
Bases de datos temporales, espaciales, espacio- temporales BD.pdf · combinados con conectores...
69
NUEVAS APLICACIONES Sistemas de ayuda a la decisión - DW, Olap, DM Recuperación de la información - IR Bases de datos multimedia - BDMétricas Bases de datos y Web - Datos semiestructurados, XML Bases de datos temporales, espaciales, espacio- temporales
Transcript of Bases de datos temporales, espaciales, espacio- temporales BD.pdf · combinados con conectores...

NUEVAS APLICACIONES
� Sistemas de ayuda a la decisión -DW, Olap, DM
� Recuperación de la información -IR
� Bases de datos multimedia -BDMétricas
� Bases de datos y Web -Datos semiestructurados, XML
� Bases de datos temporales, espaciales, espacio-temporales

SISTEMAS DE AYUDA A LA DECISIÓN
Las aplicaciones de BD se pueden clasificar en:
� procesamiento de transacciones
� sistemas de ayuda a la decisión
En las BD transaccionales las empresas almacenan grandes cantidades de datos.
� información de transaccionesde los clientes (identificación, tarjeta de crédito, artículo adquirido, precio pagado, fecha)
� información de artículos (tipo, fabricante, modelo, color, talle)
� información del cliente (identificación, ingresos anuales, domicilio, edad, nivel educativo, historial crediticio).

En VLDB puede encontrarse mucha información para la toma de decisiones.
Por ejemplo: � una compañía automovilística descubre que la mayor parte
de los coches deportivos de pequeño tamaño son adquiridos por mujeres jóvenes cuyos ingresos mensuales son mayores a $ 2000.-
� posibilidad de realizar campañas dirigidas de marketing.

Problemas de almacenamiento y recuperación de datos para la ayuda a la decisión
� Dificultad de expresar en SQL algunas consultas � necesidad de extensiones
� DML no adecuados para análisis estadísticos � utilizar paquetes estadísticos
� Orígenes de datos diversos � crear almacenes de datos (DW)

OLAP: Análisis de datos
VLDB: es necesario resumir los datos para obtener información
Para resumir los datos se utilizan: � las funciones de agregación
� en SQL son limitadas. � muchos DBMS implementaron extensiones de éstas (varianza, media, etc.)
� los histogramas� dividen en intervalos los valores tomados por el atributo y calculan una
agregación (ej. suma), de los valores de cada rango. � existen extensiones de SQL (funciones en groupby)
SELECT percentil, avg(saldo) FROM cuentaGROUPBY N_tile(saldo, 10) AS percentil
� la agregación sobre varios atributos� Por ej.: conocer el tipo de ropa que está de moda

Ejemplo
A partir de los datos puede obtenerse el esquema de relación: Ventas (color, tamaño, número)
de aquí puede generarse una tabla de referencia cruzadas:
• Datos: bidimensionales(basados en dos atributos: color y talla). • En general, los datos pueden representarse como arrays multidimensionales
→ se denominan datos multidimensionales. • Una tabla cruzada no puede generarse mediante una sola SQL, dado que los totales se toman en varios niveles diferentes.
Pequeña Mediana Grande Total
Claro 8 35 10 53
Oscuro 20 10 5 35
Total 28 45 15 88

Granularidad
� Abstracción: Pasar de datos de granularidad más fina a datos de granularidad más gruesa mediante la agregación.
� Concreción: Pasar de datos de granularidad más gruesa a datos de granularidad más fina.
� Los datos de granularidad más fina no se pueden generar a partir de los de granularidad más gruesa.
� Hay que generarlos a partir de los datos originales ó de datos de resumen de granularidad aún más fina.

Una relación n-dimensional (n atributos), generará un n-cubo de 2n vértices.
Ejemplo: Ventas (color, talla, precio) � tendríamos un cubo.
� Para obtener una tabla relacionalequivalente a una referencia cruzada se puede usar el UNION del SQL
…… y puede tardar mucho.
� Existen extensiones del SQL con un operador CUBESELECT color talla, sum(numero) FROM ventas
GROUPBY color, tallaWITH CUBE .

