

Big data vccorp
25
-
Upload
tuan-hoang -
Category
Technology
-
view
342 -
download
1
Transcript of Big data vccorp

Nội dung Giới thiệu chung
Hệ thống xử lý dữ liệu lớn – Big Data ở VCCORP
Những bài toán đã xử lý
Các bài toán mở
2

Giới thiệu VCCORP Thành lập năm 2006
Số nhân viên: 1500 người
Trụ sở chính ở Hà Nội, chi nhánh ở các thành phố lớntại Việt Nam
Là công ty dẫn đầu về Internet tại Việt Nam.
Nhà đầu tư: IDG VV, Intel Capital
Chia thành các khối: quảng cáo, nội dung, thương mạiđiện tử, game, VCCloud.
3
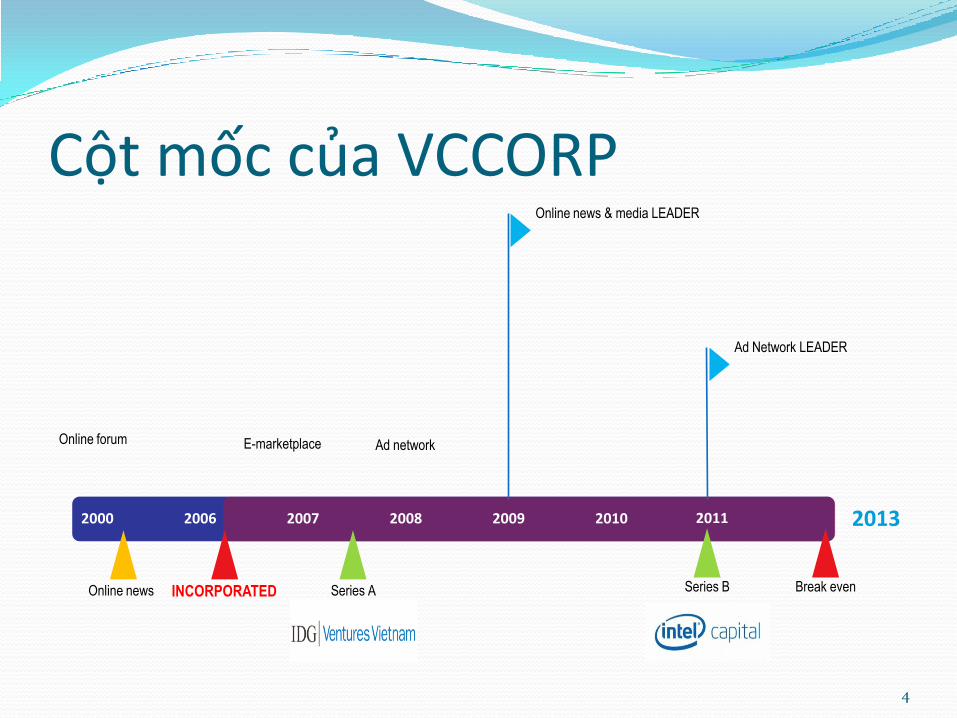
Cột mốc của VCCORP
Ad Network LEADER
Online news & media LEADER
2013
Ad networkE-marketplace
Break evenSeries BSeries AINCORPORATED
Online forum
Online news
20112000 2006 2007 2008 2009 2010
4

Giới thiệu Admicro Thành lập năm 2008.
Mạng quảng cáo lớn nhất Việt Nam, chiếm 40% thịphần.
Độ phủ 31 triệu người dùng Internet, chiếm 90% người dùng Internet Việt Nam.
30 báo độc quyền, mạng lưới Website có trên 300 sites.
5

Big Data ở VCCORP Bắt đầu sớm từ 2007 với dự án Baamboo search.
Từ năm 2008, bắt đầu thử nghiệm xây dựng hệ thốngBig Data phục vụ hệ thống quảng cáo.
Hiện nay được nghiên cứu phát triển xây dựng các sảnphẩm phục vụ cho các hệ thống quảng cáo, nội dung, thương mại điện tử…
6

Big Data ở VCCORP – Qui mô dữliệu
7
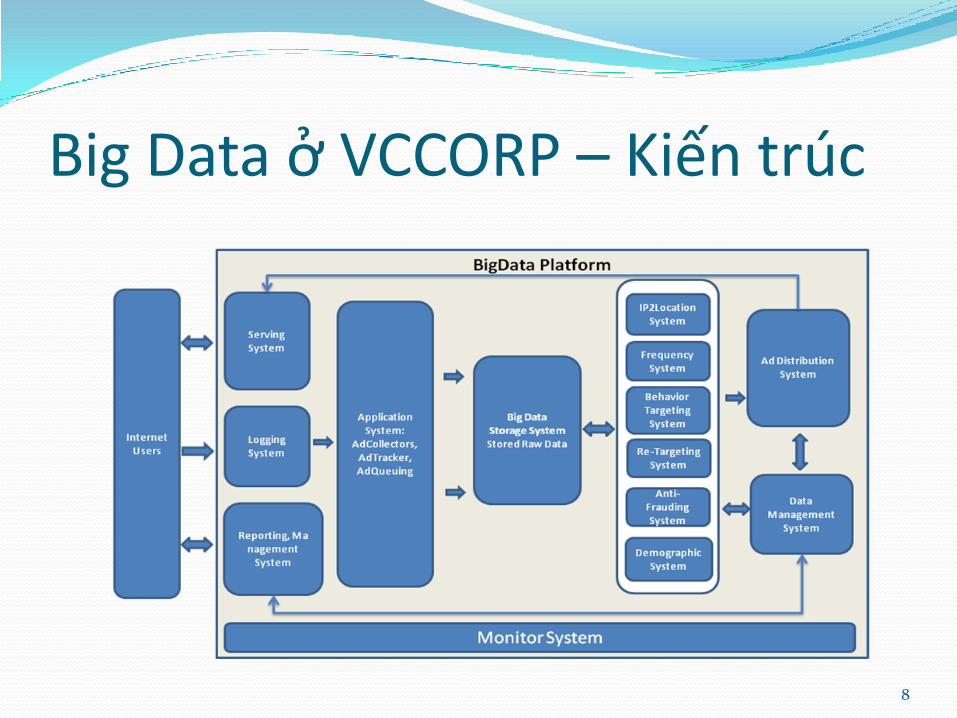
Big Data ở VCCORP – Kiến trúc
8

