
Big Data Des méandres des outils au potentiel business
54
www.neoxia.com IT for Business Performance Open Source Days 4.0 ENSA Khouribga Big Data : Des méandres des outils au potentiel Business 24/02/2014
-
Upload
mouhsine-lakhdissi -
Category
Technology
-
view
394 -
download
0
Transcript of Big Data Des méandres des outils au potentiel business

www.neoxia.com
IT for Business
Performance
Open Source Days 4.0
ENSA Khouribga
Big Data : Des méandres des outils au
potentiel Business
24/02/2014

2
Sommaire
1. Pourquoi le Big Data
2. C’est Quoi le Big Data
3. Le Comment du Big Data
4. Les impacts Business

Pourquoi le Big Data
#1

Révolution numérique
4
La révolution numérique en cours aura des
effets au moins aussi considérables qu’en leur
temps l’invention de l’écriture puis celle de
l’imprimerie.
Les notions de temps et d’espace en sont
totalement transformées et les façons
d’accéder à la connaissance profondément
modifiées.
Michel Serres, Petite Poucette, Editions Le Pommier, 2012

Révolution numérique
5
Big Data : “… data a new class of economic
asset, like currency or gold.”
The New York Times

6
Web et réseaux sociaux
72 Hours a MinuteYouTube
28 Million Wikipedia Pages
900 MillionFacebook Users
6 Billion Flickr Photos

7
Internet des objets
+ Il y avait 9 milliards d’objets connectés en 2011, nous en compterons 25 milliards en 2020, 50 voire 80 milliards en 2025 selon les études. Ceci correspond à 2 objets connectés à l'Internet pour chaque individu, en 2025, les analystes prévoient que ce ratio dépassera six.
+ En matière de santé, 50 millions d’objets médicaux connectés devraient être diffusés aux États-Unis d’ici à 2015.
+ « L’IoT fait référence à un réseau qui interconnecterait l’ensemble des objets en leur donnant la capacité de communiquer entre eux, directement ou par l’intermédiaire d’Internet, pour échanger des informations (sur leur identité, leurs caractéristiques physiques, leur environnement), pour réagir à des commandes, etc. »
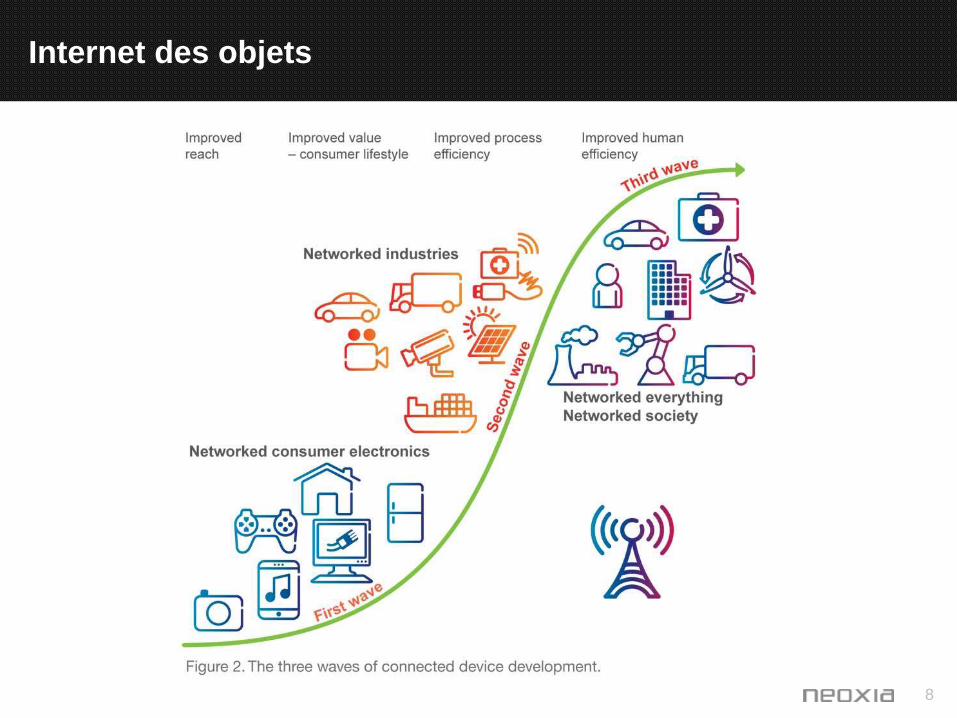
8
Internet des objets
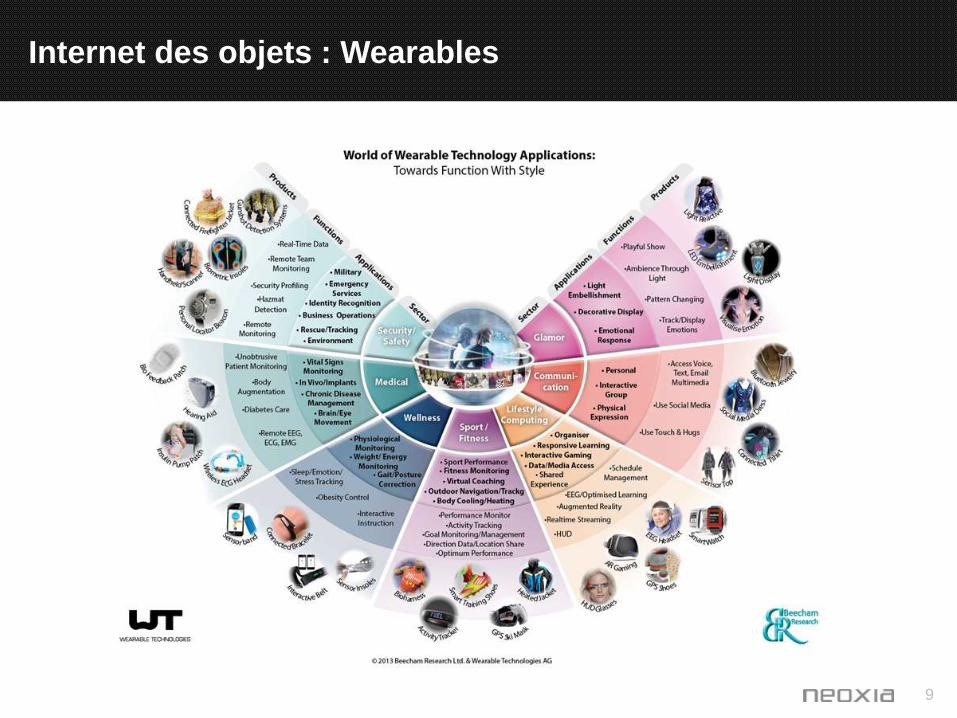
9
Internet des objets : Wearables