Data Mining
Es la búsqueda de informaciónde importancia ó
“descubrimiento del conocimiento”
engrandes volúmenes de datos.
� La información obtenida puede representarse mediante un conjunto de reglas.
Ejemplo:
“las mujeres jóvenes con ingresos mensuales superiores a $2000 son las personas con mayores probabilidades de comprar coches deportivos de tamaño pequeño”.

Representación de la información mediante reglas
Las reglas son de la forma:
∀∀∀∀ X antecedente ���� consecuentedonde: X es una lista de una ó varias variables con rangos asociados
Ejemplo: � la relación compra especifica lo que se adquiere en cada transacción
∀ transacción T, compra (T,pan) � compra (T, leche)donde: T es una variable, rango(T) = {todas las transacciones}.
� La regla dice:
“si hay una tupla (ti, pan) en la relación compra, también debe haber una tupla (ti, leche) en la misma relación”.

Las reglas tienen un soporte y una confianza asociada.
� Soporte: mide la parte de la población que satisface tanto el antecedente como el consecuente.
Ejemplo: � Si el 0,001 % de las transacciones incluye la adquisición de leche y pan, el
soporte de la regla es bajo. => Estas reglas no son de interés. � Si el 50 % de las transacciones incluye la adquisición de leche y pan, el
soporte de la regla es alto. => Estas reglas son de interés.
� Confianza: mide la frecuencia con que el consecuente es cierto cuando lo es el antecedente.
Ejemplo: � La regla vista tiene una confianza del 80% si el 80% de las transacciones que
incluyen la adquisición de pan, también incluyen la compra de leche.
=> Las reglas con confianza baja no son significativas.
� Los valores mínimos de soporte y de confianza dependen de la aplicación.

Tipos de problemas : Clasificación
Encontrar reglas que dividan los datos dados en grupos disjuntos.
Ejemplo: Una compañía de tarjeta de crédito debe decidir si la concede. � dispone de información que incluye el historial de pagosde sus clientes
actuales, el cual permite clasificarlosen: excelente - bueno - medio - malo.
� Se intenta descubrir reglasque clasifiquen a sus clientes actuales en base a los otros datos personales.
Las reglas podrán ser de la forma:
∀∀∀∀ persona P, P.título=’Licenciado’ AND p.ingresos >= 4.000 ���� P.préstamo = ‘Excelente’
∀∀∀∀ persona P, P.título=’Analista’ AND (p.ingresos < 4.000 OR p.ingresos >= 2.000) ���� P.préstamo = ‘Bueno’
� Estas reglas permitirían clasificar a un nuevo clientepara conceder ó no la tarjeta.

Tipos de problemas : Asociación
� Encontrar reglas que asociendiferentes artículos que se compren.
Ejemplo:
Quien compra pan, compra leche.
� Esto permitiría:
� colocar cerca el pan y la leche.
� colocar estos artículos en extremos opuestos para tentar con otros productos
� aumentar el pan y bajar la leche.

Almacenes de datos
Las empresas:
� poseen la información dispersaen numerosos lugares: sucursales y/o sectores.
� generalmente no guardan información histórica : modifican datos.
� Para la toma de decisiones se necesita acceder a toda la información.
Almacén de datos (DW): Depósito de la información reunida a partir de varias fuentesguardada según un esquema unificado en un único lugar.
� Se independiza del sistema transaccional para no afectar su carga de trabajo.

Arquitectura
Fuente de datos 1
Fuente de datos 2
Fuente de datos n
ExtractionTransfor-
mationLoad
DBMS
Data warehouse herramientas de análisis y de consulta: OLAP, DM,
...

