transitive closure output from the subclassOf expansion of neuron. Q6, which returns about 48 k results, takeslonger because of the intersection operation between results of the two predicates that are not joinable in the ontology or bydata association. Finally, Q8, which produces 33 k result items, is faster than Q6 because the ontology terms are connected byan edge (a join condition) that improves the selectivity of the query on the data. Table 2 shows the actual times to retrieve datarecords from the larger data sets for the same queries. The time taken is directly proportional to the size of the resulting datareturned by each source. The publications resource returns a lot of textual content (like paper abstracts) resulting in longerdata fetching time.
We also present a short evaluation of OntoQuest as a central component of BIODB. As mentioned earlier, several componentsof OntoQuest are extensions to what we have reported earlier. Lines 1–5 show the results of neighborhood operations aroundthe term 'brain'. Each query returns not only the IDs of the nodes, but the entire subgraph.1 This neighborhood of the ontologygraph is not very dense. Lines 1–3 show that the DAG index on the partOf relationship provides a reasonable speed-up oversimple edge-traversal used in lines 4-5 for the same part of the DAG. When the same query is executed in a more denseregion of the graph (lines 5–8), the performance improvement offered by the DAG-index declines and approaches that of alinear scan (Table 3).
1 Including start-node-ID, start-node-label, end-node-ID, end-node-label, property-ID, property-label.
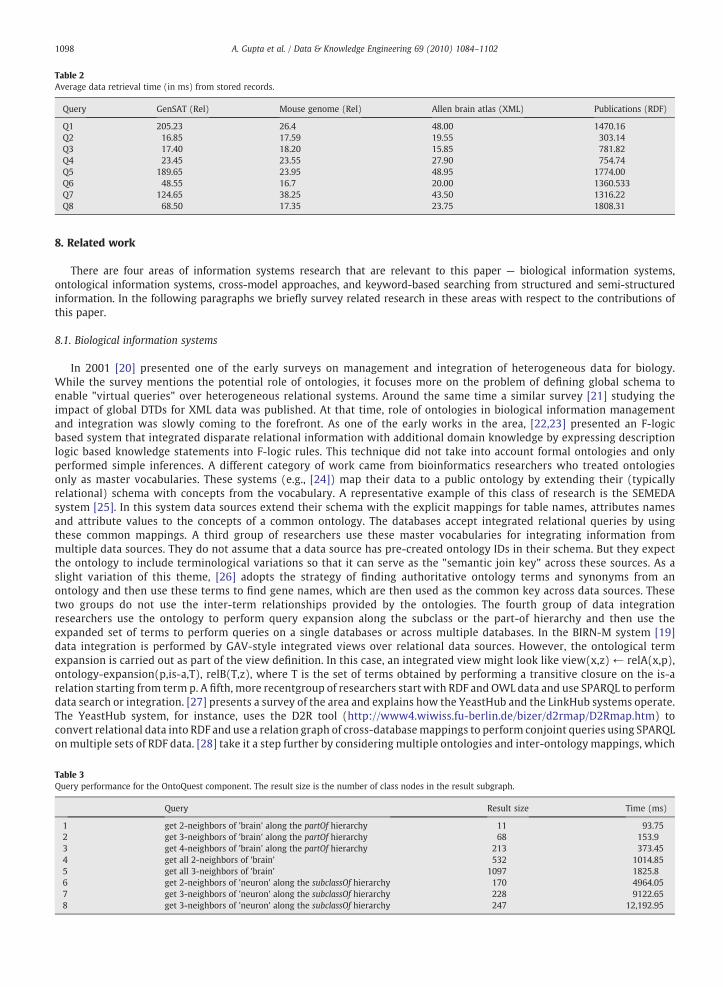
Table 2Average data retrieval time (in ms) from stored records.
