
Beyond document retrieval using semantic annotations
54
Roi Blanco ([email protected]) Beyond document retrieval using semantic annotations http://labs.yahoo.com/Yahoo_Labs_Barcelona
-
Upload
roi-blanco -
Category
Technology
-
view
150 -
download
1
Transcript of Beyond document retrieval using semantic annotations

Roi Blanco ([email protected])
Beyond document retrieval using semantic annotations
http://labs.yahoo.com/Yahoo_Labs_Barcelona

Yahoo! Research Barcelona
• Established January, 2006
• Led by Ricardo Baeza-Yates
• Research areas
• Web Mining
• Social Media
• Distributed Web retrieval
• Semantic Search
• NLP and Semantics

Contributions
Hugo Zaragoza
• “Every time I fire a linguist my performance goes up…” (Fred Jelinek)
Great strategy until you’ve fired them all… but what then?
Michael Matthews
JordiAtserias
Roi Blanco
Sebastiano Vigna (U. Milan)Paolo Boldi
- Indexing (MG4J)
Peter Mika

Agenda
• Search: this was then, this is now
• Natural Language processing and search
• Semantic Search
• Search over annotated documents
• Time Explorer

Natural Language Retrieval• How to exploit the structure and meaning of
natural language text to improve search• Current search engines perform only limited NLP
(tokenization, stemming)• Automated tools exist for deeper analysis
• Applications to diversity-aware search• Source, Location, Time, Language, Opinion,
Ranking…
• Search over semi-structured data, semantic search
• Roll-out user experiences that use higher layers of the NLP stack

WEB SEARCH


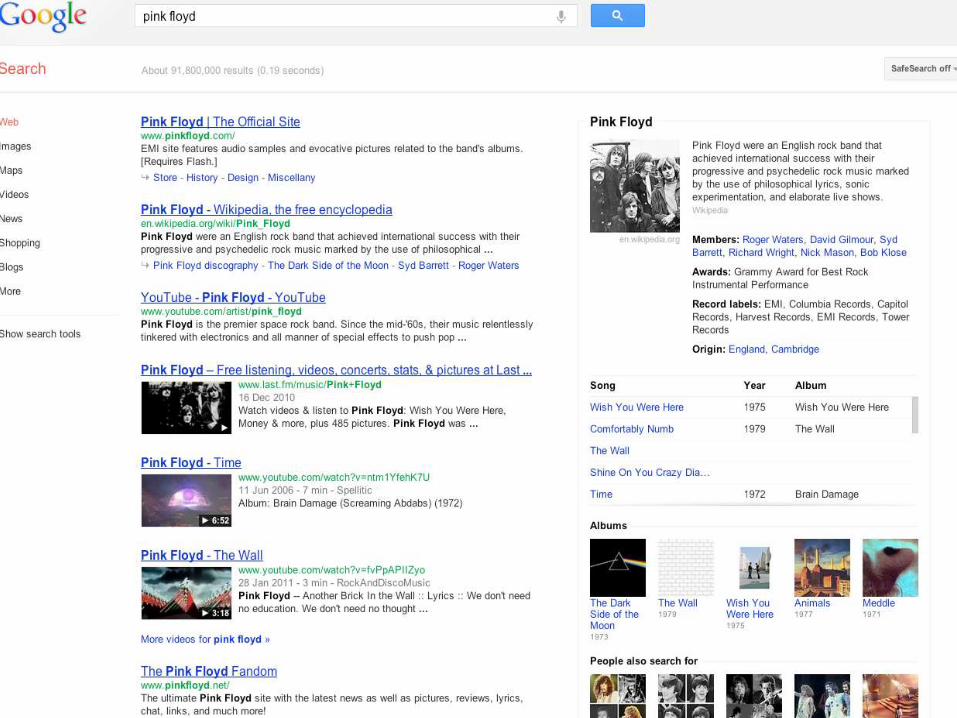

Structured data - Web search
Top-1 entity with
structured data
Related entities
Structured data
extracted from HTML

New devices
• Different interaction (e.g. voice)
• Different capabilities (e.g. display)
• More Information (geo-localization)
• More personalized

Yahoo! Axis
Smarter, Faster Searchinstant answers visual previewsinfinite browsing
Connected Experience: across devices, iPhone, iPad,Firefox, Safari, Internet Explorer, Chrome.
Pesonalized Home PageSigning:Yahoo!, Google, Facebook, direct access to favorite sites, saved articles and bookmarks.

