Hadoop, Hadoop, Hadoop!!! Jerome Mitchell Indiana University.
Upload
crs4-research-center-in-sardiniaCategory
view
44download
0
Big Data MapReduce and Hadoop Pydoop
Big Data & Hadoop
Simone Leo
Distributed Computing – CRS4http://www.crs4.it
Seminar Series 2015
Simone Leo Big Data & Hadoop

Big Data MapReduce and Hadoop Pydoop
Outline
1 Big Data
2 MapReduce and HadoopThe MapReduce ModelHadoop
3 PydoopMotivationArchitectureUsage
Simone Leo Big Data & Hadoop

Big Data MapReduce and Hadoop Pydoop
Outline
1 Big Data
2 MapReduce and HadoopThe MapReduce ModelHadoop
3 PydoopMotivationArchitectureUsage
Simone Leo Big Data & Hadoop

Big Data MapReduce and Hadoop Pydoop
The Data Deluge
sciencematters.berkeley.edu
satellites
upload.wikimedia.org
social networkswww.imagenes-bio.de
DNA sequencing
scienceblogs.com
high-energy physics
Storage costs rapidlydecreasingEasier to acquire hugeamounts of data
Social networksParticle collidersRadio telescopesDNA sequencersWearable sensors. . .
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop
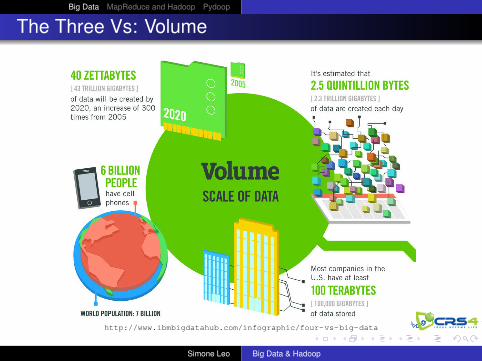
The Three Vs: Volume
http://www.ibmbigdatahub.com/infographic/four-vs-big-data
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop
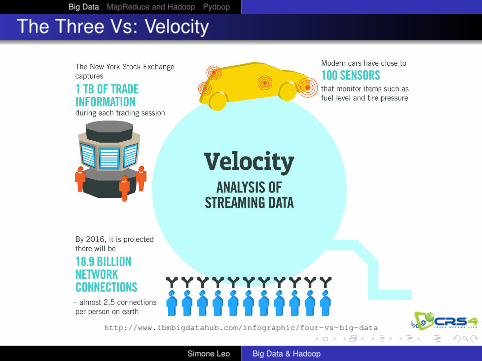
The Three Vs: Velocity
http://www.ibmbigdatahub.com/infographic/four-vs-big-data
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop
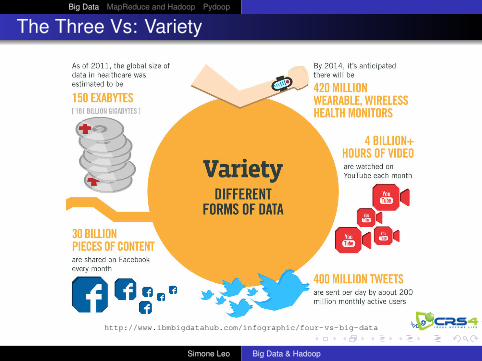
The Three Vs: Variety
http://www.ibmbigdatahub.com/infographic/four-vs-big-data
Simone Leo Big Data & Hadoop