Open Everything
+ Open Everything
• Open Source
• Open Contents
• Open Data
• Open Access
• Open Hardware 5Arduino, DIY)
• Open Coursware/Classroom
+ Il permet de bouleverser la notion de propriété intellectuelle et d’offrir un potentiel de partage et d’innovation sans précédent et notamment pour l’Afrique

11
Caractéristique de l’ère numérique
Des caractéristiques pourtant intelligibles : vers l’entreprise numérique
+ Connectée (expériences multicanales au travers du e-commerce, des applications mobiles et des tablettes, etc.),
+ Intelligente (prise de décision avertie grâce au Big Data et développement de la transversalité entre les différentes branches, etc.),
+ Agile (efficacité opérationnelle amplifiée grâce à l’automatisation et la « digitalisation » des processus),
+ Sociale (amélioration de l’image de marque et de la collaboration interne au travers de l’exploitation des médias sociaux).

Les forces derrières les tendances
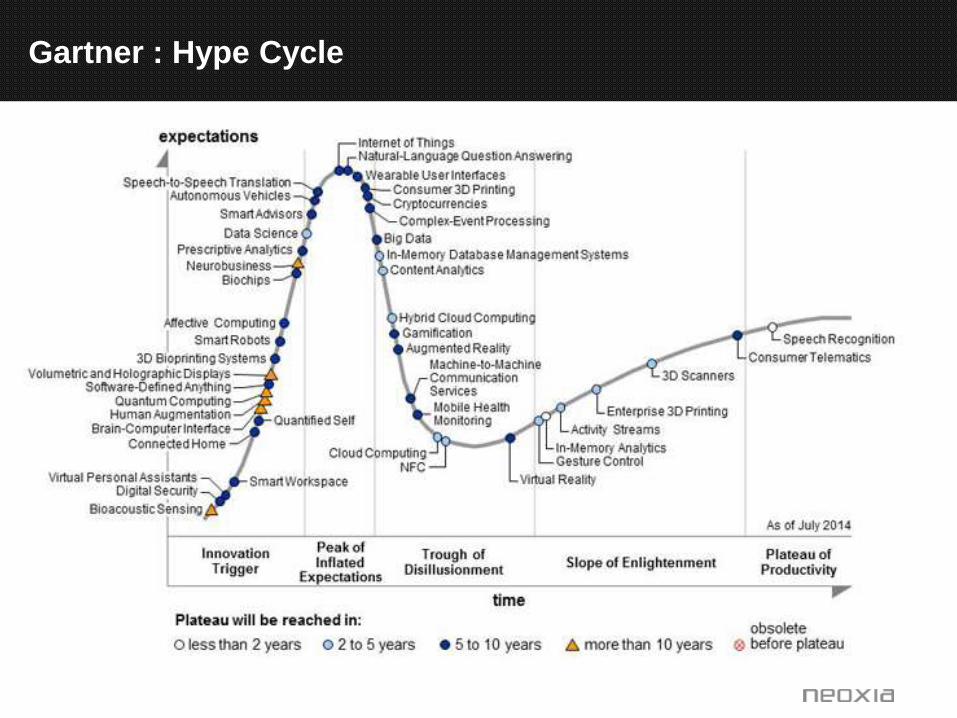
Gartner : Hype Cycle
14
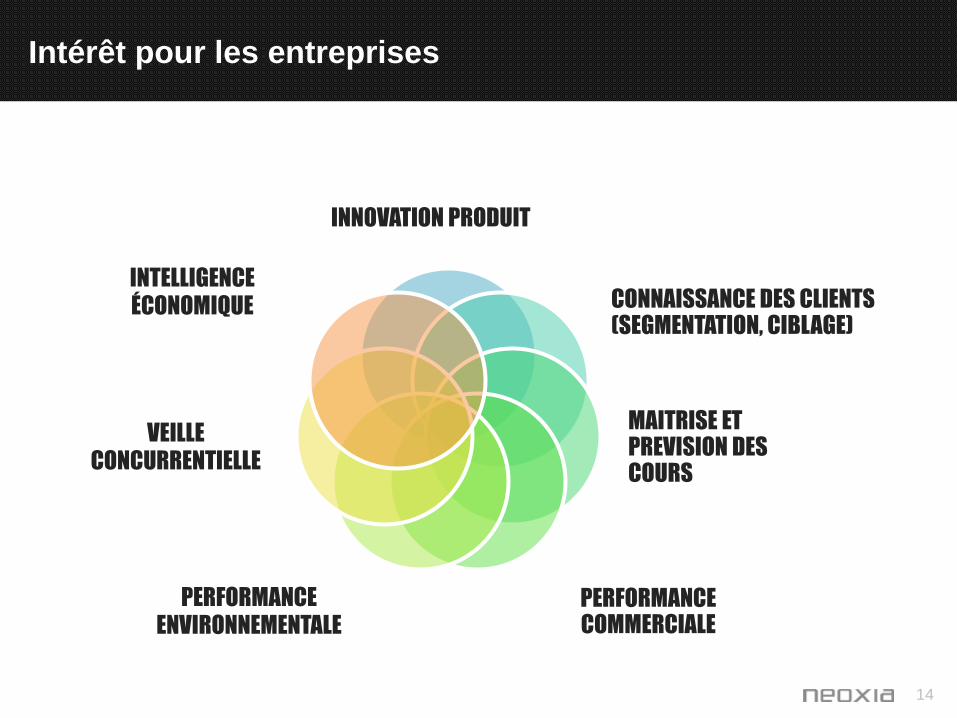
Intérêt pour les entreprises
INNOVATION PRODUIT
CONNAISSANCE DES CLIENTS (SEGMENTATION, CIBLAGE)
MAITRISE ET PREVISION DES COURS
PERFORMANCE COMMERCIALE
PERFORMANCE
ENVIRONNEMENTALE
VEILLE
CONCURRENTIELLE
INTELLIGENCE
ÉCONOMIQUE