Problemas
� Momento y manera de recoger los datos� arquitectura orientada a orígenes de datos(las fuentesde datos transmite
la información nueva)
� arquitectura orientada a destinos de datos(el almacénde datos solicita los datos a las fuentes).
El DW puede tener datos sin actualizar, esto no presenta problemas para la toma de decisiones.
� Esquema que debe utilizarseEl DW debe:
� integrar los esquemas (diseño) de las distintas fuentes de datos y
� convertir los datos al esquema integrado antes de guardarlos.

Problemas
� Propagación de las actualizaciones
Si se modifican los esquemas (diseño) de los orígenes de datos, esto deberápropagarse al DW.
� Datos que se deben resumir
� Los datosgenerados por sistemas transaccionalesson grandespara almacenarlos.
� Muchas consultas para la toma de decisiónse pueden resolver a partir de datos resumidos obtenidos por agregación.

Es la representación, almacenamiento, organización y acceso a ítems de información [Baeza-Yates, 1999].
IR versus Data Retrieval
� Recupera datos con la mejor coincidenciacon el patrón dado.
� Ordena resultados según un ranking de relevancia:
� ocurrencias
� ubicación de la palabra
� análisis de citaciones
INFORMATION RETRIEVAL

Dados:
�Un corpusde documentos textuales en lenguaje natural.
�Una consultade usuario en la forma de un string de texto.
Encontrar:
�Un conjunto rankeadode documentos que son relevantespara la consulta
Tarea típica de la RI

� Encontrar información útil en la Web es frecuentemente una tarea difícil.
� Problemaspara la búsqueda en la web [Baeza-Yates].
� con los datos.
� con los usuarios.
Problemas

Problemas con los datos
� Datos distribuidos.
� Datos volátiles.(dinámica de Internet)
� Gran volumen. (crecimiento exponencial de la Web).
� Datos no estructurados y redundantes (30% duplicado).
� Calidad de los datos.(no hay proceso ni control editorial)
� Datos heterogéneos. (estructural, semántica)
Problemas con los usuarios
� Cómo especificar la consulta
� Cómo interpretar las respuestas obtenidas
Problemas

Estrategia de Búsqueda
Unaestrategia de búsqueda es
una expresión lógica
compuesta por distintos conceptos
combinados con conectores lógicos AND, OR y NOT.
� El maximizar la cantidad de documentos relevantes obtenidos
depende de la correcta preparaciónde esta estrategia.
Contingencias� reducir la cantidad si se recuperan demasiados documentos, y
� aumentar la cantidad si no se recupera información suficiente.

Indicadores IR Tradicional
Para evaluar una estrategia de búsqueda:
� Precisión: ratio de docs relevantes sobre el número total de docs recuperados
Precisión = Número de documentos relevantes recuperadosNúmero de documentos recuperados
� Recall: proporción de docs relevantes que son recuperados.
Recall = Número de documentos relevantes recuperadosNúmero total de documentos relevantes

Realizada una búsqueda:
el conj. de docs recuperados no coincide totalmente con el conj. de docs relevantes sobre el tema de interés.
Una búsquedaseráóptima cuando estos dos conjuntos coincidan� todos los docs recuperados sean relevantes y todos los docs relevantes sean recuperados.
Docs. Recu-perados
Docs. Rele-vantes
Indicadores

Recursos lingüísticos que se utilizan en la RI
� Diccionarios
� Diccionarios multilinguales
� Ontologías
� Tesauros

Ontologías
� Permiten representar el conocimiento en la web.
� Definen conceptos y relaciones de algún dominio.
� Consisten de términos, sus definiciones y axiomas.
− Los axiomas permiten inferir conocimiento que no esté indicado explícitamente en la taxonomía de conceptos.