Big Data MapReduce and Hadoop Pydoop
Big Data: a Hard to Define Buzzword
OED: “data of a very large size, typically to the extent thatits manipulation and management present significantlogistical challenges”1
Wikipedia: “data sets so large or complex that traditionaldata processing applications are inadequate”datascience@berkeley blog: 43 definitions2
How big is big?Depends on the field and organizationVaries with time[Volume] does not fit in memory / in a hard disk[Velocity] production faster than processing time[Variety] unknown / unsupported formats . . .
1http://www.forbes.com/sites/gilpress/2013/06/18/big-data-news-a-revolution-indeed2http://datascience.berkeley.edu/what-is-big-data
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop
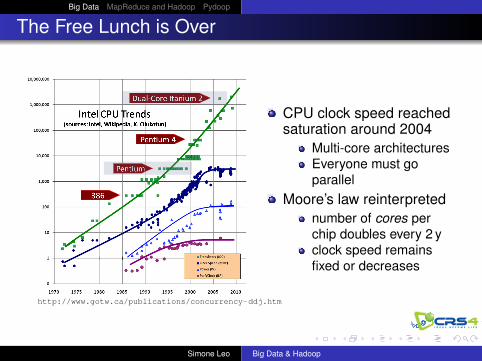
The Free Lunch is Over
CPU clock speed reachedsaturation around 2004
Multi-core architecturesEveryone must goparallel
Moore’s law reinterpretednumber of cores perchip doubles every 2 yclock speed remainsfixed or decreases
http://www.gotw.ca/publications/concurrency-ddj.htm
Simone Leo Big Data & Hadoop

Big Data MapReduce and Hadoop Pydoop
Data-Intensive Applications
https://imgflip.com/memegenerator
A new class of problemsNeeds specific solutions
InfrastructureTechnologiesProfessional background
ScalabilityAutomatically adapt tochanges in sizeDistributed computing
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop The MapReduce Model Hadoop
Outline
1 Big Data
2 MapReduce and HadoopThe MapReduce ModelHadoop
3 PydoopMotivationArchitectureUsage
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop The MapReduce Model Hadoop
Outline
1 Big Data
2 MapReduce and HadoopThe MapReduce ModelHadoop
3 PydoopMotivationArchitectureUsage
Simone Leo Big Data & Hadoop