Query GenSAT (Rel) Mouse genome (Rel) Allen brain atlas (XML) Publications (RDF)
Q1 205.23 26.4 48.00 1470.16Q2 16.85 17.59 19.55 303.14Q3 17.40 18.20 15.85 781.82Q4 23.45 23.55 27.90 754.74Q5 189.65 23.95 48.95 1774.00Q6 48.55 16.7 20.00 1360.533Q7 124.65 38.25 43.50 1316.22Q8 68.50 17.35 23.75 1808.31
Table 3Query performance for the OntoQuest component. The result size is the number of class nodes in the result subgraph.
Query Result size Time (ms)
1 get 2-neighbors of 'brain' along the partOf hierarchy 11 93.752 get 3-neighbors of 'brain' along the partOf hierarchy 68 153.93 get 4-neighbors of 'brain' along the partOf hierarchy 213 373.454 get all 2-neighbors of 'brain' 532 1014.855 get all 3-neighbors of 'brain' 1097 1825.86 get 2-neighbors of 'neuron' along the subclassOf hierarchy 170 4964.057 get 3-neighbors of 'neuron' along the subclassOf hierarchy 228 9122.658 get 3-neighbors of 'neuron' along the subclassOf hierarchy 247 12,192.95
1098 A. Gupta et al. / Data & Knowledge Engineering 69 (2010) 1084–1102
8. Related work
There are four areas of information systems research that are relevant to this paper — biological information systems,ontological information systems, cross-model approaches, and keyword-based searching from structured and semi-structuredinformation. In the following paragraphs we briefly survey related research in these areas with respect to the contributions ofthis paper.
8.1. Biological information systems
In 2001 [20] presented one of the early surveys on management and integration of heterogeneous data for biology.While the survey mentions the potential role of ontologies, it focuses more on the problem of defining global schema toenable "virtual queries" over heterogeneous relational systems. Around the same time a similar survey [21] studying theimpact of global DTDs for XML data was published. At that time, role of ontologies in biological information managementand integration was slowly coming to the forefront. As one of the early works in the area, [22,23] presented an F-logicbased system that integrated disparate relational information with additional domain knowledge by expressing descriptionlogic based knowledge statements into F-logic rules. This technique did not take into account formal ontologies and onlyperformed simple inferences. A different category of work came from bioinformatics researchers who treated ontologiesonly as master vocabularies. These systems (e.g., [24]) map their data to a public ontology by extending their (typicallyrelational) schema with concepts from the vocabulary. A representative example of this class of research is the SEMEDAsystem [25]. In this system data sources extend their schema with the explicit mappings for table names, attributes namesand attribute values to the concepts of a common ontology. The databases accept integrated relational queries by usingthese common mappings. A third group of researchers use these master vocabularies for integrating information frommultiple data sources. They do not assume that a data source has pre-created ontology IDs in their schema. But they expectthe ontology to include terminological variations so that it can serve as the "semantic join key" across these sources. As aslight variation of this theme, [26] adopts the strategy of finding authoritative ontology terms and synonyms from anontology and then use these terms to find gene names, which are then used as the common key across data sources. Thesetwo groups do not use the inter-term relationships provided by the ontologies. The fourth group of data integrationresearchers use the ontology to perform query expansion along the subclass or the part-of hierarchy and then use theexpanded set of terms to perform queries on a single databases or across multiple databases. In the BIRN-M system [19]data integration is performed by GAV-style integrated views over relational data sources. However, the ontological termexpansion is carried out as part of the view definition. In this case, an integrated view might look like view(x,z) ← relA(x,p),ontology-expansion(p,is-a,T), relB(T,z), where T is the set of terms obtained by performing a transitive closure on the is-arelation starting from term p. A fifth, more recentgroup of researchers start with RDF and OWL data and use SPARQL to performdata search or integration. [27] presents a survey of the area and explains how the YeastHub and the LinkHub systems operate.The YeastHub system, for instance, uses the D2R tool (http://www4.wiwiss.fu-berlin.de/bizer/d2rmap/D2Rmap.htm) toconvert relational data into RDF and use a relation graph of cross-databasemappings to perform conjoint queries using SPARQLon multiple sets of RDF data. [28] take it a step further by considering multiple ontologies and inter-ontology mappings, which

1099A. Gupta et al. / Data & Knowledge Engineering 69 (2010) 1084–1102
are also expressed as graphs. Marenco et al. [29] use metadata mappings perform data integration. However, none of thesesystems address the problem where multiple models of data are annotated with the ontology and are federated through it.Consequently, they build their application logic completely on top of an existing query endpoint, without developing a specificquery evaluation logic. Further, they do not support any combination of keyword and predicate-based queries like BIODB.