� Categorización automática de docs (clasifica)
� Filtrado de la Información (descarta)
� Clustering Automático de docs (genera grupos)
� Extracción de Información
� Integración de Información
Otras tareas relacionadas con la IR

� Database Management
� Library and Information Science
� Artificial Intelligence
� Natural Language Processing
� Machine Learning
Areas Relacionadas

� Database Management
� Recientemente se ha volcado a los datos semiestructurados(XML) y esto lo ha llevado más cercade la RI
� Library and Information Science� Se focaliza en los aspectos del usuario humanode la RI
(interacción humano-computadora, interface de usuario, visualización).
� El trabajo reciente sobrebibliotecas digitales la llevó más cercade las Ciencias de la Computacióny de la RI
Areas Relacionadas

� Artificial Intelligence
� El trabajo reciente en ontologíasy agentes inteligentesla
lleva más cercade la RI
� Natural Language Processing� Analizar sintaxis (estructura de la frase) y semántica
podría permitir recuperación basada en significado más que en keywords.
� Desarrolla métodospara identificar piezas específicas de información en un documento (information extraction)
Areas Relacionadas

� Machine Learning
� Se focaliza en el desarrollo de sistemas computacionalesque mejoren su performance con la experiencia.
� Clasificación Automática de docs basada en conceptos
aprendidos a partir de ejemplosde entrenamiento.
� Text Categorization� Clasificación automática de jerarquías (Yahoo).
� Text Clustering� Agrupamiento de resultados de consulta de la RI.
Areas Relacionadas

Tecnologías de las dos culturas
La Web nos provee de:
� Una infraestructura global y un conjunto de estándaresque
soportan el intercambio de documentos.
� Un formato de presentaciónpara hipertextos. (HTML)
� Interfacesbien diseñadas para recuperación de documentos. (Técnicas de recuperación de información)
� Es la base de datos más grande.
BASES DE DATOS Y WEB

Tecnologías de las dos culturas
Las bases de datos, nos ofrecen:
� Técnicas de almacenamientoy lenguajes de consulta, que
proveen acceso eficiente a grandes cuerpos de datos muy
estructurados.
� Modelos de datos, y métodos para estructurar datos.
� Mecanismos para mantener la integridad y consistenciade los
datos.

Surge la necesidad de un Puente para
poder consultar a la Web como a una base de datos
Solución:
• Un formato nuevo, XML, para intercambiar datos con estructura.
• Un nuevo modelo de datos semiestructurados, que relaja lasintaxis de sistemas de base datos muy estructurados.

� Son datos sin esquema o auto-descriptibles
� La información sobre la estructura está junto con los datos.
� Representación mediante una lista de etiquetas-valor.
Ejemplo:
{ name: {first: "Pablo", last: “Pérez"},
tel : 4494403,
email: [email protected]
}
Datos Semiestructurados

Componentes básicos: - elemento (texto)- etiquetas (definidas por el usuario)
Ejemplo: <people>
<person><name> Alan </name><age> 42 </age><email> [email protected] </email>
</person><person>
<name> Patsy </name><age> 36 </age><email> [email protected] </email>
</person></people>
XML

� Describen los elementos disponibles en un documento XML. � Esto introduce el concepto de:
� Documento-bien-formado (los tags se abren y se cierran)� Documento-válido (tiene un DTD asociado).
Ejemplo<!DOCTYPE db [
<!ELEMENT db (person*)><!ELEMENT person (name,age,email)><!ELEMENT name (#PCDATA)><!ELEMENT age (#PCDATA)><!ELEMENT email (#PCDATA)>
] >
DTD

Objetivo:
Permitir el procesamiento automático
Clave del problema:
La web actual representa la información utilizando lenguaje natural con muy poca estructura: html, gráficos...
que es comprendido por humanos pero complejo para ser procesado automáticamente.
WEB SEMÁNTICA

Alternativas:
� Máquinas más inteligentes:
� Enseñar a las computadoras a comprender el significado de la información que hay en la web
� Procesamiento de lenguaje natural, reconocimiento de imágenes, etc...
� Información más inteligente:
� Representar la información de modo que sea sencilla de comprender a las máquinas
� Expresar contenidos en un formato procesable automáticamente.
� Ejemplo: metainformación
WEB SEMÁNTICA