Big Data MapReduce and Hadoop Pydoop The MapReduce Model Hadoop
What is MapReduce?
A programming model for large-scale distributed dataprocessing
Inspired by map and reduce in functional programmingMap: map a set of input key/value pairs to a set ofintermediate key/value pairsReduce: apply a function to all values associated to thesame intermediate key; emit output key/value pairs
An implementation of a system to execute suchprograms
Fault-tolerantHides internals from usersScales very well with dataset size
Simone Leo Big Data & Hadoop
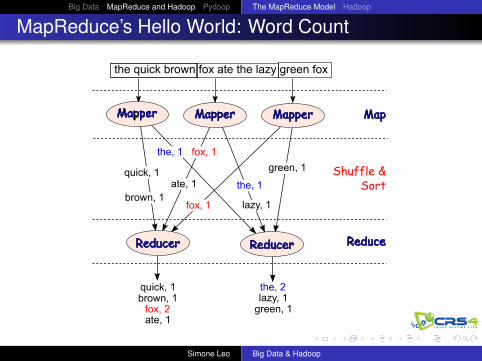
Big Data MapReduce and Hadoop Pydoop The MapReduce Model Hadoop
MapReduce’s Hello World: Word Count
the quick brown fox ate the lazy green fox
Mapper Map
Reducer ReduceReducer
Shuffle &Sort
the, 1
quick, 1
brown, 1
fox, 1
ate, 1
lazy, 1fox, 1
green, 1
quick, 1brown, 1
fox, 2ate, 1
the, 2lazy, 1
green, 1
the, 1
Mapper Mapper
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop The MapReduce Model Hadoop
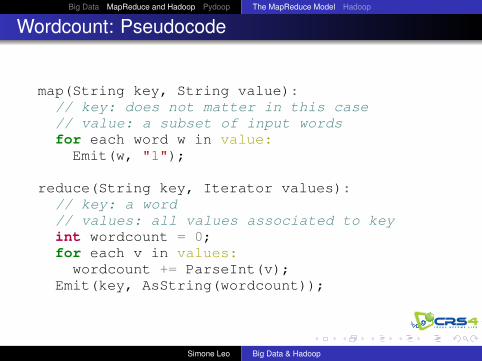
Wordcount: Pseudocode
map(String key, String value):// key: does not matter in this case// value: a subset of input wordsfor each word w in value:
Emit(w, "1");
reduce(String key, Iterator values):// key: a word// values: all values associated to keyint wordcount = 0;for each v in values:wordcount += ParseInt(v);
Emit(key, AsString(wordcount));
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop The MapReduce Model Hadoop
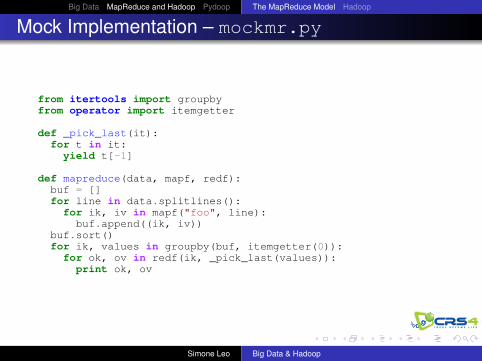
Mock Implementation – mockmr.py
from itertools import groupbyfrom operator import itemgetter
def _pick_last(it):for t in it:
yield t[-1]
def mapreduce(data, mapf, redf):buf = []for line in data.splitlines():for ik, iv in mapf("foo", line):buf.append((ik, iv))
buf.sort()for ik, values in groupby(buf, itemgetter(0)):for ok, ov in redf(ik, _pick_last(values)):print ok, ov
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop The MapReduce Model Hadoop
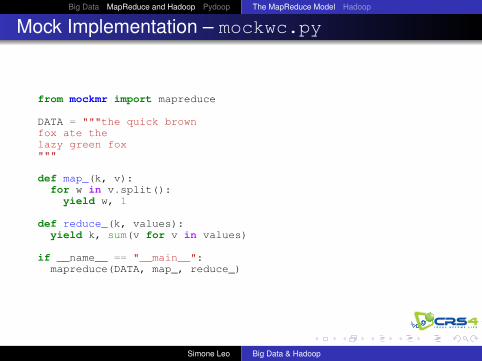
Mock Implementation – mockwc.py
from mockmr import mapreduce
DATA = """the quick brownfox ate thelazy green fox"""