C'est quoi le Big Data
#2

Big Data
+ Big Data : Grosses données : Données massive : Datamasse
+ « Des ensembles de données qui deviennent tellement volumineux qu'ils en deviennent difficiles à travailler avec des outils classiques de gestion de base de données ou de gestion de l'information. »
+ Dans ces nouveaux ordres de grandeur, la capture, le stockage, la recherche, le partage, l'analyse et la visualisation des données doivent être redéfinis.
+ L’un des défis majeurs de la décennie 2010-2020
+ Le taux de croissance annuel moyen mondial du marché de la technologie et des services du Big Data sur la période 2011-2016 devrai être de 31.7%.
+ Ce marché devrait ainsi atteindre 23,8 milliards de dollars en 2016
+ Le Big Data devrait également représenter 8% du PIB européen en 2020
Règle des 3V
+ Volumeles données numériques créées dans le monde seraient passées de 1,2 zettaoctetspar an en 2010 à 1,8 zettaoctets en 2011, puis 2,8 zettaoctets en 2012 et s'élèveront à 40 zettaoctets en 2020Twitter génère à l’heure actuelle 7 teraoctets de données chaque jour et Facebook 10 teraoctetsDe nombreux projets, de dimension pharaonique, sont ainsi en cours. Le radiotelescope“Square Kilometre Array” par exemple, produira 50 teraoctets de données analysées par jour, à un rythme de7 000 teraoctets de donnée brutes par seconde
+ VélocitéLa vélocité représente à la fois la fréquence à laquelle les données sont générées, capturées et partagées.Data Stream Mining (pour les processus chronosensibles)
+ VariétéCes données sont brutes, semi-structurées voire non structuréesFormat texte et image (Web Mining, Text Mining et Image Mining)Données provenenant des réseaux sociaux, des objets connectés, des capteurs…etcOpen data ou propres à l’entrepriseLiens entre données de natures différentes

18
Différence par rapport au BI
+ BI
Au sein d’un entreprise
Volume moyen des données
Données à forte densité
Statistiques descriptives
Mesures et indicateurs
+ Big Data
Transverse (au sein d’un écosystème)
Volume énorme des données
Donnée à faible densité
Statistiques inférentielles
Tendances et prédictions

19
Modèles
• Des bases de données NoSQL sont utilisées pour le stockage des information pour optimiser le stockage et le traitement (Graphe, Clé-valeur, Colonnes…etc)
• Des patterns d’architecture “Big Data Architecture framework (BDAF)” sont proposés par les acteurs de ce marché comme MapReduce développé par Google et utilisé dans le framework Hadoop.
• Avec ce système les requêtes sont séparées et distribuées à des nœuds parallélisés, puis exécutées en parallèles (map). Les résultats sont ensuite rassemblés et récupérés (reduce).
• Des modèles statistiques et de Data Mining sont utilisés pour extraire de la connaissance de la donnée
• Business Analytics & Optimization (BAO) permettent de gérer des bases massivement parallèles