La web actual / La web semántica

Solución: Hacer la web más semántica
� Tim Berners-Leepromueve el desarrollo de la web con conocimientos� Existen organizaciones que se encargan de estandarizar lenguajes y
herramientas para dar semántica a la web. (SemanticWeb, W3C)
Buscadores:� realizan la búsqueda mediante palabrasclave en el html de las páginas.
� existe la tendencia de implementar el uso de metadatosdentro del código html.
Agentes de búsqueda: � encontrarán la información de forma precisa, � realizarán inferenciasautomáticamente buscando información
relacionada, utilizando ontologías

La manipulación se efectúa mediante
� Lógica (forma de extraer nuevos conocimientos a partir de los existentes)
� Motor de inferencia (Extrae conclusionesa partir de un conj. de reglas y un conj. de axiomas)
Semántica� Tradicionalmente: Estudio del significado de los términos lingüísticos
� En este contexto: Dotación de significado interpretable por parte de las máquinas
Metadatos� Tradicionalmente: Son datos que describen otros datos
� En este contexto: Datos que describen recursos de la Web.
� Los metadatosy las ontologíasforman parte del campo de la representación del conocimiento
� La creación de ontologías no es una tarea trivial, para facilitarla aparecen los editores (Protégé)

Lenguajes de marcado
� XML (eXtensible Markup Language), con sus respectivos DTD
(Document Type Definition): para intercambio de datos
� RDF (Resource Description Framework): recomendado por el consorcio
W3C como estándar para los metadatos.
� OWL (Ontology Web Language): estándar para realizar anotacionesde
ontologíasen la web � es un lenguaje para publicar y compartir ontologías en la web
� desarrollado por el W3C .

RDF
� Permite la descripcióny el procesamientode metadatosde cualquier dominio
� Usa XML como lenguaje de base
Ejemplo “La página web http://www.infovis.netfue creada por Juan”
Sujeto: http://www.infovis.net (recurso)
Predicado: creada (propiedad, tiene un creador)
Objeto: Juan (el valor de la propiedad)
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://description.org/schema/">
<rdf:Description about="http://www.infovis.net">
<s:Creador>Juan</s:Creador>
</rdf:Description>
</rdf:RDF>

OWL
� Usa XML como lenguaje de base
Ejemplo
<owl: Class rdf:ID=“ Female”>
<rdfs:subClassOFrdf:resource:”# Animal ”/>
<owl:disjointWith rdf:resource:”# Male”/>
<owl: Class>

ESPACIOS METRICOS
Bases de datos tradicionales.� Los datos tienen una estructura exacta y bien definida.
� Búsquedas exactas, por igualdad/desigualdad.
� SELECT * FROM Alumno WHERE Ciudad = ‘Rosario’;
Bases de datos no estructuradas.� No se pueden realizar búsquedas exactas.
� La operación más típica es la búsqueda por similitud.
� Algunos ejemplos : imágenes, texto, huellas digitales, música, cadenas de ADN, ...

� Búsqueda por similitud: recuperar los objetos de la base de datos más semejantes a uno dado.

Función de distancia. � Ejemplo: d(anemia, anestesia) = 4
� Evaluar d tiene un coste computacional elevado. Comparar la consulta con toda la base de datos es muy costoso.
� Se utilizan índices sobre la BD para evitar la comparación de la consulta con todos los objetos de la base de datos.