def map_(k, v):for w in v.split():
yield w, 1
def reduce_(k, values):yield k, sum(v for v in values)
if __name__ == "__main__":mapreduce(DATA, map_, reduce_)
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop The MapReduce Model Hadoop
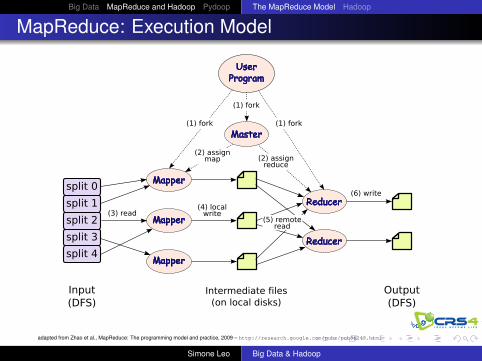
MapReduce: Execution Model
Mapper
Reducer
split 0
split 1
split 4
split 3
split 2
UserProgram
Master
Input(DFS)
Intermediate files(on local disks)
Output(DFS)
(1) fork
(2) assignmap (2) assign
reduce
(1) fork
(1) fork
(3) read(4) local
write(5) remote
read
(6) write
Mapper
Mapper
Reducer
adapted from Zhao et al., MapReduce: The programming model and practice, 2009 – http://research.google.com/pubs/pub36249.html
Simone Leo Big Data & Hadoop

Big Data MapReduce and Hadoop Pydoop The MapReduce Model Hadoop
MapReduce vs Alternatives – 1Pro
gra
mm
ing
mod
el
Decl
ara
tive
Pro
ced
ura
l
Flat raw files
Data organization
Structured
MPI
DBMS/SQL
MapReduce
adapted from Zhao et al., MapReduce: The programming model and practice, 2009 – http://research.google.com/pubs/pub36249.html
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop The MapReduce Model Hadoop
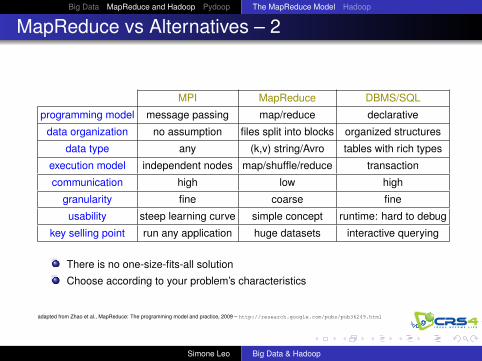
MapReduce vs Alternatives – 2
MPI MapReduce DBMS/SQL
programming model message passing map/reduce declarative
data organization no assumption files split into blocks organized structures
data type any (k,v) string/Avro tables with rich types
execution model independent nodes map/shuffle/reduce transaction
communication high low high
granularity fine coarse fine
usability steep learning curve simple concept runtime: hard to debug
key selling point run any application huge datasets interactive querying
There is no one-size-fits-all solution
Choose according to your problem’s characteristics
adapted from Zhao et al., MapReduce: The programming model and practice, 2009 – http://research.google.com/pubs/pub36249.html
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop The MapReduce Model Hadoop
Outline
1 Big Data
2 MapReduce and HadoopThe MapReduce ModelHadoop
3 PydoopMotivationArchitectureUsage
Simone Leo Big Data & Hadoop