8.2. Ontological information systems
As mentioned in the Introduction, our work is partly motivated by ontology-based databases, first proposed in [1,2] andprototyped in a system called OntoDB. The broad goal of both systems is to manage both an ontology as well as the databasecontent of an application within the same system. More recently, the OntoDB group has extended its research to accommodatemultiple ontology models within the same OBDB structure [30,31]. While our work significantly differs from theirs because wetry to accommodate multiple data models within our framework, the proposed architectures have interesting resemblances. Intheir system they create a common kernel ontology model that is common across multiple ontologies and all ontologies areviewed as extensions that can be mapped to this kernel. In our system, we keep the ontologies confined to OWL and OBO, butdeal with multiple data models. Therefore, we have created an extensible semantic metadata structure (our semantic catalog)that hold together the different data models and acts as a hub for query processing. As we also deal with inter-schemamapping across data models, we had to supplement the semantic catalog with an explicit association catalog that OBDBs donot need to consider.
8.3. Cross-model approaches
The most relevant class of research related to our work considers techniques and systems that focus on using multiple datamodels within the same system. There is a significant amount of research in this area, and somedominant themes include (a)representing XML [32] and RDF [33] data in a relational system, (b) publishing existing relational data in XML [34] and RDF [35,36],(c) mapping and semantics extraction techniques across these models [37–40], (d) creating XML [41] and RDF [42] query facilitieswithin a relational system, and (e) integrating multiple models [43–45]. The common thread across these themes is that all ofthem consider the transformation of data from one model to another or transformation of queries from one query language toanother.
Among the above, one of the more general frameworks is offered by Atzeni et al. [40], where the goal is to create amethodology that transform any model (like OO, Relational) to any other (like XML) through a set of generic constructs calleda supermodel. A supermodel is realized through a four part dictionary with two coordinates: schemas versus models andmodel-specific versus model-generic (i.e., constructs that occurs in the supermodel). A supermodel defines a meta-levelconstruct called abstract which maps to entity in the ER model, root element in and XML model, Typed Table in an ObjectRelational Model and so forth. Similarly, other constructs like abstractAttribute, generalization, aggregation etc. are specifiedat the level of the supermodel and are mapped to different data models where possible. Translations from a schema of onemodel to that of another are implemented through a set of Datalog rules. Despite the wonderful generality of this modeltranslation machinery, we found it to be not exactly applicable in our scenario. One can argue that the ontology acts as thetarget schema for our application, and all we need is to transform the schema of the data sources to this target schema usingthe principles of model generation. However, this translation does not take into account value-mapping between data fromone source to the ontology or to another source, or the mapping of domain-specific semantics that are more easily performedby user annotation of the schema elements and data values. We believe, while their model generation is clearly more general,our annotation based mapping generation technique is more pragmatic for our target users who are not sophisticated enoughto perform the kind of schema translation demonstrated in the MIDST tool. Next, consider the SWIM system [43,44] thatcreates a virtual RDFS schema over relational and XML sources and uses Datalog rules to specify mappings between them, suchthat an RDF query against the schema can be reformulated into SQL or XQuery as appropriate. The system maps XML and RDFquery expression patterns to Datalog. The user translation is performed by converting the RDF query to an equivalent internalquery in Datalog, and then transformed to a source query. An important aspect of their approach is that they consider allproperty instances to adhere to the constraints that the domain and range of an instance must be subclasses of the domain andrange of the property as defined in the schema. In our experience, since our target data sources are ad hoc systems created bydomain programmers, they are not semantically consistent and hardly satisfy classical constraints expected by theoreticaltechniques. While the OntoQuest component of BIODB formally adheres to the OWL-2 model, the ad hoc data collected byusers and mapped to the ontology hardly does. This makes it very difficult for us to satisfy the assumptions made by systemlike SWIM. Is it then possible to discover the