Espacio métrico = Universo de objetos
+ Función de distancia
Ej. Colección de palabras + Distancia de edición
� Def.: Sean O1 y O2 dos objetos del universo de objetos posibles. La distancia (disimilaridad) se denota con d(O1,O2)
� Propiedades de la distancia: � d(A,B) = d(B,A) (Simetría)
� d(A,A) = 0
� d(A,B) >= 0 (d(A,B) = 0 sii A= B)
� d(A,B) ≤ d(A,C) + d(B,C) (Desigualdad Triangular)

� Métrica de Minkowski
( ) ( )pn
i
pii cqCQd ∑ −≡
=1,
Si
p = 1 Manhattan (Rectilínea, City Block)
p = 2 Euclidea
p = ∞ Máximo

Consultas por similaridad
Dado X ⊆ D en un espacio métricoM (D,d)
se pueden definir dos tipos básicos de consulta porsimilaridad para una consultaq ∈ D
� Range query
{ x ∈ X; d(q,x) ≤ r}
� Nearest neighbours query� el vecino más cercano
� los k vecinos más cercanos.

La desigualdad triangular, base de los algoritmos de indexación.
�x, y, z�U, d(x, y)≤d(x, z)+ d(z, y)
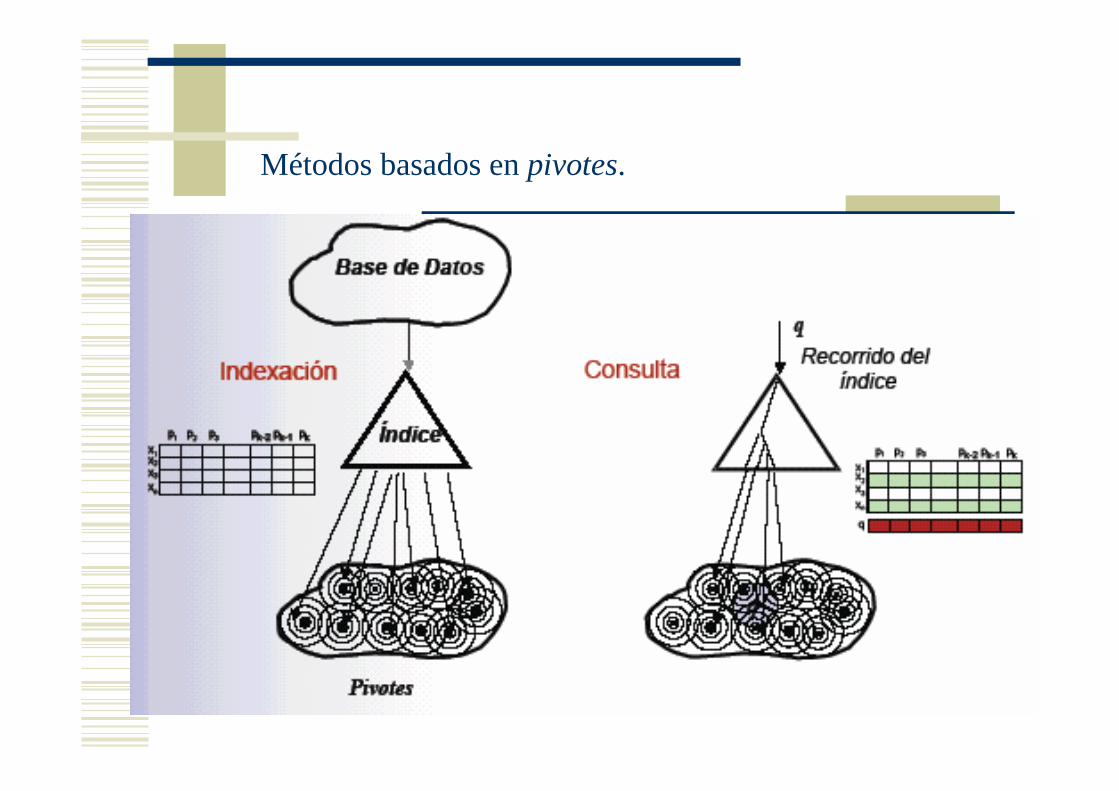
Métodos basados en pivotes.

Métodos basados en clustering.


BASES DE DATOS TEMPORALES
Ejemplos:
� Aplicaciones bancarias.� Controles de personal, � Registros médicos � Inventario.� Programación de reservas (avión, tren, hoteles...).� Muchas aplicaciones científicas (ej. monitoreo del
tiempo).