Big Data MapReduce and Hadoop Pydoop The MapReduce Model Hadoop
Hadoop: Overview
DisclaimerFirst we describe Hadoop 1Then we highlight what’s different in Hadoop 2
ScalableThousands of nodesPetabytes of data over 10M filesSingle file: Gigabytes to Terabytes
EconomicalOpen sourceCOTS Hardware (but master nodes should be reliable)
Well-suited to bag-of-tasks applications (many bio apps)Files are split into blocks and distributed across nodesHigh-throughput access to huge datasetsWORM storage model
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop The MapReduce Model Hadoop
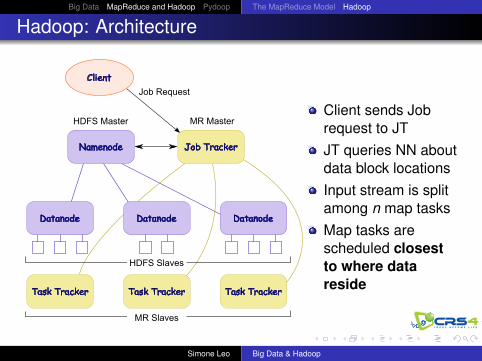
Hadoop: Architecture
MR MasterHDFS Master
Client
Namenode Job Tracker
Task Tracker Task Tracker
Datanode Datanode Datanode
Task Tracker
Job Request
HDFS Slaves
MR Slaves
Client sends Jobrequest to JTJT queries NN aboutdata block locationsInput stream is splitamong n map tasksMap tasks arescheduled closestto where datareside
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop The MapReduce Model Hadoop
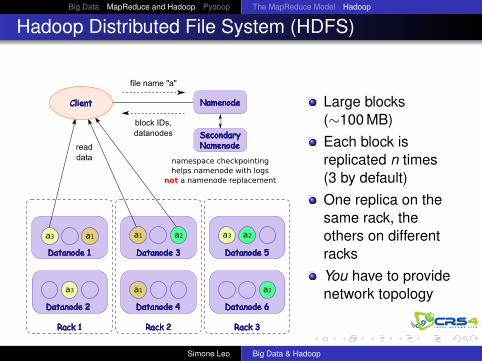
Hadoop Distributed File System (HDFS)
file name "a"
block IDs,datanodes
a3 a2
readdata
Client Namenode
SecondaryNamenode
a1
Datanode 1 Datanode 3
Datanode 2 Datanode 6
Datanode 5
Datanode 4
Rack 1 Rack 2 Rack 3
a3 a1
a3
a2
a1 a2
namespace checkpointinghelps namenode with logs
not a namenode replacement
Large blocks(∼100 MB)Each block isreplicated n times(3 by default)One replica on thesame rack, theothers on differentracksYou have to providenetwork topology
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop The MapReduce Model Hadoop
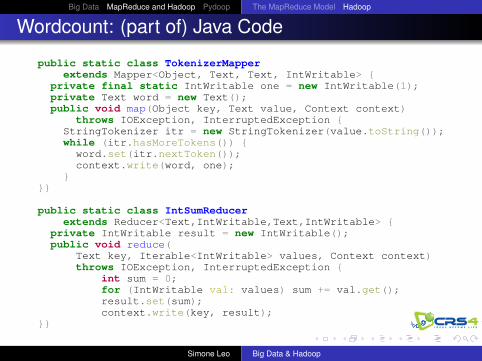
Wordcount: (part of) Java Code
public static class TokenizerMapperextends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {
word.set(itr.nextToken());context.write(word, one);
}}}
public static class IntSumReducerextends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();public void reduce(
Text key, Iterable<IntWritable> values, Context context)throws IOException, InterruptedException {
int sum = 0;for (IntWritable val: values) sum += val.get();result.set(sum);context.write(key, result);
}}
Simone Leo Big Data & Hadoop