20
Acteurs et outils

Le Comment du Big Data
#2
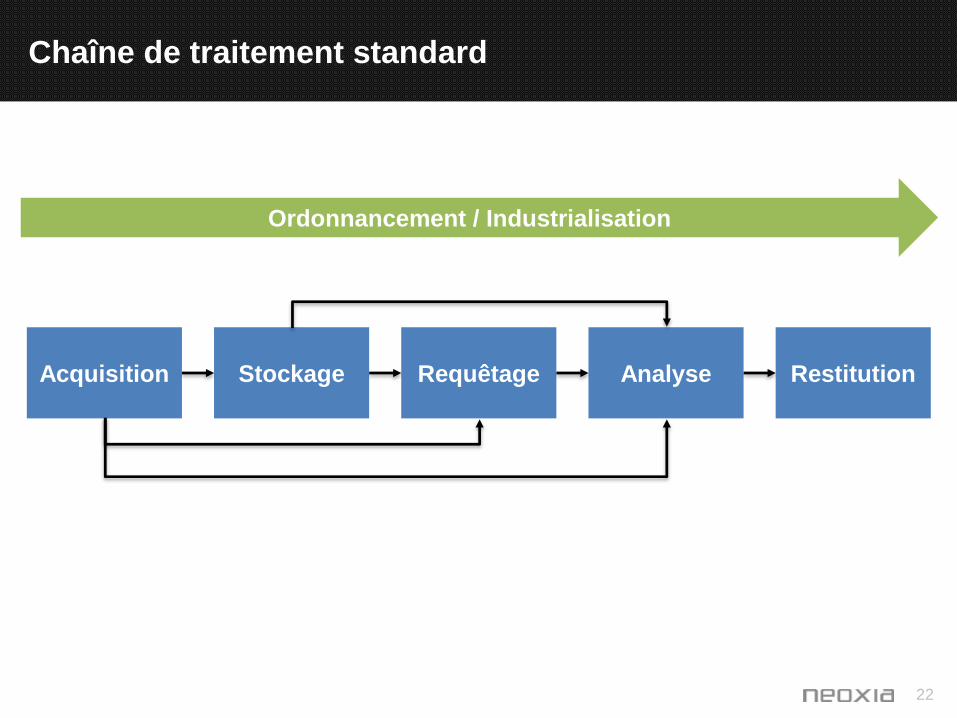
22
Chaîne de traitement standard
StockageAcquisition Requêtage RestitutionAnalyse
Ordonnancement / Industrialisation

23
• Acquisition : Apache Storm, Apache Flume, Apache Kafka, SparkStreaming
• Requêtage : Apache Pig, Apache Hive, Cloudera Impala
• Stockage : Apache HDFS, Apache HBASE, Cassandra, Redis
• Analyse : Apache Mahout, Spark MLLib
• Restitution : En général, reprise d’outils de Business Intelligence (Talend, Pentaho, Tableau Software, etc.)
• Ordonnancement/Industrialisation : Apache Mesos, Apache ZooKeeper
Quelques outils utilisés

• « Ok, c’est bien : mais mes data son BIG !! »