� En una base de datostemporal cada hecho registrado tiene una marca de tiempo.
� Tiempo válido: conj. de intervalos de t durante los que el hecho es verdadero.
� Tiempo de transacción: intervalo de t durante el cual ese hecho es cierto en el sistemade BD.
� Relación temporal: cada tupla tiene un t asociado cuando es verdadera. � El t puede ser tanto el tiempo válido, como el de transacción� Cada tupla sólo tiene un intervalo de tiempo asociado.� Los intervalos son disjuntos.


Ejemplo en TSQL2
¿Quién ha trabajado en ventas más tiempo de lo que Juan trabajó con un sueldo de $20000?
SELECT E.Nombre
FROM Empleado(Nombre, Depto) AS E,
Empleado(Nombre, Sueldo) AS D
WHERE
E.Depto = “Ventas” AND
D.Nombre=“Juan” AND
D.Sueldo = 20000 AND
CAST (E AS INTERVAL DAY) > CAST (D AS INTERVAL DAY)

Ejemplo en SQL3

Ejemplo en SQL3

Registran información en puntos, líneas y regiones.
El espacio de interés puede ser:� Una abstracción bidimensional de la superficie de la tierra.
� Un modelo del cerebro humano.
� Una representación 3D de la disposición de una cadena de moléculas de proteína.
� etc.
BASES DE DATOS ESPACIALES

Qué necesita ser representado?

Algunas operaciones

� Predicados espaciales que devuelvan valores booleanos.� Relaciones topológicas: igual, disjunto, adyacente, intersección,
cubre, contiene, fuera, etc.� Orden espacial: detrás, en_frente, debajo, por_sobre, etc.� Relaciones direccionales: norte, sur, este, noreste, etc.
� Operaciones espaciales que devuelvan valores numéricos.� Área, perímetro, diámetro, distancia, maxdist, mindist, etc.
� Operaciones espaciales que devuelva nuevos objetos espaciales.� Operaciones de construcción: unión, intersección, diferencia,
centro, borde, etc.� Operaciones de transformación: extender, rotar, trasladar, etc.
� Operaciones en colecciones de objetos espacialmente relacionados.� Operaciones generales: voronoi, mascercano, componer,
descomponer, etc.� Operaciones para particiones: fusión, superimposición, cubrir, etc.� Operaciones para redes: camino_mas_corto, etc.
Operaciones Espaciales

Ejemplo
CREATE TABLE Country(Name varchar(30),Cont varchar(30),Pop Integer,GDP Number,Shape Polygon
);
CREATE TABLE River(Name varchar(30),Origin varchar(30),Length Number,Shape LineString
);

Ejemplos
Encontrar los nombres de todos los países que son vecinos de USA.
SELECT C1.Name AS “Vecinos de USA”
FROM Country C1, Country C2
WHERE Touch(C1.Shape, C2.Shape) = 1 AND C2.Name = ´USA´
Encontrar los países que atraviesan todos los ríos listados en la tabla River.
SELECT R.Name, C.Name
FROM River R, Country C
WHERE Cross(R.Shape, C.Shape) = 1

Bases de Datos Espacio - Temporales
Es un sistema de base de datos cuyos objetos tienen una
geometría que cambia a lo largo del tiempo-> sistemas que tienen la capacidad de gestionar geometrías en cambio
continuo
Por ejemplo:
� Sistema de control del tráfico� Sistema de gestión catastral(parcelas cambian su forma
con el tiempo)

Ejemplo en STSQL
Se agregan nuevos tipos de datos: “moving point” y “moving region” :
Flights (id:string, from:string, to:string, route: mpoint)
Encontrar una ruta entre dos instantes de tiempo:
SELECT trajectory (Route(7:00..9:00))FROM flightsWHERE id=”UA207”


