Big Data MapReduce and Hadoop Pydoop The MapReduce Model Hadoop
Other MapReduce Components
Combiner (local reducer)InputFormat / RecordReader
Translates the byte-oriented view of input files into therecord-oriented view required by the MapperDirectly accesses HDFS filesProcessing unit: input split
PartitionerDecides which Reducer receives which keyTypically uses a hash function of the key
OutputFormat / RecordWriterWrites key/value pairs output by the ReducerDirectly accesses HDFS files
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop The MapReduce Model Hadoop
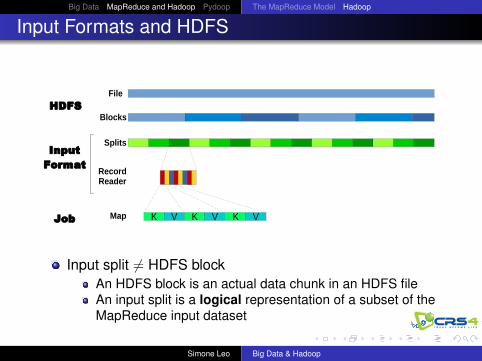
Input Formats and HDFS
HDFS
InputFormat
Job
Input split 6= HDFS blockAn HDFS block is an actual data chunk in an HDFS fileAn input split is a logical representation of a subset of theMapReduce input dataset
Simone Leo Big Data & Hadoop

Big Data MapReduce and Hadoop Pydoop The MapReduce Model Hadoop
Hadoop 2
HDFS FederationMultiple namenodes can share the burden of maintainingthe namespace(s) and managing blocksBetter scalability
HDFS high availability (HA)Can run redundant namenodes in active/passive modeAllows failover in case of crash or planned manteinance
YARNResource manager: global assignment of computeresources to applications (HA supported since 2.4.0)Application master(s) per-application scheduling andcoordination (like a per-job JT, on a slave)MapReduce is just one of many possible frameworks
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop Motivation Architecture Usage
Outline
1 Big Data
2 MapReduce and HadoopThe MapReduce ModelHadoop
3 PydoopMotivationArchitectureUsage
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop Motivation Architecture Usage
Outline
1 Big Data
2 MapReduce and HadoopThe MapReduce ModelHadoop
3 PydoopMotivationArchitectureUsage
Simone Leo Big Data & Hadoop

Big Data MapReduce and Hadoop Pydoop Motivation Architecture Usage
Developing your First MapReduce Application
The easiest path for beginners is Hadoop StreamingJava package included in HadoopUse any executable as the mapper or reducerRead key-value pairs from standard inputWrite them to standard outputText protocol: records are serialized as <k>\t<v>\n
Word count mapper (Python)
#!/usr/bin/env pythonimport sysfor line in sys.stdin:
for word in line.split():print "%s\t1" % word
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop Motivation Architecture Usage
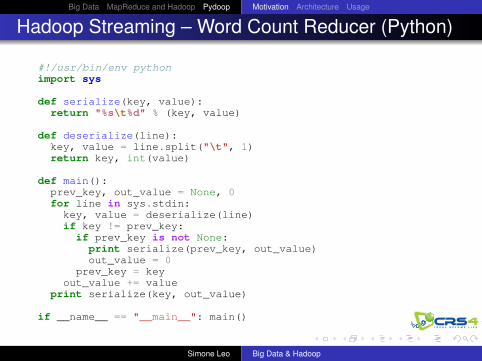
Hadoop Streaming – Word Count Reducer (Python)
#!/usr/bin/env pythonimport sys
def serialize(key, value):return "%s\t%d" % (key, value)
def deserialize(line):key, value = line.split("\t", 1)return key, int(value)
def main():prev_key, out_value = None, 0for line in sys.stdin:key, value = deserialize(line)if key != prev_key:if prev_key is not None:
print serialize(prev_key, out_value)out_value = 0
prev_key = keyout_value += value
print serialize(key, out_value)
if __name__ == "__main__": main()
Simone Leo Big Data & Hadoop