SEMANTIC SEARCH

Semantic Search
• What different kinds of search and applications beyond string matching or returning 10 blue links?
• Can we have a better understanding of documents and queries?
• New devices open new possibilities, new experiences
• Is current technology in natural language understanding mature enough?

Semantic Search (II)• Matching the user’s query with the Web’s content at a
conceptual level, often with the help of world knowledge– Natural Language Search
• Exploiting the (implicit) structure and semantics of natural language• Intersection of IR and NLP
– Semantic Web Search• Exploiting the (explicit) meaning of data• Intersection of IR and Semantic Web
• As a field– ISWC/ESWC/ASWC, WWW, SIGIR, VLDB, CIKM– Exploring Semantic Annotations in Information Retrieval
(ECIR08, WSDM09)– Semantic Search Workshop (ESWC08, WWW09, WWW10)– Future of Web Search: Semantic Search (FoWS09)

State of search
• “We are at the beginning of search.“ (Marissa Mayer)• Old battles are won
– Marginal returns on investments in crawling, indexing, ranking
– Solved large classes of queries (e.g. navigational)– Lots of tempting, but high hanging fruits
• Currently, the biggest bottlenecks in IR not computational, but in modeling user cognition– If only we could find a computationally expensive way to
solve the problem…• In particular, solving queries that require a deeper understanding of the
query, the content and/or the world at large– Corollary : go beyond string matching!

Some examples…• Ambiguous searches
– paris hilton• Multimedia search
– paris hilton sexy• Imprecise or overly precise searches
– jim hendler– pictures of strong adventures people
• Searches for descriptions
– 33 year old computer scientist living in barcelona– reliable digital camera under 300 dollars
• Searches that require aggregation
– height eiffel tower– harry potter movie review– world temperature 2020

”A child of five would understand this.
Send someone to fetch a child of five”.
Groucho Marx
Is NLU that complex?

Language is Ambiguous
The man saw the girl with the telescope

Paraphrases
• ‘This parrot is dead’
• ‘This parrot has kicked the bucket’
• ‘This parrot has passed away’
• ‘This parrot is no more'
• 'He's expired and gone to meet his maker,’
• 'His metabolic processes are now history’

Not just search…

Semantics at every step of the IR process
bla bla bla?
bla
blabla
q=“bla” * 3
Document processing bla
blabla
blabla
bla
IndexingRanking
“bla”θ(q,d)
Query interpretation
Result presentation
The IR engine The Web
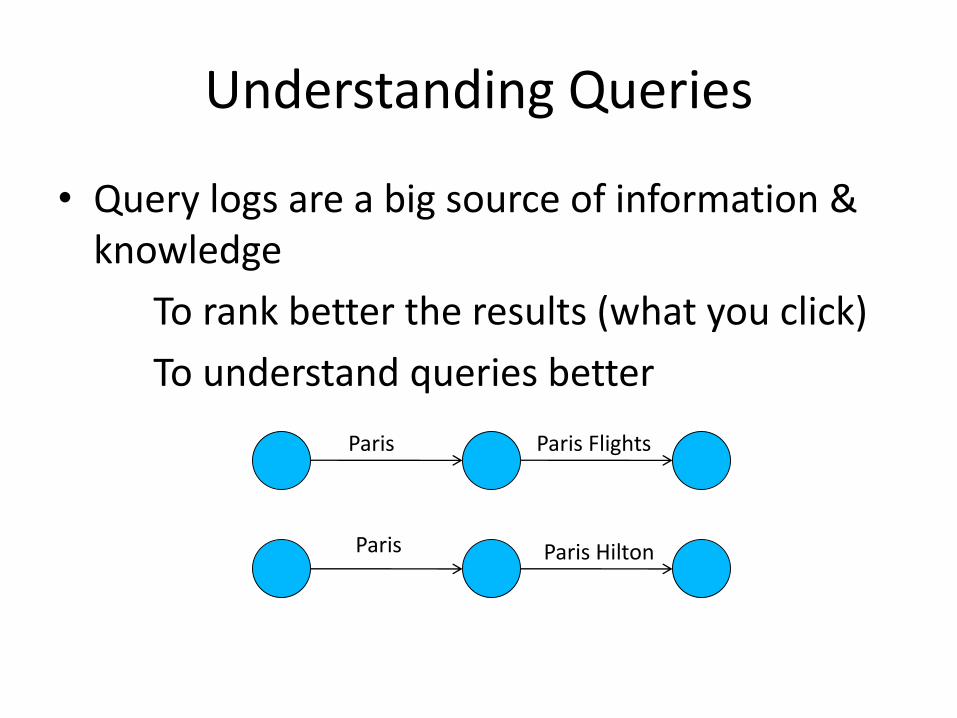
Understanding Queries
• Query logs are a big source of information & knowledge
To rank better the results (what you click)
To understand queries better
Paris Paris Flights
Paris Paris Hilton