semantics of any data object (a relational table or XML tree) from the data and anontology? [38] investigates this problem in the case where the data can be relational or XML and the "ontology" is expressedin an abstract conceptual language. Their discovery algorithms require the user to provide additional "simplecorrespondences" (attribute-to-attribute correspondences). This is similar to our work where the annotations specify thesecorrespondences. Our work can benefit from the discovery process, even though we believe we can only discover only partialmappings because our users will possibly acquire only a few tables or XML documents for their integration and analysis needs.The SchemaWeb effort [39] has taken a different approach to the problem. They have defined Relational.OWL, an OWLspecification describing the schema elements of a relational database using properties like hasColumn, isIdentifiedBy,PrimaryKeyetc. Using this specification, they have developed a SPARQL to SQL wrapper that maps a SPARQL query to directly

1100 A. Gupta et al. / Data & Knowledge Engineering 69 (2010) 1084–1102
query the underlying relational schema. The assumption in this approach is that the system uses RDF as the central model andusers query the RDF view. This assumption does not hold for BIODB where the query system is model-agnostic and is primarilydesigned for keyword queries. However, intermediary tools that autogenerate ontologies from a schema [46] may be usefultoward our goal. On the query processing side, structural queries on the ontology is a pattern that uses reachability predicatesthat SPARQL cannot directly express. This prompted us to develop our own query language which is in one sense morerestricted than SPARQL and is more powerful in another.
8.4. Keyword-based search
Answering keyword-based queries in structured and semi-structured data is an active area of research [17,18,47–51]. In ourkeyword-based search approach, we follow the standard steps of using a standard inverted index to find the potential records, andgenerating candidate results graphs. They all differ in the way they formulate the result structure and rank the results. Most ofthese approaches except [50] produce tree-like answer structures, and assume that these results are rooted at distinct nodes.Instead, [50] is designed to return subgraph structures, and use graph summarization in the computation of the top-kcomputation. Our technique, in contrast to the above, operates on multiple models, and uses the ontology both during queryformulation and result ranking. During query formulation we use the ontology for query expansion; for result ranking the score iscomputed to match the rest of the result record (XML, relational etc.) to the ontology to return a maximal match. So far, in ourwork, we do not consider algorithms for just returning the top-hkmatches.We expect to modify our current ranking algorithms toaccomplish this.
9. Conclusion
9.1. Using BioDB
In this paper we described the basic components of the BIODB system, and showed how deeply ontologies innervate itsinformation framework. This ontological connection is significantly utilized in the manner this system is used. Recall from ourIntroduction Joe, the systems biologist researching on melanoma, and his students. Typically, Joe goes through phases of dataingestion, information discovery, querying information, scientific analysis. A typical information discovery task is to findindirect correlation between known data sets and data sets just obtained. As a new gene is reported as significant in somecancers, Joe is interested in finding whether this gene may be correlated with his melanoma-motivated data sets in any way.This is not a query, but an association finding task. Currently the system navigates the ontology-based cross indices and theassociation catalog to find connections shorter that a threshold path-length between information objects. The second categoryof system use, querying data, has been discussed in Section 6. A different yet pragmatic example of ad hoc querying is as follows.A user wants to first merge all pathway graphs (whose nodes are genes or gene products and edges reflect various relationshipslike regulation) related to some biological process (e.g., a disease), and then wants to filter this merged graph by usingadditional information to construct a "high quality" interaction network, such that the edges in the resulting network satisfy anumber of conditions based upon not only the network data but also to data ontologically connected to the genes on the twoends of the edges, as well as other relationships between these genes in different correlated data sets. For example, a filteringcondition can be that the genes are co-expressed in multiple experimental settings. Finally, the analysis tasks make use of theontologies by computing statistical enrichment of some ontological terms (e.g. Gene Ontology classes) within a set of genesobtained through experimental or computational tasks.