Big Data MapReduce and Hadoop Pydoop Motivation Architecture Usage
MapReduce Development with Hadoop
Java: nativeC++: MapReduce API (via Hadoop Pipes) + libhdfs(included in the Hadoop distribution)Python: several solutions, but do they meet all of therequirements of nontrivial apps?
Reuse existing modules, including extensionsNumPy / SciPy for numerical computationSpecialized components (RecordReader/Writer, Partitioner)HDFS access. . .
Simone Leo Big Data & Hadoop

Big Data MapReduce and Hadoop Pydoop Motivation Architecture Usage
Python MR: Hadoop-Integrated Solutions
Hadoop StreamingAwkward programmingstyleCan only write mapper andreducer scripts (noRecordReader, etc.)No HDFS access
JythonIncomplete standardlibraryMost third-party packagesare only compatible withCPythonCannot use C/C++extension modulesTypically one or morereleases behind CPython
Simone Leo Big Data & Hadoop

Big Data MapReduce and Hadoop Pydoop Motivation Architecture Usage
Python MR: Third Party Solutions
Most third party packages are Hadoop Streamingwrappers
They add usability, but share many of Streaming’slimitations
Most are not actively developed anymoreOur solution: Pydoop(https://github.com/crs4/pydoop)
Actively developed since 2009(Almost) pure Python Pipes client + libhdfs wrapper
Simone Leo Big Data & Hadoop

Big Data MapReduce and Hadoop Pydoop Motivation Architecture Usage
Pydoop: Overview
Access to most MR components, including RecordReader,RecordWriter and PartitionerGet configuration, set counters and report statusEvent-driven programming model (like the Java API, butwith the simplicity of Python)
You define classes, the MapReduce framework instantiatesthem and calls their methods
CPython→ use any moduleHDFS API
Simone Leo Big Data & Hadoop

Big Data MapReduce and Hadoop Pydoop Motivation Architecture Usage
Summary of Features
Streaming Jython Pydoop
C/C++ Ext Yes No Yes
Standard Lib Full Partial Full
MR API No* Full Partial
Event-driven prog No Yes Yes
HDFS access No Yes Yes
(*) you can only write the map and reduce parts as executable scripts.
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop Motivation Architecture Usage
Outline
1 Big Data
2 MapReduce and HadoopThe MapReduce ModelHadoop
3 PydoopMotivationArchitectureUsage
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop Motivation Architecture Usage
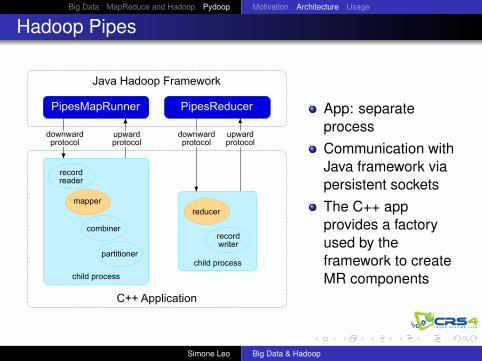
Hadoop Pipes
Java Hadoop Framework
PipesMapRunner PipesReducer
C++ Application
child process
recordwriter
reducer
child process
recordreader
mapper
partitioner
combiner
downwardprotocol
upwardprotocol
downwardprotocol
upwardprotocol
App: separateprocessCommunication withJava framework viapersistent socketsThe C++ appprovides a factoryused by theframework to createMR components
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop Motivation Architecture Usage
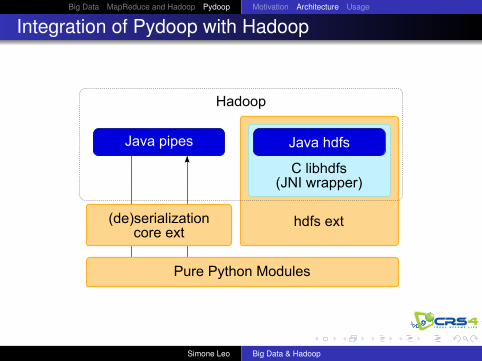
Integration of Pydoop with Hadoop
Java pipes
Hadoop
Java hdfs
C libhdfs(JNI wrapper)
(de)serializationcore ext
hdfs ext
Pure Python Modules
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop Motivation Architecture Usage
Outline
1 Big Data
2 MapReduce and HadoopThe MapReduce ModelHadoop
3 PydoopMotivationArchitectureUsage
Simone Leo Big Data & Hadoop