“Understand” Documents
NLU Still
an open
issue

NLP for IR
• Full NLU is AI complete, not scalable to the web size (parsing the web is really hard).
• BUT … what about other shallow NLP techniques?
• Hypothesis/Requirements:• Linear extraction/parsing time
• Error-prone output (e.g. 60-90%)
• Highly redundant information
• Explore new ways of browsing
• Support your answers

Usability
Sometimes
We also fail at using the technology

Support your answersErrors happen: choose the right ones!
• Humans need to “verify” unknown facts• Multiple sources of evidence• Common sense vs. Contradictions
• are you sure? is this spam? Interesting!
• Tolerance to errors greatly increases if users can verify things fast
• Importance of snippets, image search
• Often the context is as important as the fact• E.g. “S discovered the transistor in X”
• There are different kinds of errors• Ridiculous result (decreases overall confidence in system)• Reasonably wrong result (makes us feel good)

SEARCH OVER ANNOTATED DOCUMENTS

Annotated documentsBarack Obama visited Tokyo this Monday as part of an extended Asian trip.He is expected to deliver a speech at the ASEAN conference next Tuesday
Barack Obama visited Tokyo this Monday as part of an extended Asian trip.
He is expected to deliver a speech at the ASEAN conference next Tuesday
20 May 2009
28 May 2009


How does it work?
MontyPython Inverted Index
(sentence/doc level)
Forward Index(entity level)
Flying CircusJohn CleeseBrian

Efficient element retrieval
• Goal– Given an ad-hoc query, return a list of documents and
annotations ranked according to their relevance to the query• Simple Solution
– For each document that matches the query, retrieve its annotations and return the ones with the highest counts
• Problems– If there are many documents in the result set this will take too
long - too many disk seeks, too much data to search through– What if counting isn’t the best method for ranking elements?
• Solution– Special compressed data structures designed specifically for
annotation retrieval

Forward Index
• Access metadata and document contents
– Length, terms, annotations
• Compressed (in memory) forward indexes
– Gamma, Delta, Nibble, Zeta codes (power laws)
• Retrieving and scoring annotations
– Sort terms by frequency
• Random access using an extra compressed pointer list (Elias-Fano)

Parallel Indexes• Standard index contains only tokens• Parallel indices contain annotations on the tokens – the
annotation indices must be aligned with main token index • For example: given the sentence “New York has great
pizza” where New York has been annotated as a LOCATION – Token index has five entries
(“new”, “york”, “has”, “great”, “pizza”)
– The annotation index has five entries (“LOC”, “LOC”, “O”,”O”,”O”)
Can optionally encode BIO format (e.g. LOC-B, LOC-I)
• To search for the New York location entity, we search for:“token:New ^ entity:LOC token:York ^ entity:LOC”