9.2. Future research
The BIODB system illustrates how ontologies can be effectively used in practical information systems. Recently, we havestarted developing a concept mapper tool for the user to create better annotations that will connect the data to the ontology.For relational data we will use techniques like [36,52]. We will also need to resolve entities specified by different data sources[53]. This tool will adapt principles of other model mapping techniques described in Section 8. There are many open questionswe have not yet investigated. Some examples are: 1) What is an appropriate query language over the data and ontology andwhat is its expressive power? 2) Can we shift any of the pre-computed ontological reasoning to query-time reasoning and stillbe efficient? 3) What are the optimal algorithms for performing the ontology-based keyword search? 4) What is a suitablecost model for performing joint queries over the heterogeneous data sets through the Association Catalog? 5) Can weeffectively use semantic mapping algorithms from the schema mapping communities toward our work? These are some of theissues we plan to investigate.
10. Role of funding source
This research was partially funded by the NIH/NIGMS project 1R01GM084881-01 and by the Neuroscience InformationFramework (NIF) Project funded by the NIH/Neuroscience Blueprint contract HHSN271200800035C.

1101A. Gupta et al. / Data & Knowledge Engineering 69 (2010) 1084–1102
Acknowledgments
We would like to thank our biologist collaborators Profs. Maryann Martone from UCSD, and Animesh Ray from the KeckGraduate Institute, for guiding us throughmany of the design requirements and usage pattern of db.We are grateful to the refereeswhose comments led to substantial improvement of the quality and comprehensiveness of the paper.
References
[1] S. Jean, Y. Aït-Ameur, G. Pierra, Querying ontology based database using OntoQL (an ontology query language), Ontologies, Databases, and Applications ofSemantics (ODBASE'2006), 2006, pp. 704–721.
[2] S. Jean, H. Dehainsala, D.N. Xuan, G. Pierra, L. Bellatreche, Y. Aït-Ameur, OntoDB: it is time to embed your domain ontology in your database, Database Systemsfor Advanced Applications (DASFAA'07), 2007 p. (demo paper).
[3] L. Chen, M.E. Martone, A. Gupta, L. Fong, M. Wong-Barnum, Ontoquest: exploring ontological data made easy, Proc. 31st Int. Conf. on Very Large Databases(VLDB), 2006, pp. 1183–1186.
[4] A. Gupta, W. Bug, L. Marenco, X. Qian, C. Condit, A. Rangarajan, H. Müller, P. Miller, B. Sanders, J.S. Grethe, V. Astakhov, G. Shepherd, P. Sternberg, M.E.Martone, Federated access to heterogeneous information resources in the neuroscience information framework (NIF), Neuroinformatics 6 (3) (2008)205–217.
[5] C. Mungall, D.B. Emmert, A Chado case study: an ontology-based modular schema for representing genome-associated biological information, ISMB/ECCB(Supplement of Bioinformatics), 2007, pp. 337–346.