Big Data MapReduce and Hadoop Pydoop Motivation Architecture Usage
Python Wordcount, Full Program Code
import pydoop.mapreduce.api as apiimport pydoop.mapreduce.pipes as pp
class Mapper(api.Mapper):
def map(self, context):words = context.value.split()for w in words:
context.emit(w, 1)
class Reducer(api.Reducer):
def reduce(self, context):s = sum(context.values)context.emit(context.key, s)
def __main__():pp.run_task(pp.Factory(Mapper, Reducer))
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop Motivation Architecture Usage
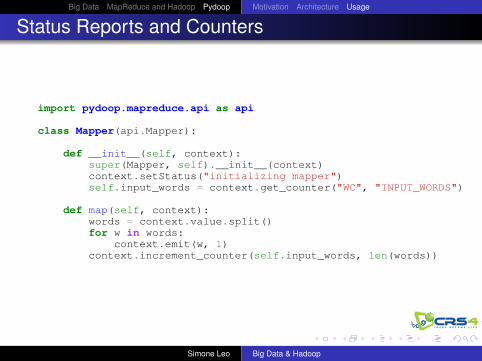
Status Reports and Counters
import pydoop.mapreduce.api as api
class Mapper(api.Mapper):
def __init__(self, context):super(Mapper, self).__init__(context)context.setStatus("initializing mapper")self.input_words = context.get_counter("WC", "INPUT_WORDS")
def map(self, context):words = context.value.split()for w in words:
context.emit(w, 1)context.increment_counter(self.input_words, len(words))
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop Motivation Architecture Usage
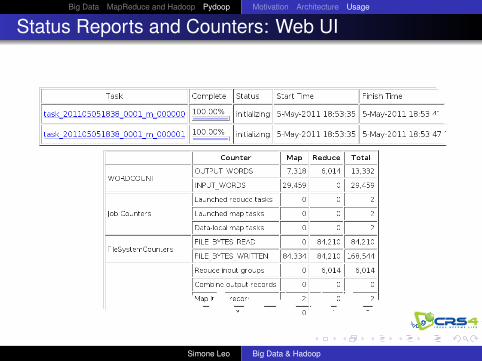
Status Reports and Counters: Web UI
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop Motivation Architecture Usage
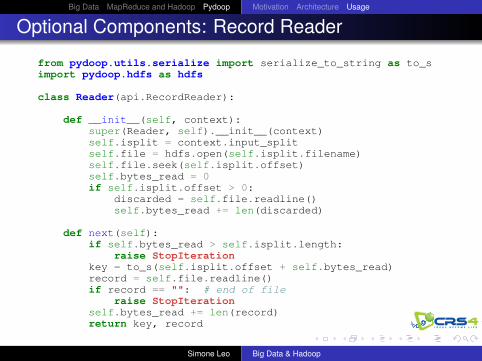
Optional Components: Record Reader
from pydoop.utils.serialize import serialize_to_string as to_simport pydoop.hdfs as hdfs
class Reader(api.RecordReader):
def __init__(self, context):super(Reader, self).__init__(context)self.isplit = context.input_splitself.file = hdfs.open(self.isplit.filename)self.file.seek(self.isplit.offset)self.bytes_read = 0if self.isplit.offset > 0:
discarded = self.file.readline()self.bytes_read += len(discarded)
def next(self):if self.bytes_read > self.isplit.length:
raise StopIterationkey = to_s(self.isplit.offset + self.bytes_read)record = self.file.readline()if record == "": # end of file
raise StopIterationself.bytes_read += len(record)return key, record
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop Motivation Architecture Usage
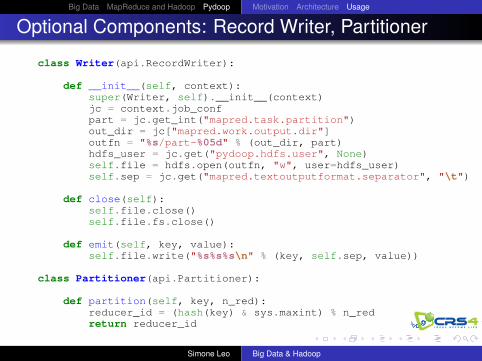
Optional Components: Record Writer, Partitioner
class Writer(api.RecordWriter):
def __init__(self, context):super(Writer, self).__init__(context)jc = context.job_confpart = jc.get_int("mapred.task.partition")out_dir = jc["mapred.work.output.dir"]outfn = "%s/part-%05d" % (out_dir, part)hdfs_user = jc.get("pydoop.hdfs.user", None)self.file = hdfs.open(outfn, "w", user=hdfs_user)self.sep = jc.get("mapred.textoutputformat.separator", "\t")
def close(self):self.file.close()self.file.fs.close()
def emit(self, key, value):self.file.write("%s%s%s\n" % (key, self.sep, value))
class Partitioner(api.Partitioner):
def partition(self, key, n_red):reducer_id = (hash(key) & sys.maxint) % n_redreturn reducer_id
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop Motivation Architecture Usage
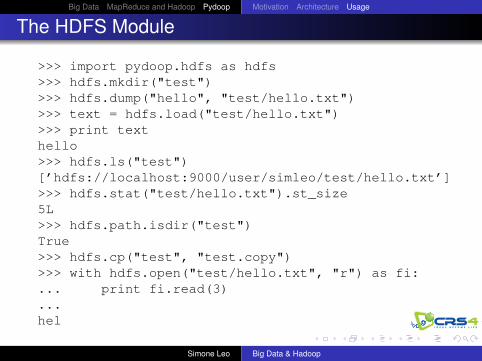
The HDFS Module
>>> import pydoop.hdfs as hdfs>>> hdfs.mkdir("test")>>> hdfs.dump("hello", "test/hello.txt")>>> text = hdfs.load("test/hello.txt")>>> print texthello>>> hdfs.ls("test")[’hdfs://localhost:9000/user/simleo/test/hello.txt’]>>> hdfs.stat("test/hello.txt").st_size5L>>> hdfs.path.isdir("test")True>>> hdfs.cp("test", "test.copy")>>> with hdfs.open("test/hello.txt", "r") as fi:... print fi.read(3)...hel
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop Motivation Architecture Usage
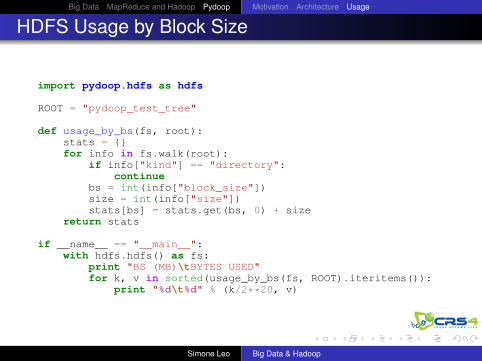
HDFS Usage by Block Size
import pydoop.hdfs as hdfs
ROOT = "pydoop_test_tree"
def usage_by_bs(fs, root):stats = {}for info in fs.walk(root):
if info["kind"] == "directory":continue
bs = int(info["block_size"])size = int(info["size"])stats[bs] = stats.get(bs, 0) + size
return stats
if __name__ == "__main__":with hdfs.hdfs() as fs:
print "BS (MB)\tBYTES USED"for k, v in sorted(usage_by_bs(fs, ROOT).iteritems()):
print "%d\t%d" % (k/2**20, v)
Simone Leo Big Data & Hadoop
Big Data MapReduce and Hadoop Pydoop
Thank you for your time!
Simone Leo Big Data & Hadoop