Parallel Indices (II)
Doc #5: Hope claims that in 1994 she run to Peter Town.
Peter D3:1, D5:9
Town D5:10
Hope D5:1
1994 D5:5
…
Doc #3: The last time Peter exercised was in the XXth century.
Possible Queries:
“Peter AND run”
“Peter AND WNS:N_DATE”
“(WSJ:CITY ^ *) AND run”
“(WSJ:PERSON ^ Hope) AND run”
WSJ:PERSON D3:1, D5:1
WSJ:CITY D5:9
WNS:V_DATE D5:5
(Bracketing can also be dealt with)
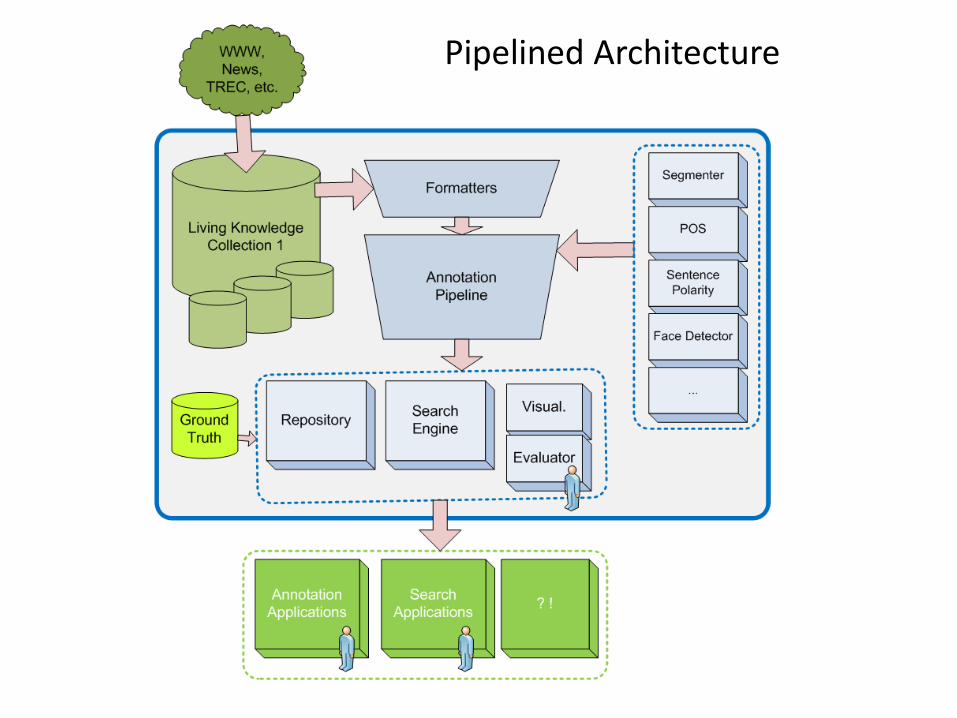
Pipelined Architecture

TIME EXPLORER

Time(ly) opportunities
Can we create new user experiences based on a deeper analysis and exploration of the time dimension?
• Goals:
– Build an application that helps users to explore, interact and ultimately understand existing information about the past and the future.
– Help the user cope with the information overload and eventually find/learn about what she’s looking for.

Original Idea
• R. Baeza-Yates, Searching the Future, MF/IR 2005
– On December 1st 2003, on Google News, there were more than 100K references to 2004 and beyond.
– E.g. 2034:
• The ownership of Dolphin Square in London must revert to an insurance company.
• Voyager 2 should run out of fuel.
• Long-term care facilities may have to house 2.1 million people in the USA.
• A human base in the moon would be in operation.

Time Explorer
• Public demo since August 2010
• Winner of HCIR NYT Challenge
• Goal: explore news through time and into the future
• Using a customized Web crawl from news and blog feeds
• http://fbmya01.barcelonamedia.org:8080/future/

Time Explorer

Time Explorer - Motivation Time is important to search Recency, particularly in news is highly related
to relevancy But, what about evolution over time?
How has a topic evolved over time?
How did the entities (people, place, etc) evolve with respect to the topic over time?
How will this topic continue to evolve over the future?
How does bias and sentiment in blogs and news change over time?
Google Trends, Yahoo! Clues, RecordedFuture…
Great research playground Open source!