[6] J. Mei, L. Ma, Y. Pan, Ontology query answering on databases, Int. Semantic Web Conf, 2006, pp. 445–458.[7] S.D. Larson, L.L. Fong, A. Gupta, C. Condit, W.J. Bug, M.E. Martone, A formal ontology of subcellular neuroanatomy, Frontiers in Neuroscience (published online
at http://frontiersin.org/neuroinformatics/paper/10.3389/neuro.11/003.2007 /).[8] W. Bug, G. Ascoli, J.G., et al., The NIFSTD and BIRNLex vocabularies: building comprehensive ontologies for neuroscience, Neuroinformatics 6 (3) (2008)
175–194.[9] L. Chen, A. Gupta, M.E. Kurul, Stack-based algorithms for pattern matching on DAGs, Proc. 31st Int. Conf. on Very Large Databases (VLDB), 2005, pp. 493–504,
Stockholm.[10] H. Tong, C. Faloutsos, Center-piece subgraphs: problem definition and fast solutions, Proc. of the 12th ACM SIGKDD Int. Conf. on Knowledge Discovery and
Data Mining (KDD), 2006, pp. 404–413.[11] C. Ramakrishnan, W.H. Milnor, M. Perry, A.P. Sheth, Discovering informative connection subgraphs in multi-relational graphs, ACM SIGKDD Exploration
Newsletter 7 (2) (2005) 56–63.[12] B. Smith, W. Ceusters, B. Klagges, J. Köhler, A. Kumar, J. Lomax, C. Mungall, F. Neuhaus, A.L. Rector, C. Rosse, Relations in biomedical ontologies, Genome
Biology 6 (5) (2005) R46.[13] D. Srivastava, Y. Velegrakis, Intensional associations between data and metadata, Proc. of the 2007 ACM SIGMOD Int. Conf. on Management of Data, ACM
Press, York, NY, USA, 2007, pp. 401–412.[14] Pato — an ontology of phenotypic qualities, http://bioontology.org/wiki/index.php/PATO:About.[15] J. Enderle, N. Schneider, T. Seidl, Efficiently processing queries on interval-and-value tuples in relational databases, Proc. 31st Int. Conf. on Very Large Data
Bases (VLDB), 2005, pp. 385–396.[16] B. Xu, P. Wang, J. Lu, Y. Li, D. Kang, Theory and semantic refinement of bridge ontology based on multi-ontologies, Proc. of the 16th IEEE Int. Conf. on Tools
with Artificial Intelligence, IEEE Computer Society, Washington, DC, USA, 2004, pp. 442–449.[17] V. Hristidis, L. Gravano, Y. Papakonstantinou, Efficient IR-style keyword search over relational databases, vldb'2003: Proc. of the 29th Int. Conf. on Very large
data bases, VLDB Endowment, 2003, pp. 850–861.[18] Y. Xu, Y. Papakonstantinou, Efficient lca based keyword search in XML data, in: CIKM '07: Proc. of the sixteenth ACM Conf. on Conf. on information and
knowledge management, ACM, New York, NY, USA, 2007, pp. 1007–1010. doi:http://doi.acm.org/10.1145/1321440.1321597.[19] A. Gupta, B. Ludäscher, M.E. Martone, BIRN-M: a semantic mediator for solving real-world neuroscience problems, Proc. 2003 ACM SIGMOD Int. Conf. on
Management of Data, ACM Press, New York, NY, USA, 2003, p. 678-678, doi:http://doi.acm.org/10.1145/872757.872869.[20] W. Sujansky, Heterogeneous database integration in biomedicine, Journal of Biomedical Informatics 34 (4) (2001) 285–298.[21] F. Achard, G. Vaysseix, E. Barillot, XML, bioinformatics and data integration, Bioinformatics 17 (2) (2001) 115–125.[22] A. Gupta, B. Ludäscher, M.E. Martone, Knowledge-based integration of neuroscience data sources, Proc. 12th Int. Conf. on Scientific and Statistical Database