Comment traiter des données de plus en plus volumineuses ?
• Approche 1 : Augmenter la capacité detraitement des ordinateurs
• Approche 2 : Augmenter le nombre deprocesseurs dans un ordinateur
• Approche 3 : Utiliser des ordinateursen parallèle
LIMITÉ TECHNIQUEMENT
SOLUTION PRÉCONISÉE
LIMITE TECHNIQUEMENT
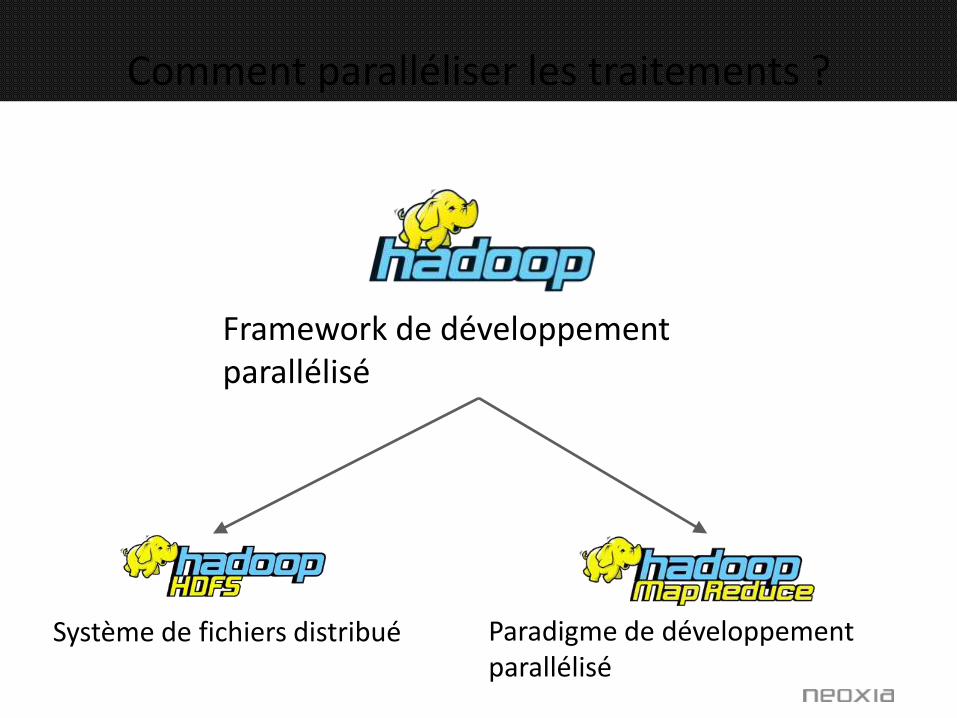
Framework de développement parallélisé
Système de fichiers distribué Paradigme de développement parallélisé
Comment paralléliser les traitements ?
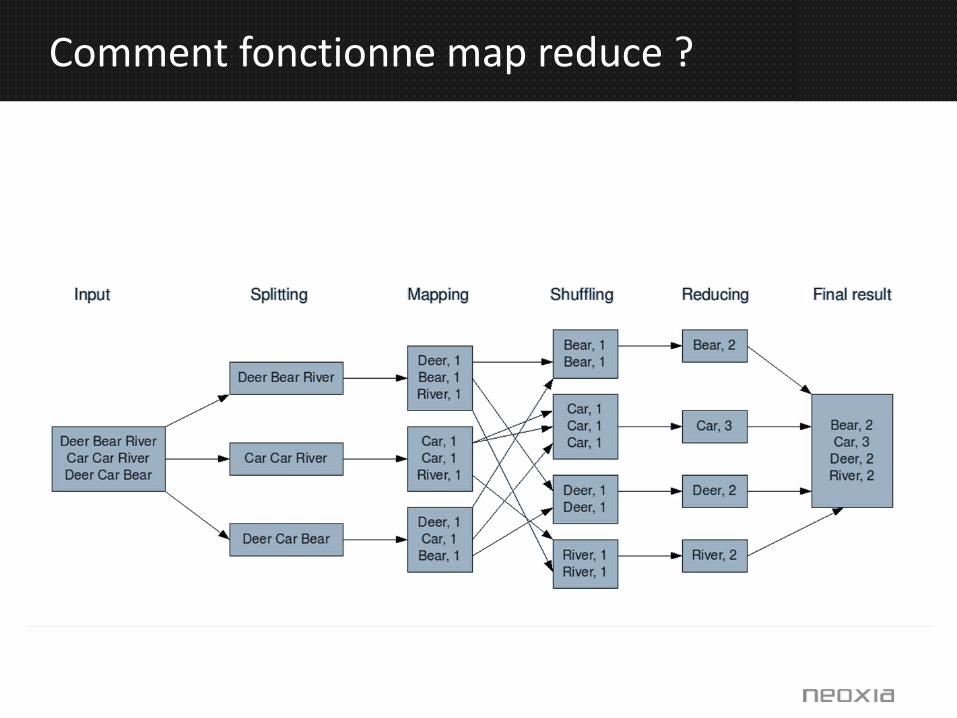
Comment fonctionne map reduce ?
29
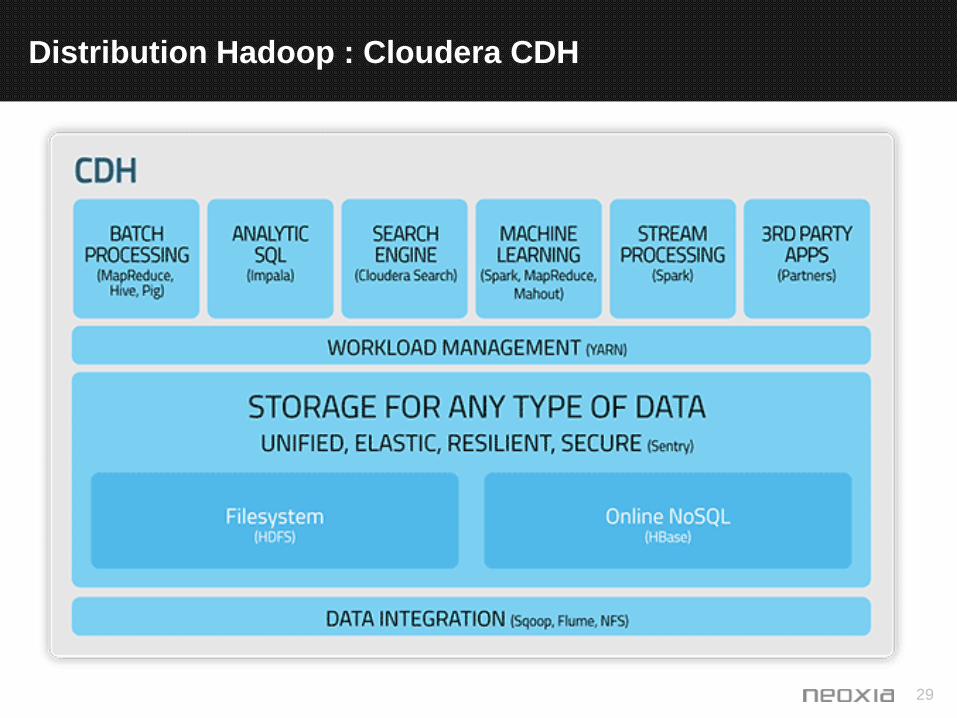
Distribution Hadoop : Cloudera CDH

30
• Apche Flume : Flume est une solution de collecte et d’agrégation de fichiers logs, destinés à être stockés et traités par Hadoop.
• Il a été conçu pour s’interfacer directement avec HDFS au travers d’une API native.
• Flume est à l’origine un projet Cloudera, reversé depuis à la fondation Apache.
• Alternatives : Apache Chukwa.
• Apache Mahout : Apache Mahout est un projet de la fondation Apache visant à créer des implémentations d’algorithmes d’apprentissage automatique et de datamining.
Configuration possible (traitement des logs
monétique)