Những bài toán xử lý Tính toán dữ liệu lớn
Ip2Location
Nhận diện hành vi người dùng
Demographic
Behavioral
Finger Printing
Cross devices
Tối ưu hóa quảng cáo
9

Tính toán dữ liệu lớn Tổng dữ liệu mới mỗi ngày: 1 tỷ bản ghi.
Dữ liệu đầu vào: raw log, lưu thông tin về lượng click, impressions của người dùng.
Các số liệu cần tính toán:
Báo cáo theo lượng click, view, pageview, tiền theo cácdomain: user, website, location, type...
Tính toán lượng Unique Visitor (UV)
Tính thời gian time on site của người dùng
10

Tính toán dữ liệu lớn Hệ thống ngăn chặn invalid, frauding:
Invalid: người dùng click/view nhầm
Frauding: cố tình tạo ra click/view để gây ảnh hưởng
Giải pháp: xây dựng tập luật để ngăn chặn.
Thực tế:
Khách hàng A nhận 10,000 fraud click trong 30 phút
Website B tạo ra 500,000 fraud click trong vòng 1h
11

Tính toán dữ liệu lớn –Mô hình Sử dụng hai nền tảng mã mở:
Hadoop eco-system: Hadoop, Hbase, Pig, Hive, Storm, Spark.
Cassandra
Cluster: 80 nodes, cấu hình:
24 CPUs
32 GB RAM
8 TB HDD
12

Ip2Location Input: dữ liệu raw log của người dùng với thông tin IP
Output: thông tin về vùng miền, tỉnh thành của ngườidùng (mở rộng quận huyện).
Tổng lượng dữ liệu: 100 tỷ bản ghi (10TB)
Giải pháp: xây dựng thuật toán lặp dựa trên quan hệ: User - IP
13

Ip2LocationKết quả:
Nhận diện được 15 triệu IP Việt Nam trên tổng số 15.5 triệu IP đã cấp phát, chiếm 96.7%
Tỉ lệ nhận diện chính xác theo vùng miền: 90%
Tỉ lệ nhận diện chính xác theo tỉnh thành: 75%
Đang triển khai theo quận – huyện.
14

Nhận diện hành vi người dùngInternet Input: dữ liệu raw log
Output: các thông tin về người dùng Internet
Demographic: giới tính, nhóm tuổi
Behavioral: sở thích, thói quen
Finger Printing: nhận diện cùng là 1 người trên 1 thiết bị(device)
Cross devices: nhận diện cùng 1 người dùng trên nhiềuthiết bị
15

Demographic - Behavioral Nhận diện theo giới tính: nam/nữ.
Nhận diện theo nhóm tuổi: dưới 18, từ 18 – 24, từ 25 –34, từ 35 – 49, trên 50.
Nhận diện theo sở thích: tập 12 sở thích cơ bản.
Kết quả:
Độ chính xác nhận diện giới tính: 82.5%
Độ chính xác nhận diện nhóm tuổi: 67.5%
16

Demographic - Behavioral
17

Finger Printing Mục tiêu: nhận diện cùng 1 người dùng trên 1 device.
Khó khăn: người dùng có thể dùng nhiều browser hoặc bị xóa cookie.
Giải pháp: xây dựng thuật toán mã hóa người dùngdựa trên các thông tin: IP, Fonts, Screen Resolution, Location, Languages, Websites…
Kết quả: đang triển khai
18

Cross devices Mục tiêu: nhận diện người dùng sử dụng laptop,
desktop, mobile… cùng là một người.
Khó khăn: thông tin sử dụng trên PC, Laptop, Mobile là rời rạc, không có độ kết dính.
Giải pháp: xây dựng thuật toán đoán nhận người dùngdựa trên các thói quen về: IP
Website
Sở thích, thói quen
Kết quả: đang thực hiện
19

Tối ưu hóa quảng cáo Đây là bài toán đã, đang và sẽ tiếp tục thực hiện.
Các kỹ thuật áp dụng:
Personalization
Audience Targeting
Real Time Bidding
Retargeting
Hàm lượng giá: ước lượng giá theo từng người dùng.
20

Các bài toán mở Xử lý ngôn ngữ tự nhiên - NLP
Recommendation Engine - RE
Sentiment Analysis
Data Management Platform - DMP
21

Các bài toán mở NLP: xây dựng các bài toán:
Tách từ theo phương pháp N-grams
Phân loại, trích rút văn bản
Độ tương đồng của từ ngữ
Recommendation Engine:
Xây dựng bộ recommendation engine service cho hệthống Website TMĐT.
Xây dựng RE cho hệ thống quảng cáo
22

Các bài toán mở Sentiment analysis:
Tìm kiếm các nội dung liên quan đến từ khóa, chủ đề.
Phân loại nội dung thu thập được theo hướng tích cựchoặc tiêu cực
DMP:
Nền tảng thu thập dữ liệu lớn theo cả first party và third party data.
Phân loại dữ liệu, trích rút thông tin để giúp ra quyếtđịnh.
23

Cơ hội hợp tác
24

Q&A
25


