Management (SSDBM'00), IEEE Comp. Soc, Washington, DC, USA, 2000, pp. 39–52.[23] B. Ludäscher, A. Gupta, M.E. Martone, Model-based mediation with domain maps, Proc. 17th Int. Conf. on Data Engineering (ICDE), IEEE Comp. Soc,
Washington, DC, USA, 2001, pp. 81–90.[24] S. Orchard, L. Montecchi-Palazzi, H. Hermjakob, R. Apweiler, The use of common ontologies and controlled vocabularies to enable data exchange and
deposition for complex proteomic experiments, in: R. Altman (Ed.), Proc. Pacific Symp. on Biocomputing, World Press, 2005, pp. 186–196.[25] J. Köhler, S. Philippi, M. Lange, Semeda: ontology based semantic integration of biological databases, Bioinformatics 19 (18) (2003) 2420–2427.[26] M. Gruenberger, R. Alberts, D. Smedley, M. Swertz, P. Schofield, T.C. Consortium, K. Schughart, Towards the integration of mouse databases — definition and
implementation of solutions to two use-cases in mouse functional genomics, BMC Research Notes 3 (2010) 16.[27] Cheung, Kei-Hoi, Smith, Andrew, Yip, Kevin, Baker, Christopher, Gerstein, Mark, Semantic Web approach to database integration in the life sciences, vol. 1,
Springer-Verlag, 2007, pp. 11–30.[28] C. Pasquier, Biological data integration using Semantic Web technologies, Biochimie 90 (4) (2008) 584–594.[29] L. Marenco, R. Wang, P. Nadkarni, Automated database mediation using ontological metadata mappings, Journal of the American Medical Informatics
Association 16 (5) (2009) 723–737.[30] C. Fankam, OntoDB2: support of multiple ontology models within ontology based database, in: Ph.D. '08: Proceedings of the 2008 EDBT Ph.D. workshop,
2008, pp. 21–27.[31] C. Fankam, S. Jean, G. Pierra, L. Bellatreche, Y.A. Ameur, Towards connecting database applications to ontologies, 1st Int. Conf. on Advances in Databases,
Knowledge, and Data Applications (DBKDA), 2009, pp. 131–137.[32] S. Kolahi, L. Libkin, XML design for relational storage, Proc. of the 16th Int. Conf. on WWW, 2007, p. 1083-1092.[33] D.J. Abadi, A. Marcus, S. Madden, K.J. Hollenbach, Scalable Semantic Web data management using vertical partitioning, Proc. of the 33 rd Int. Conf. on VLDB,
2007, pp. 411–422.[34] J. Shanmugasundaram, E.J. Shekita, R. Barr, M.J. Carey, B.G. Lindsay, H. Pirahesh, B. Reinwald, Efficiently publishing relational data as XML documents, The
VLDB Journal 10 (2–3) (2001) 133–154.[35] S. Auer, S. Dietzold, J. Lehmann, S. Hellmann, D. Aumueller, Triplify: light-weight linked data publication from relational databases, Proc. 18th Int. Conf. on
WWW, ACM, Madrid, Spain, April 20-24, 2009, pp. 621–630.[36] J.B. Rodriguez, Semantic upgrade and publication of legacy data, Ontologies for Software Engineering and Software Technology, vol. 11, Springer-Verlag,
2006, pp. 311–339.[37] M. Atay, A. Chebotko, D. Liu, S. Lu, F. Fotouhi, Efficient schema-based XML-to-relational data mapping, Information Systems 32 (3) (2007) 458–476.[38] Y. An, Discovering and using semantics for database schemas, Ph.D. thesis, Dept. of Computer Science, University of Toronto (2007).

1102 A. Gupta et al. / Data & Knowledge Engineering 69 (2010) 1084–1102
[39] C.P.D. Laborda, S. Conrad, Database to Semantic Web mapping using rdf query languages, Proc. of the Int. Conf. on Conceptual Modeling (ER), 2006,pp. 241–254.