Time Explorer

Analysis Pipeline
Tokenization, Sentence Splitting, Part-of-speech tagging, chunking with OpenNLP
Entity extraction with SuperSense tagger
Time expressions extracted with TimeML
Explicit dates (August 23rd, 2008)
Relative dates (Next year, resolved with Pub Date)
Sentiment Analysis with LivingKnowledge
Ontology matching with Yago
Image Analysis – sentiment and face detection

Indexing/Search
• Lucene/Solr search platform to index and search
– Sentence level
– Document level
• Facets for annotations (multiple fields for faster entity-type access)
• Index publication date and content date –extracted dates if they exists or publication date
• Solr Faceting allows aggregation over query entity ranking and for aggregating counts over time
• Content date enables search into the future


Timeline

Timeline - Document
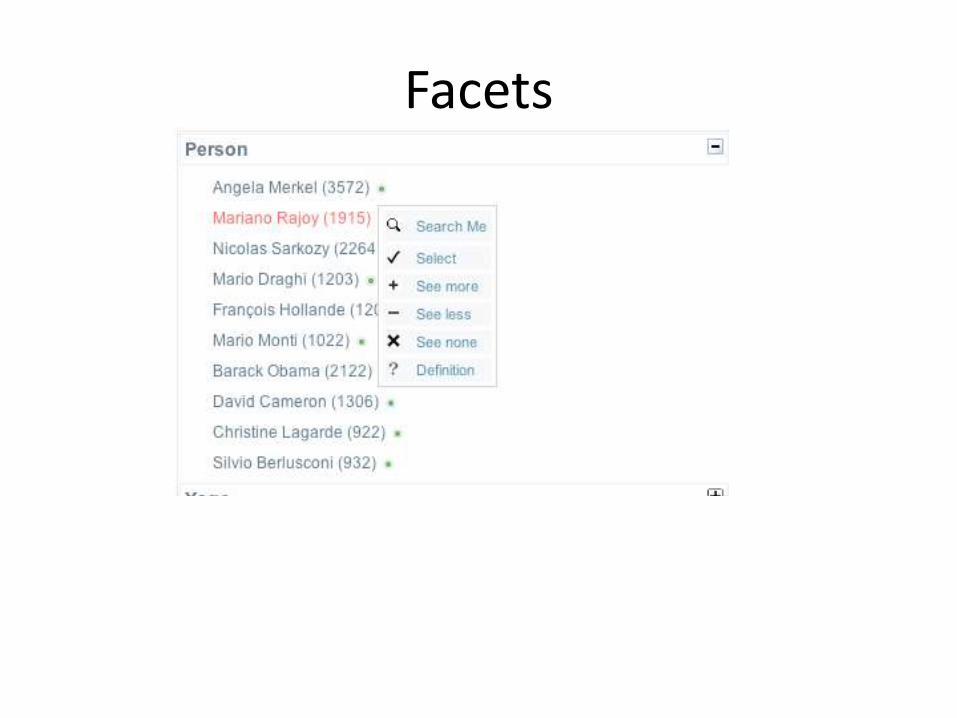
Facets
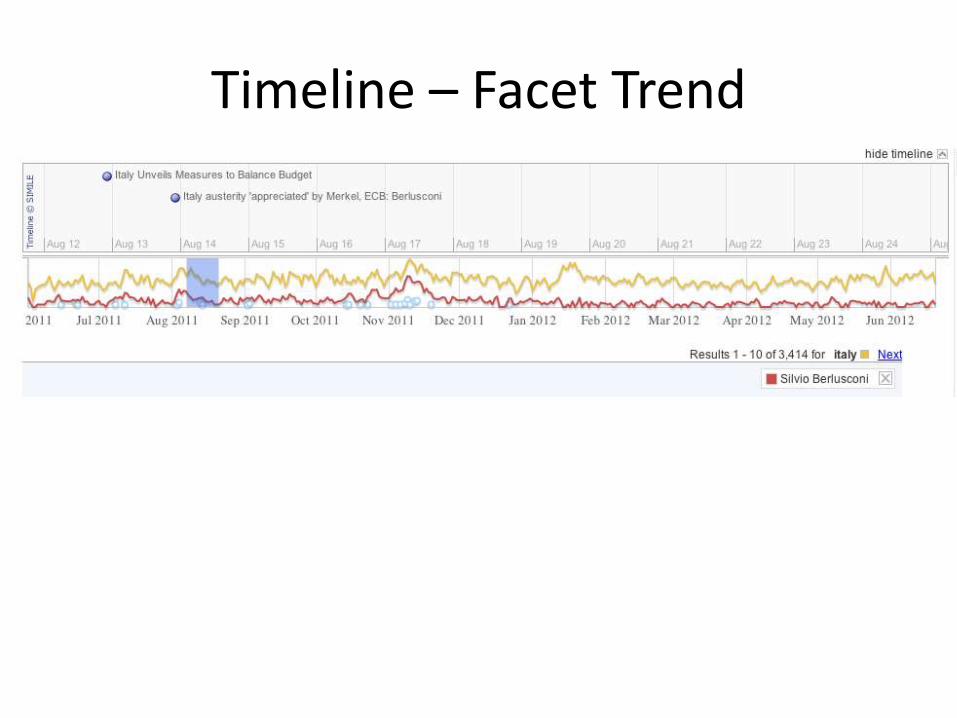
Timeline – Facet Trend