31
• Sqoop permet le transfert des données entre un cluster Hadoop et des bases de données relationnelles.
• C’est un produit développé par Cloudera.
• Il permet d’importer/exporter des données depuis/vers Hadoop et Hive.
• Pour la manipulation des données Sqoop utilise MapReduce et des drivers JDBC.
Configuration possible (traitement des logs
monétique)
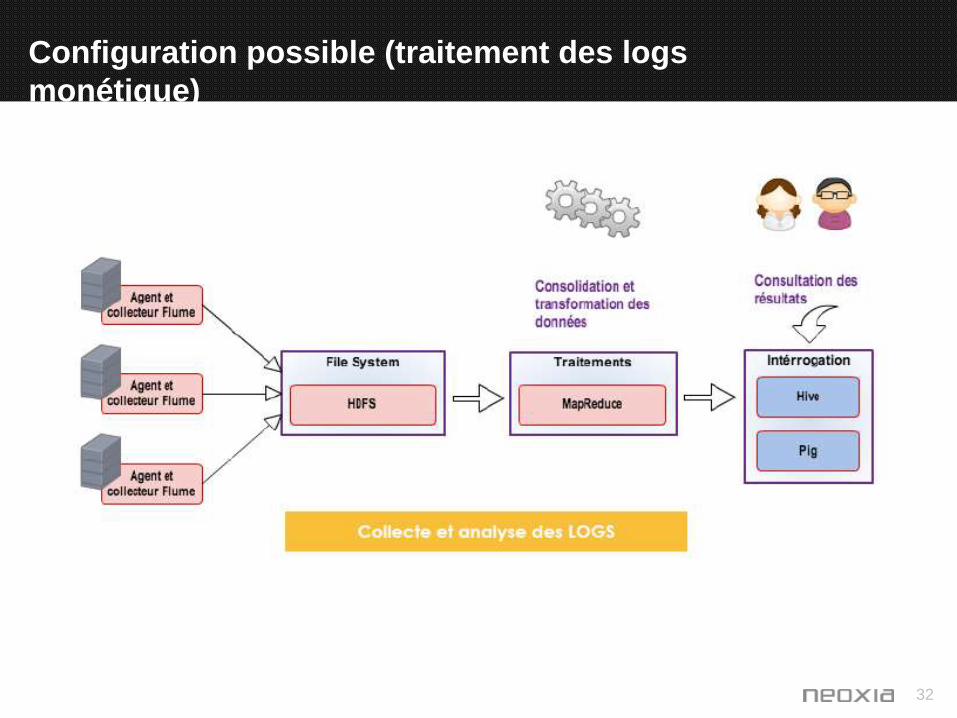
32
Configuration possible (traitement des logs
monétique)

DATA MINING ET MACHINE LEARNING
• Machine learning s’intéresse aux prédictions, basées sur des propriétés apprises par le processus d’apprentissage
• Data mining s’attache à découvrir des
nouvelles propriétés sur des données passées


Exemples de visualisation
Exemples de visualisation
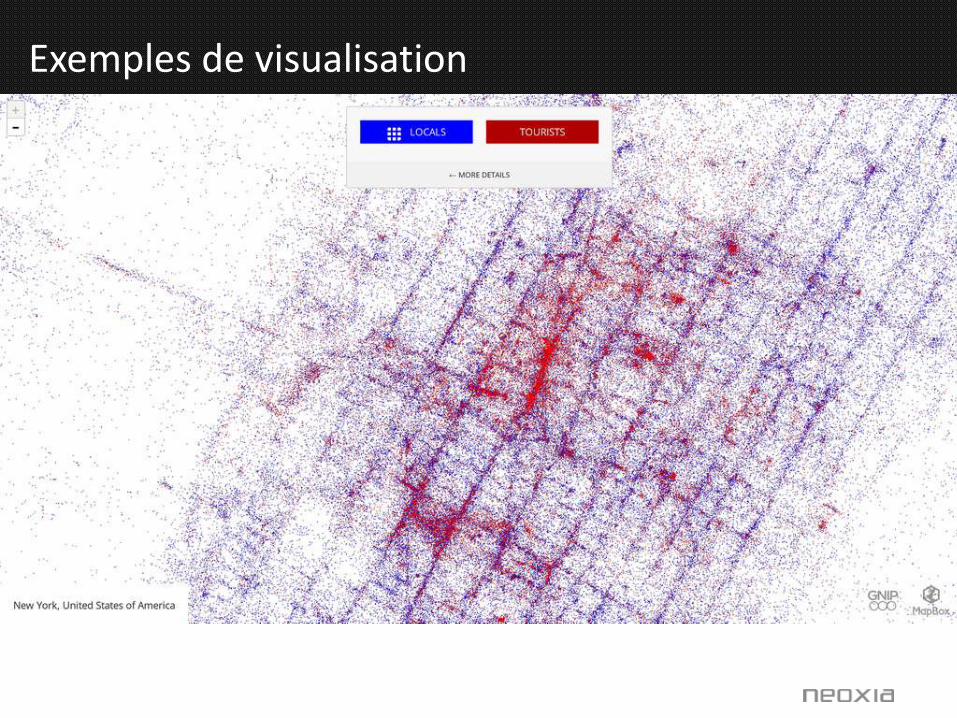
Exemples de visualisation
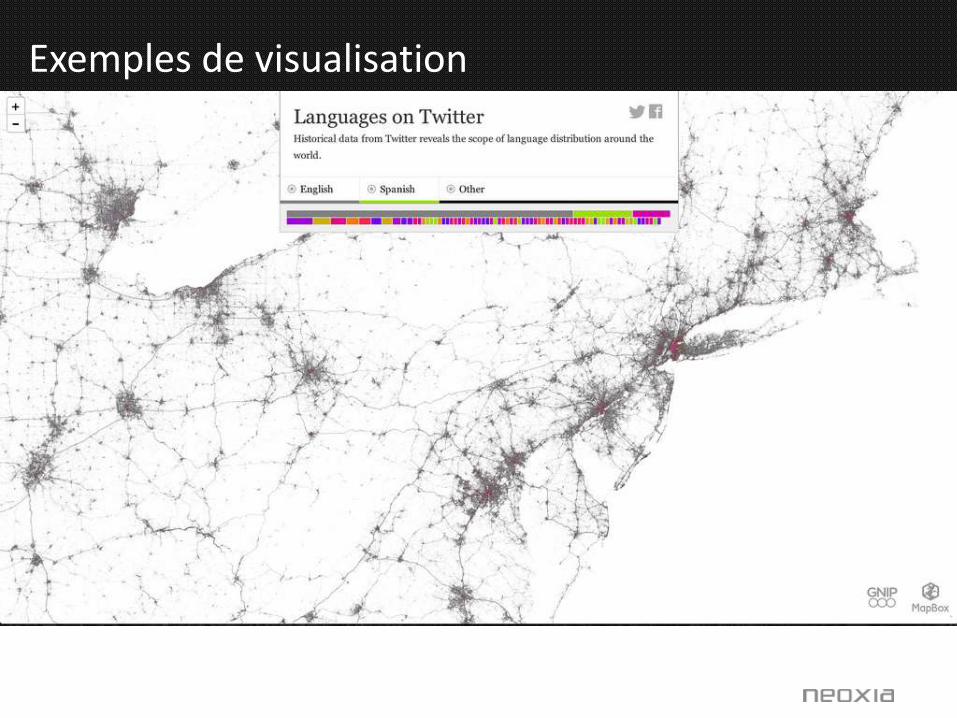
Exemples de visualisation