[40] P. Atzeni, P. Cappellari, R. Torlone, P.A. Bernstein, G. Gianforme, Model-independent schema translation, The VLDB Journal 17 (6) (2008) 1347–1370.[41] P. Boncz, T. Grust, M. van Keulen, S. Manegold, J. Rittinger, J. Teubner, Monetdb/xquery: A fast xquery processor powered by a relational engine, Proc. of the
ACM Int. Conf. on SIGMOD, 2006, pp. 479–490.[42] J. Lu, L. Ma, L. Zhang, J.-S. Brunner, C. Wang, Y. Pan, Y. Yu, Sor: A practical system for ontology storage, reasoning and search, Proc. of the 33 rd Int. Conf. on
VLDB, 2007, pp. 1402–1405.[43] V. Christophides, G. Karvounarakis, I. Koffina, I.K. Na, A. Magkanaraki, G. Kokkinidis, G. Serfiotis, D. Plexousakis, G.S. Otis, V. Tannen, The ics-forth swim: a
powerful Semantic Web integration middleware, Proc. of the Int. Conf. on Semantic Web Databases (SWDB), 2003, pp. 381–394.[44] I. Kofina, Integrating XML data sources using RDF/S schemas: The ICS-FORTH Semantic Web integration middleware (SWIM), Masters' Thesis, Univ. of Crete
(2005).[45] D. Kensche, C. Quix, X. Li, Y. Li, M. Jarke, Generic schema mappings for composition and query answering, Data & Knowledge Engineering 68 (7) (2009)
599–621.[46] N. Alalwan, H. Zedan, F. Siewe, Generating OWL ontology for database integration, Proc. 3 rd Int. Conf. on Adv. in Semantic Processing (SEMAPRO), IEEE
Computer Society, 2009, pp. 22–31.[47] V. Hristidis, Y. Papakonstantinou, Discover: keyword search in relational databases, VLDB '02: Proc. of the 28th Int. Conf. on Very Large Data Bases, VLDB
Endowment, 2002, p. 670-681.[48] V. Kacholia, S. Pandit, S. Chakrabarti, S. Sudarshan, R. Desai, H. Karambelkar, Bidirectional expansion for keyword search on graph databases, Proc. of the 31st
Int. Conf. on VLDB, 2005, pp. 505–516.[49] V. Hristidis, Y. Papakonstantinou, N. Koudas, D. Srivastava, Keyword proximity search in XML trees, IEEE Transactions on Knowledge and Data Engineering 18
(4) (2006) 525–539 http://dx.doi.org/10.1109/TKDE.2006.61.[50] T. Tran, H. Wang, S. Rudolph, P. Cimiano, Top-k exploration of query candidates for efficient keyword search on graph-shaped (rdf) data, Proc. of the 2009
IEEE Int. Conf. on Data Engineering (ICDE), IEEE Computer Society, Washington, DC, USA, 2009, pp. 405–416.[51] Y. Chen, W. Wang, Z. Liu, X. Lin, Keyword search on structured and semi-structured data, Proc. of the 35th ACM Int. Conf. on SIGMOD, ACM, 2009,
pp. 1005–1010.[52] I. Reinhartz-Berger, Towards automatization of domain modeling, Data & Knowledge Engineering 69 (5) (2010) 491–515.[53] H. Kopcke, E. Rahm, Frameworks for entity matching: a comparison, Data & Knowledge Engineering 69 (2) (2010) 197–210.
Amarnath Gupta is the Director of the Advanced Query Processing Laboratory of the San Diego Supercomputer Center at theUniversity of California San Diego. He received his Ph.D. (Engineering) in Computer Science from Jadavpur University, Calcutta, India.He was the Chief Scientist of Virage, Inc., a multimedia information management company, where he developed indexing and queryprocessing techniques for images, videos and text. At UCSD, his research is in the area of graph databases, scientific informationmanagement, semantic information integration, and more recently in event-based information systems. He is a member of the ACMand has over 60 publications and 13 patents.
Christopher Condit is on staff at the San Diego Supercomputer Center in the Data and Knowledge Systems lab. He received his BA inComputer Science in 2001 from the University of California, Berkeley. Before joining SDSC he worked as a corporate consultant anddeveloped expertise in DITA and IBMIDDoc. Currently he develops myriad engineering solutions in support of domain sciencesfocusing on information integration, cyberinfrastructure development, semantic indexing, and geospatial information systems.
Xufei Qian is a programmer analyst in the San Diego Supercomputer Center at University of California San Diego. She received her MSin 2001 from the Department of Computer Sciences of San Diego State University. Since then, she joined the Advanced QueryProcessing Lab of San Diego Supercomputer Center. Currently, she mainly works on ontological graph query processing.


