Timeline – Future
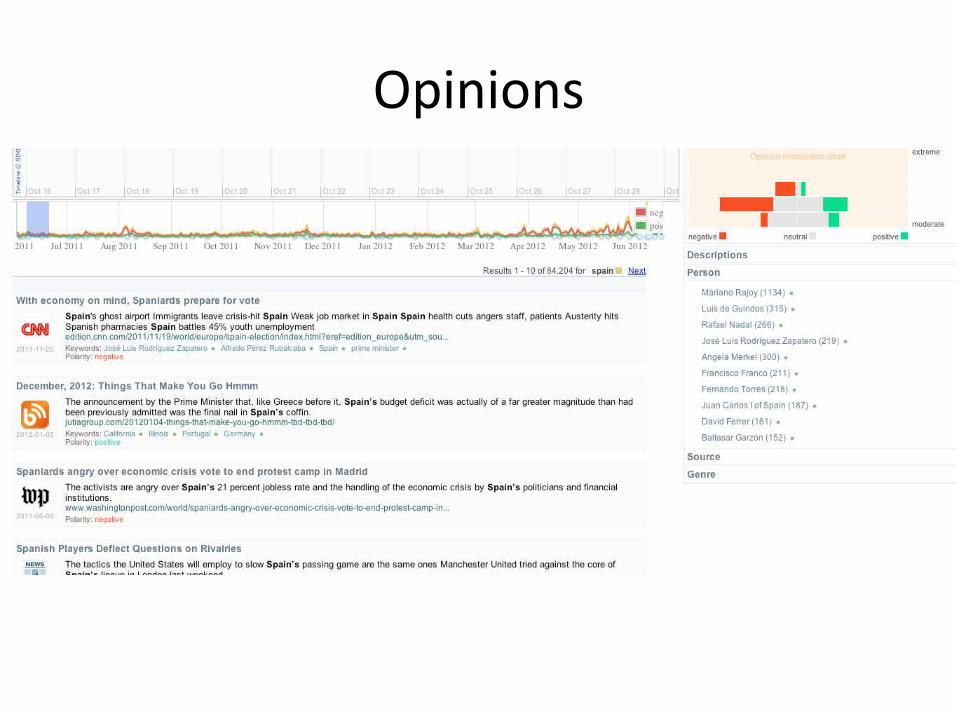
Opinions

Quotes

Other challenges– Large scale processing
• Distributed computing
• Shift from batch (Hadoop) to online (S4)
– Efficient extraction/retrieval, algorithmic/data structures
• Critical for interactive exploration
– Connection with the user experience• Measures! User engagement?
– Personalization
– Integration with Knowledge Bases (Semantic Web)
– Multilingual


