Big Data et impact Business
#4

44
Big Data dans la Banque
+ Détection de fraude : détection de patterns suspects d’utilisation des cartes en se basant sur les patterns d’usages normaux
+ Innovation produit : proposition de nouveaux produits selon les modèles d’utilisation des cartes et les informations client pour une meilleure acquisition/rétention client (permettre de proposer des cartes avec des réduction partenaires selon les besoins clients récurrents)
+ Segmentation client : utiliser les classification pour segmenter les clients selon des données sur leurs transactions (permettre de proposer une carte de plus haute valeur selon le segment)
+ Gestion de risque : meilleur calcul en ligne de risque (pour les engagements) basé sur les transactions carte
+ Prédiction du comportement futur des clients

45
Big Data dans les Télécom
+ Innovation produits sur la base de l’historique de consommation
+ Segmentation client par classe en prenant en compte les données marché
+ Vente croisée de produit et fidélisation
+ Détection de fraude (pattern de consommation)
+ Supervision réseaux et anticipation des pannes
+ Dimensionnement réseaux

46
Big Data dans l’Agriculture
+ Plantation : Ou?
Quoi?
Comment
+ Conduite technique : Quels intrants,
Quand?
A quelle quantité?
+ Vente : Connaissance du marché et de cours de prix :Quand vendre?
A quel prix
Comment le prix va évoluer?

Plantation : quoi? Où? Comment?

Conduite technique : Eau, fertilisants, pesticides, pratiques agricoles

Vente : Connaissance des marchés,cours des prix
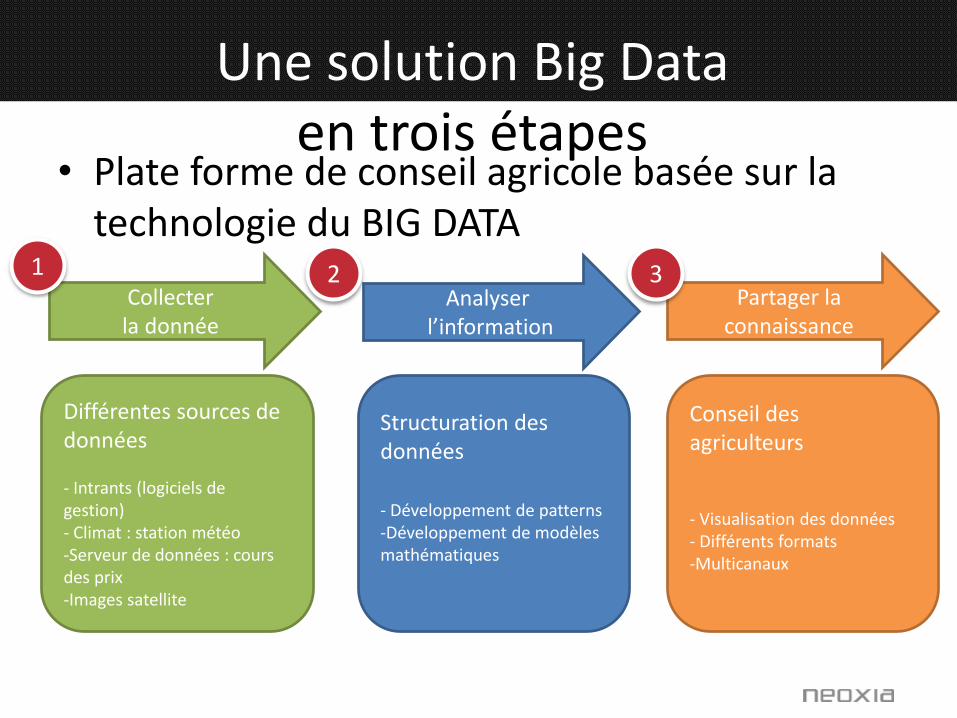
Une solution Big Data en trois étapes
• Plate forme de conseil agricole basée sur la technologie du BIG DATA
Différentes sources de données
- Intrants (logiciels de gestion)- Climat : station météo-Serveur de données : cours des prix-Images satellite
Structuration des données
- Développement de patterns-Développement de modèles mathématiques
Conseil des agriculteurs
- Visualisation des données- Différents formats-Multicanaux
Collecter la donnée
Analyserl’information
Partager la connaissance
1 2 3

Etape 1 : Collecter la donnée
Capteurs et télémétrieImages
Sattelite
Logiciels de gestion agricole
Prix des produis Météo Cartographie et déodata
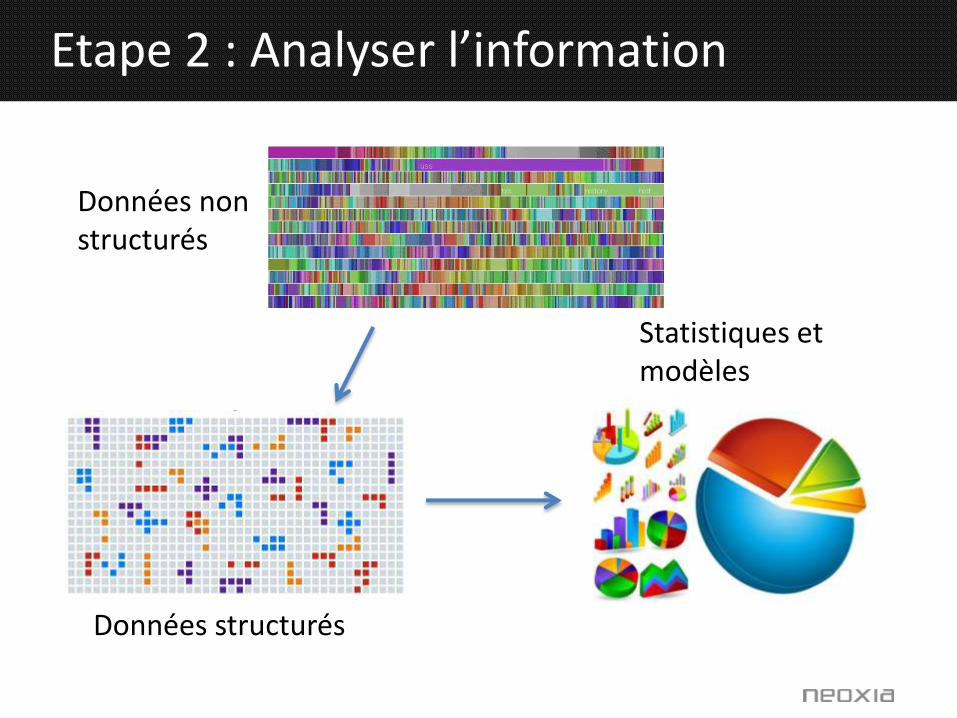
Données non structurés
Données structurés
Statistiques et modèles
Etape 2 : Analyser l’information
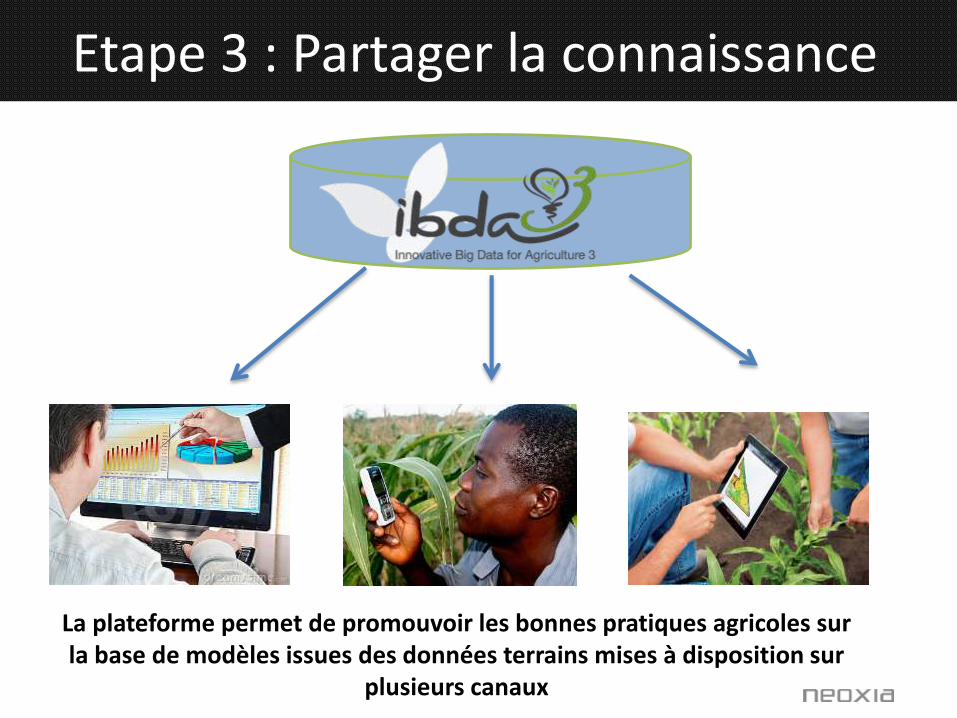
Etape 3 : Partager la connaissance
La plateforme permet de promouvoir les bonnes pratiques agricoles surla base de modèles issues des données terrains mises à disposition sur
plusieurs canaux

54
Merci


















